Материалы по тегу: hpc
|
09.02.2026 [13:17], Сергей Карасёв
«Ядерный» суперкомпьютер Teton производительностью 20,8 Пфлопс полагается только на AMD EPYC TurinНациональная лаборатория Айдахо (INL) в составе Министерства энергетики США (DOE) сообщила о запуске суперкомпьютера Teton. Система присоединилась к четырём другим НРС-комплексам лаборатории — Bitterroot, Hoodoo, Wind River и Sawtooth, увеличив доступные вычислительные ресурсы вчетверо. В основу Teton положена платформа HPE Cray EX 4000. Объединены 1024 вычислительных узла, каждый из которых содержит 384 ядра CPU и 768 Гбайт памяти. Задействованы процессоры AMD EPYC 9005 поколения Turin. Таким образом, в общей сложности используются около 393 тыс. CPU-ядер и 768 Тбайт памяти. Как отмечает INL, на сегодняшний день Teton — это один из самых мощных суперкомпьютеров в мире, архитектура которого базируется исключительно на CPU (без применения GPU и других специализированных компонентов). Такая конфигурация обусловлена спецификой использования системы: комплекс предназначен для сложных физических моделирований в рамках проектов по разработке передовых реакторов на быстрых нейтронах, малых модульных реакторов и микрореакторов. Утверждается, что традиционные CPU лучше подходят для подобных расчётов, нежели GPU. 
Источник изображений: INL «Teton позволит исследователям моделировать ядерные технологии следующего поколения с беспрецедентной точностью, что значительно сократит время работ от создания концепции до внедрения критически важных проектов в области ядерной энергетики», — отмечает Бренден Хайдрих (Brenden Heidrich), руководитель научной программы Nuclear Science User Facilities (NSUF), реализуемой DOE.  В рамках NSUF исследователям в области ядерной энергетики предоставляется доступ к широкому спектру ресурсов INL и других учреждений. Новый суперкомпьютер поможет учёным моделировать сложную физику реакторов, поведение перспективных материалов и процессы топливного цикла.
07.02.2026 [17:23], Руслан Авдеев
AWS: ни один сервер с NVIDIA A100 не выведен из эксплуатации, а некоторые клиенты всё ещё используют Intel Haswell — не всем нужен ИИПо словам главы AWS Мэтта Гармана (Matt Garman), клиенты до сих пор использует серверы на основе ИИ-ускорителей NVIDIA A100, представленных в 2020 году. Отчасти это происходит потому, что спрос на вычислительные ресурсы превышает предложение, так что устаревшие чипы по-прежнему востребованы, передаёт Datacenter Dynamics. По словам Гармана, все ресурсы фактически распроданы, а серверы с A100 из эксплуатации никогда не выводились. Комментарии Гармана перекликаются с прошлогодним заявлением Амина Вахдата (Amin Vahdat), отвечающего в Google за ИИ и инфраструктуру. По его словам, в Google одновременно работают семь поколений тензорных ускорителей (TPU). Ускорители возрастом семь-восемь лет загружены на 100 %, а спрос на TPU так высок, что Google вынуждена отказывать некоторым клиентам. Впрочем, оба топ-менеджера, возможно, несколько кривят душой и пытаются развеять опасения инвесторов относительно того, что ИИ-ускорители, на которые тратятся огромные деньги, через два-три года придётся выкинуть, чтобы купить более современные, энергоэффективные и, конечно же, дорогие. И что за это время они не успеют окупиться. Хотя Гарман назвал главной причиной сохранения работы серверов на A100 высокий спрос, он признал, что есть и другие причины. В частности, современные ИИ-чипы снижают точность вычислений с плавающей запятой. В результате некоторые клиенты попросту не могут перейти на Blackwell или вовсе вынуждены использовать Intel Xeon Haswell десятилетней давности для HPC-подобных вычислений, поскольку точности у современных ИИ-ускорителей недостаточно. В июне 2025 года AWS заявила о снижении цены доступа к устаревшим NVIDIA H100, H200 и A100 на своей платформе, причём для A100 стоимость снизилась на треть. 
Источник изображения: NVIDIA Стоит отметить, что «устаревшие» ускорители долго остаются востребованными, поскольку всё равно обладают большой производительностью. Наиболее яркий пример — разрешение на поставку в Китай чипов NVIDIA H200. Хотя США и их союзники готовятся к внедрению ускорителей поколения Vera Rubin, китайский бизнес готов покупать H200, поскольку те значительно производительнее, экономически выгоднее и удобнее отечественных ускорителей.
06.02.2026 [09:00], Руслан Авдеев
TeraWulf превратит в ИИ ЦОД бывший алюминиевый завод в Кентукки и купит электростанцию в МэрилендеБывший алюминиевый завод в Хоусвилле (Hawesville) в Кентукки превратят в дата-центр. Century Aluminum продала своё предприятие компании Raylan Data Holdings — дочерней структуре американского оператора ЦОД TeraWulf, сообщает Datacenter Dynamics. Участок площадью более 300 га, по слухам, куплен за $200 млн. Century сохранит за собой в проекте «неконтролирующую» миноритарную долю в 6,8 %. По словам главы Century, сделка принесёт пользу всему штату, а подписанное соглашение позволяет компании иметь связь с проектом и оказывать поддержку местным жителям по мере перестройки площадки. TeraWulf намерена построить на участке кампус ИИ/HPC ЦОД. Подробности сделки пока не разглашаются, но TerWulf заявила, что площадка даёт немедленный доступ к надёжной энергетической инфраструктуре, в т.ч. имеются несколько высоковольтных ЛЭП, собственная подстанция и прямое подключение к региональной электросети. Площадке уже доступно приблизительно 480 МВт с возможностью расширения в будущем. Одновременно TeraWulf объявила о покупке работающей на мазуте 210-МВт электростанции Morgantown Generating Station в Мэриленде, которая подключена к энергосети. Сделка включает электрическую инфраструктуру и связанную с ней недвижимость. Первый этап проекта предусматривает увеличение мощности до 500 МВт, а в перспективе и до 1 ГВт. Закрытие сделки зависит от согласия неких «третьих сторон» и получения одобрения регуляторов, в т.ч. Федеральной комиссии по регулированию энергетики (FERC). Ведомство нередко отказывает в выдаче тех или иных разрешений — в своё время оно не дало добро на прямую поставку энергии кампусу ЦОД Amazon (AWS) от АЭС Susquehanna. 
Источник изображения: Amy Reed/unsplash.com TeraWulf отмечает, что Хоусвилл обеспечивает немедленный доступ к масштабируемым источникам энергии, а электростанция в Мэриленде позволяет нарастить генерирующие мощности для удовлетворения растущего спроса так, чтобы это приносило пользу энергосистеме. После закрытия сделок портфель инфраструктурных объектов TeraWulf вырастет до 2,8 ГВт на пяти площадках. Недавно бизнес сообщил о создании совместного предприятия с компанией Fluidstack для строительства кампуса ЦОД в Техасе, проект поддержан Google. В своё время покупка бывшего завода Electrolux позволила xAI в кратчайшие сроки развернуть ИИ-суперкомпьютер Colossus. Площадка тоже была подключена к энергосети, хотя потом для наращивания мощности пришлось задействовать газовые турбины. Кроме того, у бывших промышленных предприятий нашёлся и ещё один плюс — их перекрытия достаточно прочны для современных ИИ-стоек.
02.02.2026 [10:17], Руслан Авдеев
Ещё один криптомайнер отказывается от биткоинов в пользу ИИ — Bitfarms переоборудует свои ЦОД под NVIDIA Vera RubinКриптомайнинговая компания Bitfarms готовится к упразднению бывшего объекта для майнинга биткоинов в штате Вашингтон — он будет переделан в HPC/ИИ ЦОД, сообщает Datacenter Dynamics. Обновлённый объект, как ожидается, будет готов к декабрю 2026 года, он пополнит растущее число дата-центров, пользующихся прохладным климатом и относительно низкими региональными ценами на электроэнергию. Объект Bitfarms на площади около 2,4 га получит ЦОД уровня Tier III площадью до 9290 м2, а также офисные помещения. По словам представителя Bitfarms, компания продолжает реализацию стратегии инфрастурктурного развития для HPC и ИИ, а в её распоряжении — полностью профинансированная цепочка поставок. Объект в Вашингтоне планируется оборудовать для использование ИИ-ускорителей NVIDIA GB300 с СЖО. Подключенная мощность объекта составляет 18 Мт и таковой, вероятно, и останется. Компания подчёркивает, что основная задача — развитие инфраструктуры для поддержки ускорителей Vera Rubin нового поколения в большей части её портфолио. Для этого доступны почти $1 млрд наличных средств, неиспользованные кредитные линии, биткоины и другие варианты финансирования. Bitfarms планирует свернуть майнинговые операции в следующие два года и уже назначила ответственного за переоборудованием объектов в США, Канаде и Аргентине. Например, мощность объекта в Шэроне (Sharon, США) вырастет с 30 МВт до 110 МВт. 
Источник изображения: Bitfarms Изменить стратегию Bitfarms пришлось после того, как компания отчиталась о чистых убытках в объёме $46 млн в III квартале 2025 года. Тогда руководство компании заявило, что ИИ-инфраструктура обещает гораздо большую отдачу, чем криптомайнинг. Хотя доля объекта в Вашингтоне составляет менее 1 % от общего портфолио компании, её руководство полагает, что одно лишь его преобразование для предоставления GPUaaS потенциально может принести больше чистого операционного дохода, чем компания когда-либо получала в результате майнинга биткоинов. Это не единственная майнинговая компания, отказывающаяся от своей основной деятельности в последнее время. Буквально на днях появились новости о том, что Riot Platforms сменит профиль и сдаст AMD 25 МВт мощностей ЦОД.
30.01.2026 [20:24], Руслан Авдеев
От технологического наследия к построению будущего — Atos перезапустила бренд Bull для HPC, ИИ и квантовых инновацийПечально известная своими финансовыми проблемами французская компания Atos официально перезапустила один из своих ведущих брендов. Теперь Bull позиционируется как глобальный лидер в HPC-, ИИ- и квантовых системах. Bull разрабатывает, внедряет и обслуживает оборудование и ПО, в том числе суперкомпьютеры. Bull позиционируется, как единственный европейский игрок, способный разрабатывать, выпускать и внедрять решения такого класса. Работа поддерживается командой исследователей и инженеров, производственными возможностями и др. Bull, как сообщают в самой компании, позволяет странам и отраслям полностью контролировать свои ИИ-мощности и данные. Бизнес Bull основан на более чем вековом опыте в сфере вычислений и исследований, связанных с data science. Как утверждают в Atos, возрождение Bull — стратегически важная веха на пути бренда к формированию частной, независимой компании после подписания соглашения о покупке акций Францией 31 июля 2025 года. Корни у бренда европейские, но сейчас он, по словам Atos, занимает лидирующие позиции ещё и в Латинской Америке и Индии. Bull владеет полным технологическим стеком, от разработки интегральных микросхем и интерконнектов до ИИ-платформ и приложений. Бренд обеспечивает надёжные решения промышленного уровня для критически важных секторов, включая, например, оборону и энергетику, одновременно снижая совокупную стоимость владения. По словам руководства бренда, с запуском Bull осуществляется «переподключение» к технологическому наследию для строительства будущего. Миссией компании называется обеспечение мощных, устойчивых и суверенных вычислений и ИИ-технологий, позволяющих уверенно и осмысленно внедрять инновации на уровне отраслей и целых наций. 
Источник изображения: Bull Примечательна судьба самой Atos Group. Хотя сама компания позиционирует себя как лидера в сфере цифровой трансформации с 63 тыс. сотрудников и ежегодной выручкой €8 млрд, действующим в 61 странах под двумя брендами (Atos для сервисов и Eviden для продуктов), дела у компании идут, мягко говоря, непросто. Atos не первый год теряет выручку по всем направлениям, а будущее компании всё более туманно. Поэтому Atos заключила сделку с французским государством, согласно которой ему будут переданы «золотые акции» Bull SA. После неоднократных попыток спасти компанию, частой смены директоров и даже новостей о её возможной национализации Францией, летом 2025 года появилась информация, что власти Франции сделали предложение купить подразделение Advanced Computing в составе группы Atos.
24.01.2026 [14:15], Сергей Карасёв
Nokia и Hypertec построили в Канаде 15-Пфлопс суперкомпьютер Nibi с погружным охлаждением
amd
emerald rapids
granite rapids
h100
hardware
hpc
intel
mi300
nokia
nvidia
ии
канада
отопление
погружное охлаждение
суперкомпьютер
Компании Nokia и Hypertec объявили о запуске суперкомпьютера Nibi, смонтированного в Университете Ватерлоо (University of Waterloo) в Канаде. Эта НРС-платформа будет использоваться для решения широкого спектра задач, в том числе в области ИИ. Проект Nibi финансируется канадским Министерством инноваций, науки и экономического развития через Канадский альянс цифровых исследований, а также Министерством колледжей, университетов, научных исследований и безопасности через некоммерческую организацию Compute Ontario. 
Источник изображения: Nokia Система насчитывает в общей сложности более 750 вычислительных узлов. Это, в частности, 700 узлов CPU, каждый из которых несёт на борту два процессора Intel Xeon 6972P поколения Granite Rapids-AP (96C/192T, до 3,9 ГГц) и 748 Гбайт оперативной памяти. Кроме того, задействованы 10 узлов с двумя чипами Xeon 6972P и 6 Тбайт памяти каждый. 
Источник изображений: Университет Ватерлоо В состав суперкомпьютера также входят 36 узлов GPU, которые содержат по два процессора Intel Xeon Platinum 8570 серии Emerald Rapids (56C/112T, до 4 ГГц), 2 Тбайт оперативной памяти и восемь ускорителей NVIDIA H100 SXM (80 GB), связанных посредством NVLink. Наконец, Nibi оперирует шестью узлами с четырьмя ускорителями AMD Instinct MI300A.  Подсистема хранения VAST Data выполнена на основе SSD суммарной вместимостью 25 Пбайт. Пропускная способность каналов передачи данных между CPU- и GPU-узлами составляет 200 Гбит/с. Подключение к хранилищу обеспечивается благодаря 24 линиям на 100 Гбит/с. Заявленная пиковая производительность Nibi достигает 15 Пфлопс. Новая НРС-платформа оборудована высокоэффективной системой погружного жидкостного охлаждения. Сгенерированное тепло используется для обогрева центра квантовых и нанотехнологий имени Майка и Офелии Лазаридис (Mike and Ophelia Lazaridis Quantum-Nano Centre).
20.01.2026 [23:54], Владимир Мироненко
Intel переманила «крёстного отца» экзафлопсного суперкомпьютера FrontierIntel провела кадровые перестановки в руководящем составе, наняв двух специалистов «со стороны» в рамках запланированного развития на рынке ИИ-инфраструктуры, сообщил ресурс CRN со ссылкой на служебную записку компании. Согласно документу, Николя Дюбе (Nicolas Dubé) ранее занимавший пост старшего вице-президента в Arm, был назначен на должность главы подразделения систем для ЦОД, а Эрик Демерс (Eric Demers), бывший топ-менджер Qualcomm, на должность главы подразделения разработки GPU. О назначениях объявил вице-президент и генеральный директор группы ЦОД Intel Кеворк Кечичян (Kevork Kechichian), которому будут непосредственно подчиняться оба руководителя. После реорганизации ему также будет подчиняться Жан-Дидье Аллегруччи (Jean-Didier Allegrucci), вице-президент по разработке SoC для ИИ. Генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) назвал способность конкурировать с чипами NVIDIA и других участников рынка одним из своих главных приоритетов в рамках плана возвращения компании на рынок после того, как она столкнулась с трудностями в привлечении клиентов к своим предыдущим ускорителям. «Объединение усилий в области Xeon, сетевых технологий и телекоммуникаций, а теперь и ИИ, укрепляет позиции x86, что является одним из ключевых преимуществ по мере того, как ИИ смещается в сторону инференса и агентных систем», — написал Кечичян в служебной записке. 
Источник изображения: Alex Kotliarskyi/unsplash.com Эта реорганизация представляет собой отмену решения Тана, который в апреле прошлого года вывел группу разработчиков ИИ-ускорителей из подразделения, ранее называвшегося группой ЦОД и ИИ. Этот шаг снова меняет организационную структуру Intel: Кечичян принимает на себя обязанности по разработке ИИ-ускорителей от Тана. Генеральный директор возглавил её в ноябре прошлого года после того, как предыдущий руководитель команды, Сачин Катти (Sachin Katti), внезапно покинул компанию в связи с переходом в OpenAI. По поводу решения Тана вернуть команду разработчиков ИИ-ускорителей в группу ЦОД, Кечичян пояснил: «ИИ и современный ЦОД фундаментально связаны». В качестве руководителя подразделения Intel по системам и решениям для ЦОД Дюбе будет «определять техническую архитектуру и стратегию [группы ЦОД] в направлении создания комплексных систем и решений, от микросхем до приложений, обеспечивая интегрированные решения в области вычислительных ресурсов, хранения данных и сетей», — сообщил Кечичян в служебной записке. Дюбе также возьмёт на себя руководство командой Intel по интегрированным решениям в области кремниевой фотоники, которая ранее подчинялась исполнительному директору компании Джеффу Маквейгу (Jeff McVeigh). При этом Дюбе будет использовать свой опыт системной инженерии в Arm, а также опыт 13 лет работы в HPE, где «он руководил проектированием, реализацией и внедрением» программы компании по созданию первого в США экзафлопсного суперкомпьютера Frontier. По поводу обязанностей Демерса, Кечичян заявил, что топ-менджер, ранее возглавлявший разработку GPU в Qualcomm, будет руководить разработкой IP-блоков для GPU и курировать решения Intel для ЦОД на базе GPU. Круг его обязанностей будет включать в себя «координацию работы по архитектуре, компиляторам и драйверам для успешной разработки интегрированного аппаратного и ПО», добавил он. Демерс «будет тесно сотрудничать» с Лизой Пирс (Lisa Pearce), корпоративным вице-президентом и генеральным директором группы разработки ПО компании, а также с командой разработчиков ПО для GPU, чтобы «оптимизировать работу команд и рабочий процесс для достижения максимального эффекта», указал Кечичян в служебной записке.
20.01.2026 [21:58], Владимир Мироненко
Tesla возобновит строительство ИИ-суперкомпьютеров DojoГендиректор Tesla (Elon Musk) Илон Маск объявил в соцсети Х о решении компании возобновить работу над Dojo3, третьим поколением суперкомпьютерных систем, о чём сообщает Data Center Dynamics. Команда, занимавшаяся проектом Dojo, была расформирована в прошлом году в связи с тем, что компания отдала предпочтение ИИ-чипам, используемых в бортовых системах электромобилей. Также ранее было объявлено, что компания будет полагаться на чипы внешних партнёров. Вместе с тем компания возвращается к проекту Dojo, поскольку, по словам Маска, достигнуты успехи в разработке чипа AI5, что создало определённый запас прочности. Маск объявил, что однокристальный чип AI5 обеспечит производительность на уровне NVIDIA Hopper, при этом двухкристальный AI5 будет равен по мощности чипу с Blackwell. Он предложил всем заинтересованным в участии в проекте и «работе над созданием самых массово производимых в мире микросхем» отправить сообщение Tesla, указав в трёх пунктах самые сложные технические проблемы, которые они решили. Илон Маск также сообщил, что разработка чипа Tesla AI5 почти завершена, а чип AI6 находится на «ранней стадии» разработки, добавив, что компания также планирует создать чипы AI7, AI8 и AI9. По его словам, нынешний чип Tesla AI4 позволит достичь «уровня безопасности при автономном вождении, намного превышающего человеческий», а AI5 сделает электромобили Tesla «почти идеальными», также значительно улучшив функционирование человекоподобного робота Optimus. «AI6 для Optimus и ЦОД. AI7/Dojo3 будут использовать ИИ для космических вычислений», — написал Маск. В ноябре 2025 года он заявил, что существует «чёткий путь к удвоению производительности по всем показателям для AI6 в течение 10–12 мес. после выпуска AI5», а теперь он намерен сократить срок создания каждого нового поколения ИИ-чипов до 9 мес. Хотя сам миллиардер не стал называть сроки производства чипа AI5, ИИ-чат-бот Grok сообщил пользователям в ответ на запросы, что ограниченное производство AI5 ожидается в 2026 году, а массовое производство запланировано на 2027 год. 
Источник изображения: Tesla В конце прошлого года Маск заявил акционерам Tesla, что компании, вероятно, потребуется построить «гигантскую фабрику» для производства своих ИИ-чипов, чтобы хотя бы частично удовлетворить в них потребности компании. Tesla уже сотрудничает с TSMC и Samsung, которые производят чипы AI5 и AI6 на заводах в Аризоне и Тайване, а также в Южной Корее и Техасе соответственно. На том же собрании акционеров Маск сказал, что, вероятно, стоит обсудить вопрос производства и с Intel. Как отметил Techpowerup, в августе прошлого года появились сообщения о присоединении к компании Маска Intel в качестве ключевого партнёра по упаковке чипов, что ознаменовало отход Tesla от прежней зависимости от TSMC в вопросах производства. Сообщается, что Intel будет управлять сборкой и тестированием, используя свою технологию EMIB. Это лучше подходит для больших блоков Tesla Dojo, объединяющих несколько чипов площадью 654 мм² в одном корпусе. В свою очередь, Samsung будет производить обучающие чипы D3 на своем заводе в Техасе с помощью 2-нм техпроцесса, оставив Intel контроль над процессами упаковки. Такое разделение труда решает проблему ограничений производственных мощностей и предоставляет Tesla большую гибкость в настройке схем межсоединений. Для автомобильных чипов AI5 компании Samsung и TSMC создадут разные версии, хотя Tesla стремится обеспечить одинаковую производительность в обоих случаях. Предполагается, что AI5 будет потреблять 150 Вт, при этом соответствуя по производительности NVIDIA H100, у которого TDP составляет до 700 Вт. Это было достигнуто путём удаления графических подсистем общего назначения и оптимизации архитектуры специально для ИИ-алгоритмов Tesla.
20.01.2026 [10:02], Владимир Мироненко
FP64 у вас ненастоящий: AMD сомневается в эффективности эмуляции научных расчётов на тензорных ядрах NVIDIAВместо создания специализированных чипов для аппаратных FP64-вычислений NVIDIA использует эмуляцию для повышения производительности HPC на ИИ-ускорителях, пишет The Register. Компания отказалась от развития FP64-блоков в поколении Blackwell Ultra, а в новейших ускорителях Rubin пиковая заявленная производительность векторных FP64-вычислений составляет 33 Тфлопс, тогда как у H100, вышедшего четыре года назад, она была равна 34 Тфлопс, а у Blackwell — около 40 Тфлопс. Если включить программную эмуляцию в библиотеках CUDA от NVIDIA, ускоритель, как утверждается, может достичь производительности до 200 Тфлопс в матричных FP64-вычислениях. Впрочем, и Blackwell с эмуляций способен выдать в этом случае до 150 Тфлопс, тогда как у Hopper были «честные» 67 Тфлопс. «В ходе многочисленных исследований с партнёрами и собственных внутренних изысканий мы обнаружили, что точность, достигаемая с помощью эмуляции, как минимум не уступает точности, получаемой от аппаратных тензорных ядер», — сообщил ресурсу The Register Дэн Эрнст (Dan Ernst), старший директор по суперкомпьютерным продуктам NVIDIA. В свою очередь, в AMD считают, что это утверждение справедливо не для всех сценариев. «В некоторых бенчмарках она показывает довольно хорошие результаты, но в реальных физических научных симуляциях это не очевидно», — говорит Николас Малайя (Nicholas Malaya), научный сотрудник AMD. Он выразил мнение, что, хотя эмуляция FP64, безусловно, заслуживает дальнейших исследований и экспериментов, такое решение ещё не готово к широкому применению. AMD и сама изучает возможность программной эмуляции FP64 на Instinct MI355X, чтобы определить области её возможного применения. 
Источник изображения: Hilda Trinidad / Unsplash Хотя чипы всё чаще используют типы данных с более низкой точностью, FP64 остаётся золотым стандартом для научных вычислений, и на то есть веские причины — FP64 не имеет себе равных по динамическому диапазону. Современные же LLM обучаются с использованием FP8-вычислений, а компактные типы данных MXFP8/MXFP4 или NVFP4 позволяют получить достаточный для ИИ диапазон значений. Это хорошее решение для нечёткой математики больших языковых моделей, но это не замена FP64 для HPC. ИИ-нагрузки обладают высокой устойчивостью к ошибкам, а HPC-задачи требуют высокой точности. AMD указала на то, что эмуляция FP64 у NVIDIA не совсем соответствует стандарту IEEE. Алгоритмы NVIDIA не учитывают такие понятия, как положительные и отрицательные нули, ошибки NaN (Not a Number) и ошибки infinite number (бесконечное число). Из-за этого небольшие ошибки в промежуточных вычислениях, используемых для эмуляции более высокой точности, могут привести к искажениям, способным повлиять на точность конечного результата, пояснил Малайя. По его словам, целесообразность использования эмуляции FP64 зависит от конкретного приложения. Эмуляция FP64 лучше всего работает для хорошо обусловленных проблем, где малые изменения «на входе» приводят к малым же изменениям в конечном результате. Ярким примером такой задачи является бенчмарк Linpack (HPL). «Но если вы посмотрите на материаловедение, коды для расчёта процессов горения, системы ленточых матриц и т.п., то увидите, что это гораздо менее обусловленные системы, и внезапно всё начинает давать сбои», — сказал он. 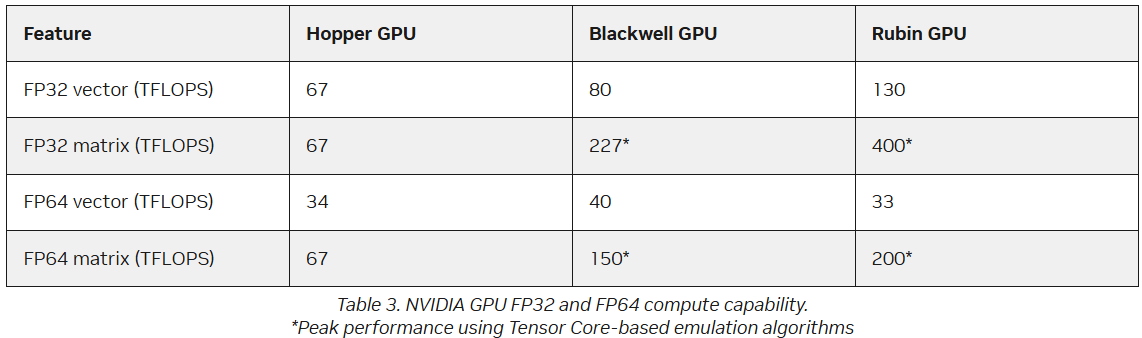
Источник изображения: NVIDIA Точность можно повысить, увеличив количество используемых операций, однако после определённого предела никаких преимуществ от эмуляции уже не будет. Вдобавок все эти операции требуют память. «У нас есть данные, которые показывают, что алгоритму Озаки требуется примерно вдвое больше памяти для эмуляции матриц FP64», — сказал Малайя. Поэтому компания готовит специализированные ускорители MI430X c повышенной FP64/FP32-производительностью, но, как опасаются учёные, она может оказаться не слишком в них заинтересована, поскольку ИИ-ускорители приносят больше денег. Эрнст утверждает, что для большинства специалистов в области HPC неполное соответствие стандарту IEEE не представляет большой проблемы. Всё во многом зависит от конкретного приложения. Тем не менее, NVIDIA разработала дополнительные алгоритмы для обнаружения и смягчения указанных выше ошибок и неэффективных операций эмуляции. Эрнст также признал, что использование памяти при эмуляции может быть несколько выше, но подчеркнул, что эти накладные расходы относятся к расчётам, а не к самому приложению — в большинстве случаев речь идёт о матрицах размером не более нескольких Гбайт. Впрочем, всё это не меняет того, что эмуляция полезна только для подмножества HPC-задач, которые полагаются на операции умножения плотных матриц (DGEMM). По словам Малайи, для 60–70 % рабочих нагрузок HPC эмуляция дает незначительные преимущества или ничего не меняет. «По нашим оценкам, подавляющее большинство реальных рабочих нагрузок HPC полагаются на векторное умножение (FMA), а не на DGEMM», — сказал он, отметив, что это действительно нишевый сегмент, хотя и не крошечная доля рынка. Для рабочих нагрузок, интенсивно использующих векторы, таких как вычислительная гидродинамика (CFD), ускорители Rubin по-прежнему будут полагаться на медленные векторные FP64-блоки.
19.01.2026 [14:16], Руслан Авдеев
100+ кВт на стойку с СЖО: Vertiv обновила модульную инфраструктуру MegaMod HDX для ИИ и HPCVertiv анонсировала новые конфигурации MegaMod HDX. Это модульное силовое и охлаждающее решение, разработанное для вычислительных сред высокой плотности. Новые конфигурации обеспечивают гибкую адаптацию к растущим требованиям к питанию и охлаждению, занимают меньше места, требуют меньше времени на развёртывание и обеспечивают воспроизводимость благодаря заранее собранным на заводе конструкциям, прошедшим интеграцию и тестирование компонентов. Vertiv MegaMod HDX сочетает прямое жидкостное охлаждение чипов и воздушное охлаждение — это помогает справиться с интенсивными ИИ-нагрузками, поддерживая модульные среды для ИИ и передовые кластеры ускорителей. Базовый модуль стандартной высоты поддерживает до 13 стоек и мощность до 1,25 МВт. Комбинированное решение отличается большей высотой и поддерживает уже до 144 стоек и мощность до 10 МВт. Оба варианта обеспечивают плотность от 50 кВт до 100+ кВт на стойку с возможностью оптимизации системы охлаждения под актуальные запросы и с возможностью масштабирования. 
Источник изображения: Vertiv Новые решения используют распределённую силовую архитектуру с резервированием. Для СЖО предусмотрен буфер, который обеспечит поддержку стабильной работы кластеров ускорителей во время техобслуживания. Обе конфигурации основаны на этом обширном портфолио, включающем, например, ИБП Vertiv Liebert APM2, блок распределения жидкости Vertiv CoolChip CDU, а также шинопровод Vertiv PowerBar и систему мониторинга инфраструктуры Vertiv Unify. Также Vertiv предлагает инфраструктуру IT-стоек, разработанную для беспрепятственной интеграции и поддержки IT-систем. В том числе речь идёт о стойках Vertiv и OCP-совместимых стойках, теплообменниках задней двери Vertiv CoolLoop RDHx, PDU и DC-системах Vertiv PowerDirect и т.п. Летом 2025 года сообщалось, что выручка Vertiv выросла на 35 % на фоне «беспрецедентного роста ЦОД», но новые тарифы, введённые США, не дают бизнесу развиваться активнее. |
|

