Материалы по тегу: коммутатор
|
23.04.2026 [22:49], Владимир Мироненко
Cisco представила прототип универсального квантового коммутатораCisco Systems представила прототип универсального сетевого коммутатора для квантовых систем Cisco Universal Quantum Switch, позволяющий соединять квантовые компьютеры разных производителей, а также квантовые датчики различных типов в единую когерентную сеть, путём перемещения запутанных фотонов с сохранением их квантового состояния. Устройство преобразует все основные режимы квантовой запутанности и кодирования и работает при комнатной температуре, на телекоммуникационных частотах, по стандартному оптоволоконному кабелю, не требует криогенной среды или специальной инфраструктуры. Исследователи и предприятия уже используют квантовые компьютеры в качестве дополнительных сопроцессоров для решения конкретных, математически сложных задач, которые недоступны для классических суперкомпьютеров. Одна из самых актуальных проблем, стоящих перед квантовыми вычислениями, связана с масштабированием. Большинство квантовых систем могут взаимодействовать с другими системами, использующими только тот же режим кодирования. Для того чтобы получить систему на миллионы кубитов, что необходимо для обеспечения научных прорывов, нужно или изыскать возможность создания более крупных и мощных квантовых компьютеров или найти способ соединения вместе нескольких квантовых компьютеров, возможно, от разных вендоров, подобно тому, как классические компьютеры соединяются в ЦОД, чтобы они функционировали как единое целое. 
Источник изображений: Cisco Cisco выбрала второй путь. Универсальный коммутатор использует запатентованную Cisco систему преобразования, которая преобразует различные режимы кодирования, используемые различными квантовыми технологиями на входе и выходе. Квантовые системы в основном используют четыре основных метода кодирования: поляризационное, временное, частотное и траекторное, и они используют различные схемы запутанности поверх них. Универсальный квантовый коммутатор Cisco разработан для поддержки всех четырёх модальностей и динамически переключается между ними, позволяя системам с различными физическими архитектурами взаимодействовать без изменения их работы. Cisco заявила, что на данный момент система протестирована с поляризацией, которая использует ориентацию фотонов для передачи информации.  Как отметил ресурс SiliconANGLE, преобразование модальностей обеспечивает реальную гетерогенность как для квантовых компьютеров, так и для квантовых датчиков. Квантовый процессор на основе нейтральных атомов может взаимодействовать с квантовым процессором на основе захваченных ионов, который, в свою очередь, может взаимодействовать с фотонным датчиком или сенсором на основе нейтральных атомов через тот же коммутатор. Квантовые ЦОД и сети квантовых датчиков, построенные таким образом, могут развиваться и интегрировать новые технологии по мере их появления, не будучи ограниченными единым стандартом модальности или архитектурой. В настоящее время квантовая индустрия развивается в нескольких направлениях. Производители создают различные типы квантовых систем, и на данный момент неизвестно, какой аппаратный подход и метод кодирования будет преобладать, и какая экосистема станет доминирующей. Поэтому создание универсального коммутатора крайне важно.  Коммутатор Cisco Universal Quantum Switch разработан с учётом реальных условий ЦОД, с целью интеграции в уже существующую инфраструктуру. За пределами ЦОД, по словам Cisco, текущая дальность действия коммутатора составляет до 100 км, хотя утверждается, что со временем расстояние перестанет быть ограничивающим фактором. Компания отметила, что коммутатор является частью масштабной инициативы Cisco Quantum Labs по созданию квантовых сетей, охватывающей все уровни — от чипов и протоколов до приложений. В прошлом году Cisco представила прототип специализированного сетевого квантового чипа для генерации запутанных фотонов, позволяющий масштабировать квантовые системы, объединяя квантовые процессоры в единую инфраструктуру.
22.04.2026 [10:45], Сергей Карасёв
Foxconn наладит массовое производство CPO-коммутаторов в III квартале 2026 годаТайваньский контрактный производитель электроники Foxconn начал пробные поставки коммутаторов с интегрированной оптикой CPO (Co-Packaged Optics). Об этом, как сообщает DigiTimes, рассказал Брэнд Ченг (Brand Cheng), председатель совета директоров Foxconn Industrial Internet (FII) — подразделения, которое специализируется на сетевых продуктах для облачных платформ. По его словам, отгрузки образцов CPO-коммутаторов FII организовала в I квартале 2026-го, тогда как их массовое производство запланировано на III четверть текущего года. Ожидается, что спрос на такое оборудование будет стремительно расти. По данным отраслевых исследований, продажи CPO-коммутаторов увеличатся с примерно 23 тыс. единиц в 2026 году до более чем 200 тыс. штук в 2030-м. Таким образом, прогнозируемый показатель CAGR (среднегодовой темп роста в сложных процентах) составляет 144 %. Как отмечает Ченг, FII рассчитывает на годовой объём продаж CPO-коммутаторов более 10 тыс. штук. По оценкам компании, выпуск таких устройств обеспечит существенно более высокую валовую прибыль по сравнению с нынешними продуктами 400–800G. Подчёркивается, что экосистема технологий CPO развивается в комплексе с архитектурами NVIDIA QuantumX и SpectrumX, а также Broadcom Tomahawk. Речь идёт о проектировании специализированных чипсетов и оптических компонентов, внедрении передовых технологий упаковки, системной интеграции и пр. По сложности такие решения значительно превосходят традиционные сетевые устройства. 
Источник изображения: Foxconn Ченг также сообщил о масштабировании производства ИИ-ускорителей NVIDIA GB200 и GB300. Кроме того, наблюдается рост заказов на выпуск ASIC-изделий со стороны крупнейших облачных провайдеров: ожидается, что отгрузки таких продуктов значительно увеличатся во II половине года. Ченг подчеркнул, что более 60 % основных элементов серверных ИИ-стоек теперь производится собственными силами. Компания сформировала необходимые запасы компонентов, в том числе чипов памяти, для выполнения заказов в сфере ИИ, включая выпуск GB200 и GB300. В 2025 году выручка FII составила ¥902,89 млрд ($132,36 млрд), что на 48,2 % больше, чем годом ранее. При этом чистая прибыль поднялась на 51,99 %, достигнув ¥35,286 млрд ($5,17 млрд). Выручка в облачном сегменте составила ¥602,679 млрд ($88,35 млрд), увеличившись на 88,7 % в годовом исчислении: на неё пришлось почти 70 % от общего объёма поступлений.
13.04.2026 [13:05], Сергей Карасёв
Aria Networks представила «думающую» сетевую платформу Deep Networking для высокоэффективных ИИ-инфраструктурКомпания Aria Networks анонсировала сетевую платформу Deep Networking, призванную повысить эффективность работы ИИ-систем. Предложенное решение объединяет специализированное коммутационное оборудование, сетевую ОС SONiC, высокоточную телеметрию на коммутаторах, трансиверах и сетевых картах, а также ИИ-алгоритмы на разных уровнях вычислительной инфраструктуры. Стартап Aria Networks основан в январе 2025 года Мансуром Карамом (Mansour Karam), учредителем фирмы Apstra, которую в 2019-м приобрёл американский производитель сетевого оборудования Juniper Networks. Aria Networks занимается разработкой высокопроизводительных решений, сочетающих возможности стандартного Ethernet со специализированным ПО для управления большим количеством модульных коммутаторов как единой системой. На сегодняшний день стартап привлёк в общей сложности $125 млн инвестиций от Sutter Hill Ventures, Atreides Management, Valor Equity Partners и Eclipse Ventures. Идея Deep Networking заключается в том, чтобы рассматривать сеть в качестве активного участника кластера ИИ, а не в роли пассивного слоя. Это достигается путём сбора детальной телеметрии с коммутационных ASIC, внедрения интеллектуальных агентов на каждом уровне и постоянного распространения обновлений ПО через облако. 
Источник изображений: Aria Networks В качестве ключевых показателей быстродействия Aria Networks рассматривает MFU (уровень утилизации оборудования при обучении) и Token Efficiency (эффективность токенов). Первый параметр отражает, какой процент от теоретической максимальной производительности ИИ-ускорителя (пиковых FLOPS) реально тратится на полезные вычисления для обучения или инференса. В свою очередь, эффективность токенов показывает, уровень MFU или время на обработку одного токена. Основное техническое преимущество Deep Networking заключается в получении детализированной телеметрии. Традиционные инструменты мониторинга сети собирают данные постфактум — с относительно невысокой точностью. Решение Aria Networks обрабатывает телеметрию в реальном времени непосредственно с ASIC. Благодаря этому обеспечивается адаптивная настройка параметров DLB (динамическая балансировка нагрузки) и DCQCN (механизм управления перегрузками). 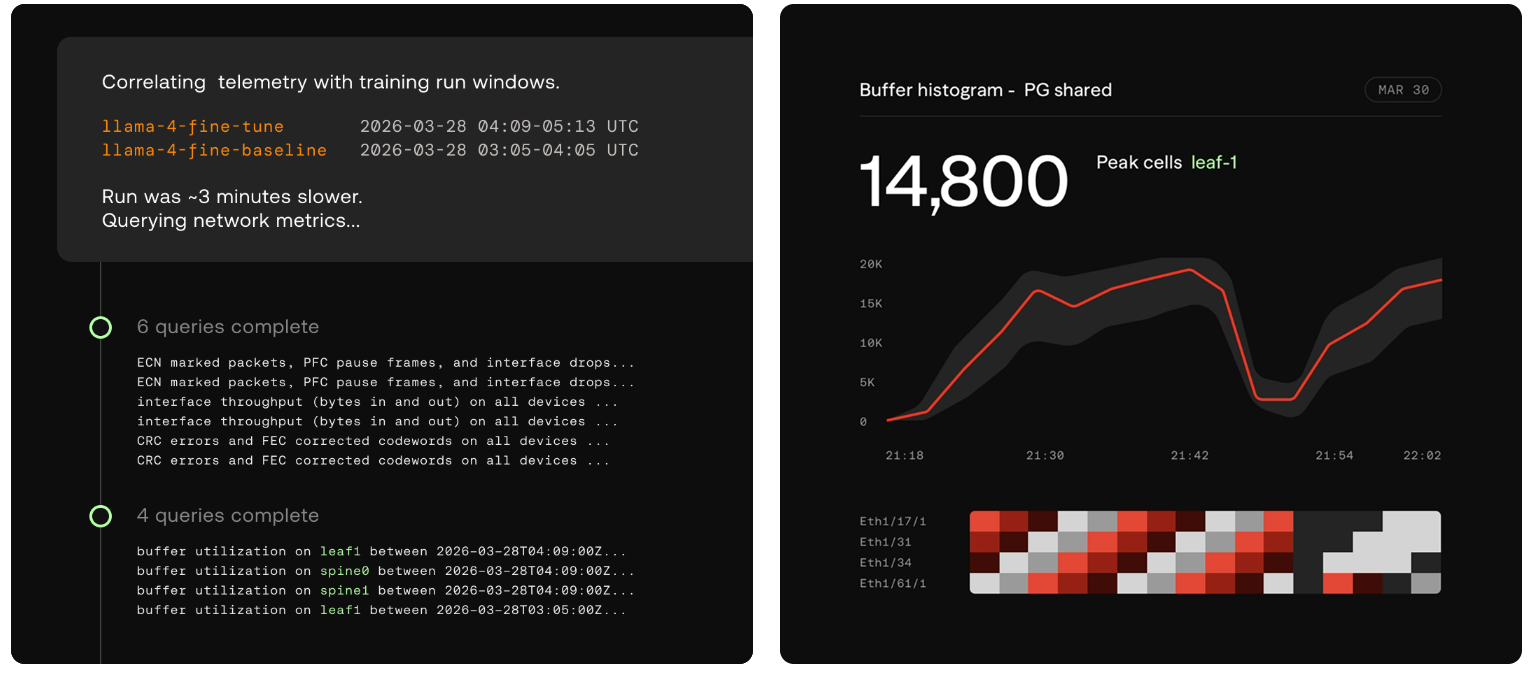 Сама платформа Deep Networking имеет многоуровневую архитектуру. На самых нижних уровнях ИИ-агенты в течение микросекунд реагируют на такие события, как сбои в работе трансиверов, перенаправляя трафик между коммутаторами. На более высоких уровнях принимаются стратегические решения о перераспределении потоков в кластере. Кроме того, внешние системы, например, планировщики заданий и маршрутизаторы, могут напрямую запрашивать сведения о состояние сети и интегрировать их в процесс принятия собственных решений. С аппаратной точки зрения инфраструктура Deep Networking базируется на коммутаторах Aria Switch 800G, Aria Switch 1.6T High Radix и Aria Switch 1.6T, оснащённых чипами Broadcom. Платформа непрерывно настраивает каждый аспект сетевой инфраструктуры для конкретного обслуживаемого ИИ-кластера без ручного вмешательства, что сводит к минимуму задержки и устраняет ошибки, обусловленные человеческим фактором. Администраторам достаточно указать свои потребности, после чего платформа соответствующим образом оптимизирует сеть. При этом система постоянно оценивает состояние сети и в режиме реального времени принимает меры для обеспечения наилучшей производительности и бесперебойной работы. 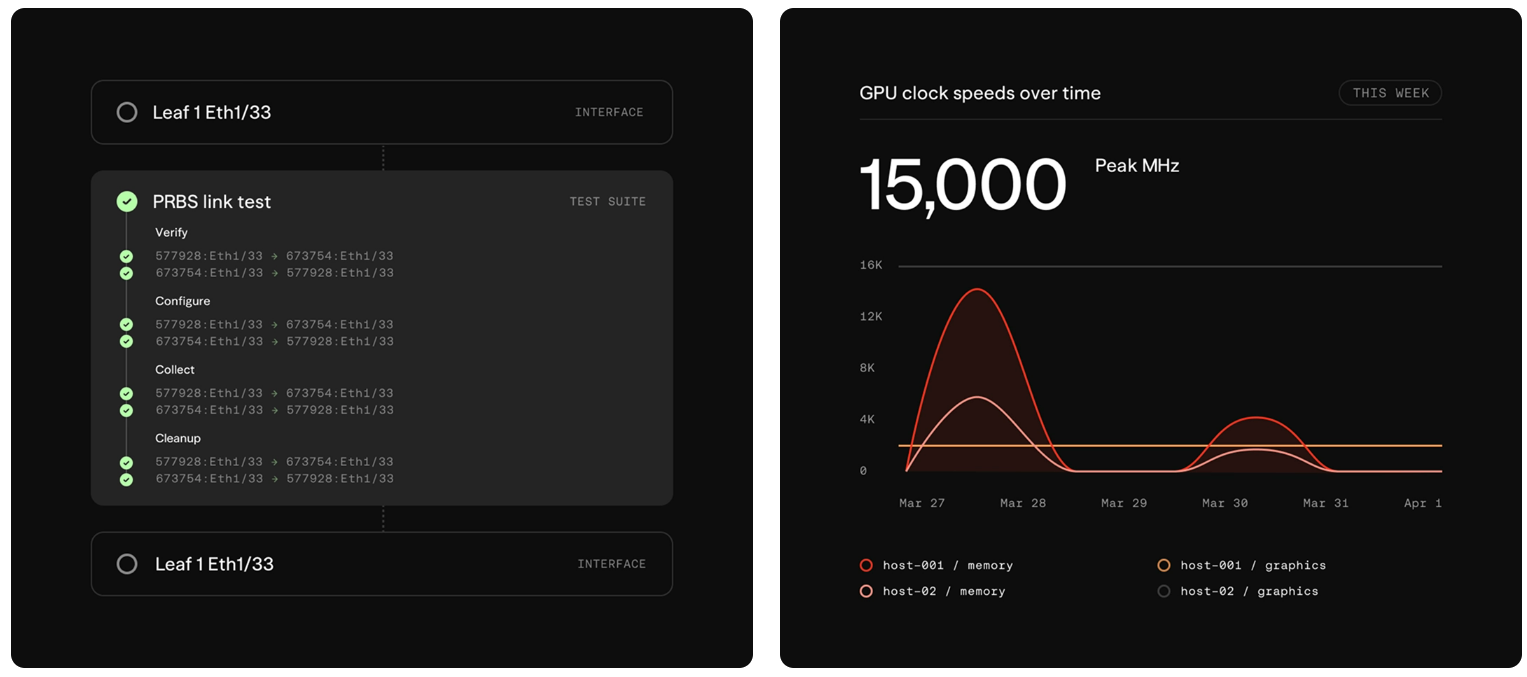 Aria Networks утверждает, что один неисправный сетевой адаптер в кластере из 10 тыс. XPU может снизить показатель MFU на 1,7 %. А сбой трансивера способен спровоцировать некорректную переадресацию трафика, что приведёт к существенным финансовым потерям. Архитектура Deep Networking позволяет эффективно решать подобные проблемы, одновременно улучшая производительность. Так, повышение MFU на 3 % в кластере из 10 тыс. XPU, по оценкам стартапа, приводит к увеличению годовой выручки на $49,8 млн.
02.04.2026 [11:43], Сергей Карасёв
QNAP выпустила управляемый коммутатор QSW-M7230-2X4F24T с портами 100GbE QSFP28Компания QNAP Systems расширила ассортимент коммутаторов, анонсировав модель QSW-M7230-2X4F24T, которая ориентирована на корпоративные сети, высокопроизводительные среды хранения данных, платформы виртуализации и инфраструктуры ИИ. Новинка, как утверждается, обеспечивает оптимальный баланс производительности, масштабируемости и экономической эффективности. Устройство относится к управляемым коммутаторам уровня L3 Lite. Новинка выполнена в форм-факторе 1U. Имеется внутренний блок питания, а диапазон рабочих температур простирается от 0 до +40 °C. 
Источник изображения: QNAP Systems В общей сложности реализованы 30 сетевых портов, включая два разъёма 100GbE QSFP28, четыре разъёма 25GbE SFP28 и 24 коннектора 10GbE RJ45. Такая конфигурация, по заявлениям QNAP, позволяет формировать магистральные соединения 100GbE, восходящие каналы 25GbE для серверов и NAS, а также подключения 10GbE для рабочих станций и агрегирующих коммутаторов. В результате, компании могут развёртывать высокоскоростные каналы 25GbE или 100GbE, сохраняя при этом существующую базовую архитектуру 10GbE: это снижает сложность модернизации и продлевает срок службы всей сетевой инфраструктуры. Общая неблокируемая пропускная способность составляет 540 Гбит/с, коммутационная способность — 1080 Гбит/с. Предусмотрена поддержка PFC (Priority Flow Control) и ECN (Explicit Congestion Notification) в средах RDMA и RoCE, что обеспечивает стабильно низкую задержку даже при обработке больших потоков трафика от серверов и NAS. Говорится о совместимости с AMIZcloud — централизованной облачной платформой QNAP для удалённого мониторинга и управления. На новинку предоставляется двухлетняя гарантия.
25.03.2026 [11:46], Сергей Карасёв
Nerpa разработала новую IP-фабрику для ЦОД и облаковРоссийский IT-бренд Nerpa, созданный в 2020 году компанией OCS Distribution, анонсировал новую IP-фабрику — современную архитектуру для построения высокопроизводительных сетей в дата-центрах и облачных инфраструктурах. Она позволяет объединять различные устройства, серверы и СХД в единую производительную экосистему. В основу решения положена архитектура Clos — многоступенчатая топология сети, разработанная для обеспечения высокой пропускной способности без блокировок. Подчёркивается, что в отличие от традиционной трёхуровневой схемы «ядро — агрегация — доступ», такая модель обеспечивает равномерное распределение нагрузки и устойчивую работу сети даже при росте трафика и масштабировании инфраструктуры. В состав IP-фабрики входят коммутаторы Nerpa HC DC (98), HC DC (685) и HC DC (557). Две первые модели спроектированы для работы в дата-центрах и облачных инфраструктурах. В свою очередь, изделие HC DC (557) играет роль управляющего элемента фабрики. Устройство на базе ASIC поддерживает двухстековое управление, статическую маршрутизацию и расширенные функции безопасности. Все коммутаторы оснащены uplink-портами с пропускной способностью до 400 Гбит/с. 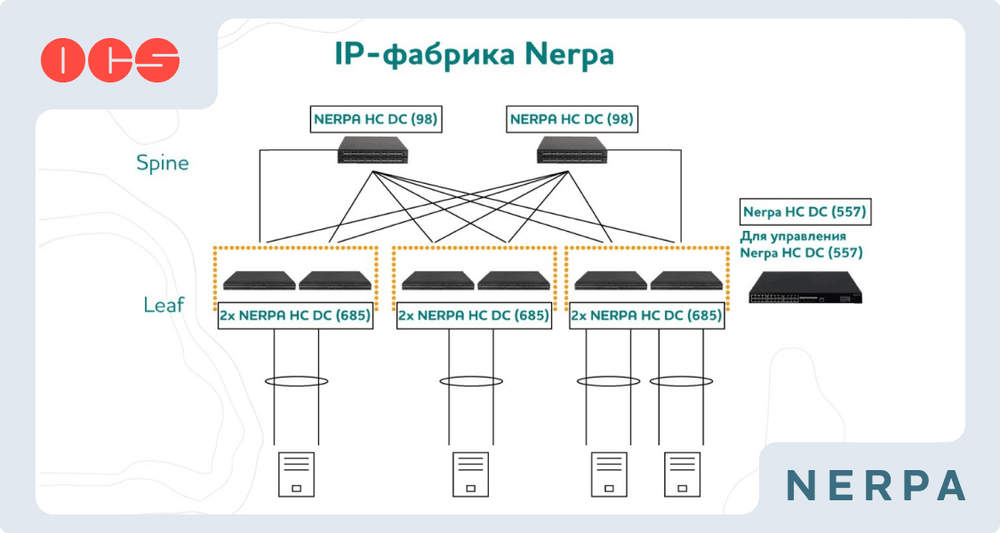
Источник изображения: Nerpa Разработчик отмечает, что IP-фабрика упрощает управление адресацией, позволяет гибко сегментировать трафик и ускоряет развёртывание виртуальных сервисов. Говорится о совместимости с серверами Nerpa, оснащёнными Ethernet-адаптерами. Упомянута поддержка протоколов VXLAN, EVPN и MLAG. На IP-фабрику Nerpa предоставляется гарантия сроком 1 год с возможностью расширения до 3 лет. Среди потенциальных заказчиков названы операторы связи, облачные провайдеры, владельцы корпоративных ЦОД и интеграторы, реализующие проекты по строительству дата-центров, говорит компания.
24.03.2026 [08:50], Сергей Карасёв
Marvell представила коммутатор Structera S 60260 с поддержкой 260 линий PCIe 6.0Компания Marvell Technology анонсировала коммутатор Structera S 60260 — это, как утверждается, первое в отрасли решение с поддержкой 260 линий PCIe 6.0. Новинка предназначена для использования в дата-центрах, ориентированных на ресурсоёмкие задачи ИИ. Одновременно компания представила и коммутатор Structera S 30260 с поддержкой 260 линий CXL 3.0. Marvell отмечает, что современные ИИ ЦОД оперируют серверами с большим количеством GPU и ускорителей других типов. На этом фоне критически важным элементом становятся коммутационные системы на основе PCIe, способные обеспечить высокую плотность вычислений и максимально эффективное использование доступных ресурсов. В традиционных инфраструктурах применяется множество коммутаторов, что приводит к увеличению энергопотребления, задержек и общей стоимости владения. Изделие Structera S 60260 позволяет решить эти проблемы. 
Источник изображения: Marvell Новинка базируется на разработках компании XConn Technologies, которую Marvell приобрела в начале текущего года за $540 млн. XConn специализируется на разработке передовых коммутаторов PCIe и CXL: в частности, с 2022 года она поставляет коммутаторы с 256 линиями PCIe 5.0. В случае решения Structera S 60260 количество линий PCIe 6.0 практически в два раза больше, чем у сопоставимых по классу продуктов конкурентов. «Коммутатор Structera S PCIe оптимизирован для обеспечения лучших в отрасли показателей производительности, гибкости, задержки и энергоэффективности при работе с ресурсоёмкими приложениями, включая ИИ, задачи машинного обучения следующего поколения и НРС», — говорит Джерри Фан (Gerry Fan), старший вице-президент Marvell. Благодаря объединению коммутаторов Structera S PCIe с ретаймерами Marvell Alaska P PCIe гиперскейлеры и операторы ИИ ЦОД получают комплексную платформу интерконнекта на основе PCIe. При использовании активных электрических кабелей (AEC) протяжённость соединений PCIe 6.0 может достигать 7 м, а при использовании активных оптических кабелей — превышать 7 м. Изделия Structera S PCIe совместимы по выводам с новыми коммутаторами Marvell Structera S CXL 3.0. Поставки тестовых образцов Structera S PCIe 6.0 уже начались. Отгрузки коммерческих коммутаторов Structera S PCIe 60260 клиентам будут организованы в III квартале 2026 года.
16.02.2026 [09:35], Сергей Карасёв
Мировой рынок оптических коммутаторов к 2029 году достигнет $2,5 млрд, но львиная доля всё равно придётся на GoogleИсследовательская компания Cignal AI повысила прогноз по глобальному рынку оптических коммутаторов (OCS). Связано это с ускоренным развёртыванием кластеров ИИ на базе тензорных ускорителей (TPU) Google. Аналитики пришли к выводу, что сектор OCS имеет гораздо больший потенциал, нежели предполагалось ранее. Google применяет оптические коммутаторы собственной разработки Apollo на базе MEMS-переключателей для формированя ИИ-кластеров. По заявлениям Google, решения OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Cignal AI полагает, что объём мирового рынка OCS в 2026 году окажется в три раза больше, чем ожидалось ранее. Прогноз на 2029 год повышен более чем на 40 % по сравнению с цифрами, опубликованными в декабре: аналитики считают, что к этому времени продажи оптических коммутаторов увеличатся как минимум до $2,5 млрд. 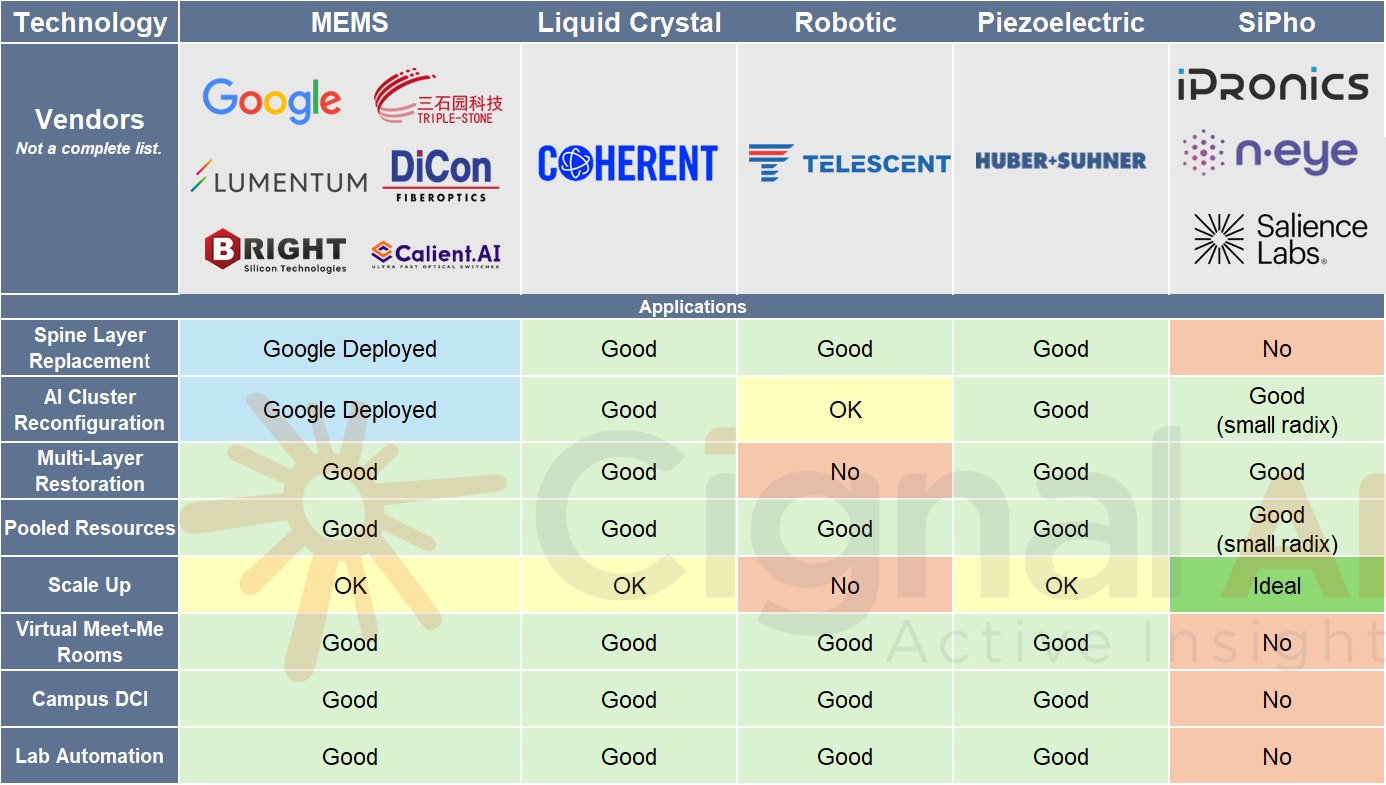
Источник изображения: Cignal AI Предполагается, что до конца десятилетия большинство развёртываний OCS будут по-прежнему сосредоточены в инфраструктуре Google. При этом в ЦОД на основе GPU-ускорителей применение OCS окажется ограниченным: связано это с тем, что в таких экосистемах переход на оптические коммутаторы сопряжён со значительными техническими сложностями. В целом, внедрение OCS за пределами дата-центров Google пока находится на стадии проверки концепции и раннего тестирования. «Общий потенциал рынка, безусловно, исчисляется миллиардами долларов, но основная часть краткосрочных инвестиций останется в пределах внутренних проектов Google», — говорит Скотт Уилкинсон (Scott Wilkinson), ведущий аналитик Cignal AI. Ранее эксперименты в этом направлении проводила Meta✴. Впрочем, не так давно в рамках OCP появилась отдельный проект OCS (Optical Circuit Switching), направленный на ускорение внедрения технологий оптической коммутации в ИИ ЦОД, что потенциально может ускорить развитие рынка.
10.02.2026 [18:34], Владимир Мироненко
Cisco представила 102,4-Тбит/с чип-коммутатор Silicon One G300Cisco представила 102,4-Тбит/с чип-коммутатор Silicon One G300, способный обеспечивать работу ИИ-кластеров гигаваттного масштаба для обучения, инференса и агентных рабочих нагрузок в реальном времени. По словам компании, новинка позволяет на треть повысить утилизацию имеющейся пропускной способности и снизить время обучения на 28 % в сравнении с альтернативнами решениями с многопутевой доставкой пакетов, передаёт The Register. G300 является конкурентом решениям Broadcom Tomahawk 6 и NVIDIA Spectrum-X Ethernet. Как и они, G300 содержит 512 блоков SerDes 200G. Огромное количество портов (radix) позволяет G300 поддерживать развёртывание до 128 тыс. GPU используя всего 750 коммутаторов, тогда как ранее требовалось 2500. SerDes можно и объединить для реализации портов 1,6 Тбит/с. Cisco также представила OSFP-трансиверы на 1,6 Тбит/с. Сообщается, что G300 предлагает уникальную интеллектуальную коллективную сеть, которая сочетает в себе ведущий в отрасли полностью общий буфер пакетов, балансировку нагрузки на основе путей и проактивную сетевую телеметрию, обеспечивая лучшую производительность и прибыльность для крупных ЦОД. «Отсутствует сегментация буферов пакетов, что позволяет пакетам поступать и обрабатываться независимо от порта. Это означает, что вы можете лучше справляться с пиковыми нагрузками», — сказал Ракеш Чопра (Rakesh Chopra), старший вице-президент Cisco. 
Источник изображения: Cisco Агент балансировки нагрузки «отслеживает потоки, проходящие через G300. Он отслеживает точки перегрузки и взаимодействует со всеми остальными G300 в сети, создавая своего рода глобальную коллективную карту того, что происходит во всем кластере ИИ», — добавил он. G300 также является программируемым, благодаря чему клиенты смогут добавлять новые сетевые функции после развёртывания по мере развития стандартов. Cisco также представила новые фиксированные и модульные коммутационные системы Nexus 9000 и Cisco 8000 на базе G300, «разработанные для экстремальных требований к энергопотреблению и теплоотводу для рабочих ИИ-нагрузок». Новые системы будут доступны как с воздушным, так и с полностью жидкостным охлаждением. Компания заявила, что конфигурация с СЖО обеспечивает значительно более высокую плотность портов и может повысить энергоэффективность почти на 70 % по сравнению с предыдущими поколениями, обеспечивая ту же пропускную способность в одной системе, для которой ранее требовалось шесть систем предыдущего поколения. 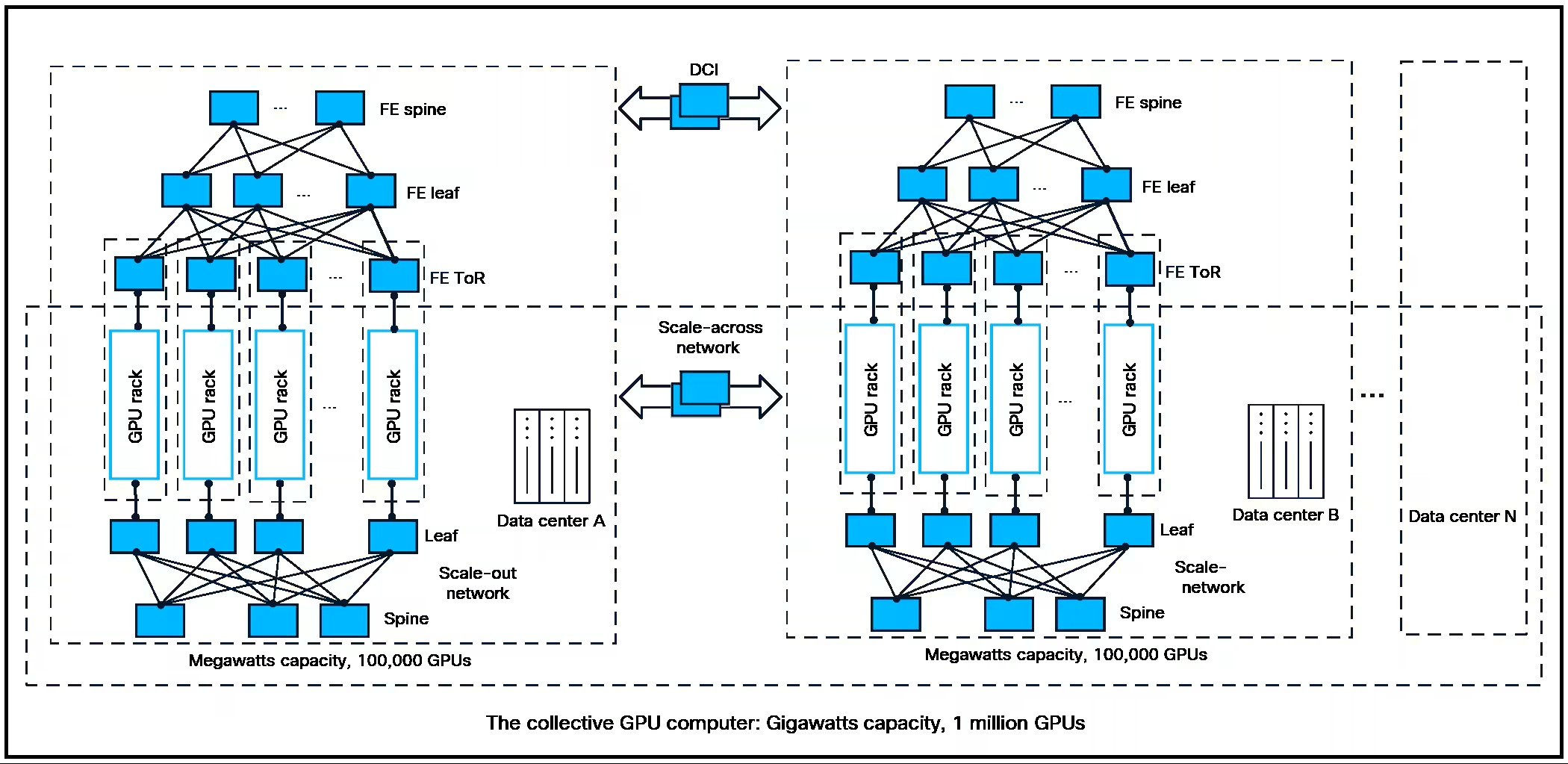
Источник изображения: Cisco Cisco представила эти системы как ответ на расширяющуюся ИИ-экосистему, в которой потребности в инфраструктуре ИИ больше не ограничиваются гипескейлерами. Вместо этого предприятия, неооблака и суверенные облачные операторы всё чаще инвестируют в собственные ИИ-кластеры и требуют более эффективной сетевой инфраструктуры для поддержки ресурсоёмких задач, отметил ресурс SiliconANGLE. «Последние два-три года мы в основном были сосредоточены на создании масштабных кластеров для обучения с гиперскейлерми, — рассказал Кевин Вольтервебер (Kevin Wolterweber), старший вице-президент и гендиректор подразделения ЦОД и интернет-инфраструктуры Cisco. — Сейчас мы наблюдаем сдвиг в сторону агентных задач ИИ и более широкое внедрение в корпоративных поставщиках услуг и среди более широкой клиентской базы». Коммутаторы Nexus работают под управлением ПО NX-OS компании Cisco — модульной сетевой операционной системы на базе Linux, разработанной для коммутаторов ЦОД серии Nexus и устройств хранения данных Multilayer Director Switch. Модели 8000 также могут поддерживать альтернативные сетевые операционные системы, включая open source платформу Sonic.
07.02.2026 [14:07], Сергей Карасёв
Broadcom представила первые в отрасли решения Wi-Fi 8 для точек доступа и коммутаторов корпоративного классаКомпания Broadcom анонсировала изделия BCM49438 и Trident X3+ BCM56390. Это, как утверждается, первые в отрасли решения для точек доступа и коммутаторов Wi-Fi 8 корпоративного класса, построенные на единой кремниевой архитектуре. Они могут применяться в сетях, ориентированных на работу с ИИ. Broadcom BCM49438 — это чип APU (Accelerated Processing Unit), который объединяет вычислительные ресурсы, сетевые функции и ускорение ИИ-операций на периферии. Изделие содержит четыре ядра с архитектурой Armv8 и нейропроцессорный блок Broadcom Neural Engine (BNE). Реализована поддержка памяти DDR4-3200, LPDDR4-4267, DDR5-5600 и LPDDR5-5500, а также двух интерфейсов USB и двух интерфейсов 10Gb MACsec. Предусмотрены четыре контроллера PCIe. Новинка может использоваться в паре с радиочипами Broadcom BCM43840, BCM43844 и BCM43820 стандарта Wi-Fi 8. На основе этих компонентов производители оборудования смогут создавать точки доступа Wi-Fi 8 с возможностями оптимизации в реальном времени, функциями постквантовой криптографии (CNSA 2.0), развитыми средствами обеспечения безопасности и ускорением ИИ-операций. 
Источник изображений: Broadcom В свою очередь, коммутационное решение Trident X3+ BCM56390 также оснащено четырьмя ядрами с архитектурой Armv8. Пропускная способность достигает 700 Гбит/с. Могут быть реализованы 48 портов на 5 Гбит/с и 16 портов на 25 Гбит/с или 28 портов на 25 Гбит/с. Платформа позволяет создавать программируемые L3-коммутаторы с поддержкой MACsec на всех портах. Реализован механизм безопасной загрузки. Trident X3+ BCM56390 может работать в связке с PHY-чипами Broadcom BCM84918, BCM54908 и BCM54908E, а также с чипами PoE PSE, обеспечивающими оптимальное энергопотребление и эффективность.  В целом, новые изделия образуют единую архитектуру, которая обеспечивает максимальную производительность и безопасность корпоративных беспроводных сетей Wi-Fi 8. Эти чипы расширяют возможности сетевой телеметрии, предлагая глубокий анализ в реальном времени для управления с помощью ИИ. Пробные поставки устройств уже начались.
06.02.2026 [11:30], Сергей Карасёв
102,4 Тбит/с и СЖО: Aria Networks представила коммутаторы на платформе Broadcom Tomahawk 6 для ИИ-инфраструктурСтартап Aria Networks, базирующийся в Санта-Кларе (Калифорния, США), вышел из скрытого режима, анонсировав высокопроизводительные коммутаторы для крупномасштабных кластеров ИИ. В основу устройств положена аппаратная платформа Broadcom Tomahawk 6 (TH6). В новое семейство вошли три модели: Aria Tomahawk 6 (High Radix), Aria Tomahawk 6 (Liquid) и Aria Tomahawk 6 (Air). Все они обеспечивают суммарную коммутационную способность до 102,4 Тбит/с. Разработчик заявляет, что устройства могут применяться в составе ИИ-платформ с любыми типами ускорителей, будь то GPU NVIDIA и AMD, тензорные чипы или специализированные решения вроде Cerebras. 
Источник изображения: Aria Networks Модель Aria Tomahawk 6 (Air) выполнена в форм-факторе 4U и оборудована воздушным охлаждением. Задействованы 512 блоков SerDes 200G. Коммутатор располагает 64 портами с пропускной способностью 1,6 Тбит/с каждый. Модификация Aria Tomahawk 6 (Liquid) имеет аналогичные технические характеристики, но заключена в 2U-корпус с жидкостным охлаждением. Наконец, вариант Aria Tomahawk 6 (High Radix) типоразмера 4U использует 1024 блока SerDes 100G. Устройство оборудовано 128 портами 800GbE; применяется воздушное охлаждение. На базе этого коммутатора могут формироваться кластеры с простой двухуровневой топологией, насчитывающие до 32 тыс. ИИ-ускорителей. Компания Aria Networks основана Мансуром Карамом (Mansour Karam), учредителем фирмы Apstra, которую в 2019 году приобрёл американский производитель сетевого оборудования Juniper Networks. Стартап Aria Networks фокусируется на разработке высокопроизводительных решений, сочетающих возможности стандартного Ethernet со специализированным программным уровнем, позволяющим управлять большим количеством модульных коммутаторов как единой системой. Утверждается, что этот унифицированный программный слой оптимизирует производительность и гарантирует надёжность инфраструктуры. Для эффективного управления коммутаторами применяются ИИ-алгоритмы. |
|

