Материалы по тегу: grace
|
10.05.2024 [23:47], Сергей Карасёв
Eviden представила семейство ИИ-серверов BullSequana AIКомпания Eviden (дочерняя структура Atos) анонсировала серверы серии BullSequana AI, предназначенные для решения ИИ-задач. В зависимости от модификации и уровня производительности устройства подходят для различных сценариев использования — от НРС-платформ до периферийных вычислений. Наиболее производительными серверами семейства являются решения BullSequana AI 1200H. Они могут применяться в составе облачных и гибридных инфраструктур, а также в дата-центрах заказчиков. По сути, это суперкомпьютер корпоративного уровня, специально разработанный для ресурсоёмких задач, таких как точная настройка ИИ-систем или обучение больших языковых моделей (LLM). Конфигурация BullSequana AI 1200H включает суперчипы NVIDIA Grace Hopper, а также интерконнект NVIDIA Quantum-2 InfiniBand. Задействовано программное обеспечение Eviden Jarvice XE, Eviden Smart Energy Management Suite, Eviden Smart Management Center и NVIDIA AI Enterprise. 
Источник изображения: Eviden Серверы BullSequana AI 1200H, насчитывающие в общей сложности 1456 ускорителей NVIDIA H100, выбраны для модернизации французского суперкомпьютера Jean Zay. Производительность этого НРС-комплекса увеличится более чем в три раза — с 36,85 до 125,9 Пфлопс. Кроме того, в новое семейство серверов вошли производительные устройства BullSequana AI 800, системы BullSequana AI 600 с воздушным и гибридным охлаждением, модели BullSequana AI 200 для частных и гибридных облачных сред, а также BullSequana AI 100 для периферийных вычислений. 
Источник изображения: Eviden В целом, как отмечается, каждая модель BullSequana AI предлагает различные уровни производительности, масштабируемости и гибкости. Таким образом, заказчики могут подобрать наиболее подходящий для себя вариант в зависимости от конкретного варианта использования, бюджета и размера бизнеса.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 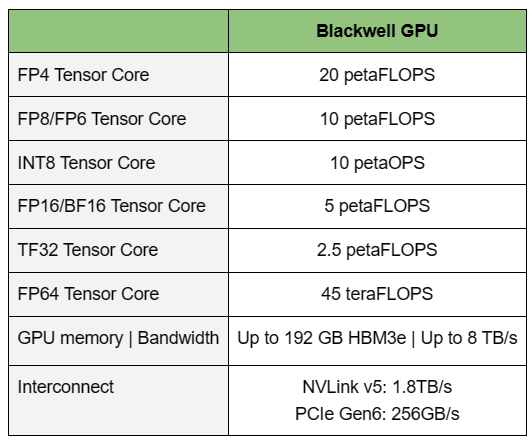 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений. 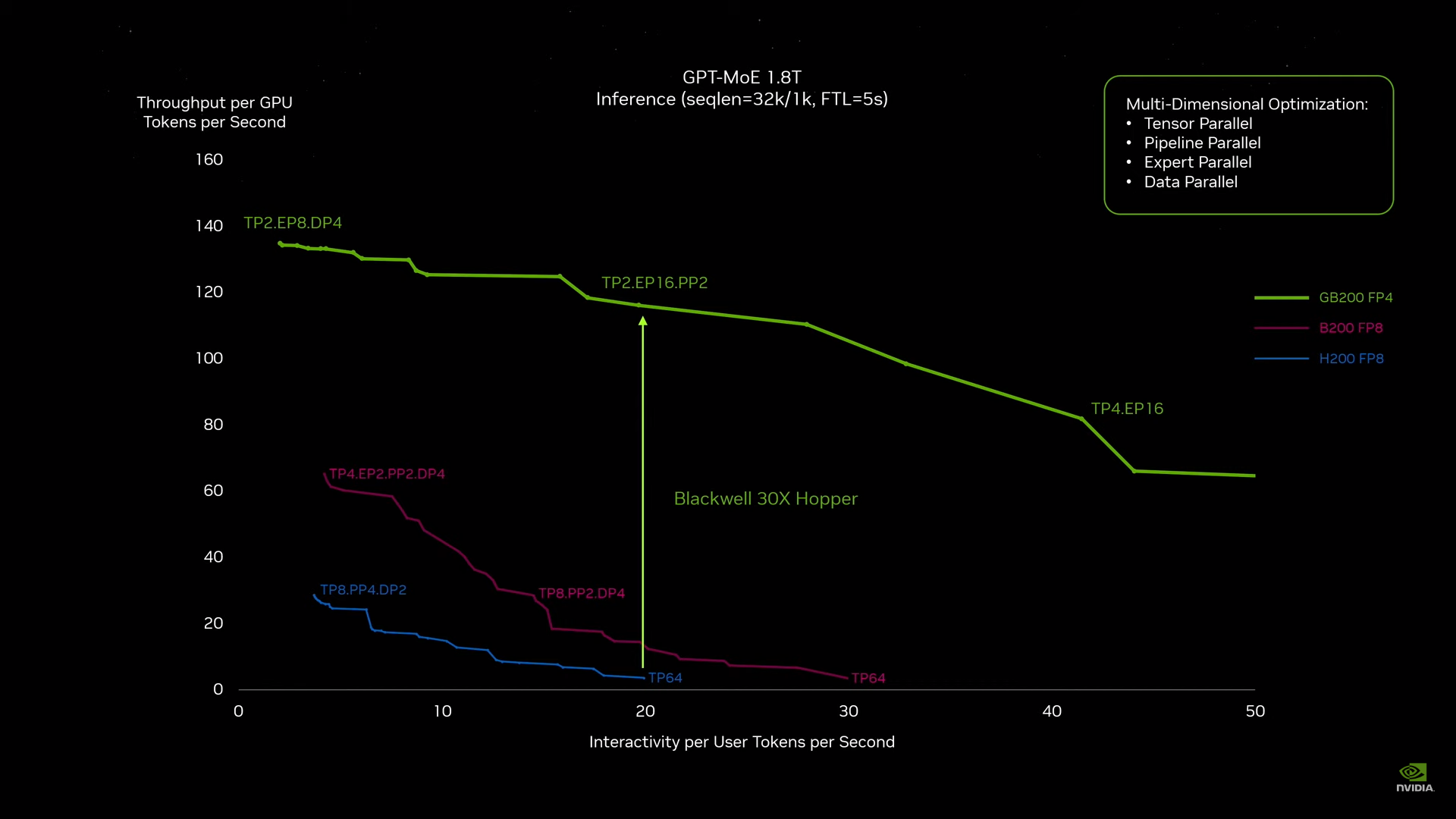 Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 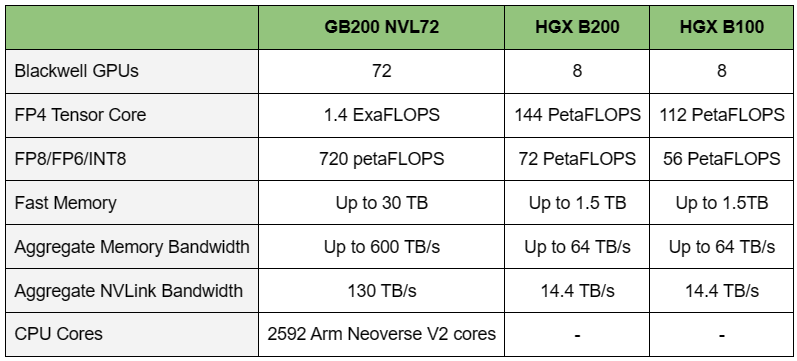 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку (Oberon), оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle.
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200.
22.03.2023 [00:09], Алексей Степин
NVIDIA показала сдвоенный серверный суперпроцессор Grace SuperchipПроект NVIDIA Grace весьма амбициозен: компания всерьёз намерена ворваться с его помощью на рынок высокопроизводительных серверных процессоров, где всё ещё доминируют решения Intel и AMD. Об этом чипе было объявлено ещё на конференции GTC 2022, а на GTC 2023 глава компании, наконец, показал его вживую. В рамках продолжающегося роста плотности упаковки вычислительных мощностей в современных ЦОД на первый план выдвинулась не голая производительность, а соотношение производительности к уровню энергопотребления и тепловыделения. По сочетанию этих параметров x86 далеко не оптимальна, и тут у NVIDIA есть все шансы. С анонсом Grace Superchip NVIDIA провозглашает (впрочем, уже не в первый раз) смерть «закона Мура» — пришло время оптимизации и отказа от устаревших, по мнению компании, вычислительных архитектур. 
Источник изображений здесь и далее: NVIDIA Процессор NVIDIA Grace воплощает в себе все современные тенденции, начиная с отказа от монолитного кристалла. Сборка Grace Superchip состоит из двух кристаллов, каждый из которых включает в себя 72 ядра Arm Neoverse V2 (Arm v9), поддерживающих векторные расширения SVE2 и оптимизированные для ИИ форматы BF16/INT8. Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с.  В сборку интегрированы чипы памяти LPDDR5x общим объёмом до 960 Гбайт, причём каждый кристалл имеет свою шину доступа к памяти с производительностью 500 Гбайт/с. При этом с точки зрения ПО Grace Superchip представляется единым 144-ядерным процессором с ПСП на уровне 1 Тбайт/с. 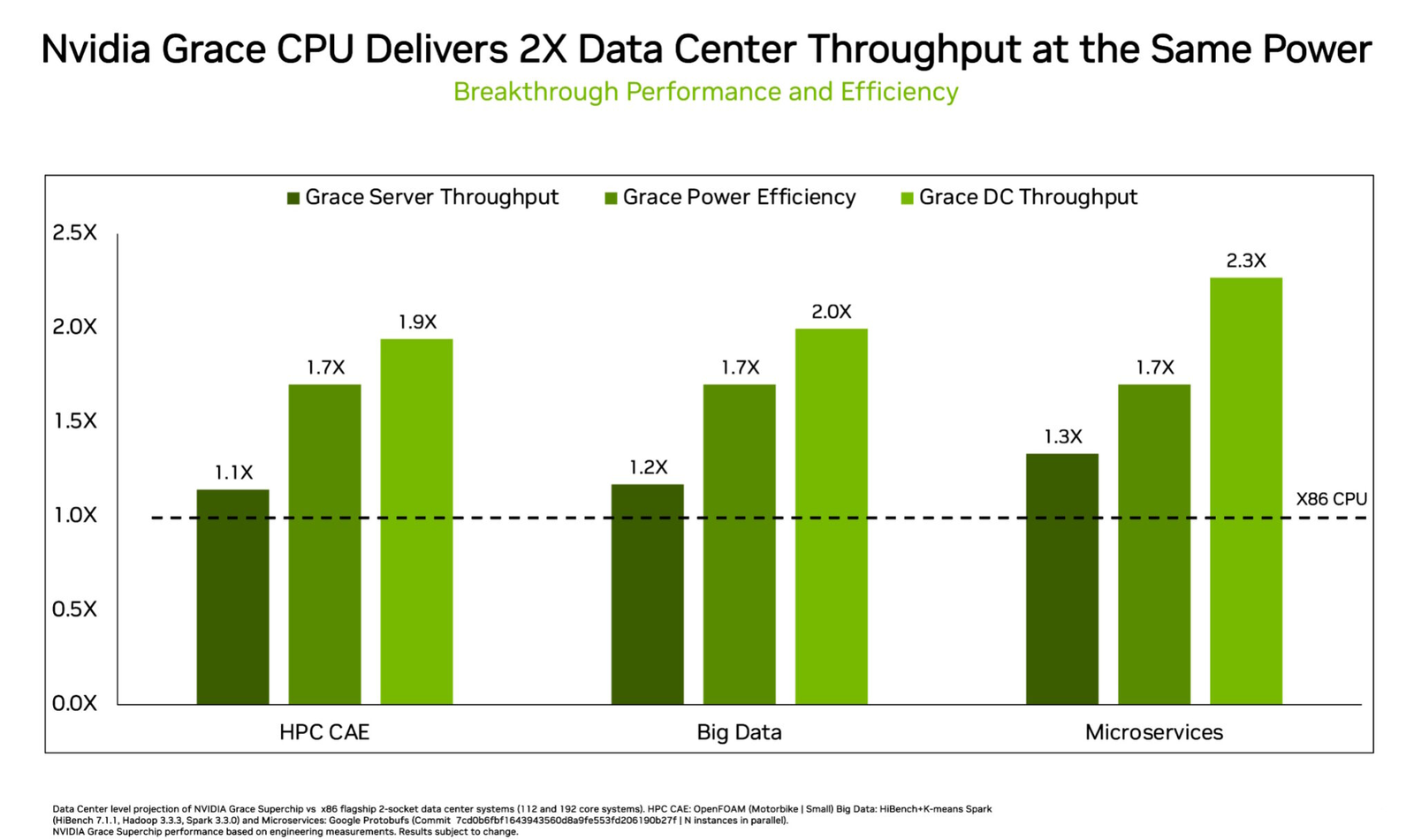 Для достижения схожих параметров в мире x86 требуется двухпроцессорная платформа AMD Genoa, куда более сложная технически и гораздо менее энергоэффективная, но при этом обладающая всеми недостатками NUMA-систем. Достаточно сравнить энергопотребление: 900 Вт против 500 у нового решения NVIDIA. 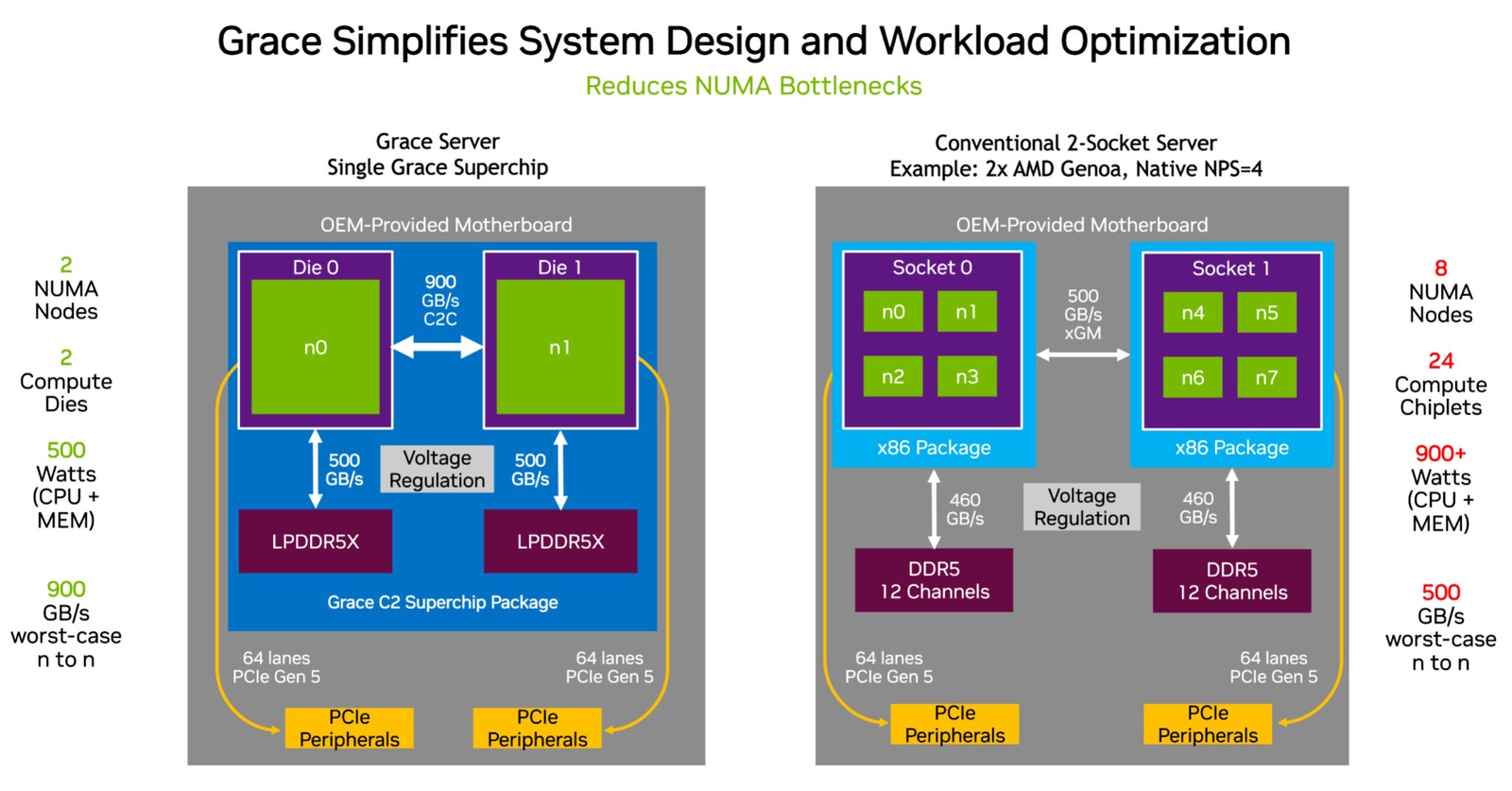 NVIDIA есть чем гордиться: при сопоставимом уровне энергопотребления Grace Superchip превосходит своих конкурентов из мира x86 в 2,3 раза при запуске микросервисов, вдвое опережает их в приложениях с интенсивным обменом данными с памятью и почти вдвое — в задачах симуляции вычислительной гидродинамики. В ряде других научно-технических задач преимущество может быть и более чем двукратным. 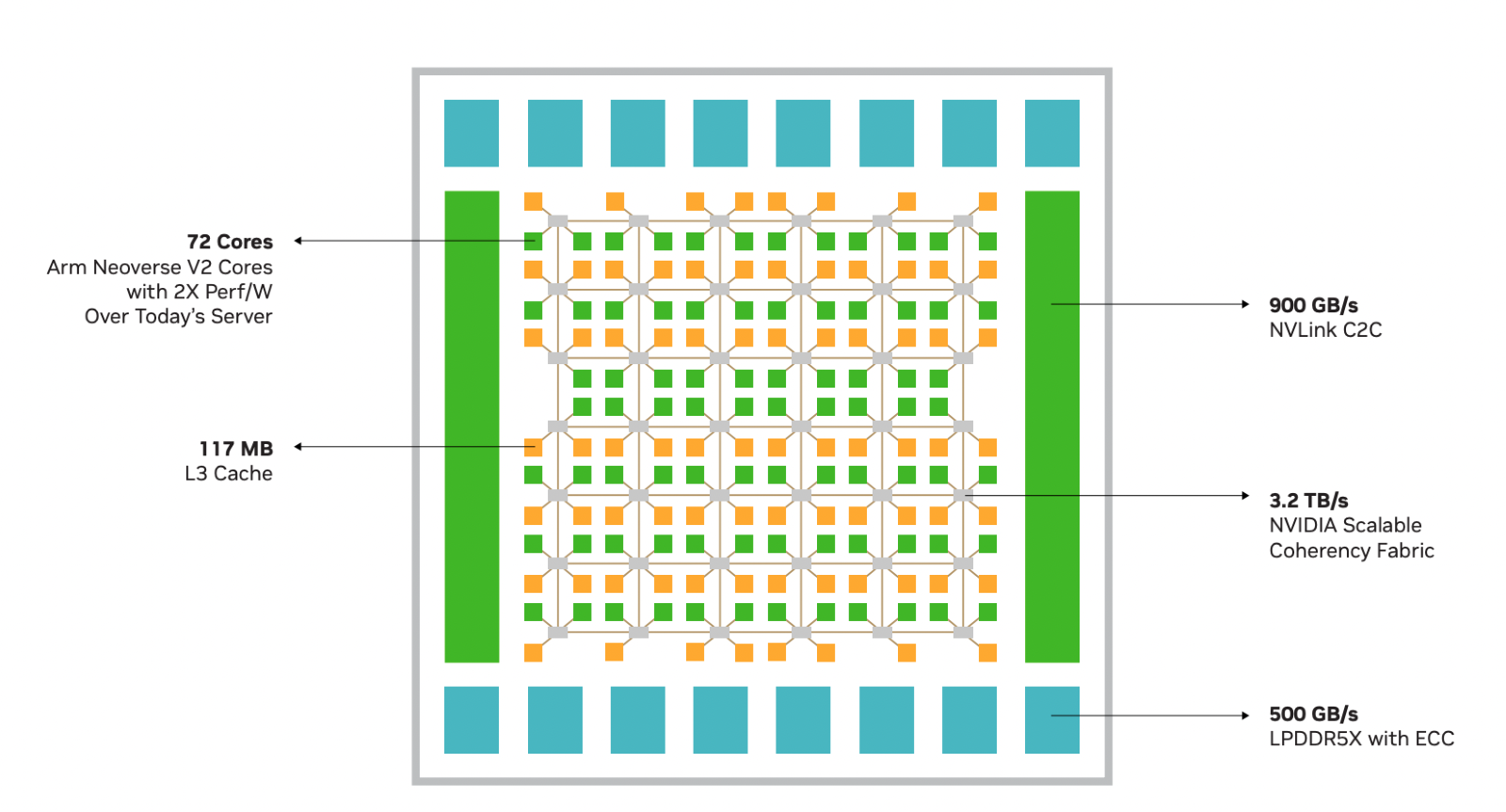 Это достигнуто в том числе благодаря изначальной оптимизации дизайна процессора с упором на максимальную производительность передачи данных. Внутренне Grace организован по принципу меш-сети с распределённой системой кеширования на базе специальных узлов коммутации CSN (Cache Switch Nodes). Называется эта сеть Scalable Coherency Fabric, она имеет пропускную способность 3,2 Тбайт/с, а объём кеша L3 составляет 117 Мбайт на кристалл и 234 Мбайт совокупно.  Сервер на базе NVIDIA Grace не только может потреблять меньше энергии, но и будет существенно проще конструктивно, поскольку модуль Grace Superchip содержит не только процессорные ядра и память, но также и регуляторы напряжения. От платформы на базе нового процессора требуется только PCIe 5.0 — у нового чипа есть два набора по 64 линии. Причём линии с поддержкой CXL 2.0, так что проблем с расширением доступного объёма памяти новинка испытывать не будет.  Даже компактные серверы высотой 1U смогут вместить две сборки Grace Superchip, что даст 288 ядер и почти 2 Тбайт оперативной памяти — труднодостижимый в таких габаритах показтель для более традиционных конструктивов процессоров и системных плат. Сравнительно невысокий теплопакет позволит таким решениям обходиться традиционным воздушным охлаждением.  При этом есть и вариант Grace Hopper, сочетающий в одном модуле кристалл Grace и новейший GPU H100, причём параметрами PCI Express последний ограничен не будет благодаря NVLink-C2C. NVIDIA уже начала первичные поставки Grace, а начало полномасштабного производства ожидается во второй половине года. Новыми процессорами заинтересовались крупные производители оборудования, включая ASUS, Atos, GIGABYTE, HPE, QCT, Supermicro, Wistron и ZT Systems.  Лос-Аламосская национальная лаборатория объявила, что использует NVIDIA Grace в новом суперкомпьютере Venado, который поможет учёным в исследованиях новых материалов и возобновляемых источников энергии. Ряд крупных европейских и азиатских ЦОД также рассматривает перспективы применения новых процессоров NVIDIA. В частности, одной из систем на базе Grace станет кластер Alps в Швейцарском национальном компьютерном центре.
21.03.2023 [19:15], Сергей Карасёв
NVIDIA представила систему DGX Quantum для гибридных квантово-классических вычисленийКомпания NVIDIA в партнёрстве с Quantum Machines анонсировала DGX Quantum — первую систему, объединяющую GPU и квантовые вычисления. Решение использует новую открытую программную платформу CUDA Quantum. Утверждается, что система предоставляет революционно архитектуру для исследователей, работающими с гибридными вычислениями с низкой задержкой. NVIDIA DGX Quantum объединяет средства ускоренных вычислений на базе Grace Hopper (Arm-процессор + ускоритель H100), модели программирования с открытым исходным кодом CUDA Quantum и передовую квантовую управляющую платформу Quantum Machines OPX+. Такая комбинация позволяет создавать ресурсоёмкие приложения, сочетающие квантовые вычисления с современными классическими вычислениями. При этом в числе прочего обеспечивается работа гибридных алгоритмов и коррекция ошибок. 
Источник изображения: NVIDIA Представленное решение предполагает соединение Grace Hopper и Quantum Machines OPX+ посредством интерфейса PCIe. Это обеспечивает задержку менее микросекунды между ускорителем и блоками квантовой обработки (QPU). Отмечается, что OPX+ — это универсальная система квантового управления. Таким образом, можно максимизировать производительность QPU и предоставить разработчикам новые возможности при использовании квантовых алгоритмов. Системы Grace Hopper и OPX+ можно масштабировать в соответствии с потребностями — от QPU с несколькими кубитами до суперкомпьютера с квантовым ускорением. 
Источник изображения: NVIDIA О намерении интегрировать CUDA Quantum в свои платформы уже заявили компании по производству квантового оборудования Anyon Systems, Atom Computing, IonQ, ORCA Computing, Oxford Quantum Circuits и QuEra, разработчики ПО Agnostiq и QMware, а также некоторые суперкомпьютерные центры.
20.01.2023 [15:28], Алексей Степин
NVIDIA Grace Superchip получит 144 Arm-ядра, 960 Гбайт набортной памяти LPDDR5x и 128 линий PCIe 5.0, а TDP составит 500 ВтGrace можно назвать одним из самых амбициозных проектов NVIDIA. О намерении ворваться на рынок мощных серверных процессоров компания объявила ещё на GTC 2022, но до недавних пор о чипах Grace были доступны лишь общие сведения. Однако ситуация меняется. NVIDIA явно располагает рабочим «кремнием», и на днях опубликовала пару деталей о Grace Superchip. Ожидается, что официальный анонс новинки состоится в марте этого года на GTC 2023. Эта сборка включает в себя два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2. Данное ядро использует набор инструкций Armv9, а также имеет четыре 128-битных блока векторных расширений SVE2, блоки для работы с матрицами и поддержку BF16/INT8. Объём кеша L1 составляет по 64 Кбайт для инструкций и данных, L2 — 1 Мбайт на ядро, а общий объём L3 на сборку достигает 234 Мбайт. 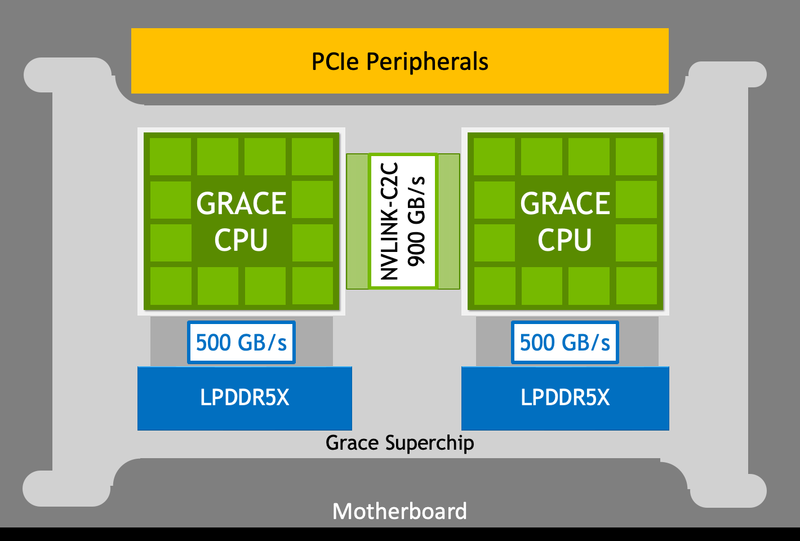
Блок-схема сборки Grace Superchip. Источник изображений здесь и далее: NVIDIA Между собой кристаллы соединены шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работают они как единый 144-ядерный процессор. Но это ещё не всё: каждый из кристаллов соединен со своим банком памяти LPDDR5x ECC шиной с пропускной способностью 500 Гбайт/с (т.е. суммарно на чип получается 1 Тбайт/с). Совокупный объём памяти может достигать 960 Гбайт. 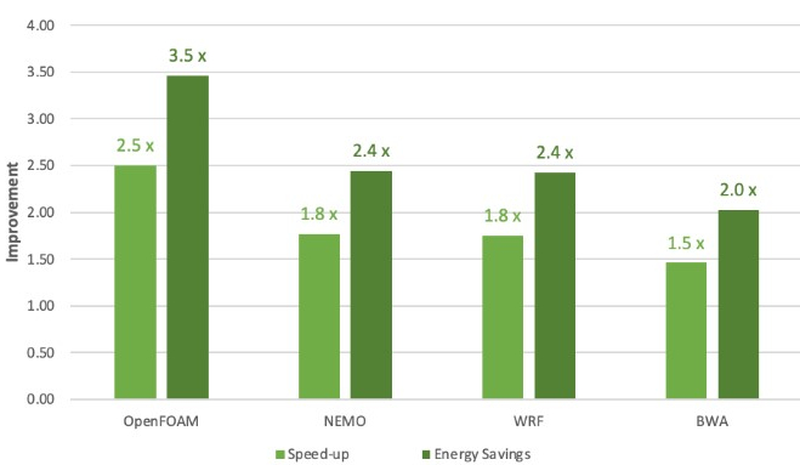
Сравнение производительности и энергоэффективности Grace Superchip с двумя AMD EPYC 7763 (Milan) Сборка Grace Superchip общается с внешним миром посредством восьми комплексов PCIe 5.0 x16 (всего 128 линий, поддерживается бифуркация). Чип при теплопакете 500 Вт (вместе с набортной памятью) способен развивать 7,1 Тфлопс на вычислениях двойной точности. С учетом интегрированной памяти это делает Grace Superchip интересной альтернативой AMD Genoa. 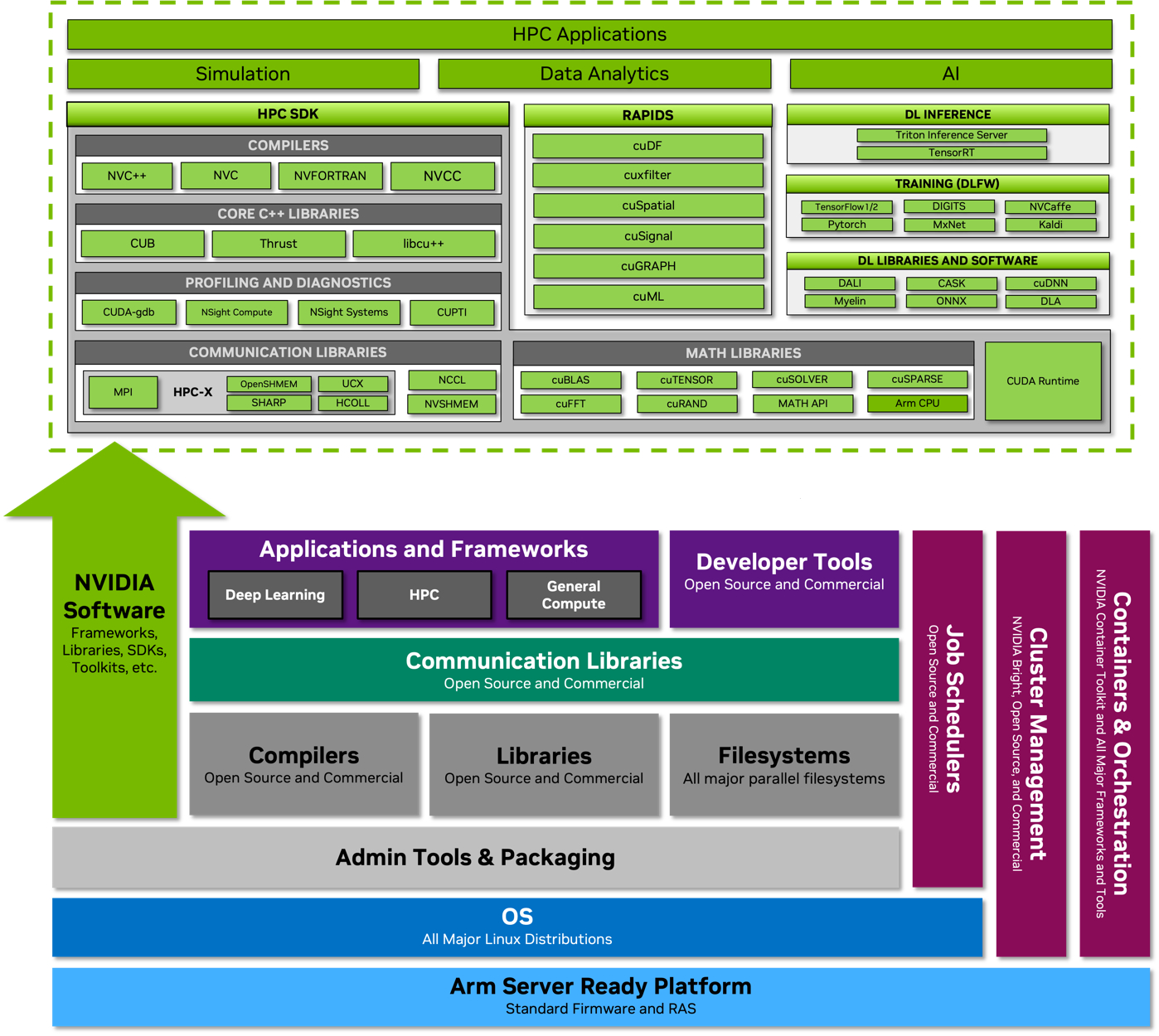
Программная экосистема платформы NVIDIA Grace. По клику открывается полноразмерная версия. Помимо данных о производительности в режиме FP64 компания уже опубликовала результаты тестов новинки в HPC-нагрузках, где сравнила своё детище с двухсокетной системой на базе AMD EPYC 7763. Выигрыш в производительности составляет от 1,5x до 2,5x, но что не менее важно — Grace Superchip намного эффективнее энергетически, здесь преимущество может достигать 3,5x. В условиях высокоплотных ЦОД или HPC-кластеров это может стать решающим.
20.08.2022 [22:30], Алексей Степин
NVIDIA поделилась некоторыми деталями о строении Arm-процессоров Grace и гибридных чипов Grace HopperНа GTC 2022 весной этого года NVIDIA впервые заявила о себе, как о производителе мощных серверных процессоров. Речь идёт о чипах Grace и гибридных сборках Grace Hopper, сочетающих в себе ядра Arm v9 и ускорители на базе архитектуры Hopper, поставки которых должны начаться в первой половине следующего года. Многие разработчики суперкомпьютеров уже заинтересовались новинками. В преддверии конференции Hot Chips 34 компания раскрыла ряд подробностей о чипах. Grace производятся с использованием техпроцесса TSMC 4N — это специально оптимизированный для решений NVIDIA вариант N4, входящий в серию 5-нм процессов тайваньского производителя. Каждый кристалл процессорной части Grace содержит 72 ядра Arm v9 с поддержкой масштабируемых векторных расширений SVE2 и расширений виртуализации с поддержкой S-EL2. Как сообщалось ранее, NVIDIA выбрала для новой платформы ядра Arm Neoverse. 
Источник: NVIDIA Процессор Grace также соответствует ряду других спецификаций Arm, в частности, имеет отвечающий стандарту RAS v1.1 контроллер прерываний (Generic Interrupt Controller, GIC) версии v4.1, блок System Memory Management Unit (SMMU) версии v3.1 и средства Memory Partitioning and Monitoring (MPAM). Базовых кристаллов у Grace два, что в сумме даёт 144 ядра — рекордное количество как в мире Arm, так и x86. 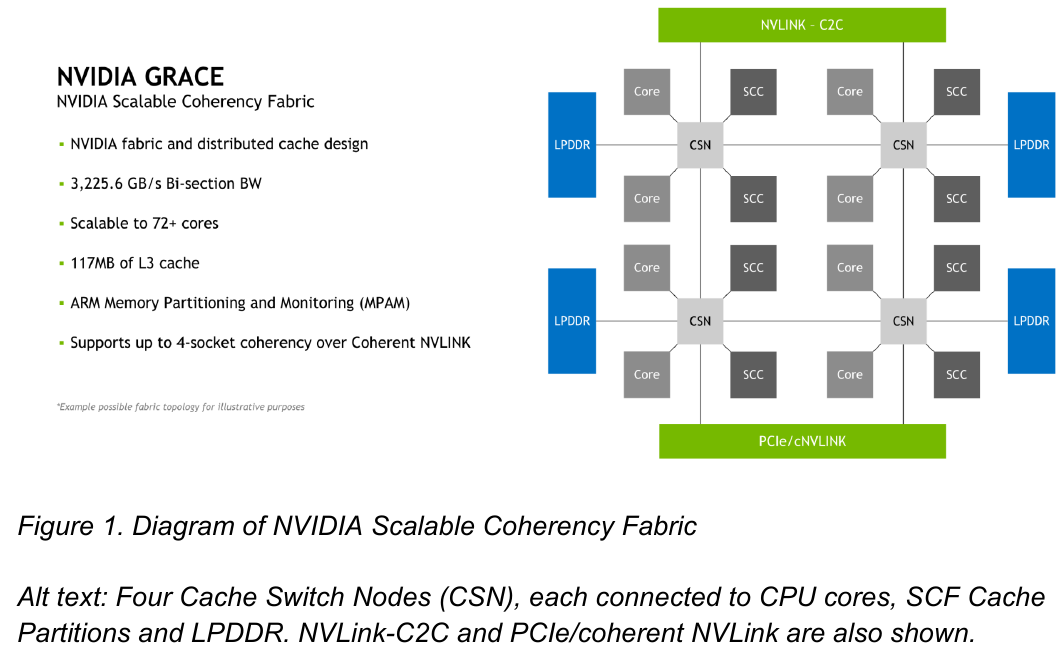
Внутренняя организация кластеров ядр в Grace. Источник: NVIDIA Внутренние блоки Grace соединяются посредством фабрики Scalable Coherency Fabric (SCF), вариации NVIDIA на тему сети CMN-700, применяемой в дизайнах Arm Neoverse. Производительность данного интерконнекта составляет 3,2 Тбайт/с. В случае Grace он предполагает наличие 117 Мбайт кеша L3 и поддерживает когерентность в пределах четырёх сокетов (посредством новой версии NVLink). Но SCF поддерживает масштабирование. Пока что в «железе» она ограничена двумя блоками Grace, а это уже 144 ядра и 234 Мбайт L3-кеша. Ядра и кеш-разделы (SCC) рапределены по внутренней mesh-фабрике SCF. Коммутаторы (CSN) служат интерфейсами для ядер, кеш-разделов и остальными частями системы. Блоки CSN общаются непосредственно друг с другом, а также с контроллерами LPDDR5X и PCIe 5.0/cNVLink/NVLink C2C. 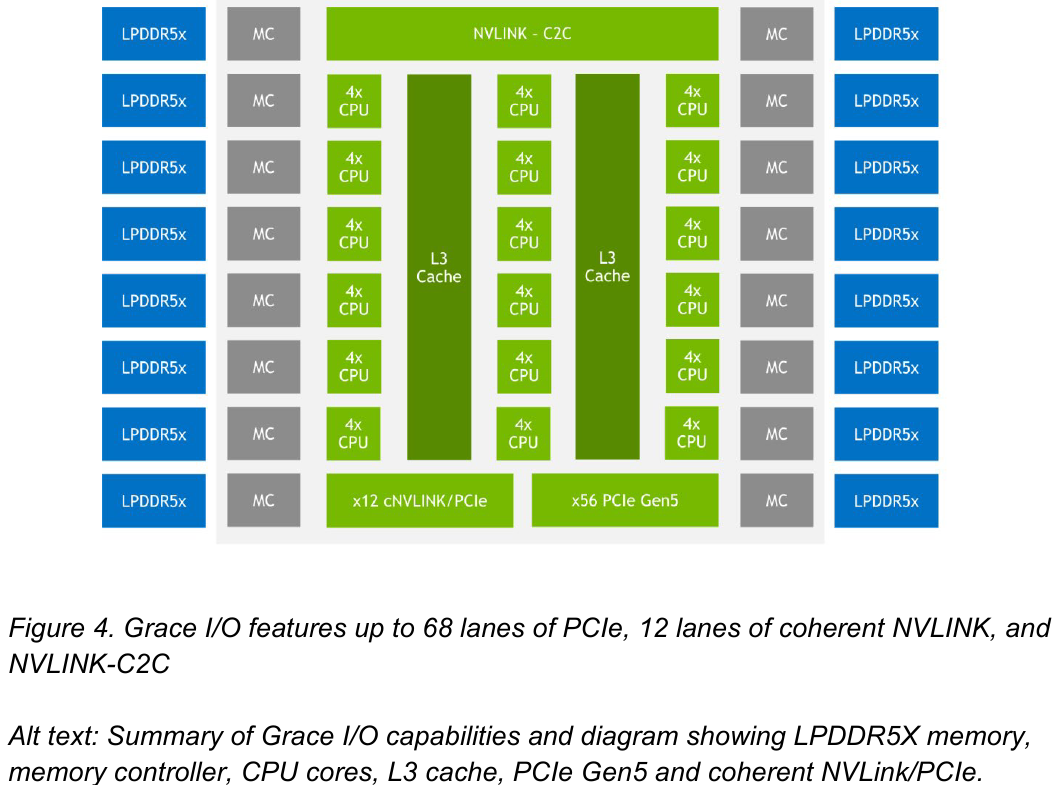
Блок-схема кристалла Grace. Источник: NVIDIA В чипе реализована поддержка PCI Express 5.0. Всего контроллер поддерживает 68 линий, 12 из которых могут также работать в режиме cNVLink (NVLink с когерентностью). x16-интерфейс посредством бифуркации может быть превращен в два x8. Также на приведённой NVIDIA диаграмме можно видеть целых 16 двухканальных контроллеров LPDDR5x. Заявлена ПСП на уровне свыше 1 Тбайт/с для сборки (до 546 Гбайт/с на кристалл CPU). 
Источник: NVIDIA Основной же межчиповой связи NVIDIA видит новую версию NVLink — NVLink-C2C, которая в семь раз быстрее PCIe 5.0 и способна обеспечить двунаправленную скорость передачи данных на уровне до 900 Гбайт/с, будучи при этом в пять раз экономичнее. Удельное потребление у новинки составляет 1,3 пДж/бит, что меньше, нежели у AMD Infinity Fabric с 1,5 пДж/бит. Впрочем, существуют и более экономичные решения, например, UCIe (~0,5 пДж/бит). 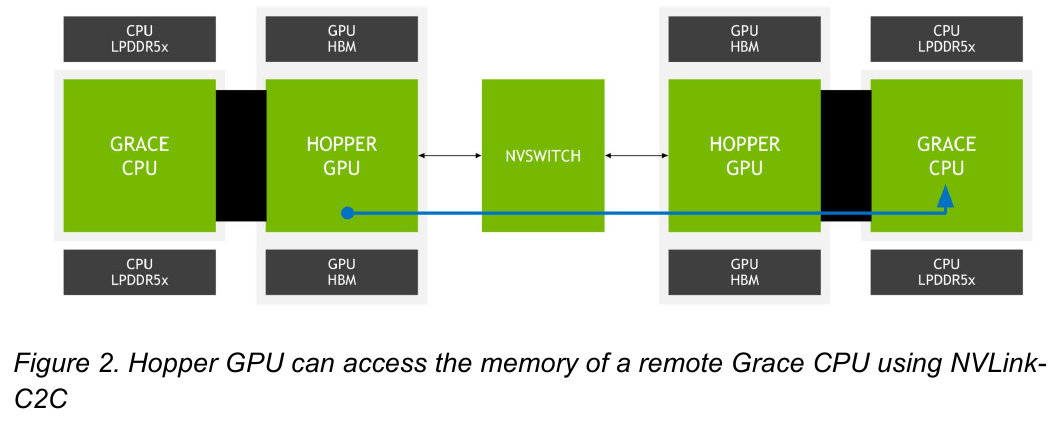
Новый вариант NVLink обеспечит кластер на базе Grace Hopper единым пространством памяти. Источник: NVIDIA NVLink-C2C позволяет реализовать унифицированный «плоский» пул памяти с общим адресным пространством для Grace Hopper. В рамках одного узла возможно свободное обращение к памяти соседей. А вот для объединения нескольких узлов понадобится уже внешний коммутатор NVSwitch. Он будет занимать 1U в высоту, и предоставлять 128 портов NVLink 4 с агрегированной пропускной способностью до 6,4 Тбайт/с в дуплексе. 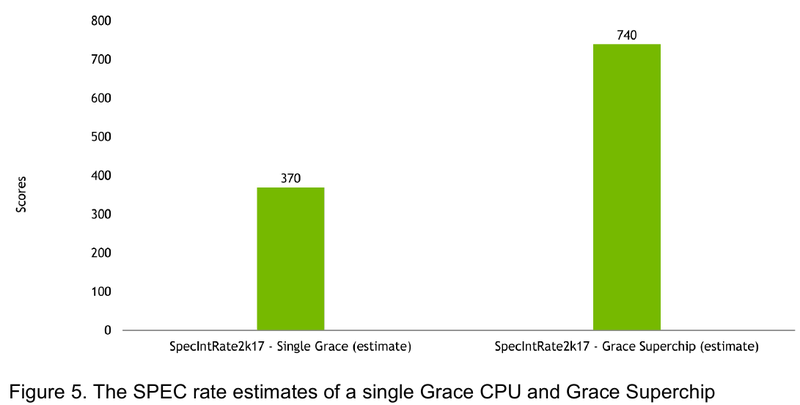
Источник: NVIDIA Производительность Grace также обещает быть рекордно высокой благодаря оптимизированной архитектуре и быстрому интерконнекту. Даже по предварительным цифрам, опубликованным NVIDIA, речь идёт о 370 очках SPECrate2017_int_base для одного кристалла Grace и 740 очках для 144-ядерной сборки из двух кристаллов — и это с использованием обычного компилятора GCC без тонких платформенных оптимизаций. Последняя цифра существенно выше результатов, показанных 128-ядерными Alibaba T-Head Yitian 710, также использующим архитектуру Arm v9, и 64-ядерными AMD EPYC 7773X.
24.05.2022 [07:00], Игорь Осколков
NVIDIA представила референсные платформы CGX, OVX и HGX на базе собственных Arm-процессоров GraceНа весенней конференции GTC 2022 NVIDIA поделилась подробностями о грядущих серверных Arm-процессорах Grace Superchip и гибридах Grace Hopper Superchip, а на Computex 2022 представила первые референсные платформы на базе этих чипов для OEM-производителей и объявила о расширении программы NVIDIA Certified. Последнее, впрочем, не означает отказ от x86-систем, поскольку программа будет просто расширена. Да и портирование стороннего и собственного ПО займёт некоторое время. Первые несколько десятков моделей серверов от ASUS, Foxconn, GIGABYTE, QCT, Supermicro и Wiwynn появятся в первой половине 2023 года. Представлены они будут в трёх категориях, причём все, за исключением одной, базируются на «сдвоенных» процессорах Grace Superchip, насчитывающих до 144 ядер. 
Источник: NVIDIA Системы серии OVX, представленной ранее, всё так же будут предназначены для цифровых двойников и Omniverse — NVIDIA продолжает наставить на том, что любое современное производство или промышленное предприятие должно быть интеллектуальным. Arm-версия OVA получит неназванные ускорители NVIDIA и DPU Bluefield-3. Новая платформа NVIDIA CGX очень похожа на OVX — она тоже получит DPU Bluefield-3 и до четырёх ускорителей NVIDIA A16. CGX создана специального для облачных гейминга и работы с графикой. А вот новое поколение платформы NVIDIA HGX гораздо интереснее. Оно заметно отличается от предыдущих, которые в основном представляли собой различные комбинации базовых плат NVIDIA с четырьмя или восемью ускорителями, вокруг которых OEM-партнёры строили системы в меру своих умений и фантазий. Нынешняя инкарнация NVIDIA HGX всё же несколько более комплексная, поскольку сейчас предлагается два варианта узлов, специально спроектированных для высокоплотных систем и явно ориентированных на высокопроизводительные вычисления (HPC). 
Источник: NVIDIA Первый вариант — это 1U-лезвие (до 84 шт. в стандартной стойке), которое включает один процессор Grace Superchip, до 1 Тбайт LPDDR5x-памяти с пропускной способностью (ПСП) до 1 Тбайт/с и DPU BlueField-3. Иные варианты сетевого подключения оставлены на усмотрение конечного производителя. Заявленный уровень TDP составляет 500 Вт, так что на выбор доступны системы с воздушным и жидкостным охлаждением. Второй вариант базируется на гибридных чипах Grace Hopper Superchip, объединяющих в себе посредством шины NVLink-C2C процессорную часть с 512 Гбайт LPDDR5x-памяти и ускоритель NVIDIA H100 c 80 Гбайт HBM3-памяти (ПСП до 3,5 Тбайт/с). Помимо DPU BlueField-3 опционально доступен и интерконнект NVLink 4.0, но и здесь вендору оставлена свобода выбора. Уровень TDP для данной платформы составляет 1 кВт, но вот обойтись одним только воздушным охлаждением (а такой вариант есть) при полном заполнении стойки всеми 42-мя 2U-лезвиями будет трудно.
22.03.2022 [18:48], Игорь Осколков
NVIDIA анонсировала 144-ядерные Arm-процессоры Grace и гибрид Grace HopperГлавным событием GTC 2022 стал анонс новых ускорителей H100 (Hopper), которые станут доступны в III квартале 2022 года. Вслед за ними в первой половине 2023 года появятся давно обещанные CPU Grace и гибридная система Grace Hopper, сочетающие, как понятно из названия, процессоры Grace (ARMv9) и ускорители Hopper. Как и было сказано ранее, для связи всех компонентов между собой будет использоваться mesh-сеть на базе всё той же шины NVLink 4.0 (900 Гбайт/с) с кеш-когерентностью. А сочетание LPDDR5X (с ECC, конечно) и HBM даст суммарный объём памяти до 600 Гбайт с общей полосой пропускания порядка 2 Тбайт/с. Для Grace Hopper компания подготовит полный стек ПО, благо портированием на Arm она начала заниматься ещё 3 года назад. 
NVIDIA Grace (Изображения: NVIDIA) Двухчиповый процессор Grace Superchip для ИИ- и HPC-нагрузок имеет 144 ядра, результат которых в SPECrate2017_int_base составляет 740, что, по словам компании, в полтора раза выше, чему у пары AMD EPYC, использующихся в DGX A100. И это, честно говоря, не такой уж и впечатляющий результат.  Но NVIDIA утверждает, что новые CPU вдвое лучше по отношению производительности к энергопотреблению, чем «традиционные серверы» — использование LPDDR5X позволяет добиться пропускной способности памяти в 1 Тбайт/с, а вся сборка CPU+RAM будет потреблять менее 500 Вт.  Чипы (или чиплеты, если хотите) в Grace Superchip тоже объединены посредством NVLink, только в данном случае этот интерконнект называется NVLink-C2C (Chip-to-Chip). И его NVIDIA предлагает использовать другим компаниям для создания кастомных сборок, объединяющих необходимые кристаллы, да и сама готова масштабировать и адаптировать свои решения под нужды заказчика. 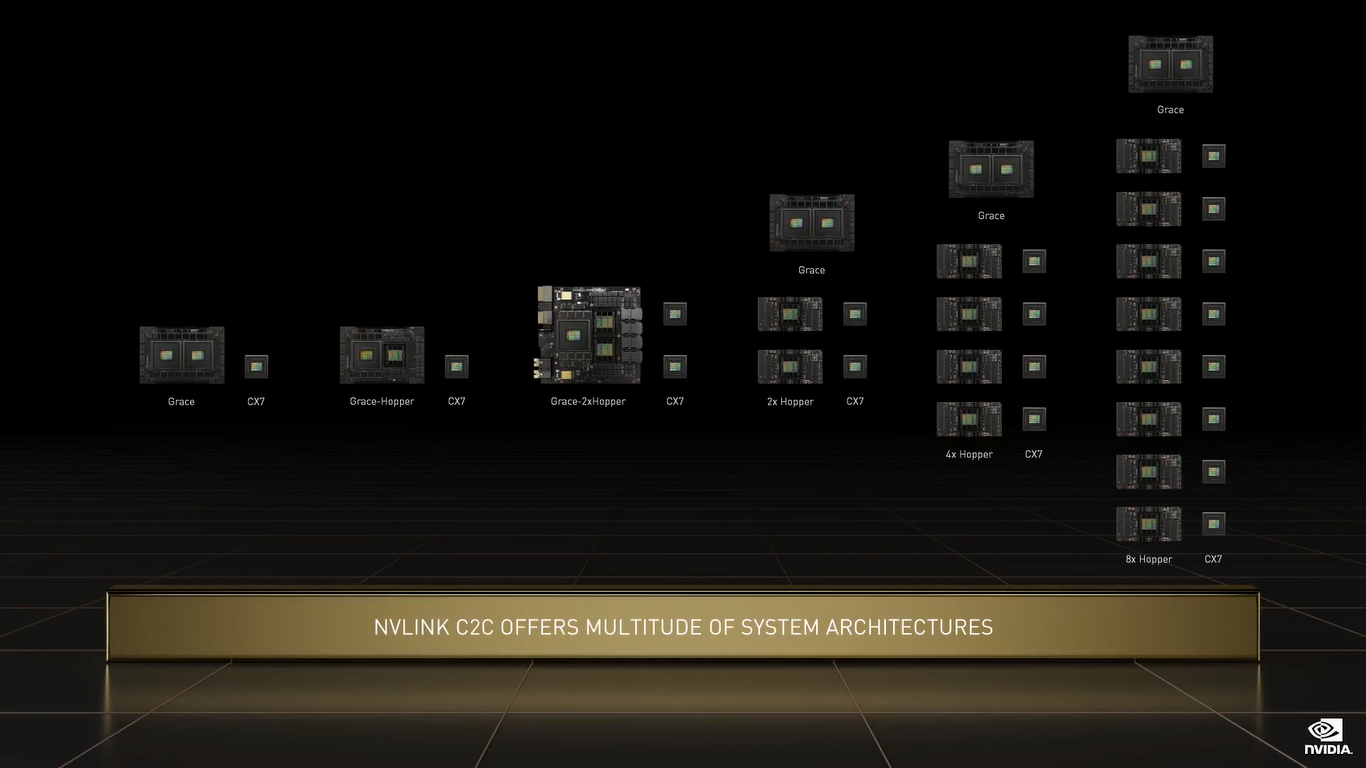 По словам NVIDIA, NVLink-C2C в 25 раз энергоэффективнее PCIe 5.0, а для его реализации нужна в 90 раз меньшая площадь кремния. Шина предлагает высокую скорость (да-да, всё те же 900 Гбайт/с), низкий уровень задержек, поддержку атомарных операций и совместимость с Arm AMBA CHI, CXL и UCIe. |
|

