Материалы по тегу: инференс
|
26.02.2026 [23:11], Владимир Мироненко
AMD инвестирует в Nutanix $250 млн и создаст совместную платформу для агентного ИИAMD и Nutanix объявили о заключении соглашения о многолетнем стратегическом партнёрстве с целью разработки открытой инфраструктурной платформы для корпоративных приложений в области агентного ИИ, первая версия которой должна появиться к концу этого года. В рамках соглашения AMD инвестирует $150 млн в обыкновенные акции Nutanix по цене $36,26/шт. и предоставит до $100 млн дополнительного финансирования для совместных инженерных и маркетинговых инициатив, а также сотрудничества в области выхода на рынок с целью ускорения внедрения совместной платформы агентного ИИ. Ожидается, что сделка по инвестиции в акционерный капитал будет завершена во II квартале 2026 года после получения необходимых разрешений регулирующих органов. Совместно разработанная платформа агентного ИИ предназначена для обеспечения ускорения инференса на базе ускорителей Instinct и процессоров EPYC, HPC и оркестрации с использованием EPYC, а также унифицированного управления жизненным циклом с помощью Nutanix Enterprise AI, что позволит развёртывать открытые и коммерческие ИИ-модели без зависимости от вертикально интегрированных стеков ИИ. В рамках сделки Nutanix также интегрирует ПО AMD ROCm и Enterprise AI в свою облачную платформу Nutanix Cloud и платформу Nutanix Kubernetes, отметил ресурс SiliconANGLE. 
Источник изображения: AMD В настоящее время Nutanix поддерживает только ускорители NVIDIA. Благодаря этой сделке Nutanix будет поддерживать и ускорители AMD, что, как ожидается, позволит AMD расширить круг клиентов. «Наша цель — предоставить клиентам выбор, — заявил глава Nutanix Раджив Рамасвами (Rajiv Ramaswami) изданию The Register. — NVIDIA — лидер рынка, а AMD — ещё одна крупная компания, владеющая платформой». О сделке было объявлено после того, как Nutanix сообщила о финансовых результатах за II квартал 2026 финансового года. Выручка компании выросла год к году на 10 % до $723 млн. Скорректированная прибыль на акцию составила 56¢. Оба показателя превысили прогнозы аналитиков, ожидавших $710,35 млн выручки и 44¢ на акцию скорректированной прибыли. Высокие показатели были достигнуты благодаря росту клиентской базы: годовой доход от регулярных платежей по состоянию на конец января составил $2,36 млрд, что на 16 % больше, чем годом ранее. Рамасвами сообщил, что за прошедший квартал компания заключила 1000 новых контрактов с клиентами, и большинство из них намерены перейти с VMware на Nutanix. Вместе с тем дефицит в цепочках поставок процессоров и комплектующих, включая память и накопители, привёл к тому, что компания снизила свой прогноз на весь год с $2,82–$2,86 млрд до $2,80–$2,84 млрд. После объявления о сделке AMD и Nutanix акции Nutanix выросли в цене на 15 %.
25.02.2026 [17:31], Владимир Мироненко
Axelera AI привлекла $250 млн для разработки европейских ИИ-чиповПроизводитель ИИ-чипов Axelera AI из Эйндховена (Нидерланды) привлёк $250 млн в рамках раунда финансирования, который возглавил европейский венчурный фонд Innovation Industries. Наряду с имеющимися инвесторами в нём также приняли участие BlackRock и SiteGround Capital в качестве новых инвесторов. Это одна из крупнейших инвестиций на сегодняшний день в европейскую компанию по производству ИИ-чипов, отметило агентство Reuters. Генеральный директор Фабрицио Дель Маффео (Fabrizio Del Maffeo) указал в своём заявлении, что компания использует привлечённые средства для расширения производства своего чипа Europa, запуск которого запланирован до июня, а также для дальнейшей разработки ПО, упрощающего использование чипов для клиентов. 
Источник изображений: Axelera AI У Axelera «большой портфель возможностей, требующих инвестиций, и этот портфель растет», — заявил Фабрицио Дель Маффео в интервью Bloomberg. По его словам, клиенты ищут более доступные вычислительные ресурсы, более высокую эффективность и способы сокращения расходов на дорогостоящую ИИ-инфраструктуру. Дель Маффео сообщил, что инференс может осуществляться на децентрализованной архитектуре, которая потребляет меньше энергии. Большие потребности крупных ЦОД в энергии, необходимой для обеспечения вычислительных мощностей для обучения ИИ-моделей, подвергаются критике на фоне опасений по поводу перегрузки электросетей и резкого роста цен на электроэнергию для потребителей, отметил Bloomberg.  С момента основания в июле 2021 года Axelera AI привлекла более $450 млн в виде акционерного капитала, грантов и венчурного кредитования. В частности, в марте 2025 года Axelera получила грант в размере €61,6 млн ($66 млн) от EuroHPC JU в рамках проекта Digital Autonomy with RISC-V for Europe (DARE) по разработке передового чипа Titania для использования в так называемых ИИ-фабриках. Ожидается, что этот чип появится в 2027 году. Компания отметила, что финансовый раунд прошёл в тот момент, когда она начала поставки своему 500-му глобальному клиенту в области физического и периферийного ИИ в таких отраслях, как оборона и общественная безопасность, промышленное производство, розничная торговля, агротехнологии, робототехника и безопасность. По словам Axelera AI, её клиентская база за последний год увеличилась более чем втрое.
24.02.2026 [23:00], Владимир Мироненко
SambaNova представила ИИ-ускоритель SN50 и объявила о расширении партнёрства с IntelSambaNova представила ИИ-ускорители пятого поколения SN50 на основе фирменных RDU (Reconfigurable Dataflow Unit), которые, по словам компании, «обеспечивает непревзойденное сочетание сверхнизкой задержки, высокой пропускной способности и энергоэффективной производительности для рабочих нагрузок ИИ-инференса, коренным образом меняя экономику генерации токенов». Кроме того, объявлено об инвестициях и сотрудничестве с Intel, которая передумала покупать SambaNova целиком. Как отметил The Register, новый чип представляет собой значительное улучшение по сравнению с SN40L 2023 года. По данным компании, SN50 обеспечивает в 2,5 раза более высокую производительность при 16-бит вычислениях (1,6 Пфлопс) и в 5 раз более высокую производительность в режиме FP8 (3,2 Пфлопс). В основе SN50 лежит архитектура потоковой обработки данных (SambaNova DataFlow). Как и в предшественнике, в SN50 используется трёхуровневая иерархия памяти, которая сочетает в себе DDR5, HBM и SRAM, что позволяет платформам на основе новинки поддерживать ИИ-модели с 10 трлн параметров и длиной контекста до 10 млн токенов. 
Источник изображений: SambaNova Каждый RDU оснащен 432 Мбайт SRAM, 64 Гбайт HBM2E с пропускной способностью 1,8 Тбайт/с и от 256 Гбайт до 2 Тбайт памяти DDR5. Доступность HBM2E и конфигурируемый объём DDR5 позволят повысить привлекательность и доступность SN50 на фоне дефицита памяти. Каждый ускоритель получил интерконнект со скоростью 2,2 Тбайт/с (в каждую сторону) для связи с другими чипами через коммутируемую фабрику. Как утверждает SambaNova, по сравнению с ускорителем NVIDIA B200, SN50 обеспечивает в 5 раз большую максимальную скорость генерации токенов на пользователя и более чем в 3 раза большую пропускную способность для агентного инференса, что было продемонстрировано на примере ряда моделей, таких как Meta✴ Llama 3.3 70B. Архитектура позволяет эффективно разгружать KV-кеш и переключаться между моделям в HBM и SRAM в режиме «горячей замены» за миллисекунды, что крайне важно для агентных рабочих нагрузок, часто переключающихся между несколькими ИИ-моделями. 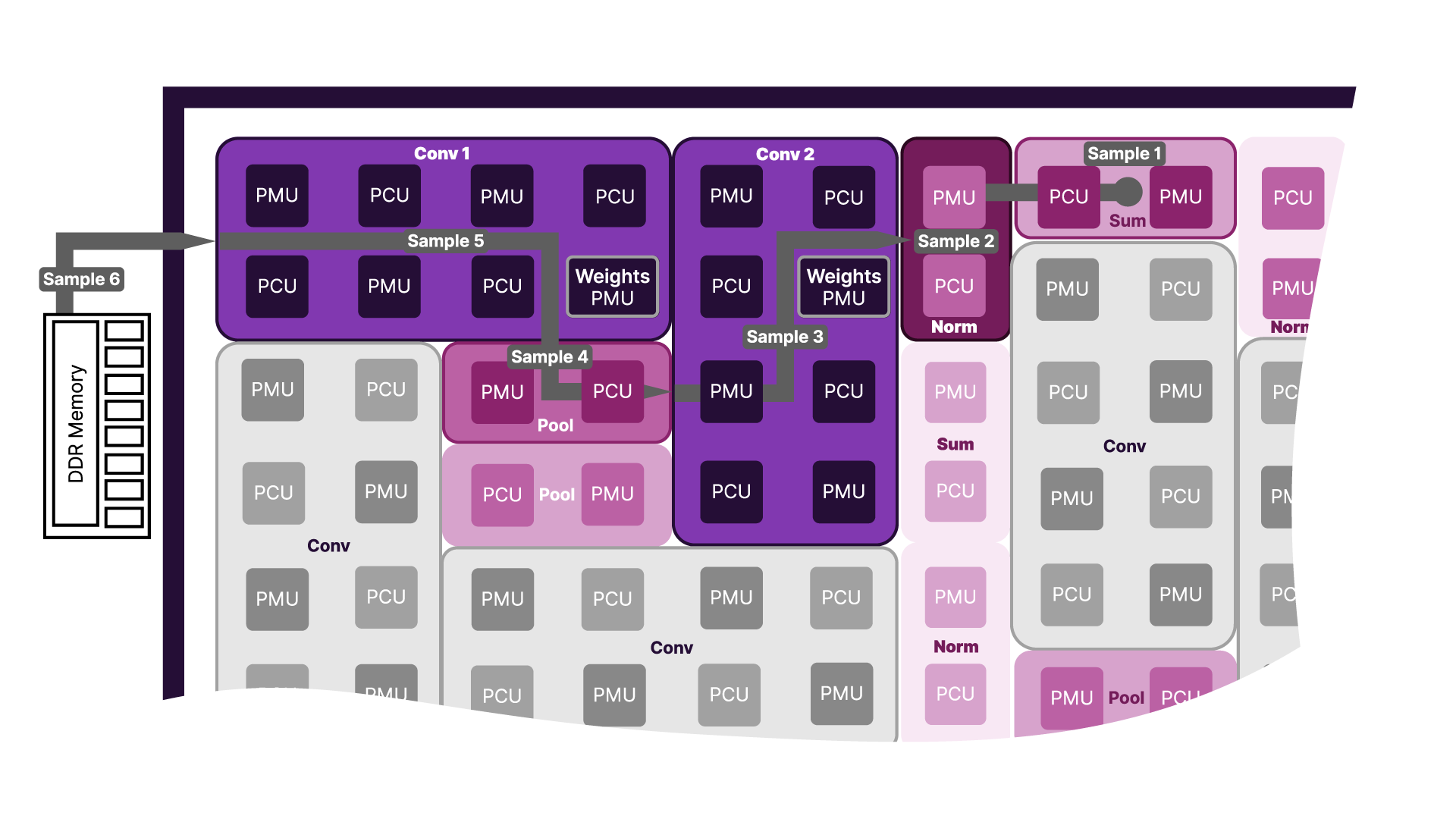 Также в SN50 входные токены могут кешироваться в памяти, сокращая время предварительной обработки и время ожидания первого токена (TTFT) для запросов. Такое сочетание производительности, эффективности и масштабируемости обеспечивает преимущество в совокупной стоимости владения (TCO), по словам компании, не имеющее аналогов на рынке, для поставщиков сервисов инференса, использующих такие модели, как OpenAI GPT-OSS, с восьмикратной экономией по сравнению с NVIDIA B200. SN50 ориентирован и на такие приложения, как голосовые помощники на основе ИИ, требующие сверхнизкой задержки для работы в режиме реального времени. По заявлению компании, он сможет обеспечить работу тысяч одновременных сессий. Также была представлена 20-кВт система SambaRack SN50, которая объединяет 16 чипов SN50. SambaRack могут масштабироваться до кластера из 256 ускорителей с пропускной способностью интерконнекта в несколько Тбайт/с, что сокращает время обработки запросов и поддерживает большие размеры пакетов. В результате можно развёртывать модели с более высокой пропускной способностью и быстродействием. Поставки SN50 клиентам начнутся во II половине 2026 года.  Раннее SambaNova сообщила о привлечении более $350 млн в рамках переподписанного раунда финансирования серии E, возглавляемого частной инвестиционной компанией Vista Equity Partners при партнёрстве с Cambium Capital. В нём также приняло «активное участие» инвестиционное подразделение Intel — Intel Capital, сообщил SiliconANGLE. Также SambaNova заявила о сотрудничестве с Intel в разработке новых высокопроизводительных и экономически эффективных систем для выполнения ИИ-задач. Цель — предоставить предприятиям альтернативу GPU, которые сегодня используются в большинстве рабочих нагрузок. Intel инвестирует в стартап, чтобы ускорить развёртывание нового «облачного решения для ИИ» на базе существующей платформы SambaNova Cloud. Обновлённая платформа, оптимизированная для многомодальных LLM, получит процессоры Xeon, а также GPU, сетевые и иные решения Intel, в том числе в области СХД. Идёт ли речь о создании специализированных моделей Xeon, как это было в случае NVIDIA, не уточняется. В дальнейшем Intel и SambaNova планируют совместно продвигать и продавать новую платформу, используя существующие связи Intel с предприятиями и партнёрские каналы.  Партнёрство несёт выгоду обеим компаниям. SambaNova сможет воспользоваться глобальным охватом и производственной базой Intel для масштабирования своих ИИ-ускорителей, а Intel получит шанс наконец-то заявить о себе на ИИ-рынке. До сих пор Intel не могла конкурировать с NVIDIA и другими производителями чипов, такими как AMD, в ИИ-сфере. Чипы SN50 от SambaNova в сочетании с процессорами Intel Xeon потенциально могут изменить эту ситуацию. Стоит отметить, что у Intel, которая сама чувствует себя не лучшим образом, есть довольно крупная сделка с NVIDIA. Компания также предлагает собственные GPU для инференса, пусть и значительно более простые в сравнении с SN50, и даже странные гибриды из ускорителей Habana Gaudi 3 и NVIDIA B200. Наконец, имеется и сделка с AWS по выпуску кастомных Xeon 6 и неких ИИ-ускорителей. Что касается старых «коллег» SambaNova в деле борьбы с NVIDIA, то Groq в итоге была поглощена последней, а Cerebras, наконец, подписала заметную сделку с действительно крупным игроком на рынке ИИ — OpenAI.
23.02.2026 [23:22], Владимир Мироненко
Astera Labs по-тихому купила PliopsAstera Labs приобрела Pliops, сообщил ресурс StorageNewsletter со ссылкой на заявление Мариуса Тудора (Marius Tudor), бывшего директора по развитию бизнеса Pliops, подтвердившего факт сделки на своей странице в соцсети LinkedIn. Финансовых подробностей о сделке не сообщается. Ресурс допустил, что компания приобрела Pliops для своего первого научно-исследовательского центра в Израиле. О создании своего передового R&D-центра в Израиле Astera Labs сообщила в начале февраля. Предполагается, что новый центр с офисами в Тель-Авиве и Хайфе ускорит разработку масштабируемых сетей следующего поколения для протоколов высокоскоростной связи, а также будет способствовать техническим исследованиям и разработкам, направленным на решение проблем с памятью в приложениях для обучения и инференса ИИ. Руководителем центра назначен ветеран полупроводниковой индустрии Гай Азрад (Guy Azrad), старший вице-президент по проектированию и генеральный директор Astera Labs Israel, а его помощником станет Идо Букспан (Ido Bukspan), вице-президент по проектированию ASIC, имеющий 20-летний стаж работы в Mellanox и NVIDIA, где он дошёл до должности старшего вице-президента по проектированию микросхем, разрабатывая высокопроизводительные решения InfiniBand, Ethernet и NVLink. 
Источник изображения: Pliops «Новый израильский дизйн-центр будет стремиться использовать лучшие в регионе инженерные таланты, чтобы сосредоточиться на полном цикле проектирования микросхем — от архитектуры до производства, включая ПО и системное проектирование для передовых ИИ-платформ и новых приложений для инференса», — заявил Азрад. Разработанная Pliops PCIe-карта расширения XDP LightningAI с программным стеком FusIOnX функционирует как ещё один уровень памяти для GPU-серверов. Она работает на базе ASIC, которая «раскладывает» KV-кеш на SSD с доступом через NVMe-oF (RDMA) и горизонтальным масштабированием. Стек Pliops FusIOnX снижает стоимость, энергопотребление и вычислительные затраты путём оптимизации рабочих процессов инференса LLM. 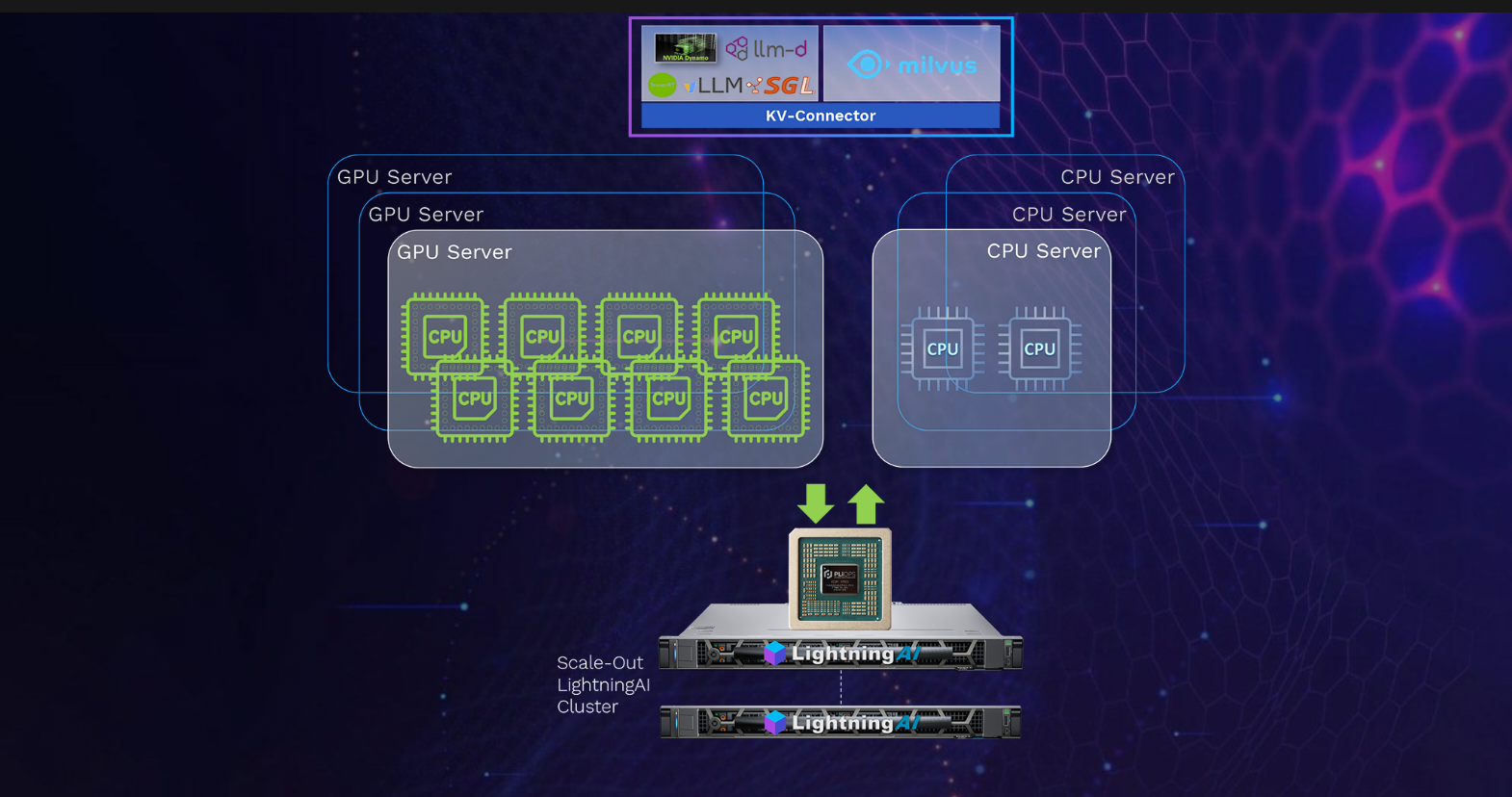
Источник изображения: Pliops «Сочетание нашего оборудования LightningAI с ПО FusIOnX устраняет узкое место, связанное с памятью GPU, обеспечивая до восьми раз более быструю обработку данных и экономию энергии на уровне стойки. И это работает от начала до конца: на любом GPU, любой LLM, любом ПО для обработки данных и любой сетевой инфраструктуре», — заявил Идо Букспан. По данным компании, Pliops XDP LightningAI вместе с ПО расширяют возможности высокоскоростной памяти (HBM) для серверов с GPU и ускоряют работу vLLM на NVIDIA в 2,5 раза.
23.02.2026 [22:57], Владимир Мироненко
Чипы AMD прожорливы, NVIDIA — дороги, а Intel — ненадёжны: Ericsson остаётся верна кастомным ASICEricsson представила свой первый набор продуктов AI-RAN, подчеркнув приверженность стратегии, основанной на собственных ASIC для повышения производительности сетей радиодоступа (RAN). В то время как беспроводная индустрия всё чаще обращается к виртуализированным/облачным RAN с использованием универсальных процессоров (GPP) Intel, Ericsson защищает свои продолжающиеся инвестиции в кастомные чипы для высокопроизводительных задач, отметил ресурс IEEE ComSoc Technology Blog. Впрочем, Intel остаётся ключевым партнёром Ericsson, а вот с AMD и NVIDIA у компании не заладилось. Портфель решений Ericsson для RAN базируется на двух основных архитектурах. Большая часть основана на ASIC, разработанных как собственными силами, так и в партнёрстве с Intel. Также портфель включает Cloud RAN, которая объединяет программный стек Ericsson с процессорами Intel Xeon EE. Несмотря на надежды отрасли, что виртуализация позволит отделить аппаратное обеспечение от программного, Intel остаётся единственным партнером Ericsson по поставке микросхем для массового развёртывания, что создаёт некоторые риски. 
Источник изображений: Ericsson Фактически Ericsson подтвердила «коммерческую поддержку» исключительно решений Intel, в то время как в случае AMD, Arm и NVIDIA всё по-прежнему ограничивается «поддержкой прототипов». Несмотря на многолетние заявления отрасли о необходимости разнообразия микросхем в экосистеме vRAN, прогресс, похоже, застопорился. Кроме того, интеграция ИИ в ПО RAN добавляет новые уровни сложности, которые могут ещё больше укрепить зависимость компании от «железа» одного вендора. Отраслевые наблюдатели по-прежнему скептически относятся к стремлению Ericsson к «единому программному стеку» для гетерогенных аппаратных платформ. Хотя аппаратная и программная дезагрегация достижима на более высоких уровнях (L2/L3), PHY-уровень L1 — наиболее ресурсоёмкая часть стека — остаётся сильно оптимизированным для конкретного «кремния». Первоначально Ericsson рассчитывала на переносимость L1-кода между x86 (в т.ч. AMD) и Arm SVE2 (NVIDIA Grace) для соответствия возможностям Intel AVX-512. Однако достижение высокой производительности на этих платформах без существенного рефакторинга остается серьёзной инженерной проблемой. 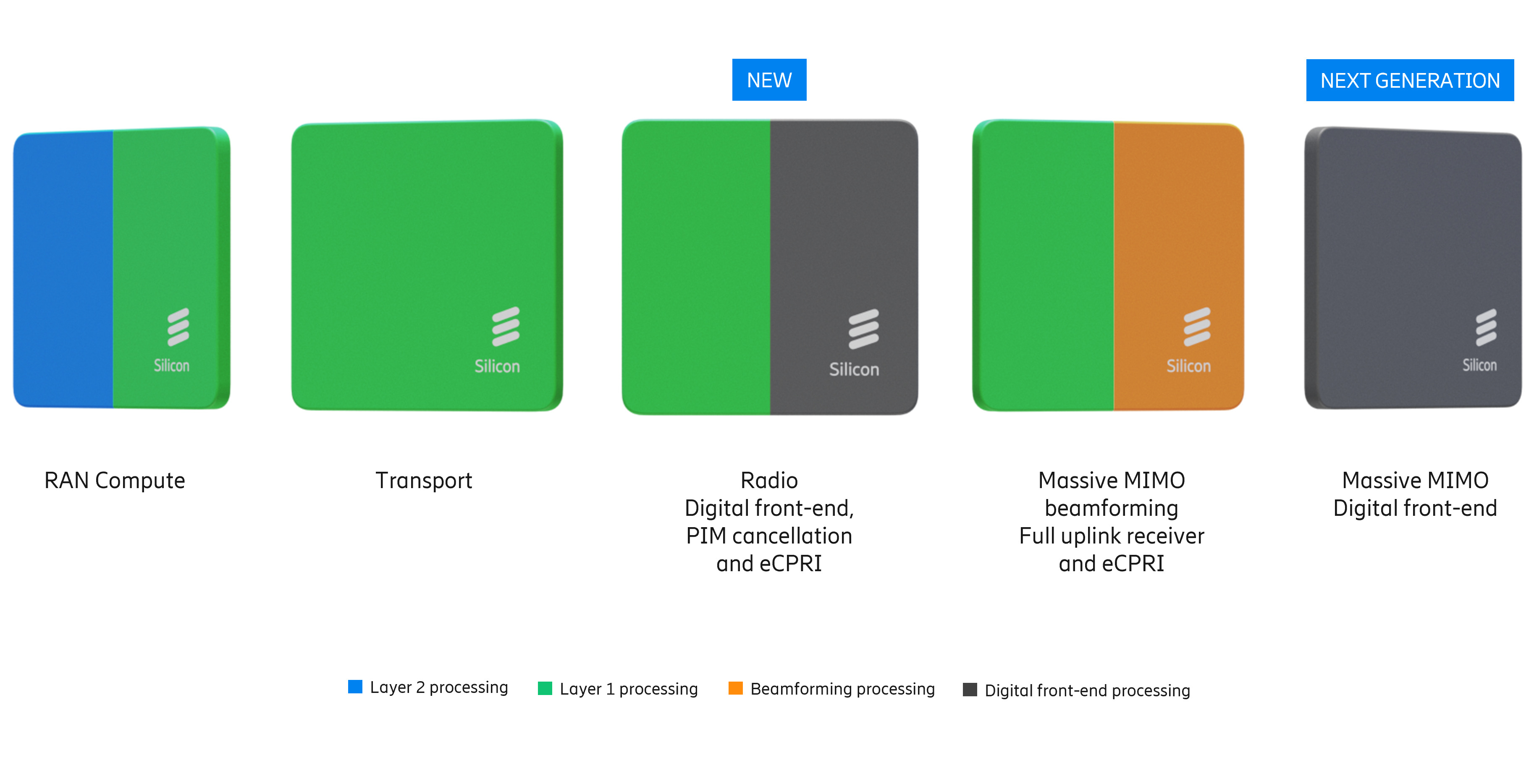 Критическим узким местом в обработке L1-трафика является коррекция ошибок (Forward Error Correction), которая традиционно требует выделенного аппаратного ускорения. Ericsson первоначально полагалась на разгрузку с переносом задач FEC на дискретные PCIe-ускорители Intel. Затем Intel внедрила ускорение FEC в Xeon EE в рамках vRAN Boost. Попытки использовать FPGA AMD показали их невысокую энергоэффективность, а GPU NVIDIA оказались слишком дороги для такой задачи. Однако развитие AI-RAN изменило экономику, поскольку теперь ускорители можно использовать как для RAN, так и для ИИ-задач. Так, Ericsson заинтересовали тензорные процессоры Google (TPU). Тем не менее, несмотря на стремление к созданию «единого ПО», планы Ericsson подтверждают существование проблем в реализации этой идеи. В то время как уровни L2 и выше используют универсальную кодовую базу для всех аппаратных платформ, уровень L1 требует адаптации под конкретные чипы.  Чтобы избежать зависимости от одного поставщика чипов, компания уделяет приоритетное внимание развитию HAL (Hardware Abstraction Layers), что позволит портировать ПО на разные аппаратные платформы с минимальными изменениями. Основные инициативы включают внедрение интерфейса BBDev (Baseband Device) для отделения ПО RAN от базового аппаратного обеспечения. Рассматривается даже возможность интеграции с NVIDIA CUDA, но здесь многое зависит от более широкой отраслевой стандартизации. Что касается радиосвязи, менее подверженной полной виртуализации, Ericsson встраивает процессоры Neural Network Accelerators (NNA) непосредственно в радиомодули. Эти программируемые матричные ядра оптимизированы для обработки данных в системах Massive MIMO, обеспечивая формирование луча и оценку канала за доли миллисекунды при соблюдении строгих ограничений по мощности. Новые AI-радиомодули оснащены ASIC Ericsson с NNA. Утверждается, что они расширяют возможности локального инференса в радиосистемах Massive MIMO, обеспечивая оптимизацию в реальном времени.
20.02.2026 [15:59], Сергей Карасёв
Узкие специалисты: Talaas, разрабатывающая оптимизированные под конкретные ИИ-модели ускорители, получила на развитие $169 млнСтартап Taalas, разрабатывающий чипы, специально оптимизированные для работы с конкретными ИИ-моделями, провел раунд финансирования на сумму в $169 млн. В число инвесторов вошли Quiet Capital и Fidelity, а также венчурный капиталист Пьер Ламонд (Pierre Lamond). Таким образом, на сегодняшний день компания получила на развитие в общей сложности более $200 млн. Фирма Taalas вышла из крытого режима (stealth mode) в марте 2023 года. Стартап занимается созданием чипов, предназначенных для определённых LLM. Первым продуктом компании стало изделие, ориентированное на ИИ-модель Llama 3.1 8B. Утверждается, что этот процессор способен генерировать до 17 тыс. выходных токенов в секунду, что в 73 раза больше по сравнению с NVIDIA H200. При этом решение Taalas потребляет в 10 раз меньше энергии. 
Источник изображения: Taalas Оптимизация аппаратных ускорителей под конкретную ИИ-модуль повышает производительность и эффективность благодаря отказу от избыточных компонентов. Однако разработка таких узкоспециализированных изделий представляет собой сложный и дорогостоящий процесс. Компании Taalas удалось решить проблему, создав архитектуру, при которой для «тонкой» настройки требуется кастомизация только двух из более чем 100 слоев, из которых состоят её чипы. Кроме того, Taalas не использует в своих изделиях дорогостоящую память HBM. Это также упрощает конструкцию, позволяя упразднить компоненты, которые необходимы для обеспечения взаимодействия с HBM-модулями. В настоящее время Taalas работает над чипом, предназначенным для запуска ИИ-модели Llama с 20 млрд параметров: выпуск этого решения намечен на лето нынешнего года. Затем появится более мощный чип, ориентированный на LLM высокого уровня.
19.02.2026 [12:50], Сергей Карасёв
Впятеро энергоэффективнее H100: HyperAccel разработала экономичный чип Bertha 500 для ИИ-инференсаЮжнокорейский стартап HyperAccel, по сообщению EETimes, готовится вывести на рынок специализированный чип Bertha 500, предназначенный для ИИ-инференса. Утверждается, что благодаря особой архитектуре изделие способно генерировать в пять раз больше токенов в секунду по сравнению с решениями на основе GPU при том же уровне TOPS. В Bertha 500 упор сделан на экономическую эффективность. С этой целью используется память LPDDR вместо дорогостоящей HBM. При этом благодаря отказу от традиционной иерархии памяти достигается утилизация пропускной способности LPDDR на 90 %. Дальнейшее повышение эффективности обеспечивается путём оптимизации архитектуры именно для задач инференса. Для сравнения, как утверждает HyperAccel, в случае GPU при инференсе используется только около 45 % пропускной способности памяти и 30 % вычислительных ресурсов. Иными словами, немного жертвуя производительностью, чип Bertha 500 позволяет достичь значительного снижения стоимости. Изделие Bertha 500 будет производиться по 4-нм техпроцессу Samsung. В состав чипа входят 32 ядра LPU (LLM Processing Unit), четыре ядра Arm Cortex-A53 и 256 Мбайт SRAM. Подсистема памяти LPDDR5x использует восемь каналов; пропускная способность достигает 560 Гбайт/с. Заявленная ИИ-производительность на операциях INT8 составляет 768 TOPS. Кроме того, поддерживаются другие 16-, 8- и 4-бит форматы, включая FP16. В целом, по заявлениям HyperAccel, пропускная способность Bertha 500 в расчёте на доллар примерно в 20 раз выше по сравнению с NVIDIA H100, тогда как энергоэффективность больше в пять раз. Чип Bertha 500 будет потреблять около 250 Вт. 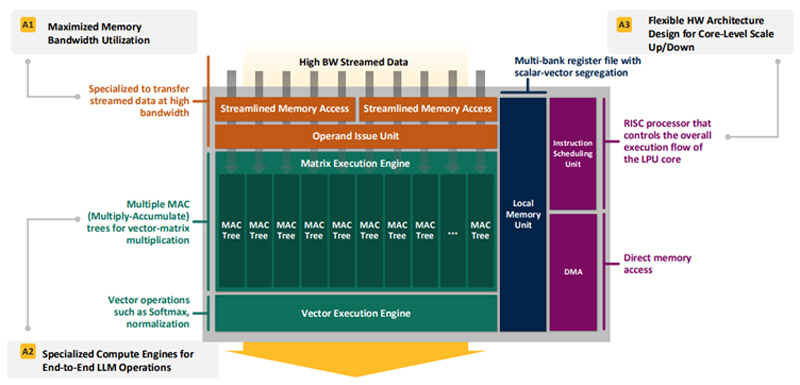
Источник изображения: EETimes Программный стек HyperAccel поддерживает все модели из репозитория HuggingFace. Кроме того, компания работает над предметно-ориентированным языком (DSL) под названием Legato, который предоставит разработчикам низкоуровневый доступ к системе. Образцы Bertha 500 появятся к концу I квартала 2026 года, а серийное производство планируется организовать в начале 2027 года. Отмечается также, что совместно с LG стартап разрабатывает «урезанную» версию Bertha 500 для периферийных устройств — Bertha 100. Эта SoC получит ядра Arm Cortex-A55 и отдельные компоненты LG, а также два канала памяти LPDDR5x. Среди возможных сфер применения названы автомобильная промышленность, бытовая электроника и робототехника. Bertha 100 планируется выпускать в виде модулей M.2: первые изделия выйдут в IV квартале текущего года. Решение сможет, например, осуществлять преобразование текста в речь или речи в текст. Стартап HyperAccel основан профессором Корейского института передовых технологий (KAIST) Джуёном Кимом (Jooyoung Kim) вместе с группой его студентов в начале 2023 года. На сегодняшний день компания привлекла $45 млн инвестиций, а её рыночная стоимость оценивается в $200 млн. Штат насчитывает около 80 человек. Первым продуктом HyperAccel стал специализированный сервер Orion на базе FPGA, предназначенный для решения ИИ-задач.
17.02.2026 [14:22], Руслан Авдеев
Индийские NeevCloud и Agnikul Cosmos тоже готовы развернуть в космосе сотни дата-центровИндийская аэрокосмическая компания Agnikul Cosmos совместно с облачным ИИ-провайдером NeevCloud планируют развернуть в космосе сотни небольших дата-центров, сообщает Datacenter Dynamics. Первый дата-центр должен заработать на орбите к концу 2026 года. NeevCloud развернёт облачный дата-центр и запустит приложения для ИИ-инференса в режиме реального времени на патентованной платформе, разработанной и построенной Agnikul. Последняя известна напечатанными на 3D-принтере ракетами для запуска малых спутников. Если пилотный запуск окажется удачным, компании намерены вывести на орбиту более 600 дата-центров Orbital Edge в следующие три года. NeevCloud заявляет, что речь идёт не только о простом строительстве дата-центров в космосе, но и полностью новом уровне инфраструктуры для орбитального инференса. По словам представителя Agnikul, технология ступени-трансформера позволяет сохранять её функциональность. Фактически речь идёт о превращении ступени в «полезные активы», в которых может размещаться оборудование и программное обеспечение, включая данные и вычислительные мощности. Это новый этап для аэрокосмической компании, позволяющий снизить цены эксплуатации и капитальные издержки, используя размещённое в многоразовых ступенях оборудование. 
Источник изображения: Agnikul Помимо SpaceX, попросившей разрешение на запуск сразу миллиона спутников, с проектами космических ЦОД выступают и другие компании, например, масштабная инициатива исходит от Google и др., хотя реальная практика внедрения, вероятно, будет довольно сложной. На днях Starcloud также подала заявку на запуск 88 тыс. спутников. Это меньше, чем мегапроект SpaceX, но тоже вполне крупный проект. Помимо этих компаний, над собственными космическими проектами работают Amazon, Blue Origin, Axiom Space, NTT, Ramon.Space, Sophia Space и др.
17.02.2026 [11:08], Сергей Карасёв
SK hynix предлагает гибридную память HBM/HBF для ускорения ИИ-инференсаКомпания SK hynix, по сообщению ресурса Blocks & Files, разработала концепцию гибридной памяти, объединяющей на одном интерпозере HBM (High Bandwidth Memory) и флеш-чипы с высокой пропускной способностью HBF (High Bandwidth Flash). Предполагается, что такое решение будет подключаться к GPU для повышения скорости ИИ-инференса. Современные ИИ-ускорители на основе GPU оснащаются высокопроизводительной памятью HBM. Однако существуют ограничения по её ёмкости, из-за чего операции инференса замедляются, поскольку доступ к данным приходится осуществлять с использованием более медленных SSD. Решить проблему SK hynix предлагает путём применения гибридной конструкции HBM/HBF под названием H3. Архитектура HBF предусматривает монтаж кристаллов NAND друг над другом поверх логического кристалла. Вся эта связка располагается на интерпозере рядом с контроллером памяти, а также GPU, CPU, TPU или SoC — в зависимости от предназначения конечного изделия. В случае H3 на интерпозере будет дополнительно размещён стек HBM. Отмечается, что время доступа к HBF больше, чем к HBM, но вместе с тем значительно меньше, нежели к традиционным SSD. Таким образом, HBF может служить в качестве быстрого кеша большого объёма. 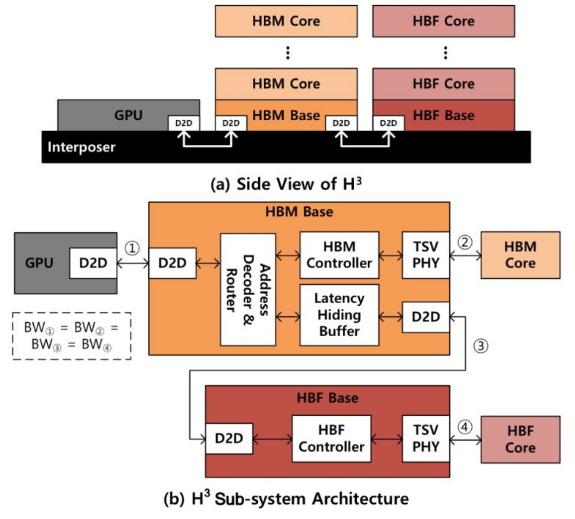
Источник изображения: SK hynix По заявлениям SK hynix, стеки HBF могут иметь до 16 раз более высокую ёмкость по сравнению с HBM, обеспечивая при этом сопоставимую пропускную способность. С другой стороны, HBF обладает меньшей износостойкостью при записи, до 4 раз более высоким энергопотреблением и большим временем доступа. HBF выдерживает около 100 тыс. циклов записи, а поэтому лучше всего подходит для рабочих нагрузок с интенсивным чтением. В результате, как утверждается, гибридная конструкция сможет эффективно решать задачи инференса при использовании больших языковых моделей (LLM) с огромным количеством параметров. В ходе моделирования работы H3, проведенного специалистами SK hynix, рассматривался ускоритель NVIDIA Blackwell B200 с восемью стеками HBM3E и таким же количеством стеков HBF. В пересчете на токены в секунду производительность системы с памятью H3 оказалась в 1,25 раза выше при использовании 1 млн токенов и в 6,14 раза больше при использовании 10 млн токенов по сравнению с решениями, оборудованными только чипами HBM. Более того отмечено 2,69-кратное повышение производительности в расчёте на 1 Вт затрачиваемой энергии по сравнению с конфигурациями без HBF. К тому же связка HBM и HBF может обрабатывать в 18,8 раз больше одновременных запросов, чем только HBM.
13.02.2026 [13:18], Руслан Авдеев
ECL представила всеядную энергетическую архитектуру для периферийных ИИ ЦОДКомпанией ECL (EdgeCloudLink) анонсирована платформа FlexGrid. Речь идёт об энергетической архитектуре, позволяющей развёртывать ИИ ЦОД высокой плотности в локациях с ограниченными возможностями питания. Решение предлагается как способ масштабирования инфраструктуры инференса за пределы крупных кампусов, в которых осуществляется обучение ИИ-моделей — в городские агломерации, периферийные локации и промзоны, где зачастую доступно не более 50–100 МВт, сообщает Converge Digest. FlexGrid обеспечивает модульное развёртывание на площадках мощностью от 2–10 МВт с возможностью масштабировать подключение до 20–25 МВт на объект с помощью интеграции дополнительных, локальных источников энергии различного происхождения. Основа платформы — патентованная система управления питанием ECL, позволяющая объединять несколько источников энергии, включая классические электросети, водородные топливные элементы, генераторы на природном газе, возобновляемые источники и дизельные генераторы. В результате обеспечивается унифицированная подача постоянного или переменного тока. В отличие от традиционных дата-центров, в норме использующих один тип источников энергии, FlexGrid позволяет менять источники энергии или добавлять к ним новые без изменения базовой энергетической инфраструктуры объектов. 
Источник изображения: ECL ECL утверждает, что это позволяет оперативно реагировать на региональные энергетические ограничения, изменения политики энергоснабжения на местах и дефицит топлива, при этом сохраняя стабильное качество электропитания ИИ-инфраструктуры. ECL подчёркивает, что FlexGrid разработана для «нормализации» подачи энергии из любых локальных источников и надёжного энергоснабжения ИИ-объектов в условиях ограничений сетевой энергоинфраструктуры. Пока конкуренты стремятся обеспечить себе мощности от 50 МВт для обучения, ECL работает на обозримую перспективу, делая ставку на периферийные объекты, где жизненно важным становится возможность агрегации и управления питанием таким образом, чтобы обеспечить гибкий выбор площадок и быстрый ввод объектов в эксплуатацию. Летом 2026 года сообщалось, что ECL напечатала свой первый модульный дата-центр, работающий от водородных элементов питания. В сентябре того же года появилась информация, что компаняи построит гигантский «зелёный» ЦОД TerraSite-TX1, а первым арендатором станет ИИ-облако Lambda. Годом позже вышла новость о том, что Lambda и ECL впервые запитали NVIDIA GB300 NVL72 от водорода, но теперь стартап перешёл к более универсальным решениям. |
|

