Материалы по тегу: nvidia
|
09.11.2023 [16:15], Сергей Карасёв
NVIDIA готовит для Китая три новых ускорителя взамен подпавших под санкции: H20, L20 и L2Компания NVIDIA, по сообщению Reuters, планирует выпустить три новых ИИ-ускорителя, модифицированных специально для Китая с учётом дополнительных санкций со стороны США. Изделия фигурируют под обозначениями HGX H20 (SXM), L20 (PCIe) и L2 (PCIe), а их официальная презентация состоится не раньше 16 ноября. Напомним, в середине октября 2023 года США ввели новые ограничения на поставку передовых чипов NVIDIA в Китай: они затронули решения A800 и H800 — модифицированные версии A100 и H100, созданные специально для рынка КНР с учетом ранее действовавших американских ограничений. После этого NVIDIA пришлось искать новые регионы сбыта для «урезанных» ускорителей, предназначавшихся для Поднебесной. Как теперь сообщается, NVIDIA снова нашла возможность поставлять ускорители на китайский рынок, который потенциально может обеспечить значительную выручку. Решения H20, L20 и L2 не подпадают ни под одно из действующих экспортных ограничений. Обратной стороной медали является то, что производительность у них серьёзно снижена (см. характеристики в таблице выше), передаёт SemiAnalysis. 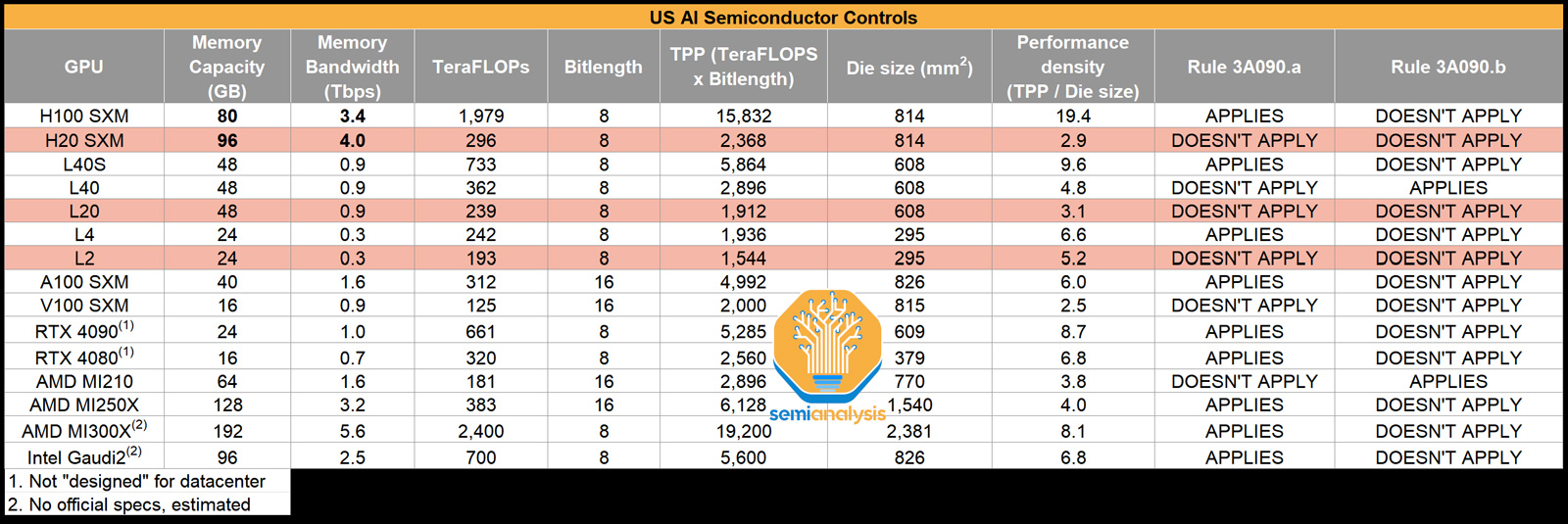
Источник: SemiAnalysis Отмечается, что у NVIDIA уже готовы образцы новых ускорителей для китайского рынка, а их массовое производство будет организовано в течение следующего месяца. Сама компания какие-либо комментарии по поводу обнародованной в интернете информации не даёт.
04.10.2023 [14:59], Сергей Карасёв
Без гиперскейлеров: NVIDIA хочет арендовать ЦОД для облачного сервиса DGX CloudКомпания NVIDIA, по сообщению ресурса The Information, ведёт переговоры об аренде площадей у одного из операторов ЦОД, но о ком именно идёт речь, не сообщается. Предполагается, что площадка будет использоваться для поддержания работы собственного облачного сервиса DGX Cloud, предназначенного для обучения передовых моделей для генеративного ИИ. О доступности облака DGX Cloud компания NVIDIA объявила в июле нынешнего года. Тогда сообщалось, что соответствующая вычислительная инфраструктура достанется в первую очередь США и Великобритании. Стоимость доступа к DGX Cloud начинается с $36 999 в месяц. Говорилось, что NVIDIA намерена продвигать DGX Cloud в партнёрстве с ведущими гиперскейлерами. Первым сервис появился в облаке Oracle Cloud Infrastructure (OCI), на очереди Microsoft Azure, Google Cloud Platform и другие. Большая часть выручки в этом случае достаётся именно NVIDIA, а не облакам. 
Источник изображения: NVIDIA Теперь же, судя по всему, NVIDIA решила частично отказаться от услуг облачных провайдеров и развернуть DGX Cloud на арендованных ЦОД-площадях. Впрочем, как отмечается, переговоры всё ещё находятся на начальной стадии, а поэтому говорить о том, что NVIDIA сама превратится в гиперскейлера, преждевременно. При этом компания неоднократно упрекали в том, что в последнее время она более благосклонна к небольшим и специализированным облачным провайдерам, которые не пытаются создавать собственные ИИ-ускорители, могущие составить прямую конкуренцию продуктам NVIDIA.
09.08.2023 [18:00], Алексей Степин
NVIDIA анонсировала L40S — новый универсальный ускоритель на базе Ada LovelaceКорпорация NVIDIA обновила серию укорителей L40, представленных осенью прошлого года в рамках платформы OVX. Новинка под названием NVIDIA L40S позиционируется как универсальный ускоритель в форм-факторе двухслотовой FHFL-карты расширения с интерфейсом PCIe 4.0 x16, пригодный для решения практически любых задач. Во многом L40S повторяет L40 — она также базируется на архитектуре Ada Lovelace, оснащена графическим процессором AD102, дополненным 48 Гбайт памяти GDDR6 ECC (384 бит, 864 Гбайт/с). В составе ускорителя работают 18176 ядер CUDA, 142 RT-ядра третьего поколения и 568 тензорных ядер четвёртого поколения. То есть в этом отличий от L40 нет. Но значение TDP у новинки выше на 50 Вт и составляет 350 Вт, она все ещё имеет пассивное охлаждение. 
Источник изображений здесь и далее: NVIDIA При этом L40S умудряется быть практически вдвое быстрее L40 во всех форматах вычислений с использованием тензорных ядер, а вот без Tensor Core её FP32-производительность выросла минимально — с 90,5 до 91,6 Тфлопс. Поддержкой NVLink-мостика новинка так и не обзавелась. L40S оснащён четырьмя портами DP 1.4a с поддержкой NVIDIA Mosaic и Quadro Sync. Также доступны профили vGPU для vDWS, GRID vApps/vPC, vCS. Имеется поддержка Secure Boot с Root of Trust и соответствие стандарту NEBS Level 3.  Таким образом, новинка подходит не только в качестве ускорителя для обучения ИИ-моделей или инференс-систем, но и в качестве основы для систем рендеринга 3D-графики, визуализации или создания и запуска приложений для мета✴-вселенных. NVIDIA отмечает, что в ИИ-задачах L40S опережает A100 в 1,2–1,7 раза, а наличие трёх движков NVENC/NVDEC с поддержкой AV1 позволяет использовать новый ускоритель в качестве эффективной платформы транскодирования видео.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила модульную архитектуру MGX для создания ИИ-систем на базе CPU, GPU и DPUКомпания NVIDIA на выставке Computex 2023 представила архитектуру MGX, которая открывает перед разработчиками серверного оборудования новые возможности для построения HPC-систем, платформ для ИИ и метавселенных. Утверждается, что MGX закладывает основу для быстрого создания более 100 вариантов серверов при относительно небольших затратах. Концепция MGX предусматривает, что разработчики на первом этапе проектирования выбирают базовую системную архитектуру для своего шасси. Далее добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. Таким образом, на базе MGX может быть построена серверная система для уникальных рабочих нагрузок в области наук о данных, больших языковых моделей (LLM), периферийных вычислений, обработки графики и видеоматериалов и пр. Говорится также, что благодаря гибридной конфигурации на одной машине могут выполняться задачи разных типов, например, и обучение ИИ-моделей, и поддержание работы ИИ-сервисов. 
Источник изображений: NVIDIA Одними из первых системы на архитектуре MGX выведут на рынок компании Supermicro и QCT. Первая предложит решение ARS-221GL-NR с NVIDIA Grace, а вторая — сервер S74G-2U на базе NVIDIA GH200 Grace Hopper. Эти платформы дебютируют в августе нынешнего года. Позднее появятся MGX-платформы ASRock Rack, ASUS, Gigabyte, Pegatron и других производителей.  Архитектура MGX совместима с нынешним и будущим оборудованием NVIDIA, включая H100, L40, L4, Grace, GH200 Grace Hopper, BlueField-3 DPU и ConnectX-7. Поддерживаются различные форм-факторы систем: 1U, 2U и 4U. Возможно применение воздушного и жидкостного охлаждения.
26.04.2023 [19:50], Сергей Карасёв
Meta✴ вынужденно пересмотрела архитектуру своих ЦОД из-за отказа от выпуска собственных ИИ-чипов в пользу ускорителей NVIDIAКомпания Meta✴, по сообщению Reuters, была вынуждена пересмотреть конфигурацию своих дата-центров из-за отставания от конкурентов в плане развития ИИ-платформ. Компания, в частности, решила отказаться от дальнейшего внедрения инференс-чипов собственной разработки. Отмечается, что до прошлого года Meta✴ применяла архитектуру, в которой традиционные CPU соседствуют с кастомизированными решениями. Однако выяснилось, что такой подход менее эффективен по сравнению с применением ускорителей (GPU). При этом ранее компания отказалась от ИИ-ускорителей Qualcomm, указав на недоработки ПО, которые, судя по всему, были устранены только недавно. А с Esperanto, вероятно, отношения у Meta✴ пока не сложились. Впрочем, теперь компании интересен генеративный ИИ, а не только рекомендательные системы, что накладывает иные требования к оборудованию. 
Источник изображения: Meta✴ В течение почти всего 2022 года Meta✴ активно инвестировала в развите инфраструктуры, однако в конце года стало известно, что она приостановила строительство целого ряда ЦОД, а затем пересмотрела расходы на дата-центры. Компания решила кардинально переосмыслить архитектуру своих ЦОД, сделав ставку на СЖО. Как теперь выясняется, связано это с тем, что Meta✴ отказалась от собственных ИИ-чипов в пользу ускорителей NVIDIA: объём заказов последних исчисляется «миллиардами долларов». Соответствующую платформу Grand Teton компания показала в конце прошлого года. 
Источник изображения: Meta✴ Но ускорители потребляют больше энергии и выделяют больше тепла, нежели CPU или узкоспециализированные ASIC. Кроме того, ускорители должны физически находиться довольно близко друг к другу, хотя с интерконнектом компания тоже уже экспериментирует. Всё это влияет на архитектуру ЦОД. Тем не менее, Meta✴ всё же разрабатывает некий секретный чип, который сгодится и для обучения ИИ-моделей, и для инференса. Ожидается, что это решение увидит свет в 2025 году. Пока что для обучения ИИ компания намерена использовать собственный ИИ-суперкомпьютер RSC и облачные кластеры Microsoft Azure. Похожий путь избрала Microsoft, решившая создать свой ИИ-чип, не отказываясь пока от ускорителей NVIDIA. The Information добавляет, что вице-президент Microsoft по разработке «кремния» Жан Буфархат (Jean Boufarhat) присоединится к Meta✴. Он возглавит команду Facebook✴ Agile Silicon Team (FAST), чтобы помочь компании в реализации проектов по созданию чипов. Ранее Meta✴ переманила из Intel руководителя разработки сетевых решений для дата-центров. У Google и Amazon уже есть свои ИИ-чипы для обучения и инференса.
22.03.2023 [20:32], Алексей Степин
Экспортный китайский вариант NVIDIA H100 получил модельный номер H800В связи с санкционными ограничениями некоторые разновидности сложных микроэлектронных чипов запрещено экспортировать в Китайскую Народную Республику. Однако производители находят выход. В частности, компания NVIDIA анонсировала экспортный вариант ускорителя H100, не нарушающий никаких санкций. Модельный номер у такого варианта изменён на H800. Введённые правительством США в 2022 году санкции сделали «невыездными» два наиболее продвинутых продукта NVIDIA: A100 и H100. Такие процессоры сегодня являются основой наиболее динамично развивающейся вычислительной отрасли — нейросетевой. Именно на кластерах из таких ускорителей «натаскивают» мощные нейросети вроде ChatGPT и подобных. 
Ускоритель Hopper H100 в SXM-исполнении. Источник изображений здесь и далее: NVIDIA Ещё осенью прошлого года NVIDIA анонсировала A800 — экспортный вариант A100, не попадающий под ограничения за счёт некоторого снижения пропускной способности NVLink, с 600 до 400 Гбайт/с. Сейчас пришло время архитектуры Hopper, которая запущена в массовое производство. По аналогии с флагманом Ampere модернизированный чип получил модельный номер H800. Ограничения в нём реализованы схожим образом: как известно, NVLink в H100 имеет производительность 900 Гбайт/с в базовом SXM-варианте. 
H100 также существует в PCIe-варианте Версия H800 использует примерно половину этого потенциала, что, впрочем, не делает её в Китае менее популярной: новинка уже используется китайскими облачными гигантами, такими, как Alibaba, Baidu и Tencent. Есть ли у H800 другие отличия от H100, не говорится — NVIDIA пока отказывается предоставлять такую информацию. Достоверно известно лишь то, что они полностью соответствуют всем санкционным ограничениям. Интересно, появится ли в будущем вариант H800 NVL на базе NVIDIA H100 NVL.
22.03.2023 [00:09], Алексей Степин
NVIDIA показала сдвоенный серверный суперпроцессор Grace SuperchipПроект NVIDIA Grace весьма амбициозен: компания всерьёз намерена ворваться с его помощью на рынок высокопроизводительных серверных процессоров, где всё ещё доминируют решения Intel и AMD. Об этом чипе было объявлено ещё на конференции GTC 2022, а на GTC 2023 глава компании, наконец, показал его вживую. В рамках продолжающегося роста плотности упаковки вычислительных мощностей в современных ЦОД на первый план выдвинулась не голая производительность, а соотношение производительности к уровню энергопотребления и тепловыделения. По сочетанию этих параметров x86 далеко не оптимальна, и тут у NVIDIA есть все шансы. С анонсом Grace Superchip NVIDIA провозглашает (впрочем, уже не в первый раз) смерть «закона Мура» — пришло время оптимизации и отказа от устаревших, по мнению компании, вычислительных архитектур. 
Источник изображений здесь и далее: NVIDIA Процессор NVIDIA Grace воплощает в себе все современные тенденции, начиная с отказа от монолитного кристалла. Сборка Grace Superchip состоит из двух кристаллов, каждый из которых включает в себя 72 ядра Arm Neoverse V2 (Arm v9), поддерживающих векторные расширения SVE2 и оптимизированные для ИИ форматы BF16/INT8. Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с.  В сборку интегрированы чипы памяти LPDDR5x общим объёмом до 960 Гбайт, причём каждый кристалл имеет свою шину доступа к памяти с производительностью 500 Гбайт/с. При этом с точки зрения ПО Grace Superchip представляется единым 144-ядерным процессором с ПСП на уровне 1 Тбайт/с. 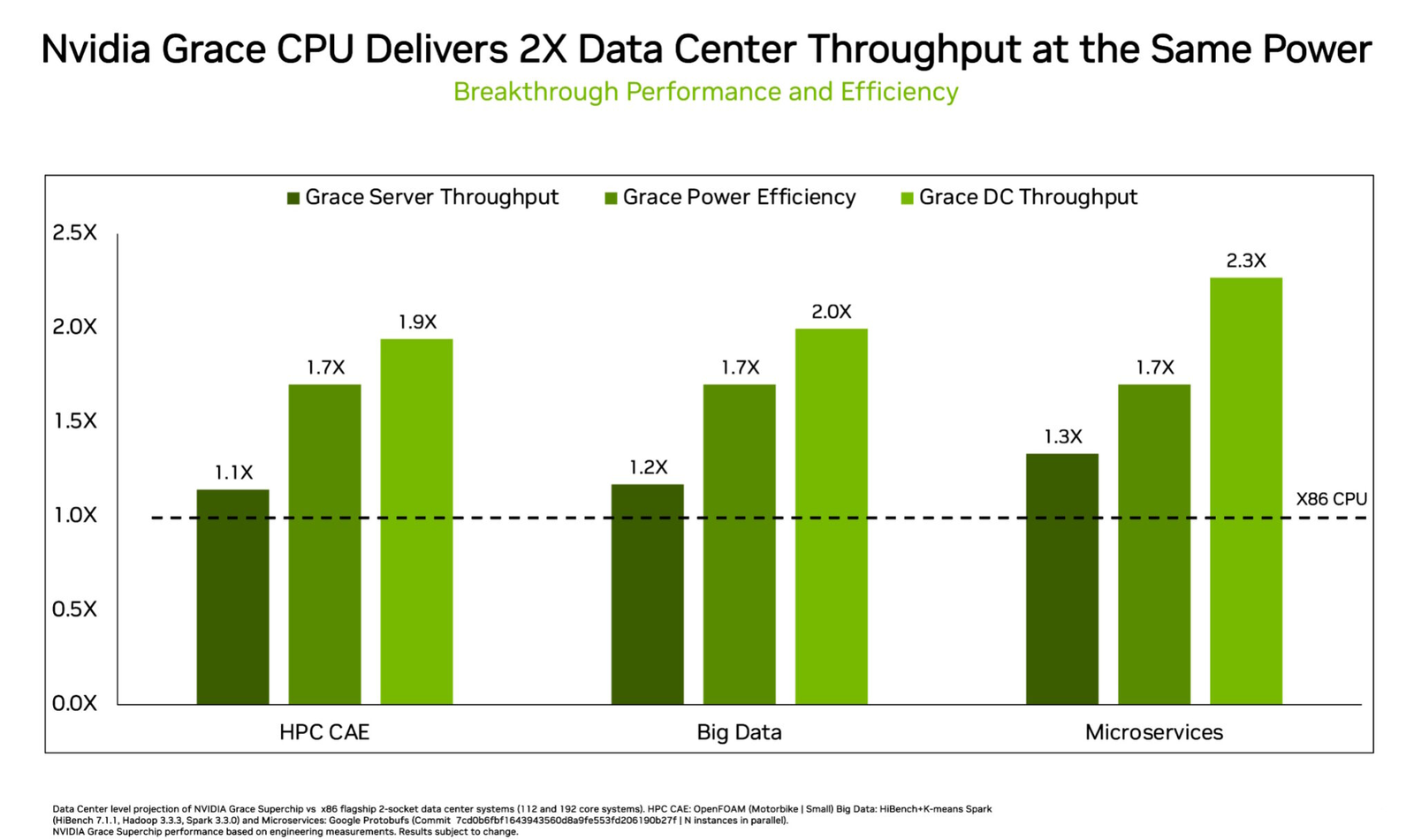 Для достижения схожих параметров в мире x86 требуется двухпроцессорная платформа AMD Genoa, куда более сложная технически и гораздо менее энергоэффективная, но при этом обладающая всеми недостатками NUMA-систем. Достаточно сравнить энергопотребление: 900 Вт против 500 у нового решения NVIDIA. 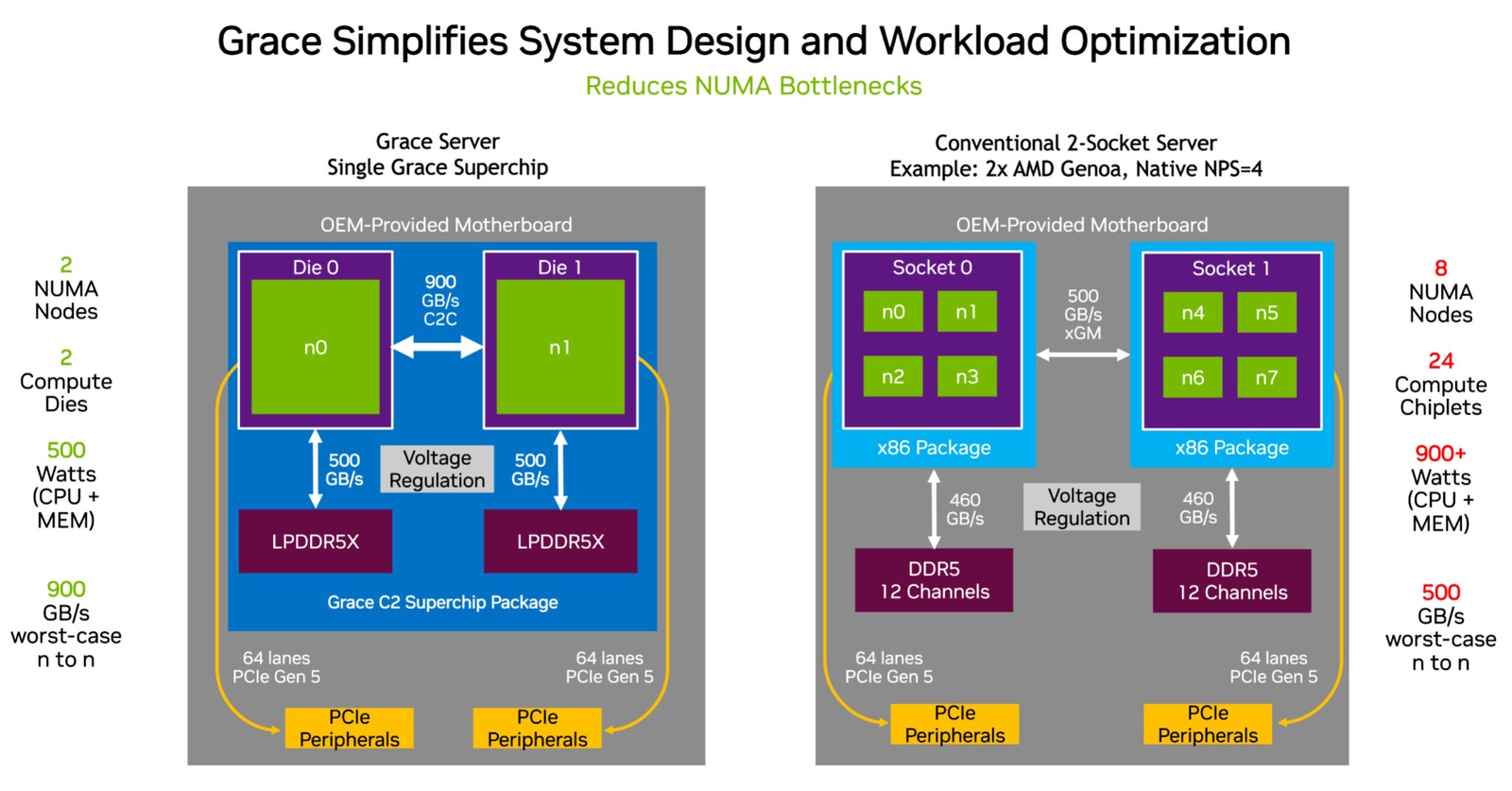 NVIDIA есть чем гордиться: при сопоставимом уровне энергопотребления Grace Superchip превосходит своих конкурентов из мира x86 в 2,3 раза при запуске микросервисов, вдвое опережает их в приложениях с интенсивным обменом данными с памятью и почти вдвое — в задачах симуляции вычислительной гидродинамики. В ряде других научно-технических задач преимущество может быть и более чем двукратным. 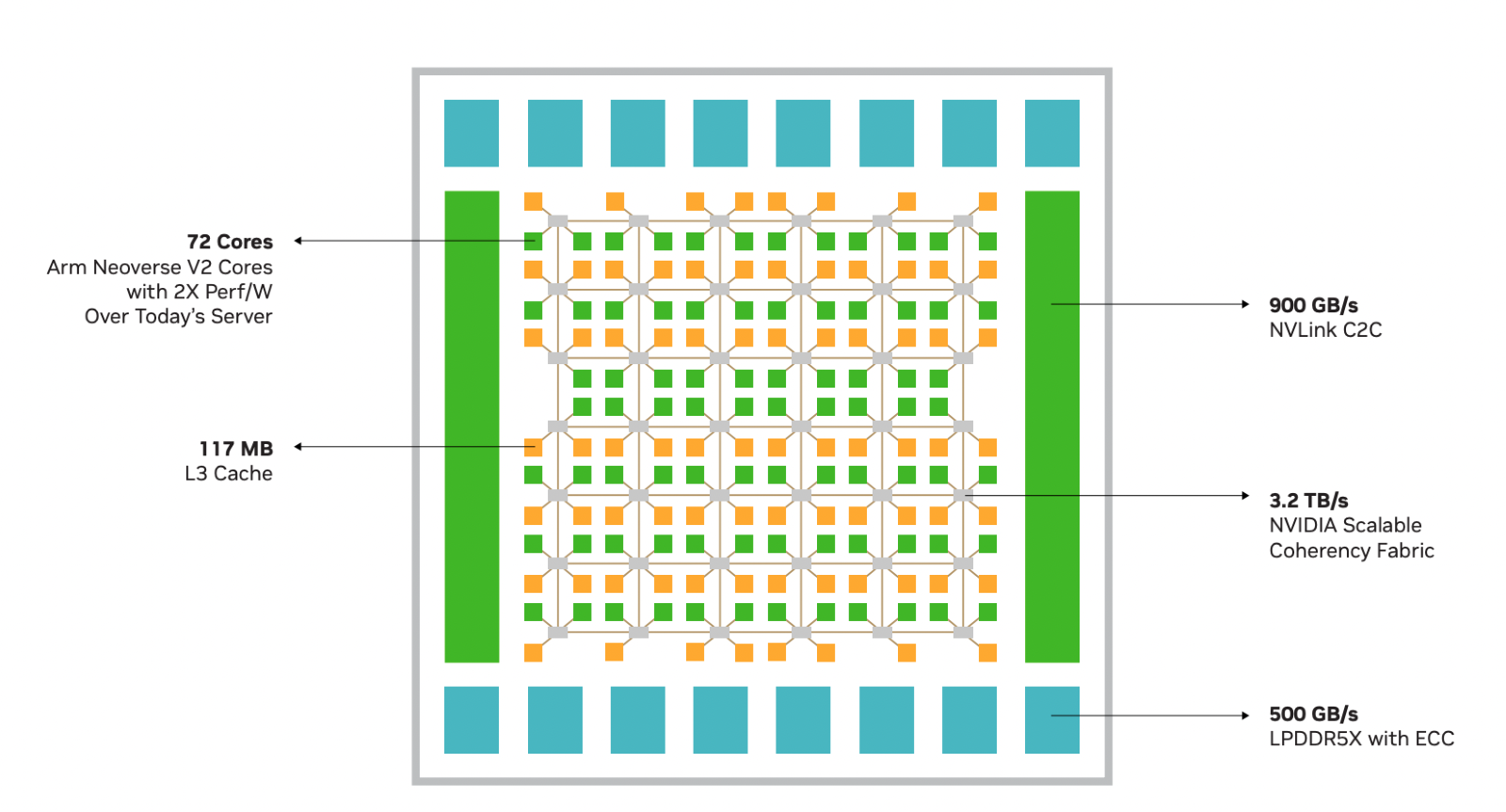 Это достигнуто в том числе благодаря изначальной оптимизации дизайна процессора с упором на максимальную производительность передачи данных. Внутренне Grace организован по принципу меш-сети с распределённой системой кеширования на базе специальных узлов коммутации CSN (Cache Switch Nodes). Называется эта сеть Scalable Coherency Fabric, она имеет пропускную способность 3,2 Тбайт/с, а объём кеша L3 составляет 117 Мбайт на кристалл и 234 Мбайт совокупно.  Сервер на базе NVIDIA Grace не только может потреблять меньше энергии, но и будет существенно проще конструктивно, поскольку модуль Grace Superchip содержит не только процессорные ядра и память, но также и регуляторы напряжения. От платформы на базе нового процессора требуется только PCIe 5.0 — у нового чипа есть два набора по 64 линии. Причём линии с поддержкой CXL 2.0, так что проблем с расширением доступного объёма памяти новинка испытывать не будет.  Даже компактные серверы высотой 1U смогут вместить две сборки Grace Superchip, что даст 288 ядер и почти 2 Тбайт оперативной памяти — труднодостижимый в таких габаритах показтель для более традиционных конструктивов процессоров и системных плат. Сравнительно невысокий теплопакет позволит таким решениям обходиться традиционным воздушным охлаждением.  При этом есть и вариант Grace Hopper, сочетающий в одном модуле кристалл Grace и новейший GPU H100, причём параметрами PCI Express последний ограничен не будет благодаря NVLink-C2C. NVIDIA уже начала первичные поставки Grace, а начало полномасштабного производства ожидается во второй половине года. Новыми процессорами заинтересовались крупные производители оборудования, включая ASUS, Atos, GIGABYTE, HPE, QCT, Supermicro, Wistron и ZT Systems.  Лос-Аламосская национальная лаборатория объявила, что использует NVIDIA Grace в новом суперкомпьютере Venado, который поможет учёным в исследованиях новых материалов и возобновляемых источников энергии. Ряд крупных европейских и азиатских ЦОД также рассматривает перспективы применения новых процессоров NVIDIA. В частности, одной из систем на базе Grace станет кластер Alps в Швейцарском национальном компьютерном центре.
21.03.2023 [20:45], Владимир Мироненко
NVIDIA запустила облачный сервис DGX Cloud — доступ к ИИ-супервычислениям прямо в браузереNVIDIA запустила сервис ИИ-супервычислений DGX Cloud, предоставляющий предприятиям доступ к инфраструктуре и программному обеспечению, необходимым для обучения передовых моделей для генеративного ИИ и других приложений. DGX Cloud предлагает выделенные ИИ-кластеры NVIDIA DGX в сочетании с фирменным набором ПО NVIDIA. С его помощью предприятие сможет получить доступ к облачному ИИ-суперкомпьютеру, используя веб-браузер и без надобности в приобретении, развёртывании и управлении собственной HPC-инфраструктурой. Правда, удовольствие это всё равно не из дешёвых — стоимость инстансов DGX Cloud начинается от $36 999/мес., причём деньги получает в первую очередь сама NVIDIA. Для сравнения — полностью укомплектованная система DGX A100 в Microsoft Azure обойдётся примерно в $20 тыс. Облачные кластеры DGX предлагаются предприятиям на условиях ежемесячной аренды, что гарантирует им возможность быстро масштабировать разработку больших рабочих нагрузок. «DGX Cloud предоставляет клиентам мгновенный доступ к супервычислениям NVIDIA AI в облаках глобального масштаба», — сообщил Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. 
Источник изображения: NVIDIA Развёртыванием инфраструктуры DGX Cloud компания NVIDIA будет заниматься в сотрудничестве с ведущими поставщиками облачных услуг. Первым среди них стала платформа Oracle Cloud Infrastructure (OCI), предлагающая суперкластер (SuperCluster) с объединёнными RDMA-сетью (в том числе на базе BlueField-3 и Connect-X7) системами DGX (bare metal), которые дополняет высокопроизводительное локальное и блочное хранилище. Cуперкластер может включать до 32 768 ускорителей, но этот рекорд был поставлен с использованием DGX A100, а вот предложение DGX H100 пока что ограничено. В следующем квартале похожее решение появится в Microsoft Azure, а потом в Google Cloud и у других провайдеров. 
Источник изображения: NVIDIA Первыми пользователями DGX Cloud стали Amgen, одна из ведущих мировых биотехнологических компаний, лидер рынка страховых технологий CCC Intelligent Solutions (CCC) и провайдер цифровых бизнес-платформ ServiceNow. «Мощные вычислительные и многоузловые возможности DGX Cloud позволили нам в 3 раза ускорить обучение белковых LLM с помощью BioNeMo и до 100 раз ускорить анализ после обучения с помощью NVIDIA RAPIDS по сравнению с альтернативными платформами», — сообщил представитель Amgen. Для управления нагрузками в DGX Cloud предлагается NVIDIA Base Command. Также DGX Cloud включает в себя набор инструментов NVIDIA AI Enterprise для создания и запуска моделей, который предоставляет комплексные фреймворки и предварительно обученные модели для ускорения обработки данных и оптимизации разработки и развёртывания ИИ. DGX Cloud предоставляет поддержку экспертов NVIDIA на всех этапах разработки ИИ. Клиенты смогут напрямую работать со специалистами NVIDIA, чтобы оптимизировать свои модели и быстро решать задачи разработки с учётом сценариев отраслевого использования.
21.03.2023 [19:45], Игорь Осколков
Толстый и тонкий: NVIDIA представила самый маленький и самый большой ИИ-ускорители L4 и H100 NVLНа весенней конференции GTC 2023 компания NVIDIA представила два новых ИИ-ускорителя, ориентированных на инференес: неприличной большой H100 NVL, фактически являющийся парой обновлённых ускорителей H100 в формате PCIe-карты, и крошечный L4, идущий на смену T4. 
Изображения: NVIDIA NVIDIA H100 NVL действительно выглядит как пара H100, соединённых мостиками NVLink. Более того, с точки зрения ОС они выглядят как пара независимых ускорителей, однако ПО воспринимает их как единое целое, а обмен данными между двумя картам идёт в первую очередь по мостикам NVLink (600 Гбайт/с). Новинка создана в первую очередь для исполнения больших языковых ИИ-моделей, в том числе семейства GPT, а не для их обучения. 
NVIDIA H100 NVL Однако аппаратно это всё же не просто пара обычных H100 PCIe. По уровню заявленной производительности NVL-вариант вдвое быстрее одиночного ускорителя H100 SXM, а не PCIe — 3958 и 7916 Тфлопс в разреженных (в обычных показатели вдвое меньше) FP16- и FP8-вычислениях на тензорных ядрах соответственно, что в 2,6 раз больше, чем у H100 PCIe. Кроме того, NVL-вариант получил сразу 188 Гбайт HBM3-памяти с суммарной пропускной способностью 7,8 Тбайт/с. 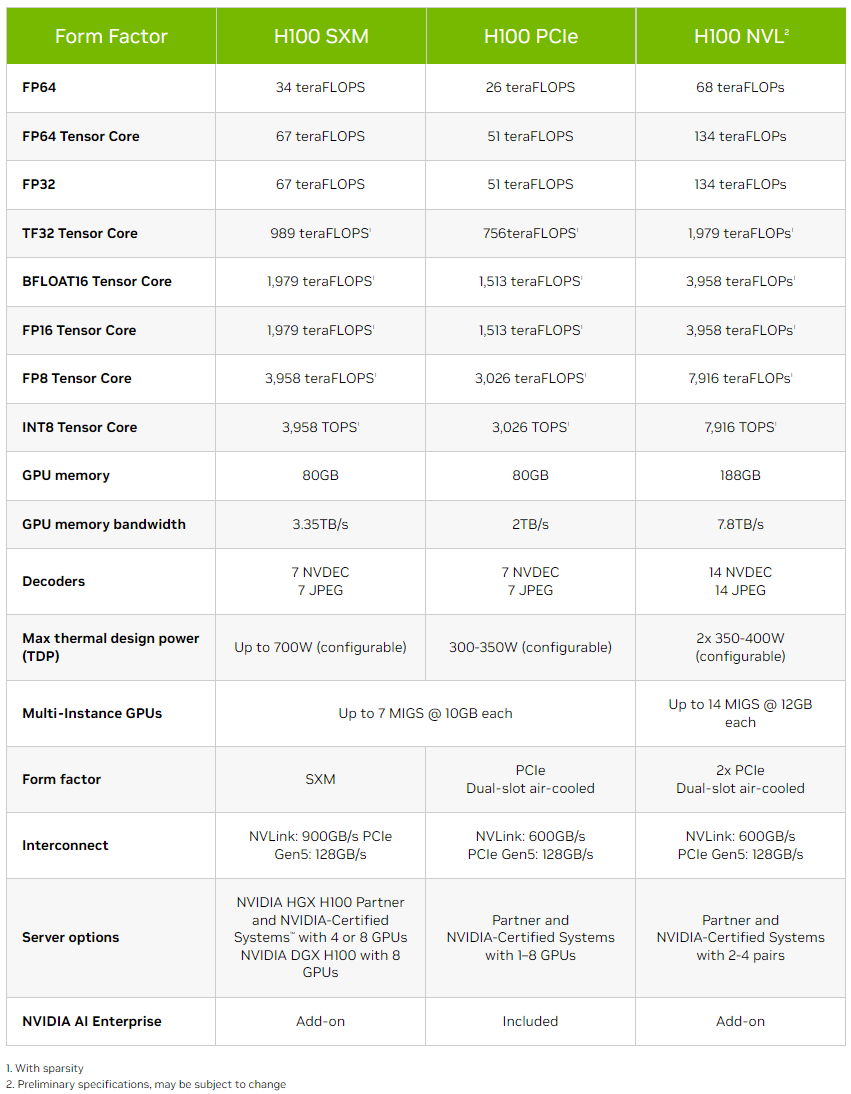 NVIDIA утверждает, что форм-фактор H100 NVL позволит задействовать новинку большему числу пользователей, хотя четыре слота и TDP до 800 Вт подойдут далеко не каждой платформе. NVIDIA H100 NVL станет доступна во второй половине текущего года. А вот ещё одну новинку, NVIDIA L4 на базе Ada, в ближайшее время можно будет опробовать в облаке Google Cloud Platform, которое первым получило этот ускоритель. Кроме того, он же будет доступен в рамках платформы NVIDIA Launchpad, да и ключевые OEM-производители тоже взяли его на вооружение. 
NVIDIA L4 Сама NVIDIA называет L4 поистине универсальным серверным ускорителем начального уровня. Он вчетверо производительнее NVIDIA T4 с точки зрения графики и в 2,7 раз — с точки зрения инференса. Маркетинговые упражнения компании при сравнении L4 с CPU оставим в стороне, но отметим, что новинка получила новые аппаратные ускорители (де-)кодирования видео и возможность обработки 130 AV1-потоков 720p30 для мобильных устройств. С L4 возможны различные сценарии обработки видео, включая замену фона, AR/VR, транскрипцию аудио и т.д. При этом ускорителю не требуется дополнительное питание, а сам он выполнен в виде HHHL-карты. 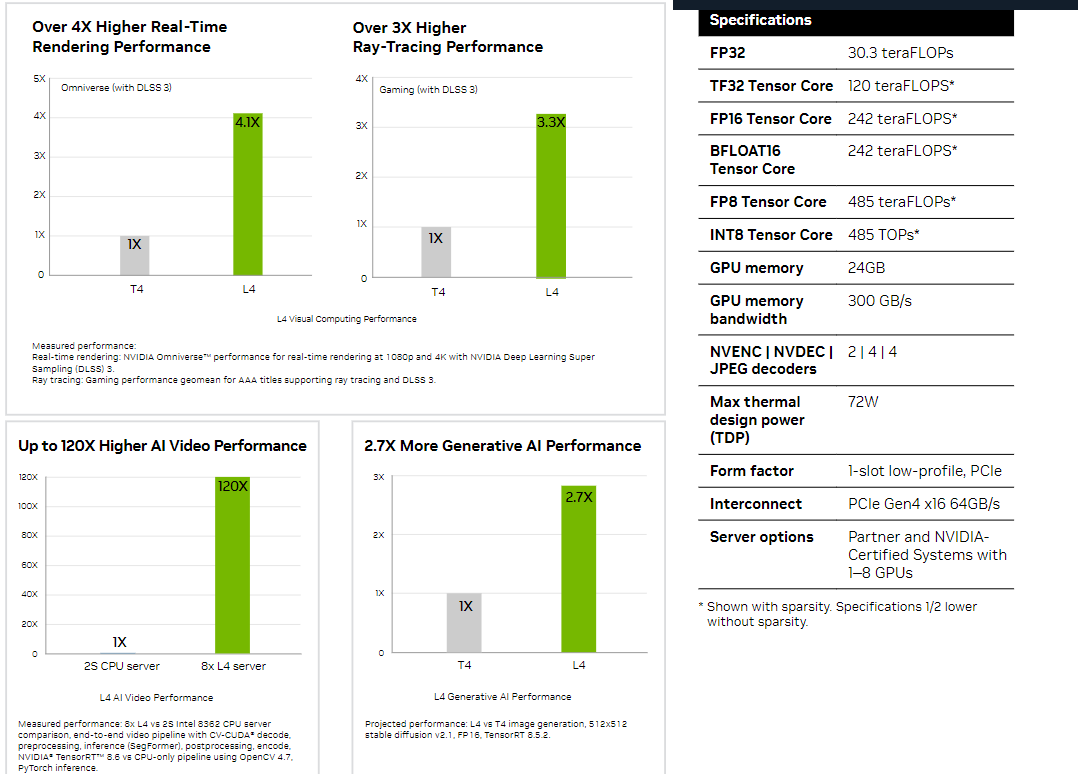 |
|

