Материалы по тегу: коммутатор
|
27.03.2024 [23:40], Сергей Карасёв
Coherent представила оптические коммутаторы для дата-центров, ориентированных на задачи ИИCoherent анонсировала специализированные оптические коммутаторы для ИИ-кластеров высокой плотности. В основу устройств Optical Circuit Switch (OCS) положена фирменная платформа кросс-коммутации Lightwave Cross-Connect (DLX). В изделиях, в отличие от традиционных коммутаторов, не применяются приемопередатчики для преобразования фотонов в электроны и обратно. Вместо этого все операции осуществляются в оптическом тракте: импульсы поступают в один порт и выходят из другого (конечно, с небольшим ослаблением). Coherent выделяет несколько ключевых преимуществ своей технологии. Прежде всего значительно возрастает производительность, что важно при решении ресурсоёмких задач, связанных с приложениями ИИ. Кроме того, благодаря отказу от преобразования среды сокращаются энерозатраты. Наконец, отпадает необходимость в обновлении собственно коммутаторов при установке в ЦОД оборудования следующего поколения. Это значительно повышает окупаемость капитальных затрат. 
Источник изображения: Coherent Представленное решение насчитывает 300 входных и 300 выходных оптических портов. Коммутаторы OCS помогают решить проблемы масштабируемости и надёжности дата-центров, ориентированных на приложения ИИ. Аналитики Dell'Oro Group отмечают, что для ИИ-задач требуется более высокий уровень отказоустойчивости, нежели для традиционных приложений. Крайне важно, чтобы коммутаторы, используемые в составе ИИ-платформ, не провоцировали никаких перебоев во время обучения или эксплуатации больших языковых моделей. Устройства Coherent, как сообщается, обеспечивают необходимый уровень надёжности. Массовые поставки новых коммутаторов планируется организовать в 2025 году. При этом Google уже использует в своих дата-центрах оптические коммутаторы (OCS) собственной разработки на базе MEMS-переключателей для формирования ИИ-кластеров, а Meta✴ совместно с MIT разработала систему TopoOpt, представляющую собой оптическую патч-панель с манипулятором, который позволяет менять топологию сети.
22.03.2024 [09:09], Алексей Степин
NVIDIA представила 800G-платформы Quantum-X800 и Spectrum-X800 для InfiniBand- и Ethernet-фабрик нового поколенияДополнением к только что представленным ИИ-ускорителям NVIDIA Blackwell станут новые сетевые 800G-платформы Quantum-X800 и Spectrum-X800, а также сетевые адаптеры ConnectX-8. Именно они позволят вывести масштабирование ИИ-кластеров на новый уровень и позволят «прокормить» гигантские массивы ускорителей в дата-центрах гиперскейлеров. Платформа NVIDIA Quantum-X800 ориентирована на наиболее производительные ИИ- и HPC-кластеры. Она использует новое поколение технологии InfiniBand, всё ещё обладающей рядом преимуществ в сравнении с Ethernet, и включает в себя обновлённые SHARP-движки. Технология SHARPv4 реализует «вычисления в сети» (In-Network Computing), что позволяет не только существенно разгрузить вычислительные узлы и серверы, но и обеспечить более высокую пропускную способность интерконнекта вкупе с более серьёзными возможностями его масштабирования. 
NVIDIA Q3400-RA 4U (справа) и SN5600. Источник изображений здесь и далее: NVIDIA Основой платформы Quantum-X800 стал 4U-коммутатор Q3400-RA, впервые в индустрии, как говорит компания, использующий 200G-блоки SerDes для каждой линии InfiniBand. Коммутатор располагает 144 портами 800G в 72 OSFP-модулях и выделенным портом для Unified Fabric Manager. Новинка имеет стандартное 19″ исполнение с воздушным охлаждением, но есть и вариант Q3400-LD с жидкостным охлаждением, предназначенный для 21″ OCP-стоек. В двухуровневом варианте fat tree коммутаторы позволят объединить 10 368 NIC.  Основным адаптером для новой платформы InfiniBand является ConnectX-8 SuperNIC с интерфейсом PCIe 6.0. Он является частью SHARPv4 и предлагается в однопортовом (OSFP224) и двухпортовом (QSFP112) вариантах и в нескольких форм-факторах, включая OCP 3.0. На платах также имеется разъём SocketDirect на 16 линий PCIe. Также компания представила компоненты NVIDIA LinkX: оптические трансиверы 2xDR4/2xFR4 и активные медные кабели (LACC).  Не забыла NVIDIA и про Ethernet: здесь вывести производительность сети на новый уровень должна платформа Spectrum-X800. Её основой служит новейший коммутатор SN5600 — это, по словам NVIDIA, первый в мире Ethernet-коммутатор класса 800GbE, специально разработанный для применения гиперскейлерами в крупных облачных ИИ-комплексах. Применяемая архитектура позволяет гарантировать каждому клиенту оптимальный и постоянный уровень производительности, а потоковая телеметрия позволит находить и ликвидировать возможные «бутылочные горлышки» в сети буквально на лету.  Общая пропускная способность SN5600 составляет 51,2 Тбит/с. Коммутатор располагает 64 портами 800GbE в формате OSFP. В нём используется ASIC пятого поколения на базе архитектуры Spectrum-4. В качестве основного адаптера предлагается SuperNIC на базе DPU BlueField-3 с двумя 400GbE-портами. 
Фото: Twitter/NVIDIANetworkng Spectrum-X800 сопровождает полноценный спектр инфраструктурных компонентов, включая кабели DAC и LACC. С оптическими трансиверами длина соединения 800GbE может достигать двух километров. Начиная со следующего года, решения на базе новых сетевых платформ NVIDIA будут доступны от широкого круга поставщиков оборудования, включая Aivres, DDN, Dell Technologies, Eviden, Hitachi Vantara, HPE, Lenovo, Supermicro и VAST Data.
17.08.2023 [20:16], Алексей Степин
Brocade представила новые FC64-продукты — 512-портовый директор X7 и Ethernet-мост 7850 Extension SwitchПодразделение Brocade Storage Networking компании Broadcom представило новые коммутаторы класса Director, предлагающие до 512 портов FC64. Предельная пропускная способность заявлена на уровне 39,6 Тбайт/с. При этом сохранена совместимость с предыдущими поколениями Fibre Channel. Кроме того, был представлен и новый мост Ethernet ↔ Fibre Channel, который позволяет создавать распределённые SAN. Новые устройства серии Brocade X7 Directors являются наиболее высокоплотными в индустрии — они представлены в вариантах с 256 и 512 портами Fibre Channel седьмого поколения (64 Гбит/с на порт) в исполнениях 8U и 14U соответственно. Первое поколение X7 увидело свет ещё в 2020 году, но тогда оно было ограничено использованием 48-портовых лезвий FC64, что давало максимум 384 порта. Новый вариант использует новые 64-портовые модули с трансиверами SFP-DD, позволившими на треть поднять плотность портов. Устройства работают под управлением Fabric OS 9.0.x. 
Источник изображений здесь и далее: Broadcom Другой интересной новинкой Brocade является коммутатор Brocade 7850 Extension Switch, делающий более простым построение географически распределённой SAN. По сути, это мост с 24 портами FC64/FICON, обеспечивающий проброс FC-трафика, для чего имеется 16 портов 25/10GbE, а также два WAN-порта 100GbE. WAN-трафик шифруется на лету на полной скорости по алгоритму AES с 256-битным ключом. Имеются механизмы защиты от кибер-атак, а также автоматическая проверка целостности ПО и аппаратного обеспечения. 
10.08.2023 [00:10], Алексей Степин
XConn Technologies представила гибридный коммутатор CXL 2.0/PCIe 5.0XConn Technologies представила первый, по её словам, в индустрии гибридный чип-коммутатор CXL 2.0/PCIe 5.0 XC50256, получивший кодовое название Apollo. Утверждается, что он обеспечивает самую низкую латентность port-to-port, а также самое низкое энергопотребление в отрасли. Коммутатор способен работать с 256 линиями интерфейса и разработан с учётом потребностей, характерных для мира ИИ и машинного обучения, а также HPC-сегмента. Чип Apollo совместим с существующей инфраструктурой CXL 1.1, но поддерживает и режим 2.0, включая актуальные режимы CXL.mem или CXL.cache. 
Источник изображений здесь и далее: XConn Technologies Но наиболее интересной особенностью Apollo является возможность работы нового коммутатора в гибридном режиме — он способен одновременно обслуживать CXL и PCI Express, что в ряде случаев позволит избежать использования дополнительных коммутаторов под каждый стандарт, а значит, и снизить стоимость и сложность разработки конечной системы. 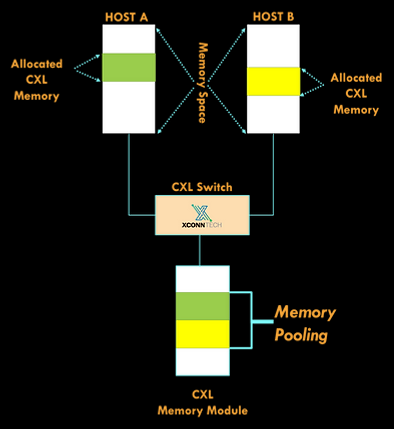
Новый коммутатор поддерживает подключение нескольких хостов к единому CXL-пулу памяти Также компания анонсировала другой коммутатор, XC51256. Он также работает с 256 линиями, но поддерживает только PCI Express 5.0. Тем не менее, это самый высокоплотный PCIe-коммутатор на сегодня, поскольку большинство решений конкурентов обеспечивает в лучшем случае вдвое меньше линий PCI Express, утверждает XConn. ТXC51256 идеален для построения систем класса JBOA (Just-a-Bunch-Of-Accelerators). В настоящее время образцы Apollo XC50256 и XC51256 уже доступны для заказчиков.
19.04.2023 [22:00], Алексей Степин
Broadcom представила чип-коммутатор Jericho3-AI для ИИ-платформ, попутно раскритиковав NVIDIAКомпания Broadcom, один из ведущих поставщиков «кремния» для сетевых решений, анонсировала новый сетевой процессор Jerico3-AI, который ориентирован на ИИ-системы. Более того, Broadcom считает подход NVIDIA к «интеллектуальным сетевым решениям» с использованием InfiniBand неверным и даже вредным для кластерных ИИ-систем. Ethernet-коммутаторы компании можно разделить три ветви: наиболее высокопроизводительные чипы Tomahawk, ориентированная на дополнительные возможности ветвь Trident и, наконец, серия Jericho, отличающаяся наибольшей гибкостью в программировании и располагающая более ёмкими буферами. Чип Jericho3-AI BCM88890 — новинка в последней категории, относящаяся к классу 28,8 Тбит/с. Новый коммутатор имеет 144 линка SerDes (106Gbps, PAM4) и может работать в конфигурации 18×800GbE, 36×400GbE или 72×200GbE. 
Источник здесь и далее: Broadcom (via ServeTheHome) В своей презентации Broadcom раскритиковала традиционный подход NVIDIA и других крупных игроков на сетевом рынке, заявив о том, что прямое наращивание пропускной способности и снижение латентности кластерной сети якобы является тупиковой ветвью развития. Вместо этого фабрика на базе Jericho3-AI, по словам компании, позволяет сделать так, чтобы процесс обучения нейросети как можно меньше времени тратил не сетевые операции.  Новый коммутатор обеспечивает идеальную балансировку загрузки, гарантирующую отсутствие заторов, и автоматическое переключение отказавшего соединения на резервное менее, чем за 10-нс, а также позволяет создавать большие «плоские» сети (до 32 тыс. портов 800GbE), характерные для ИИ-кластеров. Каждый ускоритель может получить 800G-подключение, а суммарная производительность фабрики на базе новых коммутаторов может достигать 26 Пбит/с. 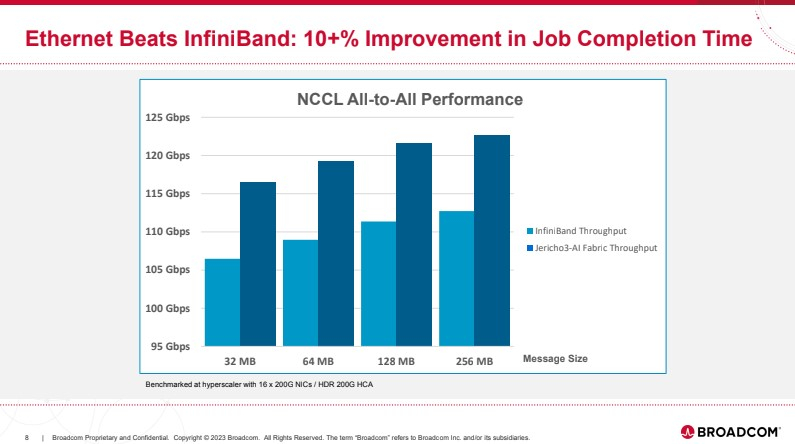 Broadcom утверждает, что сеть Ethernet на базе Jericho3-AI превосходит аналогичную по классу сеть NVIDIA InfiniBand в тестах с использованием NCCL. При этом новый коммутатор не содержит никаких вычислительных мощностей общего назначения — он проще, а за счёт использования стандарта Ethernet сети на его основе универсальны, что также снижает стоимость владения инфраструктурой.  Высокая степень интегрированности обеспечит и большую экономичность, а значит, решения на базе нового коммутатора Broadcom окажутся и более дружелюбны к экологии. Новые чипы уже доступны избранным клиентам Broadcom.
26.08.2022 [12:45], Алексей Степин
Интерконнект NVIDIA NVLink 4 открывает новые горизонты для ИИ и HPCПотребность в действительно быстром интерконнекте для ускорителей возникла давно, поскольку имеющиеся шины зачастую становились узким местом, не позволяя «прокормить» данными вычислительные блоки. Ответом NVIDIA на эту проблему стало создание шины NVLink — и компания продолжает активно развивать данную технологию. На конференции Hot Chips 34 было продемонстрировано уже четвёртое поколение, наряду с новым поколением коммутаторов NVSwitch. 
Изображения: NVIDIA Возможность использования коммутаторов для NVLink появилась не сразу, изначально использовалось соединение блоков ускорителей по схеме «точка-точка». Но дальнейшее наращивание числа ускорителей по этой схеме стало невозможным, и тогда NVIDIA разработала коммутаторы NVSwitch. Они появились вместе с V100 и предлагали до 50 Гбайт/с на порт. Нынешнее же, третье поколение NVSwitch и четвёртое поколение NVLink сделали важный шаг вперёд — теперь они позволяют вынести NVLink-подключения за пределы узла. 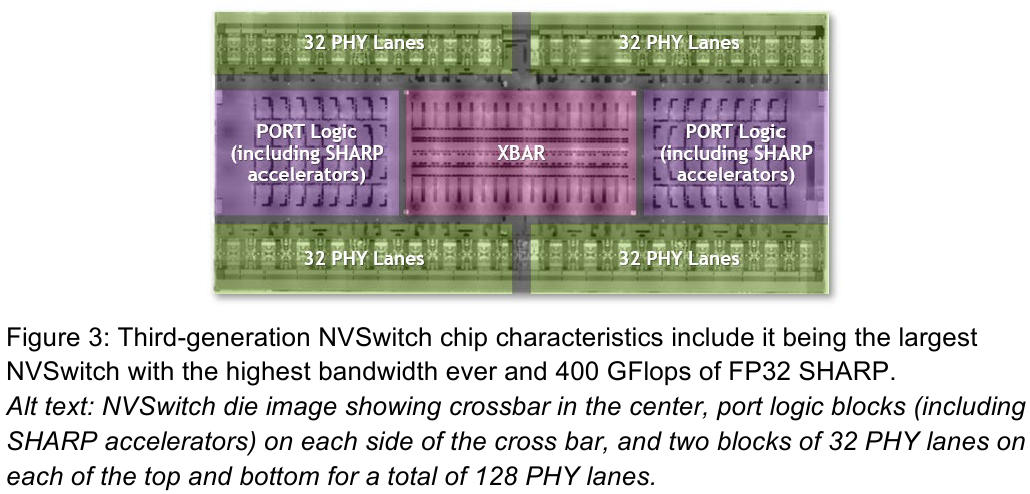 Так, совокупная пропускная способность одного чипа NVSwitch теперь составляет 3,2 Тбайт/с в обе стороны в 64 портах NVLink 4 (x2). Это, конечно, отразилось и на сложности самого «кремния»: 25,1 млрд транзисторов (больше чем у V100), техпроцесс TSMC 4N и площадь 294мм2. Скорость одной линии NVLink 4 осталась равной 50 Гбайт/с, но новые ускорители H100 имеют по 18 линий NVLink, что даёт впечатляющие 900 Гбайт/с. В DGX H100 есть сразу четыре NVSwitch-коммутатора, которые объединяют восемь ускорителей по схеме каждый-с-каждым и дополнительно отдают ещё 72 NVLink-линии (3,6 Тбайт/с). 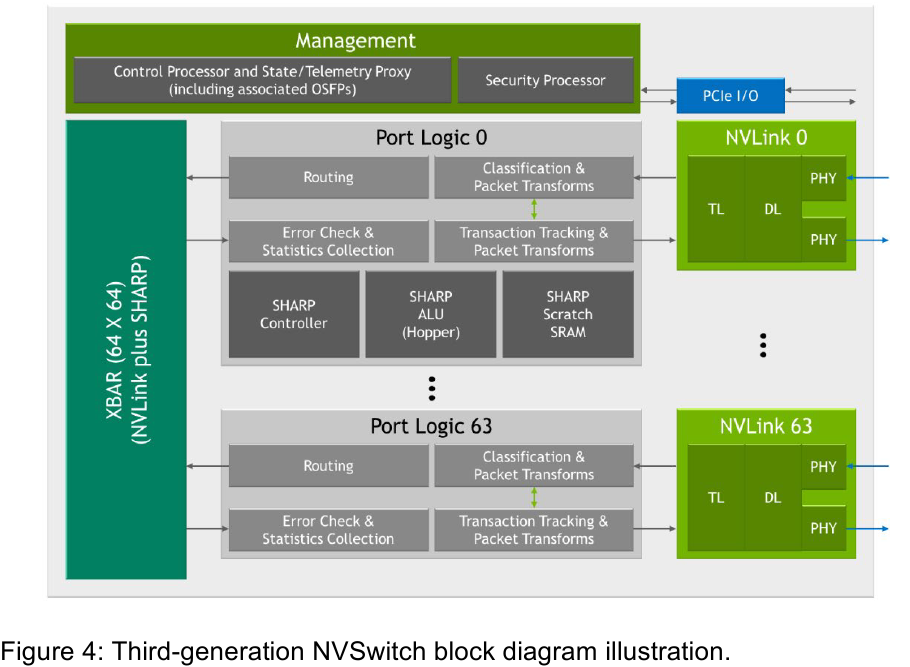 При этом у DGX H100 сохраняются прежние 400G-адаптеры Ethernet/InfiniBand (ConnectX-7), по одному на каждый ускоритель, и пара DPU BlueField-3, тоже класса 400G. Несколько упрощает физическую инфраструктуру то, что для внешних NVLink-подключений используются OSFP-модули, каждый из которых обслуживает 4 линии NVLink. Любопытно, что электрически интерфейсы совместимы с имеющейся 400G-экосистемой (оптической и медной), но вот прошивки для модулей нужны будут кастомные. 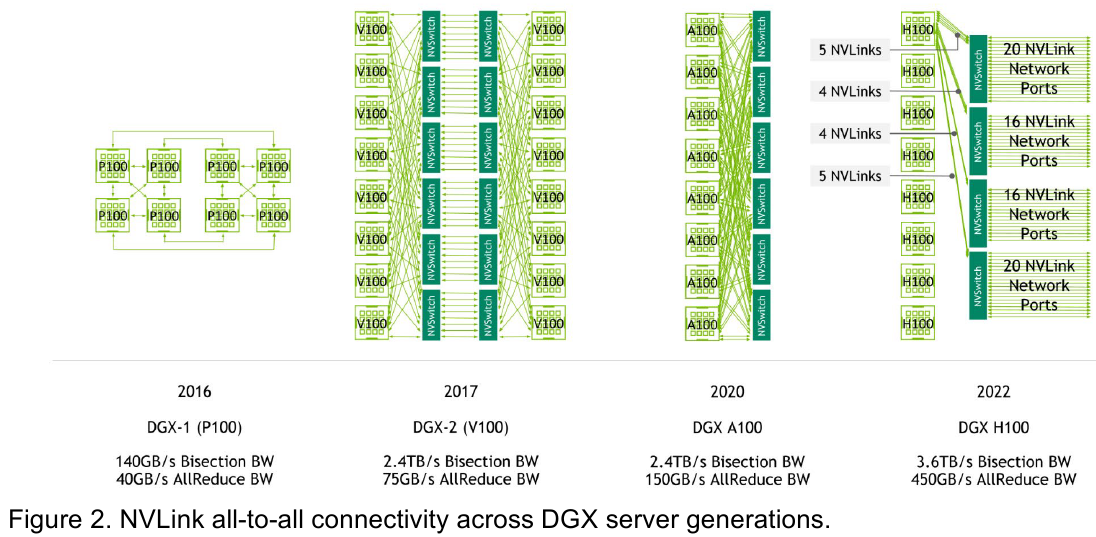 Подключаются узлы DGX H100 к 1U-коммутатору NVLink Switch, включающему два чипа NVSwitch третьего поколения: 32 OSFP-корзины, 128 портов NVLink 4 и агрегированная пропускная способность 6,4 Тбайт/с. В составе DGX SuperPOD есть 18 коммутаторов NVLink Switch и 256 ускорителей H100 (32 узла DGX). Таким образом, можно связать ускорители и узлы 900-Гбайт/с каналом. Как конкретно, остаётся на усмотрение пользователя, но сама NVLink-сеть поддерживает динамическую реконфигурацию на лету. 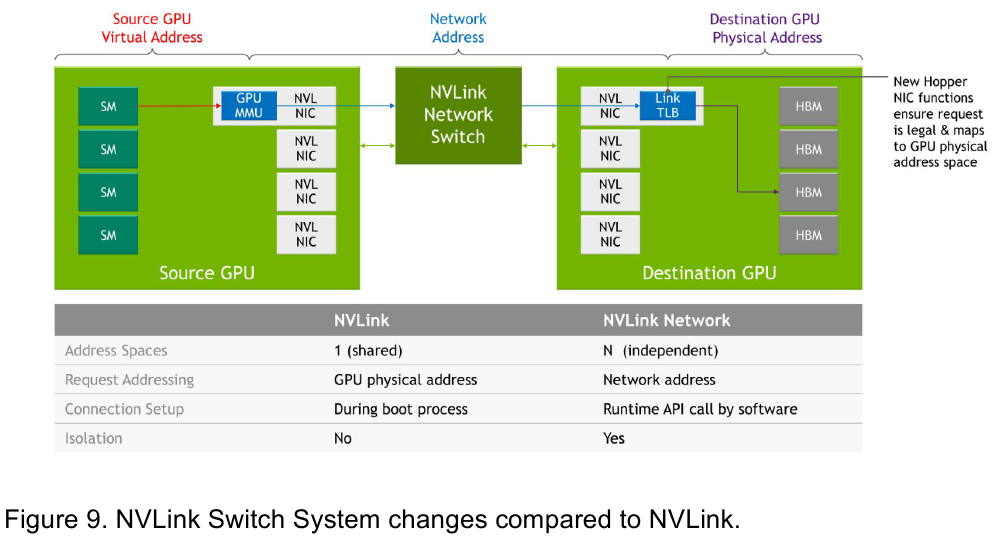 Ещё одна особенность нового поколения NVLink — продвинутые аппаратные SHARP-движки, которые избавляют CPU/GPU от части работ по подготовке и предобработки данных и избавляющие саму сеть от ненужных передач. Кроме того, в NVLink-сети реализованы разделение и изоляция, брандмауэр, шифрование, глубокая телеметрия и т.д. В целом, новое поколение NVLink получило полуторакратный прирост в скорости обмена данными, а в отношении дополнительных сетевых функций он стал трёхкратным. Всё это позволит освоить новые класса HPC- и ИИ-нагрузок, однако надо полагать, что удовольствие это будет недешёвым.
09.11.2021 [12:17], Алексей Степин
NVIDIA представила Quantum-2, первый 400G-коммутатор InfiniBand NDRNVIDIA, нынешний владелец Mellanox, представила обновления своих решений InfiniBand NDR: коммутаторы Quantum-2, сетевые адаптеры ConnectX-7 и ускорители DPU BlueField-3. Это весьма своевременный апдейт, поскольку 400GbE-решения набирают популярность, а с приходом PCIe 5.0 в серверный сегмент станут ещё более актуальными. 
NVIDIA Quantum-2 (Здесь и ниже изображения NVIDIA) Первый и самый важный анонс — это платформа Quantum-2. Новый коммутатор не только обеспечивает вдвое более высокую пропускную способность на порт (400 Гбит/с против 200 Гбит/c), но также предоставляет в три раза больше портов, нежели предыдущее поколение. Это сочетание позволяет снизить потребность в коммутаторах в 6 раз при той же суммарной ёмкости сети. При этом новая более мощная инфраструктура также окажется более экономичной и компактной.  Более того, Quantum-2 относится к серии «умных» устройств и содержит в 32 раза больше акселераторов, нежели Quantum HDR первого поколения. В нём также реализована предиктивная аналитика, позволяющая избежать проблем с сетевой инфраструктурой ещё до их возникновения; за это отвечает технология UFM Cyber-AI. Также коммутатор предлагает синхронизацию времени с наносекундной точностью, что важно для распределённых нагрузок.  7-нм чип Quantum-2 содержит 57 млрд транзисторов, то есть он даже сложнее A100 с 54 млрд транзисторов. В стандартной конфигурации чип предоставляет 64 порта InfiniBand 400 Гбит/с, однако может работать и в режиме 128 × 200 Гбит/с. Коммутаторы на базе нового сетевого процессора уже доступны у всех крупных поставщиков серверного оборудования, включая Inspur, Lenovo, HPE и Dell Technologies. Возможно масштабирование вплоть 2048 × 400 Гбит/с или 4096 × 200 Гбит/с. 
NVIDIA ConnectX-7 Конечные устройства для новой инфраструктуры InfiniBand доступны в двух вариантах: это относительно простой сетевой адаптер ConnectX-7 и куда более сложный BlueField-3. В первом случае изменения, в основном, количественные: новый чип, состоящий из 8 млрд транзисторов, позволил вдвое увеличить пропускную способность, равно как и вдвое же ускорить RDMA и GPUDirect. 
NVIDIA BlueField-3 DPU BlueField-3, анонсированный ещё весной этого года, куда сложнее с его 22 млрд транзисторов. Он предоставляет гораздо больше возможностей, чем обычный сетевой адаптер или SmartNIC, и крайне важен для будущего развития инфраструктурных решений NVIDIA. Начало поставок ConnectX-7 намечено на январь, а вот BlueField-3 появится только в мае 2022 года. Оба адаптера совместимы с PCIe 5.0.
28.10.2021 [17:02], Алексей Степин
Rockport Networks представила интерконнект с пассивным оптическим коммутаторомПроизводительность любого современного суперкомпьютера или кластера во многом зависит от интерконнекта, объединяющего вычислительные узлы в единое целое, и практически обязательным компонентом такой сети является коммутатор. Однако последнее не аксиома: компания Rockport Networks представила своё видение HPC-систем, не требующее использования традиционных коммутирующих устройств. Проблема межсоединений существовала в мире суперкомпьютеров всегда, даже в те времена, когда сам процессор был набором более простых микросхем, порой расположенных на разных платах. В любом случае узлы требовалось соединять между собой, и эта подсистема иногда бывала неоправданно сложной и проблемной. Переход на стандартные сети Ethernet, Infiniband и их аналоги многое упростил — появилась возможность собирать суперкомпьютеры по принципу конструктора из стандартных элементов. 
Пассивный оптический коммутатор SHFL Тем не менее, проблема масштабирования (в том числе и на физическом уровне кабельной инфраструктуры), повышения скорости и снижения задержек никуда не делась. У DARPA даже есть особый проект FastNIC, нацеленный на 100-кратное ускорение сетевых интерфейсов, чтобы в конечном итоге сгладить разницу в скорости обмена данными внутри узлов и между ними.  Сам по себе высокоскоростной коммутатор для HPC-систем — устройство непростое, требующее использования недешёвого и сложного кремния, и вкупе с остальными компонентами интерконнекта может составлять заметную долю от стоимости всего кластера в целом. При этом коммутаторы могут вносить задержки, по определению являясь местами избыточной концентрации данных, а также требуют дополнительных мощностей подсистем питания и охлаждения.  Подход, продвигаемый компанией Rockport Networks, свободен от этих недостатков и изначально нацелен на минимизацию точек избыточности и возможных коллизий. А достигнуто это благодаря архитектуре, в которой концепция традиционного сетевого коммутатора отсутствует изначально. Вместо этого имеется специальный модуль SHFL, в котором топология сети задаётся оптически, а все логические задачи берут на себя специализированные сетевые адаптеры, работающие под управлением фирменной ОС rNOS и имеющие на борту сконфигурированную нужным образом ПЛИС. 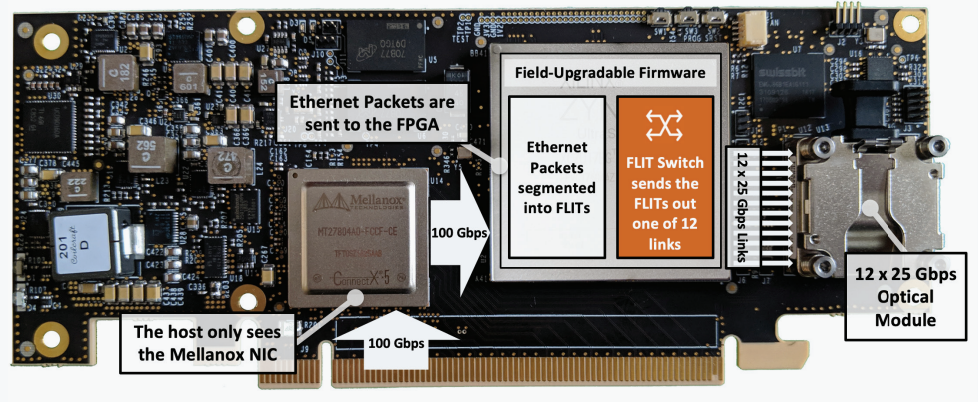 Модуль SHFL даже не требует отдельного электропитания, а вот адаптеры Rockport NC1225 его хотя и требуют, но умещаются в конструктив низкопрофильного адаптера с разъёмом PCIe x16 и потребляют всего 36 Вт. Правда, в настоящий момент речь идёт только о PCIe 3.0, поэтому полнодуплексного подключения на скорости 200 Гбит/с пока нет. Тем не менее, Техасский центр передовых вычислений (TACC) посчитал, что этого уже достаточно и стал одним из первых заказчиков — 396 узлов суперкомпьютера Frontera используют решение Rockport. 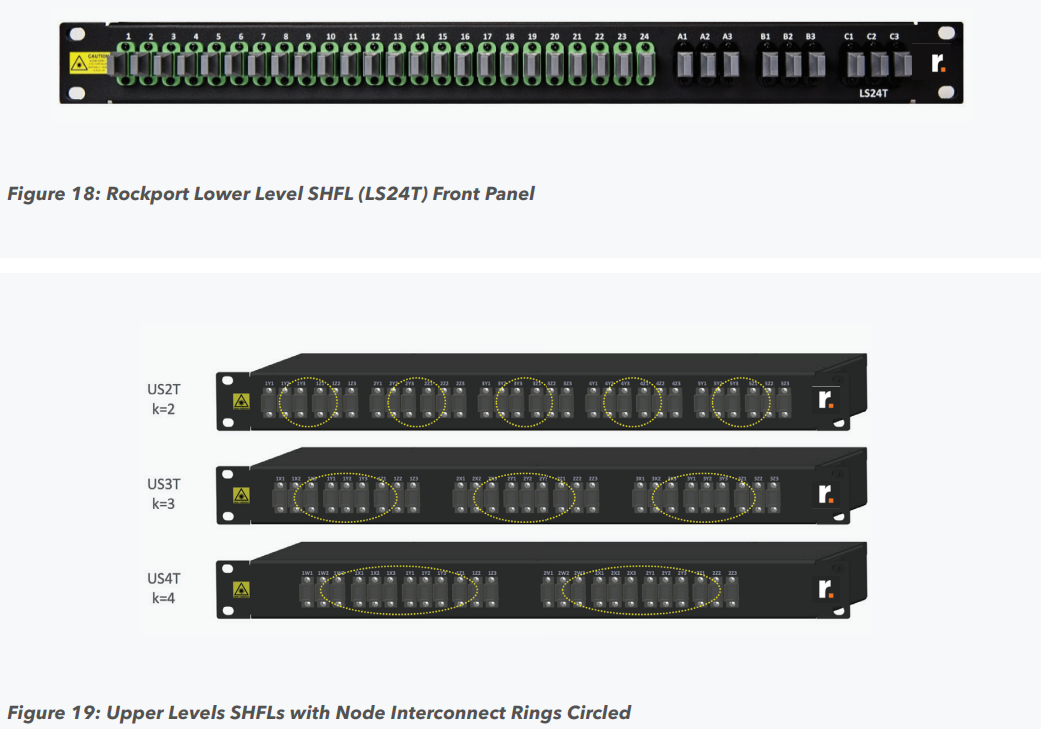 Использование не совсем традиционной оптической сети, впрочем, накладывает свои особенности: вместо популярных *SFP-корзин используются разъёмы MTP/MPO-24, а каждый кабель даёт для подключения 12 отдельных волокон, что при скорости 25 Гбит/с на волокно позволит достичь совокупной пропускной способности 300 Гбит/с. ОС и приложениям адаптер «представляется» как чип Mellanox ConnectX-5, который и входит в его состав, а потому не требует каких-то особых драйверов или модулей ядра. 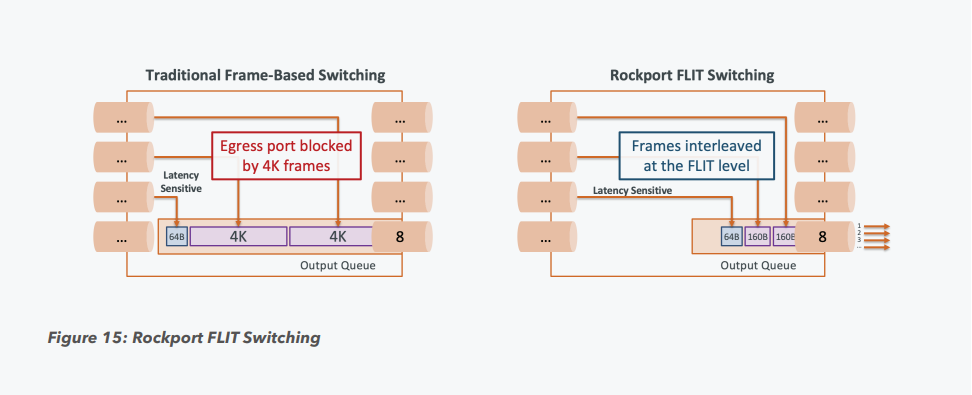 Rockport фактически занимается транспортировкой Ethernet и реализует уровень OSI 1/1.5, однако традиционной коммутации как таковой нет — адаптеры самостоятельно определяют конфигурацию сети и оптимальные маршруты передачи сигнала по отдельным волокнам с возможностью восстановления связности на лету при каких-либо проблемах. Весь трафик разбивается на маленькие кусочки (FLIT'ы) и отправляется по виртуальным каналам (VC) с чередованием, что позволяет легко управлять приоритизацией (в том числе на L2/L3) и снизить задержки. 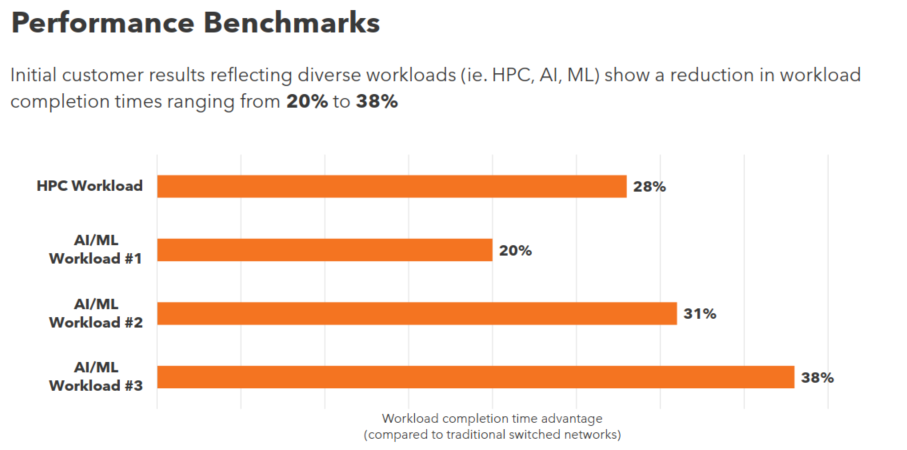 SHFL имеет 24 разъёма для адаптеров и ещё 9 для объединения с другими SHFL и Ethernet-шлюзами для подключения к основной сети ЦОД (в ней сеть Rockport видна как обычная L2). Таким образом, в составе кластера каждый узел может быть подключён как минимум к 12 другим узлам на скорости 25 Гбит/с. Однако топологию можно менять по своему усмотрению. Компания-разработчик заявляет о преимуществе своего интерконнекта на классических HPC-задачах, могущем достигать почти 30% при сравнении c InfiniBand класса 100G и даже 200G. Кроме того, для Rockport требуется на 72% меньше кабелей. |
|

