Материалы по тегу: инференс
|
19.01.2026 [10:09], Сергей Карасёв
DeepX представила ИИ-ускорители DX-H1 V-NPU, DX-H1 Quattro и DX-M1 М.2Южнокорейский стартап Deepx, специализирующийся на разработке чипов для задач ИИ, анонсировал ускорители DX-H1 V-NPU, DX-H1 Quattro и DX-M1 М.2. В основу решений, которые демонстрировались на недавней выставке CES 2026 в Лас-Вегасе (Невада, США), положен нейропроцессорный узел Genesis NPU. Устройство DX-H1 V-NPU предназначено для выполнения операций, связанных с обработкой видеоматериалов: это может быть декодирование, кодирование, перекодирование и пр. Утверждается, что новинка обеспечивает снижение стоимости оборудования примерно на 80 % и сокращение энергопотребления на 85 % по сравнению с решениями на базе GPU при той же плотности каналов. Ускоритель выполнен в виде низкопрофильной карты расширения PCIe 3.0 x16 (x8 на уровне сигналов). Он оснащён двумя аппаратными видеокодеками и двумя NPU с общей производительностью до 50 TOPS (INT8) при инференсе в реальном времени. Возможно декодирование 64 каналов H.264/265 (1080р; 30 к/с) и кодирование 32 каналов H.264/265 (1080р; 30 к/с). Секция кодирования имеет доступ к 16 Гбайт памяти LPDDR5, секция NPU — к 8 Гбайт. Упомянуты интерфейс HDMI 2.0 и флеш-модуль eMMC вместимостью 32 Гбайт. Максимальное энергопотребление составляет 40 Вт.  Решение DX-H1 Quattro, в свою очередь, оснащено четырьмя NPU с суммарной производительностью до 100 TOPS (INT8). В оснащение входят 16 Гбайт памяти LPDDR5. Ускоритель, выполненный в виде карты PCIe 3.0 x16, предназначены для выполнения ИИ-задач в дата-центрах и на периферии. Энергопотребление равно 20 Вт, диапазон рабочих температур простирается от -25 до +85 °C. Говорится о совместимости с Windows и различными вариантами Linux, включая Ubuntu.  Изделие DX-M1 М.2 представляет собой ИИ-ускоритель в виде модуля М.2 2280, выполненный на чипе DX-M1. ИИ-производительность — до 25 TOPS, а энергопотребление не превышает 5 Вт. Используется интерфейс PCIe 3.0 x4. Говорится о возможности применения устройства в системах с архитектурой х86 и Arm. Диапазон рабочих температур — от -25 до +85 °C. Упомянута совместимость с Windows 11 и Ubuntu 22.04. 
15.01.2026 [18:19], Сергей Карасёв
Модуль AI HAT+ 2 добавляет к Raspberry Pi 5 ИИ-ускоритель Hailo-10HКомпания Raspberry Pi анонсировала специализированный модуль расширения AI HAT+ 2, позволяющий использовать одноплатный компьютер Raspberry Pi 5 для ИИ-инференса. Новинка уже доступна для заказа по ориентировочной цене $130. Ранее Raspberry Pi выпустила ИИ-модуль AI HAT+, который в зависимости от модификации оснащается ускорителем Hailo-8 (26 TOPS) или Hailo-8L (13 TOPS). Такие изделия предназначены прежде всего для инференса. Решение Raspberry Pi AI HAT+ 2, в свою очередь, спроектировано под генеративный ИИ. В основу новинки положен ускоритель Hailo-10H, который позволяет использовать большие языковые модели (LLM), визуально-языковые модели (VLM) и другие модели генеративного ИИ локально. Чип функционирует в тандеме с 8 Гбайт LPDDR4/4X. Заявленная ИИ-производительность достигает 40 TOPS на операциях INT4. Для задач, основанных на машинном зрении, таких как распознавание объектов, оценка позы и сегментация сцены, производительность AI HAT+ 2 приблизительно эквивалентна быстродействию ранее выпущенного ИИ-модуля на базе Hailo-8. 
Источник изображения: Raspberry Pi При подключении модуля операционная система Raspberry Pi OS автоматически обнаруживает ускоритель и переносит на него поддерживаемые задачи ИИ. Поначалу для изделия будут доступны следующие LLM: DeepSeek-R1-Distill, Qwen2.5-Coder, Qwen2.5-Instruct и Qwen2 (все с 1,5 млрд параметров), а также Llama3.2 (с 1 млрд параметров). В дальнейшем будут предложены более крупные модели.
15.01.2026 [09:09], Владимир Мироненко
Инвесторы вкладывают сотни миллионов долларов в Etched и Cerebras в надежде, что они потеснят NVIDIA на рынке ИИЛидирующие позиции NVIDIA на рынке ИИ-ускорителей кажутся незыблемыми на долгие годы, но, как полагает ресурс SiliconANGLE, ей следует присмотреться к ближайшим конкурентам, которые пока не «дышат в спину», но стремительно наращивают свои возможности, получая солидную финансовую поддержку для роста. Согласно данным источников Bloomberg (официального сообщения пока не поступало), стартап Etched, занимающийся разработкой ИИ-чипов, привлёк около $500 млн в новом раунде финансирования, благодаря чему оценка его рыночной стоимости составила $5 млрд. Ещё более крупный конкурент NVIDIA, компания Cerebras Systems, по данным The Information, ведёт переговоры о привлечении $1 млрд инвестиций в рамках очередного раунда финансирования при оценке капитализации в $22 млрд. Всего лишь три месяца назад она уже получила $1,1 млрд при оценке в $8,1 млрд, в очередной раз перенеся IPO. По данным источников The Information, компания всё же выйдет на биржу в ближайшие месяцы. Сделка с OpenAI снизит её зависимость от базирующейся в ОАЭ компании G42. 
Источник изображения: Etched Как сообщают источники, нынешний раунд финансирования Etched возглавила компания Stripes при участии миллиардера Питера Тиля (Peter Thiel), а также компаний Positive Sum и Ribbit Capital. Ранее в инвестировании стартапа принимали участие Primary Venture Partners и известные бизнес-ангелы, такие как генеральный директор GitHub Томас Домке (Thomas Dohmke) и бывший руководитель Coinbase Баладжи Сринивасан (Balaji Srinivasan). По словам источников, с учётом этого раунда общая сумма привлечённых средств Etched приблизилась к $1 млрд. Это довольно внушительный финансовый резерв для стартапа, существующего всего два года. 
Источник изображения: Cerebras Systems Etched создал Sohu — узкоспециализированный ASIC разработанный специально для инференса ИИ-моделями на архитектуре трансформеров. При разработке чипа Etched сотрудничала с группой Emerging Businesses компании TSMC, что свидетельствует как о технических амбициях, так и о производственной надёжности. Также к участию в проекте привлекли специалистов, ранее работавших в таких компаниях, как Cypress Semiconductor и Broadcom. В свою очередь, Cerebras Systems получила известность благодаря своим царь-чипам WSE, которые, по словам компании, значительно быстрее и энергоэффективнее решений NVDIA в ИИ-задачах. В отличие от Etched, Cerebras активно наращивает клиентскую базу, не только развёртывая оборудование, но и предоставляя услуги облачных ИИ-вычислений. Среди её клиентов — Meta✴, IBM и Mistral AI.
15.01.2026 [01:05], Игорь Осколков
$10 млрд за 750 МВт ИИ-мощностей: OpenAI подписала сделку с CerebrasOpenAI подписала многолетнее соглашение с разработчиком царь-ускорителей Cerebras, который до 2028 поставит 750 МВт вычислительных мощностей. По данным CNBC, сумма сделки превышает $10 млрд. Идёт ли речь о продаже ИИ-ускорителей или предоставлении сервисов инференса, пока не уточняется. «Вычислительная стратегия OpenAI заключается в создании отказоустойчивого портфеля, в рамках которого для различных рабочих нагрузок подбираются подходящие системы», — сообщила OpenAI, отметив высокую скорость инференса решений Cerebras, что ускорит генерацию ответов, обеспечит более естественное взаимодействие и позволит масштабировать использование ИИ в реальном времени для гораздо большего числа людей. OpenAI использует комбинацию ускорителей AMD и NVIDIA, а также строит гигантские ЦОД на базе решений последней в рамках проекта Stargate. Кроме того, OpenAI сотрудничает с Google, у которой есть ускорители TPU, а также разрабатывает собственные ИИ-чипы в партнёрстве с Broadcom. Наконец, компания может повлиять на разработку нового поколения фирменных ускорителей Microsoft Maia. AWS тоже не прочь дать OpenAI свои ИИ-ускорители Trainium, но пока компании договорились лишь о масштабной аренде чипов NVIDIA. 
Источник изображения: Cerebras Примечательно, что OpenAI ещё в 2017 году раздумывала, не купить ли Cerebras при участии Tesla, глава которой Илон Маск (Elon Musk) тогда всё ещё работал в OpenAI. На тот момент Cerebras было всего два года, а свой первый ускоритель WSE она представила только в 2019 году. Серьёзную поддержку компании оказала G42 из ОАЭ, но в итоге Cerebras оказалась от неё слишком зависима, так что сделка с OpenAI сыграет компании на руку в преддверии всё откладывающегося выхода на биржу.
14.01.2026 [09:45], Владимир Мироненко
Самая загадочная сделка 2025 года: зачем NVIDIA потратила $20 млрд на Groq?Сделка NVIDIA с ИИ-стартапом Groq, фактически означающая его поглощение, вызвала вопросы по поводу целей, которые преследует лидер ИИ-рынка. Для того, чтобы избежать волокиты с одобрением сделки регулирующими органами и антимонопольных расследований, NVIDIA провела её под видом приобретения неисключительной лицензии на технологии Groq. В результате сделки ключевые кадры Groq перешли в NVIDIA, а остатки команды во главе с финансовым директором продолжат управлять инфраструктурой GroqCloud и вряд ли смогут сохранить былую конкурентоспособность стартапа. Похожую сделку NVIDIA провела немногим ранее, фактически поглотив стартап Enfabrica, занимавшийся разработкой интерконнекта. В случае с Enfabrica, по слухам, сумма сделки составила $900 млн. Это большая сумма для стартапа, находящегося на ранней стадии, но вполне обоснованная в нынешних условиях, пишет EE Times. Groq — более крупный стартап, но и стоимость сделки гораздо выше — $20 млрд при последней оценке стартапа на уровне $6,9 млрд. Если в отношении Enfabrica предполагалось, что сделка была связана, хотя бы частично, с наймом персонала, то для Groq такая большая сумма вряд ли выглядит оправданной, если речь идёт только о привлечении квалифицированных кадров. Можно допустить, что NVIDIA планирует выпускать чипы Groq. Их упомянул в электронном письме сотрудникам гендиректор NVIDIA Дженсен Хуанг: «Мы планируем интегрировать процессоры Groq с низкой задержкой в архитектуру NVIDIA AI Factory, расширив платформу для обслуживания ещё более широкого спектра задач ИИ-инференса и рабочих нагрузок в реальном времени». 
Источник изображений: Groq Вместе с тем в ходе CES 2026 Хуанг заявил, что технология Groq не станет частью основного портфолио NVIDIA для ЦОД. «[Groq] — это совсем, совсем другое, и я не ожидаю, что что-либо заменит то, что мы делаем с Vera Rubin и нашим следующим поколением, — сказал Хуанг. — Однако мы могли бы добавить его технологию таким образом, чтобы что-то постепенно улучшить, чего мир ещё не смог сделать». Судя по фразе «могли бы», NVIDIA пока окончательно не определилась с тем, что будет делать с активами Groq. Технология Groq позволит решать задачи, которые недоступны для Vera Rubin, в частности, сверхбыстрый инференс в реальном времени, пишет EE Times. Можно предположить, что NVIDIA будет производить и развёртывать чипы Groq как отдельное решение в ЦОД. Хотя Хуанг и сказал об интеграции чипов Groq с архитектурой NVIDIA AI Factory, это всё ещё кажется несколько надуманным, так как означает признание NVIDIA в том, что её GPU не вполне подходят для некоторых рабочих нагрузок. Однако Дженсен Хуанг в очередной раз подчеркнул на CES 2026, что гибкости GPU вполне хватит для любых нагрузок. Впрочем, анонс соускорителей Rubin CPX говорит скорее об обратном.  У Groq есть собственный программный стек, но насколько он хорош, сказать трудно. Для перезапуска технологий Groq в качестве продукта NVIDIA потребуется немало работы над ПО, а полноценная интеграция в программную экосистему может оказаться очень сложной. Более реалистичным вариантом может быть использование чиплета Groq вместе с большим чиплетом GPU для обработки определённых нагрузок, но и в этом случае ПО станет камнем преткновения, поскольку аппаратная часть принципиально слабо совместима с CUDA. Возникает вопрос: «Что же есть у Groq, чего нет у NVIDIA?». Одним из ответов может быть детерминизм — концепция, лежащая в основе архитектуры LPU Groq, которую компания пыталась продвинуть в автомобильной промышленности в 2020 году. Детерминизм имеет существенные преимущества для приложений, требующих функциональной безопасности, включая робототехнику — Хуанг в письме, упомянутом выше, говорит о «приложениях реального времени». Но для этого NVIDIA придется изменить свою риторику, признав, что для периферийных вычислений её ускорители подходят не всегда. В любом случае, у NVIDIA имеются огромные ресурсы и команда квалифицированных специалистов. Если бы она захотела создать ИИ-ускоритель, ориентированный на работу со SRAM, а не HBM, это обошлось бы гораздо дешевле уплаченных за Groq $20 млрд. Кроме того, утверждает EE Times, она могла бы за существенно меньшую сумму пробрести d-Matrix или даже SambaNova, которая готова продаться Intel всего за $1,6 млрд.  Как полагают аналитики EE Times, помимо лицензирования технологии и найма специалистов Groq, в принятии решения купить стартап также сыграли роль коммерческие факторы. Groq имеет обширные партнёрские отношения с крупными компаниями стран Персидского залива. У стартапа также есть соглашения о суверенном ИИ и в других странах, что могло показаться привлекательным для NVIDIA. Тем не менее, одним из главных аргументов в пользу покупки Groq до сих пор было то, что это вполне жизнеспособная и недорогая альтернатива NVIDIA для построения суверенной ИИ-инфраструктуры. То есть покупку Groq можно также объяснить желанием помешать одному из клиентов-гиперскейлеров купить Groq, будь то из-за аппаратной интеллектуальной собственности или уже развёрнутой инфраструктуры. Это может быть Meta✴, Microsoft или даже OpenAI, чьи планы по созданию собственного ИИ-оборудования всё ещё находятся на стадии подготовки или пока имеют умеренный успех, тогда как Google уже готов отдать «на сторону» свои ускорители TPU, а AWS со своими Trainium всё-таки готова сотрудничать с NVIDIA по аппаратной части.  В свою очередь, аналитики ресурса The Register объясняют покупку Groq за столь крупную сумму интересом NVIDIA к «конвейерной архитектуре» (dataflow) стартапа, которая, по сути, создана специально для ускорения вычислений линейной алгебры, выполняемых в ходе инференса. Стоит отметить, что архитектуры с управляемым потоком данных не ограничиваются проектами, ориентированными на SRAM. Например, NextSilicon использует HBM. Groq выбрал SRAM только потому, что это упростило задачу, но нет никаких причин, по которым NVIDIA не могла бы создать dataflow-ускоритель на основе IP-блоков Groq, используя SRAM, HBM или GDDR, пишет The Register. Правильно реализовать такую архитектуру очень сложно, но Groq удалось заставить её работать надлежащим образом, по крайней мере, для инференса, утверждает The Register. Таким образом, Groq даст NVIDIA оптимизированную для инференса вычислительную архитектуру, чего ей так сильно не хватало, полагают аналитики ресурса. Именно этого и не хватает NVIDIA, поскольку у неё фактически нет выделенных чипов для этой задачи. Ситуация изменится с запуском NVIDIA Rubin в 2026 году и их «напарников» Rubin CPX. При этом ускорители Groq LPU в силу малого объёма SRAM для обработки современных LLM необходимо объединять в кластеры из десятков и сотен чипов. Это верно и для других ускорителей примерно того же типа, включая Cerebras. Вместе с тем LPU, по мнению The Register, теоретически могут пригодиться для т.н. спекулятивного декодирования, когда малая модель, не больше нескольких миллиардов параметров, используется для предсказания ответов большой модели. Если малая модель правильно «угадывает» их, общая производительность инференса может вырасти в два-три раза. Стоит ли такая опция $20 млрд, вопрос отдельный, но Хуанг, по-видимому, играет вдолгую.
13.01.2026 [09:03], Руслан Авдеев
Lenovo представила серверы для ИИ-инференса: ThinkSystem SR675i V3/SR650i V4 и ThinkEdge ThinkEdge SE455i V4Lenovo представила новые серверные системы серии Lenovo Hybrid AI Advantage, оптимизированные для ИИ-инференса: ThinkSystem SR675i V3, ThinkSystem SR650i V4 и ThinkEdge SE455i V4. Если ранее акцент делался на решениях для обучения всё более производительных ИИ-моделей, то теперь бизнес обращает всё больше внимания на продукты для инференса. Новинки предлагаются параллельно с ПО для оптимизации инференса — для унификации и получения данных из разных источников для использования ИИ-моделями. 
Источник изображений: Lenovo Флагманской версией серии является ThinkSystem SR675i V3 в исполнении 3U на платформе AMD EPYC Turin 9535 (64C/128T, 2,4 ГГц, TDP 300 Вт). Сервер получил 1,5 Тбайт DDR5-6400 (24 × 64 Гбайт). За хранение данных отвечают до двух E3.S NVMe SSD по 3,84 Тбайт (PCIe 5.0 x4) и до двух M.2 NVMe SSD по 960 Гбайт (PCIe 4.0 x4). Возможна установка восьми ускорителей NVIDIA RTX PRO 6000 Blackwell Server Edition, а также пяти DPU NVIDIA BlueField-3 (4 × 400G, 1 × 200G). IPMI в данной модели не доступен. Для карт расширения доступно до шести слотов PCIe 5.0 х16 и один слот OCP 3.0 x8/x16. За питание отвечают четыре блока Titanium второго поколения (по 2300 Вт), а за охлаждение — пять вентиляторов.  ThinkSystem SR650i V4 позиционируется в качестве системы для инференса и корпоративных рабочих нагрузок. Этот 2U-сервер получил два Intel Xeon Granite Rapids-SP 6530P (32C/64T, 2,3 ГГц, TDP 225 Вт), 512 Гбайт DDR5-6400 (8 × 64 Гбайт), два ускорителя RTX PRO 6000 Blackwell Server Edition. За хранение отвечают два 3,84-Тбайт U.2 NVMe SSD (PCIe 5.0 x4), хотя всего таких слотов восемь, а также RAID1-массив из пары 960-Гбайт M.2 SATA SSD. Всего доступно шесть слотов расширения PCIe 5.0 x16 и два слота OCP 3.0 x8/x16. Имеется двухпортовый 25GbE-адаптер Broadcom 57414 (SFP28). За питание отвечают два Titanium-блока мощностью 2700 Вт каждый, а за охлаждение шесть вентиляторов, но есть и опция установки фирменной СЖО Neptune.  Наконец, Lenovo ThinkEdge SE455i V3 (2U) глубиной всего 440 мм представляет собой компактную модель, предназначенную для периферийного инференса — в ретейле, телекоммуникациях и промышленности. Сервер имеет защищённую конструкцию и может работать при температурах от -5 до +40 °C. Сервер построен на базе одного процессора AMD EPYC Embedded 8534P (64C/128T, 2,3 ГГц, TDP 200 Вт), дополненного 576 Гбайт DDR5-4800 (6 × 96 Гбайт) и двумя ускорителями NVIDIA L4 24 Гбайт (PCIe 4.0 x16). В комплекте идёт один 3,84-Тбайт NVMe SSD и один 960-Гбайт SATA SSD. Имеется два блока питания Platinum второго поколения с возможностью горячей замены. Для карт расширения есть до двух слотов PCIe 5.0 x16 и до четырёх слотов PCIe 4.0 x8, а также один слот OCP 3.0 (PCIe 5.0 x16). Установлен двухпортовый OCP-адаптер Broadcom 57416 (10GbE). IPMI отключён.  Фактически компания предлагает готовые конфигурации, которые можно переконфигурировать лишь слегка, чаще всего добавив накопители и/или сетевые адаптеры. Платформы будут доступны в рамках подписки TruScale. Также компания анонсировала новые сервисы Hybrid AI Factory Services, в том числе консультации по инференсу, которые помогают развёртывать оборудование и управлять им для оптимизации ИИ-производительности.
12.01.2026 [09:54], Владимир Мироненко
От NVMe к GPU: NVIDIA представила платформу хранения контекста инференса ICMSPВместе с официальным анонсом ИИ-платформы следующего поколения Rubin компания NVIDIA также представила платформу хранения контекста инференса NVIDIA Inference Context Memory Storage Platform (ICMSP), позволяющую решить проблемы хранения KV-кеша, который становится всё крупнее по мере роста LLM и решаемых задач. При выполнении инференса контекст растёт по мере генерации новых токенов, часто превышая доступную память ускорителя. В этом случае старые записи вытесняются из памяти, сначала в системную память, а потом на диск, чтобы не пересчитывать всё заново, когда они снова понадобятся. Проблемы существенно усугубляются при работе с агентным ИИ и обработке рабочих нагрузок с большим контекстом. Агентный ИИ приводит к появлению контекстных окон в миллионы токенов, а объём моделей может составлять уже триллионы параметров. В настоящее время эти системы полагаются на долговременную память для хранения контекста, позволяя агентам опираться на предыдущие рассуждения и расширять их на протяжении многих шагов, а не начинать с нуля при каждом запросе. По мере увеличения контекстных окон растут требования к ёмкости KV-кеша, делая эффективное хранение и повторное использование данных, в том числе совместное использование различными сервисами инференса, крайне важными для повышения производительности системы. Контекст инференса является производным и пересчитываемым, что требует архитектуры хранения, которая отдаёт приоритет энергоэффективности и экономичности, а также скорости и масштабируемости, а не традиционной надёжности хранения данных. 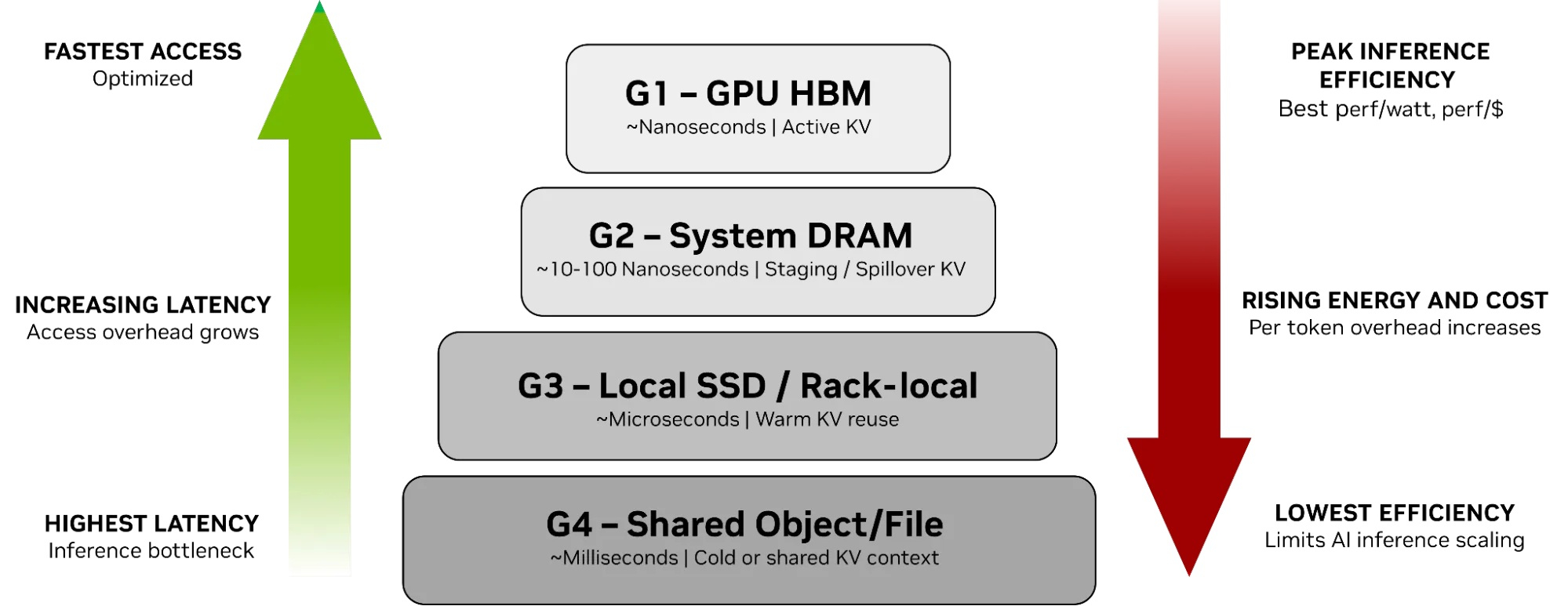
Источник изображений: NVIDIA NVIDIA отметила, что ИИ-фабрикам необходим дополнительный, специально разработанный уровень контекста, который рассматривает KV-кеш как собственный класс данных, предназначенный для ИИ, а не принудительно помещает его в дефицитную память HBM или в хранилище общего назначения. Платформа ICMSP использует DPU BlueField-4 для создания специализированного уровня памяти, чтобы преодолеть разрыв между высокоскоростной памятью GPU и масштабируемым общим хранилищем. Хранилище KV-кеша на основе NVMe должно эффективно обслуживать ускорители, узлы, стойки и кластеры целиком, говорит компания. Платформа ICMSP создаёт новый уровень (G3.5 на схеме выше) — флеш-память, подключённая через Ethernet и оптимизированная специально для KV-кеша. Этот уровень выступает в качестве долговременной агентной памяти на уровне ИИ-инфраструктуры, достаточно большой для одновременного хранения общего, развивающегося контекста многих агентов, но при этом достаточно близко расположенной для частой работы с памятью ускорителей и хостов. BlueField-4 отвечает за аппаратное ускорение размещения кеша и устранение накладных расходов на подготовку и перемещение данных и обеспечение безопасного, изолированного доступа к ним узлов с GPU, снижая зависимость от CPU хоста и минимизируя сериализацию и работу с системной памятью хоста. Программные продукты, такие как фреймворк DOCA, механизм разгрузки KV-кеша Dynamo и входящее в комплект ПО NIXL (Nvidia Inference Transfer Library), обеспечивают интеллектуальное, ускоренное совместное использование данных KV-кеша между ИИ-узлами. А Spectrum-X Ethernet обеспечивает оптимизированный RDMA-интерконнект, который связывает ICMS и узлы GPU. 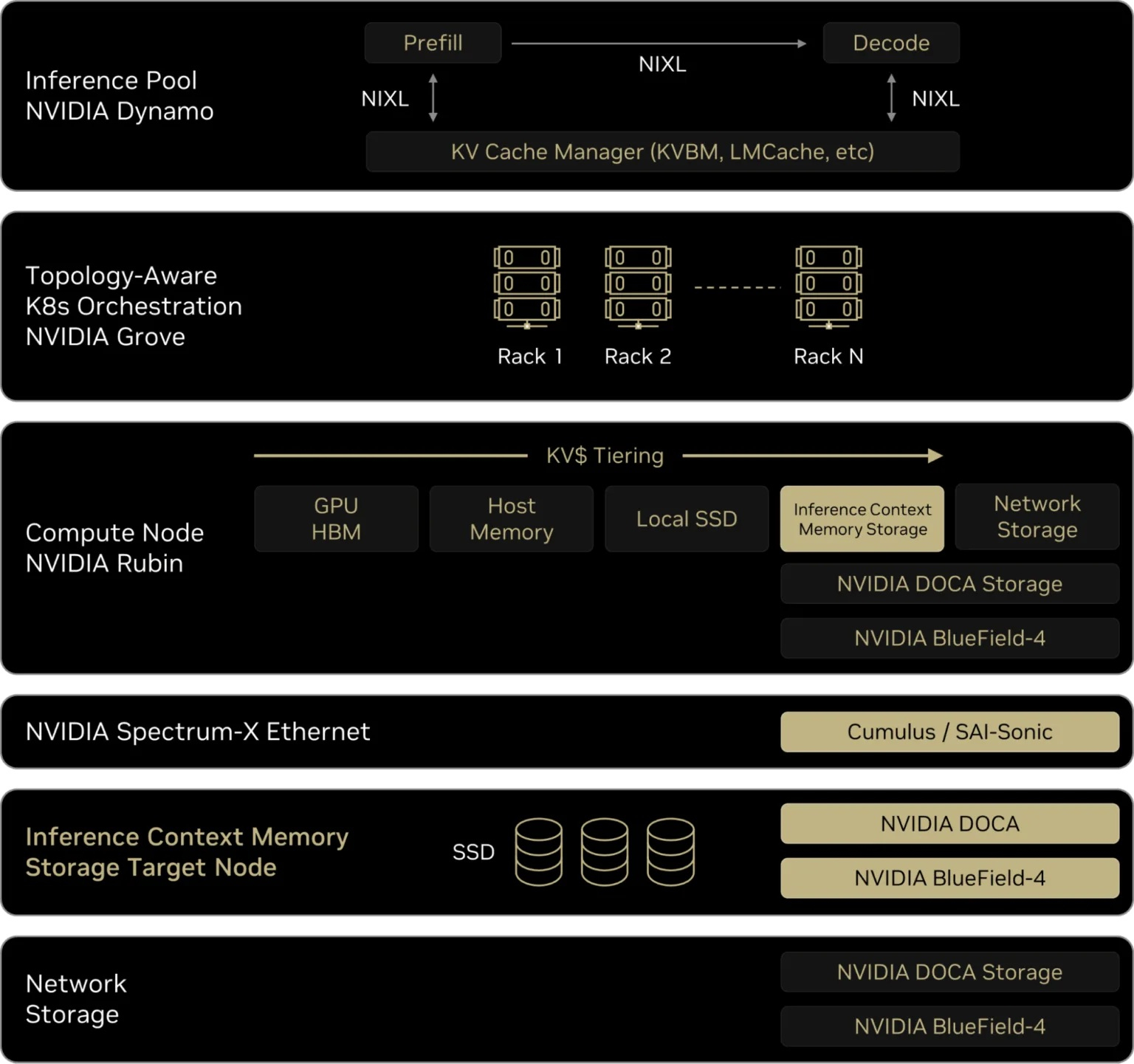 KV-кеш принципиально отличается от корпоративных данных: он является временным, производным и может быть пересчитан в случае потери. В качестве контекста инференса он не требует надёжности, избыточности или обширных механизмов защиты данных, разработанных для долговременных записей. Выделяя KV-кеш как отдельный, изначально предназначенный для ИИ класс данных, ICMS устраняет избыточные накладные расходы, обеспечивая повышение энергоэффективности до пяти раз по сравнению с универсальными подходами к хранению данных, сообщила NVIDIA. А своевременная подготовка и отдача данных более полно нагружает ускорители, что позволяет увеличить темп генерации токенов до пяти раз. Как сообщила NVIDIA, первоначальный список её партнёров, готовых обеспечить поддержку ICMSP с BlueField-4, который будет доступен во II половине 2026 года, включает AIC, Cloudian, DDN, Dell, HPE, Hitachi Vantara, IBM, Nutanix, Pure Storage, Supermicro, VAST Data и WEKA.
10.01.2026 [09:18], Руслан Авдеев
Не «пузырь», а «суперцикл» — к 2030 году на ЦОД будет потрачено $3 трлнСогласно докладу JLL 2026 Global Data Center Outlook, до 2030 года на ЦОД потребуется $3 трлн вложений. Это крупнейший инвестиционный «суперцикл» в истории. В докладе учитываются данные рынка, региональные прогнозы и стратегические сдвиги в индустрии ЦОД. По оценкам JLL, в 2025–2030 гг. появятся ЦОД общей мощностью около 97 ГВт. Общая мощность ЦОД достигнет примерно 200 ГВт, т.е. фактически удвоится, что потребует значительных инвестиций. Как считают в JLL, такой рост приведёт к созданию активов коммерческой недвижимости в объёме $1,2 трлн, что потребует около $870 млрд нового долгового финансирования. Кроме того, пользователи ЦОД потратят $1–$2 трлн на обновление парка ИИ-ускорителей и сетевой инфраструктуры. В совокупности инвестиции достигнут приблизительно $3 трлн к 2030 году. Как сообщает Datacenter Dynamics, в рамках прогноза JLL среднегодовой темп прироста глобального сектора ЦОД (CAGR) составит 14 % до 2030 года. Но, например, оценка Omdia на тот же период более консервативна. Несмотря на опасения экспертов, допускающих появление «ИИ-пузыря», в JLL утверждают, что существующие метрики не свидетельствуют о его возможном формировании. JLL утверждает, что сектор сохраняет здоровые фундаментальные показатели — глобальную загрузку мощностей на уровне 97 %, а 77 % строящихся уже объектов забронированы арендаторами. 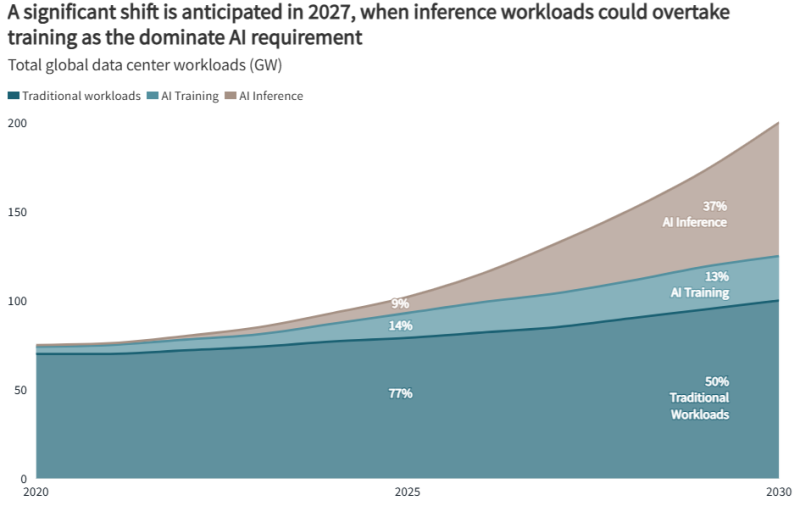
Источник изображения: JLL Research Впрочем, есть и некоторые проблемы, негативно влияющие на мировой рынок ЦОД. Например, ограничения в цепочках поставок ведут к задержкам сроком выполнения заказов на оборудование по всему миру. По данным компании, среднее время выполнения достигает 33 недель, что на 50 % дольше в сравнении с 2020 годом. Кроме того, проблемы с цепочками отражаются на стоимости строительства, CAGR в этом секторе составляет 7 % ежегодно. По прогнозам JLL, в 2026 году стоимость строительства увеличится на 6 %, до $11,3 млн/МВт. Тем не менее, аналитики JLL подчёркивают, что увеличение сроков выполнения заказов свидетельствует о росте уверенности в рынке, а не о потенциальном спаде на нём. 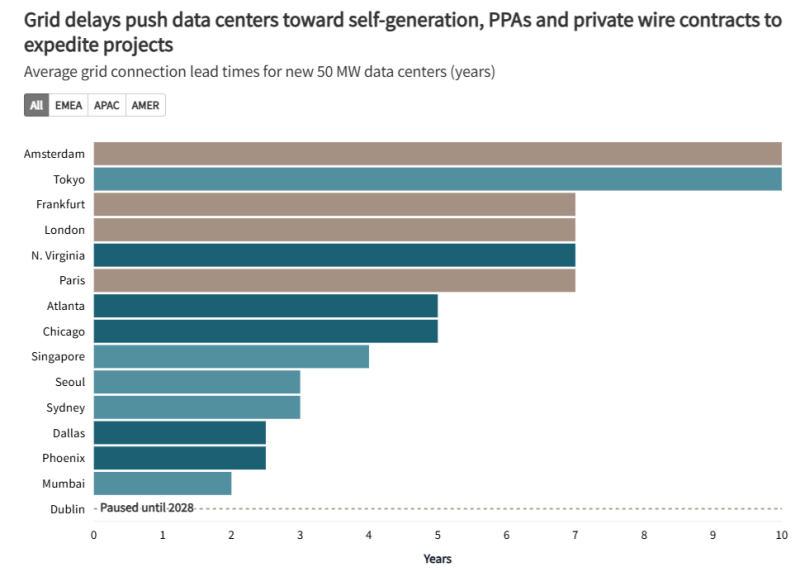
Источник изображения: JLL Research Ключевой проблемой остаются ограничения, связанные с энергетикой. Прогнозируется рост соответствующей индустрии, связанный с энергоёмкими ИИ-сервисами. В частности, время присоединения ЦОД к энергосетям на основных рынках превышает четыре года, поэтому придётся прибегнуть к «энергетическим инновациям», а некоторые операторы дата-центров стремятся организовать локальные мощности для генерации энергии. JLL ожидает, что ключевую роль в масштабировании поставок энергии в США будет играть газовая энергетика, причём и как временное, и как постоянное решение для получения энергии непосредственно на территории кампусов. Впрочем, отмечается, что для APAC и EMEA такие решения менее привлекательны, поскольку не являются «устойчивыми». Потенциальным надёжным источником электричества называется и атомная энергетика, но в JLL признают малую вероятность того, что до 2030 года появятся новые значительные мощности АЭС. 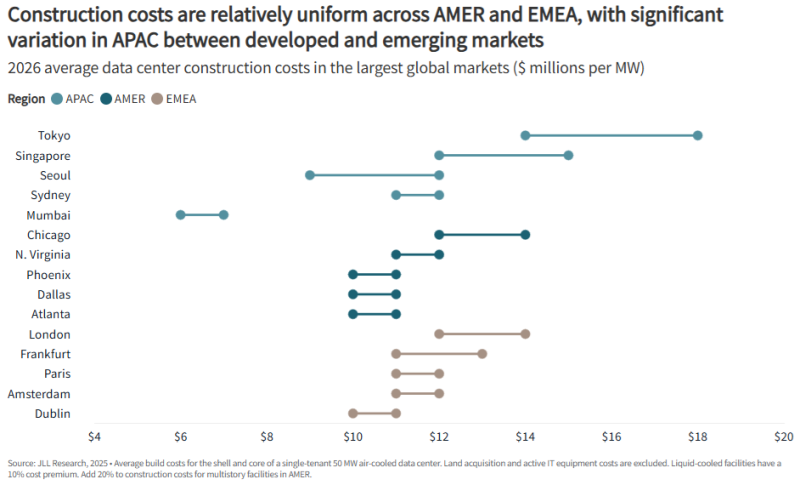
Источник изображения: JLL Research По данным JLL, на ИИ-нагрузки к 2030 году, возможно, будет приходиться половина всех мощностей ЦОД, т.е. их доля увеличится вдвое по сравнению с 2025 годом. Также прогнозируется, что к 2027 году затраты на инференс будут больше, чем на обучение, благодаря чему спрос может сместиться с централизованных кластеров на распределённые региональные центры. До 2030 года на американские проекты будет приходиться около половины всех новых мощностей ЦОД, там же будут отмечаться и самые высокие темпы прироста рынка. В Азиатско-Тихоокеанском регионе мощности почти удвоятся, с 32 ГВт до 57 ГВт к 2030 году, а EMEA прирастёт на скромные 13 ГВт. 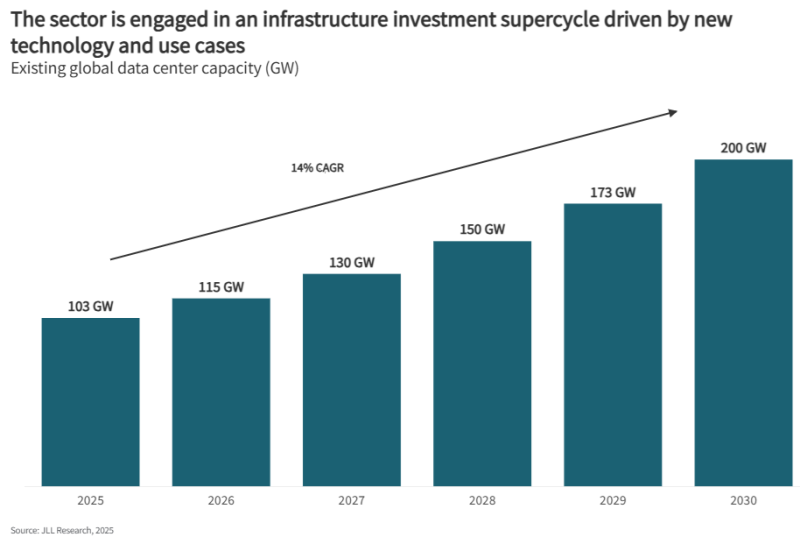
Источник изображения: JLL Research В докладе также анализируется быстрый рост на связанных с сектором рынках капитала. На базовые, с низким уровнем риска инвестиционные стратегии теперь приходится около 24 % активности по привлечению средств на ЦОД. За последние пять лет объём слияний и поглощений на рынке составил более $300 млрд и ожидается, что в будущем инвестиции сместятся в сторону рекапитализации и совместных предприятий. В компании уверены, что стремительное появление крупных сделок в сфере ИИ и неооблачного сектора определило 2025 год, как год трансформации сектора ЦОД и инфраструктуры. Структурирование капитала для новых компаний может оказаться сложным, поскольку кредиторы и партнёры по акционерному капиталу требуют надлежащих механизмов обеспечения защиты многомиллиардных инвестиций. Масштаб и особые требования к инфраструктуре сделок требуют инноваций при финансировании, позволяющих обеспечить баланс роста технологий ИИ и неооблачных проектов с надлежащим снижением рисков. Стоит отметить, что в сентябре 2025 года Bain Global Technology Report прогнозировала, что расходы ИИ-отрасли к 2030 году могут оказаться на $800 млрд больше её доходов.
25.12.2025 [02:15], Игорь Осколков
NVIDIA купит за $20 млрд активы разработчика ИИ-ускорителей Groq — это самая дорогая покупка в истории компанииNVIDIA приобретёт активы Groq, своего конкурента в области ИИ-ускорителей, за $20 млрд, передаёт CNBC. Сама Groq заявила, что «заключила неисключительное лицензионное соглашение с NVIDIA на технологии инференса» и что основатель и генеральный директор Groq Джонатан Росс (Jonathan Ross), а также президент компании Санни Мадра (Sunny Madra) и другие высокопоставленные сотрудники «присоединятся к NVIDIA, чтобы помочь продвижению и масштабированию лицензированной технологии». При этом Groq продолжит свою деятельность как независимая компания под руководством Саймона Эдвардса (Simon Edwards). Финансовый директор Nvidia Колетт Кресс (Colette Kress) отказалась комментировать сделку. По-видимому, речь фактически идёт о поглощении Groq, а столь необычная форма сделки выбрана, по примеру других, в попытке снизить внимание к ней регулирующих органов. Стоимость сделки официально не называется, однако Алекс Дэвис (Alex Davis), глава Disruptive, которая инвестировала в Groq более $500 млн, называет сумму в $20 млрд, причём «живыми» деньгами. Дэвис сообщил CNBC, что NVIDIA получит все активы Groq, за исключением её облачного бизнеса. Groq заявила, что «GroqCloud продолжит работать без перебоев». В электронном письме сотрудникам, полученном CNBC, глава NVIDIA Дженсен Хуанг (Jensen Huang) заявил, что сделка расширит возможности NVIDIA: «Мы планируем интегрировать ускорители Groq в архитектуру NVIDIA AI Factory, расширив платформу для обслуживания ещё более широкого спектра задач инференса и рабочих нагрузок в реальном времени». Хуанг добавил: «Хотя мы пополняем наши ряды талантливыми сотрудниками и лицензируем интеллектуальную собственность Groq, мы не приобретаем Groq как компанию». 
Источник изображения: Groq Эта сделка является крупнейшей покупкой NVIDIA за всю историю. До этого самой крупной сделкой была покупка Mellanox почти за $7 млрд в 2019 году. В конце октября у NVIDIA было $60,6 млрд наличных средств и краткосрочных инвестиций, что на $13,3 млрд больше, чем в начале 2023 года. По схожей с Groq схеме была организована и сделка c Enfabrica, в рамках которой NVIDIA заплатила $900 млн деньгами и акциями за лицензирование технологий и переход главы Enfabrica Рочана Санкара (Rochan Sankar) и других ключевых в NVIDIA. Всего три месяца назад Groq, основанная в 2016 году разработчиками ИИ-ускорителей Google TPU, привлекла $750 млн при оценке примерно в $6,9 млрд. Раунд возглавила Disruptive, к которой присоединились Blackrock, Neuberger Berman, Deutsche Telekom Capital Partners, Samsung, Cisco, D1, Altimeter, 1789 Capital и Infinitum. Повлияло ли на решение NVIDIA слухи о намерении Intel купить разработчика ИИ-ускорителей для инференса SambaNova, который наряду с Cerebras является одним из немногих стартапов, способных составить хоть какую-то серьёзную конкуренцию NVIDIA, не уточняется. Сама Groq планировала достичь выручки в $500 млн в этом году. По словам Дэвиса, компания не планировала продажу, когда к ней обратилась NVIDIA. В сентябре NVIDIA объявила о намерении вложить $5 млрд в Intel, а также инвестировать до $100 млрд в OpenAI. Впрочем, последняя сделка носит циклический характер и пока далеко не продвинулась.
16.12.2025 [17:50], Владимир Мироненко
Универсальный ИИ-процессор Electron E1 в 100 раз энергоэффективнее традиционных CPUСтартап из Питтсбурга (Pittsburgh) Efficient Computer выпустил оценочный набор универсального процессора Electron E1 (EVK). Как сообщает компания, Electron E1 представляет собой настоящую альтернативу чипам с использованием традиционной архитектуры фон Неймана, способную обеспечить значительно более высокую энергоэффективность, в 100 раз превышающую показатели обычных маломощных процессоров, таких как Arm Cortex-M33 и Cortex-M85. Electron E1 предназначен для выполнения сложных задач обработки сигналов и инференса. Он основан на т.н. Efficient Fabric, разработанной компанией запатентованной архитектуре пространственного потока данных, которая позволяет снизить «чрезмерное» энергопотребление, связанное с перемещением данных между памятью и вычислительными ядрами, характерное для традиционных систем фон Неймана. При этом «разработчики по-прежнему получают привычный опыт программирования, но с существенно более высокой энергоэффективностью». Генеральный директор Efficient Брэндон Лючия (Brandon Lucia) в интервью EE Times заявил, что предыдущие попытки отойти от подхода фон Неймана так и не были полностью реализованы: «Были мимолётные альтернативы, которые появлялись и исчезали». Он отметил, что одним из ограничений во многих альтернативах был отказ от универсальности вычислений: «Это действительно критически важно». Нечто похожее предлагает и NextSilicon Maverick. 
Источник изображения: Efficient Computer Процессор включает 128 Кбайт сверхэкономичной кеш-памяти, 3 Мбайт SRAM и 4 Мбайт энергонезависимой MRAM, а его производительность может достигать 21,6 GOPS (млрд операций в секунду) при 200 МГц в высоковольтном режиме и 5,4 GOPS при 50 МГц в низковольтном режиме. Архитектура Fabric коренным образом переосмысливает способ выполнения вычислений, уменьшая необходимость в перераспределении данных между памятью и процессорами, говорит Лючия. Это достигается за счёт пространственного отображения операций по сетке вычислительных элементов, каждый из которых активируется только тогда, когда доступны его входные данные в отличие от непрерывного цикла инструкций и косвенной адресации данных, которые доминируют в традиционных конвейерах CPU. Лючия отметил, что универсальный процессор важен для ИИ-технологий, поскольку он представляет собой нечто гораздо большее, чем просто алгоритмы в физическом мире — он обеспечивает, в том числе, интеграцию данных с датчиков, цифровую обработку сигналов, шифрование и преобразование: «Если ваша архитектура специализируется только на одном типе вычислений, все остальные функции остаются невостребованными». 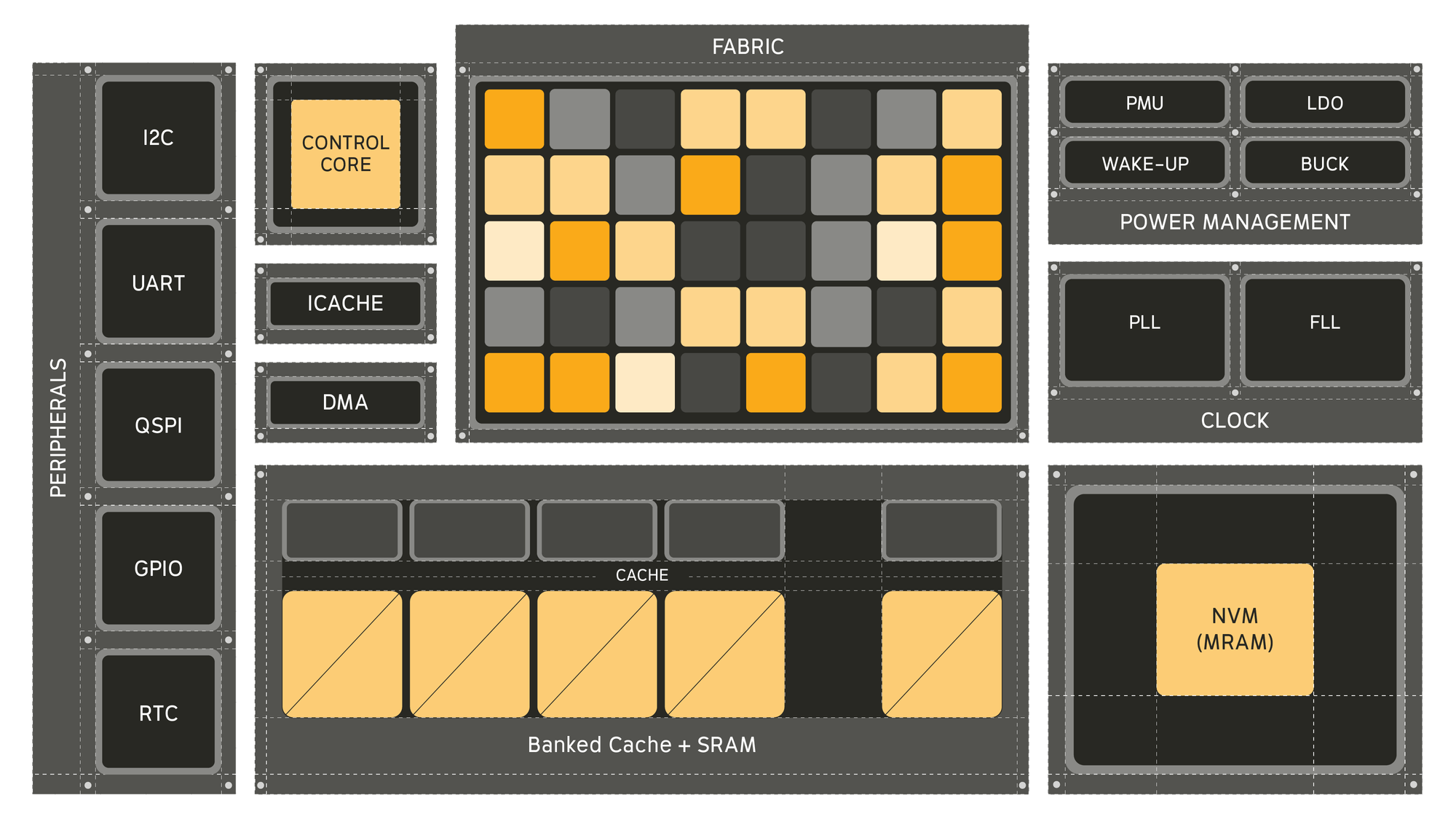
Источник изображения: Efficient Computer По словам главы Efficient, Electron E1 разработан для поддержки всего кода, необходимого для работы приложения, что делает его идеальным для периферийных вычислений, встроенных систем и ИИ-приложений: «Разработчики могут использовать уже имеющийся у них код». Лючия отметил, что процессор лучше всего подходит для устройств, требующих длительного времени автономной работы, а также условий ограниченного энергопотребления, например, для использования в дронах и промышленных датчиках. Чип уже используется в устройствах партнёра Efficient, компании BrightAI, позволяя обрабатывать ИИ-нагрузки в реальном времени на периферии и снижая потребность в энергоемких облачных вычислениях для таких задач, как обработка сигналов и инференс. Лючия сообщил, что компания видит большие перспективы для использования чипа в робототехнике, автомобилестроении, космосе и оборонных приложениях, которые имеют ограничения по размерам и мощности. Что касается E1 EVK, то он, по словам компании, разработан для того, чтобы максимально упростить изучение потенциала нового процессора. Независимо от того, разрабатываете ли вы новое ПО, проводите анализ энергопотребления или портируете существующее ПО, EVK предоставляет:
В случае отсутствия оборудования можно использовать решение Electron E1 Cloud EVK, которое предоставляет размещённую среду со всеми возможностями физической платы. Как физический EVK, так и облачный EVK доступны в рамках программы раннего доступа Efficient Computer. |
|

