Материалы по тегу: instinct
|
08.04.2026 [09:22], Владимир Мироненко
Стране нужен FP64: AMD пообещала повысить HPC-производительность ускорителей Instinct MI430XПосле анализа ограничений эмуляции FP64-вычислений с использованием схемы Озаки разработчики AMD пришли к выводу, что в настоящее время нет замены «сырой» производительности FP64. Как сообщил научный сотрудник AMD Николас Малайя (Nicholas Malaya) ресурсу HPCwire, чтобы обеспечить точность традиционных задач моделирования и симуляции, компания намерена нарастить нативную FP64-производительность ускорителя Instinct MI430X. Ускоритель станет основой суперкомпьютера Discovery, который будет установлен в Национальной лаборатории Ок-Ридж (ORNL) в 2028 году. Как отметил Кацухиса Озаки (Katsuhisa Ozaki) и два других японских исследователя, схема Ozaki — это многообещающая новая техника эмуляции, призванная позволить учёным выполнять высокоточные умножения матриц на оборудовании с поддержкой INT8/FP8, к которому относятся современные ИИ-ускорители, путём многократных вычислений с более низкой точностью. Текущие реализации Ozaki-I и Ozaki-II имеют ограничения, которые исключают их использование в реальных условиях, сообщил Малайя. Он указал на две основные проблемы. Во-первых, ПО не соответствует стандарту IEEE и не даёт того же результата, что и запуск кода на реальном оборудовании с поддержкой FP64. «В некоторых случаях это нормально, — сказал он. — Но во многих распространённых матрицах, которые мы наблюдали, влияние на точность довольно существенно.». Во-вторых, схема Озаки нацелена на квадратные матрицы. Если таковые в расчётах не используется, то итоговая производительность оказывается ниже, чем у нативного FP64-исполнения, говорит Малайя. 
Источник изображения: AMD Кроме того, HPC-приложения традиционно опираются на векторные вычисления, а не на тензорные или матричные, которые характерны для ИИ-нагрузок. Фактически ситуация ещё хуже — менее 10 % реальных HPC-приложений внесли изменения в DGEMM-коды, которые позволяют воспользоваться преимуществами Ozaki. «Насколько мне известно, с Ozaki-I, Ozaki-II или любой другой существующий метод нельзя применить к векторным инструкциям, — говорит Малайя. — Это ключевой нюанс, который, как мне кажется, упускается». На DGEMM действительно уходит много вычислительных ресурсов, что позволяет использовать схему Ozaki, «но она не решает 90 % HPC-задач». AMD собирается поддерживать эмуляцию Ozaki на своих чипах, сообщил Малайя. «Нет причин этого не делать. Это ПО. <…> И у вас могут быть библиотеки, которые позволяют динамически переключаться между нативными расчётами и Ozaki и, вероятно, оценивать его», — сказал он, добавив, что программную эмуляцию можно иметь в виду в качестве резервного варианта для FP64-вычислений. Но в конечном итоге Ozaki не является работоспособной альтернативой «железу» с FP64, сказал Малайя, уточнив, что не он один так считает. 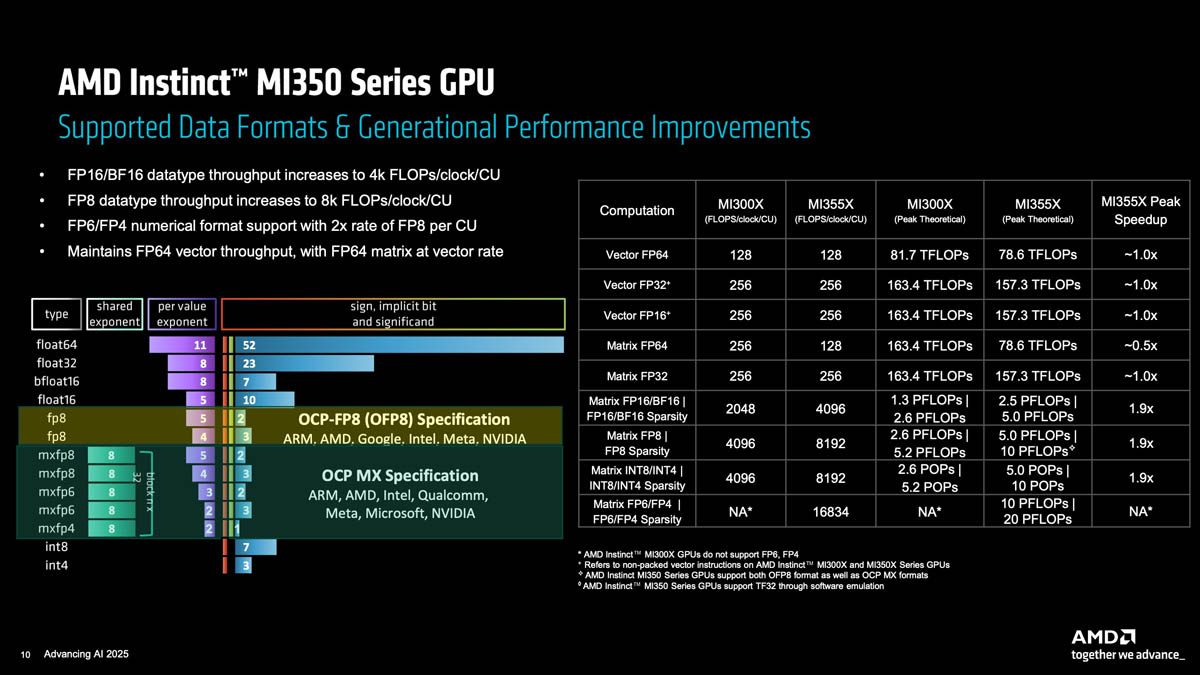
Источник изображения: AMD В настоящее время компания разрабатывает MI430X, специализированную версию ускорителя следующего поколения MI450, который будет обладать значительной FP64-производительностью. По словам Малайи, она будет значительно больше, чем у ускорителя MI355X, который обеспечивает 78,6 Тфлопс. По факту, это меньше, чем у предыдущей модели MI325X, которая обеспечивала 81,7 Тфлопс — в обоих случаях речь и про векторные, и про матричные FP64-вычисления. В любом случае, у всех этих чипов — от MI325 до MI430 — производительность больше, чем у чипов NVIDIA. И Hopper (34 Тфлопс), и Blackwell (40 Тфлопс) уже были медленнее в векторных FP64-вычислениях, но у Hopper хотя бы были нативные 67 Тфлопс в матричных расчётах, тогда как Blackwell в этом случае уже перешёл к схеме Озаки с «ненативными» 150 Тфлопс. Про Blackwell Ultra, где FP64-производительность упала до 1,3 Тфлопс, NVIDIA в данном контексте вообще не вспоминает, но обещает, что у Rubin будет 33 Тфлопс в векторных FP64-расчётах и 200 Тфлопс в матричных (тоже с Озаки). 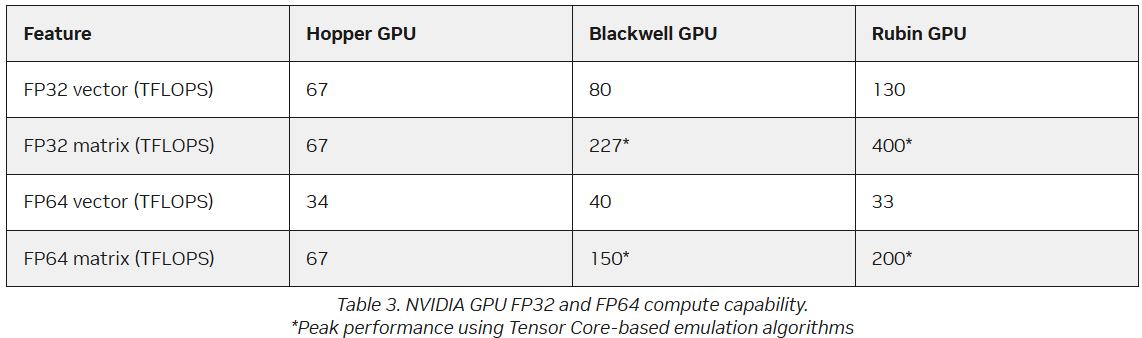
Источник изображения: NVIDIA NVIDIA обосновывает отказ от развития аппаратных FP64-блоков тем, что увеличение собственно вычислительной мощности FP64 на самом деле не ускорит научные приложения, поскольку на практике они упрутся в возможности регистров, кешей и HBM. Rubin обеспечит пропускную способность HBM до 22 Тбайт/с, что в 2,8 раза больше, чем у Blackwell. Instinct MI325X предлагает 6 Тбайт/с, MI355X — 8 Тбайт/с, а у MI430X будет уже 19,6 Тбайт/с, сообщил Малайя. По словам Малайи, лучше всего синхронно «вкладываться» и в HBM, и в количество операций с плавающей запятой. «На самом деле важен коэффициент байт/флопс. С нашей точки зрения, необходимо поддерживать гораздо более близкое соотношение к тому, что мы видим в современных продуктах, — сказал он. — Необходимо значительно приблизиться к этому соотношению с точки зрения увеличения производительности FP64, чтобы сохранить тот же уровень, как это называют, арифметической интенсивности». 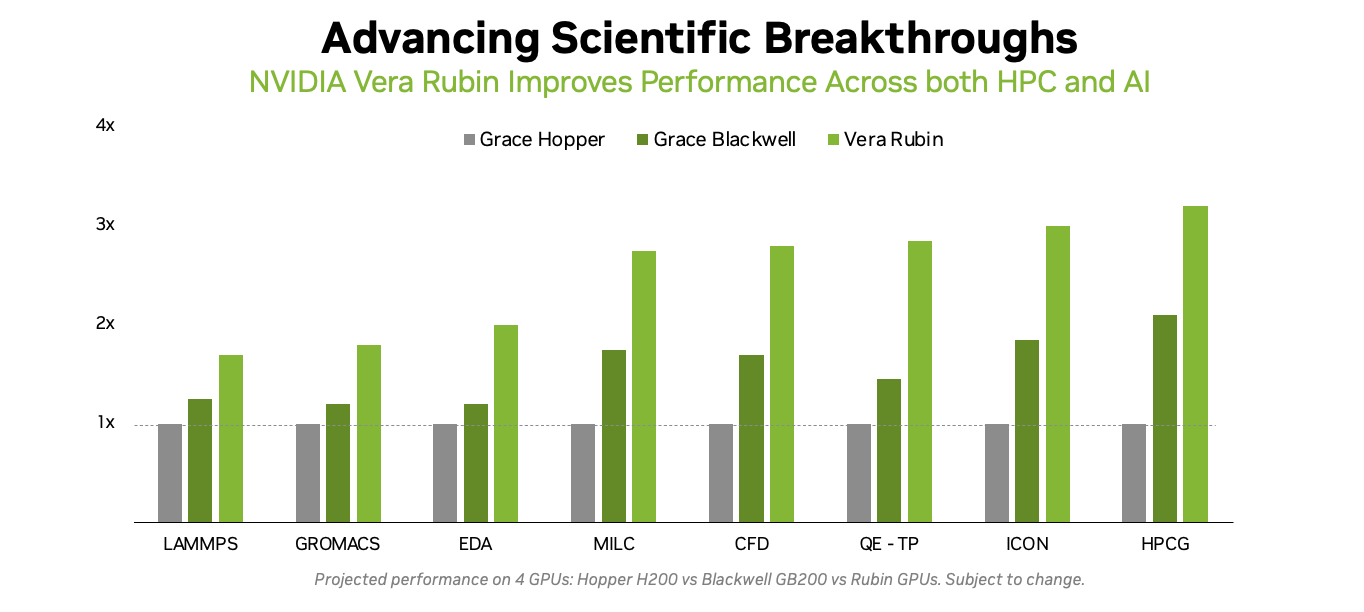
Источник изображения: NVIDIA Поскольку AMD обеспечит 2,5-кратное увеличение ПСП HBM от MI355 до MI430X, аналогичное 2,5-кратное увеличение производительности FP64 также будет оправдано. Таким образом можно примерно прикинуть, что MI430X может обеспечить производительность FP64 от 192 до 204 Тфлопс в зависимости от того, какой из них будет базовым: более новый MI355 или более быстрый MI325, сообщил HPCwire, добавив, что это всего лишь предположение, поскольку компания пока не сообщила точные характеристики будущих чипов. Кроме того, не до конца ясно, будет ли FP64-производительность одинакова для векторных и матричных расчётов. FP64-вычисления «очень важны» для «Миссии Генезис» (Genesis Mission), заявил ранее заместитель министра энергетики США (DoE) по науке и инновациям Дарио Гил (Darío Gil). Он отметил, что и глава AMD Лиза Су (Lisa Su), и глава NVIDIA Дженсен Хуанг (Jensen Huang), выразили твёрдую приверженность FP64, подтвердив, что поддержка формата будет продолжаться. «FP64 имеет решающее значение для поддержки рабочих нагрузок моделирования и симуляции, не только для дальнейшего развития традиционных научных исследований, но и для предоставления исходных данных для обучения новых ИИ-моделей», — добавил Гил. 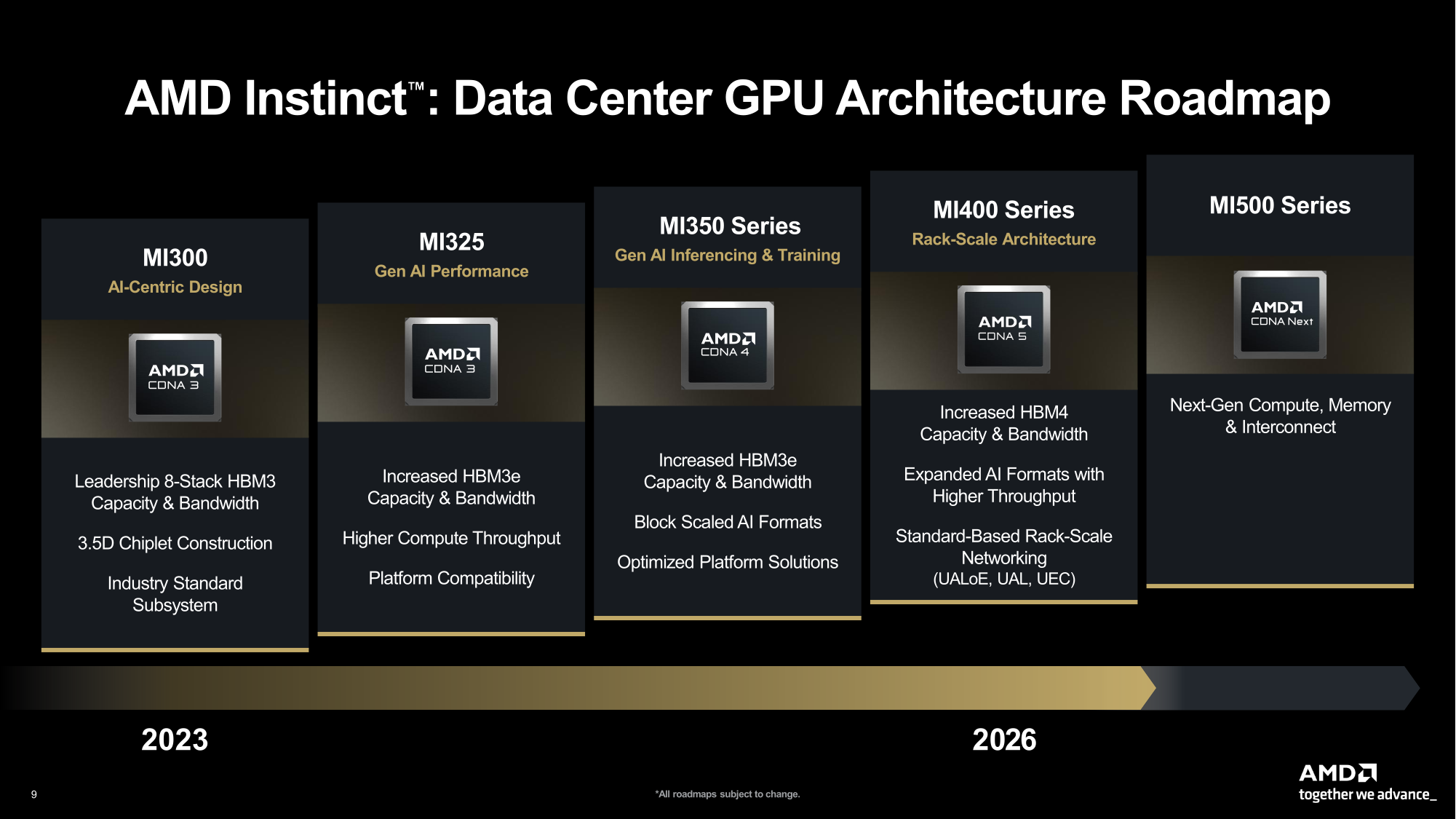
Источник изображения: AMD «Всегда существует баланс между тем, сколько требуется FP64- и FP16-вычислений», — сказал Малайя. «AMD утверждает, что нам необходимо поддерживать широкий спектр типов данных в зависимости от их потребностей. Не получится, чтобы всем были нужны FP64, которых хватит для всего.», — отметил он. Малайя сообщил, что всегда бывают исключения. Например, ИИ-симуляции сворачивания белков, такие как AlphaFold и Openfold, используют FP32. Да и некоторым традиционным HPC-задачам, таким как молекулярная динамика, не требуется FP64-точность. Тем не менее, сейчас существует значительный неудовлетворенный спрос на FP64, утверждает учёный. «Что касается высокопроизводительных вычислений, мы считаем, что им по-прежнему потребуется много FP64, — сказал он. — Будут использоваться некоторые коды, которые полностью ограничены пропускной способностью памяти, и им не нужно так много. Но есть, например, коды вычислительной химии и некоторые другие, которые действительно имеют высокую арифметическую интенсивность, и они будут использовать FP64».
03.03.2026 [14:27], Руслан Авдеев
Сделано в США: Flex начала выпуск американских ИИ-серверов с AMD InstinctАмериканская производственная компания Flex, поставляющая решения для дата-центров, анонсировала расширение стратегического сотрудничества с AMD для выпуска решений на платформе Instinct. По словам Flex, это важная веха на пути укрепления локального производства на территории США, в том числе передовых ИИ- и HPC-продуктов. В рамках партнёрства выпуск платформы AMD Instinct MI355X организован на территории головного подразделения Flex в Остине (Техас). В следующем квартале объёмы выпуска должны увеличиться. Речь идёт не только о платформе текущего поколения, компания намерена поддержать выпуск и новых платформ Instinct для удовлетворения спроса со стороны крупномасштабных ИИ-проектов. Сейчас Flex выпускает высокоплотные системы с восемью ускорителями и сопутствующей обвязкой. Каждая платформа, как утверждают в компании, проходит строгие заводские испытания и оценку. Системы оснащаются СЖО JetCool, принадлежащей Flex. По данным производителя, комбинация передовых индустриальных мощностей Flex, надёжной цепочки поставок и производственных мощностей в США с передовыми позициями AMD в HPC-сегменте позволяет клиентам масштабировать свои ИИ-проекты быстрее и с повышенной надёжностью. Головная структура Flex в Техасе занимает площадь более 130 тыс. м2 и создана для поддержки комплексного производства в больших объёмах. Всего у Flex в США есть более 650 тыс. м2 площадей на 17 объектах. 
Источник изображения: Flex Планы AMD по локализации производства включают и выпуск чипов на американских фабриках TSMC. NVIDIA идёт по тому же пути, но в части выпуска или хотя бы сборки серверов на территории США, в том числе для обслуживания гиперскейлеров, у неё гораздо больше возможностей. Но и AMD укрепила свои позиции в этой области в результате сделки с ZT Systems и Sanmina. США всеми силами стремятся локализовать производство и разработки на своей территории. В декабре 2025 года было объявлено о заключении партнёрских отношений с 24 ведущими IT-компаниями в рамках «Миссии Генезис», призванной стимулировать ИИ-разработки и производство на американской территории. Например, в конце января 2026 года сообщалось, что Corning построит крупнейшее в мире производство оптоволоконного кабеля для ЦОД в рамках сделки с Meta✴ на $6 млрд.
03.03.2026 [14:10], Сергей Карасёв
Gigabyte представила ИИ-сервер G893-ZX1-AAX4 на базе AMD Instinct MI355XGigabyte Technology анонсировала сервер G893-ZX1-AAX4, предназначенный для выполнения ресурсоёмких задач, таких как ИИ-инференс, сложное моделирование и пр. Новинка построена на аппаратной платформе AMD. Устройство типоразмера 8U рассчитано на два процессора EPYC 9005 Turin или EPYC 9004 Genoa в исполнении Socket SP5 (LGA 6096) с показателем TDP до 500 Вт. Доступны 24 слота для модулей оперативной памяти DDR5-4800/6400. Во фронтальной части расположены восемь отсеков для SFF-накопителей с интерфейсом PCIe 5.0 (NVMe). Кроме того, есть два внутренних коннектора для SSD формата M.2 2280/22110 с интерфейсом PCIe 3.0 x4 и PCIe 3.0 x1. Реализованы восемь разъёмов PCIe 5.0 x16 для однослотовых карт расширения FHHL и четыре разъёма PCIe 5.0 x16 для двухслотовых карт FHHL. В оснащение входят восемь ускорителей AMD Instinct MI355X OAM. Применяется полностью воздушное охлаждение с 15 вентиляторами диаметром 80 мм в области GPU-лотка, шестью кулерами на 60 мм в зоне материнской платы и четырьмя вентиляторами диаметром 80 мм в секции PCIe. Питание обеспечивают 12 блоков мощностью 3000 Вт каждый с сертификатом 80 PLUS Titanium. 
Источник изображения: Gigabyte Technology Сервер оборудован контроллером ASPEED AST2600, двумя сетевыми портами 10GbE на базе Intel X710-AT2 (RJ45), выделенным сетевым портом управления 1GbE (RJ45), двумя портами USB 3.2 Gen1 (5 Гбит/с), аналоговым разъёмом D-Sub. Диапазон рабочих температур — от +10 до +30 °C. Габариты составляют 447 × 351 × 923 мм.
20.02.2026 [09:10], Руслан Авдеев
AMD, Classiq и Comcast «квантово» улучшили интернетРазработчик программного обеспечения для квантовых вычислений Classiq совместно с Comcast и AMD объявили о завершении испытаний, направленных на совершенствование доставки интернет-трафика путём использования квантовых алгоритмов для повышения надёжности маршрутизации в Сети, сообщает HPC Wire. Comcast заявила, что клиентам нужно быстрое, безопасное и надёжное подключение, но при управлении большой и динамичной сетью достижение этой цели становится сложной задачей, особенно в условиях растущего спроса. Поэтому в прошлом году были начаты эксперименты по выяснению того, как квантовое ПО и технологии могут решать реальные сетевые задачи. Результаты показали, что квантовые вычисления для оптимизации сети — не теория, а вполне практическое, масштабируемое решение. В ходе тестов решалась фундаментальная задача проектирования сети — определение независимых резервных маршрутов для сетевых узлов в общей конкурентной среде при проведении технического обслуживания и изменении топологии сети, причём с сохранением минимально возможной задержки, высокой устойчивостью к одновременным сбоям и высокой же пропускной способностью. Такая задача регулярно возникает на реальных сетях, где и без планового обслуживания не обойтись, и от одновременных сбоев никто застрахован. 
Источник изображения: Dynamic Wang/unsplash.com В ходе эксперимента с использованием квантовых технологий и HPC-платформ AMD на базе ускорителей Instinct MI300X проверялась возможность квантовых алгоритмов успешно определять резервные пути для трафика в режиме реального времени в различных сценариях. Использовались как моделирование с использованием Instinct для достижения значимых вычислительных мощностей (кубитного уровня), что позволило быстро перебирать различные алгоритмы, так и реальный квантовый компьютер IonQ Forte с 29 алгоритмическими кубитами для проверки успешности реализации алгоритмов. 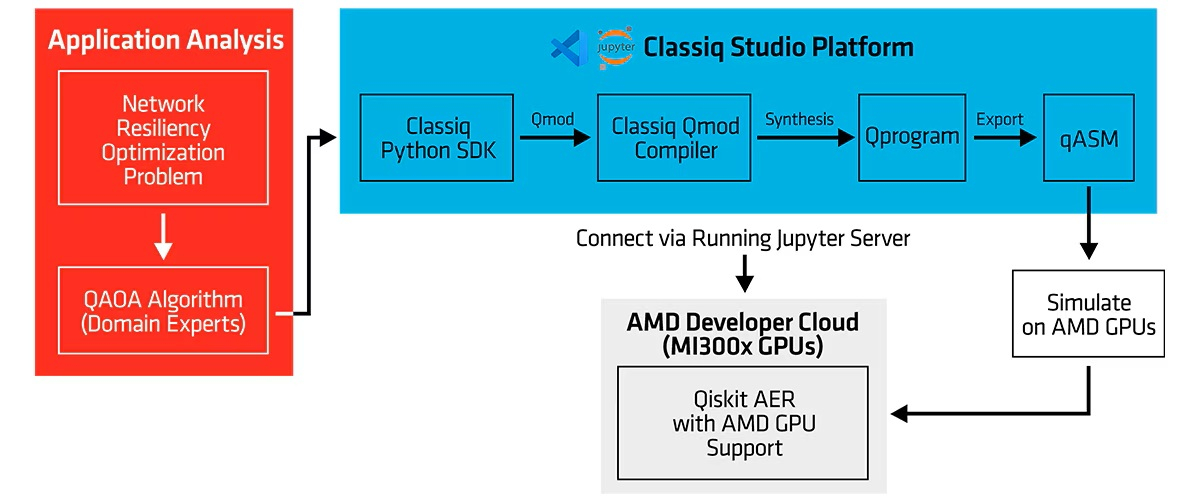
Источник изображения: AMD Задача оптимизации глобальных телекоммуникационных сетей — крайне ресурсоёмкая комбинаторная задача, экспоненциально усложняющаяся по мере роста размера сети. Такая задача является идеальным вызовом для систем квантовых вычислений. По словам представителя Classiq, исследования и разработки в сфере квантовых технологий требуют быстрых итераций с внесением улучшений на каждом цикле и воспроизводимых рабочих процессов. AMD заявила, что будущее HPC — в конвергенции классических и квантовых вычислений.
04.12.2025 [12:21], Руслан Авдеев
Скромно, но со вкусом: Vultr при поддержке AMD построит за $1 млрд ИИ-кластер с 24 тыс. Instinct MI355XОблачный провайдер Vultr строит кластер мощностью 50 МВт из ИИ-ускорителей AMD в дата-центре в Огайо. Новый проект призван обеспечить дополнительные вычислительные мощности по сниженным ценам, сообщает Bloomberg. Поддерживаемая AMD компания намерена инвестировать в объект более $1 млрд, клиенты смогут обучать и эксплуатировать ИИ-модели. Ввод в эксплуатацию запланирован на I квартал 2026 года. Vultr входит в группу облачных провайдеров, желающих заработать на ажиотажном спросе на ИИ. Новый кластер гораздо меньше гигантских объектов Microsoft, Meta✴ и Google. При этом вычислительные мощности, по словам компании, будут предлагаться по более доступным тарифам. Облако Vultr, как правило, вдвое дешевле, чем предложения гиперскейлеров, сообщают в компании. Утверждается, что её 50-МВт ЦОД с 24 тыс. AMD Instinct MI355X сопоставим с некоторыми гигаваттными проектами по эффективности. Vultr одной из первых получила MI355X, а вскоре перейдёт на MI450. Кластер называют «беспрецедентным» для облачной компании такого масштаба, но для него пока нет готовых к подписанию соглашений клиентов, хотя активные переговоры уже ведутся. По имеющимся данным, действующие клиенты вроде Clarifai Inc. и LiquidMetal AI, а также биотехнологическая MindWalk Holdings уже пользуются сервисами Vultr на базе решений AMD. В общей сложности компания обслуживает «сотни тысяч» клиентов в 185 странах. 
Источник изображения: Vultr Vultr была основана в 2014 году и многие годы предлагала доступ к решениям на базе CPU. В 2021 году Vultr начала закупать GPU. В последние пару лет ИИ-инфраструктура стала самой быстрорастущей частью бизнеса компании, т.ч. теперь она обеспечивает большую часть выручки. В 2026 году бизнес намерен уделять ИИ ещё больше внимания. В прошлом году компания привлекла $333 млн, в ходе раунда, возглавленного LuminArx Capital Management и AMD, её капитализация составила $3,5 млрд. В июне 2025 года дополнительно получены $329 млн кредитного финансирования, преимущественно от JPMorgan Chase, Bank of America и Wells Fargo. В эту сумму вошли $74 млн, обеспеченных активами компании, в т.ч. ИИ-ускорителями. Vultr значительно расширила кредитную линию для финансирования кластера AMD. Разрабатывающие ИИ-инфраструктуру компании всё чаще опасаются, что отрасль ожидает формирование пузыря. Также не исключается, что ИИ-ускорителя быстро обесценятся, что тоже способно привести рынок к кризису. В Vultr уверены, что ИИ-инфраструктура всё ещё остаётся «крайне неразвитой», даже если некоторые, чрезвычайно разросшиеся на этом рынке IT-гиганты, вероятно, потерпят неудачу. Что касается времени «обесценивания» технологий, Vultr уверена, что срок службы в шесть лет для ИИ-ускорителей — «разумная, консервативная оценка».
03.12.2025 [20:51], Владимир Мироненко
HPE одной из первых начнёт выпускать интегрированные стоечные ИИ-платформы AMD Helios AI
amd
broadcom
epyc
hardware
hpc
hpe
instinct
juniper networks
mi400
ocp
ualink
venice
германия
ии
суперкомпьютер
AMD объявила о расширении сотрудничества с HPE, в рамках которого HPE станет одним из первых поставщиков стоечных систем AMD Helios AI, которые получат коммутаторы Juniper Networking (компания с недавних пор принадлежит HPE), разработанные совместно с Broadcom, и ПО для бесперебойного высокоскоростного подключения по Ethernet. AMD Helios AI — открытая полнофункциональная ИИ-платформа на базе архитектуры OCP Open Rack Wide (ORW), разработанная для крупномасштабных рабочих нагрузок и обеспечивающая FP4-производительность до 2,9 Эфлопс на стойку благодаря ускорителям AMD Instinct MI455X, процессорам EPYC Venice шестого поколения и DPU Pensando Vulcano, работающими под управлением открытой программной экосистемы ROCm для нагрузок ИИ и HPC. Как отметил The Register, сетевая архитектура этой системы будет представлять собой масштабируемую реализацию UALink over Ethernet (UALoE) и специализированным коммутатором Juniper Networks на базе сетевого чипа Broadcom Tomahawk 6 (102,4 Тбит/с). Система разработана для упрощения развёртывания крупномасштабных ИИ-кластеров, что позволяет сократить время разработки решений и повысить гибкость инфраструктуры. В отличие от NVIDIA, AMD не выпускает коммутаторы, предлагая открытую экосистему, так что HPE и другие компании могут интегрировать собственные сетевые решения. The Register полагает, что HPE и Broadcom решили не гнаться за отдельной аппаратной реализацией UALink, если данные можно передавать поверх Ethernet. «Это первое в отрасли масштабируемое решение, использующее Ethernet, стандартный Ethernet. Это означает, что оно полностью соответствует открытому стандарту и позволяет избежать привязки к проприетарному поставщику, использует проверенную сетевую технологию HPE Juniper для обеспечения масштабируемости и оптимальной производительности для рабочих нагрузок ИИ», — заявила HPE. 
Источник изображения: HPE HPE заявила, что это позволит её стоечной системе поддерживать трафик, необходимый для обучения модели с триллионами параметров, а также обеспечить высокую пропускную способность инференса. Стоечная система HPE будет включать 72 ускорителя AMD Instinct MI455X с 31 Тбайт HBM4 с агрегиированной пропускной способностью 1,4 Пбайт/с. Агрегированная скорость интерконнекта составит 260 Тбайт/с. Новинка будет доступна в 2026 году. AMD также сообщила, что Herder, новый суперкомпьютер для Центра высокопроизводительных вычислений в Штутгарте (HLRS) (Германия), получит Instinct MI430X и EPYC Venice. Он будет построена на платформе HPE Cray Supercomputing GX5000. Поставка Herder запланирована на II половину 2027 года, а ввод в эксплуатацию — к концу 2027 года. Herder заменит используемый центром суперкомпьютер Hunter.
01.12.2025 [12:28], Сергей Карасёв
MiTAC представила ИИ-сервер G4826Z5 с ускорителями AMD Instinct MI355X и СЖОКомпания MiTAC анонсировала высокопроизводительный GPU-сервер G4826Z5 на аппаратной платформе AMD, предназначенный для ресурсоёмких задач ИИ и НРС. Кроме того, представлены стойки и вычислительные кластеры на его основе. Сервер G4826Z5U2BC-355X-755 выполнен в форм-факторе 4U. Нижняя 2U-секция содержит два процессора AMD EPYC 9005 Turin и 24 слота для модулей оперативной памяти DDR5-6400. Во фронтальной части расположены восемь отсеков для SFF-накопителей; кроме того, есть два внутренних коннектора M.2 для SSD (NVMe). Верхний 2U-модуль несёт на борту восемь ускорителей AMD Instinct MI355X, оборудованных 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. Машина G4826Z5 получила систему жидкостного охлаждения, которая охватывает CPU- и GPU-секции. Предусмотрена функция обнаружения утечек. Подсистема питания с резервированием выполнена по схеме: 1+1 мощностью 3200 Вт и 3+3 мощностью 15 600 Вт. Все блоки питания имеют сертификат 80 Plus Titanium и допускают горячую замену. 
Источник изображений: MiTAC На основе G4826Z5 формируется стоечная система (MR1100L-64355X-01): она содержит восемь GPU-серверов, что в сумме даёт 64 ускорителя и 18,4 Тбайт памяти HBM3E. Стойка также укомплектована коммутаторами 400GbE на 64 и 32 порта, двумя коммутаторами 1GbE на 48 портов, сервером управления B8056G68CE12HR-2T-TU, сервером хранения B8056T70AE26HR-2T-HE-TU и блоком распределения охлаждающей жидкости (CDU) в формате 4U.  В свою очередь, стойки объединяются в кластеры из четырёх и восьми штук. Это в сумме обеспечивает 32 и 64 сервера GPU и 256 и 512 ускорителей Instinct MI355X соответственно. Таким образом, максимальная конфигурация включает приблизительно 147 Тбайт памяти HBM3E.
26.11.2025 [12:50], Сергей Карасёв
Сервер Giga Computing G4L3-ZX1 с поддержкой AMD EPYC 9005 Turin и Instinct MI355X оснащён СЖОКомпания Giga Computing, подразделение Gigabyte, анонсировала сервер G4L3-ZX1-LAT4, предназначенный для задачи ИИ и НРС. Эта мощная машина на аппаратной платформе AMD оснащена системой прямого жидкостного охлаждения (DLC), отводящей тепло и от CPU, и от GPU. Сервер выполнен в форм-факторе 4U. Он может нести на борту два процессора EPYC 9004 Genoa или EPYC 9005 Turin (до 192 вычислительных ядер) в исполнении Socket SP5 с показателем TDP до 500 Вт. Доступны 24 слота для модулей оперативной памяти DDR5-6400. Во фронтальной части находятся восемь отсеков для SFF-накопителей NVMe; кроме того, есть два внутренних коннектора M.2 2280/22110 для SSD с интерфейсом PCIe 3.0 x4 и x1. Новинка располагает восемью ускорителями AMD Instinct MI355X OAM. Предусмотрены восемь разъёмов для однослотовых карт FHHL с интерфейсом PCIe 5.0 x16 и четыре разъёма для двухслотовых карт FHHL (также PCIe 5.0 x16). Питание обеспечивают шесть блоков с резервирование мощностью 5200 Вт (сертификат 80 PLUS Titanium). Помимо СЖО, задействован ряд системных вентиляторов: 4 × 60 мм в зоне материнской платы, 4 × 80 мм в области слотов PCIe и 4 × 60 мм в лотке GPU. Диапазон рабочих температур — от +10 до +30 °C. 
Источник изображения: Giga Computing Сервер оснащён двумя сетевыми портами 10GbE на основе адаптера Intel X710-AT2, выделенными сетевыми портами 1GbE во фронтальной и тыльной частях, контроллером Aspeed AST2600, двумя портами USB 3.2 Gen1 Type-A и аналоговым разъёмом D-Sub. Опционально может быть добавлен модуль TPM 2.0. Габариты сервера составляют 447 × 175,5 × 901 мм.
21.11.2025 [11:14], Сергей Карасёв
Supermicro представила ИИ-сервер 10U на базе AMD Instinct MI355X с воздушным охлаждениемКомпания Supermicro анонсировала высокопроизводительный GPU-сервер AS-A126GS-TNMR, построенный на аппаратной платформе AMD. Система, выполненная в форм-факторе 10U, ориентирована на НРС-нагрузки и решение ресурсоёмких задач в сфере ИИ. Сервер может нести на борту два процессора AMD EPYC 9005 Turin или EPYC 9004 Genoa со 192 ядрами каждый (показатель TDP до 500 Вт). Доступны 24 слота для модулей оперативной памяти DDR5-6400 суммарным объёмом до 6 Тбайт. Во фронтальной части расположены десять отсеков для SFF-накопителей в конфигурации 8 × NVMe (PCIe 5.0 x4) и 2 × SATA с возможностью горячей замены. Кроме того, есть два лицевых слота для SSD формата M.2 (NVMe). В оснащение входят восемь ускорителей AMD Instinct MI355X, оборудованных 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. Применяется интерконнект AMD Infinity Fabric. Реализовано воздушное охлаждение: спереди размещены пять вентиляторных блоков, сзади — десять (все они допускают горячую замену). Диапазон рабочих температур простирается от +10 до +35 °C. 
Источник изображения: Supermicro Сервер располагает двумя сетевыми портами 10GbE RJ45 на базе контроллера Intel X710, выделенным сетевым портом управления 1GbE, двумя портами USB 3.0 Type-A, аналоговым разъёмом D-Sub, модулем TPM 2.0, восемью слотами PCIe 5.0 x16 для низкопрофильных (LP) карт расширения и двумя слотами PCIe 5.0 x16 для карт FHHL. Габариты составляют 438,8 × 449 × 843,28 мм, масса — 133 кг. Питание обеспечивают шесть блоков мощностью 5250 Вт с резервированием (3 + 3), которые имеют сертификацию 80 Plus Titanium. Поставки системы AS-A126GS-TNMR уже начались.
20.11.2025 [14:00], Руслан Авдеев
AMD, Cisco и Humain развернут ИИ-инфраструктуру на 1 ГВт — первые 100 МВт с Instinct MI450 появятся в Саудовской АравииКомпании AMD, Cisco и саудовская инвестиционная компания Humain, участвующая в комплексных ИИ-проектах, объявили о создании совместного предприятия. Ожидается, что оно поддержит укрепление позиций Саудовской Аравии в качестве ведущего поставщика ИИ-решений мирового класса для клиентов регионального и мирового уровней. Совместное предприятие должно заработать в 2026 году. Партнёры рассчитывают объединить передовые ИИ ЦОД Humain и технологическими решениями AMD и Cisco, обеспечив современную вычислительную инфраструктуру с низкими капитальными затратами и эффективным энергопотреблением. Эксклюзивными технологическими партнёрами предприятия выступят AMD и Cisco, к 2030 году с помощью их продуктов и сервисов планируется обеспечить до 1 ГВт ИИ-инфраструктуры. Компании уже объявили о реализации первой очереди проекта — пока мощностью на 100 МВт, в т.ч. включающую мощности современного дата-центра Humain, ИИ-ускорители AMD Instinct MI450 и инфраструктуру Cisco. Ранее в 2025 году Cisco и AMD объявили о совместной инициативе с Humain, направленной на строительство самой открытой, масштабируемой и экономически эффективной ИИ-инфраструктуры. Новый анонс дополняет планы созданием совместного предприятия для того, чтобы ускорить преобразования и предоставить экономическую инфраструктуру для поддержки использования ИИ заказчиками. 
Источник изображения: NEOM/unsplash.com По словам главы AMD Лизы Су (Lisa Su), в рамках расширения сотрудничества в Саудовской Аравии также создаётся Центр передового опыта AMD (AMD Center of Excellence) для углубленной интеграции страны в ИИ-проекты. По данным Cisco, индекс готовности к развитию ИИ (AI Readiness Index) показывает, что, хотя 91 % организаций Саудовской Аравии готовятся к внедрению ИИ-агентов, только 29 % из них уже имеют доступ к значительным мощностям ИИ-ускорителей, что ещё раз подчёркивает острую потребность в современной инфраструктуре ЦОД. Ожидается, что партнёрство не только обеспечит вычислительные мощности для масштабного внедрения ИИ, но и будет способствовать укреплению цифровой экономики страны. Это лишь один из многих проектов для Саудовской Аравии. В 2025 году сообщалось, что Oracle выделит $14 млрд на развитие ИИ и облака в стране, xAI ведёт с Humain переговоры о создании ИИ ЦОД там же, в августе появилась информация, что саудовская center3 потратит $10 млрд на ЦОД общей мощностью 1 ГВт. |
|

