Материалы по тегу: суперкомпьютер
|
21.07.2025 [16:42], Сергей Карасёв
Запущен самый мощный в Великобритании ИИ-суперкомпьютер — комплекс Isambard-AIВ Великобритании официально введён в эксплуатацию суперкомпьютер Isambard-AI: это самый мощный в стране вычислительный комплекс, ориентированный на задачи ИИ. В июньском рейтинге TOP500 машина занимает 11-е место, а в списке наиболее энергоэффективных систем Green500 — четвёртую позицию. Суперкомпьютер назван в честь британского инженера Изамбарда Кингдома Брюнеля (Isambard Kingdom Brunel), внёсшего значимый вклад в Промышленную революцию. Проект реализован при участии компаний NVIDIA и HPE, Бристольского университета (University of Bristol) и других организаций. Создание Isambard-AI обошлось примерно в £225 млн ($302 млн). В основу комплекса положена платформа HPE Cray EX с интерконнектом Slingshot 11. Задействованы 5448 суперчипов NVIDIA GH200 Grace Hopper, которые объединяют 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H200. Применена СХД Cray ClusterStor E1000 вместимостью 25 Пбайт. Питание полностью обеспечивается от источников энергии с нулевыми выбросами углерода. Избыточное тепло может использоваться для обогрева близлежащих зданий. Развёрнута система прямого жидкостного охлаждения HPE. 
Источник изображений: NVIDIA В тесте Linpack комплекс Isambard-AI демонстрирует FP64-быстродействие на уровне 216,5 Пфлопс, тогда как теоретический пиковый показатель составляет 278,58 Пфлопс. Производительность при решении ИИ-задач достигает 21 Эфлопс (FP8). Как отмечается, Isambard-AI более чем в 10 раз превосходит по скорости второй по быстродействию суперкомпьютер в Великобритании и предоставляет больше вычислительной мощности, чем все остальные НРС-машины страны вместе взятые.  Новый комплекс будет применяться для решения наиболее сложных и ресурсоёмких задач, таких как разработка передовых лекарственных препаратов, моделирование климата, материаловедение, большие языковые модели (LLM) и др. Доступ к ресурсам Isambard-AI регулируется Министерством науки, инноваций и технологий и Департаментом исследований и инноваций Великобритании.
21.07.2025 [09:27], Сергей Карасёв
10 долгих лет: состоялся официальный запуск экзафлопсного суперкомпьютера AuroraВ Аргоннской национальной лаборатории (ANL) Министерства энергетики США (DOE) в Иллинойсе состоялась церемония торжественного разрезания ленты в честь официального запуска суперкомпьютера Aurora экзафлопсного класса. В мероприятии приняли участие руководители и исследователи Intel, HPE и DOE. Церемония была скорее формальностью, поскольку Aurora стала доступна исследователям со всего мира в начале текущего года. Aurora является одним из трёх суперкомпьютеров DOE с производительностью более 1 Эфлопс. Наряду с El Capitan в Ливерморской национальной лаборатории имени Лоуренса (LLNL) и Frontier в Национальной лаборатории Оук-Ридж (ORNL) эти НРС-комплексы занимают первые три места как в списке TOP500 самых быстрых суперкомпьютеров мира, так и в бенчмарке HPL-MxP для оценки производительности ИИ. У суперкомпьютера непростая судьба. Анонс машины состоялся в 2015 году — система с FP64-производительностью на уровне 180 Пфлопс по плану должна была заработать в 2018 году. Однако планы неоднократно корректировались, а проект в конце концов был кардинально пересмотрен. Первые тестовые кластеры системы заработали более двух лет назад, а частично запущенная система попала в TOP500 в конце 2023 года. Целиком она заработала в 2024 году. 
Источник изображения: ANL / Intel В проекте по созданию Aurora принимали участие Intel и HPE. Машина построена на платформе HPE Cray EX — Intel Exascale Compute Blade: задействованы процессоры Intel Xeon CPU Max и ускорители Intel Data Center GPU Max, объединённые интерконнектом HPE Slingshot. В общей сложности применяются 63 744 ускорителей, что делает Aurora одним из крупнейших в мире суперкомпьютеров на базе GPU. 
Источник изображения: ANL / Intel Установлена ОС SUSE Linux Enterprise Server 15 SP4. Производительность в тесте Linpack составляет 1,012 Эфлопс, а теоретический пиковый показатель достигает 1,980 Эфлопс. НРС-комплекс занимает площадь около 930 м2. Развёрнута современная инфраструктура жидкостного охлаждения. Общая протяжённость соединений превышает 480 км, а количество конечных точек сети достигает 85 тыс.  Aurora останется по-своему уникальным суперкомпьютером: CPU с HBM на борту больше не планируются, от Ponte Vecchio компания отказалась в пользу Habana Gaudi и Falcon Shores. Но и последние на рынок не попадут, а будут использоваться для внутренних тестов и обкатки технологий. На смену им должны прийти Jaguar Shores, но точных дат Intel не называет.  Вычислительные мощности Aurora, как отмечается, помогают в решении сложнейших задач в самых разных областях. В биологии и медицине исследователи используют ИИ-возможности суперкомпьютера для прогнозирования эволюции вирусов, улучшения методов лечения рака и картирования нейронных связей в мозге. В аэрокосмической сфере Aurora используется для создания двигательных установок нового поколения и моделирования аэродинамических процессов. Комплекс играет важную роль в развитии технологий термоядерной энергетики, квантовых вычислений и пр.
17.07.2025 [17:50], Владимир Мироненко
Бразилия потратит $4,2 млрд на развитие ИИ и хочет построить один из мощнейших в мире суперкомпьютеровПравительство Бразилии планирует провести модернизацию суперкомпьютера Santos Dumont (SDumont), установленного в Национальной лаборатории научных вычислений (LNCC) в Петрополисе (Petrópolis), в рамках программы Brazilian Artificial Intelligence Plan (BPIA, Бразильский план развития ИИ), пишет ресурс The Next Platform. Страна намерена получить ИИ-суперкомпьютер, который войдёт в пятёрку самых производительных в мире. С его помощью предполагается обучать собственные ИИ-модели. Как сообщает ресурс The Dannemann Siemsen Institute (IDS), проект BPIA, получивший название «ИИ на благо всех», направлен на то, чтобы вывести Бразилию в мировые лидеры в области ИИ-технологий. Он был разработан в сотрудничестве с частным сектором и другими учреждениями для определения целей и руководящих принципов развития и применения ИИ в различных областях, включая здравоохранение, образование, общественную безопасность и энергетику. Инвестиции BPIA будет получать от частного сектора, Национального фонда научно-технологического развития (FNDCT), организации Finep (Financiadora de Estudos e Projetos) Министерства науки, технологий и инноваций (MCTI), и Национального банка экономического и социального развития (BNDES). Всего на реализацию BPIA в 2025–2028 гг. будет направлено R$23 млрд ($4,2 млрд). 
Источник изображения: LNCC Программа BPIA направлена на модернизацию государственных услуг, предоставляемых населению, с помощью ИИ. План включает два основных этапа: так называемые «Меры немедленного воздействия» и «Меры структурирования». Основная доля инвестиций будет направлена на реализацию «Мер немедленного воздействия», включающих 31 инициативу, которые уже реализуются или будут запущены в ближайшее время для решения конкретных проблем в таких приоритетных областях, как здравоохранение, сельское хозяйство, окружающая среда, промышленность, торговля и сфера услуг, образование, социальное развитие и управление государственными услугами. На модернизацию Santos Dumont Бразилии будет выделено порядка R$1,8 млрд ($322 млн), что позволит вчетверо увеличить вычислительные мощности. Основным поставщиком останется Eviden (Atos), которая и развернула Santos Dumont в 2015 году. Его производительность на тот момент составляла 1,1 Пфлопс. В 2019 году эта система была модернизирована, благодаря чему её производительность выросла до 1,5 Пфлопс. Последний апгрейд были завершён в июле этого года, производительность суперкомпьютера выросла до 18,85 Пфлопс (FP64). В настоящее время Santos Dumont состоит из пяти модулей. Первый включает 62 блейд-сервера BullSequana XH3145-H: два 48-ядерных Intel Xeon 9468 (Sapphire Rapids Max) + четыре NVIDIA H100. Второй отсек содержит 20 «лезвий» BullSequana XH3420 с тремя узлами, каждый из которых оснащён парой 96-ядерных процессоров AMD EPYC 9684X (Genoa-X). Третий модуль состоит из 36 узлов BullSequana XH3515-H на базе NVIDIA Quad GH200. Четвёртый включает шесть «лезвий» по три узла с парой AMD Instinct MI300A APU. Наконец, пятый модуль состоит из четырёх узлов с NVIDIA Grace Superchip.
08.07.2025 [17:09], Владимир Мироненко
Российский суперкомпьютер «Говорун» получил два узла «РСК Экзастрим ИИ» с NVIDIA H100 и фирменной СЖО
emerald rapids
h100
h200
hpc
intel
nvidia
sapphire rapids
xeon
россия
рск
сделано в россии
сервер
суперкомпьютер
ГК РСК продемонстрировала 2U-узел (912 × 508 × 88 мм) собственной разработки «РСК Экзастрим ИИ» на базе восьми ускорителей NVIDIA H100 с прямым жидкостным охлаждением. Два таких узла были установлены в суперкомпьютере «Говорун» в Дубне. «РСК Экзастрим ИИ» включает:
«РСК Экзастрим ИИ» имеет локальную подсистему хранения «тёплых данных», сетевую подсистему с доступом на основе технологии GPUDirect. Также есть возможность расширения ресурсов путём подключения дополнительных пар ускорителей или системы внешнего хранения данных на базе пула JBOF, подключаемой напрямую. Производительность «РСК Экзастрим ИИ» составляет до 208 Тфлопс (FP64). При установке 21 сервера в шкаф «РСК Экзастрим» пиковая производительность достигает 4,26 Пфлопс (FP64). Сервер отличается высокой энергоэффективностью, сверхвысокой плотностью монтажа и надёжной работой. Он может использоваться для решения ресурсоёмких задач в области машинного обучения и ИИ, создания мощных вычислительных ресурсов облачных провайдеров и в частных облаках и т.д. 
Источник изображений: РСК Два узла «РСК Экзастрим ИИ» были установлены в суперкомпьютере «Говорун» в Лаборатории информационных технологий им М.Г. Мещерякова Объединенного института ядерных исследований (ЛИТ ОИЯИ) в Дубне в рамках нового этапа модернизации, проведенной силами специалистов ГК РСК и лаборатории.  Как сообщается, новые серверы «РСК Экзастрим ИИ» уникальны и были сконструированы и изготовлены для СК «Говорун» с учётом его архитектурных особенностей. При этом пиковая FP64-производительность GPU-компоненты суперкомпьютера «Говорун» выросла на 36 % и достигла 1,4 Пфлопс, пиковая суммарная FP64-производительность суперкомпьютера теперь составляет 2,2 Пфлопс. Характеристики серверов «РСК Экзастрим ИИ», установленных в ОИЯИ:
 В конце 2024 года было проведено расширение СХД суперкомпьютера «Говорун», после чего её ёмкость увеличилась до 10 Пбайт. В СХД вычислительного комплекса ОИЯИ были добавлены два узла хранения данных RSC Tornado AFS ёмкостью 1 Пбайт каждый. Обновленная модификация СХД RSC Tornado AFS включает серверную плату на базе процессоров Intel Xeon Sapphire Rapids, а также коммутатор с интерфейсом PCIe 4.0, что позволило установить по два адаптера интерконнекта с пропускной способностью 200 Гбит/с каждый.  СХД RSC Tornado AFS поддерживает технологию GPUDirect Storage (GDS), которая обеспечивает прямую передачу данных между локальным или удалённым хранилищем и памятью ускорителя. Две СХД, установленные ранее специалистами РСК в суперкомпьютере «Говорун» входят в мировой рейтинг IO500 самых высокопроизводительных системам хранения данных. В суперкомпьютере «Говорун» используются интегрированный программный комплекс «РСК БазИС 4» и модуль «РСК БазИС СХД» (включены в Реестр российского ПО). Микроагентная архитектура «РСК БазИС 4» обеспечивает функционирование объектов системы, позволяя также взаимодействовать с ними. «РСК БазИС» в сочетании с аппаратными платформами РСК позволяет создавать гиперконвергентные решения для HPC и эффективной обработки больших объёмов данных.
07.07.2025 [14:05], Сергей Карасёв
Суперкомпьютер Doudna получит смешанное All-Flash хранилище IBM и VAST DataНациональная лаборатория им. Лоуренса в Беркли (Berkeley Lab), принадлежащая Министерству энергетики США (DOE), сообщила о том, что суперкомпьютер Doudna получит передовую подсистему хранения данных на основе технологий IBM и VAST Data. Эта платформа сможет с высокой эффективностью справляться с интенсивными нагрузками, связанными с обучением ИИ-моделей и инференсом. НРС-комплекс Doudna (NERSC-10) расположится в Национальном вычислительном центре энергетических исследований США (NERSC) в составе Berkeley Lab. Основой суперкомпьютера послужат системы Dell Integrated Rack Scalable Systems и серверы PowerEdge с ускорителями NVIDIA Vera Rubin. По предварительным данным, машина обеспечит FP64-быстродействие до 790 Пфлопс при потреблении 5,8–8,7 МВт. С целью достижения стабильной и предсказуемой производительности в задачах, требующих анализа данных в режиме, близком к реальному времени, для Doudna выбрана гибридная подсистема хранения, включающая зоны QSS (Quality-of-service Storage System) и PSS (Platform Storage System). Первая ориентирована прежде всего на ИИ-нагрузки: предполагается применение решений VAST Data, включая платформу VAST AI OS. Эта платформа, как утверждается, «объединяет возможности хранения информации, базы данных, вычислений, обмена сообщениями и рассуждений в единую инфраструктуру, созданную с нуля для ИИ и программных агентов». 
Источник изображения: Berkeley Lab В свою очередь, PSS использует в качестве основы программно-определяемое решение IBM Storage Scale: этот сегмент будет функционировать как быстродействующая параллельная файловая система. Говорится о высокой производительности, масштабируемости и эффективности, что поможет устранить узкие места и оптимизировать рабочие процессы, связанные с обработкой данных. Для обоих сегментов СХД предусмотрено использование архитектуры All-Flash, то есть, будут задействованы исключительно SSD. Как отмечает Berkeley Lab, гибридная подсистема хранения обеспечит в пять раз более высокую производительность, нежели нынешний НРС-комплекс NERSC. Это позволит справляться с крупномасштабными рабочими нагрузками в таких областях исследований, как молекулярная динамика и геофизическое моделирование. Ввести суперкомпьютер в эксплуатацию планируется в 2026 году.
01.07.2025 [09:02], Владимир Мироненко
Крупнейший в истории AWS ИИ-суперкомпьютер Project Rainier охватит несколько ЦОД, но будет экологичнымВ настоящее время Amazon Web Services (AWS) занимается строительством ИИ-суперкомпьютера Project Rainier. Проект, охватывающий несколько ЦОД в США, по своим масштабам не похож ни на что, что когда-либо пыталась реализовать AWS. Этот огромный уникальный суперкомпьютер разработан для создания и работы ИИ-моделей следующего поколения. Партнёром AWS в реализации проекта выступает ИИ-стартап Anthropic, который будет использовать новый ИИ-кластер для создания и развёртывания будущих версий LLM Claude. У компаний довольно тесные отношения, а появление Project Rainier снизит зависимость Anthropic и AWS от дефицитных ускорителей NVIDIA, которых не хватает и для собственных нужд Amazon. «Rainier обеспечит в пять раз больше вычислительной мощности по сравнению с крупнейшим в настоящее время кластером Anthropic», — сообщил Гади Хатт (Gadi Hutt), директор по разработке и проектированию продуктов Annapurna Labs, подразделения AWS по разработке чипов. Чем больше вычислений вложить в обучение Claude, тем умнее и точнее будет модель. «Мы создаём вычислительную мощность в масштабах, которых никогда не было раньше, и мы делаем это с беспрецедентной скоростью и гибкостью», — подчеркнул Хатт. 
Источник изображений: Amazon Сообщается, что Project Rainier спроектирован как огромный кластер EC2 UltraCluster, состоящий из серверов UltraServers с Trainium2. Trainium2 — ИИ-ускоритель собственной разработки Amazon, предназначенный для обучения ИИ-моделей. UltraServer — новый тип вычислительной системы, которая объединяет четыре физических сервера, каждый из которых содержит 16 ускорителей Trainium2, взаимодействие между которыми осуществляется с помощью интерконнекта NeuronLinks (кабели синего цвета на фото). Связь между компонентами суперкомпьютера реализуется на двух критических уровнях: NeuronLinks обеспечивают высокоскоростные соединения внутри UltraServer, в то время как DPU Elastic Fabric Adapter (EFA) объединяет UltraServer внутри ЦОД и между ЦОД. Этот двухуровневый подход позволяет максимизировать скорость в местах, где в этом больше всего есть потребность, сохраняя гибкость масштабирования в рамках нескольких дата-центров.  Эксплуатация и обслуживание такого огромного вычислительного кластера отличается повышенной сложностью. И в данном случае надёжность системы имеет первостепенное значение. Именно здесь подход компании к разработке оборудования и ПО действительно выходит на первый план, говорит компания. Благодаря тому, что AWS сама занимается разработкой оборудования, она может контролировать каждый аспект технологического стека, от мельчайших компонентов чипа до ПО и архитектуры самого ЦОД. Это также позволяет ускорить внедрение технологий и снизить затраты при внедрении ИИ. «Когда у вас есть полная картина, от чипа до ПО и самих серверов, вы можете проводить оптимизацию там, где это имеет наибольший смысл», — говорит директор по инжинирингу Annapurna Labs Рами Синно (Rami Sinno). «Иногда лучшим решением может быть перепроектирование того, как подаётся питание серверов, или переписывание ПО, которое всё координирует. Это может происходить и одновременно. Поскольку у нас есть обзор всего на каждом уровне, мы можем быстро устранять неполадки и внедрять инновации гораздо быстрее», — добавил он.  Вместе с тем, по словам Amazon, внедрение мощной ИИ-инфраструктуры будет достаточно экологичным. Вся электроэнергия, потребляемая Amazon, включая её ЦОД, в 2023 году была полностью компенсирована закупками из возобновляемых источников энергии. В течение последних пяти лет Amazon была крупнейшим корпоративным покупателем возобновляемой энергии в мире. Компания инвестирует миллиарды долларов в ядерную энергию и использование аккумуляторов, а также в финансирование масштабных проектов возобновляемой энергии по всему миру. Amazon по-прежнему намерена добиться нулевого уровня выбросов углерода к 2040 году. И Project Rainier ей в этом поможет. В прошлом году AWS объявила, что будет развёртывать новые компоненты, которые объединяют достижения в области питания и охлаждения, не только в строящихся, но и в существующих ЦОД. Их использование, как ожидается, позволит снизить потребление энергии механизмами до 46 % и сократить выбросы парниковых газов при производстве бетона на 35 %. Новые объекты для Project Rainier будут включать в себя различные усовершенствования для повышения энергоэффективности и экологичности с акцентом на сокращение потребления водных ресурсов и использованию забортного воздуха для охлаждения.  Например, в ЦОД в округе Сент-Джозеф (St. Joseph), штат Индиана, с октября по март ЦОД вообще не будут использовать воду для охлаждения, а с апреля по сентябрь питьевая вода будет нужна только в течение нескольких часов в день. Amazon не уточняет, о каком именно кампусе идёт речь, но уже известно, что компания строит в Индиане дата-центр, который будет потреблять энергии как половина населения штата. Благодаря инженерным инновациям AWS является лидером отрасли по эффективности использования воды, заявляет компания. На основании результатов недавнего исследования Национальной лаборатории Лоуренса в Беркли, посвящённого эффективности использования воды в ЦОД, отраслевой стандартный показатель составляет 0,375 л/кВт·ч, тогда как у AWS он равен всего 0,15 л/кВт·ч. Компания улучшила этот параметр на 40 % по сравнению с 2021 годом.
30.06.2025 [11:11], Сергей Карасёв
Албания присоединилась к европейской суперкомпьютерной программе EuroHPC JUЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) сообщило о том, что Албания стала 36-м государством — участником проекта. Соответствующее решение принято по итогам 49-го заседания совета управляющих EuroHPC. Отмечается, что Албания принимает активное участие в программе Европейского союза по исследованиям и инновациям с 2008 года. Доступ к вычислительным ресурсам EuroHPC предоставляется научно-исследовательским институтам, государственным органам и промышленным предприятиям Албании. Теперь эта страна становится полноправным участником EuroHPC. Албанские специалисты смогут подавать заявки на исследовательские и инновационные инициативы EuroHPC JU, финансируемые в рамках программы Horizon Europe. Кроме того, Албания сможет внести свой вклад в развёртывание так называемых европейских фабрик ИИ — EuroHPC AI Factories. В 2025 году такие площадки появятся в Финляндии, Германии, Греции, Италии, Люксембурге, Испании и Швеции. В целом, EuroHPC JU курирует создание 13 фабрик ИИ по всей Европе, которые будут предоставлять ресурсы малым и средним компаниям, а также стартапам. 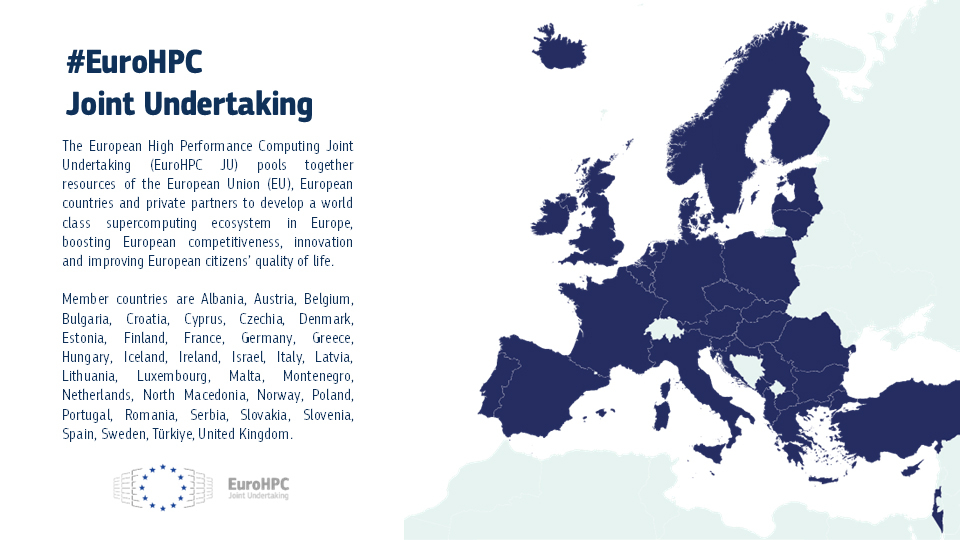
Источник изображения: EuroHPC JU Албания присоединилась к другим странам — членам EuroHPC JU, которые участвуют в программе Horizon Europe и при этом не входят в Европейский союз. Среди них — Исландия, Черногория, Северная Македония, Норвегия, Сербия, Турция и Великобритания. В целом, EuroHPC активно развивает инфраструктуру высокопроизводительных вычислений в Европе. В рамках инициативы на сегодняшний день развёрнуты десять НРС-систем. Три из суперкомпьютеров EuroHPC входят в десятку самых мощных НРС-комплексов мира: это Jupiter в Германии, который занимает 4-е место в июньском списке ТОР500, а также LUMI в Финляндии (9-я строка) и Leonardo в Италии (10-е место). Подписано соглашение с французским национальным агентством высокопроизводительных вычислений (GENCI) о размещении второго в Европе (после Jupiter) суперкомпьютера экзафлопсного класса — системы Alice Recoque. Кроме того, EuroHPC JU формирует европейскую инфраструктуру квантовых вычислений. В частности, в конце 2024 года была начата подготовка к созданию передовых сетей, которые соединят суперкомпьютеры, квантовые компьютеры и дата-центры Евросоюза. Вместе с тем Юлихский суперкомпьютерный центр в Германии (JSC) получил 100-кубитный квантовый компьютер на нейтральных атомах. EuroHPC также развернёт в Европе специализированные индустриальные суперкомпьютеры.
29.06.2025 [21:11], Сергей Карасёв
Таёжное облако: ИИ-кластер Northern Data Njoerd вошёл в рейтинг TOP500
h100
hardware
hpc
hpe
intel
northern data
nvidia
sapphire rapids
xeon
великобритания
ии
облако
суперкомпьютер
Немецкая компания Northern Data Group, поставщик решений в области ИИ и НРС, объявила о том, что её система Njoerd вошла в июньский рейтинг мощнейших суперкомпьютеров мира TOP500. Этот вычислительный комплекс, расположенный в Великобритании, построен на платформе HPE Cray XD670. Машина Njoerd попала на 26-е место списка TOP500. Она объединяет 244 узла, каждый из которых содержит восемь ускорителей NVIDIA H100. В общей сложности задействованы примерно 28,5 млн ядер CUDA. Кроме того, в составе системы используются процессоры Intel Xeon Platinum 8462Y+ (32C/64C, 2,8–4,1 ГГц, 300 Вт). Применён интерконнект Infiniband NDR400. FP64-производительность Njoerd достигает 78,2 Пфлопс, а теоретическое пиковое быстродействие составляет 106,28 Пфлопс. При рабочих нагрузках ИИ суперкомпьютер демонстрирует производительность 3,86 Эфлопс в режиме FP8 и 1,93 Эфлопс в режиме FP16. Заявленный показатель MFU (Model FLOPs Utilization) при предварительном обучении современных больших языковых моделей (LLM) находится на уровне 50–60 %. Таким образом, как утверждается, система Njoerd на сегодняшний день представляет собой наиболее эффективный кластер H100 подобного размера, оптимизированный для ресурсоёмких рабочих нагрузок ИИ и HPC. Суперкомпьютер входит в состав Taiga Cloud — одной из крупнейших в Европе облачных платформ, ориентированных на задачи генеративного ИИ. Эта вычислительная инфраструктура использует на 100 % безуглеродную энергию. Показатель PUE варьируется от 1,15 до 1,06. Доступ к ресурсам предоставляется посредством API или через портал самообслуживания. Одним из преимуществ Taiga Cloud компания Northern Data Group называет суверенитет данных. 
Источник изображения: Northern Data Group
23.06.2025 [11:58], Сергей Карасёв
Подземный суперкомпьютер Olivia стал самым мощным в НорвегииВ Норвегии введён в эксплуатацию самый мощный в стране суперкомпьютер — система Olivia, созданная корпорацией HPE. Комплекс расположен в дата-центре Лефдаль (Lefdal Mine Datacenter, LMD) на базе бывшего рудника, а для его охлаждения используется холодная вода из близлежащего фьорда. Машина построена на платформе HPE Cray Supercomputing EX (EX254n). В её состав входят 252 узла, каждый из которых содержит два 128-ядерных процессора AMD EPYC 9745 (Turin). В сумме это даёт 64 512 CPU-ядер. Кроме того, задействован GPU-кластер с 76 узлами, оснащёнными четырьмя гибридными суперчипами NVIDIA GH200: таким образом, в общей сложности применены 304 ускорителя. Используется интерконнект HPE Slingshot 11. За хранение данных отвечает система HPE Cray ClusterStor E1000 вместимостью 5,3 Пбайт. В текущей конфигурации GPU-кластер Olivia обладает производительностью 13,2 Пфлопс (FP64) и пиковым быстродействием 16,8 Пфлопс. При этом энергопотребление составляет 219 кВт. Таким образом, машина демонстрирует производительность в 60,274 Гфлопс/Вт. В июньском рейтинге мощнейших суперкомпьютеров мира TOP500 GPU-комплекс Olivia располагается на 117-й позиции, тогда как в списке самых энергоэффективных суперкомпьютеров GREEN500 он занимает 22-ю строку. CPU-блок Olivia занимает 271-е место в рейтинге с фактической и пиковой FP64-производительностью 4,25 и 4,95 Пфлопс соответственно. 
Источник изображения: Sigma2 Olivia эксплуатируется государственной компанией Sigma2. Применять суперкомпьютер планируется для проведения исследований в различных областях, включая изменения климата, здравоохранение, ИИ и пр. Суперкомпьютер обладает возможностями для дальнейшего расширения. В частности, количество ядер CPU может быть увеличено до 119 808. Кроме того, могут быть добавлены ещё 224 ускорителя.
19.06.2025 [17:13], Руслан Авдеев
Экзафлопсный суперкомпьютер Fugaku Next получит Arm-процессоры Fujitsu MONAKA-XЯпонская Fujitsu получила контракт на разработку преемника суперкомпьютера Fugaku, получившего условное название FugakuNEXT (Fugaku Next), сообщает Datacenter Dynamics. Информация об этом появилась ещё в прошлом году, но теперь заключено официальное соглашение. Новую машину разместят рядом с уже действующей в институте Riken (Япония) системой. Контракт включает и поставку вычислительного оборудования, а первая фаза проектирования продлится до конца февраля 2026 года. Fujitsu разрабатывает энергоэффективные 2-нм 144-ядерные Arm-процессоры MONAKA с 3.5D-упаковкой, начало выпуска которых запланировано на 2027 год. Для FugakuNEXT компания создаст процессоры MONAKA-X, которые позволят не только ускорить работу уже существующих приложений для Fugaku, но и добавят современные возможности ускорения ИИ-вычислений. В компании уверены, что новые процессоры пригодятся не только в очередном суперкомпьютере, но и в самых разных сферах экономики, общественной жизни и промышленности. Кроме того, компания направит усилия на создание NPU следующего поколения. 
Источник изображения: Van Tay Media/unspalsh.com Введённый в эксплуатацию весной 2020 года суперкомпьютер Fugaku несколько лет подряд занимал первые места в TOP500 и других рейтингах. В последнем списке TOP500 он занимает седьмую позицию. Министерством образования, культуры, спорта, науки и технологий Японии (MEXT) разработку FugakuNEXT анонсировало в августе 2024 года. Тогда утверждалось, что компьютер станет первой вычислительной машиной зеттафлопсного уровня. Впрочем, такая пиковая производительность относится только к ИИ-вычислениям. Так или иначе, ранее MEXT публиковало документ, согласно которому каждый узел Fugaku Next должен обеспечить пиковую производительность в сотни Тфлопс (FP64), что в совокупности может составить 1 Эфлопс. |
|

