Материалы по тегу: hpc
|
30.03.2026 [12:01], Сергей Карасёв
Производительность ирландского суперкомпьютера CASPIr составит 15 ПфлопсЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило тендер на создание в Ирландии суперкомпьютера CASPIr (Computation Analysis and Simulation Platform for Ireland). Система будет обслуживать широкий круг пользователей в научном сообществе, промышленной сфере и государственном секторе в Европе. CASPIr — это вычислительный комплекс среднего уровня. Его технические характеристики пока не раскрываются, но известно, что производительность составит около 15 Пфлопс. Использовать суперкомпьютер планируется для решения задач в области ИИ, включая обучение моделей и инференс. Система CASPIr будет находиться в совместной собственности EuroHPC JU и Университета Голуэя (University of Galway). За управление будет отвечать Ирландский центр высокопроизводительных вычислений (ICHEC). Инвестиции в проект оцениваются в €25 млн, из которых 35% предоставит EuroHPC JU, а оставшиеся 65% — власти Ирландии через свои национальные фонды. Подрядчику предстоит осуществить поставку и монтаж вычислительного комплекса с последующим техническим обслуживанием. 
Источник изображения: EuroHPC JU Отмечается, что EuroHPC JU продолжает развивать инфраструктуру высокопроизводительных вычислений в Европе. На сегодняшний день приобретены в общей сложности 12 суперкомпьютеров, включая JUPITER — первую европейскую машину экзафлопсного класса. Кроме того, EuroHPC JU курирует развёртывание так называемых ИИ-фабрик — площадок, ориентированных на ресурсоёмкие задачи в области ИИ: такие объекты создаются в Финляндии, Германии, Греции, Италии, Люксембурге, Испании, Швеции и пр. Ещё одним направление работ является формирование инфраструктуры квантовых вычислений.
27.03.2026 [10:03], Руслан Авдеев
ЦЕРН: для самых больших открытий на БАК нужны самые маленькие ИИ-модели, которые «зашиты» прямо в чипыИИ-инфраструктура Большого адронного коллайдера (БАК) имеет мало общего с классическим решениями на основе TPU или GPU. Вместо этого ЦЕРН (CERN) буквально «выжигает» кастомные ИИ-модели в «кремнии» для фильтрации огромных массивов данных практически в реальном времени, сообщает The Register. Ежегодно коллайдер «генерирует» 40 тыс. Эбайт «сырых» данных от сенсоров — приблизительно четверть объёма всего интернета. Такую информацию CERN хранить не может, поэтому приходится выбирать в режиме реального времени то, что представляет какую-либо ценность. Речь идёт о потоке данных до сотен терабайт в секунду. Алгоритмы для их обработки должны быть чрезвычайно быстрыми. Именно поэтому их приходится буквально «выжигать» непосредственно в чипах. В 27-км кольце БАК субатомные частицы сталкиваются на скоростях, близких к скорости света. По кольцу постоянно перемещаются около 2,8 тыс. пучков протонов с 25-с интервалами. Хотя учёные «помогают» частицам, столкновения случаются сравнительно редко — из миллиардов протонов в каждой сессии сталкиваются лишь порядка 60 пар. При столкновении образуются новые частицы, улавливаемые детекторами CERN. 
Источник изображения: Brandon Style/unsplash.com Каждое столкновение пары частиц генерирует несколько мегабайт данных. В секунду происходит около миллиарда столкновений, что приблизительно даёт около 1 Пбайт информации. Естественно, собирать и хранить такие объёмы «сырой» информации технически невозможно, поэтому CERN создал гигантскую вычислительную систему для разделения данных на «интересные» и «неинтересные» ещё на уровне детекторов. 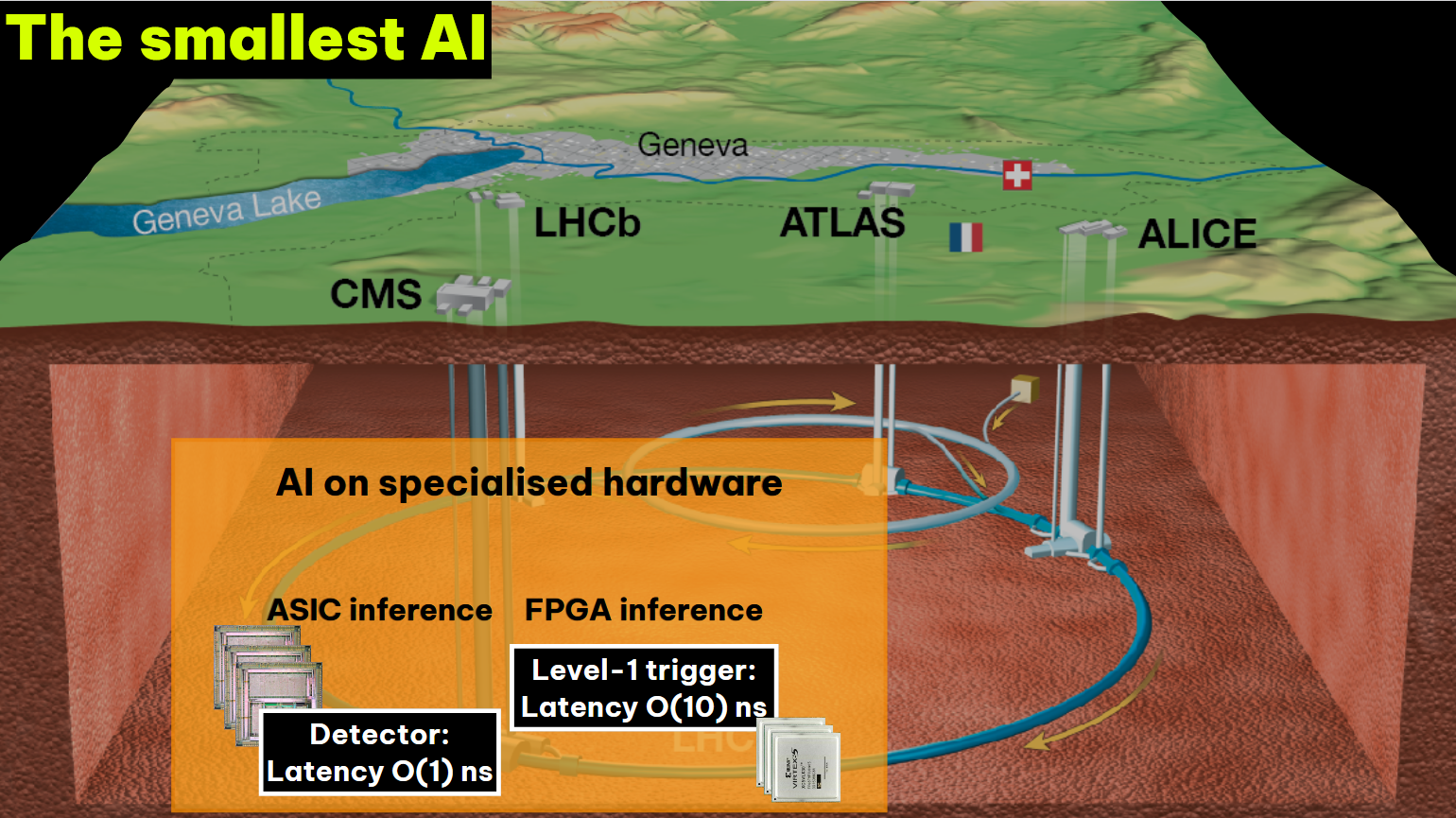
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Детекторы используют ASIC для буферизации данных за не более чем 4 мкс — они либо сохраняются, либо исчезают навсегда. Решение принимает фильтр Level One Trigger на базе порядка 1 тыс. FPGA, получающих данные по оптической линии на скорости около 10 Тбайт/с. Решения принимаются на лету силами самих чипов по мере поступления данных — даже самая быстрая внешняя память не справится с таким потоком информации. Специальный алгоритм AXOL1TL принимает решение не более чем за 50 нс. Фактически сохраняется лишь около 0,02 % информации о столкновениях, или приблизительно 110 тыс. событий в секунду. Отобранные сведения отправляются на поверхность, но даже после первичной фильтрации речь идёт о передаче терабайт данных ежесекундно. 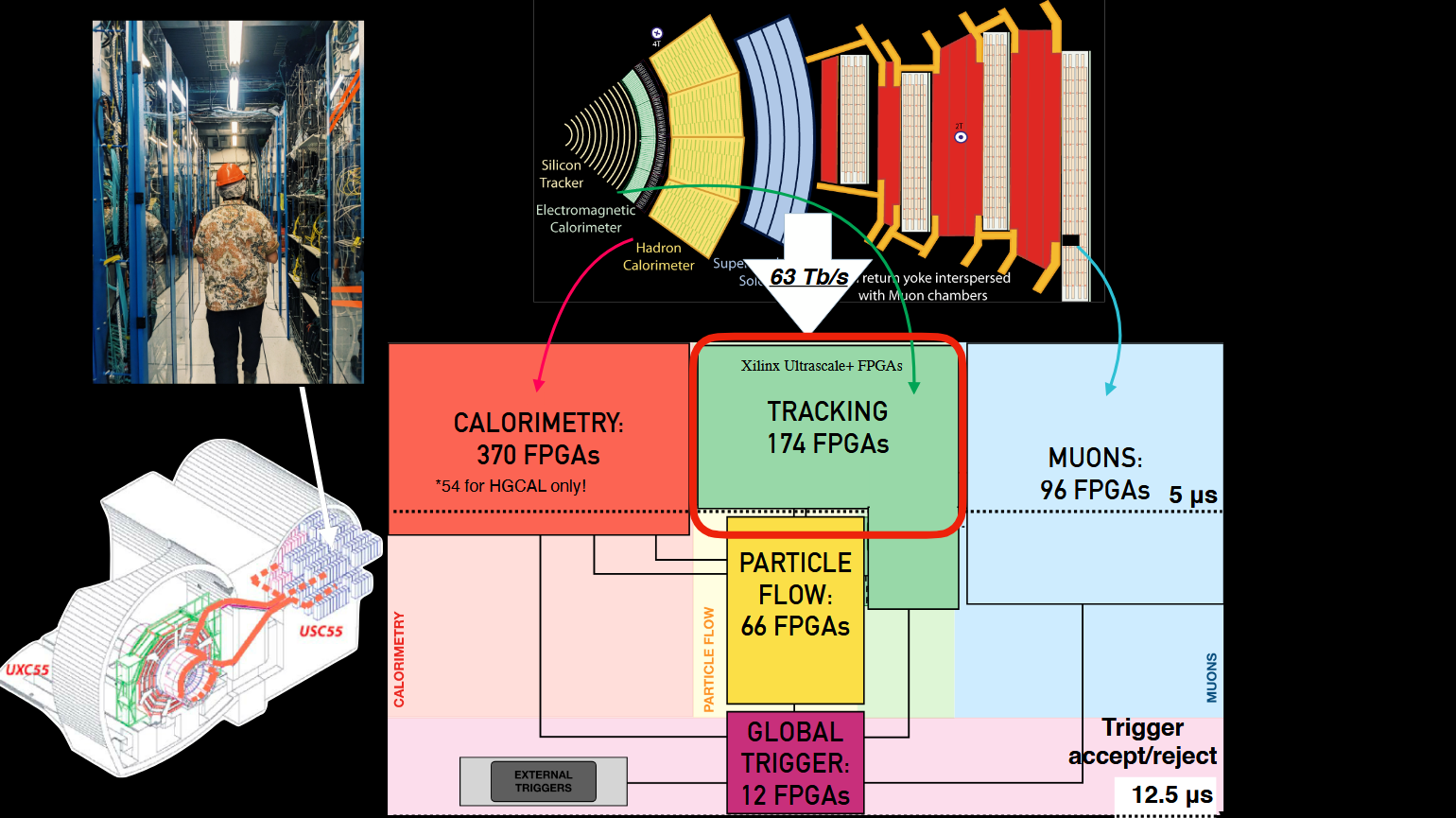
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) На поверхности второй фильтр — High Level Trigger — оставляет для изучения уже около 1 тыс. событий в секунду. Система оснащена 25,6 тыс. CPU и 400 GPU, которые реконструируют столкновения и отбирают наиболее интересные для анализа результатов. На выходе получается около 1 Пбайт/день новых данных, которые распределяются между 170 научными центрами в 42 странах, где их могут анализировать учёные со всего света. Совокупная вычислительная мощность всех участников проекта составляет около 1,4 млн ядер. CERN стремится измерить параметры столкновений с точностью 99,999 % — это «золотой стандарт», необходимый для заявлений о научных открытиях. 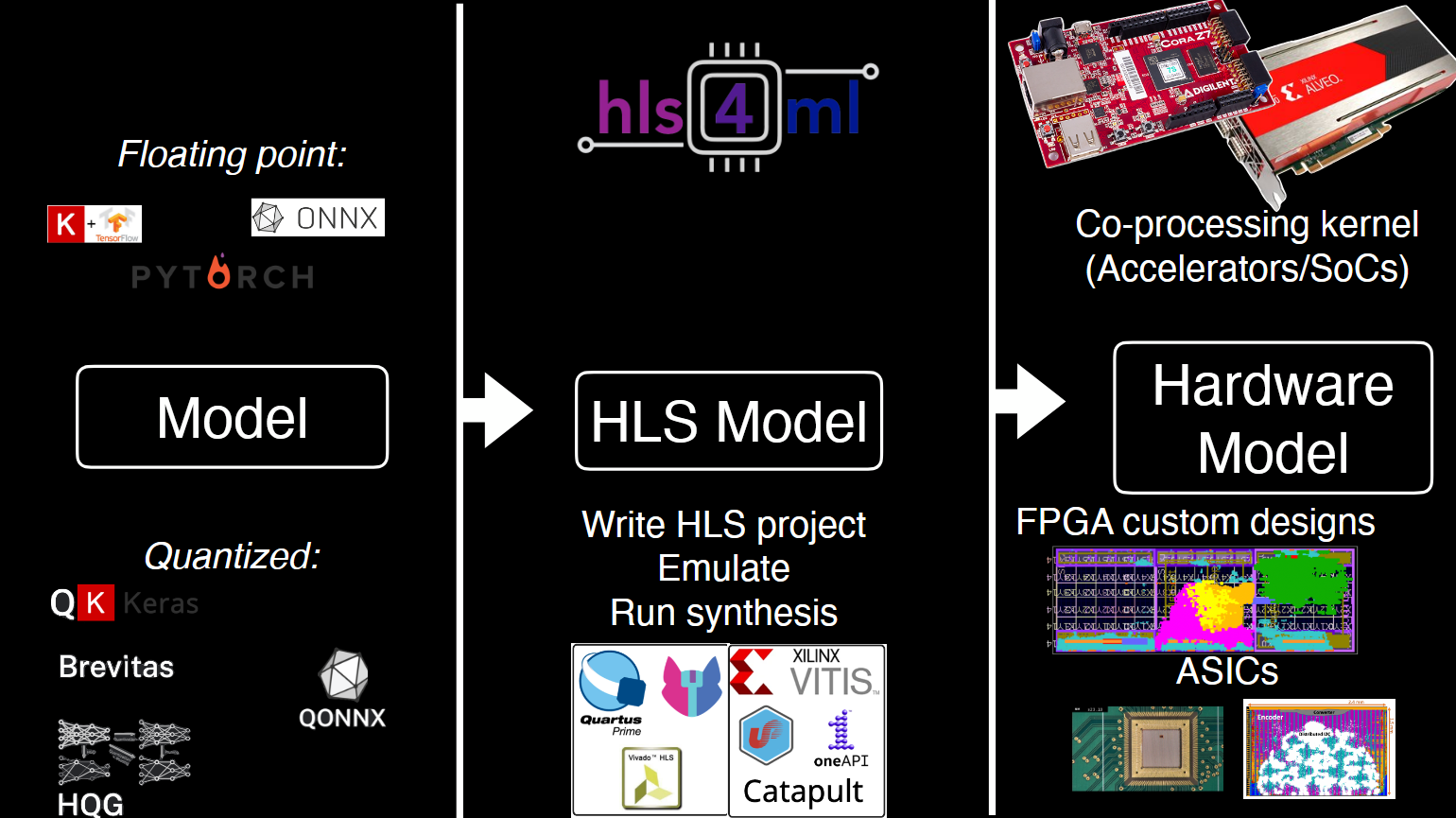
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Обычный ИИ-инструментарий плохо подходит для детекторов, поэтому инженерам CERN пришлось разработать собственный стек. ИИ-модели для БАК специально уменьшены, модернизированы, параллелизованы и «вымуштрованы» для выявления только действительно существенных данных. В случае с БАК они не менее производительны, но значительно «дешевле» традиционных ML-моделей. Для переноса моделей в аппаратную среду используется компилятор HLS4ML, конвертирующий модель в код C++, который можно запускать на ИИ-ускорителях, SoC, кастомных FPGA и даже «выжигать» в ASIC. При этом значительная часть ресурсов чипа отведена не под сам алгоритм, а под таблицы с предварительно рассчитанными результатами для типовых входящих значений, чтобы ещё быстрее фильтровать информацию. 
Источник изображения: CERN В конце года БАК закроют, а новый, более мощный коллайдер High Luminosity LHC должен заработать в 2031 году. Он получит более сильные магниты для фокусировки пучков частиц, сами пучки удвоятся в размерах, коллайдер будет генерировать в 10 раз больше данных, а объём информации от каждого события увеличится с 2 до 8 Мбайт. CERN уже накопил 1 Эбайт от БАК, но это лишь десятая часть от того, что предстоит хранить и обрабатывать в последующие 10 лет. И пока передовые ИИ-лаборатории создают LLM всё большего объёма, CERN движется в противоположном направлении, всеми силами упрощая и ускоряя выявление необычных событий с помощью искусственного интеллекта.
23.03.2026 [09:31], Сергей Карасёв
HPE представила узлы на базе NVIDIA Vera для платформы Cray Supercomputing GX5000Компания HPE анонсировала новые решения семейства NVIDIA AI Computing by HPE, ориентированные на крупномасштабные ИИ-платформы и суперкомпьютерные системы. О намерении использовать такие инфраструктурные продукты в числе прочих сообщили Аргоннская национальная лаборатория (ANL) Министерства энергетики США (DOE), Hudson River Trading (HRT), Корейский институт научно-технической информации (KISTI) и Центр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии. В частности, представлены новые узлы для суперкомпьютерной платформы HPE Cray Supercomputing GX5000 — blade-серверы HPE Cray Supercomputing GX240. Эти устройства могут нести на борту до 16 процессоров NVIDIA Vera (88C/176T). В одной стойке могут быть размещены до 40 узлов, что в сумме даёт 640 чипов Vera и 56 320 ядер Olympus. Реализовано жидкостное охлаждение. Система предназначена для решения наиболее ресурсоёмких вычислительных задач в области ИИ. Новые серверы появятся на рынке в следующем году. Для платформы HPE Cray Supercomputing GX5000 также будут доступны коммутаторы NVIDIA Quantum-X800 InfiniBand, предоставляющие 144 порта с пропускной способностью до 800 Гбит/с. В этих устройствах реализованы развитые функции снижения энергопотребления. Кроме того, HPE готовит OCP-серверы высокой плотности Compute XD700 для обучения LLM и инференса. В основу данной системы положена платформа NVIDIA HGX Rubin NVL8, а одна стойка может насчитывать до 128 ускорителей Rubin. Данное решение появится в начале 2027-го. 
Источник изображений: HPE Помимо этого, анонсирована стоечная система нового поколения NVIDIA Vera Rubin NVL72 by HPE — это флагманская ИИ-платформа, разработанная для моделей с более чем 1 трлн параметров. Конфигурация включает 36 процессоров Vera, 72 чипа Rubin, интерконнект NVIDIA NVLink шестого поколения, сетевые адаптеры NVIDIA ConnectX-9 SuperNIC и DPU NVIDIA BlueField-4. Система поступит в продажу в декабре 2026 года. 
18.03.2026 [12:14], Руслан Авдеев
Великобритания выделит £45 млн на ИИ-суперкомпьютер Sunrise для моделирования физики термоядерного синтезаВласти Великобритании намерены выделить £45 млн (порядка $60 млн) на новый ИИ-суперкомпьютер Sunrise, специально предназначенный для моделирования процессов, сопутствующих термоядерному синтезу. Систему планируют ввести в эксплуатацию летом 2026 года в кампусе Управления по атомной энергии Великобритании (UKAEA), сообщает The Register. Sunrise позиционируется как самый мощный ИИ-суперкомпьютер, специально предназначенный для исследований в сфере термоядерной энергетики. Система мощностью 1,4 МВт финансируется министерским Департаментом энергетической безопасности и нулевых выбросов (Department for Energy Security and Net Zero, DESNZ). Она должна заработать в июне и станет первым элементом «Зоны роста ИИ» (AI Growth Zone) в Калхэме (Оксфордшир). Задача Sunrise — объединение HPC- и ИИ-вычислений, оптимизированных для исследования физических процессов. Это позволит более точно моделировать различные события и создавать цифровых двойников сложных термоядерных систем до проведения дорогостоящих экспериментов в реальном мире. Сообщается, что ИИ-производительность составит до 6,76 Эфлопс. Машина получит узлы Dell PowerEdge с AMD EPYC и Instinct (всего 672 шт.), а также хранилище WEKA. По данным UKAEA, за классические вычислительные мощности отвечают 192 двухпроцессорных узла с 56-ядерными Intel Xeon Max (Sapphire Rapids с HBM). Intel является одной из компаний, поддерживающих проект, наряду с образовательными и государственными структурами — Кембриджским университетом и самим UKAEA. 
Источник изображения: Kristina Gadeikyte Gancarz/unsplash.com Представители властей подчёркивают, что система поможет решать ключевые задачи, связанные с термоядерным синтезом, от моделирования турбулентности плазмы до разработки материалов для реакторов и совершенствования технологий для получения тритиевого топлива. Кроме того, предполагается создание цифровых двойников оборудования, что позволит снизить затраты и риски. Суперкомпьютер будет работать на ряд британских энергетических инициатив, включая программу LIBRTI (Lithium Breeding Tritium Innovation), призванную решить проблему производства трития, а также флагманский правительственный проект STEP, предполагающий создание прототипа электростанции на основе сферического токамака. Великобритания рассчитывает построить его в Ноттингемшире в 2040-х гг. Sunrise является частью более широкой инициативы британского правительства, предусматривающей расширение мощностей для ИИ и HPC. Ранее в 2026 году правительство страны подтвердило инвестиции £36 млн (порядка $48 млн) в суперкомпьютерный центр в Кембридже. Тем временем кампус в Калхэме, вероятно, станет центром ИИ-вычислений, связанных с исследованиями в сфере энергетики. 
Источник изображения: www.gov.uk Пока не известно, поможет ли искусственный интеллект значительно ускорить довольно медленное продвижение к созданию коммерческих термоядерных проектов. Великобритания делает ставку на то, что увеличение вычислительных мощностей поможет решить одну из ключевых задач физики, имеющих важнейшее прикладное значение. Ещё в 2025 году сообщалось, что на появление коммерческих термоядерных реакторов рассчитывает Microsoft, средства в технологию вкладывают и другие компании — например, в сентябре 2025 года Commonwealth Fusion Systems привлекла на развитие своей термоядерной программы ещё $863 млн, а NVIDIA и General Atomics создали виртуальный термоядерный реактор с помощью ИИ. Впрочем, коммерческих версий термоядерных реакторов пока не существует.
17.03.2026 [22:28], Андрей Крупин
В России утверждён план развития высокопроизводительных вычислений и суперкомпьютерной инфраструктурыПравительство РФ утвердило план мероприятий, в рамках которого будут создаваться дополнительные условия для развития суперкомпьютерных технологий, искусственного интеллекта и вычислительных систем. Документ включает конкретные сроки мероприятий и их исполнителей, а также предполагает десятикратное увеличение совокупной мощности отечественных суперкомпьютеров к 2030 году. Согласно дорожной карте, в ближайшие несколько лет в России должна начаться реализация масштабной программы, включающей комплекс мероприятий, направленных на формирование единых требований к суперкомпьютерным центрам коллективного пользования, определение порядка предоставления доступа к ним научного сообщества и ключевых организаций промышленности, а также перспектив их дальнейшего развития и модернизации. В процессе работы по этому направлению планируется сформировать стратегию дальнейшего развития и правила функционирования национальной исследовательской компьютерной сети нового поколения, которая объединяет сотни ведущих вузов и научных организаций. Предполагается, что развитие коммуникационной инфраструктуры расширит возможности для проведения исследований, требующих обработки и передачи больших объёмов данных. 
Суперкомпьютер «Политехник РСК Торнадо» производства группы компаний РСК, установленный в Санкт-Петербургском политехническом университете Петра Великого (источник изображения: «РСК Технологии» / rscgroup.ru) Часть мероприятий дорожной карты направлена на разработку концепции профильной федеральной научно-технической программы, в рамках которой будет предусмотрено создание, развитие и внедрение отечественных алгоритмов, методов и программного обеспечения для проведения суперкомпьютерных вычислений в различных отраслях экономики. Научно-техническая программа в том числе подразумевает формирование новых и развитие имеющихся образовательных и дополнительных профессиональных программ по использованию суперкомпьютерных технологий и высокопроизводительных вычислений. По мнению «К2 НейроТех» (входит в «К2Тех»), утверждение дорожной карты — важный сигнал для всего рынка. Ключевой вызов для промышленного ИИ сегодня — не отсутствие моделей, а дефицит доступных вычислительных мощностей и зрелой инфраструктуры для их эксплуатации. При этом важно разделять два типа нагрузки: обучение моделей, требующее пиковых мощностей, и инференс — постоянную эксплуатацию, которая по мере зрелости рынка будет занимать всё большую долю вычислительных затрат. Без учёта этой специфики даже десятикратный рост мощностей может не дать ожидаемого экономического эффекта: «Особенно важно, что в дорожной карте уделено внимание подготовке кадров и развитию национальной исследовательской сети — без этого даже самые мощные суперкомпьютеры останутся невостребованными».
20.02.2026 [09:10], Руслан Авдеев
AMD, Classiq и Comcast «квантово» улучшили интернетРазработчик программного обеспечения для квантовых вычислений Classiq совместно с Comcast и AMD объявили о завершении испытаний, направленных на совершенствование доставки интернет-трафика путём использования квантовых алгоритмов для повышения надёжности маршрутизации в Сети, сообщает HPC Wire. Comcast заявила, что клиентам нужно быстрое, безопасное и надёжное подключение, но при управлении большой и динамичной сетью достижение этой цели становится сложной задачей, особенно в условиях растущего спроса. Поэтому в прошлом году были начаты эксперименты по выяснению того, как квантовое ПО и технологии могут решать реальные сетевые задачи. Результаты показали, что квантовые вычисления для оптимизации сети — не теория, а вполне практическое, масштабируемое решение. В ходе тестов решалась фундаментальная задача проектирования сети — определение независимых резервных маршрутов для сетевых узлов в общей конкурентной среде при проведении технического обслуживания и изменении топологии сети, причём с сохранением минимально возможной задержки, высокой устойчивостью к одновременным сбоям и высокой же пропускной способностью. Такая задача регулярно возникает на реальных сетях, где и без планового обслуживания не обойтись, и от одновременных сбоев никто застрахован. 
Источник изображения: Dynamic Wang/unsplash.com В ходе эксперимента с использованием квантовых технологий и HPC-платформ AMD на базе ускорителей Instinct MI300X проверялась возможность квантовых алгоритмов успешно определять резервные пути для трафика в режиме реального времени в различных сценариях. Использовались как моделирование с использованием Instinct для достижения значимых вычислительных мощностей (кубитного уровня), что позволило быстро перебирать различные алгоритмы, так и реальный квантовый компьютер IonQ Forte с 29 алгоритмическими кубитами для проверки успешности реализации алгоритмов. 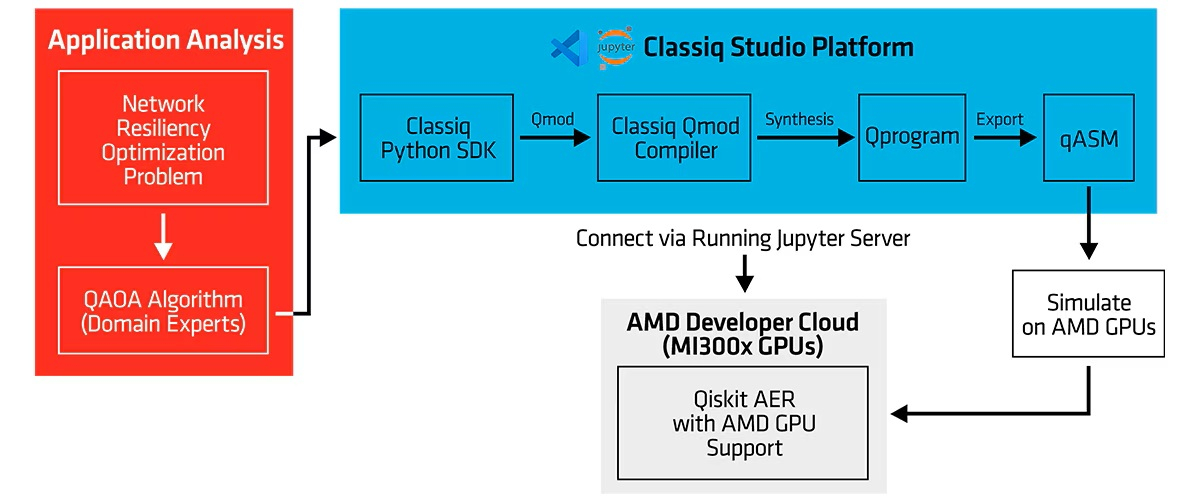
Источник изображения: AMD Задача оптимизации глобальных телекоммуникационных сетей — крайне ресурсоёмкая комбинаторная задача, экспоненциально усложняющаяся по мере роста размера сети. Такая задача является идеальным вызовом для систем квантовых вычислений. По словам представителя Classiq, исследования и разработки в сфере квантовых технологий требуют быстрых итераций с внесением улучшений на каждом цикле и воспроизводимых рабочих процессов. AMD заявила, что будущее HPC — в конвергенции классических и квантовых вычислений.
19.02.2026 [09:52], Владимир Мироненко
Американская «Миссия Генезис» будет во многом полагаться на «ненастоящие» FP64-вычисленияХотя последнее поколение GPU ориентировано на вычисления с более низкой точностью, которые предпочтительны для ИИ-задач, FP64-вычисления с более высокой точностью по-прежнему «очень важны» для «Миссии Генезис» (Genesis Mission) и её цели — ускорения научных открытий с помощью ИИ, заявил заместитель министра энергетики США по науке и инновациям Дарио Гил (Darío Gil) в интервью HPCwire. «В ходе обсуждений, которые я провел как с [генеральным директором AMD] Лизой Су (Lisa Su), так и с [генеральным директором NVIDIA] Дженсеном [Хуангом] (Jensen Huang), они выразили твёрдую приверженность FP64, подтвердив, что поддержка формата будет продолжаться, — сказал Гил. — Для нас это очень важно, потому что мы не рассматриваем это как замену. Это взаимодополняющие технологии». Он отметил, что для обеспечения вычислительных задач моделирования и симуляции, которые традиционно составляют основу научных вычислений, а также для новых методов ИИ, важно иметь высокопроизводительное оборудование. Гил добавил, что эти два типа вычислений будут работать вместе, чтобы поддержать цель миссии Genesis — расширение границ науки и техники на основе ИИ-технологий. «У вас есть высокоточные симуляционные коды, работающие с FP64. После проверки вы используете их в качестве основы для генерации примеров, на которых вы обучаете суррогатную модель, которую затем запускаете на ИИ-суперкомпьютере, — рассказал Гил. — В итоге вы получаете преимущества с точки зрения производительности и времени решения, часто в 10, 20, 100 раз». 
Источник изображений: NVIDIA Он отметил, что благодаря использованию ИИ-моделей можно получить громадное повышение производительности, но оно зависит от сохранения всего цикла работ, состоящего из экспериментов, моделирования и обучения. «Если вы разорвёте этот цикл и скажете, что у вас больше нет кодов моделирования, то возникнет проблема», — сказал Гил. «Для нас это имеет фундаментальное значение, не только для устаревших кодов, которые мы должны сопровождать и которые так важны для миссии, но и для обеспечения рабочего ИИ-процесса. Поэтому для нас очень важно поддерживать различные архитектурные подходы», — добавил он. В HPC-сообществе возникла обеспокоенность по поводу отсутствия прироста производительности для FP64 в новейших GPU. Напомним, что чип NVIDIA H100, выпущенный в 2022 году, обеспечивает 67 Тфлопс в формате FP64 на тензорных ядрах (34 Тфлопс в векторных вычислениях), в то время как B200 предлагает лишь 37 Тфлопс, а B300 — всего лишь 1,3 Тфлопс. Программная эмуляция FP64-вычислений на тензорных ядрах Blackwell позволяет получить «нечестные» 150 Тфлопс, а из новейших Rubin она позволяет «выжать» 200 Тфлопс. При этом пиковая заявленная производительность векторных FP64-вычислений у Rubin составляет лишь 33 Тфлопс, т.е. нет никакого прироста в сравнении с Hopper. 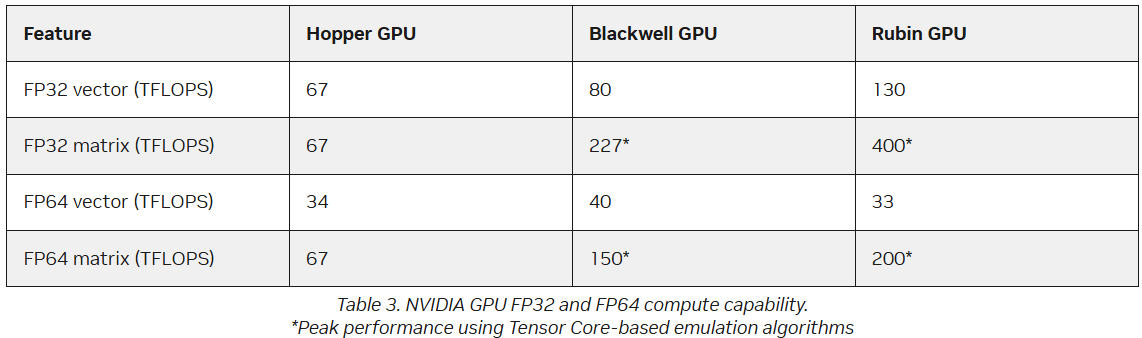 Отметим, что в AMD раскритиковали такой подход, заявив, что он эффективен не для всех сценариев и поэтому такое решение ещё не готово к широкому применению. В свою очередь, эксперты предупреждают, что смещение фокуса производителей на выпуск чипов для ИИ-нагрузок, которые отлично работают с вычислениями с низкой точностью, может привести к дефициту чипов с поддержкой FP64 для HPC, а это грозит потерей лидерства США в этом сегменте рынка. По мере того, как NVIDIA наращивает мощность для выполнения ИИ-задач с низкой точностью вычислений Rubin, компания будет всё больше полагаться на cuBLAS, библиотеку стандартных математических операций CUDA-X, которая эмулирует вычисления с двойной точностью на тензорных ядрах, чтобы постоянно наращивать показатели FP64-производительности. «Мы пытаемся предоставить эти возможности среде разработчиков, чтобы они могли… получить необходимую точность FP64», — заявил в декабре HPCwire Дион Харрис (Dion Harris), старший директор NVIDIA по ИИ/HPC-решениям для гиперскейлеров. 
NVIDIA GPU simulation performance Методы эмуляции NVIDIA основаны на схеме Озаки (Ozaki), позволяющей выполнять умножение матриц с высокой точностью, используя многократные вычисления с низкой точностью на тензорных ядрах. NVIDIA утверждает, что использование алгоритма Озаки оправдано, поскольку увеличение производительности FP64 путём добавления большего количества ядер CUDA фактически не повысит общую производительность HPC-приложений, но сделает чипы менее гибкими. По словам компании, анализ реальных нагрузок показывает, что «наивысшая устойчивая производительность FP64 часто достигается на умножении матриц». В Hopper для этого были отдельные аппаратные блоки, но в Blackwell и в Rubin NVIDIA больше опирается на эмуляцию. В то же время, производительность векторных FP64-вычислений остаётся критически важной для научных приложений, в которых не доминируют матричные ядра, признаёт NVIDIA, однако тут же утверждает, что в этих случаях производительность ограничивается перемещением данных через регистры, кеши и HBM, а не непосредственно вычислительными ресурсами. Поэтому сбалансированная конструкция GPU «обеспечивает достаточное количество ресурсов FP64 для насыщения доступной пропускной способности памяти, избегая избыточного выделения вычислительной мощности, которая не может быть эффективно использована». Иными словам, компания ничего менять не собирается. Проект Genesis Mission, вероятно, будет создавать разнообразные ИИ-приложения для научных и инженерных задач, и каждое из них, скорее всего, будет иметь несколько иные вычислительные потребности. Достигли ли NVIDIA и AMD оптимального баланса, используя вычислительные ядра для матричных вычислений и опираясь на эмуляцию Озаки для FP64, ещё предстоит выяснить, пишет HPCwire.
17.02.2026 [13:57], Владимир Мироненко
Первый европейский суверенный RISC-V-процессор Cinco Ranch изготовлен по техпроцессу Intel 3Лаборатория суперкомпьютерных вычислений (BZL) Национального центра суперкомпьютерных вычислений Барселоны (BSC-CNS) сообщила об успешном запуске тестового чипа Cinco Ranch TC1 на архитектуре RISC-V, изготовленного по передовому техпроцессу Intel 3. В заявлении отмечено, что результаты подтверждают надёжность конструкции и жизнеспособность вычислительной архитектуры на базе открытой платформы RISC-V. «Это достижение является ключевым этапом в процессе разработки чипа и качественным скачком на пути к суверенным суперкомпьютерным технологиям в Европе», — подчеркнула BZL, отметив, что готовый чип предлагает открытую, гибкую альтернативу, свободную от зависимости от проприетарных архитектур крупных транснациональных корпораций. Проект связан с Европейской инициативой по процессорам (EPI), целью которой является разработка отечественных процессоров для будущих европейских суперкомпьютеров и промышленных систем. «Успешная стабильная загрузка Linux и проверка достижения чипом ожидаемых частот подтверждают зрелость конструкции и качество работы, проделанной командами BZL», — говорит исследователь BSC и координатор аппаратной части лаборатории Zettascale в Барселоне. 
Источник изображений: BZL Cinco Ranch TC1 — это первый чип, произведенный в академической среде с использованием 3-нм техпроцесса Intel 3. На этапе проектирования, из-за невозможности прямого доступа к этой технологии, BZL провела внутренние оценки на сопоставимом техпроцессе TSMC N7, что позволило оценить конструкцию перед окончательной реализацией. Сообщается, что структура Cinco Ranch TC1 основана на трёх взаимодополняющих процессорных блоках, предназначенных для совместной работы и охвата различных вычислительных профилей. В чипе используются три блока RISC-V на одном кристалле, каждый из которых ориентировано на специализированные рабочие нагрузки. Три ядра используют микроархитектуры Sargantana, Lagarto Ka и Lagarto Ox, с основным упором на эффективность, векторные нагрузки и скалярную обработку соответственно. Подсистема CPU занимает всего 3,2 мм² на крошечном кристалле площадью 15,2 мм², который также включает высокоскоростные интерфейсы, такие как PCIe 5.0 и DDR5. Для сравнения, площадь CCD восьмиядерного процессора AMD Zen 5 составляет около 71 мм², и для этого чиплета также требуется отдельный кристалл I/O, отметил ресурс HotHardware.com.  Cinco Ranch TC1 был протестирован на оценочной плате Hawk Canyon V2, разработанной Intel для первоначальной проверки чипа после его производства. Следующим этапом станет функциональное тестирование и тестирование производительности, оптимизация ПО и полная проверка системы. В мае 2025 года на Cinco Ranch TC1 (Test Chip 1) была успешно загружена ОС Linux, а в июле 2025 года, после получения партии из 500 чипов, начались работы по характеризации и проверке. Вся партия продемонстрировала высокую функциональную производительность, при этом большинство устройств успешно запустили все три интегрированных процессора чипа. Также результаты тестов подтверждают, что Cinco Ranch TC1 работает на частоте до 1,25 ГГц, что превышает консервативные оценки, сделанные на этапе проектирования. Для BZL и её партнёров это достижение является важной вехой и доказательством того, что разработанные в Европе процессоры с открытой ISA могут быть реализованы на передовых технологиях производства и воплощены в реальных кремниевых решениях. Для Европы — это значимый шаг к технологической автономии в HPC. А для Intel это демонстрация того, что её бизнес может оказывать всестороннюю поддержку передовым внешним клиентам в сложных гетерогенных проектах.
14.02.2026 [11:52], Сергей Карасёв
В Германии запущен 54-кубитный квантовый компьютер Euro-Q-Exa в рамках проекта EuroHPCЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о запуске квантового компьютера Euro-Q-Exa, расположенного в Мюнхене (Германия). Ввод системы в эксплуатацию, как отмечается, знаменует собой важную веху в формировании современной инфраструктуры квантовых вычислений в Европе. Комплекс Euro-Q-Exa развёрнут в Суперкомпьютерном центре Лейбница (LRZ) Баварской академии наук. Проект реализован при совместной финансовой поддержке EuroHPC, Федерального министерства исследований, технологий и космоса Германии (BMFTR), а также Министерства науки и искусств Баварии (StWK). Система Euro-Q-Exa разработана компанией IQM Quantum Computers на основе платформы Radiance. Изначально машина включает 54 сверхпроводящих кубита. К концу 2026 года будет смонтирована модернизированная установка, оперирующая 150 кубитами. 
Источник изображения: EuroHPC JU Благодаря интеграции Euro-Q-Exa в НРС-среду LRZ европейские исследователи смогут разрабатывать, тестировать и масштабировать приложения на основе гибридных квантово-классических вычислений в различных областях. Среди них названы исследования нейродегенеративных заболеваний, фармакология и климатическое моделирование. Европейские исследователи смогут получить доступ к системе через Мюнхенский квантовый портал (MQP) или портал EuroHPC JU. Euro-Q-Exa — один из шести квантовых компьютеров, которые устанавливаются в передовых суперкомпьютерных центрах в Европе, наряду с системами в Чехии, Франции, Италии, Польше и Испании. Развитие данной инфраструктуры позволяет объединить сильные стороны квантовых вычислений и традиционных суперкомпьютеров, что открывает перед исследователями качественно новые возможности при решении сложнейших задач.
13.02.2026 [10:50], Сергей Карасёв
Xinnor представила All-Flash платформу хранения xiNAS для задач ИИ и НРСКомпания Xinnor анонсировала платформу xiNAS — это высокопроизводительное решение для хранения данных, ориентированное на задачи ИИ, НРС и другие ресурсоёмкие рабочие нагрузки. Изделие, относящееся к классу All-Flash, поддерживает линейное масштабирование пропускной способности по мере добавления узлов. xiNAS объединяет программный RAID-движок Xinnor xiRAID с оптимизированной файловой системой XFS и высокопроизводительным транспортным протоколом NFS over RDMA. По заявлениям разработчика, такая комбинация позволяет максимизировать быстродействие базового оборудования. В качестве последнего могут использоваться серверы Supermicro. Тестирование осуществлялось на машине Supermicro AS-1116CS-TN типоразмера 1U, оборудованной одним процессором AMD EPYC 9004 Genoa, DPU NVIDIA BlueField-3 и 12 накопителями NVMe с интерфейсом PCIe 5.0. Пропускная способность на операциях чтения составила до 74,5 Гбайт/с, на операциях записи — до 39,5 Гбайт/с. При использовании двухузловой конфигурации показатели повысились до 117 и 79,6 Гбайт/с соответственно. 
Источник изображений: Xinnor Среди преимуществ платформы xiNAS компания Xinnor выделяет отсутствие проприетарного клиентского ПО, что обеспечивает простоту развёртывания и интеграции. Благодаря xiRAID достигаются высокий уровень защиты данных и стабильность работы при сбоях.  В качестве возможных конфигураций xiNAS приводятся серверы формата 1U и 2U, оснащённые соответственно процессором AMD EPYC 9384X с 32 ядрами и EPYC 9474F с 48 ядрами. Оба устройства располагают 128 Гбайт оперативной памяти и адаптерами ConnectX-7 на 400 Гбит/с (одна и две штуки). Младшая версия несёт на борту 10 накопителей Kioxia CM7-R стандарта E3.S (PCIe 5.0) на 15 Тбайт каждый и два таких же SSD на 2 Тбайт. Пропускная способность системы при последовательном чтении достигает 45 Гбайт/с, при последовательной записи — 20 Гбайт/с. Сервер в 2U-корпусе оборудован 18 накопителями Micron 7450 стандарта U3 (PCIe 5.0) на 15 Тбайт и двумя SSD Micron 7450 E3.S вместимостью 3 Тбайт. Заявленная пропускная способность при последовательном чтении — до 90 Гбайт/с, при последовательной записи — до 45 Гбайт/с. |
|

