Материалы по тегу: arm
|
01.08.2024 [00:53], Игорь Осколков
Ampere анонсировала 512-ядерные Arm-процессоры AmpereOne Aurora с HBM-памятью и встроенным ИИ-ускорителемAmpere Computing анонсировала процессоры AmpereOne Aurora, которые получат до 512 однопоточных Arm-ядер собственной разработки, набортную HBM-память и фирменные IP-блоки для обучения и инференса ИИ-моделей. Речь, судя по всему, идёт о чиплетной компоновке, поскольку компания говорит не только о фирменном меш-интерконнекте для вычислительных блоков, но и об объединении разных кристаллов в рамках SoC. Предполагается, что Aurora появятся где-то на рубеже 2025–2026 гг. 
Источник изображений: Ampere Computing Что интересно, для Aurora обещана возможность использования воздушного охлаждения. Для гиперскейлеров, на которых Ampere по-прежнему ориентируется, это важный пункт. Впрочем, больше никаких подробностей о новинках компания не сообщила, отметив лишь, что встроенный ускоритель сгодится для RAG и векторных баз данных. Ну и сообщив, что по количеству ядер и производительности её ещё не выпущенный чип обгоняет все остальные чипы: 144-ядерные Intel Xeon 6 (Sierra Forest), которые вскоре станут 288-ядерными (при этом все варианты без Hyper-Threading), и 128-ядерные AMD EPYC Bergamo (256 потоков), которым на смену придут 192-ядерные EPYC Turin Dense (384 потока). 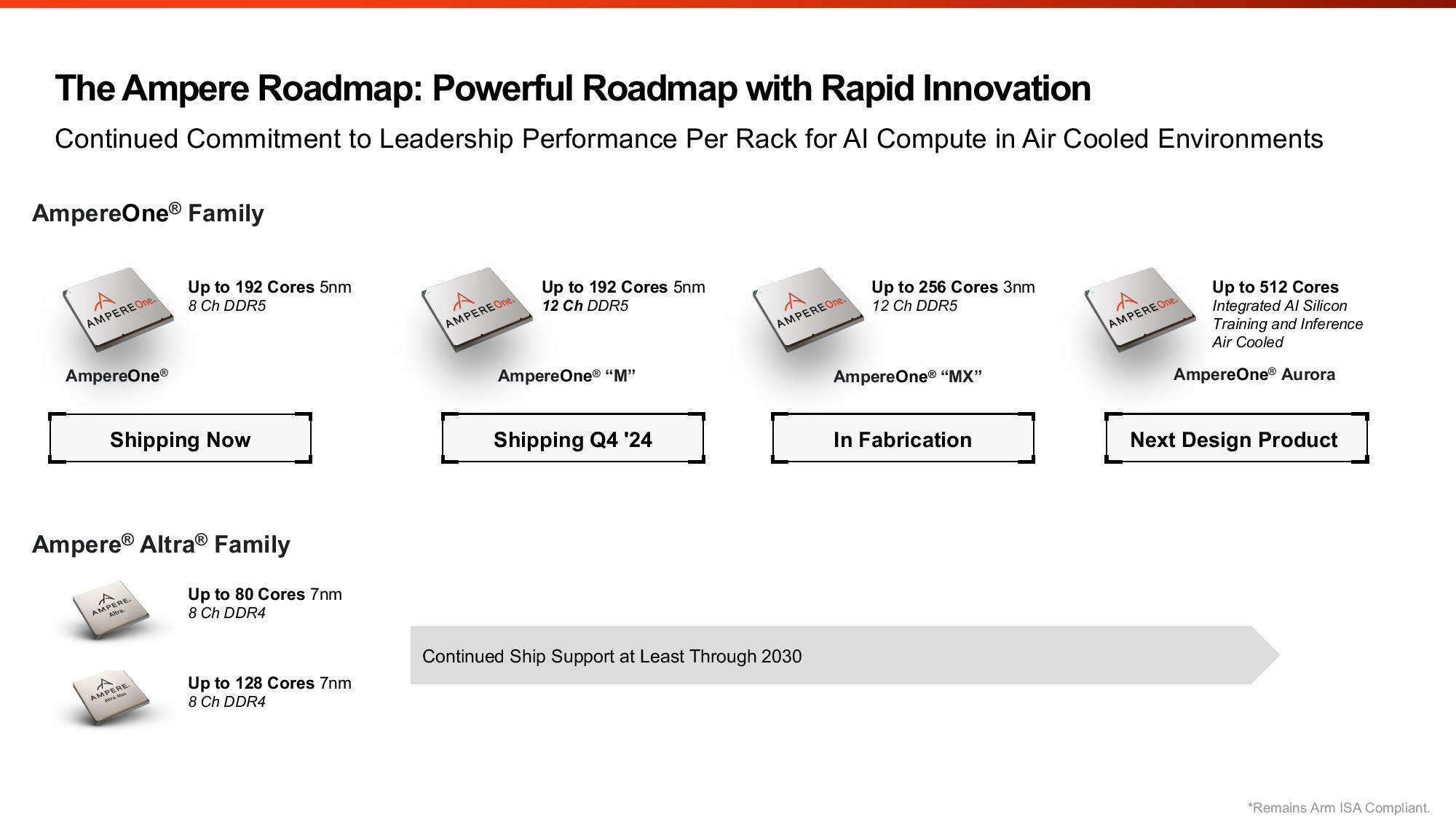 До Aurora компания выпустит ещё две серии процессоров AmpereOne: M в конце 2024 года и MX в 2025 году. 5-нм AmpereOne M получат до 192 ядер и 12-канальный контроллер памяти DDR5. 3-нм AmpereOne MX получат такой же контроллер и до 256 ядер. Заодно компания опубликовала прайс-лист актуальных CPU. В нём нет изначально заявлявшихся 136- и 172-ядерных моделей. Кроме того, остальные процессоры несколько подорожали в сравнении с прошлым поколением Altra Max, но по цене всё ещё привлекательнее решений AMD и Intel — $5555 за 192 ядра. Следует учесть, что в таблице приведён не привычный показатель TDP, а усреднённое энергопотребление чипа, из-за чего сравнивать процессоры Ampere с другими чипами затруднительно. 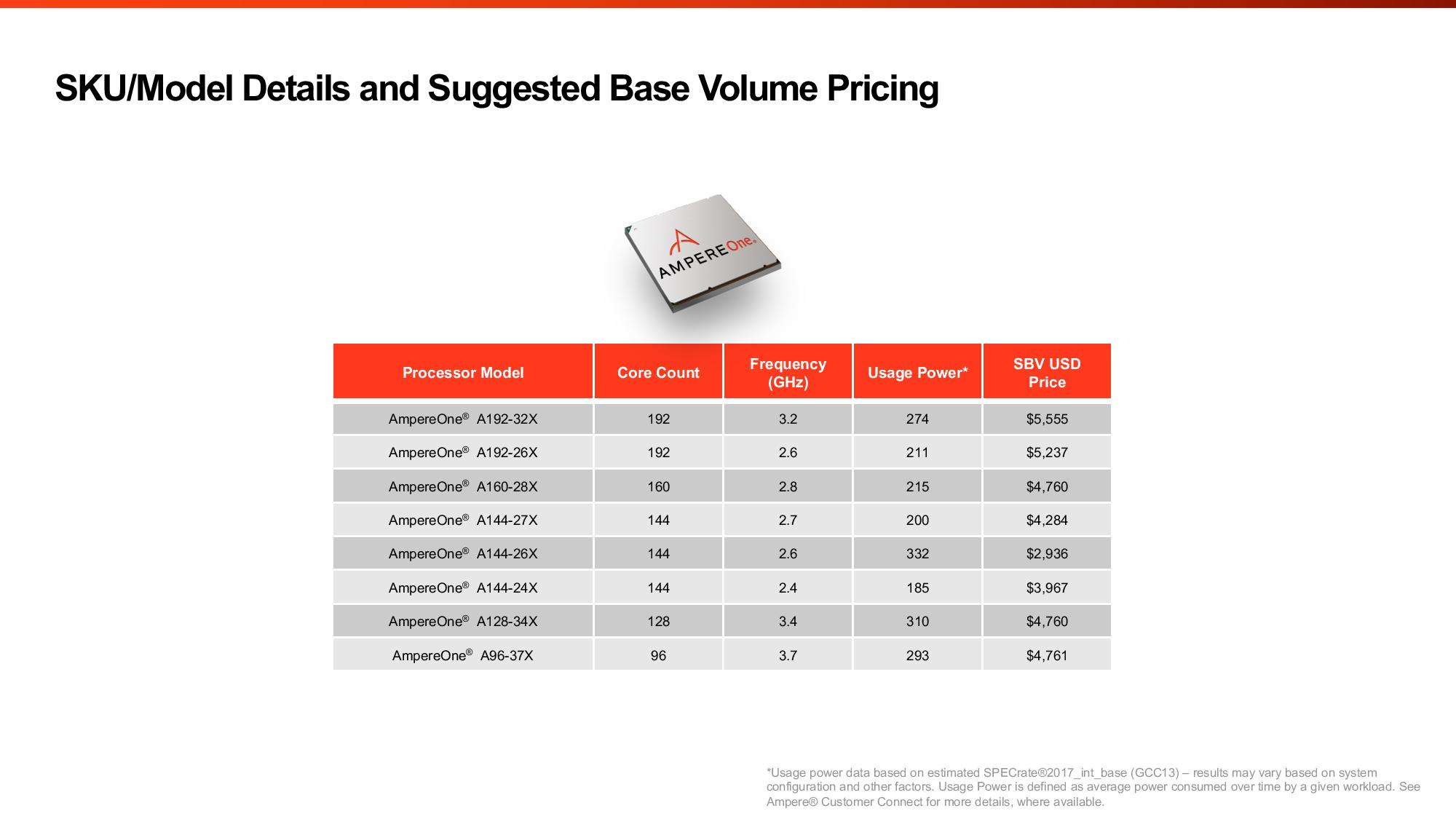 Насколько Aurora станет популярным у гиперскейлеров и других заказчиков, покажет время. У Ampere есть якорный заказчик в лице Oracle, но другие IT-гиганты уже сами разрабатывают собственные Arm-процессоры. AWS в Graviton4 довела количество ядер до 96, Microsoft анонсировала 128-ядерный Cobalt 100, Alibaba массово внедряет 128-ядерные Yitian 710, а Google готовит Axion. Fujitsu к 2027 году подготовит 144-ядерные MONAKA, которые тоже получат поддержку ИИ-нагрузок, но упор в них сделан не на HBM, а на SRAM. Собственно говоря, HBM есть только у HPC-процессоров: Fujitsu A64FX, SiPearl Rhea1 и C-DAC AUM. Даже NVIDIA Grace, которые в основном ассистируют ускорителям, обходятся LPDDR5x.
25.07.2024 [10:12], Владимир Мироненко
AMD показала превосходство чипов EPYC над Arm-процессорами NVIDIA Grace в серии бенчмарков, но не всё так простоAMD провела серию тестов, чтобы доказать преимущество своих нынешних процессоров AMD EPYC над Arm-процессорами NVIDIA Grace Superchip. Как отметила AMD, в связи с растущей востребованностью ЦОД некоторые компании начали предлагать альтернативные варианты процессоров, «часто обещающие преимущества по сравнению с обычными решениями x86». «Обычно их представляют с большой помпой и заявлениями о значительных преимуществах в производительности и энергоэффективности по сравнению с x86. Слишком часто эти утверждения довольно сложно воплотить в реальные сценарии конкурентной рабочей нагрузки — с использованием устаревших, недостаточно оптимизированных альтернатив или плохо документированных предположений», — отметила AMD. С помощью серии стандартных отраслевых тестов AMD, по её словам, продемонстрировала преимущество EPYC над решениями на базе Arm. «Благодаря проверенной архитектуре x86-64, впервые разработанной AMD, вы можете получить всё это без дорогостоящего портирования или изменений в архитектуре», — подчеркнула компания. Иными словами, тесты AMD могут быть просто попыткой развеять опасения, что архитектура x86 «выдыхается» и что Arm берёт верх. 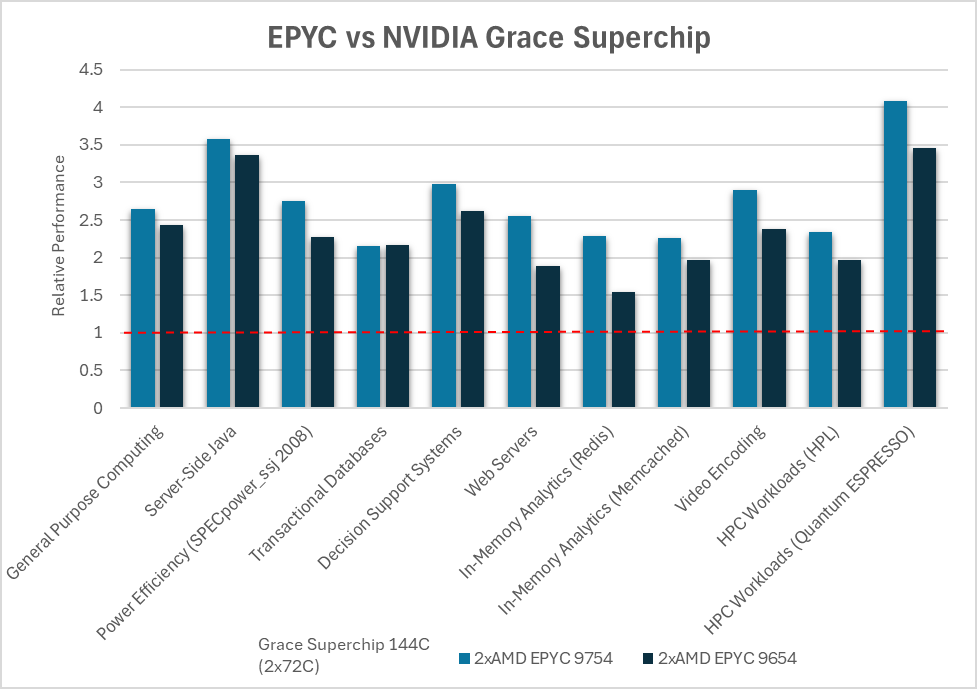
Источник изображений: AMD AMD сравнила производительность AMD EPYC и NVIDIA Grace CPU в десяти ключевых рабочих нагрузках, охватывающих вычисления общего назначения, Java, транзакционные базы данных, системы поддержки принятия решений, веб-серверы, аналитику, кодирование видео и нагрузки HPC. Согласно представленному выше графику, 128-ядерный процессор EPYC 9754 (Bergamo) и 96-ядерный EPYC 9654 (Genoa) более чем вдвое превзошли NVIDIA Grace CPU Superchip по производительности при обработке вышеуказанных нагрузок. Напомним, что Grace CPU Superchip содержит два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2, соединённых шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работает как единый 144-ядерный процессор. В свою очередь, ресурс The Register отметил, что речь идёт о версии с 480 Гбайт памяти LPDDR5x, а не с 960 Гбайт. 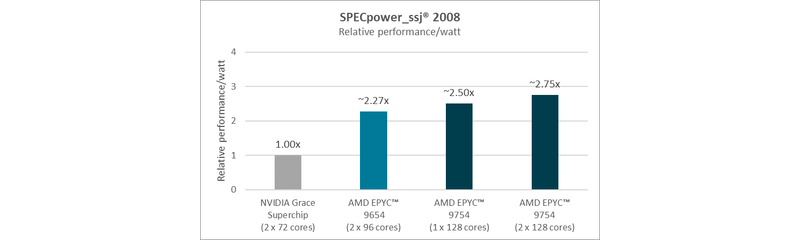 В тесте SPECpower-ssj2008, по данным AMD, одно- и двухсокетные системы на базе AMD EPYC 9754 превосходят систему NVIDIA Grace CPU Superchip по производительности на Вт примерно в 2,50 раза и 2,75 раза соответственно, а двухсокетная система AMD EPYC 9654 — примерно в 2,27 раза. Помимо производительности и эффективности, ещё одним важным фактором для операторов ЦОД является совместимость, сообщила AMD. По оценкам, во всем мире существуют триллионы строк программного кода, большая часть которого написана для архитектуры x86. EPYC основаны на архитектуре x86-64, впервые разработанной AMD, и эта архитектура является наиболее широко используемой и поддерживаемой в индустрии ЦОД, заявила компания, добавив, что изменения в архитектуре сложны, дороги и чреваты риском. AMD также отметила, что экосистема AMD EPYC включает более 250 различных конструкций серверов и поддерживает около 900 уникальных облачных инстансов. Также процессоры AMD EPYC установили более 300 мировых рекордов производительности и эффективности в широком спектре тестов. В то же время лишь немногие Arm-решения доказали свою эффективность. В свою очередь, ресурс The Register отметил, что ситуация не так проста, как AMD пытается всех убедить. В феврале сайт The Next Platform сообщил, что исследователи из университетов Стоуни-Брук и Буффало сравнили данные о производительности суперчипа NVIDIA Grace CPU Superchip и нескольких процессоров x86, предоставленные несколькими НИИ и разработчиком облачных решений. 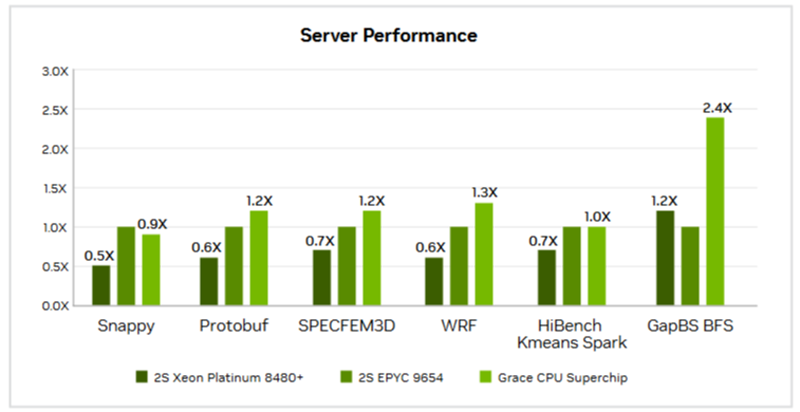
Источник изображений: NVIDIA Большинство этих тестов были ориентированы на HPC, включая Linpack, HPCG, OpenFOAM и Gromacs. И хотя производительность системы Grace сильно различалась в разных тестах, в худшем случае она находилась где-то между Intel Skylake-SP и Ice Lake-SP, превосходя AMD Milan и находясь в пределах досягаемости от показателей Xeon Max. Данные результаты отражают тот факт, что самые мощные процессоры AMD EPYC Genoa и Bergamo могут превзойти первый процессор NVIDIA для ЦОД — при правильно выбранном тесте. 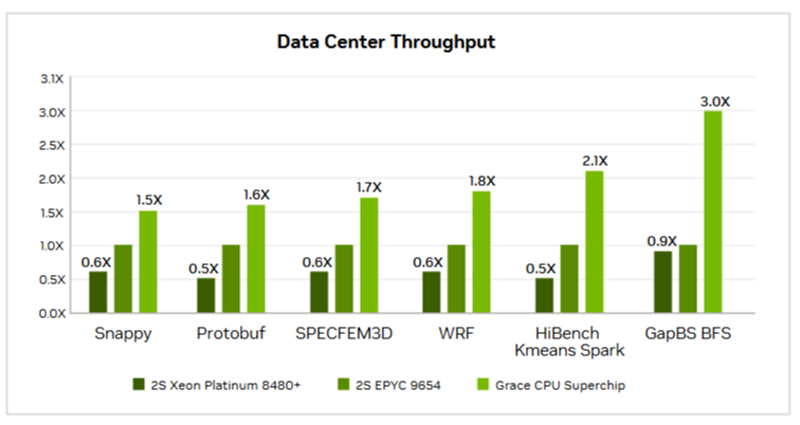 В техническом описании Grace CPU Superchip компания NVIDIA сообщает, что этот чип обеспечивает от 0,9- до 2,4-кратного увеличения производительности по сравнению с двумя 96-ядерными EPYC 9654 и предлагает до трёх раз большую пропускную способность в различных облачных и HPC-сервисах. NVIDIA отмечает, что Superchip предназначен для «обработки массивов для получения интеллектуальных данных с максимальной энергоэффективностью», говоря об ИИ, анализе данных, нагрузках облачных гиперскейлеров и приложениях HPC.
12.07.2024 [09:09], Алексей Степин
144 ядра, чиплеты, SRAM и 3D-упаковка: Fujitsu поделилась подробностями о грядущих Arm-процессорах MONAKAОпыт японской компании Fujitsu в разработке процессоров и суперкомпьютеров велик и многогранен. Долгое время основной архитектурой для решений Fujitsu была SPARC64, но времена меняются: в 2018 году компания анонсировала разработку собственного процессора на базе архитектуры Arm. Сегодня этот чип мы знаем под именем A64FX. В 2020 году японский кластер Fugaku на основе 48-ядерных A64FX с интегрированными HBM-памятью и интерконнектом занял первое место в рейтинге TOP500 с результатом 537,2 Пфлопс. Однако эти процессоры, которые всё ещё достойно трудятся не только в Fugaku, но и в других суперкомпьютерах, трудно назвать действительно универсальным и доступным. 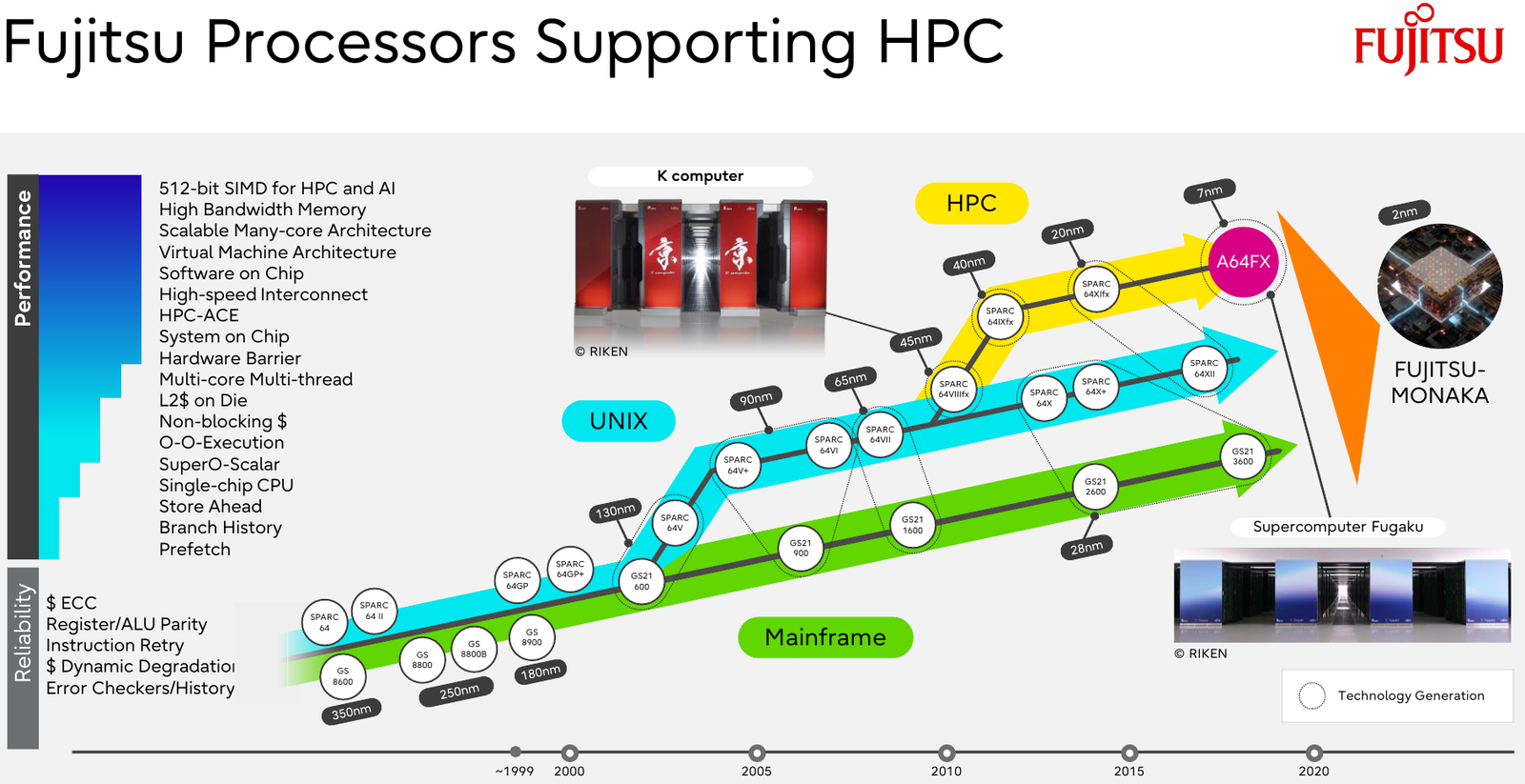
Источник изображений: Fujitsu Важность архитектурных нововведений и смену IT-ландшафта в Fujitsu прекрасно осознают. Поэтому компания объявила о разработке нового серверного процессора под кодовым именем MONAKA, для которого она намеревается вдвое увеличить показатели производительности и энергоэффективности, а также учесть растущую популярность задач класса ИИ. А совсем недавно Fujitsu впервые более детально рассказала о технических особенностях будущих CPU. 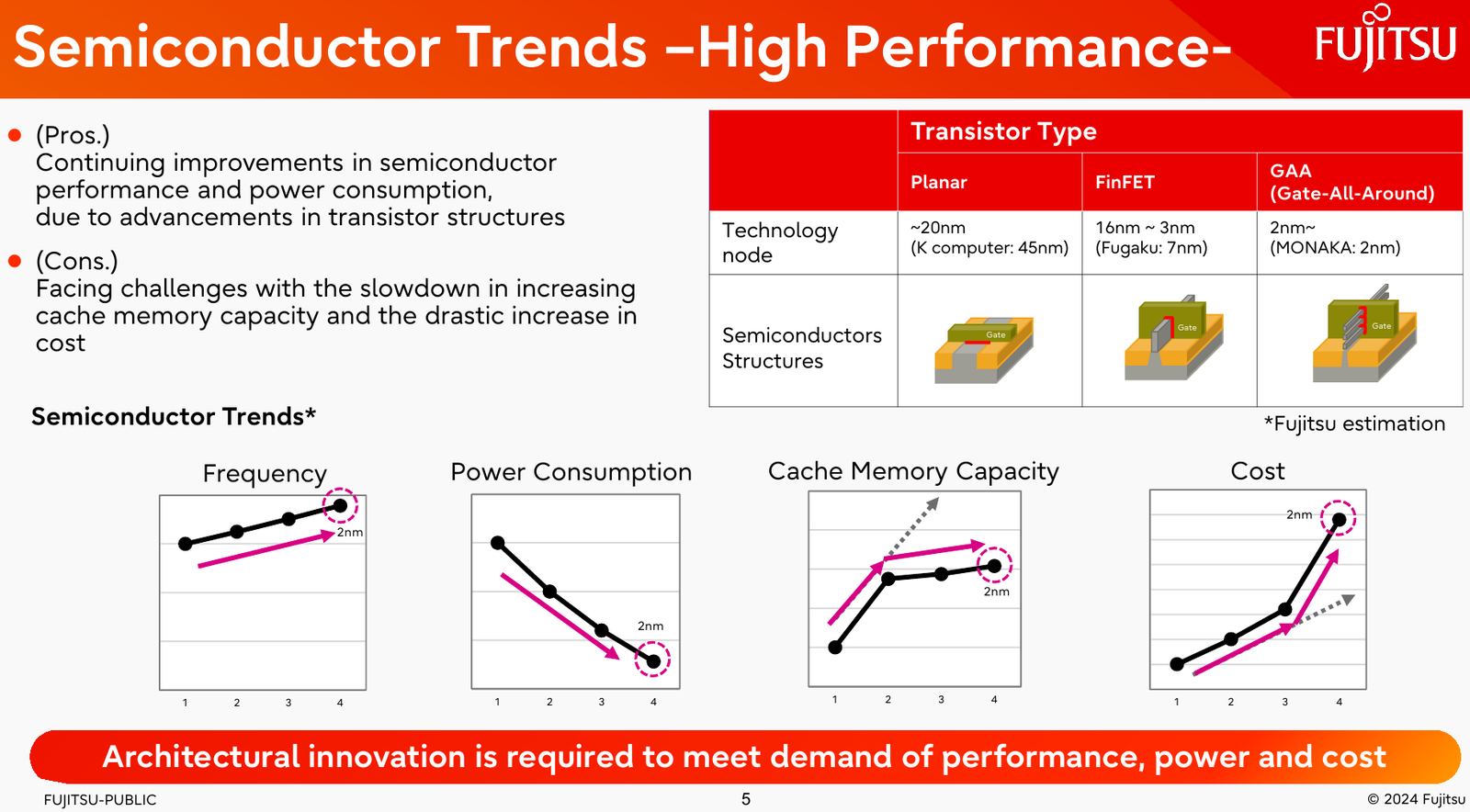 Во-первых, разработчики нового процессора хорошо осознают ограничения, накладываемые текущей транзисторной технологии. Похоже, из FinFET и её аналогов выжаты все или почти все соки и для прорывных решений нового поколения данная технология не подходит. В процессорах MONAKA будут использоваться транзисторы с затвором нового типа, так называемые GAA (Gate-all-Around). Похоже, речь идёт о технологии, которую разрабатывает и собирается внедрить в производство уже в следующем году Samsung в рамках 2-нм техпроцесса SF2. 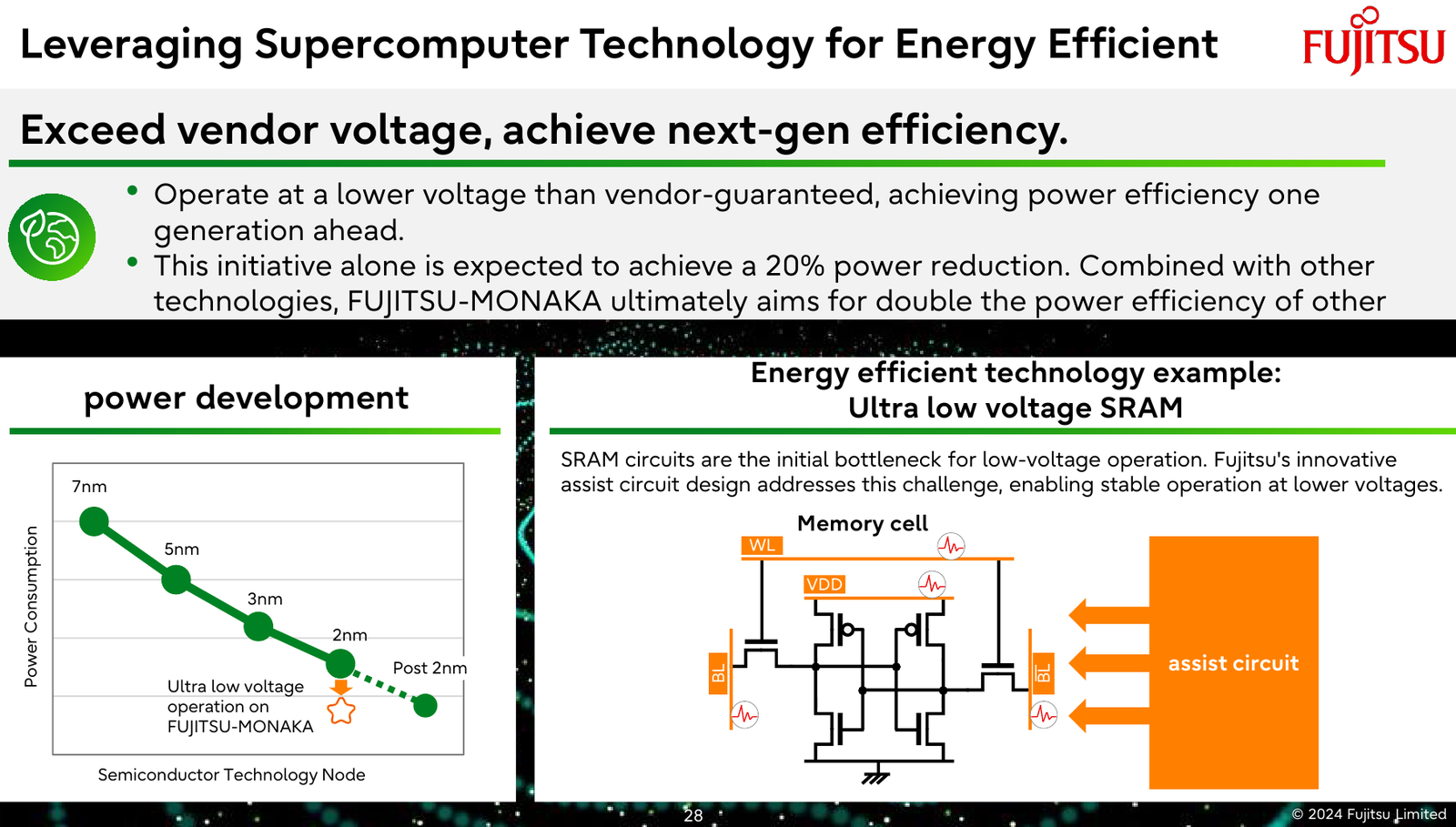 Внедрение 2-нм GAA-транзисторов позволит снизить паразитную ёмкость, а значит, добиться больших тактовых частот при меньшем напряжении питания. При этом новая технология будет применена не только в процессорных ядрах, но и в сборках кеш-памяти, также спроектированных с использованием собственного инструментария Fujitsu.  Во-вторых, MONAKA изначально проектируется как модульный процессор. В центре разместится IO-кристалл, содержащий контроллеры DDR5 (12 каналов) и PCI Express 6.0/CXL 3.0. Окружать его будут сборки из 5-нм кристаллов кеш-памяти SRAM и расположенных поверх 2-нм кристаллах с процессорными ядрами. По вертикали соединение обеспечит технология TSV, а по горизонтали — кремниевая подложка-интерпозер. Фактически речь идёт о 3D-компоновке. 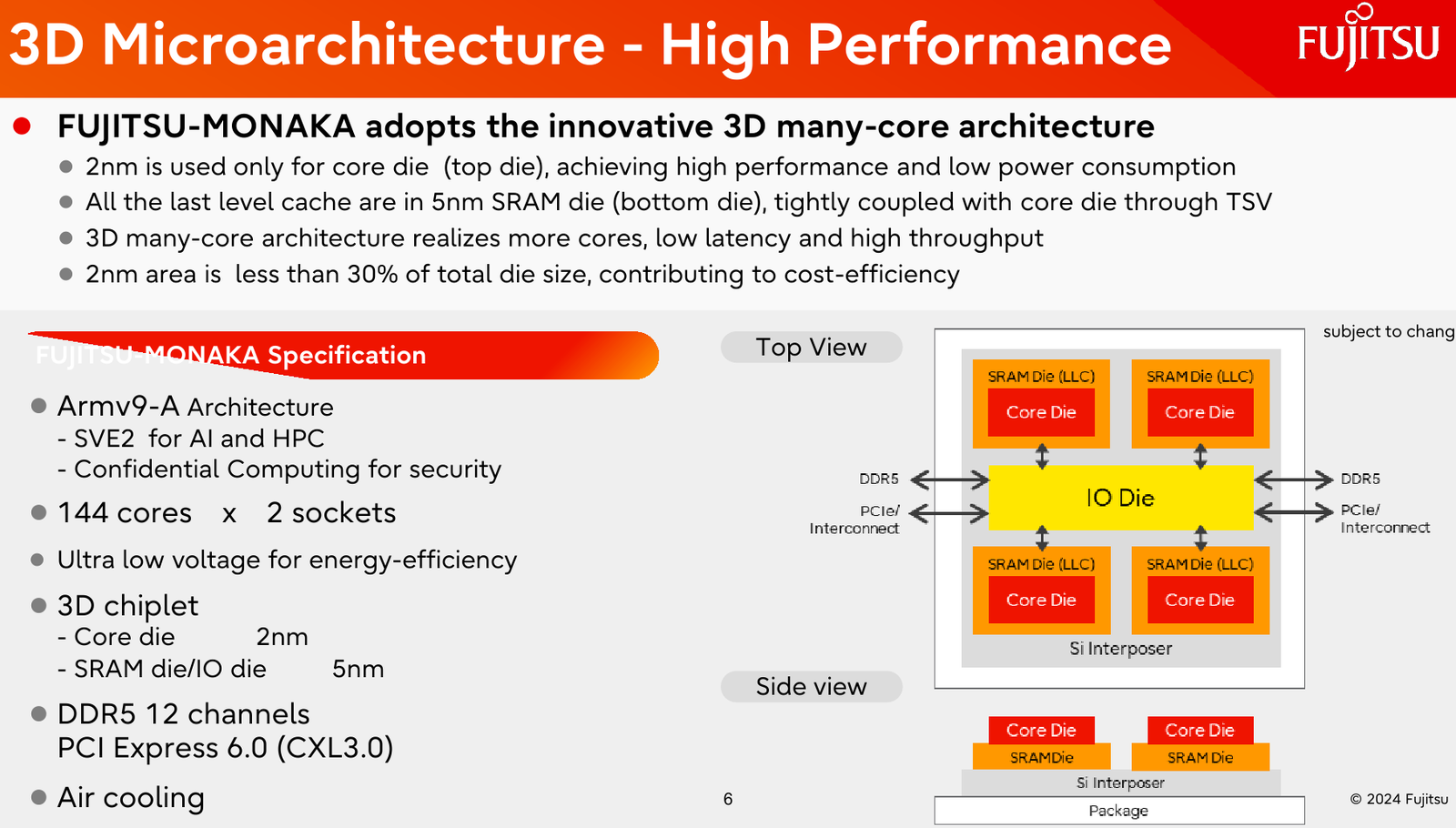 12-канальная подсистема памяти обеспечит отсутствие узких мест: у A64FX проблем с пропускной способностью благодаря использованию HBM2 не было, но объем самой памяти был ограничен 32 Гбайт. Зато у MONAKA проблем с расширением не будет — как с помощью классических модулей DIMM, так и посредством банков памяти CXL, благо, за основу сразу взята версия PCIe 6.0 с пропускной способностью 256 Гбайт/с в режиме x16. Сколько будет самих линий, пока не уточняется.  Новая платформа изначально проектируется двухсокетной, при этом в количестве ядер Fujitsu также не скромничает: процессоры MONAKA получат 144 ядра, а благодаря новому 2-нм техпроцессу они будут не такими уж горячими. Им хватит воздушного охлаждения, говорят создатели. Процессоры получат набор инструкций Armv9-A с векторными расширениями SVE2 и технологией доверенных вычислений Confidential Computing. Скорее всего, без кастомных инструкций не обойдётся и в этот раз. 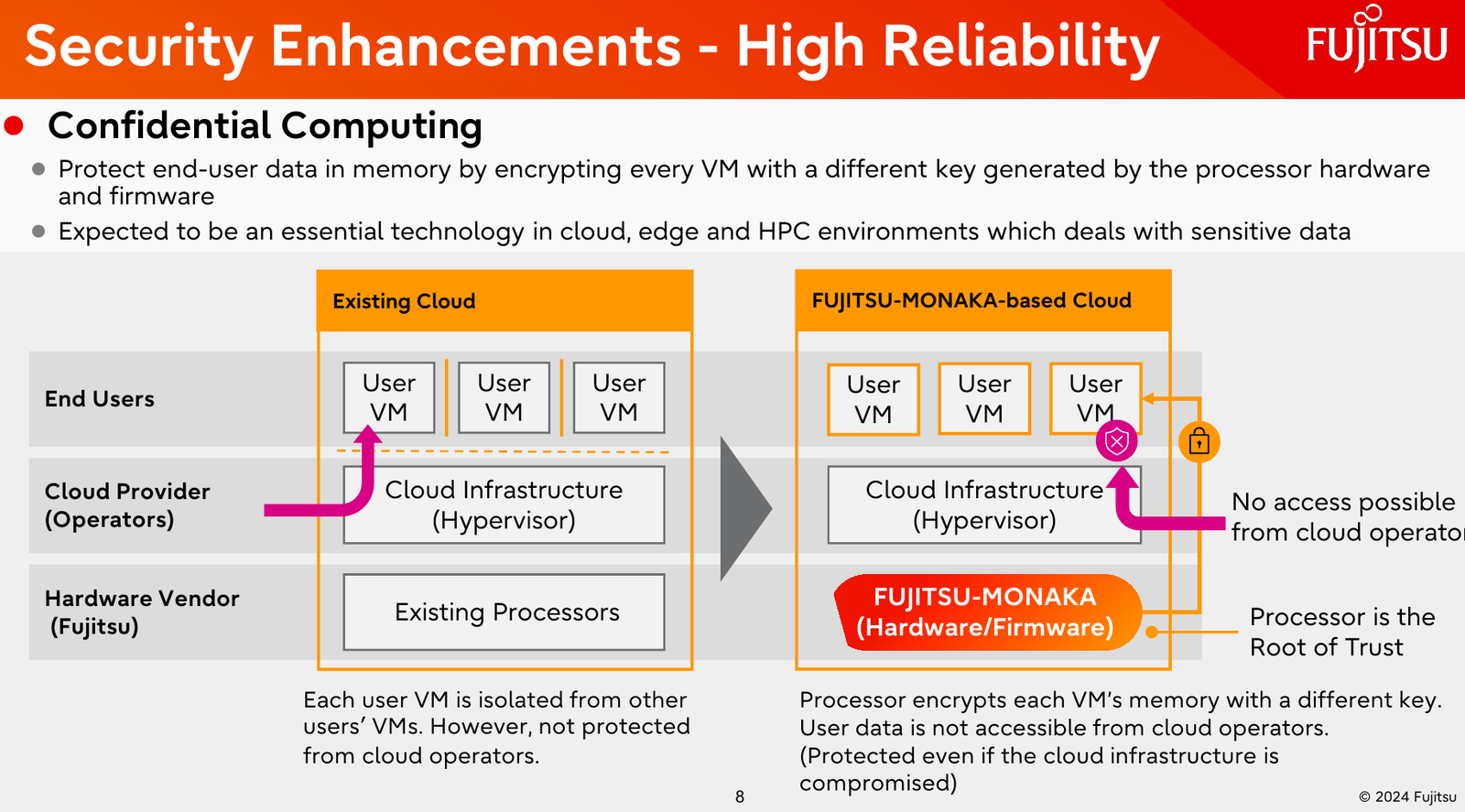 Последнее особенно важно ввиду того, что MONAKA предназначены не только для рынка HPC, но и для использования в облачных средах. Подсистема конфиденциальных вычислений позволяет шифровать содержимое каждой виртуальной машины собственным ключом, так что доступа к внутренностям ВМ не будет даже у владельцев ЦОД. Впрочем, современные HPC-комплексы всё чаще используют именно облачный подход для доступа к ресурсам. 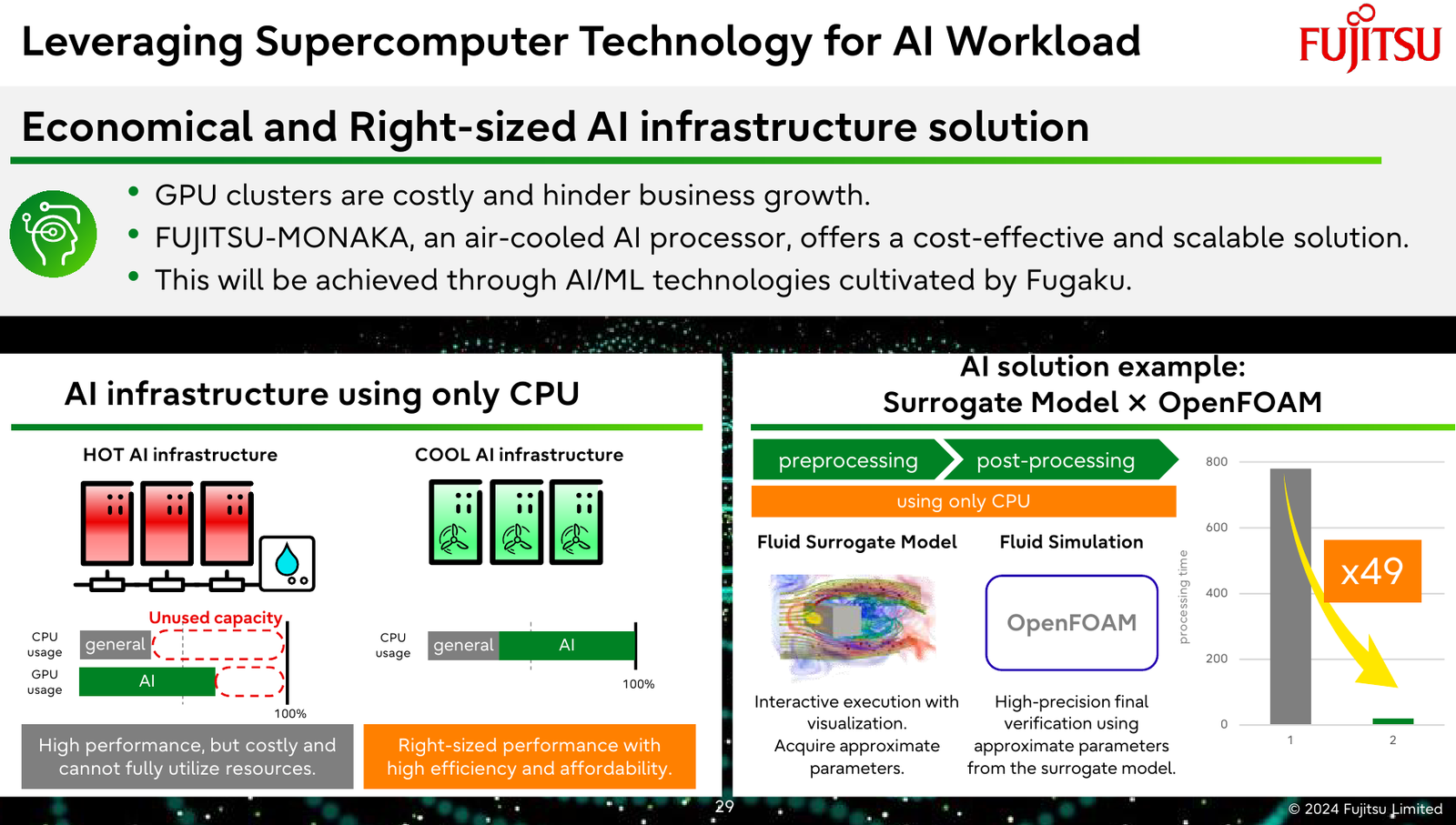 Несмотря на популярность GPU и других специализированных ускорителей, Fujitsu считает, что гетерогенная архитектура имеет существенные недостатки — она заметно дороже, особенно с учётом ценовой политики производителей, склонна к неполной утилизации ресурсов, а также не слишком экономична и зачастую требует специфических систем охлаждения. Компания полагает, что гомогенная архитектура MONAKA этих недостатков лишена и в сочетании с ПО Fujitsu может успешно обрабатывать ИИ-нагрузки.  В программной части Fujitsu активно полагается на решения с открытым кодом. Процессоры MONAKA будут отвечать стандартам Arm System Ready и получат полноценную поддержку Linux и сопутствующего инструментария, в частности, GCC, glibc, live-patch, papi и т.д. Разработка ведётся в тесном содружестве с Linaro, организацией, занимающейся консолидацией открытого ПО для Arm, а также с альянсом UXL. Для MONAKA компания подготовит, например, оптимизированную библиотеку OpenBLAS. 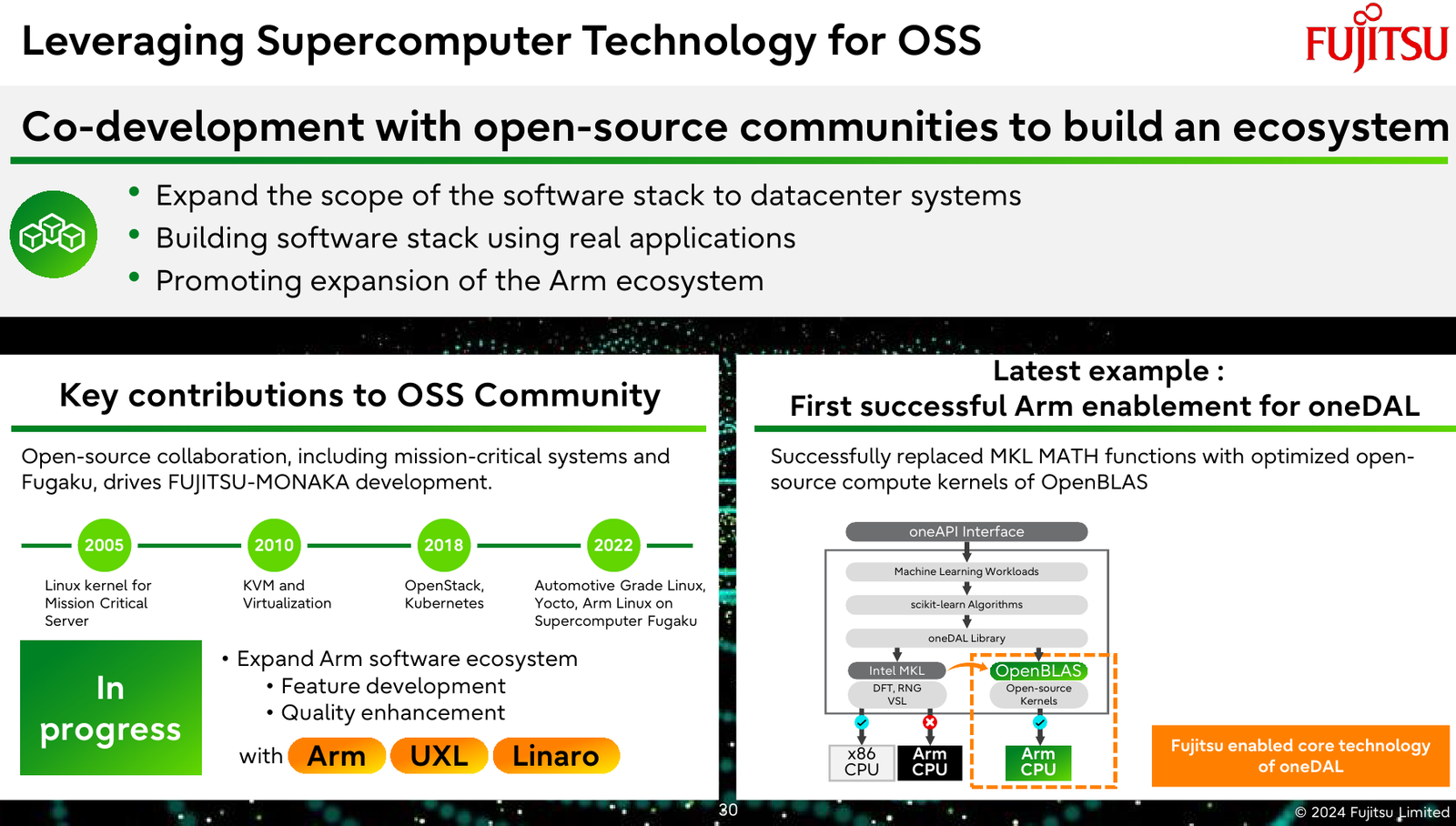 Также Fujitsu уделяет внимание экологии: напомним, одной из главных черт нового процессора будет его экономичность, что отвечает целям японской национальной программы NEDO, ставящей своей целью достижение 40 % снижения энергопотребления ЦОД к 2030 году. 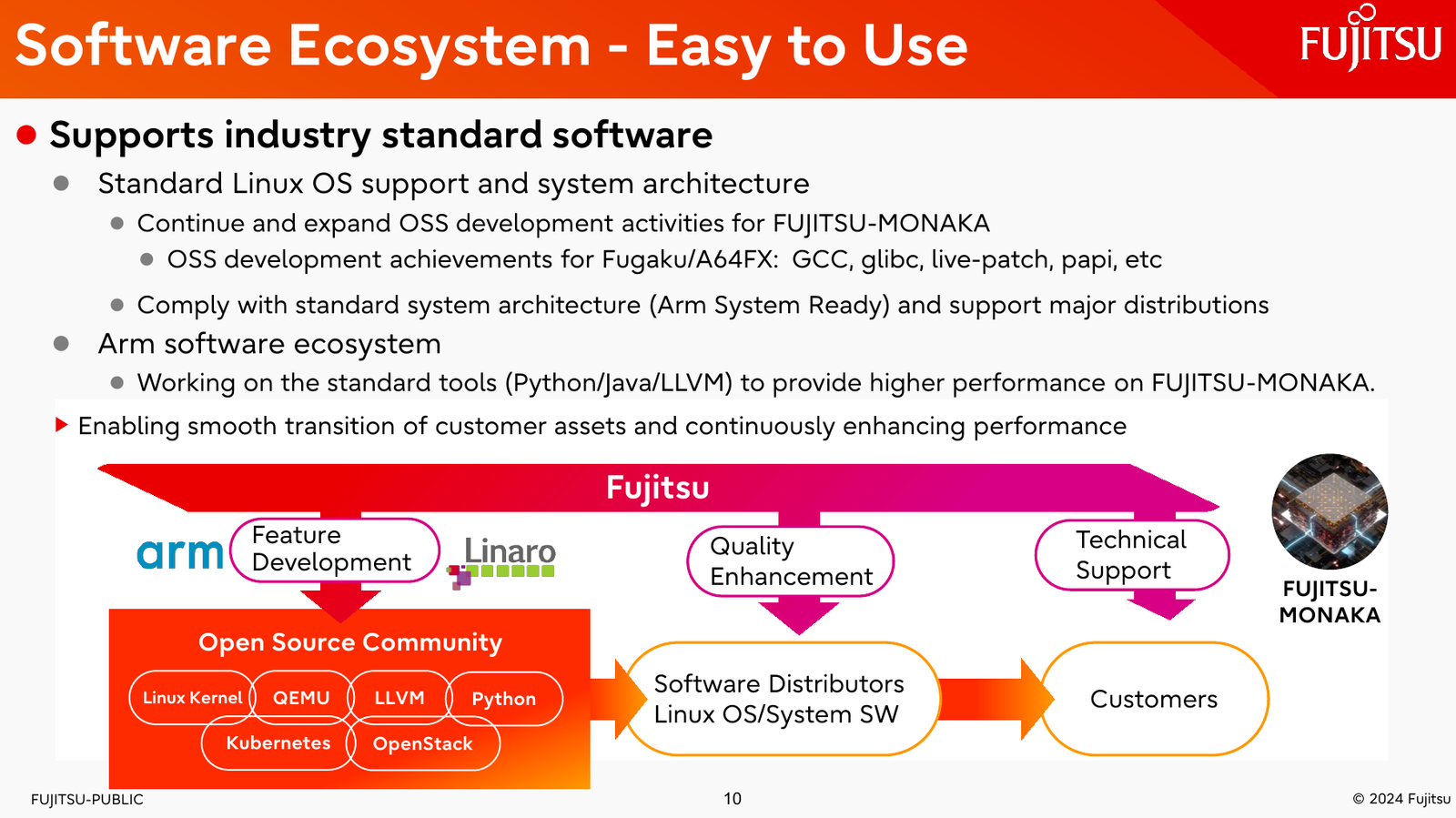 Что касается начала поставок MONAKA, здесь всё идёт по плану: первые партии новых процессоров найдут своё место в серверах и вычислительных узлах уже в 2027 году. Это вполне согласуется с циклом разработки PCI Express, согласно которому появления решений PCIe 6.0 на рынке следует ожидать не ранее 2025 года.
10.07.2024 [17:43], Владимир Мироненко
AWS объявила о доступности инстансов EC2 R8g на базе Arm-процессоров Graviton4AWS объявила о доступности инстансов EC2 R8g на базе Arm-процессоров Graviton4. По сравнению с Graviton3 они обладают на 30 % большей вычислительной мощностью, имеют на 50 % больше ядер и на 75 % выше пропускную способность памяти, говорит AWS. Также сообщается, что процессоры Graviton4 до 30 % быстрее в обработке веб-приложений, на 40 % быстрее в работе с базами данных и на 45 % быстрее при запуске больших Java-приложений, чем Graviton3. Инстансы Amazon EC2 R8g позволяют повысить производительность приложений, интенсивно использующих ресурсы памяти, включая высокопроизводительные СУБД, in-memory кеши и системы аналитики Big Data в режиме реального времени. Впрочем, согласно подсчётам The Next Platform, новые инстансы по сравнению с прошлыми по соотношению цены и производительности стали на четверть дороже. 
Источник изображений: AWS По сравнению с EC2 R7g инстансы R8g предлагают более крупные конфигурации: в три раза больше vCPU (до 192 шт.), в три раза больше памяти (до 1,5 Тбайт) и в два раза больше L2-кеша. Инстансы R8g также обеспечивают пропускную способность сети до 50 Гбит/с и пропускную способность EBS до 40 Гбит/с по сравнению с 30 Гбит/с и 20 Гбит/с соответственно у инстансов прошлого поколения. Кроме того, Amazon EC2 R8g — первые инстансы на чипах Graviton, предлагающие две крупные конфигурации bare metal (metal-24xl и metal-48xl). 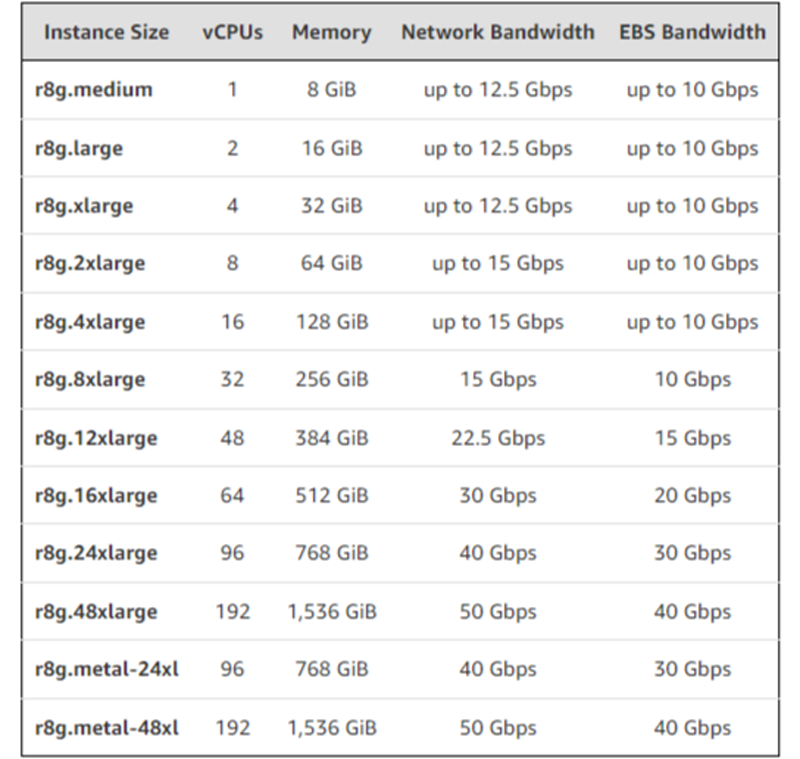 Как сообщила компания, инстансы R8g идеально подходят для всех рабочих нагрузок на базе Linux, включая контейнерные приложения и приложения на основе микросервисов, созданные с использованием EKS, ECS, ECR, Kubernetes, и Docker, а также приложения, написанные на C/C++, Rust, Go, Java, Python, .NET Core, Node.js, Ruby и PHP. Новые инстантсы используют AWS Nitro. По словам AWS, с момента анонса превью R8g более 100 клиентов, включая Epic Games, SmugMug, Honeycomb, SAP и ClickHouse, протестировали свои рабочие нагрузки на этих инстансах и отметили значительное улучшение производительности по сравнению с сопоставимыми экземплярами на Graviton3. В настоящее время R8g доступны в регионах AWS US East (Северная Вирджиния), US East (Огайо), US Wes (Орегон) и Europe (Франкфурт). Они доступны как по запросу, так в качестве спотовых и зарезервированных инстансов, а также в рамках планов Savings. На текущий момент у AWS есть уже более 2 млн процессоров Graviton разных поколений, а инстансами на их основе пользуются более 50 тыс. клиентов.
28.06.2024 [12:33], Сергей Карасёв
Представлена российская системная плата «Ключевская» для двух Arm-процессоровРоссийская технологическая компания «Е-Флопс» объявила о разработке системной платы под названием «Ключевская», которая позиционируется в качестве основы модульной серверной платформы для хранения и обработки данных. Выпуск новинки, на которую получен патент, планируется организовать в сентябре нынешнего года. Изделие имеет 20-слойную конструкцию, а его габариты составляют 446 × 203 мм. Поддерживаются два процессора с архитектурой Arm64 (48 ядер, частота до 2,2 ГГц). Доступны 12 слотов для модулей оперативной памяти DDR4-3200 (L)RDIMM. Имеется 80 линий PCIe 4.0, из которых 48 совместимы с CCIX. Название процессора не указывается, но по описанию подходит, например, Baikal-S (BE-S1000). 
Источник изображений: «Е-Флопс» Системная плата получила два разъёма M.2 2242 для NVMe SSD и два слота PCIe 4.0 x16 для карт расширения с возможностью горячей замены. Есть слот PCIe 4.0 x16 OCP 3.0, четыре разъёма PCIe 4.0 x16/CCIX для установки райзеров, а также 260-контактный коннектор SO-DIMM DDR4 для модуля удалённого мониторинга и управления стандарта RunBMC. Упомянуты интерфейсы USB 2.0 и 1GbE.  Модульная концепция предусматривает, что часть функциональности перенесена на так называемые «сателлитные платы». В частности, интерфейсы Ethernet, USB, DP, индикация и управление реализованы на IO-карте. Предусмотрена возможность дополнительного межпроцессорного соединения, увеличивающего скорость обмена данными в два раза, и возможность четырехпроцессорной SMP-сборки из двух типовых системных плат.  Изготовление плат осуществляется по контрактному производству в два основных этапа (без учета подготовительных работ, закупки сырья и материалов, функций технического контроля и пр.). Текстолит производится на заводах КНР из-за недоступности необходимых технологий в России. Вместе с тем поверхностный монтаж полностью выполняется на территории РФ.
25.06.2024 [17:01], Сергей Карасёв
Второй в Европе экзафлопсный суперкомпьютер Alice Recoque разместится во Франции, а его создание обойдётся в €544 млнЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о подписании соглашения с французским национальным агентством высокопроизводительных вычислений (GENCI) о размещении второго в Европе суперкомпьютера экзафлопсного класса. Напомним, первым европейским HPC-комплексом с производительностью более 1 Эфлопс станет Jupiter, который расположится в Юлихском исследовательском центре (FZJ) в Германии. В создании системы участвуют NVIDIA, ParTec, Eviden и SiPearl. В состав суперкомпьютера войдут модули NVIDIA Quad GH200, а также энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea. Машина будет развёрнута на базе модульного ЦОД. Ввод в эксплуатацию запланирован в 2024 году. Второй в Европе экзафлопсный суперкомпьютер получил имя Alice Recoque) — в честь французского учёного, компьютерного инженера и специалиста по компьютерной архитектуре. Она работала над созданием мини-компьютеров в 1970-х годах и руководила исследованиями, связанными с ИИ. 
Мини-компьютер Mitra-15, разработанный под руководством Алисы Рекок (Фото: Damien.b / Wikipedia) Стоимость создания машины оценивается в €544 млн. Управление суперкомпьютером возьмёт на себя Французская комиссия по альтернативным источникам энергии и атомной энергии (CEA). Комплекс будет смонтирован на территории Брюйер-ле-Шатель, к юго-западу от Парижа. Для размещения и эксплуатации машины выбран французско-нидерландский консорциум Жюля Верна. Известно, что в основу суперкомпьютера ляжет модульная энергоэффективная архитектура. По мере необходимости в состав системы могут добавляться дополнительные узлы на базе GPU или квантовых процессоров. Комплекс, в частности, будет построен на Arm-чипах SiPearl Rhea2, которые в настоящее время находятся в разработке. Не исключается также применения высокопроизводительных RISC-V процессоров EPI EPAC. Запуск Alice Recoque предварительно намечен на 2026 год, но может затянуться до 2027–2028 гг. Система будет доступна академическим организациям, государственным структурам и промышленным предприятиям. Использовать её планируется для выполнения ресурсоёмких задач в области ИИ и НРС.
22.06.2024 [00:05], Алексей Степин
Альянс CHERI будет продвигать технологию надёжной защиты памяти от атак — первой её могут получить процессоры RISC-VВ современных процессорах немало возможностей для атак связано с особенностями работы современных подсистем памяти. Для противостояния подобным угрозам Capabilities Limited, Codasip, FreeBSD Foundation, lowRISC, SCI Semiconducto и Кембриджский университет объявили о создании альянса CHERI (Capability Hardware Enhanced RISC Instructions). Целью новой организации должна стать помощь в стандартизации, популяризации и продвижении на рынок разработанных Кембриджским университетом совместно с исследовательским центром SRI International процессорных расширений, позволяющих аппаратно реализовывать механизмы защиты памяти, исключающие целый ряд потенциальных уязвимостей, например, переполнение буфера или некорректная работа с указателями. 
Источник: University of Cambridge Сама технология имеет «модульный» характер. Она может применяться выборочно для защиты функций от конкретных атак и требует лишь весьма скромной адаптации кода. Согласно заявлению CHERI Alliance, огромный пул уже наработанного ПО на языках семейств С и C++ может быть легко доработан для серьёзного повышения уровня безопасности. 
Источник: University of Cambridge Кроме того, данная технология позволяет реализовать высокопроизводительные и масштабируемые механизмы компартментализации (compartmentalization) и обеспечения минимально необходимых прав (least privilege). Такое «разделение на отсеки» должно защитить уже скомпрометированную систему и не позволить злоумышленнику развить атаку, даже если он воспользовался ранее неизвестной уязвимостью. 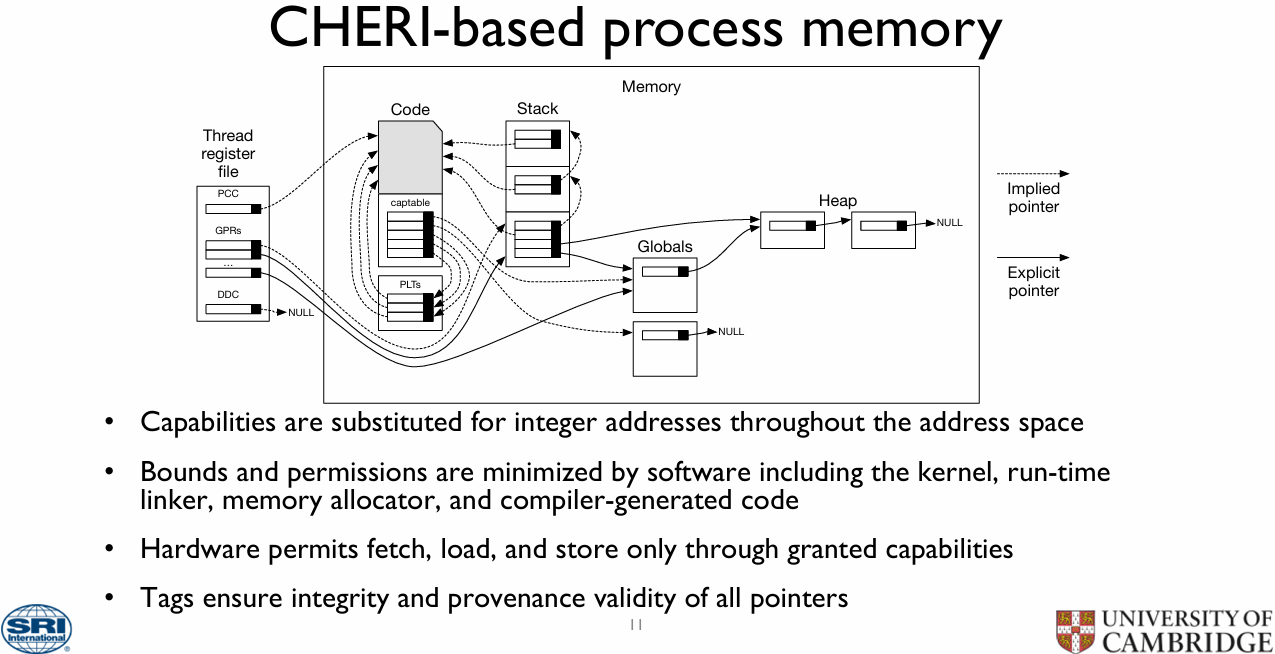
Механика работы расширений CHERI с памятью. Источник: University of Cambridge Технологии, предлагаемые альянсом CHERI, хорошо проработаны — их развитие идёт с 2010 года, а актуальность массового внедрения подобных решений за прошедшее время успела лишь назреть. Однако для успеха данной инициативы потребуется широкое содействие со стороны индустрии как аппаратного обеспечения, так и программного. 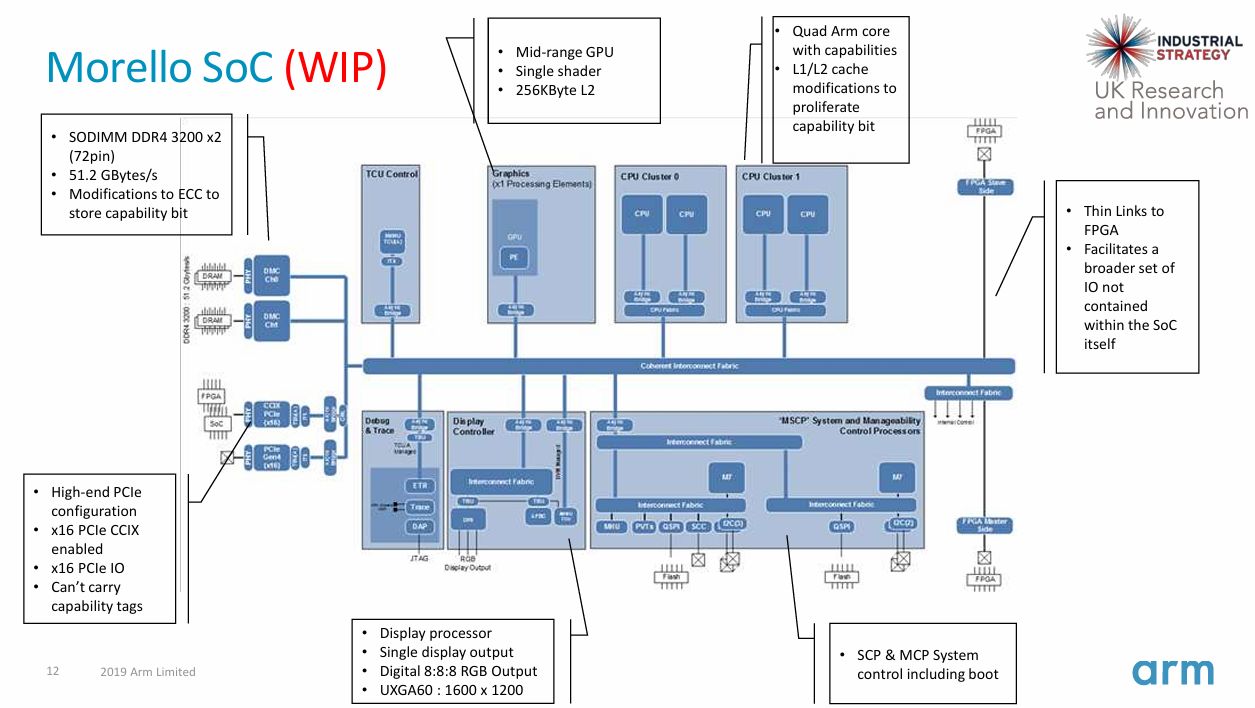
Блок-схема Arm Morello. Источник: Arm Участники альянса настроены оптимистично, однако в их число пока не входит ни один из крупных разработчиков CPU, в частности, Arm. В настоящее время главной архитектурой для приложения своих усилий они видят RISC-V, о чём свидетельствует документация на CHERI ISAv9. Впрочем, черновой вариант расширений имеется и для x86-64. Сама Arm этого оптимизма не разделяет. Компания имеет за плечами пятилетний опыт разработки проекта Morello, основанному на идеях CHERI, но, по словам представителя Arm, процесс тестирования прототипов защищённых систем выявил ряд ограничений, пока препятствующий их широкому распространению на рынке. Тем не менее, работы над платформой Morello будут продолжены. При этом буквально на днях для Arm-процессоров была выявлена атака TikTag, направленная на обход механизма защиты памяти Memory Tagging Extensions (MTE).
22.05.2024 [12:36], Сергей Карасёв
Arm-процессоры Microsoft Cobalt 100 появились в облаке AzureКорпорация Microsoft анонсировала предварительные версии новых инстансов Azure на собственных процессорах Azure Cobalt 100. Пользователи могут выбирать между версиями общего назначения (семейство Dpsv6 и Dplsv6) и конфигурациями, оптимизированными для приложений в памяти (семейство Epsv6). Чипы Cobalt 100 дебютировали в ноябре 2023 года. Они насчитывают 128 ядер Armv9 Neoverse N2 (Perseus). По заявлениям Microsoft, по сравнению с ранее использовавшимися в инфраструктуре Azure чипами Arm изделия Azure Cobalt 100 обеспечивают повышение CPU-производительности в 1,4 раза. Рост быстродействия при рабочих нагрузках на основе Java достигает 1,5 раза, на веб-серверах — 2 раз. Ранее в Azure были доступны Arm-процессоры Ampere Altra. 
Источник изображения: Microsoft Инстансы Dpsv6 и Dpdsv6 предназначены для эффективного выполнения масштабируемых рабочих нагрузок и облачных задач. Эти решения хорошо подходят для малых и средних баз данных с открытым исходным кодом, серверов приложений и веб-серверов, говорит компания. Dplsv6 и Dpldsv6 ориентированы на кодирование мультимедийных данных, игровые серверы, микросервисы и другие рабочие нагрузки, не требующие большего объема оперативной памяти. Инстансы Epsv6 и Epdsv6 способны справляться с крупными базами данных, корпоративными приложениями с высоким объёмом требуемой памяти и пр. Серия Dpsv6 предлагает до 96 vCPU с 384 Гбайт оперативной памяти (соотношение RAM к vCPU — 4:1). Семейство Dplsv6 также включает до 96 vCPU, но объём памяти составляет до 192 Гбайт (2:1). В свою очередь, Epsv6 предлагают до 96 vCPU и до 672 Гбайт RAM (8:1). Все эти варианты доступны с локальным хранилищем и без него. Инстансы доступны в регионах Central US, East US, East US 2, North Europe, Southeast Asia, West Europe и West US 2. В режиме превью сами инстансы будут бесплатны. Все виртуальные машины можно разворачивать, используя привычные инструменты, включая портал Azure, SDK, API, PowerShell и CLI. Говорится о совместимости с широким спектром дистрибутивов Linux, в том числе Canonical Ubuntu, CentOS, Debian, Red Hat Enterprise Linux, SUSE Enterprise Linux, Alma Linux, Azure Linux, Flatcar Linux и пр. Также компания подготовила Insider-сборки Windows 11 Pro и Enterprise, расширила возможности Visual Studio и оптимизировала сборки .NET 8 и OpenJDK.
18.05.2024 [20:00], Алексей Степин
256 ядер и 12 каналов DDR5: Ampere обновила серверные Arm-процессоры AmpereOne и перевела их на 3-нм техпроцессВесной прошлого года компания Ampere Computing анонсировала наследников серии процессоров Altra и Altra Max — чипы AmpereOne с более высокими показателями производительности, энергоэффективности и масштабируемости. На момент анонса AmpereOne получили до 192 ядер, восемь каналов DDR5 и 128 линий PCIe 5.0. Кроме того, эти чипы могут работать и в двухсокетных платформах. Позднее AmpereOne стали доступны у нескольких облачных провайдеров, а главным бенефециаром их появления стала Oracle, когда-то инвестировавшая в Ampere Computing значительные средства. Компания перевела все свои облачные сервисы на процессоры Ampere и даже портировала на них свою флагманскую СУБД. В общем, повторила путь AWS и Alibaba Cloud с процессорами Graviton и Yitian соответственно. Но если последние являются облачным эксклюзивом, то чипы Ampere хоть и ориентированы в первую очередь на гиперскейлеров, более-менее доступны и небольшим компаниям. Поэтому в процессорной гонке останавливаться нельзя, так что на днях Ampere объявила об обновлении модельного ряда AmpereOne, запланированного к выпуску в 2025 году. Новые модели будут использовать продвинутый техпроцесс TSMC N3. 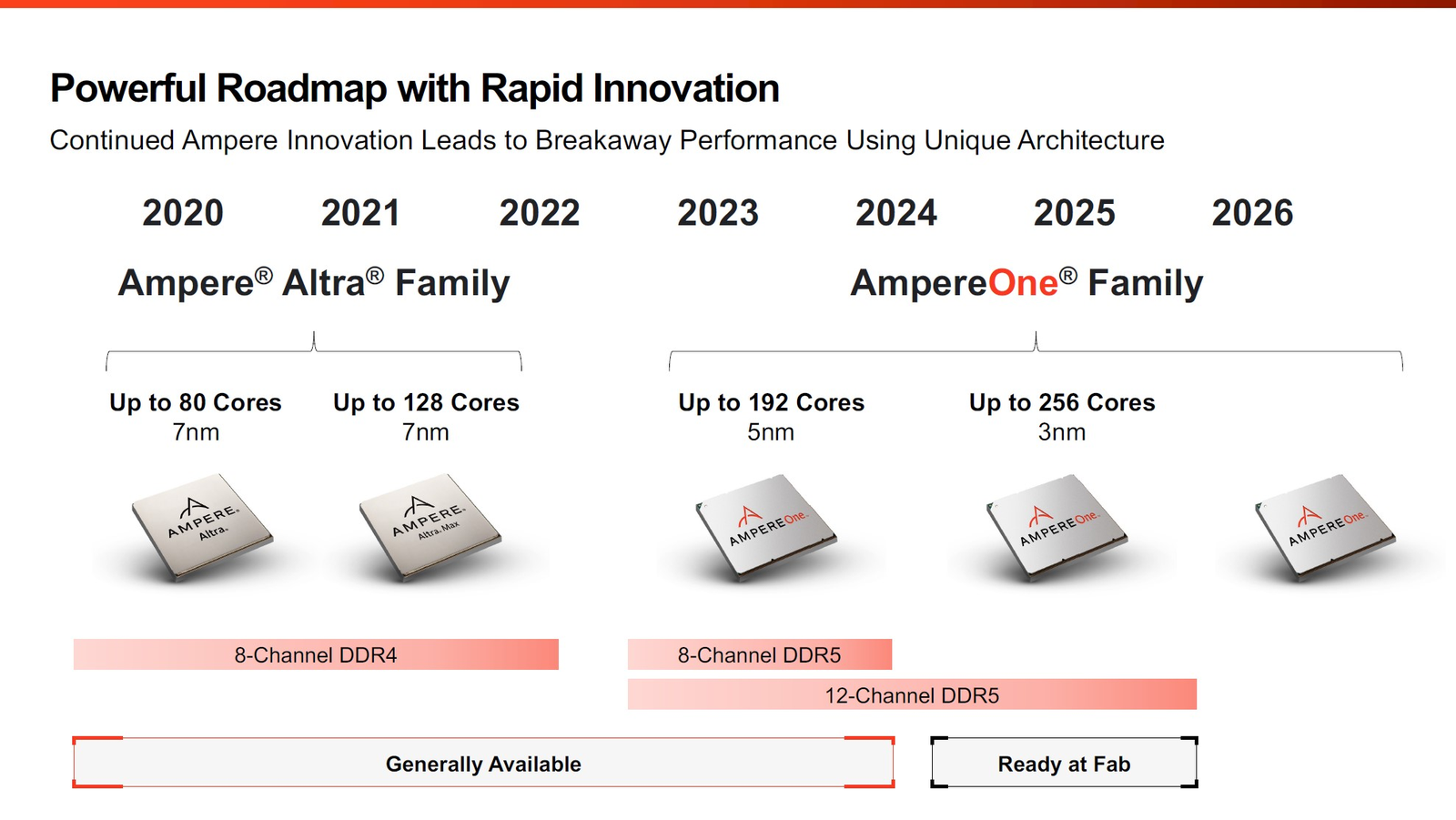
Источник здесь и далее: Ampere Computing via ServeTheHome Согласно опубликованным планам, семейство AmpereOne какое-то время будет существовать в двух ипостасях: изначальном варианте 2023 года с 8-канальным контроллером памяти и 192 ядрами в пределе, производящемся с использованием 5-нм техпроцесса, и новом 3-нм, уже готовом к массовому производству. Ожидается, что 192-ядерный вариант с 12 каналами DDR5 станет доступен в конце этого года. 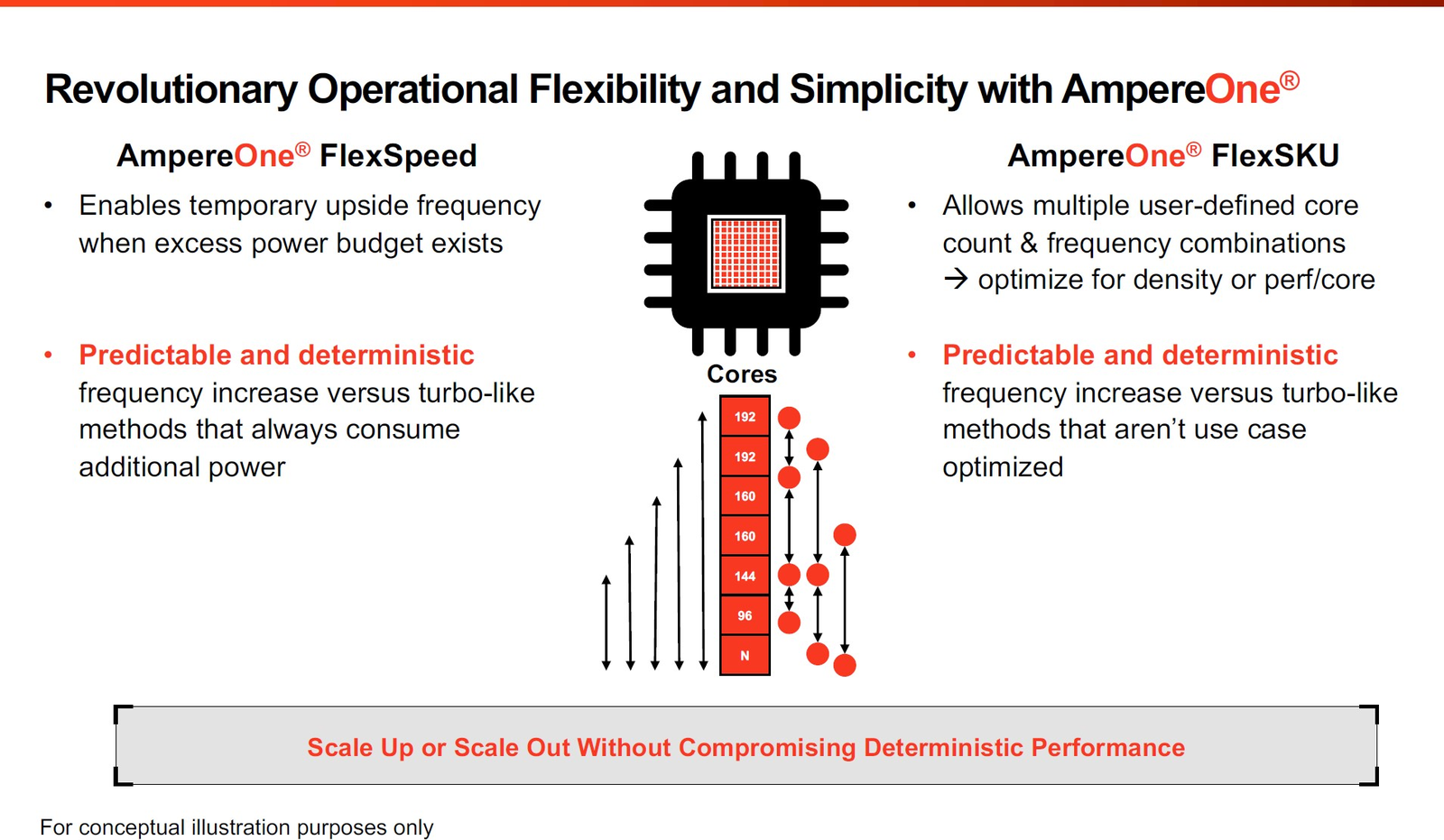
Фирменные технологии Ampere серии Flex позволят гибко управлять характеристиками платформы 3-нм вариант AmpereOne получит до 256 ядер и 12 каналов DDR5, однако отличать его будет не только это. К примеру, в нём дебютируют технологии FlexSpeed и FlexSKU, позволяющие на лету, без перезагрузок или выключения системы оперировать различными параметрами процессора — тактовой частотой, теплопакетом и даже количеством активных ядер. При этом FlexSpeed обеспечит детерминированный прирост производительности в отличие от x86-64, говорит компания. 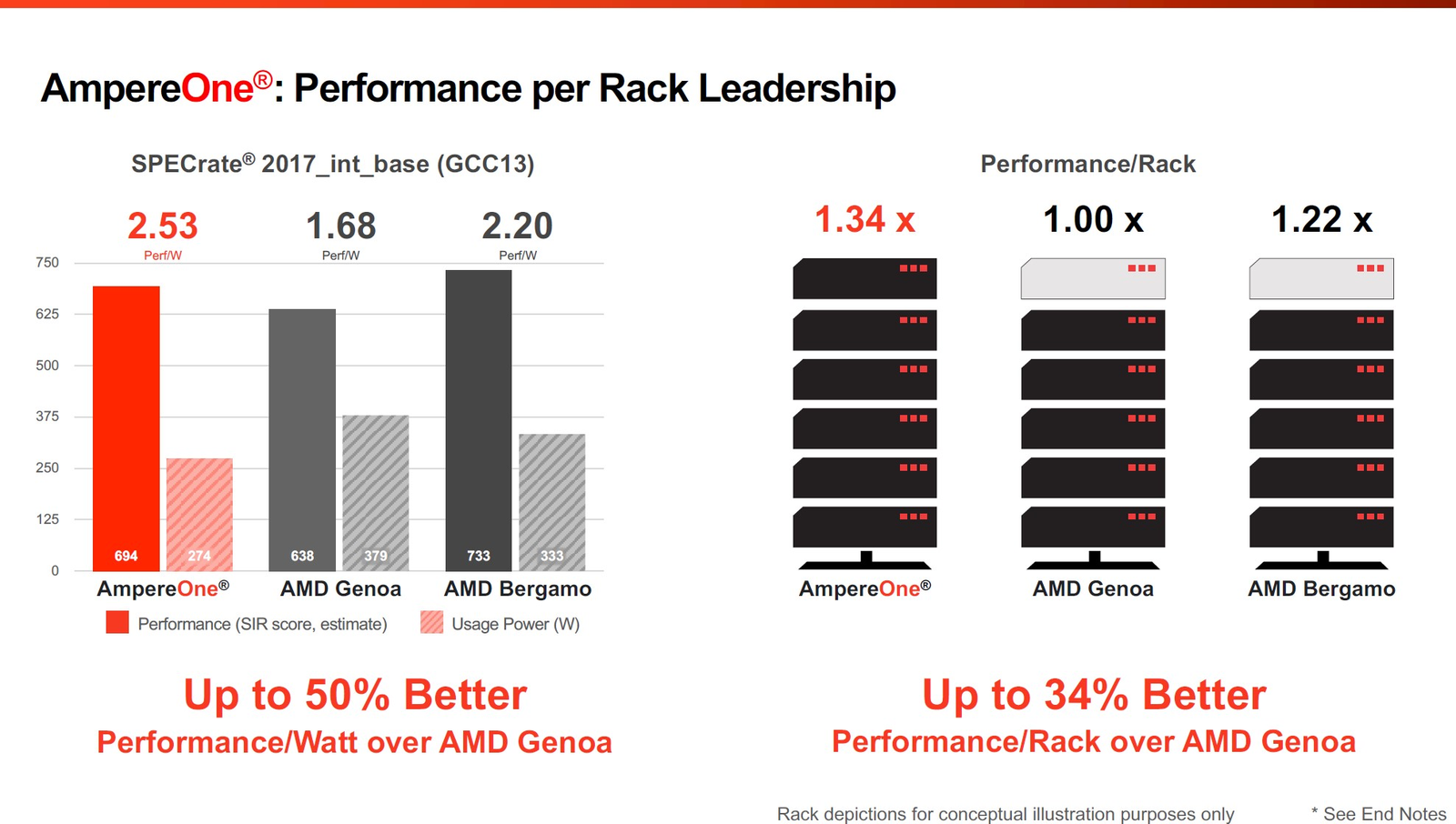 Ampere утверждает, что новые AmpereOne превзойдут в удельной производительности на Вт AMD EPYC Bergamo и обеспечат более высокую производительность в пересчёте на стойку, нежели AMD EPYC Genoa. Особенное внимание компания уделяет энергоэффективности AmpereOne, которая заключается не только в экономии электроэнергии, но и драгоценного места в ЦОД. Проще говоря, компания упирает на повышение плотности размещения вычислительных мощностей. 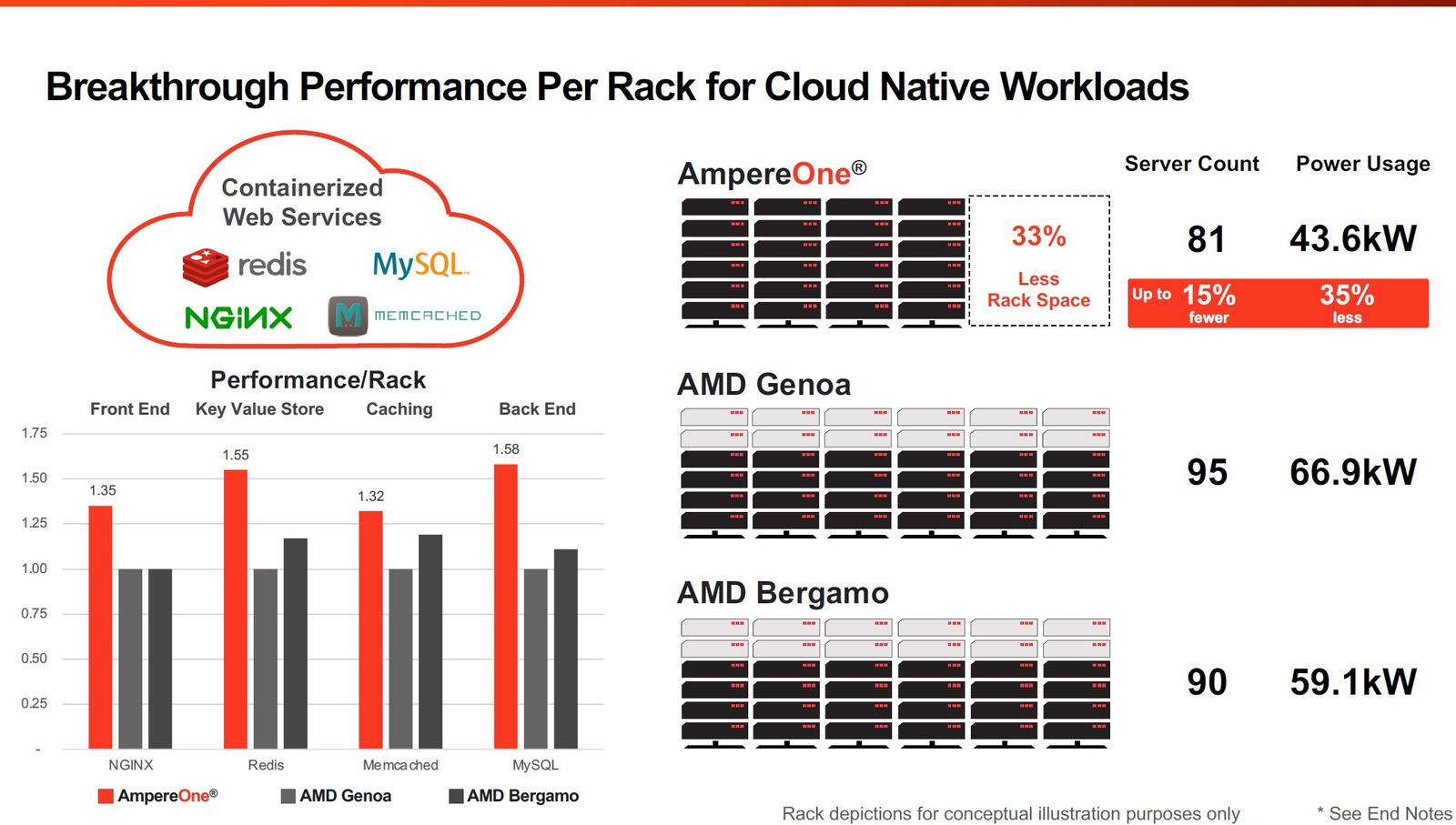 Заодно Ampere в который раз говорит, что в инференс-сценариях её процессоры сопоставимы с некоторыми ускорителями, в частности, NVIDIA A10, но при этом существенно дешевле и экономичнее. В пересчёте на токены при производительности порядка 80 токенов в секунду платформа Ampere обходится на 28% дешевле и в то же время потребляет меньше энергии на целых 67%! 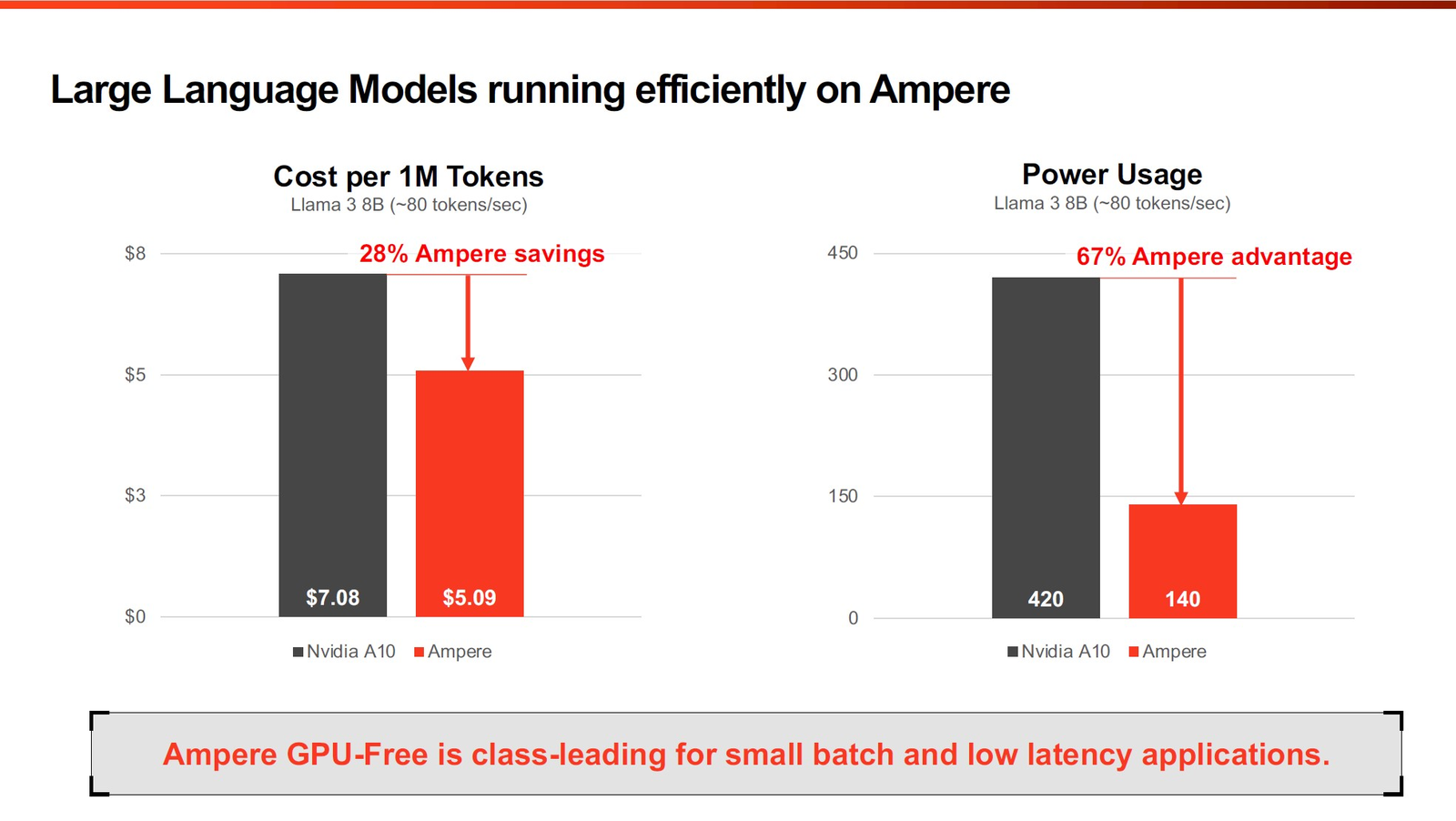 Более того, Ampere заключила союз с Qualcomm для выпуска серверной платформы, сочетающей AmpereOne в качестве процессоров общего назначения и ИИ-ускорителей Qualcomm Cloud AI 100 Ultra. Если сами процессоры успешно работают с LLM сравнительно небольшой сложности (до 7 млрд параметров), то новая платформа позволит запускать и сети с 70 млрд параметров. Кроме того, есть и готовое решение с VPU Quadra T1U.  Увидит ли свет в будущем гибридный процессор Ampere Computing с UCIe-чиплетами, будет зависеть от решений, принятых группой AI Platform Alliance, возглавленной Ampere Computing ещё осенью прошлого года. Но это вполне реальный сценарий: блоки ускорения специфических для ИИ-задач вычислений активно внедряются не только в серверных решениях, подобных Intel Xeon Sapphire/Emerald Rapids — сопроцессоры NPU уже дебютировали в потребительских и промышленных CPU Intel и AMD. При этом Ampere Computing, вероятно, придётся несколько поменять политику дальнейшего развития, поскольку основными конкурентами для неё являются не только 128-ядерные AMD EPYC Bergamo и готовящиеся 144- и 288-ядерные Intel Xeon Sierrra Forest, но и Arm-процессоры Google Axion и Microsoft Cobalt 100, которые изначально создавались гиперскейлерами под свои нужды, а потому наверняка лучше оптимизированы под их задачи и, вероятнее всего, к тому же дешевле, чем продукты Ampere.
16.05.2024 [01:05], Игорь Осколков
И для ИИ, и для HPC: первые европейские серверные Arm-процессоры SiPearl Rhea1 получат HBM-памятьКомпания SiPearl уточнила спецификации разрабатываемых ею серверных Arm-процессоров Rhea1, которые будут использоваться, в частности, в составе первого европейского экзафлопсного суперкомпьютера JUPITER, хотя основными чипами в этой системе будут всё же гибридные ускорители NVIDIA GH200. Заодно SiPearl снова сдвинула сроки выхода Rhea1 — изначально первые образцы планировалось представить ещё в 2022 году, а теперь компания говорит уже о 2025-м. При этом существенно дизайн процессоров не поменялся. Они получат 80 ядер Arm Neoverse V1 (Zeus), представленных ещё весной 2020 года. Каждому ядру полагается два SIMD-блока SVE-256, которые поддерживают, в частности, работу с BF16. Объём LLC составляет 160 Мбайт. В качестве внутренней шины используется Neoverse CMN-700. Для связи с внешним миром имеются 104 линии PCIe 5.0: шесть x16 + две x4. О поддержке многочиповых конфигураций прямо ничего не говорится. 
Источник изображения: SiPearl Очень похоже на то, что SiPearl от референсов Arm особо и не отдалялась, поскольку Rhea1 хоть и получит четыре стека памяти HBM, но это будет HBM2e от Samsung. При этом для DDR5 отведено всего четыре канала с поддержкой 2DPC, а сам процессор ожидаемо может быть поделён на четыре NUMA-домена. И в такой конфигурации к общей эффективности работы с памятью могут быть вопросы. Именно наличие HBM позволяет говорить SiPearl о возможности обслуживать и HPC-, и ИИ-нагрузки (инференс). 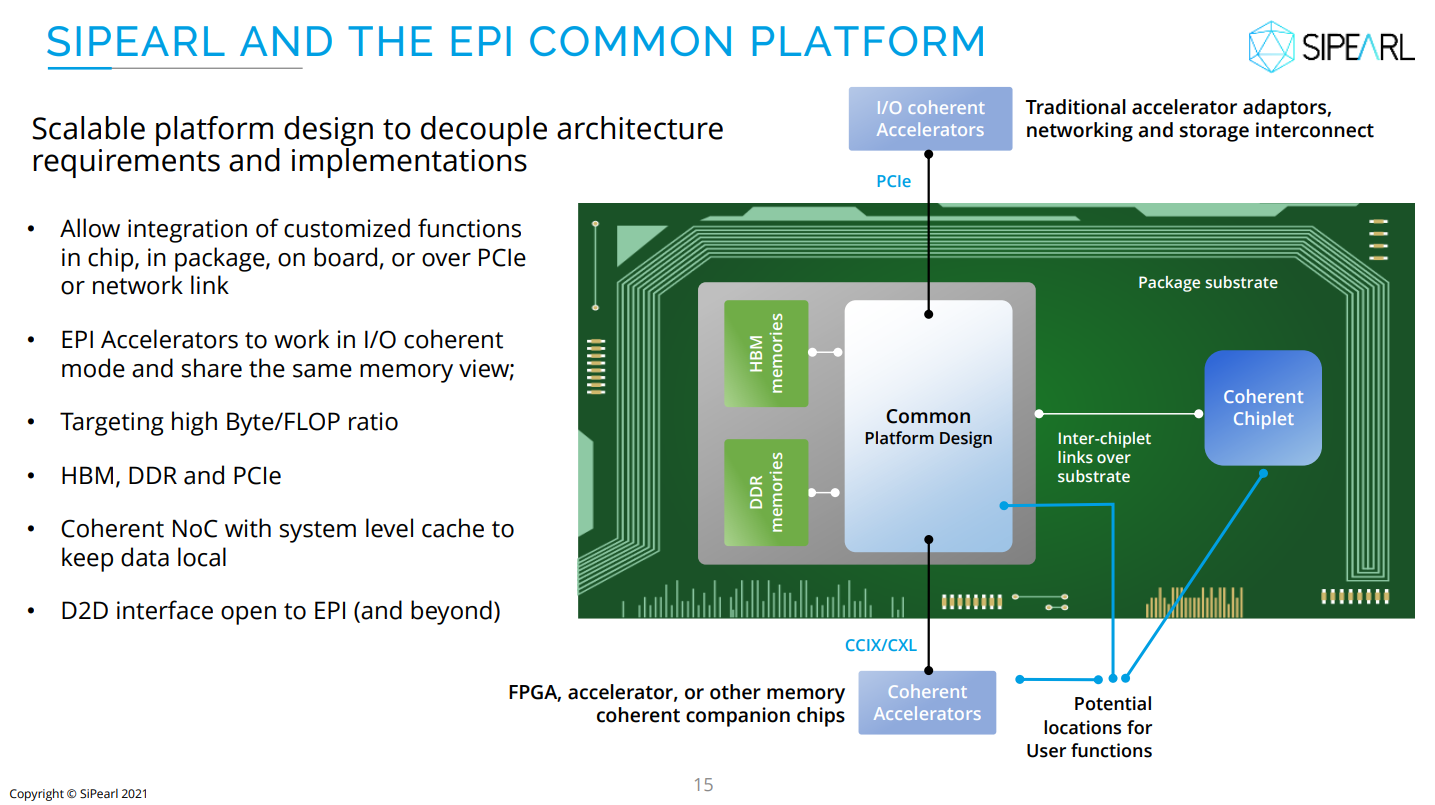
Источник изображения: SiPearl На примере Intel Xeon Max (Sapphire Rapids c 64 Гбайт HBM2e) видно, что наличие сверхбыстрой памяти на борту даёт прирост производительности в означенных задачах, хотя и не всегда. Однако это другая архитектура, другой набор инструкций (AMX), другая же подсистема памяти и вообще пока что единичный случай. С Fujitsu A64FX сравнения тоже не выйдет — это кастомный, дорогой и сложный процессор, который, впрочем, доказал эффективность и в HPC-, и даже в ИИ-нагрузках (с оговорками). В MONAKA, следующем поколении процессоров, Fujitsu вернётся к более традиционному дизайну. 
Источник изображения: EPI Пожалуй, единственный похожий на Rhea1 чип — это индийский 5-нм C-DAC AUM, который тоже базируется на Neoverse V1, но предлагает уже 96 ядер (48+48, два чиплета), восемь каналов DDR5 и до 96 Гбайт HBM3 в четырёх стеках, а также поддержку двухсокетных конфигураций. AWS Graviton3E, который тоже ориентирован на HPC/ИИ-нагрузки, вообще обходится 64 ядрами Zeus и восемью каналами DDR5. Наконец, NVIDIA Grace и Grace Hopper в процессорной части тоже как-то обходятся интегрированной LPDRR5x, да и ядра у них уже Neoverse V2 (Demeter), и своя шина для масштабирования имеется. 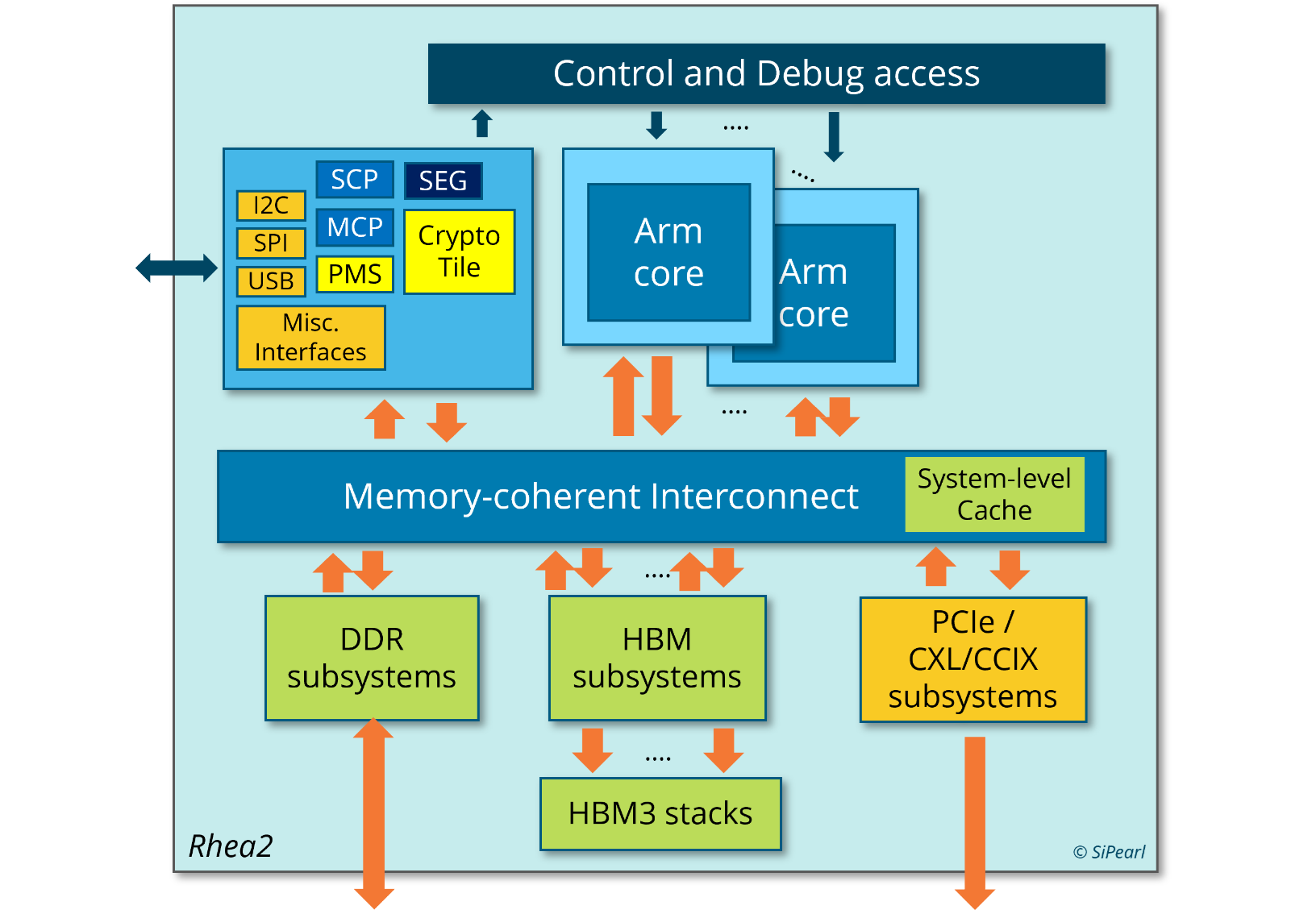
Источник изображения: EPI В любом случае в 2025 году Rhea1 будет выглядеть несколько устаревшим чипом. Но в этом же году SiPearl собирается представить более современные чипы Rhea2 и обещает, что их разработка будет не столь долгой как Rhea1. Компанию им должны составить европейские ускорители EPAC, тоже подзадержавшиеся. А пока Европа будет обходиться преимущественно американскими HPC-технологиями, от которых стремится рано или поздно избавиться. |
|

