Материалы по тегу: asic
|
19.04.2026 [21:20], Владимир Мироненко
Google договаривается с Marvell о разработке двух кастомных чипов для ИИ-инференсаКомпания Google (Alphabet) ведёт переговоры с Marvell Technology о совместной разработке двух кастомных чипов, предназначенных для более эффективного ИИ-инференса, сообщил ресурс The Information со ссылкой на информированные источники. Как отметил The Information, эти переговоры свидетельствуют о стремлении Google, исторически зависящей от Broadcom в отношении базовой инфраструктуры TPU, к диверсификации поставщиков. Этот потенциальный альянс в области разработки чипов является прямым ответом на меняющуюся экономику ИИ, когда огромные вычислительные затраты на обучение масштабных моделей быстро уступают место постоянным ежедневным расходам на инференс. Один из чипов относится к подсистеме памяти TPU, второй — собственно TPU следующего поколения, созданный специально для запуска ИИ-моделей. Эти чипы предназначены для совместной работы, при этом каждый из них выполняет свою часть задачи. Как подчёркивается в публикации, «текущие обсуждения направлены на разработку полупроводников исключительно для нужд Google». 
Источник изображения: Marvell Technology Помимо технической оптимизации ИИ-инференса, привлечение Marvell — это классическая тактика диверсификации поставщиков, пишет Startup Fortune. Broadcom долгое время занимала исключительно доминирующее положение на рынке заказных чипов, тесно сотрудничая с Google в разработке TPU. Но сильная зависимость от одного партнёра по проектированию неизбежно создаёт ценовые разногласия и узкие места. Добавление ещё одного партнёра даёт Google более сильные рычаги влияния во время переговоров по контрактам, а также защищает её ЦОД от геополитических и логистических сбоев. Следует отметить, что авторитет Marvell заметно вырос за последнее время. Компания недавно заключила многомиллиардное партнёрство с NVIDIA, ориентированное на оптические сети и кастомные чипы. Её акции выросли более чем на 50 % с начала года, в основном благодаря доверию инвесторов к её опыту в области инфраструктуры данных и проектирования заказных чипов. Вместе с тем Broadcom остается ключевым партнёром в реализации планов Google. В этом месяце компании подписали соглашение о продолжении работы над новыми чипами до 2031 года, сообщается в документе, направленном Broadcom регулятору. Если переговоры пройдут успешно, Marvell укрепит свой статус ведущей альтернативы Broadcom в сегменте разработки кастомных ИИ-микросхем. Также следует ждать, что капитальные затраты гиперскейлеров будут всё больше смещаться в сторону оптимизации инференса, а не просто увеличения вычислительной мощности. Аналитики отрасли в настоящее время прогнозируют, что поставки серверных ASIC для ИИ-вычислений утроятся к 2027 году, и эта тенденция почти полностью обусловлена потребностями в развёртывании больших языковых моделей.
27.03.2026 [10:03], Руслан Авдеев
ЦЕРН: для самых больших открытий на БАК нужны самые маленькие ИИ-модели, которые «зашиты» прямо в чипыИИ-инфраструктура Большого адронного коллайдера (БАК) имеет мало общего с классическим решениями на основе TPU или GPU. Вместо этого ЦЕРН (CERN) буквально «выжигает» кастомные ИИ-модели в «кремнии» для фильтрации огромных массивов данных практически в реальном времени, сообщает The Register. Ежегодно коллайдер «генерирует» 40 тыс. Эбайт «сырых» данных от сенсоров — приблизительно четверть объёма всего интернета. Такую информацию CERN хранить не может, поэтому приходится выбирать в режиме реального времени то, что представляет какую-либо ценность. Речь идёт о потоке данных до сотен терабайт в секунду. Алгоритмы для их обработки должны быть чрезвычайно быстрыми. Именно поэтому их приходится буквально «выжигать» непосредственно в чипах. В 27-км кольце БАК субатомные частицы сталкиваются на скоростях, близких к скорости света. По кольцу постоянно перемещаются около 2,8 тыс. пучков протонов с 25-с интервалами. Хотя учёные «помогают» частицам, столкновения случаются сравнительно редко — из миллиардов протонов в каждой сессии сталкиваются лишь порядка 60 пар. При столкновении образуются новые частицы, улавливаемые детекторами CERN. 
Источник изображения: Brandon Style/unsplash.com Каждое столкновение пары частиц генерирует несколько мегабайт данных. В секунду происходит около миллиарда столкновений, что приблизительно даёт около 1 Пбайт информации. Естественно, собирать и хранить такие объёмы «сырой» информации технически невозможно, поэтому CERN создал гигантскую вычислительную систему для разделения данных на «интересные» и «неинтересные» ещё на уровне детекторов. 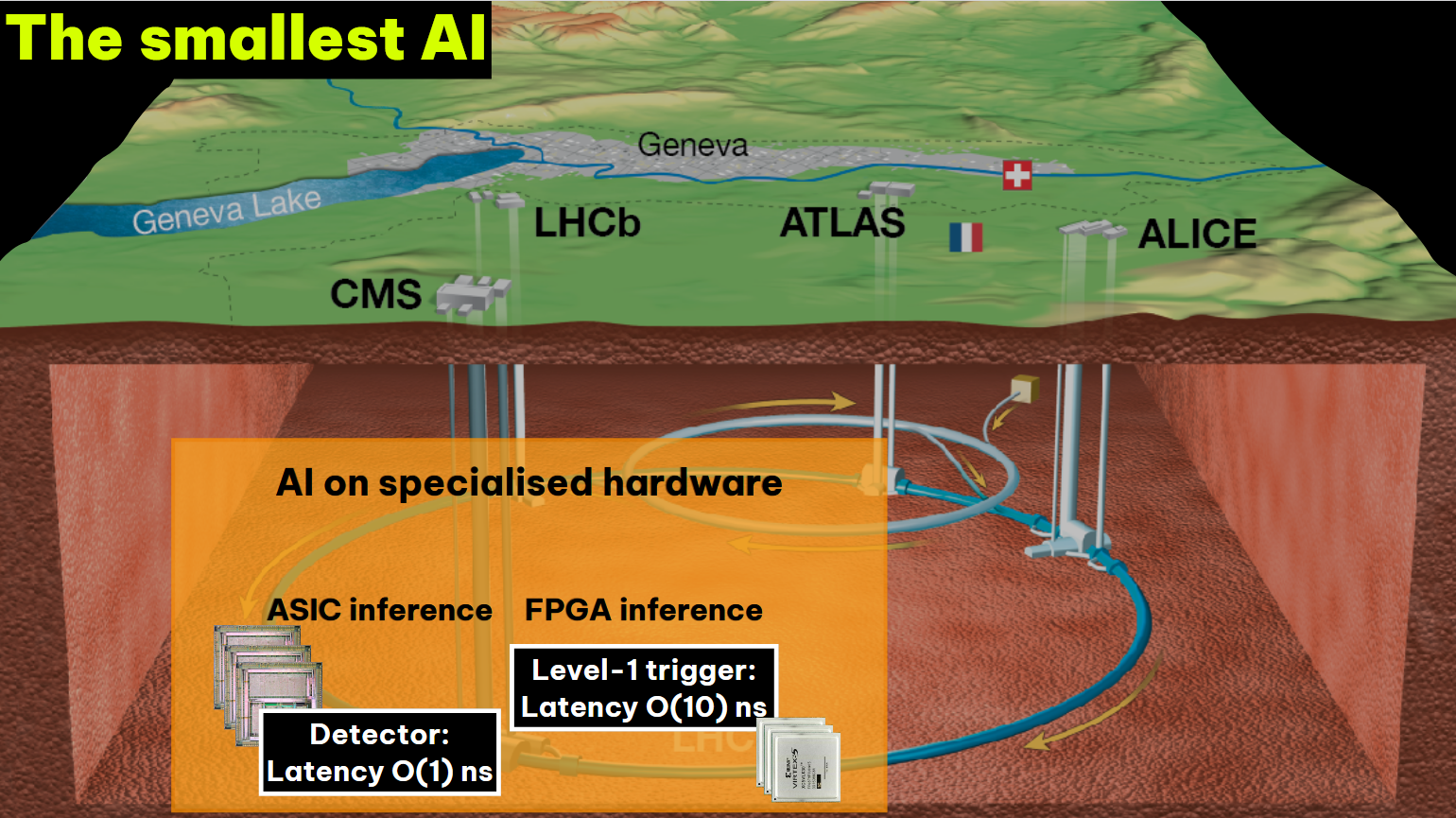
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Детекторы используют ASIC для буферизации данных за не более чем 4 мкс — они либо сохраняются, либо исчезают навсегда. Решение принимает фильтр Level One Trigger на базе порядка 1 тыс. FPGA, получающих данные по оптической линии на скорости около 10 Тбайт/с. Решения принимаются на лету силами самих чипов по мере поступления данных — даже самая быстрая внешняя память не справится с таким потоком информации. Специальный алгоритм AXOL1TL принимает решение не более чем за 50 нс. Фактически сохраняется лишь около 0,02 % информации о столкновениях, или приблизительно 110 тыс. событий в секунду. Отобранные сведения отправляются на поверхность, но даже после первичной фильтрации речь идёт о передаче терабайт данных ежесекундно. 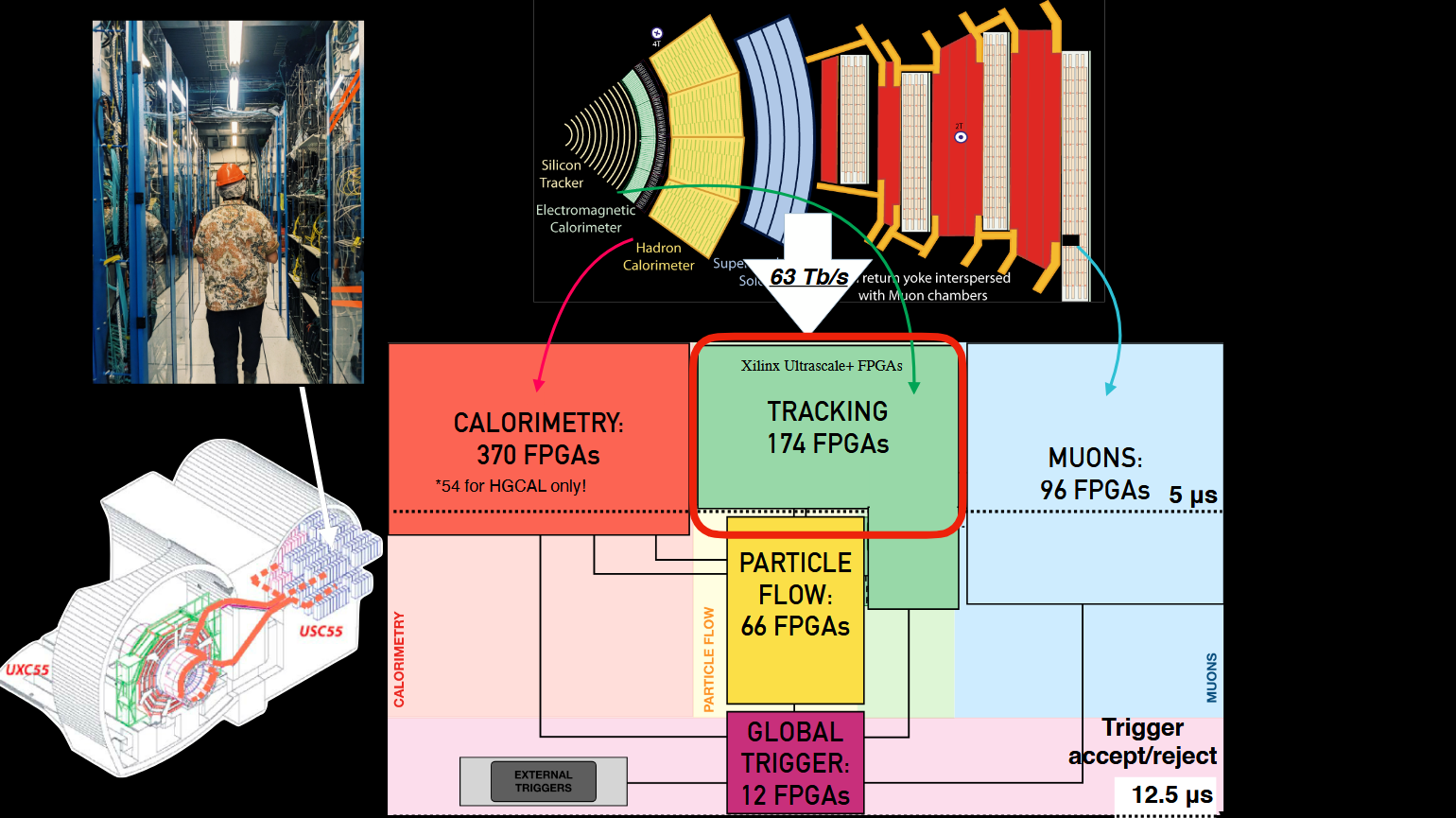
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) На поверхности второй фильтр — High Level Trigger — оставляет для изучения уже около 1 тыс. событий в секунду. Система оснащена 25,6 тыс. CPU и 400 GPU, которые реконструируют столкновения и отбирают наиболее интересные для анализа результатов. На выходе получается около 1 Пбайт/день новых данных, которые распределяются между 170 научными центрами в 42 странах, где их могут анализировать учёные со всего света. Совокупная вычислительная мощность всех участников проекта составляет около 1,4 млн ядер. CERN стремится измерить параметры столкновений с точностью 99,999 % — это «золотой стандарт», необходимый для заявлений о научных открытиях. 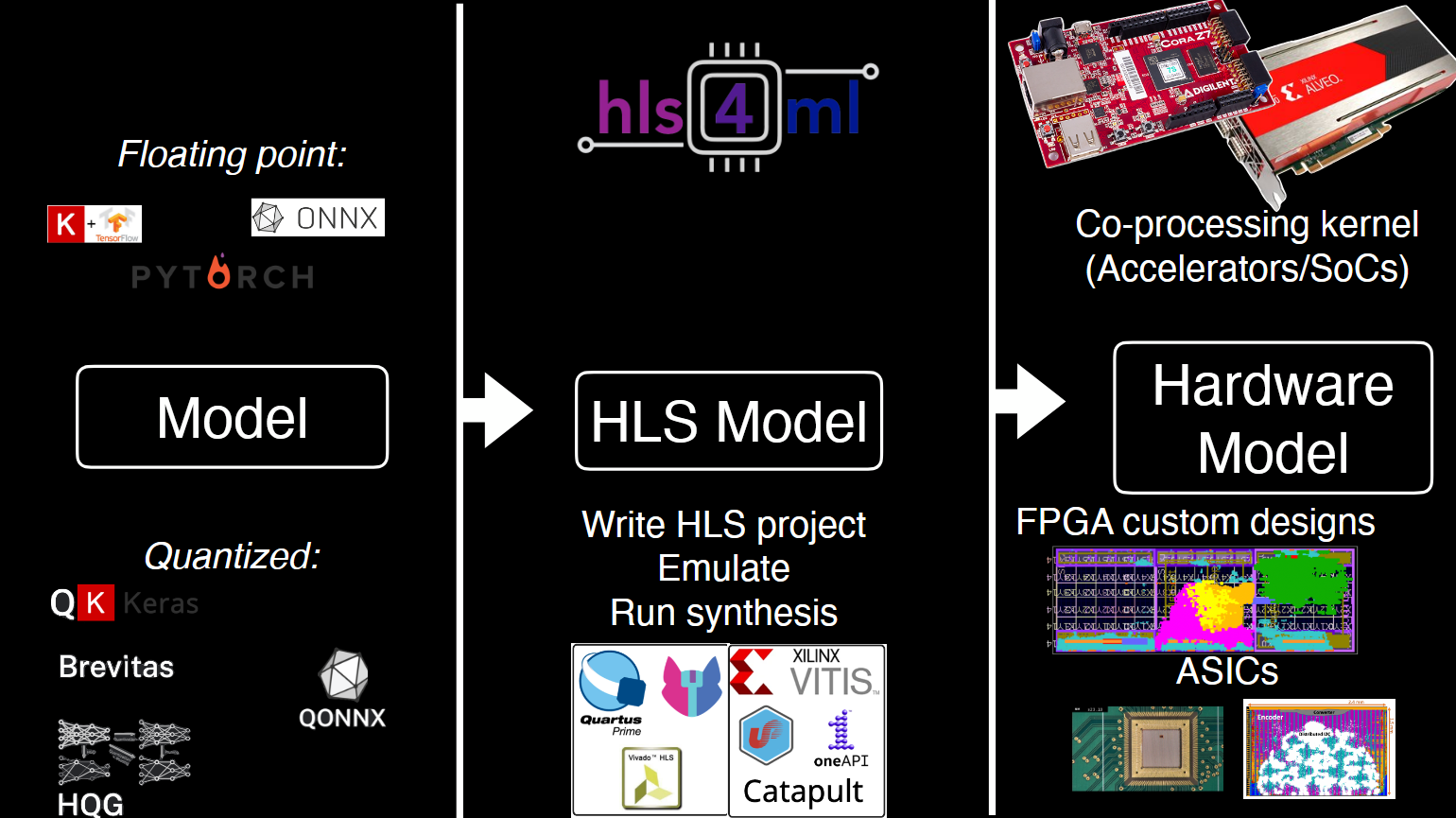
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Обычный ИИ-инструментарий плохо подходит для детекторов, поэтому инженерам CERN пришлось разработать собственный стек. ИИ-модели для БАК специально уменьшены, модернизированы, параллелизованы и «вымуштрованы» для выявления только действительно существенных данных. В случае с БАК они не менее производительны, но значительно «дешевле» традиционных ML-моделей. Для переноса моделей в аппаратную среду используется компилятор HLS4ML, конвертирующий модель в код C++, который можно запускать на ИИ-ускорителях, SoC, кастомных FPGA и даже «выжигать» в ASIC. При этом значительная часть ресурсов чипа отведена не под сам алгоритм, а под таблицы с предварительно рассчитанными результатами для типовых входящих значений, чтобы ещё быстрее фильтровать информацию. 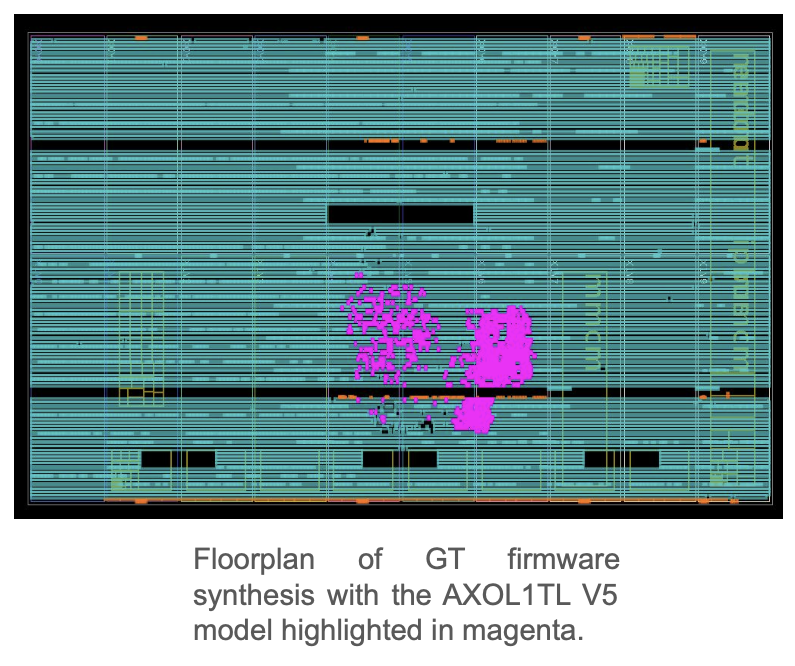
Источник изображения: CERN В конце года БАК закроют, а новый, более мощный коллайдер High Luminosity LHC должен заработать в 2031 году. Он получит более сильные магниты для фокусировки пучков частиц, сами пучки удвоятся в размерах, коллайдер будет генерировать в 10 раз больше данных, а объём информации от каждого события увеличится с 2 до 8 Мбайт. CERN уже накопил 1 Эбайт от БАК, но это лишь десятая часть от того, что предстоит хранить и обрабатывать в последующие 10 лет. И пока передовые ИИ-лаборатории создают LLM всё большего объёма, CERN движется в противоположном направлении, всеми силами упрощая и ускоряя выявление необычных событий с помощью искусственного интеллекта.
23.02.2026 [22:57], Владимир Мироненко
Чипы AMD прожорливы, NVIDIA — дороги, а Intel — ненадёжны: Ericsson остаётся верна кастомным ASICEricsson представила свой первый набор продуктов AI-RAN, подчеркнув приверженность стратегии, основанной на собственных ASIC для повышения производительности сетей радиодоступа (RAN). В то время как беспроводная индустрия всё чаще обращается к виртуализированным/облачным RAN с использованием универсальных процессоров (GPP) Intel, Ericsson защищает свои продолжающиеся инвестиции в кастомные чипы для высокопроизводительных задач, отметил ресурс IEEE ComSoc Technology Blog. Впрочем, Intel остаётся ключевым партнёром Ericsson, а вот с AMD и NVIDIA у компании не заладилось. Портфель решений Ericsson для RAN базируется на двух основных архитектурах. Большая часть основана на ASIC, разработанных как собственными силами, так и в партнёрстве с Intel. Также портфель включает Cloud RAN, которая объединяет программный стек Ericsson с процессорами Intel Xeon EE. Несмотря на надежды отрасли, что виртуализация позволит отделить аппаратное обеспечение от программного, Intel остаётся единственным партнером Ericsson по поставке микросхем для массового развёртывания, что создаёт некоторые риски. 
Источник изображений: Ericsson Фактически Ericsson подтвердила «коммерческую поддержку» исключительно решений Intel, в то время как в случае AMD, Arm и NVIDIA всё по-прежнему ограничивается «поддержкой прототипов». Несмотря на многолетние заявления отрасли о необходимости разнообразия микросхем в экосистеме vRAN, прогресс, похоже, застопорился. Кроме того, интеграция ИИ в ПО RAN добавляет новые уровни сложности, которые могут ещё больше укрепить зависимость компании от «железа» одного вендора. Отраслевые наблюдатели по-прежнему скептически относятся к стремлению Ericsson к «единому программному стеку» для гетерогенных аппаратных платформ. Хотя аппаратная и программная дезагрегация достижима на более высоких уровнях (L2/L3), PHY-уровень L1 — наиболее ресурсоёмкая часть стека — остаётся сильно оптимизированным для конкретного «кремния». Первоначально Ericsson рассчитывала на переносимость L1-кода между x86 (в т.ч. AMD) и Arm SVE2 (NVIDIA Grace) для соответствия возможностям Intel AVX-512. Однако достижение высокой производительности на этих платформах без существенного рефакторинга остается серьёзной инженерной проблемой. 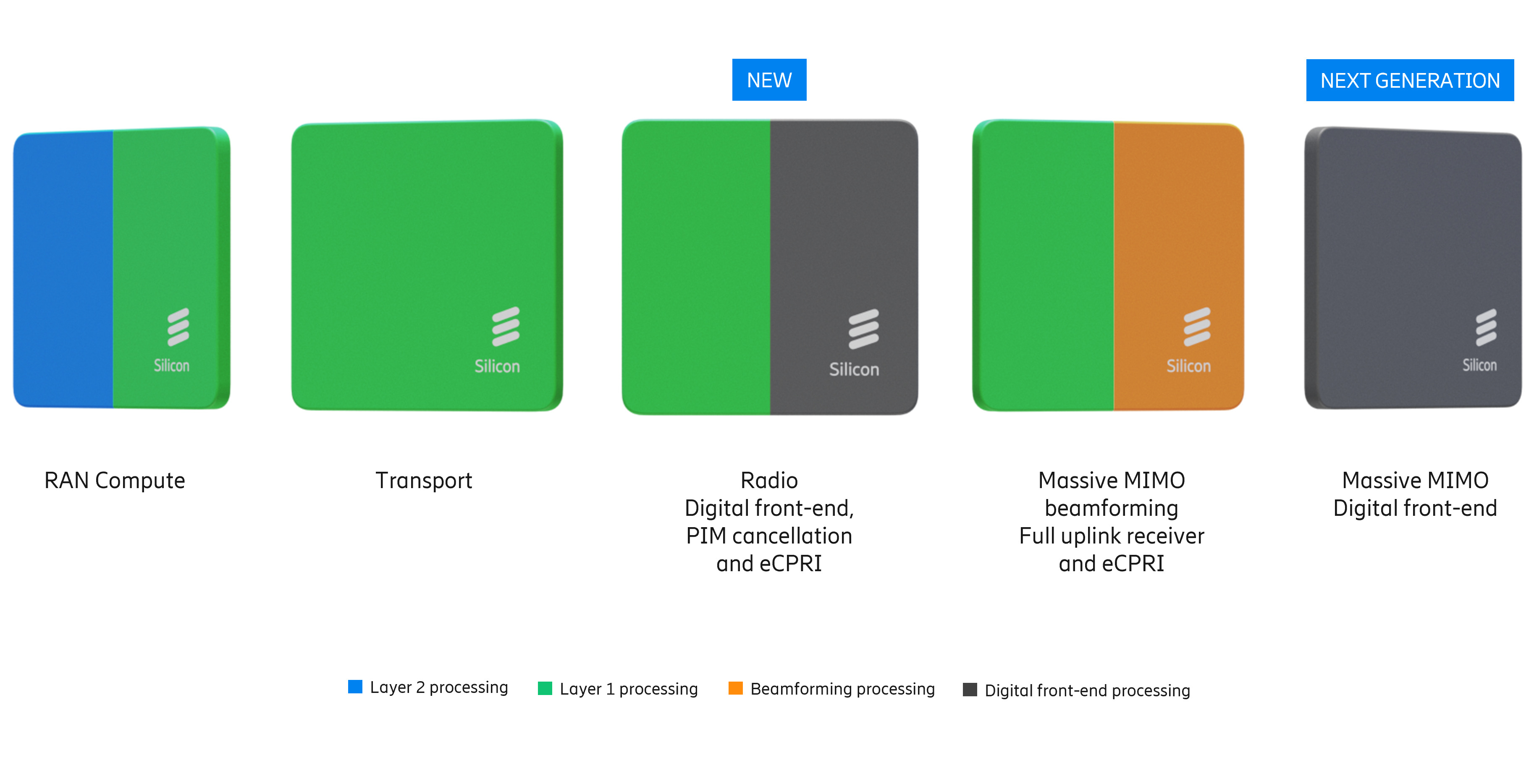 Критическим узким местом в обработке L1-трафика является коррекция ошибок (Forward Error Correction), которая традиционно требует выделенного аппаратного ускорения. Ericsson первоначально полагалась на разгрузку с переносом задач FEC на дискретные PCIe-ускорители Intel. Затем Intel внедрила ускорение FEC в Xeon EE в рамках vRAN Boost. Попытки использовать FPGA AMD показали их невысокую энергоэффективность, а GPU NVIDIA оказались слишком дороги для такой задачи. Однако развитие AI-RAN изменило экономику, поскольку теперь ускорители можно использовать как для RAN, так и для ИИ-задач. Так, Ericsson заинтересовали тензорные процессоры Google (TPU). Тем не менее, несмотря на стремление к созданию «единого ПО», планы Ericsson подтверждают существование проблем в реализации этой идеи. В то время как уровни L2 и выше используют универсальную кодовую базу для всех аппаратных платформ, уровень L1 требует адаптации под конкретные чипы.  Чтобы избежать зависимости от одного поставщика чипов, компания уделяет приоритетное внимание развитию HAL (Hardware Abstraction Layers), что позволит портировать ПО на разные аппаратные платформы с минимальными изменениями. Основные инициативы включают внедрение интерфейса BBDev (Baseband Device) для отделения ПО RAN от базового аппаратного обеспечения. Рассматривается даже возможность интеграции с NVIDIA CUDA, но здесь многое зависит от более широкой отраслевой стандартизации. Что касается радиосвязи, менее подверженной полной виртуализации, Ericsson встраивает процессоры Neural Network Accelerators (NNA) непосредственно в радиомодули. Эти программируемые матричные ядра оптимизированы для обработки данных в системах Massive MIMO, обеспечивая формирование луча и оценку канала за доли миллисекунды при соблюдении строгих ограничений по мощности. Новые AI-радиомодули оснащены ASIC Ericsson с NNA. Утверждается, что они расширяют возможности локального инференса в радиосистемах Massive MIMO, обеспечивая оптимизацию в реальном времени.
10.02.2026 [18:34], Владимир Мироненко
Cisco представила 102,4-Тбит/с чип-коммутатор Silicon One G300Cisco представила 102,4-Тбит/с чип-коммутатор Silicon One G300, способный обеспечивать работу ИИ-кластеров гигаваттного масштаба для обучения, инференса и агентных рабочих нагрузок в реальном времени. По словам компании, новинка позволяет на треть повысить утилизацию имеющейся пропускной способности и снизить время обучения на 28 % в сравнении с альтернативнами решениями с многопутевой доставкой пакетов, передаёт The Register. G300 является конкурентом решениям Broadcom Tomahawk 6 и NVIDIA Spectrum-X Ethernet. Как и они, G300 содержит 512 блоков SerDes 200G. Огромное количество портов (radix) позволяет G300 поддерживать развёртывание до 128 тыс. GPU используя всего 750 коммутаторов, тогда как ранее требовалось 2500. SerDes можно и объединить для реализации портов 1,6 Тбит/с. Cisco также представила OSFP-трансиверы на 1,6 Тбит/с. Сообщается, что G300 предлагает уникальную интеллектуальную коллективную сеть, которая сочетает в себе ведущий в отрасли полностью общий буфер пакетов, балансировку нагрузки на основе путей и проактивную сетевую телеметрию, обеспечивая лучшую производительность и прибыльность для крупных ЦОД. «Отсутствует сегментация буферов пакетов, что позволяет пакетам поступать и обрабатываться независимо от порта. Это означает, что вы можете лучше справляться с пиковыми нагрузками», — сказал Ракеш Чопра (Rakesh Chopra), старший вице-президент Cisco. 
Источник изображения: Cisco Агент балансировки нагрузки «отслеживает потоки, проходящие через G300. Он отслеживает точки перегрузки и взаимодействует со всеми остальными G300 в сети, создавая своего рода глобальную коллективную карту того, что происходит во всем кластере ИИ», — добавил он. G300 также является программируемым, благодаря чему клиенты смогут добавлять новые сетевые функции после развёртывания по мере развития стандартов. Cisco также представила новые фиксированные и модульные коммутационные системы Nexus 9000 и Cisco 8000 на базе G300, «разработанные для экстремальных требований к энергопотреблению и теплоотводу для рабочих ИИ-нагрузок». Новые системы будут доступны как с воздушным, так и с полностью жидкостным охлаждением. Компания заявила, что конфигурация с СЖО обеспечивает значительно более высокую плотность портов и может повысить энергоэффективность почти на 70 % по сравнению с предыдущими поколениями, обеспечивая ту же пропускную способность в одной системе, для которой ранее требовалось шесть систем предыдущего поколения. 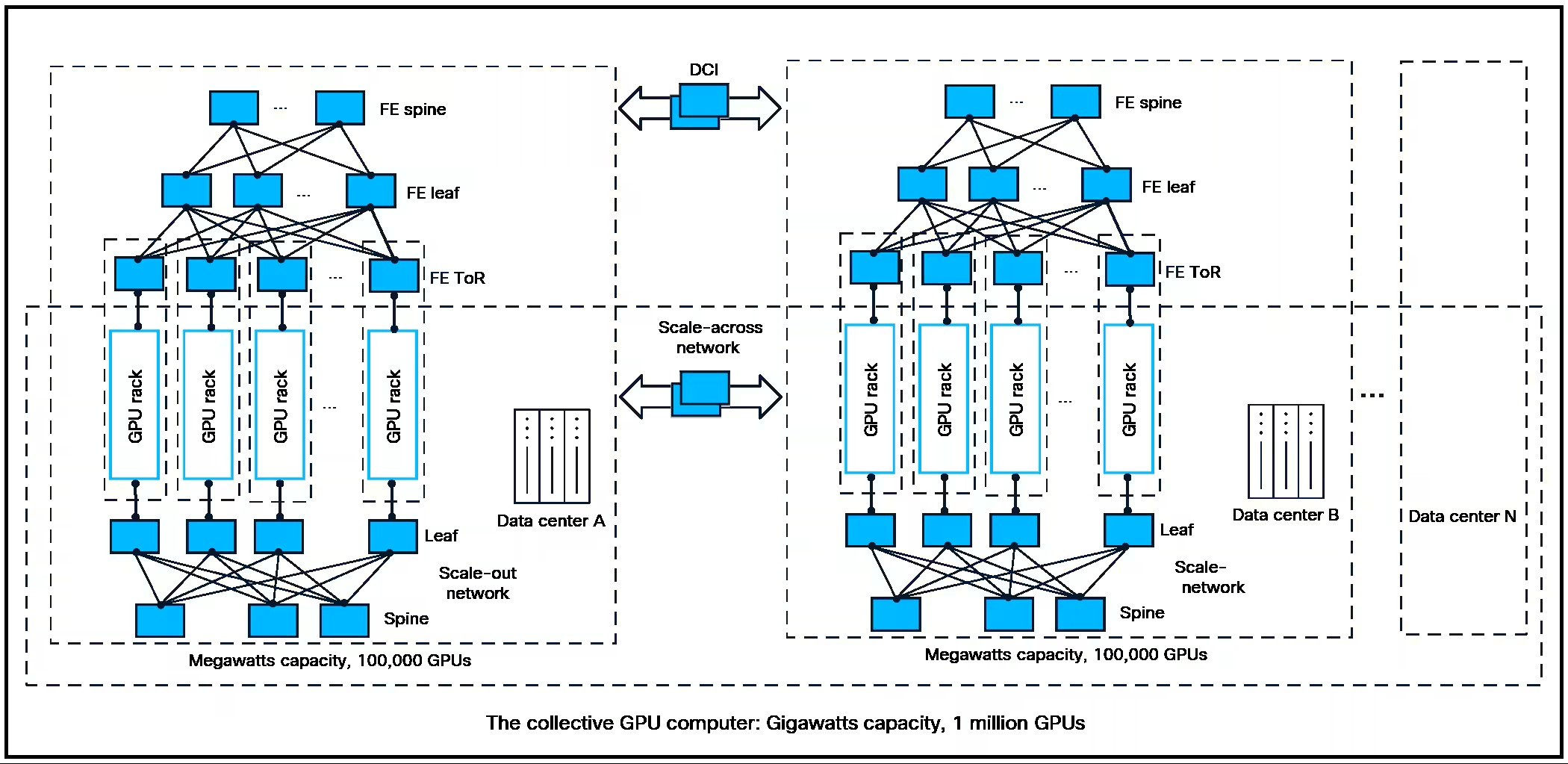
Источник изображения: Cisco Cisco представила эти системы как ответ на расширяющуюся ИИ-экосистему, в которой потребности в инфраструктуре ИИ больше не ограничиваются гипескейлерами. Вместо этого предприятия, неооблака и суверенные облачные операторы всё чаще инвестируют в собственные ИИ-кластеры и требуют более эффективной сетевой инфраструктуры для поддержки ресурсоёмких задач, отметил ресурс SiliconANGLE. «Последние два-три года мы в основном были сосредоточены на создании масштабных кластеров для обучения с гиперскейлерми, — рассказал Кевин Вольтервебер (Kevin Wolterweber), старший вице-президент и гендиректор подразделения ЦОД и интернет-инфраструктуры Cisco. — Сейчас мы наблюдаем сдвиг в сторону агентных задач ИИ и более широкое внедрение в корпоративных поставщиках услуг и среди более широкой клиентской базы». Коммутаторы Nexus работают под управлением ПО NX-OS компании Cisco — модульной сетевой операционной системы на базе Linux, разработанной для коммутаторов ЦОД серии Nexus и устройств хранения данных Multilayer Director Switch. Модели 8000 также могут поддерживать альтернативные сетевые операционные системы, включая open source платформу Sonic.
06.10.2025 [10:54], Владимир Мироненко
250 Тбит/с на чип: Ayar Labs, Alchip и TSMC предложили референс-дизайн для упаковки ASIC, памяти и оптических модулей в одном чипеКомпания Ayar Labs (США), занимающаяся разработкой интерконнекта на базе кремниевой фотоники, и тайваньский производитель ASIC-решений Alchip Technologies представили референсную платформу проектирования ИИ ASIC с несколькими оптическими IO-модулями на основе технологии кремниевой фотоники TSMC COUPE (Compact Universal Photonic Engine). В начале сентября компании объявили о стратегическом партнёрстве с целью ускорения масштабирования ИИ-инфраструктуры благодаря объединению технологии CPO компании Ayar Labs, экспертизы Alchip в области создания и упаковки кастомных ASIC, а также технологии упаковки и техпроцесса компании TSMC. Как сообщил технический директор Ayar Labs Владимир Стоянович (Vladimir Stojanovic) в интервью EE Times, платформа предназначена для устранения узких мест в передаче данных, замедляющих работу ИИ-инфраструктуры, путём эффективного сокращения времени простоя системы и создания крупных высокопроизводительных ИИ-кластеров нового поколения. Партнёры отметили, что по мере роста ИИ-моделей и размеров кластеров традиционные медные соединения достигают своих физических и энергетических пределов. Путём замены меди на интегрированную оптику (CPO) решение Alchip и Ayar Labs обеспечивает расширенную дальность связи, низкую задержку, энергоэффективность и высокий радикс, необходимые для масштабных развертываний ИИ-ускорителей. «Масштабируемые сети ИИ-кластеров ограничены расстоянием медных соединений. В то же время энергоэффективность сети ограничена плотностью мощности и возможностями систем охлаждения», — пояснил Эрез Шайзаф (Erez Shaizaf), технический директор Alchip, добавив, что CPO снимает эти ограничения. 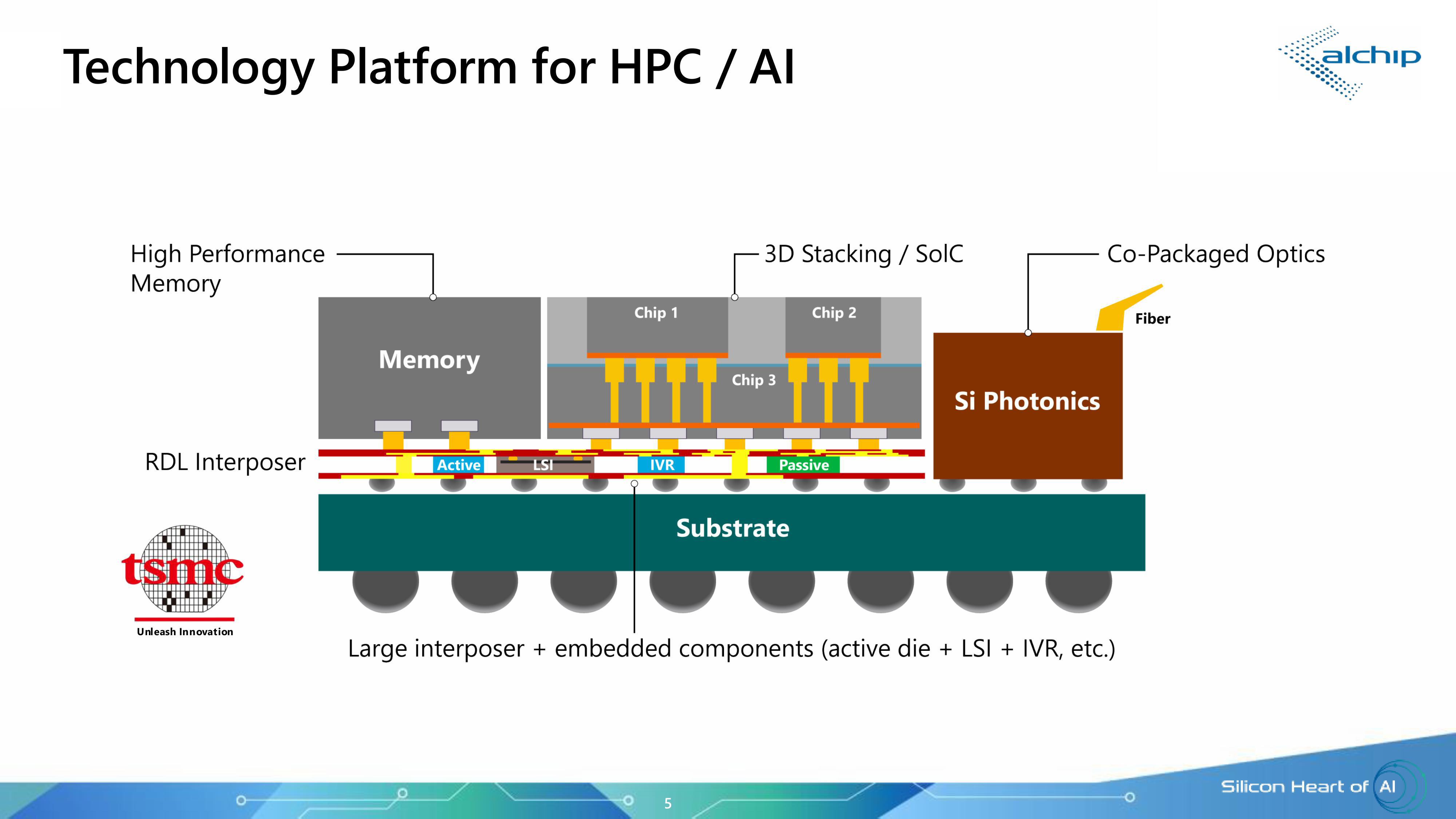
Источник изображений: Ayar Labs Новое совместное решение включает оптические модули Ayar Labs TeraPHY, размещённые вместе с решениями Alchip на общей подложке, обеспечивая прямой доступ ИИ-ускорителя к оптическому интерфейсу. Такая интеграция обеспечивает пропускную способность 100+ Тбит/с на каждый ускоритель и поддерживает более 256 оптических портов на устройство. TeraPHY не привязан к какому-либо протоколу и обеспечивает гибкую интеграцию с кастомными чиплетами. Референсный дизайн позволяет партнёрам «заложить основу» для быстрого создания подобной системы. Платформа референсного проекта включает два вычислительных кристалла с чиплетами HBM и другими чиплетами, в сочетании с восемью оптическими IO-модулями на базе чиплета TeraPHY. Такая конструкция обеспечит двустороннюю пропускную способность 200–250 Тбит/с для каждой сборки (SiP), что значительно превышает показатели современных крупных GPU, сообщил Стоянович. Это позволит масштабировать систему, а также значительно расширить объём памяти, имеющей пропускную способность, сопоставимую с HBM, добавил он. Оптический модуль Ayar Labs основан на чиплете TeraPHY PIC с двумя дополнительными слоями чиплетов, собранными с помощью TSMC COUPE. Два слоя электронных чиплетов собраны по технологии TSMC SoIC (System on Integrated Chips), которая использует вертикальное размещение нескольких кристаллов друг над другом, чтобы обеспечить более плотное соединение между ними, позволяя снизить энергопотребление, увеличить производительность и уменьшить задержки. По словам Стояновича, такой дизайн будет масштабироваться до уровня UCIe-A и выше как минимум в течение следующего десятилетия. 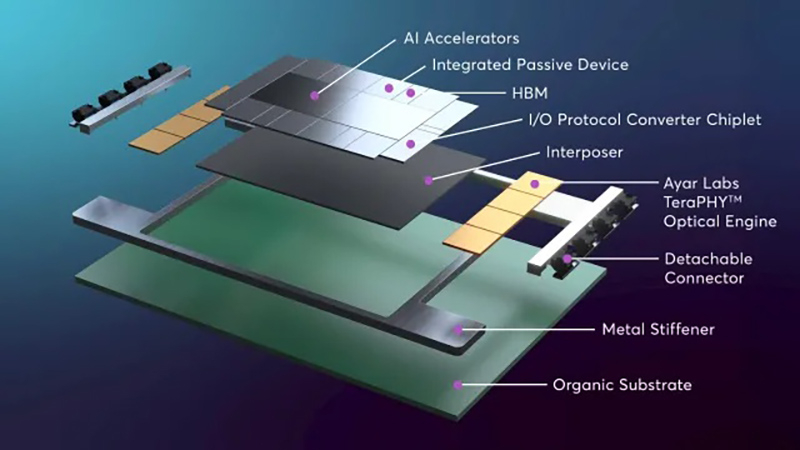 Совместное решение Alchip и Ayar Labs позволяет масштабировать многостоечную сетевую фабрику без потерь мощности и задержек, характерных для подключаемых оптических кабелей, за счёт минимизации длины электрических трасс и размещения оптических соединений вблизи вычислительного ядра. Благодаря поддержке UCIe для межкомпонентных соединений и гибкому размещению конечных точек на границе чипов, команды разработчиков могут интегрировать масштабируемое решение Alchip и Ayar Labs с существующими вычислительными блоками, стеками памяти и ускорителями, обеспечивая при этом соблюдение требований к производительности, целостности сигнала и температурному режиму на уровне всей сборки. Как сообщается, компании предоставят командам разработчиков дополнительные материалы, референсные архитектуры и варианты сборки. Платформа референсного дизайна включает в себя тестовые программы, позволяющие тестировать сборку и прошивку управления модулем, что облегчает его интеграцию в сборку. «Заказчику нужна поддержка, чтобы он понимал процессы оценки надёжности и испытаний, поэтому мы тесно сотрудничаем с Alchip, чтобы предоставить заказчику доступ ко всему этому пакету», — рассказал Стоянович.
05.08.2025 [10:39], Сергей Карасёв
HyperPort на 3,2 Тбит/с: Broadcom выпустила чип-коммутатор Jericho4 для распределённой ИИ-инфраструктурыКомпания Broadcom объявила о начале поставок коммутационного чипа Jericho4, специально разработанного для распределённой инфраструктуры ИИ. Изделие, как утверждается, позволяет объединять более миллиона ускорителей (GPU, TPU) в географически разнесённых дата-центрах, преодолевая традиционные ограничения масштабирования. Отмечается, что по мере роста размера и сложности моделей ИИ требования к инфраструктуре ЦОД повышаются: создаётся необходимость в объединении ресурсов нескольких площадок, каждая из которых обеспечивает мощность в десятки или сотни мегаватт. Для этого требуется оборудование нового поколения, оптимизированное для сверхширокополосной и безопасной передачи данных на значительные расстояния. Новинка позволяет решить проблему. Jericho4 обладает коммутационной способностью 51,2 Тбит/с. Благодаря глубокой буферизации и интеллектуальному управлению перегрузкой изделие обеспечивает поддержку RoCE без потерь на расстоянии более 100 км, что позволяет формировать распределённую инфраструктуру ИИ, говорит Broadcom. 
Источник изображений: Broadcom Могут быть задействованы интерфейсы 50GbE, 100GbE, 200GbE, 400GbE, 800GbE и 1.6TbE. Реализована технология HyperPort, которая объединяет четыре порта 800GbE в один канал с пропускной способность 3,2 Тбит/с, что упрощает проектирование и управление сетью. Единая инфраструктура на базе Jericho4 может масштабироваться до 36 тыс. портов HyperPort, каждый из которых работает со скоростью 3,2 Тбит/с. Jericho4 поддерживает шифрование MACsec на каждом порту на полной скорости для защиты передаваемой между ЦОД информации без ущерба для производительности — даже при самых высоких нагрузках. Новинка полностью соответствует спецификациям, разработанным консорциумом Ultra Ethernet (UEC): благодаря этому достигается бесшовная интеграция с широкой экосистемой сетевых карт, коммутаторов и программных стеков. 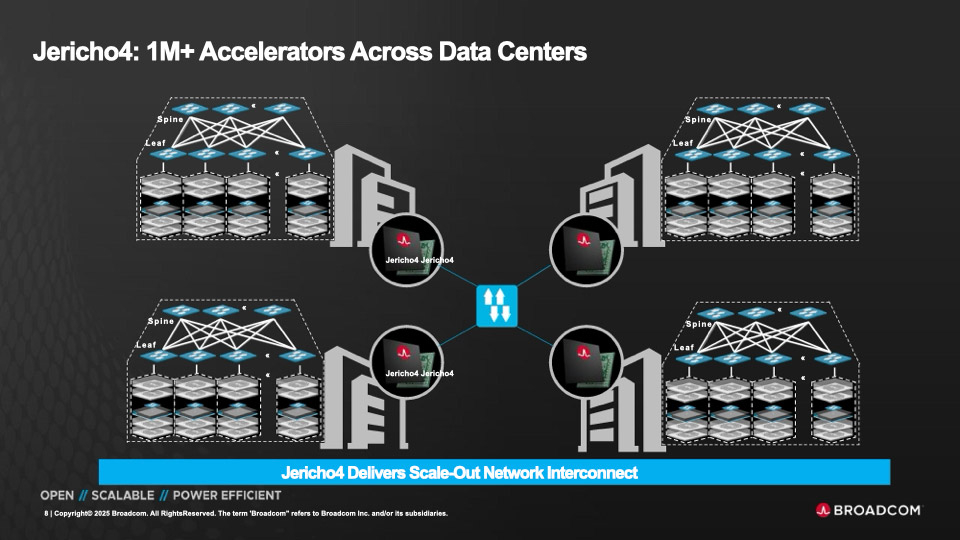 Чип Jericho4 производится по 3-нм технологии. Он оснащён модулями Broadcom PAM4 SerDes 200G. Это устраняет необходимость в дополнительных компонентах, таких как ретаймеры, что способствует снижению энергопотребления и повышению надёжности системы в целом. В частности, энергозатраты уменьшены на 40 % в расчёте на бит по сравнению с решениями предыдущего поколения. Это помогает организациям снижать эксплуатационные расходы и достигать целей устойчивого развития, говорит Broadcom.
16.07.2025 [11:44], Сергей Карасёв
Broadcom представила 51,2-Тбит/с чип-коммутатор Tomahawk Ultra — альтернативу NVIDIA InfiniBand и NVLinkКомпания Broadcom анонсировала чип-коммутатор Tomahawk Ultra, специально разработанный для кластеров НРС и платформ ИИ. Новинка, как ожидается, составит конкуренцию InfiniBand в традиционных суперкомпьютерах, NVLink в стоечных решениях вроде NVIDIA GB200 NVL72, а также Ultra Accelerator Link (UALink) в масштабируемых системах ИИ в дата-центрах. Решение Tomahawk Ultra разработано в рамках инициативы Broadcom Scaling Up Ethernet (SUE). Утверждается, что эта технология будет поддерживать масштабируемые системы с не менее чем 1024 ускорителями ИИ. Для сравнения, NVIDIA заявляет, что её коммутационная система NVLink 5/6 позволяет объединить до 576 ускорителей в одном домене. Broadcom подчёркивает, что чип Tomahawk Ultra разработан с нуля специально для удовлетворения потребностей высоконагруженных НРС-сред и ИИ-кластеров. Новинка обеспечивает коммутационную способность 51,2 Тбит/с при размере пакетов 64 байта. Задержка составляет 250 нс, что значительно меньше, чем у коммутаторов с более высокой пропускной способностью. А общая задержка при общении XPU между собой составляет не более 400 нс. Поддерживается обработка до 77 млрд пакетов в секунду. 
Источник изображений: Broadcom Основная часть трафика, передаваемого через коммутаторы Ethernet, состоит из пакетов большего размера. Поэтому при проектировании сетевого оборудования внимание уделяется прежде всего увеличению размера пакетов для оптимизации пропускной способности. Вместе с тем обмен пакетами небольшого размера широко распространен в платформах НРС/ИИ: представленная новинка Broadcom нацелена именно на такие среды.
Чип-коммутатор Tomahawk Ultra (семейство BCM78920) поддерживают 64 порта 800GbE, 128 портов 400GbE или 256 портов 200GbE. Изделие использует блоки Peregrine 106.25G PAM4 SerDes. Решение совместимо по выводам с Broadcom Tomahawk 5 (TH5). Поддерживаются функции, предназначенные для масштабируемых нагрузок ИИ и HPC, включая Link Layer Retry (LLR), Credit-based Flow Control (CBFC) и AI Fabric Headers (AFH). Кроме того, непосредственно в ASIC реализована поддержка коллективных операций вроде AllReduce and AllGather. Используются измененные заголовки Ethernet, размер которых уменьшен с 46 до 10 байт: это позволяет оптимизировать общее соотношение размера заголовка к полезной нагрузке. Упомянута совместимость с современными топологиями сетей HPC, такими как Mesh, Torus и Dragonfly. Кроме того, заявлена совместимость с Ultra Ethernet (UEC). Поставки Tomahawk Ultra уже начались.
04.06.2025 [01:00], Владимир Мироненко
Broadcom представила самые быстрые в мире Ethernet-коммутаторы Tomahawk 6: 102,4 Тбит/с на чип и 1,6 Тбит/с на портКомпания Broadcom объявила о старте поставок серии чипов-коммутаторов Tomahawk 6 (BCM78910), первых Ethernet-коммутаторов, обеспечивающий коммутационную способность 102,4 Тбит/с, что вдвое выше возможностей Ethernet-коммутаторов, доступных на рынке. Сообщается, что благодаря невероятной возможности масштабирования, энергоэффективности и оптимизированным для ИИ функциям Tomahawk 6 нацелен на использование в крупных ИИ-кластерах. В случае вертикального масштабирования (scale-up) новинка позволяет объединить до 512 XPU в один кластер. В двухуровневых горизонтально масштабируемых (scale-out) сетях Tomahawk 6 может объединить более 100 тыс. XPU со скоростью 200GbE на каждое подключение. В целом же решение позволяет объединить до 1 млн XPU. Tomahawk 6 предлагает SerDes-блоки 100G/200G PAM с поддержкой «дальнобойных» пассивных медных подключений. Есть и вариант с интегрированными оптическими интерфейсами (CPO), который обеспечивает более высокую энергоэффективность, более низкий уровень задержки, а также повышенную стабильность работы. 
Источник изображений: Broadcom Встроенная технология Cognitive Routing 2.0 автоматически выявляет перегрузки и перенаправляет потоки данных по альтернативным маршрутам, что помогает избежать узких мест в производительности. Cognitive Routing 2.0 в Tomahawk 6 включает расширенную телеметрию, динамический контроль перегрузки, быстрое обнаружение сбоев и обрезку пакетов, что обеспечивает глобальную балансировку нагрузки и адаптивное управление потоком. Эти возможности адаптированы для современных рабочих ИИ-нагрузок, включая MoE-модели, тонкую настройку, обучение с подкреплением и рассуждающие модели.  «Tomahawk 6 — это не просто обновление, это прорыв, — заявил Рам Велага (Ram Velaga), старший вице-президент и генеральный менеджер подразделения Core Switching Group компании Broadcom. — Он знаменует собой поворотный момент в проектировании ИИ-инфраструктуры, объединяя самую высокую пропускную способность, энергоэффективность и адаптивные функции маршрутизации для scale-up и scale-out сетей в одной платформе». Tomahawk 6 поддерживает как стандартные топологии, например, сеть Клоза или тор, так и сети на базе фреймворка Broadcom Scale-Up Ethernet (SUE). 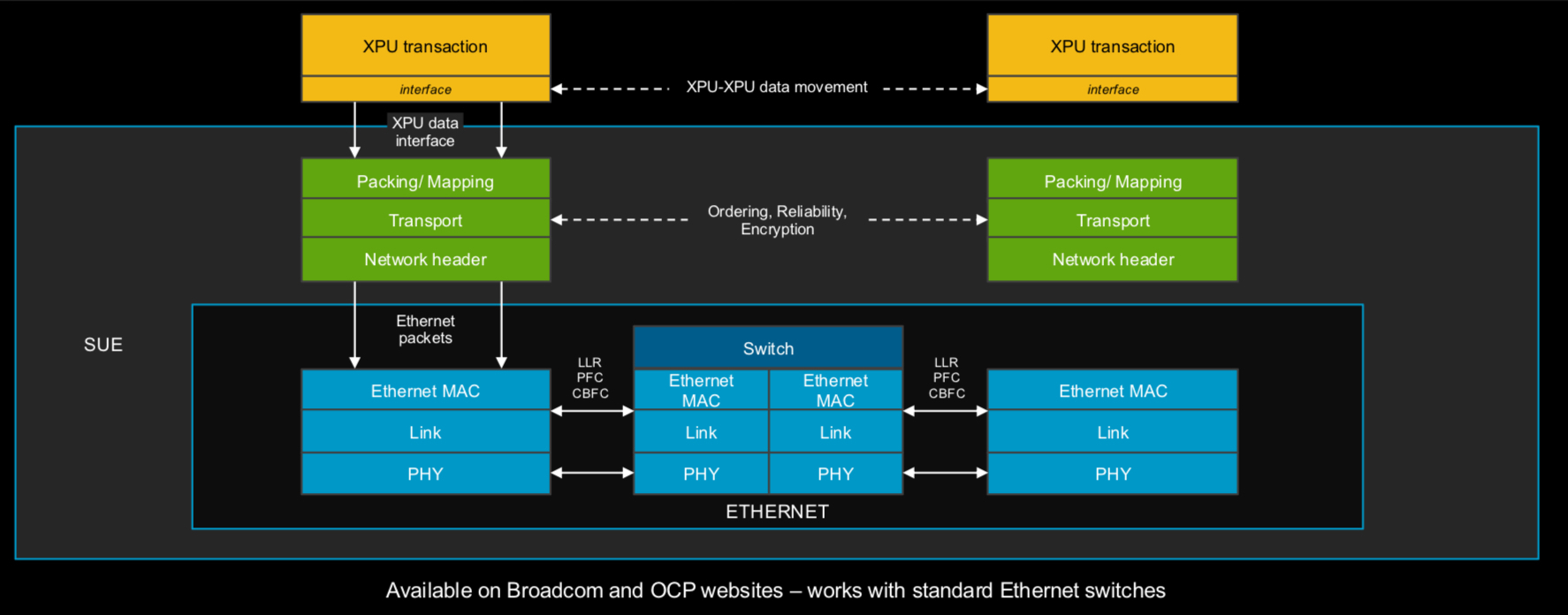 Компания отметила, что благодаря использованию 200G SerDes коммутатор обеспечивает самую большую дальность для пассивного медного соединения, что позволяет проектировать высокоэффективную систему с малой задержкой, высочайшей надежностью и самой низкой совокупной стоимостью владения (TCO). Возможные конфигурации портов: 64 × 1.6TbE, 128 × 800GbE, 256 × 400GbE, 512 × 200GbE. Но Tomahawk 6 предлагает и конфигурацию 1024 × 100GbE, т.е. высокоплотный и экономичный интерконнект на основе Ethernet. А поддержка CPO не просто избавляет от множества трансиверов, но и существенно сокращает связанные с ними перебои, что крайне важно для гиперскейлеров. 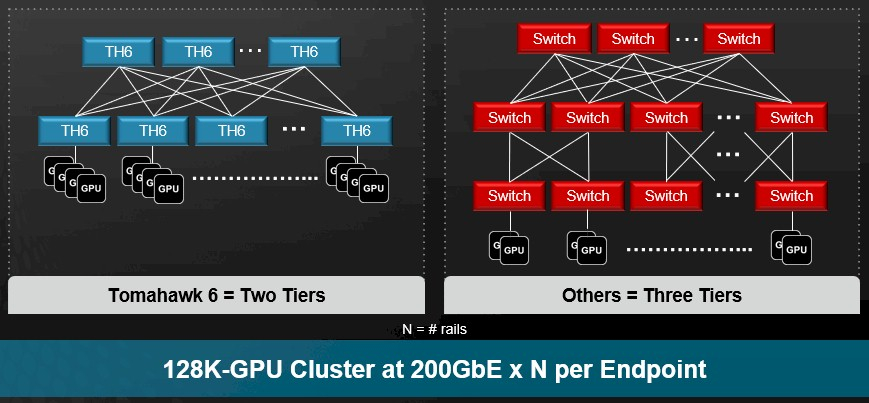 Использование Ethernet предоставляет операторам сетей значительные преимущества, позволяя им использовать единый технологический стек и согласованные инструменты во всей ИИ-инфраструктуре. Это также позволяет использовать взаимозаменяемые интерфейсы, с помощью которых облачные операторы могут динамически формировать кластеры XPU для различных рабочих нагрузок клиентов. Кроме того, Tomahawk 6 также соответствует требованиям Ultra Ethernet Consortium.
26.03.2025 [01:00], Владимир Мироненко
NVIDIA поделится с MediaTek фирменным интерконнектом NVLink для создания кастомных ASICMediaTek объявила о планах расширить сотрудничество с NVIDIA, интегрировав NVLink в разрабатываемые ей ASIC, сообщил ресурс DigiTimes. В свою очередь, ресурс smbom.com пишет, что партнёры намерены совместно разрабатывать передовые решения с использованием NVLink и 224G SerDes. Аналитики предполагают, что выход NVIDIA в сектор ASIC позволит ей ускорить дальнейшее продвижение на рынке с использованием опыта MediaTek и при этом решать имеющиеся проблемы. Как ожидают аналитики, по мере развития сотрудничества двух компаний всё больше провайдеров облачных услуг будет проявлять интерес к работе с MediaTek. Внедрение NVLink в ASIC MediaTek может значительно повысить привлекательность сетевых решений NVIDIA. Объединив усилия, NVIDIA и MediaTek смогут предложить комплексную разработку кастомных ASIC, которая будет включать поддержку HBM4e, обширную библиотеку IP-блоков, передовые процессы производства и упаковки. MediaTek отдельно подчеркнула, что её SerDes-блоки является ключевым преимуществом при разработке ASIC. 
Источник изображения: MediaTek Компании расширяют сотрудничество с ведущими мировыми производствами полупроводников, ориентируясь на передовые техпроцессы. Применяя технологию совместной оптимизации проектирования (DTCO), они стремятся достичь оптимального соотношения между производительностью, энергопотреблением и площадью (PPA). Сообщается, что несколько облачных провайдеров уже изучают объединённое IP-портфолио NVIDIA и MediaTek. 
Источник изображения: MediaTek По неофициальным данным, Google уже прибегла к услугам MediaTek при разработке 3-нм TPU седьмого поколения, которое поступит в массовое производство к III кварталу 2026 года. Ожидается, что переход на 3-нм процесс принесет MediaTek более $2 млрд дополнительных поступлений. По данным источников в цепочке поставок, восьмое поколение TPU перейдёт на 2-нм процесс TSMC, что вновь укрепит позиции MediaTek. Также прогнозируется, что предстоящий выход чипа GB10 совместной разработки NVIDIA и MediaTek, и долгожданного чипа N1x, значительно улучшат бизнес-операции MediaTek и ещё больше укрепят позиции компании в полупроводниковой отрасли. Эксперты отрасли считают, что MediaTek имеет все возможности для того, что стать ключевым бенефициаром роста спроса на ИИ-технологии, особенно для малых и средних предприятий.
28.01.2025 [00:14], Владимир Мироненко
Дороговизна и высокое энергопотребление ИИ-ускорителей NVIDIA открыли новые горизонты для Marvell и BroadcomВзрывной рост популярности ChatGPT и других решений на базе генеративного ИИ вызвал беспрецедентный спрос на вычислительные мощности, что привело к дефициту ИИ-ускорителей, пишет DIGITIMES. NVIDIA занимает львиную долю рынка ИИ-чипов, а ведущие поставщики облачных услуг, такие как Google, Amazon и Microsoft, активно занимаются проектами по разработке собственных ускорителей, стремясь снизить свою зависимость от внешних поставок. Всё большей популярностью у крупных облачных провайдеров пользуются ASIC, поскольку они стремятся оптимизировать чипы под свои конкретные требования, отметил DIGITIMES. ASIC обеспечивают высокую производительность и энергоэффективность в узком спектре задач, что делает их альтернативой универсальным ускорителям NVIDIA. Несмотря на доминирование NVIDIA на рынке, высокое энергопотребление её чипов в сочетании с высокой стоимостью позволило ASIC занять конкурентоспособную нишу. Особенно хорошо ASIC подходят для обучения и инференса ИИ-моделей, предлагая значительно более высокие показатели производительности в пересчёте на 1 Вт по сравнению с GPU общего назначения. Также ASIC предоставляют заказчикам больший контроль над своим технологическим стеком. На рынке разработки ASIC основными конкурентами являются Broadcom и Marvell, которые используют разные технологии и стратегические подходы. 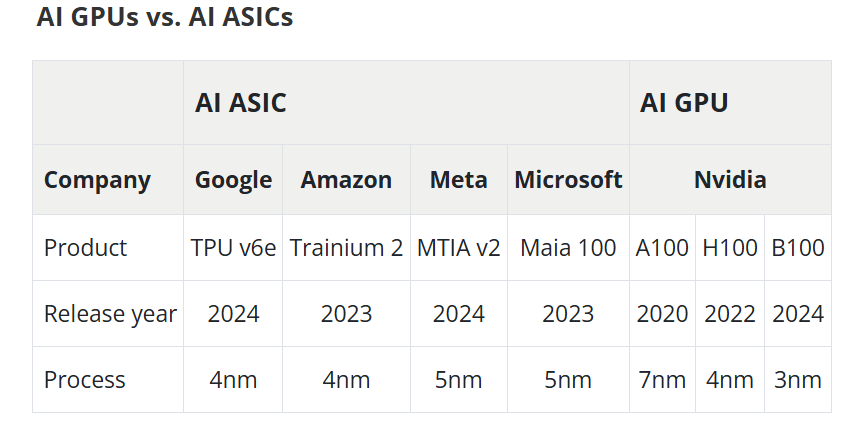
Источник изображений: DIGITIMES Marvell укрепила свои позиции на рынке, в частности, благодаря партнёрству с Google в разработке серверных Arm-чипов, расширив при этом стратегическое сотрудничество со своим основным клиентом — Amazon. TPU v6e от Google представляет собой самую передовую ASIC ИИ среди чипов, разработанных четырьмя ведущими облачными провайдерам, приближаясь по производительности к H100. Однако она всё ещё отстает от ускорителей NVIDIA примерно на два года, утверждает DIGITIMES. Созданный Marvell и Amazon ускоритель Trainium 2 по производительности находится между NVIDIA A100 и H100. В ходе последнего отчёта о финансовых результатах Marvell поделилась прогнозом значительного роста выручки от ASIC, начиная с 2024 года (2025 финансовый год), обусловленного Trainium 2 и Google Axion. В частности, совместный с Amazon проект Marvell Inferential ASIC предполагается запустить в массовое производство в 2025 году (2026 финансовый год), в то время как Microsoft Maia, как ожидается, начнет приносить доход с 2026 года (2027 финансовый год). 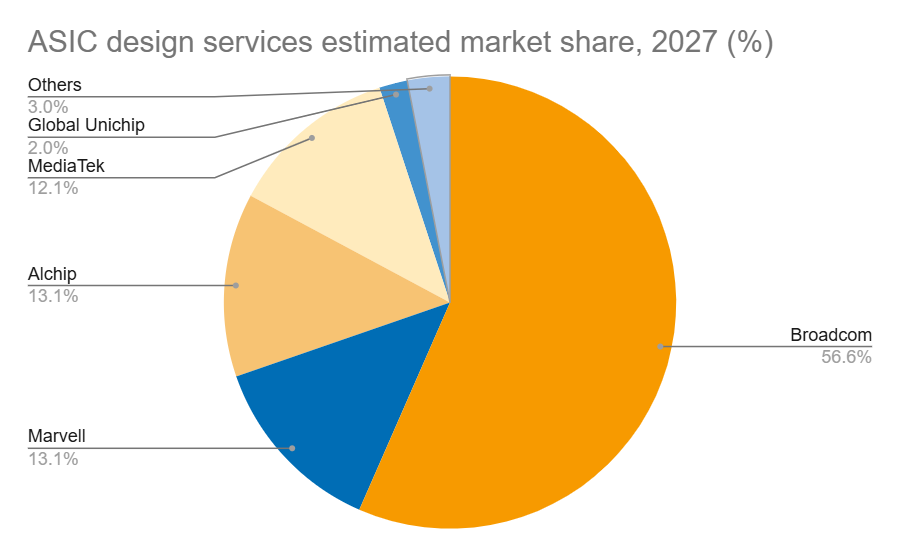 Как утверждают в Morgan Stanley, хотя бизнес Marvell по производству кастомных чипов является ключевым драйвером роста его подразделения по разработке решений для ЦОД, он также несёт в себе значительную неопределённость. Краткосрочные прогнозы Morgan Stanley для продуктов Marvell/Trainium положительны, что подтверждается возросшими мощностями TSMC по упаковке чипов методом CoWoS, планами Amazon по расширению производства и уверенностью Marvell в рыночном спросе. Однако в долгосрочной перспективе конкурентная среда создает проблемы. Появление компаний вроде WorldChip Electronics в секторе вычислительных чипов может заставить Marvell переориентироваться на сетевые решения. Кроме того, потенциальное снижение прибыли от Trainium после 2026 года означает, что Marvell нужно будет обеспечить запуск новых проектов для поддержания динамики роста, говорят аналитики. Broadcom и Marvell являют собой примеры разных стратегий развития в секторе ASIC, отмечает DIGITIMES. Broadcom отдаёт приоритет крупномасштабной интеграции и проектированию платформ, подкрепляя свой подход значительными инвестициями в НИОКР и сложной технологической интеграцией. В свою очередь, Marvell развивается за счёт стратегических приобретений, например, Cavium, Avera и Innovium, благодаря чему расширяет своё портфолио технологий. |
|


