Материалы по тегу: asic
|
20.01.2025 [07:53], Владимир Мироненко
SRAM, да и только: d-Matrix готовит ИИ-ускоритель CorsairСтартап d-Matrix создал ИИ-ускоритель Corsair, оптимизированный для быстрого пакетного инференса больших языковых моделей (LLM). Архитектура ускорителя основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости порядка 150 Тбайт/с. Новинка, по словам компании, отличается производительностью и энергоэффективностью, пишет EE Times. Массовое производство Corsair начнётся во II квартале. Среди инвесторов d-Matrix — Microsoft, Nautilus Venture Partners, Entrada Ventures и SK hynix. d-Matrix фокусируется на пакетном инференсе с низкой задержкой. В случае Llama3-8B сервер d-Matrix (16 четырёхчиплетных ускорителей в составе восьми карт) может производить 60 тыс. токенов/с с задержкой 1 мс/токен. Для Llama3-70B стойка d-Matrix (128 чипов) может производить 30 тыс. токенов в секунду с задержкой 2 мс/токен. Клиенты d-Matrix могут рассчитывать на достижение этих показателей для размеров пакетов порядка 48–64 (в зависимости от длины контекста), сообщила EE Times руководитель отдела продуктов d-Matrix Шри Ганесан (Sree Ganesan). 
Источник изображений: d-Matrix Производительность оптимизирована для исполнения моделей в расчёте до 100 млрд параметров на одну стойку. По словам Ганесан, это реалистичный сценарий использования LLM. В таких сценариях решение d-Matrix обеспечивает 10-кратное преимущество в интерактивности (время до получения токена) по сравнению с решениями на базе традиционных ускорителей, таких как NVIDIA H100. Corsair ориентирован на модели размером менее 70 млрд параметров, подходящих для генерации кода, интерактивной генерации видео или агентского ИИ, которые требуют высокой интерактивности в сочетании с пропускной способностью, энергоэффективностью и низкой стоимостью.  Ранние версии архитектуры d-Matrix использовали MAC-блоки на базе SRAM-ячеек, дополненных большим количеством транзисторов для операций умножения. Сложение же выполнялось в аналоговом виде с использованием разрядных линий, измерения тока и аналого-цифрового преобразования. В 2020 году компания выпустила чиплетную платформу Nighthawk на основе этой архитектуры. «[Nighthawk] продемонстрировал, что мы можем значительно повысить точность по сравнению с традиционными аналоговыми решениями, но мы всё ещё отстаем на пару процентных пунктов от традиционных решений типа GPU», — сказал EE Times генеральный директор d-Matrix Сид Шет (Sid Sheth). 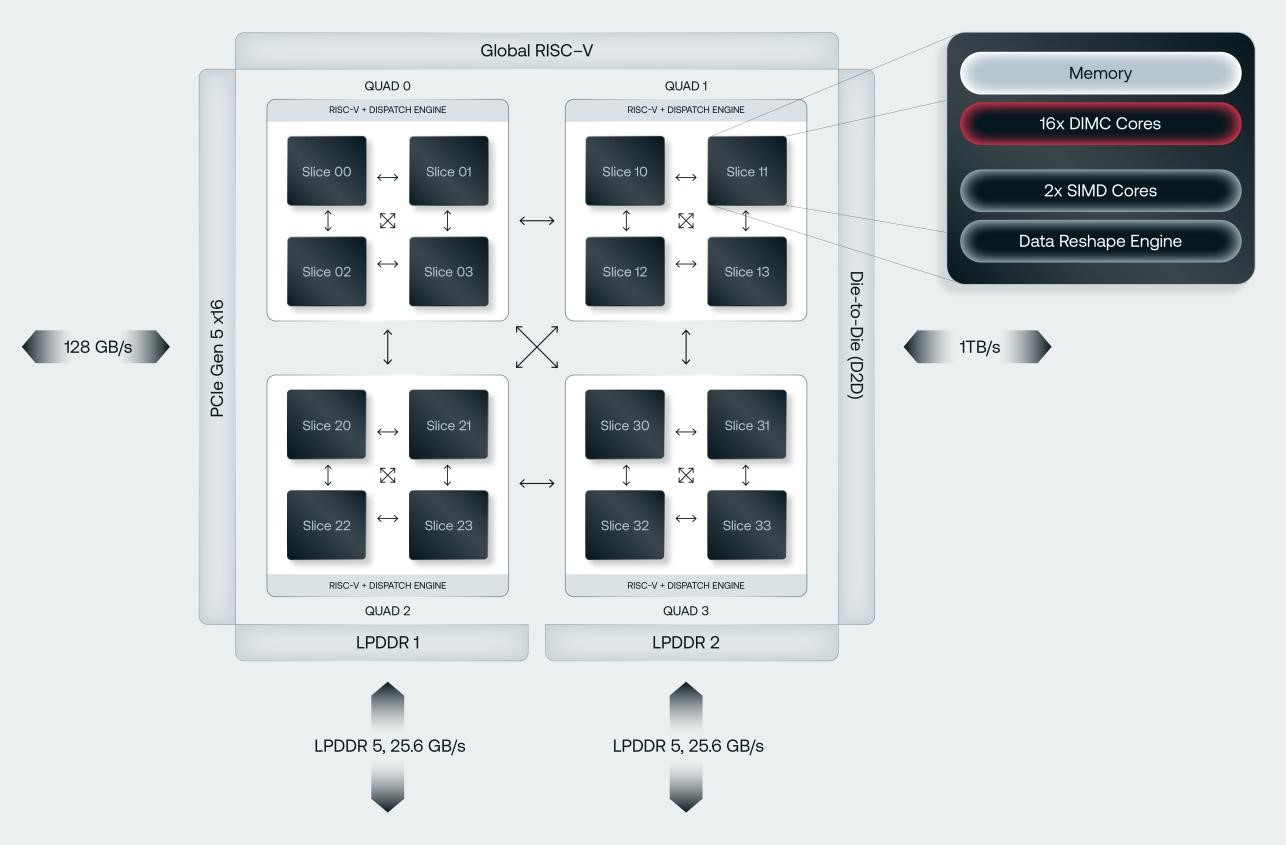 Однако потенциальным клиентам не понравилось, что при таком подходе возможно снижение точности, так что в Corsair компания вынужденно сделала выбор в пользу полностью цифрового сумматора. ASIC d-Matrix включает четыре чиплета, каждый из которых содержит по четыре вычислительных блока, объединённых посредством DMX Link по схеме каждый-с-каждым, и по одному планировщику и RISC-V ядру. Внутри каждого вычислительного блока есть 16 DIMC-ядер, состоящих из наборов SRAM-ячеек (64×64), а также два SIMD-ядра и движок преобразования данных. Суммарно доступен 1 Гбайт SRAM с пропускной способностью 150 Тбайт/с. 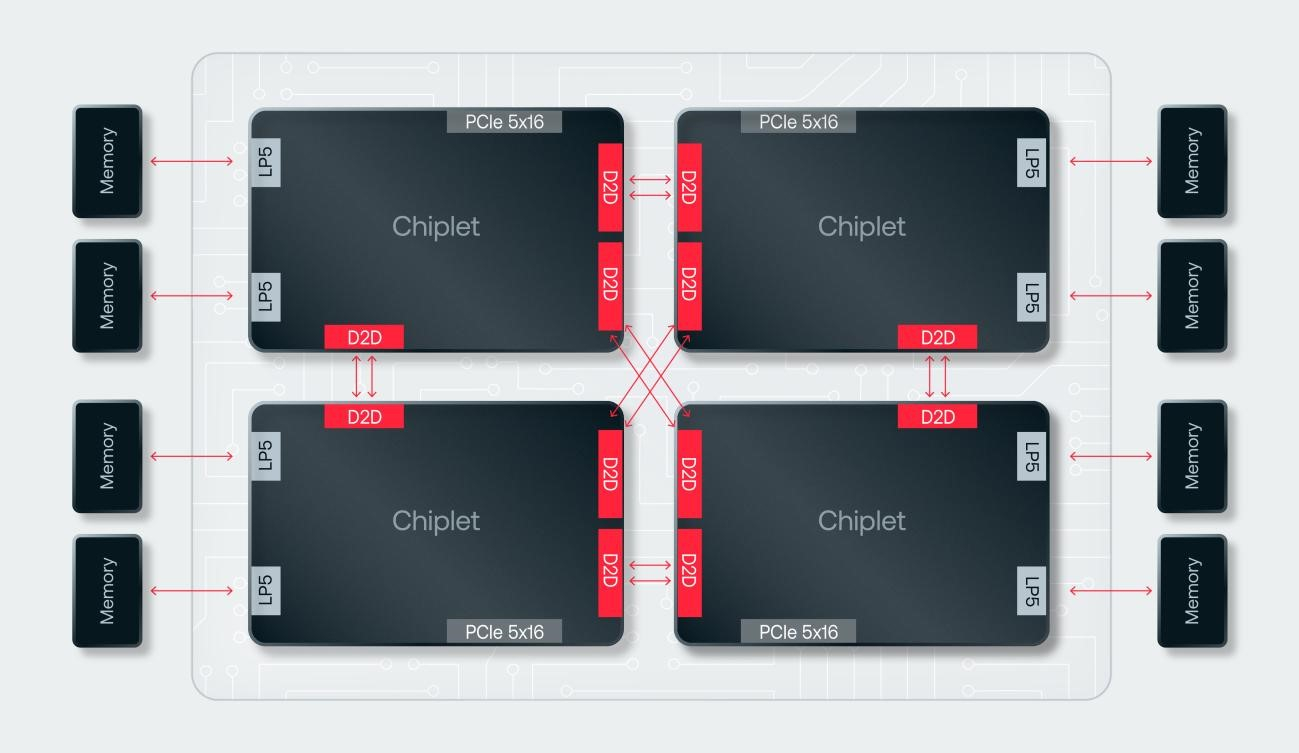 ASIC объединён со 128 Гбайт LPDDR5 (до 400 Гбайт/с) посредством органической подложки (без дорогостоящего кремниевого интерпозера). Хотя текущее поколение ASIC включает только четыре чиплета именно из-за ограничений подложки, в будущем их количество увеличится. Внешние интерфейсы ASIC представлены стандартным PCIe 5.0 x16 (128 Гбайт/с) и фирменным интерконнектом DMX Link (1 Тбайт/с) для объединения чиплетов. 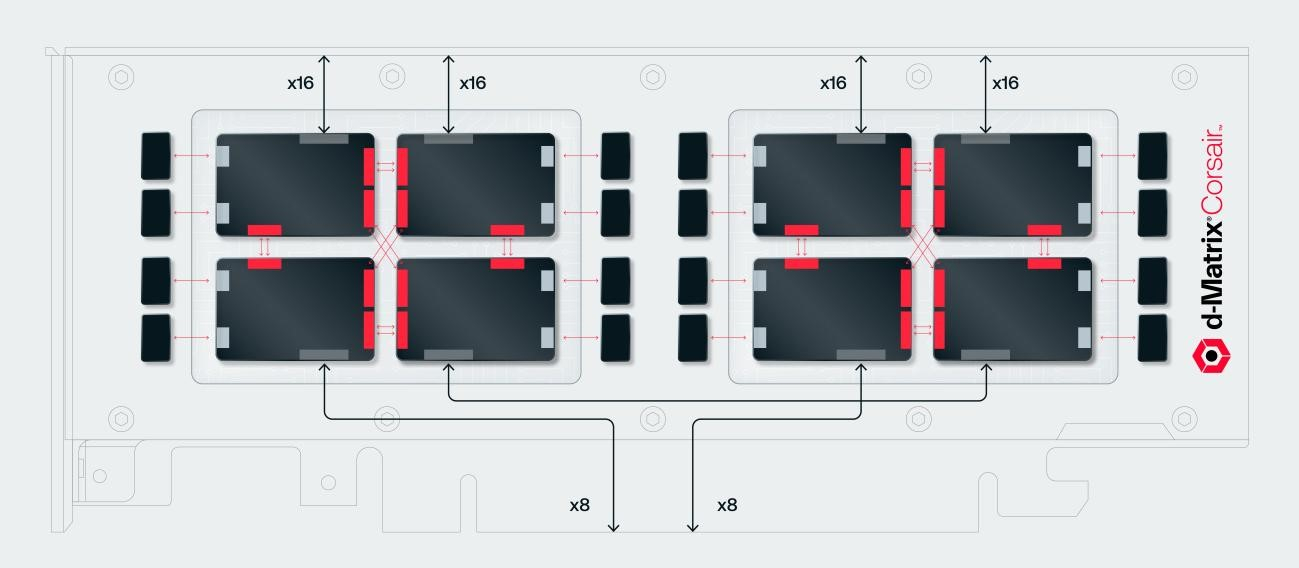 FHFL-карта Corsair включает два ASIC d-Matrix (т.е. всего восемь чиплетов) и имеет TDP на уровне 600 Вт. Ускоритель работает с форматами данных OCP MX (Microscaling Formats) и обеспечивает до 2400 Тфлопс в MXINT8-вычислениях или 9600 Тфолпс в случае MXINT4. Две карты Corsair можно объединить посредством 512-Гбайт/с мостика DMX Bridge. Их, по словам компании, достаточно для задействования тензорного параллелизма. Дальнейшее масштабирование возможно посредством PCIe-коммутации. Именно поэтому d-Matrix работает с GigaIO и Liqid. В одно шасси можно поместить восемь карт Corsair, а в стойку, которая будет потреблять порядка 6–7 кВт — 64 карты. 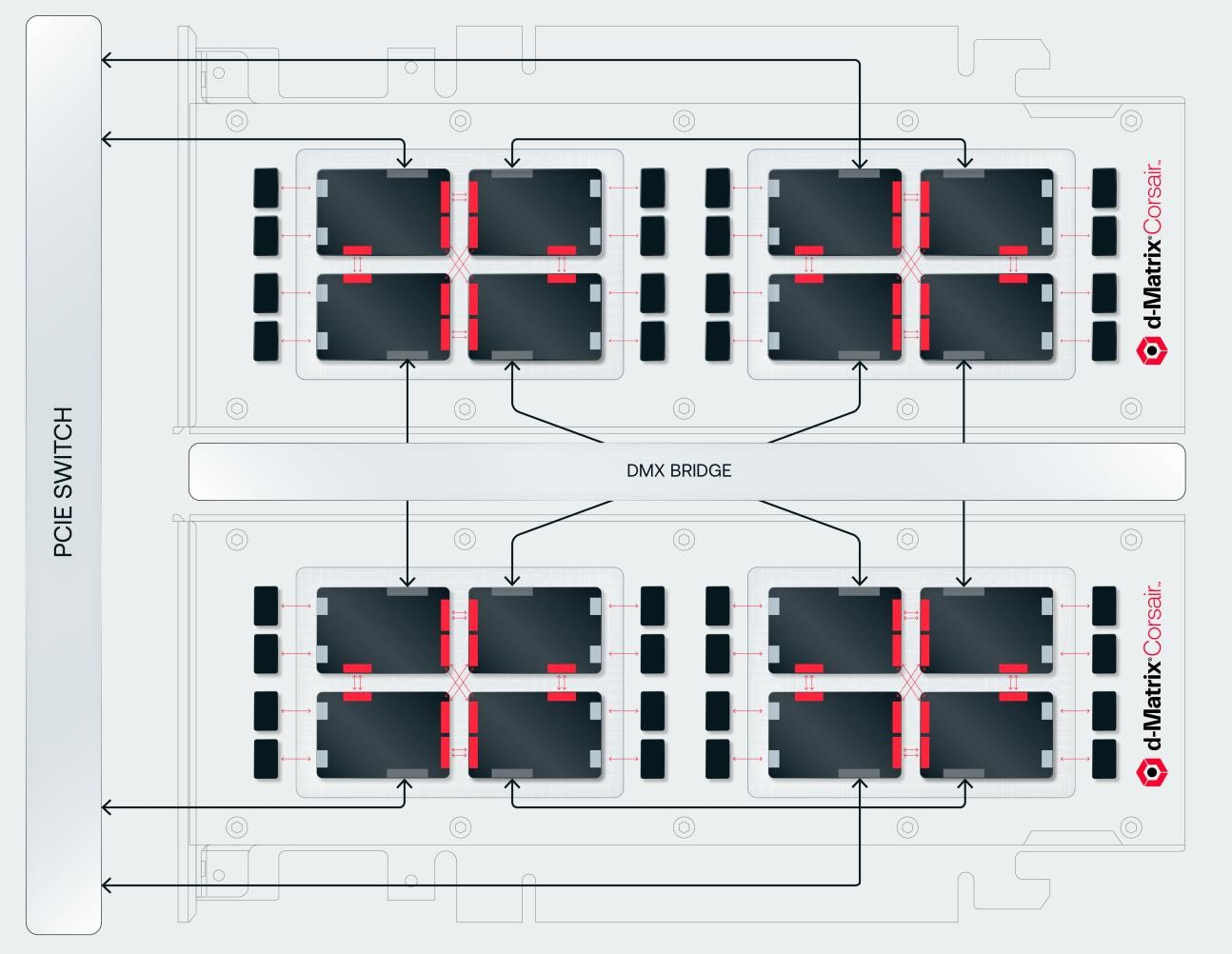 d-Matrix уже разрабатывает ASIC следующего поколения Raptor, который должен выйти в 2026 году. Raptor будет ориентирован на «думающие» модели и получит ещё больше памяти за счёт размещения DRAM непосредственно поверх вычислительных чиплетов. SRAM-чиплеты Raptor также перейдут с 6-нм техпроцесса TSMC, который используется при изготовлении Corsair, к 4 нм без существенных изменений микроархитектуры. По словам компании, она потратила два года на работу с TSMC, чтобы создать 3D-упаковку для нового поколения ASIC. 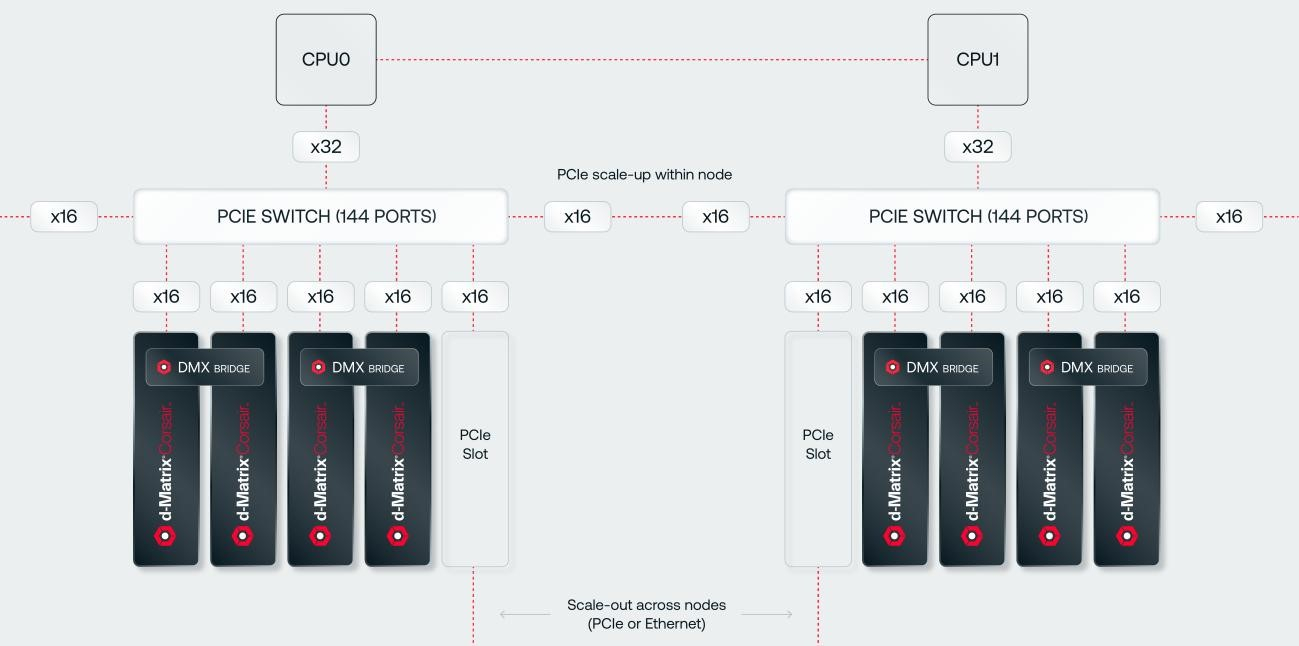 Как отмечает EETimes, команда разработчиков ПО d-Matrix в два раза больше команды разработчиков оборудования (120 против 60). Стратегия компании в области ПО заключается в максимальном использовании open source экосистемы, включая PyTorch, OpenAI Triton, MLIR, OpenBMC и т.д. Вместе они образуют программный стек Aviator, который отвечает за конвертацию моделей в числовые форматы d-Matrix, применяет к ним фирменные методы разрежения, компилирует их, распределяет нагрузку по картам и серверам, а также управляет исполнением моделей, включая обслуживание большого количества запросов.
06.01.2025 [15:39], Владимир Мироненко
NVIDIA начала переманивать тайваньских специалистов для будущего центра по разработке ASICТайваньскому изданию Commercial Times стало известно о планах NVIDIA создать подразделение для разработки специализированных ASIC. В публикации газеты сообщается, что американская компания выбрала Тайвань в качестве базы для своего центра исследований и разработок, и сейчас она активно переманивает квалифицированные кадры из крупных местных компаний по проектированию интегральных схем (ИС), что вызвало опасения у руководства отрасли по поводу потенциальной утечки мозгов. По данным источников Commercial Times, в тайваньских фирмах по производству ИС, в середине 2024 года был отмечен резкий рост предложений с целью переманивания талантов. Поскольку NVIDIA запускает центр исследований и разработок ASIC, она может усилить попытки по переманиванию квалифицированных кадров, что вынуждает крупные компании, включая MediaTek, Alchip Technologies и дочернюю компанию TSMC GUC, принимать ответные меры в рамках подготовки к предстоящему противостоянию. Источник изображения: NVIDIA Как отметил ресурс TrendForce, технологические гиганты активно занимаются разработкой альтернатив ускорителям NVIDIA, чтобы ослабить свою зависимость от неё. В июле 2024 года Apple сообщила, что ее ИИ-модели для Apple Intelligence были обучены на Google TPU. А в декабре старший директор Apple по машинному обучению и искусственному интеллекту Бенуа Дюпен (Benoit Dupin) сообщил, что компания будет также использовать для обучения ИИ чипы Amazon Trainium2. А сейчас Apple совместно с Broadcom работает над созданием собственного серверного ИИ-ускорителя. Реагируя на этот тренд, NVIDIA создаёт собственный центр ASIC, расширяя спектр своих услуг, пишет Commercial Times. Согласно её публикации, компания планирует нанять на Тайване более тысячи специалистов в таких областях, как проектирование микросхем, разработка ПО, а также исследования и разработки в сфере ИИ. С учётом того, что тайваньские компании по выпуску ASIC сыграли важную роль в разработке Microsoft Cobalt и Maia, Google TPU и кастомных чипов AWS, это делает их специалистов идеальными целями для привлечения, отметила Commercial Times.
31.10.2024 [14:56], Владимир Мироненко
DIGITIMES Research: в 2024 году Google увеличит долю на рынке кастомных ИИ ASIC до 74 %Согласно отчету DIGITIMES Research, в 2024 году глобальные поставки ИИ ASIC собственной разработки для ЦОД, как ожидается, достигнут 3,45 млн единиц, а доля рынка Google вырастет до 74 %. Как сообщают аналитики Research, до конца года Google начнёт массовое производство нового поколения ИИ-ускорителей TPU v6 (Trillium), что ещё больше увеличит её присутствие на рынке. В 2023 году доля Google на рынке ИИ ASIC собственной разработки для ЦОД оценивалась в 71 %. В отчёте отмечено, что помимо самой высокой доли рынка, Google также является первым из трёх крупнейших сервис-провайдеров в мире, кто разработал собственные ИИ-ускорители. Первый TPU компания представила в 2016 году. Ожидается, что TPU v6 будет изготавливаться с применением 5-нм процесса TSMC, в основном с использованием 8-слойных чипов памяти HBM3 от Samsung. Также в отчёте сообщается, что Google интегрировала собственную архитектуру оптического интерконнекта в кластеры TPU v6, позиционируя себя в качестве лидера среди конкурирующих провайдеров облачных сервисов с точки зрения внедрения технологий и масштаба развёртывания. Google заменила традиционные spine-коммутаторы на полностью оптические коммутаторы Jupiter собственной разработки, которые позволяют значительно снизить энергопотребление и стоимость обслуживания ИИ-кластеров TPU POD по сравнению с решениями Broadcom или Mellanox. 
Источник изображения: cloud.google.com Кроме того, трансиверы Google получил ряд усовершенствований, значительно нарастив пропускную способность. Если в 2017 году речь шла о полнодуплексном 200G-решении, то в этом году речь идёт уже о 800G-решениях с возможностью модернизации до 1,6T. Скорость одного канала также существенно выросла — с 50G PAM4 в 2017 году до 200G PAM4 в 2024 году.
26.06.2024 [01:00], Игорь Осколков
Etched Sohu — самый быстрый в мире ИИ-ускоритель, но только для трансформеровСтартап Etched, основанный в 2022 году выпускниками Гарварда, анонсировал самый быстрый, по его словам, ИИ-ускоритель Sohu. Секрет высокой производительности очень прост — Sohu представляет собой узкоспециализированный 4-нм ASIC, который умеет работать только с моделями-трансформерами. При этом в длинном анонсе новинки обещана чуть ли не революция в мире ИИ. Etched прямо говорит, что делает ставку на трансформеры, и надеется, что не прогадает. Данная архитектура ИИ-моделей была создана в недрах Google в 2017 году, но сама Google распознать её потенциал, по-видимому, вовремя не смогла. Сейчас же, по словам Etched, практически все массовые ИИ-модели являются именно трансформерами, а стремительно набирать популярность этот подход начал всего полтора года назад с выходом ChatGPT, хотя в Etched «предугадали» важность трансформеров ещё до выхода детища OpenAI. 
Источник изображений: Etched Etched в целом справедливо отмечает, что подавляющее большинство ИИ-ускорителей умышленно создаётся так, чтобы быть достаточно универсальными и уметь работать с различными типами и архитектурами ИИ-моделей. Это ведёт к взрывному росту транзисторного бюджета и уменьшению общей эффективности. Так, по словам Etched, загрузка ускорителя на базе GPU работой на практике составляет около 30 %, а у Sohu она будет на уровне 90 %.  Тут есть некоторое лукавство, потому что Etched в основном говорит о «больших» ускорителях, ориентированных и на обучение тоже, тогда как Sohu предназначен исключительно для инференса. На практике же бывают и гибридные подходы. Например, у AWS есть не только Trainium, но Inferentia. Meta✴ использует чипы NVIDIA для обучения, но для инференса разрабатывает собственные ускорители MTIA. Cerebras практически отказалась от инференса, а Groq — от обучения моделей. Корректнее было бы сравнить именно инференс-ускорители, пусть даже никто из упомянутых Etched конкурентов не ориентирован исключительно на трансформеры. 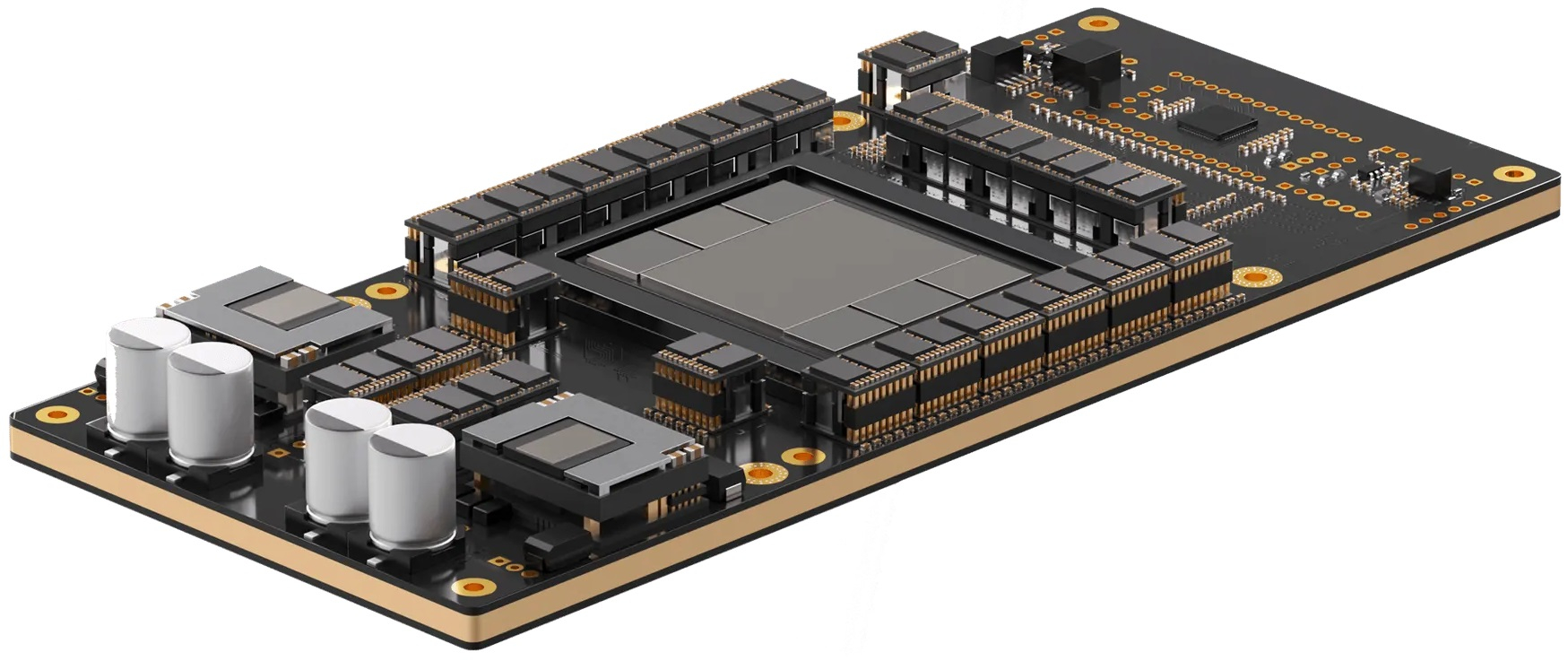 Также стартап критикует громоздкую программную экосистему для современного генеративного ИИ, к тому же не всегда открытую. Важность оптимизации ПО хороша видна на примере NVIDIA TensorRT-LLM. Но крупным компаниям этого мало, они готовы вкладывать немало средств в глубокую оптимизацию, чтобы ещё чуть-чуть повысить производительность. Дело доходит до выяснения того, у какого регистра задержка меньше при работе с каким тензорным ядром, говорит Etched. Стартап обещает, что его заказчикам не придётся заниматься такими изысканиями — весь программный стек будет open source. Впрочем, на примере AMD ROCm видно, что открытость ещё не означает мгновенный успех у пользователей. 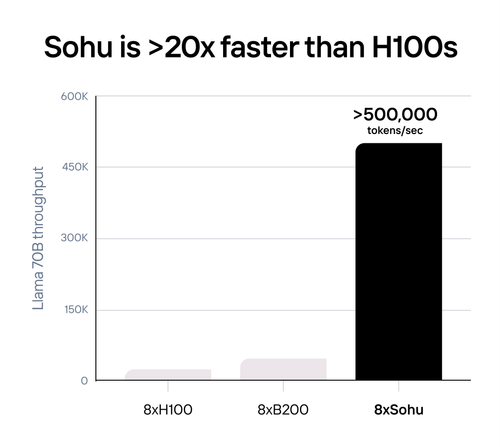 Технические характеристики Sohu не раскрываются. Явно говорится лишь о наличии 144 Гбайт HBM3e. Обещанная производительность сервера с восемью ускорителями Sohu составляет 500 тыс. токенов в секунду для Llama 70B: FP8 без разреженности, параллелизм на уровне модели, 2048 токенов на входе и 128 токенов на выходе. Иными словами, один такой сервер Sohu заменяет сразу 160 ускорителей NVIDA H100, говорит Etched. А вот про масштабируемость своих платформ компания пока ничего не говорит. Зато хвастается, что первые заказчики уже зарезервировали Sohu на десятки миллионов долларов.
19.05.2023 [10:00], Сергей Карасёв
Meta✴ анонсировала чип MSVP для ускорения обработки видеоКомпания Meta✴ представила специализированный чип MSVP, или Meta✴ Scalable Video Processor, спроектированный для ускорения выполнения операций, связанных с обработкой видеоматериалов. Это могут быть задачи по транскодированию роликов или потоковая передача контента. По данным Meta✴, пользователи соцсети Facebook✴ тратят 50 % своего времени на просмотр в общей сложности примерно 4 млрд видеороликов ежедневно. Эти материалы сжимаются после загрузки, а затем преобразовываются в другие форматы и передаются пользователям. Сложность заключается в том, чтобы быстро уменьшить размер файла, сохранить его на серверах Facebook✴ и передать в потоковом режиме с максимально возможным качеством для того или иного устройства, например, смартфона, планшета или ПК. 
Источник изображения: Meta✴ Эти задачи берёт на себя процессор MSVP. Он представляет собой интегральную схему специального назначения (ASIC). Чип предназначен для высококачественного транскодирования материалов для сервисов «видео по запросу», а также для оптимизации потоковых трансляций. В перспективе подобные процессоры, как ожидается, помогут организовать работу с видеороликами, созданными посредством генеративного ИИ. Кроме того, такие чипы будут использоваться в составе платформ AR/VR. Решение MSVP обеспечивает производительность транскодирования на уровне 4K@15в максимальном качестве в режиме «один поток на входе и пять на выходе». В стандартном качестве возможна работа в формате 4K@60.
19.04.2023 [22:00], Алексей Степин
Broadcom представила чип-коммутатор Jericho3-AI для ИИ-платформ, попутно раскритиковав NVIDIAКомпания Broadcom, один из ведущих поставщиков «кремния» для сетевых решений, анонсировала новый сетевой процессор Jerico3-AI, который ориентирован на ИИ-системы. Более того, Broadcom считает подход NVIDIA к «интеллектуальным сетевым решениям» с использованием InfiniBand неверным и даже вредным для кластерных ИИ-систем. Ethernet-коммутаторы компании можно разделить три ветви: наиболее высокопроизводительные чипы Tomahawk, ориентированная на дополнительные возможности ветвь Trident и, наконец, серия Jericho, отличающаяся наибольшей гибкостью в программировании и располагающая более ёмкими буферами. Чип Jericho3-AI BCM88890 — новинка в последней категории, относящаяся к классу 28,8 Тбит/с. Новый коммутатор имеет 144 линка SerDes (106Gbps, PAM4) и может работать в конфигурации 18×800GbE, 36×400GbE или 72×200GbE. 
Источник здесь и далее: Broadcom (via ServeTheHome) В своей презентации Broadcom раскритиковала традиционный подход NVIDIA и других крупных игроков на сетевом рынке, заявив о том, что прямое наращивание пропускной способности и снижение латентности кластерной сети якобы является тупиковой ветвью развития. Вместо этого фабрика на базе Jericho3-AI, по словам компании, позволяет сделать так, чтобы процесс обучения нейросети как можно меньше времени тратил не сетевые операции.  Новый коммутатор обеспечивает идеальную балансировку загрузки, гарантирующую отсутствие заторов, и автоматическое переключение отказавшего соединения на резервное менее, чем за 10-нс, а также позволяет создавать большие «плоские» сети (до 32 тыс. портов 800GbE), характерные для ИИ-кластеров. Каждый ускоритель может получить 800G-подключение, а суммарная производительность фабрики на базе новых коммутаторов может достигать 26 Пбит/с. 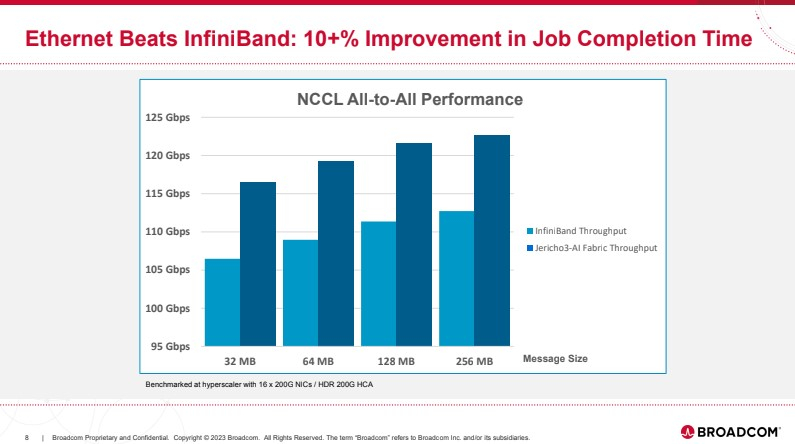 Broadcom утверждает, что сеть Ethernet на базе Jericho3-AI превосходит аналогичную по классу сеть NVIDIA InfiniBand в тестах с использованием NCCL. При этом новый коммутатор не содержит никаких вычислительных мощностей общего назначения — он проще, а за счёт использования стандарта Ethernet сети на его основе универсальны, что также снижает стоимость владения инфраструктурой.  Высокая степень интегрированности обеспечит и большую экономичность, а значит, решения на базе нового коммутатора Broadcom окажутся и более дружелюбны к экологии. Новые чипы уже доступны избранным клиентам Broadcom.
09.11.2021 [12:17], Алексей Степин
NVIDIA представила Quantum-2, первый 400G-коммутатор InfiniBand NDRNVIDIA, нынешний владелец Mellanox, представила обновления своих решений InfiniBand NDR: коммутаторы Quantum-2, сетевые адаптеры ConnectX-7 и ускорители DPU BlueField-3. Это весьма своевременный апдейт, поскольку 400GbE-решения набирают популярность, а с приходом PCIe 5.0 в серверный сегмент станут ещё более актуальными. 
NVIDIA Quantum-2 (Здесь и ниже изображения NVIDIA) Первый и самый важный анонс — это платформа Quantum-2. Новый коммутатор не только обеспечивает вдвое более высокую пропускную способность на порт (400 Гбит/с против 200 Гбит/c), но также предоставляет в три раза больше портов, нежели предыдущее поколение. Это сочетание позволяет снизить потребность в коммутаторах в 6 раз при той же суммарной ёмкости сети. При этом новая более мощная инфраструктура также окажется более экономичной и компактной.  Более того, Quantum-2 относится к серии «умных» устройств и содержит в 32 раза больше акселераторов, нежели Quantum HDR первого поколения. В нём также реализована предиктивная аналитика, позволяющая избежать проблем с сетевой инфраструктурой ещё до их возникновения; за это отвечает технология UFM Cyber-AI. Также коммутатор предлагает синхронизацию времени с наносекундной точностью, что важно для распределённых нагрузок.  7-нм чип Quantum-2 содержит 57 млрд транзисторов, то есть он даже сложнее A100 с 54 млрд транзисторов. В стандартной конфигурации чип предоставляет 64 порта InfiniBand 400 Гбит/с, однако может работать и в режиме 128 × 200 Гбит/с. Коммутаторы на базе нового сетевого процессора уже доступны у всех крупных поставщиков серверного оборудования, включая Inspur, Lenovo, HPE и Dell Technologies. Возможно масштабирование вплоть 2048 × 400 Гбит/с или 4096 × 200 Гбит/с. 
NVIDIA ConnectX-7 Конечные устройства для новой инфраструктуры InfiniBand доступны в двух вариантах: это относительно простой сетевой адаптер ConnectX-7 и куда более сложный BlueField-3. В первом случае изменения, в основном, количественные: новый чип, состоящий из 8 млрд транзисторов, позволил вдвое увеличить пропускную способность, равно как и вдвое же ускорить RDMA и GPUDirect. 
NVIDIA BlueField-3 DPU BlueField-3, анонсированный ещё весной этого года, куда сложнее с его 22 млрд транзисторов. Он предоставляет гораздо больше возможностей, чем обычный сетевой адаптер или SmartNIC, и крайне важен для будущего развития инфраструктурных решений NVIDIA. Начало поставок ConnectX-7 намечено на январь, а вот BlueField-3 появится только в мае 2022 года. Оба адаптера совместимы с PCIe 5.0. |
|

