Материалы по тегу: интерконнект
|
22.03.2022 [18:40], Игорь Осколков
NVIDIA анонсировала 4-нм ускорители Hopper H100 и самый быстрый в мире ИИ-суперкомпьютер EOS на базе DGX H100На GTC 2022 компания NVIDIA анонсировала ускорители H100 на базе новой архитектуры Hopper. Однако NVIDIA уже давно говорит о себе как создателе платформ, а не отдельных устройств, так что вместе с H100 были представлены серверные Arm-процессоры Grace, в том числе гибридные, а также сетевые решения и обновления наборов ПО. 
NVIDIA H100 (Изображения: NVIDIA) NVIDIA H100 использует мультичиповую 2.5D-компоновку CoWoS и содержит порядка 80 млрд транзисторов. Но нет, это не самый крупный чип компании на сегодняшний день. Кристаллы новинки изготавливаются по техпроцессу TSMC N4, а сопровождают их — впервые в мире, по словам NVIDIA — сборки памяти HBM3 суммарным объёмом 80 Гбайт. Объём памяти по сравнению с A100 не вырос, зато в полтора раза увеличилась её скорость — до рекордных 3 Тбайт/с. 
NVIDIA H100 (SXM) Подробности об архитектуре Hopper будут представлены чуть позже. Пока что NVIDIA поделилась некоторыми сведениями об особенностях новых чипов. Помимо прироста производительности от трёх (для FP64/FP16/TF32) до шести (FP8) раз в сравнении с A100 в Hopper появилась поддержка формата FP8 и движок Transformer Engine. Именно они важны для достижения высокой производительности, поскольку само по себе четвёртое поколение ядер Tensor Core стало втрое быстрее предыдущего (на всех форматах). 
NVIDIA H100 CNX (PCIe) TF32 останется форматом по умолчанию при работе с TensorFlow и PyTorch, но для ускорения тренировки ИИ-моделей NVIDIA предлагает использовать смешанные FP8/FP16-вычисления, с которыми Tensor-ядра справляются эффективно. Хитрость в том, что Transformer Engine на основе эвристик позволяет динамически переключаться между ними при работе, например, с каждым отдельным слоем сети, позволяя таким образом добиться повышения скорости обучения без ущерба для итогового качества модели. На больших моделях, а именно для таких H100 и создавалась, сочетание Transformer Engine с другими особенностями ускорителей (память и интерконнект) позволяет получить девятикратный прирост в скорости обучения по сравнению с A100. Но Transformer Engine может быть полезен и для инференса — готовые FP8-модели не придётся самостоятельно конвертировать в INT8, движок это сделает на лету, что позволяет повысить пропускную способность от 16 до 30 раз (в зависимости от желаемого уровня задержки). 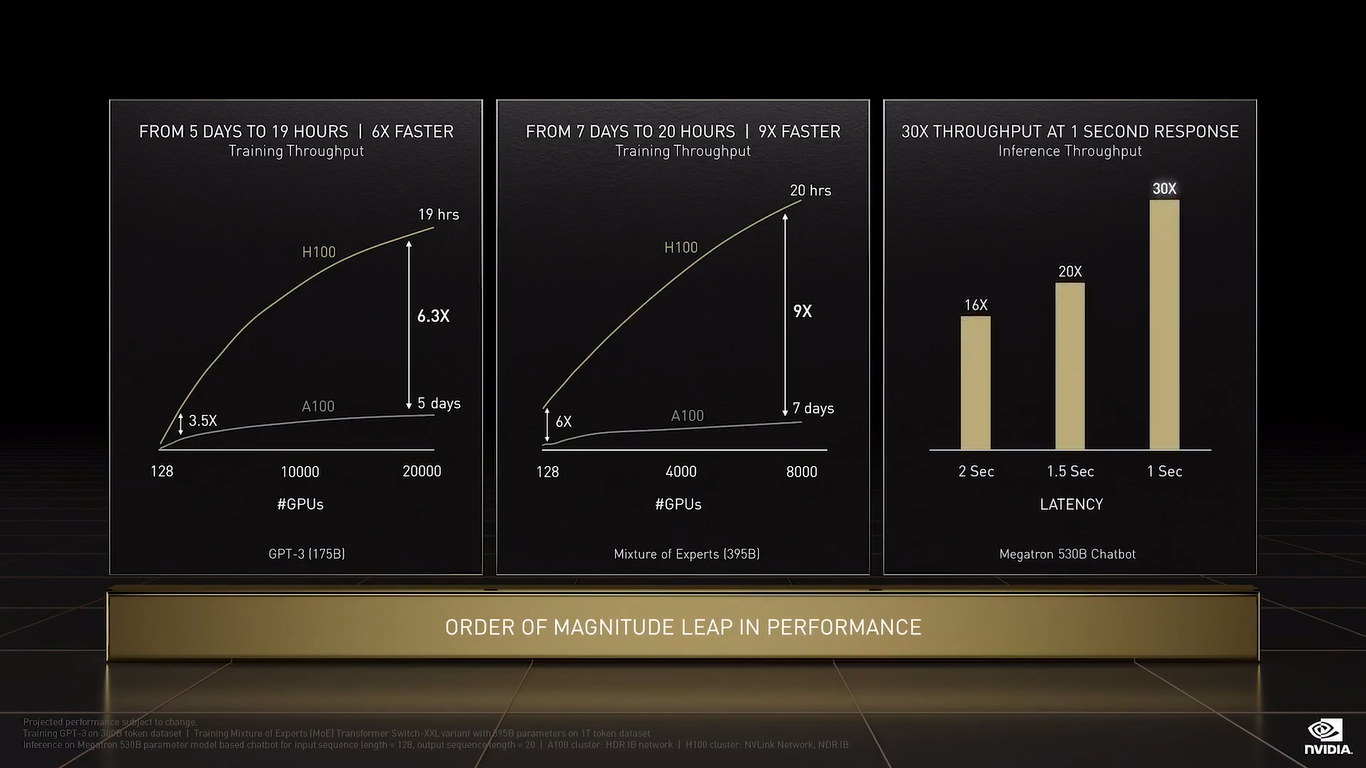 Другое любопытное нововведение — специальные DPX-инструкции для динамического программирования, которые позволят ускорить выполнение некоторых алгоритмов до 40 раз в задачах, связанных с поиском пути, геномикой, квантовыми системами и при работе с большими объёмами данных. Кроме того, H100 получили дальнейшее развитие виртуализации. В новых ускорителях всё так же поддерживается MIG на 7 инстансов, но уже второго поколения, которое привнесло больший уровень изоляции благодаря IO-виртуализации, выделенным видеоблокам и т.д.  Так что MIG становится ещё более предпочтительным вариантом для облачных развёртываний. Непосредственно к MIG примыкает и технология конфиденциальных вычислений, которая по словам компании впервые стала доступна не только на CPU. Программно-аппаратное решение позволяет создавать изолированные ВМ, к которым нет доступа у ОС, гипервизора и других ВМ. Поддерживается сквозное шифрование при передаче данных от CPU к ускорителю и обратно, а также между ускорителями.  Память внутри GPU также может быть изолирована, а сам ускоритель оснащается неким аппаратным брандмауэром, который отслеживает трафик на шинах и блокирует несанкционированный доступ даже при наличии у злоумышленника физического доступа к машине. Это опять-таки позволит без опаски использовать H100 в облаке или в рамках колокейшн-размещения для обработки чувствительных данных, в том числе для задач федеративного обучения.  NVIDIA HGX H100 Но главная инновация — это существенное развитие интерконнекта по всем фронтам. Суммарная пропускная способность внешних интерфейсов чипа H100 составляет 4,9 Тбайт/с. Да, у H100 появилась поддержка PCIe 5.0, тоже впервые в мире, как утверждает NVIDIA. Однако ускорители получили не только новую шину NVLink 4.0, которая стала в полтора раза быстрее (900 Гбайт/с), но и совершенно новый коммутатор NVSwitch, который позволяет напрямую объединить между собой до 256 ускорителей! Пропускная способность «умной» фабрики составляет до 70,4 Тбайт/с.  Сама NVIDIA предлагает как новые системы DGX H100 (8 × H100, 2 × BlueField-3, 8 × ConnectX-7), так и SuperPOD-сборку из 32-х DGX, как раз с использованием NVLink и NVSwitch. Партнёры предложат HGX-платформы на 4 или 8 ускорителей. Для дальнейшего масштабирования SuperPOD и связи с внешним миром используются 400G-коммутаторы Quantum-2 (InfiniBand NDR). Сейчас NVIDIA занимается созданием своего следующего суперкомпьютера EOS, который будет состоять из 576 DGX H100 и получит FP64-производительность на уровне 275 Пфлопс, а FP16 — 9 Эфлопс.  Компания надеется, что EOS станет самой быстрой ИИ-машиной в мире. Появится она чуть позже, как и сами ускорители, выход которых запланирован на III квартал 2022 года. NVIDIA представит сразу три версии. Две из них стандартные, в форм-факторах SXM4 (700 Вт) и PCIe-карты (350 Вт). А вот третья — это конвергентный ускоритель H100 CNX со встроенными DPU Connect-X7 класса 400G (подключение PCIe 5.0 к самому ускорителю) и интерфейсом PCIe 4.0 для хоста. Компанию ей составят 400G/800G-коммутаторы Spectrum-4.
09.11.2021 [12:17], Алексей Степин
NVIDIA представила Quantum-2, первый 400G-коммутатор InfiniBand NDRNVIDIA, нынешний владелец Mellanox, представила обновления своих решений InfiniBand NDR: коммутаторы Quantum-2, сетевые адаптеры ConnectX-7 и ускорители DPU BlueField-3. Это весьма своевременный апдейт, поскольку 400GbE-решения набирают популярность, а с приходом PCIe 5.0 в серверный сегмент станут ещё более актуальными. 
NVIDIA Quantum-2 (Здесь и ниже изображения NVIDIA) Первый и самый важный анонс — это платформа Quantum-2. Новый коммутатор не только обеспечивает вдвое более высокую пропускную способность на порт (400 Гбит/с против 200 Гбит/c), но также предоставляет в три раза больше портов, нежели предыдущее поколение. Это сочетание позволяет снизить потребность в коммутаторах в 6 раз при той же суммарной ёмкости сети. При этом новая более мощная инфраструктура также окажется более экономичной и компактной.  Более того, Quantum-2 относится к серии «умных» устройств и содержит в 32 раза больше акселераторов, нежели Quantum HDR первого поколения. В нём также реализована предиктивная аналитика, позволяющая избежать проблем с сетевой инфраструктурой ещё до их возникновения; за это отвечает технология UFM Cyber-AI. Также коммутатор предлагает синхронизацию времени с наносекундной точностью, что важно для распределённых нагрузок.  7-нм чип Quantum-2 содержит 57 млрд транзисторов, то есть он даже сложнее A100 с 54 млрд транзисторов. В стандартной конфигурации чип предоставляет 64 порта InfiniBand 400 Гбит/с, однако может работать и в режиме 128 × 200 Гбит/с. Коммутаторы на базе нового сетевого процессора уже доступны у всех крупных поставщиков серверного оборудования, включая Inspur, Lenovo, HPE и Dell Technologies. Возможно масштабирование вплоть 2048 × 400 Гбит/с или 4096 × 200 Гбит/с. 
NVIDIA ConnectX-7 Конечные устройства для новой инфраструктуры InfiniBand доступны в двух вариантах: это относительно простой сетевой адаптер ConnectX-7 и куда более сложный BlueField-3. В первом случае изменения, в основном, количественные: новый чип, состоящий из 8 млрд транзисторов, позволил вдвое увеличить пропускную способность, равно как и вдвое же ускорить RDMA и GPUDirect. 
NVIDIA BlueField-3 DPU BlueField-3, анонсированный ещё весной этого года, куда сложнее с его 22 млрд транзисторов. Он предоставляет гораздо больше возможностей, чем обычный сетевой адаптер или SmartNIC, и крайне важен для будущего развития инфраструктурных решений NVIDIA. Начало поставок ConnectX-7 намечено на январь, а вот BlueField-3 появится только в мае 2022 года. Оба адаптера совместимы с PCIe 5.0.
28.10.2021 [17:02], Алексей Степин
Rockport Networks представила интерконнект с пассивным оптическим коммутаторомПроизводительность любого современного суперкомпьютера или кластера во многом зависит от интерконнекта, объединяющего вычислительные узлы в единое целое, и практически обязательным компонентом такой сети является коммутатор. Однако последнее не аксиома: компания Rockport Networks представила своё видение HPC-систем, не требующее использования традиционных коммутирующих устройств. Проблема межсоединений существовала в мире суперкомпьютеров всегда, даже в те времена, когда сам процессор был набором более простых микросхем, порой расположенных на разных платах. В любом случае узлы требовалось соединять между собой, и эта подсистема иногда бывала неоправданно сложной и проблемной. Переход на стандартные сети Ethernet, Infiniband и их аналоги многое упростил — появилась возможность собирать суперкомпьютеры по принципу конструктора из стандартных элементов. 
Пассивный оптический коммутатор SHFL Тем не менее, проблема масштабирования (в том числе и на физическом уровне кабельной инфраструктуры), повышения скорости и снижения задержек никуда не делась. У DARPA даже есть особый проект FastNIC, нацеленный на 100-кратное ускорение сетевых интерфейсов, чтобы в конечном итоге сгладить разницу в скорости обмена данными внутри узлов и между ними.  Сам по себе высокоскоростной коммутатор для HPC-систем — устройство непростое, требующее использования недешёвого и сложного кремния, и вкупе с остальными компонентами интерконнекта может составлять заметную долю от стоимости всего кластера в целом. При этом коммутаторы могут вносить задержки, по определению являясь местами избыточной концентрации данных, а также требуют дополнительных мощностей подсистем питания и охлаждения.  Подход, продвигаемый компанией Rockport Networks, свободен от этих недостатков и изначально нацелен на минимизацию точек избыточности и возможных коллизий. А достигнуто это благодаря архитектуре, в которой концепция традиционного сетевого коммутатора отсутствует изначально. Вместо этого имеется специальный модуль SHFL, в котором топология сети задаётся оптически, а все логические задачи берут на себя специализированные сетевые адаптеры, работающие под управлением фирменной ОС rNOS и имеющие на борту сконфигурированную нужным образом ПЛИС. 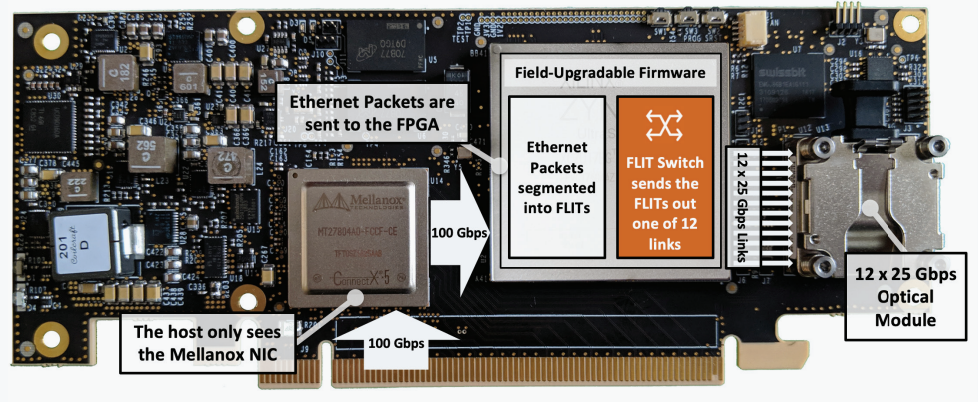 Модуль SHFL даже не требует отдельного электропитания, а вот адаптеры Rockport NC1225 его хотя и требуют, но умещаются в конструктив низкопрофильного адаптера с разъёмом PCIe x16 и потребляют всего 36 Вт. Правда, в настоящий момент речь идёт только о PCIe 3.0, поэтому полнодуплексного подключения на скорости 200 Гбит/с пока нет. Тем не менее, Техасский центр передовых вычислений (TACC) посчитал, что этого уже достаточно и стал одним из первых заказчиков — 396 узлов суперкомпьютера Frontera используют решение Rockport. 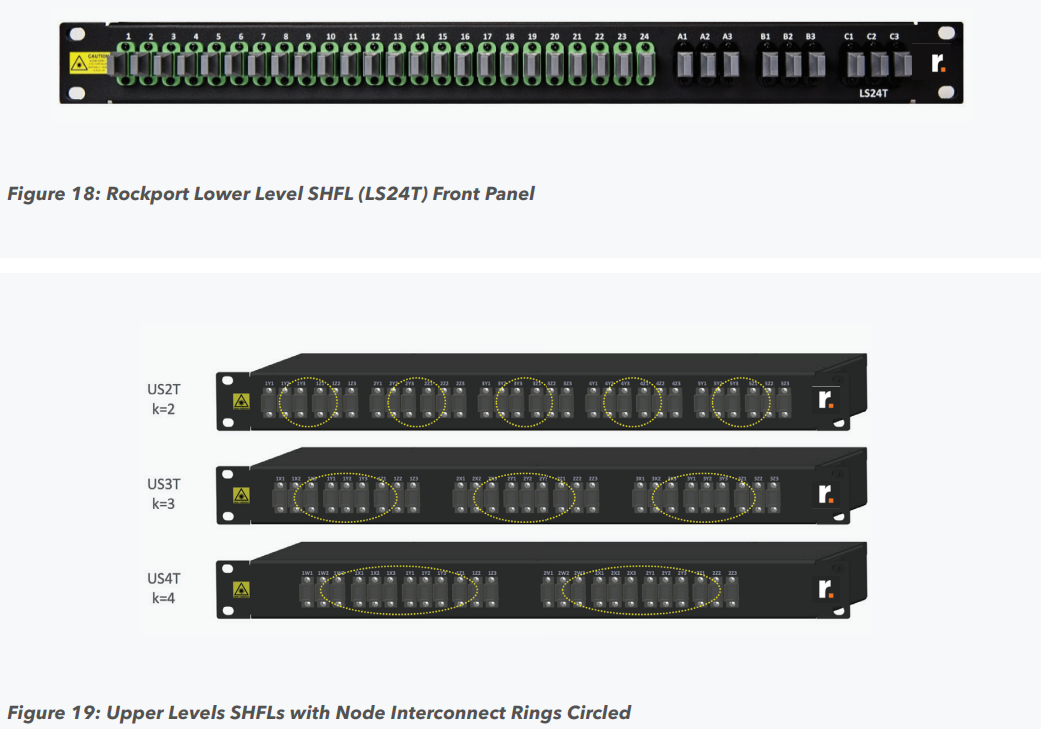 Использование не совсем традиционной оптической сети, впрочем, накладывает свои особенности: вместо популярных *SFP-корзин используются разъёмы MTP/MPO-24, а каждый кабель даёт для подключения 12 отдельных волокон, что при скорости 25 Гбит/с на волокно позволит достичь совокупной пропускной способности 300 Гбит/с. ОС и приложениям адаптер «представляется» как чип Mellanox ConnectX-5, который и входит в его состав, а потому не требует каких-то особых драйверов или модулей ядра. 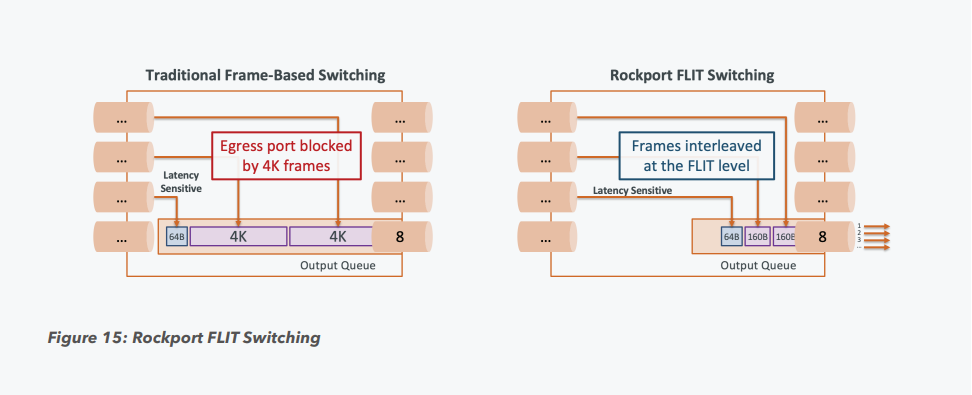 Rockport фактически занимается транспортировкой Ethernet и реализует уровень OSI 1/1.5, однако традиционной коммутации как таковой нет — адаптеры самостоятельно определяют конфигурацию сети и оптимальные маршруты передачи сигнала по отдельным волокнам с возможностью восстановления связности на лету при каких-либо проблемах. Весь трафик разбивается на маленькие кусочки (FLIT'ы) и отправляется по виртуальным каналам (VC) с чередованием, что позволяет легко управлять приоритизацией (в том числе на L2/L3) и снизить задержки.  SHFL имеет 24 разъёма для адаптеров и ещё 9 для объединения с другими SHFL и Ethernet-шлюзами для подключения к основной сети ЦОД (в ней сеть Rockport видна как обычная L2). Таким образом, в составе кластера каждый узел может быть подключён как минимум к 12 другим узлам на скорости 25 Гбит/с. Однако топологию можно менять по своему усмотрению. Компания-разработчик заявляет о преимуществе своего интерконнекта на классических HPC-задачах, могущем достигать почти 30% при сравнении c InfiniBand класса 100G и даже 200G. Кроме того, для Rockport требуется на 72% меньше кабелей.
29.06.2021 [17:49], Алексей Степин
Cornelis Networks подняла упавшее знамя Intel Omni-PathОт собственной технологии интерконнекта Omni-Path (OPA) компания Intel довольно неожиданно отказалась летом 2019 года, хотя на тот момент OPA-решения составляли достойную конкуренцию InfiniBand EDR, Ethernet и проприетарным интерконнектам как по скорости, так и по уровню задержки и поддержки необходимых для высокопроизводительных вычислений (HPC) функций. В конце прошлого года все наработки по OPA перешли к компании Cornelis Networks, образованной выходцами из Intel. В арсенале Intel были процессоры Xeon и Xeon Phi со встроенным интерфейсом Omni-Path, PCIe-адаптеры, коммутаторы и сопутствующее ПО. Казалось бы, у технологии большое будущее, однако второе поколение шины OPA, поддерживающее скорость 200 Гбит/с, так и не было выпущено, а компания сосредоточилась на Ethernet. При этом NVIDIA уже анонсировала InfiniBand NDR (400 Гбит/c), да и 200GbE-решениями сейчас никого не удивить.  Однако идеи, заложенные в Omni-Path, не умерли, и упавшее знамя нашлось, кому подхватить. Cornelis Networks быстро принялась за дело — через месяц после представления компании уже были представлены новые машины с Omni-Path, причём как на базе Intel, так и на базе AMD. А на ISC 2021 Cornelis Networks анонсировала полный спектр собственных решений под брендом Omni-Path Express, реализующих все основные достоинства технологии.  Конечно, процессоров с разъёмом Omni-Path мы по понятным причинам уже не увидим, но компания предлагает низкопрофильные хост-адаптеры с пропускной способностью до 25 Гбайт/с (100 Гбит/с в каждом направлении). Они поддерживают открытый фреймворк Open Fabrics Interface (OFI) и предлагают коррекцию ошибок с нулевой латентностью. В качестве разъёма используется популярный в индустрии QSFP28.  Также представлен ряд коммутаторов. В серии CN-100SWE есть модели с поддержкой горячей замены, которые имеют 48 портов и общую пропускную способность до 1,2 Тбайт/с при латентности, не превышающей 110 нс. Поддерживается организация виртуальных линий Omni-Path Express и фреймы большого размера, от 2 до 10 Кбайт. При этом коммутаторы компактны и занимают всего 1 слот в стандартной стойке.  Директор CN-100SWE предназначен для крупных кластерных систем. Он является модульным и может занимать от 7U до 20U, реализуя при этом от 288 до 1152 портов Omni-Path Express со скоростью 100 Гбит/с на порт. Латентность при этом не превышает 340 нс. Для сравнения, сети на базе Ethernet, как правило, оперируют значениями в десятки миллисекунд в лучшем случае.  Технологиями Cornelis Networks уже заинтересовался крупный российский поставщик HPC-систем, группа компаний РСК, которая и ранее поставляла кластеры и суперкомпьютеры с Omni-Path, в том числе с коммутаторами, снабжёнными фирменной СЖО. РСК получила наивысший партнёрский статус Elite+ у Cornelis и уже готова интегрировать Omni-Path Express в системы «РСК Торнадо» на базе третьего поколения процессоров Xeon Scalable.
02.08.2019 [14:32], Геннадий Детинич
Intel хоронит шину Omni-PathДовольно неожиданно компания Intel отказалась от развития интерконнекта Omni-Path, которую она продвигала в серверных и HPC-платформах сначала для соединения узлов, в том числе для гиперконвергентных систем. Первое поколение шины Omni-Path с пропускной способностью до 100 Гбит/с на порт появилось несколько лет назад. Но ожидаемого второго поколения решений с пропускной способностью до 200 Гбит/с уже не будет. 
Ускорители Intel Xeon Phi с интегрированными контроллером и шиной Omni-Path Информацию о прекращении разработки и выпуска продукции Intel OmniPath Architecture 200 (OPA200) компания подтвердила, например, нашим коллегам с сайта HPCwire. Компания продолжит поддержку и поставку решений с шиной OPA100, но поставок продуктов с архитектурой OPA200 на рынок больше не будет. В принципе, сравнительно слабая поддержка шины Intel OmniPath со стороны клиентов рынка высокопроизводительных систем намекала на нечто подобное. Большей популярностью у строителей суперсистем и не только продолжает пользоваться InfiniBand и её новое HDR-воплощение с той же пропускной способностью до 200 Гбит/с. В свете ликвидации OPA200 становится понятно, почему Intel схватилась с NVIDIA за право поглощения компании Mellanox. Но не вышло: приз ушёл к NVIDIA. «Вообще, половина инсталляций в TOP500 использует Ethernet, но в основном 10/25/40 Гбит/с, и лишь совсем чуть-чуть может похвастаться 100 Гбит/с. InfiniBand установлен почти в 130 машинах, а Omni-Path есть чуть больше чем в 40. Остальное — проприетарные разработки». Что остаётся Intel? У лидера рынка микропроцессоров есть I/O-активы. Компания около 8 лет активно выстраивает направление для развития коммуникаций в ЦОД. За это время она поглотила разработчика коммутационных ASIC компанию Fulcrum Microsystems, подразделение по разработке адаптеров и коммутаторов InfiniBand компании QLogic и коммуникационное подразделение компании Cray. Относительно свежей покупкой Intel стала компания Barefoot Networks, разработчик решений для Ethernet-коммутаторов. Похоже, Intel решила вернуться к классике: InfiniBand (что менее вероятно) и Ethernet (что более вероятно), а о проприетарных шинах в виде той же Omni-Path решила забыть. В конце концов, Ethernet-подразделение компании славится своими продуктами. Новое поколения Intel Ethernet 800 Series способно заменить OPA100. |
|

