Материалы по тегу: 400gbe
|
21.10.2024 [13:21], Сергей Карасёв
Xsight Labs представила 400GbE DPU серии E1Компания Xsight Labs анонсировала, как утверждается, самую производительную на рынке программно-определяемую «систему на чипе» (SoC), предназначенную для создания DPU с поддержкой RoCEv2 и UET (Ultra Ethernet Transport). Изделие под названием E1 станет доступно заказчикам для тестирования во II квартале 2025 года. Чип будет предлагаться в модификациях E1-32 и E1-64. Первая содержит 32 ядра Arm Neoverse N2 v9.0-A, имеет 16 Мбайт кеша и использует конфигурацию памяти 2 × DDR5-5200. Показатель TDP равен 65 Вт. У второго варианта количество ядер составляет 64, размер конфигурируемого кеша/буфера — 32 Мбайт. Конфигурация памяти — 4 × DDR5-5200, величина TDP — 90 Вт. В обоих случаях используется полное шифрование памяти на лету (AES-XTS). Новинка использует до восьми блоков SerDes, обеспечивая сетевую пропускную способность до 800 Гбит/с. Возможны следующие конфигурации портов: 2 × 400GbE, 4 × 200GbE и 8 × 100/50/25/10GbE. Заявлена производительность на уровне 200 Mpps и 20 млн подключений в секунду. Также есть пара 1GbE-портов для внешнего управления. Доступны программируемые DMA-движки (до 3 Тбит/с) и разгрузка типовых операций, включая шифрование AES-GCM (для IPSec) и AES-XTS (для СХД) на лету. 
Источник изображения: Xsight Labs Есть восемь двухрежимных контроллеров и 40 (32+8) линий PCIe 5.0, а также поддержка P2P-коммутации PCIe. Упомянуты поддержка до четырёх хостов/устройств, SR-IOV (64K PF/VF), а также программная эмуляция и пространства MMIO. Реализована поддержка интерфейсов I2C/I3C/SMBus, SPI/QSPI, SMI, UART, GPIO, 1588 RTC, JTAG. Говорится о высоком уровне обеспечения безопасности: возможно создание изолированных и защищённых сред, которые аутентифицируют каждого клиента. Поддерживается функция безопасной загрузки UEFI Secure Boot with Arm Trusted Firmware (TF-A). Заявлена возможность работы «из коробки» в Debian, Ubuntu, SONiC и Lightbits Labs LightOS, а также совместимость с Netdev, VirtIO, XNA/XDP и DPDK/SPDK. В частности, возможна эмуляция NVMe-, RDMA- и сетевых устройств. Изделие E1 производится по 5-нм технологии TSMC. Оно, как утверждает Xsight Labs, обеспечивает беспрецедентную энергоэффективность и вычислительные возможности, устанавливая новый стандарт производительности для DPU SoC. Новинка ориентирована на облачные платформы и периферийные дата-центры, поддерживающие интенсивные ИИ-нагрузки. DPU позволяет создавать SDN/SDS-решения, брандмауэры, NVMe-oF СХД, вычислительные хранилища, CDN-платформы, балансировщики и т.п.
11.10.2024 [11:55], Сергей Карасёв
DPU + UEC: AMD представила 400G-адаптеры Pensando Salina и PollaraКомпания AMD анонсировала сетевой сопроцессор (DPU) третьего поколения Pensando Salina 400, а также сетевую карту Pensando Pollara 400, ориентированную на применение в составе ИИ-систем. Образцы изделий станут доступны заказчикам в текущем квартале, тогда как массовые продажи начнутся в I половине 2025 года. Решение Pensando Salina 400, рассчитанное на сетевые кластеры гиперскейлеров, обеспечивает пропускную способность до 400 Гбит/с. Утверждается, что по сравнению с DPU предыдущего поколения производительность увеличилась в два раза. Устройство Pensando Salina 400 выполнено в виде карты PCIe 5.0 с двумя портами 400GbE. Задействованы 16 ядер Arm Neoverse-N1 и 232 ядра P4 MPU. Объём памяти DDR5 достигает 128 Гбайт, её пропускная способность — 102 Гбайт/с. Новинка будет применяться в том числе в интеллектуальных коммутаторах, предназначенных для решения различных задач во внешней зоне: это может быть распределение данных, балансировка нагрузки, обеспечение безопасности, шифрование и пр. 
Источник изображений: AMD В свою очередь, Pensando Pollara 400 представляет собой интеллектуальный сетевой адаптер с одним портом 400 Гбит/с. Изделие выполнено на том же чипе, что и Pensando Salina 400. Компания AMD называет Pensando Pollara 400 первой в мире сетевой картой для приложений ИИ, соответствующей стандартам, которые определяет консорциум Ultra Ethernet (UEC). Примечательно, что первые спецификации консорциум намерен представить не раньше конца текущего года.  Цель UEC — разработка основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Благодаря программируемой архитектуре P4 адаптер можно настраивать с учётом конкретных требований. В целом, как утверждается, новинка является мощным решением для повышения производительности рабочих нагрузок ИИ и улучшения надёжности сети.
02.07.2024 [23:55], Алексей Степин
15 тыс. ускорителей на один ЦОД: Alibaba Cloud рассказала о сетевой фабрике, используемой для обучения ИИAlibaba Cloud раскрыла ряд сведений технического характера, касающихся сетевой инфраструктуры и устройства своих дата-центров, занятых обработкой ИИ-нагрузок, в частности, обслуживанием LLM. Один из ведущих инженеров компании, Эньнань Чжай (Ennan Zhai), опубликовал доклад «Alibaba HPN: A Data Center Network for Large Language Model Training», который будет представлен на конференции SIGCOMM в августе этого года. В качестве основы для сетевой фабрики Alibaba Cloud выбрала Ethernet, а не, например, InfiniBand. Новая платформа используется при обучении масштабных LLM уже в течение восьми месяцев. Выбор обусловлен открытостью и универсальностью стека технологий Ethernet, что позволяет не привязываться к конкретному вендору. Кроме того, меньше шансы пострадать от очередных санкций США. Отмечается, что традиционный облачный трафик состоит из множества относительно небыстрых потоков (к примеру, менее 10 Гбит/с), тогда как трафик при обучении LLM включает относительно немного потоков, имеющих периодический характер со всплесками скорости до очень высоких значений (400 Гбит/с). При такой картине требуются новые подходы к управлению трафиком, поскольку традиционные алгоритмы балансировки склонны к перегрузке отдельных участков сети. 
Источник здесь и далее: Alibaba Cloud Разработанная Alibaba Cloud альтернатива носит название High Performance Network (HPN). Она учитывает многие аспекты работы именно с LLM. Например, при обучении важна синхронизация работы многих ускорителей, что делает сетевую инфраструктуру уязвимой даже к единичным точкам отказа, особенно на уровне внутристоечных коммутаторов. Alibaba Cloud использует для решения этой проблемы парные коммутаторы, но не в стековой конфигурации, рекомендуемой производителями. 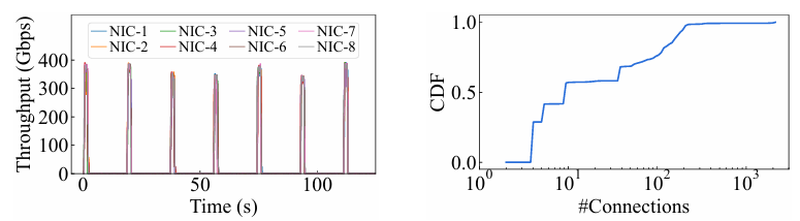
Характер трафика при обучении LLM Каждый хост содержит восемь ИИ-ускорителей и девять сетевых адаптеров. Каждый из NIC имеет по паре портов 200GbE. Девятый адаптер нужен для служебной сети. Между собой внутри хоста ускорители общаются посредством NVLink на скорости 400–900 Гбайт/с, а для общения с внешним миром каждому из них полагается свой 400GbE-канал с поддержкой RDMA. При этом порты сетевых адаптеров подключены к разным коммутаторам из «стоечной пары», что серьёзно уменьшает вероятность отказа. 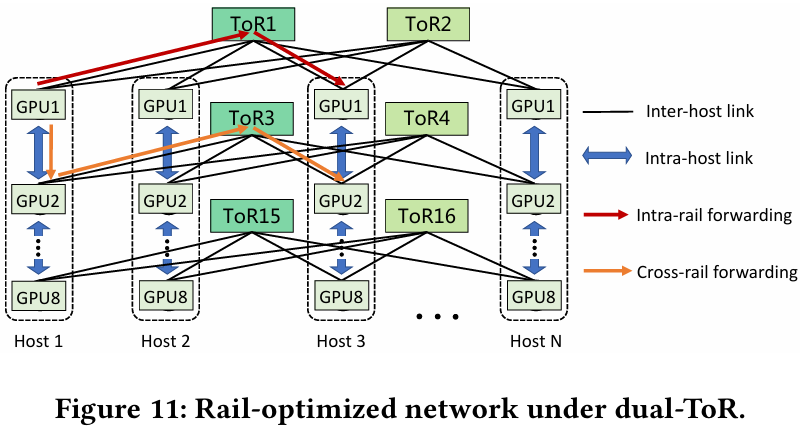 В докладе говорится, что Alibaba Cloud использует современные одночиповые коммутаторы с пропускной способностью 51,2 Тбит/с. Этим условиям отвечают либо устройства на базе Broadcom Tomahawk 5 (март 2023 года), либо Cisco Silicon One G200 (июнь того же года). Судя по использованию выражения «начало 2023 года», речь идёт именно об ASIC Broadcom. 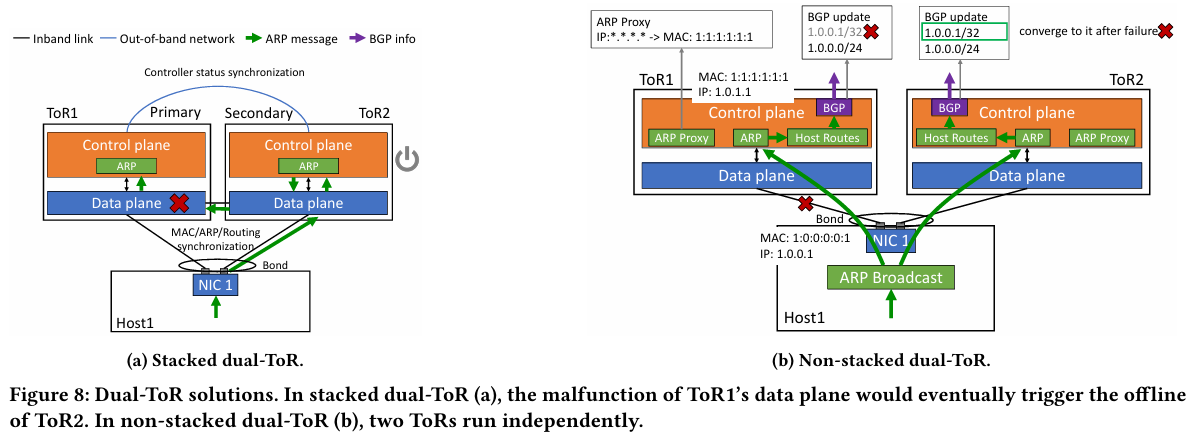 Своё предпочтение именно одночиповых коммутаторов компания объясняет просто: хотя многочиповые решения с большей пропускной способностью существуют, в долгосрочной перспективе они менее надёжны и стабильны в работе. Статистика показывает, что аппаратные проблемы у подобных коммутаторов возникают в 3,77 раза чаще, нежели у одночиповых. 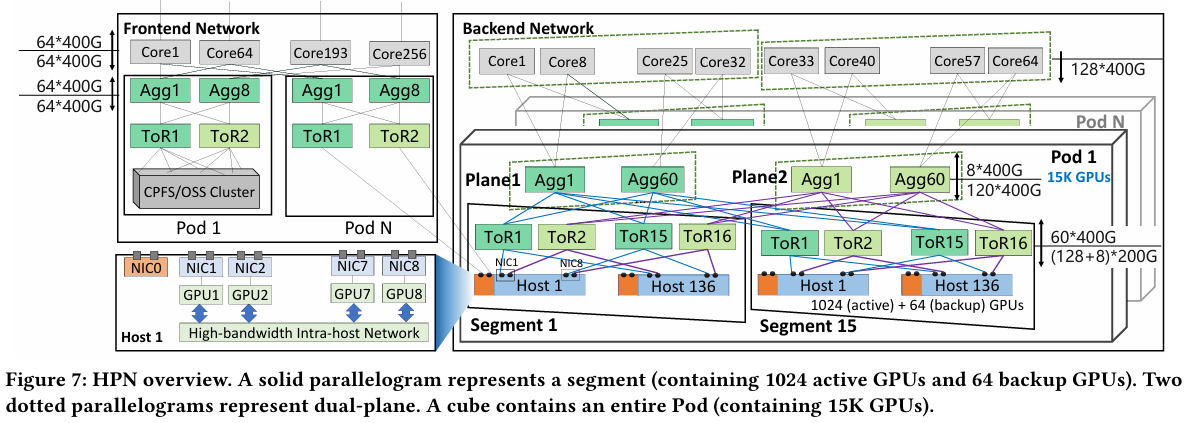 Одночиповые решения класса 51,2 Тбит/с выделяют много тепла, но ни один поставщик оборудования не смог предложить Alibaba Cloud готовые решения, способные удерживать температуру ASIC в пределах 105 °C. Выше этого порога срабатывает автоматическая защита. Поэтому для охлаждения коммутаторов Alibaba Cloud создала собственное решение на базе испарительных камер. 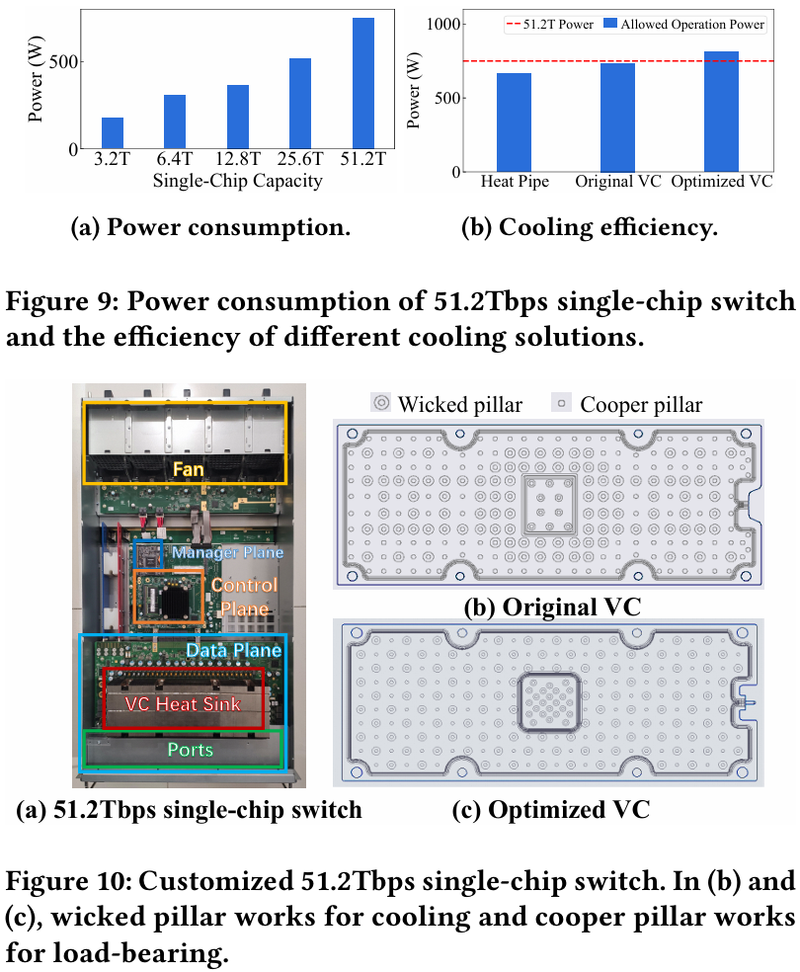 Сетевая фабрика позволяет создавать кластеры, каждый из которых содержит 15360 ускорителей и располагается в отдельном здании ЦОД. Такое высокоплотное размещение позволяет использовать оптические кабели длиной менее 100 м и более дешёвые многомодовые трансиверы, которые дешевле одномодовых примерно на 70 %. Ёмкость такого дата-центра составляет около 18 МВт. 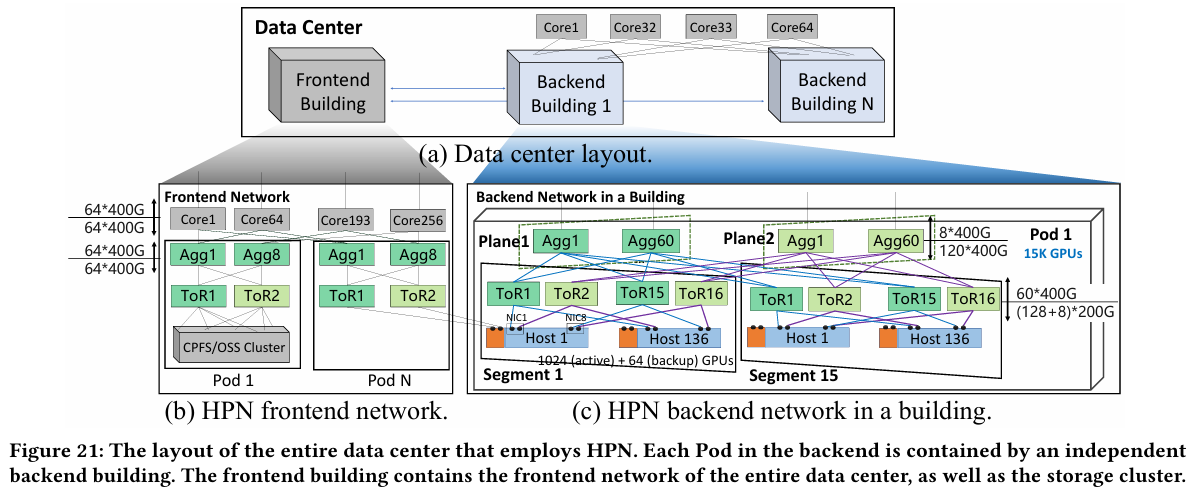 Но есть у HPN и недостаток: использование топологии с двумя внутристоечными коммутаторами и другие особенности архитектуры усложняют кабельную подсистему, поэтому инженеры поначалу столкнулись с ростом ошибок при подключении сетевых интерфейсов. В настоящее время активно используются тесты, позволяющие проверить каждое подключение на соответствие идентификаторов портов и коммутаторов рабочим схемам. Отмечается, что параметры Ethernet-коммутаторов удваиваются каждые два года, поэтому компания уже разрабатывает сетевую архитектуру следующего поколения, рассчитанную на применение будущих ASIC 102,4 Тбит/с. По словам Alibaba Cloud, обучение LLM с сотнями миллиардов параметров потребует огромного распределённого кластера, количество ускорителей в котором исчисляется миллионами. И ему требуется соответствующая сетевая инфраструктура.
09.06.2024 [12:46], Сергей Карасёв
Arista представила сетевые ИИ-решения Etherlink с прицелом на крупные кластерыКомпания Arista Networks анонсировала сетевые платформы Etherlink AI, созданные, как утверждается, для обеспечения оптимальной производительности при выполнении наиболее требовательных рабочих нагрузок ИИ, включая обучение больших языковых моделей (LLM) и их инференс. Решения Arista Etherlink AI поддерживают кластеры ИИ, насчитывающие от тысяч до сотен тысяч xPU. Используются эффективные одно- и двухуровневые сетевые топологии для обеспечения оптимальной производительности. Все коммутаторы Etherlink поддерживают новые стандарты Ultra Ethernet Consortium (UEC), которые, как ожидается, в перспективе дадут дополнительные преимущества в плане производительности. В семейство Arista Etherlink AI входят коммутаторы 7060X6 AI Leaf, построенные на базе ASIC Tomahawk 5 разработки Broadcom. Это изделие способно осуществлять коммутацию на скоростях до 51,2 Тбит/с. Новые устройства поддерживают до 60 портов 800GbE или до 128 портов 400GbE. 
Источник изображения: Arista В семействе сетевых платформ также представлены модульные системы Arista 7800R4 AI Spine 4-го поколения. В них применяются чипы-коммутаторы Broadcom Jericho3-AI, ориентированные специально на ИИ-задачи. Устройства Arista 7800R4 AI Spine поддерживают пропускную способность до 460 Тбит/с в одном шасси: 576 портов 800GbE или 1152 портов 400GbE. Наконец, дебютировали коммутаторы 7700R4 AI Distributed Etherlink Switch (DES), рассчитанные на наиболее крупные кластеры ИИ. Используя архитектуру Jericho3-AI, они обеспечивают распределение трафика без перегрузок. Это первые решения в новой серии сверхмасштабируемых интеллектуальных распределенных систем, которые способны поддерживать высочайшую пропускную способность для самых ресурсоёмких ИИ-задач, говорит компания.
24.05.2024 [10:30], Сергей Карасёв
Broadcom представила 400GbE-адаптеры P1400GD и N1400GDКорпорация Broadcom анонсировала высокопроизводительные Ethernet-адаптеры 400G, которые, как утверждается, призваны революционизировать экосистему дата-центров в эру ИИ. Изделия помогут устранить узкие места в системах коммутации на фоне стремительного роста объёмов передаваемых данных. По заявлениям Broadcom, дебютировавшие устройства — это первые на рынке адаптеры Ethernet, в основу которых положен контроллер (BCM57608), изготовленный по 5-нм технологии. В качестве ключевых сфер применения названы облачные и корпоративные среды, HPC-платформы, серверы хранения данных, приложения ИИ и машинного обучения. 
Источник изображения: Broadcom В семейство вошли модели P1400GD и N1400GD, выполненные в виде карт PCIe и OCP 3.0 соответственно. Используется интерфейс PCIe 5.0 x16. Адаптеры соответствуют стандарту 400GbE, кроме того, поддерживаются режимы 200/100/50/25GbE. В обоих случаях присутствует коннектор QSFP112-DD. Реализована поддержка RDMA over Converged Ethernet (RoCEv2). Упомянуты технологии TruFlow (ускорение сетевых операций) и TruManage (управление серверами). На аппаратном уровне реализованы инструменты обеспечения безопасности Root-of-Trust (RoT). Средства Multi-host позволяют сразу нескольким CPU обращаться к одному Ethernet-адаптеру. Говорится о совместимости с Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Ubuntu, DPDK.
22.11.2023 [11:18], Сергей Карасёв
NVIDIA представила сетевой ускоритель SuperNIC для ИИ-нагрузокКомпания NVIDIA анонсировала аппаратное решение SuperNIC — это сетевой ускоритель нового типа, предназначенный для масштабных рабочих нагрузок ИИ в системах на базе Ethernet. Устройство обеспечивает скорость передачи данных до 400 Гбит/с с использованием RDMA (RoCE). Новинка выполнена на основе DPU BlueField-3: это часть сетевой 400G/800G-платформы Spectrum-X, которая предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с). Отмечается, что сообща BlueField-3 SuperNIC и Spectrum-4 составляют основу вычислительной системы, специально разработанной для ускорения ИИ-нагрузок. При этом платформа Spectrum-X обеспечивает высокую эффективность сети, превосходя по производительности традиционные среды Ethernet. По заявления NVIDIA, DPU предоставляет множество расширенных функций, таких как высокая пропускная способность, подключение с небольшой задержкой и пр. 
Источник изображения: NVIDIA Среди ключевых особенностей SuperNIC называются: высокоскоростное переупорядочение пакетов; расширенный контроль перегрузок с использованием данных в реальном времени и специализированных сетевых алгоритмов; возможность программирования ввода-вывода (I/O); энергоэффективный низкопрофильный дизайн; полная оптимизация для ИИ (включая вычисления, сети, хранилище, системное ПО, коммуникационные библиотеки). В одной системе могут быть задействованы до восьми SuperNIC, что позволяет добиться соотношения 1:1 с GPU. А это даёт возможность максимизировать производительность при выполнении сложных задач ИИ.
19.04.2023 [22:00], Алексей Степин
Broadcom представила чип-коммутатор Jericho3-AI для ИИ-платформ, попутно раскритиковав NVIDIAКомпания Broadcom, один из ведущих поставщиков «кремния» для сетевых решений, анонсировала новый сетевой процессор Jerico3-AI, который ориентирован на ИИ-системы. Более того, Broadcom считает подход NVIDIA к «интеллектуальным сетевым решениям» с использованием InfiniBand неверным и даже вредным для кластерных ИИ-систем. Ethernet-коммутаторы компании можно разделить три ветви: наиболее высокопроизводительные чипы Tomahawk, ориентированная на дополнительные возможности ветвь Trident и, наконец, серия Jericho, отличающаяся наибольшей гибкостью в программировании и располагающая более ёмкими буферами. Чип Jericho3-AI BCM88890 — новинка в последней категории, относящаяся к классу 28,8 Тбит/с. Новый коммутатор имеет 144 линка SerDes (106Gbps, PAM4) и может работать в конфигурации 18×800GbE, 36×400GbE или 72×200GbE. 
Источник здесь и далее: Broadcom (via ServeTheHome) В своей презентации Broadcom раскритиковала традиционный подход NVIDIA и других крупных игроков на сетевом рынке, заявив о том, что прямое наращивание пропускной способности и снижение латентности кластерной сети якобы является тупиковой ветвью развития. Вместо этого фабрика на базе Jericho3-AI, по словам компании, позволяет сделать так, чтобы процесс обучения нейросети как можно меньше времени тратил не сетевые операции.  Новый коммутатор обеспечивает идеальную балансировку загрузки, гарантирующую отсутствие заторов, и автоматическое переключение отказавшего соединения на резервное менее, чем за 10-нс, а также позволяет создавать большие «плоские» сети (до 32 тыс. портов 800GbE), характерные для ИИ-кластеров. Каждый ускоритель может получить 800G-подключение, а суммарная производительность фабрики на базе новых коммутаторов может достигать 26 Пбит/с. 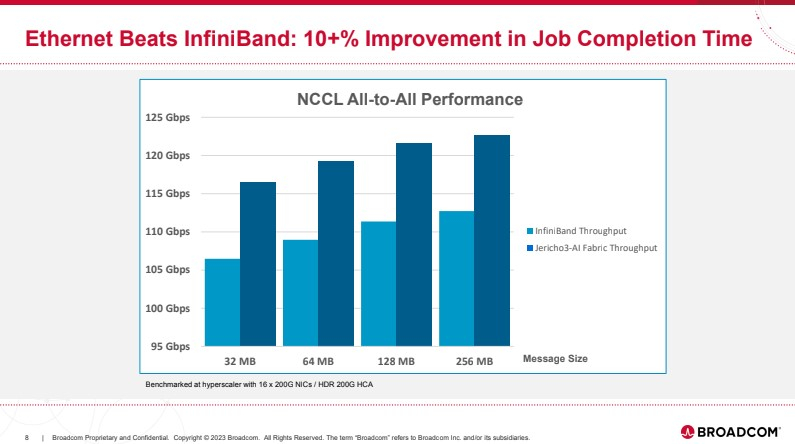 Broadcom утверждает, что сеть Ethernet на базе Jericho3-AI превосходит аналогичную по классу сеть NVIDIA InfiniBand в тестах с использованием NCCL. При этом новый коммутатор не содержит никаких вычислительных мощностей общего назначения — он проще, а за счёт использования стандарта Ethernet сети на его основе универсальны, что также снижает стоимость владения инфраструктурой.  Высокая степень интегрированности обеспечит и большую экономичность, а значит, решения на базе нового коммутатора Broadcom окажутся и более дружелюбны к экологии. Новые чипы уже доступны избранным клиентам Broadcom.
26.08.2022 [12:45], Алексей Степин
Интерконнект NVIDIA NVLink 4 открывает новые горизонты для ИИ и HPCПотребность в действительно быстром интерконнекте для ускорителей возникла давно, поскольку имеющиеся шины зачастую становились узким местом, не позволяя «прокормить» данными вычислительные блоки. Ответом NVIDIA на эту проблему стало создание шины NVLink — и компания продолжает активно развивать данную технологию. На конференции Hot Chips 34 было продемонстрировано уже четвёртое поколение, наряду с новым поколением коммутаторов NVSwitch. 
Изображения: NVIDIA Возможность использования коммутаторов для NVLink появилась не сразу, изначально использовалось соединение блоков ускорителей по схеме «точка-точка». Но дальнейшее наращивание числа ускорителей по этой схеме стало невозможным, и тогда NVIDIA разработала коммутаторы NVSwitch. Они появились вместе с V100 и предлагали до 50 Гбайт/с на порт. Нынешнее же, третье поколение NVSwitch и четвёртое поколение NVLink сделали важный шаг вперёд — теперь они позволяют вынести NVLink-подключения за пределы узла. 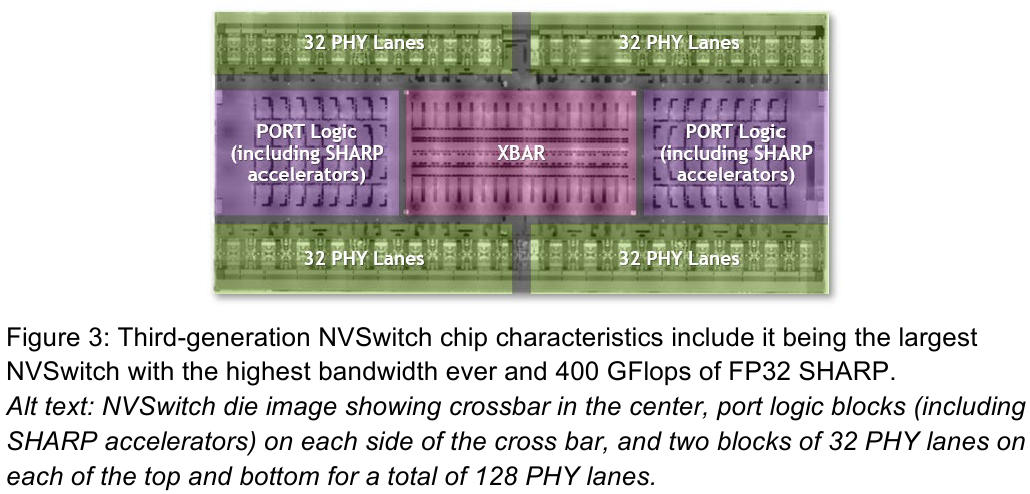 Так, совокупная пропускная способность одного чипа NVSwitch теперь составляет 3,2 Тбайт/с в обе стороны в 64 портах NVLink 4 (x2). Это, конечно, отразилось и на сложности самого «кремния»: 25,1 млрд транзисторов (больше чем у V100), техпроцесс TSMC 4N и площадь 294мм2. Скорость одной линии NVLink 4 осталась равной 50 Гбайт/с, но новые ускорители H100 имеют по 18 линий NVLink, что даёт впечатляющие 900 Гбайт/с. В DGX H100 есть сразу четыре NVSwitch-коммутатора, которые объединяют восемь ускорителей по схеме каждый-с-каждым и дополнительно отдают ещё 72 NVLink-линии (3,6 Тбайт/с). 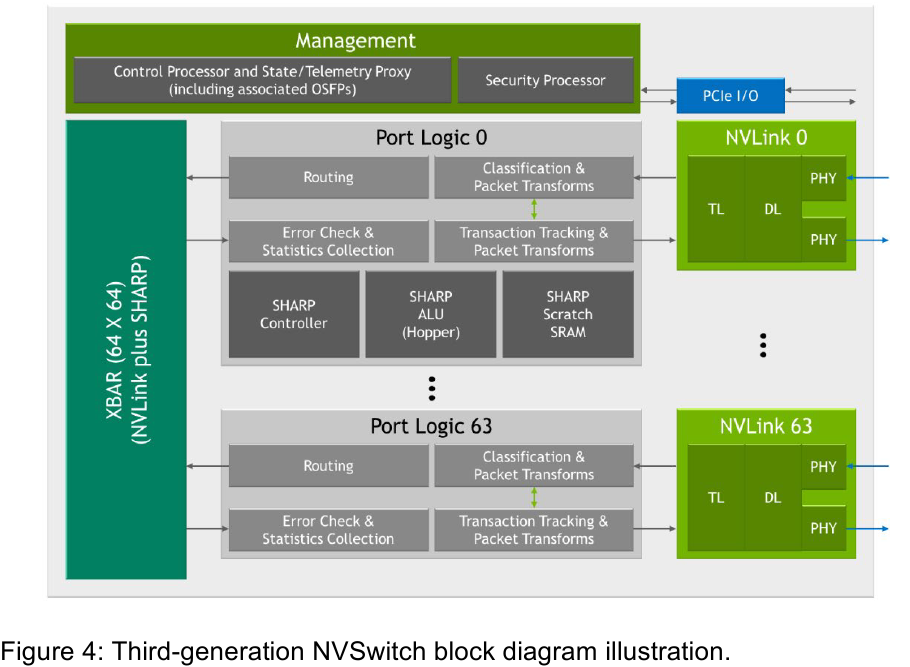 При этом у DGX H100 сохраняются прежние 400G-адаптеры Ethernet/InfiniBand (ConnectX-7), по одному на каждый ускоритель, и пара DPU BlueField-3, тоже класса 400G. Несколько упрощает физическую инфраструктуру то, что для внешних NVLink-подключений используются OSFP-модули, каждый из которых обслуживает 4 линии NVLink. Любопытно, что электрически интерфейсы совместимы с имеющейся 400G-экосистемой (оптической и медной), но вот прошивки для модулей нужны будут кастомные. 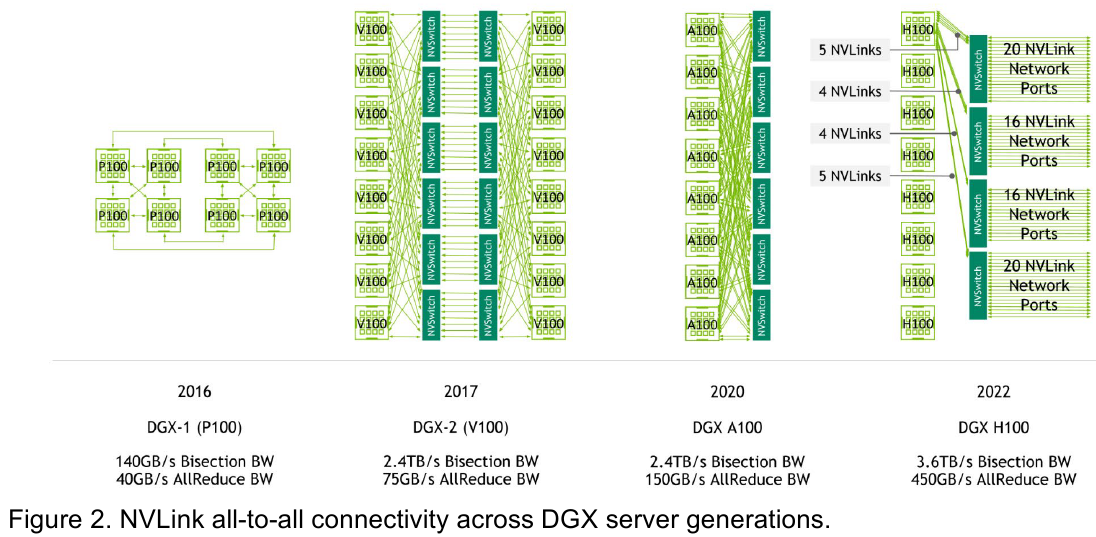 Подключаются узлы DGX H100 к 1U-коммутатору NVLink Switch, включающему два чипа NVSwitch третьего поколения: 32 OSFP-корзины, 128 портов NVLink 4 и агрегированная пропускная способность 6,4 Тбайт/с. В составе DGX SuperPOD есть 18 коммутаторов NVLink Switch и 256 ускорителей H100 (32 узла DGX). Таким образом, можно связать ускорители и узлы 900-Гбайт/с каналом. Как конкретно, остаётся на усмотрение пользователя, но сама NVLink-сеть поддерживает динамическую реконфигурацию на лету.  Ещё одна особенность нового поколения NVLink — продвинутые аппаратные SHARP-движки, которые избавляют CPU/GPU от части работ по подготовке и предобработки данных и избавляющие саму сеть от ненужных передач. Кроме того, в NVLink-сети реализованы разделение и изоляция, брандмауэр, шифрование, глубокая телеметрия и т.д. В целом, новое поколение NVLink получило полуторакратный прирост в скорости обмена данными, а в отношении дополнительных сетевых функций он стал трёхкратным. Всё это позволит освоить новые класса HPC- и ИИ-нагрузок, однако надо полагать, что удовольствие это будет недешёвым.
28.04.2022 [22:54], Алексей Степин
Chelsio представила седьмое поколение сетевых чипов Terminator: 400GbE и PCIe 5.0 x16Компания Chelsio Communications анонсировала седьмое поколение своих сетевых процессоров Terminator с поддержкой 400GbE. От предшественников T7 отличает более развитая вычислительная часть общего назначения, включающая в себя до 8 ядер Arm Cortex-A72, так что их уже можно назвать DPU. Всего представлено пять вариантов 5 чипов (T7, N7, D7, S74 и S72), которые различаются между собой набором движков и ускорителей. Референсная платформа T7 будет доступна в мае, первых же адаптеров на базе новых DPU следует ожидать в III квартале 2022 года. Для задач сжатия, дедупликации или криптографии есть отдельные сопроцессоры. Никуда не делся и привычный для серии Unified Wire встроенный L2-коммутатор. Для подключения к хосту T7 теперь использует шину PCIe 5.0 x16, причём он же содержит и root-комплекс. Более того, имеется и набортный коммутатор+мост PCIe 4.0, и NVMe-интерфейс, и даже поддержка эмуляции NVMe. Всё это, к примеру, позволяет легко и быстро создать NVMe-oF хранилище или мост NVMe-NVMe для компрессии и шифрования данных на лету. Новинка предлагает ускорение работы RoCEv2 и iWARP, FCoE и NVMe/TCP, iSCSI и iSER, а также RAID5/6. Сетевая часть поддерживает разгрузку Open vSwitch и Virt-IO. 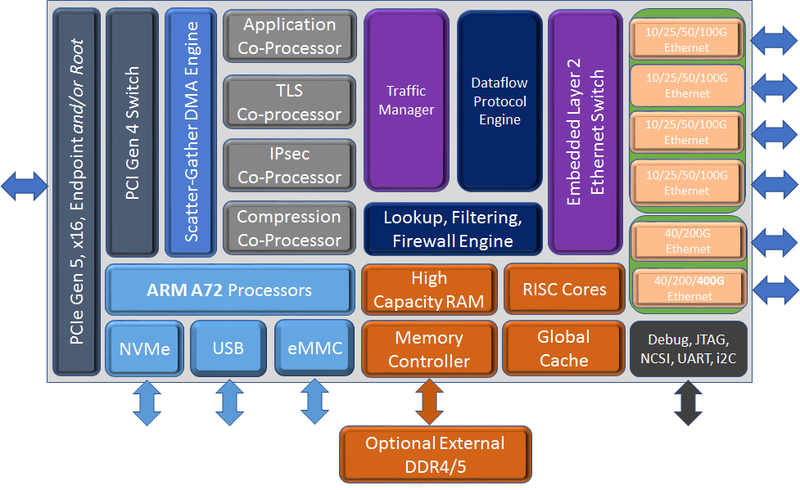
Блок-схема старшего варианта T7 (Изображения: Chelsio Communcations) Впрочем, поддержки P4 тут нет — Chelsio продолжает использовать собственные движки для обработки трафика. Но наработки, сделанные для серий T5 и T6, будет проще перенести на новое поколение чипов. Кроме того, появилась и практически обязательная нынче «глубокая» телеметрия всего проходящего через DPU трафика для повышения управляемости и его защиты. Если и этого окажется мало, то к T7 (и D7) можно напрямую подключить FPGA, а набортную память расширить банками DDR4/5. В пресс-релизе также отмечается, что T7 сможет стать достойной заменой InfiniBand в HРC-системах. 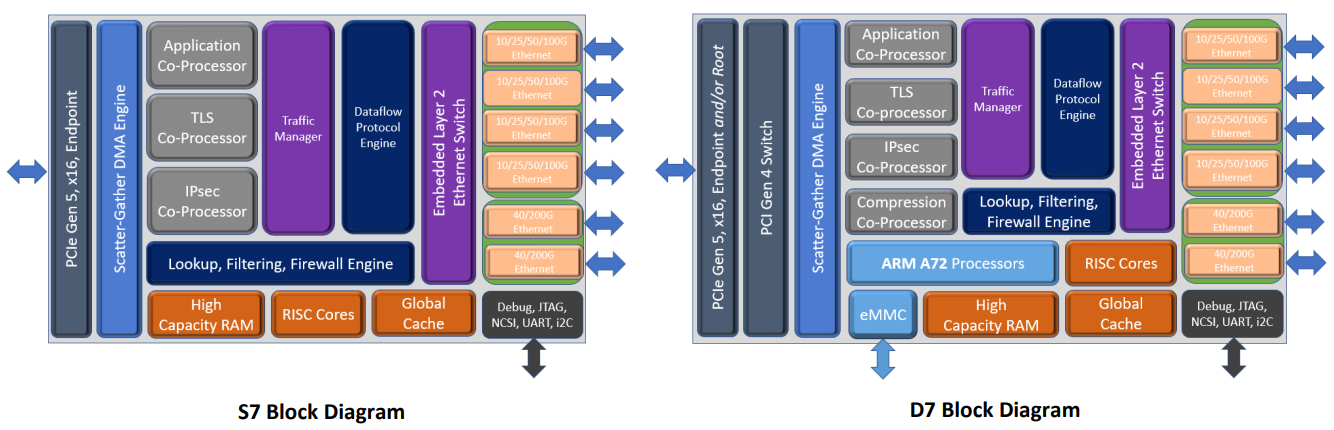 Вариант D7 наиболее близок к T7, но предлагает только 200GbE-подключение, лишён некоторых функций и второстепенных интерфейсов, да и в целом рассчитан на создание СХД. N7, напротив, лишён Arm-ядер и всех функций для работы с хранилищами, нет у него и PCIe-коммутатора и моста. Предлагает он только 200GbE-интерфейсы. Наконец, чипы серии S7 лишены целого ряда второстепенных функций и предоставляют только 100/200GbE-подключение. Они относятся скорее к SmartNIC, поскольку начисто лишены Arm-ядер и некоторых функций. Но зато они и недороги. Кроме того, в седьмом поколении Termintator появилась возможность обойтись без набортной DRAM с сохранением всей функциональности. Так что использование памяти хоста позволит дополнительно снизить стоимость конечных решений, которые будут создавать OEM-производители. Сами чипы производятся с использованием техпроцесса TSMC 12-нм FFC, так что даже у старшей версии чипов типовое энергопотребление не превышает 22 Вт.
30.06.2021 [22:44], Алексей Степин
Marvell анонсировала 5-нм DPU Octeon 10: 36 ядер ARM Neoverse N2, 400GbE, PCIe 5.0 и DDR5Концепция ускорителя для работы с данными, выделенного DPU, продолжает набирать популярность. В последнее время целый ряд компаний представил свои решения. А на днях очередь дошла до крупного разработчика микроэлектроники, компании Marvell, которая анонсировала DPU серии Octeon 10. Новые сопроцессоры построены на основе наиболее совершенного 5-нм техпроцесса TSMC и должны на равных сражаться с такими соперниками, как ускорители NVIDIA BlueField. Сама Marvell известна разработкой собственных вычислительных ядер, однако в Octeon 10 от этого подхода компания отошла, вернувшись к лицензированию ядер ARM — в основу новой серии чипов легли ядра Neoverse N2. 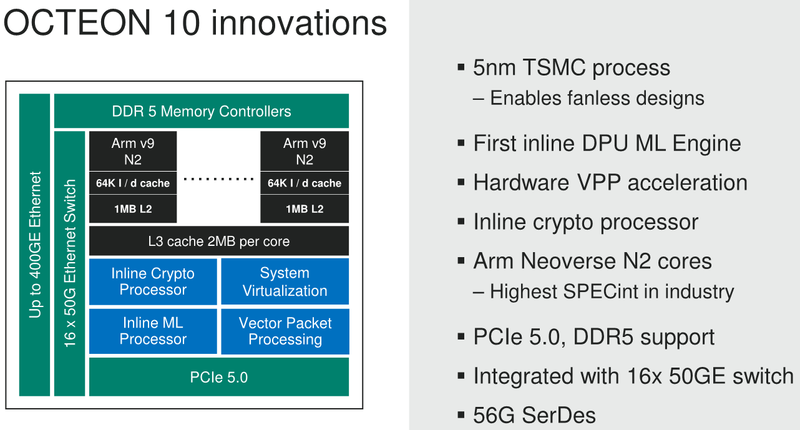 В основе данной архитектуры лежит набор команд ARM v9, появившийся не так уж давно. В сравнении с решениями на базе ARM v8.x эта архитектура может обеспечивать до 40% прироста в производительности, в том числе, за счёт поддержки 128-битных векторных расширений SVE2 и развитой подсистемы кешей. Процессорные ядра в Octeon 10 располагают по 1 и 2 Мбайт кешей второго и третьего уровня на каждое ядро. 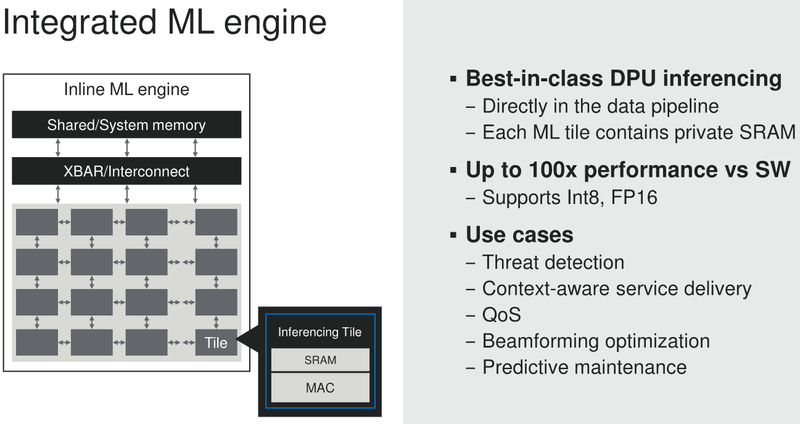 В составе новой SoC также присутствуют блоки ускорения сетевых задач и криптографические акселераторы. Кроме этого, кремний Octeon 10 получил и сетевой коммутатор, обеспечивающий работу 16 портов Ethernet со скоростью 50 Гбит/с. «Прокормить» столь требовательную «семью» непросто, но в плане подсистем ввода-вывода новые DPU также отвечают современным реалиям: они рассчитаны на работу с памятью DDR5-5200 и поддерживают интерфейс PCI Express 5.0, блоки SerDes относятся к поколению 56G. 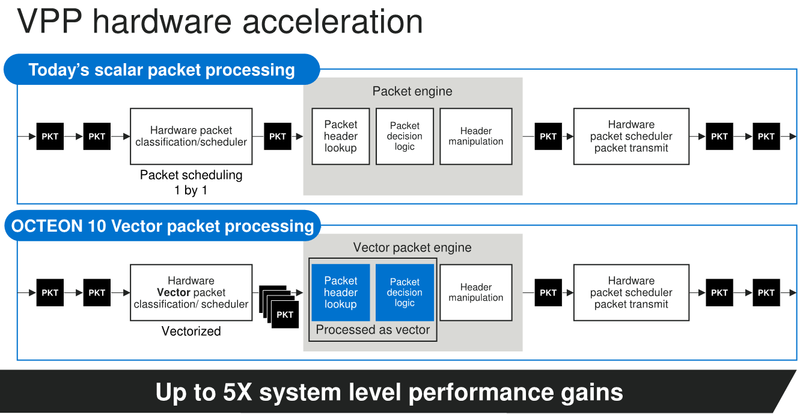 Отдельного упоминания заслуживает движок векторной обработки пакетов (Vector Packet Processing Engine), способный объединять в единую серию сетевые пакеты и «переваривать» их одновременно, как векторные данные. Такой подход позволяет серьёзно снизить латентность, что для DPU очень важно. Имеются в составе Octeon 10 и средства для работы с алгоритмами машинного обучения, причём каждый «тайл», поддерживающий INT8 и FP16, имеет свой объём SRAM. 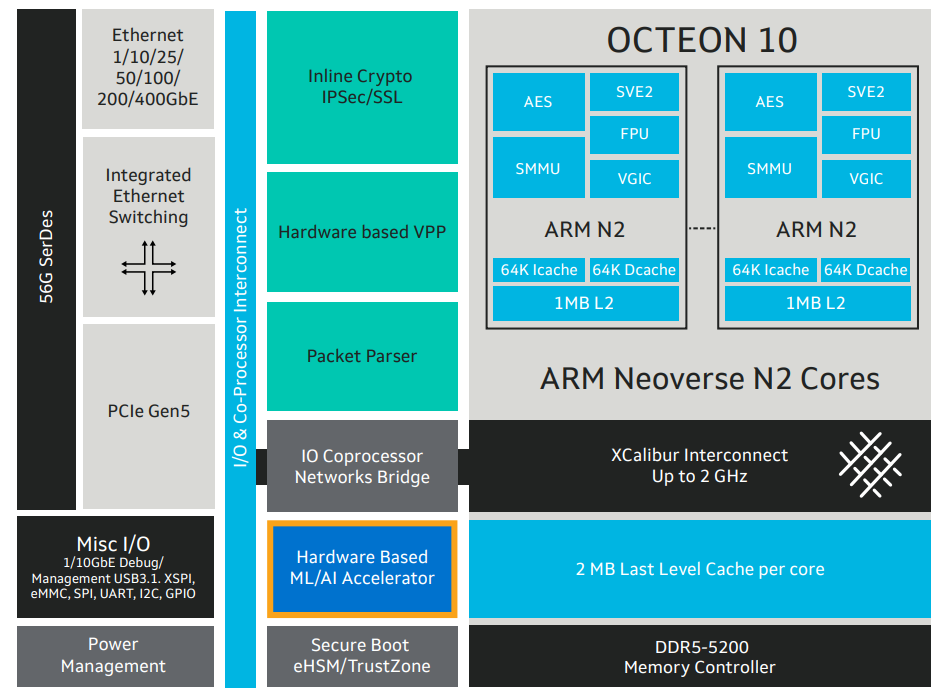 Пока семейство Octeon 10 представлено четырьмя моделями, младшая из которых может содержать до 8 ядер Neoverse N2, а старшая — до 36 таких ядер, причём о масштабировании подсистемы памяти разработчики также подумали и число контроллеров DDR5 в новых чипах варьируется от 2 до 12. Несмотря на столь солидные характеристики, теплопакеты удалось удержать в разумных рамках, и даже у наиболее мощной версии DPU400 TDP составляет всего 60 Ватт. 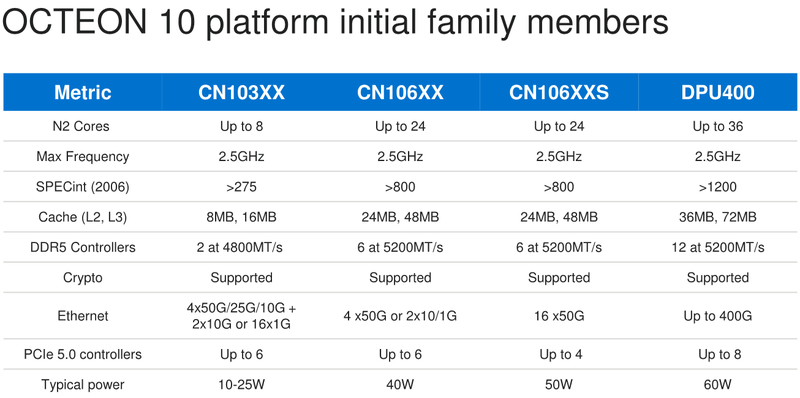 В настоящее время Marvell Octeon 10 уже находится в производстве, первые же партии новых чипов должны поступить к заказчикам во второй половине этого года. Столь многогранные DPU должны найти применение в самых разных сценариях, от поддержания инфраструктуры 5G RAN до работы в составе облачных систем, а также в высокопроизводительных маршрутизаторах. |
|


