Материалы по тегу: arm
|
11.05.2024 [00:11], Сергей Карасёв
SpiNNcloud представила первый коммерческий «нейроморфный суперкомпьютер» SpiNNaker2 на базе ArmКомпания SpiNNcloud Systems анонсировала «нейроморфный суперкомпьютер» — гибридную высокопроизводительную вычислительную ИИ-систему, основанную, по словам компании, на принципах работы человеческого мозга. Утверждается, что это первое коммерчески доступное решение данного типа. Изделие базируется на архитектуре, разработанной Стивом Фербером (Steve Furber), одним из создателей оригинального процессора Arm. Идея заключается в применении большого количества маломощных чипов для более эффективной обработки ИИ-задач и других рабочих нагрузок. SpiNNaker2 представляет собой специализированную серверную плату с 48 чипами, каждый из которых насчитывает 152 ядра Arm. Таким образом, общее количество ядер составляет 7296. В состав чипов также входят различные дополнительные узлы, включая распределённые GPU-подобные блоки для ускорения обработки нейроморфных, гибридных и обычных моделей ИИ. 
Источник изображений: SpiNNcloud Systems В одну стойку могут монтироваться до 90 плат SpiNNaker2. Масштабирование осуществляется путём объединения таких стоек в кластер. В результате, как утверждается, возможно эмулирование в реальном времени как минимум 10 млрд взаимосвязанных нейронов. На операциях машинного обучения производительность может достигать 0,3 Эопс (1018 операций в секунду). Для сравнения — исследовательский нейроморфный компьютер Intel Hala Point поддерживает до 1,15 млрд нейронов и производительность до 30 Попс.  От традиционных ИИ-платформ на базе GPU новое решение отличается универсальностью, говорит компания. Благодаря использованию многочисленных асинхронных блоков с низким энергопотреблением достигается более эффективное управление рабочими нагрузками.  Со II половины 2024 года изделия SpiNNaker2 будут доступны в составе облачной платформы. В I половине 2025-го планируется организовать поставки самостоятельных систем. В число первых заказчиков SpiNNaker2 вошли Национальные лаборатории Сандия (Sandia National Laboratories), Технический университет Мюнхена (TUM) и Гёттингенский университет (Universität Göttingen).
30.04.2024 [13:02], Сергей Карасёв
Alibaba Yitian 710 признан самым быстрым облачным Arm-процессором в ряде бенчмарковСогласно результатам исследования, обнародованным Институтом инженеров электротехники и электроники (IEEE) в журнале Transactions on Cloud Computing, процессор Alibaba Yitian 710 на сегодняшний день является самым производительным серверным чипом с архитектурой Arm из тех, которые доступны в составе различных облачных платформ, передаёт The Register. Изделие Yitian 710 было создано подразделением T-Head специально для нужд Alibaba Cloud и дебютировало в 2021 году. Этот 5-нм процессор на базе Armv9 насчитывает до 128 ядер с частотой до 3,2 ГГц. Обеспечивается поддержка восьми каналов памяти DDR5 и 96 линий PCIe 5.0. При этом чипы отличаются высокой энергетической эффективностью. Alibaba Cloud рассчитывала перенести пятую часть своих мощностей на собственные Arm-чипы к 2025 году. 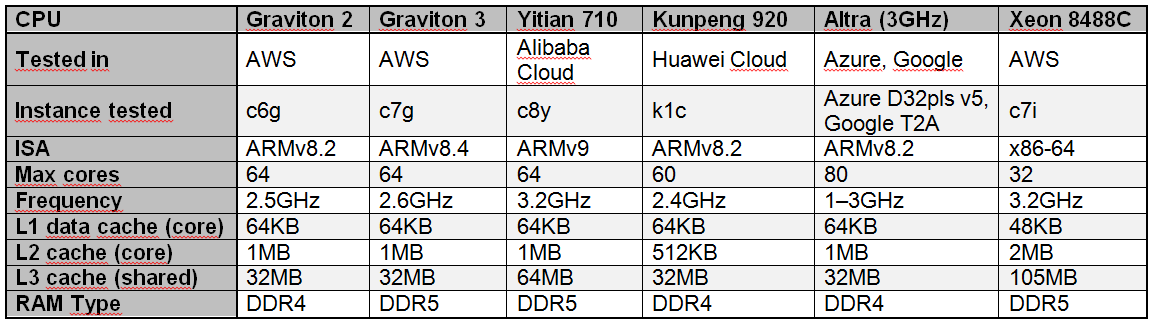 В ходе исследования чип Yitian 710 в конфигурации с 64 ядрами сравнивался с Arm-процессорами Amazon Graviton 2/3 (64 ядра), Huawei Kunpeng 920 (60 ядер) и Ampere Altra (80 ядер), а также с х86-чипом Intel Xeon Platinum 8488C поколения Sapphire Rapids. 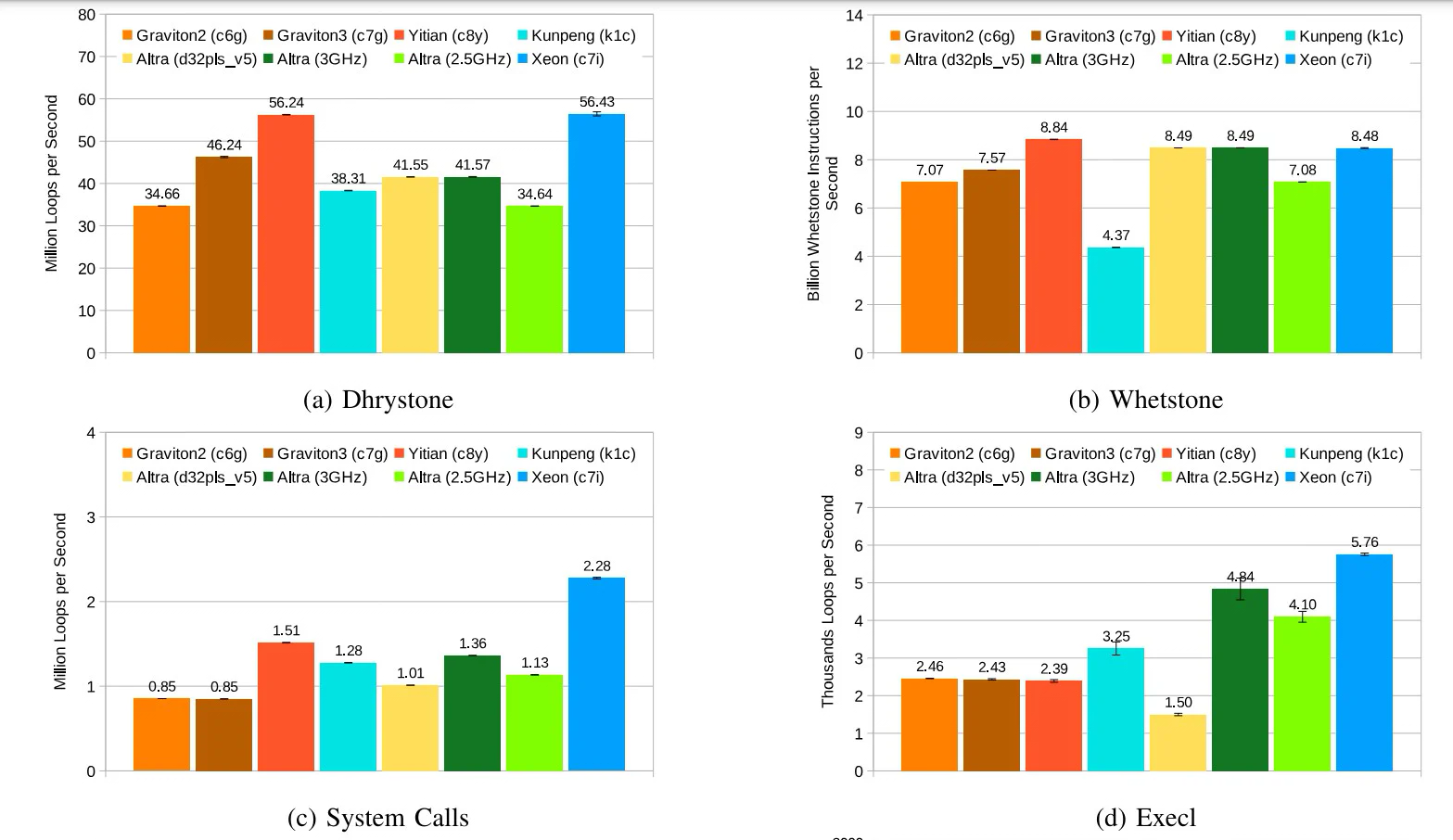
Источник изображений: The Register Тестирование проводилось в различных облачных средах, включая Amazon Web Services (AWS), Alibaba Cloud, Huawei Cloud, Microsoft Azure, Google Cloud Platform. Оценивалось быстродействие при выполнении различных задач: классические бенчмарки Dhrystone и Whetstone, ряд системных вызовов ядра и вызовов execl, скорость копирования файлов, показатель UnixBench, подписи и аутентификация с использованием криптографического алгоритма RSA 2048, а также работа с СУБД. 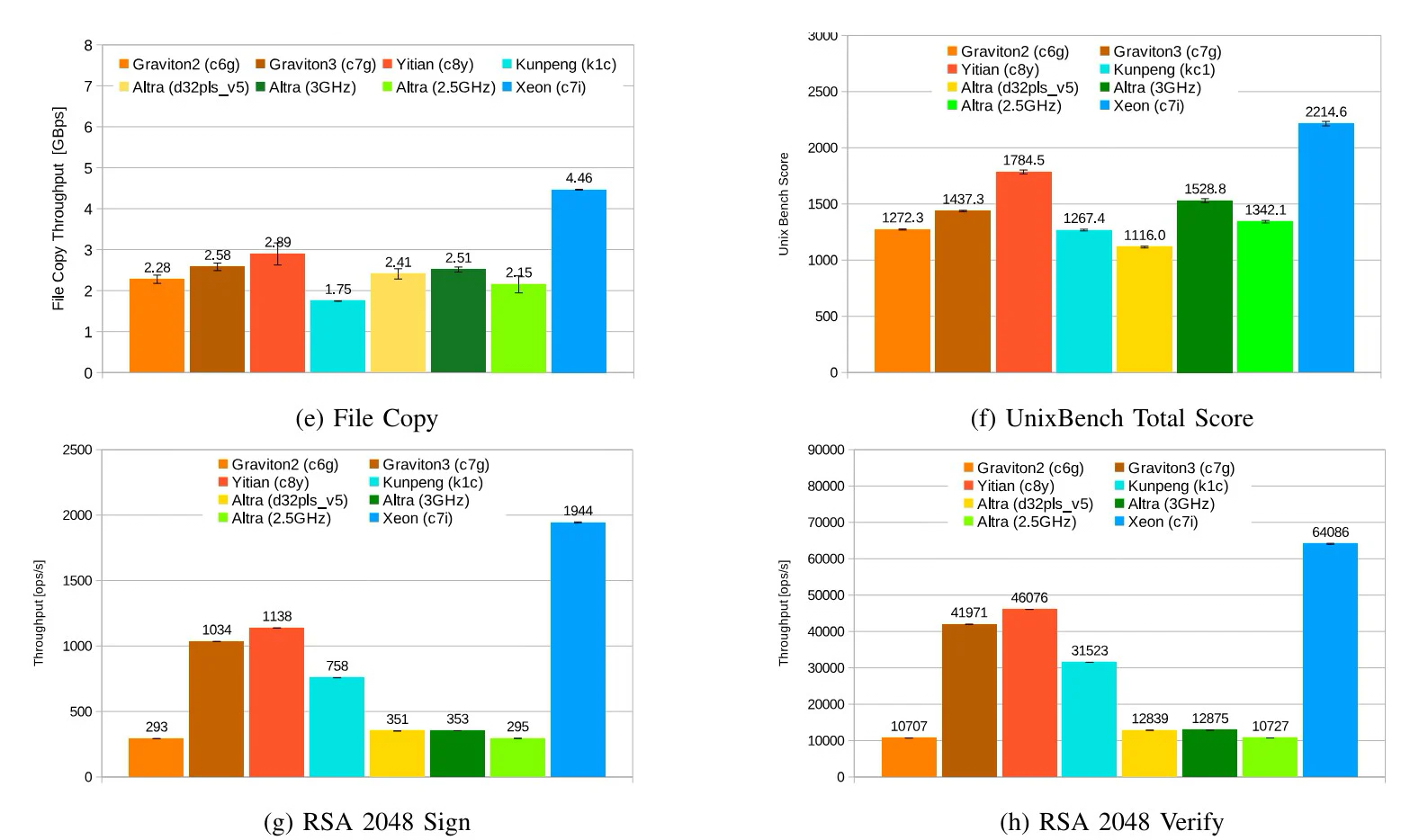 Как отмечается, практически во всех перечисленных тестах процессор Alibaba опережал конкурирующие чипы с архитектурой Arm. В задачах Whetstone изделие Yitian 710 также превзошло процессор Xeon Platinum и чип Altra. Вместе с тем Graviton 3 показал превосходство в тесте Redis. Тем не менее, Yitian 710 сохранил своё преимущество в двух из трёх задач RocksDB. В плане эффективности чипам Arm требуется больше системных вызовов, чем их конкурентам Intel. Но в некоторых сценариях использования решения Arm всё равно оказываются более предпочтительными.
23.02.2024 [01:27], Алексей Степин
Arm представила процессорные ядра Neoverse N2 и V3: упор на ИИКомпания Arm продолжает развивать инициативу Neoverse Compute Subsystem (CSS), анонсировав два новых ядра, Neoverse N3 (Hermes) и V3 (Poseidon), рассчитанных на техпроцессы 2–5 нм. Они являются преемниками N2 (Perseus) и V2 (Demeter), а упор в их архитектуре сделан главным образом на повышении производительности в задачах ИИ. Платформа CSS представляет собой комплект IP-блоков Arm, включающий в себя помимо собственно процессорных ядер подсистемы интерконнекта, контроллеры памяти, блоки ввода-вывода и управления питанием и тому подобную «обвязку», облегчающую создание и вывод на рынок новых SoC. 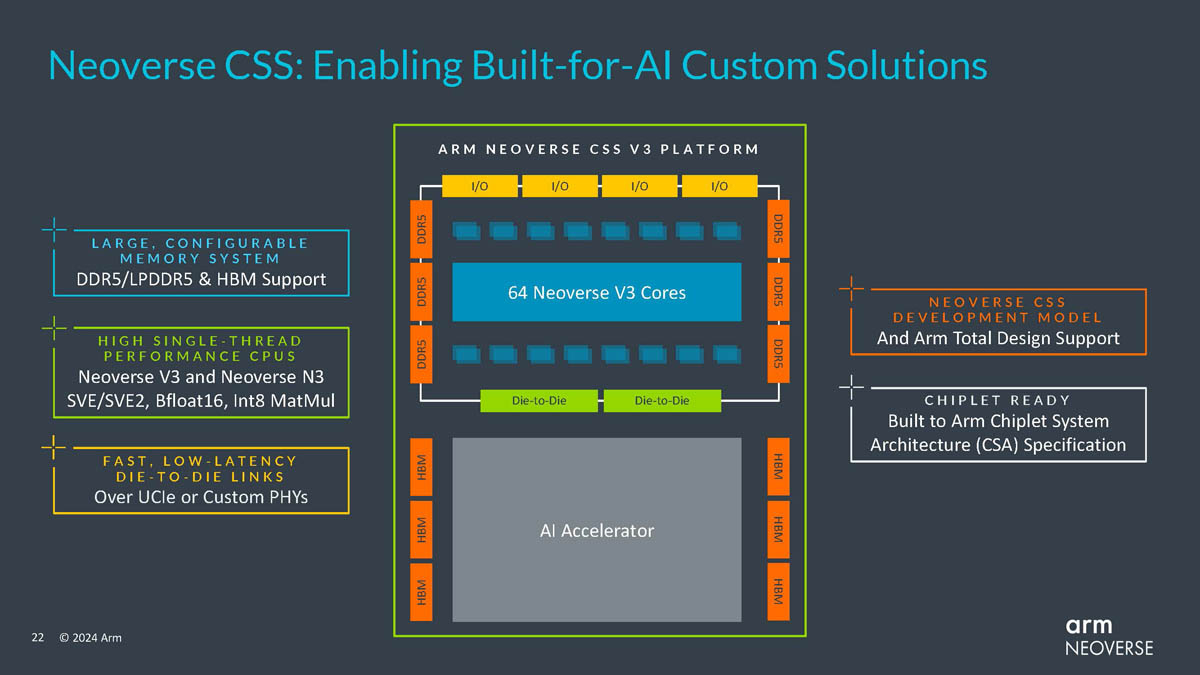
Источник изображений здесь и далее: Arm via ServeTheHome Будущие процессоры на базе Neoverse V3 получат до 64 ядер Armv9-A (v9.2) на кристалл и до 128 на сокет — в виде сборки из двух 64-ядерных кристаллов. Каждый из таких кристаллов получит шесть каналов (LP)DDR5, но также заявлена поддержка HBM3. Поддерживаются двухсокетные конфигурации. Более того, у V3 есть два блока для объедениия с чиплетами, а основным интерфейсом является UCIe 1.1, причём Arm прямо говорит о возможности подключения ИИ-ускорителя, как это сделано в NVIDIA Grace Hopper. Помимо интерконнекта для чиплетных сборок V3 будет располагать собственными контроллерами I/O с поддержкой PCIe 5.0 и CXL 3.0 — до 64 линий. 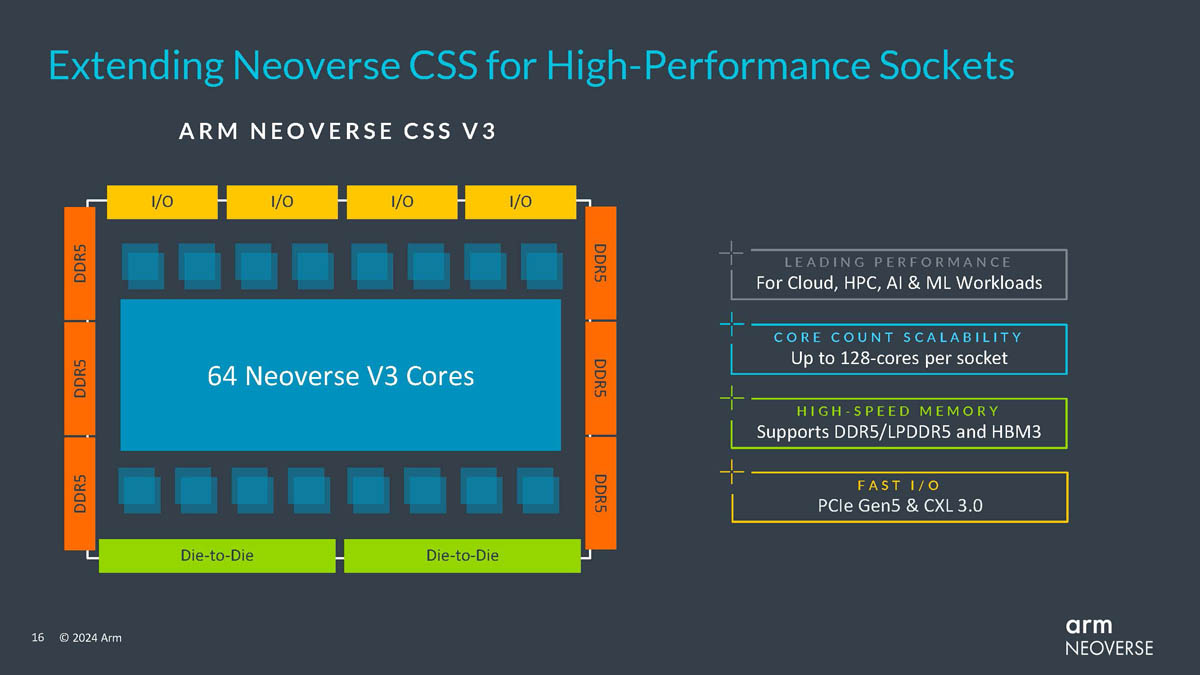 В подавляющем большинстве сценариев прирост относительно V2, обещанный Arm, не слишком велик и составляет от 9 % до 16 %, но вот производительность в ИИ-задачах подтянута аж на 84 %, что однозначно указывает на позиционирование новых ядер — это, в первую очередь, рынок гиперскейлеров, которые сегодня почти поголовно заинтересованы в применении ИИ-технологий. Сами ядра имеют по 64 Кбайт L1-кеша для инструкций и данных и до 3 Мбайт L2-кеша. Интереснее всего поддержка SVE2, но ширину и количество этих SIMD-блоков компания не раскрывает. 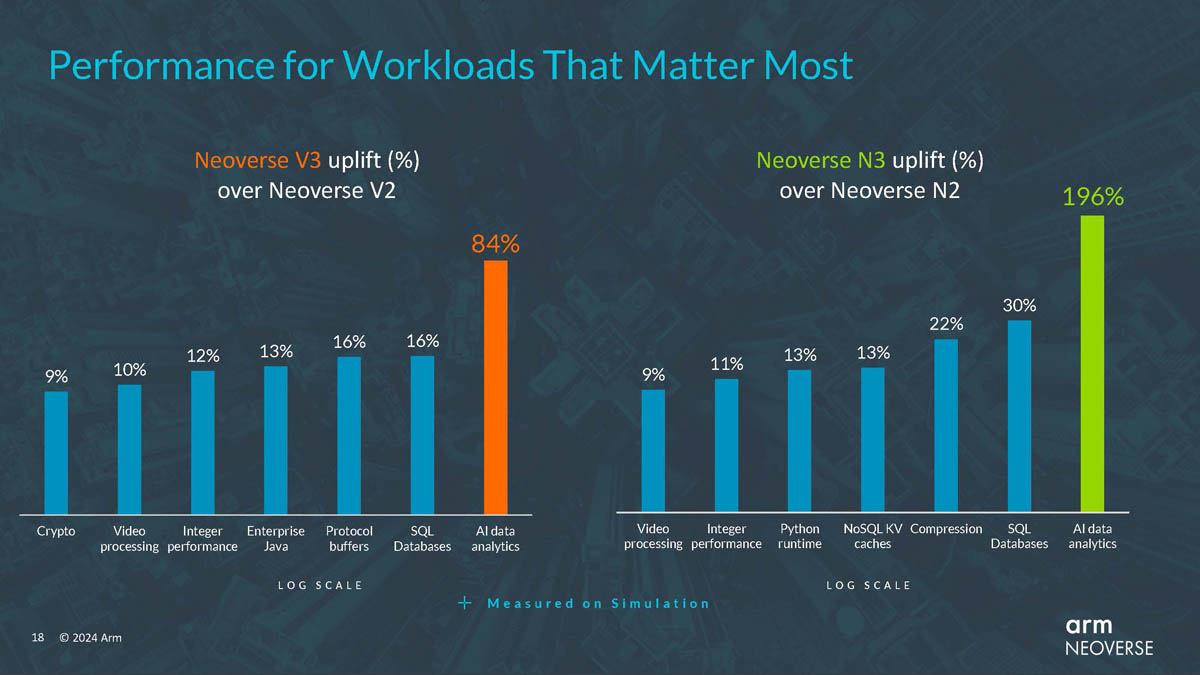 В N3 ядер меньше, от 8 до 32, а главным улучшением снова стала повышение энергоэффективности. Относительно N2 процессор N3 будет на 20 % быстрее в пересчёте на Вт. Максимальный теплопакет для 32-ядерного варианта составит всего 40 Вт. Этот дизайн должен найти своё применение в DPU и телекоммуникационных решениях. Сами ядра здесь точно такие же, что в V3, но L1-кеши можно урезать до 32 Кбайт, а L2-кеш не может быть больше 2 Мбайт. N3 также поддерживает объединение двух блоков ядер в одном чипе, двухсокетные конфигурации и UCIe-подключение стороннего чиплета, но для этого тут есть только один блок. Количество линий PCIe 5.0/CXL 3.0 вдвое меньше, до 32 шт. Каналов памяти (LP)DDR5 всего четыре.  Прирост по сценариям применения относительно N2 здесь выглядит иначе: серьёзное внимание уделено задачам сжатия и декомпрессии данных и работе с СУБД. Однако упор на ИИ-нагрузки тут даже более серьёзный, нежели у старшего собрата — прирост производительности может достигать 196 % относительно N2. Правда, в случае и N3, и V3 речь идёт о вполне конкретной библиотеке XGBoost. 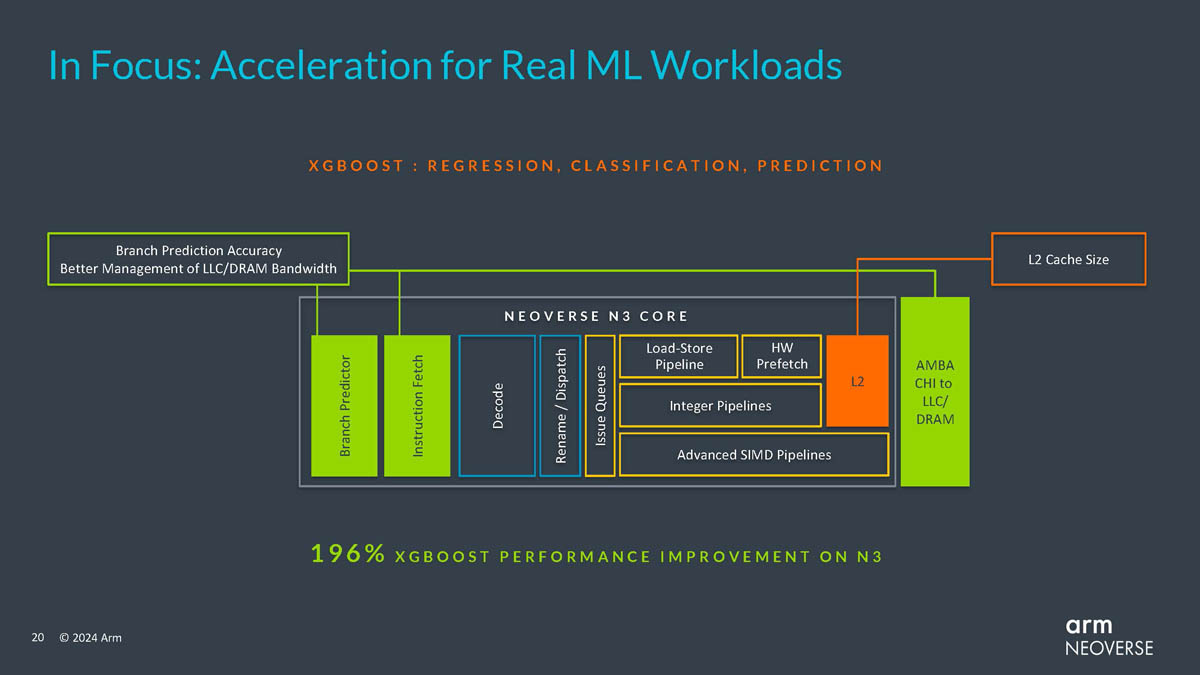 В арсенале Arm также есть ядро E3, о котором, впрочем, компания пока ничего не рассказала. Упомянуто лишь, что эта платформа ориентирована на сценарии с «прокачкой» больших объёмов данных. Заодно компания поделилась именами будущих решений четвёртого поколения. Платформа V-серии получит имя Vega с процессорными ядрами Adonis, N-серия станет называться Ranger с ядрами Dionysus, а E-серия пока никак не названа, но для ядер выбрано имя Lycius. 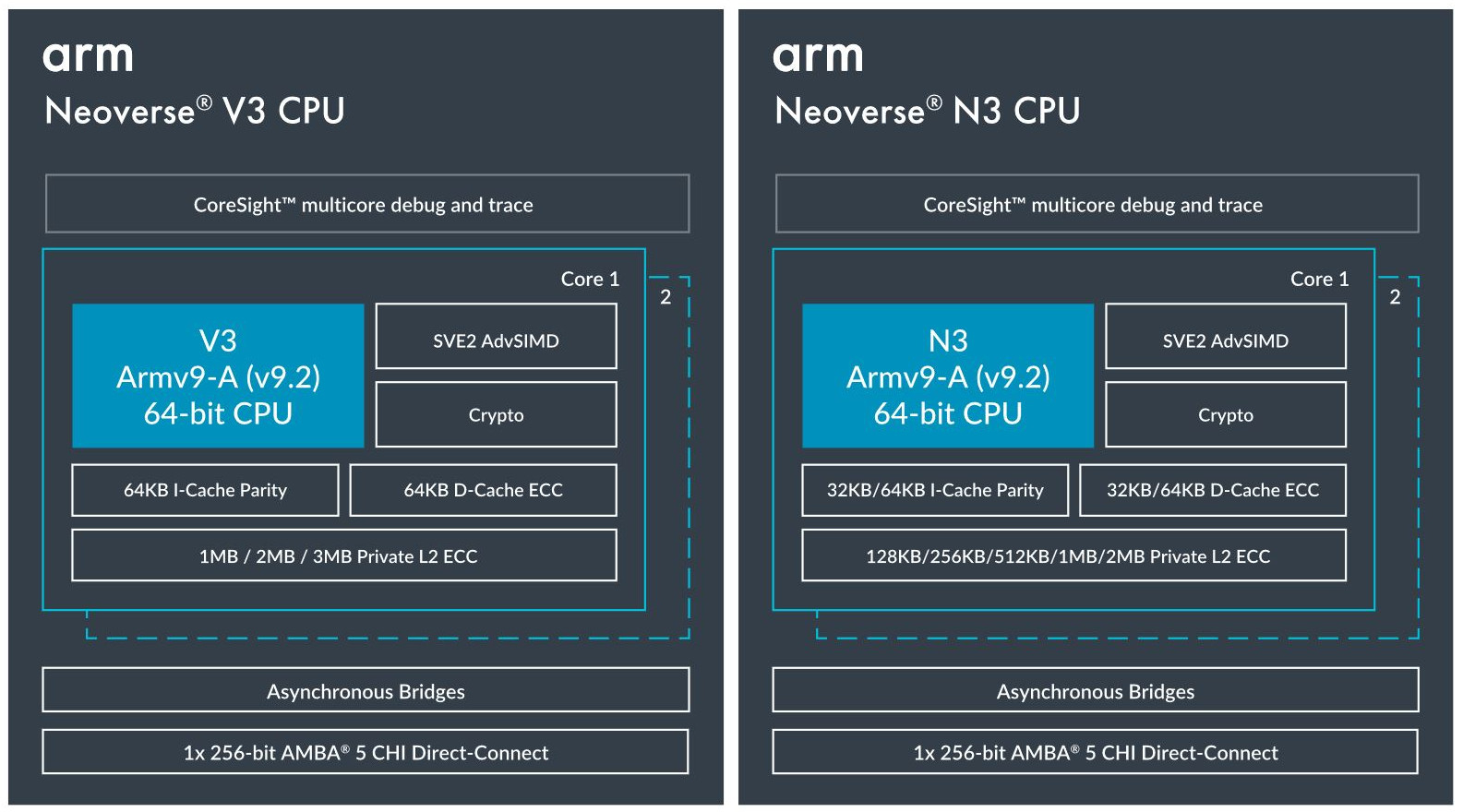 Arm не без оснований считает новые платформы и ядра лучшим поколением Neoverse на данный момент. Компания уверена в том, что за её экосистема станет основой вычислительных решений нового поколения, в том числе для ИИ. Конкурировать новым решениям предстоит, в том числе, с лучшими процессорами Intel и AMD. Сама Intel собирается поддерживать разработку технологий на базе Arm, предоставляя как интеллектуальную собственность, так и производственные мощности. 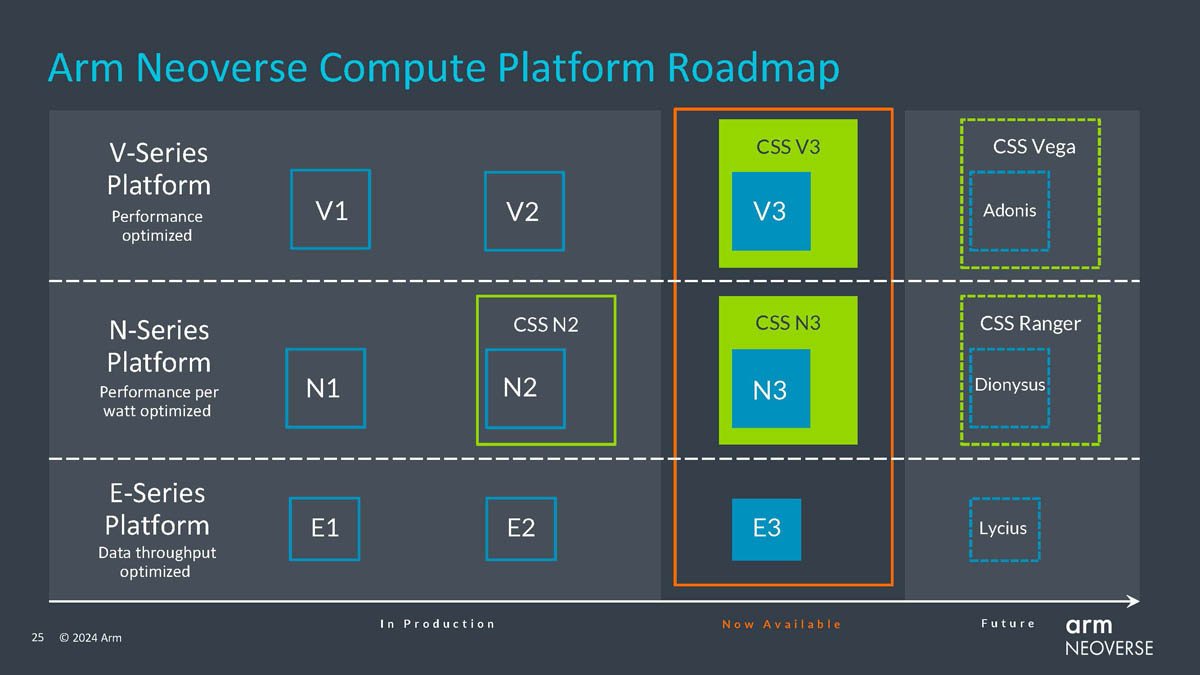 Последние два года стали для Arm весьма успешным в деле освоения рынка ЦОД. NVIDIA представила Grace и Grace Hopper, AWS создала уже четвёртое поколение собственных процессоров Graviton, Microsoft показала свой первый CPU Cobalt 100, да и Google трудится над процессорами Maple и Cypress. А основатель Oracle, которая активно перебирается на чипы Ampere, и вовсе считает, что архитектура Intel x86 теряет актуальность для серверов. Про доминирование Arm в сегменте DPU и говорить нечего.
29.11.2023 [03:43], Владимир Мироненко
AWS представила 96-ядерный Arm-процессор Graviton4 и ИИ-ускоритель Trainium2Amazon Web Services представила Arm-процессор нового поколения Graviton4 и ИИ-ускоритель Trainium2, предназначенный для обучения нейронных сетей. Всего к текущему моменту компания выпустила уже 2 млн Arm-процессоров Graviton, которыми пользуются более 50 тыс. клиентов. «Graviton4 представляет собой четвёртое поколение процессоров, которое мы выпустили всего за пять лет, и это самый мощный и энергоэффективный чип, который мы когда-либо создавали для широкого спектра рабочих нагрузок», — отметил Дэвид Браун (David Brown), вице-президент по вычислениям и сетям AWS. По сравнению с Graviton3 новый чип производительнее на 30 %, включает на 50 % больше ядер и имеет на 75 % выше пропускную способность памяти. 
Изображение: AWS Graviton4 будет иметь до 96 ядер Neoverse V2 Demeter (2 Мбайт L2-кеша на ядро) и 12 каналов DDR5-5600. Кроме того, новый чип получит поддержку шифрования трафика для всех своих аппаратных интерфейсов. Процессор изготавливается по 4-нм техпроцессу TSMC, включает 73 млрд транзисторов и, вероятно, имеет чиплетную компоновку. Возможно, это первый CPU компании, ориентированный на работу в двухсокетных платформах. 
Изображение: AWS Поначалу Graviton4 будет доступен в инстансах R8g (пока в статусе превью), оптимизированных для приложений, интенсивно использующих ресурсы памяти — высокопроизводительные базы данных, in-memory кеши и Big Data. Эти инстансы будут поддерживать более крупные конфигурации, иметь в три раза больше vCPU и в три раза больше памяти по сравнению с инстансами Rg7, которые имели до 64 vCPU и 512 Гбайт ОЗУ. 
Amazon Trainium2 (Изображение: AWS) В свою очередь, Trainium 2 предназначен для обучения больших языковых моделей (LLM) и базовых моделей. Сообщается, что ускоритель в сравнении с Trainium 1 вчетверо производительнее и при этом имеет в 3 раза больший объём памяти и в 2 раза более высокую энергоэффективность. Инстансы EC2 Trn2 получат 16 ИИ-ускорителей с возможностью масштабирования до 100 тыс. единиц в составе EC2 UltraCluster, которые суммарно дадут 65 Эфлопс, то есть по 650 Тфлопс на ускоритель. Как утверждает Amazon это позволит обучать LLM с 300 млрд параметров за недели вместо месяцев.  Со временем на Graviton4 заработает SAP HANA Cloud, портированием и оптимизацией этой платформы уже занимаются. Oracle также перенесла свою СУБД на Arm, а заодно перевела все свои облачные сервисы на чипы Ampere, в которую в своё время инвестировала. Microsoft же пошла по пути AWS и недавно анонсировала 128-ядерый Arm-процессор (Neoverse N2) Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработки. Всё это может представлять отдалённую угрозу для AMD и Intel. С NVIDIA же все всё равно пока что продолжают дружбу — именно в инфраструктуре AWS, как ожидается, появится самый мощный в мире ИИ-суперкомпьютер на базе новых GH200.
16.11.2023 [02:43], Алексей Степин
Microsoft представила 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработкиГиперскейлеры ради снижения совокупной стоимости владения (TCO) и зависимости от сторонних вендоров готовы вкладываться в разработку уникальных чипов, изначально оптимизированных под их нужды и инфраструктуру. К небольшому кругу компаний, решившихся на такой шаг, присоединилась Microsoft, анонсировавшая Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100. 
Изображения: Microsoft Первопроходцем в этой области стала AWS, которая разве что память своими силами не разрабатывает. У AWS уже есть три с половиной поколения Arm-процессоров Graviton и сразу два вида ИИ-ускорителей: Trainium для обучения и Inferentia2 для инференса. Крупный китайский провайдер Alibaba Cloud также разработал и внедрил Arm-процессоры Yitian и ускорители Hanguang. Что интересно, в обоих случаях процессоры оказывались во многих аспектах наиболее передовыми. Наконец, у Google есть уже пятое поколение ИИ-ускорителей TPU.  Microsoft заявила, что оба новых чипа уже производятся на мощностях TSMC с использованием «последнего техпроцесса» и займут свои места в ЦОД Microsoft в начале следующего года. Как минимум, в случае с Maia 100 речь идёт о 5-нм техпроцессе, вероятно, 4N. В настоящее время Microsoft Azure находится в начальной стадии развёртывания инфраструктуры на базе новых чипов, которая будет использоваться для Microsoft Copilot, Azure OpenAI и других сервисов. Например, Bing до сих пор во много полагается на FPGA, а вся ИИ-инфраструктура Microsoft крайне сложна.  Microsoft приводит очень мало технических данных о своих новинках, но известно, что Azure Cobalt 100 имеет 128 ядер Armv9 Neoverse N2 (Perseus) и основан на платформе Arm Neoverse Compute Subsystem (CSS). По словам компании, процессоры Cobalt 100 до +40 % производительнее имеющихся в инфраструктуре Azure Arm-чипов, они используются для обеспечения работы служб Microsoft Teams и Azure SQL. Oracle, вложившаяся в своё время в Ampere Comptuing, уже перевела все свои облачные сервисы на Arm.  Чип Maia 100 (Athena) изначально спроектирован под задачи облачного обучения ИИ и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Чип содержит 105 млрд транзисторов, что больше, нежели у NVIDIA H100 (80 млрд) и ставит Maia 100 на один уровень с Ponte Vecchio (~100 млрд). Для Maia организован кастомный интерконнект на базе Ethernet — каждый ускоритель располагает 4,8-Тбит/с каналом для связи с другими ускорителями, что должно обеспечить максимально эффективное масштабирование.  Сами Maia 100 используют СЖО с теплообменниками прямого контакта. Поскольку нынешние ЦОД Microsoft проектировались без учёта использования мощных СЖО, стойку пришлось сделать более широкой, дабы разместить рядом с сотней плат с чипами Maia 100 серверами и большой радиатор. Этот дизайн компания создавала вместе с Meta✴, которая испытывает аналогичные проблемы с текущими ЦОД. Такие стойки в настоящее время проходят термические испытания в лаборатории Microsoft в Редмонде, штат Вашингтон.  В дополнение к Cobalt и Maia анонсирована широкая доступность услуги Azure Boost на базе DPU MANA, берущего на себя управление всеми функциями виртуализации на манер AWS Nitro, хотя и не целиком — часть ядер хоста всё равно используется для обслуживания гипервизора. DPU предлагает 200GbE-подключение и доступ к удалённому хранилищу на скорости до 12,5 Гбайт/с и до 650 тыс. IOPS.  Microsoft не собирается останавливаться на достигнутом: вводя в строй инфраструктуру на базе новых чипов Cobalt и Maia первого поколения, компания уже ведёт активную разработку чипов второго поколения. Впрочем, совсем отказываться от партнёрства с другими вендорами Microsoft не намерена. Компания анонсировала первые инстансы с ускорителями AMD Instinct MI300X, а в следующем году появятся инстансы с NVIDIA H200. 
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
21.10.2023 [01:01], Алексей Степин
Собери сам: Arm открывает эру кастомных серверных процессоров инициативой Total DesignСегодня на наших глазах в мире процессоростроения происходит серьёзная смена парадигм: от унифицированных архитектур общего назначения и монолитных решений разработчики уходят в сторону модульности и активного использования специфических аппаратных ускорителей. Разумеется Arm не осталась в стороне — на мероприятии 2023 OCP Global Summit компания рассказала о новой инициативе Arm Total Design. Эта инициатива должна помочь как создателям новых процессоров за счёт ускорения процесса разработки и снижения его стоимости, так и владельцам крупных вычислительных инфраструктур. Последние всё больше склоняются к специализации и дифференциации в процессорных архитектурах новых поколений, но ожидают также энергоэффективности, дружественности к экологии и как можно более низкой совокупной стоимости владения. 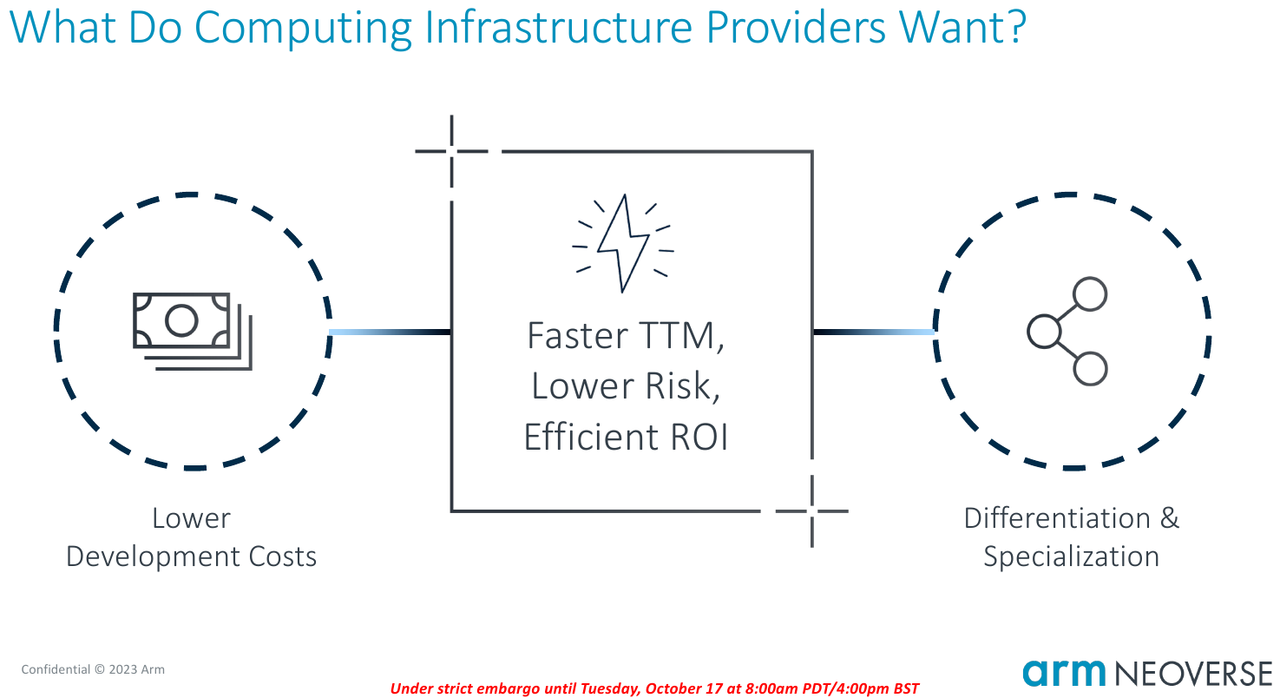
Источник изображений здесь и далее: Arm В основе инициативы Arm лежит анонсированная ещё в августе на HotChips 2023 процессорная платформа Arm Neoverse Compute Subsystem (CSS). Neoverse CSS N2 (Genesis) представляет собой готовый набор IP-решений Arm, включающий в себя процессорные ядра, внутреннюю систему интерконнекта, подсистемы памяти, ввода-вывода, управлениям питанием, но оставляющий место для интеграции партнёрских разработок — различных движков, ускорителей и т.п. 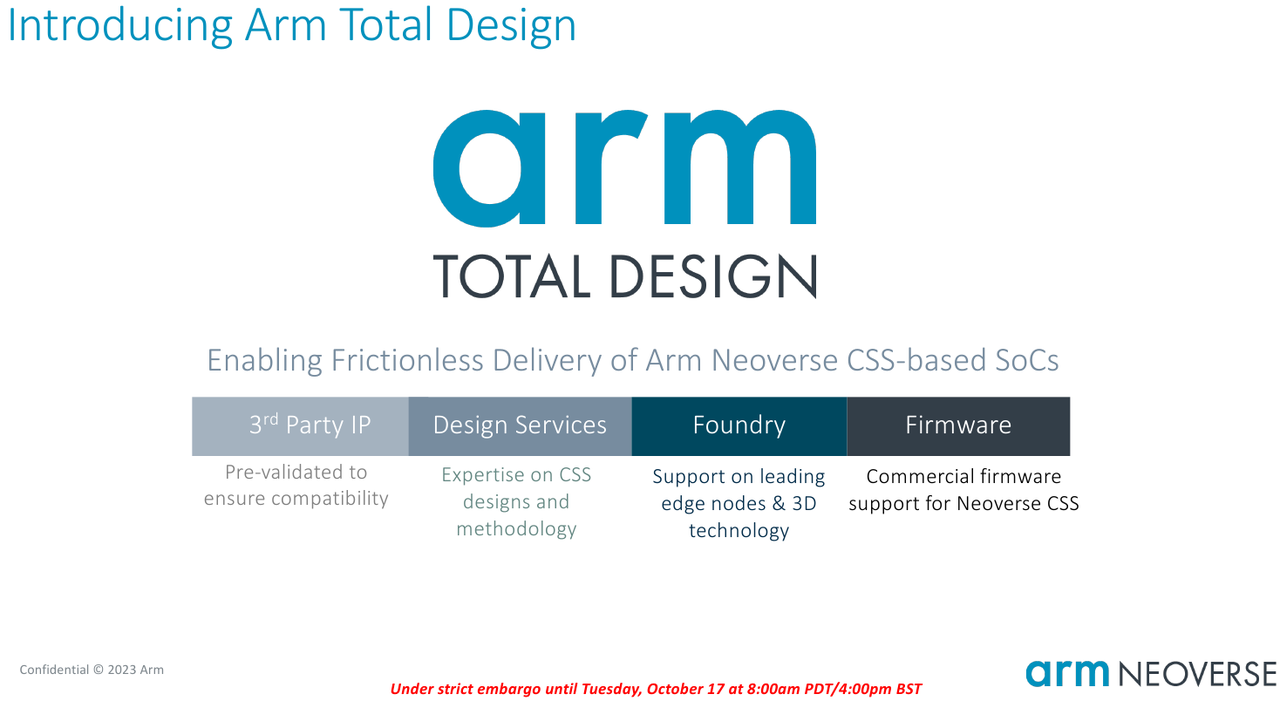 По сути, речь идёт о почти готовых процессорах, не требующих длительной разработки процессорной части с нуля и всех связанных с этим процессом действий — верификации, тестирования на FPGA, валидации дизайна и многого другого. По словам Arm такой подход позволяет сэкономить разработчикам до 80 человеко-лет труда инженеров. 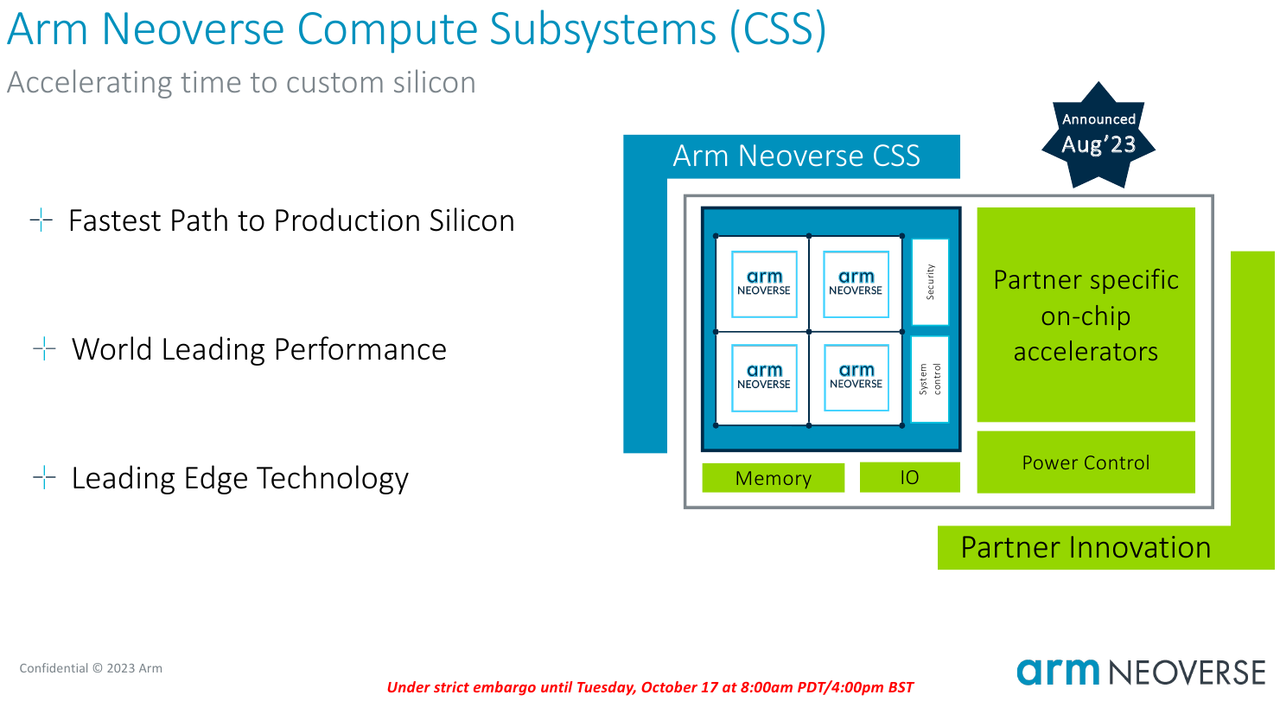 Дизайн Neoverse CSS N2 довольно гибок: финальный процессор может включать в себя от 24 до 64 ядер Arm, работающих в частотном диапазоне 2,1–3,6 ГГц. Предусмотрено по 64 Кбайт кеша инструкций и данных, а вот объёмы кешей L2 и L3 настраиваются и могут достигать 1 и 64 Мбайт соответственно. Ядра реализуют набор инструкций Arm v9 и содержат по два 128-битных векторных блока SVE2. Имеется поддержка инструкций, характерных для ИИ-задач и криптографиии. 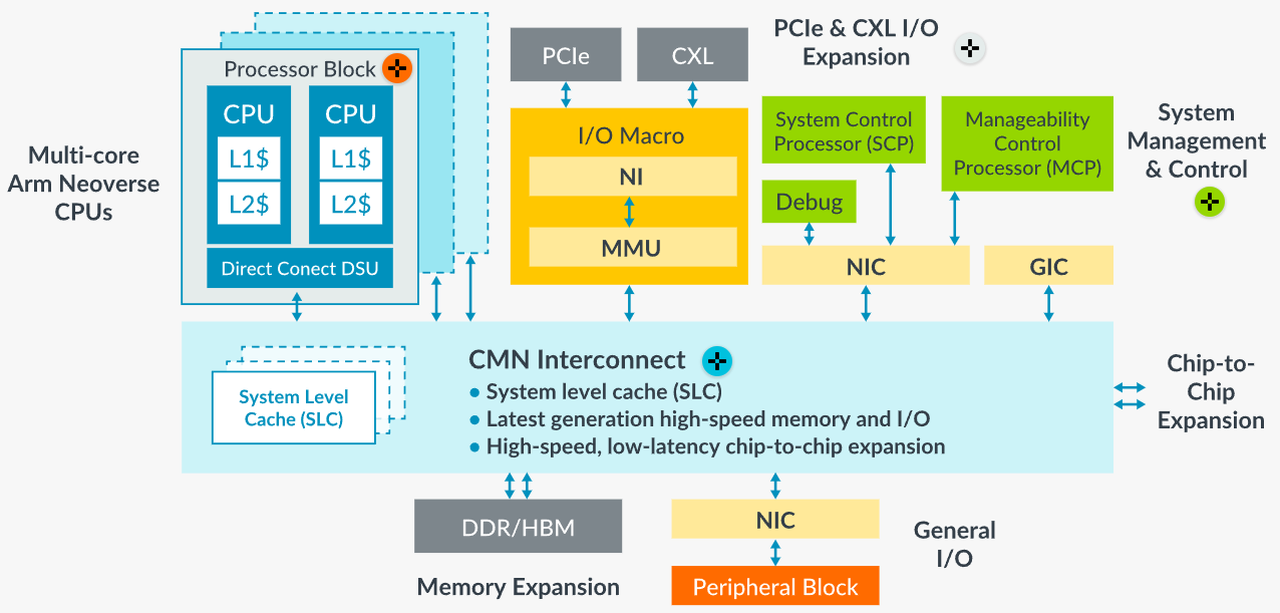 Подсистема памяти может иметь до 8 каналов DDR5, а возможности ввода-вывода включают в себя 4 блока по 16 линий PCIe или CXL. Также возможно объединение двух чипов CSS N2 в едином корпусе, что даёт до 128 ядер на чип. В качестве внутреннего интерконнекта используется меш-сеть Neoverse CMN-700. В дизайне Neoverse CSS N2 имеются и вспомогательные ядра Cortex-M7. Они работают в составе блоков System Control Processor (SCP) и Management Control Processor (MCP), то есть управляют работой основного вычислительного массива, в том числе отвечая за его питание и тактовые частоты.  Инициатива Arm Total Design расширяет рамки Neoverse Compute Subsystem: речь идёт о создании полноценной экосистемы, обеспечивающей эффективную коммуникацию между партнёрами программы Neoverse CSS и предоставление им полноценного IP-инструментария и EDA, созданных при участии Cadence, Rambus, Synopsys и др. Также подразумевается поддержка ведущих производителей «кремния» и разработчиков прошивок, в частности, AMI. В число участников проекта уже вошли такие компании, как ADTechnology, Alphawave Semi, Broadcom, Capgemini, Faraday, Socionext и Sondrel. Ожидается поддержка от Intel Foundry Services и TSMC, позволяющая говорить об эффективной реализации необходимых для мультичиповых решений технологий AMBA CHI C2C и UCIe. 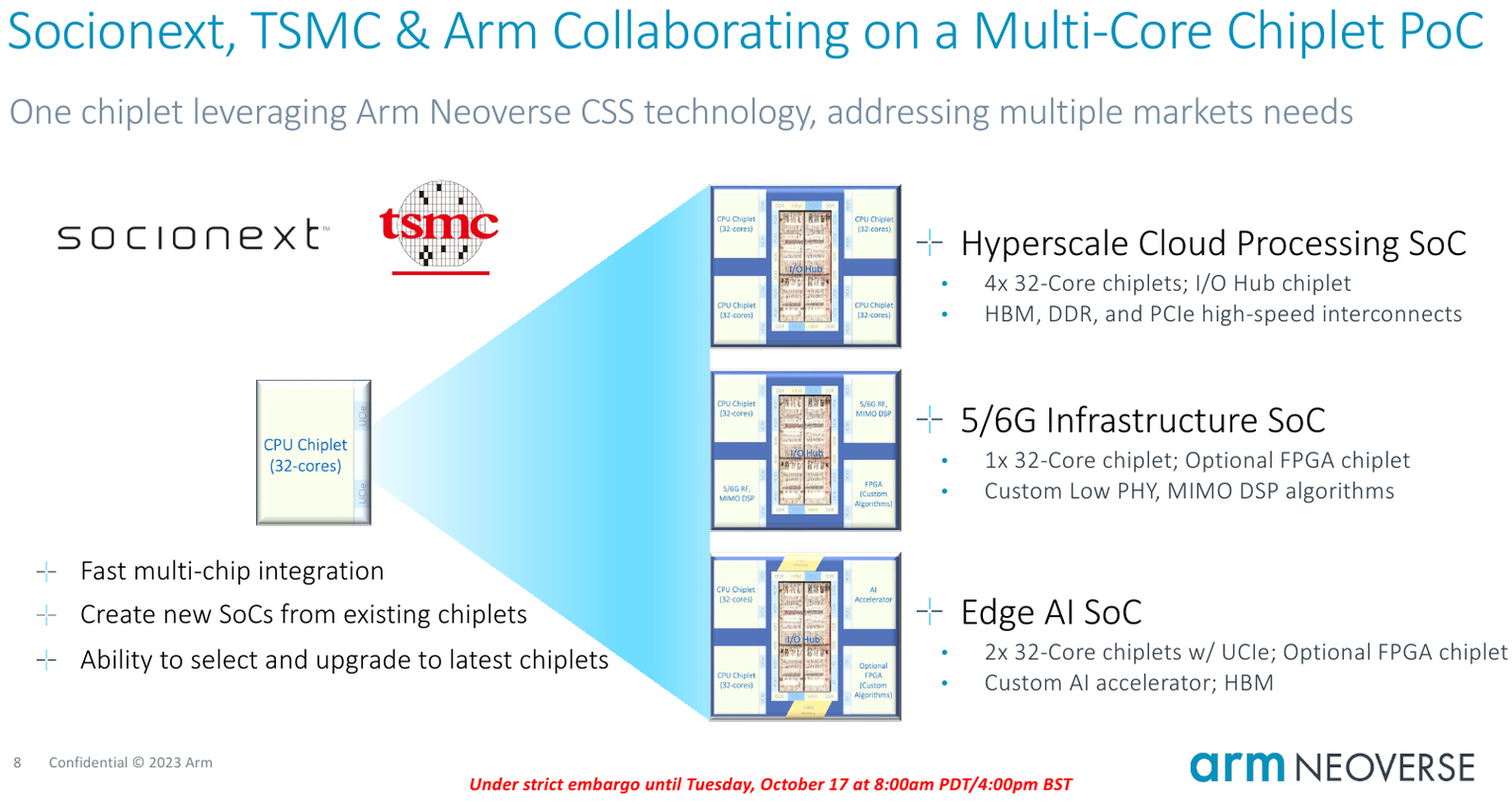 Будучи объединённым под одной крышей инициативы Arm Total Design, такой конгломерат ведущих разработчиков и производителей микроэлектроники и системного ПО для него, сможет в кратчайшие сроки не просто создавать новые процессоры, но и гибко отвечать на вызовы рынка ЦОД и HPC, наделяя чипы поддержкой востребованных технологий и ускорителей. В качестве примера можно привести совместный проект Arm, Socionext и TSMC, в рамках которого ведётся разработка универсального чиплетного процессора, который в различных вариантах компоновки будет востребован гиперскейлерами, поставщиками инфраструктуры 5G/6G и разработчиками периферийных ИИ-систем.
25.09.2023 [12:00], Владимир Мироненко
Oracle завершила миграцию всех своих облачных сервисов на Arm и представила инстансы Ampere A2 c процессорами AmpereOneOracle представила инстансы Ampere A2 следующего поколения на базе 192-ядерных Arm-процессоро AmpereOne, которые станут доступны для клиентов компании позднее в этом году. Как сообщает Oracle, новые инстансы обеспечивают на 44 % лучшее соотношение цены и производительности по сравнению с предложениями на архитектуре x86 и идеально подходят для ИИ-инференса, работы с базами данных, веб-сервисами, рабочих нагрузок транскодирования мультимедиа и поддержки среды выполнения для таких языков, как GO и Java. Инстансы OCI Ampere A2 предлагают до 320 ядер в случае bare metal и до 156 ядер в рамках одной виртуальной машины. Обладая большим объёмом приватного кеша, стабильной рабочей частотой, однопоточными ядрами и новыми функциями управления памятью, инстансы нового поколения позволяют обеспечить ещё более предсказуемую производительность за счёт снижения влияния внешних помех, как происходит в случае SMT, и одновременно предлагают безопасную микроархитектуру для многопользовательских облачных сред. 
Источник изображений: Ampere «То, что происходит с OCI и Ampere, является отражением значительных перемен, происходящих в нашей отрасли, — сказала гендиректор Ampere Рене Джеймс (Renee James). — Времена использования мощности в качестве показателя производительности переходят в эру высокопроизводительных вычислений с низким энергопотреблением. Такие клиенты, как 8X8 и другие, признают, что существует необходимость снизить затраты на инфраструктуру и в то же время сократить выбросы углекислого газа без ущерба для производительности. В нашу эру компьютеров с ИИ новая сила — это меньшая мощность». Клэй Магоуирк (Clay Magouyrk), исполнительный вице-президент Oracle Cloud Infrastructure Development, сообщил, что в связи с быстрым ростом Oracle подошла к пределам доступной мощности, и для дальнейшего масштабирования облака ей необходим рост эффективности в дополнение к производительности: «Вот почему мы используем Ampere для всего: от базы данных Oracle до приложений Fusion, а теперь и для всех наших сервисов OCI. С развитием ИИ-обработки этот сдвиг в вычислениях стал ещё более важным. Ampere — это решение OCI для устойчивого облака». СУБД Oracle Database полностью поддерживается процессорами Ampere. Кроме того, все сервисы OCI, число которых исчисляется сотнями, теперь тоже работают на CPU Ampere. Конечные клиенты могут перенести все свои рабочие нагрузки на платформу Ampere, в том числе задачи инференса, которые поддерживаются библиотеками AI Optimizer от Ampere.
30.06.2023 [21:39], Владимир Мироненко
Глава Oracle считает, что архитектура Intel x86 теряет актуальность для серверовВ 2023 году Oracle планирует потратить значительные средства на приобретение чипов AMD и Ampere Computing для новой инфраструктуры, отметив, что «старая архитектура Intel x86 достигает своего предела». «В этом году Oracle купит GPU и CPU у трёх компаний, — сообщил на прошедшем в среду мероприятии глава Oracle Ларри Эллисон (Larry Ellison). — Мы будем покупать GPU у NVIDIA, мы покупаем у неё на миллиарды долларов США. И потратим в три раза больше на центральные процессоры от Ampere и AMD. Мы по-прежнему тратим больше денег на традиционные чипы». Oracle сообщила, что впервые за 14 лет существования специализированных ПАК Exadata для СУБД она полностью отказалась от процессоров Intel в пользу чипов AMD. В платформе 12-го поколения Exadata X10M в рамках двух предложений Oracle Exadata Machine и управляемого решения Oracle Exadata Cloud@Customer будут использоваться AMD EPYC Genoa. Одной из причин такого перехода, пусть и далеко не самой важной, считается отказ Intel от Optane. 
Источник изображения: Oracle С момента запуска Exadata в 2008 году Oracle полагалась на процессоры Intel Xeon. Но ситуация начала меняться c выходом X9M в 2021 году. Для Oracle Exadata Machine и Oracle Exadata Cloud@Customer компания выбрала чипы Intel Xeon Ice Lake-SP, а в начале 2022 года для облачного решения Oracle Exadata Cloud Infrastructure решила использовать чипы AMD. При этом EPYC Milan использовались в серверах для обеспечения работы баз данных, а Ice Lake-SP — для СХД. Кроме того, на днях Oracle сделала важный шаг — перенесла свою флагманскую СУБД Oracle Database на архитектуру Arm, т.е. на процессоры компании Ampere Computing, в которую в своё время инвестировала. Эллисон отметил, что чипы Ampere Altra намного энергоэффективнее решений AMD и NVIDIA, что поможет ЦОД Oracle соответствовать будущим регуляциям. «Мы перешли на новую архитектуру и к новому поставщику, — сообщил Эллисон. — Мы думаем, что это будущее. Старая архитектура Intel x86 после многих десятилетий на рынке подошла к своему пределу». 
Источник изображения: Oracle Тем не менее, эксперты полагают, что ставка Oracle на архитектуру Arm не помешает её отношениям с AMD в ближайшее время, тем более что Intel и AMD планируют бороться с Arm-процессорами с помощью оптимизированных для облачных платформ чипов с высокой плотностью ядер и улучшенной энергоэффективностью: EPYC Bergamo и Xeon Sierra Forest. Кроме того, разработка, перенос и рефакторинг ПО для Arm требует времени и средств. В свою очередь, представитель Intel сообщил ресурсу CRN в четверг, что компания поставляет Oracle процессоры Xeon Sapphire Rapids «в течение многих месяцев и планирует продолжать поставки Xeon текущего и следующего поколения в будущем». Компании связывают долгие годы совместной работы над аппаратными и программными решениями для клиентов, а сейчас Intel поставляет чипы для облачной инфраструктуры Oracle OCI.
29.06.2023 [22:22], Владимир Мироненко
СУБД Oracle Database 19c теперь доступна и для Arm-архитектурыOracle объявила, что Oracle Database 19c Enterprise Edition, текущий долгосрочный выпуск фирменной СУБД, сертифицирован и доступен для использования на архитектуре Arm. Клиенты могут оформить подписку на сервис Oracle Database Service в Oracle Cloud Infrastructure (OCI) с использованием инстансов Ampere A1 с Arm-процессорами Ampere Altra или запускать СУБД на локальных серверах на базе таких же CPU. Как сообщает компания, оба варианта обеспечивают значительную экономию клиентам, разрабатывающим всё более сложные приложения, которые используют всё больше данных, ИИ, машинное обучение, JSON-документы и которые требуют большей интерактивности и производительности баз данных (БД). Oracle отметила, что клиенты теперь смогут запускать свои рабочие нагрузки с предсказуемой производительностью при меньших затратах, используя Ampere Altra. 
Источник изображения: Oracle «Благодаря процессорам семейства Ampere Altra клиенты самой популярной в мире базы данных — Oracle Database — теперь имеют высокопроизводительную, энергоэффективную архитектуру, построенную с учётом устойчивого развития организаций любого размера», — отметил Джефф Виттич (Jeff Wittich), директор по продуктам Ampere. Напомним, что Oracle была одним из первых крупных инвесторов Ampere и первой же предложила инстансы на базе Altra. По словам создателей, Oracle Database значительно упрощает разработку приложений, интеграцию данных и управление БД и позволяет использовать единую СУБД корпоративного уровня, которую можно развернуть где угодно, а не использовать отдельные БД для каждого типа данных и рабочих нагрузок. Полная совместимость баз данных Oracle, развёрнутых в облаке и локально, позволяет обойтись разработкой одного приложения для всех случаев. Правда, для Arm-версии (aarch64) Oracle Database 19c пока доступен не весь сопутствующий инструментарий.  Oracle Database Service теперь опирается не только на инстансы AMD E4 или Intel X9, но и на Ampere A1: от 1 до 57 OCPU, 8 Гбайт RAM на OCPU (суммарно до 456 Гбайт), 1 Гбит/с на OCPU (не более 40 Гбит/с, неблокирующая сетевая инфраструктура). Компания предлагает нескольких вариантов лицензирования Oracle Database Service, включая Enterprise Edition, High Performance и Extreme Performance. Кроме того, можно начать работу с бесплатного варианта в рамках программы Oracle Arm Accelerator, которая на год даёт предоплаченный доступ к ряду сервисов OCI. Oracle отметила, что Oracle Database 19c обходится вдвое дешевле при работе на процессорах Ampere Altra из-за низкого показателя Oracle Processor Core Factor. Как сообщается, перенос баз данных на Arm происходит быстро и просто: базы данных Oracle, работающие на существующих платформах, могут использовать Oracle Recovery Manager (RMAN) для резервного копирования баз данных на существующей платформе и переноса на платформу Arm. |
|


