Материалы по тегу: эмулятор
|
08.04.2026 [09:22], Владимир Мироненко
Стране нужен FP64: AMD пообещала повысить HPC-производительность ускорителей Instinct MI430XПосле анализа ограничений эмуляции FP64-вычислений с использованием схемы Озаки разработчики AMD пришли к выводу, что в настоящее время нет замены «сырой» производительности FP64. Как сообщил научный сотрудник AMD Николас Малайя (Nicholas Malaya) ресурсу HPCwire, чтобы обеспечить точность традиционных задач моделирования и симуляции, компания намерена нарастить нативную FP64-производительность ускорителя Instinct MI430X. Ускоритель станет основой суперкомпьютера Discovery, который будет установлен в Национальной лаборатории Ок-Ридж (ORNL) в 2028 году. Как отметил Кацухиса Озаки (Katsuhisa Ozaki) и два других японских исследователя, схема Ozaki — это многообещающая новая техника эмуляции, призванная позволить учёным выполнять высокоточные умножения матриц на оборудовании с поддержкой INT8/FP8, к которому относятся современные ИИ-ускорители, путём многократных вычислений с более низкой точностью. Текущие реализации Ozaki-I и Ozaki-II имеют ограничения, которые исключают их использование в реальных условиях, сообщил Малайя. Он указал на две основные проблемы. Во-первых, ПО не соответствует стандарту IEEE и не даёт того же результата, что и запуск кода на реальном оборудовании с поддержкой FP64. «В некоторых случаях это нормально, — сказал он. — Но во многих распространённых матрицах, которые мы наблюдали, влияние на точность довольно существенно.». Во-вторых, схема Озаки нацелена на квадратные матрицы. Если таковые в расчётах не используется, то итоговая производительность оказывается ниже, чем у нативного FP64-исполнения, говорит Малайя. 
Источник изображения: AMD Кроме того, HPC-приложения традиционно опираются на векторные вычисления, а не на тензорные или матричные, которые характерны для ИИ-нагрузок. Фактически ситуация ещё хуже — менее 10 % реальных HPC-приложений внесли изменения в DGEMM-коды, которые позволяют воспользоваться преимуществами Ozaki. «Насколько мне известно, с Ozaki-I, Ozaki-II или любой другой существующий метод нельзя применить к векторным инструкциям, — говорит Малайя. — Это ключевой нюанс, который, как мне кажется, упускается». На DGEMM действительно уходит много вычислительных ресурсов, что позволяет использовать схему Ozaki, «но она не решает 90 % HPC-задач». AMD собирается поддерживать эмуляцию Ozaki на своих чипах, сообщил Малайя. «Нет причин этого не делать. Это ПО. <…> И у вас могут быть библиотеки, которые позволяют динамически переключаться между нативными расчётами и Ozaki и, вероятно, оценивать его», — сказал он, добавив, что программную эмуляцию можно иметь в виду в качестве резервного варианта для FP64-вычислений. Но в конечном итоге Ozaki не является работоспособной альтернативой «железу» с FP64, сказал Малайя, уточнив, что не он один так считает. 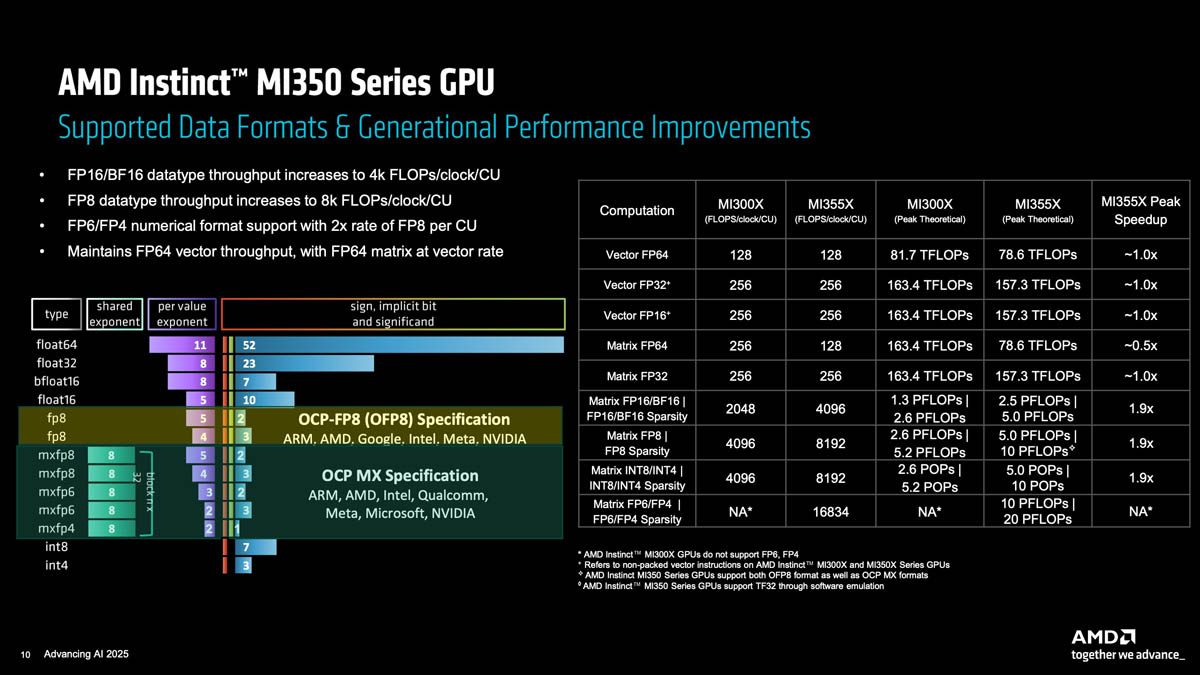
Источник изображения: AMD В настоящее время компания разрабатывает MI430X, специализированную версию ускорителя следующего поколения MI450, который будет обладать значительной FP64-производительностью. По словам Малайи, она будет значительно больше, чем у ускорителя MI355X, который обеспечивает 78,6 Тфлопс. По факту, это меньше, чем у предыдущей модели MI325X, которая обеспечивала 81,7 Тфлопс — в обоих случаях речь и про векторные, и про матричные FP64-вычисления. В любом случае, у всех этих чипов — от MI325 до MI430 — производительность больше, чем у чипов NVIDIA. И Hopper (34 Тфлопс), и Blackwell (40 Тфлопс) уже были медленнее в векторных FP64-вычислениях, но у Hopper хотя бы были нативные 67 Тфлопс в матричных расчётах, тогда как Blackwell в этом случае уже перешёл к схеме Озаки с «ненативными» 150 Тфлопс. Про Blackwell Ultra, где FP64-производительность упала до 1,3 Тфлопс, NVIDIA в данном контексте вообще не вспоминает, но обещает, что у Rubin будет 33 Тфлопс в векторных FP64-расчётах и 200 Тфлопс в матричных (тоже с Озаки). 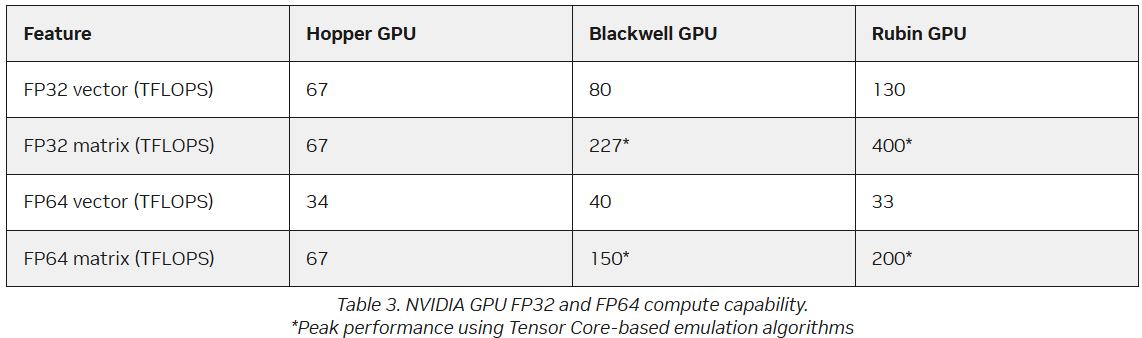
Источник изображения: NVIDIA NVIDIA обосновывает отказ от развития аппаратных FP64-блоков тем, что увеличение собственно вычислительной мощности FP64 на самом деле не ускорит научные приложения, поскольку на практике они упрутся в возможности регистров, кешей и HBM. Rubin обеспечит пропускную способность HBM до 22 Тбайт/с, что в 2,8 раза больше, чем у Blackwell. Instinct MI325X предлагает 6 Тбайт/с, MI355X — 8 Тбайт/с, а у MI430X будет уже 19,6 Тбайт/с, сообщил Малайя. По словам Малайи, лучше всего синхронно «вкладываться» и в HBM, и в количество операций с плавающей запятой. «На самом деле важен коэффициент байт/флопс. С нашей точки зрения, необходимо поддерживать гораздо более близкое соотношение к тому, что мы видим в современных продуктах, — сказал он. — Необходимо значительно приблизиться к этому соотношению с точки зрения увеличения производительности FP64, чтобы сохранить тот же уровень, как это называют, арифметической интенсивности». 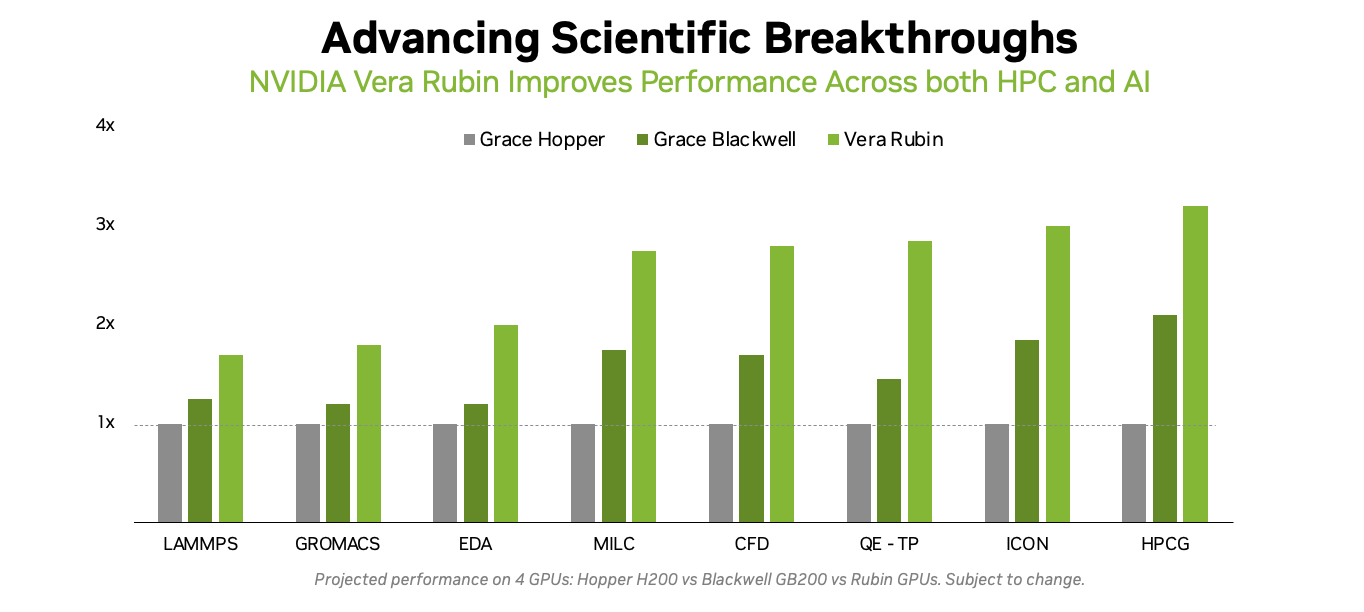
Источник изображения: NVIDIA Поскольку AMD обеспечит 2,5-кратное увеличение ПСП HBM от MI355 до MI430X, аналогичное 2,5-кратное увеличение производительности FP64 также будет оправдано. Таким образом можно примерно прикинуть, что MI430X может обеспечить производительность FP64 от 192 до 204 Тфлопс в зависимости от того, какой из них будет базовым: более новый MI355 или более быстрый MI325, сообщил HPCwire, добавив, что это всего лишь предположение, поскольку компания пока не сообщила точные характеристики будущих чипов. Кроме того, не до конца ясно, будет ли FP64-производительность одинакова для векторных и матричных расчётов. FP64-вычисления «очень важны» для «Миссии Генезис» (Genesis Mission), заявил ранее заместитель министра энергетики США (DoE) по науке и инновациям Дарио Гил (Darío Gil). Он отметил, что и глава AMD Лиза Су (Lisa Su), и глава NVIDIA Дженсен Хуанг (Jensen Huang), выразили твёрдую приверженность FP64, подтвердив, что поддержка формата будет продолжаться. «FP64 имеет решающее значение для поддержки рабочих нагрузок моделирования и симуляции, не только для дальнейшего развития традиционных научных исследований, но и для предоставления исходных данных для обучения новых ИИ-моделей», — добавил Гил. 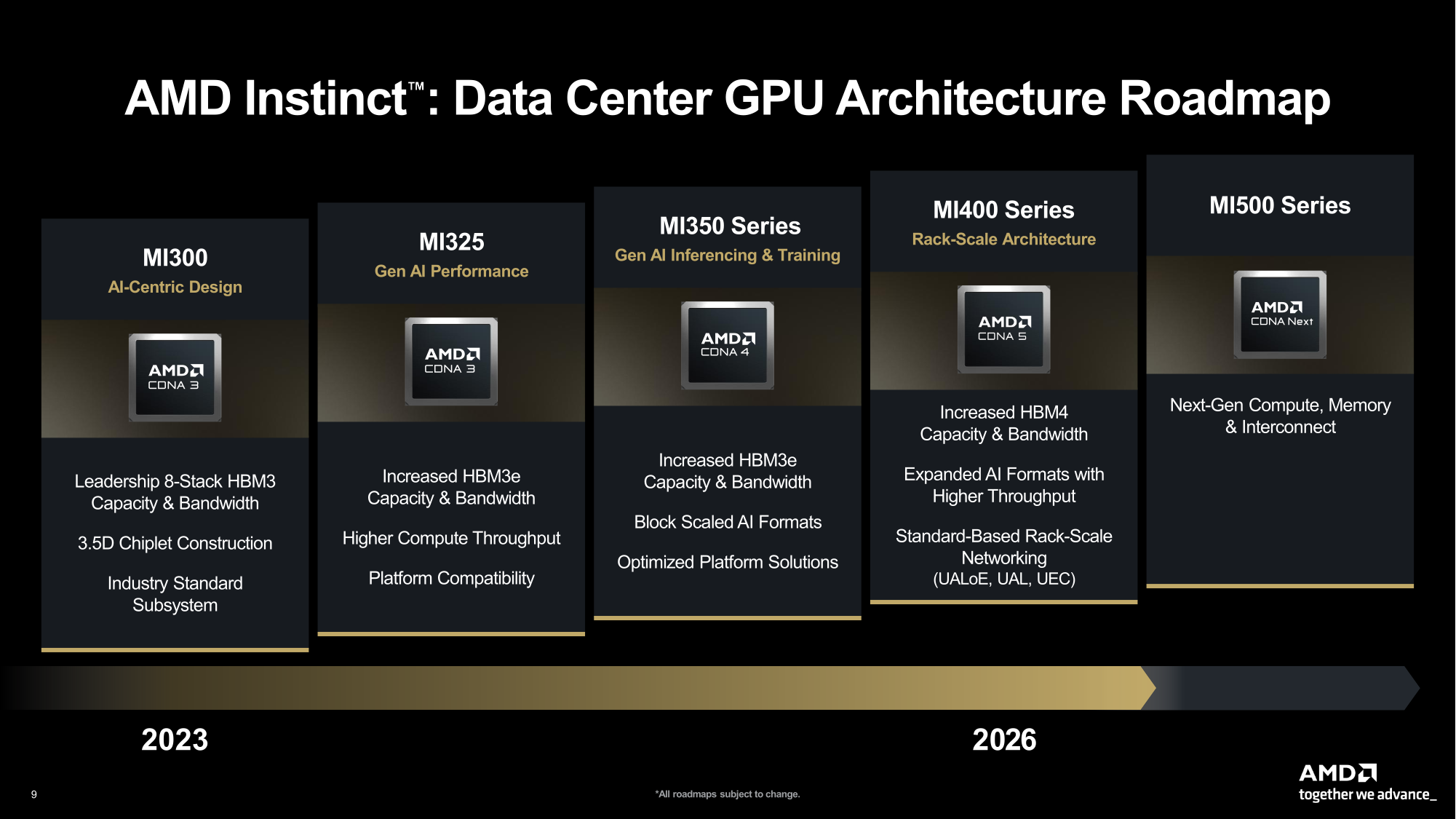
Источник изображения: AMD «Всегда существует баланс между тем, сколько требуется FP64- и FP16-вычислений», — сказал Малайя. «AMD утверждает, что нам необходимо поддерживать широкий спектр типов данных в зависимости от их потребностей. Не получится, чтобы всем были нужны FP64, которых хватит для всего.», — отметил он. Малайя сообщил, что всегда бывают исключения. Например, ИИ-симуляции сворачивания белков, такие как AlphaFold и Openfold, используют FP32. Да и некоторым традиционным HPC-задачам, таким как молекулярная динамика, не требуется FP64-точность. Тем не менее, сейчас существует значительный неудовлетворенный спрос на FP64, утверждает учёный. «Что касается высокопроизводительных вычислений, мы считаем, что им по-прежнему потребуется много FP64, — сказал он. — Будут использоваться некоторые коды, которые полностью ограничены пропускной способностью памяти, и им не нужно так много. Но есть, например, коды вычислительной химии и некоторые другие, которые действительно имеют высокую арифметическую интенсивность, и они будут использовать FP64».
19.02.2026 [09:52], Владимир Мироненко
Американская «Миссия Генезис» будет во многом полагаться на «ненастоящие» FP64-вычисленияХотя последнее поколение GPU ориентировано на вычисления с более низкой точностью, которые предпочтительны для ИИ-задач, FP64-вычисления с более высокой точностью по-прежнему «очень важны» для «Миссии Генезис» (Genesis Mission) и её цели — ускорения научных открытий с помощью ИИ, заявил заместитель министра энергетики США по науке и инновациям Дарио Гил (Darío Gil) в интервью HPCwire. «В ходе обсуждений, которые я провел как с [генеральным директором AMD] Лизой Су (Lisa Su), так и с [генеральным директором NVIDIA] Дженсеном [Хуангом] (Jensen Huang), они выразили твёрдую приверженность FP64, подтвердив, что поддержка формата будет продолжаться, — сказал Гил. — Для нас это очень важно, потому что мы не рассматриваем это как замену. Это взаимодополняющие технологии». Он отметил, что для обеспечения вычислительных задач моделирования и симуляции, которые традиционно составляют основу научных вычислений, а также для новых методов ИИ, важно иметь высокопроизводительное оборудование. Гил добавил, что эти два типа вычислений будут работать вместе, чтобы поддержать цель миссии Genesis — расширение границ науки и техники на основе ИИ-технологий. «У вас есть высокоточные симуляционные коды, работающие с FP64. После проверки вы используете их в качестве основы для генерации примеров, на которых вы обучаете суррогатную модель, которую затем запускаете на ИИ-суперкомпьютере, — рассказал Гил. — В итоге вы получаете преимущества с точки зрения производительности и времени решения, часто в 10, 20, 100 раз». 
Источник изображений: NVIDIA Он отметил, что благодаря использованию ИИ-моделей можно получить громадное повышение производительности, но оно зависит от сохранения всего цикла работ, состоящего из экспериментов, моделирования и обучения. «Если вы разорвёте этот цикл и скажете, что у вас больше нет кодов моделирования, то возникнет проблема», — сказал Гил. «Для нас это имеет фундаментальное значение, не только для устаревших кодов, которые мы должны сопровождать и которые так важны для миссии, но и для обеспечения рабочего ИИ-процесса. Поэтому для нас очень важно поддерживать различные архитектурные подходы», — добавил он. В HPC-сообществе возникла обеспокоенность по поводу отсутствия прироста производительности для FP64 в новейших GPU. Напомним, что чип NVIDIA H100, выпущенный в 2022 году, обеспечивает 67 Тфлопс в формате FP64 на тензорных ядрах (34 Тфлопс в векторных вычислениях), в то время как B200 предлагает лишь 37 Тфлопс, а B300 — всего лишь 1,3 Тфлопс. Программная эмуляция FP64-вычислений на тензорных ядрах Blackwell позволяет получить «нечестные» 150 Тфлопс, а из новейших Rubin она позволяет «выжать» 200 Тфлопс. При этом пиковая заявленная производительность векторных FP64-вычислений у Rubin составляет лишь 33 Тфлопс, т.е. нет никакого прироста в сравнении с Hopper. 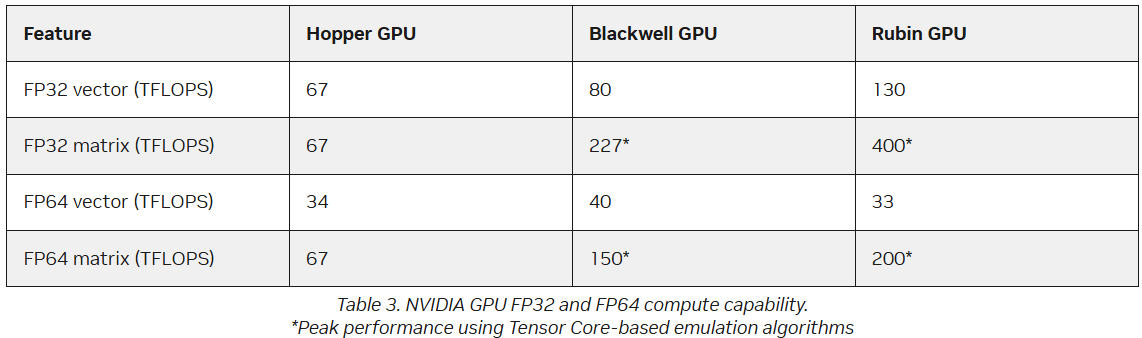 Отметим, что в AMD раскритиковали такой подход, заявив, что он эффективен не для всех сценариев и поэтому такое решение ещё не готово к широкому применению. В свою очередь, эксперты предупреждают, что смещение фокуса производителей на выпуск чипов для ИИ-нагрузок, которые отлично работают с вычислениями с низкой точностью, может привести к дефициту чипов с поддержкой FP64 для HPC, а это грозит потерей лидерства США в этом сегменте рынка. По мере того, как NVIDIA наращивает мощность для выполнения ИИ-задач с низкой точностью вычислений Rubin, компания будет всё больше полагаться на cuBLAS, библиотеку стандартных математических операций CUDA-X, которая эмулирует вычисления с двойной точностью на тензорных ядрах, чтобы постоянно наращивать показатели FP64-производительности. «Мы пытаемся предоставить эти возможности среде разработчиков, чтобы они могли… получить необходимую точность FP64», — заявил в декабре HPCwire Дион Харрис (Dion Harris), старший директор NVIDIA по ИИ/HPC-решениям для гиперскейлеров. 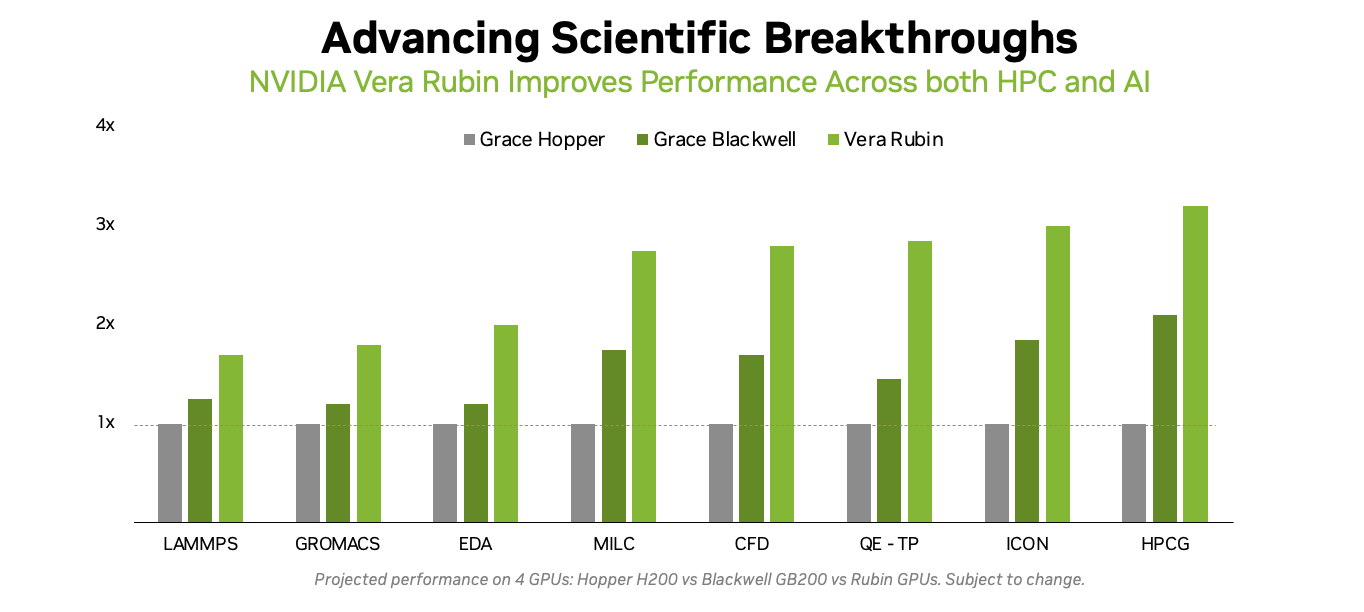
NVIDIA GPU simulation performance Методы эмуляции NVIDIA основаны на схеме Озаки (Ozaki), позволяющей выполнять умножение матриц с высокой точностью, используя многократные вычисления с низкой точностью на тензорных ядрах. NVIDIA утверждает, что использование алгоритма Озаки оправдано, поскольку увеличение производительности FP64 путём добавления большего количества ядер CUDA фактически не повысит общую производительность HPC-приложений, но сделает чипы менее гибкими. По словам компании, анализ реальных нагрузок показывает, что «наивысшая устойчивая производительность FP64 часто достигается на умножении матриц». В Hopper для этого были отдельные аппаратные блоки, но в Blackwell и в Rubin NVIDIA больше опирается на эмуляцию. В то же время, производительность векторных FP64-вычислений остаётся критически важной для научных приложений, в которых не доминируют матричные ядра, признаёт NVIDIA, однако тут же утверждает, что в этих случаях производительность ограничивается перемещением данных через регистры, кеши и HBM, а не непосредственно вычислительными ресурсами. Поэтому сбалансированная конструкция GPU «обеспечивает достаточное количество ресурсов FP64 для насыщения доступной пропускной способности памяти, избегая избыточного выделения вычислительной мощности, которая не может быть эффективно использована». Иными словам, компания ничего менять не собирается. Проект Genesis Mission, вероятно, будет создавать разнообразные ИИ-приложения для научных и инженерных задач, и каждое из них, скорее всего, будет иметь несколько иные вычислительные потребности. Достигли ли NVIDIA и AMD оптимального баланса, используя вычислительные ядра для матричных вычислений и опираясь на эмуляцию Озаки для FP64, ещё предстоит выяснить, пишет HPCwire.
20.01.2026 [10:02], Владимир Мироненко
FP64 у вас ненастоящий: AMD сомневается в эффективности эмуляции научных расчётов на тензорных ядрах NVIDIAВместо создания специализированных чипов для аппаратных FP64-вычислений NVIDIA использует эмуляцию для повышения производительности HPC на ИИ-ускорителях, пишет The Register. Компания отказалась от развития FP64-блоков в поколении Blackwell Ultra, а в новейших ускорителях Rubin пиковая заявленная производительность векторных FP64-вычислений составляет 33 Тфлопс, тогда как у H100, вышедшего четыре года назад, она была равна 34 Тфлопс, а у Blackwell — около 40 Тфлопс. Если включить программную эмуляцию в библиотеках CUDA от NVIDIA, ускоритель, как утверждается, может достичь производительности до 200 Тфлопс в матричных FP64-вычислениях. Впрочем, и Blackwell с эмуляций способен выдать в этом случае до 150 Тфлопс, тогда как у Hopper были «честные» 67 Тфлопс. «В ходе многочисленных исследований с партнёрами и собственных внутренних изысканий мы обнаружили, что точность, достигаемая с помощью эмуляции, как минимум не уступает точности, получаемой от аппаратных тензорных ядер», — сообщил ресурсу The Register Дэн Эрнст (Dan Ernst), старший директор по суперкомпьютерным продуктам NVIDIA. В свою очередь, в AMD считают, что это утверждение справедливо не для всех сценариев. «В некоторых бенчмарках она показывает довольно хорошие результаты, но в реальных физических научных симуляциях это не очевидно», — говорит Николас Малайя (Nicholas Malaya), научный сотрудник AMD. Он выразил мнение, что, хотя эмуляция FP64, безусловно, заслуживает дальнейших исследований и экспериментов, такое решение ещё не готово к широкому применению. AMD и сама изучает возможность программной эмуляции FP64 на Instinct MI355X, чтобы определить области её возможного применения. 
Источник изображения: Hilda Trinidad / Unsplash Хотя чипы всё чаще используют типы данных с более низкой точностью, FP64 остаётся золотым стандартом для научных вычислений, и на то есть веские причины — FP64 не имеет себе равных по динамическому диапазону. Современные же LLM обучаются с использованием FP8-вычислений, а компактные типы данных MXFP8/MXFP4 или NVFP4 позволяют получить достаточный для ИИ диапазон значений. Это хорошее решение для нечёткой математики больших языковых моделей, но это не замена FP64 для HPC. ИИ-нагрузки обладают высокой устойчивостью к ошибкам, а HPC-задачи требуют высокой точности. AMD указала на то, что эмуляция FP64 у NVIDIA не совсем соответствует стандарту IEEE. Алгоритмы NVIDIA не учитывают такие понятия, как положительные и отрицательные нули, ошибки NaN (Not a Number) и ошибки infinite number (бесконечное число). Из-за этого небольшие ошибки в промежуточных вычислениях, используемых для эмуляции более высокой точности, могут привести к искажениям, способным повлиять на точность конечного результата, пояснил Малайя. По его словам, целесообразность использования эмуляции FP64 зависит от конкретного приложения. Эмуляция FP64 лучше всего работает для хорошо обусловленных проблем, где малые изменения «на входе» приводят к малым же изменениям в конечном результате. Ярким примером такой задачи является бенчмарк Linpack (HPL). «Но если вы посмотрите на материаловедение, коды для расчёта процессов горения, системы ленточых матриц и т.п., то увидите, что это гораздо менее обусловленные системы, и внезапно всё начинает давать сбои», — сказал он. 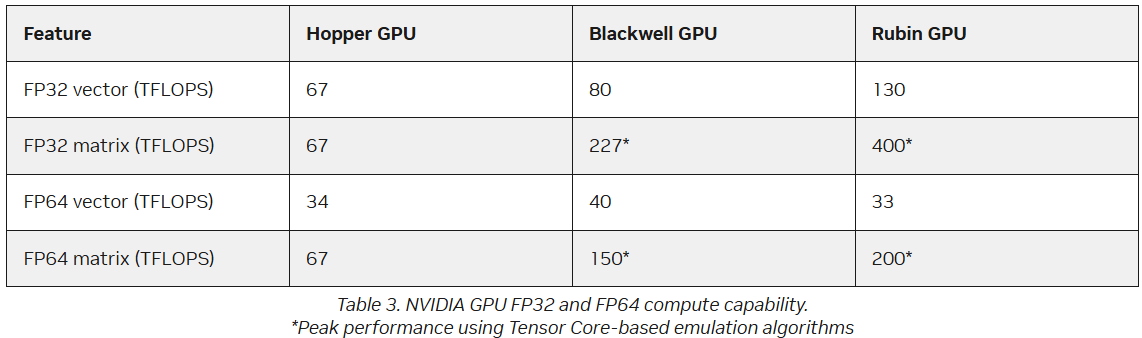
Источник изображения: NVIDIA Точность можно повысить, увеличив количество используемых операций, однако после определённого предела никаких преимуществ от эмуляции уже не будет. Вдобавок все эти операции требуют память. «У нас есть данные, которые показывают, что алгоритму Озаки требуется примерно вдвое больше памяти для эмуляции матриц FP64», — сказал Малайя. Поэтому компания готовит специализированные ускорители MI430X c повышенной FP64/FP32-производительностью, но, как опасаются учёные, она может оказаться не слишком в них заинтересована, поскольку ИИ-ускорители приносят больше денег. Эрнст утверждает, что для большинства специалистов в области HPC неполное соответствие стандарту IEEE не представляет большой проблемы. Всё во многом зависит от конкретного приложения. Тем не менее, NVIDIA разработала дополнительные алгоритмы для обнаружения и смягчения указанных выше ошибок и неэффективных операций эмуляции. Эрнст также признал, что использование памяти при эмуляции может быть несколько выше, но подчеркнул, что эти накладные расходы относятся к расчётам, а не к самому приложению — в большинстве случаев речь идёт о матрицах размером не более нескольких Гбайт. Впрочем, всё это не меняет того, что эмуляция полезна только для подмножества HPC-задач, которые полагаются на операции умножения плотных матриц (DGEMM). По словам Малайи, для 60–70 % рабочих нагрузок HPC эмуляция дает незначительные преимущества или ничего не меняет. «По нашим оценкам, подавляющее большинство реальных рабочих нагрузок HPC полагаются на векторное умножение (FMA), а не на DGEMM», — сказал он, отметив, что это действительно нишевый сегмент, хотя и не крошечная доля рынка. Для рабочих нагрузок, интенсивно использующих векторы, таких как вычислительная гидродинамика (CFD), ускорители Rubin по-прежнему будут полагаться на медленные векторные FP64-блоки.
11.11.2025 [17:14], Андрей Крупин
Вышла новая версия WineHelper — программы для запуска Windows-приложений в ОС «Альт» LinuxКомпания «Базальт СПО» представила новую версию WineHelper — программного решения для установки и запуска Windows-приложений в операционных системах семейства «Альт». Инструмент WineHelper построен на базе портативной сборки Wine, дополненной набором скриптов, автоматизирующих развёртывание ПО Windows в среде Linux. Обновлённая редакция WineHelper получила графический пользовательский интерфейс и возможность запуска программы непосредственно из меню приложений ОС «Альт». В дополнение к этому появились два режима установки Windows-программ — автоматический и ручной, новая вкладка «Менеджер префиксов» с расширенными настройками Wine, а также инструменты резервного копирования созданных префиксов. 
Источник изображения: basealt.ru WineHelper поддерживает автоматическое развёртывание более 40 программных продуктов Windows, в числе которых T-Flex CAD, «Декларация», «СТМ-Финансы», «R-Инфо», SCAD Offce, «Налогоплательщик ЮЛ», «Монитор ЭД» и многие другие востребованные в корпоративной среде решения. Программы добавляются в WineHelper по запросам заказчиков.
22.09.2024 [00:58], Владимир Мироненко
Linux запустили на Intel 4004 — загрузка заняла пять днейКак передаёт OpenNet, разработчик Дмитрий Гринберг сумел запустить ядро Linux с rootfs-окружением из Debian на 10-мкм 4-бит процессоре Intel 4004, вышедшем в конце 1971 года и считающемся первым в мире коммерчески доступным однокристалльным микропроцессором. У Intel 4004 всего 2300 транзисторов. Процессор имел всего 46 инструкций, а его пиковая производительность достигала примерно 93 тыс. операций в секунду. Из-за невозможности напрямую портировать ядро на Intel 4004 и из-за ограничений самого CPU автор решил написать эмулятор процессора MIPS R3000, внутри которого уже запускался Linux. Для запуска процессора автор в несколько подходов создал плату Linux/4004 на базе компонентов 1970-х годов, которые, как выяснилось, не так уж дёшевы. Естественно, плата содержит и гораздо более современные компоненты, позволяющие, к примеру, использовать SD-карту в качестве постоянной памяти. 
Источник изображения: dmitry.gr Из-за малой производительности Intel 4004 эмулятор работал медленно — на обработку каждой виртуальной секунды в эмулируемом окружении уходило почти 4 часа реального времени. После усовершенствования платы и ПО загрузка Linux сократилась с почти 9 дней до примерно 5 дней. Автор даже смог разогнать CPU с базовых 740 кГц до 790 кГц. Желающие повторить эксперимент могут воспользоваться опубликованными спецификациями и схемой платы, а также ПО. |
|

