Материалы по тегу: arm
|
29.04.2026 [15:34], Сергей Карасёв
Китай анонсировал 2,5-Эфлопс Arm-суперкомпьютер LineShine на домашних процессорахКитайский национальный суперкомпьютерный центр в Шэньчжэне (NSCCSZ) анонсировал проект вычислительного комплекса LineShine (LingSheng), производительность которого после полноценного ввода в эксплуатацию окажется на уровне 2 Эфлопс. Особенностью системы является то, что её конфигурация предполагает применение исключительно CPU-серверов — без ускорителей на базе GPU. Как отмечает ресурс HPC Wire, LineShine будет создаваться в несколько этапов. Одна из секций нового суперкомпьютера получит серверы Huawei Kunpeng с десятками тысяч вычислительных ядер. Предусмотрено использование 428 узлов хранения с суммарной вместимостью 650 Пбайт. Заявленная пропускная способность — 10 Тбайт/с. Вторая секция LineShine предполагает применение 20480 вычислительных узлов, каждый из которых будет оснащён двумя процессорами LX2 на архитектуре Armv9. Конструкция чипов LX2 включает два вычислительных кристалла со 152 ядрами (в сумме 304 ядра) и восемь стеков памяти HBM (32 Гбайт, 4 Тбайт/с). Каждый кристалл использует 128 Гбайт внешней памяти DDR. За обмен данными между блоками DDR и HBM отвечает специальный механизм SDMA. Каждый кристалл поделён на четыре NUMA-домена (38 ядер и 4 Гбайт HBM). Узлы соединены между собой высокоскоростным интерконнектом LingQi, обеспечивающим пропускную способность до 1,6 Тбит/с на узел. Говорится о поддержке режимов FP64/FP32/FP16/INT8. Заявленная производительность LX2 достигает 60,3 Тфлопс на операциях FP64 и 120,6 Тфлопс на операциях FP32. Таким образом, пиковая теоретическая FP64-производительность составляет 2,47 Эфлопс. 
Источник изображения: South China Morning Post Для сравнения, самый быстрый на сегодняшний день суперкомпьютер в мире по версии TOP500 — американский комплекс El Capitan — обладает быстродействием 1,809 Эфлопс с пиковым значением 2,821 Эфлопс, но в нём применяются как CPU, так и ускорители (AMD Instinct MI300A). Таким образом, LineShine станет самым мощным НРС-комплексом, построенным исключительно на базе CPU. Другой особенностью машины станет то, что в её составе будут применяться только китайские компоненты, включая процессоры, накопители и сетевое оборудование. При этом официально КНР не участвует в TOP500 уже пять лет, да и в целом не любит рассказывать о своих самых мощных суперкомпьютерах. Нужно отметить, что в Китае действует другой суперкомпьютер экзафлопсного класса — система China New-generation Intelligent Supercomputer (CNIS). Этот комплекс имеет гетерогенную конфигурацию с 5632 вычислительными узлами. Каждый из них наделён двумя 64-бит серверными процессорами на базе CISC с 64 ядрами (2,4 ГГц) и восемью ускорителями GPGPU с архитектурой SIMT с 64 Гбайт HBM (1,8 Тбайт/с). Задействованы 8-канальная подсистема памяти DDR5-6400. Каждый GPGPU обеспечивает пиковую производительность 32,7 Тфлопс в режиме FP64, 65,5 Тфлопс на операциях FP32 и 470 Тфлопс в режиме FP16, что в сумме даёт пиковую теоретическую FP64-произвоидительность на уровне 1,47 Эфлопс.
09.04.2026 [11:24], Сергей Карасёв
Uber перенесёт рабочие нагрузки на чипы AWS Graviton и Trainium нового поколенияКомпания Uber сообщила о расширении использования облачной платформы Amazon Web Services (AWS). Оператор сервисов для вызова такси и частных водителей, а также доставки еды и грузов перенесёт определённые нагрузки на чипы AWS Graviton и Trainium нового поколения. Компания уже использует Arm-процессоры Ampere в облаке Oracle. В частности, Uber будет использовать изделия Graviton4, насчитывающие до 96 ядер, для поддержания работы своих зон обслуживания поездок (Trip Serving Zones). Соответствующая инфраструктура функционирует в режиме реального времени: каждый раз, когда пользователь заказывает поездку или доставку, система рассчитывает оптимальный маршрут, выбирает подходящего водителя и определяет время. В часы пик и при проведении крупных мероприятий создаётся огромная вычислительная нагрузка: требуются анализ миллионов возможных сценариев поездок и обработка данных о местоположении пользователей и водителей. Ожидается, что применение Graviton4 позволит сократить задержки и оптимизировать затраты, а также обеспечит необходимую масштабируемость в периоды всплеска запросов без ущерба для надёжности, доступности или безопасности. 
Источник изображения: AWS Кроме того, Uber начнёт применять ускорители Trainium3 для обучения некоторых своих ИИ-моделей, которые лежат в основе приложений вызова такси и доставки. Эти изделия оснащены 144 Гбайт памяти HBM3E, а производительность на операциях FP8 достигает 2,52 Пфлопс. ИИ-модели Uber, как отмечается, анализируют данные миллиардов поездок для выбора водителя или курьера, оценки времени прибытия и генерации рекомендаций для пользователей. Обучение ИИ в таком масштабе требует колоссальных вычислительных возможностей: решения Trainium3, как подчёркивается, способны предоставить необходимые ресурсы. «Uber — одно из самых требовательных приложений в мире, работающих в режиме реального времени. Мы помогаем Uber обеспечивать надёжность, на которую рассчитывают сотни миллионов людей, а также внедрять ИИ-функции, определяющие будущее сервисов совместных поездок и доставки по запросу», — говорит Рич Гераффо (Rich Geraffo), вице-президент и управляющий директор AWS в Северной Америке.
03.04.2026 [01:00], Владимир Мироненко
IBM «подружит» мейнфреймы с Arm, но пока, похоже, сама не до конца понимает, зачем
arm
ibm
linux
software
виртуализация
конфиденциальность
мейнфрейм
миграция
разработка
сотрудничество
IBM объявила о стратегическом сотрудничестве с Arm с целью «разработки нового оборудования с двойной архитектурой, которое поможет предприятиям запускать будущие ресурсоёмкие рабочие нагрузки, связанные с ИИ и обработкой данных, с большей гибкостью, надёжностью и безопасностью». Пока что компании объявили о возможности запуска ПО для Arm на мейнфреймах IBM, а в остальном ограничились довольно общими словам об «инновациях» и «светлом будущем». Сотрудничество будет сосредоточено на трёх ключевых областях: расширение технологий виртуализации, чтобы программные среды на базе Arm могли работать на корпоративных платформах IBM; обеспечение возможности корпоративным системам распознавать и выполнять приложения Arm для соответствия Arm-сред требованиям надёжности, безопасности, эксплуатации и размещения данных, которым должны следовать регулируемые отрасли; создание в рамках долгосрочного развития экосистемы общих технологических уровней для большей гибкости предприятий в развёртывании и управлении приложениями на обеих платформах. «Этот момент знаменует собой очередной шаг на нашем пути к инновациям для будущих поколений наших систем IBM Z и LinuxONE, подтверждая, что наша комплексная системная архитектура является мощным конкурентным преимуществом», — отметил Кристиан Якоби (Christian Jacobi), главный технический директор и научный сотрудник IBM Systems Development. Компания уже представила патч для ядра Linux, добавляющий в KVM для s390-систем поддержку arm64. Иными словами, речь о запуске Arm-софта в виртуальной машине. Дополнительно IBM пополнила набор инструкций s390 для совместимости и ускорения работы Arm-гостей. 
Источник изображения: IBM Компания подчеркнула, что сотрудничество направлено на обслуживание предприятий, которые выполняют регулируемые рабочие нагрузки и не могут просто перенести их в облако. Arm утверждает, что почти половина всех вычислительных мощностей, поставленных ведущим гиперскейлерам в 2025 году, работает на чипах Arm, при этом AWS, Google и Microsoft развёртывают свои собственные Arm-чипы Graviton, Axion и Cobalt. AWS сообщила, что третий год подряд более половины всех новых CPU-мощностей приходится на Graviton. На днях и Arm представила собственный процессор Arm AGI, ориентированный на работу с ИИ. Среди крупных разработчиков серверных Arm-процессоров остались Ampere Computing (SoftBank) и Qualcomm. Исследование Signal65 показало, что Graviton4 обеспечивает до 168 % более высокую производительность при работе с LLM и на 220 % более высокую производительность по соотношению цены и качества по сравнению с аналогичными x86-чипами AMD. По мнению Рачиты Рао (Rachita Rao), старшего аналитика Everest Group, если гиперскейлеры активно осваивают Arm ради экономии средств, то IBM метит в суверенные и изолированные рабочие среды, где традиционно используются её мейнфреймы. Более того, речь идёт и о «железе», и о людях — специалистов для поддержки устаревающих систем всё меньше, передаёт NetworkWorld. Если удариться в фантазии, в таком шаге IBM можно усмотреть и потенциальный отказ от POWER в пользу Arm. 
Источник изображения: IBM Представитель IBM, отвечая на вопрос ресурса The Register о сроках появления первого плода этого партнёрства, сообщил, что об этом пока рано говорить и что это зависит от многих факторов. По мнению Рао, предприятиям следует планировать трёхлетний горизонт разработки, исходя из того, сколько времени уходило у IBM на поставки оборудования IBM. Хотя IBM представила процессор Telum II и ускоритель Spyre в августе 2024 года, мейнфреймы z17 стали доступны только в июне 2025-го, примерно тогда же были представлены LinuxONE Emperor 5, а Spyre появились лишь в ноябре. Т.е. цикл занимает примерно 12–18 мес. Параллельно IBM заключает партнёрства в области ИИ-инфраструктуры с другими производителями, включая AMD и Groq (теперь NVIDIA). При этом ПО для IBM является ключевым источником дохода, и она не скупится на крупные приобретения. По мнению Рао, «IBM не рассматривает совместимость с Arm как основное решение для масштабирования корпоративного ИИ. Крупномасштабный ИИ по-прежнему перемещается в среды с большим количеством GPU. Совместимость с Arm может помочь приблизить новые стеки и сервисы к мейнфреймам, но она не изменит основную стратегию в области ИИ-инфраструктуры».
27.03.2026 [11:32], Владимир Мироненко
Altera и Arm объединят FPGA и Arm AGI для создания платформ для ИИ ЦОДAltera, специализирующаяся на разработке FPGA, объявила о расширении сотрудничества с Arm с целью объединения оптимизированных для ЦОД программируемых решений Altera с процессором Arm AGI, что позволит создавать вычислительные платформы с низкой задержкой, высокой гибкостью и масштабируемостью для ИИ ЦОД. «Следующее поколение инфраструктуры ЦОД будет формироваться под влиянием всё более интеллектуальных рабочих нагрузок ИИ и потребности в специализированных вычислительных ресурсах», — сообщил Мохамед Авад (Mohamed Awad), исполнительный вице-президент подразделения облачных вычислений ИИ компании Arm. Он добавил, что Arm AGI обеспечивает эффективную вычислительную основу, необходимую для этих систем, а сотрудничество с Altera помогает расширить эти возможности в рамках всей экосистемы. Компании отметили, что сочетание FPGA Altera и процессора Arm AGI открывает новые возможности в быстрорастущих ИИ ЦОД, где производительность в реальном времени, детерминированная обработка и адаптивность имеют решающее значение. 
Источник изображения: Arm Рагиб Хуссейн (Raghib Hussain), президент и генеральный директор Altera отметил, что у Altera и Arm имеется значительный опыт в разработке решений SoC на базе FPGA, ориентированных на рынки встраиваемых систем. Вместе с тем Altera прочно закрепилась на рынке инфраструктурных решений для ЦОД благодаря значительной базе установленных SmartNIC и DPU на основе FPGA. По его словам, расширение сотрудничества Altera с Arm позволит создать новый класс гетерогенных вычислительных систем, разработанных для удовлетворения растущих требований к производительности и гибкости ИИ ЦОД.
25.03.2026 [17:21], Владимир Мироненко
Arm представила процессоры Arm AGI для ИИ, став конкурентом собственным клиентамArm представила свой первый собственный процессор Arm AGI, который ориентирован на рабочие нагрузки агентного ИИ в ЦОД и готов к производству. Этот шаг является отходом от её давней модели лицензирования интеллектуальной собственности компаниям, которые сами производят и продают чипы, отметил The Register. «Позвольте мне внести ясность: теперь Arm занимается новым бизнесом, и мы поставляем процессоры», — заявил генеральный директор Arm Рене Хаас (Rene Haas). Он объяснил решение Arm заняться этим направлением спросом со стороны клиентов и необходимостью отрасли в энергоэффективном решении на базе CPU для агентных нагрузок ИИ ЦОД. Исполнительный вице-президент Arm Мохаммед Авад (Mohammed Awad) сообщил, что процессор Arm AGI был разработан на основе трёх принципов: производительность, масштабируемость и эффективность. 
Источник изображений: Arm Флагманский процессор AGI от Arm — это чип SP113012 с 136 ядрами Neoverse V3 (Poseidon), работающими на частоте до 3,7 ГГц (базовая частота 3,2 ГГц), распределёнными между двумя чиплетами, изготовленными по 3-нм техпроцессу TSMC. Каждое ядро содержит два 128-бит SVE-блока для векторных вычислений. Заявлена поддержка инструкций MMLA и форматов BF16/INT8. Процессор имеет 2 Мбайт L2-кеша на ядро, а также 128 Мбайт общего системного кэша (SLC). Чип предлагает 96 линий PCIe 6.0 с CXL 3.0 (Type). Пропускная способность памяти составляет 6 Гбайт/с на ядро при целевой задержке менее 100 нс. Всего доступно 12 каналов DDR5-8800 (2DPC). Оптимизированная с точки зрения TCO модель SP113012S предлагает чуть более быстрый доступ к памяти — 6,3 Гбайт/с на ядро. Версия SP113012A имеет только 64 ядра, но всё те же 12 каналов памяти, что даёт уже 13 Гбайт/с на ядро. TDP всех моделей составляет 300 Вт. Возможно формирование двухсокетных систем. По словам Авада, Arm намеренно избежала включения ускорителей или функций, которые занимают площадь кристалла и в конечном итоге не приносят пользы целевой рабочей нагрузке. «В традиционных CPU были проблемы с поддержкой устаревших приложений, — сказал он. — Мы специально не хотели добавлять то, что не будет… на 100% использоваться в задачах этого устройства». 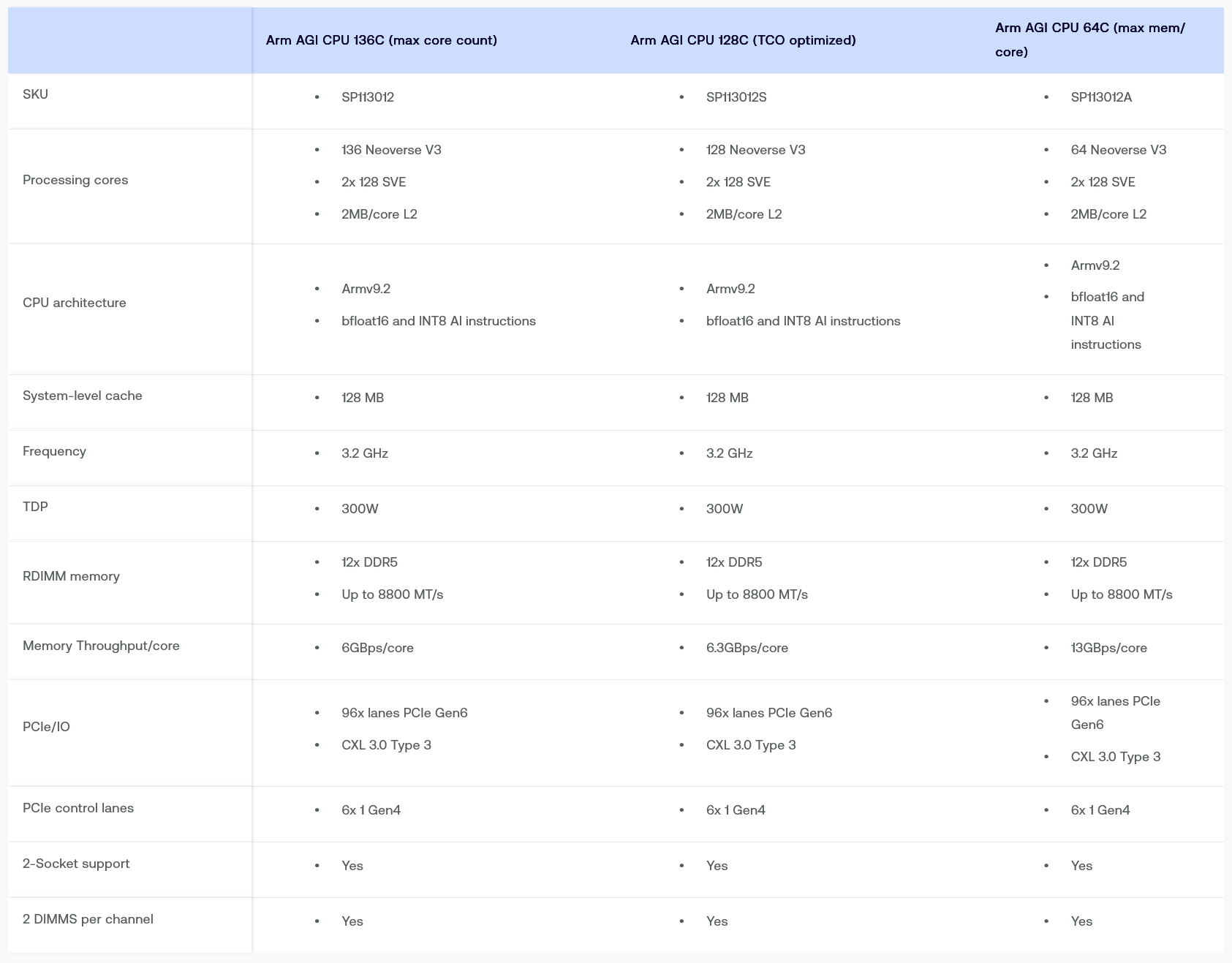 В отличие от NVIDIA Vera, разработчики Arm решили отказаться от многопоточности в процессоре, оптимизированном для работы с ИИ-агентами, поскольку один поток на ядро обеспечивает более предсказуемое масштабирование производительности. Также в отличие от многих современных процессоров, функции памяти и I/O интегрированы в тот же кристалл, что и вычислительные ресурсы, чтобы минимизировать задержку. Каждый сокет будет доступен ОС как два отдельных домена NUMA. Одним из первых крупных клиентов Arm для этих процессоров станет Meta✴, выступающая в качестве ведущего партнёра и соразработчика. Она задействует Arm AGI для оптимизации инфраструктуры для своего семейства приложений и совместной работы с ИИ-ускорителями MTIA, что обеспечит более эффективную оркестрацию в крупномасштабных ИИ-системах. «Мы работали вместе с Arm над разработкой Arm AGI для создания эффективной вычислительной платформы, которая значительно повышает плотность производительности наших ЦОД и поддерживает многопоколенную дорожную карту развития наших систем искусственного интеллекта», — сообщил Сантош Джанардан (Santosh Janardhan), руководитель инфраструктуры Meta✴.  В числе первых клиентов также указаны OpenAI, SAP, Cerebras, Cloudflare, F5, SK Telecom и Rebellions. Они будут использовать процессор Arm AGI для ключевых сценариев применения в агентных вычислительных системах в облачных и корпоративных платформах. Arm сотрудничает с ведущими OEM- и ODM-производителями, включая ASRock Rack, Lenovo, QCT и Supermicro. При этом первые системы уже доступны для оценки, а более широкое распространение ожидается во II половине года. Также Arm разработала два референсных дизайна серверов: двухузловой (1U2N) OCP-вариант высотой 1OU и более привычный 19″ 2U2P-вариант, оба с воздушным охлаждением. В частности, клиентами может использоваться 36-кВт стойка с 30 узлами — всего 8160 ядер. Компания также проверила возможность использования более плотной 200-кВт стойки с СЖО на 42 восьмиузловых сервера, что составляет 45696 ядер. Для сравнения, в процессорных стойках NVIDIA Vera ETL256 умещается только 22528 ядер.  Хаас заявил, что Arm продолжит разработку новых решений для ЦОД, назвав будущие поколения чипа как Arm AGI CPU 2 и Arm AGI CPU 3, о чём пишет MarketBeat. Глава Arm сообщил, что бизнес компании в сфере ИИ ЦОД способен обеспечить общий объём целевого рынка (TAM) в размере около $3 млрд в виде роялти, и что инициатива по созданию процессора Arm AGI может в будущем расширить возможности Arm до примерно $100 млрд TAM. По расчётам Arm, к концу десятилетия она может выйти на более $1 трлн TAM, охватывая развёртывание от периферии до облака. В то время как Meta✴ обратилась за помощью к Arm, другие гиперскейлеры всё больше рассчитывают на собственные силы. У Microsoft Arm-процессоры Cobalt 200 (132 ядра), у AWS — Graviton 5 (192 ядра), у Alibaba Cloud — Yitian 710 (128 ядер), а у Google — Axion (точное количество ядер не раскрывается, но не менее 72). Oracle долгое время полагалась на Arm-процессоры Ampere Computing. Она же была и крупным инвестором компании, которую в итоге купила SoftBank.
24.03.2026 [16:58], Владимир Мироненко
CIX анонсировала Arm-процессоры ClawCore, «заточенные» под OpenClawКитайская компания CIX Technology (Cixin Technology) провела презентацию семейства процессоров ClawCore с архитектурой Armv9.2, специально разработанного для использования ИИ-агента OpenClaw, пишет CNX Software. Семейство на данный момент включает три модели: ClawCore-P, ClawCore-A и ClawCore-E. ClawCore-P — 12-ядерный процессор с тактовой частотой до 3,2 ГГц с GPU Immortalis-G720, обладающий ИИ-производительностью 45 TOPS и поддерживающий до 64 Гбайт LPDDR5. Сообщается, что характеристики ClawCore-P похожи на спецификации анонсированного ранее 6-нм процессора CIX P1 (CD8180) с 12 ядрами с архитектурой CIX P1, включая восемь производительных и четыре энергоэффективных ядра, частота которых немного меньше — до 2,8 ГГц, тоже оснащённого Immortalis-G720. ClawCore-P предназначен для сценариев с высокой степенью параллелизма и большой производительностью. Его поставки должны начаться до конца этого месяца. В июне 2026 года ожидается выпуск процессора ClawCore-A с восемью ядрами с частотой 3,0 ГГц, ИИ-производительностью 80 TOPS (расширяемой до 200 TOPS с помощью карты PCIe AI от Huomo Intelligent Technology) и поддержкой до 64 Гбайт LPDDR5. Он разработан для круглосуточной работы, поддерживает ECC, аппаратную безопасность (шифрование/управление ключами) и позволяет снизить стоимость токенов до 50 % за счёт локального инференса. На практике 80–90 % запросов будет выполняться на устройстве благодаря этой гибридной локально-онлайн реализации — крупные модели можно будет использовать через сервис Alibaba Cloud, партнёра проекта. 
Источник изображения: CNX Software Выход ещё одного процессора — ClawCore-E, который предназначен для использования в периферийных устройствах и устройствах IoT, ожидается к декабрю 2026 года. Сообщается, что это «сверхэкономичный» вариант чипа, с ядрами с архитектурой Armv9.2 и NPU с поддержкой голосового управления. Глава CIX Technology заявил, что серия ClawCore охватывает различные сценарии разработки и применения ИИ, включая периферийный ИИ, высокопроизводительный ИИ и многое другое, что позволит удовлетворить потребности отраслевых партнёров в интеллектуальных продуктах для всех сценариев, от AI BOX, AI NAS и AI Mini PC до периферийных ИИ-серверов и встроенного/промышленного ИИ-оборудования: «Чтобы решить различные проблемы, возникающие в разработке ИИ-приложений, мы создали серию CIX ClawCore. Её цель — помочь разработчикам отойти от традиционной фрагментированной модели разработки и сформировать агентно-ориентированный подход к переосмыслению разработки и внедрения ИИ». Компания CIX также планирует создать полноценную экосистему вокруг OpenClaw. Она намерена предложить готовые Linux-образы и обеспечить программную поддержку с пятью ключевыми предложениями:
Процессоры будут ориентированы на платформу Arm SystemReady и поддерживать операционные системы Windows, Android, Ubuntu, Tongxin/UnionTech и Kylin.
17.03.2026 [10:21], Сергей Карасёв
NVIDIA представила серверные Arm-процессоры Vera с 88 ядрами Olympus для ИИ и не толькоNVIDIA анонсировала процессоры Vera, спроектированные с прицелом на современные ресурсоёмкие задачи в области ИИ. Изделия, как утверждается, обеспечивают исключительную производительность каждого ядра, а также высокую пропускную способность памяти и коммутационной сети. В основу Vera положены ядра Olympus — это первые CPU-решения NVIDIA, специально разработанные для дата-центров. Olympus используют интерфейс выборки и декодирования шириной в 10 инструкций, а также нейронный алгоритм предсказания ветвлений, позволяющий оценивать два варианта ветвления за каждый цикл. Изделие полностью совместимо с набором инструкций Arm v9.2 и существующим ПО. 
Источник изображений: NVIDIA Конфигурация Vera предусматривает наличие 88 ядер Olympus с возможностью одновременной обработки до 176 потоков инструкций. Объём кеша L3 составляет 162 Мбайт. Задействована шина NVIDIA Scalable Coherency Fabric (SCF) второго поколения, первоначально разработанная для CPU Grace. В составе процессора SCF отвечает за связь вычислительных ядер Olympus с общим кешем L3 и подсистемой памяти, обеспечивая стабильную задержку и пропускную способность на уровне 3,4 Тбайт/с: это позволяет использовать более 90 % пиковой пропускной способности памяти под нагрузкой. Каждому ядру Olympus доступна полоса до 14 Гбайт/с, что примерно в три раза превышает пропускную способность на ядро в традиционных CPU для дата-центров, говорит NVIDIA. 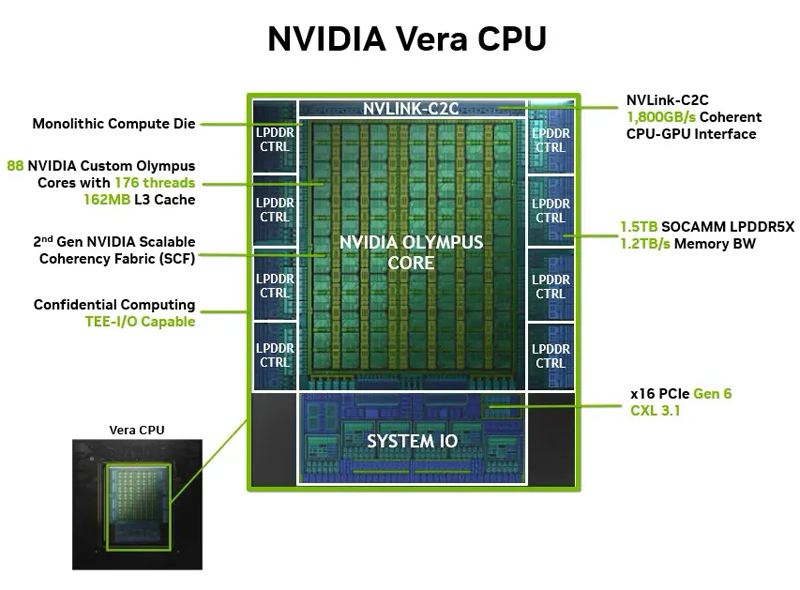 В составе Vera применяется подсистема памяти LPDDR5X на основе модулей SOCAMM. Суммарная ёмкость может составлять до 1,5 Тбайт, что втрое больше по сравнению с решениями предыдущего поколения. Пропускная способность памяти достигает 1,2 Тбайт/с, тогда как энергопотребление составляет менее 50% по сравнению с традиционными конфигурациями DDR. При этом модули SOCAMM являются заменяемыми, что упрощает модернизацию и обслуживание систем.  Процессор Vera выполнен на основе единого монолитного вычислительного кристалла. Каждое ядро обеспечивается единообразной пропускной способностью. Большинство операций, чувствительных к задержкам, выполняются локально, что позволяет минимизировать межкристальный трафик, который обычно присутствует в традиционных CPU. В целом, как утверждается, реализованные архитектурные особенности позволяют чипам Vera демонстрировать до 1,5 раз более высокую производительность одного ядра по сравнению с конкурирующими решениями x86 при выполнении задач в песочнице с максимальной нагрузкой на сокет. 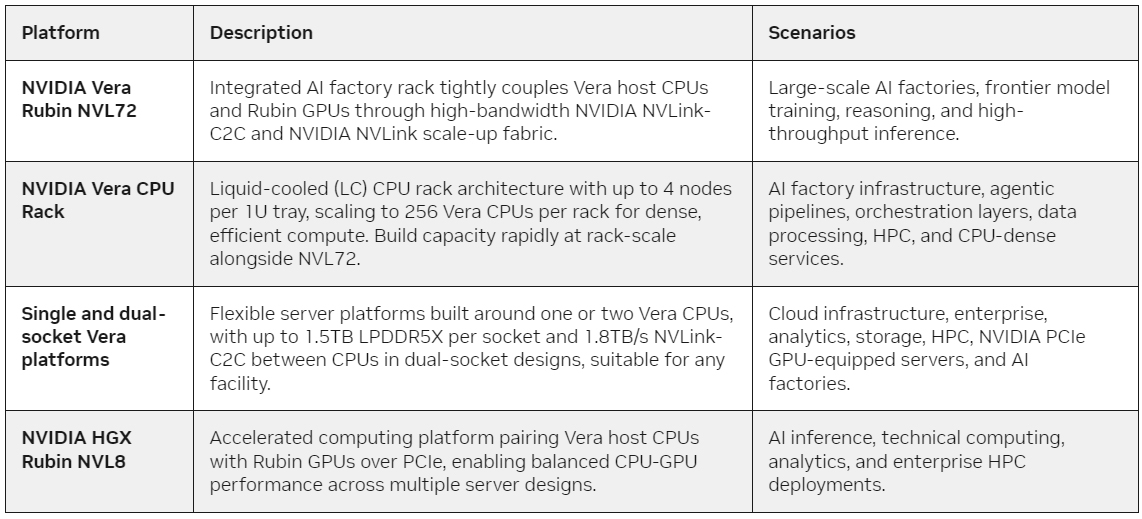 NVIDIA разработала семейство платформ на базе Vera для решения разнообразных задач в сфере ИИ. Это, в частности, CPU-стойки с жидкостным охлаждением, а также системы с ускорителями Rubin. Устройства на базе Vera будут поставляться крупными OEM-производителями, включая Cisco, Dell, HPE, Lenovo и Supermicro. Такие машины станут доступны во II половине текущего года.
14.03.2026 [10:16], Сергей Карасёв
MediaTek представила чипы Genio Pro 5100 и Genio 420 для AIoT-приложенийКомпания MediaTek представила процессоры Genio Pro 5100 и Genio 420 с архитектурой Arm для AIoT-приложений и встраиваемых систем. Первый из названных чипов подходит, в частности, для автономных мобильных роботов, дронов, периферийного оборудования и автомобильных платформ, второй — для устройств умного дома, интерактивных дисплеев и пр. Изделие Genio Pro 5100 изготавливается по 3-нм технологии. Оно содержит восемь вычислительных ядер в конфигурации 1 × Arm Cortex-X925, 3 × Arm Cortex-X4 и 4 × Arm Cortex-A720. Присутствуют графический блок Arm Immortalis-G925 MC11 с поддержкой OpenGL, Vulkan и OpenCL, а также нейропроцессорный узел (NPU) с ИИ-производительностью более 50 TOPS. Модуль VPU обеспечивает возможность кодирования материалов H.264 и H.265 (до 8K30) и декодирования H.264, H.265, AV1 и VP9 (до 8K30). 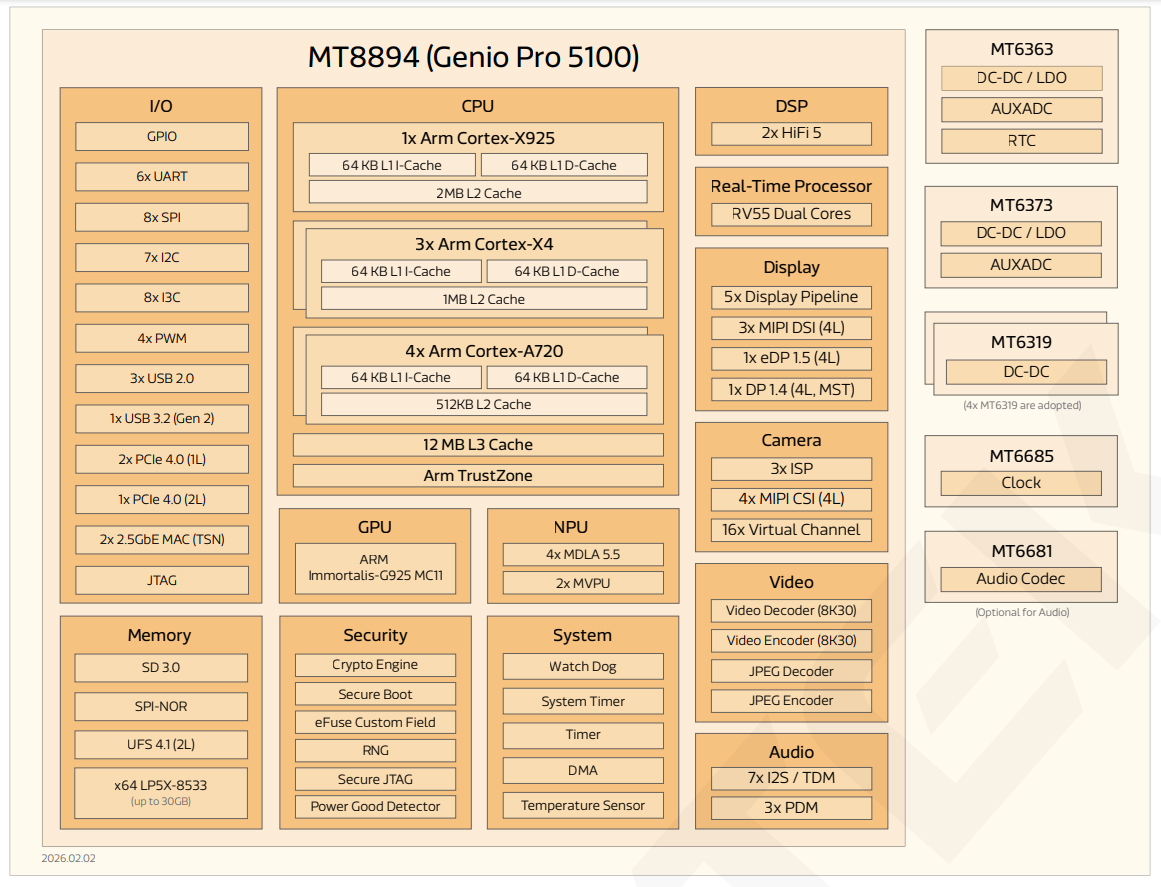
Источник изображений: MediaTek Реализована поддержка оперативной памяти LPDDR5x-8533 (до 30 Гбайт), а также флеш-памяти UFS 4.1, SD 3.0 и SPI-NOR. Допускается вывод изображения одновременно на три дисплея формата 4Kp60 через интерфейсы eDP 1.5 (4 линии), DisplayPort 1.4 (MST) и 3 × MIPI DSI (4 линии). Благодаря четырём интерфейсам MIPI-CSI (4 линии) возможно использование до 16 камер (1080p30). Среди прочего упомянута поддержка 2 × 2.5GbE, Wi-Fi 7 и Bluetooth 5.4 (через внешний модуль), 1 × PCIe 4.0 (2 линии) и 2 × PCIe 4.0 (1 линия), 6 × UART, 7 × I2C, 8 × I3C, 4 × PWM, 7 × I2S/TDM, 3 × PDM, 1 × USB 3.2 Gen2 (10 Гбит/с), 2 × USB 2.0 (Host/Device) и 1 × USB 2.0 (Host). Изделие выполнено в корпусе ETFC TFBGA с размерами 15,9 × 16,6 мм. Диапазон рабочих температур простирается от -40 до +105 °C. Вторая новинка, Genio 420, производится по 6-нм технологии. Процессор объединяет восемь ядер (2 × Arm Cortex-A78 с тактовой частотой 1,8 ГГц и 6 × Arm Cortex-A55 с частотой 1,6 ГГц) и графический ускоритель Arm Mali-G57 MC2. Модуль MediaTek NPU восьмого поколения обеспечивает ИИ-производительность на уровне 6,1 TOPS. Блок VPU поддерживает кодирование материалов H.264/H.265 (до 4Kp30) и декодирование H.264/H.265/VP9 (до 4Kp60) и MPEG4/VP8 (до 1080p60).  Чип позволяет использовать оперативную память LPDDR4X-4266 (до 8 Гбайт) и LPDDR5/LPDDR5X-6400 (до 16 Гбайт), а также флеш-память UFS 3.1 (2 линии), eMMC 5.1, SD 3.0 / SDIO 3.0, SPI-NOR. Возможен вывод изображения на монитор 4Kp60 или два дисплея 2.5Kp60 через интерфейсы eDP, DP, LVDS и MIPI-DSI. Допускается использование до шести камер 1080p30 через 2 × MIPI-CSI. Прочие характеристики процессора таковы: контроллер 1GbE, опциональные адаптеры Wi-Fi 6 (1×1) + Bluetooth 5.3 на базе MT6631X или Wi-Fi 6E (2×2) + Bluetooth 5.3 на основе MT6637X, 1 × PCIe 2.0 (1L, RC, WoWLan), 4 × UART, 9 × I2C, 6 × SPI Master, 3 × PWM, GPIO, JTAG, 3 × USB 2.0, 1 × USB 3.0 (5 Гбит/с; Host), 1 × USB 3.0 (Host/Device). Чип выполнен в корпусе VFBGA с размерами 13,8 × 11,8 × 0,9 мм. Диапазон рабочих температур — от -20 до +95 °C. Процессоры поддерживают такие средства обеспечения безопасности, как Arm TrustZone, Security Boot (RSA4096), Crypto Engine и RNG. Говорится о совместимости с различными вариантами Linux, включая Yocto и Ubuntu.
07.03.2026 [22:20], Сергей Карасёв
640 Кбайт хватит для ИИ: микроконтроллеры STM32U3B5/C5 со сверхнизким энергопотреблением могут работать даже без батарейSTMicroelectronics анонсировала микроконтроллеры STM32U3B5 и STM32U3C5, ориентированные на автономные устройства с функциями ИИ и машинного обучения. Изделия отличаются сверхнизким энергопотреблением и возможностью перехода в режим глубокого сна при отсутствии данных. Таким образом, допускается работа без батарей — исключительно за счёт преобразования энергии окружающей среды (свет, тепло, вибрации, радиоволны) в электрическую. Микроконтроллеры используют 32-бит ядро Arm Cortex-M33 с частотой 96 МГц. Заявленная производительность достигает 1,5 DMIPS/МГц (Dhrystone 2.1) и 395,4 CoreMark (4,12 CoreMark/МГц). В оснащение входит HSP (Hardware Signal Processor) — специальный блок, предназначенный для ускорения определенных вычислений, связанных с ИИ. Есть 640 Кбайт SRAM и 2 Мбайт флеш-памяти. Предусмотрены интерфейсы SDMMC и OCTOSPI с поддержкой внешней памяти SRAM, PSRAM, NOR, NAND и FRAM. 
Источник изображения: STMicroelectronics Реализована поддержка 114 × GPIO, USB 2.0, SAI (Serial Audio Interface), 4 × I2C FM+, SMBus/PMBus, 3 × I3C (SDR), 3 × USART и 2 × UART (SPI, ISO 7816, LIN, IrDA, Modem), 1 × LPUART, 4 × SPI, 2 × CAN FD, GPDMA (12 каналов), 2 × 12-bit ADC, 12-bit DAC и др. Возможны различные варианты исполнения, в том числе UFQFPN48 (7 × 7 мм), LQFP48 (7 × 7 мм), LQFP64 (10 × 10 мм), WLCSP72 (3,67 × 3,58 мм), WLCSP99 (3,67 × 3,58 мм), LQFP100 (14 × 14 мм), WLCSP126 (3,67 × 3,58 мм), UFBGA132 (7 × 7 мм) и LQFP144 (20 × 20 мм). Диапазон рабочих температур простирается от -40 до +105 °C. В микроконтроллеры встроены развитые средства безопасности, включая Arm TrustZone, генератор случайных чисел TRNG, защиту от несанкционированного доступа и пр. Единственное различие между решениями STM32U3B5 и STM32U3C5 заключается в том, что второе включает криптографическое ядро для ускорения операций шифрования и дешифрования. Цена варьируется от $2,9298 до $4,6829 за штуку в зависимости от конфигурации при заказах партий от 10 тыс. единиц.
19.02.2026 [12:50], Сергей Карасёв
Впятеро энергоэффективнее H100: HyperAccel разработала экономичный чип Bertha 500 для ИИ-инференсаЮжнокорейский стартап HyperAccel, по сообщению EETimes, готовится вывести на рынок специализированный чип Bertha 500, предназначенный для ИИ-инференса. Утверждается, что благодаря особой архитектуре изделие способно генерировать в пять раз больше токенов в секунду по сравнению с решениями на основе GPU при том же уровне TOPS. В Bertha 500 упор сделан на экономическую эффективность. С этой целью используется память LPDDR вместо дорогостоящей HBM. При этом благодаря отказу от традиционной иерархии памяти достигается утилизация пропускной способности LPDDR на 90 %. Дальнейшее повышение эффективности обеспечивается путём оптимизации архитектуры именно для задач инференса. Для сравнения, как утверждает HyperAccel, в случае GPU при инференсе используется только около 45 % пропускной способности памяти и 30 % вычислительных ресурсов. Иными словами, немного жертвуя производительностью, чип Bertha 500 позволяет достичь значительного снижения стоимости. Изделие Bertha 500 будет производиться по 4-нм техпроцессу Samsung. В состав чипа входят 32 ядра LPU (LLM Processing Unit), четыре ядра Arm Cortex-A53 и 256 Мбайт SRAM. Подсистема памяти LPDDR5x использует восемь каналов; пропускная способность достигает 560 Гбайт/с. Заявленная ИИ-производительность на операциях INT8 составляет 768 TOPS. Кроме того, поддерживаются другие 16-, 8- и 4-бит форматы, включая FP16. В целом, по заявлениям HyperAccel, пропускная способность Bertha 500 в расчёте на доллар примерно в 20 раз выше по сравнению с NVIDIA H100, тогда как энергоэффективность больше в пять раз. Чип Bertha 500 будет потреблять около 250 Вт. 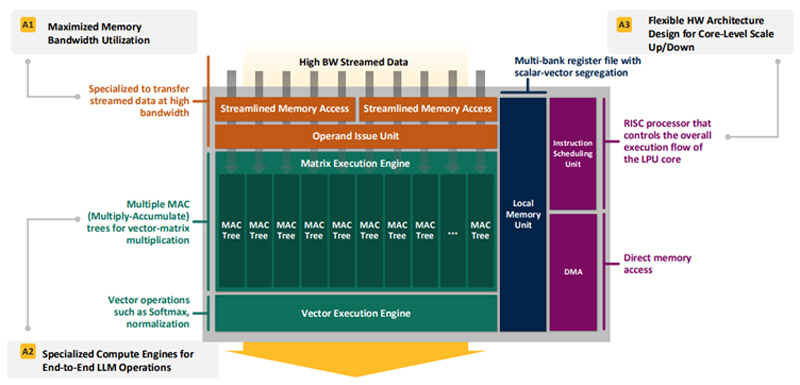
Источник изображения: EETimes Программный стек HyperAccel поддерживает все модели из репозитория HuggingFace. Кроме того, компания работает над предметно-ориентированным языком (DSL) под названием Legato, который предоставит разработчикам низкоуровневый доступ к системе. Образцы Bertha 500 появятся к концу I квартала 2026 года, а серийное производство планируется организовать в начале 2027 года. Отмечается также, что совместно с LG стартап разрабатывает «урезанную» версию Bertha 500 для периферийных устройств — Bertha 100. Эта SoC получит ядра Arm Cortex-A55 и отдельные компоненты LG, а также два канала памяти LPDDR5x. Среди возможных сфер применения названы автомобильная промышленность, бытовая электроника и робототехника. Bertha 100 планируется выпускать в виде модулей M.2: первые изделия выйдут в IV квартале текущего года. Решение сможет, например, осуществлять преобразование текста в речь или речи в текст. Стартап HyperAccel основан профессором Корейского института передовых технологий (KAIST) Джуёном Кимом (Jooyoung Kim) вместе с группой его студентов в начале 2023 года. На сегодняшний день компания привлекла $45 млн инвестиций, а её рыночная стоимость оценивается в $200 млн. Штат насчитывает около 80 человек. Первым продуктом HyperAccel стал специализированный сервер Orion на базе FPGA, предназначенный для решения ИИ-задач. |
|

