Материалы по тегу: ускоритель
|
23.04.2026 [01:20], Владимир Мироненко
Для обучения и инференса — Google анонсировала ИИ-ускорители TPU 8t и TPU 8iGoogle представила два TPU восьмого поколения: TPU 8t (Sunfish) для обучения ИИ и TPU 8i (Zebrafish) для ИИ-инференса. Компания и раньше экспериментировала с различными вариантами TPU, в частности, со своими чипами пятого поколения V5p и V5e, но последние поколения, такие как Trillium и Ironwood, в основном следовали единому подходу. По словам Амина Вахдата (Amin Vahdat), старшего вице-президента и главного технолога Google по ИИ и инфраструктуре, TPU 8t и TPU 8i — результат десятилетней разработки (первые TPU были анонсированы в мае 2016 г.), специально созданные для обеспечения работы суперкомпьютеров следующего поколения с высокой эффективностью и масштабируемостью. Вахдат описывает TPU 8t как «мощную платформу для обучения», созданную для «сокращения цикла разработки моделей с месяцев до недель». Она предлагает в 2,8 раза лучшее соотношение цены и производительности, чем предыдущее поколение. 
Источник изображений: Google В TPU 8t используются векторные, матричные и SparseCore-ядра, дополненные 128 Мбайт SRAM и 216 Гбайт HBM3e (6,5 Тбайт/с). FP4-производительность составляет до 12,6 Пфлопс (также поддерживаются BF16/FP8/INT8). Для вертикального масштабирования используется межчиповый интерконнект (ICI) со скоростью 19,2 Тбит/с (в каждую сторону), для горизонтального — 400 Гбит/с. Кластер с TPU 8t может масштабироваться до 9,6 тыс. чипов, предлагая 2 Пбайт памяти HBM, 121 Эфлопс и вдвое большую межчиповую пропускную способность по сравнению с Ironwood, позволяя самым сложным моделям использовать единый, огромный пул памяти. 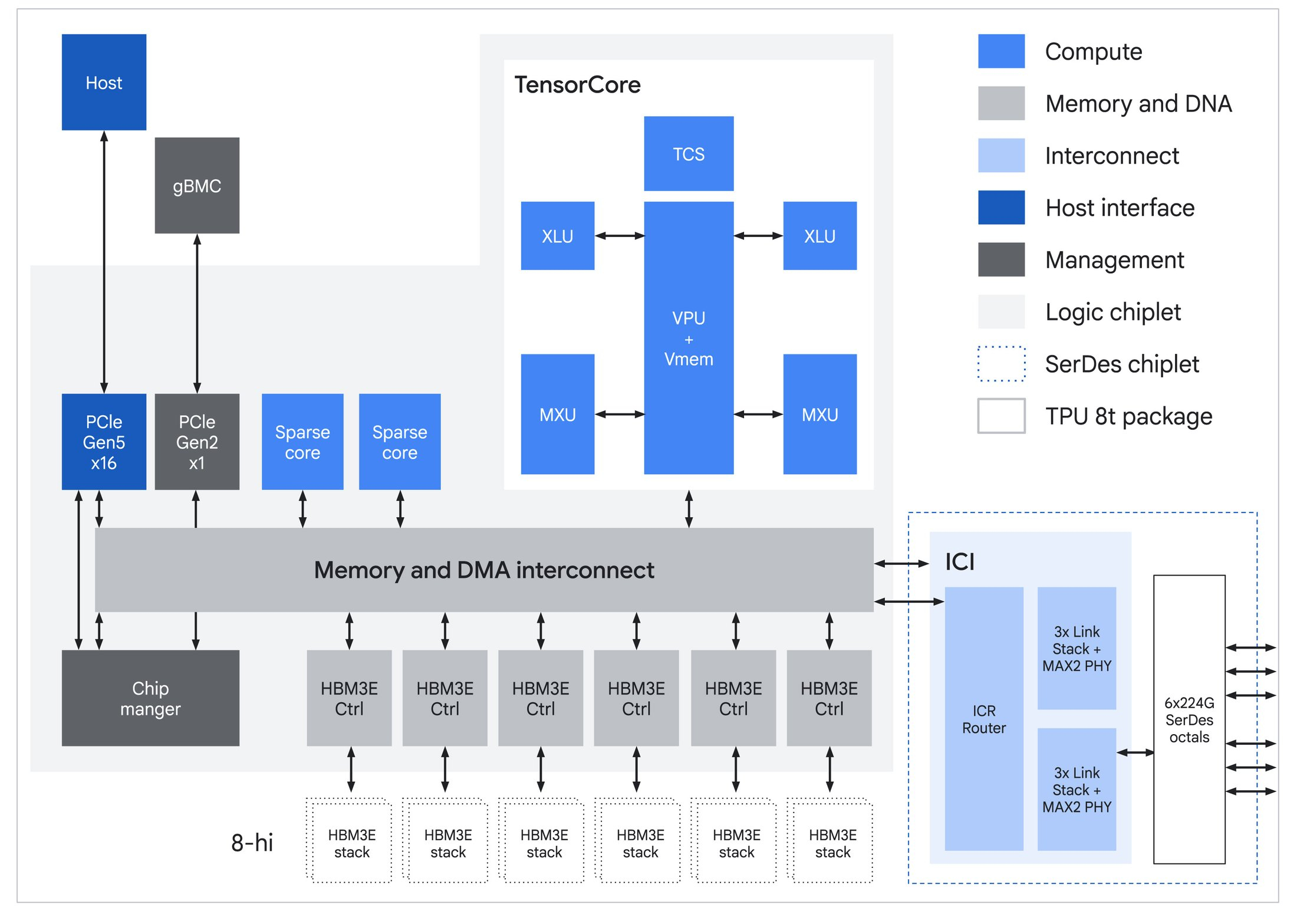 8t-кластеры объдиняет сеть Virgo Network, которая использует плоскую двухуровневую неблокирующую топологию, обеспечивает четырёхкратное увеличение пропускной способности в ЦОД и построена на коммутаторах с высокой степенью защиты, что сокращает количество сетевых уровней. В рамках одного ЦОД Virgo Network позволяет объединить до 134 тыс. чипов, что даёт до 47 Пбит/с неблокирующих соединений и более 1,6 Ифлопс с почти линейным масштабированием. А в рамках нескольких ЦОД в единый кластер можно объединить более 1 млн TPU. 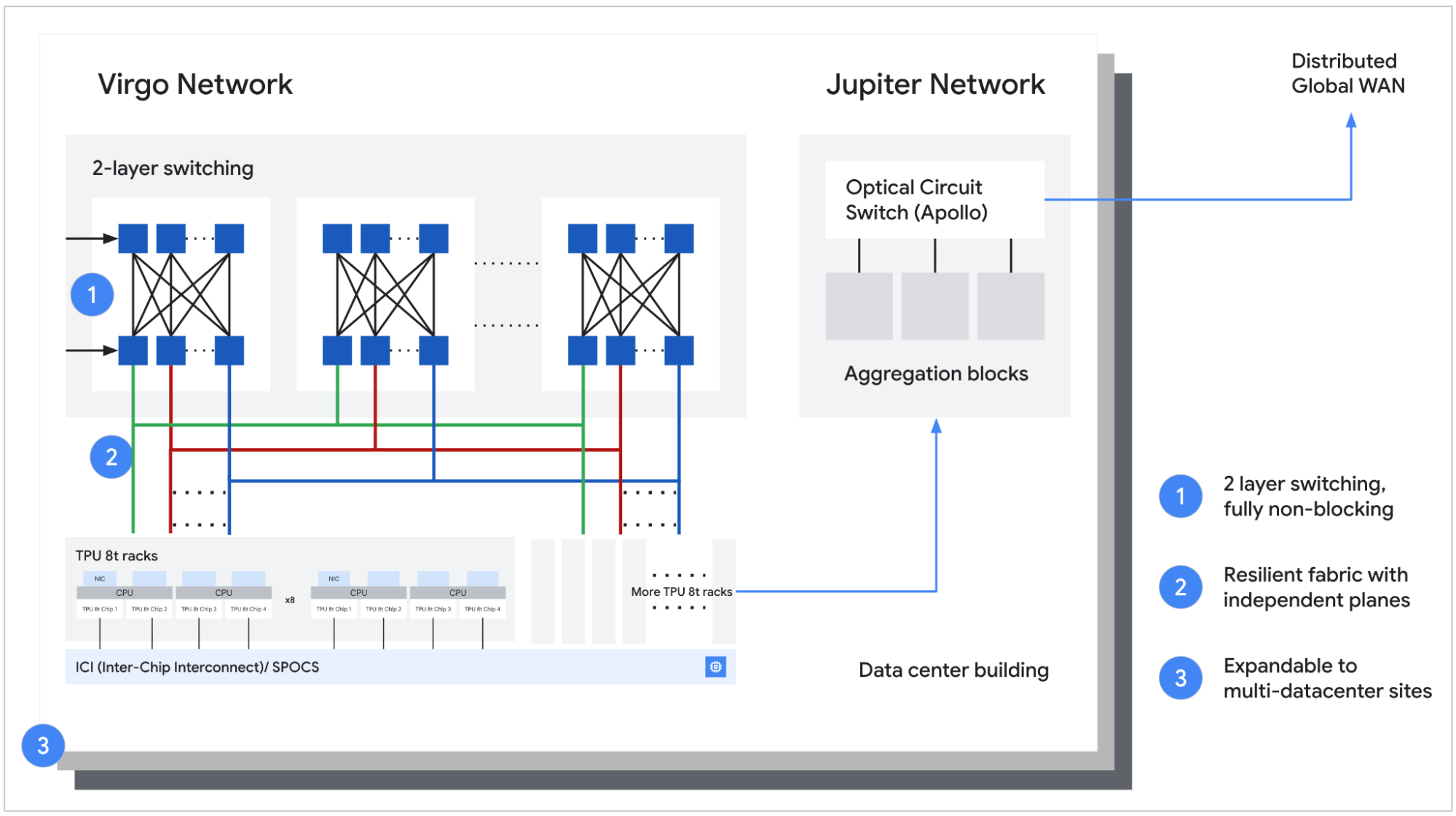 В TPU 8t используются технологии TPUDirect RDMA и TPUDirect Storage. TPU Direct RDMA обеспечивает прямую передачу данных между HBM и NIC, минуя CPU и DRAM хоста, а TPUDirect Storage напрямую связывает память TPU и СХД, таким как 10T Lustre, которая обеспечивает до 10 Тбайт/с, что даёт на порядок более быстрый доступ к хранилищу в сравнении с Ironwood и позволяет доставлять петабайты данных к ускорителям. 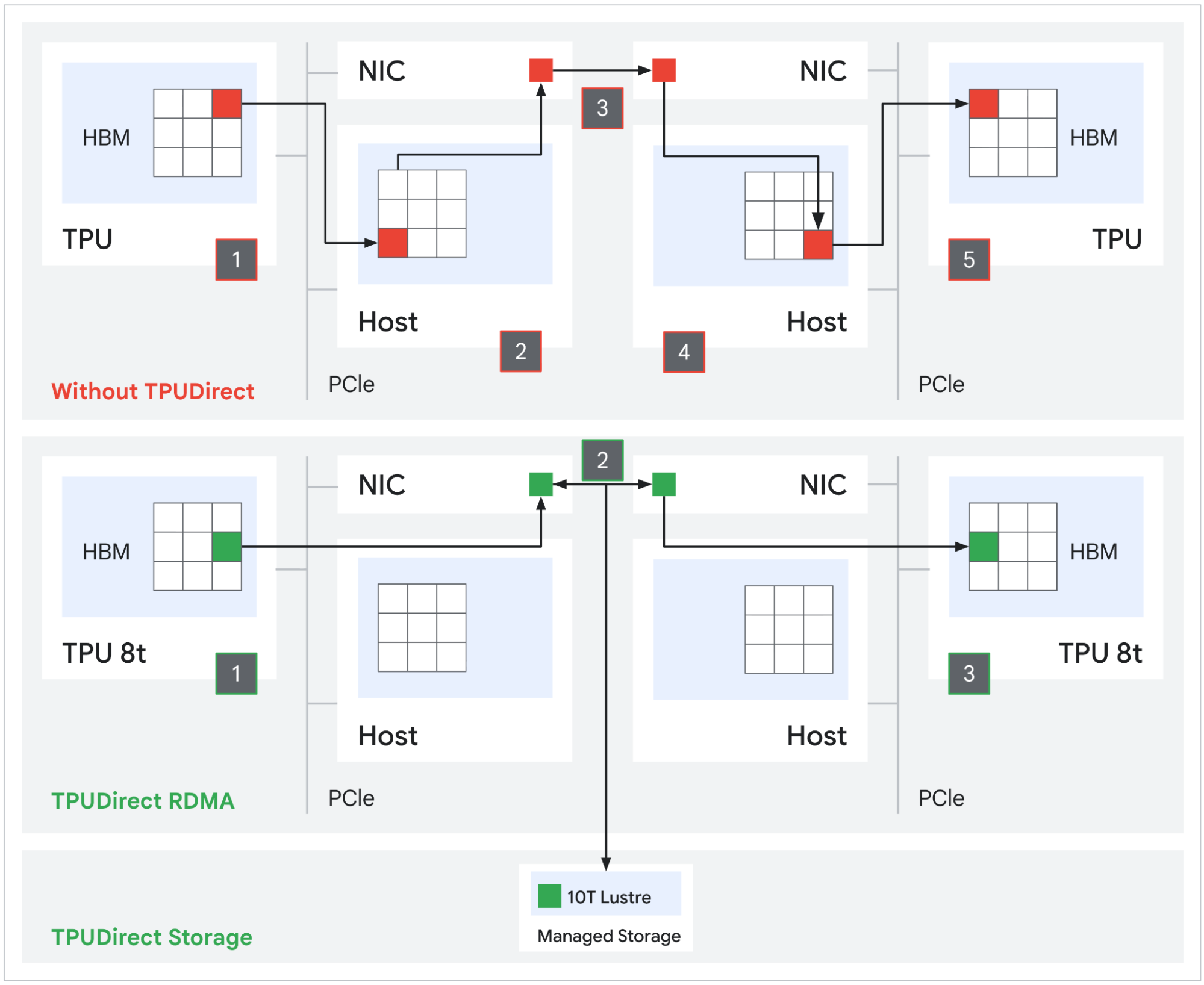 Кроме того, TPU 8t получили расширенные возможности RAS. К ним относятся телеметрия в реальном времени для десятков тысяч чипов, автоматическое обнаружение неисправных каналов ICI и перенаправление трафика без прерывания задания, а также оптическая коммутация каналов (OCS), которая перенастраивает оборудование в случае сбоев без участия человека. Всё это позволяет довести уровень утилизации чипа до 97 %.  В свою очередь, TPU 8i создан для обработки «сложной, совместной, итеративной работы множества специализированных агентов», которые появляются с развитием агентного ИИ. TPU 8i использует 288 Гбайт памяти HBM (8,6 Тбайт/с) в паре с 384 Мбайт SRAM — втрое больше, чем в предыдущем поколении. По словам Google, такой объём SRAM помогает TPU 8i удерживать большую часть KV-кеша на кристалле, что значительно сокращает время простоя ядер во время декодирования длинных контекстов. Компания отказалась от SparseCores в пользу нового встроенного механизма ускорения коллективных операций (CAE), снижая задержки на уровне кристалла и разгружая коллективные коммуникации, которые в противном случае привели бы к простою тензорных ядер чипа, отметил The Register. 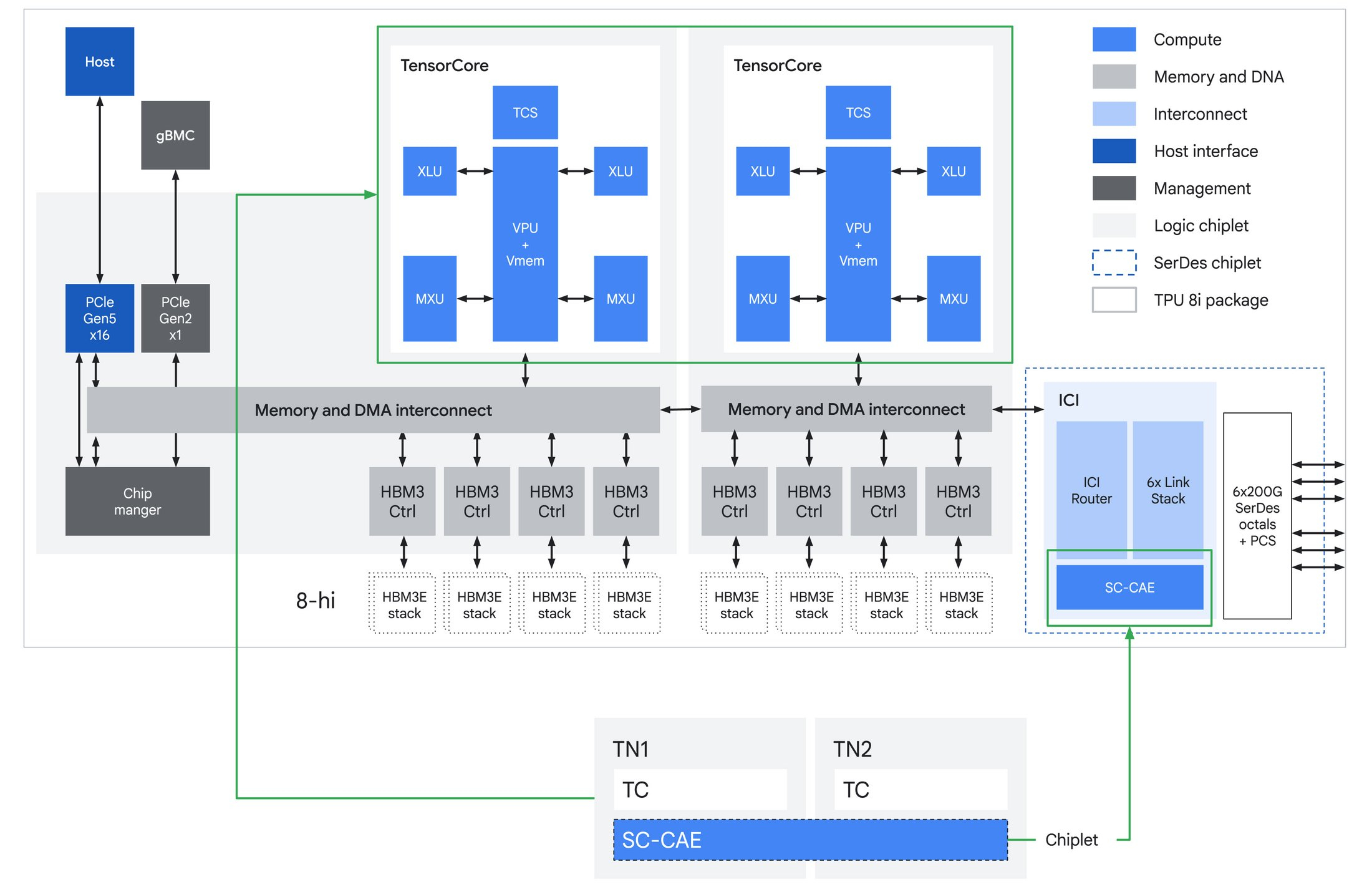 TPU 8i масштабируется до 1152 чипов в одном кластере (впрочем, в каждый момент активно не более 1024): 11,6 Эфлопс и 331,8 Тбайт HBM. ICI у 8i такой же, что у 8t, однако для объединения чипов используется топология Boardfly вместо 3D-тора, поскольку для MoE-инференса важно меньшее количество сетевых переходов между чипами. Эти инновации обеспечивают на 80 % лучшую производительность на доллар по сравнению с предыдущим поколением, позволяя предприятиям обслуживать почти вдвое больше клиентов при тех же затратах, сообщила компания. 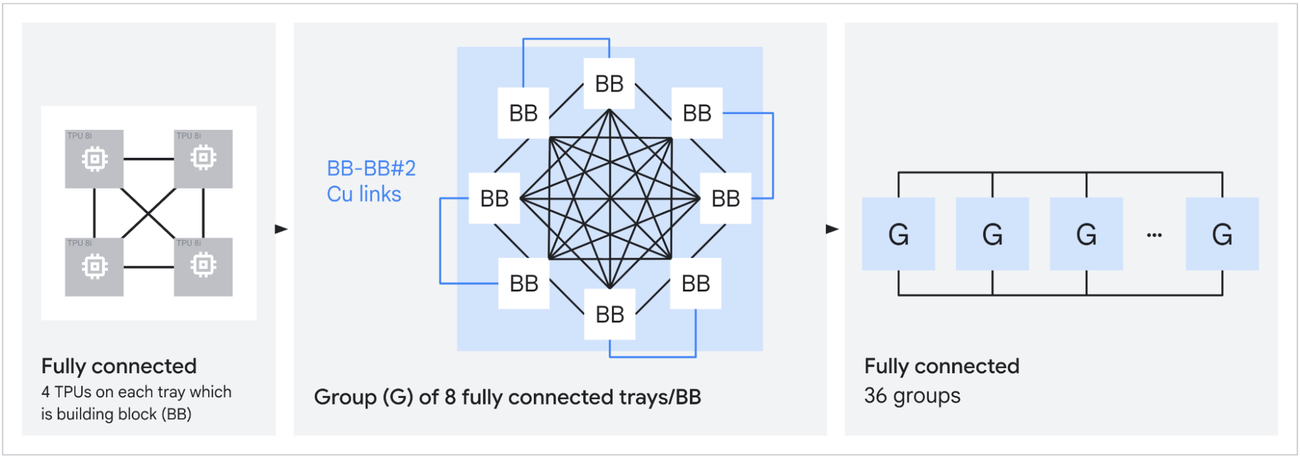 Как TPU 8t, так и 8i работают на базе собственного Arm-процессора Axion и поддерживают СЖО. Компания также заявила, что оптимизировала эффективность всей системы для обеспечения интегрированного управления питанием, которое может регулировать потребление энергии в зависимости от спроса в реальном времени, что приводит к повышению производительности на ватт до двух раз по сравнению с Ironwood. 
Фото: Sundar Pichai TPU 8 станут общедоступными на Google Cloud Platform позже в этом году в виде отдельных инстансов или как часть полнофункциональной платформы AI Hypercomputer, которая объединяет все сетевые ресурсы, хранилище, вычислительные мощности и ПО, необходимые для развёртывания или обучения LLM в масштабе. 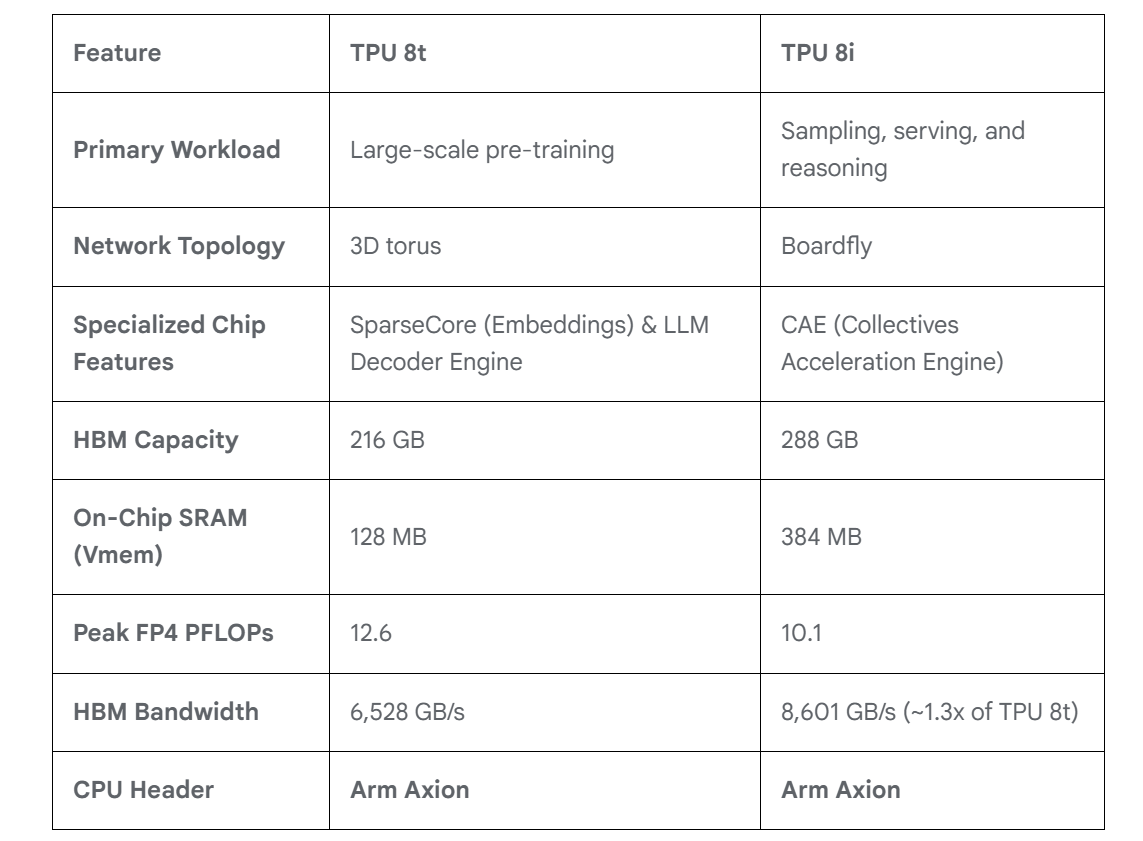
15.04.2026 [16:37], Руслан Авдеев
Broadcom поможет Meta✴ в создании нескольких поколений ИИ-ускорителейMeta✴ объявила о заключении нового соглашения с Broadcom. Оно расширяет уже имеющееся партнёрство, направленное на разработку собственных ИИ-ускорителей для IT-гиганта, сообщает Silicon Angle. На начальном этапе Meta✴ планирует развернуть собственные ускорители общей мощностью 1 ГВт для обучения ИИ-моделей и инференса. В конечном итоге партнёры планируют развернуть ускорители на основе технологий Broadcom совокупной мощностью несколько гигаватт. Отдельно Broadcom подчеркнула, что новые чипы MTIA — первые в ИИ-индустрии, использующие 2-нм техпроцесс. По словам главы Meta✴ Марка Цукерберга (Mark Zuckerberg), в MTIA будут использоваться наработки Broadcom в сфере проектирования, упаковки и сетевых решений. Ранее сообщалось, что Meta✴ столкнулась с трудностями при выпуске новых чипов MTIA, но Broadcom опровергла эту информацию, заявив, что поставки уже осуществляются, а для следующего поколения XPU планируется масштабировать производство. 
Источник изображения: Meta✴ В марте Meta✴ объявила о разработке четырёх новых вариантов MTIA. Первую версию чипа представили ещё в 2023 году. MTIA дают определённую независимость от дорогостоящих и труднодоступных моделей NVIDIA и AMD. Как и чипы Google и AWS, они представляют собой специализированные ASIC, меньше и дешевле классических ИИ-ускорителей — но их вполне достаточно для выполнения узкого круга задач. Google представила свои первые TPU задолго до бума ИИ, ещё в 2015 году. В 2018 году Amazon представила первые чипы Trainium. Обе компании полагались на технологии Broadcom для разработки своих продуктов. В последние месяцы Broadscom анонсировала ряд сделок, касающихся своих кастомных XPU. Так, Anthropic получит Google TPU на 3,5 ГВт, часть чипов будет поставляться самой Broadcom. Кроме того, Broadcom помогает Fujitsu в создании 2-нм процессора MONAKA. В 2026 году Meta✴ анонсировала ряд многомиллиардных сделок по закупке ИИ-ускорителей в рамках обязательства выделить более $135 млрд на капитальные затраты в 2026 финансовом году. Ранее она обязалась использовать 6 ГВт ИИ-ускорителей AMD, миллионы чипов NVIDIA, а также чипы, совместно разработанные с Arm. Кроме того, компания намерена потратить миллиарды долларов на аренду ускорителей у CoreWeave и Nebius.
08.04.2026 [17:04], Владимир Мироненко
ВТБ заменит ИИ-ускорители NVIDIA на китайские решенияБанк ВТБ будет использовать GPU китайских производителей вместо ИИ-ускорителей NVIDIA для работы внутрибанковских сервисов на основе ИИ, сообщил «Ведомостям» зампред правления ВТБ Вадим Кулик. По его словам, GPU будут использоваться для работы с компьютерным зрением, обработки, анализа текста и распознаванием речи, а также для моделей генеративного ИИ банка. Топ-менеджер отметил, что в ходе тестирования китайские чипы показали стабильную производительную работу с существующими IT-системами банка. «Внедрение китайских GPU проходит без существенных доработок и с высокой производительностью. Это ускорит развитие ИИ-технологий, включая цифровых помощников и ИИ-агентов», — сообщил он. Замена ускорителей NVIDIA на китайские GPU проводится в рамках совместной работы в центре компетенций ВТБ по ИИ в Китае. Центр представляет собой площадку для прикладных совместных исследований российских и китайских специалистов и быстрого тестирования устройств с ИИ без необходимости их поставки в Россию. Здесь и проходило тестирование GPU из КНР в марте. Зампред отметил, что Китай богат на технологии, но существуют сложности с их поиском, апробацией и доставкой в Россию в промышленных масштабах. «Центр создан для того, чтобы помочь компаниям из России и Китая совместно внедрять новейшие технологии. Сейчас мы сконцентрированы на поиске партнёров, заинтересованных в применении ИИ-технологий», — рассказал он. 
Источник изображения: John Lucas / Unsplash Согласно исследованию IT-холдинга Т1, совокупный рынок российских GPU в 2025 году вырос на 21 % до около 63 млрд руб. Доля NVIDIA на мировом рынке оценивается в исследовании в 80 %. По его оценкам, с учётом дополнительных затрат на серверные платформы, сетевое оборудование, ПО и обслуживание, капитальные вложения на замещение чипов NVIDIA могут составить порядка 2–5 млрд руб. Ранее «Ведомости» сообщали, что китайские серверы тестируют «Сбер» и Т-банк, а Альфа-банк тоже рассматривает возможность их использования. Среди поставщиков ИИ-ускорителей в Китае есть Huawei, Alibaba, MetaX, Moore Threads, Cambricon, Iluvatar, Biren, Sophgo и др. Собеседник «Ведомостей» в одном из топ-20 банков России считает, что реальных альтернатив чипам NVIDIA для банковской сферы всё же нет, ни сейчас, ни в обозримом будущем. Даже самые сильные китайские GPU пока уступают решениям американской компании не только по «железу», но и по зрелости программной среды, под которую уже разработано множество банковских решений. Переход на альтернативные GPU потребует серьезных вложений в адаптацию и переработку программных продуктов, а проведенные испытания показывают, что такие решения пока заметно проигрывают по скорости обработки запросов и обучению классических ML-моделей, отметил собеседник издания.
02.04.2026 [11:50], Руслан Авдеев
Китайские ИИ-ускорители заняли почти половину местного рынка на фоне снижения доли NVIDIAКитайские производители видеокарт и ИИ-чипов заняли около 41 % локального рынка ИИ-ускорителей в 2025 году. Это сказалось на позициях NVIDIA, некогда занимавшей на этом, одном из ключевых рынков за пределами США, доминирующее положение, сообщает Reuters со ссылкой на аналитику IDC. Местные производители наращивают свою долю по мере того, как Пекин всё больше внимания уделяет вопросу обеспечения независимости от иностранных чипов. Власти стимулируют использование государственными ведомствами и компаниями китайских альтернатив после того, как США несколько раз инициировали ужесточение экспортного контроля в Поднебесную. Общие поставки ИИ-ускорителей NVIDIA, AMD и китайских производителей в 2025 году достигли в КНР приблизительно 4 млн единиц. NVIDIA сохранила позицию лидера рынка, поставив около 2,2 млн ускорителей, доля компании на рынке составляет 55 %. Тем не менее назвать это успехом американского вендора нельзя, поскольку раньше компания тотально доминировала на рынке. AMD поставила скромные 160 тыс. ускорителей (доля 4 %). 
Источник изображения: James Lo/unsplash.com Китайские вендоры в совокупности поставили 1,65 млн ускорителей — 41 % рынка. Это свидетельствует о том, насколько агрессивно местные игроки действуют для компенсации дефицита ускорителей, ужесточившегося из-за американского экспортного контроля. Среди китайских производителей особенно выделяется Huawei Technologies, поставившая около 812 тыс. чипов, приблизительно половину от общих объёмов местной продукции. Второе место занимает T-Head — занимающееся разработкой чипов подразделение Alibaba, поставившее приблизительно 265 тыс. ускорителей. Kunlunxin (Baidu) и Cambricon поставили приблизительно по 116 тыс. чипов каждая, поделив третье место среди китайских вендоров. На Hygon, MetaX и Iluvatar CoreX пришлось 5 %, 4 % и 3 % соответственно. В 2025 году китайские власти инициировали новый раунд расходов на ИИ-инфраструктуру, руководство в провинциях ускорило развёртывание вычислительных центров. Многие их таких кампусов ЦОД, по данным Reuters, получили негласное указание «покупать китайское». Тем не менее, в начале 2026 года США одобрили поставки относительно современных ускорителей NVIDIA H200 в КНР, после чего поставки были официально одобрены и Пекином. В марте глава NVIDIA Дженсен Хуанг (Jensen Huang) объявил, что начат выпуск H200 для китайского рынка — это может изменить позиции NVIDIA уже в обозримом будущем.
22.03.2026 [13:10], Сергей Карасёв
Почти втрое быстрее NVIDIA H20: Huawei представила ИИ-ускоритель Atlas 350 для инференсаКомпания Huawei Technologies, по сообщению газеты South China Morning Post (SCMP), представила ускоритель Atlas 350, предназначенный для ИИ-инференса. Утверждается, что в таких задачах новинка обеспечивает прирост производительности до 2,8 раза по сравнению с NVIDIA H20. Известно, что решение Atlas 350 выполнено на чипе Ascend 950PR. Заявленная ИИ-производительность в формате FP4 достигает 1,56 Пфлопс. Показатели быстродействия в других режимах пока не раскрываются, но ранее говорилось об 1 Пфлопс в FP8. Как отмечается, Huawei использует собственную память HBM. Её объём в зависимости от конфигурации ускорителя составляет до 128 Гбайт, пропускная способность — 1,6 Тбайт/с. Прочие технические характеристики не приводятся. Ускоритель Atlas 350 оптимизирован для предварительного заполнения (Prefill) в ходе инференса — это наиболее ресурсоёмкая фаза работы больших языковых моделей (LLM) в рамках процесса генерации контента: на данном этапе производится обработка входного запроса пользователя. Скорость выполнения предварительного заполнения напрямую влияет на показатель TTFT (Time To First Token), то есть, на время, прошедшее с момента ввода запроса до начала ответа. Таким образом, решение Atlas 350 подходит для ИИ-приложений реального времени и агентных систем. 
Источник изображения: Huawei Huawei также заявила о планах масштабного обновления своих СХД, включая решения OceanStor Dorado и Pacific 9926 класса All-Flash. Кроме того, компания готовит платформу FusionCube A1000, которая поможет малым и средним предприятиям быстро разворачивать ИИ-системы. «Если первая половина эпохи ИИ была сосредоточена на вычислительной мощности, то вторая половина будет определяться данными. В 2026 году Huawei продолжит модернизацию своих СХД и будет активно участвовать в крупных национальных проектах по формированию соответствующей инфраструктуры», — говорит Юань Юань (Yuan Yuan), президент подразделения по хранению данных Huawei.
18.03.2026 [08:44], Сергей Карасёв
NVIDIA выпустила однослотовый ускоритель RTX Pro 4500 Blackwell Server Edition с 32 Гбайт памяти GDDR7Компания NVIDIA анонсировала ускоритель RTX Pro 4500 Blackwell Server Edition, подходящий для решения таких задач, как ИИ-инференс, анализ данных, обработка видеоматериалов и пр. Новинка ориентирована на дата-центры, облачные платформы и периферийные инфраструктуры. Решение выполнено на архитектуре Blackwell. Конфигурация включает 10 496 ядер CUDA, 82 ядра RT четвёртого поколения, а также 32 Гбайт GDDR7 с 256-бит шиной и пропускной способностью 800 Гбайт/с. Задействованы тензорные ядра пятого поколения, которые обеспечивают до трёх раз более высокую производительность по сравнению с более ранними изделиями и предлагают поддержку режима FP4. Карта получила однослотовое исполнение FHFL и пассивное охлаждение. Заявленное энергопотребление составляет 165 Вт. Для подключения служит интерфейс PCIe 5.0 x16. ИИ-быстродействие на операциях FP4 (Tensor Core) достигает 1,6 Пфлопс, FP8 (Tensor Core) — 811 Тфлопс, FP16/BF16 (Tensor Core) — 406 Тфлопс, TF32 (Tensor Core) — 203 Тфлопс. Как отмечает NVIDIA, по сравнению с системами, работающими только на основе CPU, ускоритель RTX Pro 4500 Blackwell Server Edition обеспечивает до 100 раз более высокую производительность при анализе видеоматериалов с помощью алгоритмов ИИ. Благодаря этому компании могут извлекать данные из видеопотока в режиме реального времени, ускоряя работу приложений компьютерного зрения — как в ЦОД, так и на периферии. 
Источник изображения: NVIDIA Предусмотрены три аппаратных движка NVIDIA NVENC девятого поколения. Они имеют поддержку кодирования 4:2:2 H.264 и HEVC, а также улучшают качество при работе с HEVC и AV1. Вместе с тем три движка NVIDIA NVDEC шестого поколения демонстрируют вдвое более высокую пропускную способность при декодировании материалов H.264, а также поддерживают 4:2:2 H.264 и HEVC.
17.03.2026 [10:32], Руслан Авдеев
NVIDIA анонсировала Space-1 Vera Rubin Module — ИИ-ускоритель для орбитальных ЦОД, который в 25 раз быстрее H100Глава NVIDIA Дженсен Хуанг (Jensen Huang) представил космический вычислительный модуль на архитектуре Vera Rubin. По его словам, модуль до 25 раз производительнее, чем NVIDIA H100, и шесть коммерческих космических компаний уже внедрили платформу, сообщает Tom’s Hardware. Space-1 Vera Rubin Module предназначен для орбитальных дата-центров, работающих с ИИ-моделями непосредственно в космосе. Он имеет тесно интегрированную архитектуру CPU–GPU и высокоскоростной интерконнект для работы с большими потоками данных от космических инструментов в режиме реального времени. Также предлагается вариант NVIDIA IGX Thor для критически важных периферийных сред с поддержкой выполнения ИИ-задач в режиме реального времени, безопасной загрузки, автономных операций и др. Наиболее компактный вариант NVIDIA Jetson Orin рассчитан на использование в спутниках с ограниченными размерами, весом и энергопотреблением — для систем бортового «зрения», навигации и обработки данных с датчиков. По данным NVIDIA, сейчас её новые платформы на Земле и в космосе используют компании Aetherflux, Axiom Space, Kepler Communications, Planet Labs PBC, Sophia Space и Starcloud. Kepler внедряет Jetson Orin в своей спутниковой группировке для управления данными и их маршрутизацией с помощью ИИ-инструментов. Jetson Orin применяется непосредственно в спутниках. 
Источник изображения: NVIDIA В октябре 2025 года основатель Amazon и Blue Origin Джефф Безос (Jeff Bezos) прогнозировал, что через 10–20 лет на орбите появятся ЦОД гигаваттного масштаба. Основными преимуществами таких решений назывались возможность непрерывного электроснабжения группировки с помощью солнечной энергии, а также упрощённая система охлаждения в космосе. Starcloud уже строит специальные орбитальные ИИ-ЦОД, предназначенные для обучения моделей и инференса непосредственно на орбите. Космические ЦОД — весьма перспективное направление в сфере ИИ. Одним из наиболее громких событий стала заявка SpaceX, попросившей у американских властей разрешение на вывод на орбиту миллиона микро-ЦОД. Инициатива подверглась критике Amazon как «спекулятивная», но компания столкнулась с критикой Федеральной комиссии по связи с США, потребовавшей навести порядок в собственном космическом бизнесе.
15.03.2026 [11:15], Сергей Карасёв
Выпуск ИИ-чипов DeepX DX-M2 отложен из-за проблем у TeslaИзменение графика разработки ИИ-ускорителя Tesla следующего поколения, по сообщению ресурса DigiTimes, привело к тому, что южнокорейская компания DeepX вынуждена отложить выпуск своих чипов DX-M2, массовое производство которых изначально было запланировано на II квартал 2027 года. Отмечается, что задержки возникли с разработкой изделия Tesla AI6. Предполагается, что это решение будет применяться для поддержания разнообразных нагрузок в инфраструктуре Tesla, включая платформы автономного вождения, системы человекоподобного робота Optimus и дата-центры для ИИ-задач. В 2025 году Tesla подписала контракт с Samsung на изготовление AI6 вплоть до декабря 2033-го: стоимость соглашения составляет $16 млрд. Первоначальный договор предусматривал производство около 16 тыс. пластин в месяц, однако затем Tesla запросила дополнительно 24 тыс. пластин, что в сумме предполагает объем до 40 тыс. пластин ежемесячно. Для Tesla AI6 планируется применение 2-нм техпроцесса Samsung. По такой же методике будут выпускаться чипы DeepX DX-M2. Для обоих этих изделий оговорено использование услуги Multi-Project Wafer (MPW), при которой на одной кремниевой пластине в рамках получения прототипов размещаются изделия нескольких разных заказчиков. Такой подход позволяет снизить затраты на разработку перед организацией массового производства.  Однако, по информации DigiTimes, с выходом Tesla AI6 на этап MPW возникли задержки. С чем именно связаны сложности, не уточняется. Отраслевые эксперты полагают, что пересмотр графика может быть обусловлен изменением сроков инвестиций в автономные транспортные средства, роботизированные платформы и суперкомпьютеры с ИИ. Компания Samsung отказалась от комментариев, сославшись на конфиденциальность проектов заказчиков. Между тем из-за задержек Tesla выпуск чипов DeepX DX-M2 по программе MPW, который планировалось начать в апреле, переносится на более поздний срок. В соответствии с новым графиком, тестирование качества этих решений будет организовано не ранее III квартала текущего года. Ожидается, что DX-M2 обеспечит ИИ-производительность на уровне 80 TOPS при максимальном энергопотреблении примерно 5 Вт. Чип поддерживает память LPDDR5X. Утверждается, что процессор способен работать с ИИ-моделями, насчитывающими до 100 млрд параметров.
12.03.2026 [11:23], Владимир Мироненко
Intel представила чип Heracles, который в 5000 раз быстрее серверных процессоров в вычислениях с FHEКомпания Intel представила на конференции ISSCC чип Heracles с поддержкой полностью гомоморфного шифрования (FHE), который превосходит топовый серверный процессор Intel по скорости вычислений с FHE в 5 тыс. раз, сообщил ресурс IEEE Spectrum. FHE позволяет выполнять вычисления над данными в зашифрованном виде без их расшифровки, но на стандартных процессорах и видеокартах оно работает крайне медленно. Heracles построен на основе 3-нм технологии FinFET и примерно в 20 раз больше большинства исследовательских чипов FHE, имеющих размеры 10 мм2 или менее. В основе Heracles лежат 64 вычислительных ядра — так называемые пары тайлов, — расположенные в сетке восемь на восемь и служащие в качестве SIMD-движков для полиномиальных вычислений, манипуляций и других операций, составляющих вычисления в FHE, а также для их параллельного выполнения. Встроенная в кристалл сеть 2D-mesh соединяет тайлы друг с другом широкими шинами по 512 байт. На чипе данные размещаются в 64 Мбайт кеша, откуда они могут передаваться по массиву со скоростью 9,6 Тбайт/с, переходя от одной пары тайлов к другой. Чтобы предотвратить взаимное влияние перемещения данных и математических вычислений, Heracles использует три синхронизированных потока инструкций: один для перемещения вне чипа, один для перемещения внутри чипа и один для арифметических операций. Чип размещён в корпусе с жидкостным охлаждением вместе с двумя стеками памяти HBM по 24 Гбайт (суммарно 48 Гбайт с ПСП 819 Гбайт/с). 
Источник изображения: Intel Данная конструкция позволяет Heracles, работающему на частоте 1,2 ГГц, выполнять критически важные математические преобразования FHE всего за 39 мс, что в 2355 раз быстрее, чем может предложить Intel Xeon, работающий на частоте 3,5 ГГц. По семи ключевым операциям Heracles быстрее него в 1074–5547 раз в зависимости от объёма необходимых операций перераспределения (shuffling). Компания продемонстрировала на ISSCC возможности Heracles на примере простого частного запроса к защищённому серверу. Он имитировал запрос избирателя на проверку правильности регистрации его бюллетеня. В данном случае у штата есть зашифрованная база данных избирателей и их голосов: избиратель шифрует свой идентификационный номер и голос, а сервер проверяет совпадение без расшифровки и возвращает зашифрованный ответ, который пользователь затем расшифровывает на своей стороне. На Xeon этот процесс занял 15 мс, а Heracles справился с задачей за 14 мкс. Казалось бы, эта разница незаметна для отдельного человека, но проверка 100 млн бюллетеней занимает более 17 дней работы Xeon против всего 23 минут на Heracles. Проект Heracles был запущен пять лет назад в рамках программы DARPA по ускорению FHE с помощью специализированного оборудования. Разработкой подобных чипов также занимается ряд стартапов, включая Fabric Cryptography, Cornami и Optalysys. Сану Мэтью (Sanu Mathew), руководитель исследований в области защищённых схем в Intel, считает, что у компании есть большое преимущество, поскольку её чип может выполнять больше вычислений, чем любой другой ускоритель FHE, созданный до сих пор. «Heracles — это первое оборудование, работающее в масштабе», — говорит он. В дальнейшем компания планирует повышать скорость вычислений чипа за счёт тонкой настройки ПО. Она также будет испытывать более масштабные задачи FHE и изучать улучшения аппаратного обеспечения для потенциального следующего поколения. «Это как первый микропроцессор… начало целого пути», — отмечает Мэтью.
12.03.2026 [09:13], Сергей Карасёв
Meta✴ представила четыре новых ИИ-ускорителя MTIA — с FP8-производительностью до 10 ПфлопсКомпания Meta✴ анонсировала ИИ-ускорители MTIA (Meta✴ Training and Inference Accelerator) сразу четырёх новых поколений. Это решения MTIA 300, 400, 450 и 500: внедрение некоторых из них уже началось, тогда как развёртывание других запланировано на текущий и следующий годы. Устройства ориентированы на различные ИИ-нагрузки, включая инференс и генеративные сервисы. ИИ-процессор MTIA первого поколения (MTIA 100), напомним, дебютировал в 2023 году: изделие получило в общей сложности 128 ядер RISC-V и 128 Мбайт памяти SRAM. В 2024-м вышло решение второго поколения MTIA 200 с повышенной производительностью. В каждом из четырёх новых продуктов, по заявлениям Meta✴, упор сделан на улучшении вычислительных характеристик, пропускной способности памяти и эффективности. Конструкция ускорителя MTIA 300 включает один вычислительный чиплет, два сетевых чиплета (NIC) и несколько стеков HBM. Каждый вычислительный чиплет состоит из матрицы процессорных элементов (PE), содержащих по два векторных ядра RISC-V. Объём памяти HBM составляет 216 Гбайт, её пропускная способность — 6,1 Тбайт/с. Заявленная ИИ-производительность в режимах FP8/МХ8 достигает 1,2 Пфлопс. Показатель TDP равен 800 Вт. Реализован движок DMA для взаимодействия с локальной памятью. Ускоритель, уже применяющийся в дата-центрах Meta✴, оптимизирован для задач обучения по принципу Rephrase and Respond (R&R). 
Источник изображений: Meta✴ Ступенью выше располагается решение MTIA 400 общего назначения. Оно объединяет два вычислительных чиплета, а объём памяти HBM увеличен до 288 Гбайт (пропускная способность — 9,2 Тбайт/с). У этого ускорителя быстродействие на операциях FP8/МХ8 составляет до 6 Пфлопс. Величина TDP равна 1200 Вт. 72 ускорителя MTIA 400, «провязанные» в одной стойке, образуют единый масштабируемый домен. При этом может использоваться жидкостное охлаждение с воздушной поддержкой или полностью жидкостное охлаждение. На сегодняшний день Meta✴ завершила тестирование MTIA 400 и находится на этапе внедрения изделий. Вариант MTIA 450, в свою очередь, ориентирован на задачи инференса в сфере генеративного ИИ. Этот ускоритель также использует 288 Гбайт памяти HBM, но её пропускная способность достигает 18,4 Тбайт/с. Значение TDP подросло до 1400 Вт. Решение обеспечивает ИИ-производительность в режимах FP8/МХ8 до 7 Пфлопс, в режиме МХ4 — 21 Пфлопс. MTIA 450 также поддерживает смешанные вычисления с низкой точностью без дополнительного программного преобразования данных. Внедрение этой модели в ЦОД Meta✴ намечено на начало 2027 года. 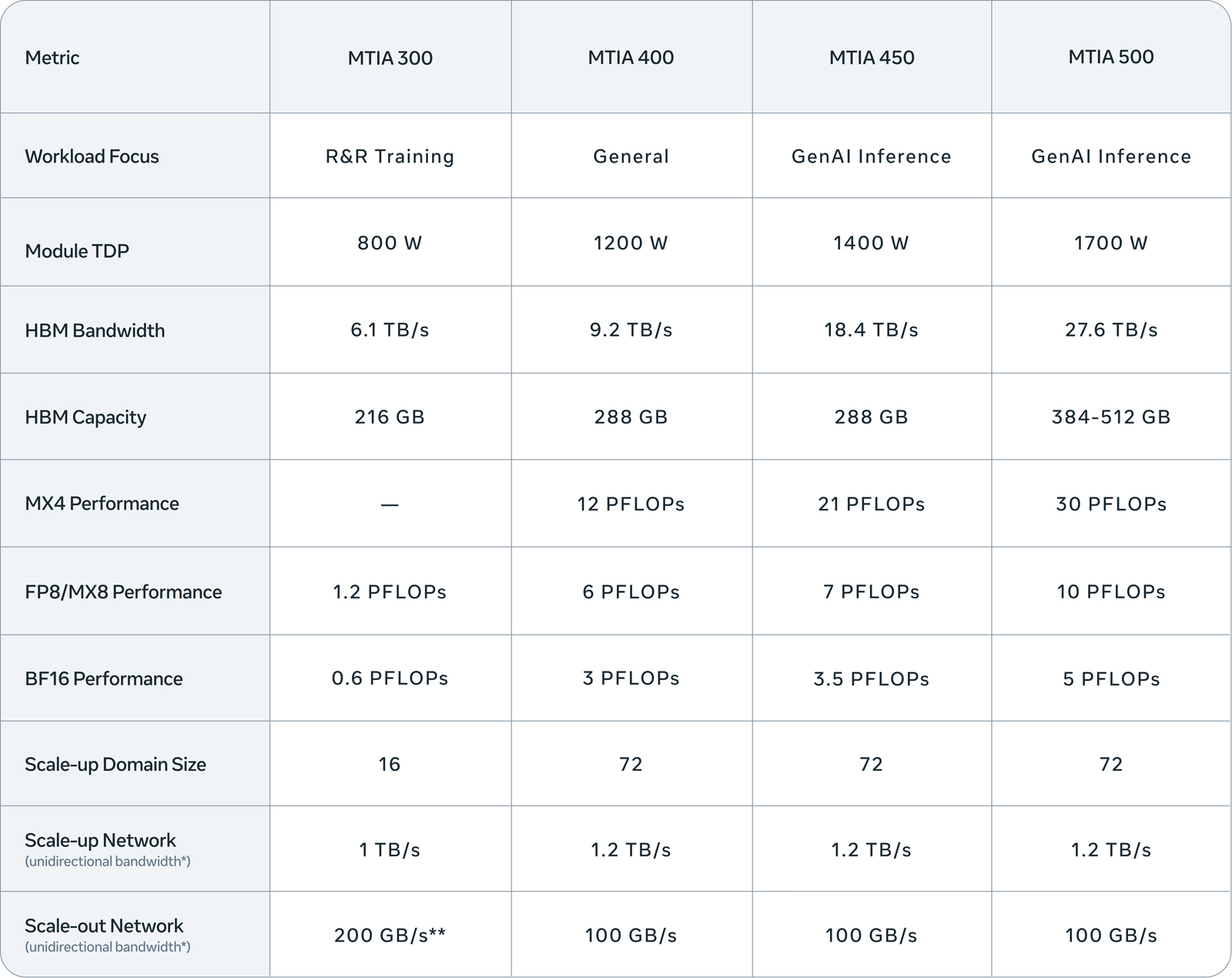 Наконец, самый мощный из готовящихся ускорителей — MTIA 500 — также рассчитан на инференс в сфере генеративного ИИ. Используется конфигурация вычислительных чиплетов 2 × 2, окруженных несколькими стеками HBM и двумя сетевыми чиплетами. Это устройство может использовать от 384 до 512 Гбайт памяти HBM с пропускной способностью до 27,6 Тбайт/с. Показатель TDP достигает 1700 Вт. Заявленная производительность FP8/МХ8 — до 10 Пфлопс, МХ4 — до 30 Пфлопс. Массовое внедрение MTIA 500 запланировано на 2027 год. На системном уровне MTIA 400, 450 и 500 используют одно и то же шасси, стойку и сетевую инфраструктуру. Это обеспечивает возможность модернизации с минимальными затратами при переходе на изделия следующего поколения. |
|

