Материалы по тегу: инференс
|
13.03.2026 [17:10], Руслан Авдеев
Crusoe представила периферийные ИИ ЦОД Crusoe Edge Zones на базе модулей SparkКомпания Crusoe анонсировала запуск периферийных зон доступности Crusoe Edge Zones на базе модульных ЦОД Crusoe Spark, обеспечивающих ИИ-вычисления практически в любой локации. Edge Zones предоставят ИИ-инфраструктуру с низкой задержкой и позволят внедрять суверенные ИИ-решения клиентам со всего мира. Crusoe Edge Zones на базе Crusoe Spark — дальнейшее масштабирование вертикально интегрированных ИИ-фабрик. Модули Crusoe Spark выпускаются на недавно представленном заводе Spark Factory. Благодаря контролю над полным стеком работы над ИИ-инфраструктурой — от заводской сборки до облачной оркестрации — Crusoe способна развёртывать новые периферийные облака всего за три месяца. При этом они значительно дешевле, чем классические ЦОД. Зоны оптимизированы для работы с облачной платформой Crusoe Cloud и инференс-службой Managed Inference. Благодаря запатентованной технологии Crusoe MemoryAlloy можно сократить «время до первого токена» в 9,9 раза. Кроме того, система обеспечит в пять раз более высокую пропускную способность, чем стандартные конфигурации для инференса, говорит Crusoe. В результате периферийные пользователи получат доступ к сверхэффективной инфраструктуре с высоким быстродействием. 
Источник изображения: Crusoe Ключевые сценарии применения:
В компании уверены, что в будущем ИИ-инфраструктура будет включать как гигантские кампусы гигаваттного масштаба для обучения ИИ, так и распределённые модули для обработки информации на периферии. На данный момент Crusoe инвестирует в оба направления. Концепция сетей модульных ЦОД, практически независимых от крупных кампусов, в последнее время на фоне конфликта на Ближнем Востоке становится всё популярнее. Независимо от этих событий недавно Akamai пообещала развернуть тысячи ускорителей NVIDIA RTX Blackwell для распределённого инференса.
12.03.2026 [09:13], Сергей Карасёв
Meta✴ представила четыре новых ИИ-ускорителя MTIA — с FP8-производительностью до 10 ПфлопсКомпания Meta✴ анонсировала ИИ-ускорители MTIA (Meta✴ Training and Inference Accelerator) сразу четырёх новых поколений. Это решения MTIA 300, 400, 450 и 500: внедрение некоторых из них уже началось, тогда как развёртывание других запланировано на текущий и следующий годы. Устройства ориентированы на различные ИИ-нагрузки, включая инференс и генеративные сервисы. ИИ-процессор MTIA первого поколения (MTIA 100), напомним, дебютировал в 2023 году: изделие получило в общей сложности 128 ядер RISC-V и 128 Мбайт памяти SRAM. В 2024-м вышло решение второго поколения MTIA 200 с повышенной производительностью. В каждом из четырёх новых продуктов, по заявлениям Meta✴, упор сделан на улучшении вычислительных характеристик, пропускной способности памяти и эффективности. Конструкция ускорителя MTIA 300 включает один вычислительный чиплет, два сетевых чиплета (NIC) и несколько стеков HBM. Каждый вычислительный чиплет состоит из матрицы процессорных элементов (PE), содержащих по два векторных ядра RISC-V. Объём памяти HBM составляет 216 Гбайт, её пропускная способность — 6,1 Тбайт/с. Заявленная ИИ-производительность в режимах FP8/МХ8 достигает 1,2 Пфлопс. Показатель TDP равен 800 Вт. Реализован движок DMA для взаимодействия с локальной памятью. Ускоритель, уже применяющийся в дата-центрах Meta✴, оптимизирован для задач обучения по принципу Rephrase and Respond (R&R). 
Источник изображений: Meta✴ Ступенью выше располагается решение MTIA 400 общего назначения. Оно объединяет два вычислительных чиплета, а объём памяти HBM увеличен до 288 Гбайт (пропускная способность — 9,2 Тбайт/с). У этого ускорителя быстродействие на операциях FP8/МХ8 составляет до 6 Пфлопс. Величина TDP равна 1200 Вт. 72 ускорителя MTIA 400, «провязанные» в одной стойке, образуют единый масштабируемый домен. При этом может использоваться жидкостное охлаждение с воздушной поддержкой или полностью жидкостное охлаждение. На сегодняшний день Meta✴ завершила тестирование MTIA 400 и находится на этапе внедрения изделий. Вариант MTIA 450, в свою очередь, ориентирован на задачи инференса в сфере генеративного ИИ. Этот ускоритель также использует 288 Гбайт памяти HBM, но её пропускная способность достигает 18,4 Тбайт/с. Значение TDP подросло до 1400 Вт. Решение обеспечивает ИИ-производительность в режимах FP8/МХ8 до 7 Пфлопс, в режиме МХ4 — 21 Пфлопс. MTIA 450 также поддерживает смешанные вычисления с низкой точностью без дополнительного программного преобразования данных. Внедрение этой модели в ЦОД Meta✴ намечено на начало 2027 года. 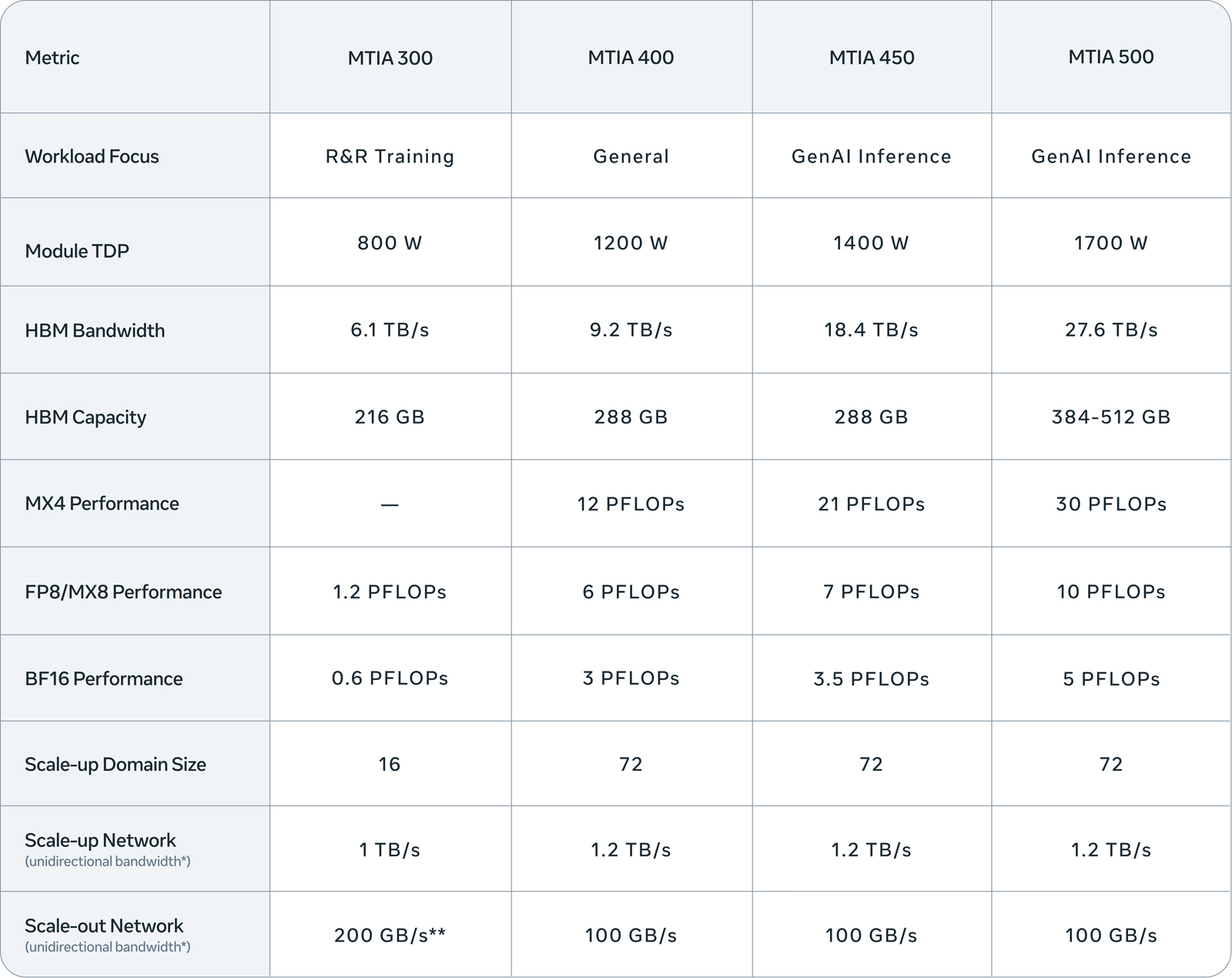 Наконец, самый мощный из готовящихся ускорителей — MTIA 500 — также рассчитан на инференс в сфере генеративного ИИ. Используется конфигурация вычислительных чиплетов 2 × 2, окруженных несколькими стеками HBM и двумя сетевыми чиплетами. Это устройство может использовать от 384 до 512 Гбайт памяти HBM с пропускной способностью до 27,6 Тбайт/с. Показатель TDP достигает 1700 Вт. Заявленная производительность FP8/МХ8 — до 10 Пфлопс, МХ4 — до 30 Пфлопс. Массовое внедрение MTIA 500 запланировано на 2027 год. На системном уровне MTIA 400, 450 и 500 используют одно и то же шасси, стойку и сетевую инфраструктуру. Это обеспечивает возможность модернизации с минимальными затратами при переходе на изделия следующего поколения.
06.03.2026 [17:01], Руслан Авдеев
Инференс-нагрузки Perplexity прописались в облаке CoreWeaveКомпания CoreWeave объявила о заключении долгосрочного соглашения с Perplexity. Стратегическое партнёрство призвано обеспечить выполнение рабочих ИИ-нагрузок последней, также предусмотрено пилотное внедрение в обеих организациях новых сервисов. Утверждается, что CoreWeave позволяет клиентам переходить от разработки непосредственно к внедрению без перепроектирования систем и инструментов. Соглашение предусматривает, что платформа CoreWeave будет использоваться Perplexity для инференса нового поколения. Выделенные кластеры на основе суперускорителей NVIDIA GB200 NVL72 гарантируют соответствие инфраструктуры облачного провайдера изменению задач Perplexity и высоким требованиям экосистемы на основе Sonar и Search API. В своё время Perplexity начинала с выполнения задач инференса с помощью CoreWeave Kubernetes Service и применения платформы W&B Models для (до-)обучения моделей и управления ими на всех этапах, от экспериментального до ввода в эксплуатацию. Дополнительно CoreWeave повсеместно внедрит в своей организации инструменты Perplexity Enterprise Max, что позволит её специалистам искать информацию в интернете и внутренней базе данных, проводить углублённые исследования, анализировать данные и визуализировать их. Партнёрство является свидетельством «мультиоблачной» стратегии Perplexity. Чуть более месяца назад Microsoft заключила крупную облачную сделку с Perplexity, но ключевым провайдером ИИ-поисковика останется AWS. 
Источник изображения: CoreWeave/Perplexity Это лишь последняя из удачных сделок CoreWeave, сдающей в аренду мощности даже таким компаниям, как Microsoft, Meta✴ и OpenAI. В 2025 году компания получила средства от NVIDIA, которая арендовала свои же ускорители у CoreWeave. В сентябре 2025 года компания обязалась выкупить у неооблачного оператора все нераспроданные мощности. CoreWeave на волне роста спроса на облачные услуги удвоит в 2026 году капитальные затраты, хотя некоторые инвесторы сомневаются в целесообразности таких мер.
06.03.2026 [08:58], Руслан Авдеев
Akamai развернёт тысячи ускорителей NVIDIA RTX Blackwell для распределённого инференсаОблачный провайдер Akamai анонсировал покупку «тысяч» ИИ-ускорителей для развития своей распределённой облачной инфраструктуры по всему миру. Развёртывание новых чипов позволит создать единую оптимизированную ИИ-платформу для быстрого и распределённого инференса в глобальной сети Akamai. По словам компании, она готовит базовую инфраструктуру для «физического» и «агентного» ИИ, где решения необходимо принимать в режиме реального времени. Ранее компания анонсировала проект Akamai Inference Cloud. Как заявляет Akamai, пока крупные облачные бизнесы расширяют проекты обучения ИИ, компания сосредоточилась на удовлетворении потребностей эпохи инференса. Централизованные ИИ-фабрики имеют важное значение для создания моделей, но для их масштабной эксплуатации необходима децентрализованная «нервная система». Внедрение NVIDIA Blackwell в распределённая инфраструктуру, как ожидается, позволит ИИ взаимодействовать с «физическим» миром на местах — с системами автономной доставки, умными энергосетями, роботами-хирургами, антифрод-системами т.п. — без географических и финансовых ограничений, характерных для классических облаков. Интеграция ускорителей Blackwell обеспечит:
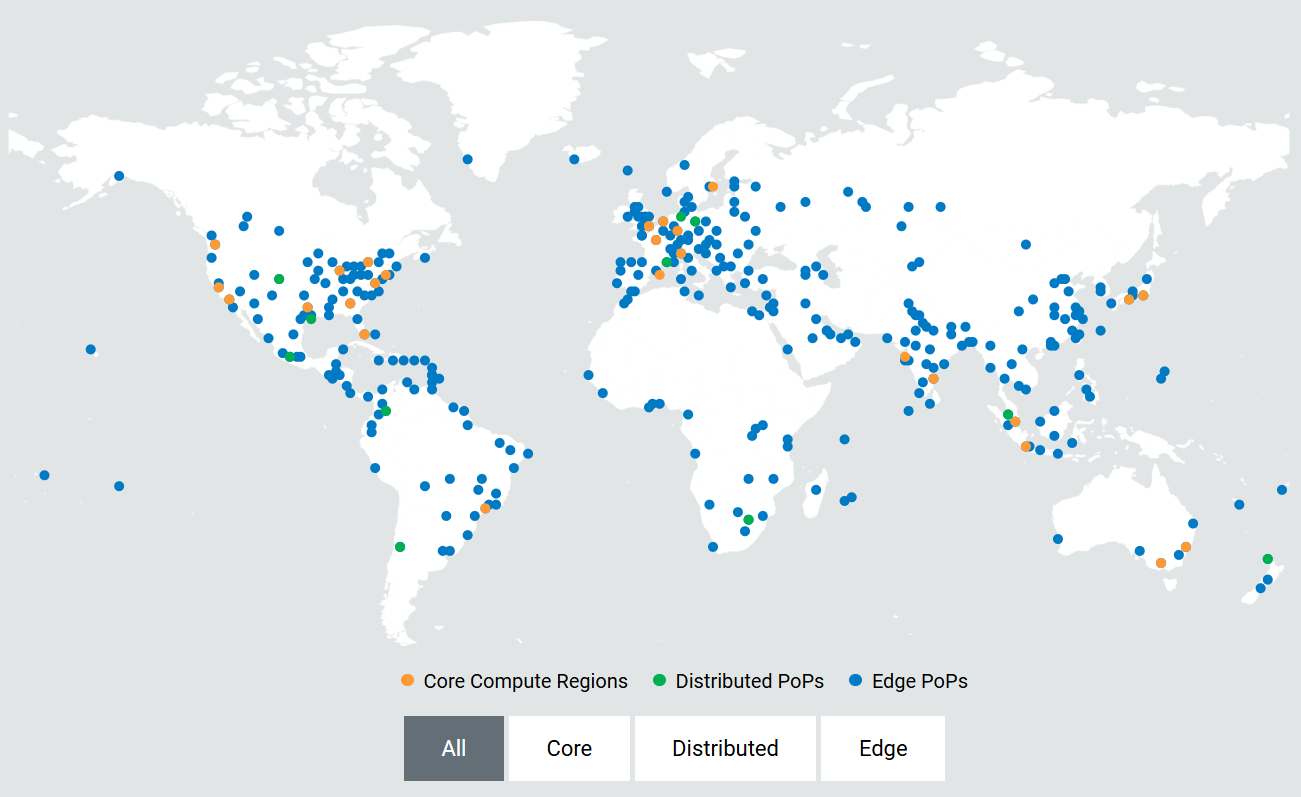
Источник изображения: Akamai Предоставляя инструментарий для выполнения задач ближе к конечным пользователям, Akamai обеспечивает высокую пропускную способность и, как утверждается, одновременно снижает задержку до 2,5 раз. Это позволит бизнесам экономить до 86 % на инференсе в сравнении с обычными облачными компаниями-гиперскейлерами. Платформа объединяет серверы на основе ускорителей NVIDIA RTX Pro 6000 Blackwell Server Edition с DPU NVIDIA BlueField-3 и распределённую облачную инфраструктуру Akamai с 4,4 тыс. точек присутствия. Cloudflare применяет платформу с «бессерверным» инференсом в более чем 200 городах. Её Workers AI обеспечивают глобальный инференс с задержкой менее 100 мс без специального выделения кластеров ускорителей. Fastly применяет платформу периферийных вычислений, но предлагает меньшее количество локальных точек присутствия (PoP) для выполнения задач на GPU/CPU.
26.02.2026 [23:11], Владимир Мироненко
AMD инвестирует в Nutanix $250 млн и создаст совместную платформу для агентного ИИAMD и Nutanix объявили о заключении соглашения о многолетнем стратегическом партнёрстве с целью разработки открытой инфраструктурной платформы для корпоративных приложений в области агентного ИИ, первая версия которой должна появиться к концу этого года. В рамках соглашения AMD инвестирует $150 млн в обыкновенные акции Nutanix по цене $36,26/шт. и предоставит до $100 млн дополнительного финансирования для совместных инженерных и маркетинговых инициатив, а также сотрудничества в области выхода на рынок с целью ускорения внедрения совместной платформы агентного ИИ. Ожидается, что сделка по инвестиции в акционерный капитал будет завершена во II квартале 2026 года после получения необходимых разрешений регулирующих органов. Совместно разработанная платформа агентного ИИ предназначена для обеспечения ускорения инференса на базе ускорителей Instinct и процессоров EPYC, HPC и оркестрации с использованием EPYC, а также унифицированного управления жизненным циклом с помощью Nutanix Enterprise AI, что позволит развёртывать открытые и коммерческие ИИ-модели без зависимости от вертикально интегрированных стеков ИИ. В рамках сделки Nutanix также интегрирует ПО AMD ROCm и Enterprise AI в свою облачную платформу Nutanix Cloud и платформу Nutanix Kubernetes, отметил ресурс SiliconANGLE. 
Источник изображения: AMD В настоящее время Nutanix поддерживает только ускорители NVIDIA. Благодаря этой сделке Nutanix будет поддерживать и ускорители AMD, что, как ожидается, позволит AMD расширить круг клиентов. «Наша цель — предоставить клиентам выбор, — заявил глава Nutanix Раджив Рамасвами (Rajiv Ramaswami) изданию The Register. — NVIDIA — лидер рынка, а AMD — ещё одна крупная компания, владеющая платформой». О сделке было объявлено после того, как Nutanix сообщила о финансовых результатах за II квартал 2026 финансового года. Выручка компании выросла год к году на 10 % до $723 млн. Скорректированная прибыль на акцию составила 56¢. Оба показателя превысили прогнозы аналитиков, ожидавших $710,35 млн выручки и 44¢ на акцию скорректированной прибыли. Высокие показатели были достигнуты благодаря росту клиентской базы: годовой доход от регулярных платежей по состоянию на конец января составил $2,36 млрд, что на 16 % больше, чем годом ранее. Рамасвами сообщил, что за прошедший квартал компания заключила 1000 новых контрактов с клиентами, и большинство из них намерены перейти с VMware на Nutanix. Вместе с тем дефицит в цепочках поставок процессоров и комплектующих, включая память и накопители, привёл к тому, что компания снизила свой прогноз на весь год с $2,82–$2,86 млрд до $2,80–$2,84 млрд. После объявления о сделке AMD и Nutanix акции Nutanix выросли в цене на 15 %.
25.02.2026 [17:31], Владимир Мироненко
Axelera AI привлекла $250 млн для разработки европейских ИИ-чиповПроизводитель ИИ-чипов Axelera AI из Эйндховена (Нидерланды) привлёк $250 млн в рамках раунда финансирования, который возглавил европейский венчурный фонд Innovation Industries. Наряду с имеющимися инвесторами в нём также приняли участие BlackRock и SiteGround Capital в качестве новых инвесторов. Это одна из крупнейших инвестиций на сегодняшний день в европейскую компанию по производству ИИ-чипов, отметило агентство Reuters. Генеральный директор Фабрицио Дель Маффео (Fabrizio Del Maffeo) указал в своём заявлении, что компания использует привлечённые средства для расширения производства своего чипа Europa, запуск которого запланирован до июня, а также для дальнейшей разработки ПО, упрощающего использование чипов для клиентов. 
Источник изображений: Axelera AI У Axelera «большой портфель возможностей, требующих инвестиций, и этот портфель растет», — заявил Фабрицио Дель Маффео в интервью Bloomberg. По его словам, клиенты ищут более доступные вычислительные ресурсы, более высокую эффективность и способы сокращения расходов на дорогостоящую ИИ-инфраструктуру. Дель Маффео сообщил, что инференс может осуществляться на децентрализованной архитектуре, которая потребляет меньше энергии. Большие потребности крупных ЦОД в энергии, необходимой для обеспечения вычислительных мощностей для обучения ИИ-моделей, подвергаются критике на фоне опасений по поводу перегрузки электросетей и резкого роста цен на электроэнергию для потребителей, отметил Bloomberg.  С момента основания в июле 2021 года Axelera AI привлекла более $450 млн в виде акционерного капитала, грантов и венчурного кредитования. В частности, в марте 2025 года Axelera получила грант в размере €61,6 млн ($66 млн) от EuroHPC JU в рамках проекта Digital Autonomy with RISC-V for Europe (DARE) по разработке передового чипа Titania для использования в так называемых ИИ-фабриках. Ожидается, что этот чип появится в 2027 году. Компания отметила, что финансовый раунд прошёл в тот момент, когда она начала поставки своему 500-му глобальному клиенту в области физического и периферийного ИИ в таких отраслях, как оборона и общественная безопасность, промышленное производство, розничная торговля, агротехнологии, робототехника и безопасность. По словам Axelera AI, её клиентская база за последний год увеличилась более чем втрое.
24.02.2026 [23:00], Владимир Мироненко
SambaNova представила ИИ-ускоритель SN50 и объявила о расширении партнёрства с IntelSambaNova представила ИИ-ускорители пятого поколения SN50 на основе фирменных RDU (Reconfigurable Dataflow Unit), которые, по словам компании, «обеспечивает непревзойденное сочетание сверхнизкой задержки, высокой пропускной способности и энергоэффективной производительности для рабочих нагрузок ИИ-инференса, коренным образом меняя экономику генерации токенов». Кроме того, объявлено об инвестициях и сотрудничестве с Intel, которая передумала покупать SambaNova целиком. Как отметил The Register, новый чип представляет собой значительное улучшение по сравнению с SN40L 2023 года. По данным компании, SN50 обеспечивает в 2,5 раза более высокую производительность при 16-бит вычислениях (1,6 Пфлопс) и в 5 раз более высокую производительность в режиме FP8 (3,2 Пфлопс). В основе SN50 лежит архитектура потоковой обработки данных (SambaNova DataFlow). Как и в предшественнике, в SN50 используется трёхуровневая иерархия памяти, которая сочетает в себе DDR5, HBM и SRAM, что позволяет платформам на основе новинки поддерживать ИИ-модели с 10 трлн параметров и длиной контекста до 10 млн токенов. 
Источник изображений: SambaNova Каждый RDU оснащен 432 Мбайт SRAM, 64 Гбайт HBM2E с пропускной способностью 1,8 Тбайт/с и от 256 Гбайт до 2 Тбайт памяти DDR5. Доступность HBM2E и конфигурируемый объём DDR5 позволят повысить привлекательность и доступность SN50 на фоне дефицита памяти. Каждый ускоритель получил интерконнект со скоростью 2,2 Тбайт/с (в каждую сторону) для связи с другими чипами через коммутируемую фабрику. Как утверждает SambaNova, по сравнению с ускорителем NVIDIA B200, SN50 обеспечивает в 5 раз большую максимальную скорость генерации токенов на пользователя и более чем в 3 раза большую пропускную способность для агентного инференса, что было продемонстрировано на примере ряда моделей, таких как Meta✴ Llama 3.3 70B. Архитектура позволяет эффективно разгружать KV-кеш и переключаться между моделям в HBM и SRAM в режиме «горячей замены» за миллисекунды, что крайне важно для агентных рабочих нагрузок, часто переключающихся между несколькими ИИ-моделями.  Также в SN50 входные токены могут кешироваться в памяти, сокращая время предварительной обработки и время ожидания первого токена (TTFT) для запросов. Такое сочетание производительности, эффективности и масштабируемости обеспечивает преимущество в совокупной стоимости владения (TCO), по словам компании, не имеющее аналогов на рынке, для поставщиков сервисов инференса, использующих такие модели, как OpenAI GPT-OSS, с восьмикратной экономией по сравнению с NVIDIA B200. SN50 ориентирован и на такие приложения, как голосовые помощники на основе ИИ, требующие сверхнизкой задержки для работы в режиме реального времени. По заявлению компании, он сможет обеспечить работу тысяч одновременных сессий. Также была представлена 20-кВт система SambaRack SN50, которая объединяет 16 чипов SN50. SambaRack могут масштабироваться до кластера из 256 ускорителей с пропускной способностью интерконнекта в несколько Тбайт/с, что сокращает время обработки запросов и поддерживает большие размеры пакетов. В результате можно развёртывать модели с более высокой пропускной способностью и быстродействием. Поставки SN50 клиентам начнутся во II половине 2026 года.  Раннее SambaNova сообщила о привлечении более $350 млн в рамках переподписанного раунда финансирования серии E, возглавляемого частной инвестиционной компанией Vista Equity Partners при партнёрстве с Cambium Capital. В нём также приняло «активное участие» инвестиционное подразделение Intel — Intel Capital, сообщил SiliconANGLE. Также SambaNova заявила о сотрудничестве с Intel в разработке новых высокопроизводительных и экономически эффективных систем для выполнения ИИ-задач. Цель — предоставить предприятиям альтернативу GPU, которые сегодня используются в большинстве рабочих нагрузок. Intel инвестирует в стартап, чтобы ускорить развёртывание нового «облачного решения для ИИ» на базе существующей платформы SambaNova Cloud. Обновлённая платформа, оптимизированная для многомодальных LLM, получит процессоры Xeon, а также GPU, сетевые и иные решения Intel, в том числе в области СХД. Идёт ли речь о создании специализированных моделей Xeon, как это было в случае NVIDIA, не уточняется. В дальнейшем Intel и SambaNova планируют совместно продвигать и продавать новую платформу, используя существующие связи Intel с предприятиями и партнёрские каналы.  Партнёрство несёт выгоду обеим компаниям. SambaNova сможет воспользоваться глобальным охватом и производственной базой Intel для масштабирования своих ИИ-ускорителей, а Intel получит шанс наконец-то заявить о себе на ИИ-рынке. До сих пор Intel не могла конкурировать с NVIDIA и другими производителями чипов, такими как AMD, в ИИ-сфере. Чипы SN50 от SambaNova в сочетании с процессорами Intel Xeon потенциально могут изменить эту ситуацию. Стоит отметить, что у Intel, которая сама чувствует себя не лучшим образом, есть довольно крупная сделка с NVIDIA. Компания также предлагает собственные GPU для инференса, пусть и значительно более простые в сравнении с SN50, и даже странные гибриды из ускорителей Habana Gaudi 3 и NVIDIA B200. Наконец, имеется и сделка с AWS по выпуску кастомных Xeon 6 и неких ИИ-ускорителей. Что касается старых «коллег» SambaNova в деле борьбы с NVIDIA, то Groq в итоге была поглощена последней, а Cerebras, наконец, подписала заметную сделку с действительно крупным игроком на рынке ИИ — OpenAI.
23.02.2026 [23:22], Владимир Мироненко
Astera Labs по-тихому купила PliopsAstera Labs приобрела Pliops, сообщил ресурс StorageNewsletter со ссылкой на заявление Мариуса Тудора (Marius Tudor), бывшего директора по развитию бизнеса Pliops, подтвердившего факт сделки на своей странице в соцсети LinkedIn. Финансовых подробностей о сделке не сообщается. Ресурс допустил, что компания приобрела Pliops для своего первого научно-исследовательского центра в Израиле. О создании своего передового R&D-центра в Израиле Astera Labs сообщила в начале февраля. Предполагается, что новый центр с офисами в Тель-Авиве и Хайфе ускорит разработку масштабируемых сетей следующего поколения для протоколов высокоскоростной связи, а также будет способствовать техническим исследованиям и разработкам, направленным на решение проблем с памятью в приложениях для обучения и инференса ИИ. Руководителем центра назначен ветеран полупроводниковой индустрии Гай Азрад (Guy Azrad), старший вице-президент по проектированию и генеральный директор Astera Labs Israel, а его помощником станет Идо Букспан (Ido Bukspan), вице-президент по проектированию ASIC, имеющий 20-летний стаж работы в Mellanox и NVIDIA, где он дошёл до должности старшего вице-президента по проектированию микросхем, разрабатывая высокопроизводительные решения InfiniBand, Ethernet и NVLink. 
Источник изображения: Pliops «Новый израильский дизйн-центр будет стремиться использовать лучшие в регионе инженерные таланты, чтобы сосредоточиться на полном цикле проектирования микросхем — от архитектуры до производства, включая ПО и системное проектирование для передовых ИИ-платформ и новых приложений для инференса», — заявил Азрад. Разработанная Pliops PCIe-карта расширения XDP LightningAI с программным стеком FusIOnX функционирует как ещё один уровень памяти для GPU-серверов. Она работает на базе ASIC, которая «раскладывает» KV-кеш на SSD с доступом через NVMe-oF (RDMA) и горизонтальным масштабированием. Стек Pliops FusIOnX снижает стоимость, энергопотребление и вычислительные затраты путём оптимизации рабочих процессов инференса LLM. 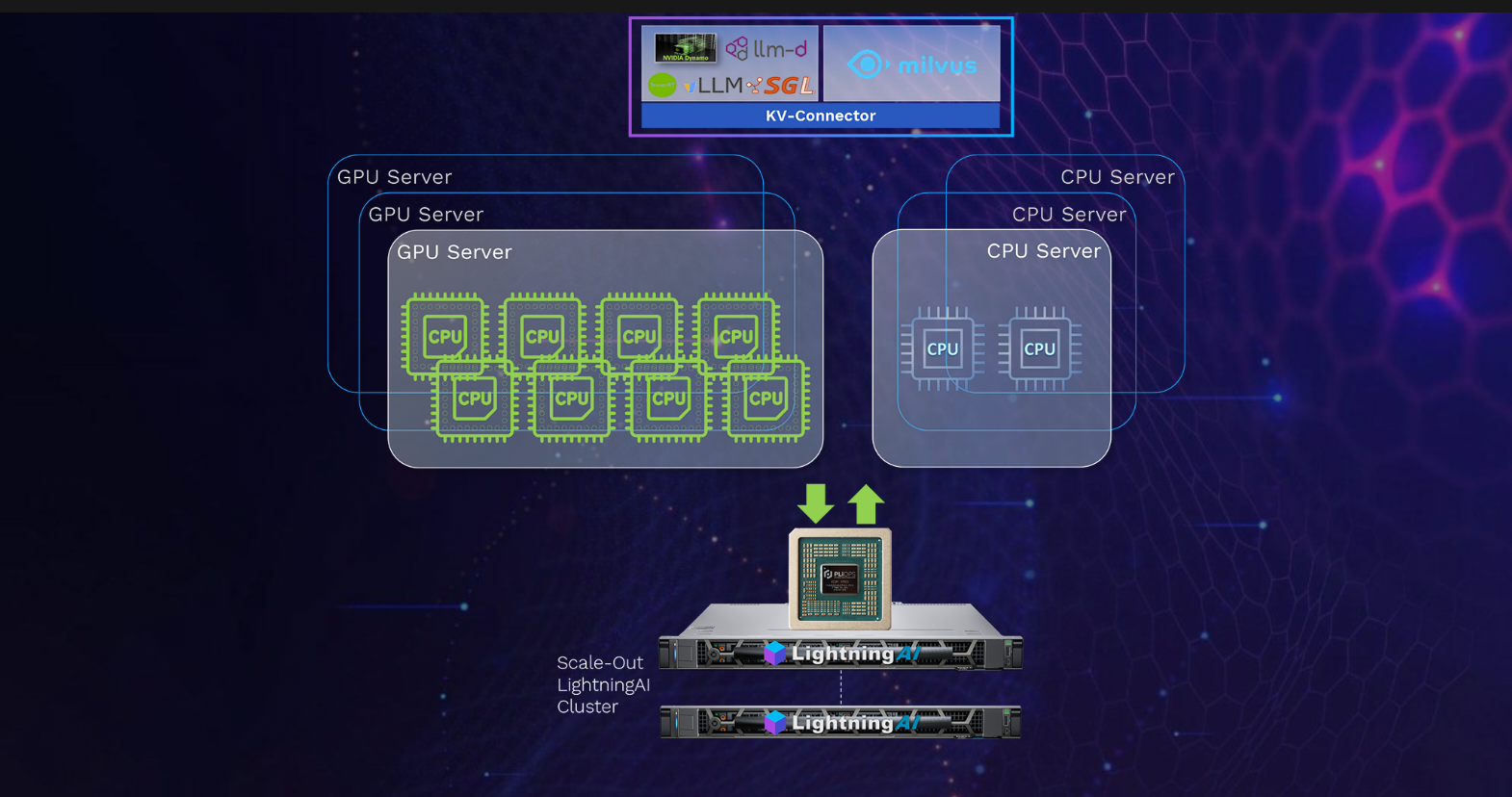
Источник изображения: Pliops «Сочетание нашего оборудования LightningAI с ПО FusIOnX устраняет узкое место, связанное с памятью GPU, обеспечивая до восьми раз более быструю обработку данных и экономию энергии на уровне стойки. И это работает от начала до конца: на любом GPU, любой LLM, любом ПО для обработки данных и любой сетевой инфраструктуре», — заявил Идо Букспан. По данным компании, Pliops XDP LightningAI вместе с ПО расширяют возможности высокоскоростной памяти (HBM) для серверов с GPU и ускоряют работу vLLM на NVIDIA в 2,5 раза.
23.02.2026 [22:57], Владимир Мироненко
Чипы AMD прожорливы, NVIDIA — дороги, а Intel — ненадёжны: Ericsson остаётся верна кастомным ASICEricsson представила свой первый набор продуктов AI-RAN, подчеркнув приверженность стратегии, основанной на собственных ASIC для повышения производительности сетей радиодоступа (RAN). В то время как беспроводная индустрия всё чаще обращается к виртуализированным/облачным RAN с использованием универсальных процессоров (GPP) Intel, Ericsson защищает свои продолжающиеся инвестиции в кастомные чипы для высокопроизводительных задач, отметил ресурс IEEE ComSoc Technology Blog. Впрочем, Intel остаётся ключевым партнёром Ericsson, а вот с AMD и NVIDIA у компании не заладилось. Портфель решений Ericsson для RAN базируется на двух основных архитектурах. Большая часть основана на ASIC, разработанных как собственными силами, так и в партнёрстве с Intel. Также портфель включает Cloud RAN, которая объединяет программный стек Ericsson с процессорами Intel Xeon EE. Несмотря на надежды отрасли, что виртуализация позволит отделить аппаратное обеспечение от программного, Intel остаётся единственным партнером Ericsson по поставке микросхем для массового развёртывания, что создаёт некоторые риски. 
Источник изображений: Ericsson Фактически Ericsson подтвердила «коммерческую поддержку» исключительно решений Intel, в то время как в случае AMD, Arm и NVIDIA всё по-прежнему ограничивается «поддержкой прототипов». Несмотря на многолетние заявления отрасли о необходимости разнообразия микросхем в экосистеме vRAN, прогресс, похоже, застопорился. Кроме того, интеграция ИИ в ПО RAN добавляет новые уровни сложности, которые могут ещё больше укрепить зависимость компании от «железа» одного вендора. Отраслевые наблюдатели по-прежнему скептически относятся к стремлению Ericsson к «единому программному стеку» для гетерогенных аппаратных платформ. Хотя аппаратная и программная дезагрегация достижима на более высоких уровнях (L2/L3), PHY-уровень L1 — наиболее ресурсоёмкая часть стека — остаётся сильно оптимизированным для конкретного «кремния». Первоначально Ericsson рассчитывала на переносимость L1-кода между x86 (в т.ч. AMD) и Arm SVE2 (NVIDIA Grace) для соответствия возможностям Intel AVX-512. Однако достижение высокой производительности на этих платформах без существенного рефакторинга остается серьёзной инженерной проблемой. 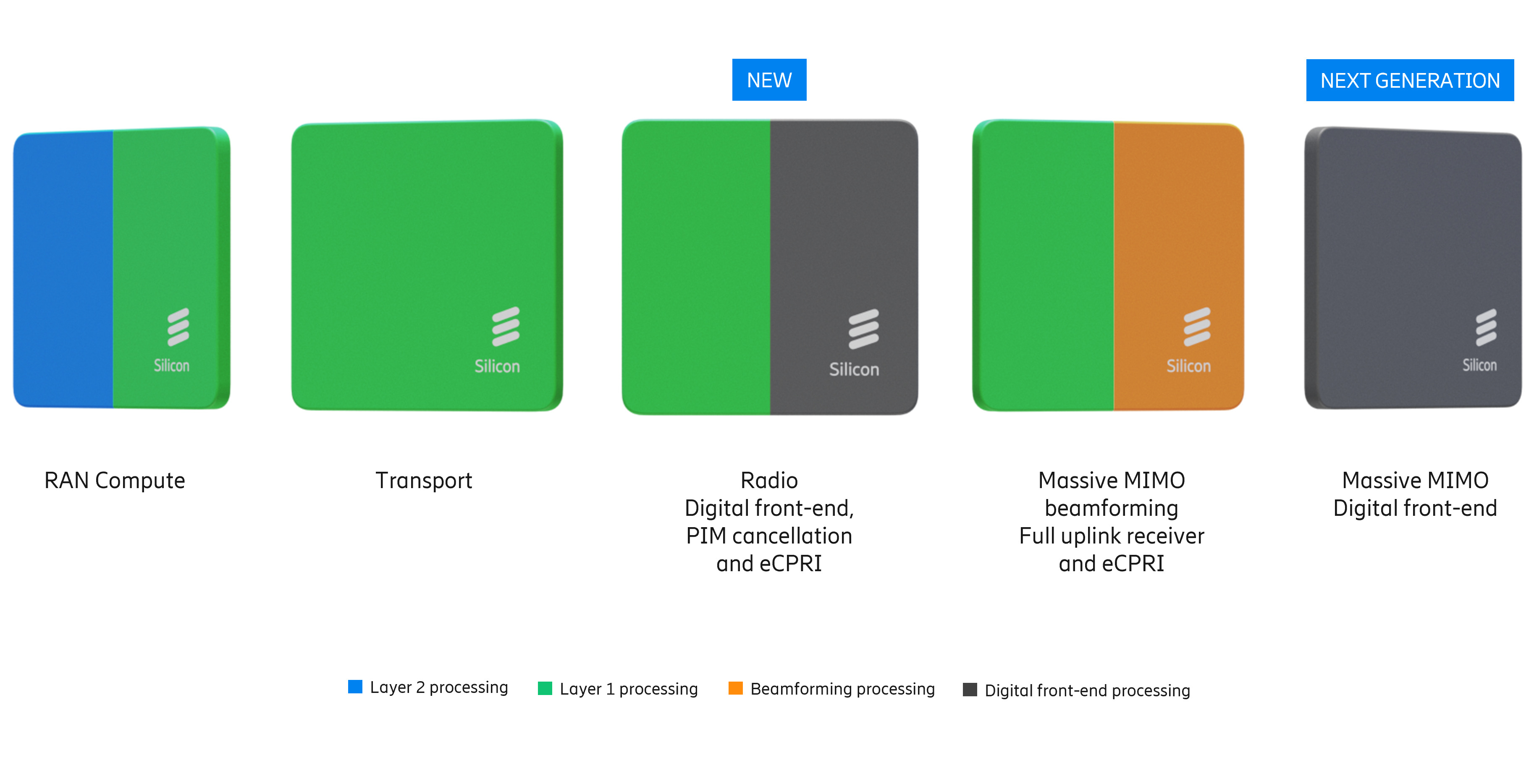 Критическим узким местом в обработке L1-трафика является коррекция ошибок (Forward Error Correction), которая традиционно требует выделенного аппаратного ускорения. Ericsson первоначально полагалась на разгрузку с переносом задач FEC на дискретные PCIe-ускорители Intel. Затем Intel внедрила ускорение FEC в Xeon EE в рамках vRAN Boost. Попытки использовать FPGA AMD показали их невысокую энергоэффективность, а GPU NVIDIA оказались слишком дороги для такой задачи. Однако развитие AI-RAN изменило экономику, поскольку теперь ускорители можно использовать как для RAN, так и для ИИ-задач. Так, Ericsson заинтересовали тензорные процессоры Google (TPU). Тем не менее, несмотря на стремление к созданию «единого ПО», планы Ericsson подтверждают существование проблем в реализации этой идеи. В то время как уровни L2 и выше используют универсальную кодовую базу для всех аппаратных платформ, уровень L1 требует адаптации под конкретные чипы.  Чтобы избежать зависимости от одного поставщика чипов, компания уделяет приоритетное внимание развитию HAL (Hardware Abstraction Layers), что позволит портировать ПО на разные аппаратные платформы с минимальными изменениями. Основные инициативы включают внедрение интерфейса BBDev (Baseband Device) для отделения ПО RAN от базового аппаратного обеспечения. Рассматривается даже возможность интеграции с NVIDIA CUDA, но здесь многое зависит от более широкой отраслевой стандартизации. Что касается радиосвязи, менее подверженной полной виртуализации, Ericsson встраивает процессоры Neural Network Accelerators (NNA) непосредственно в радиомодули. Эти программируемые матричные ядра оптимизированы для обработки данных в системах Massive MIMO, обеспечивая формирование луча и оценку канала за доли миллисекунды при соблюдении строгих ограничений по мощности. Новые AI-радиомодули оснащены ASIC Ericsson с NNA. Утверждается, что они расширяют возможности локального инференса в радиосистемах Massive MIMO, обеспечивая оптимизацию в реальном времени.
20.02.2026 [15:59], Сергей Карасёв
Узкие специалисты: Talaas, разрабатывающая оптимизированные под конкретные ИИ-модели ускорители, получила на развитие $169 млнСтартап Taalas, разрабатывающий чипы, специально оптимизированные для работы с конкретными ИИ-моделями, провел раунд финансирования на сумму в $169 млн. В число инвесторов вошли Quiet Capital и Fidelity, а также венчурный капиталист Пьер Ламонд (Pierre Lamond). Таким образом, на сегодняшний день компания получила на развитие в общей сложности более $200 млн. Фирма Taalas вышла из крытого режима (stealth mode) в марте 2023 года. Стартап занимается созданием чипов, предназначенных для определённых LLM. Первым продуктом компании стало изделие, ориентированное на ИИ-модель Llama 3.1 8B. Утверждается, что этот процессор способен генерировать до 17 тыс. выходных токенов в секунду, что в 73 раза больше по сравнению с NVIDIA H200. При этом решение Taalas потребляет в 10 раз меньше энергии. 
Источник изображения: Taalas Оптимизация аппаратных ускорителей под конкретную ИИ-модуль повышает производительность и эффективность благодаря отказу от избыточных компонентов. Однако разработка таких узкоспециализированных изделий представляет собой сложный и дорогостоящий процесс. Компании Taalas удалось решить проблему, создав архитектуру, при которой для «тонкой» настройки требуется кастомизация только двух из более чем 100 слоев, из которых состоят её чипы. Кроме того, Taalas не использует в своих изделиях дорогостоящую память HBM. Это также упрощает конструкцию, позволяя упразднить компоненты, которые необходимы для обеспечения взаимодействия с HBM-модулями. В настоящее время Taalas работает над чипом, предназначенным для запуска ИИ-модели Llama с 20 млрд параметров: выпуск этого решения намечен на лето нынешнего года. Затем появится более мощный чип, ориентированный на LLM высокого уровня. |
|

