Материалы по тегу: инференс
|
29.06.2024 [21:18], Владимир Мироненко
Omdia: ИИ-приложения станут основной нагрузкой в ЦОД и подстегнут рост расходов на серверыВ настоящее время ИИ является основным драйвером инвестиций в ЦОД, капитальные затраты на которые в этом году вырастут почти на 30 %, пишет The Register со ссылкой на исследование Omdia. Согласно прогнозу аналитиков, в течение нескольких лет ИИ станет основной серверной рабочей нагрузкой в ЦОД. Приложения ИИ являются наиболее быстрорастущей категорией среди нагрузок, исходя из количества развёртываемых в год серверов. Согласно данным Omdia, рост расходов на серверы в прошлом году полностью приходится на ИИ-оборудование. В 2024 году спрос на использование ИИ ускорил инвестиции в ЦОД — капитальные затраты, «подкреплённые корпоративными денежными резервами крупных гиперскейлеров», как ожидает Omdia, вырастут на 28,5 %. По подсчётам Omdia, продажи серверов в этом году вырастут на 74 % до $210 млрд с $121 млрд в 2023 году. В дальнейшем количество серверов для обучения ИИ будет расти примерно на 5 % в год до чуть менее 1 млн/год в 2029 году. А количество серверов для инференса будет расти со скоростью 17 % в год, и к 2029 году годовые поставки достигнут 4 млн шт. Это объясняется тем, что серверы для обучения ИИ в основном нужны небольшому количеству гиперскейлеров. Они сосредоточены на достижении максимальной эффективности своего ИИ-оборудования и у них нет потребности закупать много серверов. 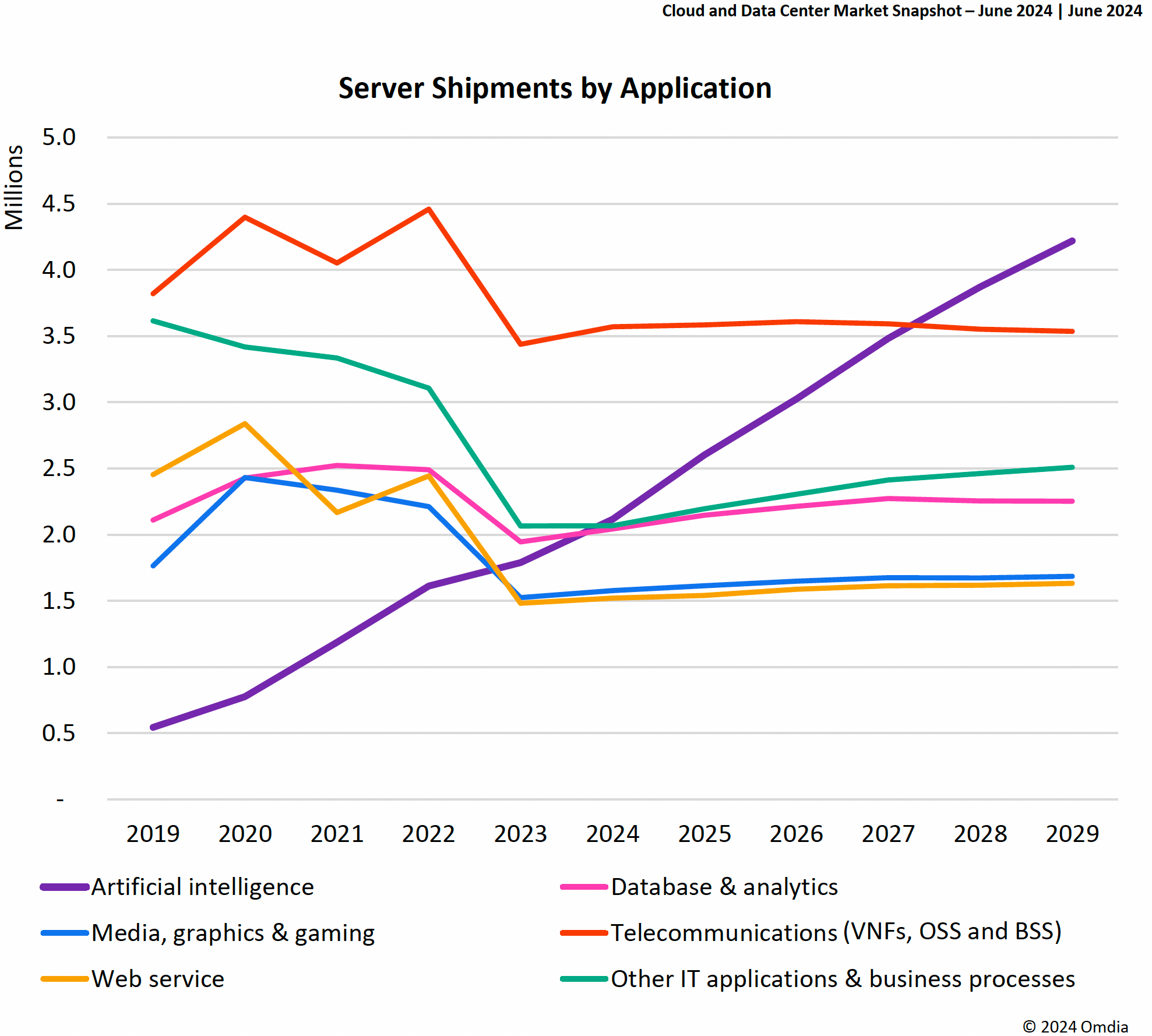
Источник изображений: Omdia В Omdia считают, что обучение ИИ можно классифицировать как деятельность в области НИОКР, и поэтому, оно будет подлежать плановому распределению бюджета, то есть реинвестированию доли доходов. А количество серверов, необходимых для инференса, наоборот, будет расти по мере увеличения аудитории пользователей приложений ИИ. Как утверждают в Omdia, в основном в течение следующих пяти лет будут продолжать быстро расти продажи ИИ-серверов, а рост поставок других типов серверов будет значительно меньше. 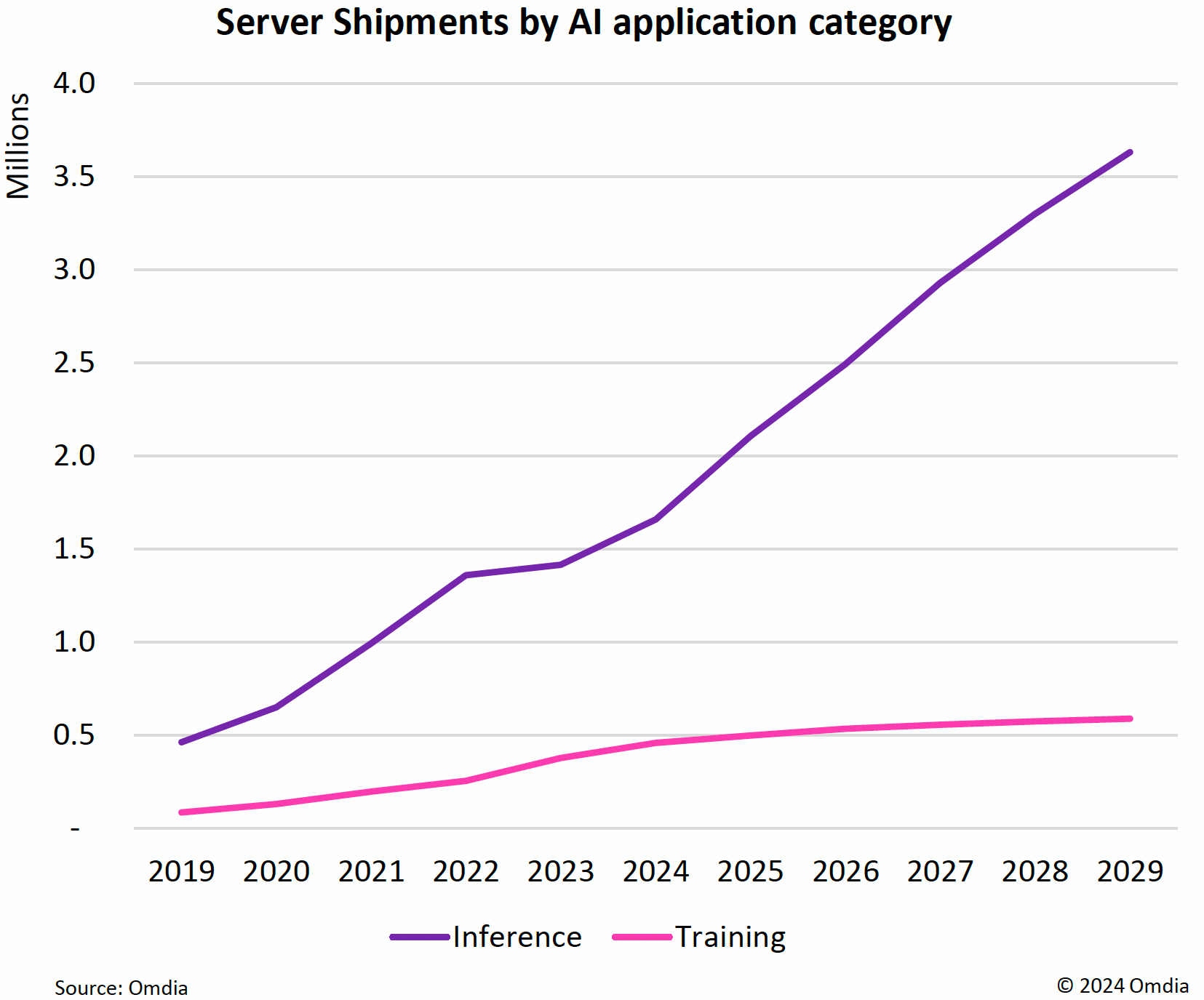 Прогнозируется, что расходы на управление температурным режимом в ЦОД вырастут в 2024 году на 22 % год к году до $9,4 млрд. Побочным эффектом роста спроса на более мощное серверное оборудование стал бум внедрения СЖО. По прогнозам Omdia, общий доход от СЖО превысит к концу этого года отметку в $2 млрд, а к 2028 году будет больше $5 млрд. Доходы от инфраструктуры распределения электроэнергии в этом году впервые превысят $4 млрд, а доходы от источников бесперебойного питания вырастут на 10 % до $13 млрд.
26.06.2024 [01:00], Игорь Осколков
Etched Sohu — самый быстрый в мире ИИ-ускоритель, но только для трансформеровСтартап Etched, основанный в 2022 году выпускниками Гарварда, анонсировал самый быстрый, по его словам, ИИ-ускоритель Sohu. Секрет высокой производительности очень прост — Sohu представляет собой узкоспециализированный 4-нм ASIC, который умеет работать только с моделями-трансформерами. При этом в длинном анонсе новинки обещана чуть ли не революция в мире ИИ. Etched прямо говорит, что делает ставку на трансформеры, и надеется, что не прогадает. Данная архитектура ИИ-моделей была создана в недрах Google в 2017 году, но сама Google распознать её потенциал, по-видимому, вовремя не смогла. Сейчас же, по словам Etched, практически все массовые ИИ-модели являются именно трансформерами, а стремительно набирать популярность этот подход начал всего полтора года назад с выходом ChatGPT, хотя в Etched «предугадали» важность трансформеров ещё до выхода детища OpenAI. 
Источник изображений: Etched Etched в целом справедливо отмечает, что подавляющее большинство ИИ-ускорителей умышленно создаётся так, чтобы быть достаточно универсальными и уметь работать с различными типами и архитектурами ИИ-моделей. Это ведёт к взрывному росту транзисторного бюджета и уменьшению общей эффективности. Так, по словам Etched, загрузка ускорителя на базе GPU работой на практике составляет около 30 %, а у Sohu она будет на уровне 90 %.  Тут есть некоторое лукавство, потому что Etched в основном говорит о «больших» ускорителях, ориентированных и на обучение тоже, тогда как Sohu предназначен исключительно для инференса. На практике же бывают и гибридные подходы. Например, у AWS есть не только Trainium, но Inferentia. Meta✴ использует чипы NVIDIA для обучения, но для инференса разрабатывает собственные ускорители MTIA. Cerebras практически отказалась от инференса, а Groq — от обучения моделей. Корректнее было бы сравнить именно инференс-ускорители, пусть даже никто из упомянутых Etched конкурентов не ориентирован исключительно на трансформеры.  Также стартап критикует громоздкую программную экосистему для современного генеративного ИИ, к тому же не всегда открытую. Важность оптимизации ПО хороша видна на примере NVIDIA TensorRT-LLM. Но крупным компаниям этого мало, они готовы вкладывать немало средств в глубокую оптимизацию, чтобы ещё чуть-чуть повысить производительность. Дело доходит до выяснения того, у какого регистра задержка меньше при работе с каким тензорным ядром, говорит Etched. Стартап обещает, что его заказчикам не придётся заниматься такими изысканиями — весь программный стек будет open source. Впрочем, на примере AMD ROCm видно, что открытость ещё не означает мгновенный успех у пользователей. 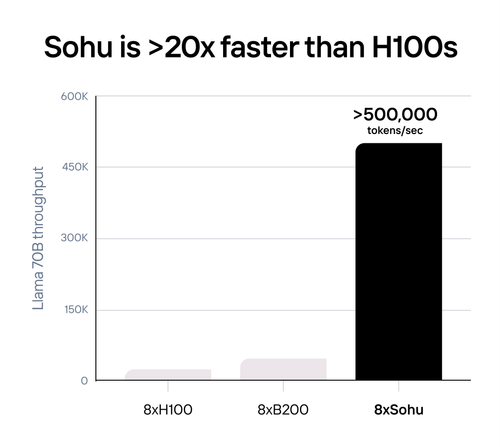 Технические характеристики Sohu не раскрываются. Явно говорится лишь о наличии 144 Гбайт HBM3e. Обещанная производительность сервера с восемью ускорителями Sohu составляет 500 тыс. токенов в секунду для Llama 70B: FP8 без разреженности, параллелизм на уровне модели, 2048 токенов на входе и 128 токенов на выходе. Иными словами, один такой сервер Sohu заменяет сразу 160 ускорителей NVIDA H100, говорит Etched. А вот про масштабируемость своих платформ компания пока ничего не говорит. Зато хвастается, что первые заказчики уже зарезервировали Sohu на десятки миллионов долларов.
22.06.2024 [14:34], Сергей Карасёв
Галлюцинации от радиации: аппаратные сбои могут провоцировать ошибки в работе ИИ-системКомпания Meta✴, по сообщению The Register, провела исследование, результаты которого говорят о том, что ошибки в работе ИИ-систем могут возникать из-за аппаратных сбоев, а не только по причине несовершенства алгоритмов. Это может приводить к неточным, странным или просто плохим ответам ИИ. Говорится, что аппаратные сбои способны провоцировать повреждение данных. Речь идёт, в частности, о так называемом «перевороте битов» (bit flip), когда значение ячейки памяти может произвольно меняться с логического «0» на логическую «1» или наоборот. Это приводит к появлению ложных значений, что может обернуться некорректной работой ИИ-приложений. Одной из причин ошибок является космическое излучение, причём с ростом плотности размещения ресурсов его влияние нарастает. Впрочем, в современных комплексных системах такие ошибки по разным причинам могут возникать на любом из этапов хранения, передачи и обработки информации. 
Ошибка в одном бите одного параметра существенно меняет ответ ИИ (Источник: Meta✴) Такие необнаруженные аппаратные сбои, которые не могут быть выявлены и устранены «на лету», называют тихими повреждениями данных (Silent Data Corruption, SDC). Подобные ошибки могут провоцировать изменения ИИ-параметров, что, в конечном счёте, приводит к некорректному инференсу. Утверждается, что в среднем 4 из 1000 результатов инференса неточны именно из-за аппаратных проблем. «Растущая сложность и неоднородность платформ ИИ делает их всё более восприимчивыми к аппаратным сбоям», — говорится в исследовании Meta✴. При этом изменение одного бита может привести к тому, что ошибки будут расти как снежный ком. Для оценки возможных неисправностей предлагается ввести новую величину — «коэффициент уязвимости параметров» (Parameter Vulnerability Factor, PVF). PVF показывает вероятность того, как повреждение конкретного параметра в конечном итоге приведёт к некорректному ответу ИИ-модели Эта метрика, как предполагается, позволит стандартизировать количественную оценку уязвимости модели ИИ к возможным аппаратным сбоям. Показатель PVF может быть оптимизирован под различные модели и задачи. Метрику также предлагается использовать на этапе обучения ИИ и для выявления параметров, целостность которых надо отслеживать. Производители аппаратного оборудования также принимают меры к повышению надёжности и устойчивости работы своих решений. Так, NVIDIA отдельно подчеркнула важность RAS в ускорителях Blackwell. Правда, делается это в первую очередь для повышения стабильности сверхкрупных кластеров, простой которых из-за ошибок обойдётся очень дорого.
15.06.2024 [00:25], Алексей Степин
Intel поймала AMD на подтасовке результатов в ИИ-тестах EPYC против XeonНа Computex 2024 AMD анонсировала новое поколение серверных процессоров EPYC Turin на базе архитектуры Zen 5. При этом компания продемонстрировала слайды, из которых следует, что новые решения серьёзно опережают процессоры Intel Xeon. Так, 128-ядерный Turin сравнивается с 64-ядерным Xeon Platinum 8592+ (Emerald Rapids). AMD говорит о 2,5–5,4-кратном превосходстве, однако Intel опровергает полученные результаты и достаточно подробно разбирает вопрос тестирования в своём блоге. Конечно, превосходство AMD в чисто количественных показателях очевидно, но в сложных вычислительных задачах, к которым относятся HPC- и ИИ-сценарии, не меньшую, а то и большую роль может играть оптимизация ПО. Intel отмечает, что AMD не привела в своём анонсе конкретных сведений о версиях и настройках ПО, и, вероятнее всего, отказалась от различных расширений. Но, например, Intel Extension for PyTorch (IPEX) позволяет добиться более чем пятикратного прироста производительности по сравнению с «чистой» версией PyTorch. Для системы с двумя Xeon Platinum 8592+ применение IPEX позволяет поднять производительность инференса в режиме INT4 с чат-ботом на базе Llama2-7B со 127 до 686 запросов в секунду при заданной задержке не более 50 мс. Для своей 256-ядерной платформы на базе Turin AMD говорит про 671 запрос — как видно, с оптимизацией результаты получаются вполне сопоставимыми. 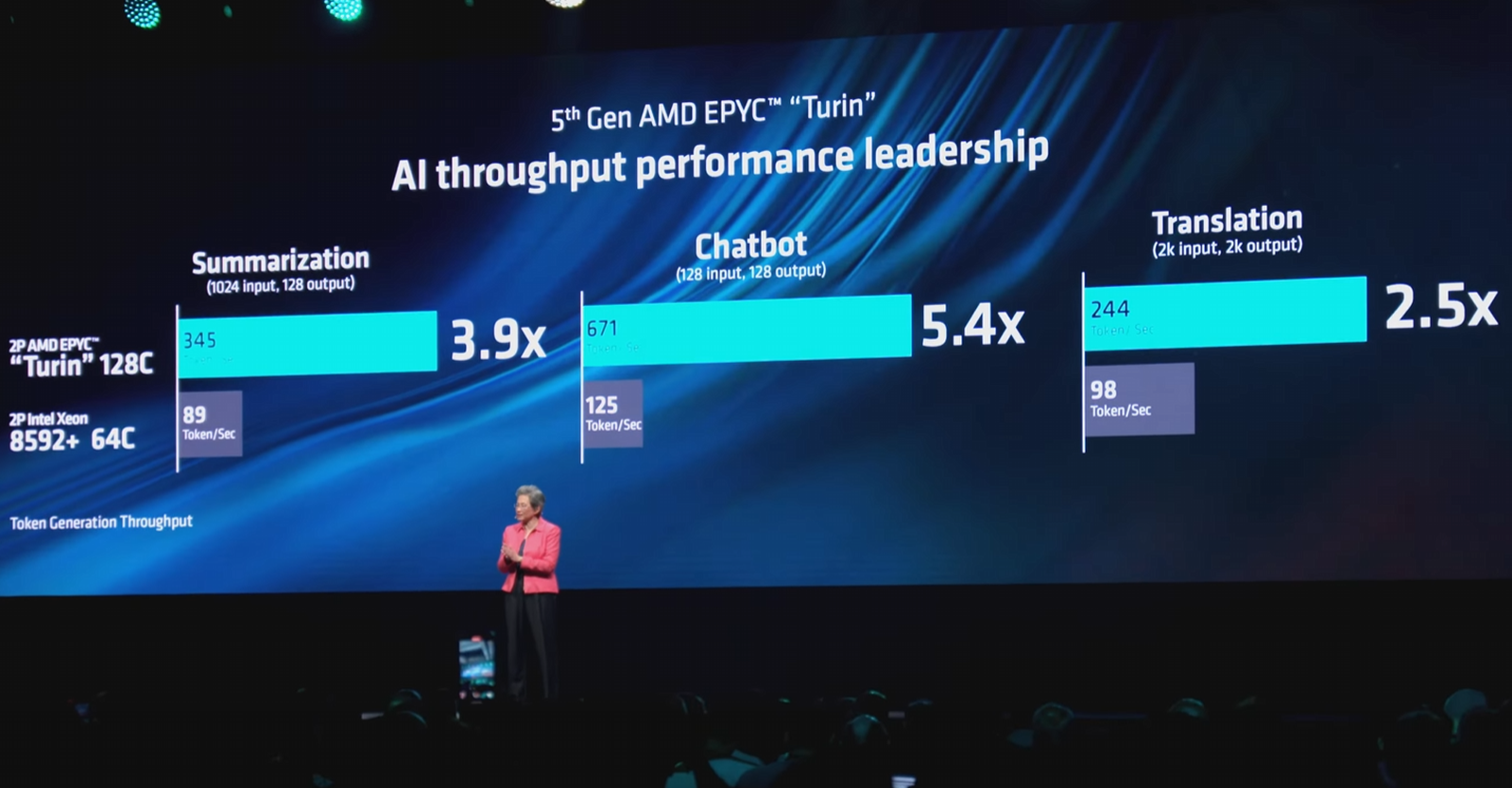
Источник: AMD И потенциал для дальнейшего роста у Xeon есть: Intel сообщает, что при отключении функции Sub-NUMA Clustering результат может достигать 740 запросов. К сожалению, для других тестов компания диаграмм не опубликовала, хотя и там оптимизация позволяет добиться увеличения производительности в 1,2–2,3 раза. Этого уже не хватает, чтобы бороться с платформой Turin, которая, помимо превосходства в числе ядер, использует и более мощную 12-канальную подсистему памяти. 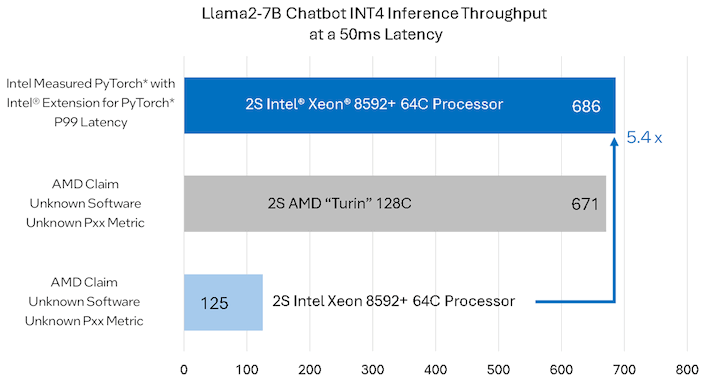
Источник: Intel Следует отметить, что Intel не сказала последнего слова: Xeon Platinum 8592+ уже не нов, а в ближайшем будущем AMD Turin придётся столкнуться с Xeon 6 с большим числом ядер. Пока эти чипы доступны лишь в исполнении с энергоэффективными ядрами, но уже в III квартале появятся и 128-ядерные Granite Rapids с производительными P-ядрами и 12-канальной памятью. 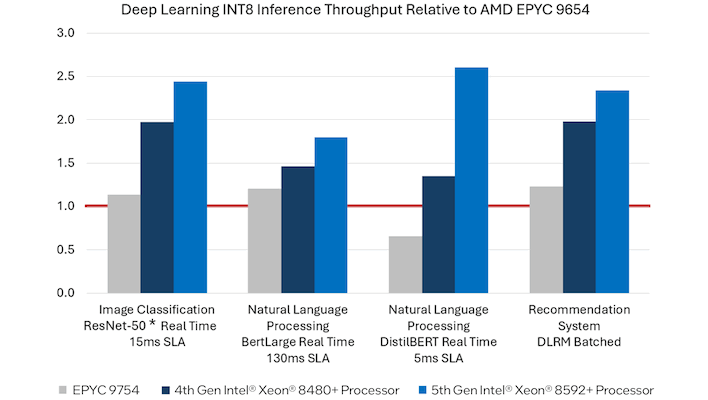
Источник: Intel Тем не менее, тема затронута достаточно фундаментальная: свои плюсы имеет как чисто количественный подход, которого придерживается AMD, так и подход Intel, позволяющий добиться высоких результатов при тщательной оптимизации под более комплексную архитектуру. Нельзя сказать, что результаты AMD являются мошенничеством, хотя случай и не первый — согласно тестам компании, ускоритель Instinct MI300X серьёзно опередил NVIDIA H100, но при этом AMD точно так же «забыла» про оптимизированный фреймворк TensorRT-LLM. Правда, в тот раз «честь мундира» отстоять удалось и с оптимизациями NVIDIA.
11.06.2024 [21:45], Руслан Авдеев
Apple создала кастомные серверы и ОС для безопасного ИИ-облакаВ ходе конференции Worldwide Developer Conference (WWDC), состоявшейся в понедельник, компания Apple упомянула о том, что её серверы на собственных чипах и ОС используются для новых ИИ-сервисов Apple Intelligence. Как отмечает The Register, прямо компания не говорила ни о CPU, ни об ОС и никогда не подтверждала слухи об ИИ-серверах собственной разработки, но отсылки ко всем этим компонентам оказались разбросаны по презентациям на WWDC. Новые функции завязаны на Apple Private Cloud Compute — серверную экосистему, где IT-гигант применяет большие ИИ-модели, которые справляются с некоторыми задачами намного лучше, чем компактные модели на пользовательских устройствах. В компании отмечают, что Private Cloud Compute использует мощные и безопасные кастомные серверы в своих ЦОД. Также упоминается термин «вычислительный узел», но нет точных данных о том, является ли он синонимом слова «сервер». 
Источник изображения: Apple Подчёркивается, что облачные мощности используют те же аппаратные технологии обеспечения безопасности, что и, например, iPhone, включая Secure Enclave и Secure Boot. Машины используют новую защищённую ОС на базе iOS и macOS, где отсутствуют некоторые административные компоненты. К минимуму свели даже телеметрию, обычно критически важную для поддержания работы облака. Другими словами, доступ к данным получит только пользователь, доступа не будет даже у системных администраторов. Если в ряде случаев возможностей смартфона или планшета будет не хватать для конкретной ИИ-задачи, Apple будет определять, какой необходимый минимум данных нужен для решения задачи и отправлять их в зашифрованным виде в облаке. В облаке для каждой такой задачи будет создавать зашифрованный же анклав, который после обработки данных и отправки результата пользователю (тоже с шифрованием) будет полностью удалён. Другими словами, исходные фото, видео и другой контент никогда не будут покидать устройства пользователя, а их отслеживание и расшифровка весьма проблематичны. Уже сейчас в своих облаках Arm-чипы AWS, Google, Oracle и Microsoft. По соотношению цена/производительность они нередко лучше, чем чипы Intel или AMD, во всяком случае при решении некоторых задач, в том числе инференса, поэтому вполне логично, если к таким же решениям прибегнет и Apple.
03.06.2024 [09:21], Владимир Мироненко
NVIDIA объявила об интеграции NIM с KServeNVIDIA объявила, что набор инференес-микросервисов NVIDIA NIM будет работать с open source платформой KServe на базе Kubernetes, которая позволит автоматизировать развёртывание ИИ-моделей. Это также делает NIM широкодоступным на платформах различных компаний, таких как Canonical, Nutanix и Red Hat. Интеграция NIM в KServe позволяет расширить возможность использования технологий NVIDIA сообществом, партнёрами по экосистеме и клиентами. Благодаря интеграции с KServe пользователи смогут получить доступ к NIM на многих корпоративных платформах, таких как Charmed KubeFlow от Canonical, Charmed Kubernetes, Nutanix GPT-in-a-Box 2.0, Red Hat OpenShift AI и многих других. 
Источник изображения: NVIDIA В рамках интеграции NIM компания NVIDIA планирует активно участвовать в продвижении KServe, опираясь на свой портфель ПО с открытым исходным кодом, включая Triton и TensorRT-LLM. NVIDIA также является активным членом фонда Cloud Native Computing Foundation. NVIDIA и ранее участвовала в разработке KServe и адаптации этого инструмента под свои нужды, равно как и AWS, Bloomberg, Canonical, Cisco, Hewlett Packard Enterprise, IBM, Red Hat, Zillow.
02.06.2024 [15:30], Владимир Мироненко
NVIDIA объявила о доступности NIM для разработчиков ИИNVIDIA объявила о доступности NVIDIA NIM, микросервисов инференса, которые предоставляют готовые модели в виде заранее оптимизированных контейнеров, доступных для развёртывания в облаках, ЦОД или на рабочих станциях. Это, по словам компании, позволяет разработчикам возможность без труда создавать приложения генеративного ИИ за считанные минуты, хотя ранее на это уходили недели. Сложность приложений генеративного ИИ растёт и часто в них используется несколько моделей с различными возможностями для генерации текста, изображений, видео, речи и т.д. NVIDIA NIM позволяет значительно повысить производительность разработчиков, предоставляя простой стандартизированный способ добавления генеративного ИИ в их приложения. NIM также позволяет компаниям максимизировать свои инвестиции в инфраструктуру. Например, NIM-контейнер с оптимизированным вариантом Meta✴ Llama 3-8B выдаёт втрое больше токенов за единицу времени, чем LLM без оптимизаций. 
Источник изображений: NVIDIA Более 200 технологических партнёров NVIDIA, включая Cadence, Cloudera, Cohesity, DataStax, NetApp, Scale AI и Synopsys, уже используют NIM, чтобы ускорить развёртывание генеративного ИИ для приложений, специфичных для их индустрии, таких как ИИ-помощники, помощники по созданию кода, цифровые человеческие аватары и многое другое. Кроме того, экосистему NIM поддерживают Canonical, Red Hat, Nutanix, VMware, Kinetica и Redis. Доступна и интеграция с KServe. NIM интегрирован в платформу NVIDIA AI Enterprise. Начиная со следующего месяца участники программы NVIDIA Developer Program получат бесплатный доступ к NIM для исследований, разработки и тестирования. Контейнеры NIM могут включать ПО NVIDIA CUDA, NVIDIA Triton Inference Server и NVIDIA TensorRT-LLM. А на ai.nvidia.com уже доступно более 40 готовых моделей, включая Databricks DBRX, Google Gemma, Meta✴ Llama 3, Microsoft Phi-3, Mistral Large, Mixtral 8x22B и Snowflake Arctic. Компания также представила и NVIDIA BioNeMo NIM для биомедицинской сферы.  Ведущие провайдеры ИИ-решений и MLOps-платформ, включая Amazon SageMaker, Microsoft Azure AI, Dataiku, DataRobot, deepset, Domino Data Lab, LangChain, Llama Index, Replicate, Run.ai, ServiceNow, Securiti AI и Weights & Biases также внедрили NIM. Hugging Face теперь тоже предлагает NIM-контейнейры и позволяет развернуть модели в различных облаках всего за несколько кликов. Микросервисы NIM также интегрированы в AWS, Google Cloud, Microsoft Azure и Oracle Cloud. Наконец, компетенциями в области NIM обзавелись Accenture, Deloitte, Infosys, Latentview, Quantiphi, SoftServe, TCS и Wipro. Предприятия могут запускать приложения с поддержкой NIM практически в любом месте, в том числе на сертифицированных NVIDIA системах Cisco, Dell, HPE, Lenovo и Supermicro, а также ASRock Rack, ASUS, GIGABYTE, Ingrasys, Inventec, Pegatron, QCT, Wistron и Wiwynn. Более того, например, Foxconn и Pegatron уже используют NIM для разработки предметно-ориентированных LLM для собственных производственных нужд.
25.05.2024 [20:50], Сергей Карасёв
EdgeCortix представила ИИ-ускоритель SAKURA-II Edge AI с производительностью до 60 TOPSКомпания EdgeCortix, по сообщению CNX Software, анонсировала ускоритель SAKURA-II Edge AI, предназначенный для выполнения ИИ-задач на периферии. Новинка, как утверждается, способна справляться с обработкой больших языковых моделей (LLM), больших визуальных моделей (LVM) и пр. В основу изделия положен нейропроцессорный движок с архитектурой Dynamic Neural Accelerator (DNA) второго поколения. Заявленная производительность достигает 60 TOPS на операциях INT8 и 30 Тфлопс на операциях BF16. 
Источник изображений: CNX Software Ускоритель может нести на борту 8, 16 или 32 Гбайт памяти LPDDR4x с пропускной способностью 68 Гбайт/с. Есть 20 Мбайт памяти SRAM. Заявленное типовое энергопотребление составляет 8 Вт. Изделие имеет упаковку BGA с размерами 19 × 19 мм. Диапазон рабочих температур простирается от -40 до +85 °C. Для ускорителя доступен программный комплект MERA с поддержкой PyTorch, TensorFlow Lite и ONNX. Помимо собственно ускорителя SAKURA-II Edge AI, компания EdgeCortix представила решения на его основе. Это, в частности, модуль формата M.2 2280: он использует интерфейс PCIe Gen 3.0 x4, а энергопотребление равно 10 Вт. Доступны модификации с 8 и 16 Гбайт памяти LPDDR4. Стоят такие модули $249 и $299.  Кроме того, выпущены однослотовые низкопрофильные карты расширения с интерфейсом PCIe 3.0 x8. Такие устройства существуют в вариантах с одним и двумя чипами SAKURA-II Edge AI. Во втором случае производительность удваивается и достигает 120 TOPS на операциях INT8 и 60 Тфлопс на операциях BF16. Младшая версия оснащена 16 Гбайт памяти и имеет энергопотребление 10 Вт. Старший вариант несёт на борту 32 Гбайт памяти и обладает энергопотреблением 20 Вт. Цена — $429 и $749 соответственно.
18.05.2024 [20:00], Алексей Степин
256 ядер и 12 каналов DDR5: Ampere обновила серверные Arm-процессоры AmpereOne и перевела их на 3-нм техпроцессВесной прошлого года компания Ampere Computing анонсировала наследников серии процессоров Altra и Altra Max — чипы AmpereOne с более высокими показателями производительности, энергоэффективности и масштабируемости. На момент анонса AmpereOne получили до 192 ядер, восемь каналов DDR5 и 128 линий PCIe 5.0. Кроме того, эти чипы могут работать и в двухсокетных платформах. Позднее AmpereOne стали доступны у нескольких облачных провайдеров, а главным бенефециаром их появления стала Oracle, когда-то инвестировавшая в Ampere Computing значительные средства. Компания перевела все свои облачные сервисы на процессоры Ampere и даже портировала на них свою флагманскую СУБД. В общем, повторила путь AWS и Alibaba Cloud с процессорами Graviton и Yitian соответственно. Но если последние являются облачным эксклюзивом, то чипы Ampere хоть и ориентированы в первую очередь на гиперскейлеров, более-менее доступны и небольшим компаниям. Поэтому в процессорной гонке останавливаться нельзя, так что на днях Ampere объявила об обновлении модельного ряда AmpereOne, запланированного к выпуску в 2025 году. Новые модели будут использовать продвинутый техпроцесс TSMC N3. 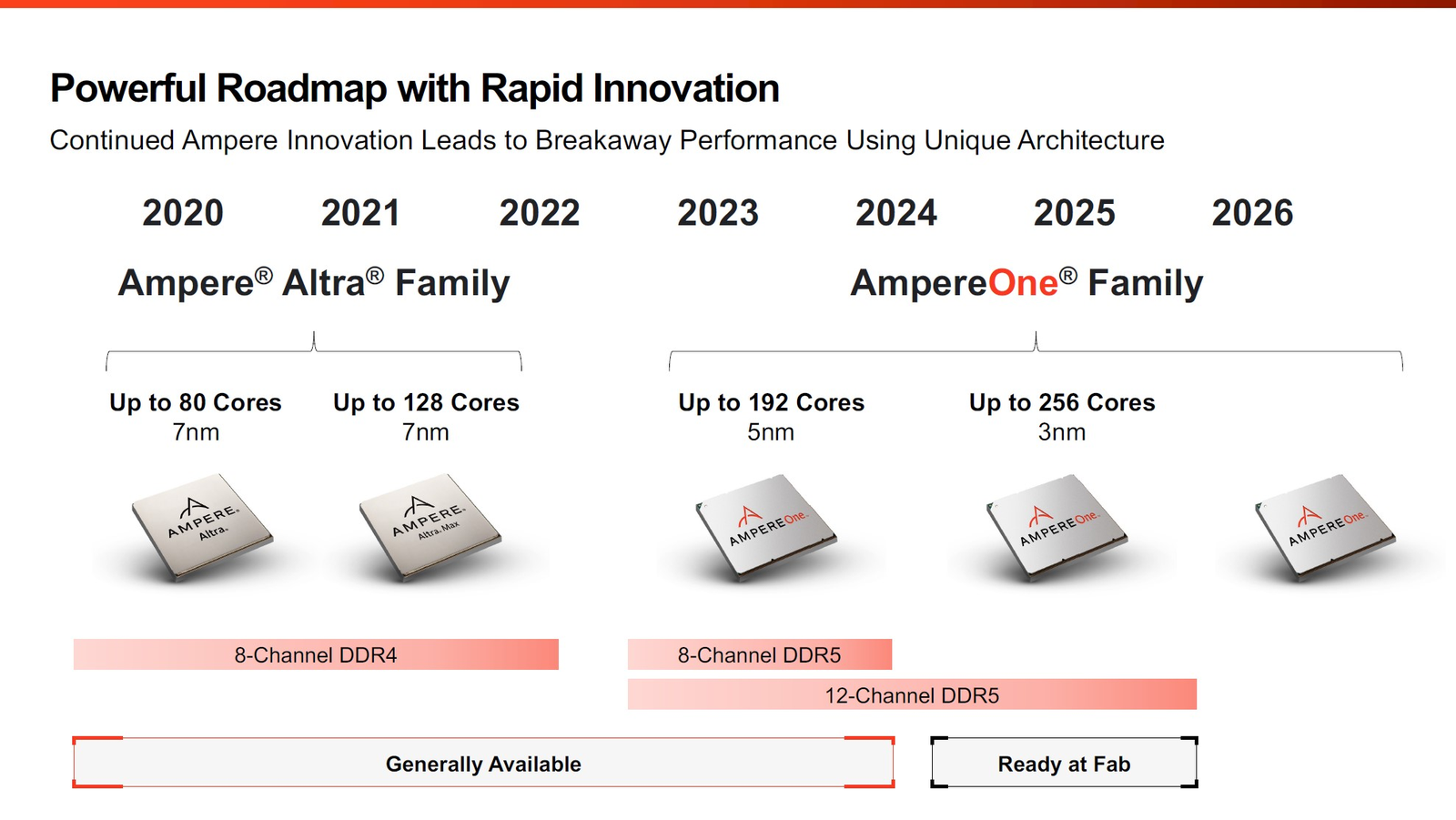
Источник здесь и далее: Ampere Computing via ServeTheHome Согласно опубликованным планам, семейство AmpereOne какое-то время будет существовать в двух ипостасях: изначальном варианте 2023 года с 8-канальным контроллером памяти и 192 ядрами в пределе, производящемся с использованием 5-нм техпроцесса, и новом 3-нм, уже готовом к массовому производству. Ожидается, что 192-ядерный вариант с 12 каналами DDR5 станет доступен в конце этого года. 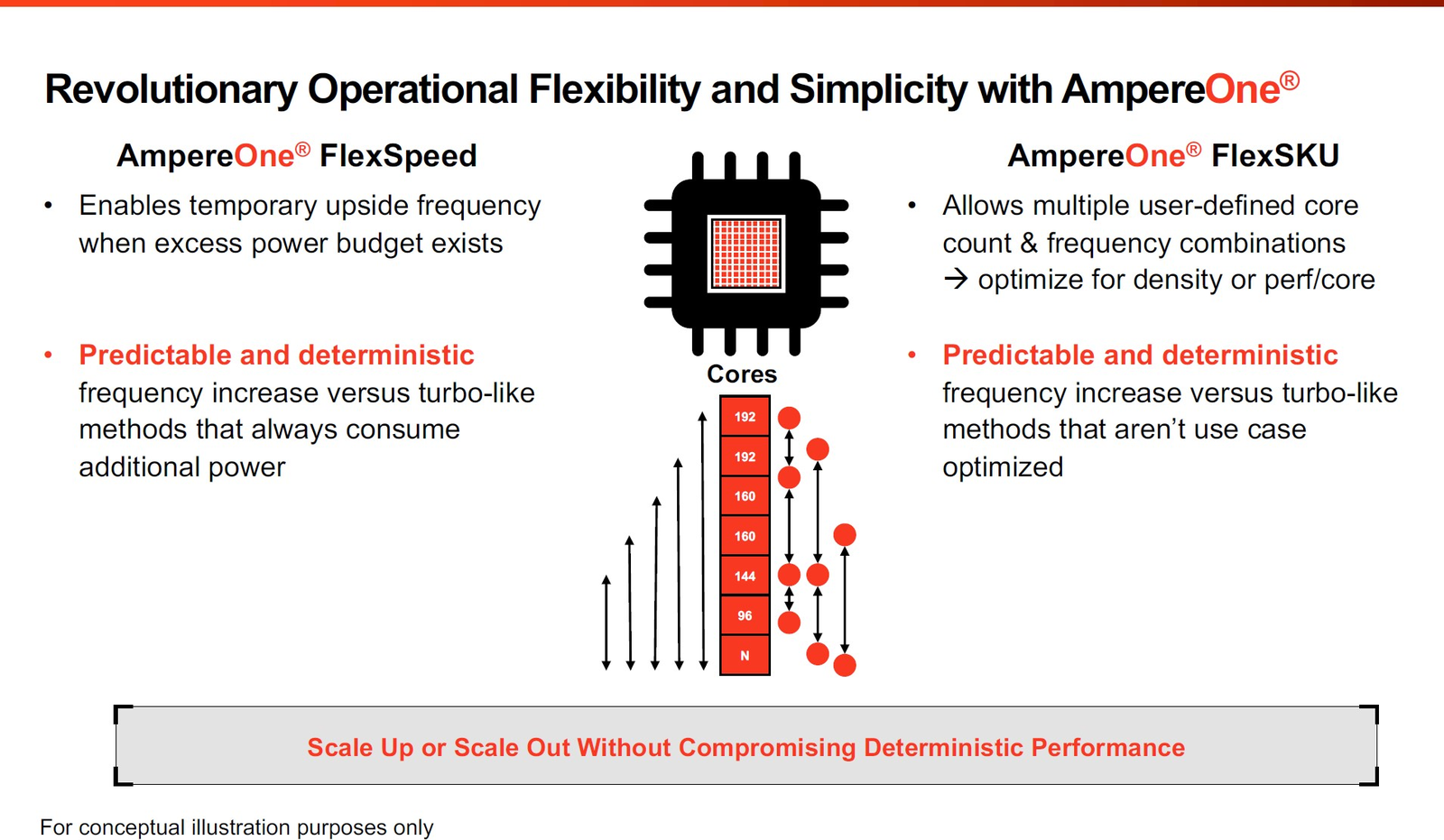
Фирменные технологии Ampere серии Flex позволят гибко управлять характеристиками платформы 3-нм вариант AmpereOne получит до 256 ядер и 12 каналов DDR5, однако отличать его будет не только это. К примеру, в нём дебютируют технологии FlexSpeed и FlexSKU, позволяющие на лету, без перезагрузок или выключения системы оперировать различными параметрами процессора — тактовой частотой, теплопакетом и даже количеством активных ядер. При этом FlexSpeed обеспечит детерминированный прирост производительности в отличие от x86-64, говорит компания. 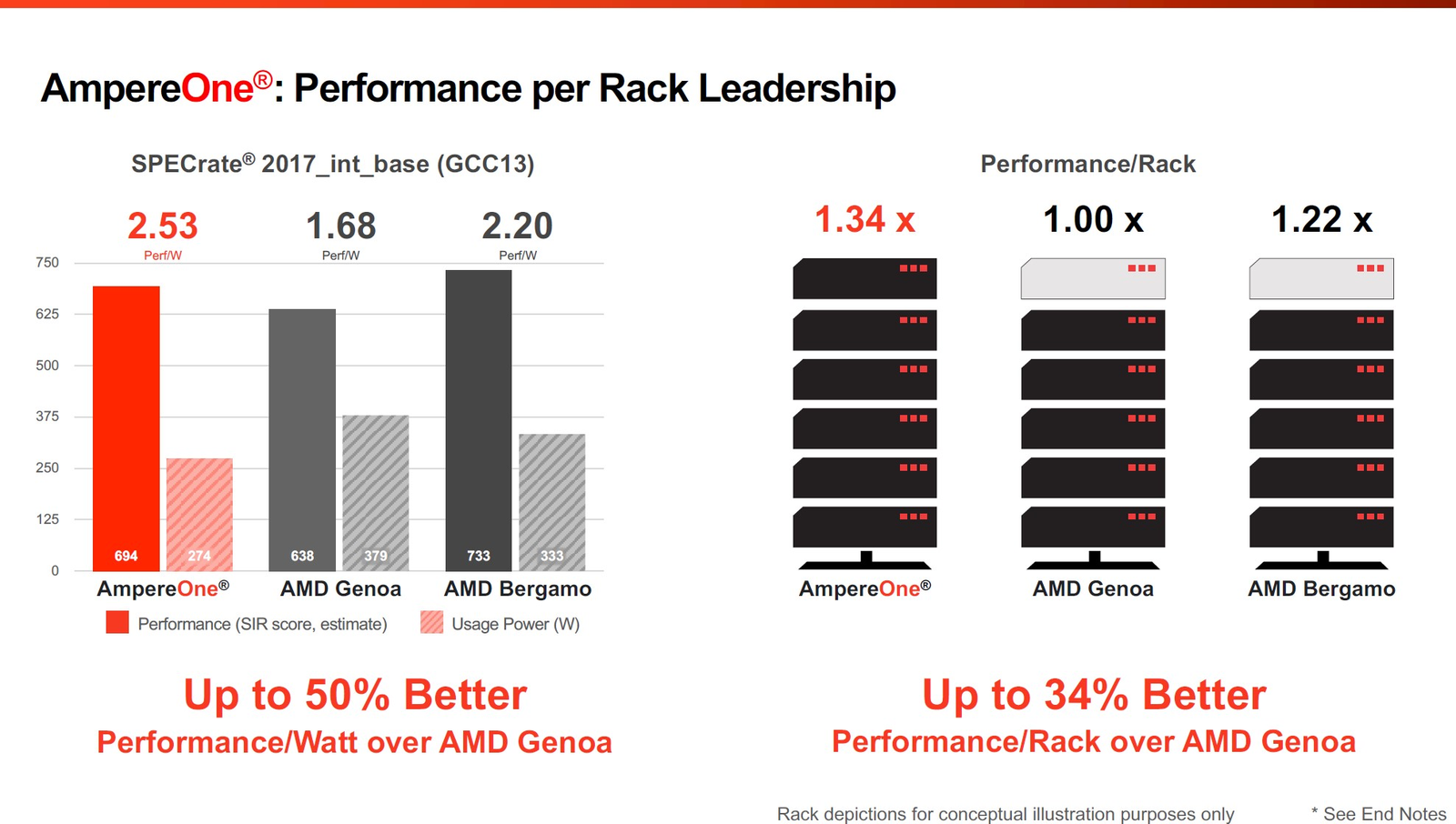 Ampere утверждает, что новые AmpereOne превзойдут в удельной производительности на Вт AMD EPYC Bergamo и обеспечат более высокую производительность в пересчёте на стойку, нежели AMD EPYC Genoa. Особенное внимание компания уделяет энергоэффективности AmpereOne, которая заключается не только в экономии электроэнергии, но и драгоценного места в ЦОД. Проще говоря, компания упирает на повышение плотности размещения вычислительных мощностей. 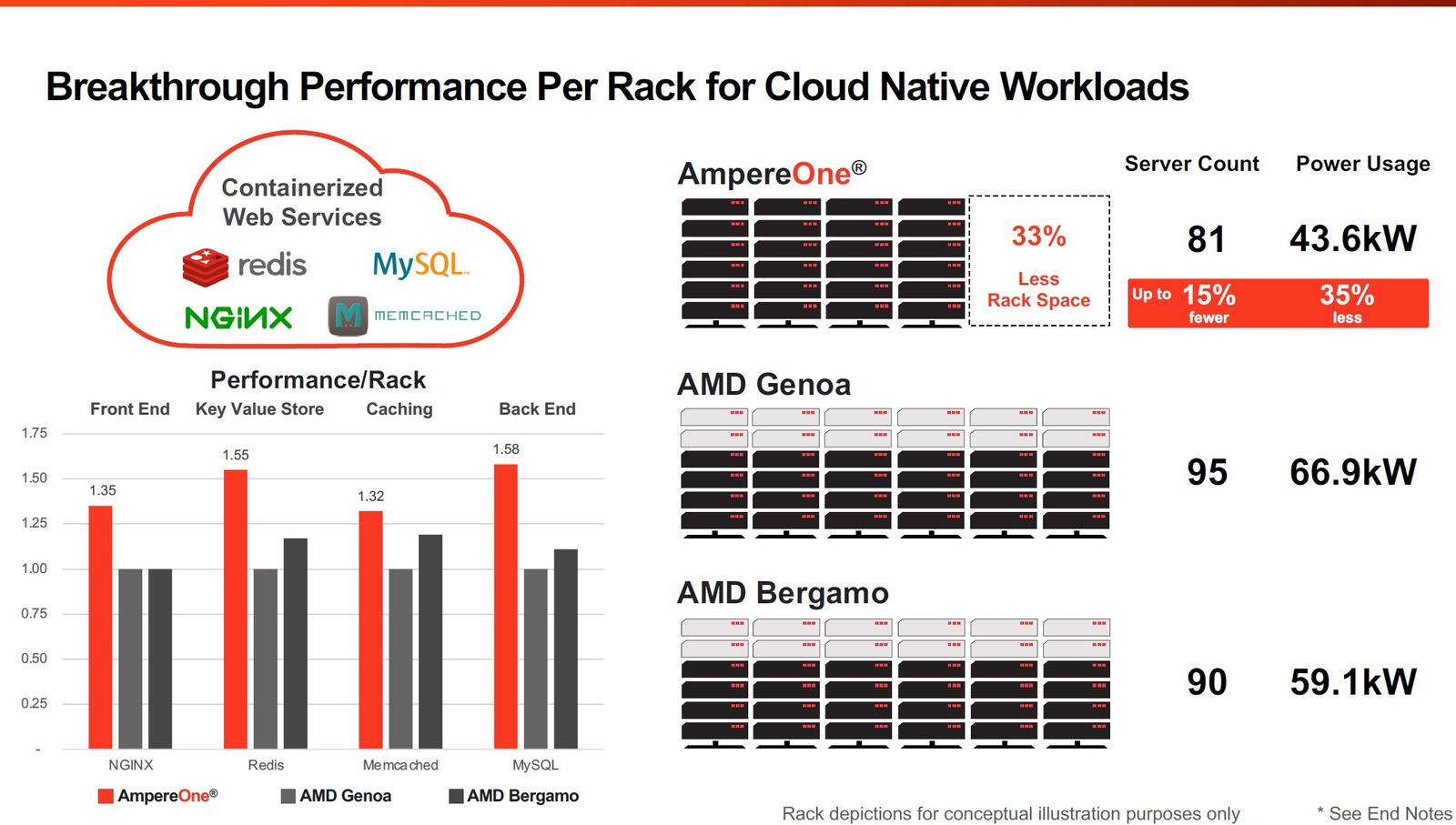 Заодно Ampere в который раз говорит, что в инференс-сценариях её процессоры сопоставимы с некоторыми ускорителями, в частности, NVIDIA A10, но при этом существенно дешевле и экономичнее. В пересчёте на токены при производительности порядка 80 токенов в секунду платформа Ampere обходится на 28% дешевле и в то же время потребляет меньше энергии на целых 67%! 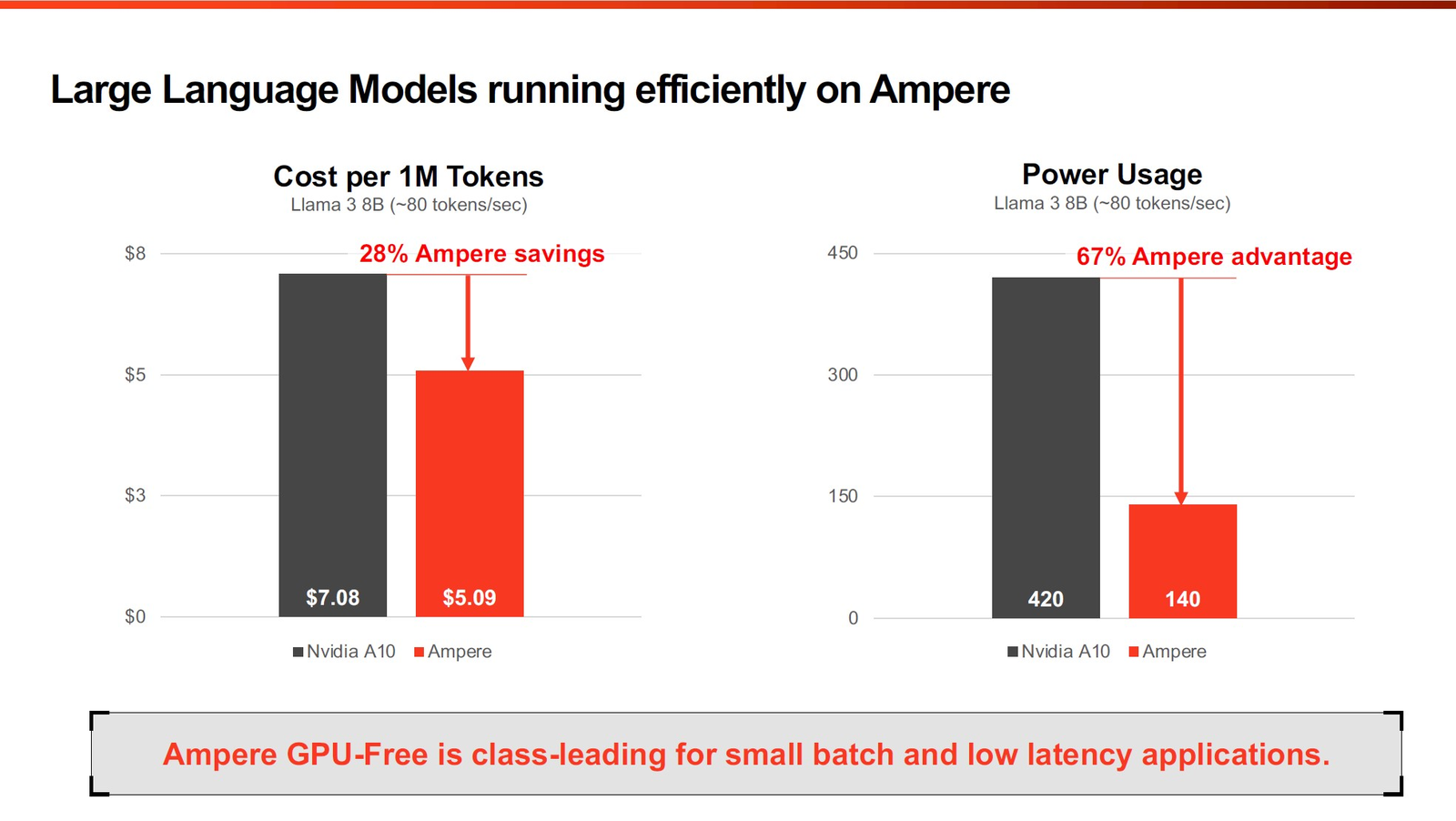 Более того, Ampere заключила союз с Qualcomm для выпуска серверной платформы, сочетающей AmpereOne в качестве процессоров общего назначения и ИИ-ускорителей Qualcomm Cloud AI 100 Ultra. Если сами процессоры успешно работают с LLM сравнительно небольшой сложности (до 7 млрд параметров), то новая платформа позволит запускать и сети с 70 млрд параметров. Кроме того, есть и готовое решение с VPU Quadra T1U.  Увидит ли свет в будущем гибридный процессор Ampere Computing с UCIe-чиплетами, будет зависеть от решений, принятых группой AI Platform Alliance, возглавленной Ampere Computing ещё осенью прошлого года. Но это вполне реальный сценарий: блоки ускорения специфических для ИИ-задач вычислений активно внедряются не только в серверных решениях, подобных Intel Xeon Sapphire/Emerald Rapids — сопроцессоры NPU уже дебютировали в потребительских и промышленных CPU Intel и AMD. При этом Ampere Computing, вероятно, придётся несколько поменять политику дальнейшего развития, поскольку основными конкурентами для неё являются не только 128-ядерные AMD EPYC Bergamo и готовящиеся 144- и 288-ядерные Intel Xeon Sierrra Forest, но и Arm-процессоры Google Axion и Microsoft Cobalt 100, которые изначально создавались гиперскейлерами под свои нужды, а потому наверняка лучше оптимизированы под их задачи и, вероятнее всего, к тому же дешевле, чем продукты Ampere.
16.05.2024 [01:05], Игорь Осколков
И для ИИ, и для HPC: первые европейские серверные Arm-процессоры SiPearl Rhea1 получат HBM-памятьКомпания SiPearl уточнила спецификации разрабатываемых ею серверных Arm-процессоров Rhea1, которые будут использоваться, в частности, в составе первого европейского экзафлопсного суперкомпьютера JUPITER, хотя основными чипами в этой системе будут всё же гибридные ускорители NVIDIA GH200. Заодно SiPearl снова сдвинула сроки выхода Rhea1 — изначально первые образцы планировалось представить ещё в 2022 году, а теперь компания говорит уже о 2025-м. При этом существенно дизайн процессоров не поменялся. Они получат 80 ядер Arm Neoverse V1 (Zeus), представленных ещё весной 2020 года. Каждому ядру полагается два SIMD-блока SVE-256, которые поддерживают, в частности, работу с BF16. Объём LLC составляет 160 Мбайт. В качестве внутренней шины используется Neoverse CMN-700. Для связи с внешним миром имеются 104 линии PCIe 5.0: шесть x16 + две x4. О поддержке многочиповых конфигураций прямо ничего не говорится. 
Источник изображения: SiPearl Очень похоже на то, что SiPearl от референсов Arm особо и не отдалялась, поскольку Rhea1 хоть и получит четыре стека памяти HBM, но это будет HBM2e от Samsung. При этом для DDR5 отведено всего четыре канала с поддержкой 2DPC, а сам процессор ожидаемо может быть поделён на четыре NUMA-домена. И в такой конфигурации к общей эффективности работы с памятью могут быть вопросы. Именно наличие HBM позволяет говорить SiPearl о возможности обслуживать и HPC-, и ИИ-нагрузки (инференс). 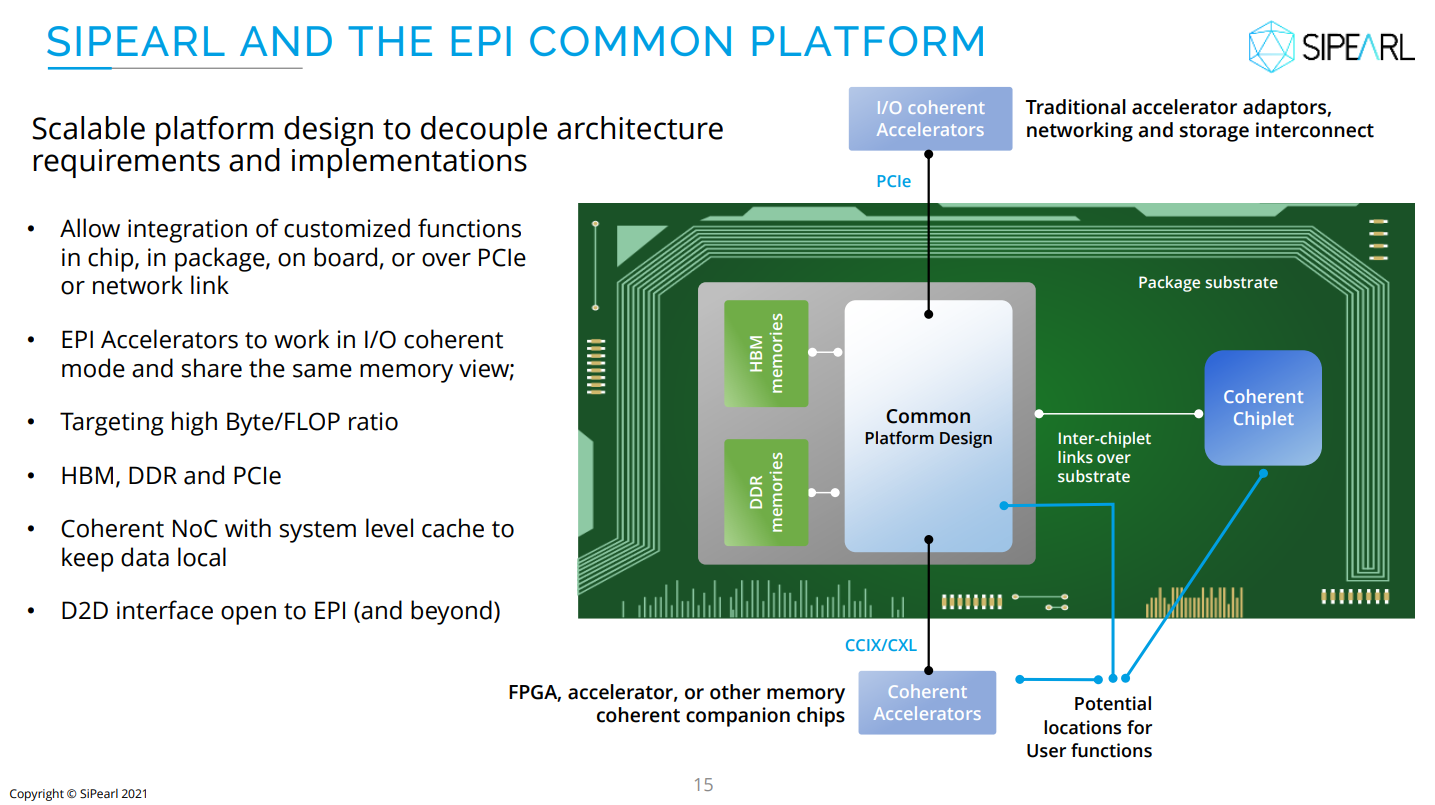
Источник изображения: SiPearl На примере Intel Xeon Max (Sapphire Rapids c 64 Гбайт HBM2e) видно, что наличие сверхбыстрой памяти на борту даёт прирост производительности в означенных задачах, хотя и не всегда. Однако это другая архитектура, другой набор инструкций (AMX), другая же подсистема памяти и вообще пока что единичный случай. С Fujitsu A64FX сравнения тоже не выйдет — это кастомный, дорогой и сложный процессор, который, впрочем, доказал эффективность и в HPC-, и даже в ИИ-нагрузках (с оговорками). В MONAKA, следующем поколении процессоров, Fujitsu вернётся к более традиционному дизайну. 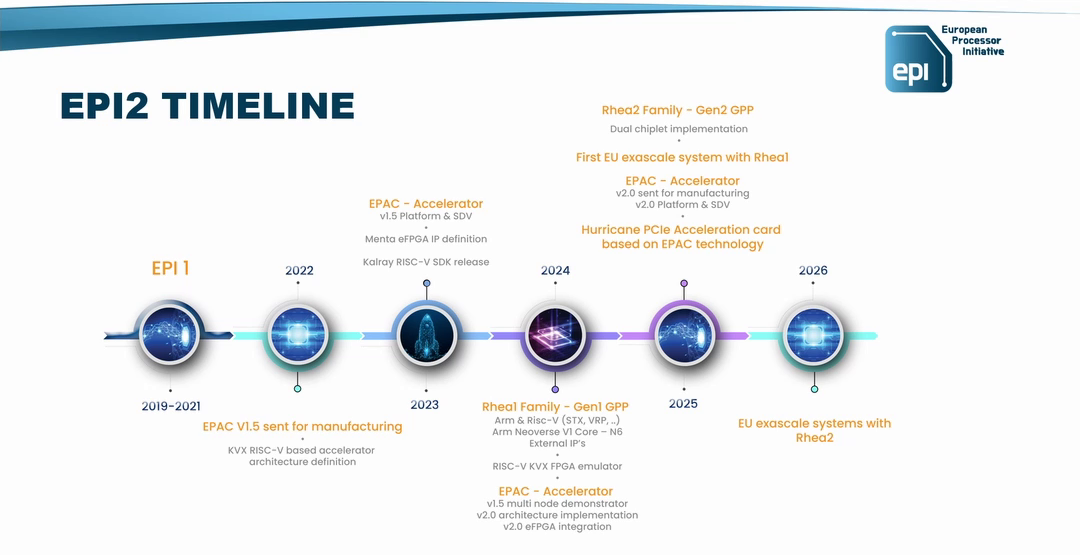
Источник изображения: EPI Пожалуй, единственный похожий на Rhea1 чип — это индийский 5-нм C-DAC AUM, который тоже базируется на Neoverse V1, но предлагает уже 96 ядер (48+48, два чиплета), восемь каналов DDR5 и до 96 Гбайт HBM3 в четырёх стеках, а также поддержку двухсокетных конфигураций. AWS Graviton3E, который тоже ориентирован на HPC/ИИ-нагрузки, вообще обходится 64 ядрами Zeus и восемью каналами DDR5. Наконец, NVIDIA Grace и Grace Hopper в процессорной части тоже как-то обходятся интегрированной LPDRR5x, да и ядра у них уже Neoverse V2 (Demeter), и своя шина для масштабирования имеется. 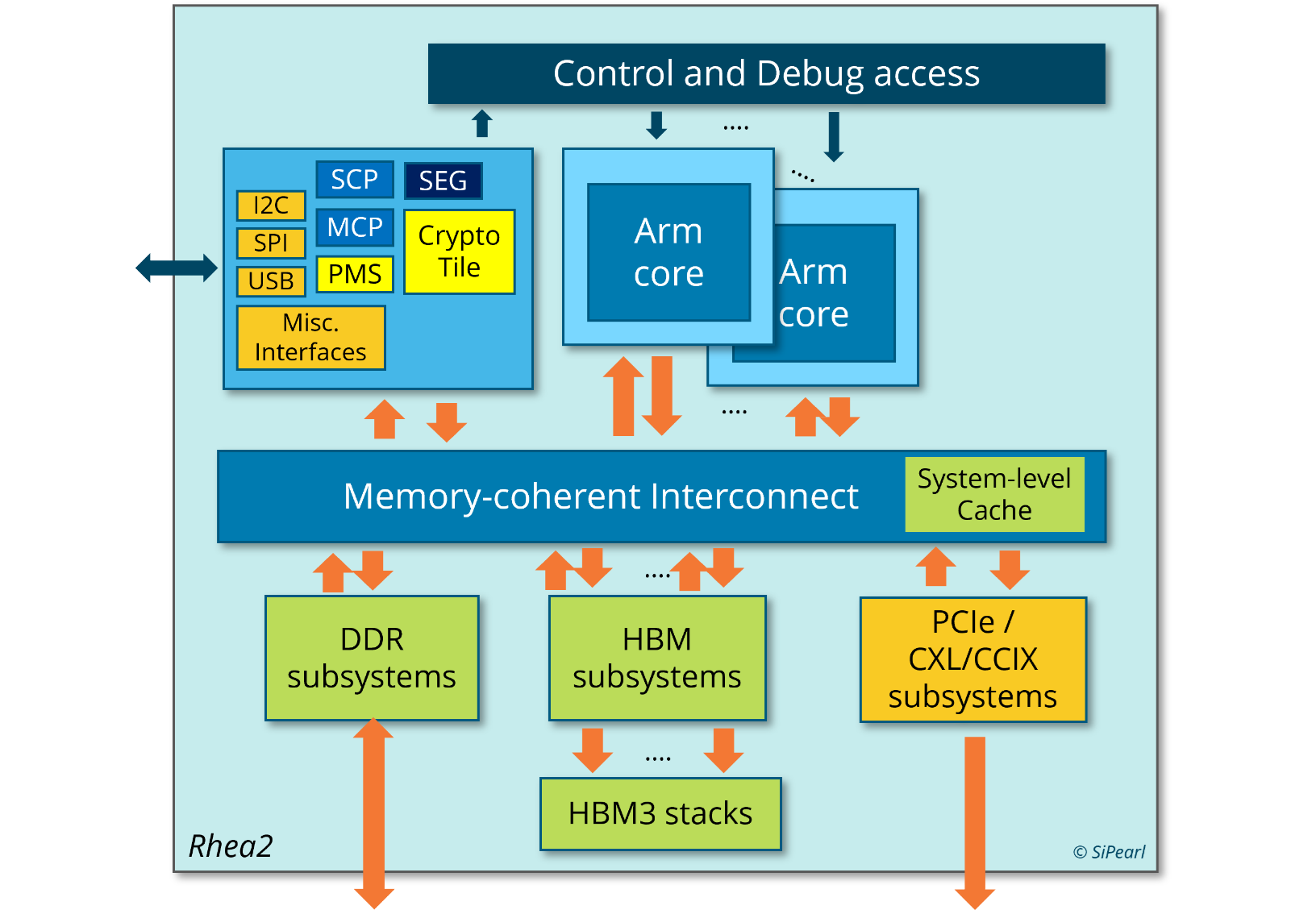
Источник изображения: EPI В любом случае в 2025 году Rhea1 будет выглядеть несколько устаревшим чипом. Но в этом же году SiPearl собирается представить более современные чипы Rhea2 и обещает, что их разработка будет не столь долгой как Rhea1. Компанию им должны составить европейские ускорители EPAC, тоже подзадержавшиеся. А пока Европа будет обходиться преимущественно американскими HPC-технологиями, от которых стремится рано или поздно избавиться. |
|

