Материалы по тегу: llm
|
10.11.2025 [12:05], Сергей Карасёв
Фабрика токенов: Nebius, бывшая Yandex NV, запустила платформу Token Factory для инференса на базе открытых ИИ-моделейКомпания Nebius (бывшая материнская структура «Яндекса») представила платформу Nebius Token Factory для инференса: она позволяет разворачивать и оптимизировать открытые и кастомизированные ИИ-модели в больших масштабах с высоким уровнем надёжности и необходимым контролем. Nebius отмечает, что применение закрытых ИИ-моделей может создавать трудности при масштабировании. С другой стороны, открытые и кастомизированные модели позволяют устранить эти ограничения, но управление ими и обеспечение безопасности остаются технически сложными и ресурсоёмкими задачами для большинства команд. Платформа Nebius Token Factory призвана решить существующие проблемы: она сочетает гибкость открытых моделей с управляемостью, производительностью и экономичностью, которые необходимы организациям для реализации масштабных проектов в сфере ИИ. Nebius Token Factory базируется на комплексной ИИ-инфраструктуре Nebius. Новая платформа объединяет высокопроизводительный инференс, пост-обучение и управление доступом. Обеспечивается поддержка более 40 open source моделей, включая новейшие версии Deep Seek, Llama, OpenAI и Qwen. 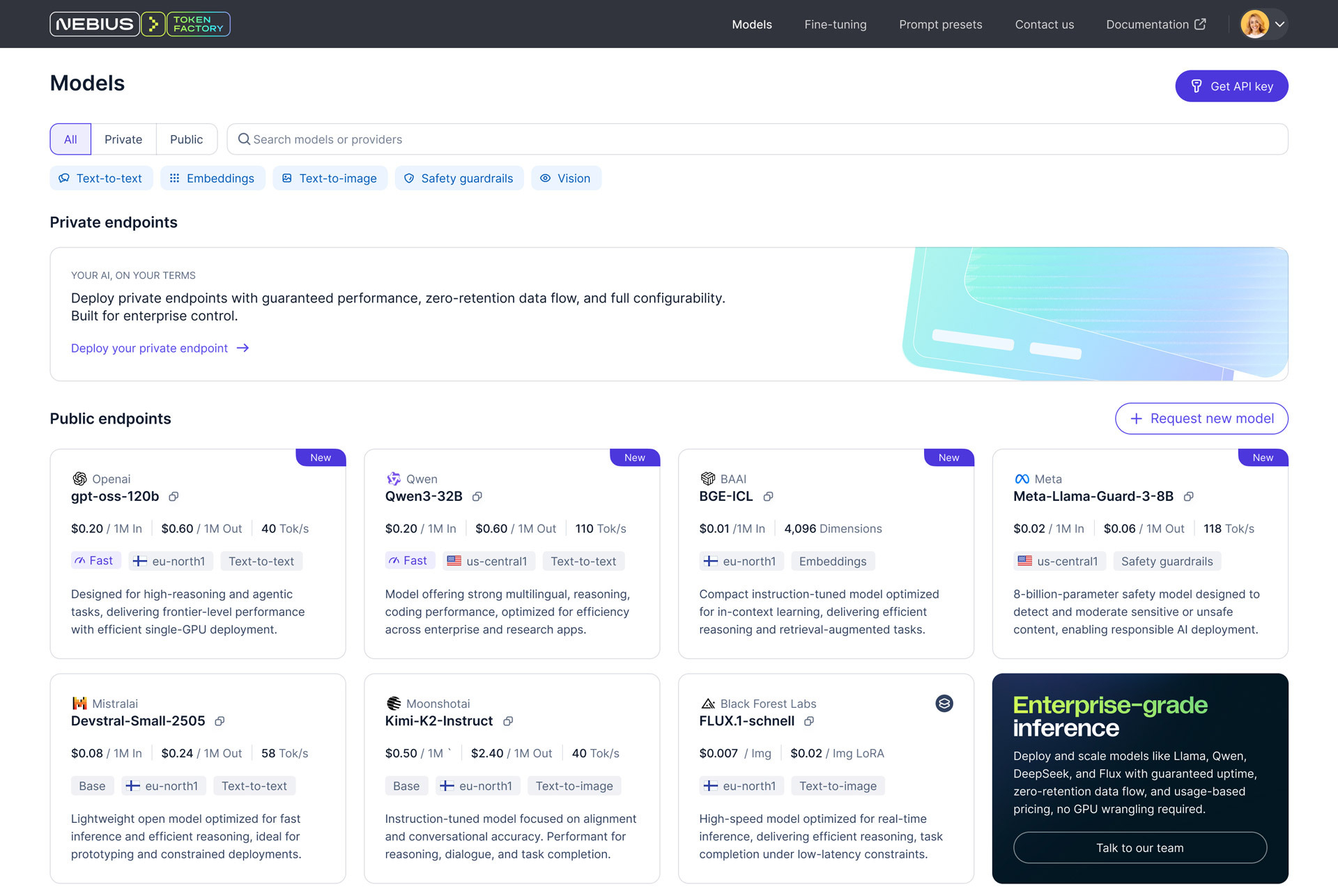
Источник изображения: Nebius Среди ключевых преимуществ Nebius Token Factory заявлены соответствие требованиям корпоративной безопасности (HIPAA, ISO 27001 и ISO 27799), предсказуемая задержка (менее 1 с), автоматическое масштабирование пропускной способности и доступность на уровне 99,9 %. Инференс выполняется в дата-центрах на территории Европы и США без сохранения данных на серверах Nebius. Задействована облачная экосистема Nebius AI Cloud 3.0 Aether, что, как утверждается, обеспечивает безопасность корпоративного уровня, проактивный мониторинг и стабильную производительность. Отмечается, что Nebius Token Factory может применяться для решения широкого спектра ИИ-задач: от интеллектуальных чат-ботов, помощников по написанию программного кода и генерации с дополненной выборкой (RAG) до высокопроизводительного поиска, анализа документов и автоматизированной поддержки клиентов. Интегрированные инструменты тонкой настройки и дистилляции позволяют компаниям адаптировать большие открытые модели к собственным данным. При этом достигается сокращение затрат на инференс до 70 %. Оптимизированные модели затем можно быстро разворачивать без ручной настройки инфраструктуры.
20.10.2025 [01:23], Владимир Мироненко
Ускорителей хватит на всех — Alibaba Aegaeon оптимизировал обработку ИИ-нагрузок, снизив использование дефицитных NVIDIA H20 на 82 %Alibaba Cloud представила Aegaeon, систему пулинга вычислений, позволяющую сократить количество ускорителей NVIDIA, необходимых для обслуживания ИИ-моделей, на 82 %, пишет ресурс SCMP. По словам разработчиков, благодаря Aegaeon количество ускорителей NVIDIA H20, необходимых для обслуживания десятков моделей с 72 млрд параметров, удалось сократить с 1192 до 213 единиц. «Aegaeon — это первое решение на рынке, которое выявило чрезмерные затраты, связанные с обслуживанием параллельных рабочих нагрузок LLM», — сообщили исследователи из Пекинского университета и Alibaba Cloud. Провайдеры облачных сервисов, такие как Alibaba Cloud и ByteDance Volcano Engine, предоставляют пользователям одновременно тысячи ИИ-моделей — множество вызовов API обрабатывается одновременно. Однако на практике для инференса чаще всего используются лишь несколько моделей, таких как Qwen и DeepSeek, а большинство других моделей применяются лишь эпизодически. Это приводит к неэффективному использованию вычислительных ресурсов: исследователи обнаружили, что 17,7 % ускорителей выделяется на обслуживание лишь 1,35 % запросов в Alibaba Cloud. Aegaeon выполняет «автоматическое масштабирование» на уровне токенов, обеспечивая переключение ускорителей между обслуживанием различных моделей в процессе генерации. В рамках системы один ускоритель поддерживает обработку до семи моделей по сравнению с двумя-тремя моделями в альтернативных системах. При этом задержка, связанная с переключением между моделями, снижена на 97 %, заявили исследователи. Alibaba Cloud сообщила, что решение уже используется на её торговой площадке моделей Bailian. 
Источник изображения: Alibaba Глава NVIDIA Дженсен Хуанг (Jensen Huang) объявил, что из-за экспортных ограничений доля компании на рынке передовых чипов в Китае сократилась с 95 % до нуля. Этому также способствовала стратегия Пекина, направленная на самообеспечение местного рынка. В связи с этим планы NVIDIA возобновить отгрузки ИИ-ускорителей H20, на которые ранее были установлены ограничения правительством США, встретили в Китае довольно прохладно. Более того, в Китае вынесли запрет местным компаниям на покупку разработанного специально для местного рынка ускорителя NVIDIA RTX Pro 6000D, поскольку пришли к выводу, что китайские ИИ-чипы не уступают продукции NVIDIA, разрешённой к экспорту в Китай.
29.08.2025 [17:53], Руслан Авдеев
ИИ и IIoT помогли Aramco сократить время простоев на 40 % и снизить расходы на техобслуживание на 30 %Внедрение ИИ позволило нефтегазовой компании Aramco из Саудовской Аравии весьма эффективно оптимизировать бизнес, сообщает VAST Data. Благодаря комбинации алгоритмов машинного обучения с сетями IoT-датчиков в инфраструктуре компании — на буровых установках, трубопроводах предприятиях по нефтепереработке и т.д. — Aramco добилась сокращения времени незапланированных простоев на 40 % и снижении расходов на техническое обслуживание на 30 %. Системы компании позволяют выявлять признаки перегрузки оборудования задолго до того, как произойдёт серьёзный инцидент, своевременно предотвратив поломки и каскад аварий. Важен и экологический аспект. Сжигание попутного и «лишнего» газа всегда было неприятным пятном на репутации отрасли. Теперь ИИ Aramco использует более 18 тыс. датчиков для прогнозирования того, где и когда придётся сжигать газ и можно ли этого избежать. В результате с 2010 года сжигание сократилось более чем наполовину и уже более десяти лет сжигается менее 1 % от общего уровня добычи газа. На одном из крупнейших в мире месторождении Хурайс (Khurais) Aramco развёрнуто 40 тыс. датчиков на 500 нефтяных скважинах, потоки данных интегрируются в системы машинного обучения и роботизированные платформы. Фактически создан «живой» цифровой двойник месторождения с постоянным обновлением данных и возможностью моделирования процессов. 
Источник изображения: Zbynek Burival/unsplash.com Знаковой стала разработка первой в своём роде ИИ-модели Aramco METABRAIN c 7 млрд параметров, созданной из датасета на основе данных, накопленных компанией за 90 лет. В своём роде это всезнающий промышленный консультант. Модель обеспечивает предиктивную аналитику, оптимизирует рабочие процессы и поддерживает принятие тех или иных решений. Фактически речь идёт о банке памяти, объединённом с «рассуждающей» моделью, в том числе обрабатывается историческая информация для получения рекомендаций. Мегапроекты вроде реализуемого в Хурайсе, предусматривают использование не периодической отчётности, а данных от многочисленных сенсоров, поэтому стратегическое планирование поддерживается ИИ METABRAIN. С появлением ИИ роль руководителя проекта меняется от административного контроля к стратегической интерпретации. Контроль всё ещё важен, но теперь он тесно связан с непрерывным использованием ИИ-технологий, говорит компания. ИИ может порекомендовать перераспределить ресурсы или сообщить о вероятном сбое, но общение с другими людьми всё равно остаётся прерогативой человека. Aramco активно участвует в ИИ-проектах в Саудовской Аравии. Так, в сентябре 2024 года Aramco Digital объявила о партнёрстве с Cerebras, Groq и Qualcomm для развития ИИ и 5G IoT в стране. В феврале 2025 года Groq и Aramco Digital объявили об открытии крупнейшего в EMEA вычислительного ИИ-центра для инференса.
22.08.2025 [17:23], Руслан Авдеев
Google: медианный промпт Gemini потребляет 0,24 Вт·ч энергии и 0,26 мл водыКомпания Google опубликовала документ, в котором описывается методология измерения потребления энергии и воды, а также выбросов и воздействия на окружающую среду ИИ Gemini. Как утверждают в Google, «медианное» потребление энергии на одно текстовое сообщение в Gemini Apps составляет 0,24 Вт·ч, выбросы составляют 0,03 г эквивалента углекислого газа (CO2e), а воды расходуется 0,26 мл. В компании подчёркивают, что показатели намного ниже в сравнении со многими публичными оценками, а на каждый запрос тратится электричества столько же, сколько при просмотре телевизора в течение девяти секунд. Google на основе данных о сокращении выбросов в ЦОД и декарбонизации энергопоставок полагает, что за последние 12 месяцев энергопотребление и общий углеродный след сократились в 33 и 44 раза соответственно. В компании надеются, что исследование внесёт вклад в усилия по разработке эффективного ИИ для общего блага. Методологии расчёта энергопотребления учитывает энергию, потребляемую активными ИИ-ускорителями (TPU), CPU, RAM, а также затраты простаивающих машин и общие расходы ЦОД. При этом из расчёта исключаются затраты на передачу данных по внешней сети, энергия устройств конечных пользователей, расходы на обучение моделей и хранение данных. 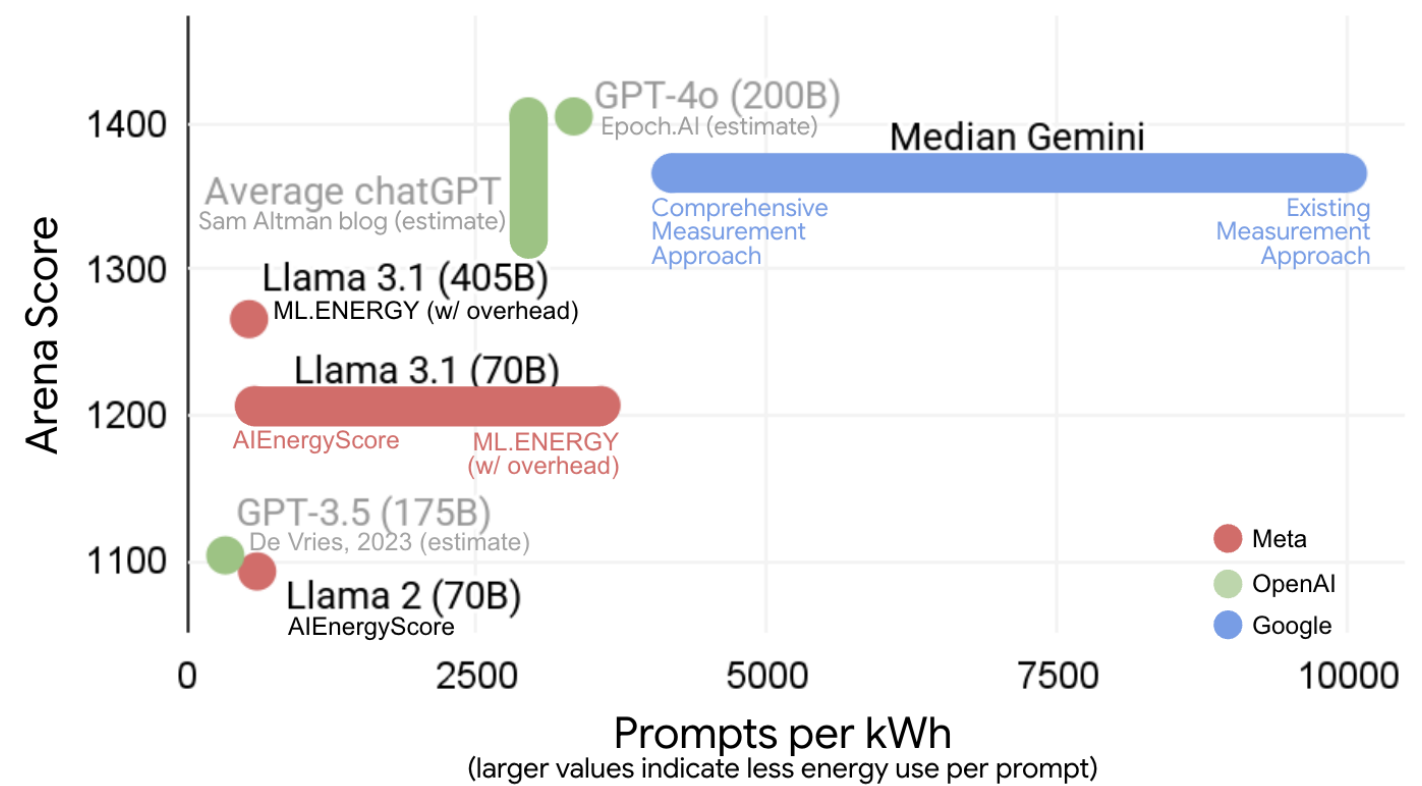
Источник изображений: Google Впрочем, по мнению некоторых экспертов, данные вводят в заблуждение, поскольку часть информации не учитывается. Так, не принимается в расчёт «косвенное» использование воды, поскольку считается только вода, которую ЦОД применяют для охлаждения, хотя значительная часть водопотребления приходится на генерирующие мощности, а не на их потребителей. Кроме того, при учёте углеродных выбросов должны приниматься во внимание не купленные «зелёные сертификаты», а реальное загрязняющее действие ЦОД в конкретной локации с учётом использования «чистой» и «обычной» энергии в местной электросети. 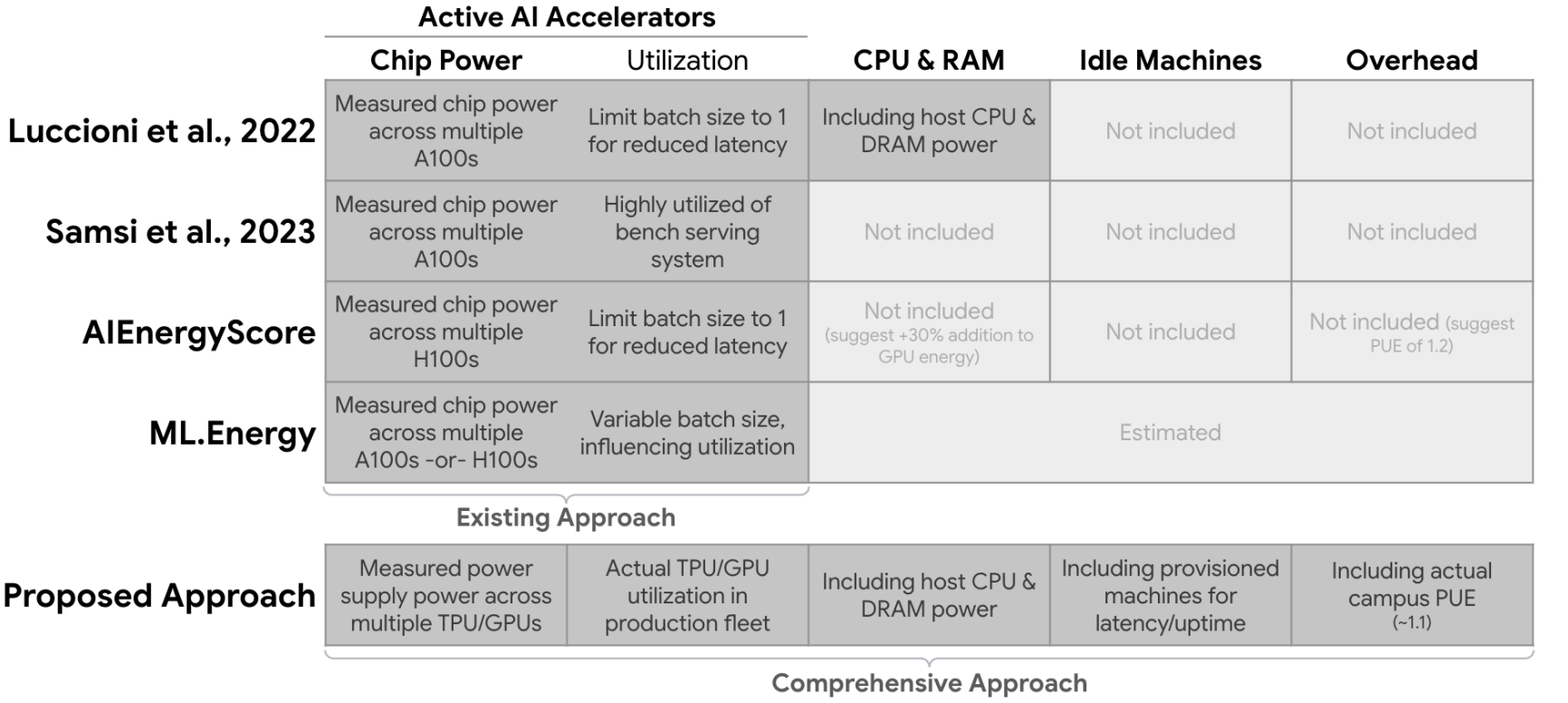 OpenAI также недавно оказалась в центре внимания экспертов и общественности, поскольку появилась информация, что её новейшая модель GPT-5 потребляет более 18 Вт·ч электроэнергии, до 40 Вт·ч на ответ средней длины. Сам глава компании Сэм Альтман (Sam Altman) объявил, что в среднем на выполнение запроса тратится около 0,34 Вт∙ч и около 0,32 мл воды. Это несколько больше, чем заявленные показатели Google Gemini, однако, согласно расчётам исследователей, эти цифры, скорее всего, актуальны для GPT-4o.
14.08.2025 [17:29], Руслан Авдеев
Умнее, но прожорливее: GPT-5 потребляет до 20 раз больше энергии, чем предыдущие моделиНедавно представленной модели OpenAI GPT-5 в сравнении с ChatGPT образца середины 2023 года для обработки идентичного запроса потребуется до 20 раз больше энергии, сообщает The Guardian. Официальную информацию об энергопотреблении OpenAI, как и большинство её конкурентов, не публикует. В июне 2025 года глава компании Сэм Альтман (Sam Altman) сообщил, что речь идёт о 0,34 Вт∙ч и 0,00032176 л на запрос, но о какой именно модели идёт речь, не сообщалось. Документальные подтверждения этих данных тоже отсутствуют. По словам представителя Университета штата Иллинойс (University of Illinois), GPT-5 будет потреблять намного больше энергии в сравнении с моделями-предшественницами как при обучении, так и при инференсе. Более того, в день премьеры GPT-5 исследователи из Университета Род-Айленда (University of Rhode Island) выяснили, что модель может потреблять до 40 Вт∙ч для генерации ответа средней длины из приблизительно 1 тыс. токенов. Для сравнения, в 2023 году на обработку одного запроса уходило порядка 2 Вт∙ч. Сейчас среднее потребление GPT-5 составляет чуть более 18 Вт∙ч на запрос, что выше, чем у любых других сравнивавшихся учёными моделей, за исключением апрельской версии «рассуждающей» o3 и DeepSeek R1. Предыдущая модель GPT-4o потребляет значительно меньше. 18 Вт∙ч эквивалентны 18 минутам работы лампочки накаливания. С учётом того, что ChatGPT обрабатывает около 2,5 млрд запросов ежедневно, за сутки тратится энергии, достаточной для снабжения 1,5 млн домохозяйств в США. 
Источник изображения: Dean Brierley / Unsplash В целом учёные не удивлены, поскольку GPT-5 в разы производительнее своих предшественниц. Летом 2025 года ИИ-стартап Mistral опубликовал данные, в которых выявлена «сильная корреляция» между масштабом модели и её энергопотреблением. По её данным, GPT-5 использует на порядок больше ресурсов, чем GPT-3. При этом многие предполагают, что даже GPT-4 в 10 раз больше GPT-3. Впрочем, есть и дополнительные факторы, влияющие на потребление ресурсов. Так, GPT-5 использует более эффективное оборудование и новую, более экономичную экспертную архитектуру с оптимизацией расхода ресурсов на ответы, что в совокупности должно снизить энергопотребление. С другой стороны, в случае с GPT-5 речь идёт о «рассуждающей» модели, способной работать с видео и изображениями, поэтому реальное потребление ресурсов, вероятно, будет очень высоким. Особенно в случае длительных рассуждений. 
Источник изображения: Tim King / Unsplash Чтобы посчитать энергопотребление, группа из Университета Род-Айленда умножила среднее время, необходимое модели для ответа на запрос на среднюю мощность, потребляемую моделью в ходе работы. Важно отметить, что это только примерные оценки, поскольку достоверную информацию об использовании моделями конкретных чипов и распределении запросов найти очень трудно. Озвученная Альтманом цифра в 0,34 Вт∙ч практически совпадает с данными, рассчитанными для GPT-4o. Учёные подчёркивают необходимость большей прозрачности со стороны ИИ-бизнесов по мере выпуска всё более производительных моделей. В университете считают, что OpenAI и её конкуренты должны публично раскрыть информацию о воздействии GPT-5 на окружающую среду. Ещё в 2023 году сообщалось, что на обучение модели уровня GPT-3 требуется около 700 тыс. л воды, а на диалог из 20-50 вопросов в ChatGPT уходило около 500 мл. В 2024 году сообщалось, что на генерацию ста слов у GPT-4 уходит до трёх бутылок воды.
07.08.2025 [16:00], Владимир Мироненко
В Yandex Cloud AI Studio появились открытые модели OpenAIYandex B2B Tech открыла API-доступ на платформе Yandex Cloud AI Studio к новым рассуждающим open source моделям OpenAI gpt-oss-120b и gpt-oss-20b. С помощью новых моделей можно создавать агентские системы для выполнения различных задач, например, для автоматизации рекрутмента и технической поддержки, анализа и обработки документов и первичной коммуникации с клиентами, говорит компания. Доступность новых моделей по API позволяет российскому бизнесу использовать технологии OpenAI в бизнес-процессах без задействования собственной инфраструктуры. Использовать ИИ-модели напрямую у разработчика российским компаниям вряд ли удастся, так как для этого нужно передавать данные для обработки за рубеж, что идёт вразрез с требованиями российского законодательства. Как отметила Yandex B2B Tech, при использовании Yandex Cloud AI Studio данные компаний хранятся и обрабатываются в российских ЦОД, и её сервис полностью соответствует требованиям закона «О персональных данных». 
Источник изображения: Yandex Cloud Сообщается, что указанные нейросети сопоставимы по качеству с ведущими моделями OpenAI o3-mini и o4-mini, и в некоторых сценариях превосходят GPT-4o и o1. В них допускается регулировка интенсивности рассуждений и скорости генерации ответа. Вскоре для этих моделей будет доступен вызов функций для взаимодействия с внешними приложениями, что позволит осуществлять поиск информации в интернете при генерации ответа.
12.07.2025 [01:00], Руслан Авдеев
NVIDIA, Cisco и Indosat помогут Индонезии встать на ИИ-рельсы
cisco
indosat ooredoo hutchison
llm
nvidia
software
ии
индонезия
информационная безопасность
конфиденциальность
обучение
разработка
Индонезия сделала важный шаг к созданию суверенного ИИ, объявив о создании «Центра передового опыта в сфере ИИ» (AI Center of Excellence, CoE). Проект реализуется под руководством Министерства цифровых коммуникаций и информации (Komdigi) и при поддержке NVIDIA, Cisco и телеком-оператора Indosat Ooredoo Hutchison (IOH). Центр станет частью национальной инициативы «Золотое видение 2045» (Golden 2045 Vision), направленной на цифровую трансформацию экономики и развитие инноваций. В задачи CoE входят развитие локальной ИИ-инфраструктуры, подготовка кадров и поддержка стартапов. Частью CoE станет NVIDIA AI Technology Center, который обеспечит поддержку исследований в области ИИ, предоставит доступ к программе NVIDIA Inception для стартапов и предложит обучение в экосистеме NVIDIA Deep Learning Institute. Также CoE получит типовую суверенную ИИ-фабрику с новейшими ускорителями Blackwell. Дополнительно курируемый государством форум разработает надёжные ИИ-фреймворки для создания решений, соответствующих местным ценностям. Важное внимание уделяется вопросам кибербезопасности. На базе центра заработает система Sovereign Security Operations Center Cloud Platform, разработанная Cisco, сочетающая ИИ-распознавание угроз, локальное управление данными и управляемые сервисы обеспечения безопасности. Проект строится на четырёх стратегических столпах:

Источник изображения: Jeremy Bishop/unspalsh.com Уже сейчас около 30 независимых разработчиков и стартапов используют ИИ-инфраструктуру IOH на базе NVIDIA. С учётом того, что Indosat покрывает связью весь индонезийский архипелаг, компания может обслуживать сотни миллионов носителей индонезийского языка (Bahasa Indonesia) с помощью приложений на основе специальных LLM, таких как Indosat Sahabat-AI. В будущем Indosat и NVIDIA намерены внедрять технологии AI-RAN, позволяющие охватывать ещё более широкий круг людей, которые смогут пользоваться ИИ с помощью беспроводных сетей. Индонезия давно стала весьма привлекательным рынком для инвесторов. Так, Microsoft намерена в течение четырёх лет инвестировать в облачную инфраструктуру и ИИ-проекты Индонезии $1,7 млрд. А NVIDIA и Indosat Ooredoo Hutchison планируют построить ИИ-центр стоимостью $200 млн в Центральной Яве, $500 млн намерена инвестировать Tencent. Даже «Яндекс» имеет там собственные интересы.
15.06.2025 [23:29], Владимир Мироненко
Большая жатва: AMD назначила вице-президентом по ИИ гендиректора ИИ-стартапа Lamini, в который сама же и вложиласьAMD продолжает укреплять команду специалистов в сфере ИИ за счёт привлечения талантливых разработчиков, а также поглощения ИИ-стартапов. На минувшей неделе Шарон Чжоу (Sharon Zhou, вторая справа на фото ниже), соучредитель и гендиректор ИИ-стартапа Lamini (PowerML Inc.) сообщила в соцсети X, что она и несколько сотрудников присоединяются к AMD. Комментируя переход, представитель AMD сообщил ресурсу CRN, что это было наймом специалистов, а не приобретением команды, как это было в случае с разработчиком ИИ-чипов Untether AI, который фактически прекратил существование после сделки. В настоящее время неизвестно, какой будет дальнейшая судьба Lamini, которую в прошлом году покинул Грег Диамос (Greg Diamos), бывший архитектор ПО NVIDIA CUDA, основавший компанию вместе с Чжоу в 2022 году. До основания Lamini Чжоу работала менеджером по ML-продуктам в Google, менеджером по продуктам в ИИ-стартапах Kensho Technologies и Tamr, а также занимала должность внештатного преподавателя компьютерных наук в Стэнфордском университете, где она получила докторскую степень по этой же специальности. В AMD её назначили на должность вице-президента по ИИ. 
Источник изображения: Sharon Zhou/X Платформа Lamini позволяет компаниям настраивать и кастомизировать большие языковые модели (LLM) с использованием собственных данных. В частности, Lamini предложила новый подход под названием Mixture of Memory Experts (MoME), направленный на повышение производительности LLM и фактической точности путем радикального снижения частоты галлюцинаций с 50 % до 5 %. Утверждается, что этот подход позволяет значительно сократить объём вычислительных ресурсов для обучения LLM, а также продолжительность этого процесса. В 2023 году AMD представила Lamini как одного из первых независимых поставщиков ПО, поддержавших её ускорители Instinct. В сентябре того же года Lamini сообщила, что использует более чем 100 ускорителей серии Instinct MI200 и что платформа AMD ROCm «достигла программного паритета» с NVIDIA CUDA. До определённого момента ИИ-платформа Lamini была единственной коммерческой платформой, целиком и полностью работающей на базе AMD Instinct. 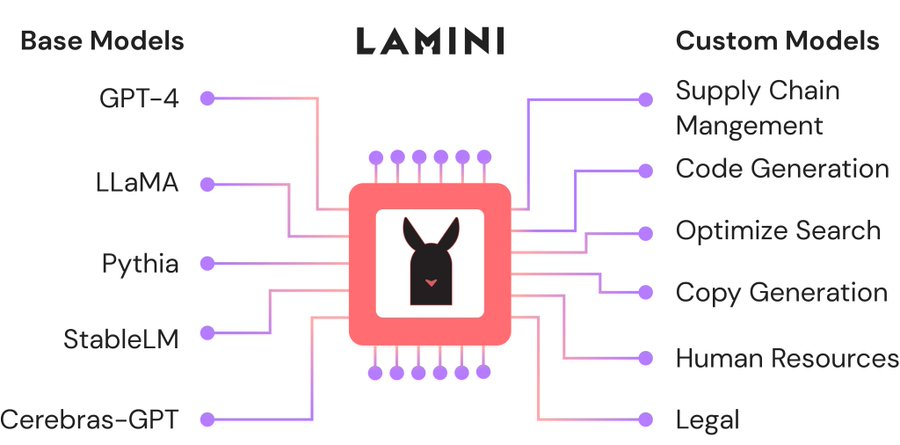 В прошлом году стартап привлек финансирование в размере $25 млн от нескольких инвесторов, включая венчурное подразделение AMD, Эндрю Ына (Andrew Ng), гендиректора Dropbox Дрю Хьюстона (Drew Houston), и Лип-Бу Тана (Lip-Bu Tan), который в начале этого года стал гендиректором Intel. Помимо команды Untether AI, AMD приобрела в течение последних нескольких неделе разработчика систем кремниевой фотоники Enosemi и стартапа Brium, специализирующегося на инструментах оптимизации ИИ ПО для различной аппаратной инфраструктуры.
14.06.2025 [17:04], Владимир Мироненко
Scale AI получила от Meta✴ более $14 млрд, но потеряла гендиректора и рискует лишиться крупных контрактов с Gooogle, Microsoft, OpenAI и xAIИИ-стартап Scale AI, занимающийся подготовкой, оценкой и разметкой данных для обучения ИИ-моделей, объявил о крупной инвестиционной сделке с Meta✴, по результатм которой его рыночная стоимость превысила $29 млрд. Сделка существенно расширит коммерческие отношения Scale и Meta✴. Также её условиями предусмотрен переход гендиректора Scale AI Александра Ванга (Alexandr Wang) и ещё ряда сотрудников в Meta✴. Вместо Ванга, который останется в совете директоров стартапа, временно исполняющим обязанности гендиректора Scale AI назначен Джейсон Дроги (Jason Droege), директор по стратегии, имеющий «20-летний опыт создания и руководства знаковыми технологическими компаниями, включая Uber Eats и Axon». Представитель Scale AI уточнил в интервью ресурсу CNBC, что Meta✴ вложит в компанию $14,3 млрд, в результате чего получит в ней 49-% долю акций, но без права голоса. «Мы углубим совместную работу по созданию данных для ИИ-моделей, а Александр Ванг присоединится к Meta✴ для работы над нашими усилиями по созданию суперинтеллекта», — рассказал представитель Meta✴. Переманивая Ванга, который не имея опыта в R&D, сумел с нуля создать крупный бизнес в сфере ИИ, гендиректор Meta✴ Марк Цукерберг (Mark Zuckerberg) делает ставку на его организаторские способности, полагая, что укрепить позиции Meta✴ в сфере ИИ под силу опытному бизнес-лидеру, больше похожему на Сэма Альтмана (Sam Altman), чем на учёных, стоящих у руля большинства конкурирующих ИИ-лабораторий, пишет Reuters. 
Источник изображения: Scale AI Инвестиции в Scale AI станут вторыми по величине в истории Meta✴ после приобретения WhatsApp за $19 млрд. Однако сделка может оказаться не совсем выгодной для Scale AI, предупреждает Reuters, поскольку многие компании, являющиеся клиентами Scale AI, могут отказаться от дальнейшего сотрудничества из-за опасений по поводу того, что Ванг, оставаясь в совете директоров стартапа, будет предоставлять Meta✴ внутреннюю информацию о приоритетах конкурентов. Представитель Scale AI заверил, что инвестиции Meta✴ и переход Ванга не повлияют на клиентов стартапа, и что Meta✴ не будет иметь доступа к его какой-либо деловой информации или данным. Тем не менее, по словам источников Reuters, Google, один их крупнейших клиентов Scale AI, планирует разорвать отношения со стартапом. Источники сообщили, что Google планировала потратить $200 млн только в этом году на услуги Scale AI по подгтовке и разметке данных людьми. После объявления о сделке поисковый гигант уже провёл переговоры с несколькими конкурентами Scale AI. Scale AI получила в 2024 году размере $870 млн, из них около около $150 млн от Google, утверждают источники. По их словам, другие крупные клиенты, включая Microsoft, OpenAI и xAI, тоже планируют отказаться от услуг Scale AI. Официальных подтверждений этой информации пока не поступало. А финансовый директор OpenAI заявил в пятницу, что компания, которой источники тоже приписывают намерение отказаться от услуг Scale AI, продолжит работать со стартапом, как с одним из своих многочисленных поставщиков данных.
07.06.2025 [22:49], Владимир Мироненко
От «железа» до агентов: «К2 НейроТех» представил ПАК-AI для разработки и внедрения ИИ на предприятиях«К2 НейроТех», подразделение компании «К2Тех», представило программно-аппаратный комплекс ПАК-AI, позволяющий оперативно интегрировать ИИ в действующую ИТ-среду организации в соответствии с её требованиями и политиками безопасности. ПАК-AI включает аппаратную часть, программную платформу, а также инструменты для работы с данными, ИИ-моделями, промтами, визуализациями, API-интеграцией и т. д. Первый вариант ПАК-AI построен на базе оборудования YADRO: шесть серверов, включая ИИ-сервер с восемью GPU и сетевые коммутаторы KORNFELD. Управление ПАК-AI осуществляется через портал — специализированную GUI-платформу, служащую единой точкой входа для работы с вычислительными ресурсами, для запуска моделей, настройки среды и контроля загрузки. Платформа обеспечивает управление виртуальными машинами с ускорителями для изолированных задач и контейнерами Kubernetes для обеспечения гибкости и масштабируемости. Платформа обеспечивает доступ к предустановленному ПО: ОС (Astra Linux, CentOS, РЕД ОС), ML-инструментам, моделям и средам разработки. 
Источник изображений: «К2 НейроТех» Клиенту доступны функции маршрутизации данных, оркестрации, мониторинга, управления файловыми системами и каталогами, резервного копирования и обеспечения безопасности. Использование ресурсов фиксируется автоматически с отображением их стоимости в разделе биллинга. Разработчикам предоставляется весь необходимый стек инструментов для администрирования моделей. Помимо доступа к востребованным средам, таким как TensorFlow, PyTorch, Keras, HuggingFace Transformers, специалисты имеют возможность разворачивать собственные окружения в виде ВМ или контейнеров, устанавливать дополнительные библиотеки, использовать кастомные образы и конфигурации. Также предоставляется возможность построения MLOps-конвейеров с использованием MLflow, Hydra, Optuna.  Прикладной слой платформы представляет собой каталог готовых агентов и моделей, разработанных К2 НейроТех. Он включает решения как на базе открытых, так и вендорских моделей, в том числе YandexGPT mini, GigaChat lite, DeepSeek, Llama, Qwen и другие. Пользователи смогут их обучать на корпоративных данных, адаптировать под бизнес-процессы и применять в прикладных сценариях: от обработки документов и генерации контента до автоматизации клиентского взаимодействия, производственной аналитики и других узкоспециализированных прикладных задач. В ПАК-AI может использоваться отечественное оборудование любых вендоров и ПО, разработанное как на основе решений из реестров Минцифры и Минпромторга России, так и на открытом ПО, что позволяет менять конфигурацию с соответствии с требованиями регуляторов. ПАК-AI реализован в формате IaaS (предоставление вычислительных ресурсов), PaaS (маркетплейс приложений для ML-команд с предоставлением доступа к нужной инфраструктуре и сервисам), SaaS (доступ к предустановленным приложениям от сторонних вендоров). Также с его помощью можно организовать внутренний сервис ИИ-как-услуга (AIaaS) для предоставления LLM и агентов. |
|

