Материалы по тегу: кластер
|
19.09.2024 [00:18], Юрий Лебедев
Кластер на столе: Mini-ITX плата Turing Pi 2.5 объединяет до четырёх одноплатных компьютеровTuring Pi 2.5 представляет собой четырёхузловую плату формата Mini-ITX со встроенным 1GbE-коммутатором. Плата поддерживает вычислительные модули Turing RK1, Raspberry Pi CM4 и NVIDIA Jetson с коннектором SO-DIMM, которые можно комбинировать. Решение компактно, бесшумно и энергоэффективно. Оно подходит для создания домашних лабораторий, хостинга, работы с облачными стеками (например, Kubernetes или Docker Swarm), а также для запуска ИИ-приложений. Плата оснащена встроенным BMC на базе чипа Allwinner T113-S3 с 256 Мбайт флеш-памяти. BMC предоставляет возможности удалённого управления, причём узлы остаются активными при перезагрузке BMC. Также имеется встроенный преобразователь UART↔USB-C для отладки, кнопка FEL для быстрого восстановления после неудачных обновлений прошивки, четырёхконтактный разъем с ШИМ для управления корпусным вентилятором и часы реального времени с питанием от батареи CR2032. 
Источник изображений: Turing Machines Плата оснащена слотом microSD, двумя портами SATA-3, а также четырьмя портами M.2 2260/2280 M-Key для подключения NVMe SSD. Доступно четыре порта USB 3.0 (два Type-A + колодка для ещё двух) и один USB 2.0. Встроенный L2-коммутатор с поддержкой VLAN подключён к каждому модулю, а на заднюю панель от него выведены два порта RJ45. Отдельно отмечается, что теперь каждая плата имеет собственный MAC-адрес.  Два слота Mini PCIe, подведённые к узлам № 1 и № 2, позволяют модулям RK1 и Jetson использовать адаптеры Wi-Fi, Bluetooth или 4G/5G (есть слот для SIM-карты), в том числе по USB. Внутренний USB-концентратор позволяет одновременно подключаться к хранилищу всех модулей в режиме MSD (Mass Storage Device), а для заливки образов на модули есть отдельный порт USB-C. Также имеется интерфейс DSI для дисплеев и 40-контактная площадка GPIO, совместимая с Raspberry Pi. Есть и восьмиконтактные разъёмы для I²C-подключения экранов, кнопок, динамиков и т.д.  К первому узлу подведены порт HDMI 4K и один из портов USB Type-A (детали не уточняются), что позволяет использовать его в качестве настольного компьютера, подключив клавиатуру, мышь и монитор. Питается плата от стандартного разъёма ATX 24, а общее энергопотребление системы не превышает 80 Вт. Стоит новинка $279. 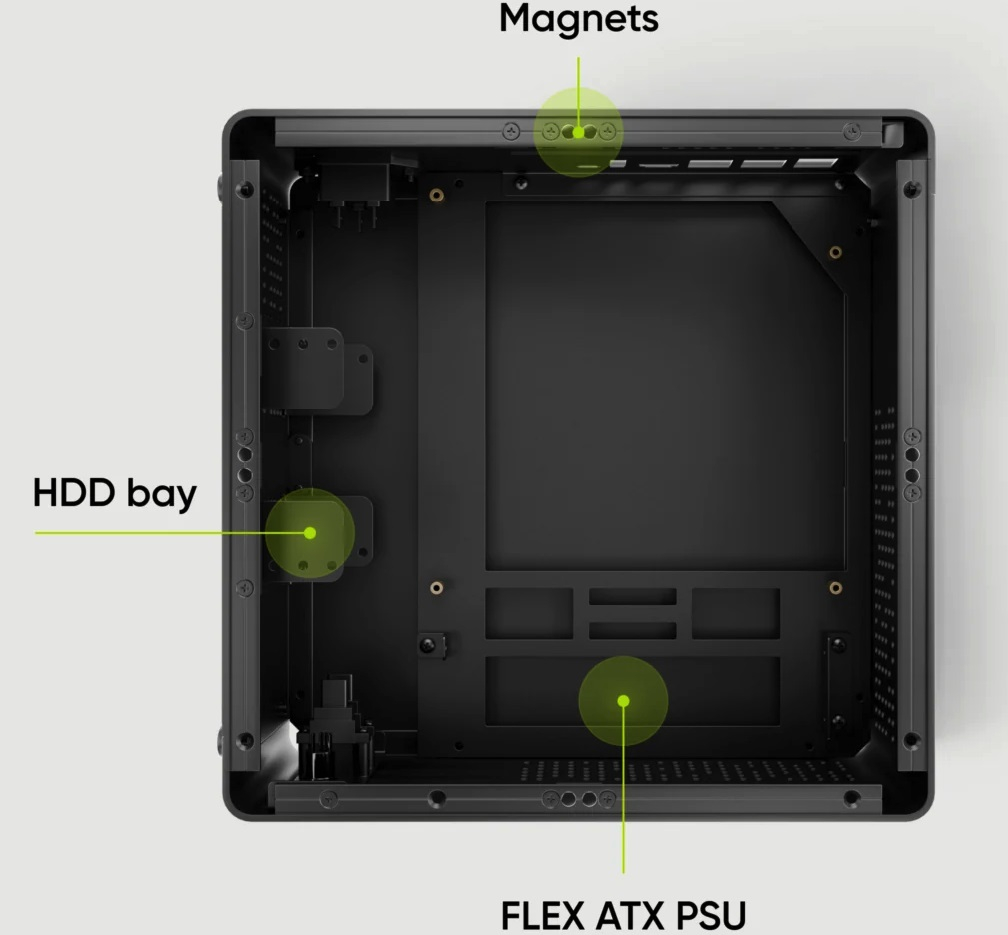 Для платы предлагается корпус Turing Pi mini-ITX (240 × 240 × 100 мм) стоимостью $149. Корпус выполнен из алюминия и совместим с платами Turing Pi 2 и 2.5. Он оснащён магнитными крышками для упрощения замены модулей и аксессуаров, поддерживает установку до трёх SFF-накопителей, одного 120-мм вентилятора и блоков питания Flex ATX PSU или Pico PSU с внешним адаптером. На корпусе есть LED-индикатор, кнопка питания, два порта USB Type-A, а также отверстия для внешних антенн.
11.09.2024 [18:55], Игорь Осколков
Oracle анонсировала зеттафлопсный облачный ИИ-суперкомпьютер из 131 тыс. NVIDIA B200Oracle и NVIDIA анонсировали самый крупный на сегодняшний день облачный ИИ-кластер, состоящий из 131 072 ускорителей NVIDIA B200 (Blackwell). По словам компаний, это первая в мире система производительностью 2,4 Зфлопс (FP8). Кластер заработает в I половине 2025 года, но заказы на bare-metal инстансы и OCI Superclaster компания готова принять уже сейчас. Заказчики также смогут выбрать тип подключения: RoCEv2 (ConnectX-7/8) или InfiniBand (Quantum-2). По словам компании, новый ИИ-кластер вшестеро крупнее тех, что могут предложить AWS, Microsoft Azure и Google Cloud. Кроме того, компания предлагает и другие кластеры с ускорителями NVIDIA: 32 768 × A100, 16 384 × H100, 65 536 × H200 и 3840 × L40S. А в следующем году обещаны кластеры на основе GB200 NVL72, объединяющие более 100 тыс. ускорителей GB200. В скором времени также появятся и куда более скромные ВМ GPU.A100.1 и GPU.H100.1 с одним ускорителем A100/H100 (80 Гбайт). Прямо сейчас для заказы доступны инстансы GPU.H200.8, включающие восемь ускорителей H200 (141 Гбайт), 30,7-Тбайт локальное NVMe-хранилище и 200G-подключение. Семейство инстансов на базе NVIDIA Blackwell пока включает лишь два варианта. GPU.B200.8 предлагает восемь ускорителей B200 (192 Гбайт), 30,7-Тбайт локальное NVMe-хранилище и 400G-подключение. Наконец, GPU.GB200 фактически представляет собой суперускоритель GB200 NVL72 и включает 72 ускорителя B200, 36 Arm-процессоров Grace и локальное NVMe-хранилище ёмкостью 533 Тбайт. Агрегированная скорость сетевого подключения составляет 7,2 Тбит/с. 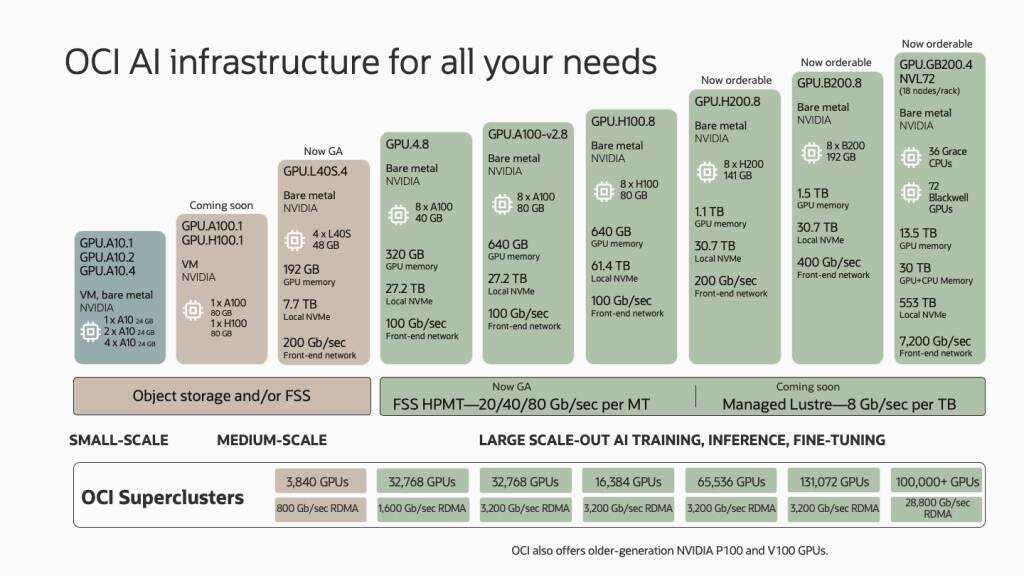
Источник изображения: Oracle Для всех новых инстансов Oracle подготовит управляемое Lustre-хранилище с производительностью до 8 Гбит/с на каждый Тбайт. Кроме того, компания предложит расширенные средства мониторинга и управления, помощь в настройке инфраструктуры для достижения желаемого уровня реальной производительности, а также набор оптимизированного ПО для работы с ИИ, в том числе для Arm.
29.08.2024 [13:43], Сергей Карасёв
«К2 НейроТех» представила российские ПАК для HPC-нагрузок, ИИ и машинного обученияКомпания К2Тех объявила о формировании нового бизнес-подразделения — «К2 НейроТех», специализацией которого являются проектирование, поддержка и масштабирование суперкомпьютерных кластеров. Созданное предприятие предлагает комплексные услуги по развёртыванию суперкомпьютеров «под ключ». Кроме того, «К2 НейроТех» представила два программно-аппаратных комплекса — ПАК-HPC и ПАК-ML. Отмечается, что в штат «К2 НейроТех» вошли высококвалифицированные инженеры, разработчики и системные архитекторы. Специалисты имеют опыт проектирования и построения суперкомпьютерных систем для добывающей промышленности и машиностроительной отрасли, а также для научных и образовательных организаций. В частности, команда участвовала в создании суперкомпьютера «Оракул» на базе Новосибирского государственного университета (НГУ), который победил в конкурсе «Проект года». ПАК-HPC и ПАК-ML построены на основе российских аппаратных и программных решений из реестров Минцифры и Минпромторга. Благодаря этому, как утверждается, снижаются риски, связанные с зависимостью от зарубежных поставок, и появляются возможности для стабильной техподдержки решений и дальнейшего их масштабирования по запросу. ПАК-HPC предназначен для ускорения научных исследований и разработки в таких отраслях, как фармацевтика, добывающая промышленность и машиностроение. В свою очередь, ПАК-ML ориентирован на работу с ресурсоёмкими приложениями ИИ и машинного обучения. 
Источник изображения: К2Тех Конфигурация обоих комплексов включает 18 серверов на стойку. Задействовано высокоскоростное соединение NVLink/Infinity Fabric. Объём оперативной памяти варьируется от 128 до 512 Гбайт на сервер. Для хранения данных применяются SSD вместимостью 1 Тбайт и более. Версия ПАК-HPC обеспечивает пиковую производительность до 7,6 Тфлопс (FP64) на один сервер. Вариант ПАК-ML, который, судя по всему, несёт восемь ускорителей NVIDIA H100, обладает пиковым быстродействием 536 Тфлопс (FP64 Tensor Core) на сервер. Преимуществами ПАК названы: высокая производительность, гибкая конфигурация, масштабируемость, единый графический интерфейс, безопасность, надёжность и импортонезависимость. «Создание бренда "К2 НейроТех" — это логичный ответ на запросы рынка по расширению вычислительных мощностей, необходимых для внедрения ИИ и ускорения проводимых исследований в условиях импортозамещения. Мало у кого сейчас есть практический опыт по созданию систем на базе отечественного оборудования с учётом оптимизации производительности. Именно поэтому мы решили вложить наши компетенции и опыт в создание комплексного предложения по построению суперкомпьютерных кластеров и разработку двух ПАК для задач HPC и ML под единым брендом», — отмечает директор по продвижению решений «К2 НейроТех».
05.08.2024 [08:16], Сергей Карасёв
Новые кластеры Supermicro SuperCluster с ускорителями NVIDIA L40S ориентированы на платформу Omniverse
emerald rapids
hardware
intel
l40
nvidia
omniverse
sapphire rapids
supermicro
xeon
ии
кластер
сервер
Компания Supermicro расширила семейство высокопроизводительных вычислительных систем SuperCluster, предназначенных для обработки ресурсоёмких приложений ИИ/HPC. Представленные решения оптимизированы для платформы NVIDIA Omniverse, которая позволяет моделировать крупномасштабные виртуальные миры в промышленности и создавать цифровых двойников. Системы SuperCluster for NVIDIA Omniverse могут строиться на базе серверов SYS-421GE-TNRT или SYS-421GE-TNRT3 с поддержкой соответственно восьми и четырёх ускорителей NVIDIA L40S. Обе модели соответствуют типоразмеру 4U и допускают установку двух процессоров Intel Xeon Emerald Rapids или Sapphire Rapids в исполнении Socket E (LGA-4677) с показателем TDP до 350 Вт (до 385 Вт при использовании СЖО). Каждый из узлов в составе новых систем SuperCluster несёт на борту 1 Тбайт оперативной памяти DDR5-4800, два NVMe SSD вместимостью 3,8 Тбайт каждый и загрузочный SSD NVMe M.2 на 1,9 Тбайт. В оснащение включены четыре карты NVIDIA BlueField-3 (B3140H SuperNIC) или NVIDIA ConnectX-7 (400G NIC), а также одна карта NVIDIA BlueField-3 DPU Dual-Port 200G. Установлены четыре блока питания с сертификатом Titanium мощностью 2700 Вт каждый. В максимальной конфигурации система SuperCluster for NVIDIA Omniverse объединяет пять стоек типоразмера 48U. В общей сложности задействованы 32 узла Supermicro SYS-421GE-TNRT или SYS-421GE-TNRT3, что в сумме даёт 256 или 128 ускорителей NVIDIA L40S. 
Источник изображения: Supermicro Кроме того, в состав такого комплекса входят три узла управления Supermicro SYS-121H-TNR Hyper System, три коммутатора NVIDIA Spectrum SN5600 Ethernet 400G с 64 портами, ещё два коммутатора NVIDIA Spectrum SN5600 Ethernet 400G с 64 портами для хранения/управления, два коммутатора управления NVIDIA Spectrum SN2201 Ethernet 1G с 48 портами. При необходимости конфигурацию SuperCluster for NVIDIA Omniverse можно оптимизировать под задачи заказчика, изменяя масштаб вплоть до одной стойки. В этом случае применяются четыре узла Supermicro SYS-421GE-TNRT или SYS-421GE-TNRT3.
01.08.2024 [15:32], Руслан Авдеев
У Twitter нашёлся заброшенный кластер из когда-то дефицитных NVIDIA V100Работавший в Twitter во времена продажи социальной сети Илону Маску (Elon Musk) разработчик Тим Заман (Tim Zaman), ныне перешедший в Google DeepMind, рассказал о необычной находке, передаёт Tom’s Hardware. По его словам, через несколько недель после сделки специалисты обнаружили кластер из 700 простаивающих ускорителей NVIDIA V100. Сам Заман охарактеризовал находку как «честную попытку построить кластер в рамках Twitter 1.0». Об этом событии Заману напомнили новости про ИИ-суперкомпьютер xAI из 100 тыс. ускорителей NVIDIA H100. Находка наводит на печальные размышления о том, что Twitter годами имел в распоряжении 700 высокопроизводительных ускорителей на архитектуре NVIDIA Volta, которые были включены, но простаивали без дела. Они были в дефиците на момент выпуска в 2017 году, а Заман обнаружил бездействующий кластер только в 2022 году. Нет ничего удивительного, что приблизительно тогда же было решено закрыть часть дата-центров социальной сети. Примечательно, что в кластере использовались PCIe-карты, а не SXM2-версии V100 с NVLink, которые намного эффективнее в ИИ-задачах. 
Источник изображения: Alexander Shatov/unsplash.com Заман поделился и соображениями об «ИИ-гигафабрике». Он предположил, что использование 100 тыс. ускорителей в рамках одной сетевой фабрики должно стать эпическим вызовом, поскольку на таких масштабах неизбежны сбои, которыми необходимо грамотно управлять для сохранения работоспособности всей системы. По его мнению, следует разделить систему на независимые домены (крупные кластеры так и устроены). Заман также задался вопросом, какое максимальное количество ускорителей может существовать в рамках одного кластера. По мере того, как компании создают всё более масштабные системы обучения ИИ, будут выявляться как предсказуемые, так и неожиданные пределы того, сколько ускорителей можно объединить.
05.06.2024 [22:51], Илья Коваль
ИИ-кластер в один клик и без долгого ожидания: Lambda Labs представила услугу краткосрочной аренды до 512 NVIDIA H100Облачный провайдер Lambda Labs представил услугу 1-Click Clusters, которая позволяет без длительного ожидания получить ИИ-кластер, включающий от 64 до 512 ускорителей NVIDIA H100, на срок от двух недель по единой цене $4,49/час за каждый ускоритель. По словам сооснователя компании, данное предложение является уникальным и с рыночной, и с технической точки зрения. Lambda Labs говорит, что на практике большинству ИИ-разработчиков как правило требуется доступ к кластерам из десятков или сотен ускорителей на относительно короткие периоды обучения и проверки моделей длительностью несколько недель. При этом долгосрочная аренда кластера, который будет периодически простаивать, обходится дорого. А аренда на короткий срок нередко сопряжена с длительным ожиданием доступности ускорителей как раз в тот момент, когда они больше всего нужны. При этом без общения с отделом продаж вряд ли удастся обойтись. Именно поэтому Lambda Lambs и предложила услугу 1-Click Clusters, в рамках которой на получение ИИ-кластера уходит не более нескольких дней. 
Источник изображения: Lambda Labs Аппаратная составляющая включает узлы на базе HGX H100 с 208 vCPU, 1,9 Тбайт RAM и локальным NVMe-хранилищем ёмкостью 24 Тбайт. Все узлы связаны 400G-интерконнектом NVIDIA Quantum-2 InfiniBand, а каждому ускорителю полагается свой адаптер NVIDIA ConnectX-7. Как утверждает сооснователь Lambda Labs, мало кто из облачных провайдеров способен «нарезать» крупную InfiniBand-фабрику, объединяющую тысячи ускорителей, на небольшие виртуализированные кластеры, причём делать это без участия человека. В состав каждого кластера также входят три управляющих узла: 8 vCPU, 34 Гбайт RAM, 208 Гбайт NVMe SSD и один внешний IP-адрес. За интернет-подключение отвечают два общих 100-Гбит/с канала, причём плата не берётся ни за входящий, ни за исходящий трафик. Дополнительно можно арендовать сетевое хранилище по цене $0,20/мес. за каждый Гбайт. Кластеры поставляются вместе с набором ПО Lambda Stack, который включает все необходимые драйверы и библиотеки, популярные фреймворки и средства разработки. |
|

