Материалы по тегу: ускоритель
|
19.11.2023 [03:00], Сергей Карасёв
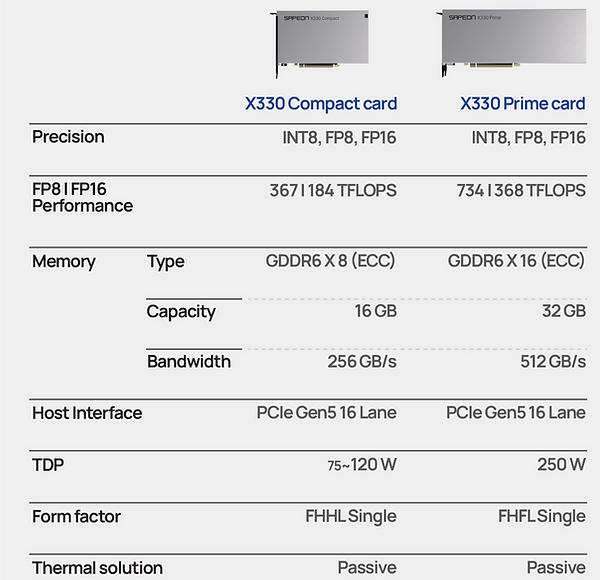
Южнокорейский стартап Sapeon представил 7-нм ИИ-чип X330ИИ-стартап Sapeon, поддерживаемый южнокорейским телекоммуникационным гигантом SK Group, анонсировал чип X330, предназначенный для инференса и обслуживания больших языковых моделей (LLM). Изделие ляжет в основу специализированных ускорителей для дата-центров. Sapeon заявляет, что новый нейропроцессор (NPU) обеспечивает примерно вдвое более высокую производительность и в 1,3 раза лучшую энергоэффективность, чем продукты конкурентов, выпущенные в этом году. По сравнению с предыдущим решением самой компании — Sapeon X220 — достигается увеличение быстродействия в четыре раза и повышение энергоэффективности в два раза. 
Изображения: Sapeon Новинка будет изготавливаться на TSMC по 7-нм технологии. Массовое производство запланировано на I полугодие 2024 года. На базе чипа будут предлагаться два ускорителя — X330 Compact Card и X330 Prime Card. Оба имеют однослотовое исполнение и оснащаются системой пассивного охлаждения. Для подключения применяется интерфейс PCIe 5.0 х16. Карты могут осуществлять вычисления INT8, FP8 и FP16.  Модель X330 Compact Card уменьшенной длины несёт на борту 16 Гбайт памяти GDDR6 с пропускной способностью до 256 Гбайт/с. Заявленная производительность на операциях FP8 и FP16 достигает соответственно 367 и 184 Тфлопс. Энергопотребление варьируется в диапазоне от 75 до 120 Вт. Полноразмерная модификация X330 Prime Card получила 32 Гбайт памяти GDDR6 с пропускной способностью до 512 Гбайт/с. Заявленное быстродействие FP8 и FP16 составляет до 734 и 368 Тфлопс. Энергопотребление — 250 Вт. 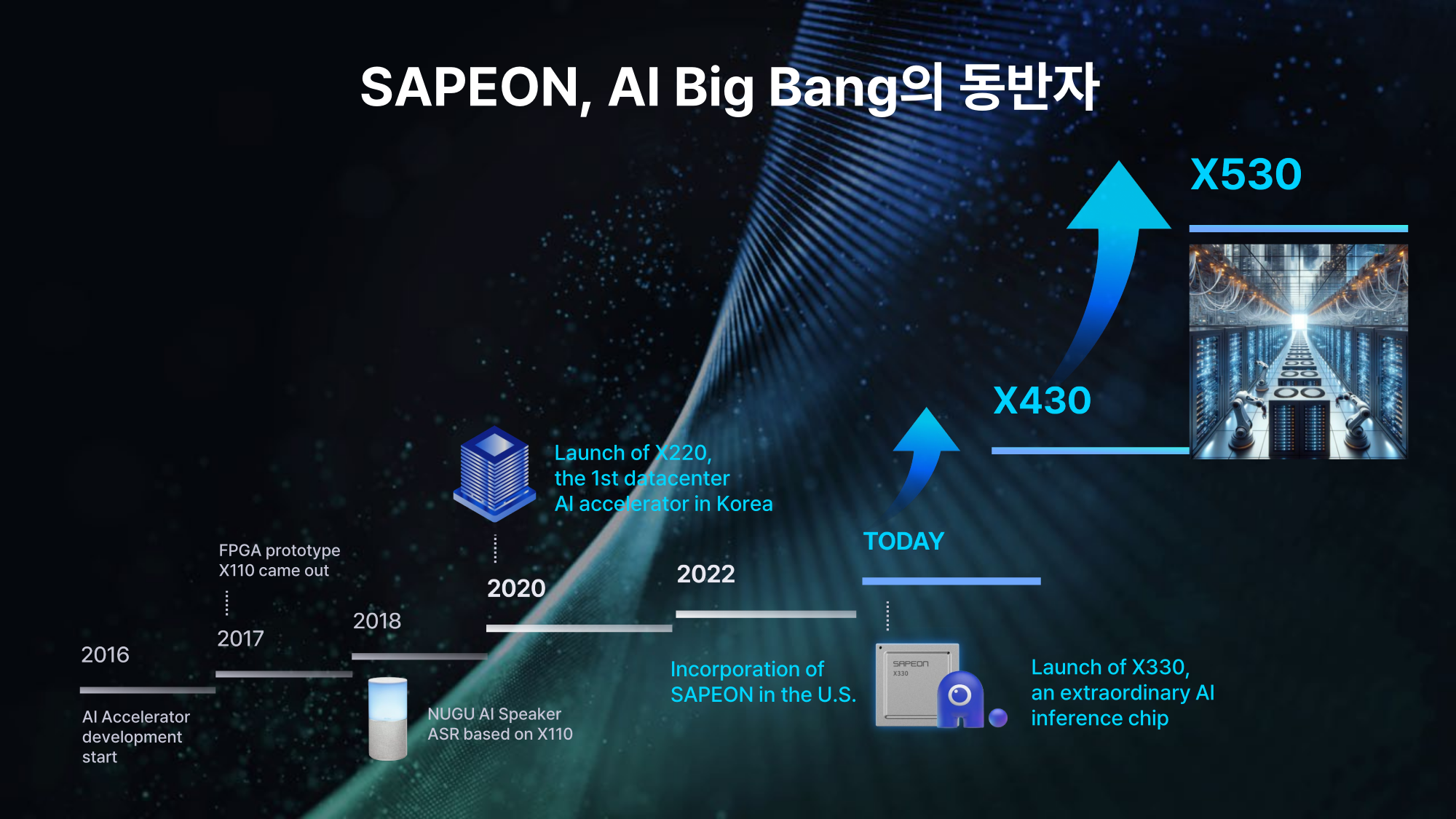 Группа SK в последнее время активно вкладывается в развитие ИИ, инвестируя напрямую или через дочерние структуры как в софт, так и в железо. С ней, в частности, связан ещё один южнокорейский разработчик ИИ-чипов Rebellions, также поддерживаемый правительством страны, которое намерено к 2030 году довести долю отечественных ИИ-чипов в местных дата-центрах до 80 %. Делается это для того, чтобы снизить зависимость от иностранных решений и избежать дефицита. Сама же Sapeon готовит ещё минимум два поколения своих чипов.
16.11.2023 [02:43], Алексей Степин
Microsoft представила 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработкиГиперскейлеры ради снижения совокупной стоимости владения (TCO) и зависимости от сторонних вендоров готовы вкладываться в разработку уникальных чипов, изначально оптимизированных под их нужды и инфраструктуру. К небольшому кругу компаний, решившихся на такой шаг, присоединилась Microsoft, анонсировавшая Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100. 
Изображения: Microsoft Первопроходцем в этой области стала AWS, которая разве что память своими силами не разрабатывает. У AWS уже есть три с половиной поколения Arm-процессоров Graviton и сразу два вида ИИ-ускорителей: Trainium для обучения и Inferentia2 для инференса. Крупный китайский провайдер Alibaba Cloud также разработал и внедрил Arm-процессоры Yitian и ускорители Hanguang. Что интересно, в обоих случаях процессоры оказывались во многих аспектах наиболее передовыми. Наконец, у Google есть уже пятое поколение ИИ-ускорителей TPU.  Microsoft заявила, что оба новых чипа уже производятся на мощностях TSMC с использованием «последнего техпроцесса» и займут свои места в ЦОД Microsoft в начале следующего года. Как минимум, в случае с Maia 100 речь идёт о 5-нм техпроцессе, вероятно, 4N. В настоящее время Microsoft Azure находится в начальной стадии развёртывания инфраструктуры на базе новых чипов, которая будет использоваться для Microsoft Copilot, Azure OpenAI и других сервисов. Например, Bing до сих пор во много полагается на FPGA, а вся ИИ-инфраструктура Microsoft крайне сложна.  Microsoft приводит очень мало технических данных о своих новинках, но известно, что Azure Cobalt 100 имеет 128 ядер Armv9 Neoverse N2 (Perseus) и основан на платформе Arm Neoverse Compute Subsystem (CSS). По словам компании, процессоры Cobalt 100 до +40 % производительнее имеющихся в инфраструктуре Azure Arm-чипов, они используются для обеспечения работы служб Microsoft Teams и Azure SQL. Oracle, вложившаяся в своё время в Ampere Comptuing, уже перевела все свои облачные сервисы на Arm.  Чип Maia 100 (Athena) изначально спроектирован под задачи облачного обучения ИИ и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Чип содержит 105 млрд транзисторов, что больше, нежели у NVIDIA H100 (80 млрд) и ставит Maia 100 на один уровень с Ponte Vecchio (~100 млрд). Для Maia организован кастомный интерконнект на базе Ethernet — каждый ускоритель располагает 4,8-Тбит/с каналом для связи с другими ускорителями, что должно обеспечить максимально эффективное масштабирование.  Сами Maia 100 используют СЖО с теплообменниками прямого контакта. Поскольку нынешние ЦОД Microsoft проектировались без учёта использования мощных СЖО, стойку пришлось сделать более широкой, дабы разместить рядом с сотней плат с чипами Maia 100 серверами и большой радиатор. Этот дизайн компания создавала вместе с Meta✴, которая испытывает аналогичные проблемы с текущими ЦОД. Такие стойки в настоящее время проходят термические испытания в лаборатории Microsoft в Редмонде, штат Вашингтон.  В дополнение к Cobalt и Maia анонсирована широкая доступность услуги Azure Boost на базе DPU MANA, берущего на себя управление всеми функциями виртуализации на манер AWS Nitro, хотя и не целиком — часть ядер хоста всё равно используется для обслуживания гипервизора. DPU предлагает 200GbE-подключение и доступ к удалённому хранилищу на скорости до 12,5 Гбайт/с и до 650 тыс. IOPS.  Microsoft не собирается останавливаться на достигнутом: вводя в строй инфраструктуру на базе новых чипов Cobalt и Maia первого поколения, компания уже ведёт активную разработку чипов второго поколения. Впрочем, совсем отказываться от партнёрства с другими вендорами Microsoft не намерена. Компания анонсировала первые инстансы с ускорителями AMD Instinct MI300X, а в следующем году появятся инстансы с NVIDIA H200. 
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
09.11.2023 [16:15], Сергей Карасёв
NVIDIA готовит для Китая три новых ускорителя взамен подпавших под санкции: H20, L20 и L2Компания NVIDIA, по сообщению Reuters, планирует выпустить три новых ИИ-ускорителя, модифицированных специально для Китая с учётом дополнительных санкций со стороны США. Изделия фигурируют под обозначениями HGX H20 (SXM), L20 (PCIe) и L2 (PCIe), а их официальная презентация состоится не раньше 16 ноября. Напомним, в середине октября 2023 года США ввели новые ограничения на поставку передовых чипов NVIDIA в Китай: они затронули решения A800 и H800 — модифицированные версии A100 и H100, созданные специально для рынка КНР с учетом ранее действовавших американских ограничений. После этого NVIDIA пришлось искать новые регионы сбыта для «урезанных» ускорителей, предназначавшихся для Поднебесной. Как теперь сообщается, NVIDIA снова нашла возможность поставлять ускорители на китайский рынок, который потенциально может обеспечить значительную выручку. Решения H20, L20 и L2 не подпадают ни под одно из действующих экспортных ограничений. Обратной стороной медали является то, что производительность у них серьёзно снижена (см. характеристики в таблице выше), передаёт SemiAnalysis. 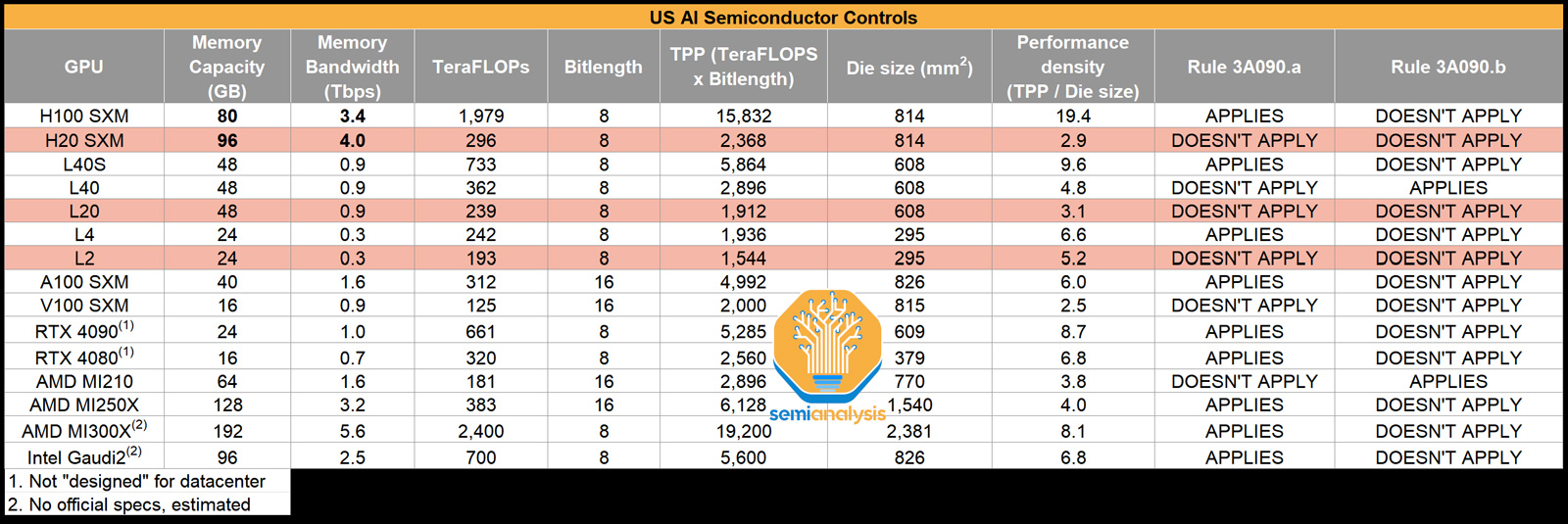
Источник: SemiAnalysis Отмечается, что у NVIDIA уже готовы образцы новых ускорителей для китайского рынка, а их массовое производство будет организовано в течение следующего месяца. Сама компания какие-либо комментарии по поводу обнародованной в интернете информации не даёт.
23.10.2023 [20:57], Алексей Степин
Новый нейроморфный ИИ-процессор IBM NorthPole на порядок превосходит современные GPUПо большей части современные нейросетевые технологии используют ускорители на базе GPU или родственных архитектур как для обучения, так и для инференса. Впрочем, разработчики альтернативных решений не дремлют. В число последних входит компания IBM, недавно сообщившая об успешном завершении испытаний нового нейроморфного процессора NorthPole. Разработкой чипов, в том или ином виде пытающихся имитировать работу живого мозга, компания занимается давно — чипы IBM TrueNorth второго поколения увидели свет более пяти лет назад. Уже тогда разработчики отошли от традиционных архитектур, отказавшись от понятия памяти как внешнего устройства. 
Источник изображений здесь и далее: IBM Research В итоге TrueNorth получил 400 Мбит (~50 Мбайт) сверхбыстрой интегрированной памяти SRAM (~100 Кбайт на ядро, всего 4096 ядер) и мог эмулировать 1 млн нейронов с 256 млн межнейронных связей. Чип моделировал бинарные нейроны, а вес каждого синапса был закодирован двумя битами. 
FPGA (слева) используется только в качестве PCIe-моста Новый 12-нм нейрочип NorthPole устроен несколько иначе: он состоит из 256 ядер, которые, впрочем, всё так же используют внутреннюю память общим объёмом 192 Мбайт. Дополнительно имеется буфер объёмом 32 Мбайт для IO-тензоров. Каждое из ядер NorthPole за такт способно выполнять 2048 операций с 8-бит точностью вычислений. В режимах 4- и 2-бит точности производительность растёт соответствующим образом. По словам IBM, новый NPU превосходит предшественника в 4000 раз и на частоте 400 МГц мог бы развивать производительность в районе 840 Топс. Из-за довольно ограниченного объёма памяти NorthPole не подходит для запуска сложных нейросетей вроде GPT-4, но его главное назначение не в этом — чип позиционируется в качестве основы систем машинного зрения, в том числе в системах автопилотов, хирургических роботов и т.п. И в этом качестве новинка, состоящая из 22 млрд транзисторов и имеющая площадь кристалла 800 мм2, проявляет себя очень хорошо. 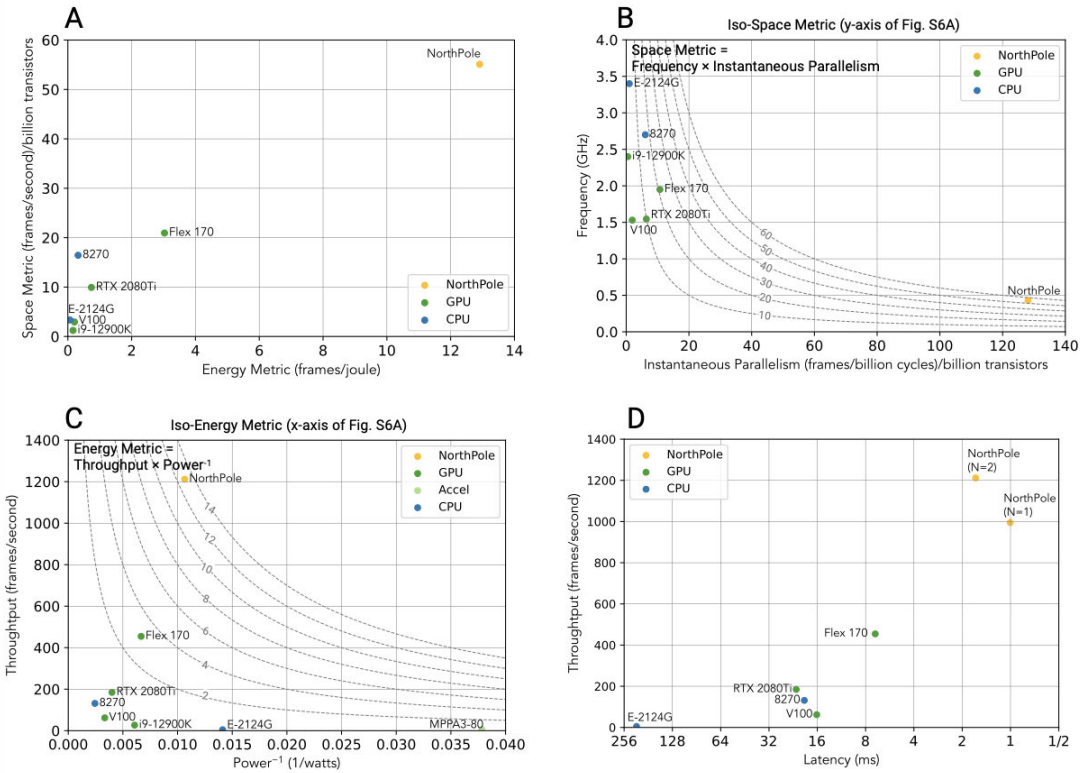
Результаты тестов на эффективность архитектуры NorthPole Так, в тестах ResNet-50 NorthPole в 25 раз превзошёл по энергоэффективности сопоставимые по техпроцессу GPU, а показатели латентности при этом оказались в 22 раза лучше. В пересчёте на транзисторную сложность IBM говорит о превосходстве даже над новейшими 4-нм решениями NVIDIA. Полные результаты тестирования доступны на science.org. К сожалению, речь всё ещё идёт об экспериментальном прототипе с довольно грубым по современным меркам 12-нм техпроцессом. По словам исследователей, производительность NorthPole благодаря более совершенным техпроцессам удалось поднять бы ещё в 25 раз. Параллельно IBM ведёт разработки в области ИИ-чипов с элементами аналоговой логики. Достигнутые в рамках 14-нм техпроцесса результаты позволяют говорить об удельной производительности в районе 10,5 Топс/Вт или 1,59 Топс/мм2.
20.09.2023 [20:05], Алексей Степин
SambaNova представила ИИ-ускоритель SN40L с памятью HBM3, который в разы быстрее GPUБум больших языковых моделей (LLM) неизбежно порождает появление на рынке нового специализированного класса процессоров и ускорителей — и нередко такие решения оказываются эффективнее традиционного подхода с применением GPU. Компания SambaNova Systems, разработчик таких ускорителей и систем на их основе, представила новое, третье поколение ИИ-процессоров под названием SN40L. Осенью 2022 года компания представила чип SN30 на базе уникальной тайловой архитектуры с программным управлением, уже тогда вполне осознавая тенденцию к увеличению объёмов данных в нейросетях: чип получил 640 Мбайт SRAM-кеша и комплектовался оперативной памятью объёмом 1 Тбайт. 
Источник изображений здесь и далее: SambaNova (via EE Times) Эта наработка легла и в основу новейшего SN40L. Благодаря переходу от 7-нм техпроцесса TSMC к более совершенному 5-нм разработчикам удалось нарастить количество ядер до 1040, но их архитектура осталась прежней. Впрочем, с учётом реконфигурируемости недостатком это не является. Чип SN40L состоит из двух больших чиплетов, на которые приходится 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной HBM3. Последняя была добавлена в SN40L в качестве буфера между сверхбыстрой SRAM и относительно медленной DDR. Это должно улучшить показатели чипа при работе в режиме LLM-инференса. Для эффективного использования HBM3 программный стек SambaNova был соответствующим образом доработан. 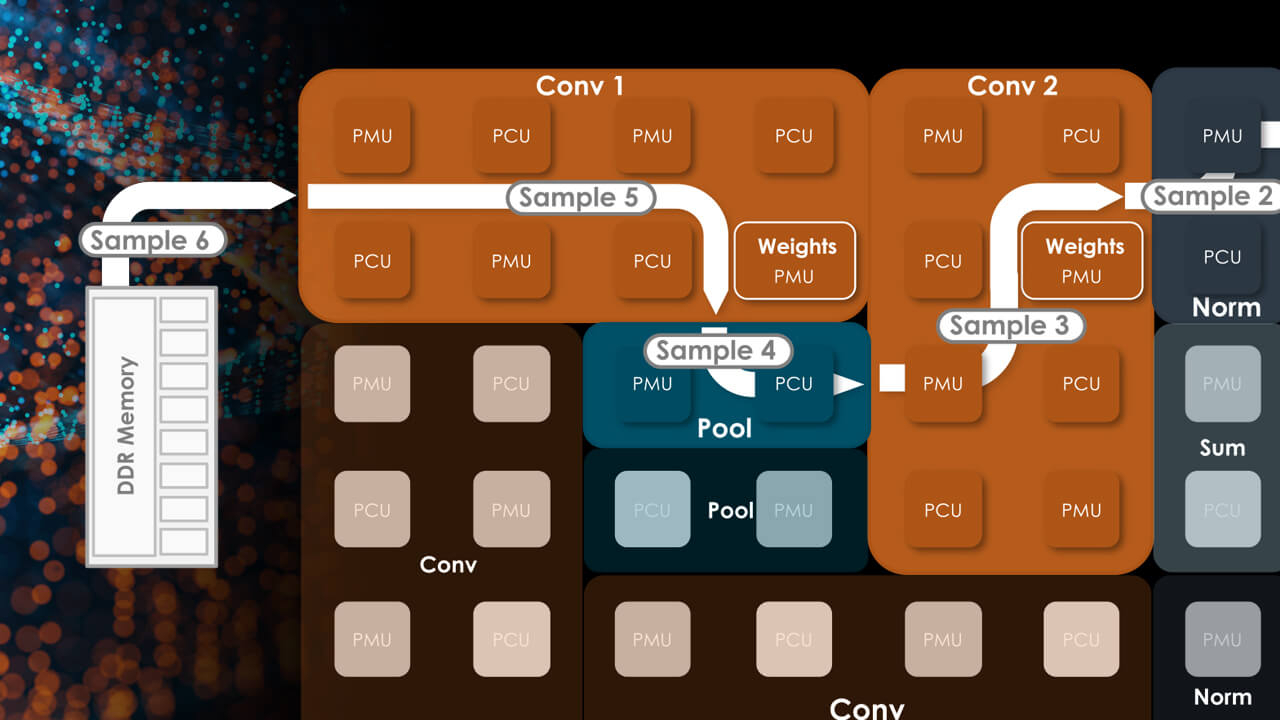
Тайловая архитектура SambaNova состоит из вычислительных тайлов PCU, SRAM-тайлов PMU, управляющей логики и меш-интерконнекта По сведениям SambaNova, восьмипроцессорная система на базе SN40L сможет запускать и обслуживать ИИ-модель поистине титанических «габаритов» — с 5 трлн параметров и глубиной запроса более 256к. В описываемой модели речь идёт о наборе экспертных моделей с LLM Llama-2 в качестве своеобразного дирижёра этого оркестра. Архитектура с традиционными GPU потребовала бы для запуска этой же модели 24 сервера с 8 ускорителями каждый; впрочем, модель ускорителей не уточняется. Как и прежде, сторонним клиентам чипы SN40L и отдельные вычислительные узлы на их основе поставляться не будут. Компания продолжит использовать модель Dataflow-as-a-Service (DaaS) — расширяемую платформу ИИ-сервисов по подписке, включающей в себя услуги по установке оборудования, вводу его в строй и управлению в рамках сервиса. Однако SN40L появится в рамках этой услуги позднее, а дебютирует он в составе облачной службы SambaNova Suite.
15.09.2023 [20:52], Алексей Степин
Groq назвала свои ИИ-чипы TSP четырёхлетней давности идеальными для LLM-инференсаТензорный процессор TSP, разработанный стартапом Groq, был анонсирован ещё осенью 2019 года и его уже нельзя назвать новым. Тем не менее, как сообщает Groq, TSP всё ещё является достаточно мощным решением для инференса больших языковых моделей (LLM). Теперь Groq позиционирует своё детище как LPU (Language Processing Unit) и продвигает его в качестве идеальной платформы для запуска больших языковых моделей (LLM). Согласно имеющимся данным, в этом качестве четырёхлетний процессор проявляет себя весьма неплохо. Groq открыто хвастается своим преимуществом над GPU, но в последних раундах MLPerf участвовать не желает. 
Источник изображений здесь и далее: Groq В своё время Groq разработала не только сам тензорный процессор, но и дизайн ускорителя на его основе, а также продумала вопрос взаимодействия нескольких TSP в составе вычислительного узла с дальнейшим масштабированием до уровня мини-кластера. Именно для такого кластера и опубликованы свежие данные о производительности Groq в сфере LLM. 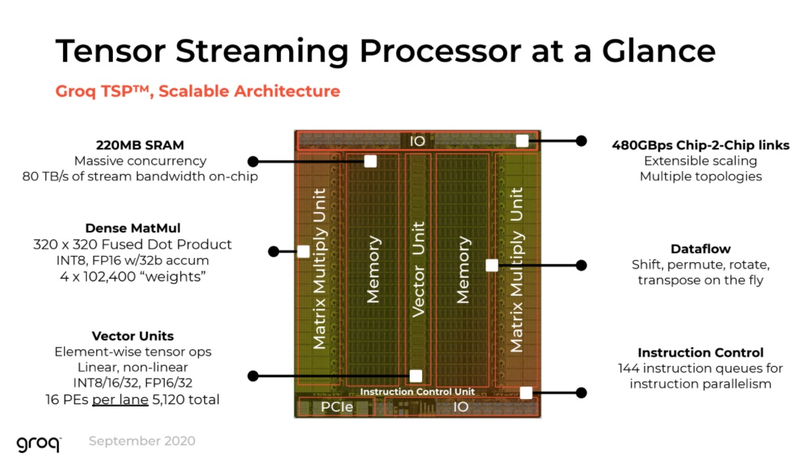 Система разработки, содержащая в своём составе 640 процессоров Groq TSP, была успешно использована для запуска модели Meta✴ Llama-2 с 70 млрд параметров. Как показали результаты тестов, модель на данной платформе работает с производительностью 240 токенов в секунду на пользователя. Для адаптации и развёртывания Llama-2, по словам создателей Groq, потребовалось всего несколько дней. В настоящее время усилия Groq будут сконцентрированы на адаптации имеющейся платформы в сфере LLM-инференса, поскольку данный сектор рынка растёт быстрее, нежели сектор обучения ИИ-моделей. Для LLM-инференса важнее умение эффективно масштабировать потоки небольших блоков (8–16 Кбайт) на большое количество чипов. 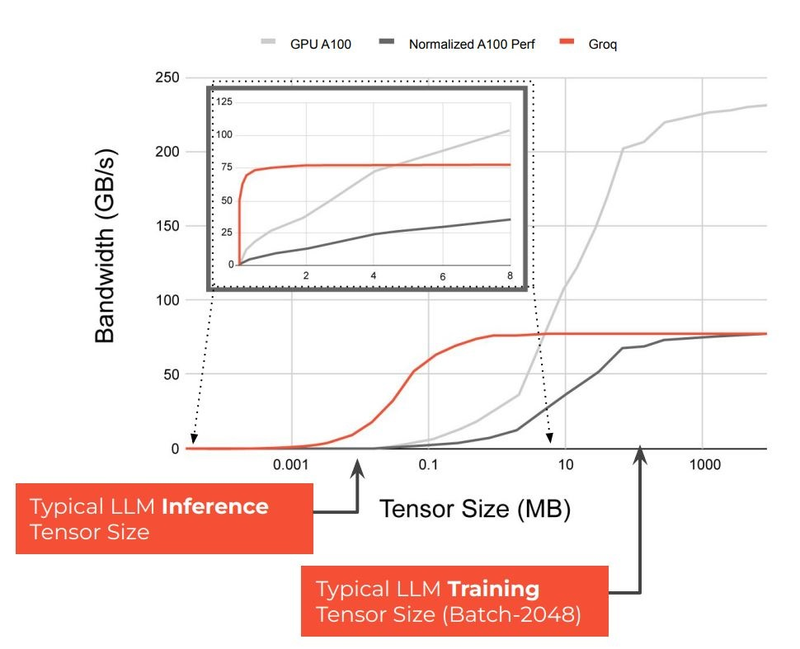 В этом Groq TSP превосходит NVIDIA A100: если в сравнении двух серверов выиграет решение NVIDIA, то уже при 40 серверах показатели латентности у Groq TSP будут намного лучше. В распоряжении Groq имеется пара 10-стоечных кластеров с 640 процессорами, один из которых используется для разработки, а второй — в качестве облачной платформы для клиентов Groq в области финансовых услуг. Работает система Groq и в Аргоннской национальной лаборатории (ALCF), где она используется для исследований в области термоядерной энергетики.  В настоящее время Groq TSP производятся на мощностях GlobalFoundries, а упаковка чипов происходит в Канаде, но компания работает над вторым поколением своих процессоров, которое будет производиться уже на заводе Samsung в Техасе. Параллельно Groq работает над созданием 8-чипового ускорителя на базе TSP первого поколения. Это делается для уплотнения вычислений, а также для более полного использования проприетарного интерконнекта и обхода ограничений, накладываемых шиной PCIe 4.0. Также ведётся дальнейшая оптимизация ПО для кремния первого поколения.  Простота и скорость разработки ПО для платформы Groq TSP объясняется историей создания этого процессора — начала Groq с создания компилятора и лишь затем принялась за проектирование кремния с учётом особенностей этого компилятора. Перекладывание на плечи компилятора всех задач оркестрации вычислений позволило существенно упростить дизайн TSP, а также сделать предсказуемыми показатели производительности и латентности ещё на этапе сборки ПО. При этом архитектура Groq TSP вообще не предусматривает использования «ядер» (kernels), то есть не требует блоков низкоуровневого кода, предназначенного для общения непосредственно с аппаратной частью. В случае с TSP любая задача разбивается на набор небольших инструкций, реализованных в кремнии и выполняемых непосредственно чипом. 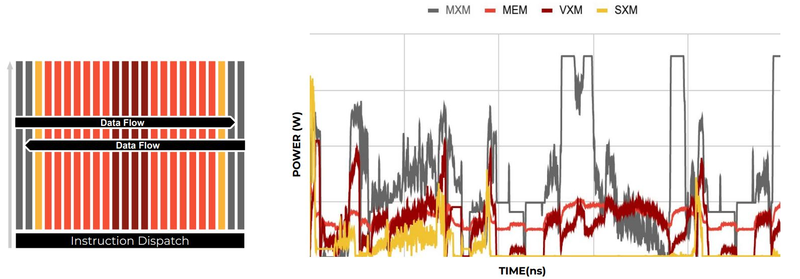
Компилятор Groq позволяет визуализировать и предсказывать энергопотребление с точностью до наносекунд. Источник: Groq Предсказуемость Groq TSP распространяется и на энергопотребление: оно полностью профилируется ещё на этапе компиляции, так что пики и провалы можно спрогнозировать с точностью вплоть до наносекунд. Это позволяет добиться от платформы более надёжного функционирования, избежав так называемой «тихой» порчи данных — сбоев, происходящих в результате резких всплесков энергетических и тепловых параметров кремния. 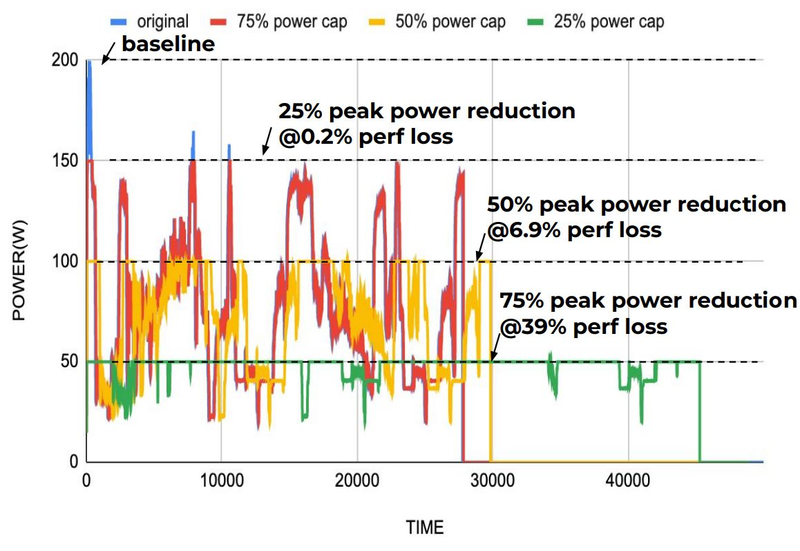
Энергопотребление Groq TSP поддаётся тонкой настройке на уровне программного обеспечения. Источник: Groq Что касается будущего LLM-инференса, то Groq считает, что этой отрасли есть, куда расти. В настоящее время LLM дают ответ на запрос сразу, и затем пользователи могут уточнить его в последующих итерациях, но в будущем они начнут «рефлексировать» — то есть, «продумывать» несколько вариантов одновременно, используя совокупный результат для более точного «вывода» и ответа. Разумеется, такой механизм потребует больших вычислительных мощностей, и здесь масштабируемая и предсказуемая архитектура Groq TSP может прийтись как нельзя более к месту.
30.08.2023 [16:04], Алексей Степин
Google Cloud анонсировала новое поколение собственных ИИ-ускорителей TPU v5eКак известно, Google Cloud использует в своей инфраструктуре не только сторонние ускорители, но и TPU собственной разработки. Эти кастомные ASIC компания продолжает активно развивать — она анонсировала предварительную доступность виртуальных машин с новейшими TPU v5e, разработка которых заняла более двух лет. Сам чип TPU v5e позиционируется Google как эффективный со всех точек зрения ускоритель, предназначенный для обучения нейросетей или инференс-систем среднего и большого классов. В сравнении с TPU v4 он, по словам Google, обеспечивает вдвое более высокую производительность в пересчёте на доллар для обучения больших языковых моделей (LLM) и генеративных нейросетей. Для инференс-систем преимущество по тому же критерию составляет 2,5x. В сравнении с аналогичными решениями на базе других чипов, например, GPU, выигрыш может составить и 4x. Каждый чип TPU v5e включает четыре блока матричных вычислений, по одному блоку для скалярных и векторных расчётов, а также HBM2-память. 
Источник изображения: Google Компания отмечает, что не экономит на технических характеристиках TPU v5e в угоду рентабельности. Кластеры могут включать до 256 чипов TPU v5e, объединённых высокоскоростным интерконнектом с совокупной пропускной способностью более 400 Тбит/с. Производительность такой платформы составляет 100 Попс (Петаопс) в INT8-вычислениях. Правда, здесь есть нюанс: INT8-производительности TPU v5e составляет 393 Тфлопс против 275 Тфлопс у v4, но вот BF16-производительность у TPU v4 составляет те же 275 Тфлопс, тогда как у v5e этот показатель равен уже 197 Тфлопс. 
Источник изображения: Google В настоящее время для предварительного тестирования доступно уже восемь вариантов инстансов на базе v5e, а в зависимости от конфигурации количество TPU может составлять от 1 до более чем 250. В рамках платформы обеспечена полная интеграция с Google Kubernetes Engine, собственной платформой Vertex AI, а также с большинством современных фреймворков, включая PyTorch, TensorFlow и JAX. Работа с TPU v5e будет значительно дешевле, чем с TPU v4 — $1,2/час против $3,4/час (за чип). 
Источник изображения: Google В настоящее время машины с TPU v5e доступны только в североамериканском регионе (us-west4), но в дальнейшем возможность их использования появится в регионах EMEA (Нидерланды) и APAC (Сингапур). Также Google предлагает опробовать технологию Multislice, позволяющей объединять в единый комплекс десятки тысяч TPU v5e или TPU v4, где каждый «слайс» может содержать до 3072 чипов TPU (v4). В максимальной конфигурации можно развернуть 64 инстанса, работающих с 256 кластерами TPU v5e. Сама компания уже использует новые чипы для своего поисковика и Google Photos.
09.08.2023 [18:00], Алексей Степин
NVIDIA анонсировала L40S — новый универсальный ускоритель на базе Ada LovelaceКорпорация NVIDIA обновила серию укорителей L40, представленных осенью прошлого года в рамках платформы OVX. Новинка под названием NVIDIA L40S позиционируется как универсальный ускоритель в форм-факторе двухслотовой FHFL-карты расширения с интерфейсом PCIe 4.0 x16, пригодный для решения практически любых задач. Во многом L40S повторяет L40 — она также базируется на архитектуре Ada Lovelace, оснащена графическим процессором AD102, дополненным 48 Гбайт памяти GDDR6 ECC (384 бит, 864 Гбайт/с). В составе ускорителя работают 18176 ядер CUDA, 142 RT-ядра третьего поколения и 568 тензорных ядер четвёртого поколения. То есть в этом отличий от L40 нет. Но значение TDP у новинки выше на 50 Вт и составляет 350 Вт, она все ещё имеет пассивное охлаждение. 
Источник изображений здесь и далее: NVIDIA При этом L40S умудряется быть практически вдвое быстрее L40 во всех форматах вычислений с использованием тензорных ядер, а вот без Tensor Core её FP32-производительность выросла минимально — с 90,5 до 91,6 Тфлопс. Поддержкой NVLink-мостика новинка так и не обзавелась. L40S оснащён четырьмя портами DP 1.4a с поддержкой NVIDIA Mosaic и Quadro Sync. Также доступны профили vGPU для vDWS, GRID vApps/vPC, vCS. Имеется поддержка Secure Boot с Root of Trust и соответствие стандарту NEBS Level 3.  Таким образом, новинка подходит не только в качестве ускорителя для обучения ИИ-моделей или инференс-систем, но и в качестве основы для систем рендеринга 3D-графики, визуализации или создания и запуска приложений для мета✴-вселенных. NVIDIA отмечает, что в ИИ-задачах L40S опережает A100 в 1,2–1,7 раза, а наличие трёх движков NVENC/NVDEC с поддержкой AV1 позволяет использовать новый ускоритель в качестве эффективной платформы транскодирования видео.
01.08.2023 [10:02], Сергей Карасёв
Esperanto готовит универсальный чип ET-SoC-2 на базе RISC-V для задач НРС и ИИСтартап Esperanto Technologies, по сообщению ресурса HPC Wire, готовит новый чип с архитектурой RISC-V, ориентированный на системы высокопроизводительных вычислений (НРС) и задачи ИИ. Изделие получит обозначение ET-SoC-2. Нынешний чип ET-SoC-1 объединяет 1088 энергоэффективных ядер ET-Minion и четыре высокопроизводительных ядра ET-Maxion. Решение предназначено для инференса рекомендательных систем, в том числе на периферии. Чип ET-SoC-2 будет включать в себя новые высокопроизводительные ядра CPU на базе RISC-V с векторными расширениями. Точные данные о производительности не раскрываются, но говорится, что изделие обеспечит быстродействие с двойной точностью более 10 Тфлопс. Архитектура ET-SoC-2 предполагает совместную работу сотен и тысяч чипов для организации платформ НРС. При этом Esperanto делает упор на энергетической эффективности своих решений. 
Источник изображения: Esperanto Technologies По словам Дейва Дитцеля (Dave Ditzel), генерального директора Esperanto, чипы RISC-V смогут взять на себя функции и CPU, и GPU при обработке ресурсоёмких приложений, в частности, машинного обучения. Процессоры RISC-V отстают по производительности от чипов x86 и Arm, хотя разрыв постепенно сокращается. Дитцель сказал, что стойки с чипами ET-SoC-1 могут обеспечить производительность в петафлопсы. Однако проблема с внедрением RISC-V заключается в слабо развитой экосистеме ПО. |
|


{kind=link}