Материалы по тегу: kaist
|
19.02.2026 [12:50], Сергей Карасёв
Впятеро энергоэффективнее H100: HyperAccel разработала экономичный чип Bertha 500 для ИИ-инференсаЮжнокорейский стартап HyperAccel, по сообщению EETimes, готовится вывести на рынок специализированный чип Bertha 500, предназначенный для ИИ-инференса. Утверждается, что благодаря особой архитектуре изделие способно генерировать в пять раз больше токенов в секунду по сравнению с решениями на основе GPU при том же уровне TOPS. В Bertha 500 упор сделан на экономическую эффективность. С этой целью используется память LPDDR вместо дорогостоящей HBM. При этом благодаря отказу от традиционной иерархии памяти достигается утилизация пропускной способности LPDDR на 90 %. Дальнейшее повышение эффективности обеспечивается путём оптимизации архитектуры именно для задач инференса. Для сравнения, как утверждает HyperAccel, в случае GPU при инференсе используется только около 45 % пропускной способности памяти и 30 % вычислительных ресурсов. Иными словами, немного жертвуя производительностью, чип Bertha 500 позволяет достичь значительного снижения стоимости. Изделие Bertha 500 будет производиться по 4-нм техпроцессу Samsung. В состав чипа входят 32 ядра LPU (LLM Processing Unit), четыре ядра Arm Cortex-A53 и 256 Мбайт SRAM. Подсистема памяти LPDDR5x использует восемь каналов; пропускная способность достигает 560 Гбайт/с. Заявленная ИИ-производительность на операциях INT8 составляет 768 TOPS. Кроме того, поддерживаются другие 16-, 8- и 4-бит форматы, включая FP16. В целом, по заявлениям HyperAccel, пропускная способность Bertha 500 в расчёте на доллар примерно в 20 раз выше по сравнению с NVIDIA H100, тогда как энергоэффективность больше в пять раз. Чип Bertha 500 будет потреблять около 250 Вт. 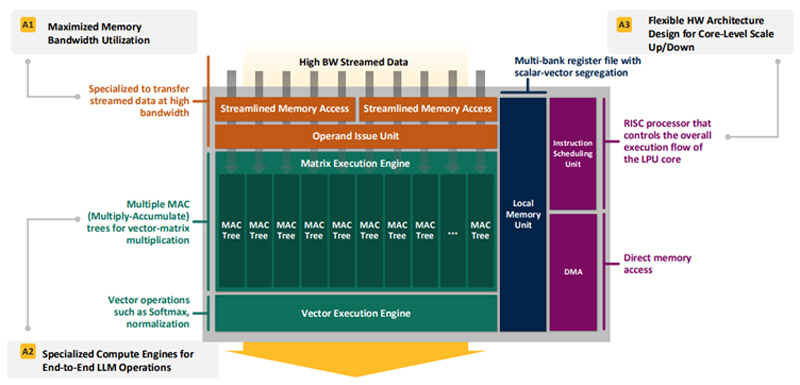
Источник изображения: EETimes Программный стек HyperAccel поддерживает все модели из репозитория HuggingFace. Кроме того, компания работает над предметно-ориентированным языком (DSL) под названием Legato, который предоставит разработчикам низкоуровневый доступ к системе. Образцы Bertha 500 появятся к концу I квартала 2026 года, а серийное производство планируется организовать в начале 2027 года. Отмечается также, что совместно с LG стартап разрабатывает «урезанную» версию Bertha 500 для периферийных устройств — Bertha 100. Эта SoC получит ядра Arm Cortex-A55 и отдельные компоненты LG, а также два канала памяти LPDDR5x. Среди возможных сфер применения названы автомобильная промышленность, бытовая электроника и робототехника. Bertha 100 планируется выпускать в виде модулей M.2: первые изделия выйдут в IV квартале текущего года. Решение сможет, например, осуществлять преобразование текста в речь или речи в текст. Стартап HyperAccel основан профессором Корейского института передовых технологий (KAIST) Джуёном Кимом (Jooyoung Kim) вместе с группой его студентов в начале 2023 года. На сегодняшний день компания привлекла $45 млн инвестиций, а её рыночная стоимость оценивается в $200 млн. Штат насчитывает около 80 человек. Первым продуктом HyperAccel стал специализированный сервер Orion на базе FPGA, предназначенный для решения ИИ-задач.
21.06.2025 [08:41], Руслан Авдеев
Через 10 лет ИИ-ускорители получат терабайты HBM и будут потреблять 15 кВт — это изменит подход к проектированию, питанию и охлаждению ЦОДИИ-чипы нового поколения не просто будут быстрее — они станут потреблять беспрецедентно много энергии и потребуют кардинально изменить инфраструктуру ЦОД. По данным учёных, к 2035 году энергопотребление ИИ-ускорителей может вырасти до порядка 15 кВт, из-за чего окажется под вопросом способность инфраструктуры современных ЦОД обслуживать их, сообщает Network World. Исследователи лаборатории TeraByte Interconnection and Package Laboratory (TeraLab), подведомственной Корейскому институту передовых технологий (KAIST), подсчитали, что переход к HBM4 состоится в 2026 году, а к 2038 году появится уже HBM8. Каждый этап развития обеспечит повышение производительности, но вместе с ней вырастут и требования к питанию и охлаждению. В лаборатории полагают, что мощность только одного GPU вырастет с 800 Вт до 1200 Вт к 2035 году. В сочетании с 32 стеками HBM, каждый из которых будет потреблять 180 Вт, общая мощность может увеличиться до 15 360 Вт (в таблице ниже дан расчёт для стеков HBM8, а не HBM7 — прим. ред.). Ожидается, что отдельные модули HBM8 обеспечат ёмкость до 240 Гбайт и пропускную способность памяти до 64 Тбайт/с. В рамках ускорителя можно суммарно получить порядка 5–6 Тбайт HBM с ПСП до 1 Пбайт/с. Это приведёт к изменению конструкции самого ускорителя. Ключевым элементом становятся стеки HBM — процессоры, контроллеры и ускорители будут интегрированы в единую подложку с HBM-модулями. Возможен переход к 3D-упаковке с использованием двусторонних интерпозеров-подложек или даже нескольких интерпозеров на разных «этажах» кристаллов. 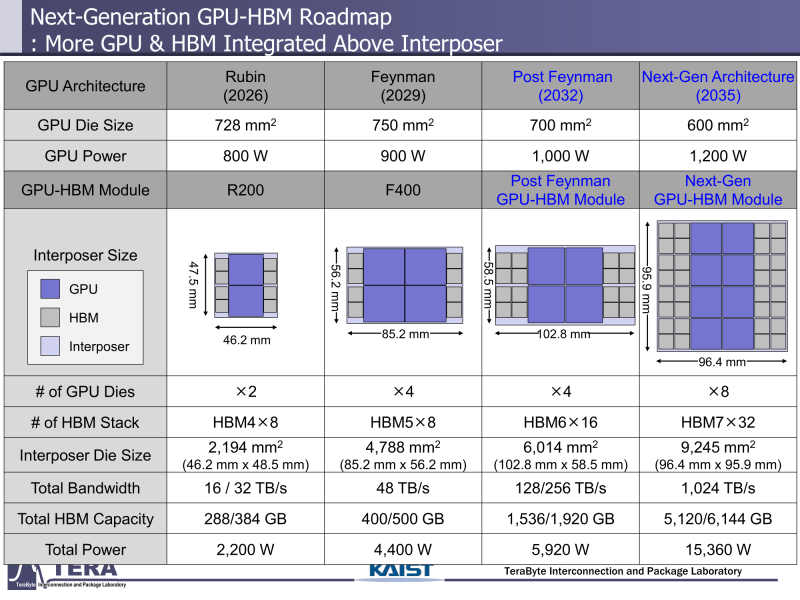
Источник изображений: KAIST Кроме того, для ускорителей придётся разработать и новые системы охлаждения. К уже традиционным прямому жидкостному охлаждению (DLC) и погружным СЖО, вероятно, придётся добавить системы теплоотвода, интегрированные непосредственно в корпуса чипов. Также будут использоваться «жидкостные сквозные соединения» (F-TSVs) для отвода тепла из многослойных чипов, «бесстыковые» соединения Cu–Cu, термодатчики в кристаллах и интеллектуальные системы управления, позволяющие чипам адаптироваться к температурным изменениям. 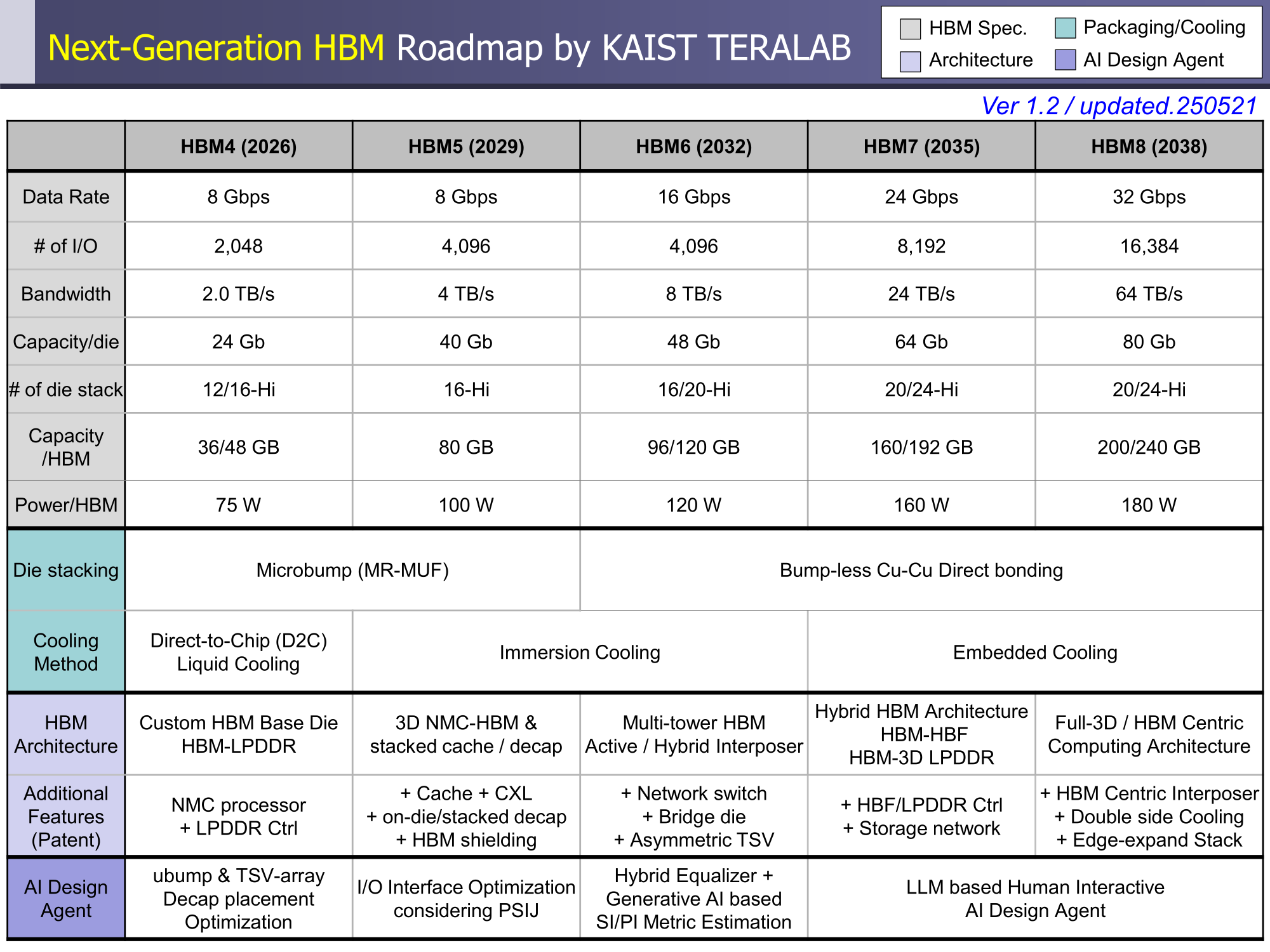 На уровне ЦОД изменится и контур охлаждения, и температурное зонирование всего объекта. В KAIST подчёркивают, что высокую плотность размещения мощностей объекты в большинстве регионов попросту не смогут поддерживать. Пока гиперскейлеры резервируют гигаватты на десятилетия вперёд, региональным коммунальным службам потребуется 7–15 лет на модернизацию ЛЭП. А где-то этого может и не произойти. Так, в Дублине (Ирландия) по-прежнему действует мораторий на строительство новых ЦОД, во Франкфурте-на-Майне похожий запрет действует до 2030 года, а в Сингапуре сегодня доступно всего лишь 7,2 МВт. 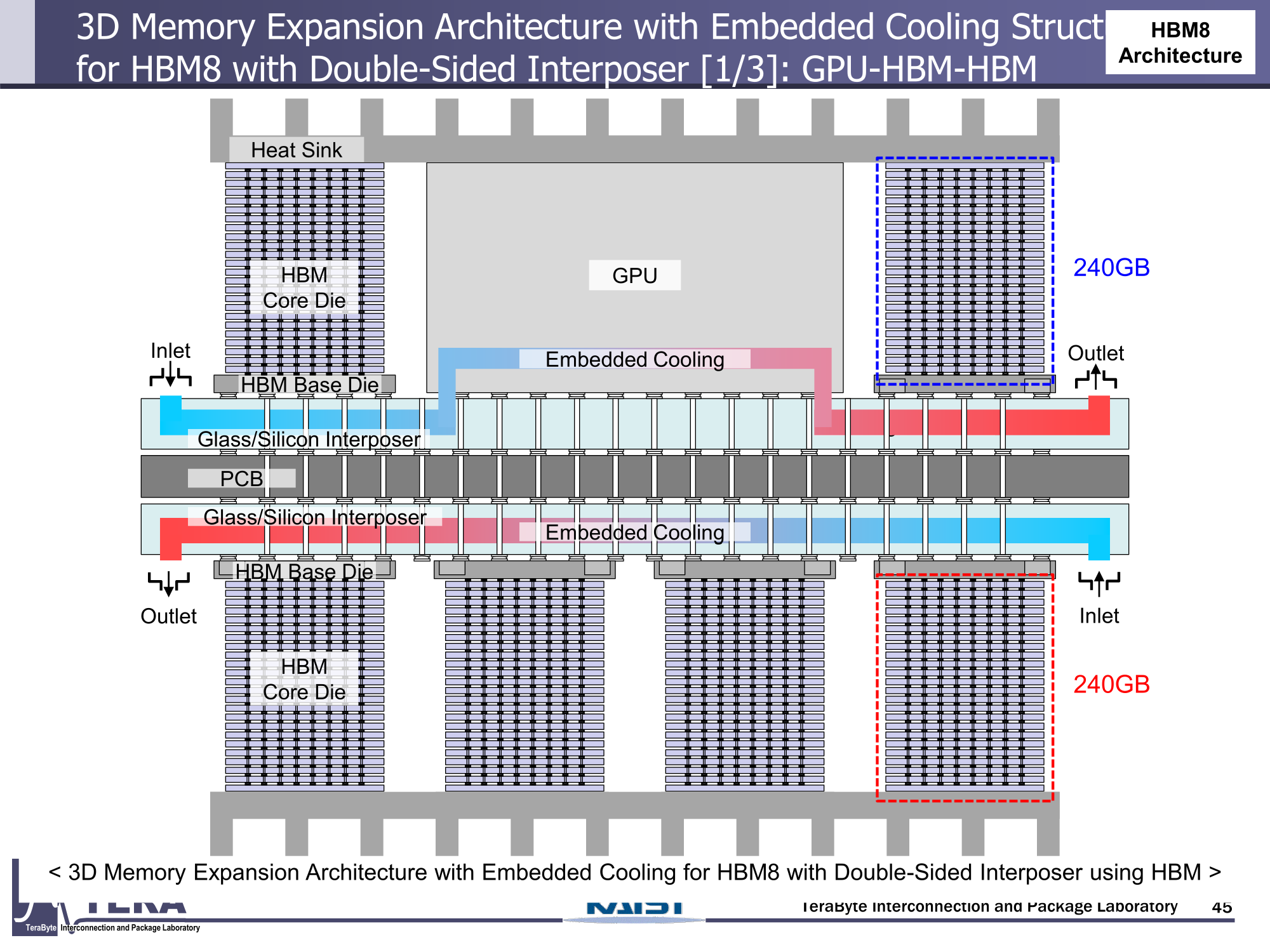 Как считают эксперты, электричество превратилось из одной из статей расходов в определяющий фактор — от его доступности будет зависеть сама возможность реализации ИИ-проектов. На электричество приходится 40-60 % операционных расходов в современной инфраструктуре ИИ, облачной и локальной. Как отмечают в TechInsights, один 15-кВт ускоритель при круглосуточной работе может «съедать» энергии на $20 тыс./год, и это без учёта стоимости охлаждения. 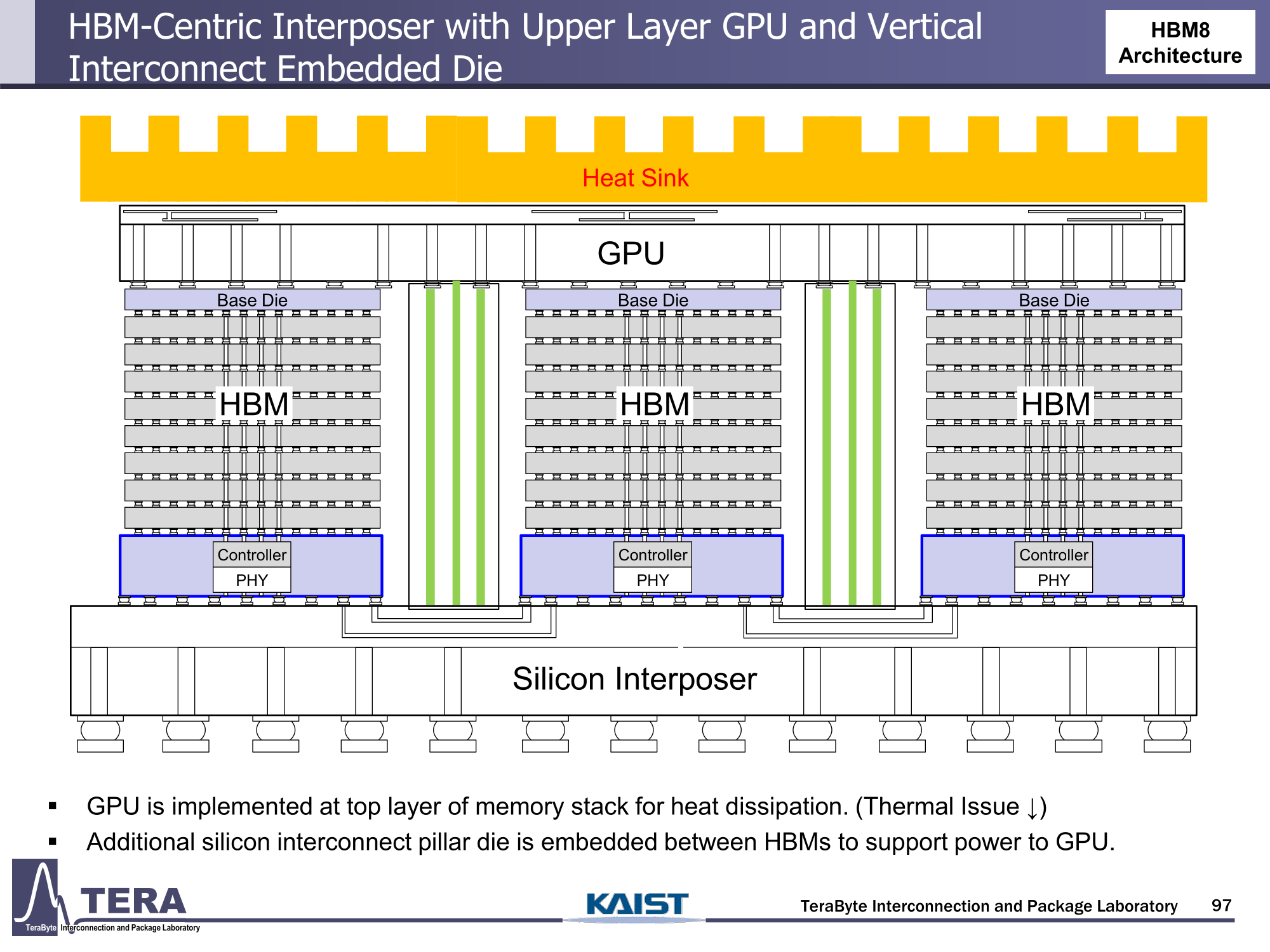 Компании уже вынуждены пересматривать стратегии развёртывания инфраструктуры, учитывая соответствие регуляторным требованиям, региональные тарифы на электроэнергию и др. Гиперскейлеры получают дополнительное преимущество благодаря более низкому PUE, доступу к возобновляемой энергии и оптимизированным схемам закупки энергии. В новой реальности производительность измеряется не только в долларах или флопсах, но и киловаттах. 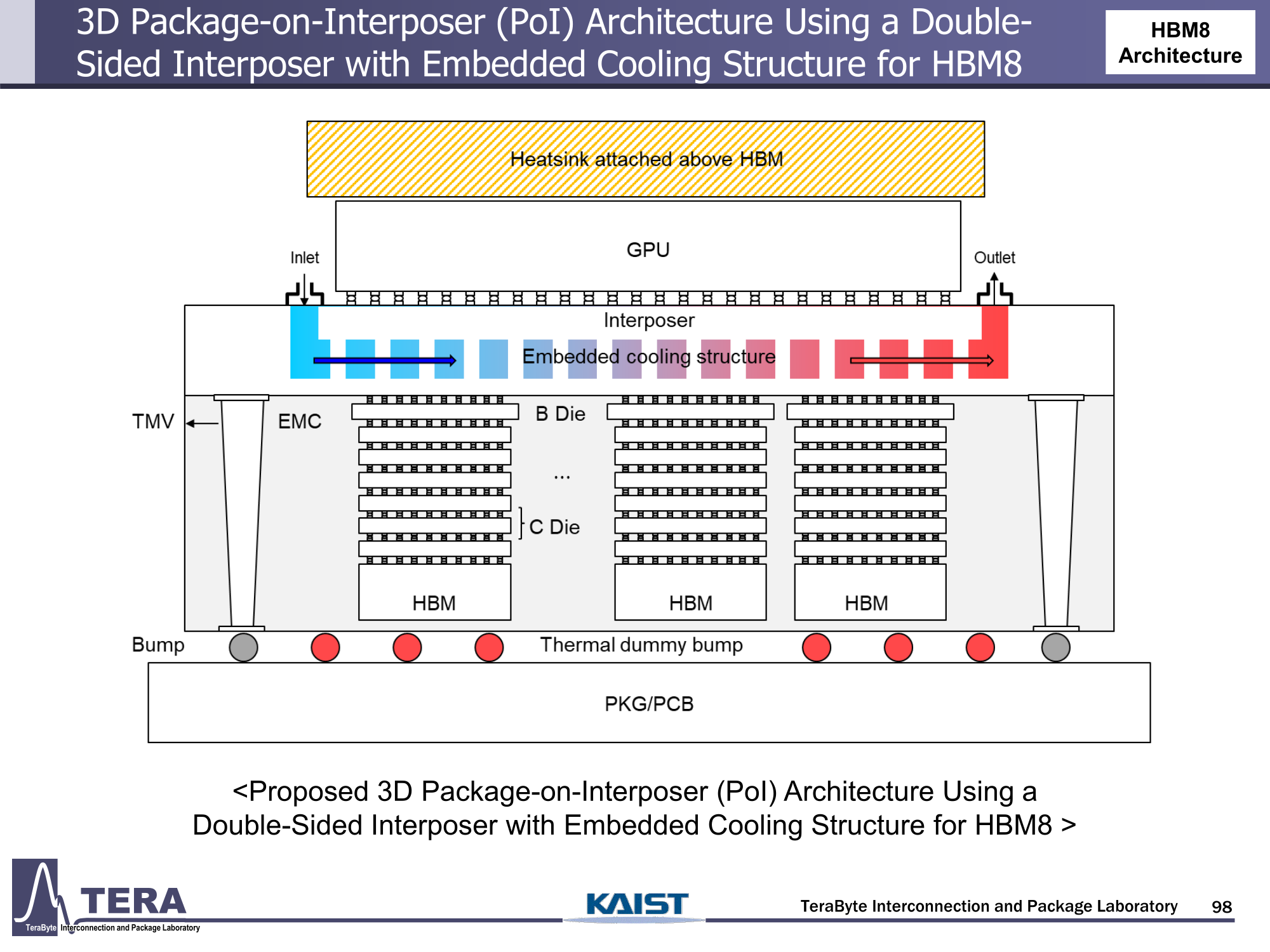 Более того, меняется география рынка ЦОД. Богатые энергией регионы вроде США, Скандинавии или стран Персидского залива привлекают всё больше инвестиций для строительства дата-центров, а регионы со слабыми энергосистемами рискуют превратиться в «ИИ-пустыни», в которых масштабировать мощности невозможно. 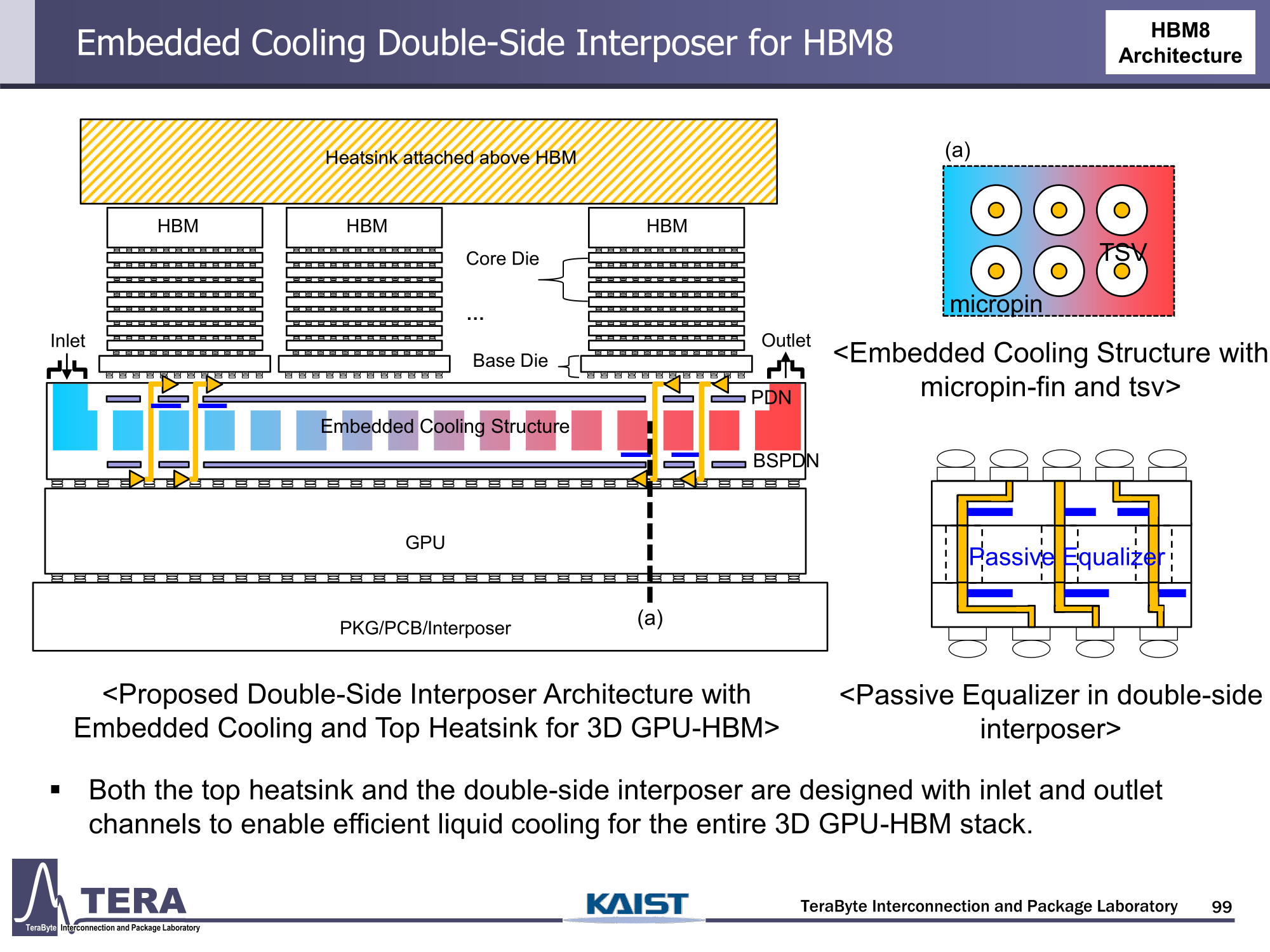 Строителям ИИ-инфраструктуры теперь придётся уделять очень много внимания вопросам энергетики: расходами на электричество, наличие источников энергии, прозрачностью выбросов, близостью ЦОД к электросетям и др. Буквально на днях американский регулятор NERC, отвечающий за надзор за электросетями и сопутствующей инфраструктурой в США, заявил, что подключение к сетям ЦОД в настоящее время весьма рискованно из-за непредсказуемости ЦОД.
10.03.2024 [21:00], Сергей Карасёв
В Южной Корее создан сверхэффекттивный ИИ-чип, сочетающий классический и нейроморфный подходыИсследователи из Южной Кореи разработали, как утверждается, первый в мире полупроводниковый ИИ-чип, который обладает высоким быстродействием при минимальном энергопотреблении. Изделие, предназначенное для обработки больших языковых моделей (LLM), основано на принципах, имитирующих структуру и функции человеческого мозга. В работе приняли участие специалисты Корейского института передовых технологий (KAIST). Утверждается, что при обработке модели GPT-2 новинка по сравнению с ускорителем NVIDIA A100 затрачивает в 625 раз меньше энергии и занимает в 41 раз меньше физического пространства. Таким образом, южнокорейский ИИ-чип теоретически может применяться даже в смартфонах. Чип производится по 28-нм процессу Samsung Electronics. 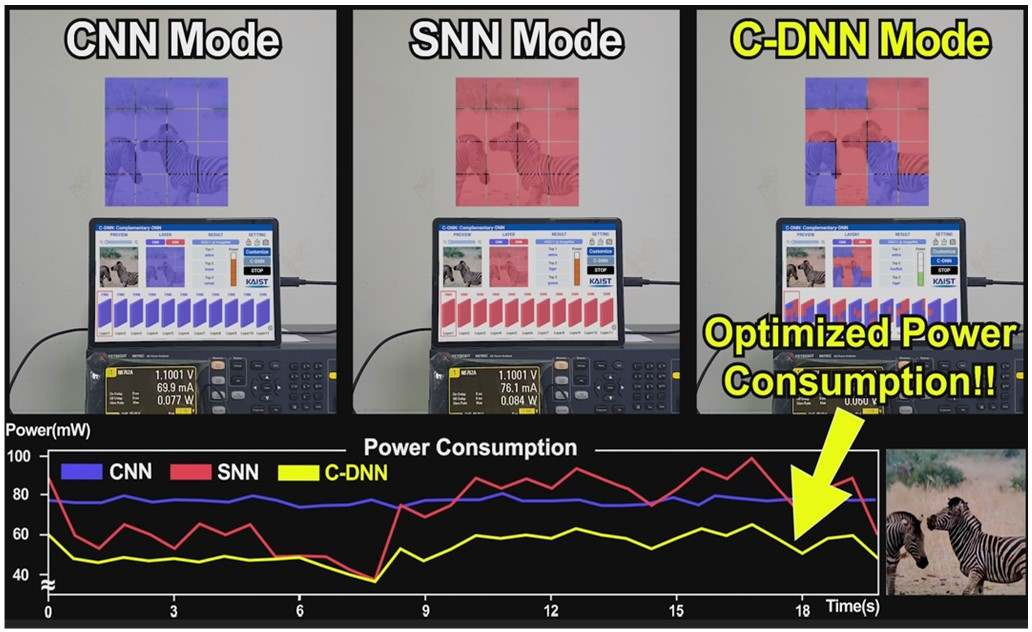
Источник изображений: KAIST Отмечается, что обычно для обработки модели GPT-2 требуются ускорители на базе GPU, потребляющие около 250 Вт энергии. Разработанное изделие требует для этого всего от 40 мВт, а его размеры составляют 4,5 × 4,5 мм. Причём на выполнение операций затрачивается только 0,4 с. Чип наделён 552 Кбайт памяти SRAM. Напряжение питания варьируется от 0,7 до 1,1 В. Тактовая частота варьируется в диапазоне 50–200 МГц. 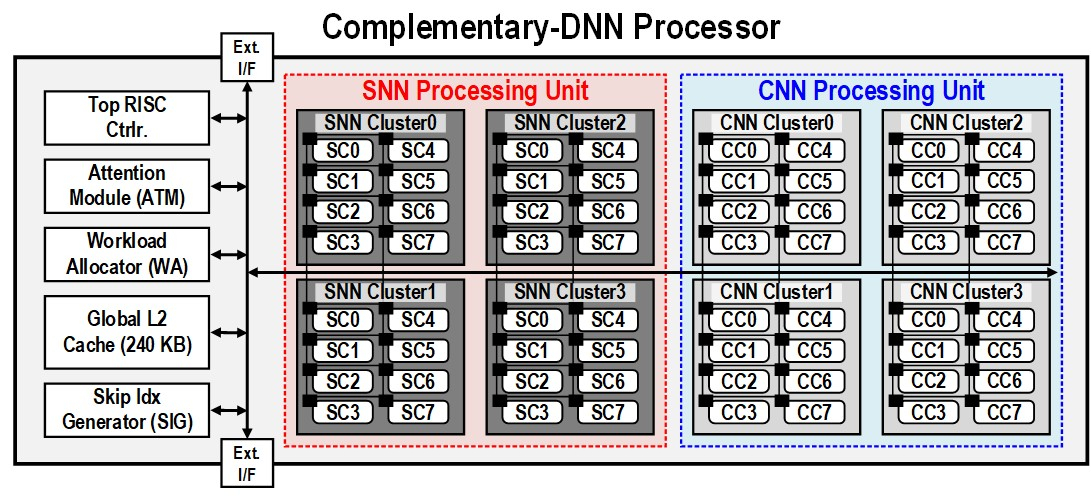 Технология, получившая название C-DNN (Complementary Deep Neural Network) позволяет использовать свёрточные нейронные сети (CNN) и импульсные нейронные сети (SNN), имитирующие процессы, которые задействованы в человеческом мозге при обработке информации. Иными словами, обучение происходит через несколько слоёв нейронных сетей, а потребление энергии варьируется в зависимости от когнитивной нагрузки. Технология минимизирует энергозатраты благодаря использованию DNN для больших входных значений и SNN для меньших. Правда, чип поддерживает максимум INT16. 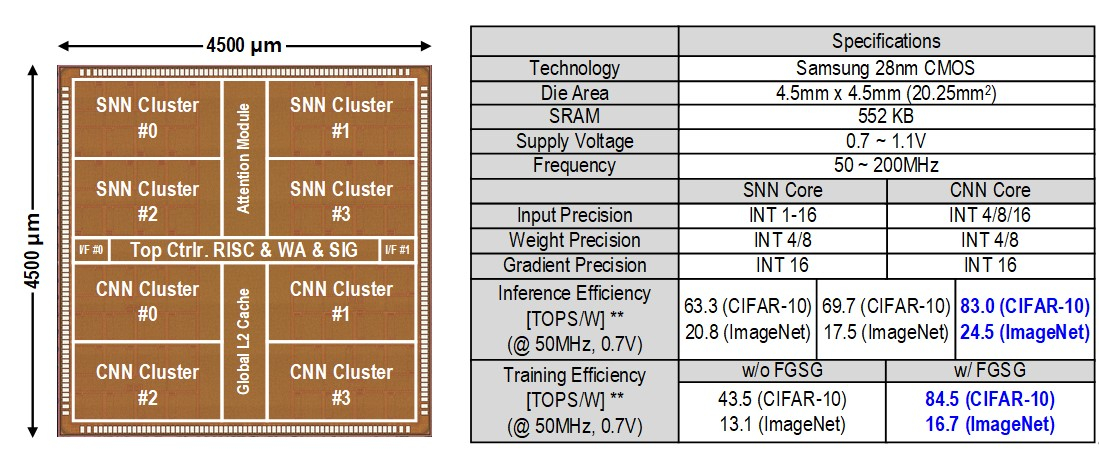 Утверждается, что C-DNN является первым ускорителем, который может поддерживать распределение рабочей нагрузки CNN/SNN, используя компромисс между производительностью и энергопотреблением. Изделие обеспечивает энергоэффективность на уровне 85,8 TOPS/Вт и 79,9 TOPS/Вт для инференса с наборами данных CIFAR-10 и CIFAR-100 соответственно (VGG-16). Энергоэффективность в случае ResNet-50 составляет 24,5 TOPS/Вт. При обучении чип C-DNN демонстрирует энергоэффективность в 84,5 TOPS/Вт и 16,7 TOPS/Вт для CIFAR-10 и ImageNet соответственно. Результаты получены при напряжении 0,7 В и частоте 50 МГц. 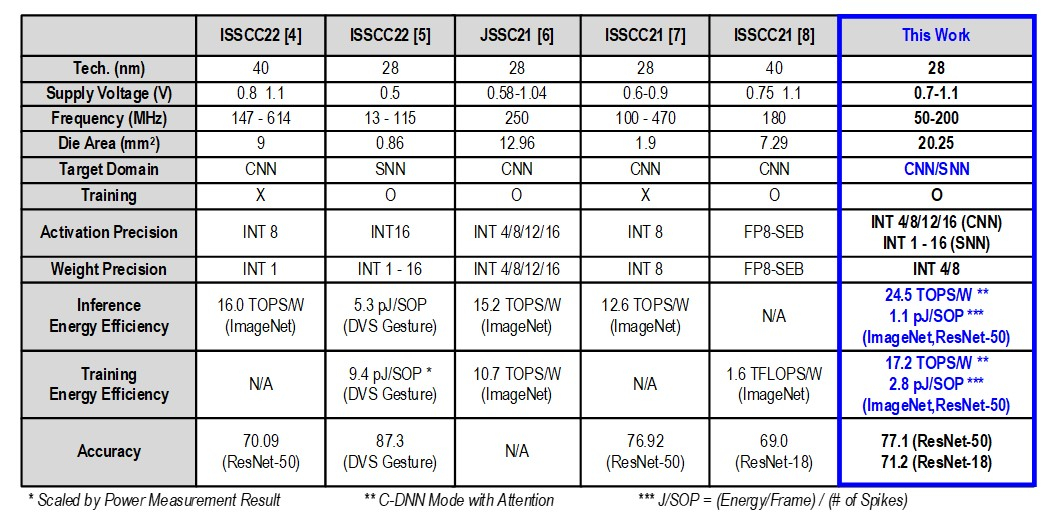 «Нейроморфные вычисления, имитирующие функции мозга, — это технология, которую такие крупные компании, как IBM и Intel, пока по-настоящему не реализовали. Мы гордимся тем, что первыми в мире начали использовать LLM со сверхэффективным нейроморфным ускорением», — говорит руководитель проекта профессора Ю Хой-Джун (Yu Hoi-jun). |
|

