Материалы по тегу: nvidia
|
20.10.2025 [16:00], Сергей Карасёв
Экономичный гибрид: Intel объединила ускорители Gaudi 3 и NVIDIA B200 в одной ИИ-платформеКорпорация Intel показала гибридную стоечную систему Устройство объединяет посредством Ethernet массивы ускорителей Gaudi3 и NVIDIA B200. Платформа Gaudi3 Rack Scale 64 содержит до 16 вычислительных узлов. Каждый из них оснащён двумя неназванными процессорами Intel Xeon, четырьмя OAM-ускорителями Intel Gaudi 3 (64 в одном домене), четырьмя 400GbE-адаптерами NVIDIA ConnectX-7 и одним DPU NVIDIA BlueField-3, отмечает SemiAnalysis. Суммарно доступно 8,2 Тбайт HBM2e, а агрегированная пропускная способность составляет 76,8 Тбайт/с. Мощность суперускорителя составляет 120 кВт. Кроме того, задействованы 12 коммутаторов на чипах Broadcom Tomahawk 5 (51,2 Тбит/с). Для масштабирования и связи с другими узлами, в том числе NVIDIA, используется именно Ethernet. В составе гибридной системы ускорители Intel Gaudi 3 используются на decode-стадии, т.е. для генерации токенов, где важен объём и пропускная способность памяти, тогда как чипы NVIDIA B200 отвечают за prefill-задачи инференса, т.е. за обработку контекста и заполнение KVCache, где важна скорость вычислений. NVIDIA сама стремится к этому же подходу и уже анонсировала соускорители Rubin CPX, которые как раз будут заниматься работой с контекстом в сверхбольших моделях и созданием KV-кеша. 
Источник изображений: Intel Intel утверждает, что гибридная конфигурация из Gaudi3 и B200 позволяет достичь 1,7-кратного прироста производительности в расчёте на доллар совокупной стоимости владения (TCO) по сравнению с платформами, использующими только B200. Однако, как отмечается, эти заявления пока не подтверждены независимыми тестами. К тому же, программная платформа Gaudi3 отстаёт от платформы NVIDIA и является закрытой. Кроме того, нынешняя архитектура Gaudi приближается к концу своего существования, что ставит под сомнение жизнеспособность предложенной платформы в долгосрочной перспективе.  Для Intel это, возможно, один из немногих шансов продать остатки Gaudi3. Между тем Intel недавно анонсировала GPU-ускоритель Crescent Island, разработанный специально для ИИ-инференса. Решение, в основу которого положена архитектура Xe3P, получит 160 Гбайт памяти LPDDR5X. Массовые поставки будет организованы не ранее 2027 года. Ранее компания отказалась от планов по выпуску Falcon Shores, сосредоточившись на Jaguar Shores. Сейчас же компания начала сворачивать поддержку ускорителей Ponte Vecchio (Intel Max) и Arctic Sound (Flex).
20.10.2025 [09:11], Сергей Карасёв
Pegatron представила ИИ-систему RA4802-72N2 на базе NVIDIA GB300 NVL72Компания Pegatron представила систему RA4802-72N2, предназначенную для наиболее ресурсоёмких ИИ-нагрузок, включая обучение больших языковых моделей (LLM) в масштабе и инференс. В основу положена платформа NVIDIA GB300 NVL72. Изделие GB300 содержит Arm-процессор Grace с 72 ядрами Neoverse V2 (Demeter) и два чипа Blackwell Ultra. В составе RA4802-72N2 объединены 18 вычислительных лотков, каждый из которых несёт на борту два Grace и четыре Blackwell Ultra. В сумме это даёт 36 процессоров Grace и 72 чипа Blackwell Ultra. Каждый из вычислительных узлов располагает 960 Гбайт памяти LPDDR5X и 1152 Гбайт памяти HBM3e. Таким образом, в общей сложности система оперирует примерно 17 Тбайт LPDDR5X и 20 Тбайт HBM3e. ИИ-производительность достигает 720 Пфлопс на операциях FP8/FP6. 
Источник изображения: Pegatron В состав RA4802-72N2 также входят девять коммутационных лотков. Общая пропускная способность интерконнекта NVLink составляет 130 Тбайт/с. В расчёте на вычислительный узел используются два адаптера NVIDIA ConnectX-8 и один DPU NVIDIA BlueField-3. Прочие характеристики включают контроллер Aspeed AST2600, модуль TPM 2.0, восемь отсеков для накопителей E1.S NVMe, коннектор M.2 2280/22110 NVMe. Система выполнена в форм-факторе 48U MGX с габаритами 600 × 2296 × 1200 мм. Применяется полностью жидкостное охлаждение. Полка питания оснащена шестью 1U-модулями мощностью 33 кВт. Поставки машины RA4802-72N2 уже начались.
20.10.2025 [01:23], Владимир Мироненко
Ускорителей хватит на всех — Alibaba Aegaeon оптимизировал обработку ИИ-нагрузок, снизив использование дефицитных NVIDIA H20 на 82 %Alibaba Cloud представила Aegaeon, систему пулинга вычислений, позволяющую сократить количество ускорителей NVIDIA, необходимых для обслуживания ИИ-моделей, на 82 %, пишет ресурс SCMP. По словам разработчиков, благодаря Aegaeon количество ускорителей NVIDIA H20, необходимых для обслуживания десятков моделей с 72 млрд параметров, удалось сократить с 1192 до 213 единиц. «Aegaeon — это первое решение на рынке, которое выявило чрезмерные затраты, связанные с обслуживанием параллельных рабочих нагрузок LLM», — сообщили исследователи из Пекинского университета и Alibaba Cloud. Провайдеры облачных сервисов, такие как Alibaba Cloud и ByteDance Volcano Engine, предоставляют пользователям одновременно тысячи ИИ-моделей — множество вызовов API обрабатывается одновременно. Однако на практике для инференса чаще всего используются лишь несколько моделей, таких как Qwen и DeepSeek, а большинство других моделей применяются лишь эпизодически. Это приводит к неэффективному использованию вычислительных ресурсов: исследователи обнаружили, что 17,7 % ускорителей выделяется на обслуживание лишь 1,35 % запросов в Alibaba Cloud. Aegaeon выполняет «автоматическое масштабирование» на уровне токенов, обеспечивая переключение ускорителей между обслуживанием различных моделей в процессе генерации. В рамках системы один ускоритель поддерживает обработку до семи моделей по сравнению с двумя-тремя моделями в альтернативных системах. При этом задержка, связанная с переключением между моделями, снижена на 97 %, заявили исследователи. Alibaba Cloud сообщила, что решение уже используется на её торговой площадке моделей Bailian. 
Источник изображения: Alibaba Глава NVIDIA Дженсен Хуанг (Jensen Huang) объявил, что из-за экспортных ограничений доля компании на рынке передовых чипов в Китае сократилась с 95 % до нуля. Этому также способствовала стратегия Пекина, направленная на самообеспечение местного рынка. В связи с этим планы NVIDIA возобновить отгрузки ИИ-ускорителей H20, на которые ранее были установлены ограничения правительством США, встретили в Китае довольно прохладно. Более того, в Китае вынесли запрет местным компаниям на покупку разработанного специально для местного рынка ускорителя NVIDIA RTX Pro 6000D, поскольку пришли к выводу, что китайские ИИ-чипы не уступают продукции NVIDIA, разрешённой к экспорту в Китай.
17.10.2025 [17:18], Руслан Авдеев
Poolside и CoreWeave построят в Техасе 2-ГВт кампус ИИ ЦОД, работающий на газе из Пермского бассейнаИИ-стартап Poolside объединился с CoreWeave для строительства кампуса ЦОД Project Horizon мощностью 2 ГВт на площади 230 га на территории ранчо Longfellow в Западном Техасе. Для электроснабжения планируется использовать природный газ, добываемый в местном Пермском бассейне, сообщает Datacenter Dynamics. ЦОД построят с использованием «гибридного модульного подхода», предполагающего «параллельное, а не последовательное строительство», которое будет завершено в I квартале 2027 года. CoreWeave станет ключевым арендатором первой фазы проекта, которая должна обеспечить мощность 250 МВт в соответствии с договором аренды на 15 лет. В будущем допускается увеличение арендуемых мощностей до 500 МВт. Также соглашение компаний предусматривает, что с декабря CoreWeave предоставит Poolside кластер NVIDIA GB300 NVL72 с более чем 40 тыс. чипов. По словам Poolside, партнёрство с CoreWeave обеспечит немедленный доступ к ускорителям новейшего поколения, что позволит обучать модели с триллионами параметров. Poolside основана в 2023 году. Стартап разрабатывает ПО для автоматизации написания программного кода с высокими корректностью и безопасностью, достаточных для того, чтобы его можно было использовать в государственных учреждениях. По данным Bloomberg, в 2024 году компания выпустила ИИ-агента для разработчиков государственного и оборонного секторов. Также ведутся работы и в области создания «общего искусственного интеллекта» (AGI). 
Источник изображения: Bailey Alexander/unsplash.com Пока Poolside проводит раунд привлечения $2 млрд инвестиций, оценка стоимости компании по его итогам должна составить $14 млрд. Большую часть средств направят на приобретение 40 тыс. ускорителей NVIDIA. В 2024 года стартап уже привлёк $500 млн, получив оценку в $3 млрд. Компания является известным клиентом Fluidstack, а также арендовала некоторое количество NVIDIA H100 у Iris Energy. Благодаря большим запасам природного газа и относительно доступной электроэнергии в целом Техас стал весьма привлекательным местом для строителей дата-центров. По информации CBRE, сегодня это второй по величине рынок ЦОД в США. В штате реализуется первый проект в рамках инициативы Stargate, Meta✴ инициировала строительство ЦОД на 1 ГВт в Эль-Пасо, а Fermi America, будучи новичком на рынке дата-центров, заранее договорилась о подключение к газопроводу своего будущего 11-ГВт кампуса в Амарилло (Amarillo).
16.10.2025 [15:53], Руслан Авдеев
NVIDIA поможет Starcloud отправить в космос первый ИИ-спутник с H100Появление массовых космических дата-центров уже не за горами. В скором времени вывести на орбиту ИИ-спутник намерен стартап Starcloud (ранее Lumen Orbit), участвующий в грантовой программе NVIDIA Inception. В Starcloud заявляют, что в космосе доступна практически неограниченная возобновляемая энергия, которая даже с учётом расходов на запуск на порядок дешевле, чем на Земле. При этом постоянное нахождение Солнца в «пределах прямой видимости» позволяет отказаться от мощных резервных источников питания. Затраты ожидаются в основном до вывода в космос, а после предполагается десятикратная «экономия» углеродных выбросов в течение всего жизненного цикла в сравнении с ЦОД на Земле. Охлаждение в космосе тоже практически «бесплатное» и «безлимитное». Запуск спутника запланирован на ноябрь 2025 года. Речь идёт о дебютном использовании ИИ-ускорителей NVIDIA H100 в космосе. 60-килограммовый спутник Starcloud-1 размером с небольшой холодильник должен обеспечить в 100 раз более эффективные вычисления, чем любой предыдущий космический проект аналогичного назначения. 
Источник изображения: Starcloud На начальном этапе космические дата-центры будут применяться для анализа данных наблюдений за земной поверхностью. Обработка данных в режиме реального времени в космосе обеспечивает огромные преимущества в критических ситуациях — при распознавании лесных пожаров, получении сигналов о бедствии и др. Инференс в космосе, т.е. там же, где будут собираться данные, позволяет выдавать результаты практически немедленно, снижая задержки с часов до минут. Методы наблюдения за Землёй включают съёмки камерами в нескольких диапазонах и радарами с синтезированной апертурой (SAR) для создания трёхмерных карт с высоким разрешением. SAR, в частности, генерируют около 10 Гбайт данных в секунду, поэтому обрабатывать информацию на месте намного выгоднее, чем отправлять её на Землю. 
Источник изображения: Starcloud В Starcloud подчёркивают необходимость быть конкурентоспособными на фоне наземных ЦОД, поэтому компания выбрала ИИ-ускорители NVIDIA. Вместе с тем Starcloud — недавний «выпускник» программы Google for Startups Cloud AI Accelerator, поэтому для тестов будет использоваться LLM Gemma. Что касается будущих запусков, в перспективе Starcloud рассчитывает перейти на платформу NVIDIA Blackwell. Ещё осенью 2024 года сообщалось, что Lumen Orbit проектирует на орбите гигантские гигаваттные дата центры. Идея популярна — основатель Amazon Джефф Безос (Jeff Bezos) в начале октября заявлял, что в космосе скоро появится множество ЦОД гигаваттного масштаба.
16.10.2025 [12:12], Руслан Авдеев
Группа инвесторов, включающая NVIDIA, под руководством Macquarie Asset Management купит Aligned Data Centers за $40 млрд — это одна из крупнейших сделок на рынке ЦОДГруппа AI Infrastructure Partnership (AIP), фонд MGX из ОАЭ и Global Infrastructure Partners (GIP) под руководством Macquarie Asset Management намерены приобрести техасского оператора ЦОД Aligned Data Centers за $40 млрд. Сделка заключена в рамках более широкого проекта по развитию ИИ-инфраструктуры, сообщает пресс-служба Macquaire, и станет одной из крупнейших на рынке ЦОД. Ожидается, что сделка будет закрыта в I полугодии 2026 года. AIP включает NVIDIA, BlackRock, Microsoft, xAI, Global Infrastructure Partners (GIP, принадлежит BlackRock) и государственную инвесткомпанию (создана при участии Mubadala и G42) из ОАЭ. AI Infrastructure Partnership была сформирована в 2024 году с целью ускорения инвестиций в ИИ-инфраструктуру нового поколения. По словам BlackRock, благодаря инвестициям в Aligned будет обеспечено создание инфраструктуры, необходимой для будущих ИИ-проектов. Aligned располагает 50 дата-центрами и 5 ГВт доступной мощности. Помимо США Aligned имеет серьёзный бизнес в Латинской Америке — компания приобрела OData, владеющей объектами в Бразилии, Чили, Колумбии и Мексике в мае 2023 года. Также она является инвестором канадского оператора ЦОД QScale SEC. 
Источник изображения: Aligned Data Centers Как сообщает Datacenter Knowledge, в последние месяцы IT-гиганты тратили миллиарды долларов на создание достаточной для удовлетворения спроса инфраструктуры ЦОД на фоне нарастающего интереса бизнеса к ИИ. В UBS утверждают, что мировые инвестиции в искусственный интеллект могут составить в 2025 году $375 млрд, а к 2026 году — $500 млрд. Руководство Aligned Data Centers заявило, что новое партнёрство будет способствовать ускоренному выполнению миссии по созданию инфраструктуры, обеспечивающей будущее цифровой экономики. Компания утверждает, что готова к более активному масштабированию, дальнейшим инновациям и переосмыслению возможностей устойчивой инфраструктуры ЦОД. Руководителем Aligned останется Эндрю Шаап (Andrew Schaap), а компания сохранит штаб-квартиру в Далласе (Техас).
15.10.2025 [15:25], Руслан Авдеев
OpenAI и Oracle развернут 450 тыс. ускорителей NVIDIA в техасском дата-центре StargateПо словам председателя Oracle Ларри Эллисона (Larry Ellison), дата-центр проекта Stargate а Абилине (Abilene, Техас) вместит более 450 тыс. ускорителей на базе NVIDIA GB200, сообщает Datacenter Dynamics. Дата-центр Stargate получит 1,2 ГВт энергии — по словам Эллисона, энергии достаточно, чтобы обеспечить миллион домохозяйств в США. Как заявил миллиардер, «это довольно большой город». Питаться кампус будет как от энергосети штата, так и от газовых турбин. Информация подтверждает данные о том, что OpenAI и Oracle освоят всю ёмкость кампуса, застраиваемого Crusoe. Первые два строения уже функционируют, они введены в эксплуатацию в сентябре 2025 года. Строительство оставшихся шести зданий должны быть завершены к середине 2026 года. В марте 2025 года заявлялось, что площадка получит 64 тыс. ускорителей NVIDIA к концу 2026 года. С тех пор OpenAI подписала не имеющее обязательной силы письмо о намерении арендовать оборудование NVIDIA на 10 ГВт, которая в ответ пообещала инвестировать в OpenAI $100 млрд. 
Источник изображения: OpenAI О росте числа используемых Stargate ускорителей можно было догадаться после анонса Oracle облачного ИИ-суперкомпьютера Zettascale10, который должен заработать во II половине 2026 года. Он объединит до 800 тыс. ускорителей в нескольких близко расположенных ЦОД. В Oracle отмечали, что суперкомпьютер станет основой флагманского суперкластера, создаваемого при участии OpenAI в Абилине в рамках проекта Stargate.
14.10.2025 [20:58], Владимир Мироненко
Oracle анонсировала крупнейший в мире зеттафлопсный ИИ-кластер OCI Zettascale10: до 800 тыс. ускорителей NVIDIA в нескольких ЦОД
800gbe
ethernet
hardware
hpc
nvidia
oracle
oracle cloud infrastructure
stargate
ии
интерконнект
кластер
сша
цод
Oracle анонсировала облачный ИИ-кластер OCI Zettascale10 на базе сотен тысяч ускорителей NVIDIA, размещённых в нескольких ЦОД, который имеет пиковую ИИ-производительность 16 Зфлопс (точность вычислений не указана). OCI Zettascale10 — это инфраструктура, на которой базируется флагманский ИИ-суперкластер, созданный совместно с OpenAI в техасском Абилине (Abilene) в рамках проекта Stargate и основанный на сетевой архитектуре Oracle Acceleron RoCE нового поколения. OCI Zettascale10 использует NVIDIA Spectrum-X Ethernet — первую, по словам NVIDIA, Ethernet-платформу, которая обеспечивает высокую масштабируемость, чрезвычайно низкую задержку между ускорителями в кластере, лидирующее в отрасли соотношение цены и производительности, улучшенное использование кластера и надежность, необходимую для крупномасштабных ИИ-задач. Как отметила Oracle, OCI Zettascale10 является «мощным развитием» первого облачного ИИ-кластера Zettascale, который был представлен в сентябре 2024 года. Кластеры OCI Zettascale10 будут располагаться в больших кампусах ЦОД мощностью в гигаватты с высокоплотным размещением в радиусе двух километров, чтобы обеспечить наилучшую задержку между ускорителями для крупномасштабных задач ИИ-обучения. Именно такой подход выбран для кампуса Stargate в Техасе. Oracle отметила, что помимо возможности создавать, обучать и развёртывать крупнейшие ИИ-модели, потребляя меньше энергии на единицу производительности и обеспечивая высокую надёжность, клиенты получат свободу работы в распределённом облаке Oracle со строгим контролем над данными и суверенитетом ИИ. 
Источник изображения: OpenAI Изначально кластеры OCI Zettascale10 будут рассчитаны на развёртывание до 800 тыс. ускорителей NVIDIA, обеспечивая предсказуемую производительность и высокую экономическую эффективность, а также высокую пропускную способность между ними благодаря RoCEv2-интерконнекту Oracle Acceleron со сверхнизкой задержкой. Acceleron предлагает 400G/800G-подключение со сверхнизкой задержкой, двухуровневую топологию, множественное подключение одного NIC к нескольким коммутатором с физической и логической изоляцией сетевых потоков, поддержку LPO/LRO и гибкость конфигурации. DPU Pensando от AMD в Acceleron место тоже нашлось. 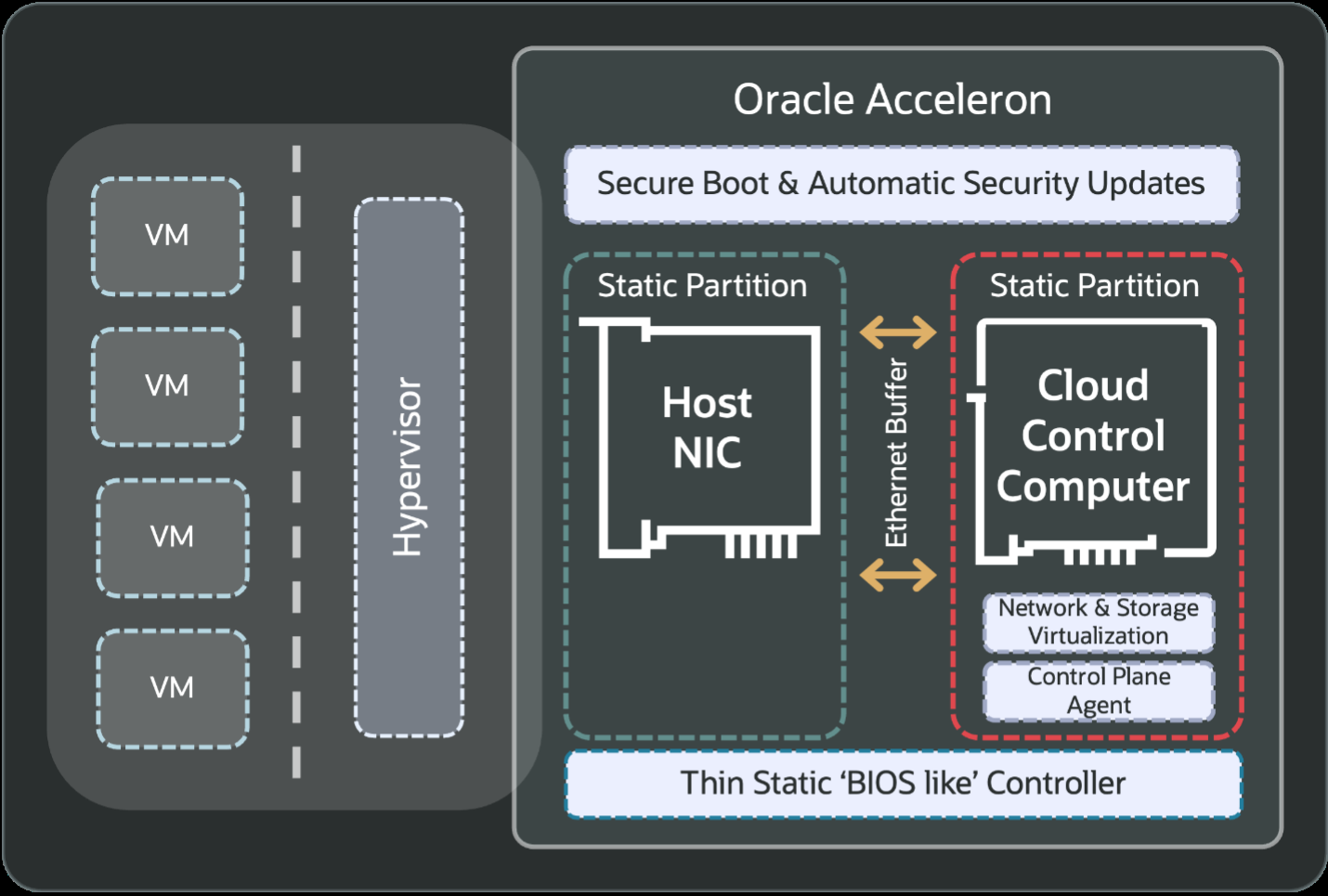
Источник изображения: Oracle OCI уже принимает заказы на OCI Zettascale10, который поступит в продажу во II половине следующего календарного года. В августе NVIDIA анонсировала решение Spectrum-XGS Ethernet для объединения нескольких ЦОД в одну ИИ-суперфабрику, которым, по-видимому, воспользуется не только Oracle, но и Meta✴.
14.10.2025 [17:24], Руслан Авдеев
ABB поддержит NVIDIA во внедрении 800 В питания для мегаваттных ИИ-стоекКомпания ABB Group, специализирующаяся на электрификации и автоматизации, объявила об ускоренной разработке новых решений для дата-центров совместно с NVIDIA. В первую очередь речь идёт о создании и внедрении передовых энергетических решений, необходимых для эффективной и масштабируемой подачи энергии, сообщает пресс-служба ABB. ABB будет развивать платформу 800 В DC для мегаваттных серверных стоек. Прогнозируется, что мировой спрос на ЦОД вырастет с 80 ГВт в 2024 году до около 220 ГВт к 2030 году. Капитальные затраты, по мнению экспертов, превысят $1 трлн, сообщает Dell'Oro Group. На рабочие нагрузки ИИ придётся порядка 70 % этого роста. Чтобы эффективно обеспечивать мощность такого уровня, потребуются новые технологии и архитектура распределения электроэнергии. Будущие ЦОД получат комбинацию источника бесперебойного питания среднего напряжения (MV) и систему распределения постоянного тока в серверных с использованием твердотельных преобразователей, заменяющих классические трансформаторы и иные компоненты. 
Источник изображения: Frames For Your Heart/unsplash.com В ABB заявляют, что компания возглавляет разработку новых технологий распределения электричества, позволяющих создавать дата-центры нового поколения. Утверждается, что она одной из первых стала инвестировать в новые ИБП, DC-системы и твердотельные компоненты. Портфолио решений ABB для дата-центров включает интеллектуальные системы распределения электроэнергии, специальные решения для резервного питания ЦОД, средства цифрового мониторинга и прочие ключевые технологии, обеспечивающие бесперебойную работу оборудования и оптимизирующие использование энергии для ИИ-серверов. Около 40 % научных исследований ABB в сфере электроснабжения приходится на тематики, имеющие решающее значение для ЦОД нового поколения — это касается работ в области электрической архитектуры, систем защиты, распределения постоянного тока и охлаждения. В конце мая сообщалось, что Infineon Technologies объединит усилия с NVIDIA для разработки централизованной архитектуры высоковольтного питания постоянным током (HVDC) на 800 В для нужд ИИ ЦОД.
14.10.2025 [13:26], Руслан Авдеев
«Нервная система» ИИ-фабрик: Meta✴ и Oracle развернут сетевые платформы NVIDIA Spectrum-X Ethernet в своих ЦОДNVIDIA объявила, что Meta✴ и Oracle развернут в своих ИИ ЦОД Ethernet-платформы NVIDIA Spectrum-X. В NVIDIA подчёркивают, что модели на триллионы параметров трансформируют дата-центры в ИИ-фабрики гигаваттного уровня, а лидеры индустрии стандартизируют использование решений Spectrum-X Ethernet в качестве одного из драйверов промышленной революции. По словам компании, речь идёт не просто о быстром Ethernet, а о «нервной системе» ИИ-фабрик, позволяющей гиперскейлерам объединять миллионы ИИ-ускорителей в гигантские кластеры для обучения крупнейших за всю историю моделей. Oracle намерена строить ИИ-гигафабрики из ускорителей NVIDIA Vera Rubin с интерконнектами Spectrum-X Ethernet. В Oracle подчёркивают, что инфраструктура Oracle Cloud «с нуля» строится для ИИ-задач, и партнёрство с NVIDIA способствует лидерству Oracle в сфере ИИ. Использование Spectrum-X Ethernet позволит клиентам связывать миллионы ускорителей и быстрее обучать, внедрять и пользоваться благами генеративных и «рассуждающих» ИИ нового поколения. Meta✴ намерена интегрировать коммутаторы в свою сетевую инфраструктуру для программной платформы Facebook✴ Open Switching System (FBOSS), как раз разработанной для управления и контроля массивами сетевых коммутаторов. Интеграция решений ускорит масштабное внедрение для повышения эффективности ИИ-проектов. Интеграция NVIDIA Spectrum Ethernet в коммутатор Minipack3N и использование FBOSS позволит повысить эффективность и предсказуемость, необходимые для обучения крупнейших в истории ИИ-моделей и доступа к ИИ-приложениям миллионам людей. 
Источник изображения: NVIDIA Платформа NVIDIA Spectrum-X Ethernet включает как собственно коммутаторы Spectrum-X Ethernet, так и адаптеры Spectrum-X Ethernet SuperNIC. Spectrum-X Ethernet уже продемонстрировала рекордную эффективность, позволившую крупнейшему в мире суперкомпьютеру Colossus компании xAI добиться использования 95 % возможной полосы, тогда как обычные Ethernet-платформы обеспечивают лишь 60 %, утверждает NVIDIA. 
Источник изображения: Meta✴ В июне сообщалось, что продажи Ethernet-коммутаторов NVIDIA за год выросли на 760 % благодаря росту спроса на ИИ, а в последнем квартале рост составил +98 %. Акции Arista, одного из ключевых поставщиков коммутаторов для Meta✴, упали после анонса NVIDIA и объявления Meta✴, что коммутаторы Minipack3N теперь используют ASIC Spectrum-4 и производятся Accton. |
|

