Материалы по тегу: ускоритель
|
01.04.2022 [21:41], Владимир Мироненко
Meta✴ назвала ИИ-чипы Qualcomm Cloud AI 100 наиболее эффективными, но отказалась от них из-за проблем с ПОQualcomm, крупнейший в мире поставщик процессоров для мобильных устройств, заявил в 2019 году о намерении использовать свои наработки в области повышения энергоэффективности микросхем для выхода на быстрорастущий рынок чипов искусственного интеллекта, используемых в центрах обработки данных. Согласно данным The Information, чипмейкер пытался заинтересовать Meta✴ (Facebook✴) в использовании своего первого серверного ИИ-ускорителя Qualcomm Cloud AI 100. Осенью 2020 года Meta✴ сравнила его с рядом альтернатив, включая ускорители, которые она уже использует, и специализированный ИИ-чип собственной разработки. По словам источников The Information, чип Qualcomm показал лучшую производительность в пересчёте на Ватт, что позволило бы значительно снизить операционные расходы Meta✴, чьи дата-центры обслуживают миллиарды пользователей. На масштабах в десятки тысяч серверов даже небольшое увеличение энергоэффективности приводит к экономии значительных средств. 
Источник: Qualcomm Однако энергоэффективность — это далеко не единственный фактор. Как утверждают источники The Information, весной прошлого года Meta✴ решила отказаться от использования чипа Qualcomm. По их словам, Meta✴ задалась вопросом, достаточно ли проработано программное обеспечение Qualcomm для того, чтобы можно было добиться максимальной производительности и будущих задачах компании. После оценки этого аспекта, Meta✴ отказалась от массового внедрения Cloud AI 100. Наиболее полный спектр программно-аппаратных решений для ИИ-нагрузок сейчас предлагает NVIDIA, однако крупные гиперскейлеры обращаются к собственными разработкам. Так, у Google есть уже четвёртое поколение TPU. Amazon в конце прошлого года вместе с анонсом третьего поколения собственных CPU Graviton3 представила и ускорители Trainium для обучения ИИ-моделей, которые дополняют уже имеющиеся чипы Inferentia. У Alibaba тоже есть связка из собственных процессора Yitian 710 и ИИ-ускорителя Hanguang 800.
23.03.2022 [01:10], Алексей Степин
Анонсирован ускоритель AMD Instinct MI210: половинка MI250 в форм-факторе PCIe-картыAMD продолжает активно осваивать рынок ускорителей и ИИ-сопроцессоров. Вслед за сверхмощными Instinct MI250 и MI250X, анонсированными ещё осенью прошлого года, «красные» представили новинку — ускоритель Instinct MI210. Это менее мощная, одночиповая версия ускорителя с архитектурой CDNA 2, дополняющая семейство MI200 и имеющая более универсальный форм-фактор PCIe-карты. Если Instinct MI250/250X существует только как OAM-модуль, то новый Instinct MI210 имеет вид обычной платы расширения с разъёмом PCI Express 4.0. Это неудивительно, ведь MI250 физически невозможно уложить в тепловые и энергетические рамки, обеспечиваемые таким форм-фактором, поскольку два чипа Aldebaran требуют 560 Вт против привычных для PCIe-плат 300 Вт. Для питания MI210 используется как слот PCIe, так и 8-контактный разъём EPS12V.  Поскольку ускоритель на борту новинки только один, она вдвое уступает MI250/250X по всем параметрам, но всё равно обеспечивает весьма неплохую производительность во всех форматах вычислений. Стоит отметить, что функциональные возможности MI210 не уменьшились. Осталась, например, поддержка Infinity Fabric 3.0 — соответствующие разъёмы расположены в верхней части карты, и она поддерживает работу в кластерном режиме из двух или четырёх ускорителей. 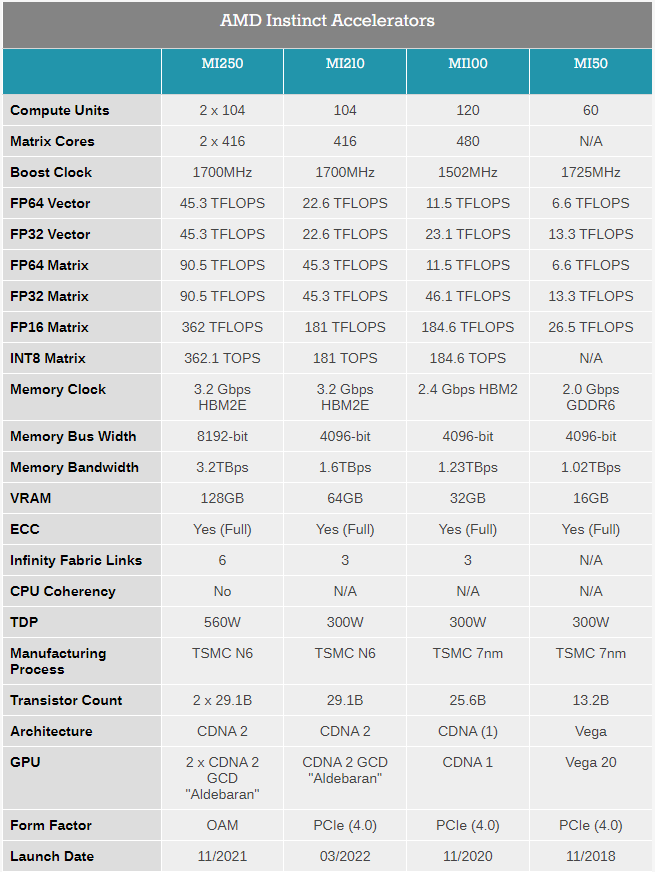
Таблица опубликована AnandTech В MI210 используется более простой вариант Aldebaran с одним кристаллом. Что интересно, по количеству вычислительных блоков этот вариант уступает более старому MI100 (104 CU против 120, 416 матричных ядер против 480). Однако последний использует первую итерацию архитектуры CDNA и работает на меньшей частоте — 1500 против 1700 МГц у новинки. В некоторых форматах вычислений MI100 может быть быстрее, но разница крайне незначительна. 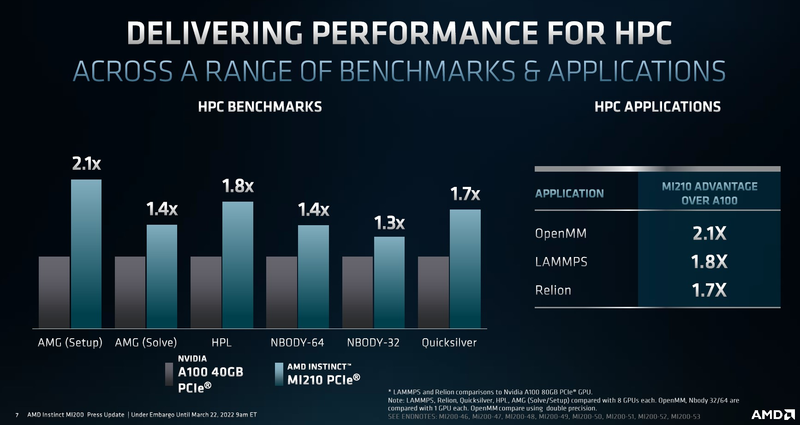
Производительность AMD Instinct MI210 в сравнении с NVIDIA A100 40GB PCIe CDNA2 позволяет использовать уникальные форматы данных, вроде packed FP32, однако это требует поддержки со стороны разработчиков, что несколько затруднит создание универсального ПО, способного полностью задействовать возможности MI210. Но в первую очередь, это ускоритель, не «зажимающий» FP64-производительность: свыше 22 Тфлопс в векторных операциях и 45 Тфлопс — в матричных. Сервер с одним или несколькими MI210 может использоваться в качестве универсальной платформы разработки ПО для суперкомпьютеров на базе более мощных ускорителей AMD Instinct MI250/250X. Новинка уже доступна у традиционных партнёров AMD по выпуску серверов, включая ASUS, Dell, HPE, Supermicro и Lenovo, которые также предлагают более мощные решения на базе MI250/250X.
22.03.2022 [18:40], Игорь Осколков
NVIDIA анонсировала 4-нм ускорители Hopper H100 и самый быстрый в мире ИИ-суперкомпьютер EOS на базе DGX H100На GTC 2022 компания NVIDIA анонсировала ускорители H100 на базе новой архитектуры Hopper. Однако NVIDIA уже давно говорит о себе как создателе платформ, а не отдельных устройств, так что вместе с H100 были представлены серверные Arm-процессоры Grace, в том числе гибридные, а также сетевые решения и обновления наборов ПО. 
NVIDIA H100 (Изображения: NVIDIA) NVIDIA H100 использует мультичиповую 2.5D-компоновку CoWoS и содержит порядка 80 млрд транзисторов. Но нет, это не самый крупный чип компании на сегодняшний день. Кристаллы новинки изготавливаются по техпроцессу TSMC N4, а сопровождают их — впервые в мире, по словам NVIDIA — сборки памяти HBM3 суммарным объёмом 80 Гбайт. Объём памяти по сравнению с A100 не вырос, зато в полтора раза увеличилась её скорость — до рекордных 3 Тбайт/с. 
NVIDIA H100 (SXM) Подробности об архитектуре Hopper будут представлены чуть позже. Пока что NVIDIA поделилась некоторыми сведениями об особенностях новых чипов. Помимо прироста производительности от трёх (для FP64/FP16/TF32) до шести (FP8) раз в сравнении с A100 в Hopper появилась поддержка формата FP8 и движок Transformer Engine. Именно они важны для достижения высокой производительности, поскольку само по себе четвёртое поколение ядер Tensor Core стало втрое быстрее предыдущего (на всех форматах). 
NVIDIA H100 CNX (PCIe) TF32 останется форматом по умолчанию при работе с TensorFlow и PyTorch, но для ускорения тренировки ИИ-моделей NVIDIA предлагает использовать смешанные FP8/FP16-вычисления, с которыми Tensor-ядра справляются эффективно. Хитрость в том, что Transformer Engine на основе эвристик позволяет динамически переключаться между ними при работе, например, с каждым отдельным слоем сети, позволяя таким образом добиться повышения скорости обучения без ущерба для итогового качества модели. На больших моделях, а именно для таких H100 и создавалась, сочетание Transformer Engine с другими особенностями ускорителей (память и интерконнект) позволяет получить девятикратный прирост в скорости обучения по сравнению с A100. Но Transformer Engine может быть полезен и для инференса — готовые FP8-модели не придётся самостоятельно конвертировать в INT8, движок это сделает на лету, что позволяет повысить пропускную способность от 16 до 30 раз (в зависимости от желаемого уровня задержки). 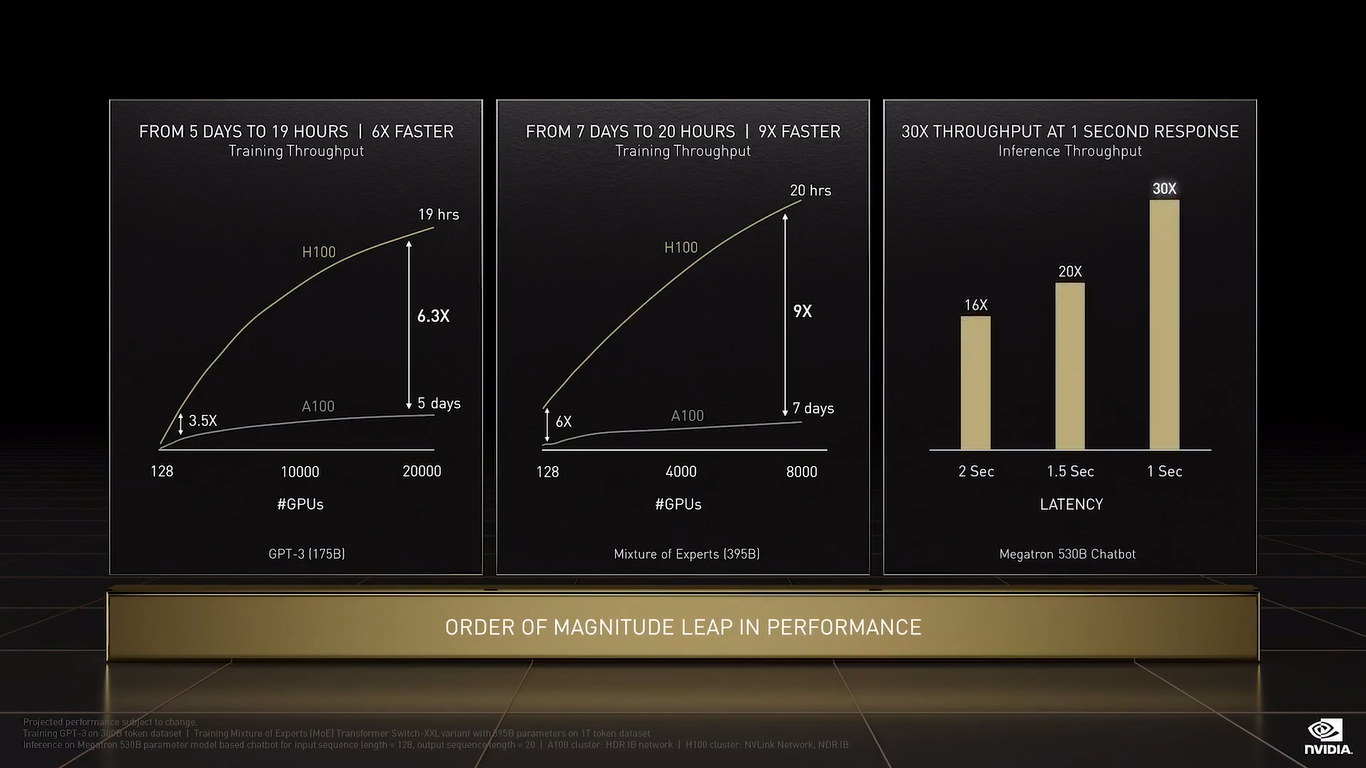 Другое любопытное нововведение — специальные DPX-инструкции для динамического программирования, которые позволят ускорить выполнение некоторых алгоритмов до 40 раз в задачах, связанных с поиском пути, геномикой, квантовыми системами и при работе с большими объёмами данных. Кроме того, H100 получили дальнейшее развитие виртуализации. В новых ускорителях всё так же поддерживается MIG на 7 инстансов, но уже второго поколения, которое привнесло больший уровень изоляции благодаря IO-виртуализации, выделенным видеоблокам и т.д.  Так что MIG становится ещё более предпочтительным вариантом для облачных развёртываний. Непосредственно к MIG примыкает и технология конфиденциальных вычислений, которая по словам компании впервые стала доступна не только на CPU. Программно-аппаратное решение позволяет создавать изолированные ВМ, к которым нет доступа у ОС, гипервизора и других ВМ. Поддерживается сквозное шифрование при передаче данных от CPU к ускорителю и обратно, а также между ускорителями.  Память внутри GPU также может быть изолирована, а сам ускоритель оснащается неким аппаратным брандмауэром, который отслеживает трафик на шинах и блокирует несанкционированный доступ даже при наличии у злоумышленника физического доступа к машине. Это опять-таки позволит без опаски использовать H100 в облаке или в рамках колокейшн-размещения для обработки чувствительных данных, в том числе для задач федеративного обучения.  NVIDIA HGX H100 Но главная инновация — это существенное развитие интерконнекта по всем фронтам. Суммарная пропускная способность внешних интерфейсов чипа H100 составляет 4,9 Тбайт/с. Да, у H100 появилась поддержка PCIe 5.0, тоже впервые в мире, как утверждает NVIDIA. Однако ускорители получили не только новую шину NVLink 4.0, которая стала в полтора раза быстрее (900 Гбайт/с), но и совершенно новый коммутатор NVSwitch, который позволяет напрямую объединить между собой до 256 ускорителей! Пропускная способность «умной» фабрики составляет до 70,4 Тбайт/с.  Сама NVIDIA предлагает как новые системы DGX H100 (8 × H100, 2 × BlueField-3, 8 × ConnectX-7), так и SuperPOD-сборку из 32-х DGX, как раз с использованием NVLink и NVSwitch. Партнёры предложат HGX-платформы на 4 или 8 ускорителей. Для дальнейшего масштабирования SuperPOD и связи с внешним миром используются 400G-коммутаторы Quantum-2 (InfiniBand NDR). Сейчас NVIDIA занимается созданием своего следующего суперкомпьютера EOS, который будет состоять из 576 DGX H100 и получит FP64-производительность на уровне 275 Пфлопс, а FP16 — 9 Эфлопс.  Компания надеется, что EOS станет самой быстрой ИИ-машиной в мире. Появится она чуть позже, как и сами ускорители, выход которых запланирован на III квартал 2022 года. NVIDIA представит сразу три версии. Две из них стандартные, в форм-факторах SXM4 (700 Вт) и PCIe-карты (350 Вт). А вот третья — это конвергентный ускоритель H100 CNX со встроенными DPU Connect-X7 класса 400G (подключение PCIe 5.0 к самому ускорителю) и интерфейсом PCIe 4.0 для хоста. Компанию ей составят 400G/800G-коммутаторы Spectrum-4.
05.03.2022 [01:28], Алексей Степин
Graphcore анонсировала ИИ-ускорители BOW IPU с 3D-упаковкой кристаллов WoWРазработка специализированных ускорителей для задач и алгоритмов машинного обучения в последние несколько лет чрезвычайно популярна. Ещё в 2020 году британская компания Graphcore объявила о создании нового класса ускорителей, которые она назвала IPU: Intelligence Processing Unit. Их архитектура оказалась очень любопытной. Основной единицей IPU является не ядро, а «тайл» — область кристалла, содержащая как вычислительную логику, так и некоторое количество быстрой памяти с пропускной способностью в районе 45 Тбайт/с (7,8 Тбайт/с между тайлами). В первой итерации чип Graphcore получил 1216 таких тайлов c 300 Мбайт памяти, а сейчас компания анонсировала следующее поколение своих IPU. 
Изображения: Graphcore Новый чип, получивший название BOW, можно условно отнести к «поколению 2,5». Он использует кристалл второго поколения Colossus Mk2: 892 Мбайт SRAM в 1472 тайлах, способных выполнять одновременно 8832 потока. Этот кристалл по-прежнему производится с использованием 7-нм техпроцесса TSMC, но теперь Graphcore перешла на использование более продвинутой упаковки типа 3D Wafer-on-Wafer (3D WoW). Новый IPU стал первым в индустрии чипом высокой сложности, использующем новый тип упаковки, причём технология 3D WoW была совместно разработана Graphcore и TSMC с целью оптимизации подсистем питания. Процессоры такой сложности отличаются крайней прожорливостью, а «накормить» их при этом не просто. В итоге обычная упаковка не позволяет добиться от чипа уровня Colossus Mk2 максимальной производительности — слишком велики потери и паразитный нагрев. 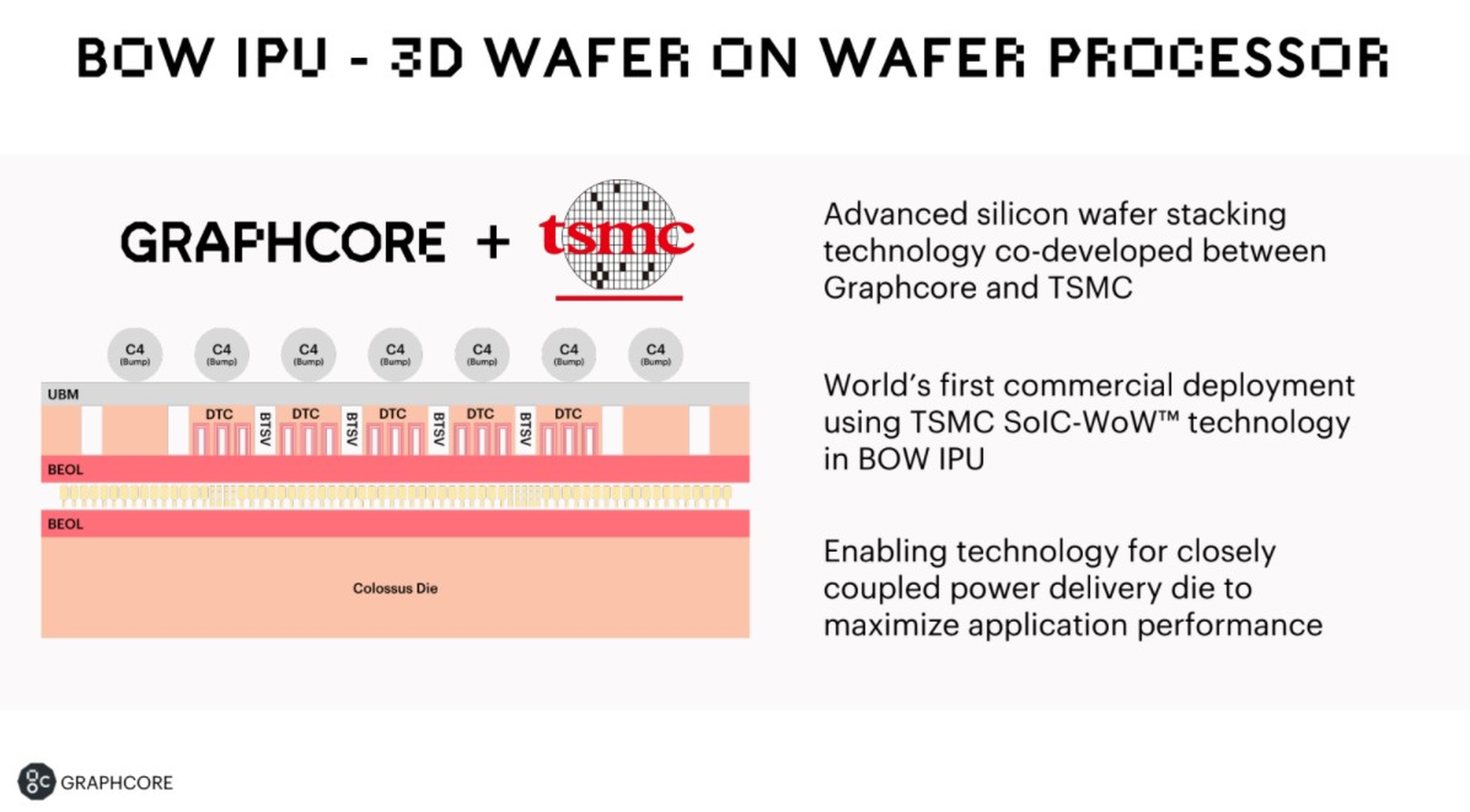 Реализована 3D WoW во многом аналогично технологии, применённой AMD в серверных чипах Milan-X. Упрощённо говоря, медные структуры-стержни пронизывают кристалл и позволяют соединить его напрямую с другим кристаллом, причём «склеиваются» они друг с другом благодаря. В случае с BOW роль нижнего кристалла отводится распределителю питания с системой стабилизирующих конденсаторов, который питает верхний кристалл Colossus Mk2. За счёт перехода с плоских структур на объёмные можно как увеличить подводимый ток, так и сделать путь его протекания более короткими. В итоге компании удалось дополнительно поднять частоту и производительность BOW, не прибегая к переделке основного процессора или переводу его на более тонкий и дорогой техпроцесс. Если у оригинального IPU второго поколения максимальная производительность составляла 250 Тфлопс, то сейчас речь идёт уже о 350 Тфлопс — для системы BOW-2000 с четырьмя чипами заявлено 1,4 Пфлопс совокупной производительности. И это хороший выигрыш, полученный без критических затрат. 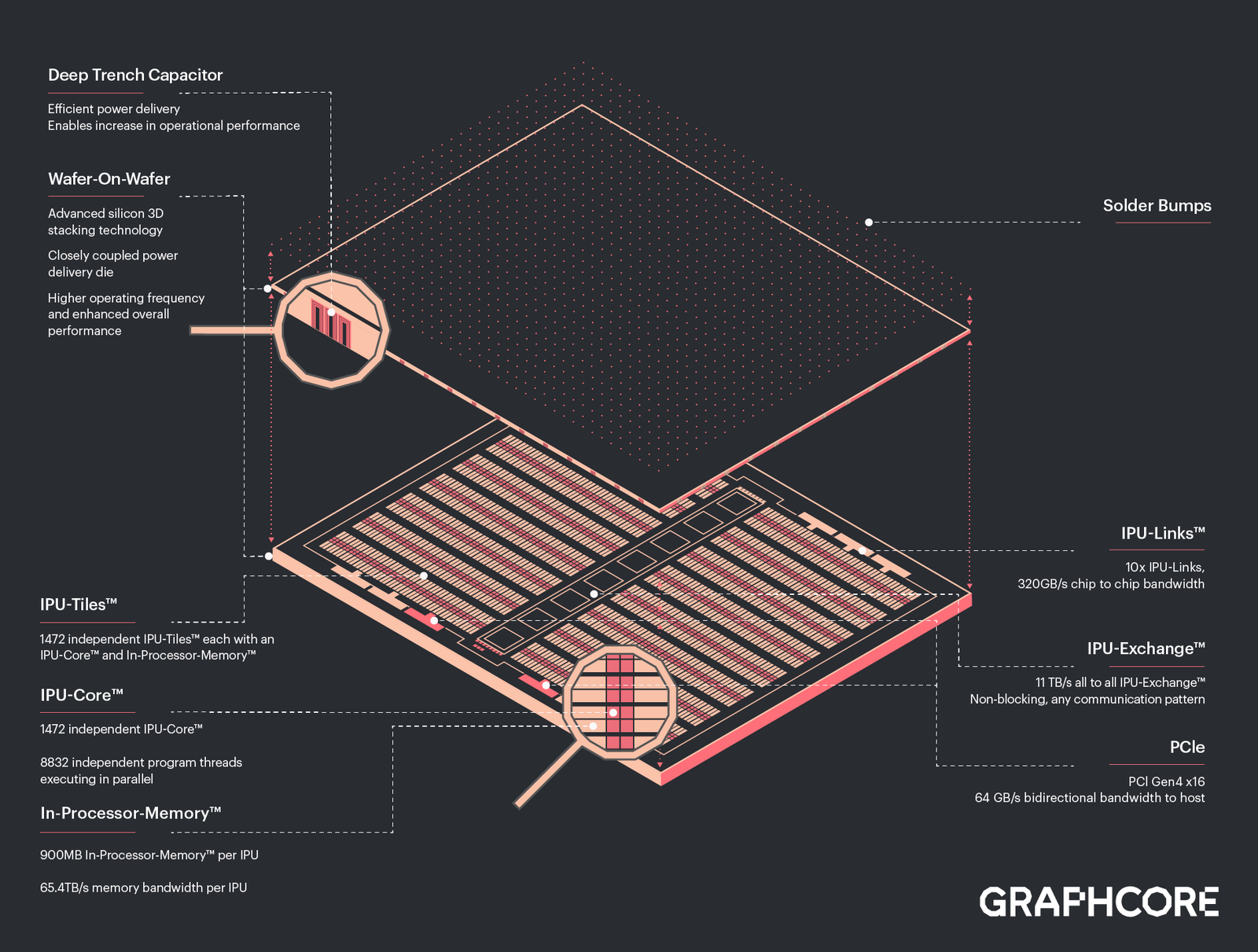 С внешним миром IPU общается по-прежнему посредством 10 каналов IPU-Link (320 Гбайт/с). Внутренней памяти в такой системе уже почти 4 Гбайт, причём работает она на скорости 260 Тбайт/с — критически важный параметр для некоторых задач машинного обучения, которые требуют всё большие по объёму наборов данных. Ёмкость набортной памяти далека от предлагаемой NVIDIA и AMD, но выигрыш в скорости даёт детищу Graphcore серьёзное преимущество. Узлы BOW-2000 совместимы с узлами предыдущей версии. Четыре таких узла (BOW POD16) с управляющим сервером — всё в 5U-шасси — имеют производительность до 5,6 Пфлопс. А полная стойка с 16 узлами BOW-2000 (BOW POD64) даёт уже 22,4 Пфлопс. По словам компании, производительность новой версии возросла на 30–40 %, а прирост энергоэффективности составляет от 10 % до 16 %. 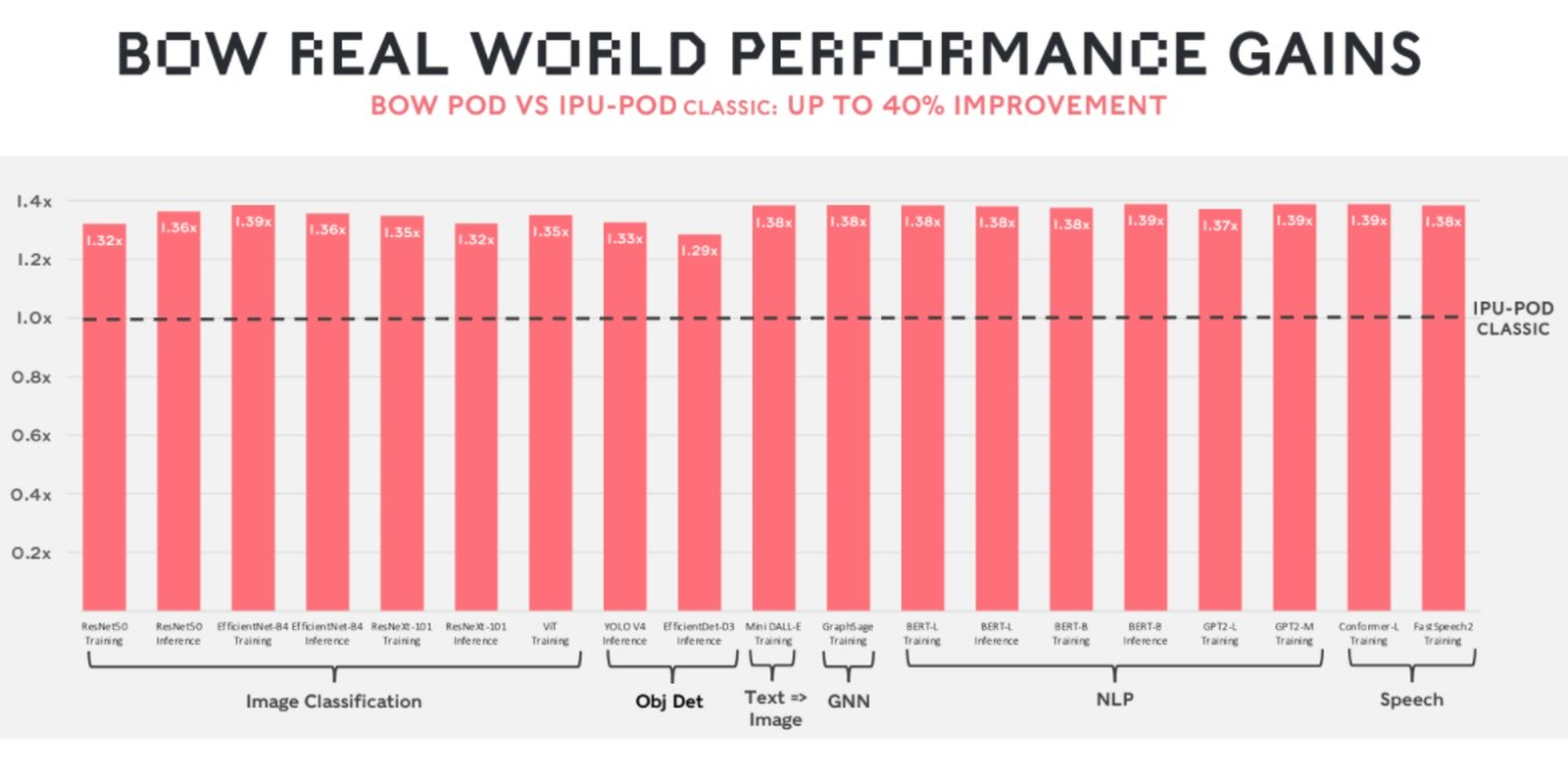 Graphcore говорит о десятикратном превосходстве BOW POD16 над NVIDIA DGX-A100 в полной стоимости владения (TCO). Cтоит BOW POD16 вдвое дешевле DGX-A100. К сожалению, говорить о завоевании рынка машинного обучения Graphcore рано: клиентов у компании уже довольно много, но среди них нет таких гигантов, как Google или Baidu. В долгосрочной перспективе ситуация для Graphcore далеко не безоблачна, но компания уже готовит третье поколение IPU на базе 3-нм техпроцесса.
23.02.2022 [16:35], Руслан Авдеев
«Сингулярность» планетарного масштаба: ИИ-инфраструктура Microsoft включает более 100 тыс. GPU, FPGA и ASICMicrosoft неожиданно раскрыла подробности использования своей распределённой службы планирования «планетарного масштаба» Singularity, предназначенной для управления ИИ-нагрузками. В докладе компании целью Singularity названа помощь софтверному гиганту в контроле затрат путём обеспечения высокого коэффициента использования оборудования при выполнении задач, связанных с глубоким обучением. Singularity удаётся добиться этого с помощью нового планировщика, способного обеспечить высокую загрузку ускорителей (в том числе FPGA и ASIC) без роста числа ошибок или снижения производительности. Singularity предлагает прозрачное выделение и эластичное масштабирование выделяемых каждой задаче вычислительных ресурсов. Фактически она играет роль своего рода «умной» прослойки между собственно аппаратным обеспечением и программной платформой для ИИ-нагрузок. 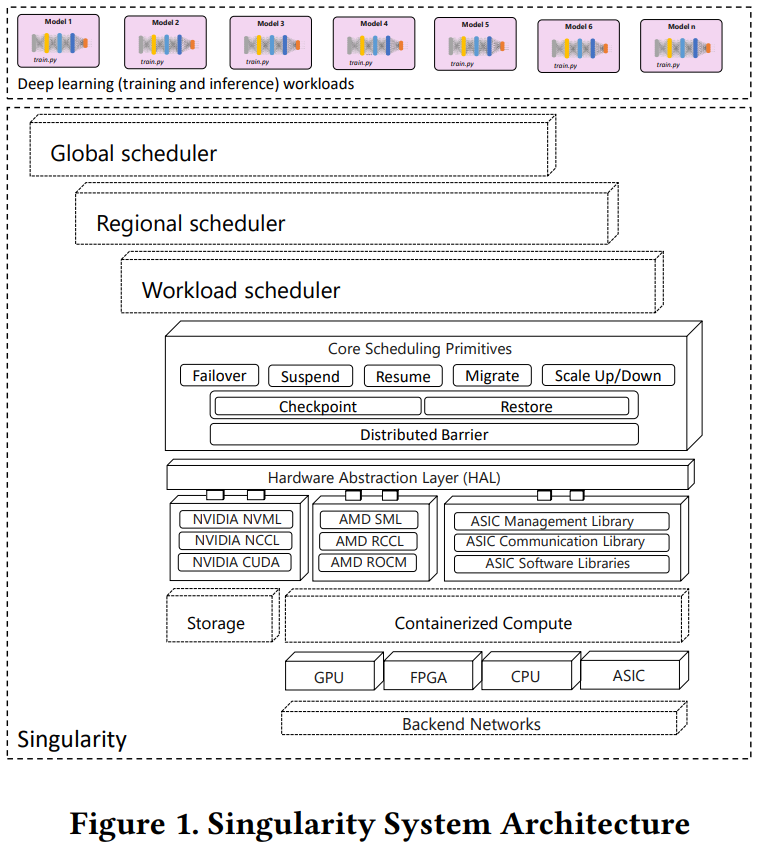
Изображение: Microsoft Singularity позволяет разделять задачи, поручаемые ресурсам ускорителей. Если необходимо масштабирование, система не просто меняет число задействованных устройств, но и управляет распределением и выделением памяти, что крайне важно для ИИ-нагрузок. Правильное планирование позволяет не простаивать без нужды весьма дорогому «железу», благодаря чему и достигается положительный экономический эффект. 
NVIDIA DGX-2 В докладе также прямо говорится, что у Microsoft есть сотни тысяч GPU и других ИИ-ускорителей. В частности, упоминается, что Singularity используется на платформах NVIDIA DGX-2: два Xeon Platinum 8168 (по 20 ядер каждый), восемь ускорителей V100 с NVSwitch, 692 Гбайт RAM и интерконнект InfiniBand. Таким образом, ИИ-парк компании должен включать десятки тысяч узлов, поэтому эффективное управление им очень важно.
24.01.2022 [15:37], Сергей Карасёв
Нейроморфный ИИ-ускоритель BrainChip Akida AKD1000 оценён в $499Компания BrainChip сообщила о начале продаж специализированной карты расширения Akida AKD1000, предназначенной для организации периферийных ИИ-вычислений. Цена изделия составляет $499: оно доступно для заказа в количестве до десяти штук. Сама плата имеет размеры 76 × 40 × 5,3 мм и использует интерфейс PCI Express 2.0 x1. В основу положен одноимённый нейроморфный процессор, дополненный ядром Arm Cortex-M4 (300 МГц). Akida AKD1000 предлагает 1,2 млн нейронов и 10 млрд синапсов. Решение содержит 512 Мбайт памяти LPDDR4-2400 и 128 Мбит флеш-памяти Quad SPI NOR. 
Источник изображений: BrainChip Отмечается, что BrainChip предоставит заказчикам всю необходимую документацию, что позволит системным интеграторам и разработчикам создавать собственные решения на базе ИИ-акселератора. Создание, обучение и тестирование нейросетей осуществляется в среде MetaTF с поддержкой Tensorflow и Keras, а также набором готовых моделей и конвертером CNN-SNN.  На поставку новых карт Akida AKD1000 будет уходить около восьми недель после оформления заказа. Эти сроки будут варьироваться в зависимости от работы логистических цепочек. Впрочем, это временные ограничения, так как, по словам компании, налажено массовое производство. Ранее BrainChip выпустила комплекты разработчика на базе ПК Shuttle и Raspberry Pi
14.12.2021 [21:11], Владимир Агапов
Китайская Enflame выпустила новый ИИ-ускоритель Cloudblazer Yunsui i20Компания Enflame, которая летом этого года представляла ускорители на базе второго поколения своих ИИ-чипов DTU, выпустила новый инференс-ускоритель Cloudblazer Yunsui i20 с чипом Suixi 2.5. Он изготовлен по 12-нм FinFET-техпроцессу GlobalFoundries и имеет обновлённую высокопроизводительную архитектуру вычислительных ядер GCU-CARE 2.0, благодаря чему, по словам создателей, удалось достичь эффективности, сопоставимой с массовыми 7-нм GPU. В числе ключевых особенностей новинки компания отмечает возросшую вычислительную мощность, возможность исполнения тензорных, векторных и скалярных вычислений, API для C++ и Python, а также поддержку основных фреймворков и форматов моделей (TensorFlow, PyTorch, ONNX). Комплектное ПО предоставляет гибкие возможности для миграции с поддержкой технологий виртуализации, а также многопользовательских и многозадачных окружений с безопасной изоляцией процессов.  Yunsui i20 обладает 16 Гбайт памяти HBM2e с пропускной способностью до 819 Гбайт/c. Новинка поддерживает работу со всеми ключевыми форматами и предоставляет универсальную инференс-платформу, в том числе для облаков. Пиковая вычислительная FP32-производительность достигает 32 Тфлопс, TF32 (не уточняется, идёт ли речь о совместимости с NVIDIA) — 128 Тфлопс, FP16/BF16 — 128 Тфлопс, а INT8 достигает 256 Топс. По сравнению с первым поколением продуктов, Yunsui i20 увеличил FP-производительность в 1,8 раза, а INT-вычислений — в 3,6 раза.  Для сравнения — у PCIe-версии NVIDIA A100 производительность в расчётах FP32, TF32, FP16/BF16 и INT8 составляет 19,5, 156, 312 и 624 Тфлопс (Топс для INT), а объём и пропускная способность памяти равны 40/80 Гбайт и 1555/1935 Гбайт/с соответственно. У AMD MI100 объём HBM2-памяти равен 32 Гбайт (1,23 Тбайт/с), а производительность FP32, FP16 и BF16 равна 46,1, 184,6 и 92,3 Тфлопс соответственно. Все три ускорителя имеют интерфейс PCIe 4.0. 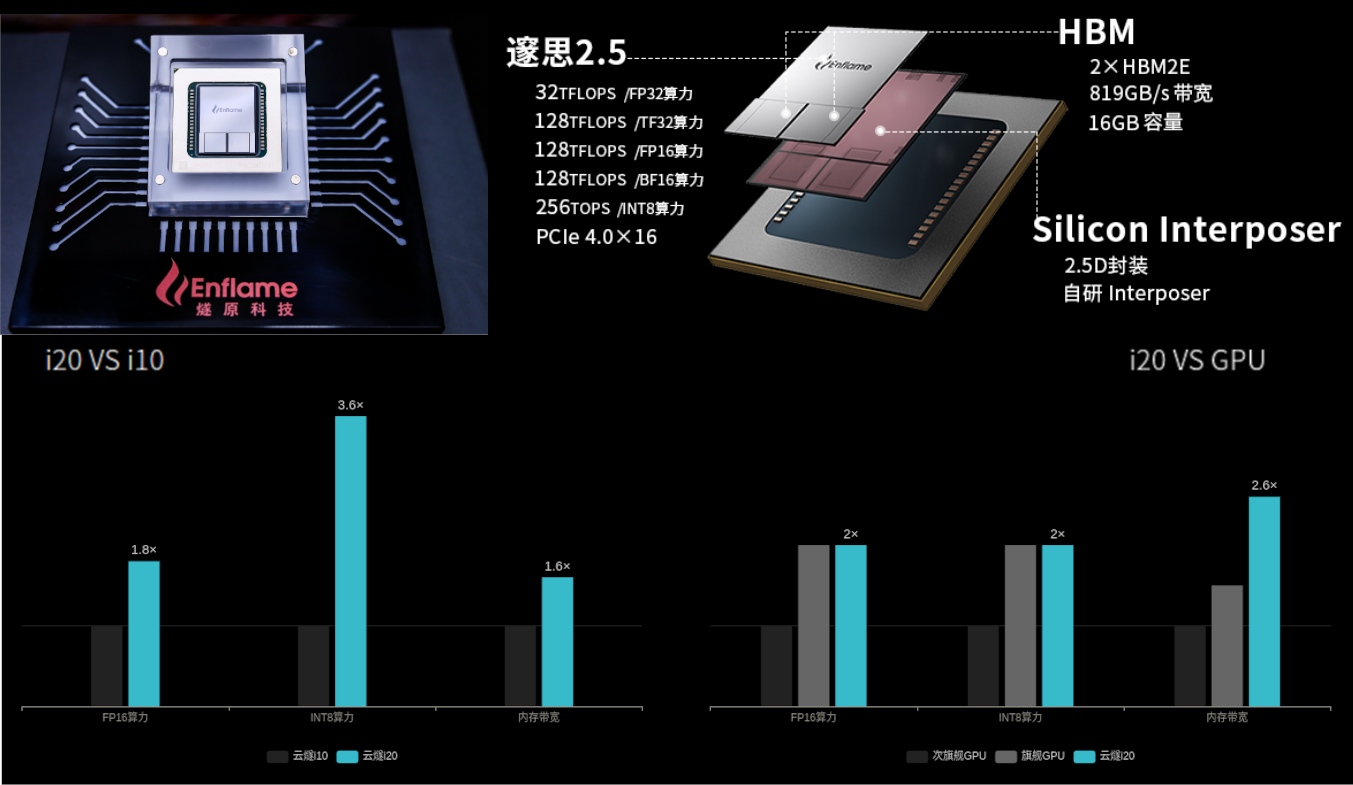 Значительный вклад в повышение производительности принесла оптимизация фирменного программного стека TopsRider, благодаря которой снизилась нагрузка на подсистему памяти. В результате средняя производительность исполнения моделей увеличилась в 3,5 раза, а эффективность использование вычислительной мощности — в среднем в 2 раза. Кроме того, новая модель программирования и технологии автоматизации позволяют ускорить эффективность разработки и снизить стоимость миграции моделей. В компании убеждены, что всё это сделает Yunsui i20 более конкурентноспособным решением.  Благодаря технологии виртуализации, Yunsui i20 можно разделить на 6 независимых, изолированных друг от друга доменов — такое ранее предлагала только NVIDIA. Вместе с другими продуктами, которые также полностью переведены на новое поколение ИИ-ускорителей, Enflame рассчитывает получить значимую долю рынка в таких инновационных секторах как умные города и цифровое правительство, а также в традиционных отраслях вроде финансов, транспорта и энергетики, где будут востребованы более совершенные решения на основе ИИ.  Несмотря на очевидные успехи, достигнутые командой Enflame и другими китайскими разработчиками — SoC от YITU Technology для глубокого обучения, IoT-чип Horizon Robotics Sunrise 2 с интегрированными ИИ-возможностями, Hanguang 800 от T-Head Semiconductor («дочка» Alibaba), серии Huawei Ascend и других — иностранные производители ИИ-чипов, по данным People's Daily, по-прежнему доминируют на китайском рынке с долей более 80%.
07.12.2021 [00:36], Алексей Степин
ИИ-ускорители AWS Trainium: 55 млрд транзисторов, 3 ГГц, 512 Гбайт HBM и 840 Тфлопс в FP32GPU давно применяются для ускорений вычислений и в последние годы обросли поддержкой специфических форматов данных, характерных для алгоритмов машинного обучения, попутно практически лишившись собственно графических блоков. Но в ближайшем будущем их по многим параметрам могут превзойти специализированные ИИ-процессоры, к числу которых относится и новая разработка AWS, чип Trainium. На мероприятии AWS Re:Invent компания рассказала о прогрессе в области машинного обучения на примере своих инстансов P3dn (Nvidia V100) и P4 (Nvidia A100). Первый вариант дебютировал в 2018 году, когда модель BERT-Large была примером сложности, и благодаря 256 Гбайт памяти и сети класса 100GbE он продемонстрировал впечатляющие результаты. Однако каждый год сложность моделей машинного обучения растёт почти на порядок, а рост возможностей ИИ-ускорителей от этих темпов явно отстаёт. 
Сложность моделей машинного обучения будет расти всё быстрее Когда в прошлом году был представлен вариант P4d, его вычислительная мощность выросла в четыре раза, а объём памяти и вовсе на четверть, в то время как знаменитая модель GPT-3 превзошла по сложности BERT-Large в 500 раз. А теперь и 175 млрд параметров последней — уже ничто по сравнению с 10 трлн в новых моделях. Приходится наращивать и объём локальной памяти (у Trainium имеется 512 Гбайт HBM с суммарной пропускной способностью 13,1 Тбайт/с), и активнее использовать распределённое обучение.  Для последнего подхода узким местом стала сетевая подсистема, и при разработке стека Elastic Fabric Adapter (EFA) компания это учла, наделив новые инстансы Trn1 подключением со скоростью 800 Гбит/с (вдвое больше, чем у P4d) и с ультранизкими задержками, причём доступен и более оптимизированный вариант Trn1n, у которого пропускная способность вдвое выше и достигает 1,6 Тбит/с. Для связи между самими чипами внутри инстанса используется интерконнект NeuroLink со скоростью 768 Гбайт/с. 
Прогресс подсистем сети и памяти в ИИ-инстансах AWS Но дело не только в возможности обучить GPT-3 менее чем за две недели: важно и количество используемых для этого ресурсов. В случае P3d это потребовало бы 600 инстансов, работающих одновременно, и даже переход к архитектуре Ampere снизил бы это количество до 200. А вот обучение на базе чипов Trainium требует всего 130 инстансов Trn1. Благодаря оптимизациям, затраты на «общение» у новых инстансов составляют всего 7% против 14% у Ampere и целых 49% у Volta. 
Меньше инстансов, выше эффективность при равном времени обучения — вот что даст Trainium Trainium опирается на систолический массив (Google использовала тот же подход для своих TPU), т.е. состоит из множества очень тесно связанных вычислительных блоков, которые независимо обрабатывают получаемые от соседей данные и передают результат следующему соседу. Этот подход, в частности, избавляет от многочисленных обращений к регистрам и памяти, что характерно для «классических» GPU, но лишает подобные ускорители гибкости.  В Trainium, по словам AWS, гибкость сохранена — ускоритель имеет 16 полностью программируемых (на С/С++) обработчиков. Есть и у него и другие оптимизации. Например, аппаратное ускорение стохастического округления, которое на сверхбольших моделях становится слишком «дорогим» из-за накладных расходов, хотя и позволяет повысить эффективность обучения со смешанной точностью. Всё это позволяет получить до 3,4 Пфлопс на вычислениях малой точности и до 840 Тфлопс в FP32-расчётах.  AWS постаралась сделать переход к Trainium максимально безболезненным для разработчиков, поскольку SDK AWS Neuron поддерживает популярные фреймворки машинного обучения. Впрочем, насильно загонять заказчиков на инстансы Trn1 компания не собирается и будет и далее предоставлять на выбор другие ускорители поскольку переход, например, с экосистемы CUDA может быть затруднён. Однако в вопросах машинного обучения для собственных нужд Amazon теперь полностью независима — у неё есть и современный CPU Graviton3, и инфереренс-ускоритель Inferentia.
08.11.2021 [20:00], Игорь Осколков
AMD анонсировала Instinct MI200, самые быстрые в мире ускорители вычислений на базе CDNA 2В прошлом году AMD окончательно развела ускорители для графики и вычислений, представив Instinct MI100, первый продукт на базе архитектуры CDNA, который позволил компании противостоять NVIDIA. Теперь же AMD подготовила новую версию архитектуры CDNA 2 и ускорители MI200 на неё основе. Новинки, согласно внутренним тестам, в ряде задач на голову выше того, что сейчас может предложить NVIDIA. 
AMD Instinct MI200 в OAM-варианте (Здесь и ниже изображения AMD) Циркулировавшие ранее слухи оказались верны — MI200 являются двухчиповыми решениями с 2.5D-упаковкой кристаллов (GCD) самих ускорителей, четырёх линий Infinity Fabric между ними и восьми стеков памяти HBM2e (8192 бит, 1600 МГц, 128 Гбайт, 3,2 Тбайт/c). В данном случае используется мостик EFB (Elevated Fanout Bridge), который позволяет задействовать стандартные подложки, что удешевляет и упрощает производство и тестирование ускорителей, не потеряв при этом в производительности и, что важнее, без существенного увеличения задержек в обмене данными. 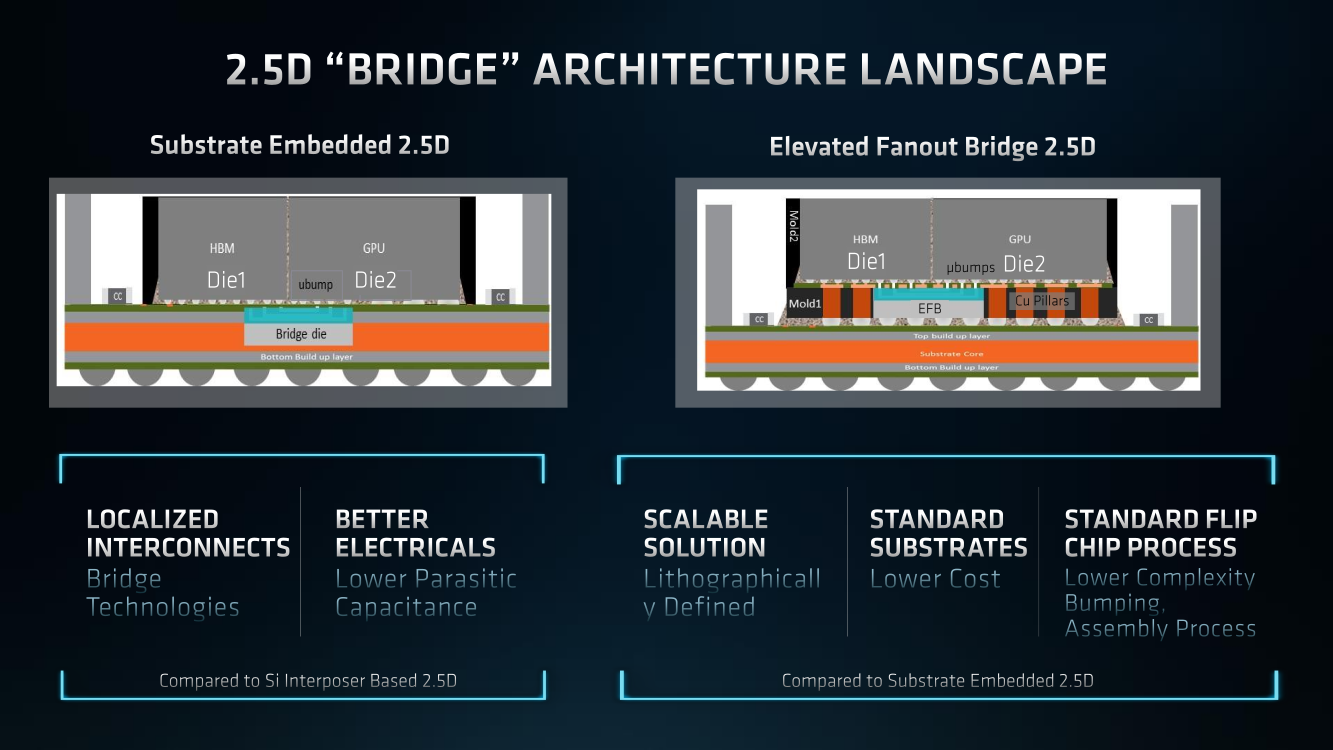 Несмотря на то, что в составе ускорителя два GCD, системе они представляются как единое целое с общей же памятью. Каждый GCD в случае CDNA 2 включает 112 CU (Compute Unit), но в конечных продуктах они задействованы не все. CU разбиты на четыре группы (с индивидуальным планировщиком) с общим L2-кешем объёмом 8 Мбайт и пропускной способностью 6,96 Тбайт/с, который поделён на 32 отдельных блока. А сами блоки имеют индивидуальные подключения к контроллерам памяти в GCD.  Важное отличие CDNA 2 заключается в «подтягивании» производительности векторных FP64- и FP32-вычислений — они исполняются с одинаковой скоростью в отличие от CDNA первого поколения. Кроме того, появилась поддержка сжатых (packed) инструкций для операций FMA/FADD/FMUL для FP32-векторов. Второй крупный апдейт касается матричных вычислений. Для них теперь тоже есть отдельная поддержка FP64, и с той же производительностью, что и для FP32. Новые инструкции рассчитаны на блоки 16×16×4 и 4×4×4. 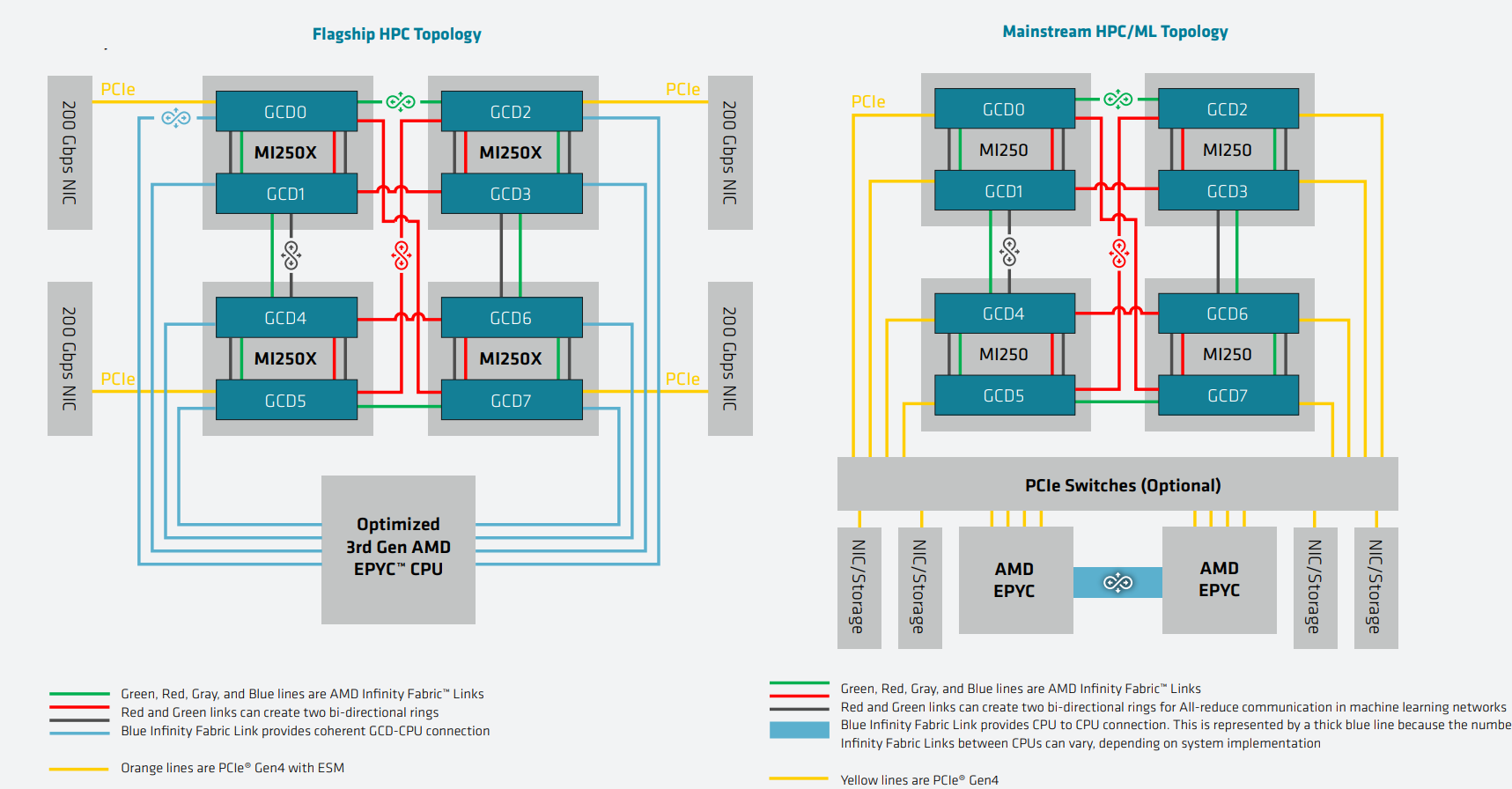 Поддержка FP16/BF16 в матричных ядрах, конечно, тоже есть, что позволяет задействовать их и для ИИ-задач, а не только HPC. Подспорьем для них в некоторых задачах будут два блока VCN (Video Codec Next) в каждом GCD. Они поддерживают декодирование H.264/AVC, H.265/HEVC, VP9 и JPEG, а также кодирование H.264/H.265, что потенциально позволит более эффективно работать ИИ-алгоритмам с изображениями и/или видео. 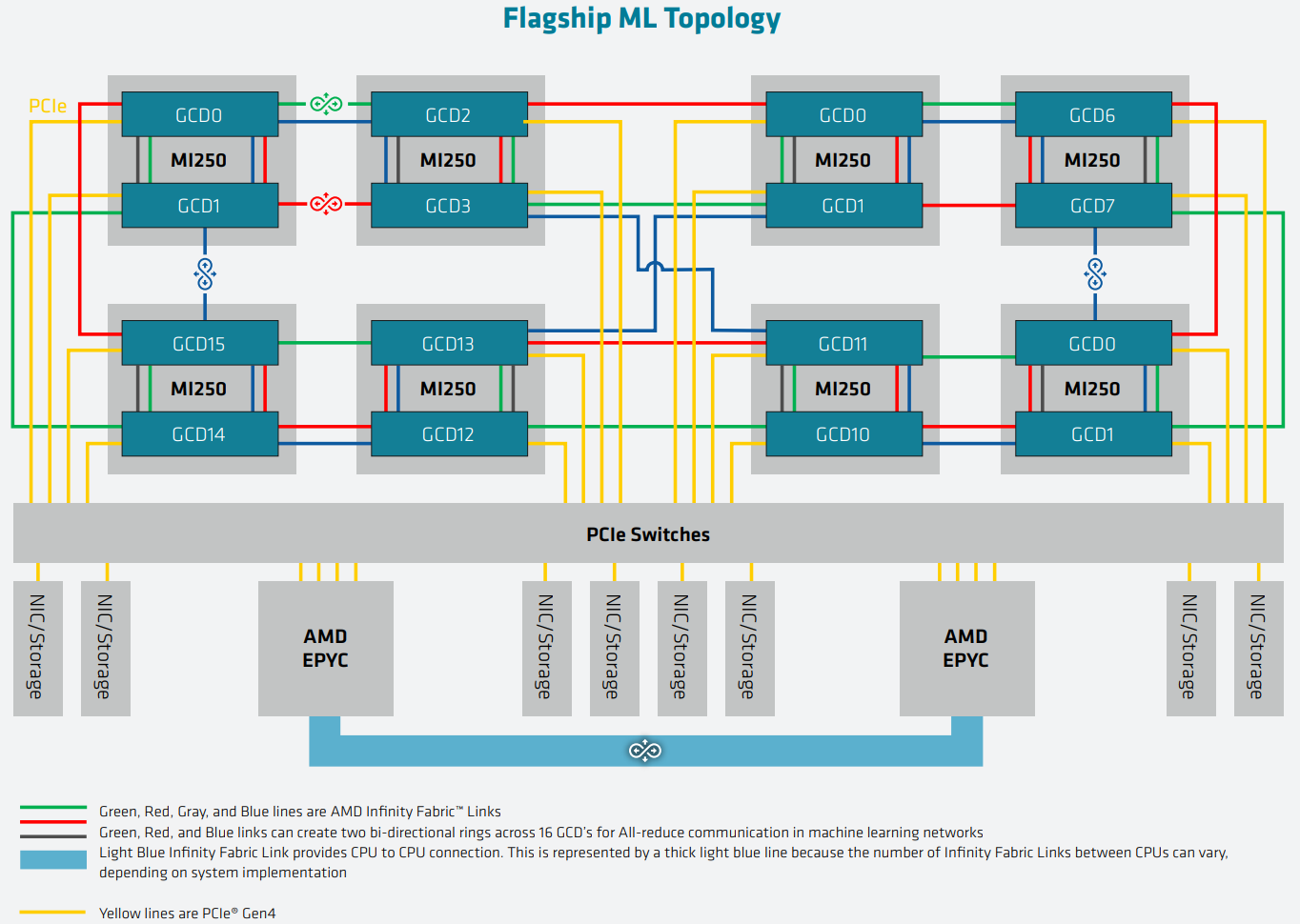 Для обмена данными между ускорителями и CPU используется единая шина Infinity Fabric (IF) с поддержкой кеш-когерентности. Всего на ускоритель приходится до восьми внешних линий IF, а суммарная скорость обмена данными может достигать 800 Гбайт/c. В наиболее плотной компоновке из четырёх MI200 и одного EPYC каждый ускоритель имеет по две линии для связи с CPU и со своим соседом. Причём внутренние и внешние IF-линии образуют два двунаправленных кольца между ускорителями. Каждая IF-линия опирается на x16-подключение PCIe 4.0, но в данном случае есть ряд оптимизаций конкретно под HPC-системы HPE Cray.  Дополнительно у каждого ускорителя есть собственный root-комплекс, что позволяет напрямую подключить сетевой адаптер класса 200G. И это явный намёк на возможность непосредственного RDMA-соединения с внешними хранилищами, поскольку в такой схеме на локальные NVMe-накопители линий попросту не остаётся. Более простые топологии уже предполагают использование половины линий IF в качестве обычного PCIe-подключения и задействуют коммутатор(-ы) для связи с CPU и NIC. В этом случае IF-подключение остаётся только между процессорами. Зато в одной системе можно объединить восемь MI200.  Чипы ускорителей MI250X изготовлены по 6-нм техпроцессу FinFet, содержат 58 млрд транзисторов и предлагают 220 CU, включающих 880 ядер для матричных вычислений и 14080 шейдерных ядер второго поколения. У MI250 их 208, 832 и 13312 соответственно. Для обеих моделей уровень TDP составляет 500 или 560 Вт, поэтому поддерживается как воздушное, так и жидкостное охлаждение. В дополнение к OAM-версиям MI250(X) чуть позже появится и более традиционная PCIe-модель MI210.  Для сравнения — у NVIDIA A100 объём и пропускная способность памяти (тоже HBM2e) составляют до 80 Гбайт и 2 Тбайт/с соответственно. Шина же NVLink 3.0 имеет пропускную способность 600 Гбайт/c, а коммутатор NVSwitch для связи между восемью ускорителями — 1,8 Тбайт/с. Потребление SXM3-версии составляет 400 Вт. Стоит также отметить, что первая версия A100 появилась ещё весной 2020 года, и скоро ожидается анонс следующего поколения ускорителей на базе архитектуры Hopper. На носу и выход ускорителей Intel Xe Ponte Vecchio.  И если про первые мы пока ничего толком не знаем, то вторые, похоже, уже проиграли MI250X в «голой» производительности как минимум по одной позиции (FP32). AMD говорит, что создавала Instinct MI200 как серию универсальных ускорителей, пригодных и для «классических» HPC-задач, и для ИИ. Отсюда и практически пятикратная разница в пиковой FP64-производительности с NVIDIA A100. 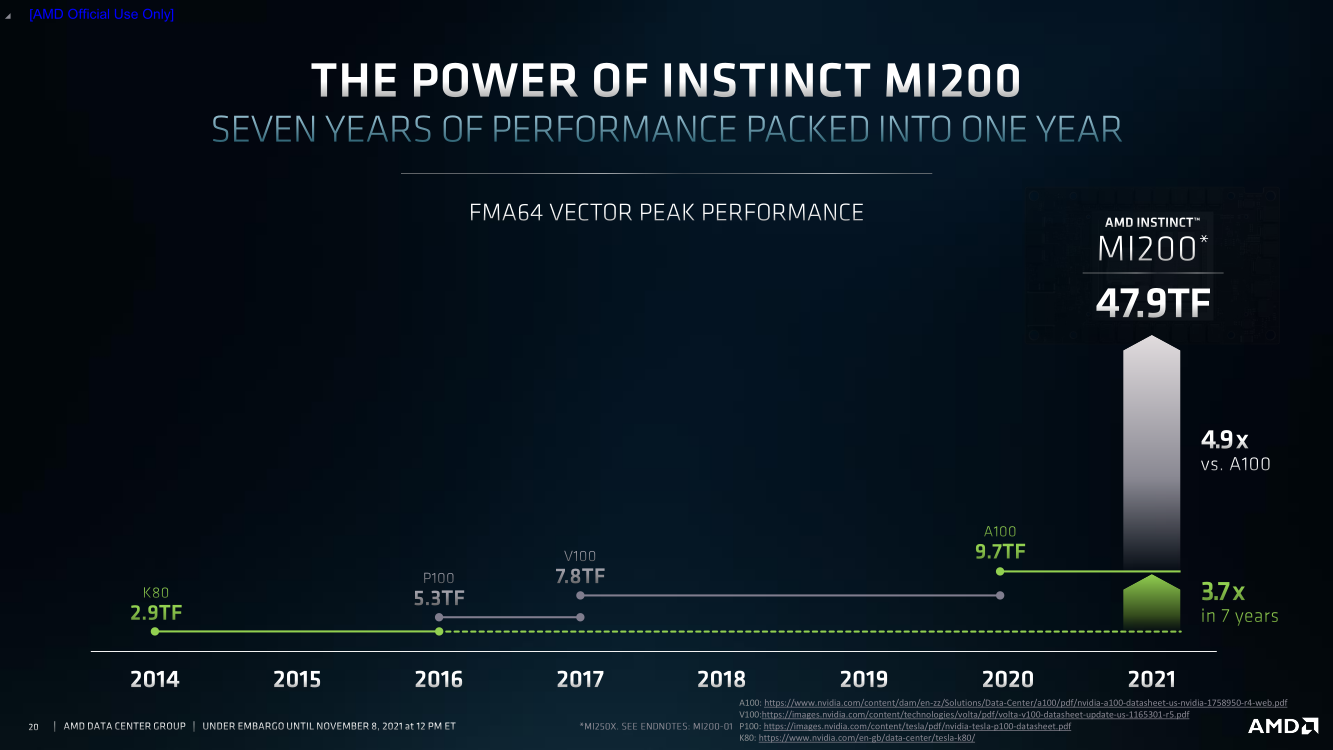 Но вот с нейронками всё не так однозначно. Предпочтительным форматом для обучения у NVIDIA является собственный TF32, поддержка которого есть в Tensor-ядрах Ampere. Ядра для матричных вычислений в CDNA2 про него ничего не знают, поэтому сравнить производительность в лоб нельзя. Разница в BF16/FP16 между MI250X и A100 уже не так велика, так что AMD говорит о приросте в 1,2 раза для обучения со смешанной точностью. 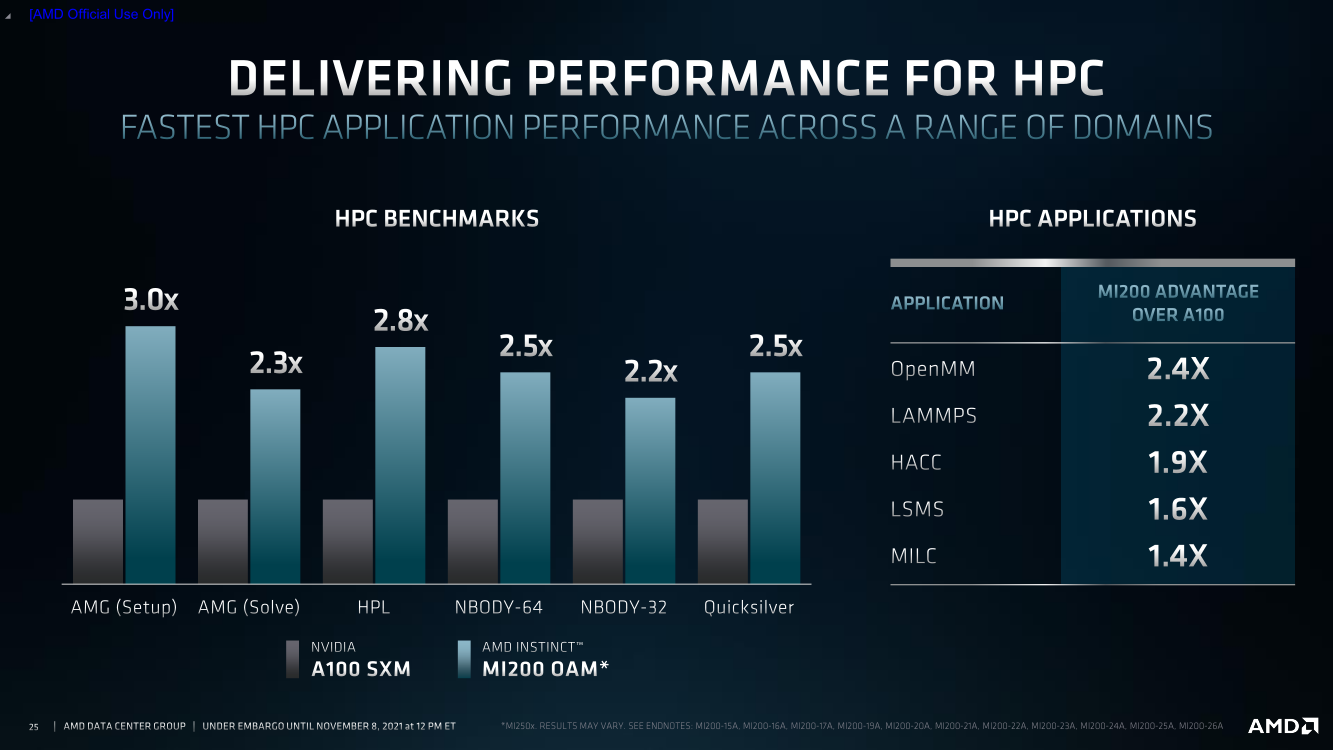 Данные по INT8 и INT4 в презентацию не вынесены, что неудивительно. Пиковый показатель для обоих форматов у MI250X составляет 383 Топс, тогда как тензорные ядра NVIDIA A100 выдают 624 и 1248 Топс соответственно. В данном случае больший объём памяти сыграл бы на руку MI200 в задачах инференса для крупных моделей. Наконец, у A100 есть ещё одно преимущество — поддержка MIG (Multi-Instance GPU), которая позволяет более эффективно задействовать имеющиеся ресурсы, особенно в облачных системах.  Вместе с Instinct MI200 была анонсирована и новая версия открытой (open source) платформы ROCm 5.0, которая обзавелась поддержкой и различными оптимизациями не только для этих ускорителей, но и, например, Radeon Pro W6800. В этом релизе компания уделит особое внимание расширению программной экосистемы и адаптации большего числа приложений. Кроме того, будет развиваться и новый портал Infinity Hub, где будет представлено больше готовых к использованию контейнеров с популярным ПО с рекомендациями по настройке и запуску.  AMD Instinct MI200 появятся в I квартале 2022 года. Новинки, в первую очередь MI210, будут доступны у крупных OEM/ODM-производителей: ASUS, Atos (X410-A5 2U1N2S), Dell Technologies, Gigabyte (G262-ZO0), HPE, Lenovo и Supermicro. Ускорители Instinct MI250X пока остаются эксклюзивом для систем HPE Cray Ex. Именно они вместе с «избранными» процессорами AMD EPYC (без уточнения, будут ли это Milan-X) станут основой для самого мощного в США суперкомпьютера Frontier.  Окончательный ввод в эксплуатацию этого комплекса запланирован на будущий год. Ожидается, что его пиковая производительность превысит 1,5 Эфлопс. При этом он должен стать самой энергоэффективной системой подобного класса. А адаптация ПО под него позволит несколько потеснить NVIDIA CUDA в некоторых областях. И это для AMD сейчас, пожалуй, гораздо важнее, чем победа по флопсам.
28.08.2021 [00:16], Владимир Агапов
Кластер суперчипов Cerebras WSE-2 позволит тренировать ИИ-модели, сопоставимые по масштабу с человеческим мозгомВ последние годы сложность ИИ-моделей удваивается в среднем каждые два месяца, и пока что эта тенденция сохраняется. Всего три года назад Google обучила «скромную» модель BERT с 340 млн параметров за 9 Пфлоп-дней. В 2020 году на обучение модели Micrsofot MSFT-1T с 1 трлн параметров понадобилось уже порядка 25-30 тыс. Пфлоп-дней. Процессорам и GPU общего назначения всё труднее управиться с такими задачами, поэтому разработкой специализированных ускорителей занимается целый ряд компаний: Google, Groq, Graphcore, SambaNova, Enflame и др.  Особо выделятся компания Cerebras, избравшая особый путь масштабирования вычислительной мощности. Вместо того, чтобы печатать десятки чипов на большой пластине кремния, вырезать их из пластины, а затем соединять друг с другом — компания разработала в 2019 г. гигантский чип Wafer-Scale Engine 1 (WSE-1), занимающий практически всю пластину. 400 тыс. ядер, выполненных по 16-нм техпроцессу, потребляют 15 кВт, но в ряде задач они оказываются в сотни раз быстрее 450-кВт суперкомпьютера на базе ускорителей NVIDIA.  В этом году компания выпустила второе поколение этих чипов — WSE-2, в котором благодаря переходу на 7-нм техпроцесс удалось повысить число тензорных ядер до 850 тыс., а объём L2-кеша довести до 40 Гбайт, что примерно в 1000 раз больше чем у любого GPU. Естественно, такой подход к производству понижает выход годных пластин и резко повышает себестоимость изделий, но Cerebras в сотрудничестве с TSMC удалось частично снизить остроту этой проблемы за счёт заложенной в конструкцию WSE избыточности. 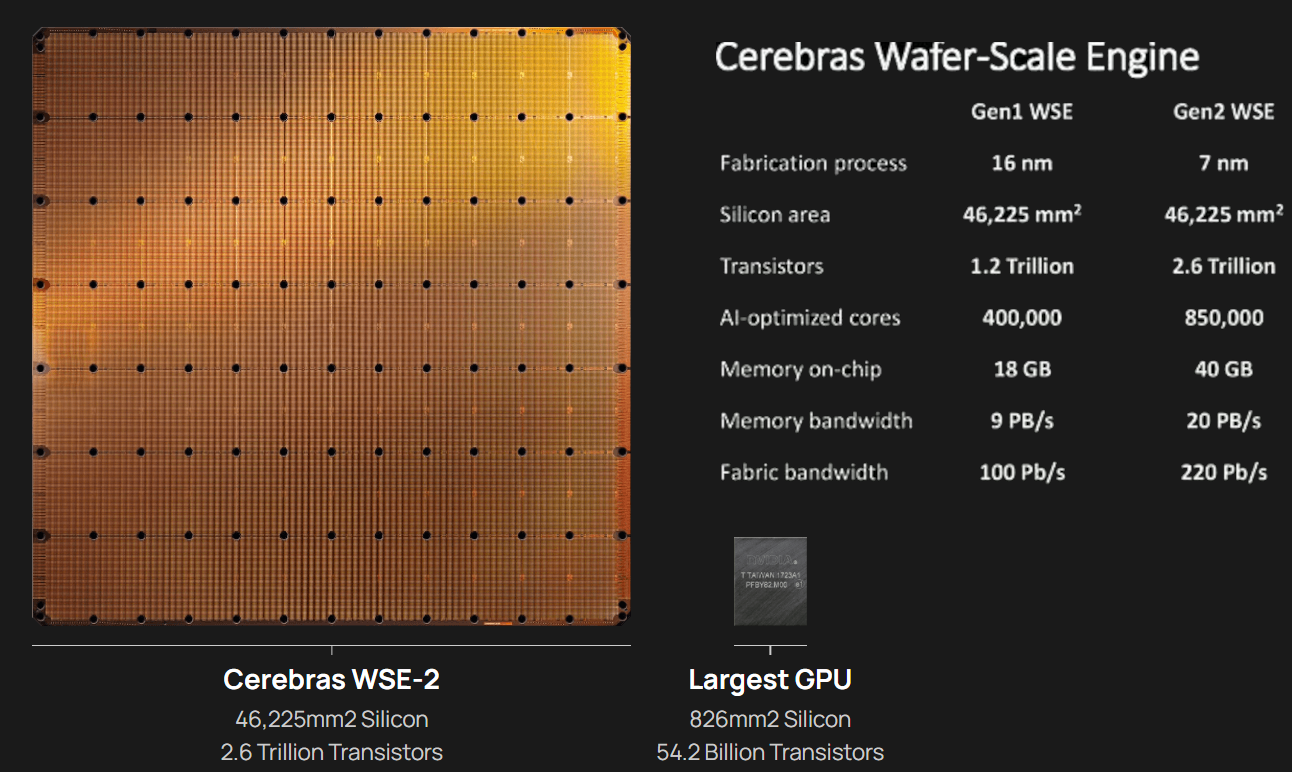 Благодаря идентичности всех ядер, даже при неисправности некоторых их них, изделие в целом сохраняет работоспособность. Тем не менее, себестоимость одной 7-нм 300-мм пластины составляет несколько тысяч долларов, в то время как стоимость чипа WSE оценивается в $2 млн. Зато система CS-1, построенная на таком процессоре, занимает всего треть стойки, имея при этом производительность минимум на порядок превышающую самые производительные GPU. Одна из причин такой разницы — это большой объём быстрой набортной памяти и скорость обмена данными между ядрами.  Тем не менее, теперь далеко не каждая модель способна «поместиться» в один чип WSE, поэтому, по словам генерального директора Cerebras Эндрю Фельдмана (Andrew Feldman), сейчас в фокусе внимания компании — построение эффективных систем, составленных из многих чипов WSE. Скорость роста сложности моделей превышает возможности увеличения вычислительной мощности путём добавления новых ядер и памяти на пластину, поскольку это приводит к чрезмерному удорожанию и так недешёвой системы.  Инженеры компании рассматривают дезагрегацию как единственный способ обеспечить необходимый уровень производительности и масштабируемости. Такой подход подразумевает разделение памяти и вычислительных блоков для того, чтобы иметь возможность масштабировать их независимо друг от друга — параметры модели помещаются в отдельное хранилище, а сама модель может быть разнесена на несколько вычислительных узлов CS, объединённых в кластер. 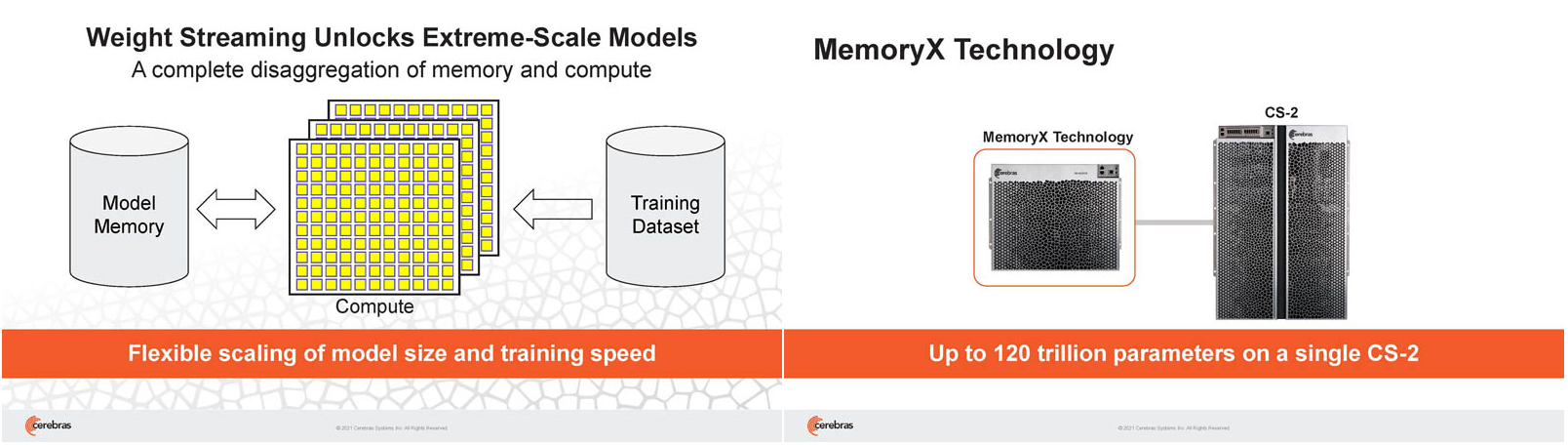 На Hot Chips 33 компания представила особое хранилище под названием MemoryX, сочетающее DRAM и флеш-память суммарной емкостью 2,4 Пбайт, которое позволяет хранить до 120 трлн параметров. Это, по оценкам компании, делает возможным построение моделей близких по масштабу к человеческому мозгу, обладающему порядка 80 млрд. нейронов и 100 трлн. связей между ними. К слову, флеш-память размером с целую 300-мм пластину разрабатывает ещё и Kioxia.  Для обеспечения масштабирования как на уровне WSE, так и уровне CS-кластера, Cerebras разработала технологию потоковой передачи весовых коэффициентов Weight Streaming. С помощью неё слой активации сверхкрупных моделей (которые скоро станут нормой) может храниться на WSE, а поток параметров поступает извне. Дезагрегация вычислений и хранения параметров устраняет проблемы задержки и узости пропускной способности памяти, с которыми сталкиваются большие кластеры процессоров. 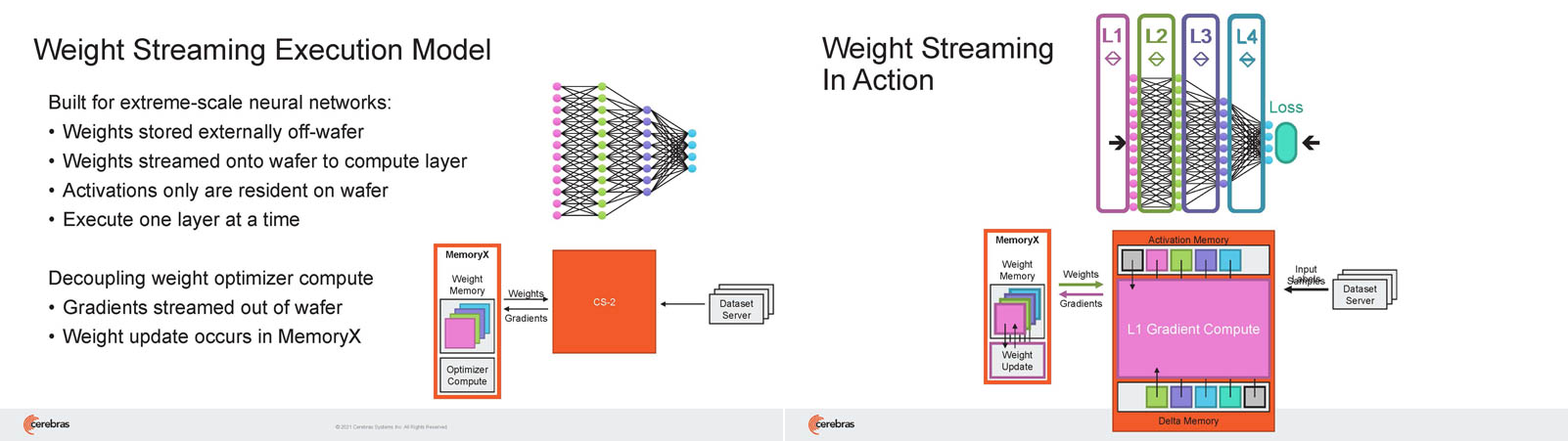 Это открывает широкие возможности независимого масштабирования размера и скорости кластера, позволяя хранить триллионы весов WSE-2 в MemoryX и использовать от 1 до 192 CS-2 без изменения ПО. В традиционных системах по мере добавления в кластер большего количества вычислительных узлов каждый из них вносит всё меньший вклад в решение задачи. Cerebras разработала интерконнект SwarmX, позволяющий подключать до 163 млн вычислительных ядер, сохраняя при этом линейность прироста производительности. 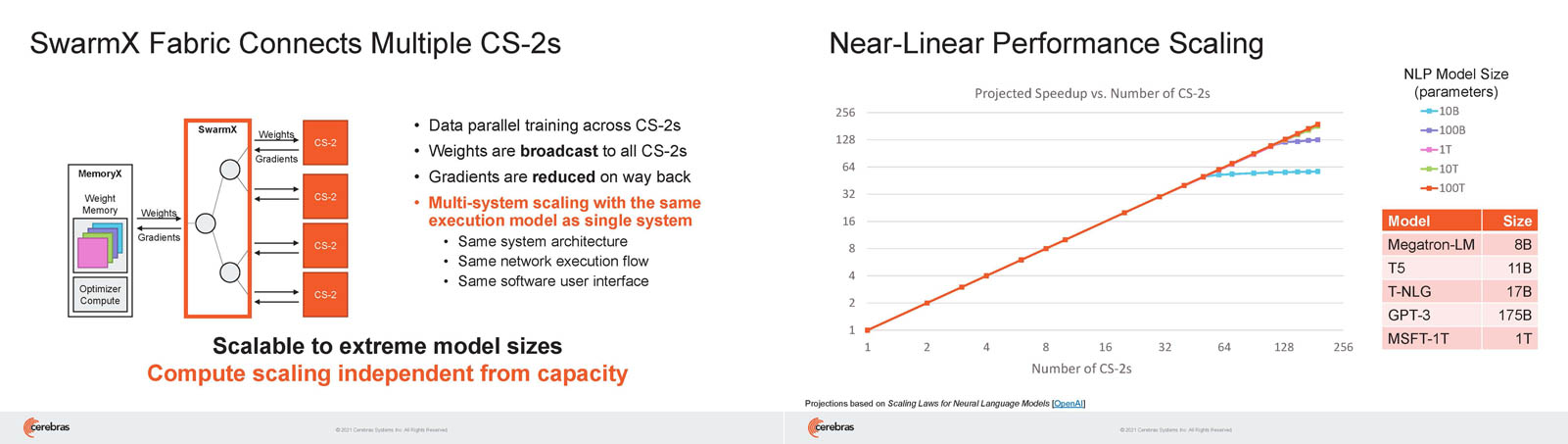 Также, компания уделила внимание разрежённости, то есть исключения части незначимых для конечного результата весов. Исследования показали, что должная оптимизации модели позволяет достичь 10-кратного увеличения производительности при сохранении точности вычислений. В CS-2 доступна технология динамического изменения разрежённости Selectable Sparsity, позволяющая пользователям выбирать необходимый уровень «ужатия» модели для сокращение времени вычислений.  «Крупные сети, такие как GPT-3, уже изменили отрасль машинной обработки естественного языка, сделав возможным то, что раньше было невозможно и представить. Индустрия перешла к моделям с 1 трлн параметров, а мы расширяем эту границу на два порядка, создавая нейронные сети со 120 трлн параметров, сравнимую по масштабу с мозгом» — отметил Фельдман. |
|

