Материалы по тегу: ускоритель
|
09.06.2023 [22:52], Сергей Карасёв
Анонсирован китайский ускоритель Metax Xisi N100 для ИИ и потоковой обработки видеоКитайская компания Metax, по сообщению ресурса ITHome, разработала ускоритель Xisi N100, предназначенный для решения задач, связанных с обработкой видеоматериалов, алгоритмами ИИ и пр. Новинка уже готова к серийному производству и в скором времени поступит на местный рынок. Технических подробностей относительно Xisi N100 пока не слишком много. Известно, что основой ускорителя служит GPU с обозначением MXN100. Обеспечивается 128-канальное кодирование и 96-канальное декодирование. Заявлена поддержка форматов HEVC, H.264, AV1 и AVS2, а также разрешений вплоть до 8К. Ускоритель выполнен в виде однослотовой карты расширения с интерфейсом PCIe. Применено пассивное охлаждение. Заявленное быстродействие достигает 160 TOPS при вычислениях INT8 и 80 Тфлопс на операциях FP16. 
Источник изображений: ITHome Metax намерена в 2025 году выпустить GPU для игровых приложений. Чип получит поддержку всех основных методов рендеринга графики и сможет использовать современные API. Кроме того, Metax обещает предоставить оптимизированное ПО и необходимые драйверы: это, как ожидается, поможет в продвижении продукта на коммерческом рынке.  Разработка собственных GPU важна для Китая в условиях торговой войны с США. Из-за американских санкций NVIDIA прекратила поставки в Поднебесную ускорителей A100 и H100: компании пришлось выпустить экспортные варианты названных изделий, не подпадающие под ограничения.
19.05.2023 [10:20], Сергей Карасёв
Meta✴ представила ИИ-процессор MTIA для дата-центров — 128 ядер RISC-V и потребление всего 25 ВтMeta✴ анонсировала свой первый кастомизированный процессор, разработанный специально для ИИ-нагрузок. Изделие получило название MTIA v1, или Meta✴ Training and Inference Accelerator: оно оптимизировано для обработки рекомендательных моделей глубокого обучения. Проект MTIA является частью инициативы Meta✴ по модернизации архитектуры дата-центров в свете стремительного развития ИИ-платформ. Утверждается, что чип MTIA v1 был создан ещё в 2020 году. Это интегральная схема специального назначения (ASIC), состоящая из набора блоков, функционирующих в параллельном режиме. 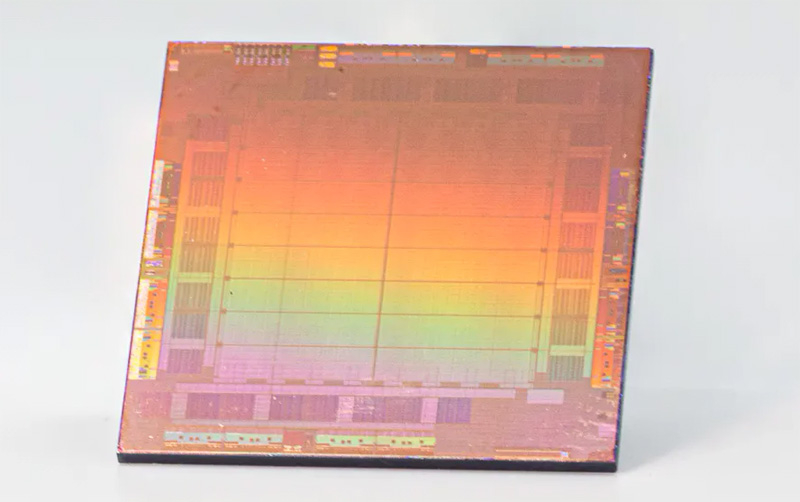
Источник изображений: Meta✴ Известно, что при производстве MTIA v1 используется 7-нм технология. Конструкция включает 128 Мбайт памяти SRAM. Чип может использовать до 64/128 Гбайт памяти LPDDR5. Задействован фреймворк машинного обучения Meta✴ PyTorch с открытым исходным кодом, который может применяться для решения различных задач в области компьютерного зрения, обработки естественного языка и пр. 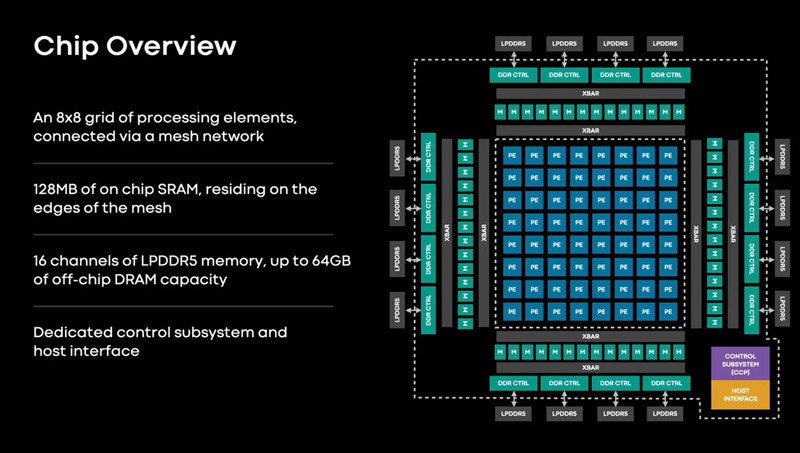 Процессор MTIA v1 имеет размеры 19,34 × 19,1 мм. Он содержит 64 вычислительных элемента в виде матрицы 8 × 8, каждый из которых объединяет два ядра с архитектурой RISC-V. Тактовая частота достигает 800 МГц, заявленный показатель TDP — 25 Вт. Meta✴ признаёт, что у MTIA v1 присутствуют «узкие места» при работе с ИИ-моделями большой сложности: требуется оптимизация подсистем памяти и сетевых соединений. Однако в случае приложений низкой и средней сложности платформа, как утверждается, обеспечивает более высокую эффективность по сравнению с GPU. 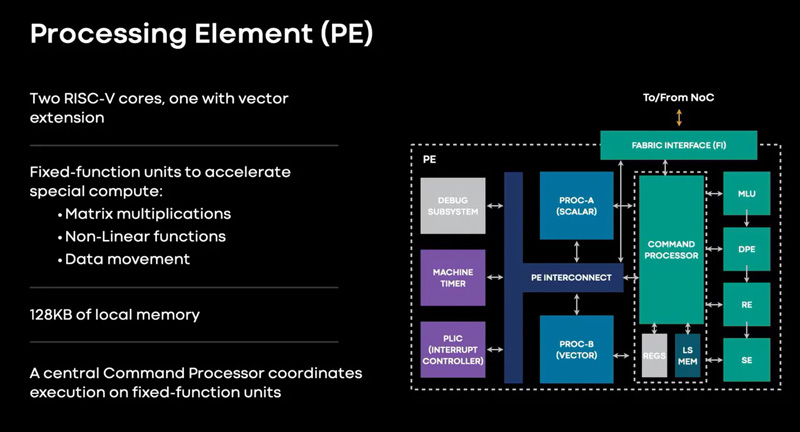 В дальнейшем в семействе MTIA появятся более производительные изделия, но подробности о них не раскрываются. Ранее говорилось, что Meta✴ создаёт некий секретный чип, который подойдёт и для обучения ИИ-моделей, и для инференса: это решение может увидеть свет в 2025 году.
19.05.2023 [10:00], Сергей Карасёв
Meta✴ анонсировала чип MSVP для ускорения обработки видеоКомпания Meta✴ представила специализированный чип MSVP, или Meta✴ Scalable Video Processor, спроектированный для ускорения выполнения операций, связанных с обработкой видеоматериалов. Это могут быть задачи по транскодированию роликов или потоковая передача контента. По данным Meta✴, пользователи соцсети Facebook✴ тратят 50 % своего времени на просмотр в общей сложности примерно 4 млрд видеороликов ежедневно. Эти материалы сжимаются после загрузки, а затем преобразовываются в другие форматы и передаются пользователям. Сложность заключается в том, чтобы быстро уменьшить размер файла, сохранить его на серверах Facebook✴ и передать в потоковом режиме с максимально возможным качеством для того или иного устройства, например, смартфона, планшета или ПК. 
Источник изображения: Meta✴ Эти задачи берёт на себя процессор MSVP. Он представляет собой интегральную схему специального назначения (ASIC). Чип предназначен для высококачественного транскодирования материалов для сервисов «видео по запросу», а также для оптимизации потоковых трансляций. В перспективе подобные процессоры, как ожидается, помогут организовать работу с видеороликами, созданными посредством генеративного ИИ. Кроме того, такие чипы будут использоваться в составе платформ AR/VR. Решение MSVP обеспечивает производительность транскодирования на уровне 4K@15в максимальном качестве в режиме «один поток на входе и пять на выходе». В стандартном качестве возможна работа в формате 4K@60.
26.04.2023 [19:50], Сергей Карасёв
Meta✴ вынужденно пересмотрела архитектуру своих ЦОД из-за отказа от выпуска собственных ИИ-чипов в пользу ускорителей NVIDIAКомпания Meta✴, по сообщению Reuters, была вынуждена пересмотреть конфигурацию своих дата-центров из-за отставания от конкурентов в плане развития ИИ-платформ. Компания, в частности, решила отказаться от дальнейшего внедрения инференс-чипов собственной разработки. Отмечается, что до прошлого года Meta✴ применяла архитектуру, в которой традиционные CPU соседствуют с кастомизированными решениями. Однако выяснилось, что такой подход менее эффективен по сравнению с применением ускорителей (GPU). При этом ранее компания отказалась от ИИ-ускорителей Qualcomm, указав на недоработки ПО, которые, судя по всему, были устранены только недавно. А с Esperanto, вероятно, отношения у Meta✴ пока не сложились. Впрочем, теперь компании интересен генеративный ИИ, а не только рекомендательные системы, что накладывает иные требования к оборудованию. 
Источник изображения: Meta✴ В течение почти всего 2022 года Meta✴ активно инвестировала в развите инфраструктуры, однако в конце года стало известно, что она приостановила строительство целого ряда ЦОД, а затем пересмотрела расходы на дата-центры. Компания решила кардинально переосмыслить архитектуру своих ЦОД, сделав ставку на СЖО. Как теперь выясняется, связано это с тем, что Meta✴ отказалась от собственных ИИ-чипов в пользу ускорителей NVIDIA: объём заказов последних исчисляется «миллиардами долларов». Соответствующую платформу Grand Teton компания показала в конце прошлого года. 
Источник изображения: Meta✴ Но ускорители потребляют больше энергии и выделяют больше тепла, нежели CPU или узкоспециализированные ASIC. Кроме того, ускорители должны физически находиться довольно близко друг к другу, хотя с интерконнектом компания тоже уже экспериментирует. Всё это влияет на архитектуру ЦОД. Тем не менее, Meta✴ всё же разрабатывает некий секретный чип, который сгодится и для обучения ИИ-моделей, и для инференса. Ожидается, что это решение увидит свет в 2025 году. Пока что для обучения ИИ компания намерена использовать собственный ИИ-суперкомпьютер RSC и облачные кластеры Microsoft Azure. Похожий путь избрала Microsoft, решившая создать свой ИИ-чип, не отказываясь пока от ускорителей NVIDIA. The Information добавляет, что вице-президент Microsoft по разработке «кремния» Жан Буфархат (Jean Boufarhat) присоединится к Meta✴. Он возглавит команду Facebook✴ Agile Silicon Team (FAST), чтобы помочь компании в реализации проектов по созданию чипов. Ранее Meta✴ переманила из Intel руководителя разработки сетевых решений для дата-центров. У Google и Amazon уже есть свои ИИ-чипы для обучения и инференса.
22.03.2023 [22:02], Алексей Степин
AMD и NVIDIA победили: NEC останавливает разработку уникальных векторных процессоров SX-AuroraЯпонская компания NEC была одной из немногих, отстаивавших собственный уникальный путь в сфере развития вычислительных технологий со своими векторными процессорами SX-Aurora. Хотя данное направление до недавних пор активно развивалось, компания, похоже, не выдержала давления со стороны NVIDIA и AMD и объявила о прекращении разработок новых решений в серии Aurora. Работы над усовершенствованием векторной архитектуры NEC продолжались до конца прошлого года, когда компания объявила о подготовке новых вычислительных узлов SX-Aurora TSUBASA C401-8 на базе ускорителей с 16 блоками Vector Engine 3.0 и 96 Гбайт интегрированной памяти HBM2. И хотя в августе этого года в Научном центре Университета Тохоку будет запущен новый суперкомпьютер на их основе, новых разработок в этой сфере не будет. 
Вычислительный модуль SX-Aurora TSUBASA C401-8. Источник изображений здесь и далее: NEC Как отметил Сатоши Мацуока (Satoshi Matsuoka), глава крупнейшего в Японии суперкомпьютерного центра RIKEN, где был создан суперкомпьютер Fugaku, NEC неслучайно объявила об отказе от разработки нового поколения процессоров SX-Aurora. Хотя в целях компании значилось 10-кратное повышение энергоэффективности, теперь NEC считает, что эта цель может быть достигнута с использованием стандартных коммерческих ускорителей. Главной причиной называется появление решений AMD и NVIDIA, на голову превосходящих все наработки NEC. В частности, упоминается AMD Instinct MI300. При этом отмечено, что это решение «похоронило» бы даже новое поколение SX-Aurora, когда речь заходит о ПСП. Целью NEC был показатель 2+ Тбайт/с, в то время как новинка AMD, располагая памятью HBM3 с 8192-бит шиной, может обеспечить 6,8 Тбайт/с. 
Планы NEC по развитию VE-архитектуры. Похоже, им уже не суждено сбыться Также «естественным врагом» SX-Aurora является NVIDIA Grace Hopper с его мощной процессорной частью и развитой инфраструктурой NVLink, демонстрирующий к тому же выдающуюся энергоэффективность. Примечательно, что оба продукта от AMD и NVIDIA являются APU, то есть гибридными чипами, объединяющими ускорители и CPU собственной разработки, а также быструю память. Финансовый кризис 2009 года ударил по разработкам NEC в области процессоростроения сильно, но ситуацию тогда спасла общая незрелость рынка GPGPU и технологии HBM. Сейчас на это надеяться нельзя, да и ситуация с точки зрения программной экосистемы в мире HPC говорит не в пользу NEC. По всей видимости, прямо на наших глазах ещё одна уникальная вычислительная архитектура становится достоянием истории.  При этом в Японии пока что сохраняется ещё одна уникальная отечественная архитектура — PEZY-SC. Arm-процессоры Fujitsu A64FX, ставшие основой Fugaku, тоже достаточно уникальны, однако их наследники в лице MONAKA переориентированы на более массовый сегмент. Таким образом, собственные массовые HPC-решения сейчас есть только у Китая, которому новейшие американские и британские ускорители достанутся в кастрированном виде.
22.03.2023 [20:32], Алексей Степин
Экспортный китайский вариант NVIDIA H100 получил модельный номер H800В связи с санкционными ограничениями некоторые разновидности сложных микроэлектронных чипов запрещено экспортировать в Китайскую Народную Республику. Однако производители находят выход. В частности, компания NVIDIA анонсировала экспортный вариант ускорителя H100, не нарушающий никаких санкций. Модельный номер у такого варианта изменён на H800. Введённые правительством США в 2022 году санкции сделали «невыездными» два наиболее продвинутых продукта NVIDIA: A100 и H100. Такие процессоры сегодня являются основой наиболее динамично развивающейся вычислительной отрасли — нейросетевой. Именно на кластерах из таких ускорителей «натаскивают» мощные нейросети вроде ChatGPT и подобных. 
Ускоритель Hopper H100 в SXM-исполнении. Источник изображений здесь и далее: NVIDIA Ещё осенью прошлого года NVIDIA анонсировала A800 — экспортный вариант A100, не попадающий под ограничения за счёт некоторого снижения пропускной способности NVLink, с 600 до 400 Гбайт/с. Сейчас пришло время архитектуры Hopper, которая запущена в массовое производство. По аналогии с флагманом Ampere модернизированный чип получил модельный номер H800. Ограничения в нём реализованы схожим образом: как известно, NVLink в H100 имеет производительность 900 Гбайт/с в базовом SXM-варианте. 
H100 также существует в PCIe-варианте Версия H800 использует примерно половину этого потенциала, что, впрочем, не делает её в Китае менее популярной: новинка уже используется китайскими облачными гигантами, такими, как Alibaba, Baidu и Tencent. Есть ли у H800 другие отличия от H100, не говорится — NVIDIA пока отказывается предоставлять такую информацию. Достоверно известно лишь то, что они полностью соответствуют всем санкционным ограничениям. Интересно, появится ли в будущем вариант H800 NVL на базе NVIDIA H100 NVL.
21.03.2023 [19:45], Игорь Осколков
Толстый и тонкий: NVIDIA представила самый маленький и самый большой ИИ-ускорители L4 и H100 NVLНа весенней конференции GTC 2023 компания NVIDIA представила два новых ИИ-ускорителя, ориентированных на инференес: неприличной большой H100 NVL, фактически являющийся парой обновлённых ускорителей H100 в формате PCIe-карты, и крошечный L4, идущий на смену T4. 
Изображения: NVIDIA NVIDIA H100 NVL действительно выглядит как пара H100, соединённых мостиками NVLink. Более того, с точки зрения ОС они выглядят как пара независимых ускорителей, однако ПО воспринимает их как единое целое, а обмен данными между двумя картам идёт в первую очередь по мостикам NVLink (600 Гбайт/с). Новинка создана в первую очередь для исполнения больших языковых ИИ-моделей, в том числе семейства GPT, а не для их обучения. 
NVIDIA H100 NVL Однако аппаратно это всё же не просто пара обычных H100 PCIe. По уровню заявленной производительности NVL-вариант вдвое быстрее одиночного ускорителя H100 SXM, а не PCIe — 3958 и 7916 Тфлопс в разреженных (в обычных показатели вдвое меньше) FP16- и FP8-вычислениях на тензорных ядрах соответственно, что в 2,6 раз больше, чем у H100 PCIe. Кроме того, NVL-вариант получил сразу 188 Гбайт HBM3-памяти с суммарной пропускной способностью 7,8 Тбайт/с. 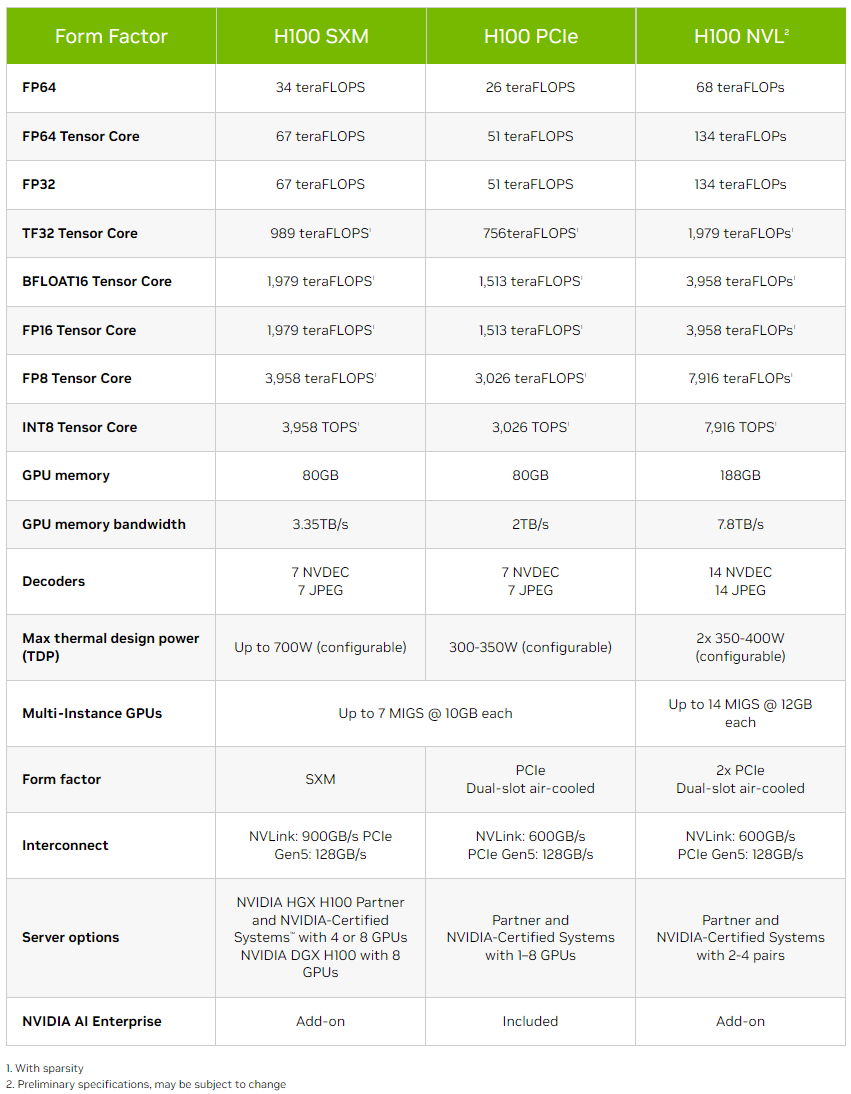 NVIDIA утверждает, что форм-фактор H100 NVL позволит задействовать новинку большему числу пользователей, хотя четыре слота и TDP до 800 Вт подойдут далеко не каждой платформе. NVIDIA H100 NVL станет доступна во второй половине текущего года. А вот ещё одну новинку, NVIDIA L4 на базе Ada, в ближайшее время можно будет опробовать в облаке Google Cloud Platform, которое первым получило этот ускоритель. Кроме того, он же будет доступен в рамках платформы NVIDIA Launchpad, да и ключевые OEM-производители тоже взяли его на вооружение. 
NVIDIA L4 Сама NVIDIA называет L4 поистине универсальным серверным ускорителем начального уровня. Он вчетверо производительнее NVIDIA T4 с точки зрения графики и в 2,7 раз — с точки зрения инференса. Маркетинговые упражнения компании при сравнении L4 с CPU оставим в стороне, но отметим, что новинка получила новые аппаратные ускорители (де-)кодирования видео и возможность обработки 130 AV1-потоков 720p30 для мобильных устройств. С L4 возможны различные сценарии обработки видео, включая замену фона, AR/VR, транскрипцию аудио и т.д. При этом ускорителю не требуется дополнительное питание, а сам он выполнен в виде HHHL-карты. 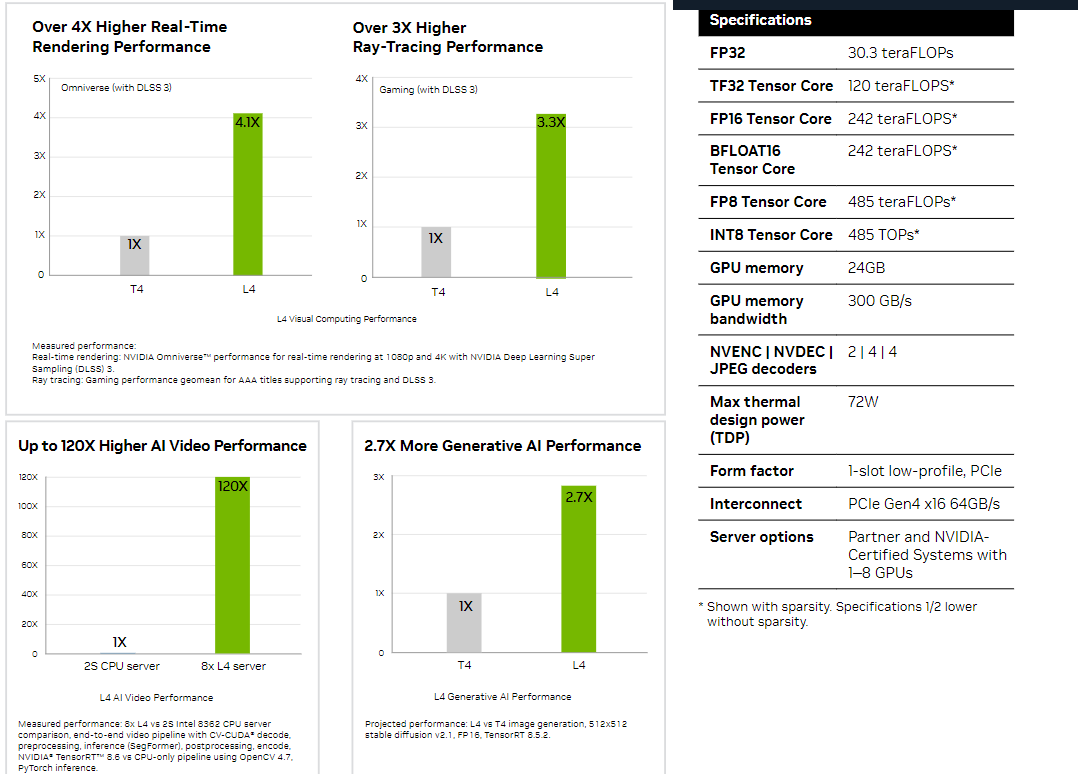
28.01.2023 [21:20], Алексей Степин
Ускоритель Pliops XDP получил новые возможности: XDP-RAIDplus, XDP-AccelDB и XDP-AccelKVКомпания Pliops, разработавшая собственный вариант DPU-ускорителя XDP, объявила о расширении его функциональности. Нововведения должны повысить производительность NVMe SSD, продлить им жизнь и ускорить процесс восстановления в случае сбоя. Анонс Pliops говорит о новых службах XDP-RAIDplus, XDP-AccelDB и XDP-AccelKV, назначение которых понятно из названия. XDP-RAIDplus предназначена для максимизации скорости ввода-вывода накопителей с интерфейсом NVMe, а также позволяет создавать защищённые массивы без потери эффективной ёмкости. Заявляется о 26,6 % прироста по объёму при использовании 6 дисков ёмкостью 15 Тбайт в сравнении с обычным RAID5. При этом в случае сбоя ускоритель перестраивает массив только в части, затронутой отказавшим и заменённым накопителем, а не целиком, что ускоряет процесс перестройки на 65 %, при этом меньше страдает производительность и минимизируется время простоя. Благодаря сочетанию этих функций стоимость владения флеш-массивом может снижаться на величину до 50 %. 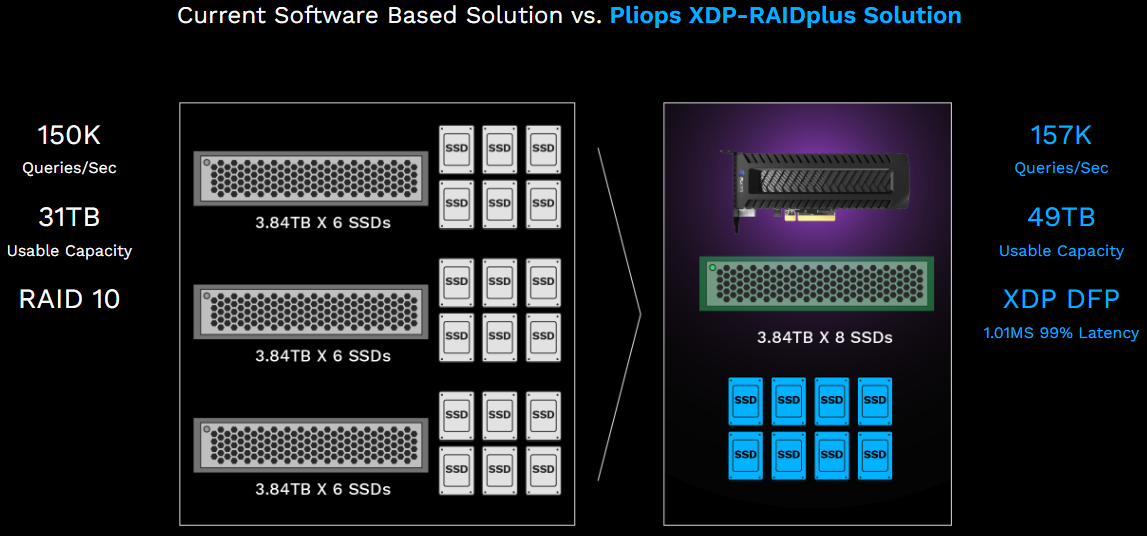
Преимущества XDP-RAIDplus в сравнении с классическими решениями. Источник: Pliops Функция XDP-AccelDB представляет собой движок-ускоритель для СУБД (MySQL/MariaDB, MongoDB) и программно определяемых хранилищ. Движок поддерживает атомарную запись, умную буферизацию и выравнивание данных, что позволяет говорить о 3,2-кратном увеличении количества транзакций за единицу времени, а также о трёхкратном снижении латентности. Наконец, XDP-AccelKV — ускоритель Key-Value хранилищ, предназначенный для решений типа RocksDB или WiredTiger. В сравнении с полностью программными решениями он, как утверждается, способен повысить производительность на порядок.
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 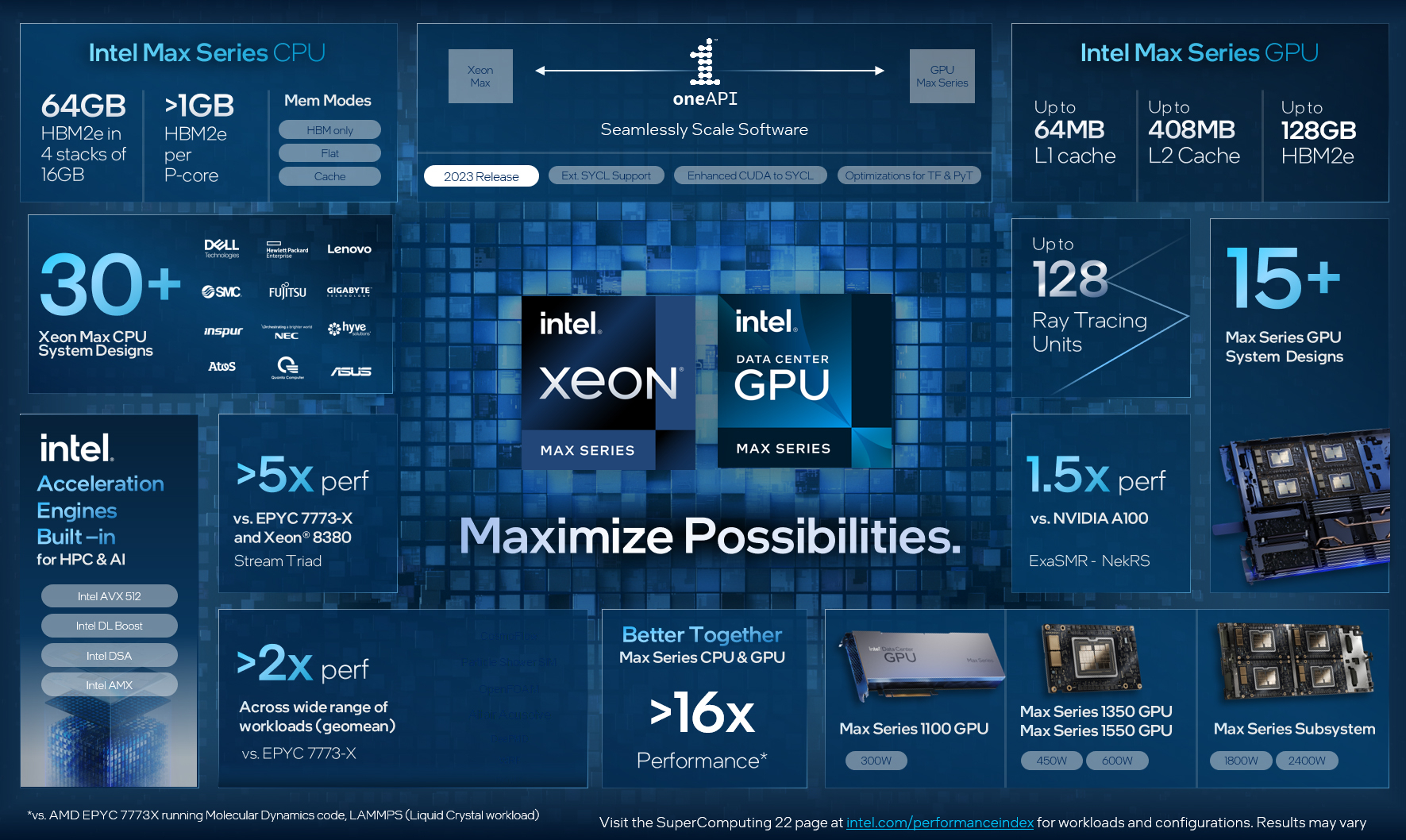
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 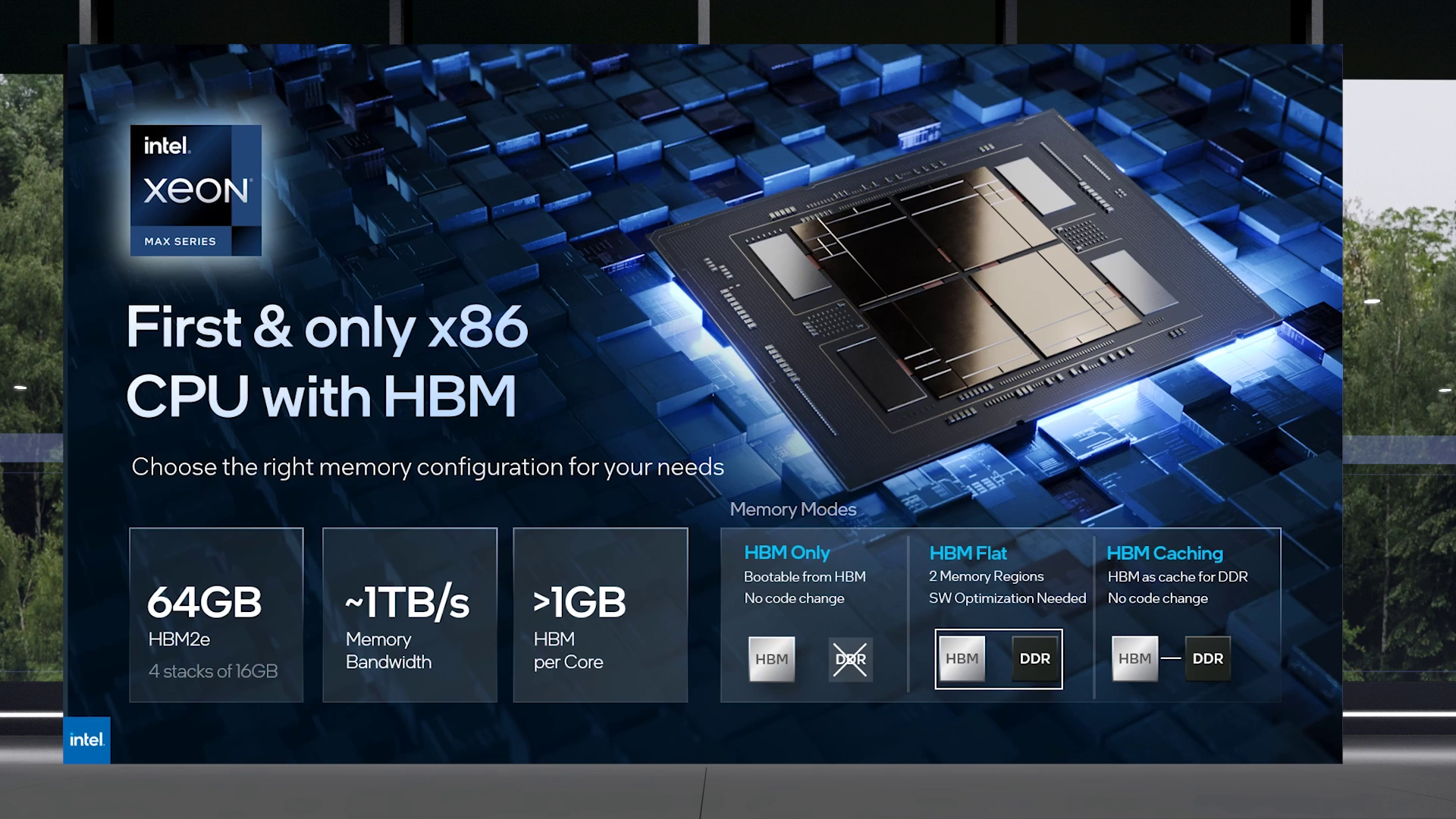 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA.
09.11.2022 [14:50], Владимир Мироненко
Производители специально ухудшают характеристики чипов для китайских серверов, чтобы избежать санкций СШАВ связи с вводом Соединёнными Штатами новых экспортных ограничений на поставки в Китай, производители стали намеренно снижать производительность чипов, чтобы соответствовать требованиям экспортного контроля США и избежать проблем с получением специальных лицензий. Как отметил ресурс The Register, у систем, построенных на чипах NVIDIA, изготовленных на производственных мощностях TSMC для поставок в Китай, характеристики хуже по сравнению с теми, что были ранее. В частности, китайский производитель серверов Inspur указал на использование вместо ускорителя NVIDIA A100 чипа A800, разработанного NVIDIA специально для Китая в соответствии с экспортными ограничениями. Китайские производители H3C и Omnisky тоже представили решения на базе A800. Данный ускоритель, по словам NVIDIA, начала производиться в III квартале этого года. У A800 скорость передачи данных составляет 400 Гбайт/с, тогда как у A100 этот показатель равен 600 Гбайт/с, причём обойти эти ограничения, по словам NVIDIA, невозможно. Речь, судя по всему, идёт о характеристиках интерконнекта NVLink, которые прямо влияют на производительность кластеров из двух и более ускорителей в машинном обучении и других задачах. Изменения касаются 40- и 80-Гбайт вариантов с интерфейсами PCIe и SXM. 
Источник изображения: Inspur Между тем ускорители, находящиеся в разработке и выпускаемые TSMC по контракту с Alibaba и стартапом Biren Technology, тоже, как сообщается, имеют пониженную скорость передачи данных. Это позволит выпускать данные чипы на заводе TSMC, не опасаясь санкций США. До этого TSMC приостановила выпуск 7-нм чипов ускорителей Biren BR100 как раз из-за возможных санкций со стороны Вашингтона. |
|


