Материалы по тегу: gpu
|
14.08.2025 [09:21], Сергей Карасёв
Gigabyte представила MGX-сервер с восемью ускорителями NVIDIA RTX Pro 6000Компания Gigabyte расширила ассортимент серверов для ИИ-задач, анонсировав модель XL44-SX2-AAS1 в форм-факторе 4U с модульной архитектурой NVIDIA MGX. Новинка предназначена для формирования ИИ-фабрик, работы с большими языковыми моделями (LLM) корпоративного уровня, научной визуализации, создания цифрового контента и других ресурсоёмких нагрузок. Сервер допускает установку двух процессоров Intel Xeon 6700/6500 и 32 модулей оперативной памяти DDR5 RDIMM/MRDIMM. В оснащение входят до восьми ускорителей NVIDIA RTX Pro 6000 Blackwell Server Edition, которые ориентированы на требовательные приложения ИИ. Эти карты несут на борту 96 Гбайт памяти GDDR7 (ECC) с пропускной способностью до 1,6 Тбайт/с. Во фронтальной части располагаются отсеки для восьми накопителей SFF с интерфейсом PCIe 5.0 (NVMe). Есть восемь разъёмов PCIe 5.0 x16 для двухслотовых карт FHFL, а также коннектор PCIe 5.0 x16 для однослотового DPU NVIDIA BlueField-3. В конструкции задействованы коммутационная плата NVIDIA MGX PCIe 6.0 на базе ASIC ConnectX-8 и контроллер Intel X710-AT2, на базе которого реализованы два сетевых порта 10GbE. 
Источник изображения: Gigabyte За питание отвечают четыре блока с сертификатом 80 PLUS Titanium мощностью 3200 Вт каждый с резервированием по схеме 3+1, благодаря чему обеспечиваются стабильность и надёжность во время непрерывной круглосуточной эксплуатации. На лицевую панель выведены гнёзда RJ45 для сетевых кабелей и порты USB Type-A. Прочие технические характеристики сервера Gigabyte XL44-SX2-AAS1 пока не раскрываются.
13.08.2025 [11:51], Сергей Карасёв
HPE представила серверы ProLiant с ускорителями NVIDIA RTX Pro 6000 Blackwell Server EditionКомпания HPE анонсировала серверы ProLiant DL385 Gen11 и ProLiant Compute DL380a Gen12, построенные соответственно на аппаратной платформе AMD и Intel. Устройства оснащаются ускорителями NVIDIA RTX Pro 6000 Blackwell Server Edition, которые ориентированы на требовательные приложения ИИ и рендеринг высококачественной графики. 
Источник изображений: HPE Модель ProLiant DL385 Gen11 выполнена в форм-факторе 2U. Она может нести на борту два процессора AMD EPYC 9004 (Genoa) или EPYC 9005 (Turin), а также до 6 Тбайт оперативной памяти DDR5-6000 в конфигурации 12 × 512 Гбайт. Поддерживаются до восьми слотов PCIe 5.0 и до двух слотов OCP. Установлены две карты RTX Pro 6000 Blackwell Server Edition. В зависимости от модификации во фронтальной части могут располагаться до 12 отсеков для накопителей LFF HDD/SSD с интерфейсом SAS/SATA, до 24 отсеков для устройств SFF HDD/SSD (SAS/SATA/NVMe), до 36 посадочных мест для изделий EDSFF E3.S 1T или до 48 отсеков для SFF HDD/SSD.  Внутри могут размещаться до восьми устройств SFF SAS/SATA/NVMe или до четырёх LFF SAS/SATA, сзади — два накопителя SFF SAS/SATA/NVMe или четыре LFF SAS/SATA. Кроме того, есть два коннектора M.2 NVMe. Применяется воздушное охлаждение с возможностью опционального развёртывания прямого жидкостного охлаждения Direct Liquid Cooling (DLC). Мощность блоков питания — до 2200 Вт. Сервер оснащён системой удалённого управления iLO 6.  В свою очередь, ProLiant Compute DL380a Gen12 имеет формат 4U. Это устройство комплектуется двумя чипами Intel Xeon 6, насчитывающими до 144 ядер. Объём оперативной памяти DDR5 достигает 4 Тбайт в виде 32 модулей. Допускается установка до восьми GPU, накопителей SFF (NMVe) и EDSFF. Питание обеспечивают восемь блоков. Упомянута система HPE iLO 7. В продажу данная модель поступит в сентябре текущего года.
12.08.2025 [14:51], Владимир Мироненко
NVIDIA анонсировала компактные ускорители RTX PRO 4000 Blackwell SFF Edition и RTX PRO 2000 BlackwellNVIDIA объявила о предстоящем выходе GPU NVIDIA RTX PRO 4000 Blackwell SFF Edition и NVIDIA RTX PRO 2000 Blackwell, «воплощающих мощь архитектуры NVIDIA Blackwell в компактном и энергоэффективном форм-факторе», которые «обеспечат ИИ-ускорение для профессиональных рабочих процессов в различных отраслях». Новинки отличаются вдвое меньшими размерами по сравнению с традиционными GPU, и при этом оснащены RT-ядрами четвёртого поколения и тензорными ядрами пятого поколения с пониженным энергопотреблением. Как сообщает NVIDIA, новые ускорители разработаны для обеспечения производительности нового поколения для различных профессиональных рабочих процессов, обеспечивая «невероятное» ускорение процессов проектирования, дизайна, создания контента, ИИ и 3D-визуализации. По сравнению с ускорителем предыдущего поколения RTX A4000 SFF, модель RTX PRO 4000 SFF обеспечивает до 2,5 раза более высокую производительность в обработке ИИ-нагрузок и в 1,5 раза более высокую пропускную способность памяти, обеспечивая большую эффективность при том же максимальном энергопотреблении 70 Вт. 
Источник изображений: NVIDIA Ускоритель включает 8960 ядер NVIDIA CUDA, 24 Гбайт памяти GDDR7 ECC со 192-бит шиной и пропускной способностью 432 Гбайт/с. Используется интерфейс PCIe 5.0 x8. ИИ-производительность составляет 770 TOPS, RT-ядер — 73 TOPS, в формате FP32 — 24 TOPS. Доступно 2 движка NVENC девятого поколения и 2 движка NVDEC шестого поколения. Есть 4 разъёма DisplayPort 2.1b. Оптимизированная для массового проектирования и рабочих ИИ-процессов, RTX PRO 2000 обеспечивает до 1,6 раза более быстрое 3D-моделирование, в 1,4 раза более высокую производительность систем автоматизированного проектирования (САПР) и в 1,6 раза более высокую скорость рендеринга по сравнению с предыдущим поколением. Компания отметила, что инженеры САПР, продуктовые инженеры и специалисты творческих профессий по достоинству оценят 1,4-кратный прирост производительности RTX PRO 2000 при генерации изображений и 2,3-кратный прирост производительности при генерации текста, что обеспечивает более быструю итерацию, быстрое прототипирование и бесперебойную совместную работу.  RTX PRO 2000 оснащена 4352 ядрами NVIDIA CUDA, 16 Гбайт памяти GDDR7 ECC со 128-бит шиной и пропускной способностью 288 Гбайт/с. Используется интерфейс PCIe 5.0 x8. ИИ-производительность составляет 545 TOPS, RT-ядер — 54 TOPS, в формате FP32 — 17 TOPS. Доступно по одному движку NVENC девятого поколения и NVDEC шестого поколения. Есть 4 разъёма DisplayPort 2.1b. NVIDIA сообщила, что ускорители NVIDIA RTX PRO 2000 Blackwell и NVIDIA RTX PRO 4000 Blackwell SFF Edition поступят в продажу позже в этом году, не указав конкретные сроки.
10.08.2025 [15:21], Сергей Карасёв
Graid представила платформу SupremeRAID HE: массивы NVMe RAID для НРС-средКомпания Graid Technology объявила о глобальной доступности платформы SupremeRAID HE (HPC Edition), предназначенной для создания программно-определяемых массивов NVMe RAID с ускорением на базе GPU. SupremeRAID HE переносит операции RAID с CPU на GPU, что, как утверждается, позволяет полностью раскрыть потенциал производительности NVMe SSD. Заявлена совместимость с такими параллельными файловыми системами, как Ceph, Lustre, MinIO и IBM SpectrumScale. Возможно развёртывание JBOF в системах с коммутаторами Broadcom. Благодаря GPU-ускорению заявленная пропускная способность достигает 132 Гбайт/с при чтении данных и 83 Гбайт/с при записи (после выполнения RAID-операций). Заявлена поддержка RAID 0/1/5/6/10, NVMe-oF, конфигураций с двумя контроллерами и функции миграции массива. Допускается использование до 32 накопителей. SupremeRAID HE предлагается в виде комплекта из GPU-ускорителя и лицензии на ПО. В качестве аппаратной составляющей могут использоваться карты NVIDIA RTX A1000 (8 Гбайт GDDR6) или NVIDIA RTX 2000 Ada (16 Гбайт GDDR6). 
Источник изображения: Graid Technology «Перенося операции RAID на GPU, мы предоставляем клиентам возможность масштабировать производительность накопителей NVMe, сохраняя при этом высокую доступность узлов — без сложностей репликации и компромиссов», — говорит Леандер Ю (Leander Yu), президент и генеральный директор Graid Technology. Отмечается, что SupremeRAID HE допускает развёртывание в широком спектре инфраструктур, включая платформу Supermicro High Availability Dual Node All-Flash петафлопсного класса. Новое RAID-решение ориентировано на среды с высокими нагрузками, включая НРС. Говорится о совместимости с Ubuntu 20.04–24.04 и RHEL 8.x–9.x.
25.07.2025 [09:23], Владимир Мироненко
Импортозамещение по-южнокорейски: LG AI Research выбрала ускорители FuriosaAI RNGD для своих ИИ-серверовКомпания LG AI Research (ИИ-подразделение LG Group) из Южной Кореи заключила соглашение с южнокорейским стартапом FuriosaAI о выпуске серверов с ИИ-ускорителями RNGD для работы с собственным семейством LLM Exaone, сообщил The Register. Как сообщил генеральный директор FuriosaAI Джун Пайк (June Paik) изданию EE Times, серверы LG с чипами RNGD будут ориентированы на предприятия, использующие модели ExaOne в сфере электроники, финансов, телекоммуникаций и биотехнологий. Серверы поступят в продажу в конце этого года. «После тщательного тестирования широкого спектра опций мы пришли к выводу, что RNGD — высокоэффективное решение для развёртывания моделей Exaone», — заявил Киджонг Чон (Kijeong Jeon), руководитель подразделения продуктов LG AI Research. «RNGD обеспечивает убедительное сочетание преимуществ: превосходную производительность в реальных условиях, значительное снижение совокупной стоимости владения и удивительно простую интеграцию», — добавил он. Подобно системам на базе NVIDIA RTX Pro Blackwell, серверы LG RNGD будут включить до восьми ускорителей с интерфейсом PCIe 5.0. Эти системы будут работать на базе того, что FuriosaAI описывает как высокоразвитый программный стек, включающий библиотеку vLLM. LG также предложит собственную платформу агентского ИИ ChatExaone, которая адаптирована для корпоративных сценариев использования. Она объединяет ряд фреймворков для анализа документов, глубоких исследований, анализа данных и RAG. 
Источник изображений: FuriosaAI LG AI Research протестировала работу модели ExaOne-32B на восьмичиповом 4U-сервере c воздушным охлаждением, который был разработан совместно с Supermicro. В 15-кВт стойке можно разместить пять таких серверов. По словам Пайка, LG AI Research протестировала оборудование от нескольких поставщиков оборудования из Южной Кореи и других стран, взяв за основу ускорители NVIDIA A100. «LG AI Research также тестировала облачные решения, но, по их словам, наше решение на данный момент оказалось единственным, отвечающим их требованиям», — сказал Пайк.  Как полагает The Register, выбор для сравнения ускорителя NVIDIA A100, дебютировавшего в 2020 году, а не более свежих моделей, вызван тем, что LG AI Research больше интересует энергоэффективность оборудования, чем производительность. И, как отметил Джун Пайк, хотя за пять лет с момента появления A100 ускорители NVIDIA, безусловно, стали мощнее, но произошло это за счёт увеличения энергопотребления и площади кристалла. 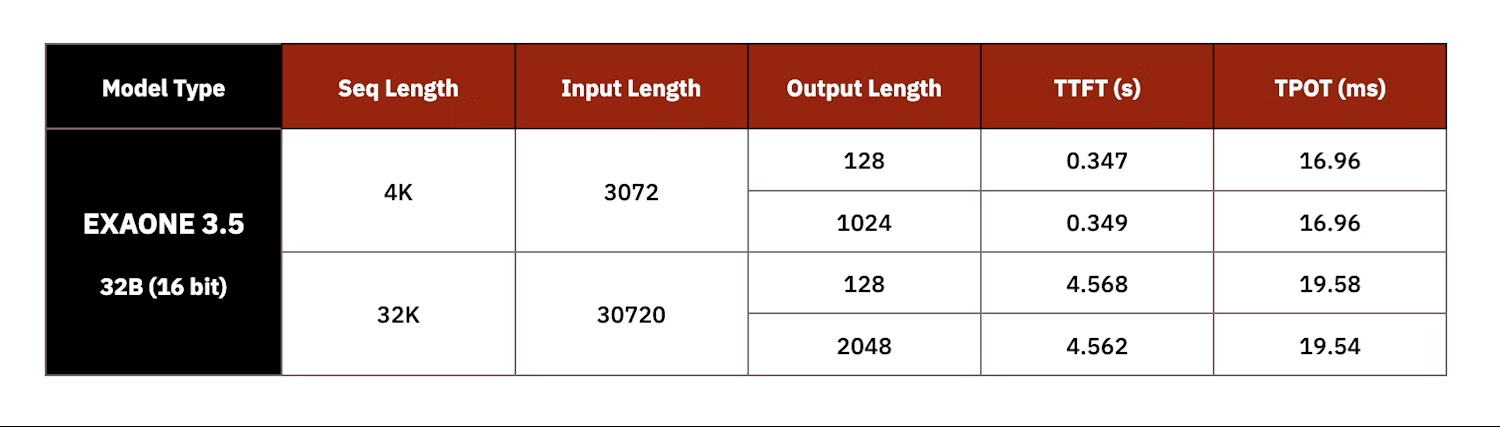 Сообщается, что LG AI фактически использовала четыре PCIe-ускорителя RNGD, задействовав тензорный параллелизм для запуска модели Exaone 32B с 16-бит точностью. По словам Пайка, у LG были очень чёткие целевые показатели производительности, которые она стремилась достичь при валидации чипа. В частности, ограничения включали время до отдачи первого токена (TTFT) — примерно 0,3 с для небольших запросов на 3 тыс. токенов или 4,5 с для более крупных запросов на 30 тыс. токенов. Результат в 60 токенов/с достигается для контекстного окна размером 4 тыс. токенов или 50 токенов/с для контекстного окна размером 32 тыс. токенов.  По словам Пайка, тесты проводились в режиме BF16, поскольку сравниваемые A100 не имеет встроенной поддержки FP8, так что использование RNGD в FP8-режиме позволит удвоить эффективность инференса и снизить TTFT. Кроме того, сервер продемонстрировал в 2,25 раза более высокую производительность инференса LLM на Ватт по сравнению с A100, а полная стойка сможет генерировать в 3,75 раза больше токенов, чем стойка с A100 при том же энергопотреблении. Чип FuriosaAI RNGD обеспечивает производительность 512 Тфлопс (FP8) при TDP 180 Вт. В отличие от ускорителей NVIDIA, оснащённых высокоскоростным интерконнектом NVLink (600 Гбайт/с), FuriosaAI использует интерфейс PCIe 5.0 (128 Гбайт/с). По словам FuriosaAI, чтобы избежать узких мест и накладных расходов, связанных с интерконнектом, компилятор компании помогает оптимизировать процесс обмена данными и собственно вычисления.
08.07.2025 [13:54], Сергей Карасёв
«Инферит» выпустил российскую рабочую станцию для ИИ-задач с четырьмя GPU и СЖОРоссийский поставщик IT-решений «Инферит» (ГК Softline) представил рабочую станцию Inferit, разработанную для ресурсоёмких ИИ-задач, включая обучение больших языковых моделей (LLM). Устройство, как утверждается, сочетает в себе надёжность, компактность, низкий уровень шума и высокую производительность. Новинка выполнена в форм-факторе 4U с габаритами 439 × 681 × 177 мм (без ручек и выступающих элементов) и массой 45 кг. Допускается настольное размещение или монтаж в 19″ серверную стойку. Задействована материнская плата типоразмера E-ATX. В зависимости от модификации предусматривается установка процессоров AMD или Intel и до 2 Тбайт RAM. Машина допускает использование до четырёх ИИ-ускорителей на базе GPU. Могут применяться карты AMD W7800 и W7900 или NVIDIA RTX 5090, RTX 6000 ADA, L40, L40S, H100, H200 и RTX Pro 6000. Рабочая станция изначально спроектирована под жидкостное охлаждение: этот контур охватывает зоны CPU (включая VRM) и GPU (включая DDR и VRM). Благодаря СЖО, по заявлениям компании «Инферит», достигается стабильное функционирование системы на повышенных частотах, что обеспечивает высокую производительность и небольшой уровень шума при максимальных нагрузках. Диапазон рабочих температур — от +3 до +38 °C. 
Источник изображений: «Инферит» Возможна установка до восьми NVMe SSD формата M.2, а также двух LFF-накопителей и шести SFF-изделий с интерфейсом SATA. Питание обеспечивают три блока SFX-L мощностью 1200 Вт каждый. Упомянуты два сетевых порта 10GbE. Заявлена совместимость с «МСВСфера» разработки «Инферит», Ubuntu, Windows 10 и Windows Server.  «Рабочая станция Inferit ориентирована на самые ресурсоёмкие сценарии в области искусственного интеллекта, научных исследований и графики. Это мощный инструмент для тех, кто каждый день работает с технологическими задачами», — сообщает «Инферит Техника».
04.07.2025 [12:56], Сергей Карасёв
«Инферит» представил российские GPU-серверы с СЖО на платформах AMD и IntelРоссийский поставщик IT-решений «Инферит» (ГК Softline) анонсировал отечественные GPU-серверы, предназначенные для работы с ИИ-моделями, инференса, глубокого обучения и других ресурсоёмких задач. Новинки оснащены системой жидкостного охлаждения. Серверы предлагаются в одно- и двухпроцессорных конфигурациях. В первом случае могут применяться чипы AMD Threadripper Pro 5000 WX, 7000 WX, EPYC 9004 (Genoa) и EPYC 9005 (Turin) или изделия Intel Xeon W-2400/2500/3400/3500, Xeon Sapphire Rapids, Xeon Emerald Rapids и Xeon 6. Двухсокетные версии несут на борту процессоры AMD EPYC 9004/9005 или Xeon Sapphire Rapids / Emerald Rapids и Xeon 6. Объём оперативной памяти достигает 2 Тбайт. Максимальная конфигурация предполагает установку до восьми PCIe-ускорителей. Могут использоваться карты AMD W7800 и W7900 или NVIDIA RTX 5090, RTX 6000 ADA, L40, L40S, H100, H200 и RTX Pro 6000. Подсистема хранения данных выполнена на основе высокоскоростных SSD. Для охлаждения задействованы два контура — жидкостный и воздушный с тремя вентиляторами (6200 об/мин). За питание отвечают до четырёх блоков мощностью 2000 Вт в режимах 4+0, 3+1, 2+2. Серверы наделены средствами удалённого мониторинга, которые позволяют анализировать работу охлаждения и других компонентов в реальном времени. 
Источник изображений: «Инферит» Говорится о совместимости с «МСВСфера Сервер» 9, Ubuntu, Windows 10 и Windows Server. В качестве потенциальных заказчиков «Инферит» называет ИИ-разработчиков, аналитиков данных, конструкторов и других специалистов, которым требуется высокая производительность для решения различных задач. На машины предоставляется двухлетняя гарантия, которую можно расширить до трёх или пяти лет. Клиентская поддержка осуществляется специалистами «Инферит» на всей территории России.  «Новый Multi-GPU сервер Inferit — это ответ на запрос рынка на надёжные, производительные и при этом удобные в эксплуатации решения. Благодаря партнёрству с разработчиком систем жидкостного охлаждения нам удалось реализовать модель, которая справляется с самыми требовательными задачами, сохраняя эффективность и доступность», — говорит руководитель департамента продуктовых решений «Инферит Техника».
27.05.2025 [10:00], Владимир Мироненко
Стартовало демо-тестирование отечественных GPU-серверов YADRO G4208P G3YADRO объявила о запуске программы демонстрационного тестирования платформы на базе GPU-сервера G4208P G3, которая сейчас проходит совместные испытания в прикладных сценариях в ИТ-инфраструктуре ключевых технологических партнёров компании. Высокопроизводительная серверная платформа YADRO G4208P G3 в форм-факторе 4U, ориентированная на ЦОД и компании с повышенными требованиями к вычислительным ресурсам, поддерживает установку до восьми GPU двойной ширины (PCIe 5.0 x16) с энергопотреблением до 450 Вт каждый, в том числе с мостиком NVLink Bridge. Сервер поддерживает до двух процессоров с TDP до 350 Вт и до 8 Тбайт оперативной памяти DDR5. 
Источник изображений: YADRO Спецификации также включают до 12 накопителей (8 × SAS/SATA, 4 × SAS/SATA/NVMe) с возможностью установки HBA/RAID-контроллера, выделенный порт управления BMC (1GbE RJ45), 11 слотов PCIe 5.0 x16 FHFL и 1 слот OCP 3.0 (PCIe 5.0 x8). За питание отвечают четыре БП (3+1) мощностью 2700 Вт каждый. Сервер оптимизирован под обучение, дообучение и инференс современных ИИ-моделей, позволяя предприятиям создавать собственную ИИ-инфраструктуру в рамках on-premise-развёртываний.  Платформа YADRO G4208P G3 способна удовлетворить потребности самых разных заказчиков, обеспечивая высокую производительность и масштабируемость в любых сценариях применения ИИ. В числе ключевых сфер компания указала здравоохранение — для анализа медицинских изображений и диагностики с помощью ИИ; финансовый сектор — при оценке рисков и обработки больших данных; промышленные предприятия — для автоматизации производства и управления процессами; научные и образовательные учреждения — в моделировании и исследованиях; а также медиа и игровую индустрию. Как сообщает компания, платформа успешно прошла серию внутренних тестов в лаборатории YADRO, включая нагрузочные испытания под ИИ-сценарии и термовалидацию, продемонстрировав стабильную работу под высокой вычислительной нагрузкой. В настоящее время сервер G4208P G3 проходит регистрацию в Едином реестре российской радиоэлектронной продукции (ЕРРРП) Минпромторга.  В настоящее время доступно демонстрационное тестирование платформы. Подать заявку и ознакомиться с техническими характеристиками можно на официальном сайте YADRO.
29.03.2025 [10:11], Алексей Степин
Bolt Graphics анонсировала универсальную видеокарту со слотами SO-DIMM, которая может потягаться с RTX 5080Все современные графические ускорители предлагаются с жёстко заданным при производстве объёмом видеопамяти, а в наиболее производительных моделях память типа HBM вообще интегрирована на одной с основным кристаллом подложке. Однако требования к объёму памяти в последнее время растут быстрее, а за дополнительный объём вендор просят всё больше. Кардинально иной подход предлагает компания Bolt Graphics, недавно анонсировавшая серию ускорителей Zeus. Несмотря на «ИИ-пандемию», Bolt Graphics в своём анонсе не делает упор на искусственный интеллект, а называет Zeus первым GPU, специально созданным для целей HPC, рендеринга, трассировки лучей и даже компьютерных игр. Что интересно, в основе Zeus лежит не некая закрытая архитектура: скалярная часть нового GPU построена на базе спецификации RISC-V RVA23, векторная представлена FP64 ALU на базе несколько модифицированной RVV 1.0. Прочие функции реализованы путём кастомных расширений и отдельных блоков-ускорителей. Все они пользуются общим кешем объёмом 128 Мбайт. Дополняет картину блок телеметрии и внутренний интерконнект для общения с другими вычислительным блоками. 
Zeus 1c26-032 (Источник изображений: Bolt Graphics) Используется чиплетный подход. Базовый «строительный блок» Zeus 1c26-032 включает GPU-чиплет, который соединён с 32 Гбайт набортной памяти LPDDR5x (273 Гбайт/с) и контроллером внешней памяти DDR5 (90 Гбайт/с), т.е. при желании можно установить ещё 128 Гбайт RAM (два модуля SO-DIMM). В GPU-чиплет встроены контроллеры DisplayPort 2.1a и HDMI 2.1b, а с внешним миром он общается посредством IO-чиплета, с которым он соединён 256-Гбайт/с каналом. IO-чиплет предлагает необычный набор портов. Помимо сразу двух интерфейсов PCIe 5.0 x16 (64 Гбайт/с каждый) имеется выделенный порт RJ-45 для BMC и 400GbE-порт QSFP-DD. Наконец, есть аппаратный блок видеокодирования, способный справиться с двумя потоками 8K@60 AV1/H.264/H.265.  Заявленный уровень производительности в векторных FP64/FP32/FP16-вычислениях составляет 5/10/20 Тфлопс, а в матричных INT16/INT8 — 307,2/614,4 Топс. Аппаратный блок ускорения лучей (path tracing) выдаёт до 77 гигалучей. Для сравнения: NVIDIA RTX 5090 способна выдавать 32 гигалуча, а FP64-производительность составляет 1,6 Тфлопс. В то же время в расчётах пониженной точности актуальные решения NVIDIA всё равно быстрее Zeus 1c26-032. Однако у новинки есть важное преимущество — её уровень TDP составляет всего 120 Вт. Второй интерфейс PCIe 5.0 x16 можно использовать для прямого объединения двух карт. 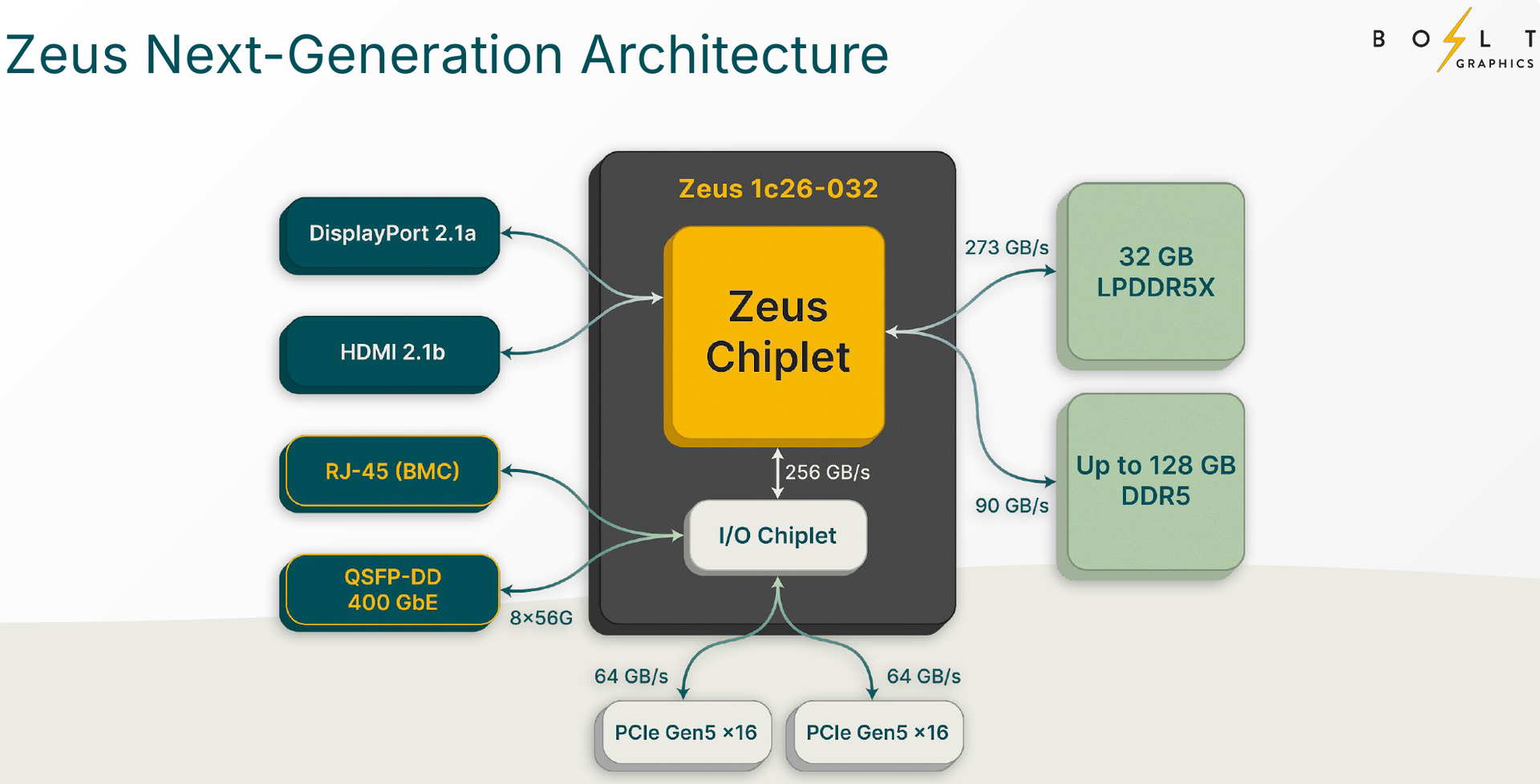 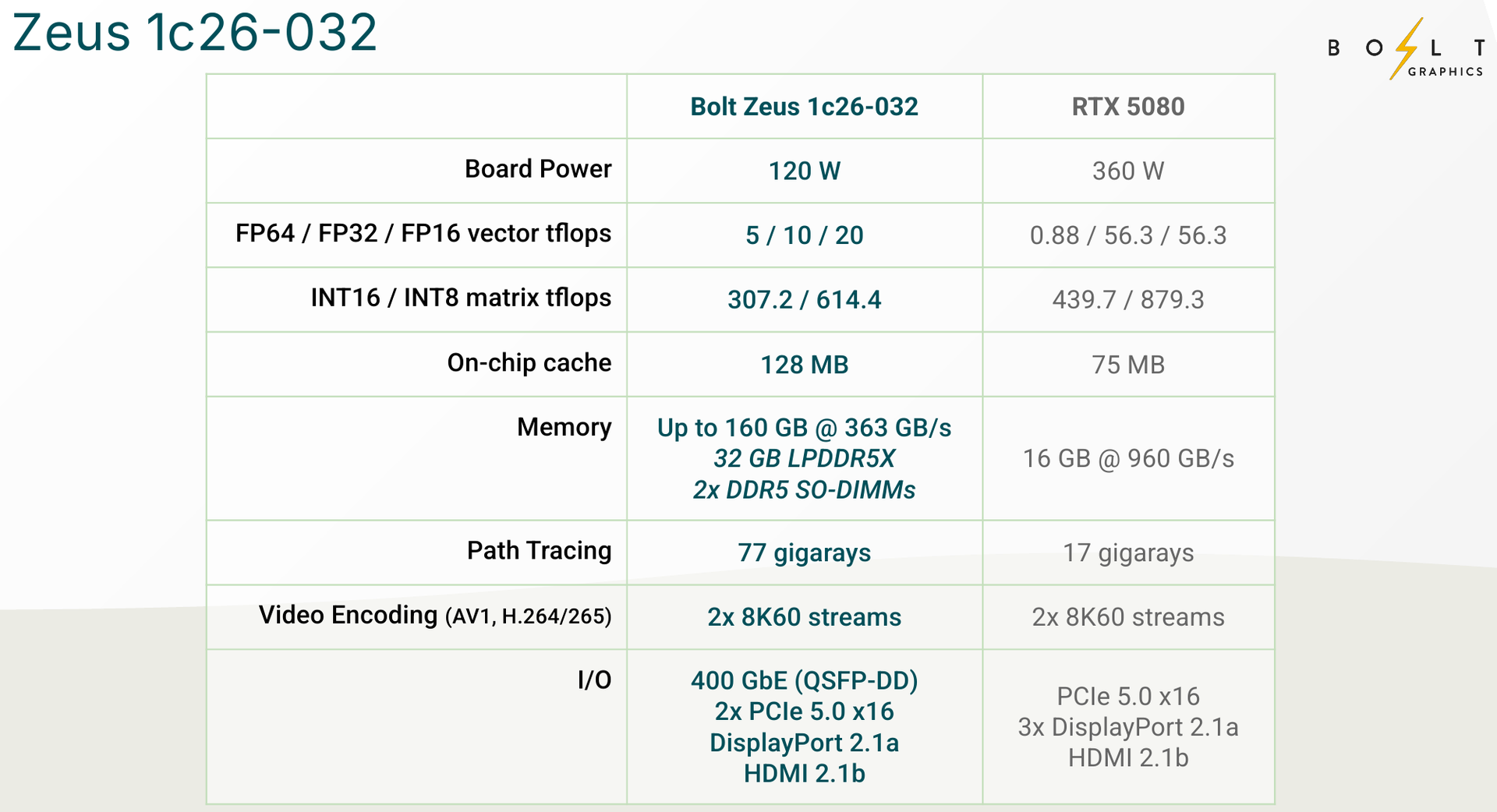 Вариант ускорителя с двумя чиплетами носит название Zeus 2c26-064/128, а с четырьмя — 4c26-256. Последние числа обозначают объём распаянной памяти LPDDR5X. Что касается расширяемой памяти, то количество доступных разъёмов SO-DIMM также зависит от модели и составляет до восьми, так что во флагманской конфигурации базовые 256 Гбайт LPDDR5x можно дополнить аж 2 Тбайт DDR5. Производительность с увеличением количеств GPU-чиплетов растёт практически пропорционально, но есть некоторые другие нюансы. Так, в Zeus 2c26-064 и Zeus 2c26-128 (оба варианта имеют TDP 250 Вт) есть только один IO-чиплет, а GPU-чиплеты объединены шиной со скоростью 768-Гбайт. 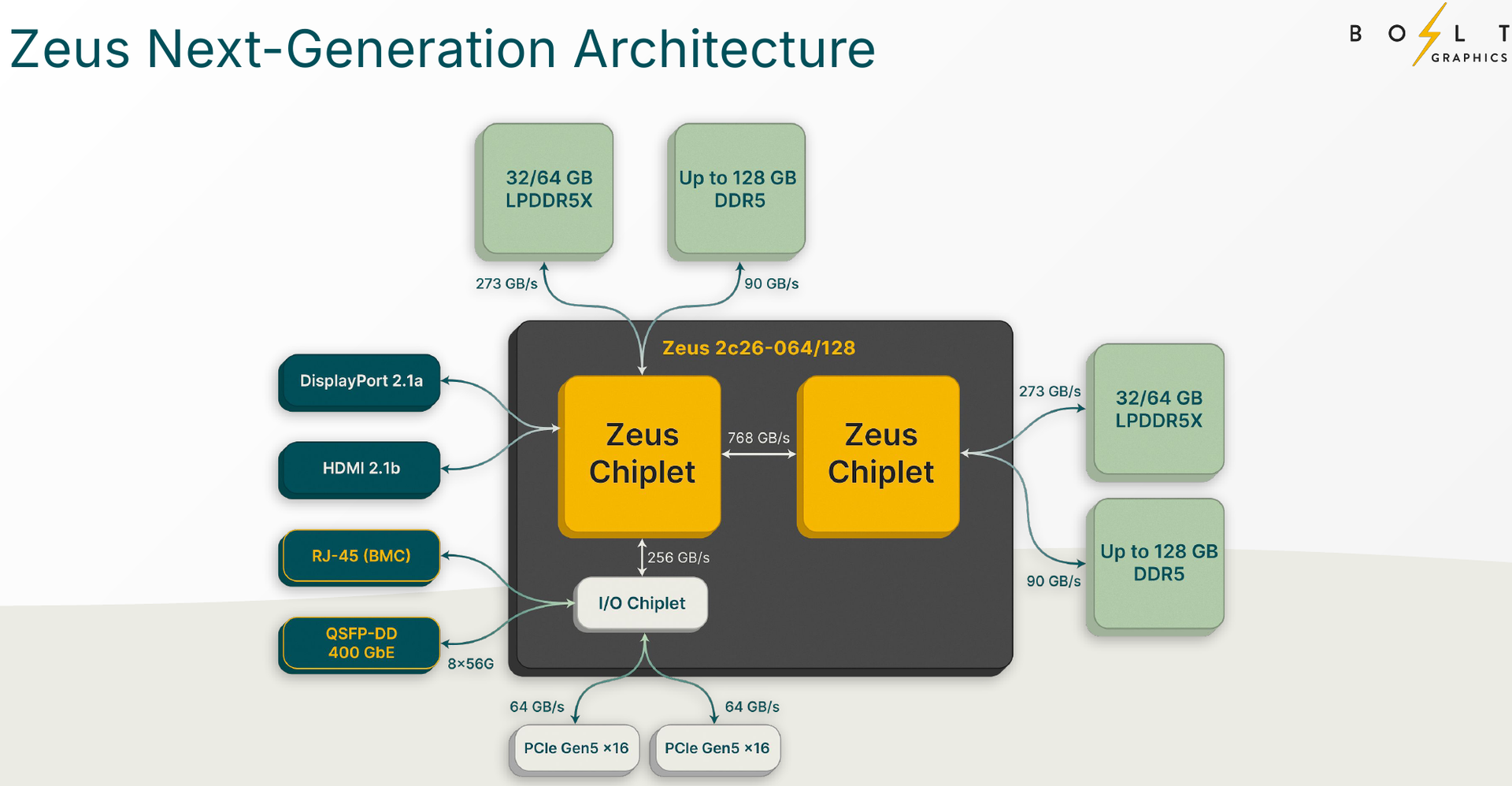  Zeus 4c26-256 имеет сразу четыре I/O чиплета в составе, которые дают восемь контроллеров PCIe 5.0 x4 (один чиплет, совокупно 32 линии) и шесть 800GbE-портов OSFP (три чиплета). Между собой GPU-чиплеты объединены шиной со скоростью 512-Гбайт/с. Каждый из них соединён с собственным IO-чиплетом на скорости 256 Гбайт/с. Теплопакет флагмана составляет 500 Ватт, ускоритель, если верить Bolt Graphnics, развивает 20 Тфлопс в режиме FP64, почти 2500 Топс на вычислениях FP8 и способен обрабатывать до 307 гигалучей. 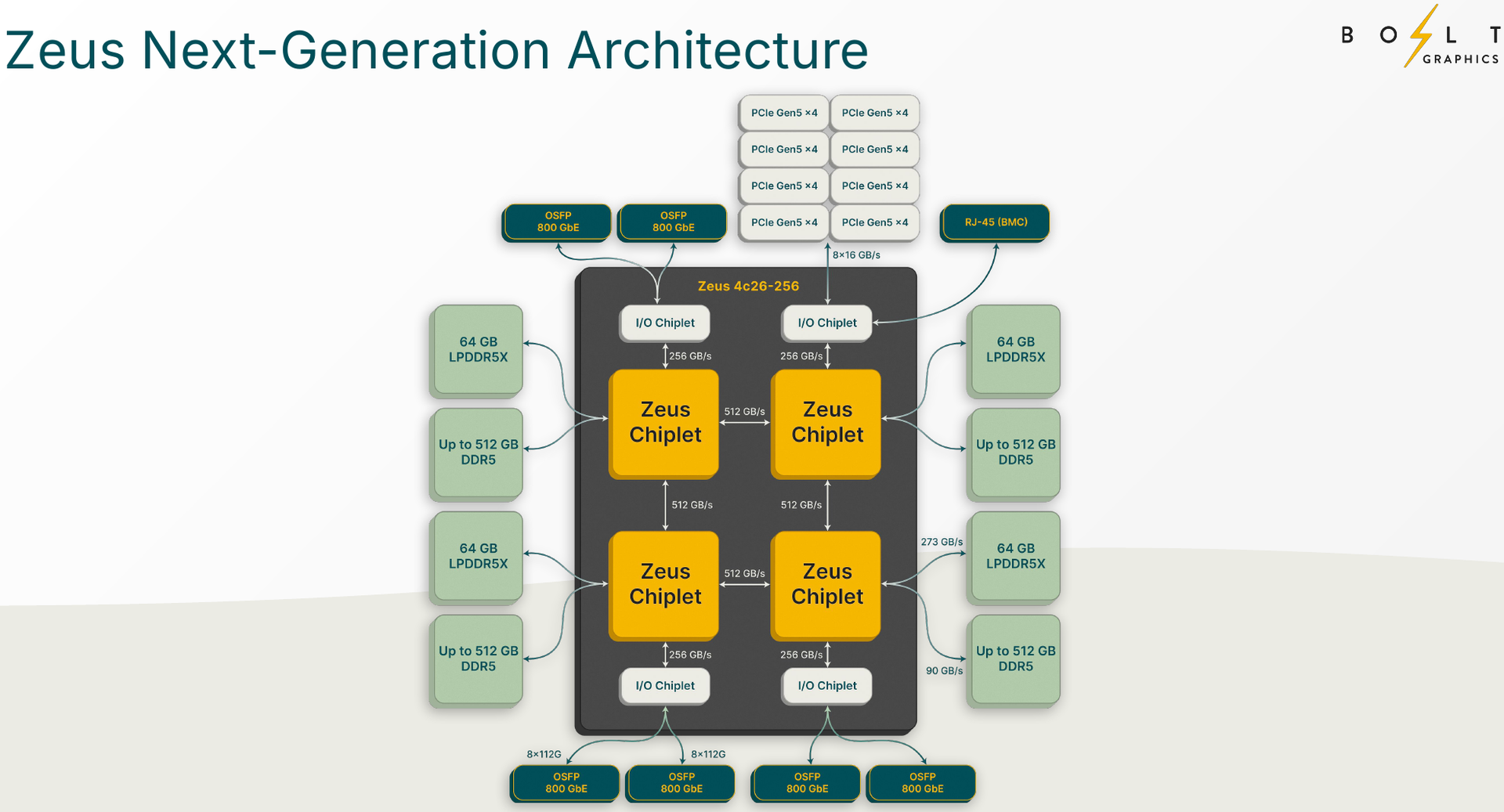 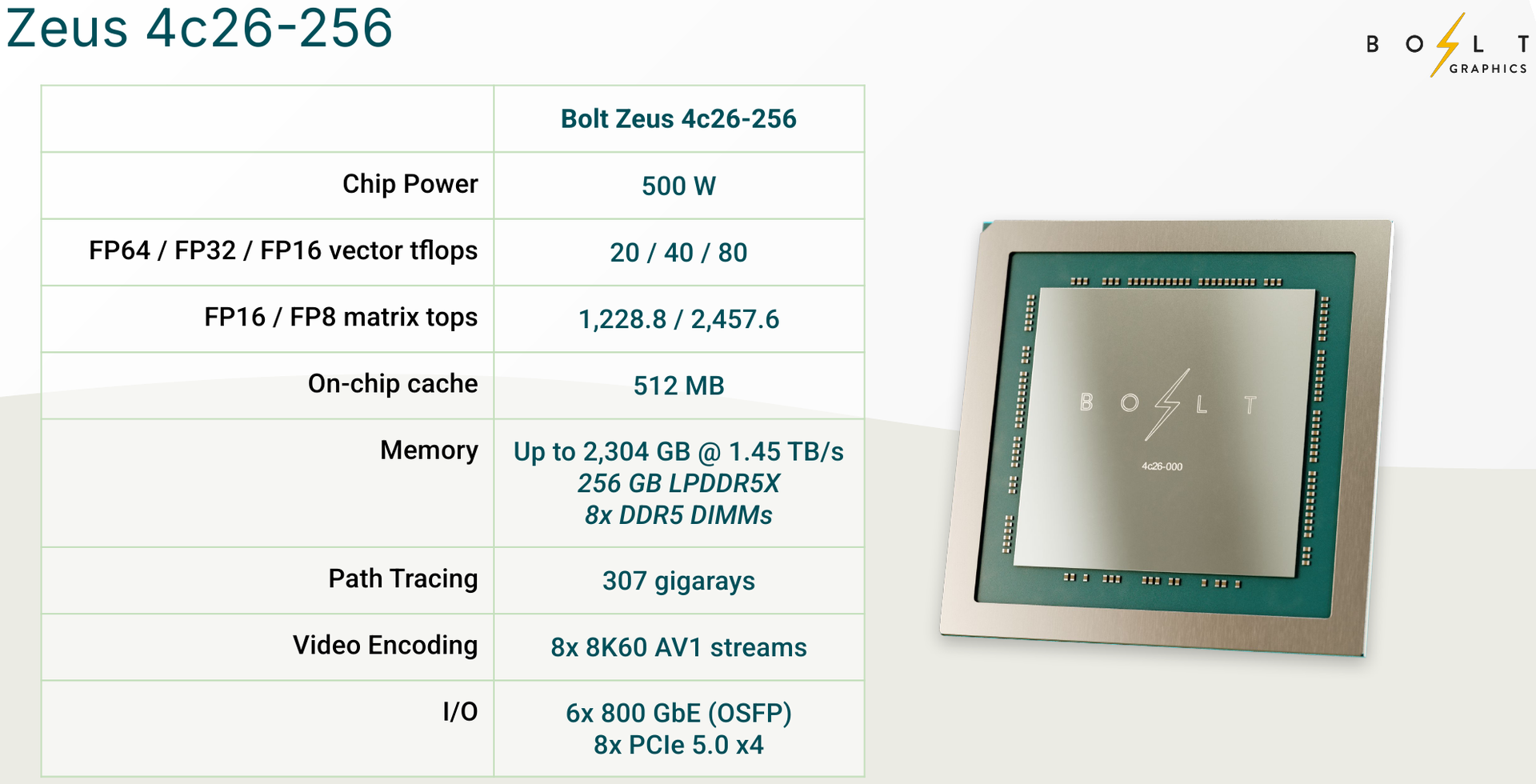 Разработчики явно заложили в своё детище широкие возможности кластеризации, о чём свидетельствует наличие мощной сетевой подсистемы. Поддерживаются как скромные конфигурации из двух GPU, соединённых непосредственно по Ethernet 400GbE, так и масштабные системы уровня стойки, содержащей 80 плат Zeus 4c26-256, соединённых как с коммутатором, так и напрямую друг с другом. Такой кластер потребляет 44 кВт, но зато способен обеспечивать запуск крупных физических симуляций или обучение ИИ моделей за счёт огромного массива общей памяти, составляющего 160 Тбайт. Вычислительная производительность такого кластера достигает 1,6 Пфлопс в режиме FP64 и 196 Попс в режиме FP8. 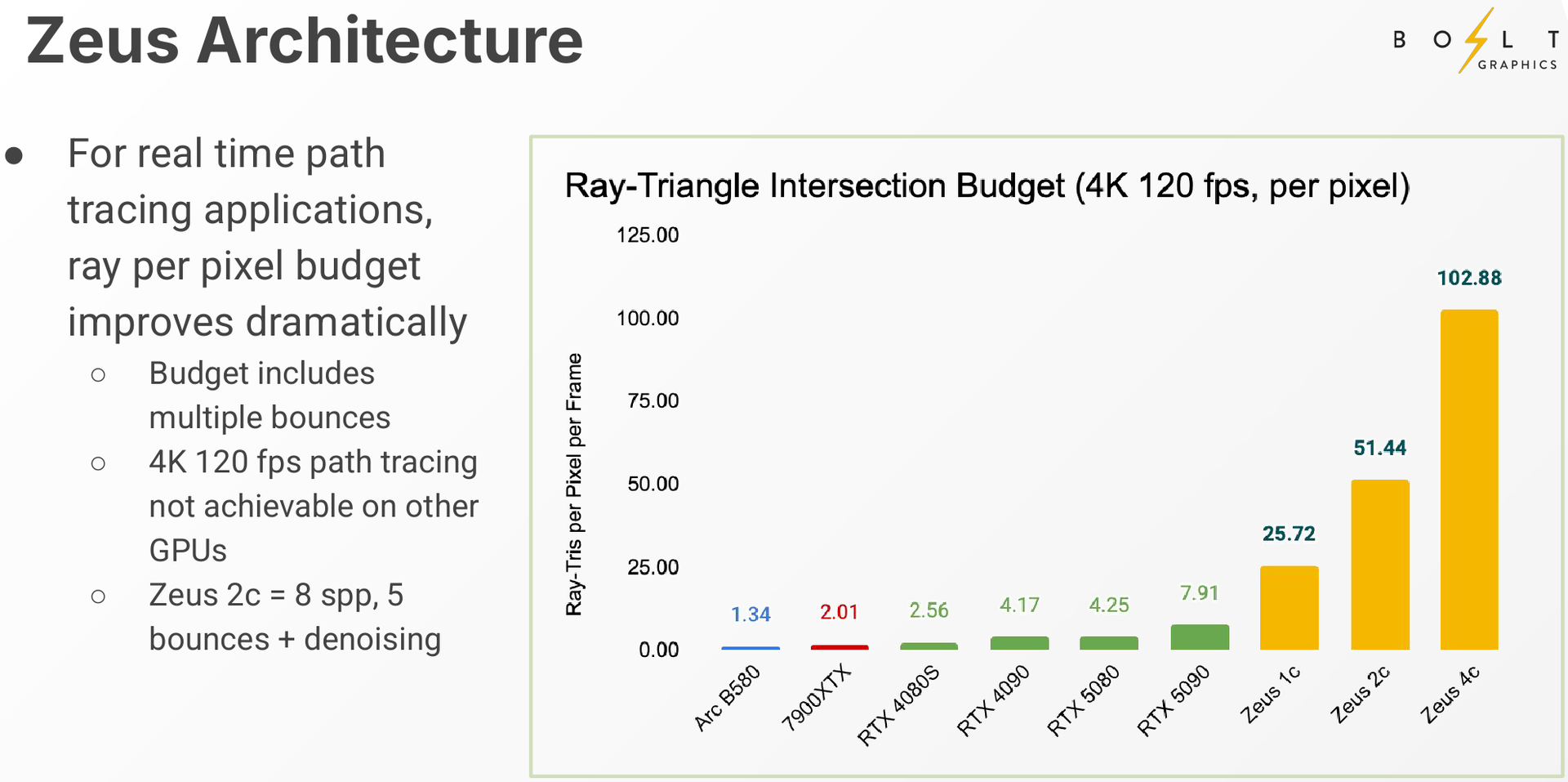  Одной из особенностей новинок является трассировщик лучей Glowstick, способный работать в режиме реального времени практически во всех современных пакетах 3D-моделирования или видеоредактирования, таких как Maya, 3ds Max, Blender, SketchUp, Houdini и Nuke. Он будет дополнен фирменной библиотекой Bolt MaterialX, содержащей более 5000 текстур высокого качества. А благодаря поддержке стандарта OpenUSD он сможет легко интегрироваться в любую цепочку рендеринга и пост-обработки. Также запланирован электромагнитный симулятор Bolt Apollo. Обещаны фирменные драйверы Vulkan/DirectX и SDK с использованием LLVM. 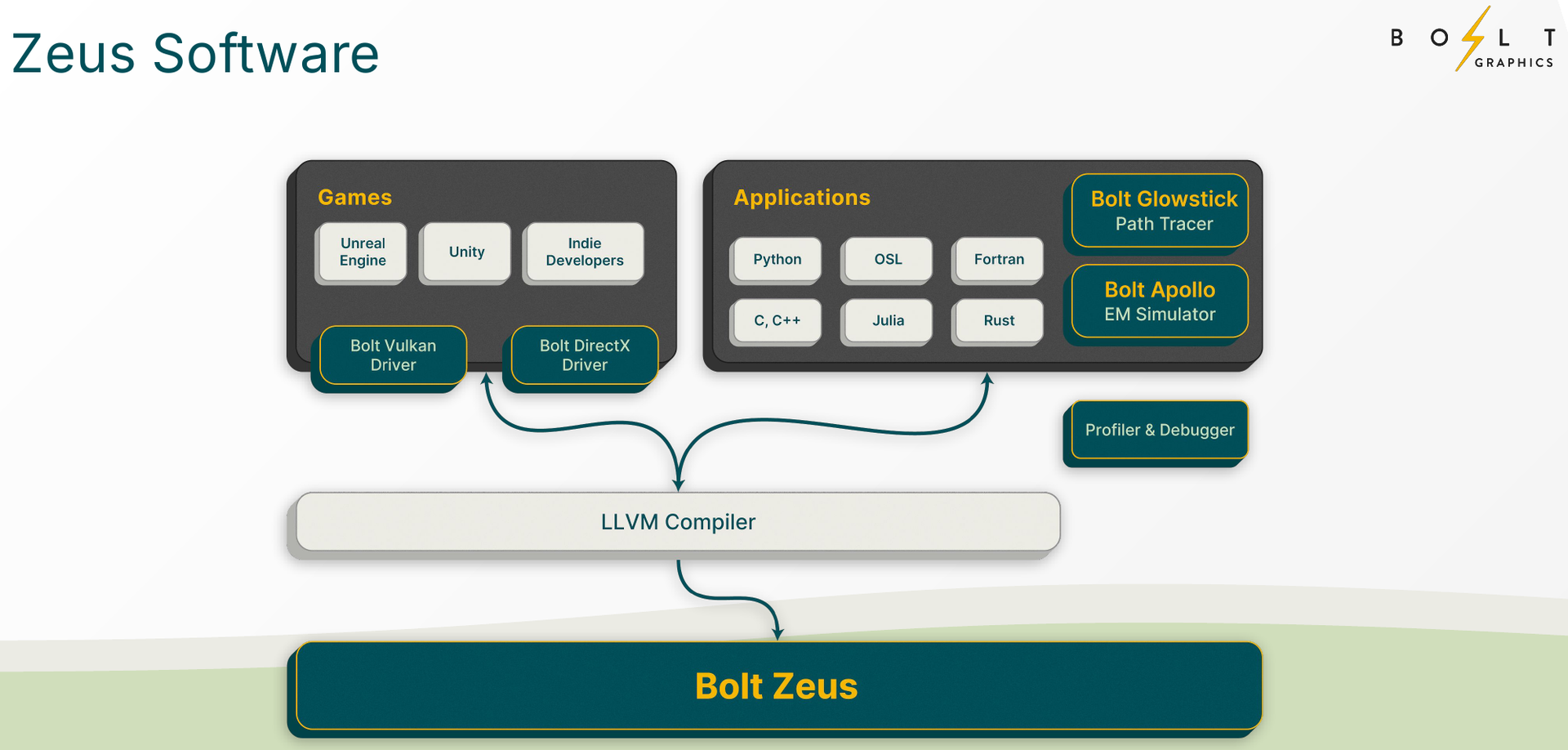 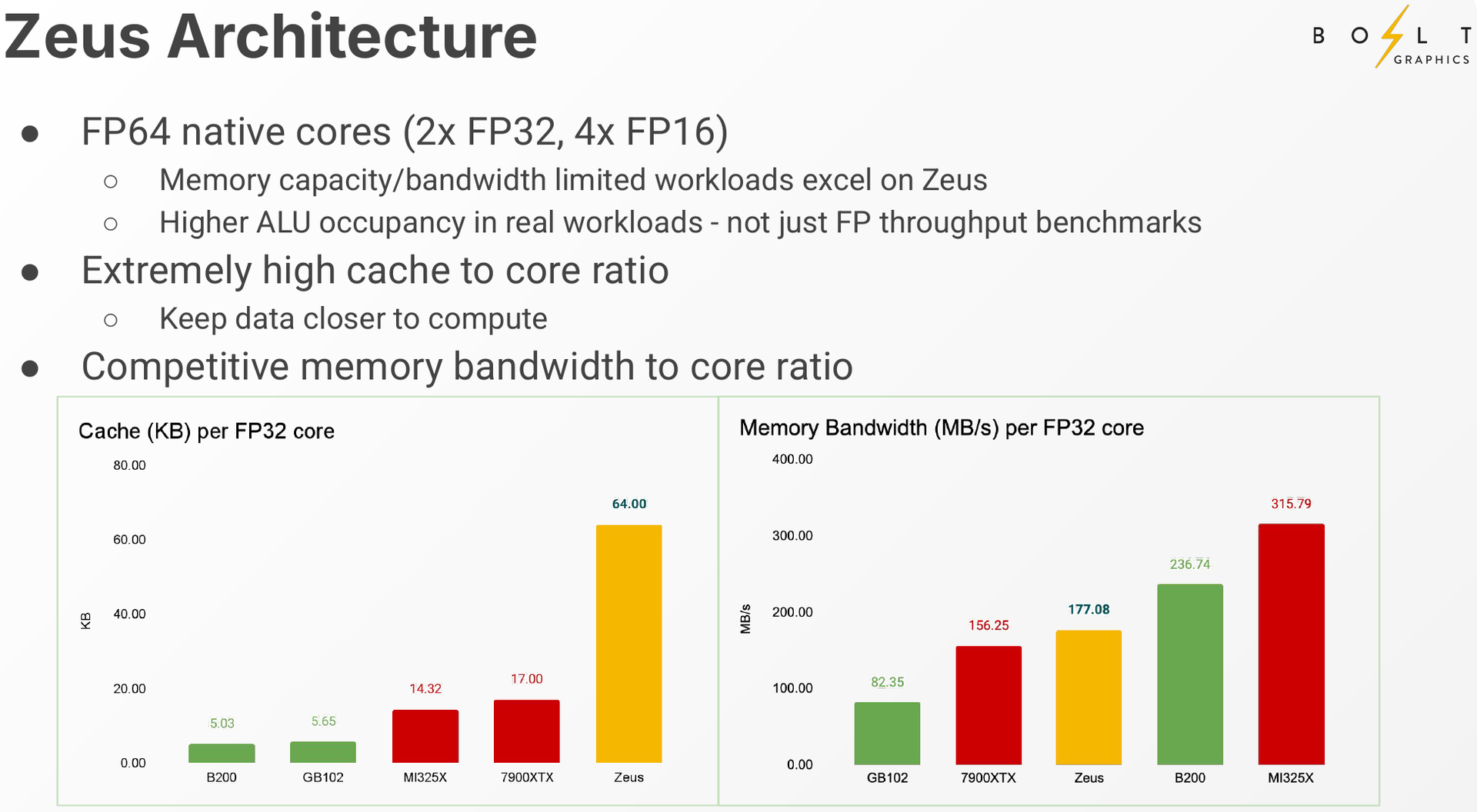 Ранний доступ к комплектам разработчика Bolt Graphics наметила на IV квартал текущего года. В III квартале 2026 года должны появиться 2U-серверы на базе Zeus, а массовые поставки серверов и PCIe-карт начнутся не ранее IV квартала того же года. Пока сложно сказать, насколько хорошо новая архитектура себя проявит, но если верить предварительным тестам Zeus, выигрыш в сравнении с существующими ускорителями существенен, особенно в энергопотреблении.
27.03.2025 [10:21], Сергей Карасёв
HighPoint представила шасси RocketStor для подключения мощных ИИ-ускорителей к компактным рабочим станциямКомпания HighPoint анонсировала внешние шасси серии RocketStor, предназначенные для подключения мощных ИИ-ускорителей к рабочим станциям, у которых внутри корпуса отсутствует необходимое пространство для установки двух- или трёхслотовых карт расширения. Дебютировали изделия RocketStor 8531AW и RocketStor 8631CW с поддержкой интерфейса PCIe 4.0 x16 и PCIe 5.0 x16 соответственно. Применён PCIe-коммутатор roadcom PEX 89048. Устройства, как утверждается, позволяют полностью раскрыть потенциал новейших ускорителей NVIDIA, AMD и Intel. Соединение с хостом осуществляется через низкопрофильную карту расширения Rocket 1634C посредством метрового кабеля CDFP. Заявлены «надёжность корпоративного уровня и подключение с малой задержкой». 
Источник изображений: HighPoint Корпуса RocketStor оборудованы активным охлаждением с двумя вентиляторами с интеллектуальным управлением скоростью вращения крыльчатки: применённая система предотвращает перегрев, обеспечивая стабильную высокопроизводительную работу, говорит компания. Возможно также ручное управление с пятью режимами. Диапазон рабочих температур простирается от +5 до +55 °C. Заявлена совместимость с картами полной высоты в двух- и трёхслотовом исполнении с габаритами до 360 × 120 × 75 мм. Обеспечивается возможность подачи до 600 Вт для установленного GPU.  Среди областей применения изделий RocketStor названы приложения ИИ, машинного обучения и аналитики больших данных, высокопроизводительные вычисления, создание и рендеринг контента, научные исследования, рабочие нагрузки корпоративного класса и пр. |
|

