Материалы по тегу: hardware
|
07.02.2026 [23:53], Игорь Осколков
Tenstorrent принудительно «отрезала» ИИ-ядра у ускорителей Blackhole, даже у уже проданныхРазработчик ИИ-ускорителей Tenstorrent, возглавляемый Джимом Келлером, неожиданно изменил конфигурацию своих чипов Blackhole. Последнее обновление прошивки для карт p150a/p150b принудительно снижает количество активных ИИ-ядер Tensix со 140 до 120, причём это касается уже выпущенных и проданных карт. Описание p150a/p150b на сайте тоже обновилось. Хотя количество ядер уменьшится более чем на 14 %, компания обещает, что в типичных рабочих нагрузках разница в производительности составит лишь 1–2 %. Однако если ранее пиковая заявленная производительность составляла 774 Тфлопс (BLOCKFP8), то теперь она равна 664 Тфлопс. Таким образом, формально вычислительные блоки у младшей p100a и старших p150a/p150b теперь одинаковые. Вся разница в технических характеристиках между ними, помимо сетевого интерфейса, теперь заключается в объёме и скорости набортной памяти — 28 Гбайт GDDR6 (448 Гбайт/с) у младшей модели против 32 Гбайт (512 Гбайт/с) у старших. 
Источник изображений: Tenstorrent Причину такого внезапного изменения характеристик компания не назвала. В Сети есть предположения, что Tenstorrent таким образом пытается, к примеру, увеличить выход годных чипов. Или же она столкнулась с какими-то другими ограничениями, к примеру, по питанию и/или охлаждению. В частности, в том же самом апдейте снижен TDP у решения Galaxy на базе ускорителей Wormhole, чтобы, как сказано в описании, оставаться в рамках лимита по питанию. Наконец, изменение может быть связано и с подготовкой двухчиповой версии ускорителей Blackhole p300, которые получат 64 Гбайт памяти (1 Тбайт/с). 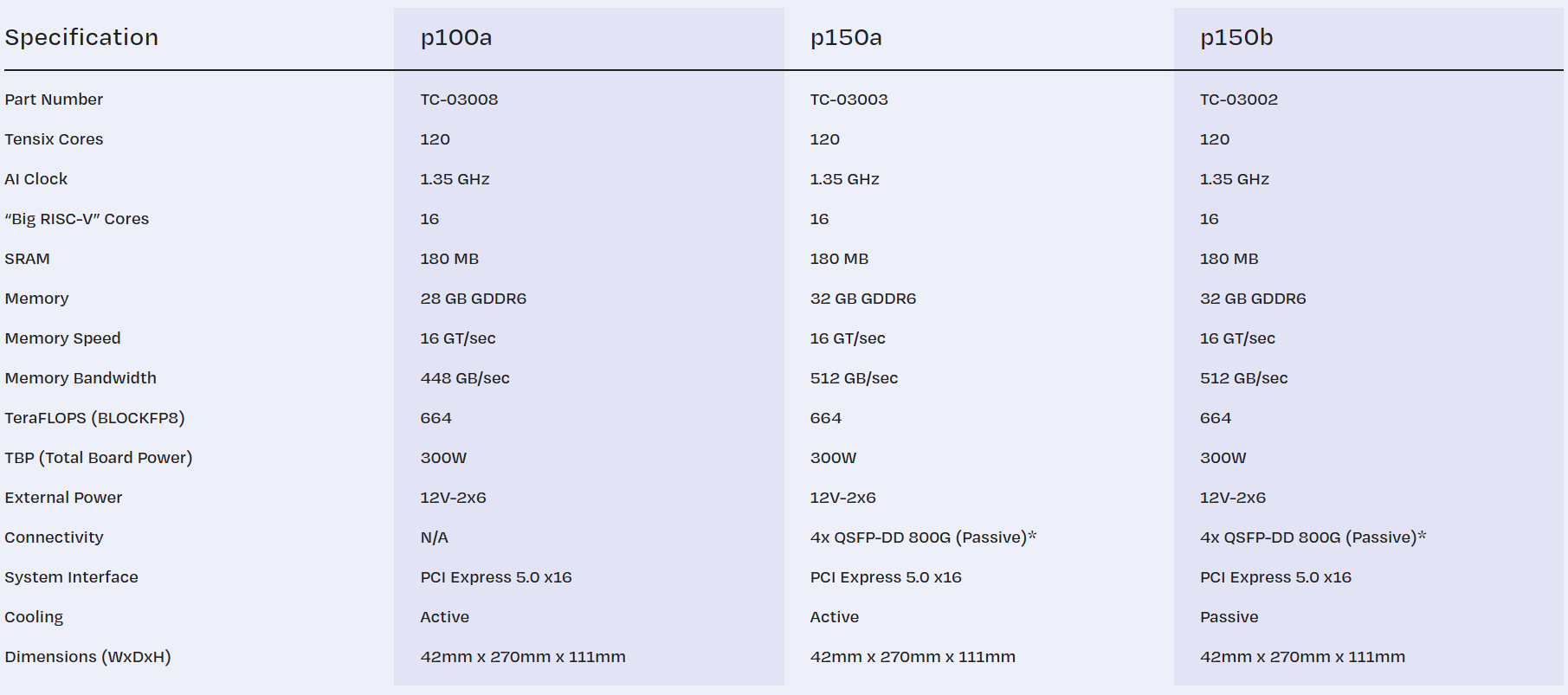
07.02.2026 [17:23], Руслан Авдеев
AWS: ни один сервер с NVIDIA A100 не выведен из эксплуатации, а некоторые клиенты всё ещё используют Intel Haswell — не всем нужен ИИПо словам главы AWS Мэтта Гармана (Matt Garman), клиенты до сих пор использует серверы на основе ИИ-ускорителей NVIDIA A100, представленных в 2020 году. Отчасти это происходит потому, что спрос на вычислительные ресурсы превышает предложение, так что устаревшие чипы по-прежнему востребованы, передаёт Datacenter Dynamics. По словам Гармана, все ресурсы фактически распроданы, а серверы с A100 из эксплуатации никогда не выводились. Комментарии Гармана перекликаются с прошлогодним заявлением Амина Вахдата (Amin Vahdat), отвечающего в Google за ИИ и инфраструктуру. По его словам, в Google одновременно работают семь поколений тензорных ускорителей (TPU). Ускорители возрастом семь-восемь лет загружены на 100 %, а спрос на TPU так высок, что Google вынуждена отказывать некоторым клиентам. Впрочем, оба топ-менеджера, возможно, несколько кривят душой и пытаются развеять опасения инвесторов относительно того, что ИИ-ускорители, на которые тратятся огромные деньги, через два-три года придётся выкинуть, чтобы купить более современные, энергоэффективные и, конечно же, дорогие. И что за это время они не успеют окупиться. Хотя Гарман назвал главной причиной сохранения работы серверов на A100 высокий спрос, он признал, что есть и другие причины. В частности, современные ИИ-чипы снижают точность вычислений с плавающей запятой. В результате некоторые клиенты попросту не могут перейти на Blackwell или вовсе вынуждены использовать Intel Xeon Haswell десятилетней давности для HPC-подобных вычислений, поскольку точности у современных ИИ-ускорителей недостаточно. В июне 2025 года AWS заявила о снижении цены доступа к устаревшим NVIDIA H100, H200 и A100 на своей платформе, причём для A100 стоимость снизилась на треть. 
Источник изображения: NVIDIA Стоит отметить, что «устаревшие» ускорители долго остаются востребованными, поскольку всё равно обладают большой производительностью. Наиболее яркий пример — разрешение на поставку в Китай чипов NVIDIA H200. Хотя США и их союзники готовятся к внедрению ускорителей поколения Vera Rubin, китайский бизнес готов покупать H200, поскольку те значительно производительнее, экономически выгоднее и удобнее отечественных ускорителей.
06.02.2026 [18:44], Руслан Авдеев
Время — деньги: SiTime отчиталась о росте на рынке ЦОД и объявила о покупке смежных активов Renesas ElectronicsКомпания SiTime, занимающаяся разработкой и выпуском высокоточных устройств синхронизации времени для IT-индустрии, отчиталась о благоприятных финансовых итогах IV квартала и 2025 года в целом, связанных с успехами в сегменте, связанном с телеком-индустрией, корпоративными клиентами и ЦОД (Communications, Enterprise and Datacenter, CED). Кроме того, она потратит $1,5 млрд на покупку ключевых активов тайминг-бизнеса Renesas Electronics, сообщает Converge Digest. В IV квартале 2025 года выручка SiTime составила $113,3 млн, на 36 % выше к/к и на 66 % г/г. Валовая маржа по GAAP составила 56,4 %, «не по GAAP» — 61,2 %, что превысило прогнозы. Чистая прибыль по GAAP составила $9,2 млн, или по $0,34 на каждую разводнённую акцию. Чистая прибыль не по GAAP — $41,3 млн или по $1,52 на акцию. В 2025 финансовом году выручка составила $326,7 млн, на 61 % выше год к году. Валовая маржа по GAAP составила 59,3 %, чистый убыток по GAAP — $42,9 млн, или по $1,72 на акцию с учётом разводнения. Валовая маржа не по GAAP составила $82,6 млн или $3,20 на акцию с учётом разводнения. SiTime завершила год с $808,4 млн денежных средств, их эквивалентов и краткосрочных инвестиций. По словам главы SiTime Раджеша Вашишта (Rajesh Vashist), IV квартал — уже седьмой квартал подряд, в котором сегмент CED компании продемонстрировал рост более 100 % г/г. Отмечен широкий спрос во всех клиентских сегментах и ожидается, что динамика сохранится и в 2026 году, благодаря приложениям в сфере коммуникаций и ЦОД, связанным с ИИ-задачами. 
Источник изображения: SiTime На фоне успехов компания объявила о покупке ключевых активов тайминг-бизнеса Renesas Electronics Corporation. Этот шаг существенно расширяет портфолио решений SiTime и углубляет присутствие компании на растущих рынках ИИ ЦОД и телекоммуникаций. Предполагается, что купленный бизнес позволит генерировать около $300 млн выручки в течение 12 месяцев после того, как сделка будет закрыта, приблизительно 75 % будет приходиться на ИИ ЦОД и коммуникационную сферу, а валовая маржа составит около 70 %. В портфолио добавятся разнообразные продукты, включая генераторы тактовых импульсов (clock generators), буферы (buffers), сетевые синхронизаторы (network synchronizers) и подавители джиттера (jitter attenuators) — дополняя имеющуюся линейку MEMS-осцилляторов компании. Это расширяет присутствие SiTime на рынке коммутаторов ЦОД, SmartNIC, маршрутизаторов, промышленных систем и автомобильных платформ. По условиям сделки SiTime выплатит Renesas $1,5 млрд наличными и передаст приблизительно 4,13 млн своих акций. На это потратят собственные средства компании, ещё $900 млн будет взято в долг Wells Fargo. Ожидается, что сделка будет закрыта к концу 2026 года, после чего глава Renesas Хидетоси Сибата (Hidetoshi Shibata) войдёт в совет директоров SiTime. Дополнительно подписан меморандум о взаимопонимании для изучения возможности интеграции MEMS-резонаторов SiTime во встраиваемые продукты Renesas, это должно снизить сложность печатных плат с повышением эффективности и производительности готовых решений.
06.02.2026 [18:00], Сергей Карасёв
ИИ-пирамида: M5Stack представила мини-компьютер AI Pyramid Computing Box в необычном корпусеКомпания M5Stack, по сообщению CNX Software, выпустила компьютер небольшого форм-фактора AI Pyramid Computing Box, подходящий для работы с ИИ-приложениями. Главной особенностью новинки является необычное исполнение: устройство заключено в пирамидальный корпус, в верхней части которого располагается настраиваемая кнопка с подсветкой. В основу положен процессор Axera AX8850 с восемью ядрами Arm Cortex-A55, работающими на частоте до 1,7 ГГц. Встроенный NPU-блок обеспечивает ИИ-производительность до 24 TOPS на операциях INT8. Возможно кодирование материалов 8K (30 к/с) и декодирование 8K (60 к/с) в форматах H.264/H.265. В оснащение входят флеш-модуль eMMC 5.1 вместимостью 32 Гбайт и слот для карты microSD. 
Источник изображения: CNX Software Стандартная версия AI Pyramid Computing Box несёт на борту 4 Гбайт LPDDR4Х-4266 (по 2 Гбайт для ОС и NPU). Есть два выхода HDMI с поддержкой 4Kp60. Более мощный вариант AI Pyramid Computing Box Pro располагает 8 Гбайт ОЗУ (по 4 Гбайт для ОС и NPU), а также выходом и входом HDMI с поддержкой 4Kp60. Устройство наделено аудиокодеком ES8311, массивом из четырёх микрофонов ES7210, четырьмя портами USB 3.0 Type-A (5 Гбит/с) и двумя портами USB Type-C (один поддерживает стандарт PD 3.0), двумя сетевыми портами 1GbE (RJ45) и двумя 4-контактными коннекторами UART/I2C. Все разъёмы сосредоточены на одной из боковых граней. Там же находится небольшой информационный OLED-дисплей с разрешением 128 × 32 точки. Габариты составляют 144,5 × 105,0 × 62,0 мм, масса — 195 г. Питание (9 В / 3 А) подаётся через коннектор USB Type-C. На мини-компьютере применяется платформа Linux на базе Ubuntu. Модель AI Pyramid Computing Box предлагается за $200, а вариант AI Pyramid Computing Box Pro стоит на $50 больше.
06.02.2026 [17:43], Руслан Авдеев
Затраты четырёх американских гиперскейлеров на ИИ ЦОД и оборудование превысят в 2026 году $650 млрдСовокупные капитальные затраты четырёх американских гиперскейлеров в 2026 году составят $650 млрд. Огромную сумму выделили на новые ИИ ЦОД и сопутствующее оборудование, необходимое для их функционирования, в т.ч. ИИ-чипы, сетевые кабели, резервные генераторы и т.п., сообщает Bloomberg. Запланированные Alphabet (Google), Amazon (AWS), Meta✴ и Miсrosoft расходы должны помочь в достижении доминирующего положения на рынке ИИ-инструментов, на котором наблюдается беспрецедентный бум. Как утверждают в Bloomberg, вероятные затраты каждой из этих компаний в 2026 году установят рекорд по капитальным затратам любой корпорации за последние десять лет. Сравнить заоблачные расходы можно, разве что, с «пузырём» на телеком-рынке в 1990-х гг. или даже со стремительным развитием железнодорожных сетей в США в XIX веке. Рост расходов на 60 % в сравнении с предыдущим годом означает новую волну ускоренного строительства дата-центров, ведущих к непрекращающемуся дефициту электроснабжения и росту тарифов для обычных пользователей, конфликтам между застройщиками на почве конкуренции за энергию и чистую воду. Также расходы малой группы состоятельной компании могут исказить общие экономические показатели в стране. При этом, по мнению экспертов, рынок вычислительных ресурсов для ИИ рассматривается как очередное поле битвы, где победитель заберёт всё или большую часть. 
Источник изображения: Obie Fernandez/unsplash.com На днях Meta✴ объявила, что капитальные затраты за год вырастут до $135 млрд, рост может составить порядка 87 %. Тогда же Microsoft объявила об увеличении капитальных затрат во II квартале на 66 %, что превышает предыдущие прогнозы. Аналитики полагают, что годовые капитальные затраты компании вырастут почти вдвое до $145 млрд, как и у Oracle — до $55 млрд. Alphabet обнародовала прогноз капитальных вложений, превосходящий расходы значительной части американской промышленности, на уровне до $185 млрд. Наконец, Amazon даже превзошла этот показатель, запланировав потратить $200 млрд в 2026 году. По прогнозам Bloomberg, крупнейшие американские автопроизводители, компании, выпускающие строительную технику, железнодорожные компании, ВПК, мобильные операторы, службы доставки посылок, а также Exxon Mobil, Intel, Walmart и др. (всего 21 компания) потратят суммарно $180 млрд. При этом расходы гиперскейлеров даже по отдельности уже превысили ВВП целых стран. У каждого из гиперскейлеров разные подходы к обеспечению окупаемости инвестиций. Но все затраты основаны на предпосылке, что инструменты вроде ChatGPT будут играть всё более важную роль в бизнесе и дома. Создание передовых ИИ с помощью тысяч чипов — чрезвычайно дорогой процесс, но затраты оправдываются предполагаемым экспоненциальным ростом доходов в будущем. Всего несколько лет назад даже IT-гиганты имели относительно небольшие вычислительные мощности, обслуживая миллиарды людей, но теперь ситуация изменилась. Например, в 2026 году Meta✴ впервые за шесть лет потратила на капитальные проекты больше, чем на исследования и разработки (в основном, на зарплаты разработчикам). На конец 2025 года она уже владела активами и оборудованием на $176 млрд, это приблизительно впятеро больше, чем на конец 2019 года. 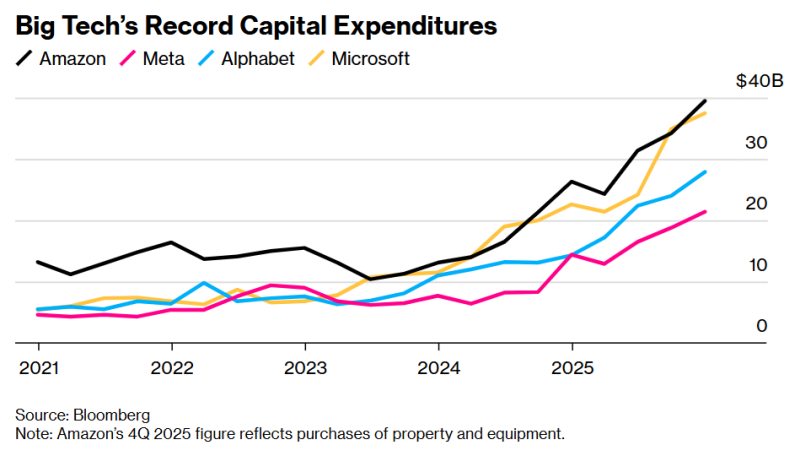
Источник изображения: Bloomberg По мере роста объёмов работ пока неизвестно, способны ли компании реализовать свои амбиции. Идёт конкуренция за ограниченное количество электриков, грузовиков-цементовозов и ИИ-ускорители NVIDIA, выпускаемые TSMC в ограниченных объёмах. Кроме того, прибыль Meta✴ и Google поступает в основном от цифровой рекламы, Amazon является крупнейшим ретейлером и поставщиком облачных сервисов, Microsoft является крупнейшим продавцом ПО для бизнеса — все они лидируют в своих отраслях и имеют значительные денежные резервы. Готовность тратить эти резервы на ИИ-проекты не может не беспокоить инвесторов. По словам представителя Theory Ventures, ранее работавшего в Google, раньше средства вкладывались в настоящие «машины для производства денег», а теперь им сами понадобились эти деньги, и даже кредиты. Более того, инвесторы, в последний год стремившиеся скупить акции техногигантов, теперь весьма осторожны на фоне растущих капитальных затрат. В некоторых случаях акции продаются даже тогда, когда основные направления бизнеса от онлайн-рекламы до электронной коммерции оставались стабильными и выручка даже превышала прогнозы. По словам некоторых экспертов, инвесторов пугают «аналитические обзоры и риторика». Не исключено, что перед их глазами — пример менее успешных компаний. Например, Fermi, очень успешно стартовавшая со сбором средств, теперь подозревается в манипуляциях с ценными бумагами и против неё уже подали коллективный иск от имени инвесторов. А, например, Oracle банки уже не очень хотят давать деньги в долг. На неё, кстати, тоже подали в суд в связи непрозрачностью финансирования ИИ ЦОД в интересах OpenAI, на которую завязано очень многое.
06.02.2026 [15:18], Владимир Мироненко
Акции Amazon упали после объявления о $200 млрд капзатрат на 2026 годАкции Amazon рухнули более чем на 10 % на внебиржевых торгах в четверг после объявления финансовых результатов за IV квартал и весь 2025 год и повышения прогноза капитальных затрат на 2026 год до $200 млрд. Выручка Amazon в IV квартале 2025 года, закончившемся 31 декабря, выросла год к году на 14 %, до $213,39 млрд, превысив прогноз аналитиков в $211,33 млрд (согласно опросу LSEG). Скорректированная прибыль на разводнённую акцию составила $1,95, что ниже консенсус-прогноза Уолл-стрит в $1,97. Чистая прибыль выросла до $21,19 млрд с $20,00 млрд годом ранее. В текущем квартале Amazon прогнозирует выручку в диапазоне от $173,5 млрд до $178,5 млрд, что означает рост год к году примерно на 11–15 %. Средняя точка этого диапазона соответствует прогнозу аналитиков в $175,6 млрд. За весь 2025 год выручка Amazon выросла 12 % до $716,92 млрд с $637,96 млрд годом ранее. Чистая прибыль увеличилась до $77,67 млрд или $7,17 на разводнённую акцию с $59,25 млрд или $5,53 на разводнённую акцию в 2024 году. 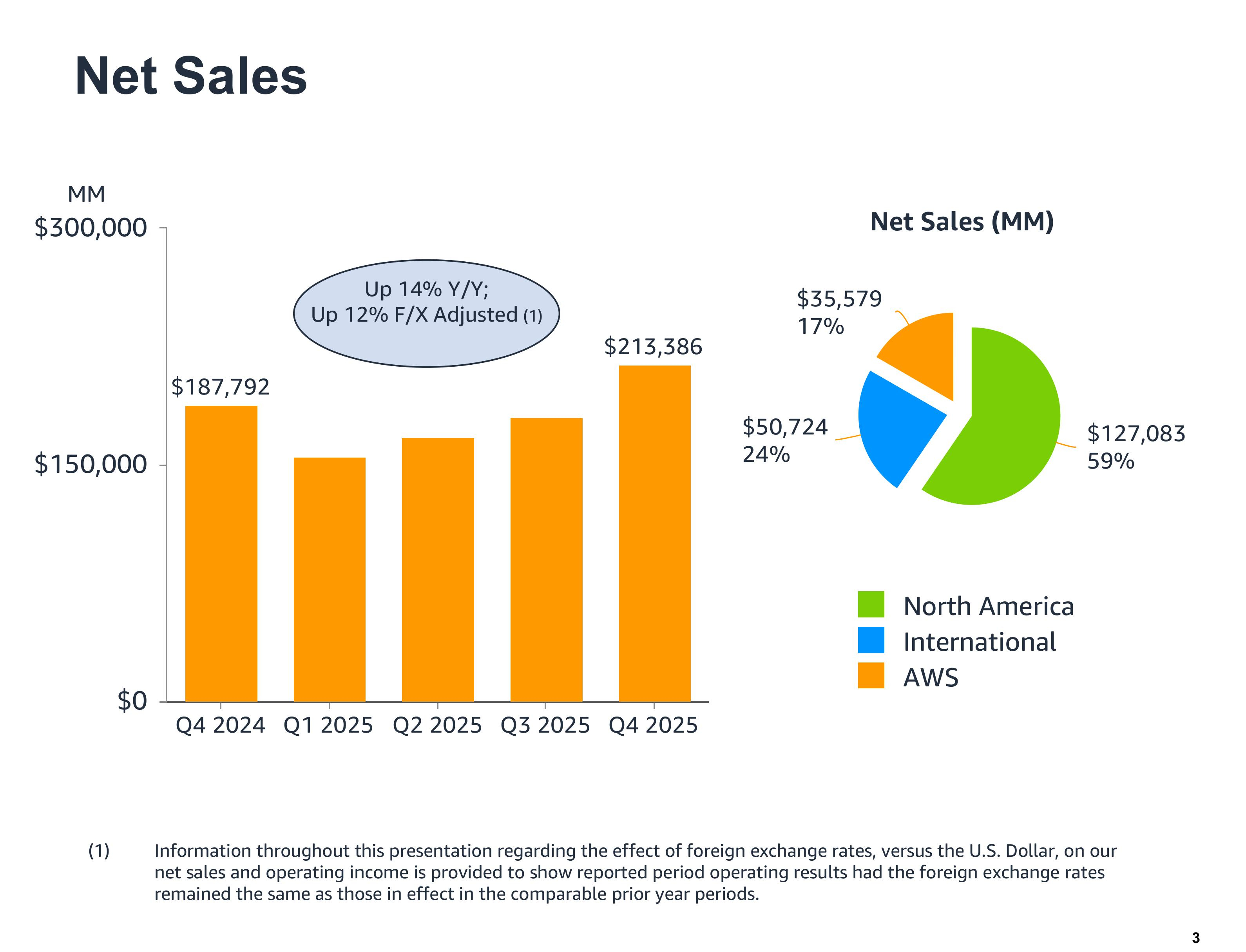
Источник изображений: Amazon Выручка облачного подразделения Amazon Web Services (AWS) за квартал увеличилась на 24 % до $35,58 млрд, превзойдя ожидания аналитиков, опрошенных StreetAccount, в размере $34,93 млрд. Операционная прибыль сегмента AWS достигла $12,47 млрд по сравнению с $10,63 млрд годом ранее. По словам гендиректора Amazon Энди Джасси (Andy Jassy), это был самый быстрый темп роста AWS за 13 кварталов. Как отметил ресурс SiliconANGLE, облачный бизнес Amazon по-прежнему намного больше, чем у конкурентов, но его рыночная доля постепенно сокращается из-за роста Microsoft Azure и Google Cloud. На прошлой неделе Microsoft сообщила о росте выручки Azure на 39 %, а продажи Google Cloud выросли на 48 %, что представляет собой самый быстрый темп роста с 2021 года. Аналитики сообщили, что Azure и Google Cloud также быстрее растут в сегменте ИИ-сервисов. 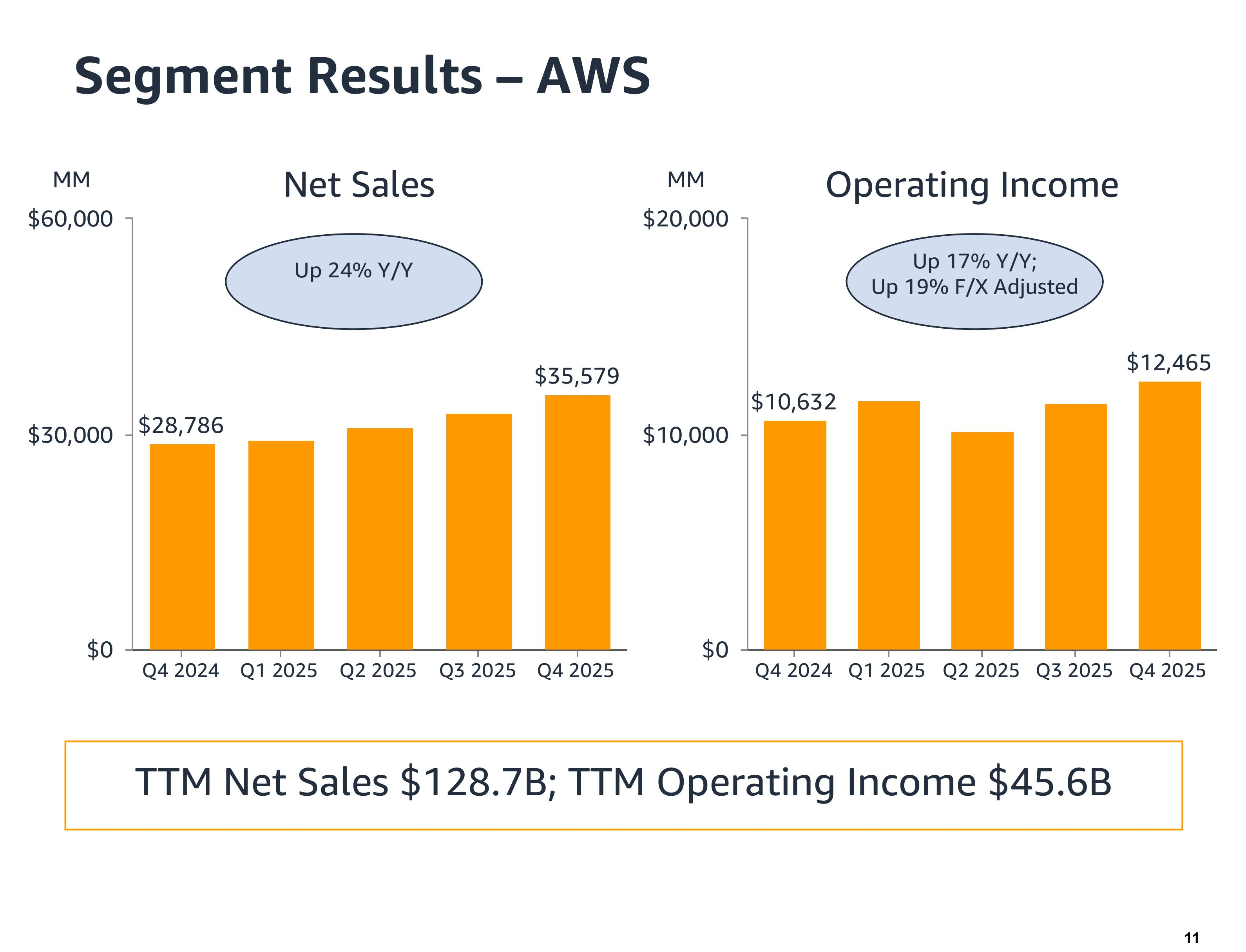 «Учитывая высокий спрос на наши существующие продукты и перспективные возможности, такие как ИИ, микросхемы, робототехника и LEO-спутники, мы планируем инвестировать около $200 млрд в капитальные вложения в Amazon в 2026 году и ожидаем высокой долгосрочной окупаемости вложенного капитала», — заявил Джасси. В ходе конференции с аналитиками Джасси пояснил, что основная часть капитальных затрат в 2026 году будет направлена в AWS, где, по его словам, «рабочие нагрузки, не связанные с ИИ, растут быстрее, чем мы ожидали». «У нас очень высокий спрос, — добавил Джасси. — Клиенты действительно хотят использовать AWS для основных и ИИ-задач, и мы монетизируем мощности так быстро, как только можем их установить». Объявленная сумма значительно превышает прогноз Уолл-стрит в $146,6 млрд и намного превосходит $131 млрд капзатрат в 2025 году. Ранее на этой неделе материнская компания Google, Alphabet, заявила, что планирует потратить от $175 до $185 млрд на капитальные затраты, а Meta✴ Platforms — от $115 до $135 млрд. Ожидаемые затраты Microsoft составят $145 млрд, а Oracle — $55 млрд. Несмотря на опасения инвесторов по поводу значительных капитальных затрат, некоторые аналитики считают, что позиции Amazon остаются сильными. «Развитие ИИ, безусловно, значительно ускоряет переход компаний в облако, что является основной причиной значительно более высоких, чем прогнозировалось, капитальных затрат, которые мы считаем фундаментально позитивными», — написал аналитик Pivotal Research Group Джефф Влодарчак (Jeff Wlodarczak) в записке для клиентов. Он отметил, что Amazon управляет двумя высокорентабельными быстрорастущими предприятиями и огромным низкорентабельным логистическим бизнесом с беспрецедентным масштабом, который «потенциально может существенно повысить маржу в среднесрочной и долгосрочной перспективе, используя ИИ в сочетании с робототехникой».
06.02.2026 [11:04], Руслан Авдеев
Cerebras привлекла ещё $1 млрд инвестиций после сделки с OpenAIЧерез четыре месяца после завершения раунда финансирования в объёме $1,1 млрд Cerebras Systems заявила о привлечении ещё $1 млрд, во многом от прежних инвесторов, сообщает Datacenter Dynamics. Сделку серии H возглавила Tiger Global, к ней присоединились AMD, Fidelity Management, Atreides Management, Alpha Wave Global, Altimeter, Coatue, 1789 Capital и другие компании. Сегодня оценка рыночной капитализации Cerebras составляет $23 млрд. Новый раунд привлечения средств объявлен через несколько недель после того, как компания заключила с OpenAI сделку на $10 млрд. Cerebras сегодня предлагает суперчип WSE-3 с 4 трлн транзисторов, это в 19 раз больше, чем может обеспечить NVIDIA Blackwell B200. Чип включает 44 Гбайт SRAM, что, как считается, позволяет добиться большей скорости инференса и меньше зависеть от поставок всё более дефицитных HBM и DDR. 
Источник изображения: Cerebras В сентябре 2024 года Cerebras подала заявку на IPO. Тогда компания сообщала, что в I полугодии 2024 года её выручка составила $136,4 млн, это более чем в 10 раз выше год к году. Убытки за тот же период сократились с $77,8 млн до $66,6 млн. В 2025 году компания отозвала заявку на IPO, посчитав, что документ более не отражает состояние бизнеса. В частности, в 2025 году значительно выросла выручка и теперь компания рассчитывает повторно подать документы для выхода на биржу уже во II квартале 2026 года.
06.02.2026 [10:53], Владимир Мироненко
Без дефицитной HBM: Positron AI готовит ИИ-ускоритель Asimov с терабайтами LPDDR5xКомпания Positron AI сообщила о привлечении $230 млн инвестиций в рамках переподписанного раунда финансирования серии B, в результате которого оценка её рыночной стоимости превысила $1 млрд. Раунд возглавили ARENA Private Wealth, Jump Trading и Unless при участии новых инвесторов Qatar Investment Authority (QIA), Arm и Helena, а также существующих инвесторов Valor Equity Partners, Atreides Management, DFJ Growth, Resilience Reserve, Flume Ventures и 1517. Объявление было сделано на мероприятии Web Summit Qatar, что подчеркивает растущий международный авторитет компании, отметил ресурс eWeek. На то, чтобы перейти в категорию единорогов, Positron AI потребовалось 34 месяца. Positron AI отметила решение Jump Trading стать одним из лидеров раунда после того, как эта компания стала её клиентом. «Для рабочих нагрузок, которые нас интересуют, узкими местами всё чаще становятся память и энергопотребление, а не теоретические вычисления», — сказал технический директор Jump Trading. — В ходе наших тестов Positron Atlas показал примерно в три раза меньшую сквозную задержку, чем сопоставимая система на базе NVIDIA H100, при оценке рабочих нагрузок инференса, в готовом к производству корпусе с воздушным охлаждением и цепочкой поставок, которую мы можем спланировать». 
Источник изображения: Positron AI Полученные инвестиции позволят ускорить выход платформы следующего поколения Asimov, разработанной на заказ. Компания планирует завершить тестирование Asimov к концу III квартала, а пробные версии появятся в конце I квартала 2027 года. В Asimov будет использоваться память LPDDR (без HBM), но возможность приблизиться к теоретической пиковой пропускной способности памяти означает, что компании и не нужно полагаться на HBM для быстрой генерации токенов, сообщил ресурсу EE Times технический директор Positron. Вычислительные элементы Asimov — это эволюция блоков Atlas с добавлением ядер Arm и улучшенным интерконнектом. Расширить память LPDDR5x в Asimov можно с помощью CXL — с 864 Гбайт до 2,3 Тбайт на чип. Чип позволяет создать два независимых домена памяти, чтобы лучше утилизировать её. Хосит-интерфейс чипа — PCI 6.0 x32. Хотя LPDDR5x дешевле и ёмче HBM, она значительно уступает ей по пропускной способности. Если ускорители Rubin от NVIDIA оснащены 288 Гбайт памяти HBM4 с пиковой пропускной способностью 22 Тбайт/с, то для Asimov, по-видимому, потолок составляет около 3 Тбайт/с, пишет The Register (в спецификациях указано 2,76 Тбайт/с). По словам Positron, разница в том, что её чипы действительно могут использовать 90 % этой пропускной способности, в то время как GPU на базе HBM в реальных условиях едва достигают 30 % пиковой пропускной способности, хотя память Rubin даже в этом случае примерно в 2,4 раза быстрее, чем у Asimov. 
Источник изображения: Positron AI Компания сообщила, что 400-Вт чип оснащён систолической матрицей 512×512, работающей на частоте 2 ГГц и поддерживающей типы данных TF32, FP16/BF16, FP8, NVFP4 и INT4. Эта матрица управляется рядом ядер Armv9 и может быть переконфигурирована, например, в 128×512 (GEMV) или 512×128 (GEMM), в зависимости от того, какой вариант более выгоден для решения конкретной задачи. Четыре чипа Asimov образуют 4U-платформу Titan с воздушным охлаждением и пропускной способностью между чипами 16 Тбит/с. Компания отметила, что Asimov рассчитан на поддержку 2 Тбайт памяти на ускоритель и 8 Тбайт памяти на систему Titan с аналогичной пропускной способностью памяти, как у ускорителя NVIDIA Rubin. В масштабе стойки это означает объём памяти более 100 Тбайт. До 4096 систем Titan (16384 ускорителя) могут быть объединены в единый масштабируемый домен с более чем 32 Пбайт памяти. Это достигается с помощью чистого межчипового интерконнекта, а не коммутируемых масштабируемых сетей, как в стоечных архитектурах NVIDIA или AMD. Positron подчеркнула, что её архитектура, ориентированная на память, открывает доступ к высокоэффективным задачам инференса, включая большие языковые модели с длинным контекстом, агентные рабочие процессы и модели медиа и видео следующего поколения.
06.02.2026 [09:00], Руслан Авдеев
TeraWulf превратит в ИИ ЦОД бывший алюминиевый завод в Кентукки и купит электростанцию в МэрилендеБывший алюминиевый завод в Хоусвилле (Hawesville) в Кентукки превратят в дата-центр. Century Aluminum продала своё предприятие компании Raylan Data Holdings — дочерней структуре американского оператора ЦОД TeraWulf, сообщает Datacenter Dynamics. Участок площадью более 300 га, по слухам, куплен за $200 млн. Century сохранит за собой в проекте «неконтролирующую» миноритарную долю в 6,8 %. По словам главы Century, сделка принесёт пользу всему штату, а подписанное соглашение позволяет компании иметь связь с проектом и оказывать поддержку местным жителям по мере перестройки площадки. TeraWulf намерена построить на участке кампус ИИ/HPC ЦОД. Подробности сделки пока не разглашаются, но TerWulf заявила, что площадка даёт немедленный доступ к надёжной энергетической инфраструктуре, в т.ч. имеются несколько высоковольтных ЛЭП, собственная подстанция и прямое подключение к региональной электросети. Площадке уже доступно приблизительно 480 МВт с возможностью расширения в будущем. Одновременно TeraWulf объявила о покупке работающей на мазуте 210-МВт электростанции Morgantown Generating Station в Мэриленде, которая подключена к энергосети. Сделка включает электрическую инфраструктуру и связанную с ней недвижимость. Первый этап проекта предусматривает увеличение мощности до 500 МВт, а в перспективе и до 1 ГВт. Закрытие сделки зависит от согласия неких «третьих сторон» и получения одобрения регуляторов, в т.ч. Федеральной комиссии по регулированию энергетики (FERC). Ведомство нередко отказывает в выдаче тех или иных разрешений — в своё время оно не дало добро на прямую поставку энергии кампусу ЦОД Amazon (AWS) от АЭС Susquehanna. 
Источник изображения: Amy Reed/unsplash.com TeraWulf отмечает, что Хоусвилл обеспечивает немедленный доступ к масштабируемым источникам энергии, а электростанция в Мэриленде позволяет нарастить генерирующие мощности для удовлетворения растущего спроса так, чтобы это приносило пользу энергосистеме. После закрытия сделок портфель инфраструктурных объектов TeraWulf вырастет до 2,8 ГВт на пяти площадках. Недавно бизнес сообщил о создании совместного предприятия с компанией Fluidstack для строительства кампуса ЦОД в Техасе, проект поддержан Google. В своё время покупка бывшего завода Electrolux позволила xAI в кратчайшие сроки развернуть ИИ-суперкомпьютер Colossus. Площадка тоже была подключена к энергосети, хотя потом для наращивания мощности пришлось задействовать газовые турбины. Кроме того, у бывших промышленных предприятий нашёлся и ещё один плюс — их перекрытия достаточно прочны для современных ИИ-стоек.
05.02.2026 [22:55], Владимир Мироненко
Вложимся в ИИ, а там посмотрим: Alphabet удвоит капзатраты в 2026 году на фоне полуторакратного роста выручки Google CloudХолдинг Alphabet, включающий компанию Google, объявил финансовые результаты IV квартала и всего 2025 финансового года, закончившегося 31 декабря 2025 года. Финансовые результаты компании за IV квартал превзошли прогнозы Уолл-стрит как по выручке, так и по прибыли. Как сообщил Alphabet, это отражает сильную динамику развития бизнеса и ускорение роста как в сервисах Google, так и в Google Cloud. Видимо, поэтому холдинг готов нарастить инвестиции в ИИ-инфраструктуру. Выручка за квартал выросла год к году на 18 % до $113,83 млрд, превысив консенсус-прогноз аналитиков, опрошенных LSEG, в размере $111,43 млрд (по данным CNBC). Разводнённая прибыль на акцию холдинга за квартал выросла до $2,82 с $2,15 в предыдущем году, что также выше прогнозируемых Уолл-стрит $2,63 (по данным Reuters). Годовая выручка достигла $402,8 млрд, а разводнённая прибыль на акцию — $10,81. Финансовый директор Alphabet Анат Ашкенази (Anat Ashkenazi) заявила, что Alphabet будет осуществлять свои инвестиции в 2026 году «таким образом, чтобы сохранить очень здоровое финансовое положение организации». Облачный бизнес компании — Google Cloud — продемонстрировал впечатляющий рост в IV квартале, главным образом за счёт роста доходов Google Cloud Platform (GCP) по основным продуктам, ИИ-инфраструктуре и решениям для генеративного ИИ, увеличившись на 48 % до $17,66 млрд, что превзошло ожидания аналитиков StreetAccount в размере $16,18 млрд. Это был самый высокий темп роста за более чем четыре года. Операционная прибыль сегмента составила $5,31 млрд против $2,09 млрд годом ранее. Рост облачного подразделения «впервые за несколько лет оказался значительно выше, чем у Microsoft Azure», что помогло материнской компании оправдать увеличение капитальных затрат, сказал Гил Лурия (Gil Luria), аналитик D.A. Davidson. 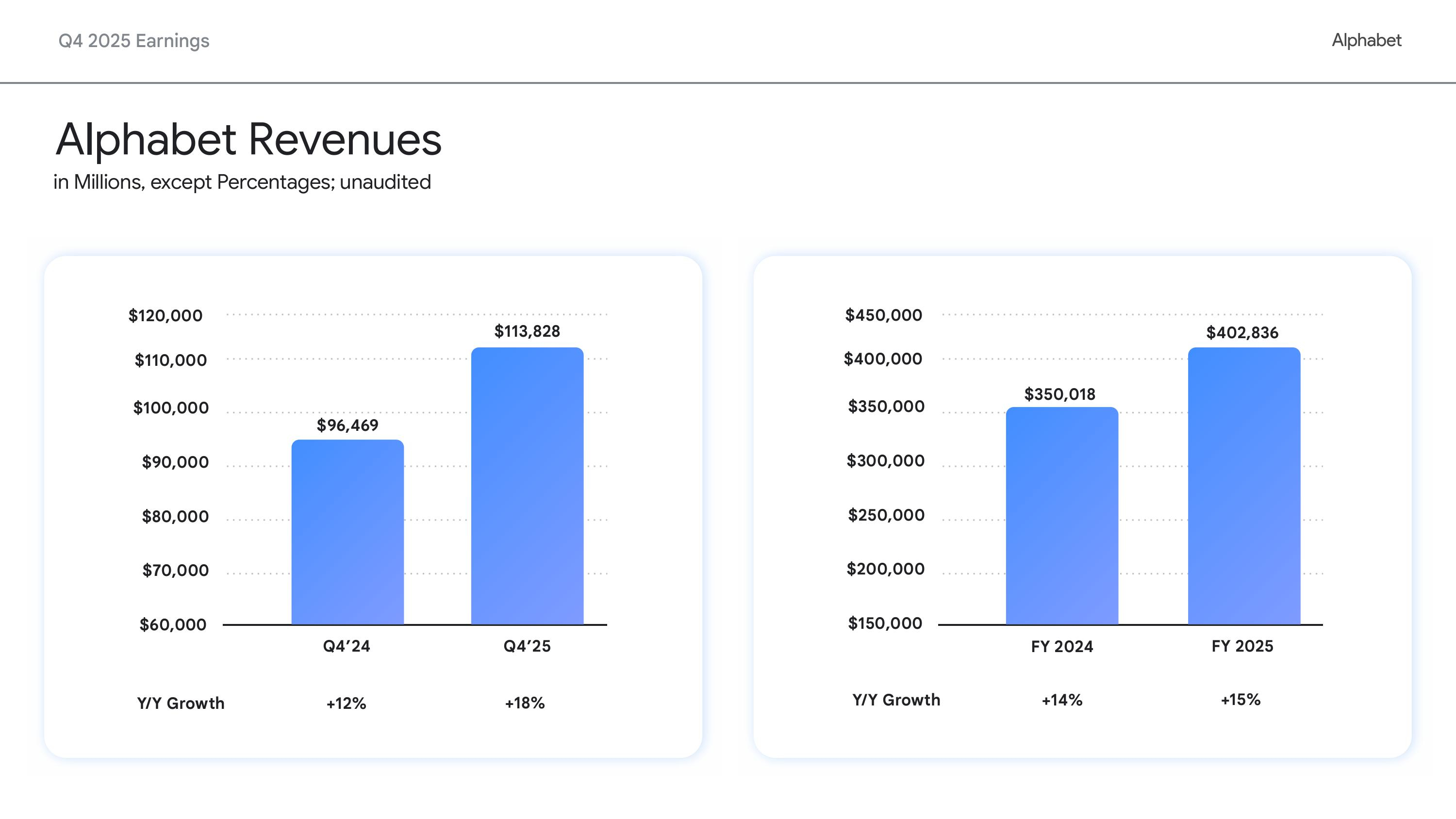
Источник изображений: Alphabet Сообщается, что акции Alphabet поначалу упали после отчёта на 6 %, поскольку объявление, что капитальные затраты в 2026 году составят от $175 до $185 млрд, что примерно вдвое больше, чем $91,4 млрд, инвестированных компанией в 2025 году и выше прогноза Уолл-стрит в $115,26 млрд, вызвало сомнения инвесторов в масштабах и устойчивости инвестиционных планов холдинга в связи с ростом капзатрат. Впрочем, в течение дня инвесторы отыграли падение акций Alphabet до 1 %, сопоставив рост расходов с резким ростом выручки и прибыли. Ожидается, что Alphabet и её конкуренты из числа крупных технологических компаний в совокупности потратят более полутриллиона долларов на ИИ в этом году. Meta✴ на прошлой неделе объявила об увеличении инвестиций в разработку ИИ в этом году на 73 %, в то время как Microsoft также сообщила о рекордных квартальных капитальных затратах. Сообщается, что капзатраты Meta✴ составят $125 млрд (по сравнению с $70 млрд в 2025 году), Alphabet — $180 ($91 млрд), Amazon — $175 млрд ($125 млрд), Microsoft — $145 млрд ($83 млрд), Oracle — $55 млрд ($35 млрд). То есть только эти пять компаний увеличат в 2026 году капзатраты по сравнению с прошлым годом почти на $300 млрд — с $404 млрд до $680 млрд. «Мы испытывали ограничения в поставках, даже несмотря на то, что наращивали наши мощности», — сказал гендиректор Сундар Пичаи (Sundar Pichai). — Очевидно, что наши капитальные затраты в этом году — это взгляд в будущее». «Мы видим, что наши инвестиции в ИИ и инфраструктуру стимулируют рост выручки», — отметил он в ходе общения с аналитиками, дополнительно высказав опасения, что Alphabet столкнётся с продолжающимися ограничениями в поставках в течение всего года. 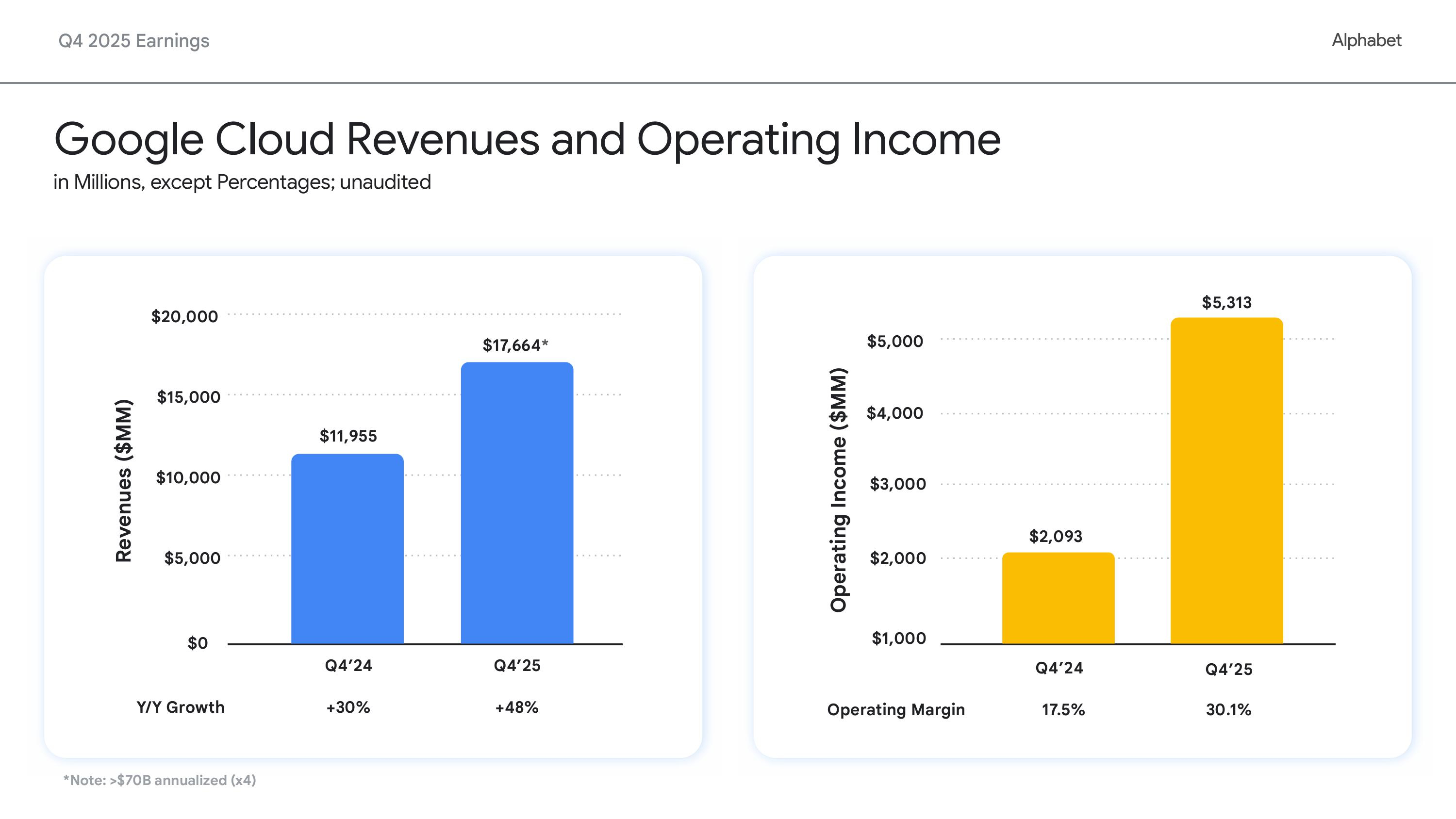 Пичаи отметил, что почти 75 % клиентов Google Cloud используют вертикально оптимизированный ИИ компании — от чипов и моделей до ИИ-платформ и корпоративных ИИ-агентов, которые обеспечивают высокую производительность, качество, безопасность и экономичность. «Эти клиенты, использующие ИИ, применяют в 1,8 раза больше продуктов, чем те, кто этого не делает, что позволяет нам диверсифицировать портфель продуктов, углублять отношения с клиентами и ускорять рост доходов», — подчеркнул гендиректор. Аналитики Barclays отметили: «Рост облачных сервисов поразителен, если измерять его любыми показателями: выручка, портфель заказов, количество полученных токенов API, внедрение Gemini в корпоративном секторе. Эти показатели в сочетании с прогрессом DeepMind в разработке моделей начинают оправдывать 100-% увеличение капитальных затрат в 2026 году». В RBC Capital Markets заявили, что динамика развития Gemini и резкий рост выручки Google Cloud в IV квартале являются «достаточными доказательствами, оправдывающими увеличение инвестиций» в 2026 году. Аналитики Deutsche Bank отметили, что Alphabet «поразила мир» своим масштабным планом капитальных затрат. «В условиях нынешних перемен в технологическом секторе неясно, хорошо это или плохо», — написали они. Добавим, что выручка сегмента Google Services — включающего доходы от рекламы в поиске и YouTube, на который приходится большая часть выручки Alphabet — выросла за квартал лишь на 14 % по сравнению с предыдущим годом до $95,86 млрд, что выше прогнозируемых $94,9 млрд согласно консенсус-прогнозам аналитиков, опрошенных Bloomberg. Акции Alphabet взлетели более чем на 70 % за последние шесть месяцев, и в прошлом месяце холдинг стала четвёртой компанией в истории, достигшей рыночной капитализации в $4 трлн, присоединившись к NVIDIA, Microsoft и Apple, отметил ресурс Forbes. |
|

