Материалы по тегу: суперкомпьютер
|
07.05.2024 [14:05], Сергей Карасёв
Самый производительный японский суперкомпьютер Fugaku будет работать в тандеме с квантовой системой IBMКорпорация IBM сообщила о том, что её квантовая платформа Quantum System Two будет интегрирована с суперкомпьютером Fugaku в рамках совместного проекта с японским Институтом физико-химических исследований (RIKEN). Кроме того, IBM будет работать над новым ПО для выполнения квантово-классических задач. Напомним, вычислительный комплекс Fugaku на базе Arm-процессоров Fujitsu A64FX в 2020 году стал самым высокопроизводительным суперкомпьютером в мире. В текущем рейтинге ТОР500 эта НРС-система занимает четвёртое место с быстродействием приблизительно 442 Пфлопс. В свою очередь, квантовый компьютер IBM Quantum System Two был представлен в конце 2023 года. В нём применяется 133-кубитный квантовый процессор Heron. Отмечается, что Quantum System Two будет единственной квантовой системой, размещённой рядом с Fugaku в Центре вычислительных наук RIKEN в Кобе (Япония). Такая связка поможет в разработке приложений нового поколения для квантово-ориентированных суперкомпьютеров. 
Источник изображения: IBM Совместная инициатива IBM и RIKEN стала частью проекта, поддерживаемого японской Организацией по развитию новых энергетических и промышленных технологий (NEDO). Целью программы является демонстрация преимуществ гибридных вычислительных платформ при выполнении сложных и ресурсоёмких задач в эпоху «после 5G». «С точки зрения HPC, квантовые компьютеры — это системы, которые позволяют ускорить научные приложения, обычно выполняемые на суперкомпьютерах. Кроме того, квантовые платформы дают возможность решать задачи, которые не по силам традиционным вычислительным комплексам», — отмечает доктор Мицухиса Сато (Mitsuhisa Sato), руководитель подразделения RIKEN Quantum HPC Collaborative Platform. При этом Fujitsu совместно с RIKEN уже развернули в Осакском университете (Osaka University) собственный 64-кубитный квантовый компьютер с облачным доступом.
05.05.2024 [13:56], Сергей Карасёв
Власти США продали на аукционе 5,34-ПФлопс суперкомпьютер Cheyenne из-за растущего числа сбоев и протечек СЖОАдминистрация общих служб США (GSA) реализовала на аукционе НРС-систему под названием Cheyenne, которая была введена в строй в Центре суперкомпьютерных вычислений NCAR-Wyoming (NWSC) штата Вайоминг в 2016 году. Стоимость лота составила $480 085, тогда как затраты на строительство машины оцениваются как минимум в $25 млн. Cheyenne стал одним из последних суперкомпьютеров компании Silicon Graphics International (SGI). Корпорация HPE приобрела эту фирму после того, как Cheyenne был смонтирован, но до фактического запуска системы в эксплуатацию. На момент начала работы производительность комплекса составляла 5,34 Пфлопс, что соответствовало 20 месту в актуальном тогда списке ТОР500. Cheyenne представляет собой кластер SGI ICE XA с 4032 узлами, каждый из которых содержит два процессора Intel Xeon E5-2697v4 Broadwell (18C/36; 2,3 ГГц). Таким образом, суммарное количество ядер достигает 145 152. Применяется оперативная память DDR4-2400 ECC общей ёмкостью 313 Тбайт (4890 модулей на 64 Гбайт). В состав машины изначально входило хранилище данных вместимостью 40 Пбайт. Энергопотребление — приблизительно 1,7 МВт. Задействована система жидкостного охлаждения. 
Источник изображения: GSA Две стойки управления с воздушным охлаждением состоят из 26 серверов типоразмера 1U (20 со 128 Гбайт ОЗУ и ещё 6 с 256 Гбайт ОЗУ), 10 коммутаторов и двух блоков питания. Суперкомпьютер эксплуатировался с 12 января 2017 года по 31 декабря 2023-го, решая задачи в области изменений климата и в других сферах, связанных с науками о Земле. Cheyenne превзошёл свой запланированный срок службы: в заявлении NWSC говорилось, что он будет эксплуатироваться до 2021 года. Однако к концу 2023-го количество сбоев и проблем стало слишком большим. В описании лота говорится, что «примерно 1 % узлов столкнулись с отказами за последние шесть месяцев», в основном из-за модулей памяти. Кроме того, система испытывает ограничения по техническому обслуживанию из-за неисправных быстроразъёмных соединений, вызывающих протечки воды. Таким образом, «учитывая затраты и время простоя, связанные с устранением проблем», дальнейшее использование комплекса признано нецелесообразным, в связи с чем он пущен с молотка. Вместе с тем, как отмечает Tom's Hardware, новый владелец суперкомпьютера может реализовать его основные компоненты на вторичном рынке. Например, стоимость чипов Xeon E5-2697 v4 на eBay составляет около $50, а модулей DDR4-2400 ECC ёмкостью 64 Гбайт — примерно $65. То есть, по самым скромным подсчётам, только эти компоненты могут принести новому владельцу суперкомпьютера приблизительно $700 тыс. без учёта затрат на демонтаж и вывоз машины массой 43 т, а также на тестирование компонентов. Впрочем, массовый выброс на рынок CPU и RAM в таких объёмах приведёт к снижению цен.
13.03.2024 [22:40], Алексей Степин
Больше флопс за те же ватты: Cerebras представила царь-ускоритель WSE-3 и подружилась с QualcommКомпания Cerebras Systems, известная своими разработками в области сверхбольших ИИ-процессоров, рассказала о третьем поколении чипов Wafer Scale Engine. В своё время компания произвела фурор, представив процессор, занимающий всю площадь кремниевой пластины (46225 мм2). В первом поколении WSE речь шла о 1,2 трлн транзисторов при 400 тыс. ядер и 18 Гбайт сверхбыстрой памяти. WSE-2 состоял из 2,6 трлн транзисторов, имел 850 тыс. ядер и 40 Гбайт интегрированной памяти. В WSE-3 разработчики перешли на использование 5-нм техпроцесса TSMC, что позволило разместить на пластине такого же размера уже 4 трлн транзисторов, составляющих 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность набортной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. 
Источник изображений: Cerebras Казалось бы, выигрыш в количестве ядер по сравнению с WSE-2 не так уж велик, однако на этот раз Cerebras сделала упор на архитектуру. Если верить заявлениям разработчиков, WSE-3 практически вдвое быстрее WSE-2 при сопоставимом уровне энергопотребления (15 кВт) и той же цене: 125 Пфлопс против 75 Пфлопс в разреженных FP16-вычислениях. WSE-3 в 62 раза быстрее NVIDIA H100, хотя и сам чип WSE-3 в 57 раз больше. 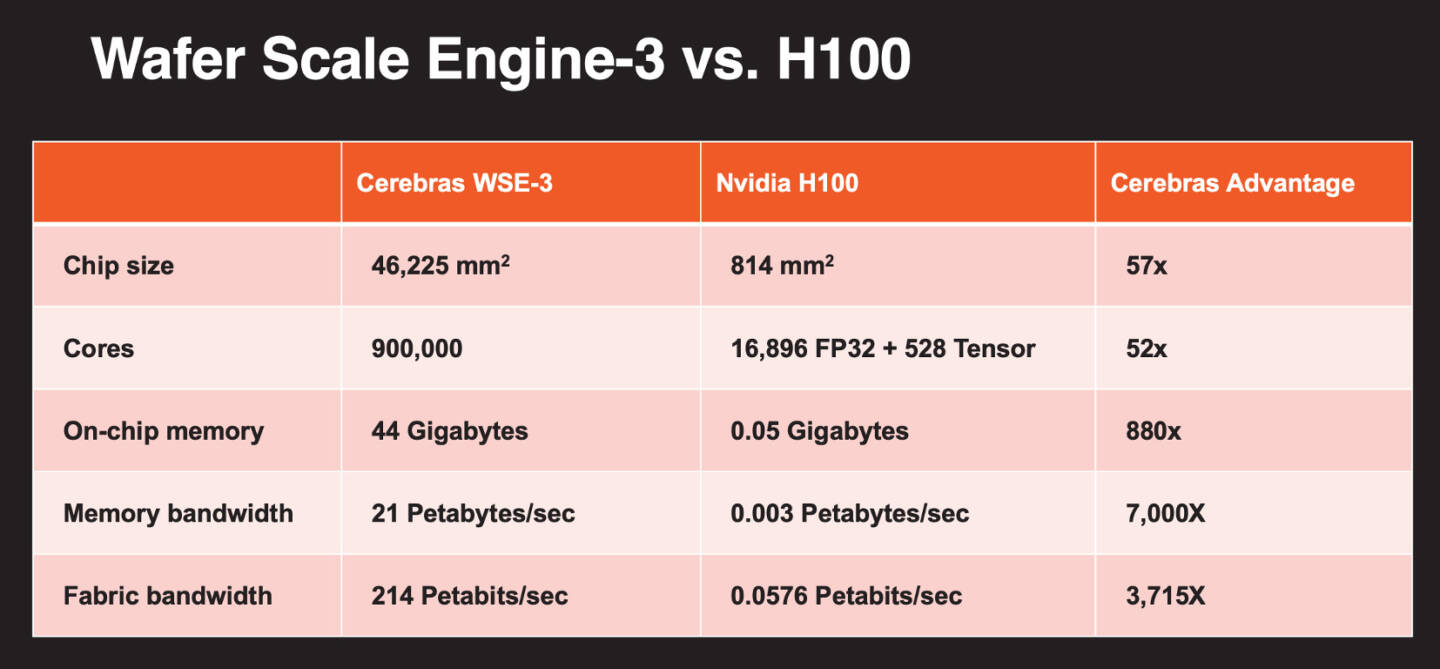 WSE-3 по-прежнему требует специфического окружения. Он станет сердцем новой системы CS-3 (23 кВт), содержащей всю необходимую сопутствующую инфраструктуру, включая СЖО, подсистемы питания, а также сетевого интерконнекта Ethernet. Последний не изменился и состоит из 12 каналов со скоростью 100 Гбит/с. Для подготовки «сырых» данных по-прежнему будет использоваться внешний суперсервер. А для их хранения будут использоваться узлы MemoryX ёмкостью до 1200 Тбайт (1,2 Пбайт). 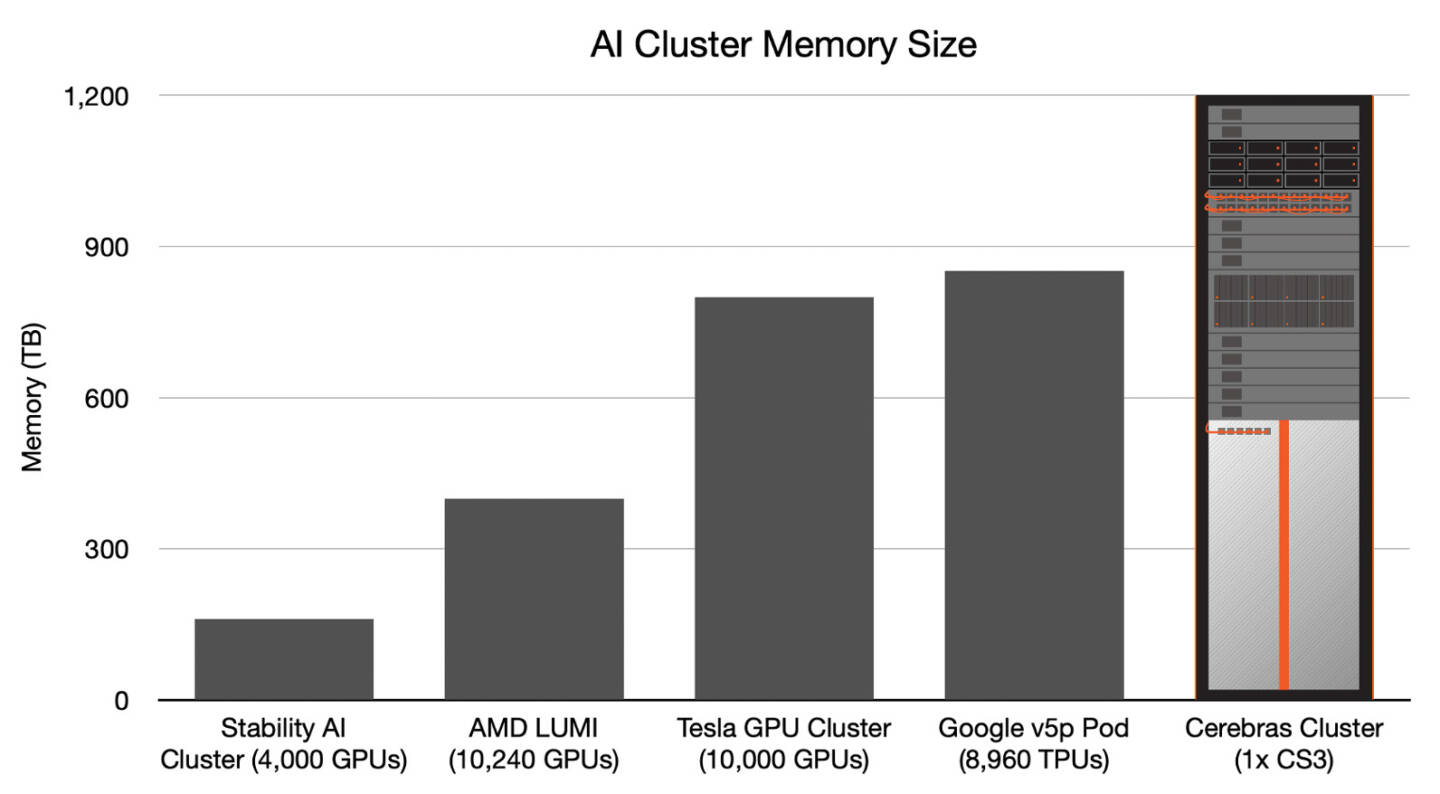 Главной задачей CS-3 станет «натаскивание» сверхбольших языковых моделей, в 10 раз превышающих по количеству параметров GPT-4 и Google Gemini. Cerebras говорит о 24 трлн параметров, причём без необходимости различных ухищрений для эффективного распараллеливания процесса обучения, что требуется в случае с GPU-кластерами. По словам компании, для обучения Megatron 175B на таких кластерах требуется 20 тыс. строка кода Python/C++/CUDA, а в случае WSE-3 потребуется лишь 565 строк на Python.  CS-3 поддерживает масштабирование вплоть до 2048 систем. Такая конфигурация вкупе с MemoryX сможет обучить модель типа Llama 70B всего за день. Первый суперкомпьютер на базе CS-3 — 8-Эфлопс Condor Galaxy 3 — будет скромнее и получит всего 64 стойки CS-3, которые разместятся в Далласе (США). В совокупности с уже имеющимися кластерами на базе CS-1 и CS-2 вычислительная мощность систем Cerebras должна достигнуть 16 Эфлопс. В сотрудничестве c группой G42 запланировано создание ещё шести систем CS-3, что в сумме позволит довести производительность до 64 Эфлопс.  Condor Galaxy 3 будет отличаться от предшественников ещё одним нововведением: в рамках сотрудничества с Qualcomm Cerebras установит в новом кластере существенное число инференс-ускорителей Qualcomm Cloud AI100 Ultra. Каждый такой ускоритель имеет 64 ядра, 128 Гбайт памяти LPDDR4x, потребляет 140 Вт и развивает 870 Топс на INT8-операциях. Причём програмнный стек полностью интегрирован, что позволит в один клик запустить обученные WSE-3 модели на ускорителях Qualcomm. 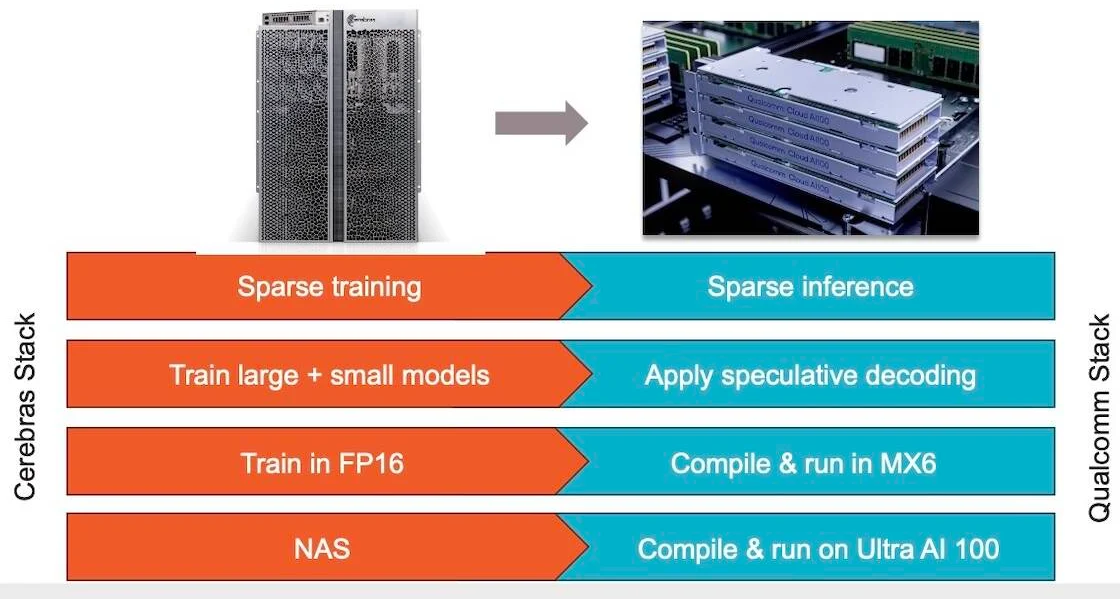 Сотрудничество Cerebras и Qualcomm носит официальный характер, его целью является оптимизация ИИ-моделей для запуска на AI100 Ultra с учетом различных продвинутых техник, таких как разреженные вычисления, спекулятивное исполнение (сочетание малых LLM для получения быстрого результата с проверкой большой LLM), использование «сжатого» формата MxFP6 для весов и других. Благодаря мощностям, предоставляемым WSE-3, цикл разработки, оптимизации и тестирования таких моделей удастся существенно ускорить, что в итоге должно обеспечить десятикратное улучшение удельной производительности новых решений.
28.11.2023 [22:20], Игорь Осколков
NVIDIA анонсировала суперускоритель GH200 NVL32 и очередной самый мощный в мире ИИ-суперкомпьютер Project CeibaAWS и NVIDIA анонсировали сразу несколько новых совместно разработанных решений для генеративного ИИ. Основным анонсом формально является появление ИИ-облака DGX Cloud в инфраструктуре AWS, вот только облако это отличается от немногочисленных представленных ранее платформ DGX Cloud тем, что оно первом получило гибридные суперчипах GH200 (Grace Hoppper), причём в необычной конфигурации. 
Изображения: NVIDIA В основе AWS DGX Cloud лежит платформа GH200 NVL32, но это уже не какой-нибудь сдвоенный акселератор вроде H100 NVL, а целая, готовая к развёртыванию стойка, включающая сразу 32 ускорителя GH200, провязанных 900-Гбайт/с интерконнектом NVLink. В состав такого суперускорителя входят 9 коммутаторов NVSwitch и 16 двухчиповых узлов с жидкостным охлаждением. По словам NVIDIA, GH200 NVL32 идеально подходит как для обучения, так и для инференса действительно больших LLM с 1 трлн параметров.  Простым перемножением количества GH200 на характеристики каждого ускорителя получаются впечатляющие показатели: 128 Пфлопс (FP8), 20 Тбайт оперативной памяти, из которых 4,5 Тбайт приходится на HBM3e с суммарной ПСП 157 Тбайтс, и агрегированная скорость NVLink 57,6 Тбайт/с. И всё это с составе одного EC2-инстанса! Да, новая платформа использует фирменные DPU AWS Nitro и EFA-подключение (400 Гбит/с на каждый GH200). Новые инстансы, пока что безымянные, можно объединять в кластеры EC2 UltraClasters.  Одним из таких кластеров станет Project Ceiba, очередной самый мощный в мире ИИ-суперкомпьютер с FP8-производительность 65 Эфлопс, объединяющий сразу 16 384 ускорителя GH200 и имеющий 9,1 Пбайт памяти, а также агрегированную пропускную способность интерконнекта на уровне 410 Тбайт/с (28,8 Тбайт/с NVLink). Он и станет частью облака AWS DGX Cloud, которое будет доступно в начале 2024 года. В скором времени появятся и EC2-инстансы попроще: P5e с NVIDIA H200, G6e с L40S и G6 с L4. 
25.10.2023 [11:49], Сергей Карасёв
Экзафлопсный суперкомпьютер Frontier назван лучшим изобретением 2023 года по версии TimeЕжегодно американский журнал Time публикует список из лучших изобретений человечества в самых разных сферах. В нынешнем году в рейтинг вошли 200 продуктов и технологий, которые сгруппированы более чем в 35 категорий. Это, в частности, ПО, связь, виртуальная и дополненная реальность, ИИ, потребительская электроника, чистая энергии, здравоохранение, безопасность, робототехника и многое другое. Одним из направлений являются экспериментальные системы и устройства. В данной категории победителем назван вычислительный комплекс Frontier — самый мощный суперкомпьютер 2023 года. Исследователи уже используют его для самых разных целей: от изучения чёрных дыр до моделирования климата. «Специалисты сравнивают это с эквивалентом высадки на Луну с точки зрения инженерных достижений. Это больше, чем чудо. Это статистическая невозможность», — сказал Ник Дюбе (Nic Dubé), руководитель проекта в HPE. 
Источник изображения: ORNL Система Frontier, созданная специалистами HPE, установлена в Национальной лаборатории Окриджа (ORNL) Министерства энергетики США. Она занимает первое место в рейтинге TOP500 с производительностью 1,194 Эфлопс. В составе системы применяются процессоры AMD EPYC Milan, ускорители Instinct MI250X и интерконнект Cray Slingshot. В общей сложности задействованы 8 699 904 вычислительных ядра. Теоретическое пиковое быстродействие достигает 1,680 Эфлопс.
21.07.2023 [15:35], Сергей Карасёв
NVIDIA, подвинься: Cerebras представила 4-Эфлопс ИИ-суперкомпьютер Condor Galaxy 1 и намерена построить ещё восемь таких жеКомпания Cerebras Systems анонсировала суперкомпьютер Condor Galaxy 1 (CG-1), предназначенный для решения ресурсоёмких задач с применением ИИ. Это одна из первых действительно крупных машин на базе уникальных чипов Cerebras. В проекте стоимостью $100 млн приняла участие холдинговая группа G42 из ОАЭ, которая занимается технологиями ИИ и облачными вычислениями. G42 является основным заказчиком комплекса. В текущем виде комплекс CG-1, расположенный в Санта-Кларе (Калифорния, США), объединяет 32 системы Cerebras CS-2 и обеспечивает производительность на уровне 2 Эфлопс (FP16). В IV квартале ткущего года будут добавлены ещё 32 системы Cerebras CS-2, что позволит довести быстродействие до 4 Эфлопс (FP16). Ожидаемый уровень энергопотребления составит порядка 1,5 МВт или более. 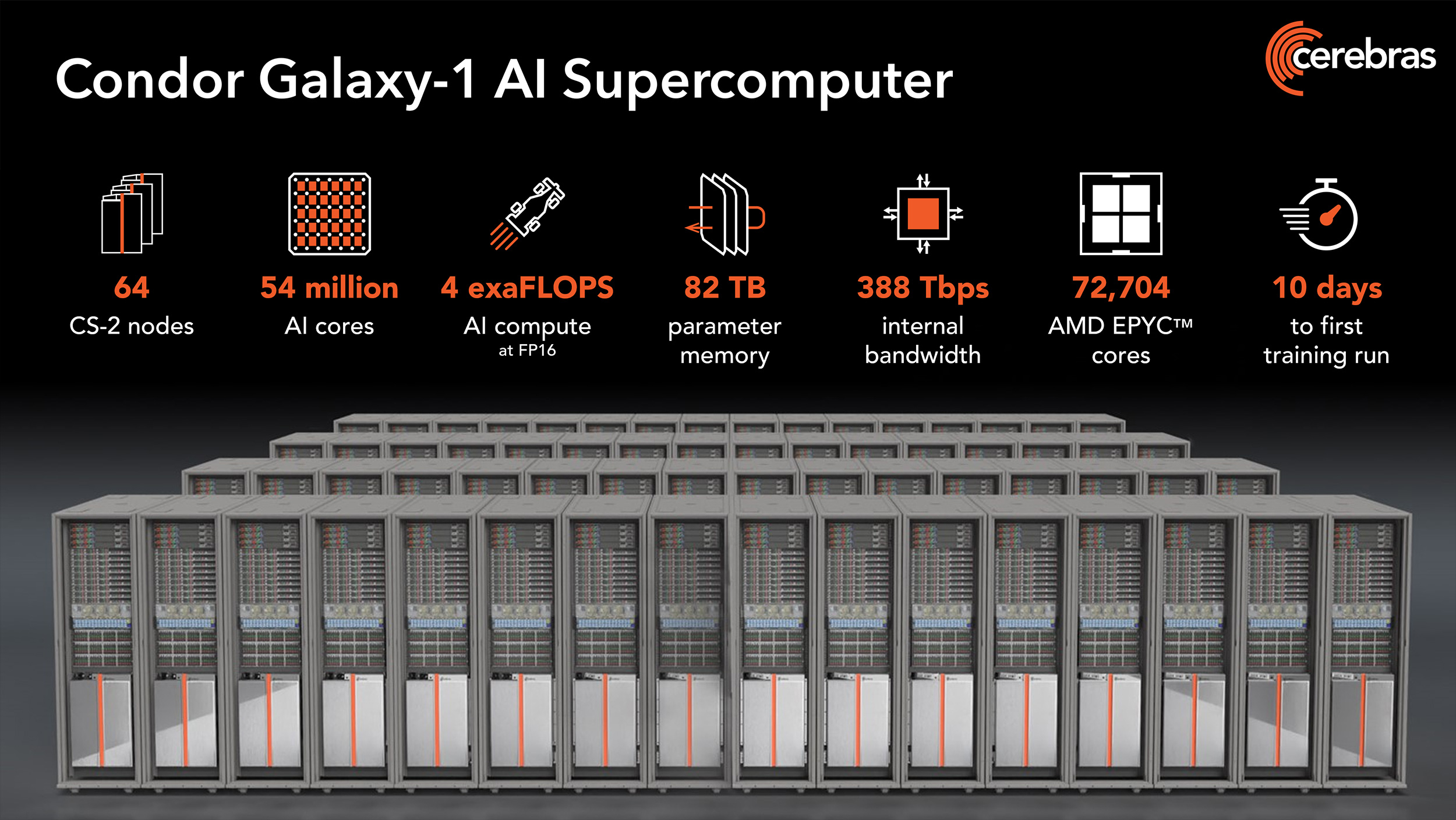
Источник изображений: Cerebras (via ServeTheHome) В системах Cerebras CS-2 применяются гигантские чипы Wafer-Scale Engine 2 (WSE-2), насчитывающие 2,6 трлн транзисторов. Такие чипы имеют 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Системы выполнены в формате 15 RU и укомплектованы шестью блоками питания мощностью 4 кВт каждый. Задействована технология жидкостного охлаждения. Отдельно отмечается, что программный стек позволит без проблем и существенных модификаций кода работать с ИИ-моделями.  После ввода в строй второй очереди комплекс CG-1 суммарно получит 54,4 млн ИИ-ядер, 2,56 Тбайт SRAM и внутренний интерконнект со скоростью 388 Тбит/с. Их дополнят 72 704 ядра AMD EPYC Milan и 82 Тбайт памяти для хранения параметров. По словам создателей, мощностей суперкомпьютера хватит для обучения модели с 600 млрд параметров и на очередях длиной до 50 тыс. токенов. При этом производительность масштабируется практически линейно.  Cerebras и G42 будут предоставлять доступ к CG-1 по облачной схеме, что позволит заказчикам использовать ресурсы ИИ-суперкомпьютера без необходимости управлять моделями или распределять их по узлам и ускорителям. CG-1 — первый из трёх ИИ-суперкомпьютеров нового поколения. В I полугодии 2024 года будут построены комплексы CG-2 и CG-3, полностью аналогичные CG-1, которые будут объединены в распределённый ИИ-кластер. А к концу следующего года у Cerebras будет уже девять систем CG.  Для Cerebras это означает, что компания более не является стартапом, поскольку в её решения заказчики поверили и без участия в индустриальных тестах вроде MLPerf. Кроме того, теперь компания является не просто очередным производителем «железа», а предоставляет услуги, которые и помогут ей заработать в будущем.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200.
23.05.2023 [15:26], Сергей Карасёв
Intel рассказала о суперкомпьютере Aurora производительностью более 2 ЭфлопсКорпорация Intel в ходе конференции ISC 2023, как сообщает AnandTech, поделилась информацией о проекте Aurora по созданию суперкомпьютера с производительностью экзафлопсного уровня. Эта система создаётся для Аргоннской национальной лаборатории Министерства энергетики США. Изначально анонс HPC-комплекса Aurora состоялся ещё в 2015 году с предполагаемым запуском в 2018-м: ожидалось, что машина обеспечит быстродействие на уровне 180 Пфлопс. Однако реализация проекта значительно затянулась, а технические параметры платформы неоднократно менялись. Пока что развёрнуты тестовый кластер Sunspot. Как теперь сообщается, в конечной конфигурации Aurora объединит 10 624 узла, каждый из которых будет включать два процессора Xeon Max и шесть ускорителей Ponte Vecchio. Таким образом, общее количество CPU будет достигать 21 248, число GPU — 63 744. Быстродействие FP64, как и было заявлено ранее, превысит 2 Эфлопс. 
Источник изображений: Intel (via AnandTech) Каждый процессор оперирует 64 Гбайт памяти HBM, ускоритель — 128 Гбайт. В сумме это даёт соответственно 1,36 Пбайт и 8,16 Пбайт памяти HBM с пиковой пропускной способностью 30,5 Пбайт/с и 208,9 Пбайт/с. В дополнение система сможет использовать 10,9 Пбайт памяти DDR5 с пропускной способностью до 5,95 Пбайт/с. Вместимость подсистемы хранения данных составит 230 Пбайт со скоростью работы до 31 Тбайт/с.  На сегодняшний день Intel поставила более 10 тыс. «лезвий» для Aurora, а это означает, что практически все узлы готовы к окончательному монтажу. Ввод суперкомпьютера в эксплуатацию намечен на текущий год. Для НРС-платформы готовится специализированная научная модель генеративного ИИ — Generative AI for Science, насчитывающая около 1 трлн параметров. Применять Aurora планируется для решения наиболее ресурсоёмких задач в различных областях.
07.04.2023 [20:36], Сергей Карасёв
Google заявила, что её ИИ-кластеры на базе TPU v4 и оптических коммутаторов эффективнее кластеров на базе NVIDIA A100 и InfiniBandКомпания Google обнародовала новую информацию о своей облачной суперкомпьютерной платформе Cloud TPU v4, предназначенной для решения задач ИИ и машинного обучения с высокой эффективностью. Система может использоваться в том числе для работы с крупномасштабными языковыми моделями (LLM). Один кластер Cloud TPU Pod содержит 4096 чипов TPUv4, соединённых между собой через оптические коммутаторы (OCS). По словам Google, решение OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Google также утверждает, что в составе её платформы на OCS приходится менее 5 % от общей стоимости. Причём данная технология даёт возможность динамически менять топологию для улучшения масштабируемости, доступности, безопасности и производительности. Отмечается, что платформа Cloud TPU v4 в 1,2–1,7 раза производительнее и расходует в 1,3–1,9 раза меньше энергии, чем платформы на базе NVIDIA A100 в системах аналогичного размера. Правда, пока компания не сравнивала TPU v4 с более новыми ускорителями NVIDIA H100 из-за их ограниченной доступности и 4-нм архитектуры (по сравнению с 7-нм у TPU v4). 
Изображение: Google Благодаря ключевым инновациям в области интерконнекта и специализированных ускорителей (DSA, Domain Specific Accelerator) платформа Google Cloud TPU v4 обеспечивает почти 10-кратный прирост в масштабировании производительности по сравнению с TPU v3. Это также позволяет повысить энергоэффективность примерно в 2–3 раза по сравнению с современными DSA ML и сократить углеродный след примерно в 20 раз по сравнению с обычными дата-центрами.
29.11.2022 [12:20], Сергей Карасёв
В Италии официально запущен суперкомпьютер Leonardo — четвёртая по мощности HPC-система в миреСовместная инициатива по высокопроизводительным вычислениям в Европе EuroHPC JU и некоммерческий консорциум CINECA, состоящий из 69 итальянских университетов и 21 национальных исследовательских центров, провели церемонию запуска суперкомпьютера Leonardo. В основу комплекса положены платформы Atos BullSequana X2610 и X2135. Система Leonardo состоит из двух секций — общего назначения и с ускорителями вычислений (Booster). Когда строительство системы будет завершено, первая будет включать 1536 узлов, каждый из которых содержит два процессора Intel Xeon Sapphire Rapids с 56 ядрами и TDP в 350 Вт, 512 Гбайт оперативной памяти DDR5-4800, интерконнект NVIDIA InfiniBand HDR100 и NVMe-накопитель на 8 Тбайт. 
Источник изображения: HPCwire Секция Booster объединяет 3456 узлов, каждый из которых содержит один чип Intel Xeon 8358 с 32 ядрами, 512 Гбайт ОЗУ стандарта DDR4-3200, четыре кастомных ускорителя NVIDIA A100 с 64 Гбайт HBM2-памяти, а также два адаптера NVIDIA InfiniBand HDR100. Кроме того, в состав комплекса входят 18 узлов для визуализации: 6,4 Тбайт NVMe SSD и два ускорителя NVIDIA RTX 8000 (48 Гбайт) в каждом. Вычислительный комплекс объединён фабрикой с топологией Dragonfly+. 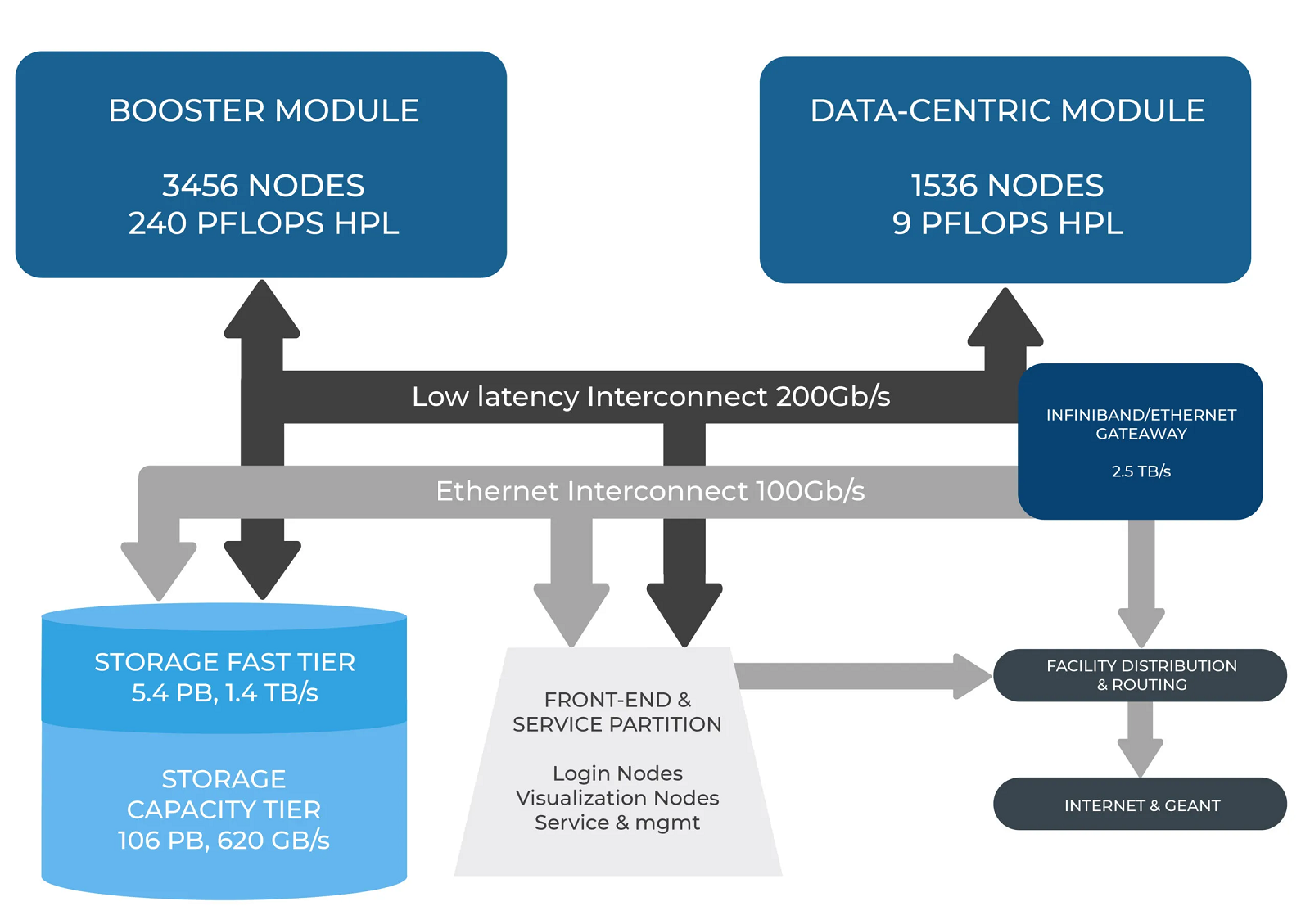
Источник: CINECA Для хранения данных служит двухуровневая система. Производительный блок (5,4 Пбайт, 1400 Гбайт/с) содержит 31 модуль DDN Exascaler ES400NVX2, каждый из которых укомплектован 24 NVMe SSD вместимостью 7,68 Тбайт и четырьмя адаптерами InfiniBand HDR. Второй уровень большой ёмкости (106 Пбайт, чтение/запись 744/620 Гбайт/с) состоит из 31 массива DDN EXAScaler SFA799X с 82 SAS HDD (7200 PRM) на 18 Тбайт и четырьмя адаптерами InfiniBand HDR. Каждый из массивов включает два JBOD-модуля с 82 дисками на 18 Тбайт. Для хранения метаданных используются 4 модуля DDN EXAScaler SFA400NVX: 24 × 7,68 Тбайт NVMe + 4 × InfiniBand HDR. 
Изображение: CINECA В настоящее время Leonardo обеспечивает производительность более 174 Пфлопс. Ожидается, что суперкомпьютер будет полностью запущен в первой половине 2023 года, а его пиковое быстродействие составит 250 Пфлопс. Уже сейчас система занимает четвёртое место в последнем рейтинге самых мощных суперкомпьютеров мира TOP500. В Европе Leonardo является второй по мощности системой после LUMI. Leonardo оборудован системой жидкостного охлаждения для повышения энергоэффективности. Кроме того, предусмотрена возможность регулировки энергопотребления для обеспечения баланса между расходом электричества и производительностью. Суперкомпьютер ориентирован на решение высокоинтенсивных вычислительных задач, таких как обработка данных, ИИ и машинное обучение. Половина вычислительных ресурсов Leonardo будет предоставлена пользователям EuroHPC. |
|

