Материалы по тегу: nvidia
|
21.03.2023 [19:15], Сергей Карасёв
NVIDIA представила систему DGX Quantum для гибридных квантово-классических вычисленийКомпания NVIDIA в партнёрстве с Quantum Machines анонсировала DGX Quantum — первую систему, объединяющую GPU и квантовые вычисления. Решение использует новую открытую программную платформу CUDA Quantum. Утверждается, что система предоставляет революционно архитектуру для исследователей, работающими с гибридными вычислениями с низкой задержкой. NVIDIA DGX Quantum объединяет средства ускоренных вычислений на базе Grace Hopper (Arm-процессор + ускоритель H100), модели программирования с открытым исходным кодом CUDA Quantum и передовую квантовую управляющую платформу Quantum Machines OPX+. Такая комбинация позволяет создавать ресурсоёмкие приложения, сочетающие квантовые вычисления с современными классическими вычислениями. При этом в числе прочего обеспечивается работа гибридных алгоритмов и коррекция ошибок. 
Источник изображения: NVIDIA Представленное решение предполагает соединение Grace Hopper и Quantum Machines OPX+ посредством интерфейса PCIe. Это обеспечивает задержку менее микросекунды между ускорителем и блоками квантовой обработки (QPU). Отмечается, что OPX+ — это универсальная система квантового управления. Таким образом, можно максимизировать производительность QPU и предоставить разработчикам новые возможности при использовании квантовых алгоритмов. Системы Grace Hopper и OPX+ можно масштабировать в соответствии с потребностями — от QPU с несколькими кубитами до суперкомпьютера с квантовым ускорением. 
Источник изображения: NVIDIA О намерении интегрировать CUDA Quantum в свои платформы уже заявили компании по производству квантового оборудования Anyon Systems, Atom Computing, IonQ, ORCA Computing, Oxford Quantum Circuits и QuEra, разработчики ПО Agnostiq и QMware, а также некоторые суперкомпьютерные центры.
20.01.2023 [15:28], Алексей Степин
NVIDIA Grace Superchip получит 144 Arm-ядра, 960 Гбайт набортной памяти LPDDR5x и 128 линий PCIe 5.0, а TDP составит 500 ВтGrace можно назвать одним из самых амбициозных проектов NVIDIA. О намерении ворваться на рынок мощных серверных процессоров компания объявила ещё на GTC 2022, но до недавних пор о чипах Grace были доступны лишь общие сведения. Однако ситуация меняется. NVIDIA явно располагает рабочим «кремнием», и на днях опубликовала пару деталей о Grace Superchip. Ожидается, что официальный анонс новинки состоится в марте этого года на GTC 2023. Эта сборка включает в себя два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2. Данное ядро использует набор инструкций Armv9, а также имеет четыре 128-битных блока векторных расширений SVE2, блоки для работы с матрицами и поддержку BF16/INT8. Объём кеша L1 составляет по 64 Кбайт для инструкций и данных, L2 — 1 Мбайт на ядро, а общий объём L3 на сборку достигает 234 Мбайт. 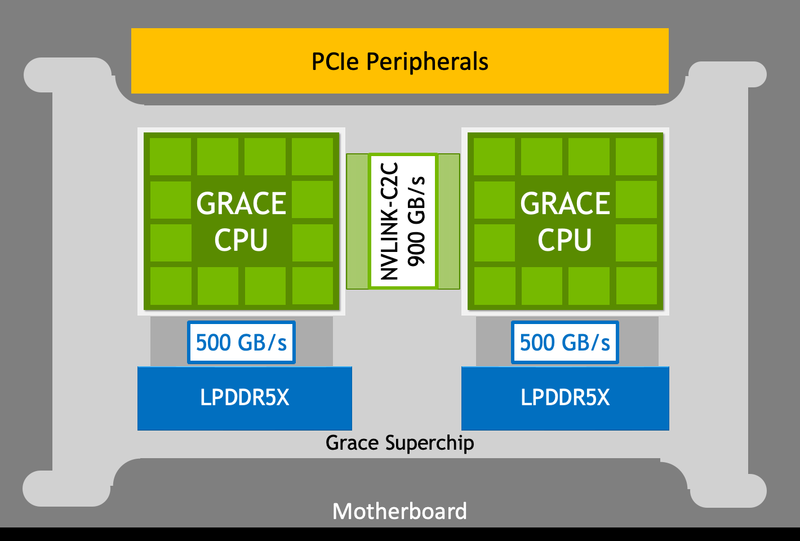
Блок-схема сборки Grace Superchip. Источник изображений здесь и далее: NVIDIA Между собой кристаллы соединены шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работают они как единый 144-ядерный процессор. Но это ещё не всё: каждый из кристаллов соединен со своим банком памяти LPDDR5x ECC шиной с пропускной способностью 500 Гбайт/с (т.е. суммарно на чип получается 1 Тбайт/с). Совокупный объём памяти может достигать 960 Гбайт. 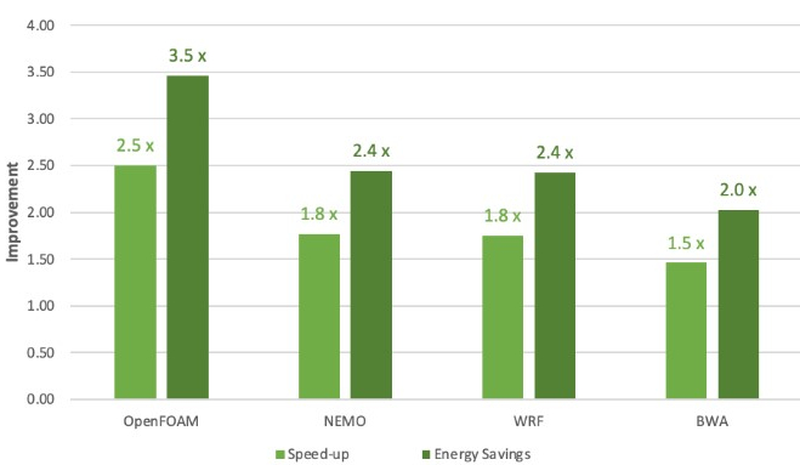
Сравнение производительности и энергоэффективности Grace Superchip с двумя AMD EPYC 7763 (Milan) Сборка Grace Superchip общается с внешним миром посредством восьми комплексов PCIe 5.0 x16 (всего 128 линий, поддерживается бифуркация). Чип при теплопакете 500 Вт (вместе с набортной памятью) способен развивать 7,1 Тфлопс на вычислениях двойной точности. С учетом интегрированной памяти это делает Grace Superchip интересной альтернативой AMD Genoa. 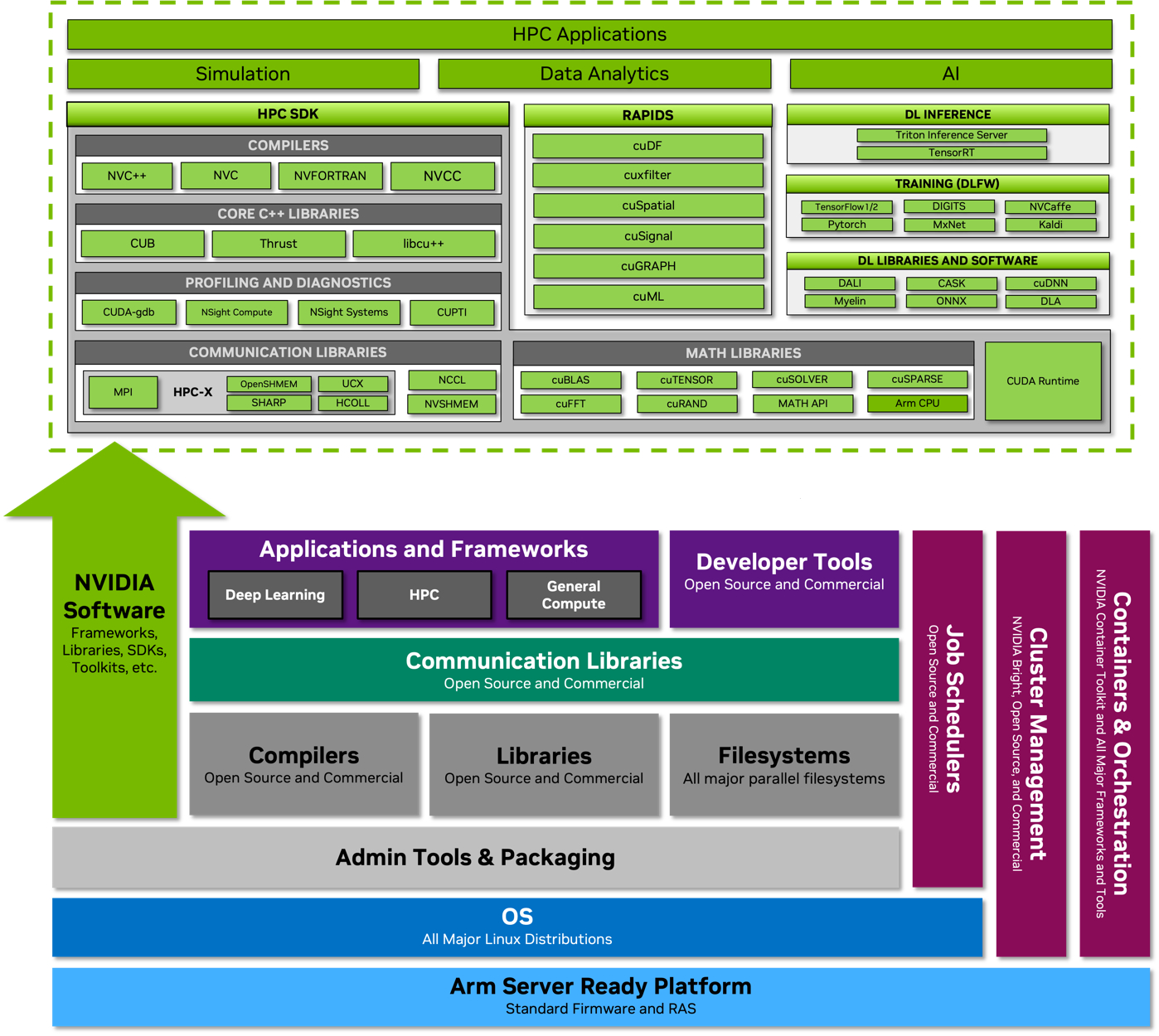
Программная экосистема платформы NVIDIA Grace. По клику открывается полноразмерная версия. Помимо данных о производительности в режиме FP64 компания уже опубликовала результаты тестов новинки в HPC-нагрузках, где сравнила своё детище с двухсокетной системой на базе AMD EPYC 7763. Выигрыш в производительности составляет от 1,5x до 2,5x, но что не менее важно — Grace Superchip намного эффективнее энергетически, здесь преимущество может достигать 3,5x. В условиях высокоплотных ЦОД или HPC-кластеров это может стать решающим.
10.11.2022 [17:15], Владимир Мироненко
HPE анонсировала недорогие, энергоэффективные и компактные суперкомпьютеры Cray EX2500 и Cray XD2000/6500Hewlett Packard Enterprise анонсировала суперкомпьютеры HPE Cray EX и HPE Cray XD, которые отличаются более доступной ценой, меньшей занимаемой площадью и большей энергоэффективностью по сравнению с прошлыми решениями компании. Новинки используют современные технологии в области вычислений, интерконнекта, хранилищ, питания и охлаждения, а также ПО. 
Изображение: HPE Суперкомпьютеры HPE обеспечивают высокую производительность и масштабируемость для выполнения ресурсоёмких рабочих нагрузок с интенсивным использованием данных, в том числе задач ИИ и машинного обучения. Новинки, по словам компании, позволят ускорить вывода продуктов и сервисов на рынок. Решения HPE Cray EX уже используются в качестве основы для больших машин, включая экзафлопсные системы, но теперь компания предоставляет возможность более широкому кругу организаций задействовать супервычисления для удовлетворения их потребностей в соответствии с возможностями их ЦОД и бюджетом. В семейство HPE Cray вошли следующие системы:
Все три системы задействуют те же технологии, что и их старшие собратья: интерконнект HPE Slingshot, хранилище Cray Clusterstor E1000 и пакет ПО HPE Cray Programming Environment и т.д. Система HPE Cray EX2500 поддерживает процессоры AMD EPYC Genoa и Intel Xeon Sapphire Rapids, а также ускорители AMD Instinct MI250X. Модель HPE Cray XD6500 поддерживает чипы Sapphire Rapids и ускорители NVIDIA H100, а для XD2000 заявлена поддержка AMD Instinct MI210. 
Изображение: Intel В качестве примеров выгод от использования анонсированных суперкомпьютеров в разных отраслях компания назвала:
09.11.2022 [14:50], Владимир Мироненко
Производители специально ухудшают характеристики чипов для китайских серверов, чтобы избежать санкций СШАВ связи с вводом Соединёнными Штатами новых экспортных ограничений на поставки в Китай, производители стали намеренно снижать производительность чипов, чтобы соответствовать требованиям экспортного контроля США и избежать проблем с получением специальных лицензий. Как отметил ресурс The Register, у систем, построенных на чипах NVIDIA, изготовленных на производственных мощностях TSMC для поставок в Китай, характеристики хуже по сравнению с теми, что были ранее. В частности, китайский производитель серверов Inspur указал на использование вместо ускорителя NVIDIA A100 чипа A800, разработанного NVIDIA специально для Китая в соответствии с экспортными ограничениями. Китайские производители H3C и Omnisky тоже представили решения на базе A800. Данный ускоритель, по словам NVIDIA, начала производиться в III квартале этого года. У A800 скорость передачи данных составляет 400 Гбайт/с, тогда как у A100 этот показатель равен 600 Гбайт/с, причём обойти эти ограничения, по словам NVIDIA, невозможно. Речь, судя по всему, идёт о характеристиках интерконнекта NVLink, которые прямо влияют на производительность кластеров из двух и более ускорителей в машинном обучении и других задачах. Изменения касаются 40- и 80-Гбайт вариантов с интерфейсами PCIe и SXM. 
Источник изображения: Inspur Между тем ускорители, находящиеся в разработке и выпускаемые TSMC по контракту с Alibaba и стартапом Biren Technology, тоже, как сообщается, имеют пониженную скорость передачи данных. Это позволит выпускать данные чипы на заводе TSMC, не опасаясь санкций США. До этого TSMC приостановила выпуск 7-нм чипов ускорителей Biren BR100 как раз из-за возможных санкций со стороны Вашингтона.
21.09.2022 [19:39], Алексей Степин
NVIDIA представила новые сверхкомпактные модули Jetson Orin NanoКомпания NVIDIA полна решимости занять лидирующие позиции на рынке робототехники: помимо новой платформы IGX, предназначенной для «умной» промышленности и медицины, на конференции GTC 2022 она представила и другие новинки в этой сфере. В частности, анонсированы новые модули в серии Jetson. Если в основу IGX лёг старший вариант, Jetson AGX Orin (Arm Cortex-A78AE + 1792 ядра Ampere + 56 тензорных ядер), то для более простых сценариев, требующих пониженного энергопотребления, он подходит не лучшим образом. Но именно для таких случаев предназначено пополнение серии — Jetson Orin Nano. 
NVIDIA Jetson Orin Nano 8GB (слева) и 4GB. Здесь и далее источник изображений: NVIDIA Архитектурно Orin Nano похож на старшего собрата, но вычислительных ресурсов у него поменьше: 6 ядер Arm Cortex-A78AE и кластер GPC Ampere, состоящий из 1024 ядер CUDA и 32 тензорных ядер. Имеется отдельный процессор управления питанием, широко развиты подсистемы различных шин, от SPI, CAN и I2C до USB 3.2 Gen2, Ethernet и PCIe 3.0. 
Архитектура процессора Orin Nano Доступны новые модули будут в самом начале следующего года по цене от $199, причём изначально компания планирует выпустить два варианта, с 4 и 8 Гбайт оперативной памяти LPDDR5. Старший вариант будет сконфигурирован в рамках теплопакета 7–15 Вт, его пиковая производительность в INT8 составит 40 Топс. Младший вариант с усечённой вдвое конфигурацией GPU будет ограничен 5–10 Вт и 20 Топс. 
Характеристики семейства Jetson Orin Nano Модули Orin Nano совместимы по контактам с Orin NX и имеют тот же форм-фактор, 70 × 45 мм SODIMM, но за счёт использования более продвинутой архитектуры в задачах инференса новинки могут опережать предшественников в 80 раз. Благодаря обновлению фирменного SDK начать разработку приложений под Orin Nano заказчики смогут уже сейчас, пусть и в режиме эмуляции.
21.09.2022 [19:32], Алексей Степин
NVIDIA представила ускорители L40 и новую Omniverse-платформу OVX на их основеНа конференции GTC 2022 NVIDIA анонсировала второе поколение систем для симуляции и запуска «цифровых двойников» OVX. Это вовсе не развлечение: использование точных моделей реальных физических объектов, пространств и устройств потенциально весьма выгодно, поскольку симуляция городского квартала для обучения автопилотов или фабрики для оценки взаимодействия роботов с живыми работниками априори будет стоить намного меньше, нежели проведение натурных испытаний. Зачастую такие симуляции используют тензорные и матричные вычисления, поэтому основой новой платформы OVX стали новые ускорители NVIDIA L40 с архитектурой Ada Lovelace, располагающие ядрами трассировки лучей третьего поколения и тензорными ядрами четвёртого поколения. Они поддерживают как классический трассировку лучей (ray tracing), так и трассировку путей (path tracing), что важно для корректной симуляции поведения различных материалов. 
NVIDIA L40. Здесь и далее источник изображений: NVIDIA Физически L40 представляют собой двухслотовую FHFL-плату расширения PCIe с пассивным охлаждением — теплопакет новинки ограничен рамками 300 Вт. Объём оперативной памяти GDDR6 составляет 48 Гбайт, вдвое больше, нежели у игровых GeForce RTX 4090, и, в отличие от последних, поддерживается совместная работа двух карт в режиме NVLink, что может оказаться полезным в симуляциях с большим объёмом данных. Для вывода изображения служат четыре порта DP 1.4a. 
NVIDIA OVX Server Каждый сервер NVIDIA OVX будет содержать 8 ускорителей L40 и три сетевых адаптера ConnectX-7 с портами класса 200GbE и поддержкой шифрования сетевого трафика на лету. От 4 до 16 таких серверов составят OVX POD, а 32 или более —кластер SuperPOD. Такие кластеры станут домом для новой облачной платформы NVIDIA Omniverse Cloud, услуги которой компания планирует предоставлять робототехникам, создателям автономных транспортных средств, «умной инфраструктуры» и вообще всем, кому нужна точная симуляция сложных объектов и систем с качественной визуализацией результатов.
21.09.2022 [01:10], Алексей Степин
NVIDIA представила платформу IGX для «умной» промышленности и медициныПомимо новых GPU с архитектурой Ada компания NVIDIA на конференции GTC 2022 анонсировала множество новинок и не последней из них стала новая периферийная платформа IGX, призванная вывести «умную» промышленность на новый уровень. Главный упор в IGX сделан на обеспечении повышенной безопасности, причём как информационной, так и физической. Использовать совместный труд роботов в промышленности пытаются уже давно, но до недавних пор такие решения были нестандартными и весьма дорогостоящими. IGX призвана обеспечить безопасность, стандартизацию и высокий уровень производительности, достаточный для современной робототехники. Сердцем платформы IGX являются высокоинтегрированные модули серии Jetson AGX Orin, сочетающие в себе достаточно мощный процессор общего назначения, GPU-ускоритель, ускорители ИИ, машинного зрения, а также отдельный сопроцессор sMCU, отвечающий за обеспечение безопасности в проактивном режиме. Последний работает в комплексе с новыми программными расширениями, легко интегрируемыми в большинство коммерческих ОС благодаря сопутствующему программному стеку NVIDIA AI Enterprise. 
NVIDIA IGX. Здесь и далее источник изображений: NVIDIA Что касается проактивной защиты, то, к примеру, получив сигнал с видеокамер о том, что человек приближается к «зоне ответственности» роботов, система автоматически изменит траекторию движения последних, предупредит сотрудников, а также на основании полученных данных скорректирует поведение роботов в дальнейшем. Также с помощью технологии «цифровых двойников» можно будет провести симуляцию, дабы заранее выяснить возможные точки потенциально опасных столкновений машин и людей. 
NVIDIA IGX сделает подобные сценарии безопасными Производительность центрального модуля IGX составляет 275 Топс в режиме INT8. Обеспечение сетевых возможностей возложено на плечи современного сетевого адаптера ConnectX-7, гарантирующего прецизионные тайминги, позволяющие использовать платформу не только в промышленности, но и в медицине, где вопросы безопасности и точности жизненно важны. Естественно, индустрия нового поколения не может обойтись без унифицированных средств управления и обеспечения кибербезопасности. Весь комплекс решений на базе новой платформы IGX может развёртываться и управляться с единой консоли с помощью облачной системы NVIDIA Fleet Command. За безопасность при этом отвечает выделенный контроллер. На более высоком уровне за интеграцию новой платформы в единую экосистему отвечает фреймворк NVIDIA Metropolis, с помощью которого можно создавать по-настоящему крупномасштабные комплексы, включая целые «умные города». 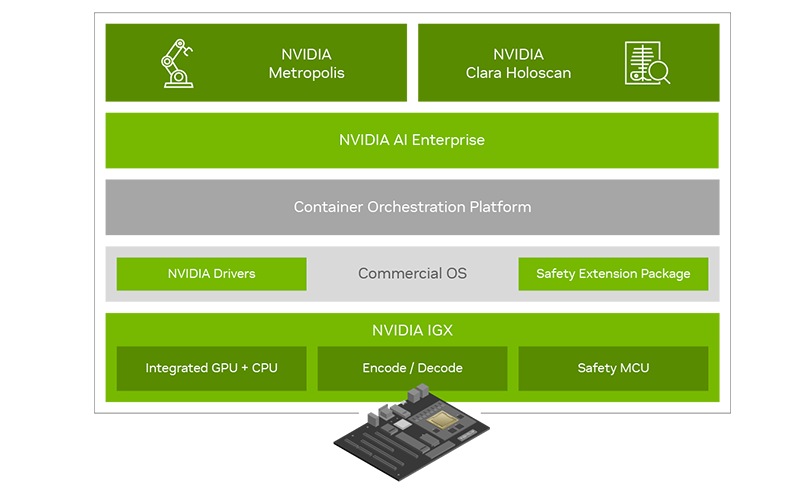
Программно-аппаратный состав новой платформы Отдельного упоминания заслуживает то, что новая платформа NVIDIA IGX избрана в качестве основы разработчиками медицинских систем, в частности, цифровой и робо-хирургии, такими как Activ Surgical, Moon Surgical и Proximie. Это стало возможным как благодаря аппаратным свойствам платформы, таким как низкая латентность и гарантированное время отклика, так и сочетанию фреймворков MONAI и Clara Holoscan.  Первый позволяет обучать специфические ИИ-модели на основании массивов медицинских данных. Эти модели затем могут интегрироваться с помощью Clara Holoscan SDK в реальные системы ультразвукового сканирования, эндоскопии или робохирургии. Помимо встроенных средств ускорения IGX, Clara Holoscan поддерживает и внешние ускорители NVIDIA RTX A6000, а технология Rivermax обеспечит передачу видеоданных для робота-хирурга на скорости 100 Гбит/с прямо в набортную память GPU. 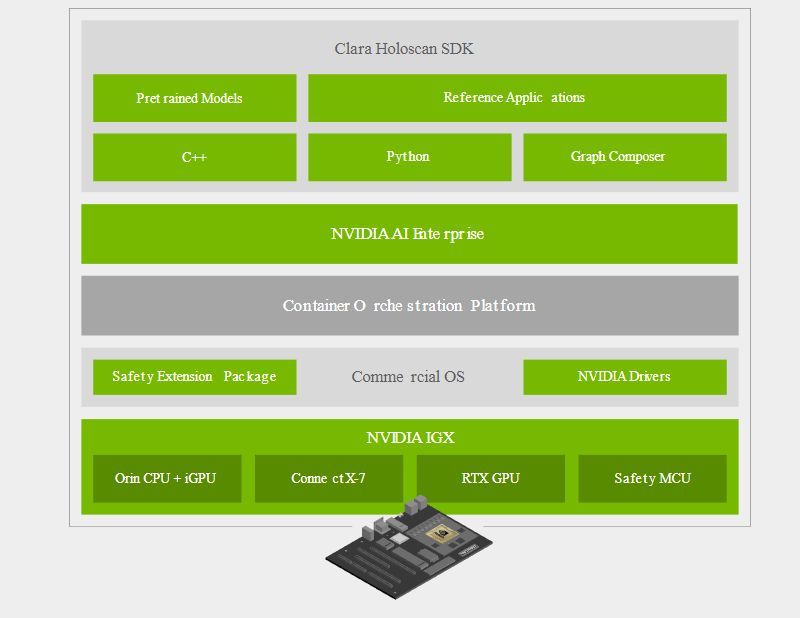 Комплекты разработчика IGX Orin будут доступны заказчикам в начале следующего года. Уже достигнуты соглашения с производителями встраиваемого оборудования ADLINK, Advantech, Dedicated Computing, Kontron, Leadtek, MBX, Onyx, Portwell, Prodrive Technologies и YUAN; уже испытывает новинку в деле Siemens. Также NVIDIA сотрудничает с Canonical, Red Hat и SUSE в целях обеспечения долговременной поддержки платформы, срок которой составит не менее 10 лет.
26.08.2022 [12:45], Алексей Степин
Интерконнект NVIDIA NVLink 4 открывает новые горизонты для ИИ и HPCПотребность в действительно быстром интерконнекте для ускорителей возникла давно, поскольку имеющиеся шины зачастую становились узким местом, не позволяя «прокормить» данными вычислительные блоки. Ответом NVIDIA на эту проблему стало создание шины NVLink — и компания продолжает активно развивать данную технологию. На конференции Hot Chips 34 было продемонстрировано уже четвёртое поколение, наряду с новым поколением коммутаторов NVSwitch. 
Изображения: NVIDIA Возможность использования коммутаторов для NVLink появилась не сразу, изначально использовалось соединение блоков ускорителей по схеме «точка-точка». Но дальнейшее наращивание числа ускорителей по этой схеме стало невозможным, и тогда NVIDIA разработала коммутаторы NVSwitch. Они появились вместе с V100 и предлагали до 50 Гбайт/с на порт. Нынешнее же, третье поколение NVSwitch и четвёртое поколение NVLink сделали важный шаг вперёд — теперь они позволяют вынести NVLink-подключения за пределы узла. 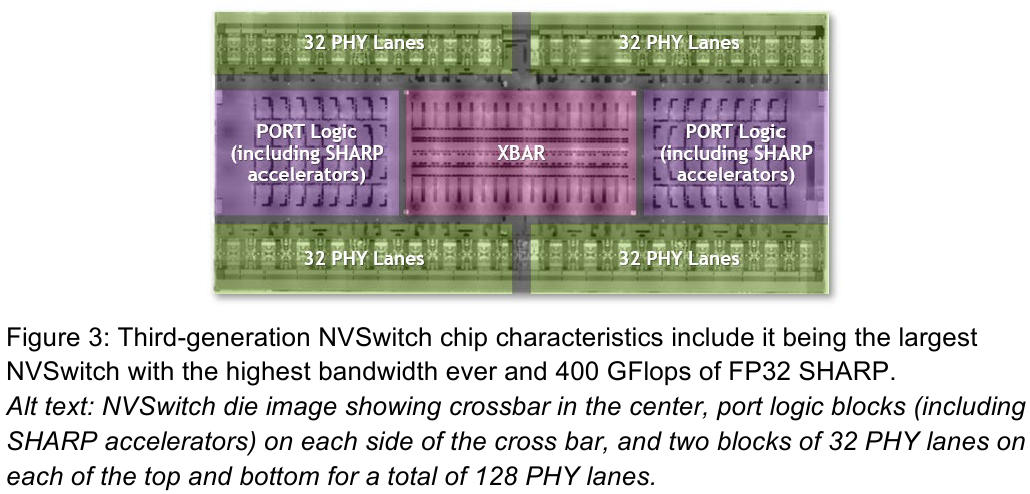 Так, совокупная пропускная способность одного чипа NVSwitch теперь составляет 3,2 Тбайт/с в обе стороны в 64 портах NVLink 4 (x2). Это, конечно, отразилось и на сложности самого «кремния»: 25,1 млрд транзисторов (больше чем у V100), техпроцесс TSMC 4N и площадь 294мм2. Скорость одной линии NVLink 4 осталась равной 50 Гбайт/с, но новые ускорители H100 имеют по 18 линий NVLink, что даёт впечатляющие 900 Гбайт/с. В DGX H100 есть сразу четыре NVSwitch-коммутатора, которые объединяют восемь ускорителей по схеме каждый-с-каждым и дополнительно отдают ещё 72 NVLink-линии (3,6 Тбайт/с). 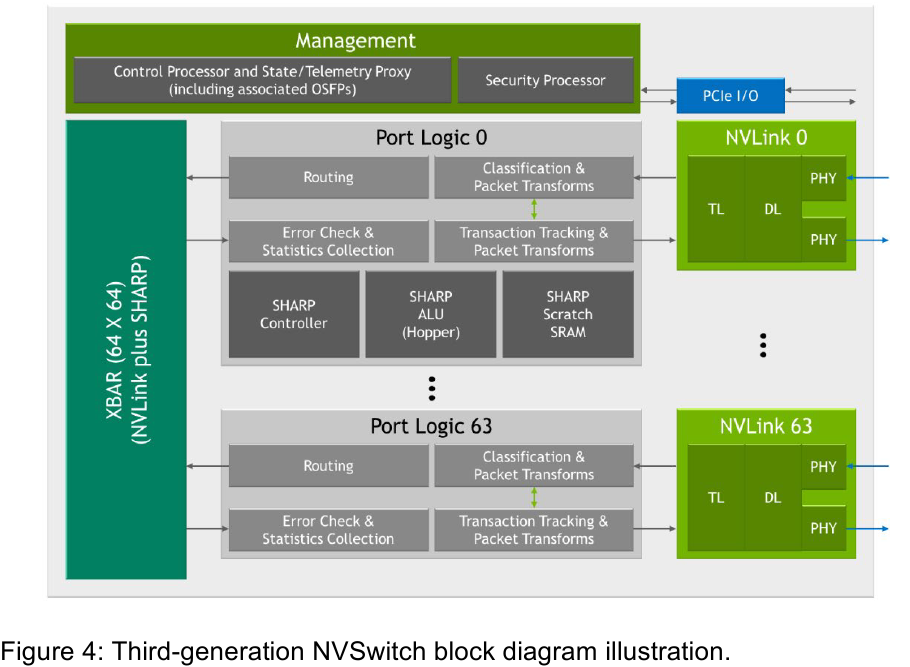 При этом у DGX H100 сохраняются прежние 400G-адаптеры Ethernet/InfiniBand (ConnectX-7), по одному на каждый ускоритель, и пара DPU BlueField-3, тоже класса 400G. Несколько упрощает физическую инфраструктуру то, что для внешних NVLink-подключений используются OSFP-модули, каждый из которых обслуживает 4 линии NVLink. Любопытно, что электрически интерфейсы совместимы с имеющейся 400G-экосистемой (оптической и медной), но вот прошивки для модулей нужны будут кастомные. 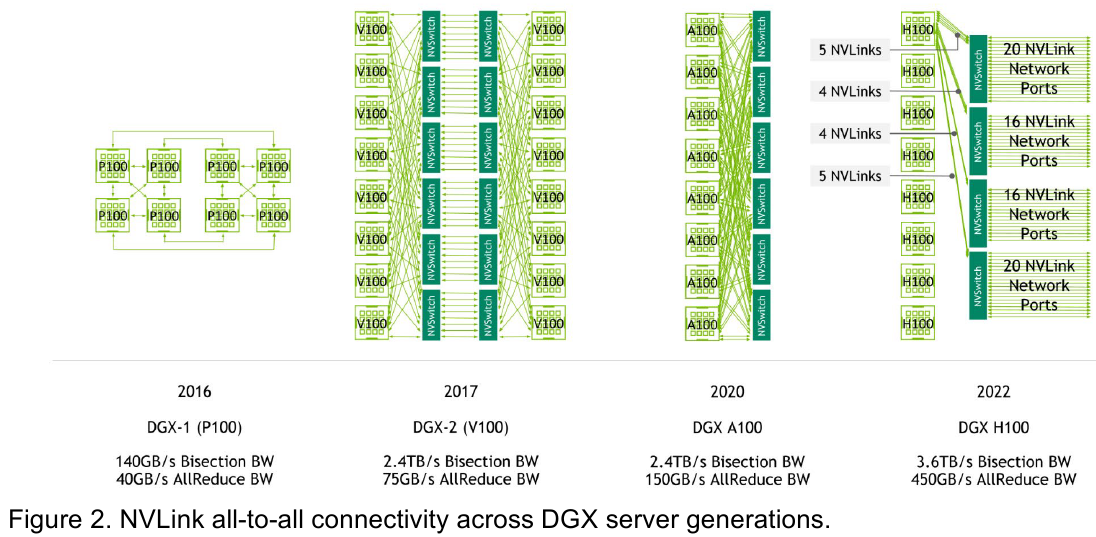 Подключаются узлы DGX H100 к 1U-коммутатору NVLink Switch, включающему два чипа NVSwitch третьего поколения: 32 OSFP-корзины, 128 портов NVLink 4 и агрегированная пропускная способность 6,4 Тбайт/с. В составе DGX SuperPOD есть 18 коммутаторов NVLink Switch и 256 ускорителей H100 (32 узла DGX). Таким образом, можно связать ускорители и узлы 900-Гбайт/с каналом. Как конкретно, остаётся на усмотрение пользователя, но сама NVLink-сеть поддерживает динамическую реконфигурацию на лету. 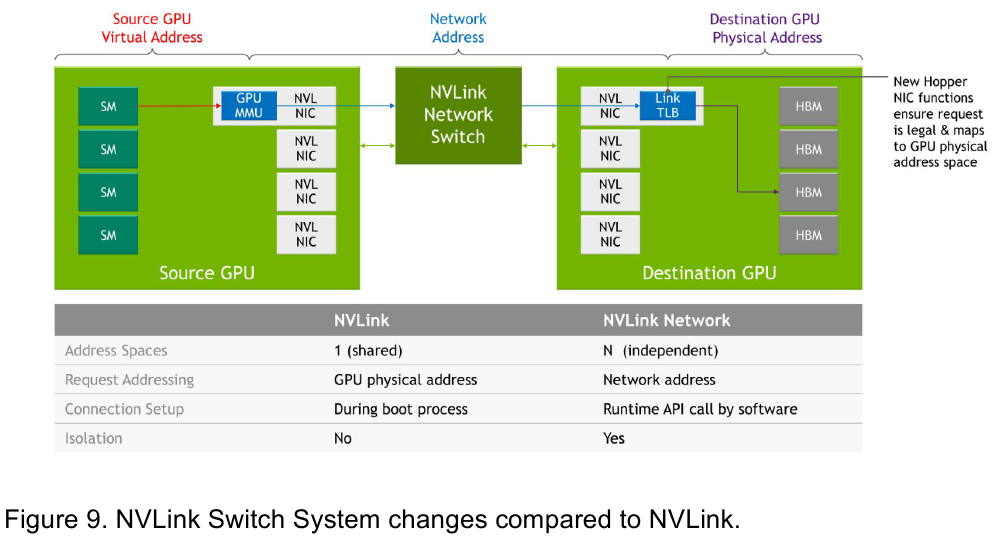 Ещё одна особенность нового поколения NVLink — продвинутые аппаратные SHARP-движки, которые избавляют CPU/GPU от части работ по подготовке и предобработки данных и избавляющие саму сеть от ненужных передач. Кроме того, в NVLink-сети реализованы разделение и изоляция, брандмауэр, шифрование, глубокая телеметрия и т.д. В целом, новое поколение NVLink получило полуторакратный прирост в скорости обмена данными, а в отношении дополнительных сетевых функций он стал трёхкратным. Всё это позволит освоить новые класса HPC- и ИИ-нагрузок, однако надо полагать, что удовольствие это будет недешёвым.
20.08.2022 [22:30], Алексей Степин
NVIDIA поделилась некоторыми деталями о строении Arm-процессоров Grace и гибридных чипов Grace HopperНа GTC 2022 весной этого года NVIDIA впервые заявила о себе, как о производителе мощных серверных процессоров. Речь идёт о чипах Grace и гибридных сборках Grace Hopper, сочетающих в себе ядра Arm v9 и ускорители на базе архитектуры Hopper, поставки которых должны начаться в первой половине следующего года. Многие разработчики суперкомпьютеров уже заинтересовались новинками. В преддверии конференции Hot Chips 34 компания раскрыла ряд подробностей о чипах. Grace производятся с использованием техпроцесса TSMC 4N — это специально оптимизированный для решений NVIDIA вариант N4, входящий в серию 5-нм процессов тайваньского производителя. Каждый кристалл процессорной части Grace содержит 72 ядра Arm v9 с поддержкой масштабируемых векторных расширений SVE2 и расширений виртуализации с поддержкой S-EL2. Как сообщалось ранее, NVIDIA выбрала для новой платформы ядра Arm Neoverse. 
Источник: NVIDIA Процессор Grace также соответствует ряду других спецификаций Arm, в частности, имеет отвечающий стандарту RAS v1.1 контроллер прерываний (Generic Interrupt Controller, GIC) версии v4.1, блок System Memory Management Unit (SMMU) версии v3.1 и средства Memory Partitioning and Monitoring (MPAM). Базовых кристаллов у Grace два, что в сумме даёт 144 ядра — рекордное количество как в мире Arm, так и x86. 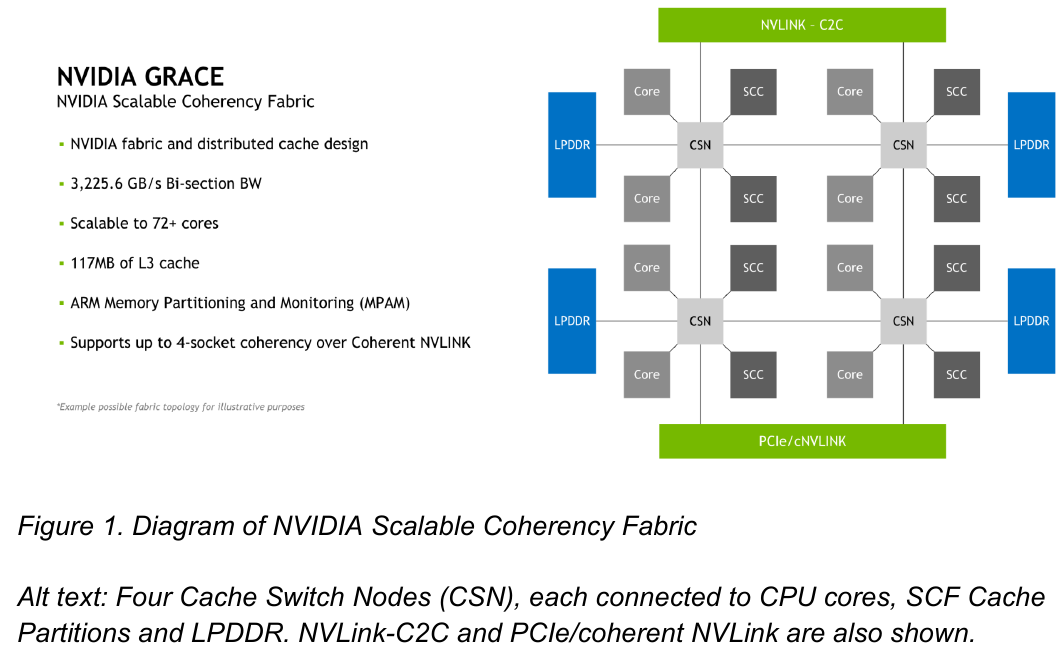
Внутренняя организация кластеров ядр в Grace. Источник: NVIDIA Внутренние блоки Grace соединяются посредством фабрики Scalable Coherency Fabric (SCF), вариации NVIDIA на тему сети CMN-700, применяемой в дизайнах Arm Neoverse. Производительность данного интерконнекта составляет 3,2 Тбайт/с. В случае Grace он предполагает наличие 117 Мбайт кеша L3 и поддерживает когерентность в пределах четырёх сокетов (посредством новой версии NVLink). Но SCF поддерживает масштабирование. Пока что в «железе» она ограничена двумя блоками Grace, а это уже 144 ядра и 234 Мбайт L3-кеша. Ядра и кеш-разделы (SCC) рапределены по внутренней mesh-фабрике SCF. Коммутаторы (CSN) служат интерфейсами для ядер, кеш-разделов и остальными частями системы. Блоки CSN общаются непосредственно друг с другом, а также с контроллерами LPDDR5X и PCIe 5.0/cNVLink/NVLink C2C. 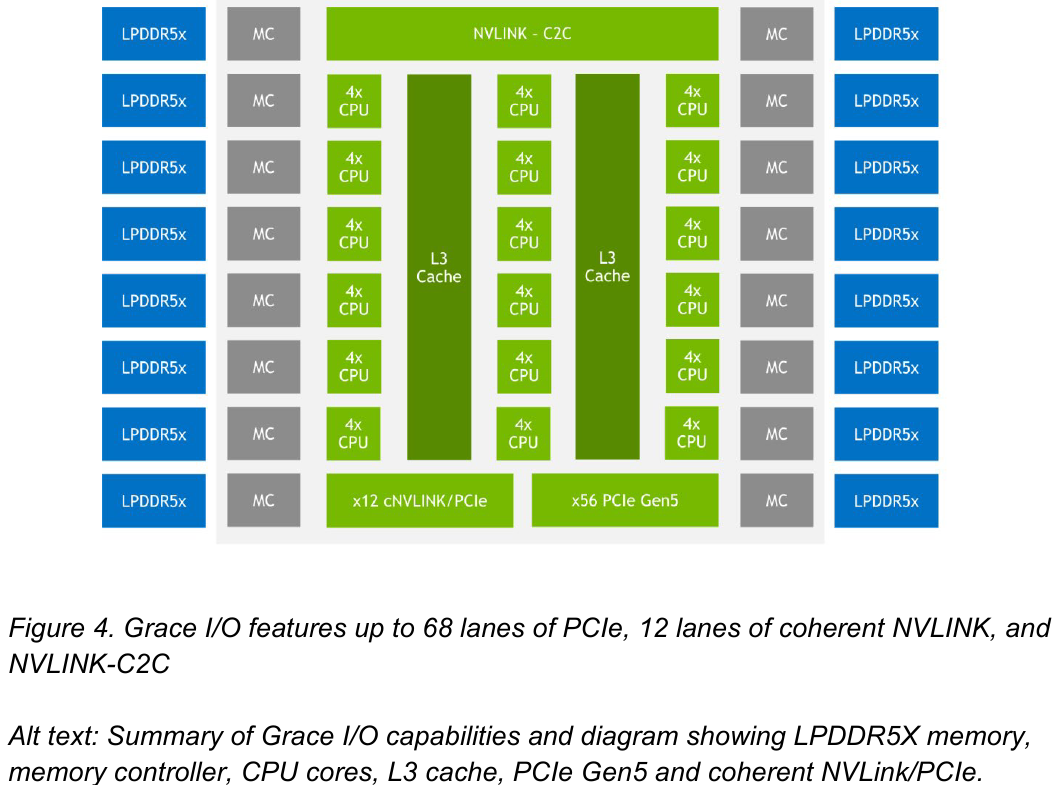
Блок-схема кристалла Grace. Источник: NVIDIA В чипе реализована поддержка PCI Express 5.0. Всего контроллер поддерживает 68 линий, 12 из которых могут также работать в режиме cNVLink (NVLink с когерентностью). x16-интерфейс посредством бифуркации может быть превращен в два x8. Также на приведённой NVIDIA диаграмме можно видеть целых 16 двухканальных контроллеров LPDDR5x. Заявлена ПСП на уровне свыше 1 Тбайт/с для сборки (до 546 Гбайт/с на кристалл CPU). 
Источник: NVIDIA Основной же межчиповой связи NVIDIA видит новую версию NVLink — NVLink-C2C, которая в семь раз быстрее PCIe 5.0 и способна обеспечить двунаправленную скорость передачи данных на уровне до 900 Гбайт/с, будучи при этом в пять раз экономичнее. Удельное потребление у новинки составляет 1,3 пДж/бит, что меньше, нежели у AMD Infinity Fabric с 1,5 пДж/бит. Впрочем, существуют и более экономичные решения, например, UCIe (~0,5 пДж/бит). 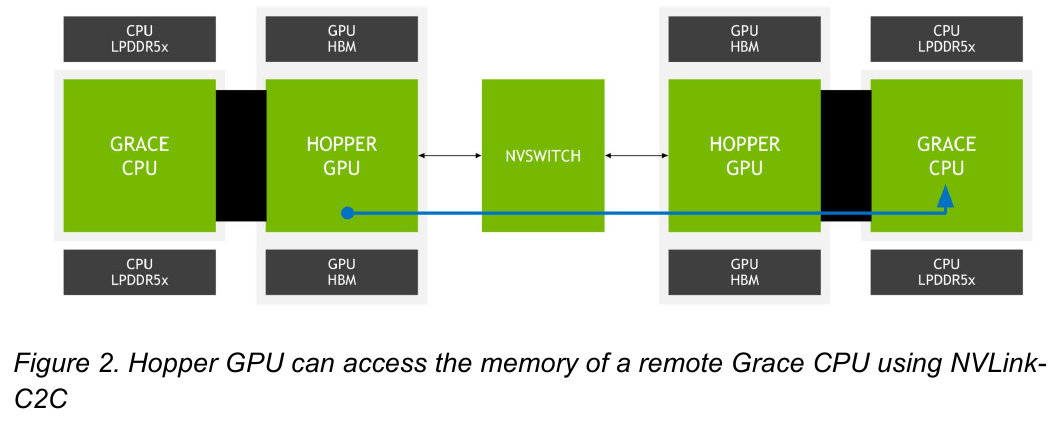
Новый вариант NVLink обеспечит кластер на базе Grace Hopper единым пространством памяти. Источник: NVIDIA NVLink-C2C позволяет реализовать унифицированный «плоский» пул памяти с общим адресным пространством для Grace Hopper. В рамках одного узла возможно свободное обращение к памяти соседей. А вот для объединения нескольких узлов понадобится уже внешний коммутатор NVSwitch. Он будет занимать 1U в высоту, и предоставлять 128 портов NVLink 4 с агрегированной пропускной способностью до 6,4 Тбайт/с в дуплексе. 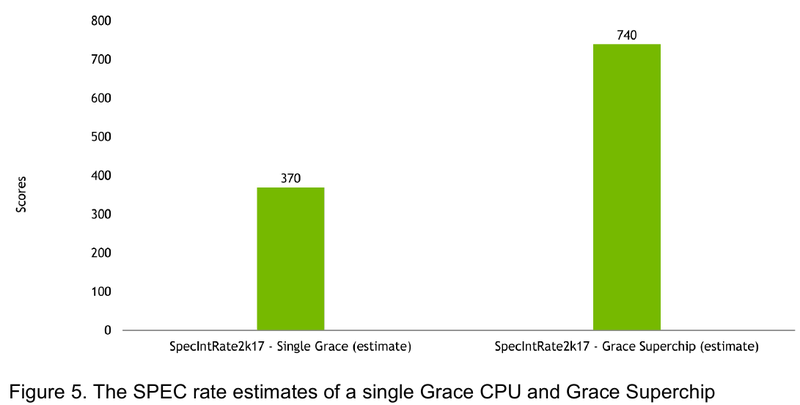
Источник: NVIDIA Производительность Grace также обещает быть рекордно высокой благодаря оптимизированной архитектуре и быстрому интерконнекту. Даже по предварительным цифрам, опубликованным NVIDIA, речь идёт о 370 очках SPECrate2017_int_base для одного кристалла Grace и 740 очках для 144-ядерной сборки из двух кристаллов — и это с использованием обычного компилятора GCC без тонких платформенных оптимизаций. Последняя цифра существенно выше результатов, показанных 128-ядерными Alibaba T-Head Yitian 710, также использующим архитектуру Arm v9, и 64-ядерными AMD EPYC 7773X.
10.08.2022 [22:05], Владимир Мироненко
На пути к Aurora: запущен «тренировочный» суперкомпьютер PolarisАргоннская национальная лаборатория (ANL) Министерства энергетики США объявила о доступности суперкомпьютера Polaris, ранний вариант которого занял 14-е место в последней версии списка TOP500. Он будет использоваться для проведения научных исследований и в качестве испытательного стенда для 2-Эфлопс суперкомпьютера Aurora, запуск которой намечен на ближайшие месяцы. Правда, аппаратно Aurora и Polaris отличаются. Созданная HPE система Polaris состоит из 560 узлов Apollo 6500, каждый из которых оснащён процессором AMD EPYC Milan, четырьмя ускорителями NVIDIA A100 (40 Гбайт) и 512 Гбайт DDR4-памяти. Эти узлы объединены в сеть интерконнектом HPE Slingshot 10 (осенью он будет обновлен до Slingshot 11) и подключены к сдвоенному 100-Пбайт Lustre-хранилищу (Grand и Eagle). Заявленная пиковая производительность должна составить 44 Пфлопс. «Polaris примерно в четыре раза быстрее нашего суперкомпьютера Theta, что делает его самым мощным компьютером в Аргонне на сегодняшний день», — отметил Майкл Папка (Michael Papka), директор Argonne Leadership Computing Facility (ALCF). Он добавил, что возможности Polaris позволят пользователям выполнять моделирование, анализ данных и ИИ-задачи с такими масштабом и скоростью, которые были невозможны с предыдущими вычислительными системами. 
Фото: ANL Помимо работы над подготовкой к запуску Aurora, суперкомпьютер Polaris будет обслуживать внутренние потребности лаборатории, например, работу с комплексом Advanced Photon Source (APS) X-ray. «Благодаря тесной интеграции суперкомпьютеров ALCF с APS, CNM и другими экспериментальными установками мы можем помочь ускорить проведение анализа данных и предоставить информацию, которая позволит исследователям управлять своими экспериментами в режиме реального времени», — заявил Майкл Папка. |
|

