Материалы по тегу: ускоритель
|
07.05.2024 [21:26], Руслан Авдеев
Apple работает над собственными серверными ИИ-ускорителямиКомпания Apple занимается разработкой собственных ИИ-полупроводников для дата-центров, передаёт The Wall Street Journal. В перспективе это поможет ей в «гонке вооружений», развернувшейся на рынке ИИ-решений. И у Apple есть ресурсы для создания передовых ИИ-чипов. В последние десять лет компания уже выбилась в лидеры полупроводниковой индустрии, представляя всё новые чипсеты для мобильных устройств и компьютеров Mac-серии. Как свидетельствуют источники СМИ, серверный проект Project ACDC (Apple Chips in Data Center) задействует компетенции компании в деле создания решений для ЦОД. Недавно сообщалось, что Apple наняла создателя ИИ-кластеров Google. Реализацию проекта Apple начала несколько лет назад, но данных о том, когда будут готовые первые чипы, пока нет. По имеющимся данным, компания уже тесно сотрудничает с TSMC. Предполагается, что чипы для серверов Apple будут оптимизированы для запуска ИИ-моделей, а не их обучения — на этом рынке по-прежнему будет доминировать NVIDIA. Время поджимает, поскольку Google и Microsoft уже имеют собственные ИИ-ускорители, хотя и разных классов — TPU и Maia 100. Обе компании имеют компетенции в области LLM, а Microsoft весьма дружна с OpenAI, которая тоже не прочь заняться «железом». 
Источник изображения: GR Stocks/unsplash.com Такое положение дел не устраивает инвесторов Apple, поскольку компания не продемонстрировала никаких впечатляющих успехов в соответствующей сфере, в то время как цена акций конкурентов продолжает расти на фоне новостей об их достижениях. В Apple пытаются убедить инвесторов, что это лишь временное явление и скоро грядут анонсы, связанные с ИИ. Опыт Apple в сфере разработки современных полупроводников должен помочь в создании ИИ-чипов. Сегодня компания представила 3-нм процессор M4 с самым мощным, по её словам, NPU в мире. Хотя компания добилась определённых успехов в разработке чипов для потребительской и профессиональной электроники, определённые задачи даются ей с трудом. Например, она всё ещё бьётся над созданием собственного беспроводного модуля. Хотя в Apple предпочли бы, чтобы большинство ИИ-вычислений осуществлялись силами самих чипов, некоторые задачи будут по-прежнему выполняться в облаке, где и пригодятся новые полупроводники. Это позволит компании лучше контролировать свою стратегию развития в сфере ИИ.
30.04.2024 [11:24], Сергей Карасёв
Разработчик ИИ-чипов для ЦОД и периферийных систем Blaize получил на развитие $106 млнСтартап в области ИИ Blaize объявил о проведении раунда финансирования, в ходе которого привлечено $106 млн. Деньги предоставили существующие и новые инвесторы, включая Bess Ventures, Franklin Templeton, DENSO, Mercedes Benz, Temasek, Rizvi Traverse, Ava Investors и BurTech LP LLC. Blaize разрабатывает специализированные чипы, предназначенные для ускорения выполнения ИИ-задач в дата-центрах и на периферии. Утверждается, что по сравнению с традиционными ускорителями на базе GPU и FPGA устройства Blaize обеспечивают более высокую энергетическую эффективность. В основе архитектуры решений Blaize лежит обработка графов, а многие модели ИИ можно как раз представить представить в виде графов. 
Источник изображений: Blaize Платформа Blaize включает специализированное ПО Blaize AI Studio и Blaize Picasso SDK, предоставляющее клиентам удобные средства для быстрого создания и развёртывания ИИ-приложений. В ассортименте Blaize присутствуют различные ИИ-устройства на основе чипа Blaize 1600 SoC, содержащего 16 ядер GSP (Graph Streaming Processor). Заявленная ИИ-производительность достигает 16 TOPS.  В частности, доступны модуль Blaize Xplorer X600M M.2 (PCIe 3.0 х4; 2 Гбайт LPDDR4), ускоритель Blaize Xplorer X1600E EDSFF (PCIe 3.0 х4; 4 Гбайт LPDDR4), карта расширения Blaize Xplorer X1600P PCIe (PCIe 3.0 х4; 4 Гбайт LPDDR4), ускоритель Xplorer X1600P-Q PCIe на базе четырёх чипов Blaize 1600 SoC (PCIe 3.0 х16; 16 Гбайт LPDDR4), встраиваемое решение Blaize Pathfinder P1600 Embedded System on Module, а также сервер Blaize Inference Server на базе 24 ускорителей Blaize Xplorer X1600E EDSFF. Привлечённые средства Blaize будет использовать для дальнейшей разработки и коммерциализации продуктов. В декабре 2023-го стартап сообщил о намерении выйти на биржу посредством SPAC-сделки с BurTech Acquisition Corp. Ожидается, что это позволит получить $71 млн при оценке компании в $894 млн.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 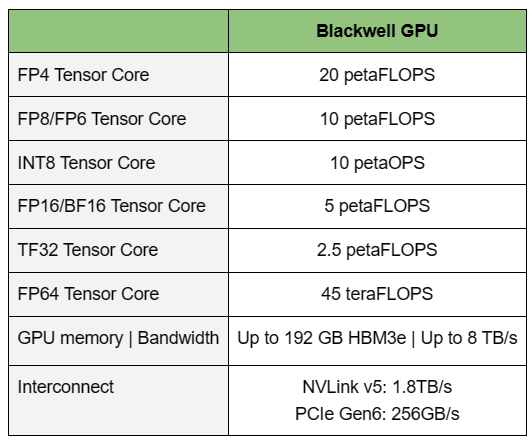 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений.  Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 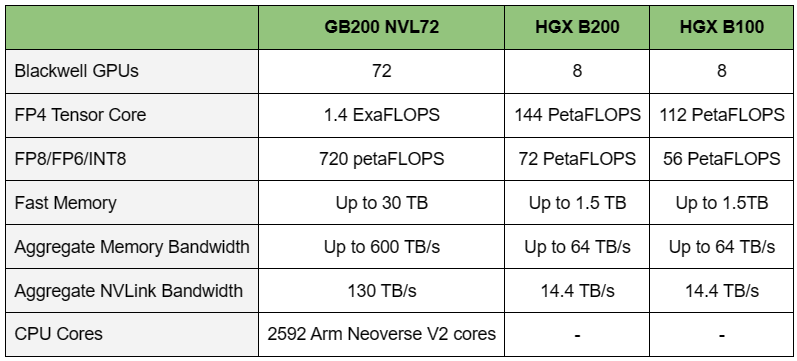 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку (Oberon), оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle.
15.03.2024 [22:43], Алексей Степин
Tenstorrent под руководством Джима Келлера представила свои первые ИИ-ускорители Grayskull на базе RISC-VКанадский разработчик микрочипов Tenstorrent, возглавляемый легендарным Джимом Келлером (Jim Keller), наконец, представил свои первые решения на базе архитектуры RISC-V — ИИ-процессоры Grayskull и ускорители на их основе, Grayskull e75 и e150. Оба варианта доступны для приобретения уже сейчас по цене $599 за младшую версию и $799 за старшую. Данные решения предназначены для инференс-систем, разработки и отладки ПО. В комплект разработчика входят инструменты TT-Buda и TT-Metalium. В первом случае речь идёт о высокоуровневом стеке, предназначенном для компиляции и запуска ИИ-моделей на аппаратном обеспечении Tenstorrent, а во втором — о низкоуровневой программной платформе, обеспечивающей прямой доступ к аппаратным ресурсам. Поддерживается PyTorch, ONNX и другие фреймворки. Создатели делают особенный упор на простоте программирования в сравнении с классическими GPU. Поддерживается широкий спектр ИИ-моделей, но Tenstorrent особенно выделяет BERT, ResNet, Whisper, YOLOv5 и U-Net. 
Источник изображений здесь и далее: Tenstorrent Архитектура Grayskull базируется на RISC-V, в настоящий момент максимальное количество фирменных ядер Tensix достигает 120, работают они на частотах вплоть до 1,2 ГГц. Каждое такое ядро содержит пять полноценных ядер RISC-V, блок тензорных операций, блок SIMD для векторных операций, а также ускорители сетевых операций и сжатия/декомпрессии данных. Дополнительно каждое ядро может иметь до 1,5 Мбайт сверхбыстрой памяти SRAM. Между собой ядра общаются напрямую.  В случае Grayskull e150 процессор работает в полной конфигурации со 120 ядрами и 120 Мбайт SRAM, объём внешней памяти LPDDR4 составляет 8 Гбайт (ПСП 118,4 Гбайт/с). Ускоритель выполнен в формате полноразмерной платы расширения с теплопакетом 200 Вт и интерфейсом PCIe 4.0 x16. У младшей модели, Grayskull e75, активных ядер только 96, их частота снижена до 1 ГГц, а пропускная способность внешней памяти при том же объёме снижена до 102,4 Гбайт/с. При этом теплопакет составляет всего 75 Вт, что позволило выполнить ускоритель в виде низкопрофильной платы расширения и обойтись без дополнительного питания.  Чипы Wormhole тоже используют Tensix. В составе Wormhole n300 таких ядер 128 (2 × 64), частота равна 1 ГГц при теплопакете 300 Вт. Объём SRAM составляет 1,5 Мбайт на ядро, а внешняя подсистема памяти включает 24 Гбайт GDDR6 и с ПСП 576 Гбайт/с. Wormhole n150 оснащены 72 ядрами Tensix, 108 Мбайт SRAM и 12 Гбайт GDDR6 с ПСП 288 Гбайт/с. TDP составляет 160 Вт. От Grayskull эти решения отличаются возможностью масштабирования путём прямого объединения плат. Также есть по паре сетевых интерфейсов 200GbE. Возможна работа с форматами FP8/16/32, TF32, BFP2/4/8, INT8/16/32 и UINT8. Чипы Tenstorrent Grayskull и Wormhole лежат в основе уникальных масштабируемых платформ собственной разработки — AICloud и Galaxy. В первом случае используются процессоры Grayskull, поскольку Wormhole на рынке должен появиться позже. Платформа предназначена в качестве аппаратной для ИИ и HPC-нагрузок в облаке Tenstorrent. 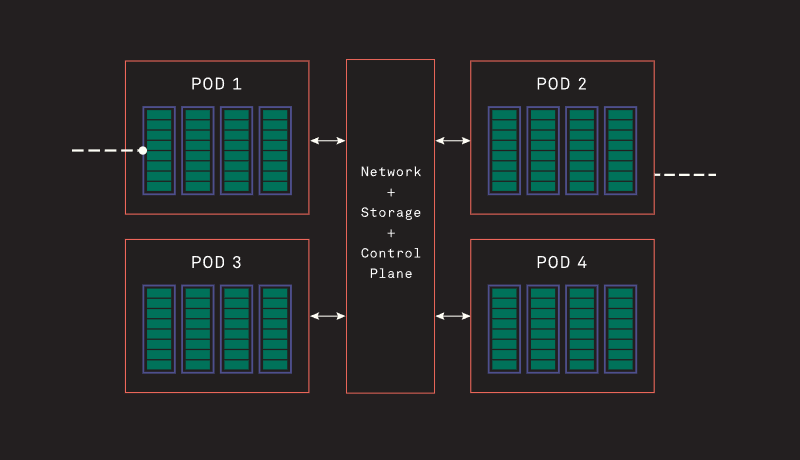 Каждый 4U-узел AICloud высотой содержит восемь карт (16 чипов) и способен предоставить в распоряжение пользователей от 30 до 60 vCPU и от 256 до 1024 Гбайт памяти, вкупе с дисковым пространством объёмом 100–400 Гбайт. Восемь таких узлов составляют стойку, а четыре стойки — кластер Server Pod. Четыре таких кластера объединены общей системой интерконнекта, управления и СХД (до 200 Тбайт), дальнейшее масштабирование уже выходит на уровень ЦОД. 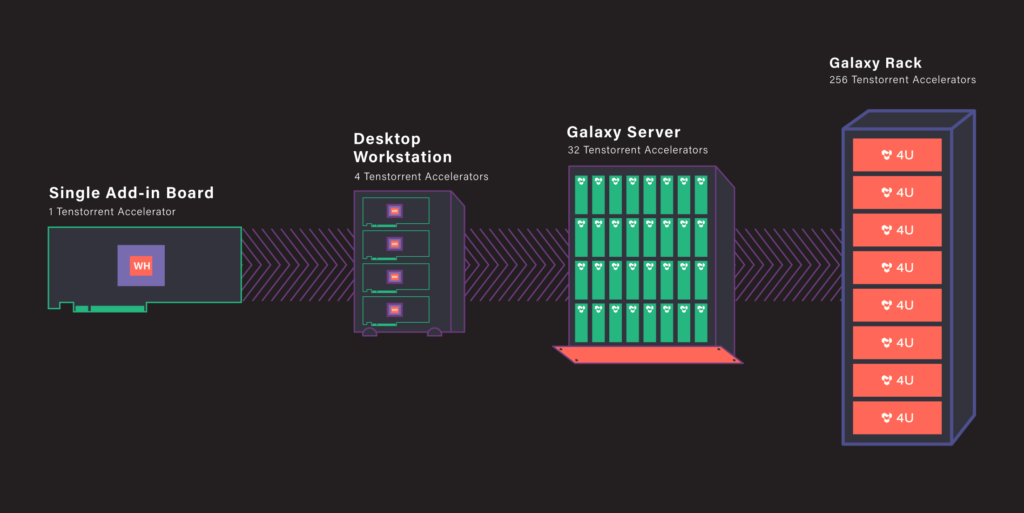 В Tenstorrent Galaxy упор сделан на возможность создания высокопроизводительных ИИ-систем с быстрым интерконнектом на базе Ethernet. Строительным блоком здесь являются 80-ядерные модули Wormhole. 4U-сервер вмещает 32 таких модуля, что в совокупности даёт 2560 ядер Tensix и 384 Гбайт глобально адресуемой GDDR6. Наличие 16 каналов 200GbE в каждом модуле обеспечивает производительность интерконнекта на уровне 3,2 Тбитс. На уровне стойки высотой 48U это дает 256 чипов Wormhole, общий объём SRAM в этом случае достигает 30,7 Гбайт, а GDDR6 — 3 Тбайт. Производительность стойки оценивается разработчиками в 20 Попс (Петаопс), а совокупная скорость интерконнекта — в 76,8 Тбит/с. Расплатой за универсальность и производительность станет энергопотребление, достигающее 60 КВт.
13.03.2024 [22:40], Алексей Степин
Больше флопс за те же ватты: Cerebras представила царь-ускоритель WSE-3 и подружилась с QualcommКомпания Cerebras Systems, известная своими разработками в области сверхбольших ИИ-процессоров, рассказала о третьем поколении чипов Wafer Scale Engine. В своё время компания произвела фурор, представив процессор, занимающий всю площадь кремниевой пластины (46225 мм2). В первом поколении WSE речь шла о 1,2 трлн транзисторов при 400 тыс. ядер и 18 Гбайт сверхбыстрой памяти. WSE-2 состоял из 2,6 трлн транзисторов, имел 850 тыс. ядер и 40 Гбайт интегрированной памяти. В WSE-3 разработчики перешли на использование 5-нм техпроцесса TSMC, что позволило разместить на пластине такого же размера уже 4 трлн транзисторов, составляющих 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность набортной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. 
Источник изображений: Cerebras Казалось бы, выигрыш в количестве ядер по сравнению с WSE-2 не так уж велик, однако на этот раз Cerebras сделала упор на архитектуру. Если верить заявлениям разработчиков, WSE-3 практически вдвое быстрее WSE-2 при сопоставимом уровне энергопотребления (15 кВт) и той же цене: 125 Пфлопс против 75 Пфлопс в разреженных FP16-вычислениях. WSE-3 в 62 раза быстрее NVIDIA H100, хотя и сам чип WSE-3 в 57 раз больше. 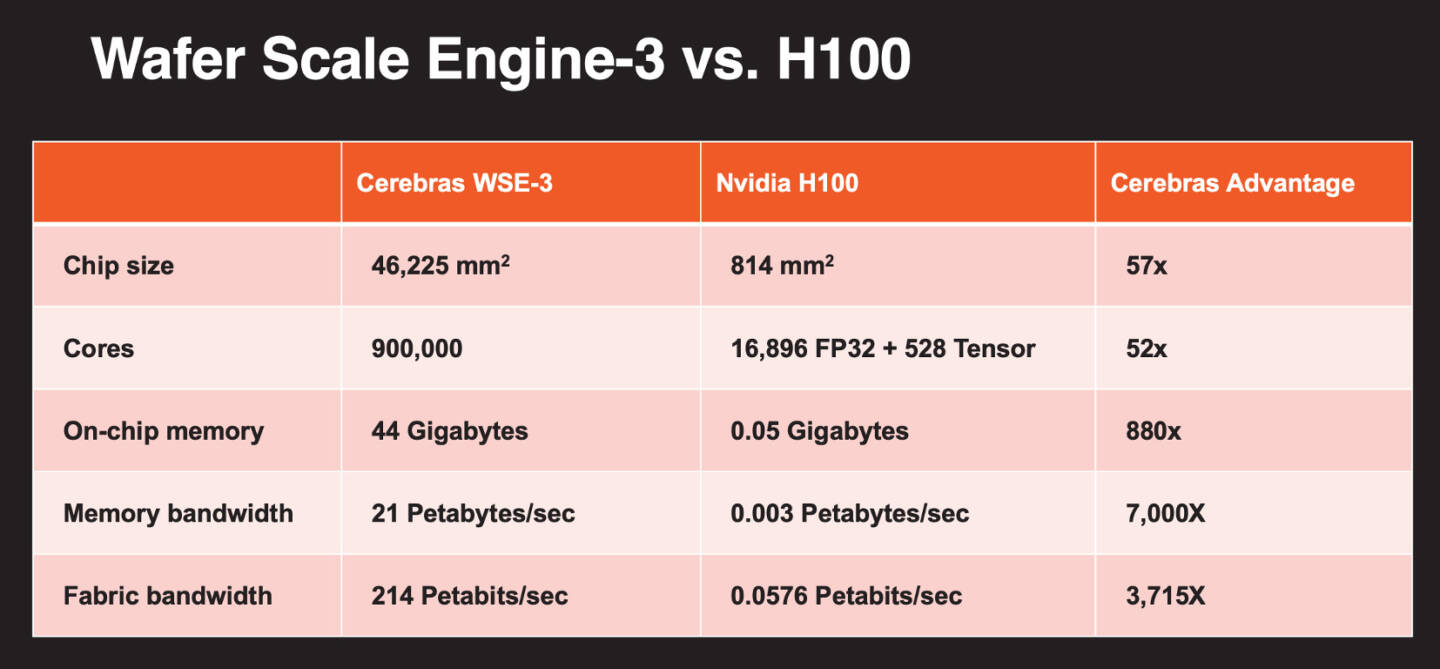 WSE-3 по-прежнему требует специфического окружения. Он станет сердцем новой системы CS-3 (23 кВт), содержащей всю необходимую сопутствующую инфраструктуру, включая СЖО, подсистемы питания, а также сетевого интерконнекта Ethernet. Последний не изменился и состоит из 12 каналов со скоростью 100 Гбит/с. Для подготовки «сырых» данных по-прежнему будет использоваться внешний суперсервер. А для их хранения будут использоваться узлы MemoryX ёмкостью до 1200 Тбайт (1,2 Пбайт). 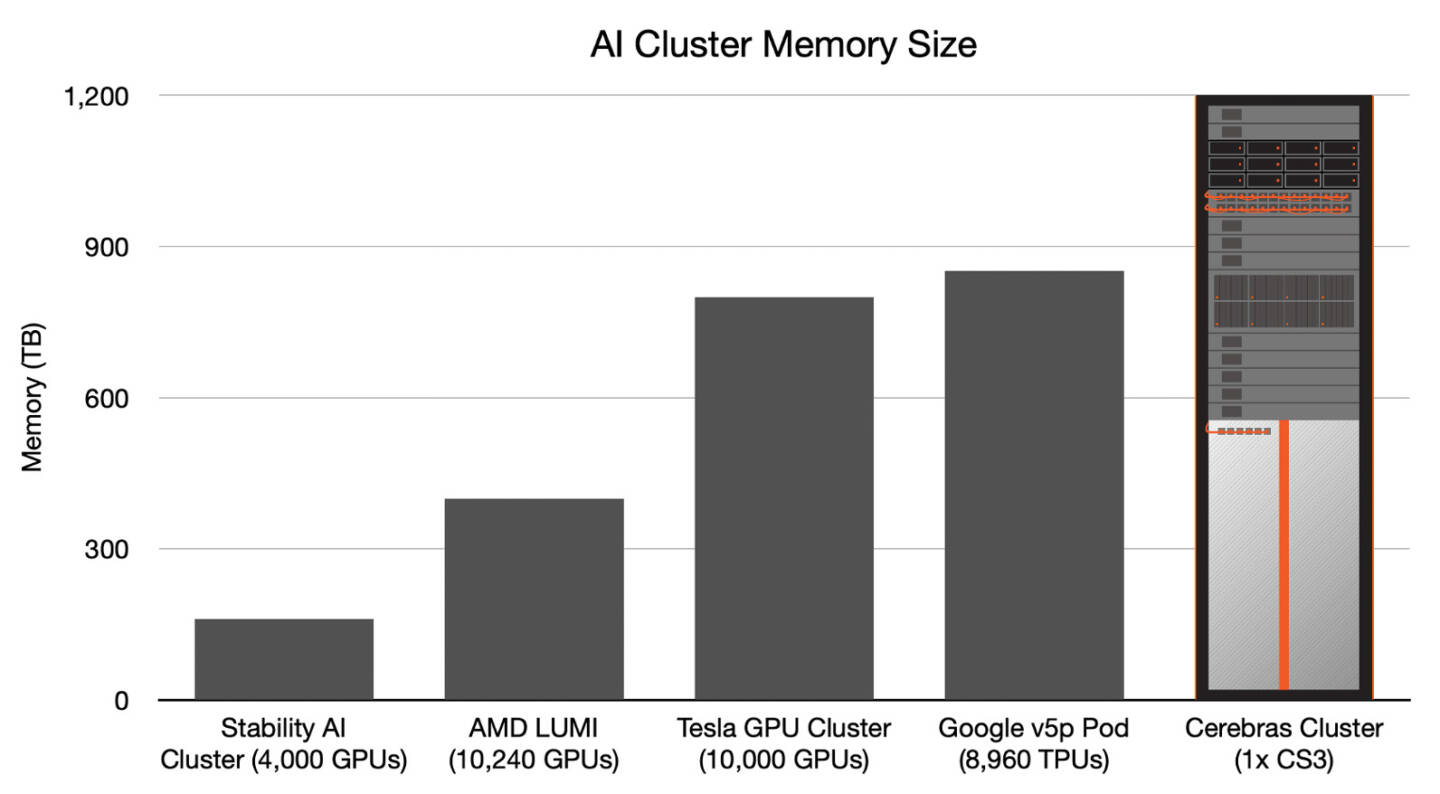 Главной задачей CS-3 станет «натаскивание» сверхбольших языковых моделей, в 10 раз превышающих по количеству параметров GPT-4 и Google Gemini. Cerebras говорит о 24 трлн параметров, причём без необходимости различных ухищрений для эффективного распараллеливания процесса обучения, что требуется в случае с GPU-кластерами. По словам компании, для обучения Megatron 175B на таких кластерах требуется 20 тыс. строка кода Python/C++/CUDA, а в случае WSE-3 потребуется лишь 565 строк на Python.  CS-3 поддерживает масштабирование вплоть до 2048 систем. Такая конфигурация вкупе с MemoryX сможет обучить модель типа Llama 70B всего за день. Первый суперкомпьютер на базе CS-3 — 8-Эфлопс Condor Galaxy 3 — будет скромнее и получит всего 64 стойки CS-3, которые разместятся в Далласе (США). В совокупности с уже имеющимися кластерами на базе CS-1 и CS-2 вычислительная мощность систем Cerebras должна достигнуть 16 Эфлопс. В сотрудничестве c группой G42 запланировано создание ещё шести систем CS-3, что в сумме позволит довести производительность до 64 Эфлопс.  Condor Galaxy 3 будет отличаться от предшественников ещё одним нововведением: в рамках сотрудничества с Qualcomm Cerebras установит в новом кластере существенное число инференс-ускорителей Qualcomm Cloud AI100 Ultra. Каждый такой ускоритель имеет 64 ядра, 128 Гбайт памяти LPDDR4x, потребляет 140 Вт и развивает 870 Топс на INT8-операциях. Причём програмнный стек полностью интегрирован, что позволит в один клик запустить обученные WSE-3 модели на ускорителях Qualcomm. 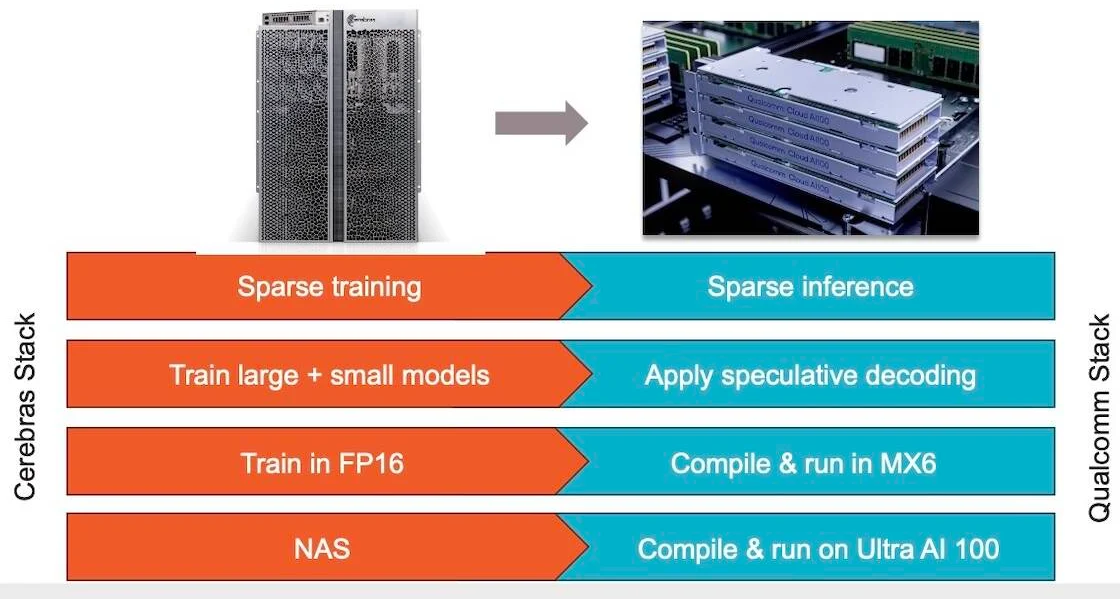 Сотрудничество Cerebras и Qualcomm носит официальный характер, его целью является оптимизация ИИ-моделей для запуска на AI100 Ultra с учетом различных продвинутых техник, таких как разреженные вычисления, спекулятивное исполнение (сочетание малых LLM для получения быстрого результата с проверкой большой LLM), использование «сжатого» формата MxFP6 для весов и других. Благодаря мощностям, предоставляемым WSE-3, цикл разработки, оптимизации и тестирования таких моделей удастся существенно ускорить, что в итоге должно обеспечить десятикратное улучшение удельной производительности новых решений.
10.03.2024 [21:00], Сергей Карасёв
В Южной Корее создан сверхэффекттивный ИИ-чип, сочетающий классический и нейроморфный подходыИсследователи из Южной Кореи разработали, как утверждается, первый в мире полупроводниковый ИИ-чип, который обладает высоким быстродействием при минимальном энергопотреблении. Изделие, предназначенное для обработки больших языковых моделей (LLM), основано на принципах, имитирующих структуру и функции человеческого мозга. В работе приняли участие специалисты Корейского института передовых технологий (KAIST). Утверждается, что при обработке модели GPT-2 новинка по сравнению с ускорителем NVIDIA A100 затрачивает в 625 раз меньше энергии и занимает в 41 раз меньше физического пространства. Таким образом, южнокорейский ИИ-чип теоретически может применяться даже в смартфонах. Чип производится по 28-нм процессу Samsung Electronics. 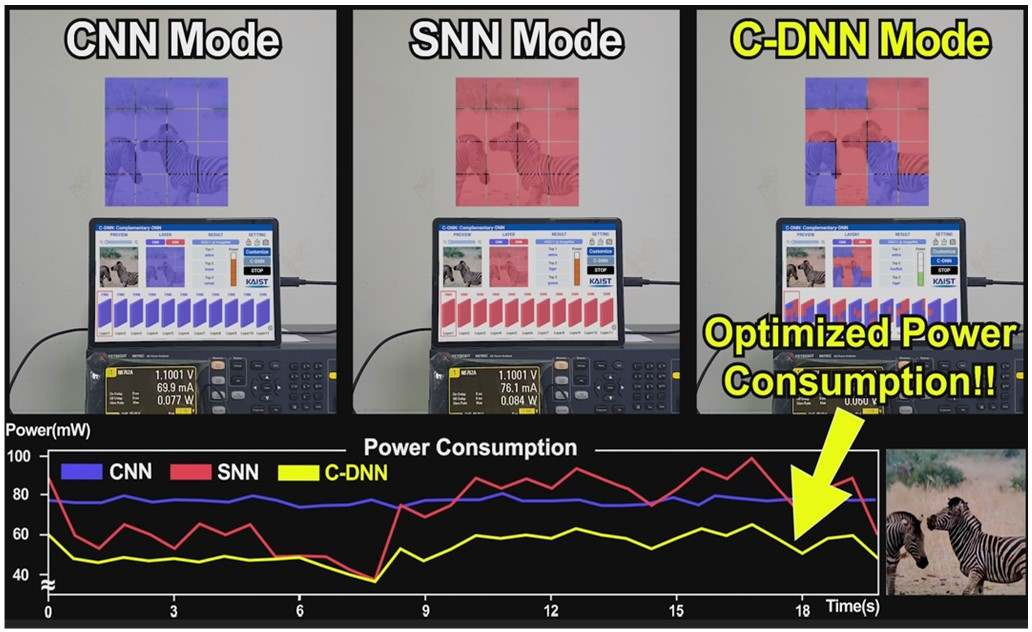
Источник изображений: KAIST Отмечается, что обычно для обработки модели GPT-2 требуются ускорители на базе GPU, потребляющие около 250 Вт энергии. Разработанное изделие требует для этого всего от 40 мВт, а его размеры составляют 4,5 × 4,5 мм. Причём на выполнение операций затрачивается только 0,4 с. Чип наделён 552 Кбайт памяти SRAM. Напряжение питания варьируется от 0,7 до 1,1 В. Тактовая частота варьируется в диапазоне 50–200 МГц. 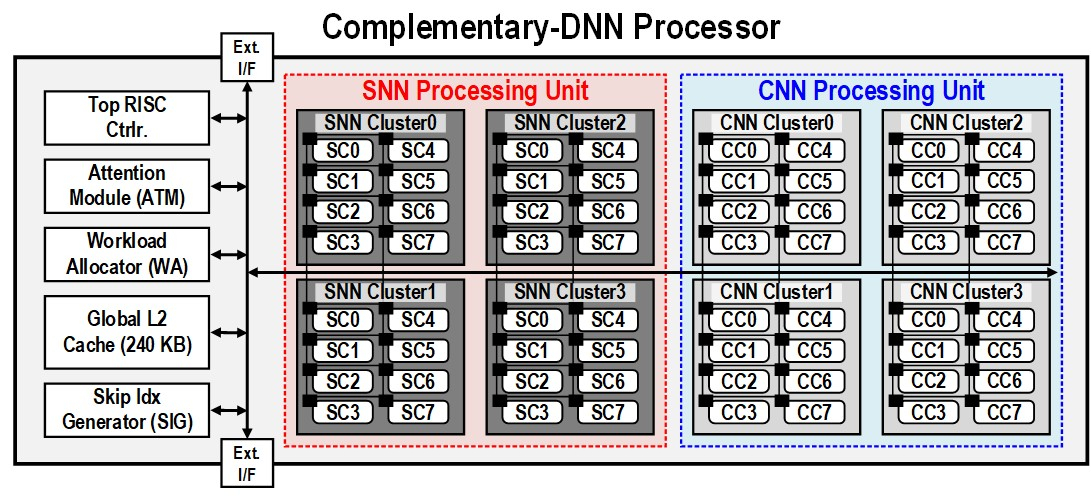 Технология, получившая название C-DNN (Complementary Deep Neural Network) позволяет использовать свёрточные нейронные сети (CNN) и импульсные нейронные сети (SNN), имитирующие процессы, которые задействованы в человеческом мозге при обработке информации. Иными словами, обучение происходит через несколько слоёв нейронных сетей, а потребление энергии варьируется в зависимости от когнитивной нагрузки. Технология минимизирует энергозатраты благодаря использованию DNN для больших входных значений и SNN для меньших. Правда, чип поддерживает максимум INT16. 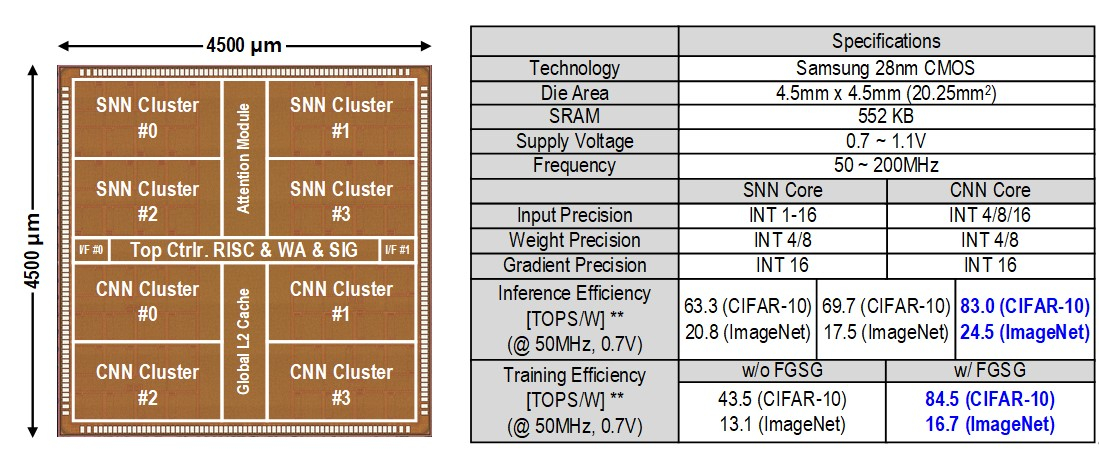 Утверждается, что C-DNN является первым ускорителем, который может поддерживать распределение рабочей нагрузки CNN/SNN, используя компромисс между производительностью и энергопотреблением. Изделие обеспечивает энергоэффективность на уровне 85,8 TOPS/Вт и 79,9 TOPS/Вт для инференса с наборами данных CIFAR-10 и CIFAR-100 соответственно (VGG-16). Энергоэффективность в случае ResNet-50 составляет 24,5 TOPS/Вт. При обучении чип C-DNN демонстрирует энергоэффективность в 84,5 TOPS/Вт и 16,7 TOPS/Вт для CIFAR-10 и ImageNet соответственно. Результаты получены при напряжении 0,7 В и частоте 50 МГц. 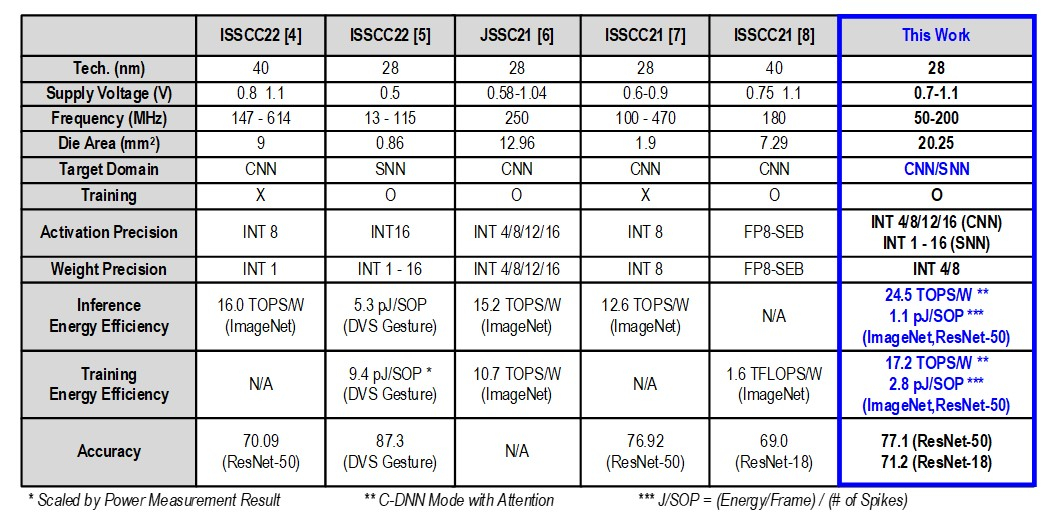 «Нейроморфные вычисления, имитирующие функции мозга, — это технология, которую такие крупные компании, как IBM и Intel, пока по-настоящему не реализовали. Мы гордимся тем, что первыми в мире начали использовать LLM со сверхэффективным нейроморфным ускорением», — говорит руководитель проекта профессора Ю Хой-Джун (Yu Hoi-jun).
04.03.2024 [17:00], Руслан Авдеев
Евросоюз намерен добиться полупроводникового суверенитета, используя архитектуру RISC-VВ Евросоюзе активно инвестируют в инициативы, призванные обеспечить полупроводниковый суверенитет благодаря использованию открытой архитектуры RISC-V. EE Times сообщает, что инициативу курирует Барселонский суперкомпьютерный центр (Barcelona Supercomputing Center или BSC) — пионер в разработке европейских решений RISC-V. 
Источник изображений: European Processor Initiative (EPI) Страны ЕС беспокоит полупроводниковая зависимость от иностранных компаний, и это беспокойство усугубляется относительно недавним дефицитом чипов в мире. В то же время за использование в своих решениях архитектуры RISC-V никому не надо платить и ни у кого не нужно получать разрешений на её применение, поэтому технология так привлекательна для разработчиков. BSC представляет собой один из ведущих исследовательских центров Европы. Он играет ключевую роль в разработке чипов на архитектуре RISC-V и возглавляет несколько проектов, связанных с этой технологией, в частности, European Processor Initiative (EPI). В рамках инициативы EPI стоимостью €70 млн разрабатывается новое поколение высокопроизводительных процессоров. Связанная с BSC компания OpenChip должна найти коммерческое применение разработанным технологиям.  BSC начал создавать собственные чипы семейства Lagarto довольно давно — первые 65-нм варианты представили ещё в мае 2019 года. Сегодня речь идёт уже о четвёртом поколении, которое будет выпускаться в соответствии с 7-нм техпроцессом. Центр работает и с другими европейскими компаниями и исследовательскими организациями над созданием комплексной экосистемы RISC-V, включающей ПО, ОС и компиляторы. Подобные инициативы должны снизить зависимость Евросоюза от американских и азиатских производителей — отсутствие в ЕС зрелой индустрии высокопроизводительных чипов расценивается как значимая уязвимость. Европа считает, что RISC-V — идеальная платформа для достижения суверенитета, при этом бесплатная. Впрочем, эксперты признают, что о полной независимости не может быть речи из-за сложности экосистемы полупроводниковой индустрии. Но у Европы есть большая база знаний и потенциал разработки новых решений, предпринимаются и шаги к организации производства.  В BSC уже экспериментировали с Arm-процессорами, но после Brexit и приобретения компании Arm группой Softbank, выяснилось, что собственной региональной технологии у ЕС нет, тогда и обратили внимание на общедоступную RISC-V. В 2019 году Еврокомиссию убедили в необходимости начать выпуск чипов на этой архитектуре для суперкомпьютеров. В числе других европейских компаний, предлагающих RISC-V продукты, есть Gaiser, Esperanto Technologies, Semidynamics и Codasip, но они уделяют больше внимания процессорам и ускорителям, а не конечным готовые решения. По оценкам экспертов, в Евросоюзе компаний, работающих с RISC-V, пока недостаточно. Тем не менее, организаторы новых инициатив предостерегают от нереалистичных ожиданий и призывают к стратегическому сотрудничеству — для производства требуются не только разработки, но и сырьё, высокоточное оборудование, и др. Европа может рассчитывать на выпуск решений в пределах 7-нм, более современные техпроцессы пока слишком дороги. Впрочем, ЕС уже добился значительного прогресса в достижении полупроводникового суверенитета с помощью RISC-V.
07.12.2023 [21:04], Сергей Карасёв
Google представила Cloud TPU v5p — свой самый мощный ИИ-ускорительКомпания Google анонсировала свой самый высокопроизводительный ускоритель для задач ИИ — Cloud TPU v5p. По сравнению с изделием предыдущего поколения TPU v4 обеспечивается приблизительно 1,7-кратный пророст быстродействия на операциях BF16. Впрочем, для Google важнее то, что она наряду с AWS является одной из немногих, кто при разработке ИИ не зависит от дефицитных ускорителей NVIDIA. К этому же стремится сейчас и Microsoft. Решение Cloud TPU v5p оснащено 95 Гбайт памяти HBM с пропускной способностью 2765 Гбайт/с. Для сравнения: конфигурация TPU v4 включает 32 Гбайт памяти HBM с пропускной способностью 1228 Гбайт/с. 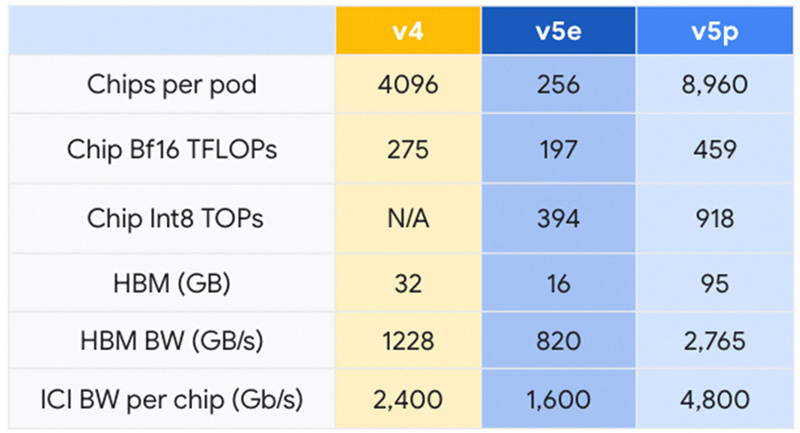
Источник изображений: Google Кластер на базе Cloud TPU v5p может содержать до 8960 чипов, объединённых высокоскоростным интерконнектом со скоростью передачи данных до 4800 Гбит/с на чип. В случае TPU v4 эти значения составляют соответственно 4096 чипов и 2400 Гбит/с. Что касается производительности, то у Cloud TPU v5p она достигает 459 Тфлопс (BF16) против 275 Тфлопс у TPU v4. На операциях INT8 новинка демонстрирует результат до 918 TOPS. 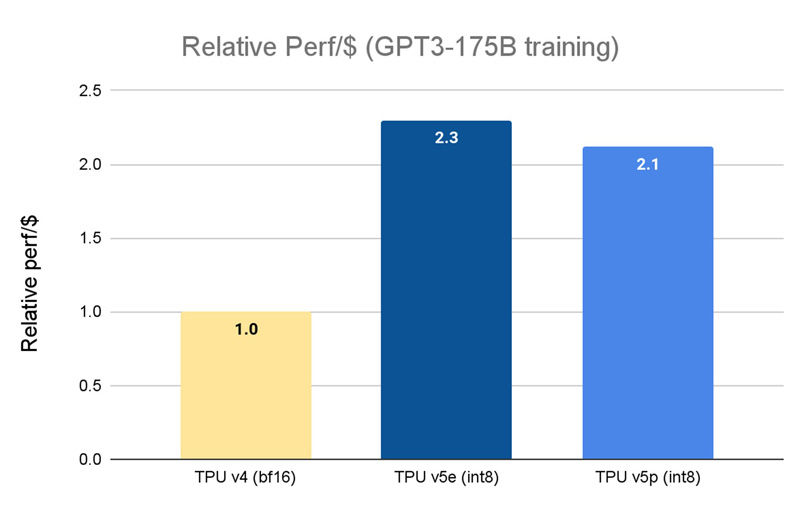 В августе нынешнего года Google представила ИИ-ускоритель TPU v5e, созданный для обеспечения наилучшего соотношения стоимости и эффективности. Это изделие с 16 Гбайт памяти HBM (820 Гбит/с) показывает быстродействие 197 Тфлопс и 394 TOPS на операциях BF16 и INT8 соответственно. При этом решение обеспечивает относительную производительность на доллар на уровне $1,2 в пересчёте на чип в час. У TPU v4 значение равно $3,22, а у новейшего Cloud TPU v5p — $4,2 (во всех случаях оценка выполнена на модели GPT-3 со 175 млрд параметров). 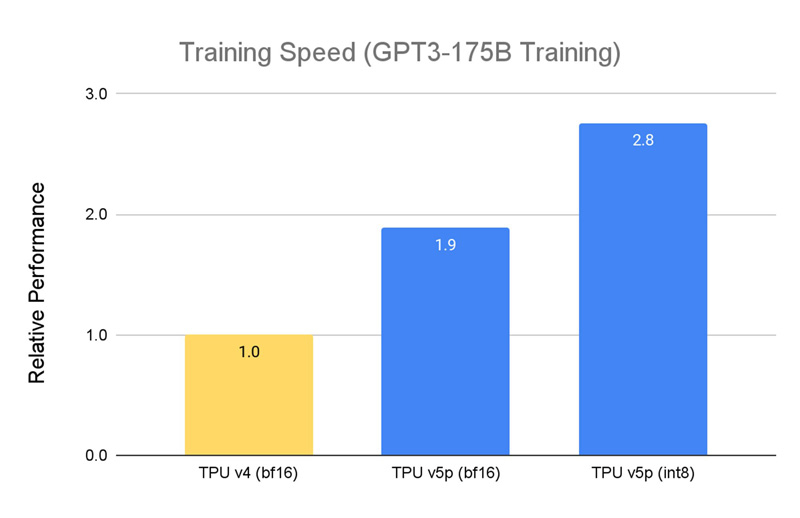 По заявлениям Google, чип Cloud TPU v5p может обучать большие языковые модели в 2,8 раза быстрее по сравнению с TPU v4. Более того, благодаря SparseCores второго поколения скорость обучения моделей embedding-dense увеличивается приблизительно в 1,9 раза. На базе TPU и GPU компания предоставляет готовый программно-аппаратный стек AI Hypercomputer для комплексной работы с ИИ. Система объединяет различные аппаратные ресурсы, включая различные типы хранилищ и оптический интерконнект Jupiter, сервисы GCE и GKE, популярные фреймворки AX, TensorFlow и PyTorch, что позволяет быстро и эффективно заниматься обучением современных моделей, а также организовать инференс.
29.11.2023 [03:43], Владимир Мироненко
AWS представила 96-ядерный Arm-процессор Graviton4 и ИИ-ускоритель Trainium2Amazon Web Services представила Arm-процессор нового поколения Graviton4 и ИИ-ускоритель Trainium2, предназначенный для обучения нейронных сетей. Всего к текущему моменту компания выпустила уже 2 млн Arm-процессоров Graviton, которыми пользуются более 50 тыс. клиентов. «Graviton4 представляет собой четвёртое поколение процессоров, которое мы выпустили всего за пять лет, и это самый мощный и энергоэффективный чип, который мы когда-либо создавали для широкого спектра рабочих нагрузок», — отметил Дэвид Браун (David Brown), вице-президент по вычислениям и сетям AWS. По сравнению с Graviton3 новый чип производительнее на 30 %, включает на 50 % больше ядер и имеет на 75 % выше пропускную способность памяти. 
Изображение: AWS Graviton4 будет иметь до 96 ядер Neoverse V2 Demeter (2 Мбайт L2-кеша на ядро) и 12 каналов DDR5-5600. Кроме того, новый чип получит поддержку шифрования трафика для всех своих аппаратных интерфейсов. Процессор изготавливается по 4-нм техпроцессу TSMC, включает 73 млрд транзисторов и, вероятно, имеет чиплетную компоновку. Возможно, это первый CPU компании, ориентированный на работу в двухсокетных платформах. 
Изображение: AWS Поначалу Graviton4 будет доступен в инстансах R8g (пока в статусе превью), оптимизированных для приложений, интенсивно использующих ресурсы памяти — высокопроизводительные базы данных, in-memory кеши и Big Data. Эти инстансы будут поддерживать более крупные конфигурации, иметь в три раза больше vCPU и в три раза больше памяти по сравнению с инстансами Rg7, которые имели до 64 vCPU и 512 Гбайт ОЗУ. 
Amazon Trainium2 (Изображение: AWS) В свою очередь, Trainium 2 предназначен для обучения больших языковых моделей (LLM) и базовых моделей. Сообщается, что ускоритель в сравнении с Trainium 1 вчетверо производительнее и при этом имеет в 3 раза больший объём памяти и в 2 раза более высокую энергоэффективность. Инстансы EC2 Trn2 получат 16 ИИ-ускорителей с возможностью масштабирования до 100 тыс. единиц в составе EC2 UltraCluster, которые суммарно дадут 65 Эфлопс, то есть по 650 Тфлопс на ускоритель. Как утверждает Amazon это позволит обучать LLM с 300 млрд параметров за недели вместо месяцев.  Со временем на Graviton4 заработает SAP HANA Cloud, портированием и оптимизацией этой платформы уже занимаются. Oracle также перенесла свою СУБД на Arm, а заодно перевела все свои облачные сервисы на чипы Ampere, в которую в своё время инвестировала. Microsoft же пошла по пути AWS и недавно анонсировала 128-ядерый Arm-процессор (Neoverse N2) Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработки. Всё это может представлять отдалённую угрозу для AMD и Intel. С NVIDIA же все всё равно пока что продолжают дружбу — именно в инфраструктуре AWS, как ожидается, появится самый мощный в мире ИИ-суперкомпьютер на базе новых GH200.
28.11.2023 [22:20], Игорь Осколков
NVIDIA анонсировала суперускоритель GH200 NVL32 и очередной самый мощный в мире ИИ-суперкомпьютер Project CeibaAWS и NVIDIA анонсировали сразу несколько новых совместно разработанных решений для генеративного ИИ. Основным анонсом формально является появление ИИ-облака DGX Cloud в инфраструктуре AWS, вот только облако это отличается от немногочисленных представленных ранее платформ DGX Cloud тем, что оно первом получило гибридные суперчипах GH200 (Grace Hoppper), причём в необычной конфигурации. 
Изображения: NVIDIA В основе AWS DGX Cloud лежит платформа GH200 NVL32, но это уже не какой-нибудь сдвоенный акселератор вроде H100 NVL, а целая, готовая к развёртыванию стойка, включающая сразу 32 ускорителя GH200, провязанных 900-Гбайт/с интерконнектом NVLink. В состав такого суперускорителя входят 9 коммутаторов NVSwitch и 16 двухчиповых узлов с жидкостным охлаждением. По словам NVIDIA, GH200 NVL32 идеально подходит как для обучения, так и для инференса действительно больших LLM с 1 трлн параметров.  Простым перемножением количества GH200 на характеристики каждого ускорителя получаются впечатляющие показатели: 128 Пфлопс (FP8), 20 Тбайт оперативной памяти, из которых 4,5 Тбайт приходится на HBM3e с суммарной ПСП 157 Тбайтс, и агрегированная скорость NVLink 57,6 Тбайт/с. И всё это с составе одного EC2-инстанса! Да, новая платформа использует фирменные DPU AWS Nitro и EFA-подключение (400 Гбит/с на каждый GH200). Новые инстансы, пока что безымянные, можно объединять в кластеры EC2 UltraClasters.  Одним из таких кластеров станет Project Ceiba, очередной самый мощный в мире ИИ-суперкомпьютер с FP8-производительность 65 Эфлопс, объединяющий сразу 16 384 ускорителя GH200 и имеющий 9,1 Пбайт памяти, а также агрегированную пропускную способность интерконнекта на уровне 410 Тбайт/с (28,8 Тбайт/с NVLink). Он и станет частью облака AWS DGX Cloud, которое будет доступно в начале 2024 года. В скором времени появятся и EC2-инстансы попроще: P5e с NVIDIA H200, G6e с L40S и G6 с L4.  |
|


