Материалы по тегу: ускоритель
|
26.08.2021 [03:07], Алексей Степин
Получены первые образцы 1000-ядерного суперкомпьютера-на-чипе Esperanto ET-SoC-1Рекомендательные системы, активно используемые социальными сетями, рекламными платформами и т.д. имеют специфические особенности. От них требуется высокая скорость отклика, но вместе с тем их ИИ-модели весьма объёмны, порядка 100 Гбайт или более. А для их эффективной работы нужен ещё и довольно большой кеш. Для инференса чаще всего используется либо CPU (много памяти, но относительно низкая скорость) или GPU (высокая скорость, но мало памяти), но они не слишком эффективны для этой задачи. При этом существуют ещё и физические ограничения со стороны гиперскейлеров: в сервере не так много полноценных PCIe-слотов и свободного места + есть жёсткие ограничения по энергопотреблению и охлаждению (чаще всего воздушному). Всё это было учтено компанией Esperanto, чьей специализацией является разработка чипов на базе архитектуры RISC-V. На днях она получила первые образцы ИИ-ускорителя ET-SoC-1, который она сама называет суперкомпьютером-на-чипе (Supercomputer-on-Chip).  Новинка предназначена для инференса рекомендательных систем, в том числе на периферии, где на первый план выходит экономичность. Компания поставила для себя непростую задачу — весь комплекс ускорителей с памятью и служебной обвязкой должен потреблять не более 120 Вт. Для решения этой задачи пришлось применить немало ухищрений. Самое первое и очевидное — создание относительно небольшого, но универсального чипа, который можно было бы объединять с другими такими же чипами с линейным ростом производительности.  Для достижения высокой степени параллелизма основой такого чипа должны стать небольшие, но энергоэффективные ядра. Именно поэтому выбор пал на 64-бит ядра RISC-V, поскольку они «просты» не только с точки зрения ISA, но и по транзисторному бюджету. Чип ET-SoC-1 сочетает в себе два типа ядер RISC-V: классических «больших» ядер (ET-Maxion) с внеочередным выполнением у него всего 4, зато «малых» ядер (ET-Minion) с поддержкой тензорных и векторных вычислений — целых 1088. 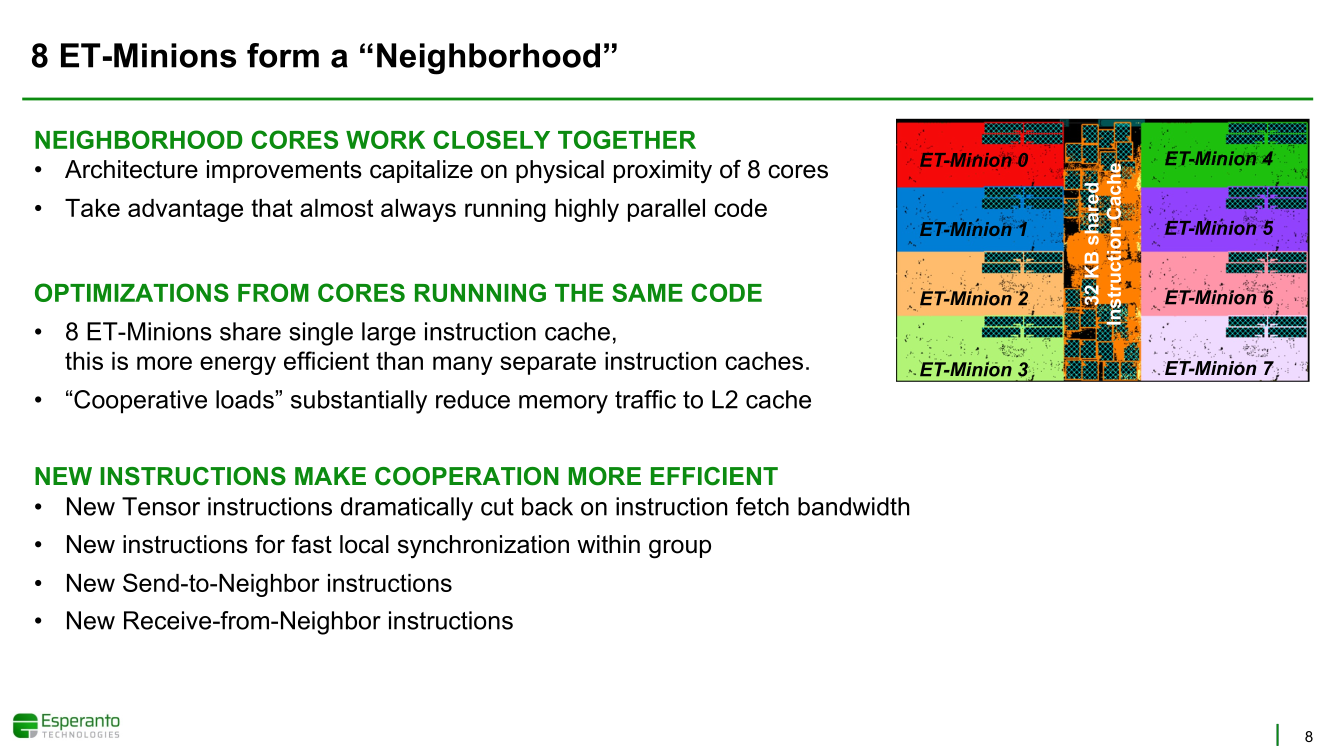 На комплекс ядер ET-Maxion возлагаются задачи общего назначения и в ИИ-вычислениях он напрямую не участвует, зато позволяет быть ET-SoC-1 полностью автономным, так как прямо на нём можно запустить Linux. Помогает ему в этом ещё один служебный RISC-V процессор для периферии. А вот ядра ET-Minion довольно простые: внеочередного исполнения инструкций в них нет, зато есть поддержка SMT2 и целый набор новых инструкций для INT- и FP-операций с векторами и тензорами. 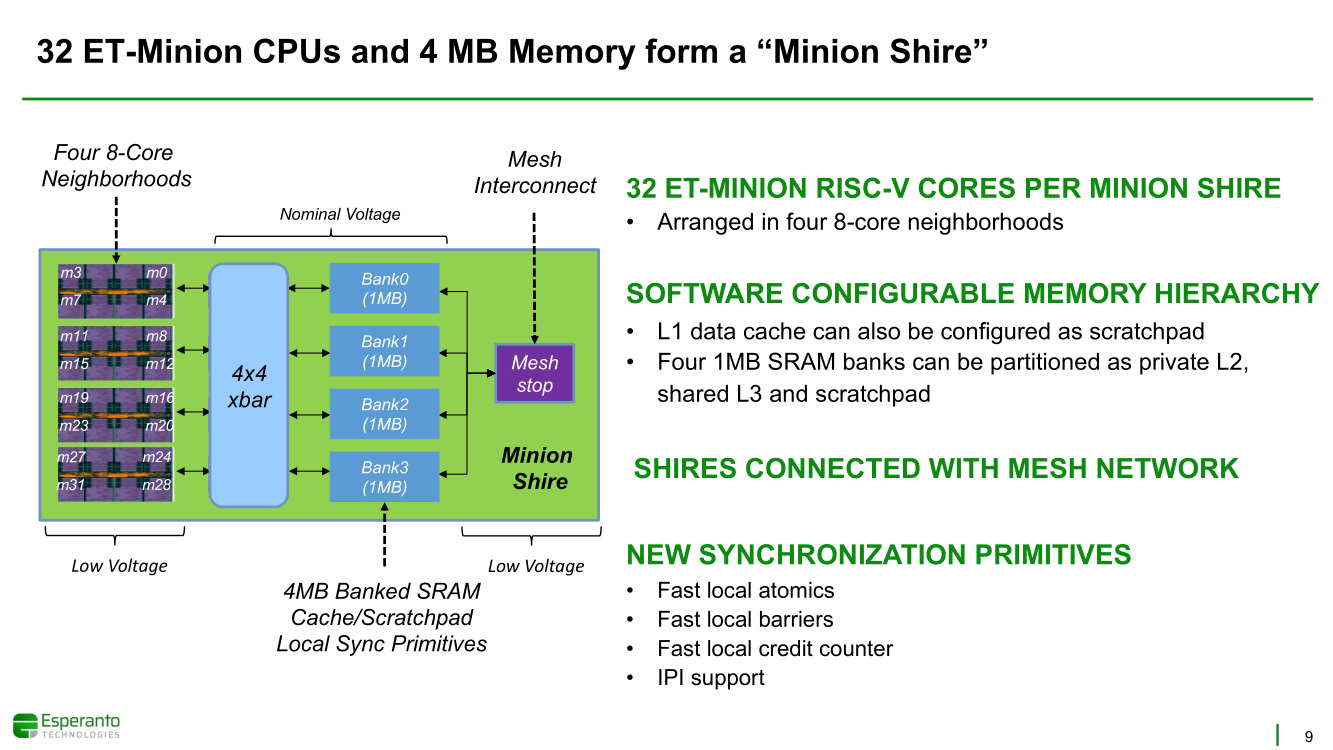 За каждый такт ядро ET-Minion способно выполнять 128 INT8-операций с сохранением INT32-результата, 16 FP32-операций или 32 — FP16. «Длинные» тензорные операции могут непрерывно исполняться в течение 512 циклов (до 64 тыс. операций), при этом целочисленные блоки в это время отключаются для экономии питания. Система кешей устроена несколько непривычным образом. На ядро приходится 4 банка памяти, которые можно использовать как L1-кеш для данных и как быструю универсальную память (scratchpad). 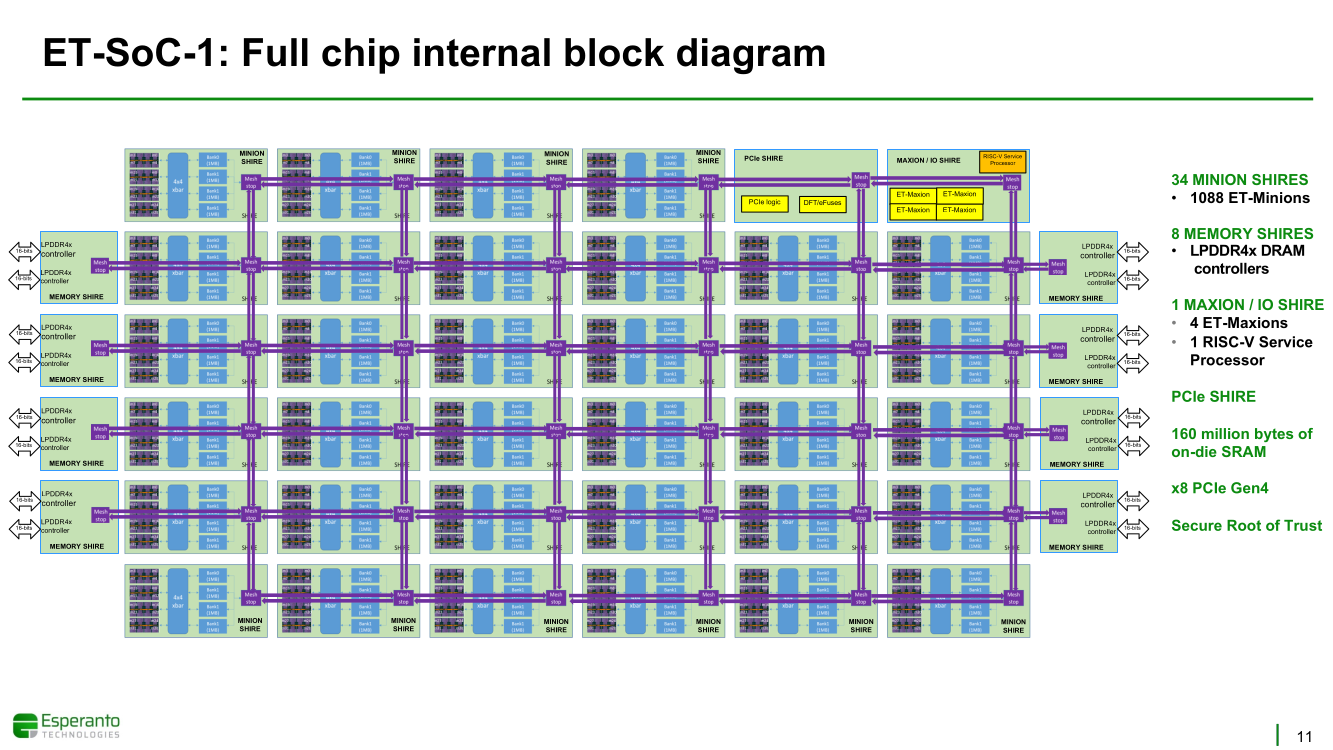 Восемь ядер ET-Minion формируют «квартал» вокруг общего для них кеша инструкций, так как на таких задачах велика вероятность того, что инструкции для всех ядер действительно будут одни и те же. Кроме того, это энергоэффективнее, чем восемь индивидуальных кешей, и позволяет получать и отправлять данные большими блоками, снижая нагрузку на L2-кеш. Восемь «кварталов» формируют «микрорайон» с коммутатором и четырьмя банками SRAM объёмом по 1 Мбайт, которые можно использовать как приватный L2-кеш, как часть общего L3-кеша или как scratchpad. 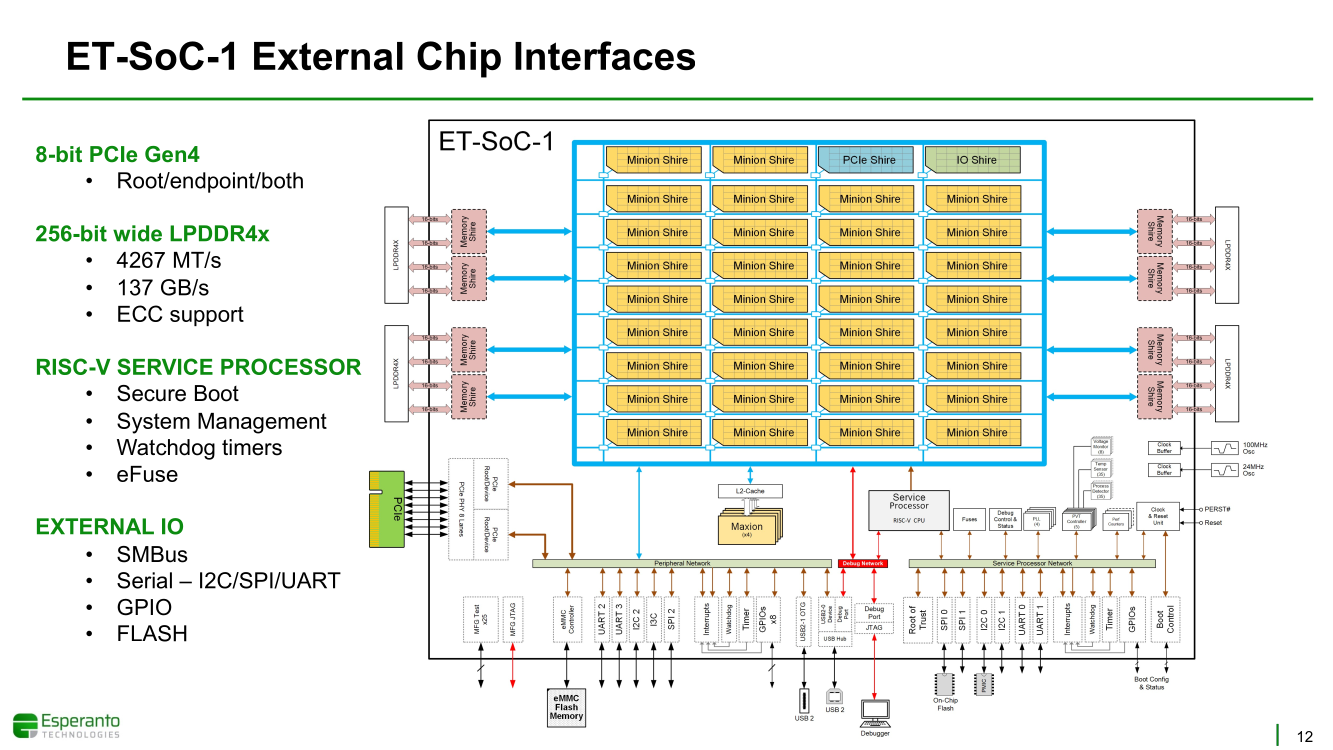 Посредством mesh-сети «микрорайоны» общаются между собой и с другими блоками: ET-Maxion, восемь двухканальных контроллеров памяти, два root-комплекса PCIe 4.0 x8, аппаратный RoT. Суммарно на чип приходится порядка 160 Мбайт SRAM. Контроллеры оперативной памяти поддерживают модули LPDDR4x-4267 ECC (256 бит, до 137 Гбайт/с). Тактовая частота ET-Minion варьируется в пределах от 500 МГц до 1,5 ГГц, а ET-Maxion — от 500 МГц до 2 ГГц. 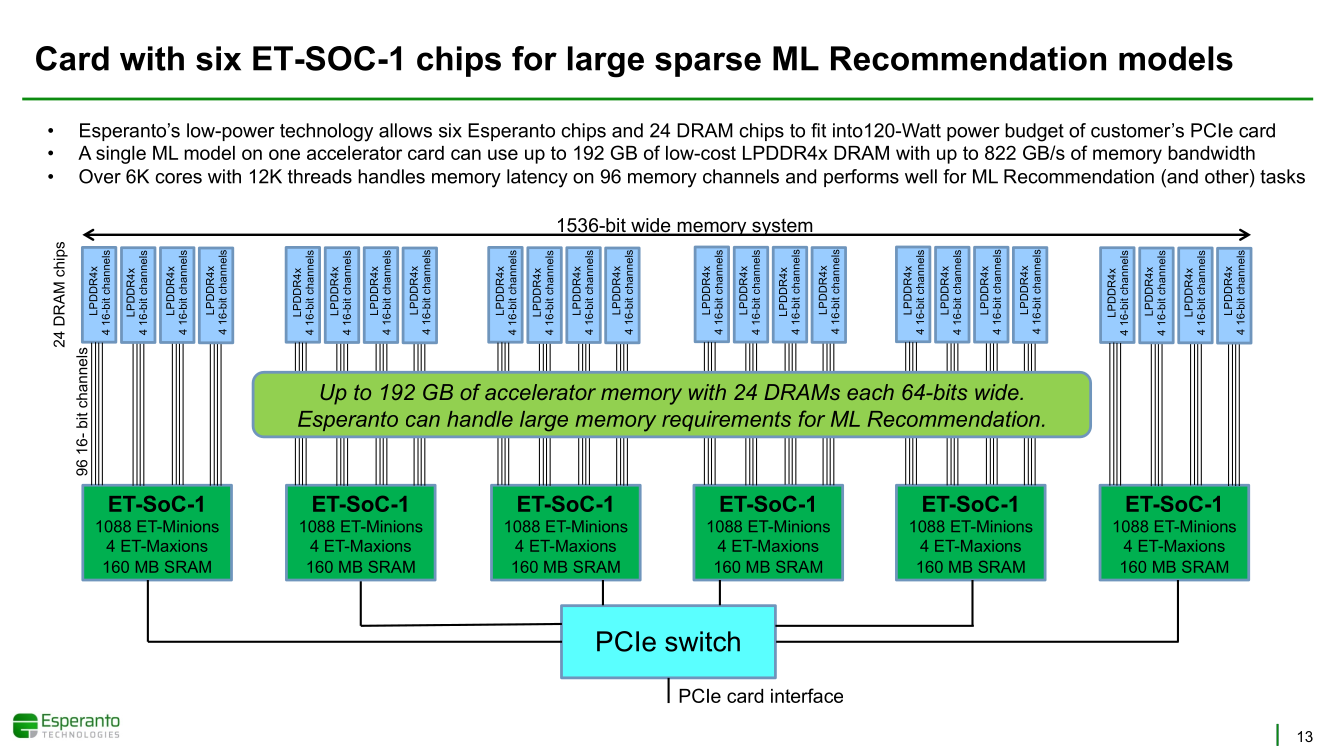 В рамках OCP-блока Glacier Point V2 компания объединила на одной плате шесть ET-SoC-1 (всего 6558 ядер RISC-V), снабдив их 192 Гбайт памяти (822 Гбайт/с) — это больше, нежели у NVIDIA A100 (80 Гбайт). Такая связка развивает более 800 Топс, требуя всего 120 Вт. В среднем же она составляет 100 ‒ 200 Топс на один чип с потреблением менее 20 Вт. Это позволяет создать компактный M.2-модуль или же наоборот масштабировать систему далее. Шасси Yosemite v2 может вместить 64 чипа, а стойка — уже 384 чипа. 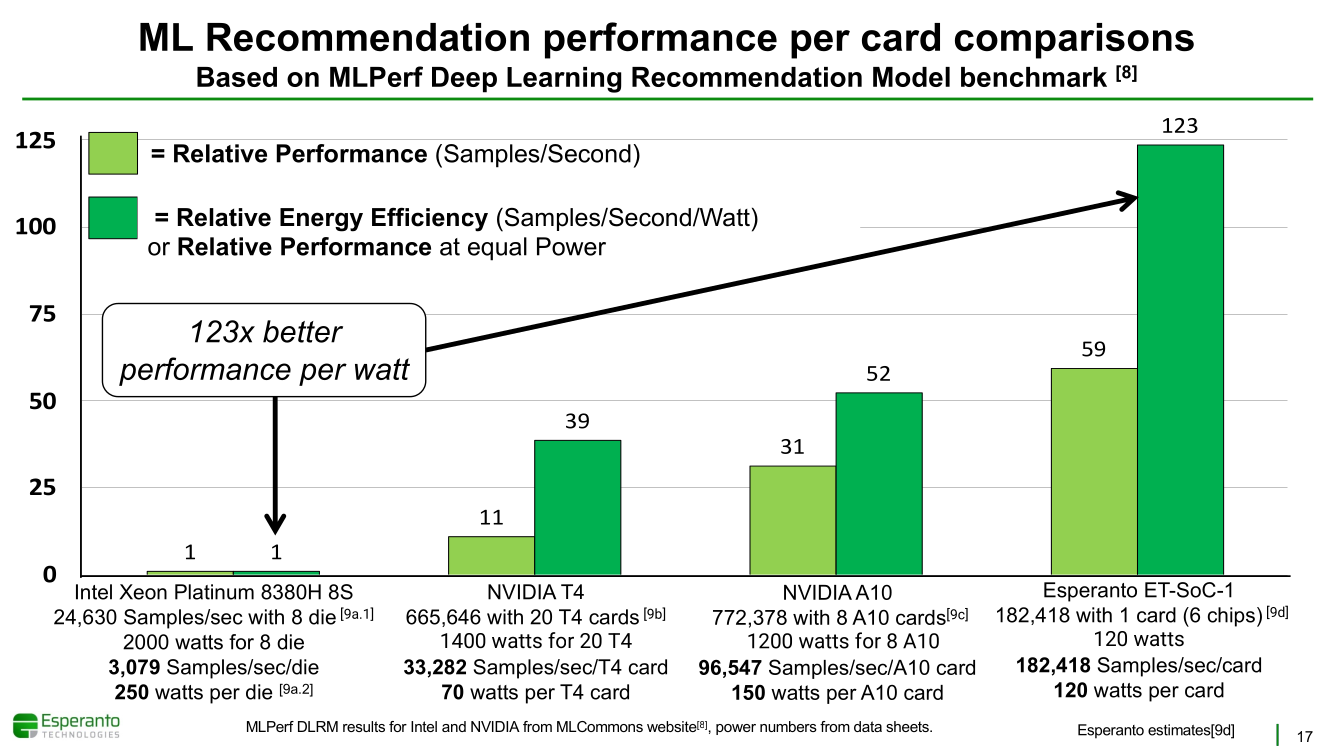 В тесте MLPerf для рекомендательных систем производительность указанной выше связки из шести чипов в пересчёте на Ватт оказалась в 123 раза выше, чем у Intel Xeon Platinum 8380H (250 Вт), и в два-три раза выше, чем у NVIDIA A10 (150 Вт) и T4 (70 Вт). В «неудобном» для чипа тесте ResNet-50 разница с CPU и ускорителем Habana Goya уже не так велика, а вот с решениями NVIDIA, напротив, более заметна. 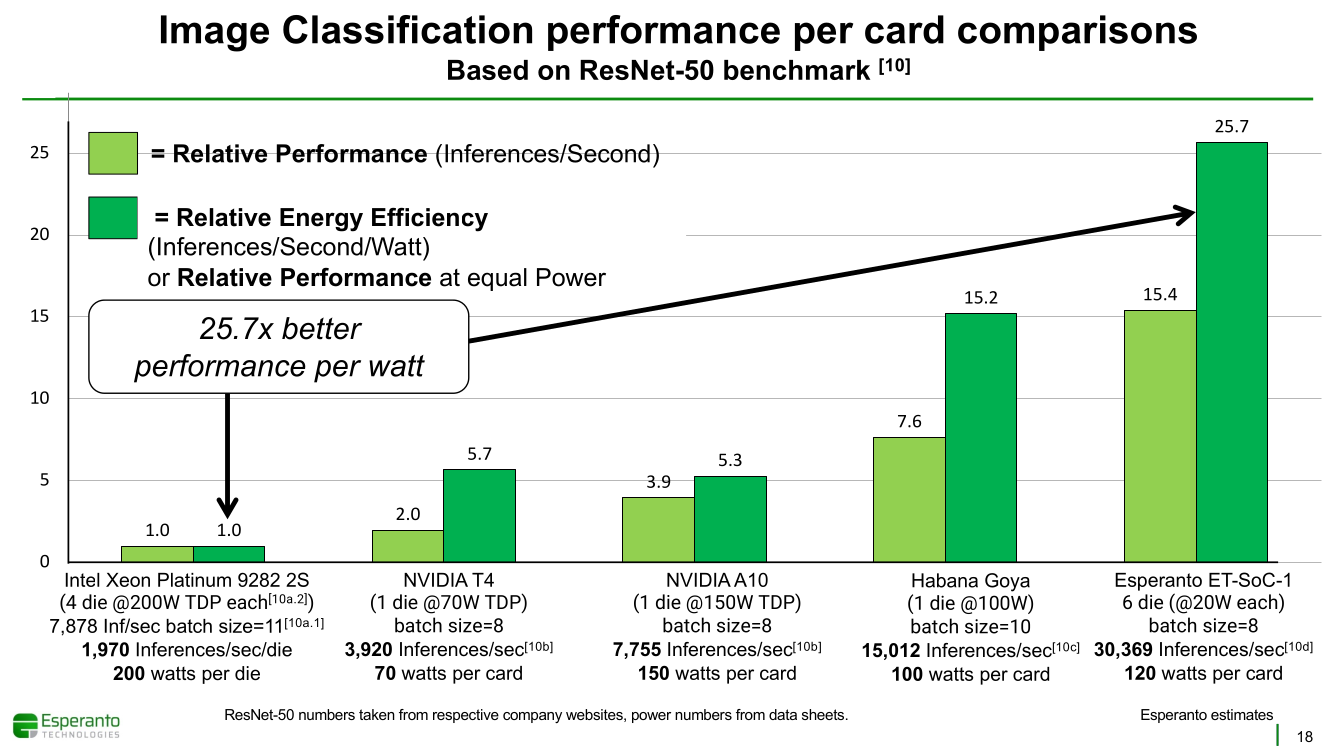 При этом о поддержке со стороны ПО разработчики также подумали: чипы Esperanto могут работать с широко распространёнными фреймворками PyTorch, TensorFlow, MXNet и Caffe2, а также принимать готовые ONNX-модели. Есть и SDK для C++, а также драйверы для x86-хостов.  Опытные образцы изготовлены на TSMC по 7-нм техпроцессу. Кристалл площадью 570 мм2 содержит 24 млрд транзисторов. Чип имеет упаковку BGA2494 размерами 45 × 45 мм2. Энергопотребление (а вместе с ним и производительность) настраивается в диапазоне от 10 до 60+ Ватт. Потенциальным заказчикам тестовые чипы станут доступны до конца года. Компания также готова адаптировать ET-SoC-1 под другие техпроцессы и фабрики, но демо на базе OCP-платформы и сравнение с Cooper Lake — это недвусмысленный намёк для Facebook✴, что Esperanto будет рада видеть её в числе первых клиентов.
19.08.2021 [16:00], Игорь Осколков
Intel анонсировала ускорители Xe HPC Ponte Vecchio: 100+ млрд транзисторов, микс 5/7/10-нм техпроцессов Intel и TSMC и FP32-производительность 45+ ТфлопсКак и было обещано несколько лет назад, основным «строительным блоком» для графики и ускорителей Intel станут ядра Xe, которые можно будет гибко объединять и сочетать с другими аппаратными блоками для получения заданной производительности и функциональности. Компания уже анонсировала первые «настоящие» дискретные GPU серии Arc, а на Intel Architecture Day она поделилась подробностями о серверных ускорителях Xe HPC и Ponte Vecchio.  Основой Xe HPC является вычислительное ядро Xe Core, которое включает по восемь векторных и матричных движков для данных шириной 512 и 4096 бит соответственно. Они делят между собой L1-кеш объёмом 512 Кбайт, с которым можно общаться на скорости 512 байт/такт.  Заявленная производительность для векторного движка (бывший EU), ориентированного на «классические» вычисления, составляет 256 операций/такт для FP32 и FP64 или 512 — для FP16. Матричный движок нужен скорее для ИИ-нагрузок, поскольку работает только с данными TF32, FP16, BF16 и INT8 — 2048, 4096, 4096 и 8192 операций/такт соответственно. Данный движок работает с инструкциями XMX (Xe Matrix eXtensions), которые в чём-то схожи с AMX в Intel Xeon Sapphire Rapids.  Отдельные ядра объединяются в «слайсы» (slice) — по 16 Xe-Core в каждом, которые дополнены 16 блоков аппаратной трассировки лучей. Именно слайс является базовым функциональным блоком. Он изготавливается на TSMC по 5-нм техпроцессу в рамках инициативы Intel IDM 2.0. Слайсы объединяются в стеки — по 4 шт. в каждом.  Стек включает также базовую (Base) «подложку» (или тайл), четыре контроллерами памяти HBM2e (сама память вынесена в отдельные тайлы), общим L2-кешем объёмом 144 Мбайт, один медиа-движок с аппаратными кодеками, а также тайл Xe Link и контроллер PCIe 5. Base-тайл изготовлен по техпроцессу Intel 7 и использует EMIB для объединения всех блоков. 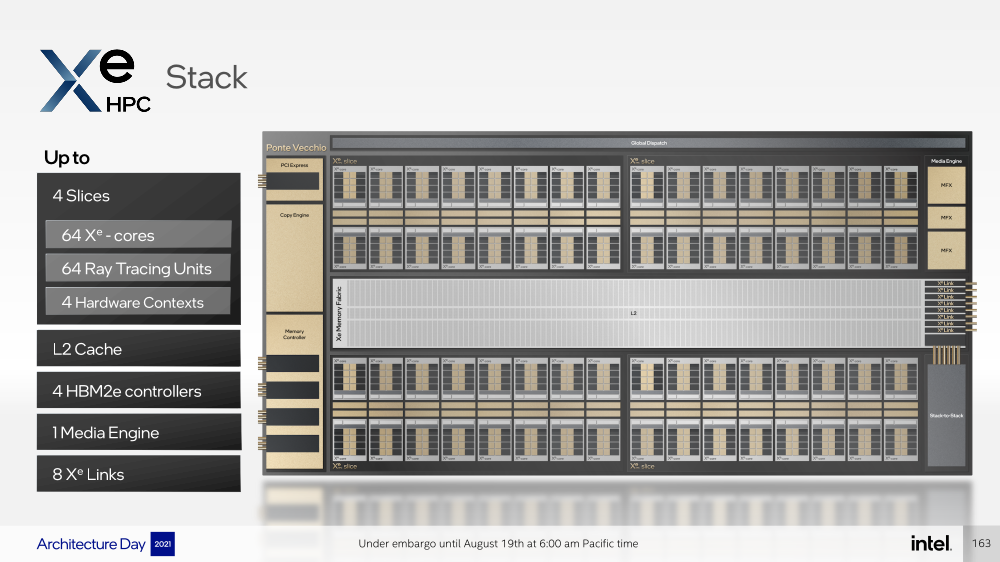 Тайлы Xe Link, изготавливаемые по 7-нм техпроцессу TSMC, включают 8 интерфейсов для стеков/ускорителей вкупе с 8-портовыми коммутатором и используют SerDes-блоки класса 90G. Всё это позволяет объединить до 8 стеков по схеме каждый-с-каждым, что, в целом, напоминает подход NVIDIA, хотя у последней NVSwitch всё же (пока) является внешним компонентом. 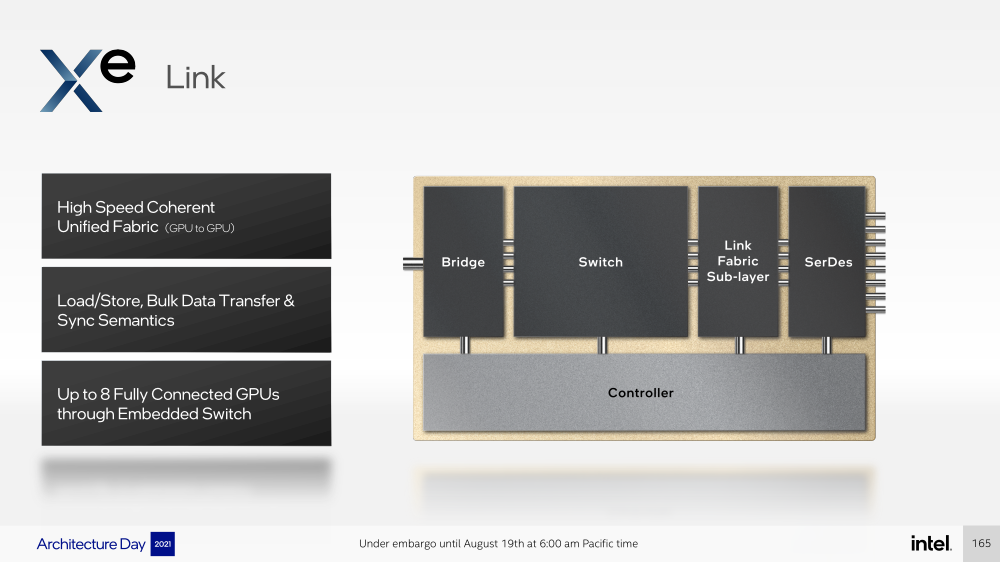  В самом ускорителе в зависимости от конфигурации стеков может быть один или два. В случае Ponte Vecchio их как раз два, и Intel приводит некоторые данные о его производительности: более 45 Тфлопс в FP32-вычислениях, более 5 Тбайт/с пропускной способности внутренней фабрики памяти и более 2 Тбайт/с — для внешних подключений. Для сравнения, у NVIDIA A100 заявленная FP32-производительность равняется 19,5 Тфлопс, а AMD Instinct MI100 — 23,1 Тфлопс. 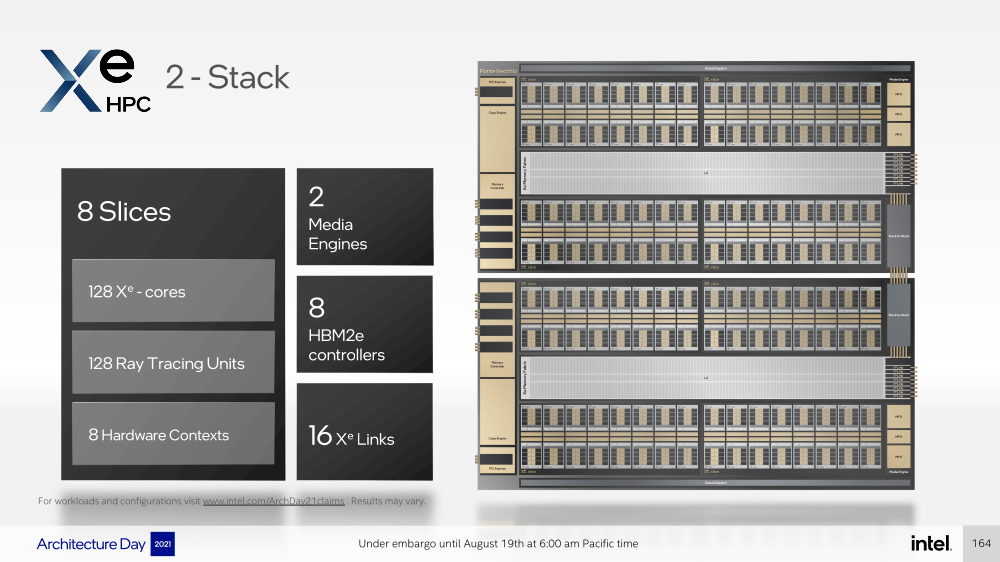 Также Intel показала результаты бенчмарка ResNet-50 в обучении и инференсе: 3400 и 43000 изображений в секунду соответственно. Эти результаты являются предварительными, поскольку получены не на финальной версии «кремния». Но надо учитывать, что Ponte Vecchio есть ещё одно преимущество — отдельный Rambo-тайл с дополнительным сверхбыстрым кешем, который, вероятно, можно рассматривать в качестве L3-кеша.  В целом, Ponte Vecchio — это один из самых сложны чипов на сегодняшний день. Он объединяет с помощью EMIB и Foveros 47 тайлов, изготовленных по пяти разным техпроцессам, а общий транзисторный бюджет превышает 100 млрд. Данные ускорители будут доступны в форм-факторе OAM и виде готовых плат с четырьмя ускорителями на борту (на ум опять же приходит NVIDIA HGX). И именно такие платы в паре с двумя процессорами Sapphire Rapids войдут в состав узлов суперкомпьютера Aurora. Ещё одной машиной, использующей связку новых CPU и ускорителей Intel станет SuperMUC-NG (Phase 2).  Официальный выход Ponte Vecchio запланирован на 2022 год, но и выход следующих поколений ускорителей AMD и NVIDIA, с которыми и надо будет сравнивать новинки, тоже не за горами. Пока что Intel занята не менее важным делом — развитием программной экосистемы, основой которой станет oneAPI, набор универсальных инструментов разработки приложений для гетерогенных (CPU, GPU, IPU, FPGA и т.д.) приложений, который совместим с оборудованием AMD и NVIDIA.
28.07.2021 [15:27], Алексей Степин
Pliops анонсировала высокопроизводительный DPU XDP ExtremeКонцепция сопроцессора данных (DPU) продолжает набирать популярность — анонсы новых решений в этой области следуют один за другим. Компания Pliops, ранее представившая ускоритель для СУБД, представила свой новый продукт — XDP Extreme, который имеет более широкую сферу применения и предназначен для разгрузки процессоров современных систем хранения данных, целиком построенных на энергонезависимой памяти. 
Источник изображений: Pliops Внешне новинка выглядит как обычная плата расширения с разъёмом PCIe x8, в основе лежит мощная ПЛИС производства Xilinx. В будущем компания планирует заменить её на более экономичный ASIC-вариант. У XDP Extreme нет сетевых портов, вместо этого разработчики сконцентрировали свои усилия на ускорении общих для СХД задач и повышении эффективности использования пула флеш-памяти. 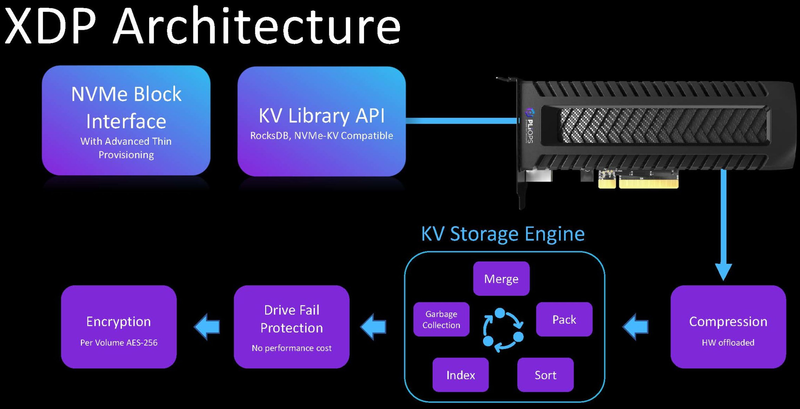 XDP использует так называемый KV Storage Engine — движок, работающий с Key-Value данными. За счёт фирменного API обеспечена совместимость со всеми приложениями, которые используют KV-подход. Уровнем ниже всё так же находится NVMe, как протокол, наиболее отвечающий устройствам на базе флеш-памяти. KV Storage Engine берёт на себя всю обработку ключей БД, включая их сортировку, индексацию и сборку мусора, а значит, этим не придётся заниматься центральным процессорам системы. Также ускоритель обеспечивает разгрузку ЦП при сжатии, отвечает за защиту от сбоев SSD и выполняет шифрование томов с использованием AES-256.  Востребованность XDP высока: KV-движки сегодня используются в подавляющем большинстве баз данных, также они применяются в комплексах машинной аналитики на базе Elastic или Hadoop и в распределённых файловых системах. Эффективность XDP Extreme, если верить данным Pliops, внушает уважение: даже на операциях чтения можно добиться двухкратного прироста линейной производительности, а выигрыш при записи может составлять и три-четыре раза. Более того, флеш-массив под управлением XDP оказывается быстрее, нежели классический RAID0. А снижение коэффициента усиления записи (write amplification) позволяет использовать недорогую, но априори менее надёжную память QLC. Впрочем, с Optane новый DPU тоже прекрасно работает.  Фактически, компания говорит о производительности, сопоставимой с решениями на базе DRAM, но с куда более низкой стоимостью владения. Экономия достигается и за счёт более эффективного использования SSD: в частности, при равном уровне надёжности с классическим массивом RAID 10, система на базе Pliops XDP позволяет обойтись меньшим количеством серверов и накопителей, что, естественно, отразится и на стоимости. Поставки новых ускорителей Pliops XDP Extreme уже развёрнуты.
12.04.2021 [20:00], Сергей Карасёв
NVIDIA представила младшие серверные ускорители A10 и A30Компания NVIDIA в рамках конференции GPU Technology Conference 2021 анонсировала ускорители A10 и A30, предназначенные для обработки приложений искусственного интеллекта и других задач корпоративного класса. Модель NVIDIA A10 использует 72 ядра RT и может оперировать 24 Гбайт памяти GDDR6 с пропускной способностью до 600 Гбайт/с. Максимальное значение TDP составляет 150 Вт. Новинка выполнена в виде полноразмерной карты расширения с интерфейсом PCIe 4.0: в корпусе сервера устройство займёт один слот расширения. Производительность в вычислениях одинарной точности (FP32) заявлена на уровне 31,2 терафлопса. Новинку можно рассматривать как замену NVIDIA T4.  Модель NVIDIA A30, в свою очередь, получила исполнение в виде двухслотовой карты расширения с интерфейсом PCIe 4.0. Задействованы 24 Гбайт памяти HBM2 с пропускной способностью до 933 Гбайт/с. Показатель TDP равен 165 Вт. Обе новинки используют архитектуру Ampere с тензорными ядрами третьего поколения.  Решения подходят для применения в серверах массового сегмента, рабочих станциях, а также в составе платформы NVIDIA EGX и для периферийных вычислений. 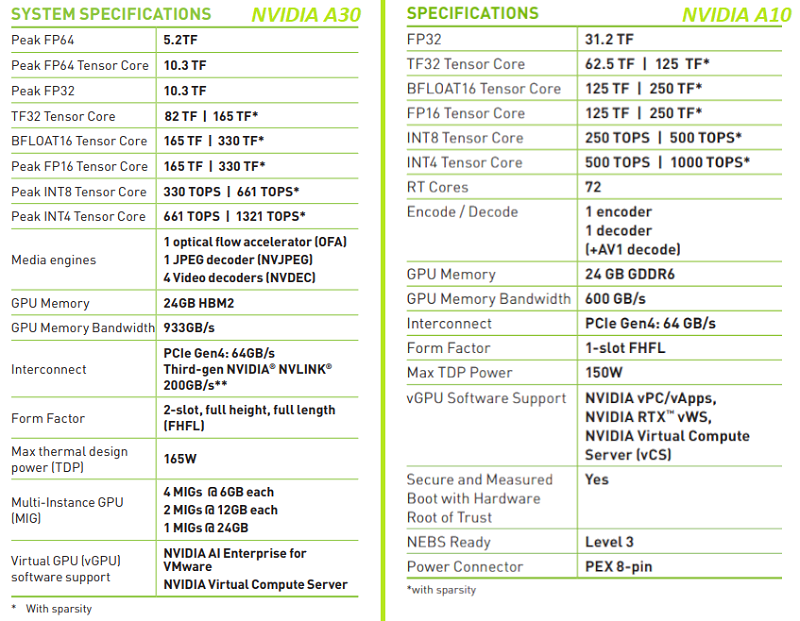
20.11.2020 [16:45], Сергей Карасёв
NEC выводит на рынок векторный ускоритель SX-Aurora TSUBASA Vector Engine 2.0Компания NEC сообщила о том, что с января следующего года заказчикам по всему миру станет доступен акселератор Vector Engine 2.0 серии SX-Aurora TSUBASA, анонсированный ещё летом. Изделие Type 20B выполнено в виде двухслотовой карты расширения с интерфейсом PCIe. Оно содержит восемь векторных блоков с частотой 1,6 ГГц, обеспечивающих производительность на уровне 2,45 Тфлопс FP64, и 48 Гбайт памяти HBM2 с пропускной способностью приблизительно 1,53 Тбайт/с. При этом энергопотребление находится на уровне 200 Вт. Также есть версия ускорителя Type 20A, которая имеет 10 векторных блоков и производительность 3,07 Тфлопс FP64.  Благодаря векторной архитектуре крупные объёмы данных можно обрабатывать в пределах каждого цикла. Это открывает широкие возможности при решении задач в области искусственного интеллекта, машинного обучения, интенсивных научных вычислений и пр. 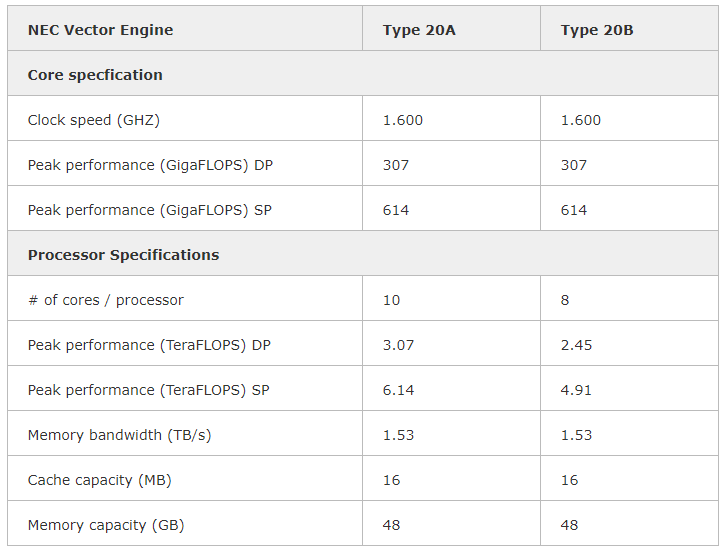 Векторный ускоритель Vector Engine 2.0 может использоваться в составе стандартных серверов и рабочих станций с архитектурой х86 от сторонних поставщиков оборудования. Таким образом, заказчики смогут сформировать вычислительную платформу в соответствии со своими требованиями и объёмом финансирования. Данное решение, по словам NEC, ориентировано на предприятия малого и среднего бизнеса, у которых есть потребность в формировании платформы высокопроизводительных вычислений (HPC).
16.11.2020 [17:00], Игорь Осколков
SC20: NVIDIA представила ускоритель A100 с 80 Гбайт HBM2e и настольный «суперкомпьютер» DGX STATIONNVIDIA представила новую версию ускорителя A100 с увеличенным вдвое объёмом HBM2e-памяти: 80 Гбайт вместо 40 Гбайт у исходной A100, представленной полгода назад. Вместе с ростом объёма выросла и пропускная способность — с 1,555 Тбайт/с до 2 Тбайт/с. В остальном характеристики обоих ускорителей совпадают, даже уровень энергопотребления сохранился на уровне 400 Вт. Тем не менее, объём и скорость работы быстрой набортной памяти влияет на производительность ряда приложений, так что им такой апгрейд только на пользу. К тому же MIG-инстансы теперь могут иметь объём до 10 Гбайт. PCIe-варианта ускорителя с удвоенной памятью нет — речь идёт только об SXM3-версии, которая используется в собственных комплексах NVIDIA DGX и HGX-платформах для партнёров. 
NVIDIA A100 80 Гбайт  Последним ориентировочно в первом квартале следующего года будут предоставлены наборы для добавления новых A100 в существующие решения, включая варианты плат на 4 и 8 ускорителей. У самой NVIDIA обновлению подверглись, соответственно, DGX A100 POD и SuperPOD for Enterprise. Недавно анонсированные суперкомпьютеры Cambridge-1 и HiPerGator на базе SuperPOD одними из первых получат новые ускорители с 80 Гбайт памяти. Ожидается, что HGX-решения на базе новой A100 будут доступны от партнёров компании — Atos, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Inspur, Lenovo, Quanta и Supermicro — в первой половине 2021 года.   Но, пожалуй, самый интересный анонс касается новой рабочей станции NVIDIA DGX STATION A100, которую как раз и можно назвать настольным «суперкомпьютером». В ней используются четыре SXM3-ускорителя A100 с не требующей обслуживания жидкостной системой охлаждения и полноценным NVLink-подключением. Будут доступны две версии, со 160 или 320 Гбайт памяти с 40- и 80-Гбайт A100 соответственно. Базируется система на 64-ядерном процессоре AMD EPYC, который можно дополнить 512 Гбайт RAM.   Для ОС доступен 1,92-Тбайт NVMe M.2 SSD, а для хранения данных — до 7,68 Тбайт NVMe U.2 SSD. Сетевое подключение представлено двумя 10GbE-портами и выделенным портом управления. Видеовыходов четыре, все mini Display Port. DGX STATION A100 отлично подходит для малых рабочих групп и предприятий. В том числе благодаря тому, что функция MIG позволяет эффективно разделить ресурсы станции между почти тремя десятками пользователей. В продаже она появится у партнёров компании в феврале следующего года.  Вероятно, все выпускаемые сейчас A100 c увеличенным объёмом памяти идут на более важные проекты. Новинкам предстоит конкурировать с первым ускорителем на базе новой архитектуры CDNA — AMD Instinct MI100.
02.10.2020 [16:47], Алексей Степин
Groq начала поставки самой быстрой в мире ИИ-платформы TSPСистемы машинного интеллекта и особенно инференс-системы, чьей задачей является принятие решений в нейросетевых сценариях обработки, требуют особого подхода к реализации аппаратной части для достижения действительно высокой производительности при приемлемом уровне энергопотребления. Стартап Groq, который ещё осенью 2019 года анонсировал свой тензорный процессор Groq TSP, начал поставки систем на базе этого чипа. В своё время Groq наделали немало шума, заявив о создании самого быстрого ИИ-процессора с производительностью 1 Петаопс (PetaOPS, 1015 операций в секунду, обычно целочисленных), оставляющего позади даже таких монстров, как NVIDIA Tesla V100. Добиться этого удалось благодаря уникальной многоядерной архитектуре, из которой Groq исключила всё лишнее для тех задач, на которые ориентирован свой процессор.  Подход оказался плодотворным: прототип ускорителя на базе Groq TSP, работая на частоте 1 ГГц, развил 205 Тфлопс в режиме FP16 и 820 Топс в режиме INT8. Для сравнения, V100 при аналогичном потреблении 300 Ватт показала лишь 125 Тфлопс и 250 Топс соответственно. В тесте ResNet-50 новый чип смог достичь производительности на уровне 21700 распознаваний в секунду, уступив лишь проприетарному ASIC Alibaba HanGuang, недоступному для приобретения. 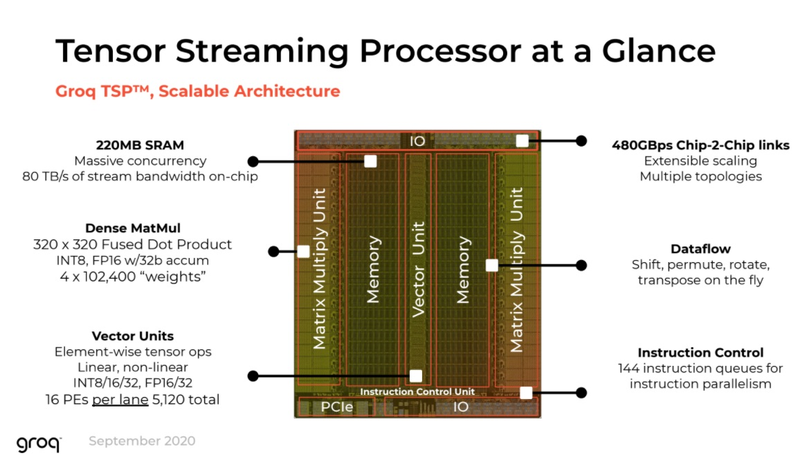
Архитектура Groq TSP (Изображение: The Next Platform) Об архитектуре Groq до недавних пор было известно немного, однако компания-разработчик, похоже, успешно набирает обороты: начались коммерческие поставки ускорителей на базе Groq TSP и даже законченных вычислительных узлов, позволяющих организовывать целые кластеры с высочайшим уровнем производительности. На днях компания рассказала The Next Platform об особенностях своих решений. 
Шасси Groq (Изображение: The Next Platform) Главной особенностью своего TSP разработчики по-прежнему называют наличие блока SRAM объёмом 220 Мбайт. Такая память обеспечивает пропускную способность на уровне 80 Тбайт/с, что является настоящим подарком для инференс-сценариев. Кроме того, теперь известно, что каждый TSP содержит два блока матричной математики (320×320 Fused Dot Product, INT8 или FP16, 32-битный аккумулятор) и один блок векторных вычислений (тензорные линейные и нелинейные вычисления в режимах INT8/16/32 и FP16/32, 5120 вычислительных элементов). 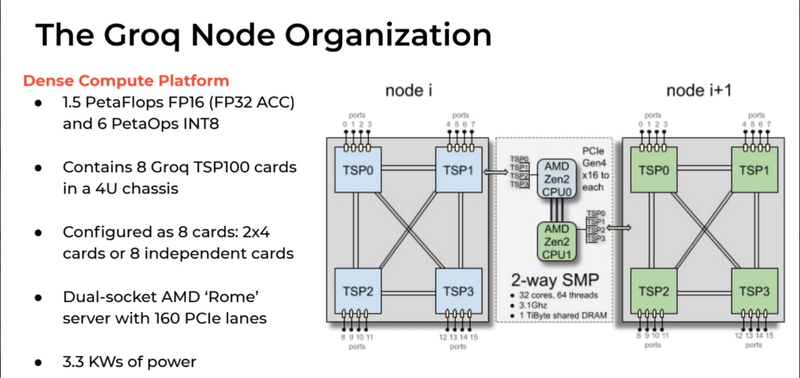
Структура узла Groq (Изображение: The Next Platform) Как обычно, по краям кристалла расположены различные блоки ввода-вывода, в частности, контроллер PCI Express 4.0, а также два I/O-модуля для межпроцессорной связи. Последние обеспечивают Groq TSP 16 линиями с общей пропускной способностью 512 Гбайт/с, так что узким местом в многопроцессорных кластерах на базе TSP они стать не должны. Кроме того, на кристалле присутствует и небольшой блок управления, могущий оперировать очередями из 144 инструкций, так что полностью отказываться от управляющих структур в TSP разработчики всё-таки не стали.  Структура вычислительной системы на базе Groq TSP довольно проста. Она состоит из трёх функциональных блоков, два из которых занимаются собственно вычислениями и управляющего блока с классическими процессорами. Каждый из вычислительных модулей содержит по четыре ускорителя Groq TSP, соединённых по схеме «каждый с каждым» и имеет 16 свободных портов для дальнейшего масштабирования и добавления новых модулей TSP. Ускорители могут использоваться независимо, каждый для своей задачи, либо работать вместе над одной задачей, развивая большую производительность. 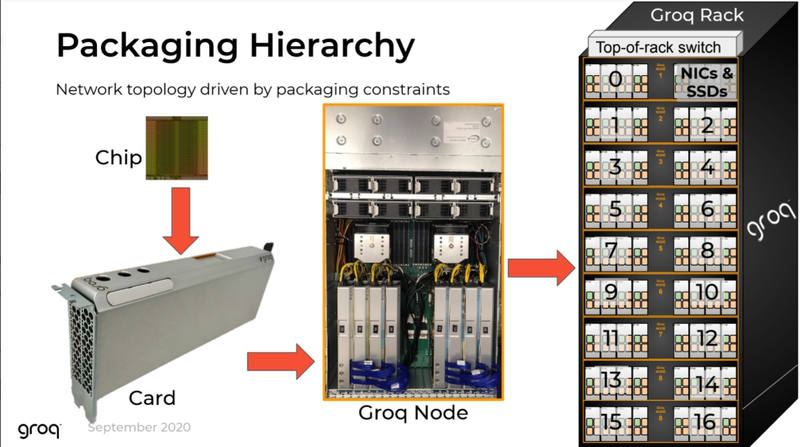
Стартовавший, как отдельный ускоритель, Groq TSP вырос в масштабируемый кластер (Изображение: The Next Platform) Управляющая часть с точки зрения архитектуры выглядит несложно: это обычная двухпроцессорная система на базе AMD EPYC 7002, и каждый из четырёх ускорителей подключен к своему процессору посредством PCI Express 4.0 x16. В этой части используются 32-ядерные процессоры AMD и установлен общий пул оперативной памяти объёмом 1 Тбайт. Вся система занимает модифицированный стоечный корпус высотой 5U и потребляет в пределе 3,3 кВт. Производительность такого комплекса заявлена на уровне 6 Петаопс в режиме INT8 и 1,5 Пфлопс в режиме FP16. 
Сервер Groq Node И это далеко не предел, недаром Groq называет своё решение Node Scalable Compute System. Новинка действительно масштабируется, поскольку каждый из ускорителей имеет по четыре свободных порта интерконнекта. Стойка, разработанная и представленная Groq, может включать в себя 17 вычислительных модулей с вышеописанной архитектурой. 18-ое место занято модулем, содержащим в себе сетевые интерфейсы и дисковую подсистему. 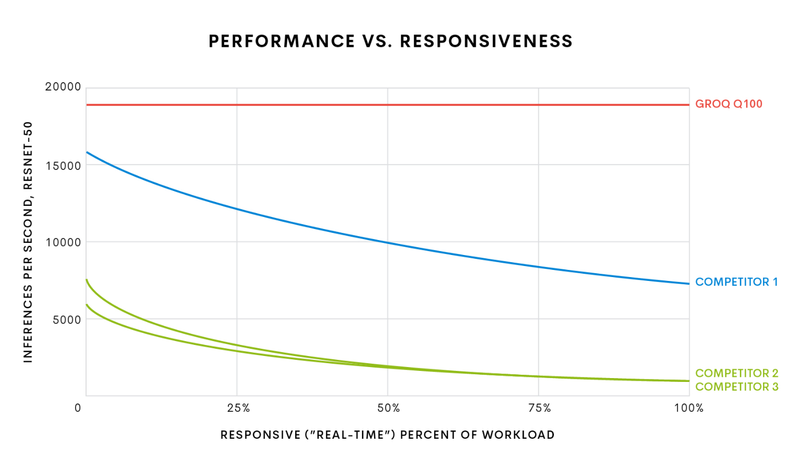 Без программного обеспечения любая система мертва, тем более, с учётом архитектурных особенностей Groq TSP, практически целиком полагающегося на компилятор. Компания сопровождает новые системы комплектом ПО Groqware SDK. Он включает в себя все необходимые средства разработки и набор API, что позволит разработчикам в кратчайшие сроки начать создавать ПО, в полной мере раскрывающее немалый потенциал новой платформы. 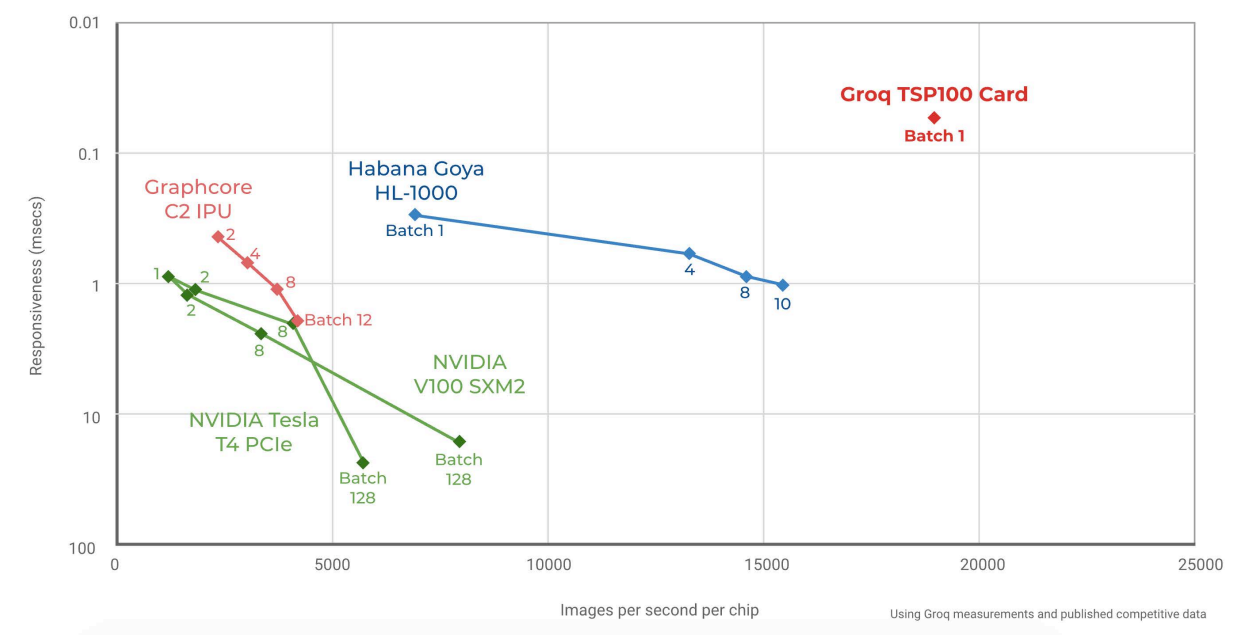 Из-за того, что Groq лучше всего раскрывается на задачах с небольшой очередью (в пределе при batch size 1), эта инференс-платформа обеспечивает великолепную латентность, что делает её привлекательной для финансовых структур. Интересна платформа и учёным, но те более заинтересованы в возможностях TSP в области классических вычислений, в частности, линейной алгебры. Из-за этого сложилась любопытная ситуация: стартовал Groq TSP как инференс-ускоритель, но первые клиенты компании потребовали большей универсальности, так что разработчикам пришлось создать сначала Groq Node, описанный выше, а потом и целый масштабируемый кластер на базе таких узлов. Таким образом, платформа, стартовавшая как узкоспециализированное решение, эволюционировала в более универсальный вычислительный комплекс, гибкий и масштабируемый.
01.10.2020 [11:51], Юрий Поздеев
Hailo: новые модули ускорения ИИ для периферийных вычисленийHailo, производитель микросхем для систем искусственного интеллекта (ИИ), выпустила новые высокопроизводительные модули в форм-факторах M.2 и mini PCIe для расширения возможностей периферийных систем. 
Источник изображений: Hailo Модули на базе процессора Hailo-8 можно подключать к различным периферийным устройствам, что позволяет использовать возможности ИИ в умных домах, розничной торговле и промышленности.  Модули Hailo легко интегрируются в стандартные платформы, такие как TensorFlow и ONNX, что позволяет значительно упростить использование новинок в комплексных решениях. Заказчики могут оперативно перенести свои решения с нейронными сетями на модули Hailo-8. 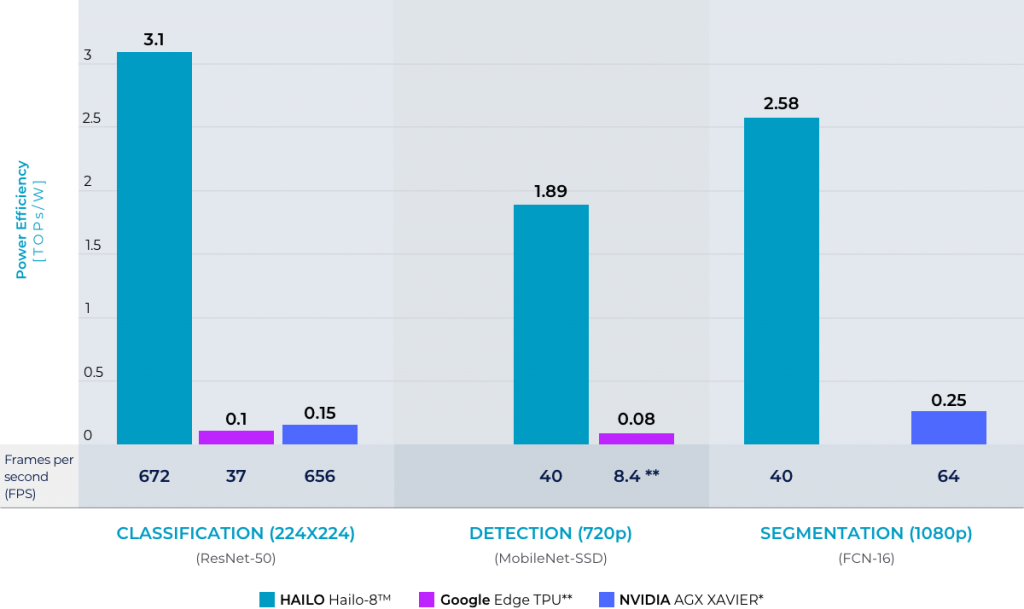 Спрос на высокопроизводительные периферийные устройства постоянно растет, поэтому безвентиляторные модули Hailo-8 будут востребованы, например, в видеоаналитике, либо для подключения большого количества внешних датчиков для сбора и обработки информации в режиме реального времени. Процессор Hailo-8 способен обеспечить 26 TOPS, при этом имеет энергоэффективность 3 TOPS/Вт. 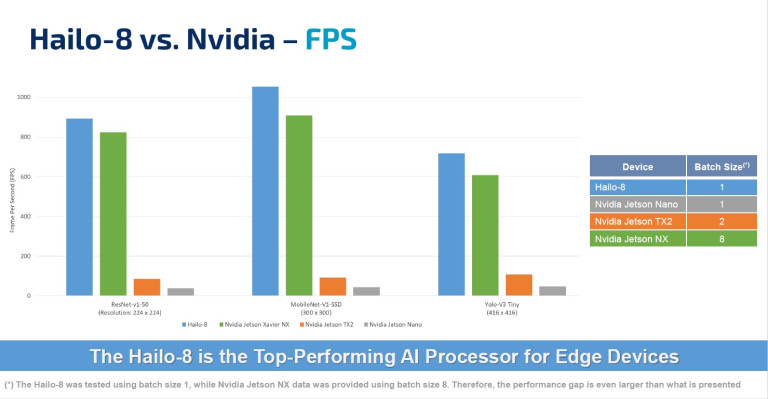 Модуль Hailo-8 M.2 уже интегрирован в следующее поколение Foxconn BOXiedge (24-ядерный мини сервер, который потребляет всего 30 Вт, при этом обладает неплохими показателями производительности). Наличие готового продукта позволит ускорить внедрение новых модулей в периферийные вычисления и значительно упростить этот процесс для конечного заказчика.
18.09.2020 [15:55], Алексей Степин
ИИ-ускоритель Qualcomm Cloud AI 100 обещает быть быстрее и экономичнее NVIDIA T4Ускорители работы с нейросетями делятся, грубо говоря, на две категории: для обучения и для исполнения (инференса). Именно для последнего случая важна не столько «чистая» производительность, сколько сочетание производительности с экономичностью, так как работают такие устройства зачастую в стеснённых с точки зрения питания условиях. Компания Qualcomm предлагает новые ускорители Cloud AI 100, сочетающие оба параметра.  Сам нейропроцессор Cloud AI 100 был впервые анонсирован ещё весной прошлого года, и Qualcomm объявила, что этот чип разработан с нуля и обеспечивает вдесятеро более высокий уровень производительности в пересчёте на ватт, в сравнении с существовавшими на тот момент решениями. Начало поставок было запланировано на вторую половину 2019 года, но как мы видим, по-настоящему ускорители на базе данного чипа на рынке появились только сейчас, причём речь идёт о достаточно ограниченных, «пробных» объёмах поставок. 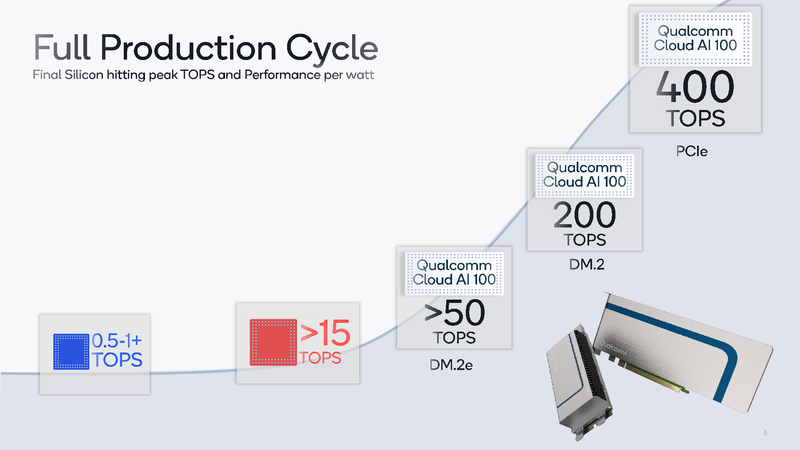 В отличие от графических процессоров и ПЛИС-акселераторов, которые часто применяются при обучении нейросетей и, будучи универсальными, потребляют при этом серьёзные объёмы энергии, инференс-чипы обычно представляют собой специализированные ASIC. Таковы, например, Google TPU Edge, к этому же классу относится и Cloud AI 100. Узкая специализация позволяет сконцентрироваться на достижении максимальной производительности в определённых задачах, и Cloud AI 100 более чем в 50 раз превосходит блок инференс-процессора, входящий в состав популярной SoC Qualcomm Snapdragon 855. 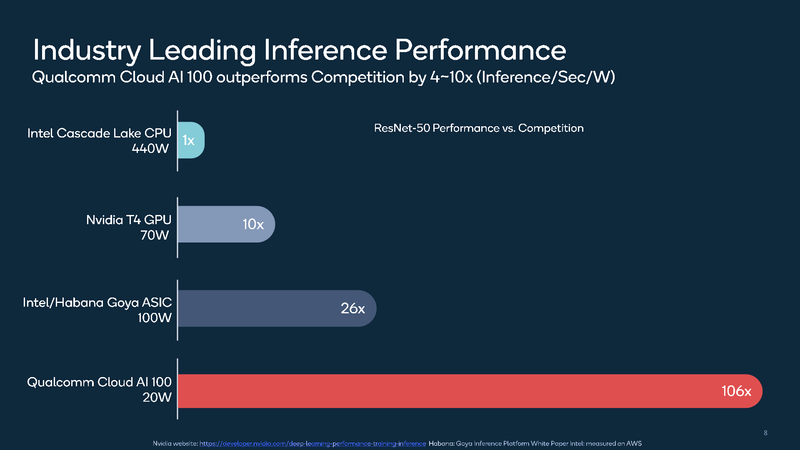 На приводимых Qualcomm слайдах архитектура Cloud AI 100 выглядит достаточно простой: чип представляет собой набор специализированных интеллектуальных блоков (IP, до 16 юнитов в зависимости от модели), дополненный контроллерами LPDDR (4 канала, до 32 Гбайт, 134 Гбайт/с), PCI Express (до 8 линий 4.0), а также управляющим модулем. Имеется некоторый объём быстрой набортной SRAM (до 144 Мбайт). С точки зрения поддерживаемых форматов вычислений всё достаточно универсально: реализованы INT8, INT16, FP16 и FP32. Правда, bfloat16 не «доложили». 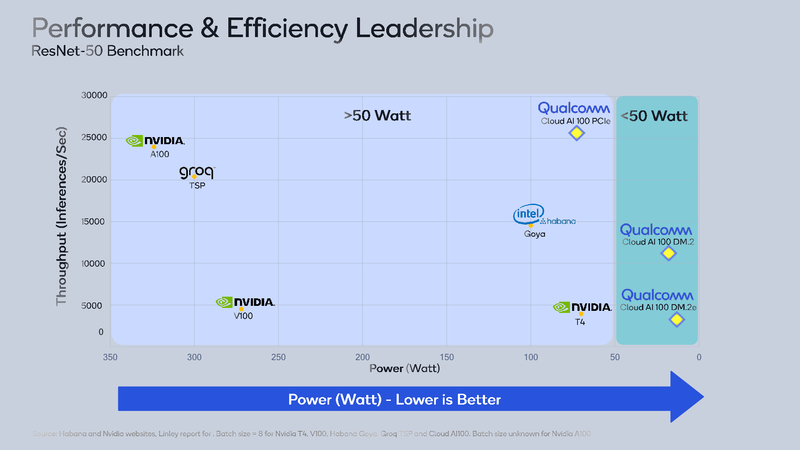 Об эффективности новинки говорят приведённые самой Qualcomm данные: если за базовый уровень принять систему на базе процессоров Intel Cascade Lake с потреблением 440 Ватт, то Qualcomm Cloud AI 100 в тесте ResNet-50 быстрее на два порядка при потреблении всего 20 Ватт. Это, разумеется, не предел: на рынок новый инференс-ускоритель может поставляться в трёх различных вариантах, два из которых компактные, форм-факторов M.2 и M.2e с теплопакетами 25 и 15 Ватт соответственно. Даже в этих вариантах производительность составляет 200 и около 500 Топс (триллионов операций в секунду), а существует и 75-Ватт PCIe-плата формата HHHL производительностью 400 Топс; во всех случаях речь идёт о режиме INT8. 
Данные для NVIDIA Tesla T4 и P4 приведены для сравнения Основными конкурентами Cloud AI 100 можно назвать Intel/Habana Gaia и NVIDIA Tesla T4. Оба этих процессора также предназначены для инференс-систем, они гибче архитектурно — особенно T4, который, в сущности, базируется на архитектуре Turing —, однако за это приходится платить как ценой, так и повышенным энергопотреблением — это 100 и 70 Ватт, соответственно. Пока речь идёт о распознавании изображений с помощью популярной сети ResNet-50, решение Qualcomm выглядит великолепно, оно на голову выше основных соперников. Однако в иных случаях всё может оказаться не столь однозначно. 
Новые ускорители Qualcomm будут доступны в разных форм-факторах Как T4, так и Gaia, а также некоторые другие решения, вроде Groq TSP, за счёт своей гибкости могут оказаться более подходящим выбором за пределами ResNet в частности и INT8 вообще. Если верить Qualcomm, то компания в настоящее время проводит углублённое тестирование Cloud AI 100 и на других сценариях в MLPerf, но в открытом доступе результатов пока нет. Разработчики сосредоточены на удовлетворении конкретных потребностей заказчиков. Также заявлено о том, что высокая производительность на крупных наборах данных может быть достигнута путём масштабирования — за счёт использования в системе нескольких ускорителей Cloud AI 100.  В настоящее время для заказа доступен комплект разработчика на базе Cloud Edge AI 100. Основная его цель заключается в создании и отработке периферийных ИИ-устройств. Система достаточно мощная, она включает в себя процессор Snapdragon 865, 5G-модем Snapdragon X55 и ИИ-сопроцессор Cloud AI 100. Выполнено устройство в металлическом защищённом корпусе с четырьмя внешними антеннами. Начало крупномасштабных коммерческих поставок намечено на первую половину следующего года.
27.08.2020 [19:13], Алексей Степин
TSMC и Graphcore создают ИИ-платформу на базе технологии 3 нмНесмотря на все проблемы в полупроводниковой индустрии, технологии продолжают развиваться. Технологические нормы 7 нм уже давно не являются чудом, вовсю осваиваются и более тонкие нормы, например, 5 нм. А ведущий контрактный производитель, TSMC, штурмует следующую вершину — 3-нм техпроцесс. Одним из первых продуктов на базе этой технологии станет ИИ-платформа Graphcore с четырьмя IPU нового поколения. Британская компания Graphcore разрабатывает специфические ускорители уже не первый год. В прошлом году она представила процессор IPU (Intelligence Processing Unit), интересный тем, что состоит не из ядер, а из так называемых тайлов, каждый из которых содержит вычислительное ядро и некоторое количество интегрированной памяти. В совокупности 1216 таких тайлов дают 300 Мбайт сверхбыстрой памяти с ПСП до 45 Тбайт/с, а между собой процессоры IPU общаются посредством IPU-Link на скорости 320 Гбайт/с. 
Colossально: ИИ-сервер Graphcore с четырьмя IPU на борту Компания позаботилась о программном сопровождении своего детища, снабдив его стеком Poplar, в котором предусмотрена интеграция с TensorFlow и Open Neural Network Exchange. Разработкой Graphcore заинтересовалась Microsoft, применившая IPU в сервисах Azure, причём совместное тестирование показало самые положительные результаты. Следующее поколение IPU, Colossus MK2, представленное летом этого года, оказалось сложнее NVIDIA A100 и получило уже 900 Мбайт сверхбыстрой памяти.  Машинное обучение, в основе которого лежит тренировка и использование нейронных сетей, само по себе требует процессоров с весьма высокой степенью параллелизма, а она, в свою очередь, автоматически означает огромное количество транзисторов — 59,4 млрд в случае Colossus MK2. Поэтому освоение новых, более тонких и экономичных техпроцессов является для этого класса микрочипов ключевой задачей, и Graphcore это понимает, заявляя о своём сотрудничестве с TSMC. 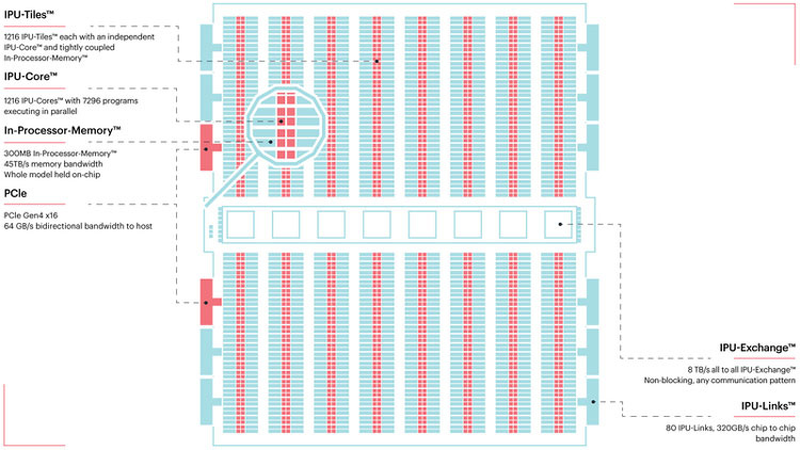
Тайловая архитектура Graphcore Colossus MK2 В настоящее время TSMC готовит к началу «рискового» производства новый техпроцесс с нормами 3 нм, причём скорость внедрения такова, что первые продукты на его основе должны увидеть свет уже в 2021 году, а массовое производство будет развёрнуто во второй половине 2022 года. И одним из первых продуктов на базе 3-нм технологических норм станет новый вариант IPU за авторством Graphcore, известный сейчас как N3. Судя по всему, использовать 5 нм британский разработчик не собирается. 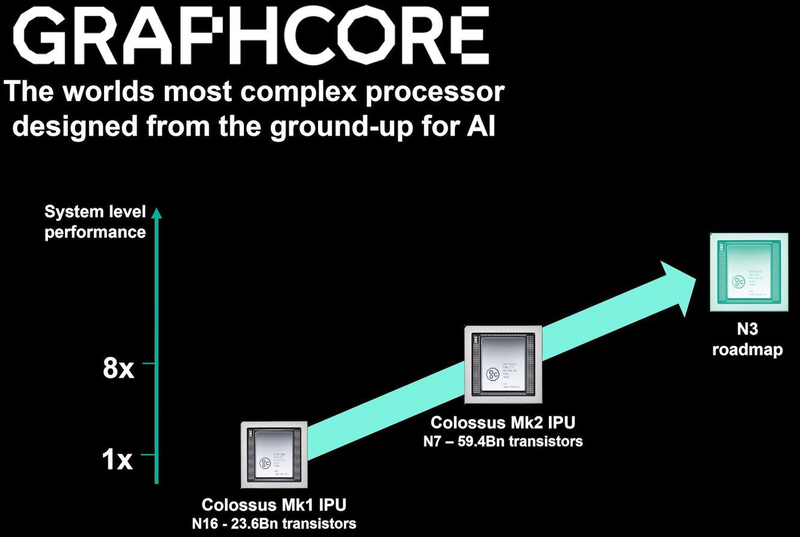
В планах компании явно указано использование 3-нм техпроцесса В настоящее время чипы Colossus MK2 производятся с использованием техпроцесса 7 нм (TSMC N7). Они включают в себя 1472 тайла и способны одновременно выполнять 8832 потока. В режиме тренировки нейросетей с использованием вычислений FP16 это даёт 250 Тфлопс, но существует удобное решение мощностью 1 Пфлопс — это специальный 1U-сервер Graphcore, в нём четыре IPU дополнены 450 Гбайт внешней памяти. Доступны также платы расширения PCI Express c чипами IPU на борту. Дела у Graphcore идут неплохо, её технология оказалась востребованной и среди инвесторов числятся Microsoft, BMW, DeepMind и ряд других компаний, разрабатывающих и внедряющих комплексы машинного обучения. Разработка 3-нм чипа ещё более упрочнит позиции этого разработчика. Более тонкие техпроцессы существенно увеличивают стоимость разработки, но финансовые резервы у Graphcore пока есть; при этом не и исключён вариант более тесного сотрудничества, при котором часть стоимости разработки возьмёт на себя TSMC. |
|

