Материалы по тегу: ускоритель
|
31.07.2020 [18:37], Алексей Степин
Сопроцессор для SSD от Pliops ускорит работу с базами данных в 10 разКомпания Pliops ещё молода: она была основана в 2017 году выходцами из Samsung, M-Systems и XtremIO; все основатели являются специалистами в области СХД и энергонезависимой памяти. В 2019 году Pliops получила существенный объём инвестиций от Mellanox. А в 2020 году компания анонсирует свой новейший продукт — сопроцессор, берущий на себя тяжёлые задачи по работе с флеш-памятью. Подобные чипы разрабатывают многие, но Pliops обещает, что её решение ускорит работу с такого рода памятью более чем в 10 раз. Впервые технология была продемонстрирована на саммите Flash Memory 2019, и вот, наконец, концепция обратилась в реальный осязаемый продукт, доступный к приобретению. Решение Pliops достаточно необычное: это не контроллер NAND-массива, а именно сопроцессор-ускоритель, выполненный в виде отдельной платы с разъёмом PCI Express и берущий на себя всю работу по обслуживанию массивов SSD. И делает это новый ускоритель максимально эффективно: серьёзные флеш-СХД могут нагружать хост-процессоры весьма сильно, но решение Pliops позволяет решить эту проблему. 
Источник изображений: Pliops Особенно сильно эффект проявится в системах, используемых для работы с базами данных. Pliops объясняет это тем, что СУБД, будь то реляционные или NoSQL, традиционно разделяют непосредственно данные и ключи или индексы. А отдельная единица хранения данных имеет переменный размер, и эта структура не слишком хорошо сочетатся с традиционными устройствами хранения данных, у которых размер блока фиксирован.  Если в случае с обычными HDD вычислительная нагрузка невелика, поскольку случайных операций такие устройства выдают немного (в районе сотен), то твердотельные накопители, способные выдать 500 тысяч IOPS и более, создают и серьёзную вычислительную нагрузку, «утрамбовывая» вариабельные блоки данных в свой жёсткий формат. К этому добавляет проблем использование сжатия данных, которое тоже создаёт нагрузку. 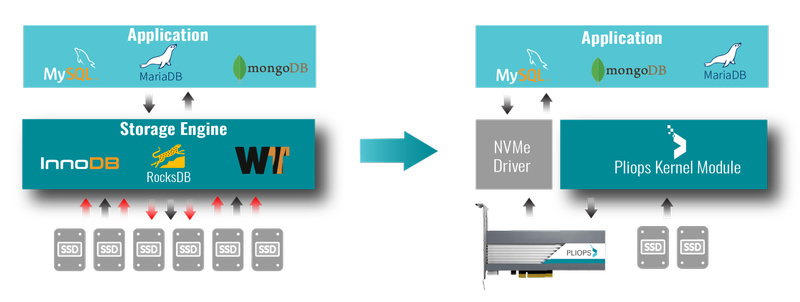 Сопроцессор, разработанный Pliops и получивший название PSP, как раз и призван взять на себя все обязанности по работе с данными в формате Key:Value (KV), что особенно важно в крупных СХД, работающих с огромными массивами БД. Немаловажно то, что сопроцессор Pliops делает свою работу полностью прозрачно и не требует модификации программного обеспечения пользователя.  Со стороны ПО он выглядит, как обычный блочный SSD, однако за счёт аппаратного акселератора работа с базами данных может ускориться более, чем в 10 раз, а время отклика — параметр также весьма немаловажный, когда речь заходит о БД — снизится еще сильнее, в 100 раз. Новинка уже прошла предварительную проверку более чем у десяти крупных провайдеров облачных и корпоративных услуг по хранению данных и запуску БД. 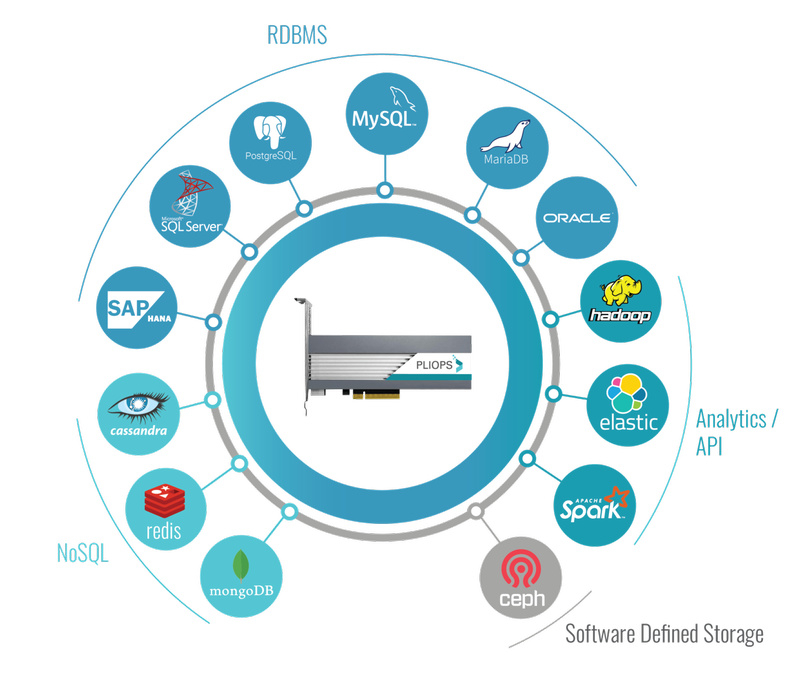 Сопроцессор PSP позволяет использовать обычные недорогие SSD (даже с QLC-памятью) а это уменьшает стоимость владения на величину до 90%, поскольку крупные специализированные твердотельные СХД всё ещё очень дороги. Pliops PSP ускоряет работу с MySQL, MariaDB, mogoDB, Redis, Oracle, Apache Spark и Cassandra и системы на его основе прекрасно масштабируются. Разработчики PSP полагают, что данного рода сопроцессоры образуют отдельный популярный класс устройств, подобно тому, как это случилось с графическими процессорами и сейчас происходит с тензорными ускорителями. Что ж, у Pliops есть все шансы стать в сфере работы с All-Flash СХД тем, чем стала NVIDIA в области ускорения машинного интеллекта. Естественно, это далеко не первый проект по ускорению работы SSD вообще и оптимизации их для СУБД в частности. Например, у Samsung есть экспериментальный продукт KV Stacks — Key:Value SSD, созданный специально для баз данных одноимённого типа. Другие проекты зачастую опираются на FPGA. Та же Samsung совместно с Xilinx представила SmartSSD, обрабатывающий часть данных непосредственно на накопителе. А SmartIOPS уже не первый год поставляет SSD с фирменным контролером на базе ПЛИС. Вероятно, следующим большим шагом станет массовое внедрение зонирования, которое подходит для HDD с SMR и уже включено в стандарт NVMe, и «вынос» FTL (Flash Translation Layer) за пределы отдельного накопителя с программной или аппаратной эмуляцией FTL на уровней всей СХД сразу.
27.06.2020 [18:54], Алексей Степин
ISC 2020: NEC анонсировала новые векторные ускорители SX-AuroraВ японском сегменте рынка супервычислений продолжает доминировать свой, уникальный подход к построению систем класса HPC. Fujitsu сделала ставку на гомогенную архитектуру A64FX с памятью HBM2 и заняла первое место в Top500, но и другая японская компания, NEC, не отказалась от своего видения суперкомпьютерной архитектуры. На предыдущей конференции SC19 NEC пополнила свой арсенал новыми ускорителями SX-Aurora 10E, которые получили более быстрые сборки HBM2. О новых ускорителях «Type 20» речь заходила ещё до начала эпидемии COVID-19; к сожалению, она внесла свои коррективы и анонс новинок состоялся лишь сейчас, летом 2020 года.  Изначально процессор SX-Aurora, используемый во всей серии ускорителей «Type 10» имеет 8 векторных блоков, каждый из которых дополнен 2 Мбайт кеша и 6 сборок памяти HBM2 общим объёмом 24 или 48 Гбайт. Из-за сравнительно грубого 16-нм техпроцесса уровень тепловыделения достаточно высок и составляет примерно 225 Ватт. В отличие от Fujitsu A64FX, NEC SX-Aurora требует для своей работы управляющего хост-процессора, и обычно компания комбинирует его с Intel Xeon, но существуют варианты и с AMD EPYC второго поколения. 
ISC 2018: HPC-модуль с восемью векторными ускорителями NEC SX-Aurora Type 10 Это роднит SX-Aurora с более широко распространёнными ускорителями на базе графических процессоров, однако позиционирование у них всё-таки выглядит иначе. ГП-ускорители, по мнению NEC, гораздо сложнее в программировании, хотя и обеспечивают высокую производительность. 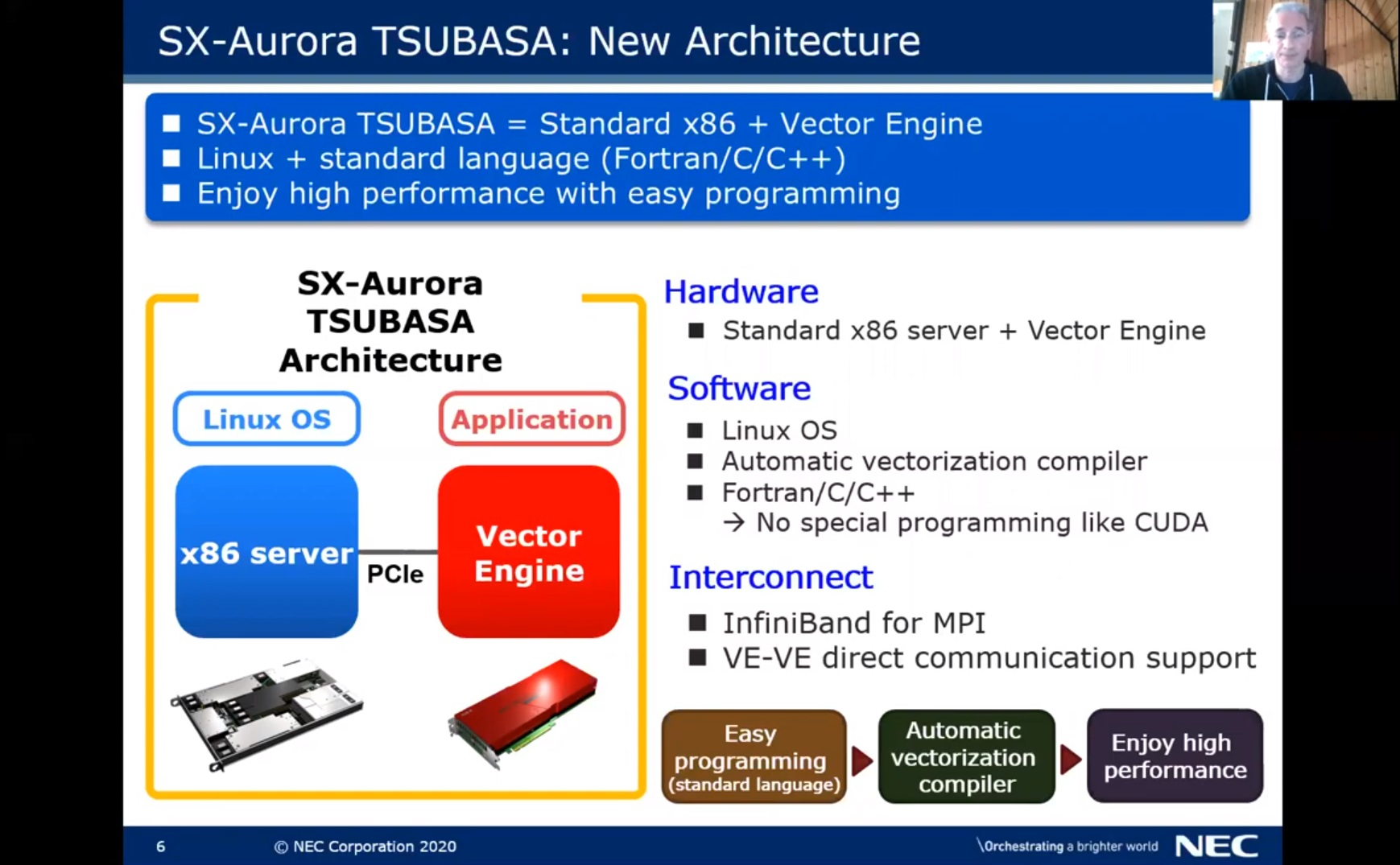 Свою же разработку компания относит к решениям с похожим уровнем производительности, но гораздо более простым в программировании. Упор также делается на высокую пропускную способность памяти, составляющую у новинок «Type 20» 1,5 Тбайт/с.  Новая версия NEC Vector Engine, VE20, структурно, скорее всего, не изменилась. Вместо восьми ядер новый процессор получил 10, и, как уже было сказано, новые сборки HBM2, в результате чего ПСП удалось поднять с 1,35 до 1,5 Тбайт/с, а вычислительную мощность с 2,45 до 3,07 Тфлопс. 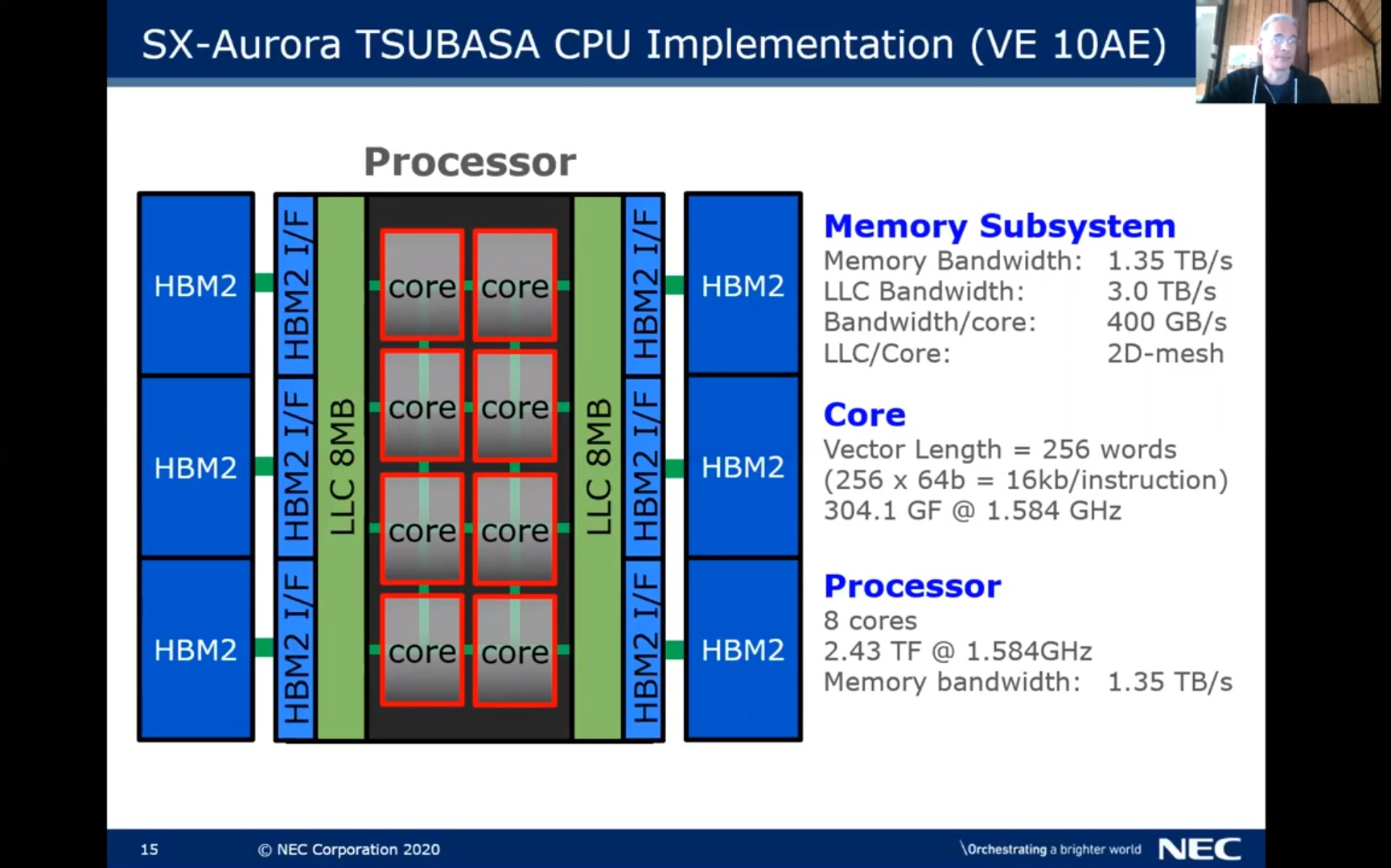 В серии пока представлено два новых ускорителя, Type 20A и 20B, последний аналогичен по конфигурации решениям Type 10 и использует усечённый вариант процессора с 8 ядрами. Говорится о неких архитектурных улучшениях, но деталей компания пока не раскрывает. Оба варианта процессора VE20 работают на частоте 1,6 ГГц, а прирост производительности в сравнении с VE10 достигается в основном за счёт повышения ПСП.  Похоже, VE20 лишь промежуточная ступень. В 2022 году планируется выпуск процессора VE30, который получит подсистему памяти с пропускной способностью свыше 2 Тбайт/с, в 2023 должен появиться его наследник VE40, но настоящий прорыв, судя по всему, откладывается до 2024 года, когда NEC планирует представить VE50, об архитектуре и возможностях которого пока ничего неизвестно. 
22.06.2020 [12:39], Илья Коваль
NVIDIA представила PCIe-версию ускорителя A100Как и предполагалось, NVIDIA вслед за SXM4-версией ускорителя A100 представила и модификацию с интерфейсом PCIe 4.0 x16. Обе модели используют идентичный набор чипов с одинаковыми характеристикам, однако, помимо отличия в способе подключения, у них есть ещё два существенных отличия. 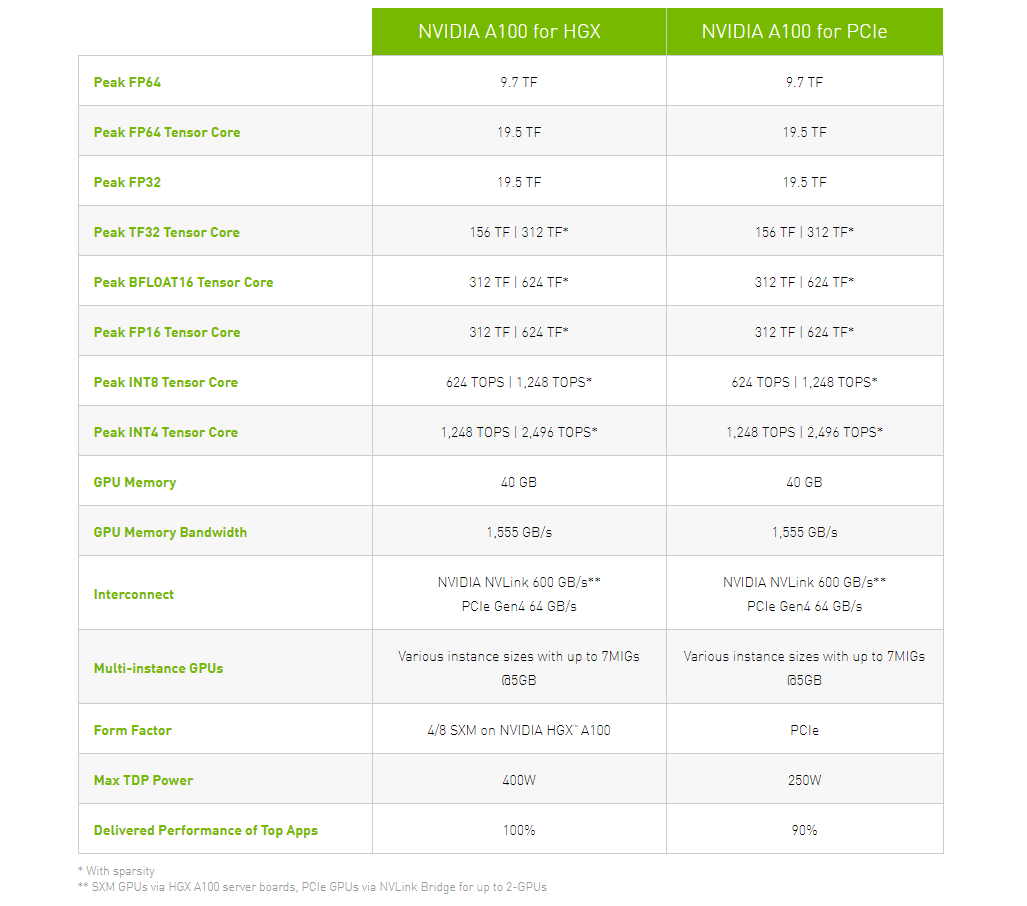 Первое — сниженный с 400 Вт до 250 Вт показатель TDP. Это прямо влияет на величину устоявшейся скорости работы. Сама NVIDIA указывает, что производительность PCIe-версии составит 90% от SXM4-модификации. На практике разброс может быть и больше. Естественным ограничением в данном случае является сам форм-фактор ускорителя — только классическая двухслотовая FLFH-карта с пассивным охлаждением совместима с современными серверами.  Второе отличие касается поддержки быстрого интерфейса NVLink. В случае PCIe-карты посредством внешнего мостика можно объединить не более двух ускорителей, тогда как для SXM-версии есть возможность масштабирования до 8 ускорителей в рамках одной системы. С одной стороны, NVLink в данном случае практически на порядок быстрее PCIe 4.0. С другой — PCIe-версия наверняка будет заметно дешевле и в этом отношении универсальнее. 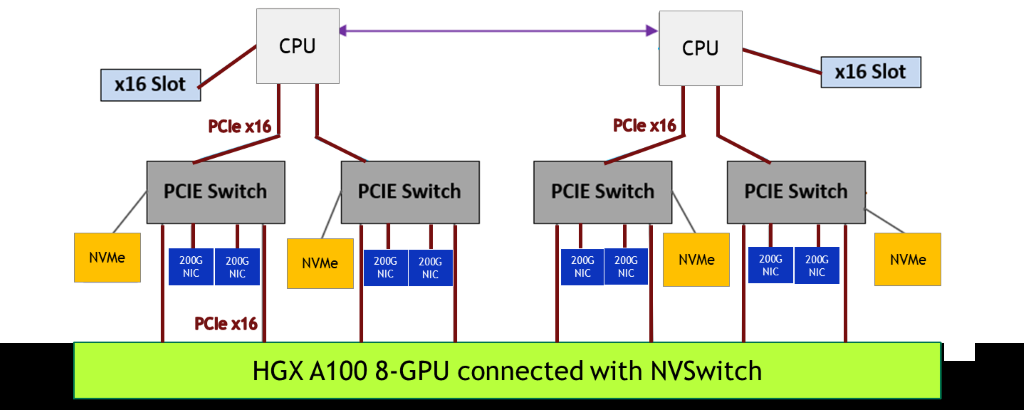 Производители серверов уже объявили о поддержке новых ускорителей в своих системах. Как правило, это уже имеющиеся платформы с возможностью установки 4 или 8 (реже 10) карт. Любопытно, что фактически единственным разумным вариантом для плат PCIe 4.0, как и в случае HGX/DGX A100, является использование платформ на базе AMD EPYC 7002.
14.05.2020 [18:52], Рамис Мубаракшин
NVIDIA представила ускорители A100 с архитектурой Ampere и систему DGX A100 на их основеNVIDIA официально представила новую архитектуру графических процессоров под названием Ampere, которая является наследницей представленной осенью 2018 года архитектуры Turing. Основные изменения коснулись числа ядер — их теперь стало заметно больше. Кроме того, новинки получили больший объём памяти, поддержку bfloat16, возможность разделения ресурсов (MIG) и новые интерфейсы: PCIe 4.0 и NVLink третьего поколения. NVIDIA A100 выполнен по 7-нанометровому техпроцессу и содержит в себе 54 млрд транзисторов на площади 826 мм2. По словам NVIDIA, A100 с архитектурой Ampere позволяют обучать нейросети в 40 раз быстрее, чем Tesla V100 с архитектурой Turing. 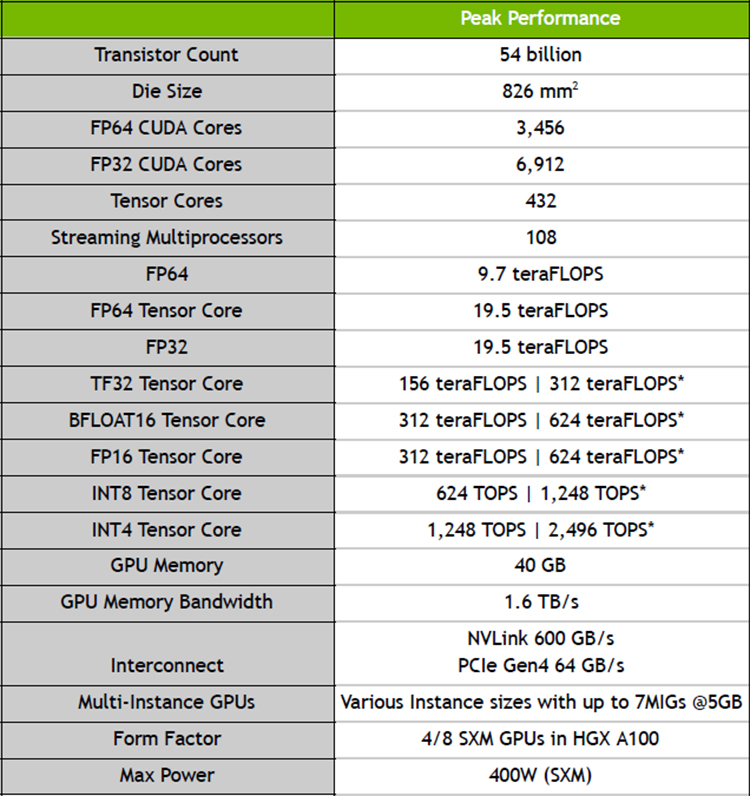
Характеристики A100 Первой основанной на ней вычислительной системой стала фирменная DGX A100, состоящая из восьми ускорителей NVIDIA A100 с NVSwitch, имеющих суммарную производительность 5 Пфлопс. Стоимость одной системы DGX A100 равна $199 тыс., они уже начали поставляться некоторым клиентам. Известно, что они будут использоваться в Аргоннской национальной лаборатории для поддержания работы искусственного интеллекта, изучающего COVID-19 и ищущего от него лекарство. Так как некоторые группы исследователей не могут себе позволить покупку системы DGX A100 из-за ее высокой стоимости, их планируют купить поставщики услуг по облачным вычислений и предоставлять удалённый доступ к высоким мощностям. На данный момент известно о 18 провайдерах, готовых к использованию систем и ускорителей на основе архитектуры Ampere, и среди них есть Google, Microsoft и Amazon. 
Система NVIDIA DGX A100 Помимо системы DGX A100, компания NVIDIA анонсировала ускорители NVIDIA EGX A100, предназначенная для периферийных вычислений. Для сегмента интернета вещей компания предложила плату EGX Jetson Xavier NX размером с банковскую карту.
02.12.2019 [14:58], Алексей Степин
NEC обновила серию ускорителей SX-Aurora и опубликовала планы относительно HPCКомпания NEC не спешит отказываться от своего уникального пути на рынке супервычислений и продолжает развивать серию векторных процессоров SX-Aurora. На конференции SC19 компания представила ряд новых решений, сочетающих в себе SX-Aurora и новейшие процессоры AMD «Rome» Intel Xeon 9200. 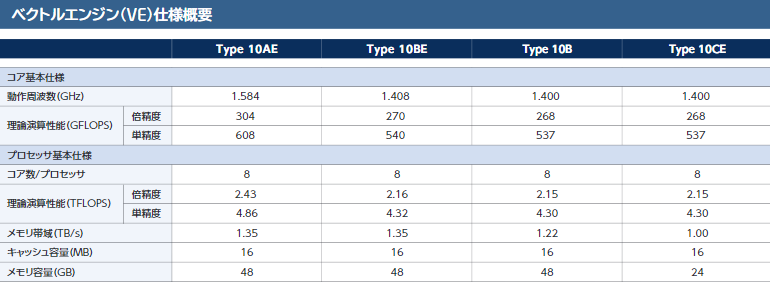
Типы ускорителей SX-Aurora Как и два года назад, основой платформы NEC является плата расширения «Type 10»; впрочем, в настоящее время производитель заменяет его на усовершенствованный «Type 10E» с более быстрыми сборками HBM2 на борту. За счёт этого ПСП удалось поднять на 10%, и даже в самом доступном варианте «Type 10CE» данный параметр теперь составляет 1 Тбайт/с против ранних 750 Гбайт/с. 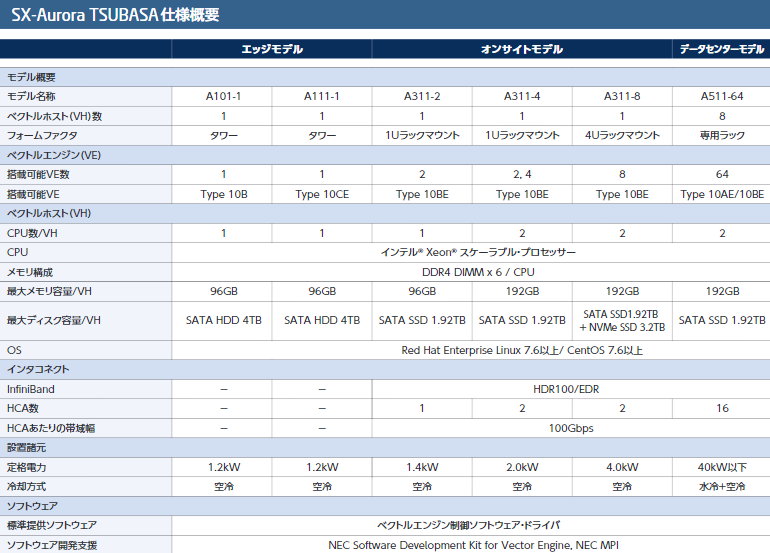
Системы NEC на базе SX-Aurora Массовый выпуск плат NEC «Type 10E» намечен на январь 2020 года. Всего в семействе будет четыре модели, отличающиеся тактовыми частотами, объёмом HBM2 и системой охлаждения. Последняя будет представлена в воздушном активном и пассивном вариантах, также будет выпускаться и вариант с жидкостным охлаждением. 
Сервер NEC A412-8 сочетает в себе SX-Aurora и AMD Rome Компания не собирается останавливаться на достигнутом и чип текущего поколения VE10 будет заменён на VE20 уже в середине или конце 2020 года. Он получит ещё более быструю память, больше векторных ядер (возможно 10 против 8 сегодняшних) и неизвестные пока новые функции. Следующее за ним поколение, VE30, должно появиться в 2022 году. Об этом поколении данных пока нет — известно лишь, что эти процессоры будут иметь новую архитектуру. 
27.09.2019 [09:36], Владимир Мироненко
LEGO для ускорителей: Inspur представила референсную OCP-систему для модулей OAMКомпания Inspur анонсировала 26 сентября на саммите OCP Regional Summit в Амстердаме новую референсую платформу с UBB-платой (Universal Baseboard) для ускорителей в форм-факторе Open Accelerator Module (OAM). OAM был представлен Facebook✴ в марте этого года. Он очень похож на слегка увеличенный (102 × 165 мм) модуль NVIDIA SXM2: «плиточка» с группами контактов на дне и радиатором на верхней крышке. 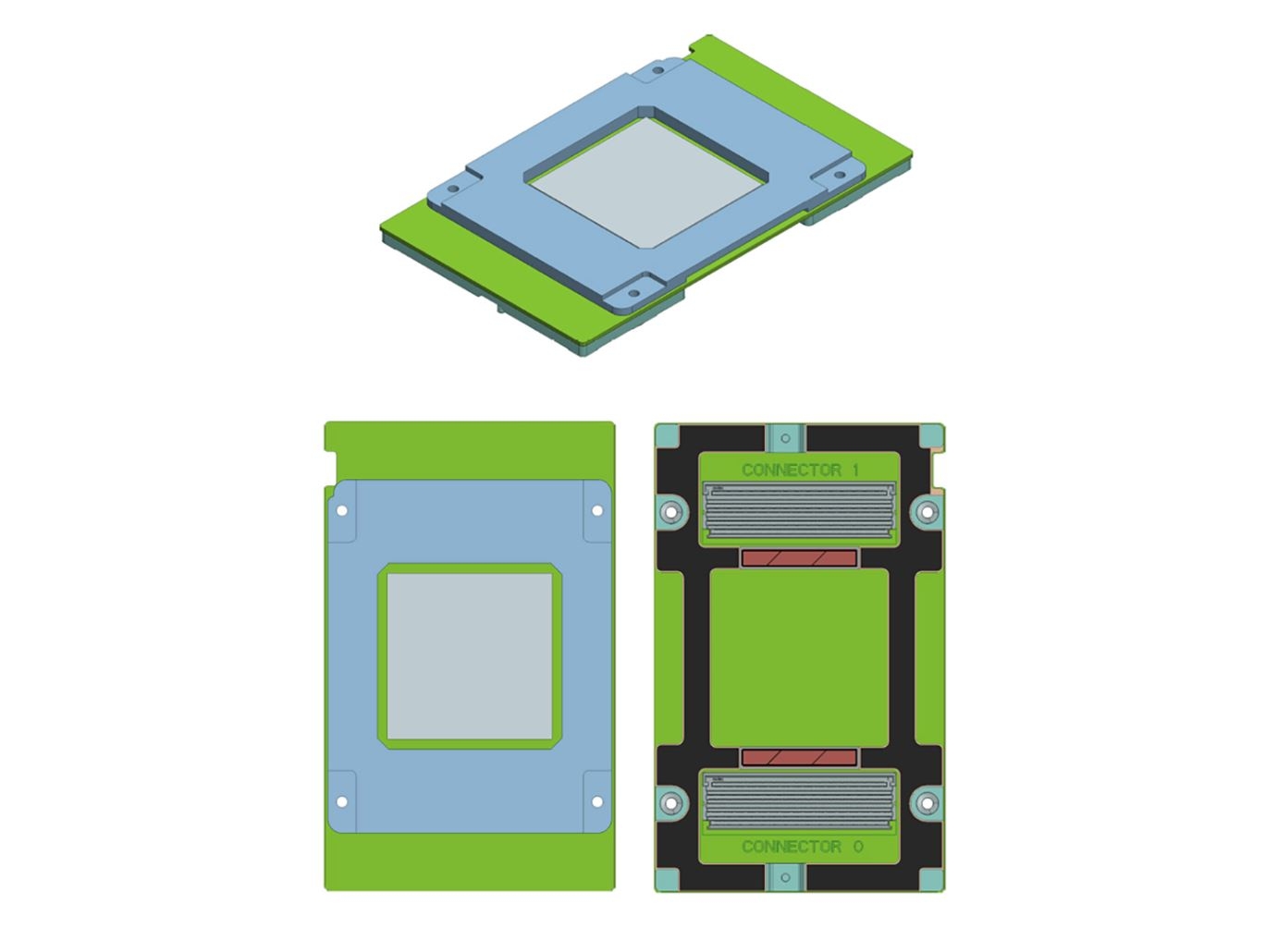 Ключевые спецификации модуля OAM:
 OAM, в отличие от классических карт PCI-E, позволяет повысить плотнсть размещения ускорителей в системе без ущерба их охлаждению, а также увеличить скорость обмена данными между модулями, благодаря легко настраиваемой топологии соединений между ними. В числе поддержавших проект OCP Accelerator Module такие компании, как Intel, AMD, NVIDIA, Google,Microsoft, Baidu и Huawei. 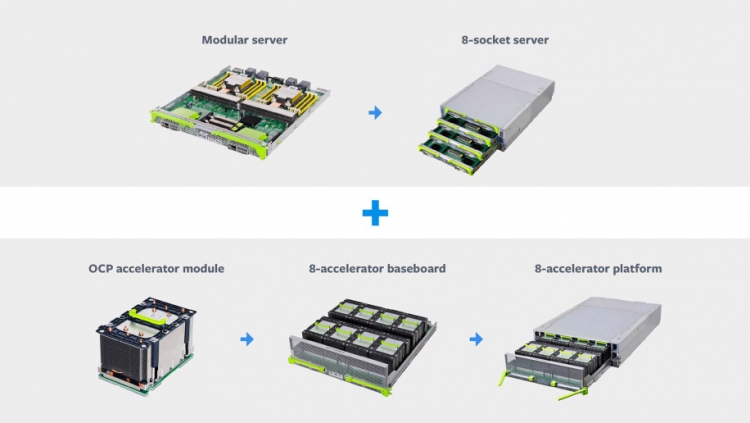 Inspur приступил к разработке референс-системы для ускорителей OAM в связи растущими требованиями, предъявляемыми к приложениям ИИ и необходимостью обеспечения взаимодействия между несколькими модулями на основе ASIC или GPU. Данная платформа представляет собой 21" шасси стандарта Open Rack V2 с BBU для восьми модулей OAM. Плата BBU снабжена восемью коннекторами QSFP-DD для прямого подключения к другим BBU. Система Inspur OAM позволяет создавать кластеры из 16, 32, 64 и 128 модулей OAM и имеет гибкую архитектуру для поддержки инфраструктур с несколькими хостами. По требованию заказчика Inspur также может поставлять 19-дюймовые системы OAM. Одной из первых преимущества новинки для задач, связанных с ИИ и машинным обучением, оценила китайская Baidu, продемонстрировавшая собственное серверное решение X-Man 4.0 на базе платформы Inspur и восьми ускорителей. 
27.08.2019 [11:00], Геннадий Детинич
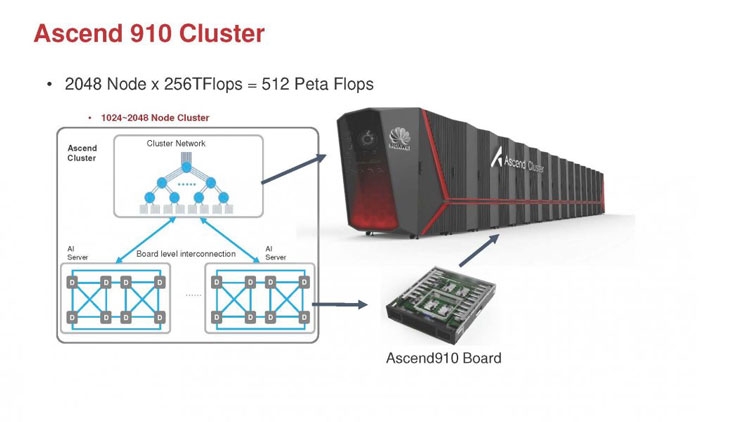
Huawei Ascend 910: китайская альтернатива ИИ-платформам NVIDIAГлубокое машинное обучение ― это сравнительно новая область приложения для вычислительных архитектур. Как всё новое, ML заставляет искать альтернативные пути решения задач. В этом поиске китайские разработчики оказались на равных и даже в привилегированных условиях, что привело к появлению в Китае мощнейших ИИ-платформ. Как всем уже известно, на конференции Hot Chips 31 компания Huawei представила самый мощный в мире ИИ-процессор Ascend 910. Процессоры для ИИ каждый разрабатывает во что горазд, но все разработчики сравнивают свои творения с ИИ-процессорами компании NVIDIA (а NVIDIA с процессорами Intel Xeon). Такова участь пионера. NVIDIA одной из первых широко начала продвигать свои модифицированные графические архитектуры в качестве ускорителей для решения задач с машинным обучением.  Гибкость GPU звездой взошла над косностью x86-совместимой архитектуры, но во время появления новых подходов и методов тренировки машинного обучения, где пока много открытых дорожек, она рискует стать одной из немногих. Компания Huawei со своими платформами вполне способна стать лучшей альтернативой решениям NVIDIA. Как минимум, это произойдёт в Китае, где Huawei готовится выпускать и надеется найти сбыт для миллионов процессоров для машинного обучения. 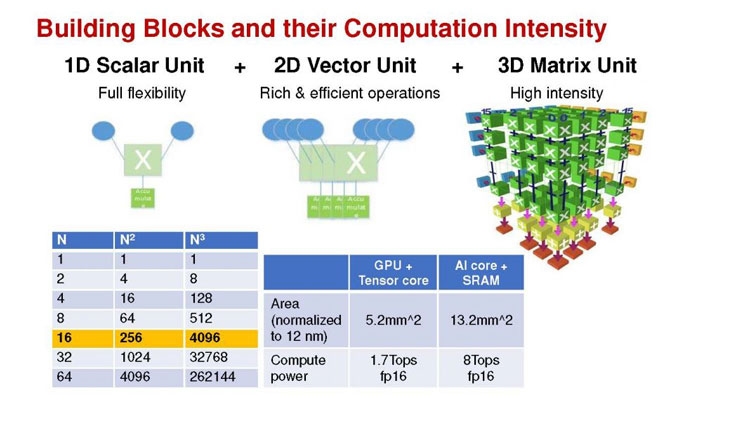 Мы уже публиковали анонс наиболее мощного ускорителя для ML чипа Huawei Ascend 910. Сейчас посмотрим на это решение чуть пристальнее. Итак, Ascend 910 выпускается компанией TSMC с использованием второго поколения 7-нм техпроцесса (7+ EUV). Это техпроцесс характеризуется использованием сканеров EUV для изготовления нескольких слоёв чипа. На конференции Huawei сравнивала Ascend 910 с ИИ-решением NVIDIA на архитектуре Volta, выпущенном TSMC с использованием 12-нм FinFET техпроцесса. Выше на картинке приводятся данные для Ascend 910 и Volta, с нормализацией к 12-нм техпроцессу. Площадь решения Huawei на кристалле в 2,5 раза больше, чем у NVIDIA, но при этом производительность Ascend 910 оказывается в 4,7 раза выше, чем у архитектуры Volta. 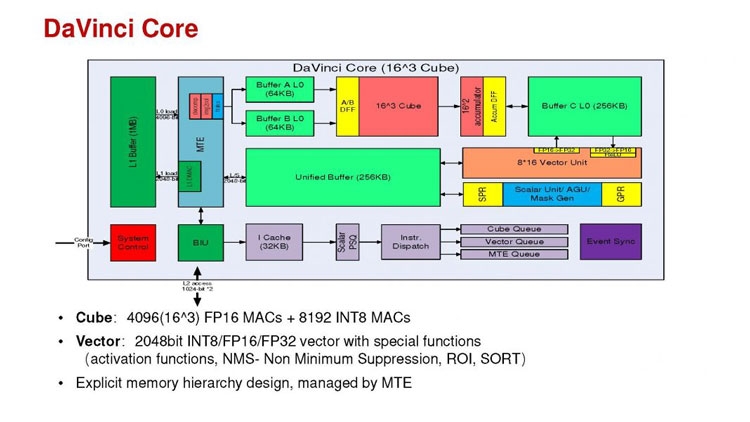 Также на схеме видно, что Huawei заявляет о крайне высокой масштабируемости архитектуры. Ядра DaVinci, лежащие в основе Ascend 910, могут выпускаться в конфигурации для оперирования скалярными величинами (16), векторными (16 × 16) и матричными (16 × 16 × 16). Это означает, что архитектура и ядра DaVinci появятся во всём спектре устройств от IoT и носимой электроники до суперкомпьютеров (от платформ с принятием решений до машинного обучения). Чип Ascend 910 несёт матричные ядра, как предназначенный для наиболее интенсивной работы. 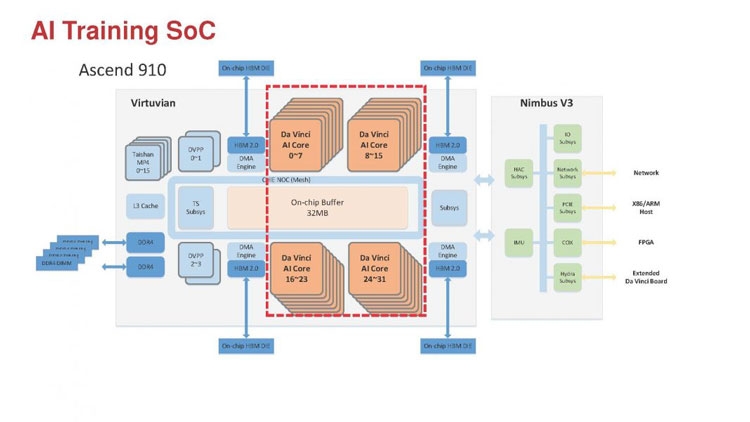 Ядро DaVinci в максимальной конфигурации (для Ascend 910) содержит 4096 блоков Cube для вычислений с половинной точностью (FP16). Также в ядро входят специализированные блоки для обработки скалярных (INT8) и векторных величин. Пиковая производительность Ascend с 32 ядрами DaVinci достигает 256 терафлопс для FP16 и 512 терафлопс для целочисленных значений. Всё это при потреблении до 350 Вт. Альтернатива от NVIDIA на тензорных ядрах способна максимум на 125 терафлопс для FP16. Для решения задач ML чип Huawei оказывается в два раза производительнее. 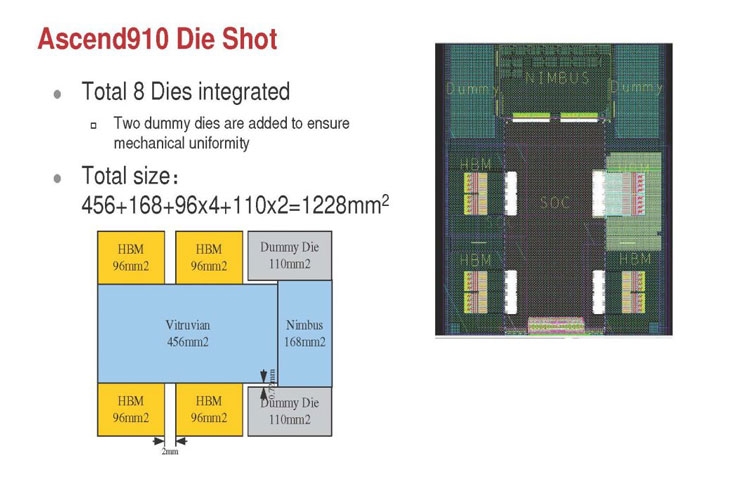 Помимо ядер DaVinci на кристалле Ascend 910 находятся несколько других блоков, включая контроллер памяти HBM2, 128-канальный движок для декодирования видеопотоков. Мощный чип для операций ввода/вывода Nimbus V3 выполнен на отдельном кристалле на той же подложке. Рядом с ним для механической прочности всей конструкции пришлось расположить два кристалла-заглушки, каждый из которых имеет площадь 110 мм2. С учётом болванок и четырёх чипов HBM2 площадь всех кристаллов достигает 1228 мм2. 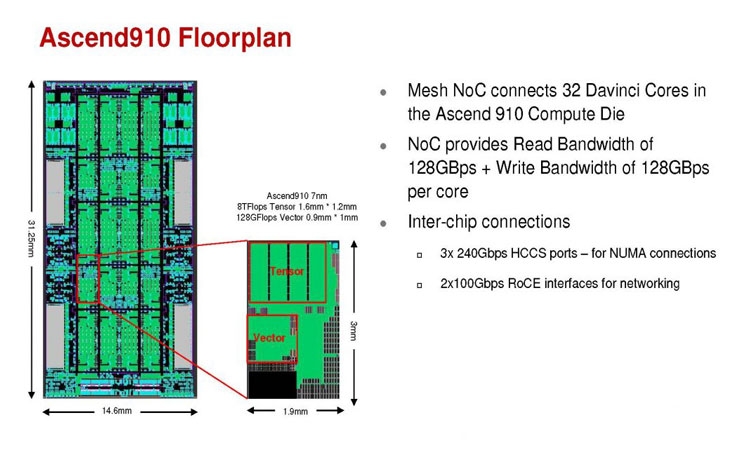 Для связи ядер и памяти на кристалле создана ячеистая сеть в конфигурации 6 строк на 4 колонки со скоростью доступа 128 Гбайт/с на каждое ядро для одновременных операций записи и чтения. Для соединения с соседними чипами предусмотрена шина со скоростью 720 Гбит/с и два линка RoCE со скоростью 100 Гбит/с. К кеш-памяти L2 ядра могут обращаться с производительностью до 4 Тбайт/с. Скорость доступа к памяти HBM2 достигает 1,2 Тбайт/с.  В каждый полочный корпус входят по 8 процессоров Ascend 910 и блок с двумя процессорами Intel Xeon Scalable. Спецификации полки ниже на картинке. Решения собираются в кластер из 2048 узлов суммарной производительностью 512 петафлопс для операций FP16. Кластеры NVIDIA DGX Superpod обещают производительность до 9,4 петафлопс для сборки из 96 узлов. В сравнении с предложением Huawei это выглядит бледно, но создаёт стимул рваться вперёд. 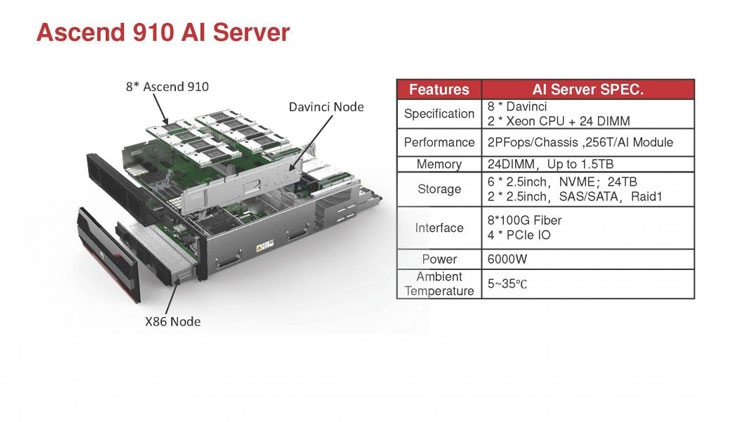
20.06.2016 [19:30], Илья Гавриченков
Intel представила процессоры Xeon Phi Knights LandingМногоядерные ускорители вычислений Intel Xeon Phi продолжают своё развитие. Об их очередном поколении с кодовым именем Knights Landing разработчик рассказывает уже почти три года, а с конца прошлого года даже поставляет образцы систем с ними своим избранным партнёрам. Однако до официального анонса дело дошло только сейчас. В рамках проходящей в эти дни в Германии конференции ISC High Performance 2016 компания Intel официально объявила о выходе принципиально новых Xeon Phi на базе дизайна Knights Landing, ключевое свойство которых заключается в том, что теперь это — не сопроцессоры, а полноценные x86-процессоры, способные взять на себя роль центрального компонента системы. Иными словами, новые Xeon Phi могут работать полностью самостоятельно, не нуждаясь ни в каком дополнительном управляющем CPU. И это очень важное улучшение, так как проведённое коренное изменение архитектуры ликвидирует узкое место — шину PCI Express, которую используют для передачи данных предшествующие и конкурирующие ускорители вычислений, например, базирующиеся на GPU. 
Источник изображений: Intel Knights Landing воплощают собой уже третье поколение многоядерной x86-архитектуры Intel. Предыдущее поколение, известное под кодовым именем Knights Corner, базировалось на Pentium-подобных ядрах P54C. Новая же версия ускорителей переехала на модифицированную 14-нм микроархитектуру Airmont, известную по процессорам Atom. Однако в Knights Landing ядра Airmont попарно объединены в модули, которые включают также мегабайтный L2-кеш и четыре блока VPU (Vector Processing Unit), отвечающих за поддержку векторных инструкций AVX-512. Всего в новых процессорах Xeon Phi содержится до 36 таких модулей, то есть, общее число ядер в ускорителе может достигать 72. При этом каждое ядро дополнительно поддерживает технологию Hyper-Threading и способно выполнять до четырёх потоков одновременно, что наделяет Xeon Phi впечатляющим арсеналом средств для работы с параллельными вычислениями. Учитывая, что в Knights Landing производительность на поток по сравнению с Knights Corner выросла примерно втрое только за счёт смены микроархитектуры, обновление ускорителей Xeon Phi дало им возможность дотянуться до планки в 3 Тфлопс. Процессоры Knights Landing снабжены также интегрированной памятью MCDRAM с пропускной способностью до 500 Гбайт/с и объёмом 16 Гбайт, которая может взаимодействовать с системной шестиканальной DDR4-памятью по нескольким принципиально различным алгоритмам. Упоминания заслуживает и реализация в новых Xeon Phi отдельного двухпортового 100 Гбит/с-контроллера Omni-Path, который предполагается использовать для высокоскоростного объединения узлов, основанных на Knights Landing, в вычислительные кластеры. Объявленная сегодня линейка процессоров Xeon Phi поколения Knights Landing включает четыре модели с числом ядер от 64 до 72 и частотой от 1,3 до 1,5 ГГц.  Стоит отметить, что в настоящее время для заказчиков доступны лишь три младшие модели: Xeon Phi 7250, 7230 и 7210. Самая же мощная 72-ядерная версия ускорителя, Xeon Phi 7290, обещана к сентябрю. Также пока Intel не поставляет варианты с интегрированным контроллером Omni-Path, который по плану появится в перечисленных моделях в октябре этого года. Высокая производительность процессоров Xeon Phi, простая масштабируемость систем на их основе, а также полная совместимость с x86-экосистемой и знакомым всем средствами разработки, делает новинки отличным вариантом для использования в массе областей, где требуются параллельные высокопроизводительного вычисления. И особенно Intel подчёркивает применимость построенных на Xeon Phi кластеров в системах машинного обучения и искусственного интеллекта, то есть тех областях, где в последнее время высокую активность развила NVIDIA, реализующая свои ускорители семейства Tesla. В подтверждение лидирующих характеристик Knights Landing, компания Intel приводит информацию о кратном превосходстве системы на базе Xeon Phi 7250 над системой, в которой используется конкурирующий ускоритель вычислений NVIDIA Tesla K80 и пара центральных процессоров Xeon E5-2697 v4.  При этом, Intel говорит не только о достигающем пятикратного размера преимуществе Xeon Phi в производительности. Согласно информации компании, конфигурация с процессором Xeon Phi 7250 оказывается в восемь раз экономичнее и в девять — дешевле. Учитывая всё сказанное, Intel ожидает, что внедрение новых Xeon Phi пойдёт очень быстрыми темпами. До конца года производитель намеревается продать более ста тысяч процессоров, а готовые системы на базе Knights Landing будут поставлять более 50 компаний, включая Dell, Fujitsu, Hitachi, HP, Inspur, Lenovo, NEC, Oracle, Quanta, SGI, Supermicro, Colfax и другие. Кстати, в этом списке место нашлось и для российского интегратора — группы компаний РСК — которая собирается поставлять высокоплотные кластерные решения на базе Xeon Phi, оснащённые системами жидкостного охлаждения. |
|


