Материалы по тегу: amd
|
08.01.2024 [00:28], Алексей Степин
Oxide Cloud Computer: переизобретая облакоПубличные облака очень популярны, но не всегда в должной мере отвечают поставленным целям и задачам компании. В то же время, классическая серверная инфраструктура дорога в содержании, хлопотна в настройке и не всегда безопасна — не в последнюю очередь из-за фрагментированности программных и аппаратных архитектур, уходящей корнями в далёкое прошлое. Компания Oxide Computer заявила, что разработанная ею интегрированная платформа должна вернуть компьютерным системам нового поколения холизм, присущий самым ранним вычислительным решениям, когда аппаратное и программное обеспечение создавалось совместно и с взаимным учётом особенностей. Разлад, по мнению Oxide, начался в этой сфере давно — с появлением BIOS, отделившей «железо» от системного ПО. В дальнейшем этот разрыв только нарастал, как и степень закрытости компонентов вкупе со всё большим и большим количеством слоёв абстракций. 
Источник изображений здесь и далее: Oxide Computer Появление UEFI лишь усугубило эту проблему. Причём речь здесь не только о прошивках: можно вспомнить SMM и интеграцию в процессоры «вспомогательных ядер», обслуживающих I/O-подсистемы, но полностью скрытых от системного ПО. По мнению Oxide, такой подход представляет серьёзную угрозу безопасности, поскольку со стороны «железа» операционной системе доступно всё меньше информации об истинных аппаратных возможностях и ресурсах сервера.  Появление BIOS с открытым кодом проблемы не решает — вспомогательные аппаратные компоненты сегодня не просто слишком сложны, но и работают под управлением проприетарных прошивок, а информации в открытом доступе о них крайне мало. Крупные гиперскейлеры борются с этой фрагментацией путём создания собственных, уникальных решений. Oxide Computer же решила распространить этот подход на традиционный корпоративный рынок.  В своих новых системах компания отказалась не только от традиционных прошивок BIOS и UEFI, но и от использования закрытых BMC и сервисных процессоров, равно как и блоков Root-of-Trust (RoT). Вместо них используются чипы STM32H753 и LP55S28, работающие под управлением специально разработанной для этих целей операционной системы Hubris, полностью открытой, написанной на языке Rust. 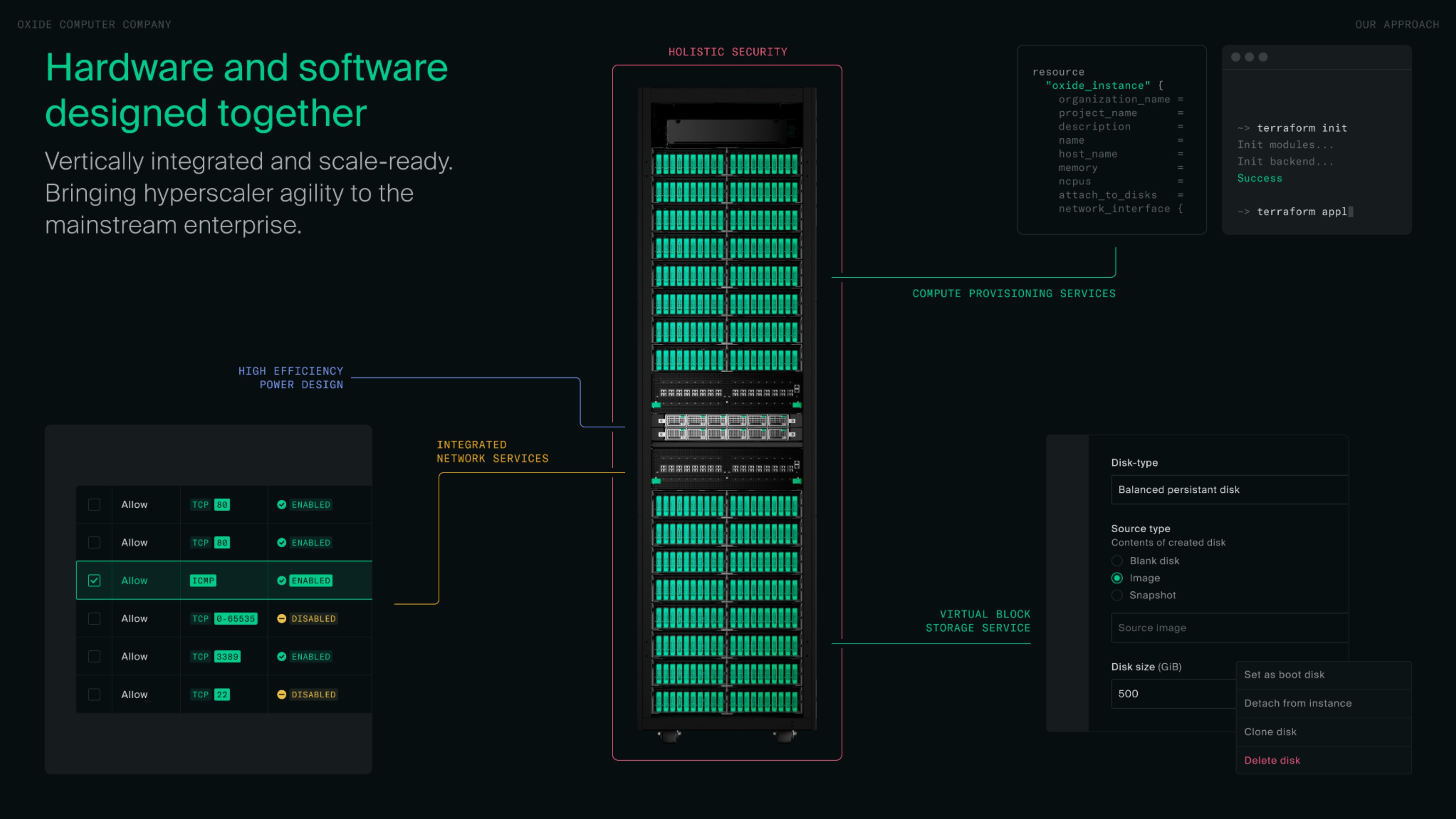 Полностью избавиться от проприетарности на платформе AMD невозможно, поскольку Platform Security Processor (PSP) отвечает за старт и инициализацию процессора и памяти. Но вот дальнейший процесс загрузки управляется не BIOS/UEFI, а фирменной открытой ОС Helios, часть которой «живёт» в SPI-памяти. Helios является своего рода наследницей illumos, восходящей ещё к OpenSolaris. Стек включает гипервизор bhyve, Propolis для работы с VMM, а также Omicron для управления всей платформой в целом на уровне стойки. Естественно, для подсистемы хранения задействованы ZFS-пулы.  Результатом работ Oxide стала платформа под названием Cloud Computer. Для неё не просто было разработано уникальное программное обеспечение — практически с нуля была создана и вся аппаратная часть, от вычислительных узлов до сетевых коммутаторов и подсистемы питания. Об этом компания рассказывает в своём блоге. При этом практически вся программная часть этого программно-аппаратного комплекса открыта, но вот аппаратную часть кому-то со стороны просто так повторить вряд ли удастся.  Oxide позиционирует Cloud Computer в качестве универсальной платформы для частных облаков, обеспечивающей единство архитектуры и удобства конфигурирования с гибкостью и простотой использования публичных облаков. По словам компании, развёртывание облака на базе Oxide Cloud Computer занимает считаные часы, что является заслугой в том числе и уникальной архитектуры новинки. Фактически для первичного запуска системы достаточно подключить питание и сеть.  Платформа (фактически готовая стойка) может включать в себя 16, 24 или 32 вычислительных узла на базе 64-ядерных процессоров AMD EPYC 7713P (Milan) с 512 или 1 Тбайт RAM, что даёт до 2048 ядер и до 32 Тбайт памяти на стойку. Каждый узел имеет 10 U.2-отсеков и комплектуется NVMe SSD объёмом 3,2 Тбайт, так что суммарный объём хранилища может достигать 931,5 Тбайт. В качестве интерконнекта используется 100GbE, в состав системы входит два программируемых коммутатора на базе Intel Tofino 2 (12,8 Тбит/с). В них также применяется ПО Oxide, написанное на P4.  Подсистема хранения использует OpenZFS для построения распределённого блочного хранилища и реализует проактивную защиту данных, быстрое снятие снимков, их преобразование в дисковые образы и обратно, а также многое другое. Шифрование данных обеспечивается на всех уровнях, а за безопасность и хранение ключей отвечает фирменный RoT-контроллер, упомянутый ранее. Полка питания содержит 6 БП (5+1), максимальная потребляемая стойкой мощность не превышает 15 кВт. Питание у системы трёхфазное. Высота стойки Oxide составляет 2354 мм, ширина — стандартные 600 мм, глубина — 1060 мм. Платформа может генерировать почти 61500 BTU/час и нуждается в соответствующем воздушном охлаждении. Система работоспособна при температурах окружающей среды в пределах от +2 до +35 °C при относительно влажности не выше 80 %. Масса стойки составляет до 1145 кг.
18.09.2023 [21:55], Алексей Степин
AMD представила процессоры EPYC 8004 Siena — Zen 4c для периферийных вычисленийКомпания AMD продолжает экспансию на серверном рынке: сегодня она анонсировала выпуск новой разновидности процессоров EPYC четвёртого поколения — чипы EPYC 8004, известные под кодовым именем Siena. Это энергоэффективные процессоры, предназначенные для применения в сфере периферийных вычислений и телекоммуникационного оборудования. Архитектурно ничего нового в EPYC 8004 нет — основе лежит тот же дизайн ядер Zen 4c, применяемый в процессорах EPYC Bergamo и позволивший создать AMD первые в мире 128-ядерные процессоры с архитектурой x86. В числе прочего, это означает и наличие поддержки AVX-512. 
Источник изображений здесь и далее: AMD Компания продолжает придерживаться уже хорошо освоенной модели создания новых процессоров путём компоновки вычислительных 5-нм чиплетов CCD вокруг унифицированного 6-нм чиплета IOD, выполняющего роль хаба ввода-вывода. Однако есть и существенные изменения. Так, в процессорах серии Siena была серьёзно усечена подсистема памяти, с 12 до 6 каналов DDR5. Также пострадала подсистема PCI Express, включающая 96 линий PCIe 5.0 вместо 128. Всё это позволило сделать процессоры компактнее, но потребовало введения нового сокета SP6 с меньшим числом контактов — 4844 против 6096 контактов у SP5. Такой ход позволит снизить себестоимость производства системных плат для EPYC 8004, тем более что поддержки двухпроцессорных конфигураций новые чипы AMD не предусматривают. 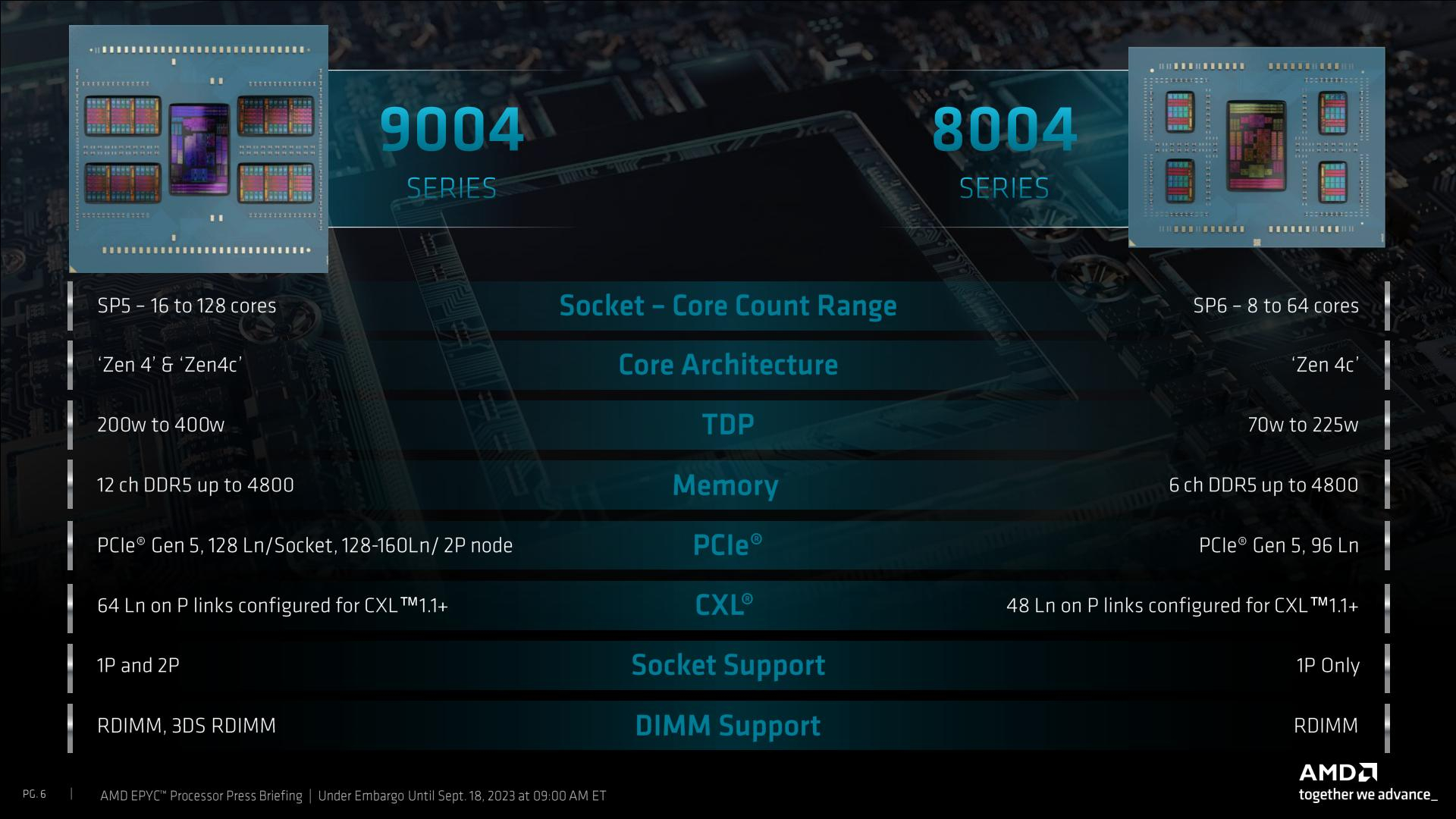 Всего в новой серии AMD анонсировала 12 процессоров, с количеством ядер от 8 до 64 (16—128 потоков), в вариациях с настраиваемым теплопакетом и фиксированным в соответствии со стандартом NEBS (Network Equipment-Building System); последний также предусматривает более широкий диапазон рабочих температур (от -5 до +85 °C). 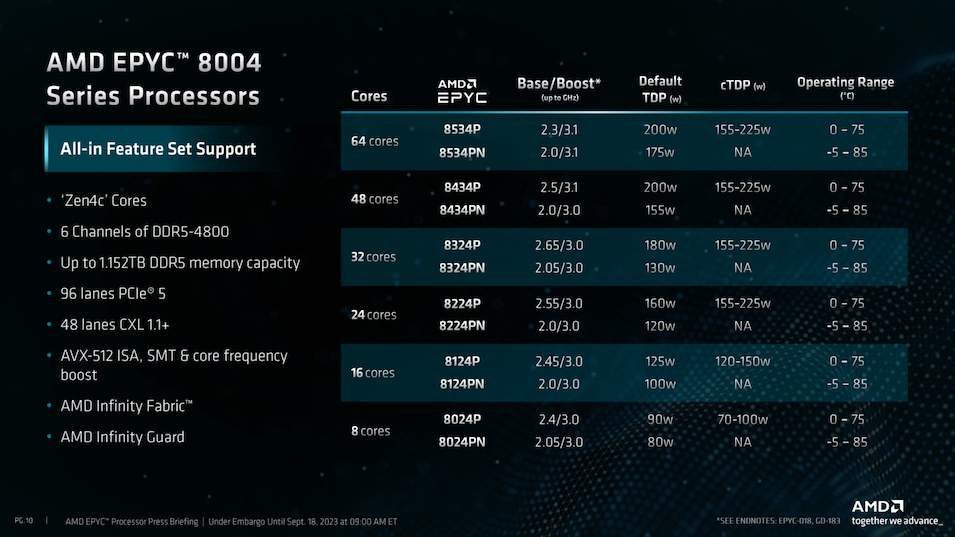 Нельзя, впрочем, сказать, что теплопакет как-то особенно низок даже у младших 8-ядерных моделей — он стартует с отметки 80 Вт (для модели с настраиваемым TDP этот показатель можно снизить до 70 Вт), а в максимальных конфигурациях система охлаждения CPU должна справляться с отводом 175–225 Ватт. Для периферийных систем и телекоммуникационного оборудования этого добиться не всегда просто.  Можно назвать и другие ограничения: так, использование прежнего дизайна IOD-чиплета означает поддержку памяти со скоростью до DDR5-4800, причём лишь при одном модуле DIMM на канал, а поддержка 3DS RDIMM отсутствует, что ограничивает максимальный объём оперативной памяти отметкой 1152 Гбайт (12 × 96 Гбайт RDIMM). Из 96 линий PCIe лишь половина может работать в режиме CXL. 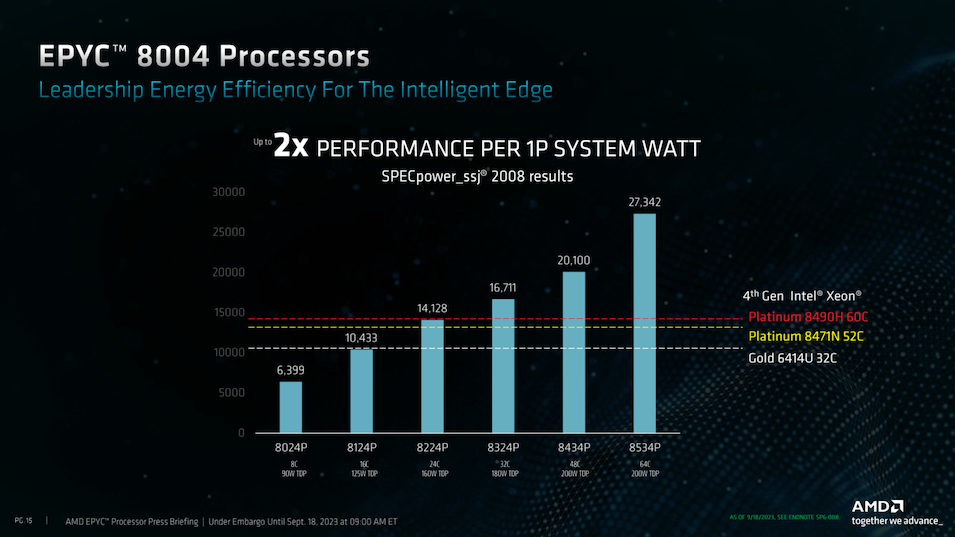 А конкуренция со стороны Intel в этом сегменте будет очень жёсткой: поскольку речь идёт о телекоммуникационном оборудовании, у «синих» имеется готовый стек решений vRAN и отлично подходящие для его запуска процессоры Xeon EE с поддержкой vRAN Boost, а также ещё более экономичные Xeon D-2700 с интегрированным 100GbE-контроллером, поддерживающие третье поколение Quick Assist и полноценные расширения AVX-512 и VNNI/DL. 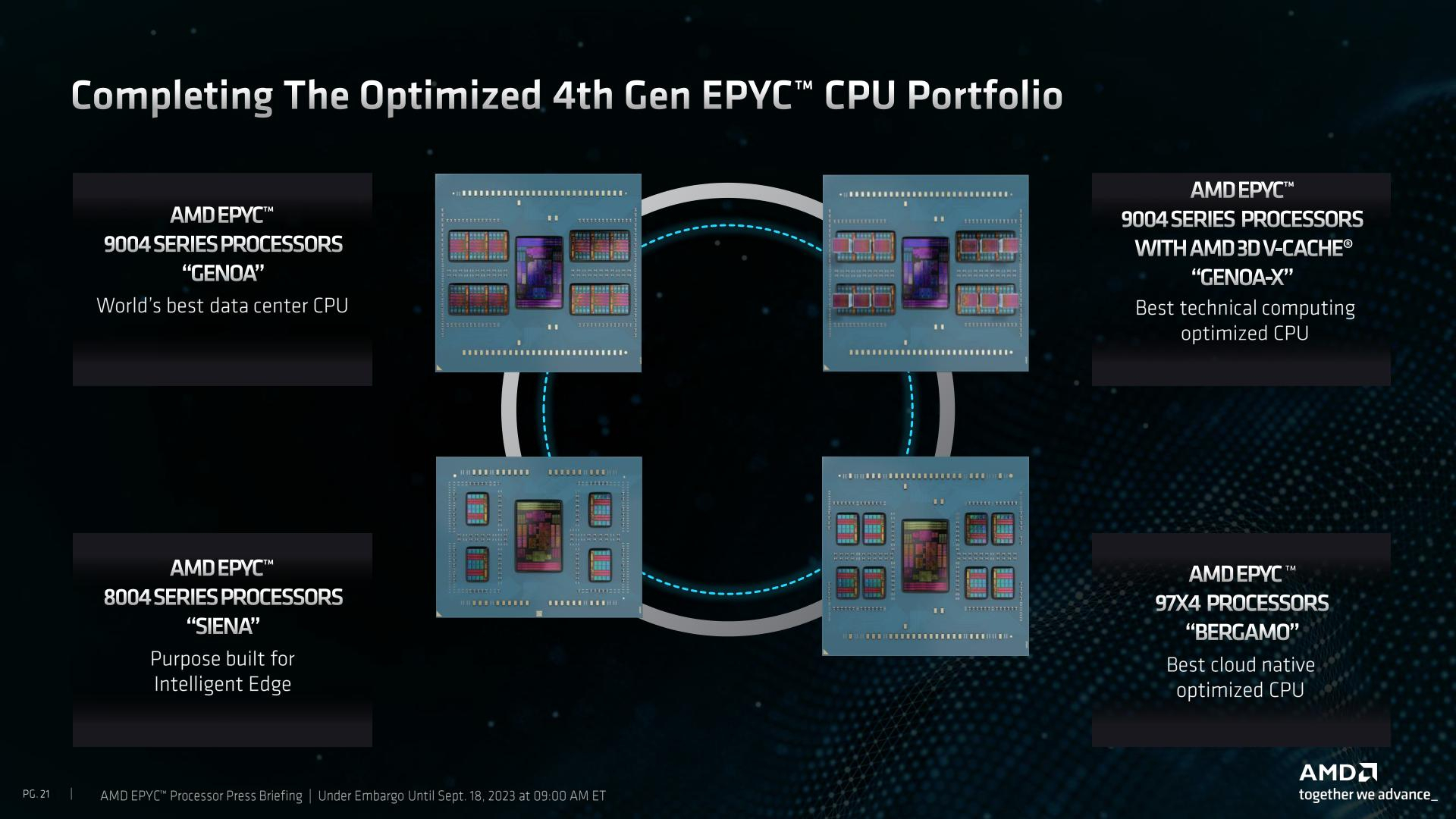 AMD хочет противопоставить этому «чистую» вычислительную мощность, достигаемую за счёт количества ядер. Это может сыграть решающую роль при использовании программного обеспечения, неспособного использовать все преимущества ускорителей в процессорах Intel. Также потенциальных заказчиков должна привлечь низкая совокупная стоимость владения для систем на базе EPYC Siena, достигаемой за счёт высокой удельной производительности новых процессоров. Компания сообщает, что процессоры EPYC 8004 уже доступны в новых периферийных серверах таких производителей, как Dell, Lenovo и Supermicro, анонсировала новые решения и Giga Computing. Также поддержали выпуск новых чипов Microsoft Azure и Ericsson. Последняя, напомним, весной этого года подписала с AMD соглашение о разработке открытого RAN-стека, что позволит ей «отвязаться» в своих продуктах от решений исключительно Intel.
30.06.2023 [21:39], Владимир Мироненко
Глава Oracle считает, что архитектура Intel x86 теряет актуальность для серверовВ 2023 году Oracle планирует потратить значительные средства на приобретение чипов AMD и Ampere Computing для новой инфраструктуры, отметив, что «старая архитектура Intel x86 достигает своего предела». «В этом году Oracle купит GPU и CPU у трёх компаний, — сообщил на прошедшем в среду мероприятии глава Oracle Ларри Эллисон (Larry Ellison). — Мы будем покупать GPU у NVIDIA, мы покупаем у неё на миллиарды долларов США. И потратим в три раза больше на центральные процессоры от Ampere и AMD. Мы по-прежнему тратим больше денег на традиционные чипы». Oracle сообщила, что впервые за 14 лет существования специализированных ПАК Exadata для СУБД она полностью отказалась от процессоров Intel в пользу чипов AMD. В платформе 12-го поколения Exadata X10M в рамках двух предложений Oracle Exadata Machine и управляемого решения Oracle Exadata Cloud@Customer будут использоваться AMD EPYC Genoa. Одной из причин такого перехода, пусть и далеко не самой важной, считается отказ Intel от Optane. 
Источник изображения: Oracle С момента запуска Exadata в 2008 году Oracle полагалась на процессоры Intel Xeon. Но ситуация начала меняться c выходом X9M в 2021 году. Для Oracle Exadata Machine и Oracle Exadata Cloud@Customer компания выбрала чипы Intel Xeon Ice Lake-SP, а в начале 2022 года для облачного решения Oracle Exadata Cloud Infrastructure решила использовать чипы AMD. При этом EPYC Milan использовались в серверах для обеспечения работы баз данных, а Ice Lake-SP — для СХД. Кроме того, на днях Oracle сделала важный шаг — перенесла свою флагманскую СУБД Oracle Database на архитектуру Arm, т.е. на процессоры компании Ampere Computing, в которую в своё время инвестировала. Эллисон отметил, что чипы Ampere Altra намного энергоэффективнее решений AMD и NVIDIA, что поможет ЦОД Oracle соответствовать будущим регуляциям. «Мы перешли на новую архитектуру и к новому поставщику, — сообщил Эллисон. — Мы думаем, что это будущее. Старая архитектура Intel x86 после многих десятилетий на рынке подошла к своему пределу». 
Источник изображения: Oracle Тем не менее, эксперты полагают, что ставка Oracle на архитектуру Arm не помешает её отношениям с AMD в ближайшее время, тем более что Intel и AMD планируют бороться с Arm-процессорами с помощью оптимизированных для облачных платформ чипов с высокой плотностью ядер и улучшенной энергоэффективностью: EPYC Bergamo и Xeon Sierra Forest. Кроме того, разработка, перенос и рефакторинг ПО для Arm требует времени и средств. В свою очередь, представитель Intel сообщил ресурсу CRN в четверг, что компания поставляет Oracle процессоры Xeon Sapphire Rapids «в течение многих месяцев и планирует продолжать поставки Xeon текущего и следующего поколения в будущем». Компании связывают долгие годы совместной работы над аппаратными и программными решениями для клиентов, а сейчас Intel поставляет чипы для облачной инфраструктуры Oracle OCI.
14.06.2023 [01:30], Игорь Осколков
AMD представила 128-ядерные EPYC Bergamo, а также EPYC Genoa-X с 1152 Мбайт L3-кешаAMD официально представила два новых, пока что очень небольших семейства серверных процессоров EPYC на базе архитектуры Zen 4. Это давно обещанные CPU серии EPYC 97x4, известные под кодовым именем Bergamo и рассчитанные на гиперскейлеров и облачных провайдеров, а также EPYC 9x84X Genoa-X с 3D V-Cache, которые предлагают до 1152 Мбайт L3-кеша и которые ориентированы на HPC-нагрузки. Ничего нового относительно архитектурных особенностей Bergamo компания не поведала. Более высокая плотность компоновки ядер Zen 4c достигнута, в частности, путём модификации кешей (они проще и меньше) и компромиссными решениями в отношении упаковки, частот и т.д. В итоге получается интересная картина — ядер в сравнении с EPYC Genoa (до 96 шт.) стало больше, а вот общее число транзисторов уменьшилось с 90 до 82 млрд. Показатель TDP сохранился на прежнем уровне. 
Изображения: AMD AMD говорит, что ядра Zen 4c примерно на треть меньше Zen 4: 2,48 мм2 против 3,84 мм2 (ядро + L2-кеш). Оба варианта производятся по 5-нм техпроцессу TSMC. В CCD теперь содержится 16 ядер вместо 8, а в самом процессоре теперь 8 CCD вместо 12. Центральный IO-мостик у Genoa и Bergamo предлагает одни и те же возможности: 128 линий PCIe 5.0 (CXL) и 12 каналов памяти DDR5-4800. При этом оба варианта совместимы не только на уровне сокета (SP5), но и ISA, и платформы целиком — достаточно обновления BIOS. 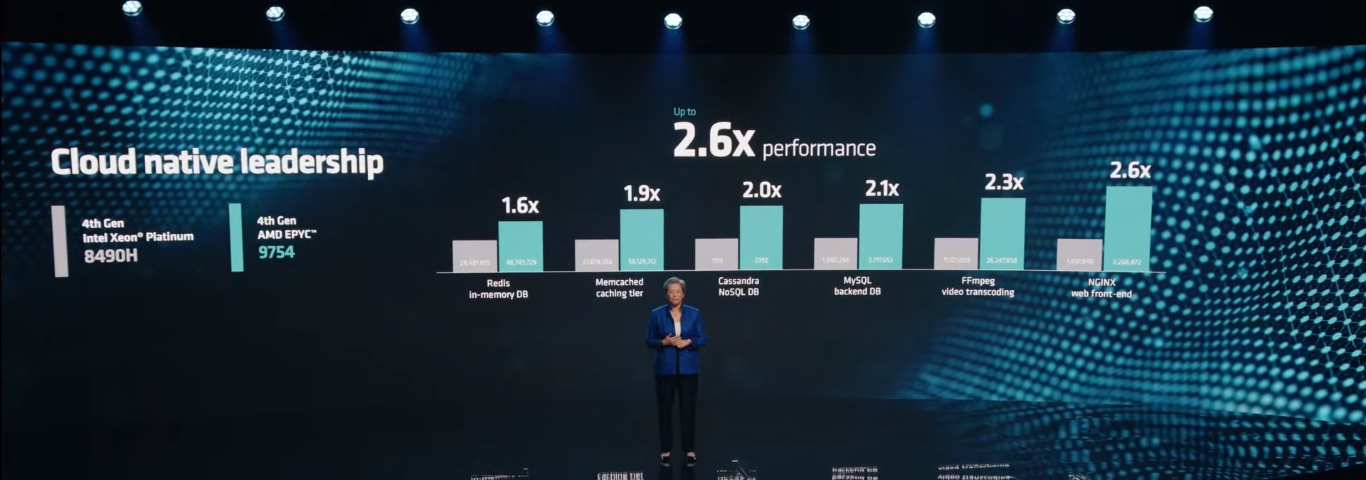 В случае Bergamo компания, как и прежде, напирает на относительно низкую совокупную стоимость владения и на ещё более высокую энергоэффективность в сравнении с Genoa. Поскольку SMT на месте, в 2U4N-шасси с двухсокетными узлами теперь можно получить 2048 vCPU. Отдельный вопрос, как это всё ещё сбалансировать с точки зрения IO. Но в любом случае такое решение должно привлечь гиперскейлеров, среди которых была упомянута Meta✴, уже использующая сотни тысяч процессоров EPYC.  Любопытно, что в пресс-релизе AMD сравнивает общую производительность Bergamo с Ampere Altra, утверждая, что в ключевых облачных нагрузках они в 3,7 раз быстрее. Кроме того, новинки в 2,7 раз энергоэффективнее конкурентов. При этом оба документа, описывающих условия тестирования, на момент написания публикации доступны не были. Возможно, как и в других тестах, речь идёт о 128-ядерных Altra Max, которые уже доступны у ключевых облачных провайдеров.  По-видимому, в этой области AMD воспринимает как важного (если не ключевого) конкурента именно Ampere, а не Intel, с продукцией которой были показаны сравнения во время презентации. Так, старший AMD EPYC 9754 до 2,6 раз быстрее старшего же Intel Xeon 8490H (Sapphire Rapids), который предлагает всего 60 ядер при сравнимом TDP. До выхода Sierra Forest с E-ядрами (до 144 шт.) в следующем году Intel отвечать AMD нечем. А вот Ampere уже представила 192-ядерные (но без SMT) AmpereOne, которые, по слухам, уже давно поставляются избранным клиентам. 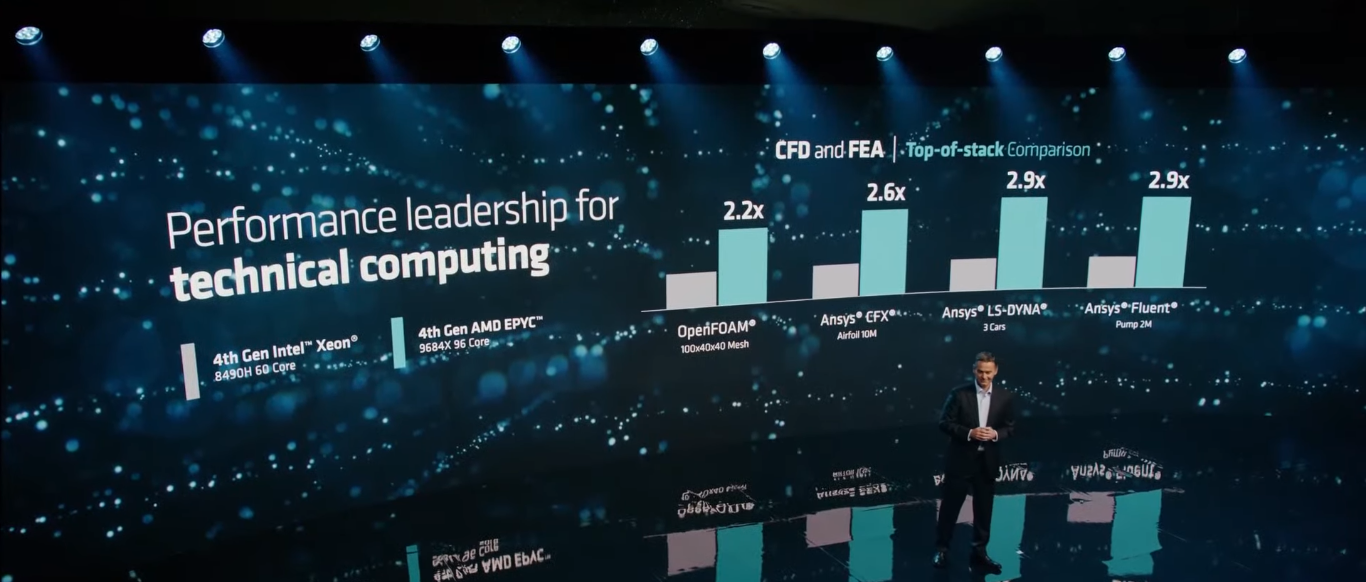 Да и сама AMD заявляет, что Bergamo тоже уже отгружаются. Заодно AMD объявила о доступности EPYC Genoa-X (9x84X). Концептуально они повторяют Milan-X, то есть поверх каждого CCD в обычном Genoa располагается плитка V-Cache с 64 Мбайт L3-кеша (с небольшим штрафом при обращении). 12 CCD дают 768 Мбайт дополнительного кеша, а суммарно выходят умопомрачительные 1152 Мбайт L3-кеша на процессор. 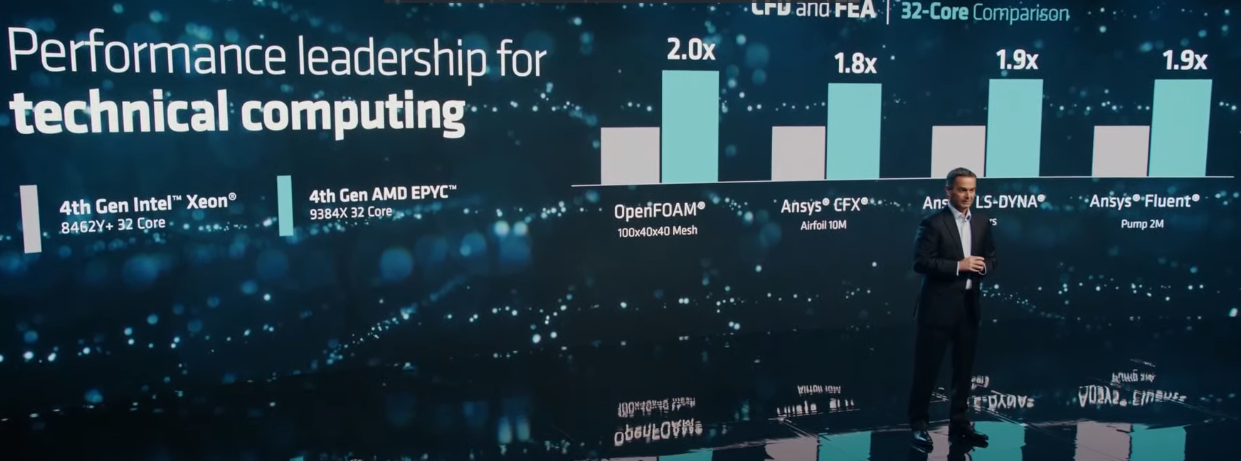 Выгоду от столь большого объёма кешей могут получить не все приложения. Речь в основном идёт об HPC, CFD, EDA и СУБД. При этом, что удивительно, AMD сравнивает новинки с «обычными» Intel Xeon Sapphire Rapids, а не с Intel Xeon Max, оснащённых 64 Гбайт набортной HBM2e-памяти (1,2 Тбайт/с) и ориентированных, в целом, на те же задачи — в таком случае они оказываются до 2,9 раз быстрее. 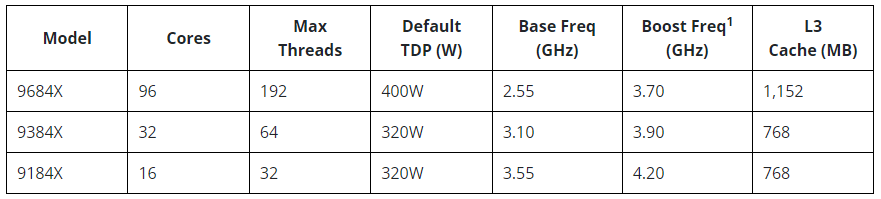
14.03.2023 [15:56], Алексей Степин
AMD анонсировала процессоры EPYC Embedded 9004 для промышленных системВстраиваемые решения AMD привлекают не так много внимания как настольные или серверные, но в арсенале компании представлены широко — от экономичных Ryzen Embedded для индустриальных и встраиваемых ПК до мощных EPYC Embedded. Именно о последних сегодня пойдет речь, поскольку на выставке Embedded World 2023 компания представила новую серию процессоров EPYC Embedded 9004 (Genoa). Свою родословную новые EPYC Embedded ведут от обычных серверных чипов EPYC Genoa. AMD позиционирует новинки в качестве решений для автоматизации в промышленности, телекоммуникациях, (I)IoT и периферийных вычислениях — везде, где требуется сочетание высокой удельной производительности с энергоэффективностью. 
Источник изображений здесь и далее: AMD Новая платформа представлена в одно- и двухсокетных вариантах. Максимальное количество процессорных ядер Zen 4 составляет 96 (SMT2), а объём кеша L3 может достигать внушительных 384 Мбайт. 12-канальный контроллер памяти с поддержкой DDR5-4800 ECC (3DS) RDIMM и NV-DIMM (важно для устойчивости к потере питания и быстрого восстановления работоспособности) тоже никуда не делся. 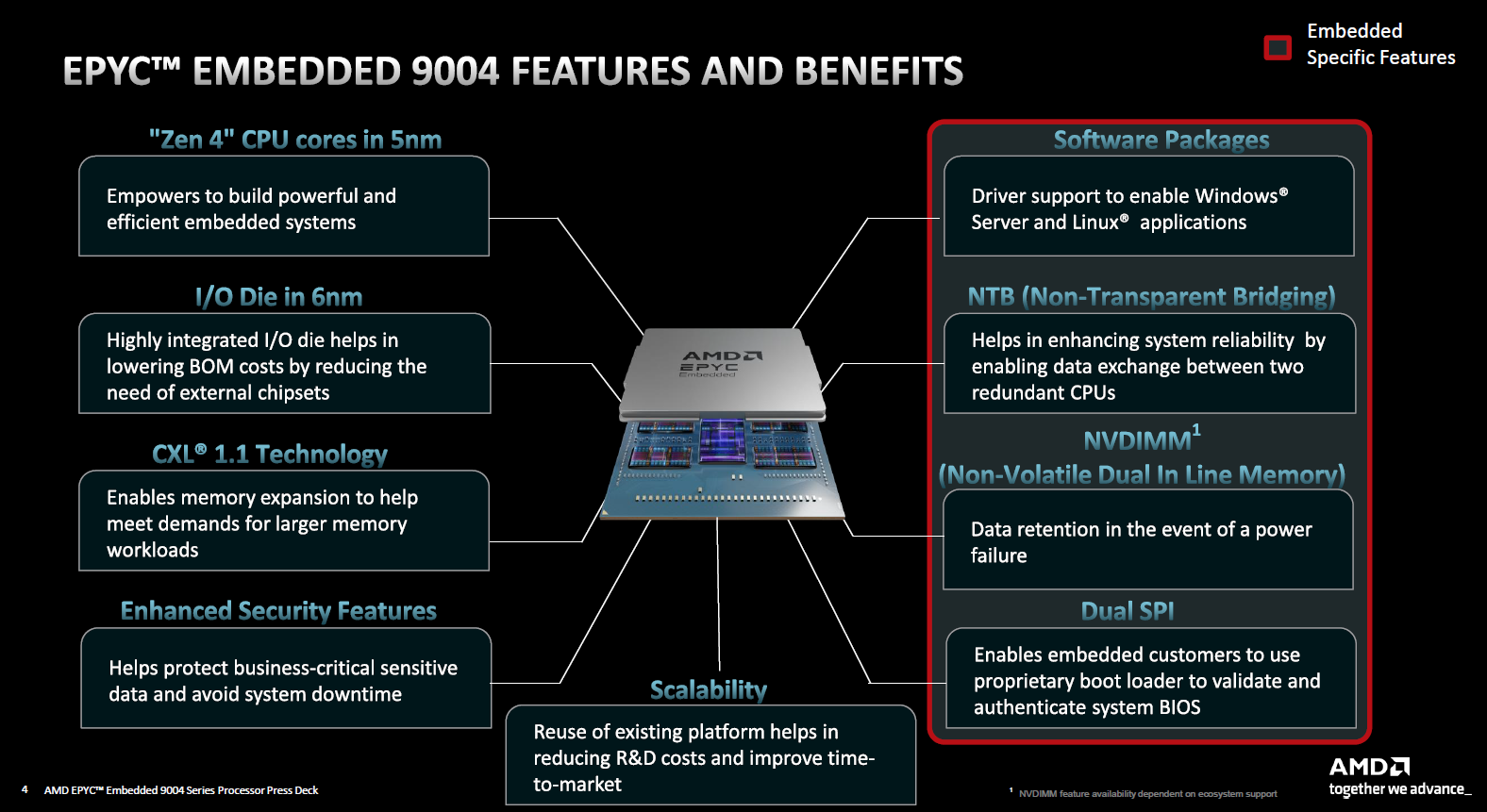 Всего в новой серии AMD представила 10 моделей EPYC Embedded 9004, с числом ядер от 16 до 96, различными частотными формулами, объёмами кеша L3 и теплопакетами в диапазоне от 200 до 360 Вт (cTDP до 400 Вт). Варианты для однопроцессорных систем располагают 128 линиями PCIe 5.0, а 2S-системы предлагают до 160 линий. Поддерживается CXL 1.1, включая устройства CXL.mem. Сокет CPU всё тот же — 6096-контактный SP5. 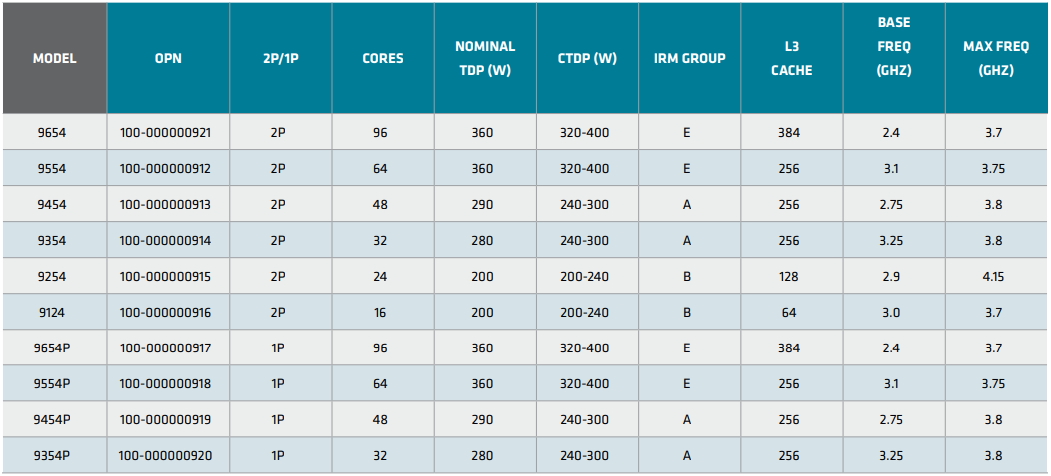 Кое-чем новые EPYC Embedded отличаются от своих обычных собратьев. В частности, отдельно отмечается поддержка Non-Transparent Bridge (NTB), что важно для формирования двухконтроллерных платформ, а также наличие технологии Scalable Control Fabric, которая позволяет более тонко конфигурировать межсоединения между чиплетами. Кроме того, например, сообщается о наличии второго канала SPI, что позволяет обеспечить дополнительную защиту и верификацию образов BIOS/UEFI. 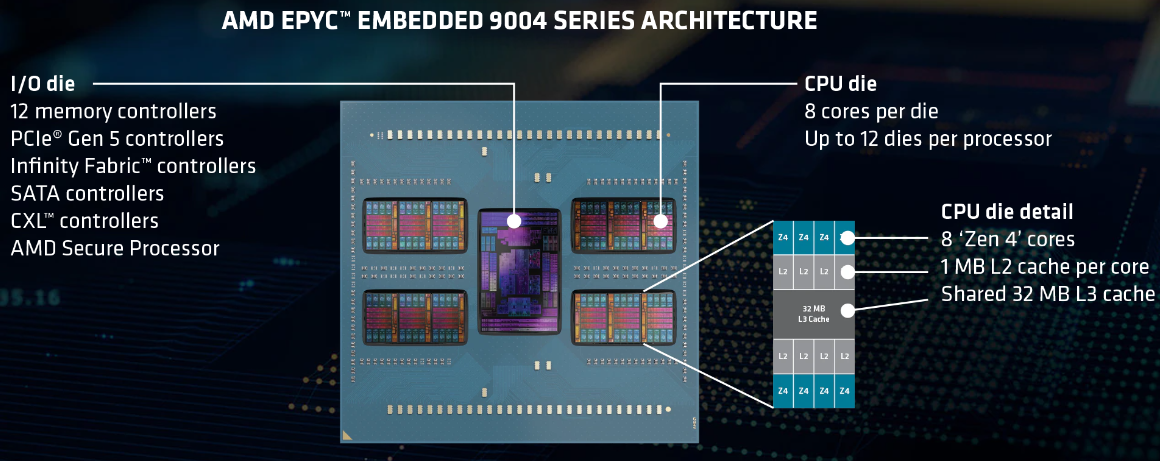 В числе главных партнёров AMD по внедрению новой платформы EPYC Embedded числятся компании Advantech и Siemens, уже анонсировавшие решения на базе новых процессоров. В качестве примера можно привести новый сервер Siemens SIMATIC IPC RS-828A или системную плату Advantech ASMB-831. Процессоры AMD EPYC Embedded 9004 уже доступны в небольших пробных партиях, но и начало массовых поставок не за горами, оно намечено уже на апрель текущего года.  В настоящее время «пробный комплект разработчика», в который входит референс-плата с процессором, полный комплект документации и программный инструментарий, доступен избранным партнёрам AMD. Также стоит отметить, что у новой платформы расширенный жизненный цикл, составляющий 7 лет, и без поддержки в ближайшее десятилетие оборудование на базе EPYC Embedded 9004 не останется.
14.11.2022 [00:00], Игорь Осколков
Игра по новым правилам: AMD представила Genoa, четвёртое поколение серверных процессоров EPYCВсего за десять лет AMD совершила почти невозможное — практически полностью потеряла серверный рынок, а теперь не просто успешно его отвоёвывает, но и предлагает комплексное портфолио решений. Анонс четвёртого поколения процессоров EPYC под кодовым именем Genoa — это не технологическая победа над Intel, поскольку AMD даже не думала бороться с Sapphire Rapids и уж тем более с Ice Lake-SP, а ориентировалась на Granite Rapids. Но годовая задержка с выпуском Sapphire Rapids позволила AMD не только в более спокойном темпе доделывать чипы Genoa, которые вышли на полгода позже, чем задумывалось ранее, но и поработать с разработчиками и заказчиками. Компании удалось вернуть их доверие — победа в умах гораздо важнее, чем просто технологическое превосходство. А оно неоспоримо. 
Источник: AMD EPYC Genoa заключены в корпус 72×75 мм, содержат до 90 млрд транзисторов и состоят из 13 чиплетов: 12 CCD, изготовленных по 5-нм техпроцессу TSMC плюс один, изрядно увеличившийся в размерах, IO-блок, сделанный там же, но уже по 6-нм нормам. Отказ от услуг GlobalFoundries, которая так и не смогла освоить тонкие техпроцессы, случился как нельзя кстати, поскольку IO-блок становится крайне важным компонентом при таком количестве ядер, которые необходимо вовремя накормить данными. И Genoa интересны в первую очередь с точки зрения полноты и разнообразия IO, а не рекордного количества ядер. IO-чиплет оснащён новыми SerDes-блоками, которые обслуживают и PCIe 5.0, и Infinity Fabric 3.0 (IF/GMI3). Формально каждому чипу полагается 128 линий PCIe 5.0, но реальная конфигурация чуть сложнее. Во-первых, у каждого чипа есть ещё восемь (2 x4) бонусных линий PCIe 3.0 для подключения нетребовательных устройств и обвязки, но в 2S-конфигурации таких линий будет только 12. Во-вторых, для 2S можно задействовать три (3Link) или четыре (4Link) IF-подключения, получив 160 или 128 свободных линий PCIe 5.0 соответственно. 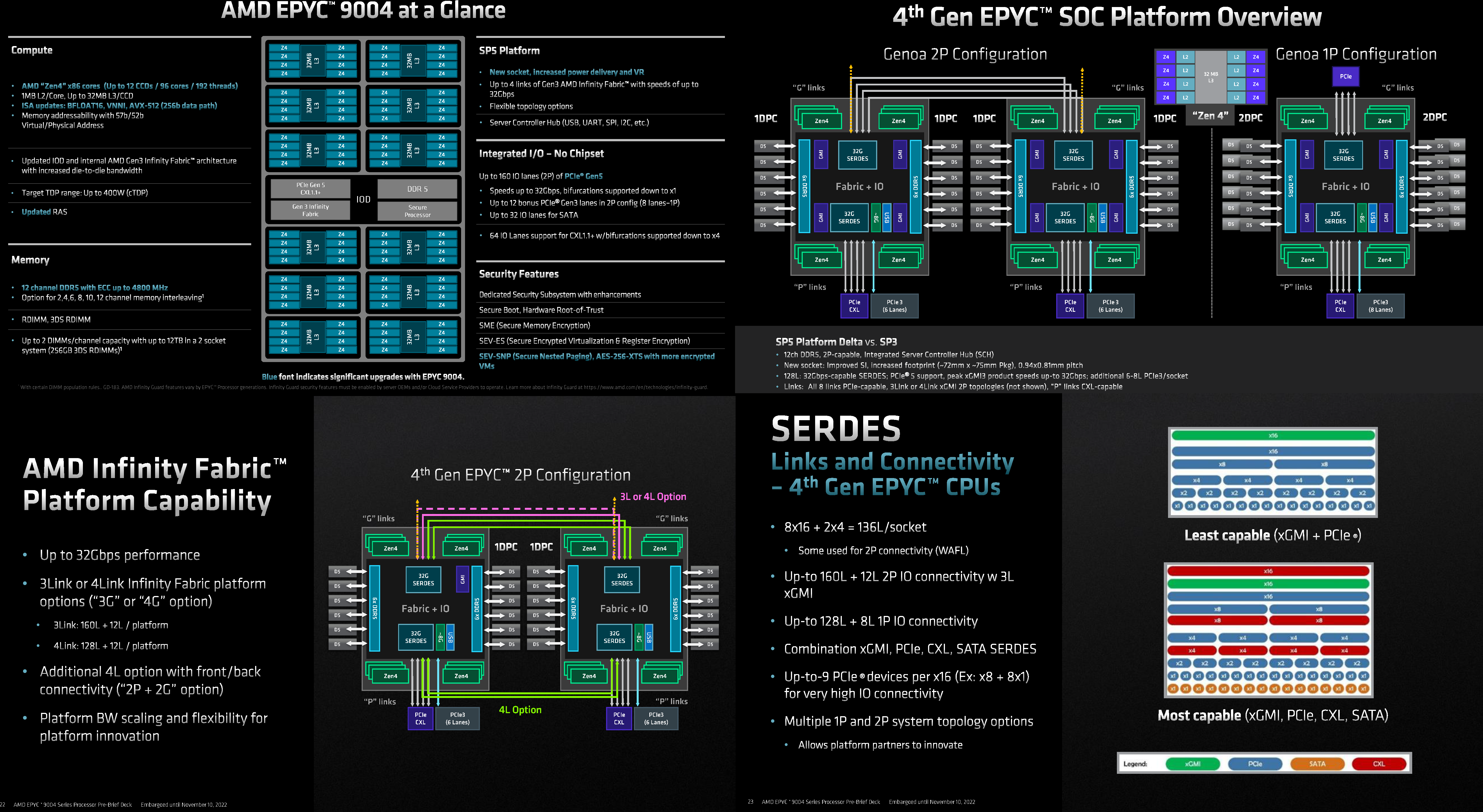
Изображения: AMD (via SemiAnalysis) В-третьих, каждый root-комплекс x16 может быть поделён между девятью устройствами (вплоть до x8 + восемь x1). Часть линий можно отдать на SATA (до 32 шт.), хотя это довольно расточительно. Но главное не это! Из 128 линий 64 поддерживают в полном объёме CXL 1.1 и частично CXL 2.0 Type 3, причём возможна бифуркация вплоть до x4. Ради такой поддержки CXL выход Genoa задержался на два квартала, но оно того определённо стоило — к процессору можно подключать RAM-экспандеры. И решения SK Hynix уже валидированы для новой платформы. CXL-память будет выглядеть как NUMA-узел (без CPU) — задержки обещаны примерно те же, что и при обращении к памяти в соседнем сокете, а пропускная способность одного CXL-подключения x16 почти эквивалентна двум каналам DDR5. При этом для CXL-памяти прозрачно поддерживаются всё те же функции безопасности, включая SME/SEV/SNP (теперь ключей стало аж 1006, а алгоритм обновлён до 256-бит AES-XTS). Отдельно для CXL-памяти внедрена поддержка SMKE (secure multi-key encryption), с помощью которой гипервизор может оставлять зашифрованными выбранные области SCM-устройств (до 64 ключей) между перезагрузками. 
Изображения: AMD (via SemiAnalysis) Такая гибкость при работе с памятью крайне важна для тех же гиперскейлеров. DDR5 по сравнению с DDR4 вчетверо плотнее, вполовину быстрее и… пока значительно дороже. И здесь AMD снова пошла им навстречу, добавив поддержку 72-бит памяти, а не только стандартной 80-бит, сохранив и расширив механизмы коррекции ошибок. 10-% разница в количестве DRAM-чипов при сохранении той же ёмкости на масштабах в десятки и сотни тысяч серверов выливается в круглую сумму. Кроме того, в Genoa сглажена разница в производительности между одно- и двухранговыми модулями с 25 % (в случае Milan) до 4,5 %. Что примечательно, AMD удалось сохранить сопоставимый уровень задержки обращений к памяти между поколениями CPU: 118 нс против 108 нс, из которых только 3 нс приходится на IO-блок, а 10 нс уже на саму память. Теоретическая пиковая пропускная способность памяти составляет 460,8 Гбайт/с на сокет. Однако тут есть нюансы. Genoa имеет 12 каналов памяти DDR5-4800, которые способны вместить до 6 Тбайт RAM. Однако сейчас фактически доступен только режим 1DPC, а вот 2DPC, судя по всему, появится только в следующем году. Genoa поддерживает модули (3DS) RDIMM и предлагает чередование с шагом в 2, 4, 6, 8, 10 или 12 каналов. 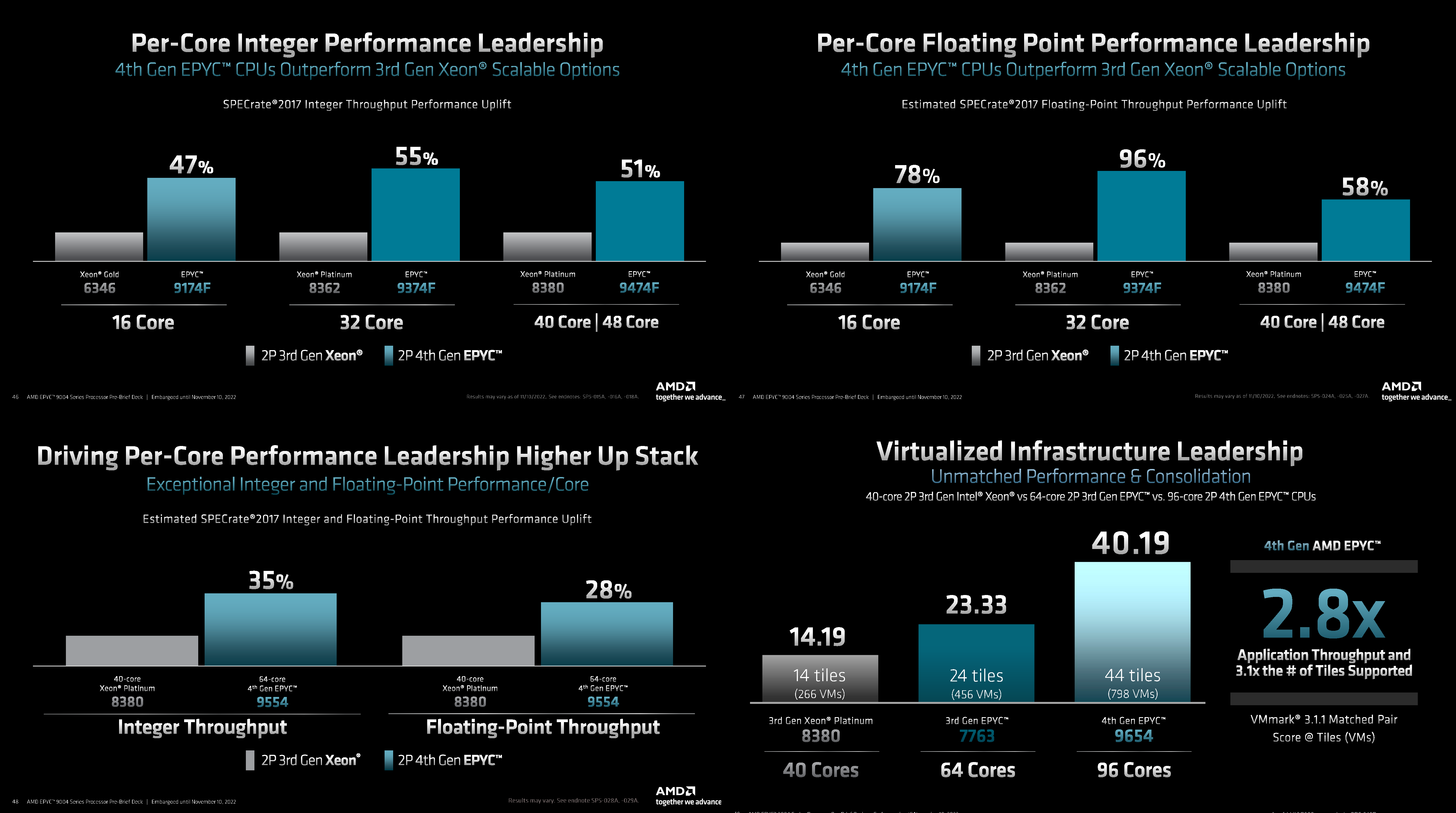
Изображения: AMD (via SemiAnalysis)
Каждый чип можно разбить на два (NPS2) или четыре (NPS4) равных NUMA-домена, а при большом желании и «прибить» L3-кеш к ядрам в том же CCD, получив уже 12 доменов. Но, по словам AMD, это нужно лишь в редких случаях, чтобы выжать ещё несколько процентов производительности. И это снова возвращает нас к особенностям IO-блока. Дело в том, что у каждого CCD есть сразу два GMI-порта. Но в конфигурациях с 8 и 12 CCD используется только один из них, а вот в случае 4 CCD — оба. Интересно, задействует ли AMD «лишние» порты для подключения других блоков. Впрочем, AMD, имея столь гибкие возможности конфигурации моделей, ограничилась относительно скромным начальным набором CPU, которые включает всего 18 моделей с числом ядер от 16 до 96, из которых четыре имеют индекс P (односокетные, чуть дешевле) и четыре — F (выше частота, больше объём L3-кеша). Модельный ряд условно делится на три группы: повышенная производительность на ядро (F-серия), повышенная плотность ядер и повышенный показатель TCO (с относительно малым количеством ядер). 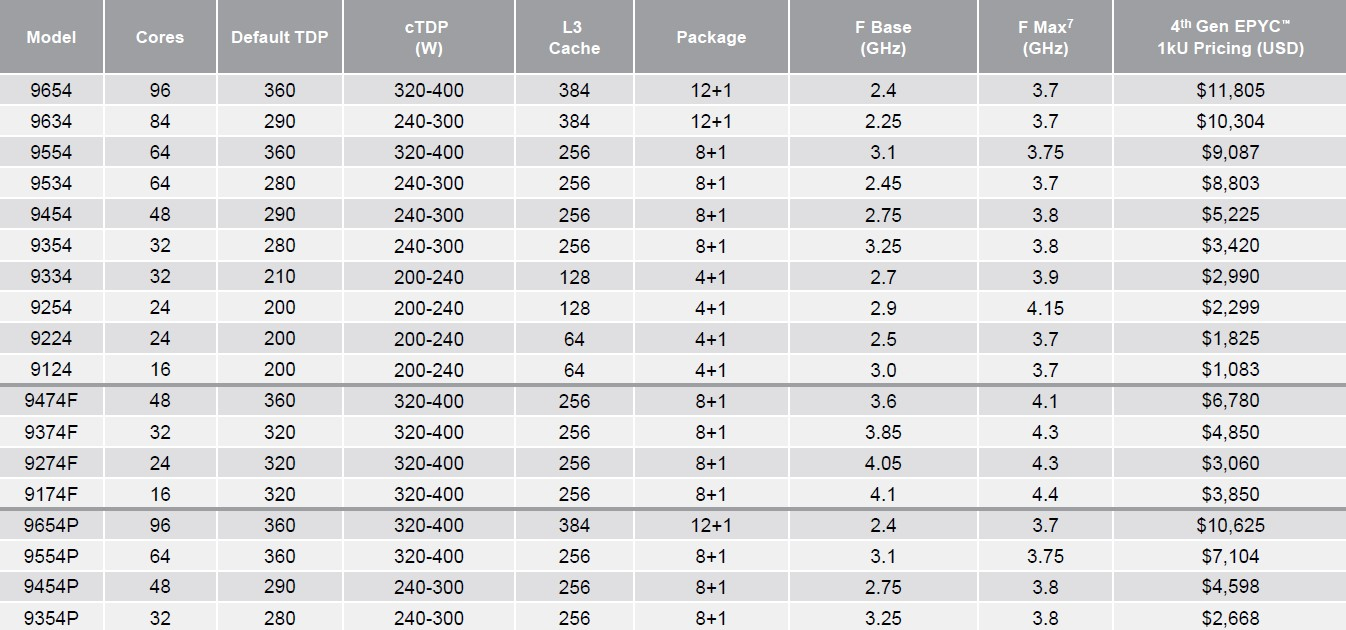
Источник: AMD (via ServeTheHome) На первый взгляд может показаться, что и цены на новинки заметно выросли, но это не совсем так. Например, у топовых моделей условная стоимость одного ядра (а их стала в полтора раза больше) так и крутится около «магического» значения в $123. Но с учётом возросшей производительности на ценовую политику AMD просто грех жаловаться. Прирост IPC между Zen3 и Zen4 составил 14 %, в том числе благодаря увеличению L2-кеша до 1 Мбайт на ядро (L1 и L3 остались без изменений), но не только. Есть и другие улучшения. Например, обновлённый контроллер прерываний AVIC позволяет практически полностью насытить не только 200G, но 400G NIC. С учётом чуть возросших частот и просто катастрофической разнице в количестве ядер топовый вариант Genoa не только значительно обгоняет Milan, но и в два-три раза быстрее старшего Ice Lake-SP. Дело ещё в и том, что Genoa обзавелись поддержкой AVX-512, в том числе инструкций VNNI (DL Boost), которыми так долго хвасталась Intel, а также BF16. Но реализация сделана иначе. У Intel используются «полноценные» 512-бит блоки, дорогие с точки зрения энергопотребления и затрат кремния. AMD же пошла по старому пути, используя 256-бит операции и несколько циклов, что позволяет не так агрессивно сбрасывать частоты. 
Изображения: AMD (via SemiAnalysis) Переход на новый техпроцесс, а также обновлённые подсистемы мониторинга и управления питанием позволили сохранить TDP в разумных пределах от 200 Вт до 360 Вт (cTDP до 400 Вт), что всё ещё позволяет обойтись воздушным охлаждением — всего + 80 Вт для старших процессоров при полуторакратном росте числа ядер. Таким образом, AMD имеет полное право заявлять, что Genoa лидирует по производительности, плотности размещения вычислительных мощностей, энергоэффективности и, в целом, по уровню TCO. У Intel же пока преимущество в более высокой доступности продукции в сложившейся геополитической обстановке. Отдельный вопрос, как AMD будет распределять имеющиеся мощности по выпуску Genoa между гиперскейлерами, корпоративным сектором и HPC-сегментом. Впрочем, компания в любом случае меняет рынок, иногда неожиданным образом. В частности, VMware, которая когда-то из-за EPYC изменила политику лицензирования, была вынуждена дополнительно оптимизировать свои продукты для Genoa. В конце концов, где вы раньше видели 2S-платформу со 192 ядрами и 384 потоками?
10.11.2022 [17:15], Владимир Мироненко
HPE анонсировала недорогие, энергоэффективные и компактные суперкомпьютеры Cray EX2500 и Cray XD2000/6500Hewlett Packard Enterprise анонсировала суперкомпьютеры HPE Cray EX и HPE Cray XD, которые отличаются более доступной ценой, меньшей занимаемой площадью и большей энергоэффективностью по сравнению с прошлыми решениями компании. Новинки используют современные технологии в области вычислений, интерконнекта, хранилищ, питания и охлаждения, а также ПО. 
Изображение: HPE Суперкомпьютеры HPE обеспечивают высокую производительность и масштабируемость для выполнения ресурсоёмких рабочих нагрузок с интенсивным использованием данных, в том числе задач ИИ и машинного обучения. Новинки, по словам компании, позволят ускорить вывода продуктов и сервисов на рынок. Решения HPE Cray EX уже используются в качестве основы для больших машин, включая экзафлопсные системы, но теперь компания предоставляет возможность более широкому кругу организаций задействовать супервычисления для удовлетворения их потребностей в соответствии с возможностями их ЦОД и бюджетом. В семейство HPE Cray вошли следующие системы:
Все три системы задействуют те же технологии, что и их старшие собратья: интерконнект HPE Slingshot, хранилище Cray Clusterstor E1000 и пакет ПО HPE Cray Programming Environment и т.д. Система HPE Cray EX2500 поддерживает процессоры AMD EPYC Genoa и Intel Xeon Sapphire Rapids, а также ускорители AMD Instinct MI250X. Модель HPE Cray XD6500 поддерживает чипы Sapphire Rapids и ускорители NVIDIA H100, а для XD2000 заявлена поддержка AMD Instinct MI210. 
Изображение: Intel В качестве примеров выгод от использования анонсированных суперкомпьютеров в разных отраслях компания назвала:
28.09.2022 [12:37], Алексей Степин
AMD анонсировала Ryzen Embedded V3000 — процессоры для встраиваемых систем с архитектурой Zen 3Семейство процессоров AMD Ryzen Embedded V получило долгожданное обновление: компания представила чипы V3000 с архитектурой Zen 3. Процессоры предназначены для широкого круга задач и могут использоваться в системах хранения данных, маршрутизаторах, сетевых брандмауэрах и коммутаторах — для этого у них достаточно как производительности, так и возможностей подсистем ввода-вывода. Новые чипы отличаются высокой энергоэффективностью: их номинальный теплопакет составляет от 15 до 45 Ватт в зависимости от модели; более тонкая настройка TDP позволяет регулировать потребление в диапазоне 10-54 Ватта. Это очень полезная возможность для периферийных систем, часто обходящихся пассивным охлаждением в виде оребренного корпуса. 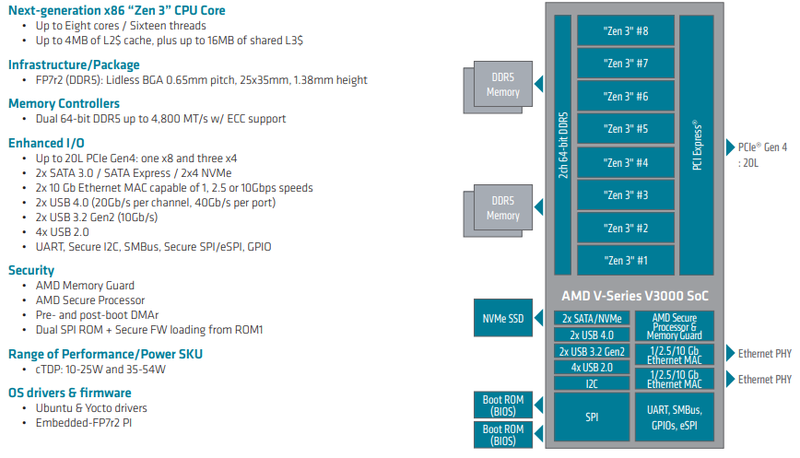
Источник изображений здесь и далее: AMD Всего в серии Ryzen Embedded V3000 представлено пять новых процессоров с количеством ядер от четырёх до восьми. Они отличаются базовой частотой от 1,9 до 3,5 ГГц, объёмами кешей, а также диапазоном рабочих температур: например, в серии есть модель V3C18I, способная функционировать в окружающей среде с температурой от -40 до +105 °C. В остальном новые процессоры очень похожи: все они используют компактные корпуса BGA, у всех максимальная частота в турборежиме составляет 3,8 ГГц, все чипы способны работать с памятью DDR5-4800, имеют 20 линий PCIe 4.0 и два интегрированных MAC-блока 10GbE. 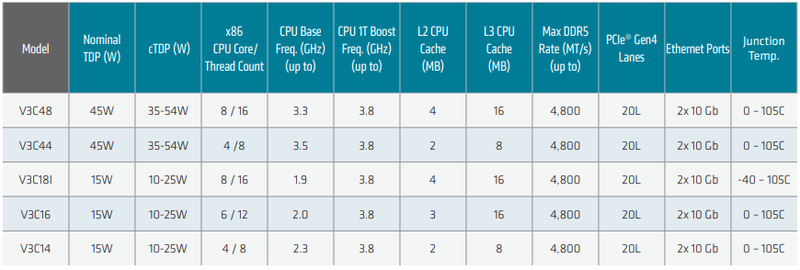
Модельный ряд Ryzen Embedded V3000 Новые процессоры AMD могут похвастаться повышенной защищённостью за счёт поддержки технологий AMD Memory Guard и AMD Platform Secure Boot. Компания-производитель рассчитывает на долгую службу новинок — жизненный цикл Ryzen Embedded V3000 составляет 10 лет. Также они будут иметь драйверную поддержку для будущих версий Linux Ubuntu и Yocto. Поставки новых чипов Ryzen Embedded V3000 ведущим OEM- и ODM-производителям оборудования уже начаты. AMD считает, что эти процессоры станут идеально сбалансированным выбором для СХД и сетевых устройств, как сочетающие в себе достаточно высокую производительность и низкий уровень тепловыделения, особенно важный в ограниченном пространстве серверных стоек.
10.08.2022 [22:05], Владимир Мироненко
На пути к Aurora: запущен «тренировочный» суперкомпьютер PolarisАргоннская национальная лаборатория (ANL) Министерства энергетики США объявила о доступности суперкомпьютера Polaris, ранний вариант которого занял 14-е место в последней версии списка TOP500. Он будет использоваться для проведения научных исследований и в качестве испытательного стенда для 2-Эфлопс суперкомпьютера Aurora, запуск которой намечен на ближайшие месяцы. Правда, аппаратно Aurora и Polaris отличаются. Созданная HPE система Polaris состоит из 560 узлов Apollo 6500, каждый из которых оснащён процессором AMD EPYC Milan, четырьмя ускорителями NVIDIA A100 (40 Гбайт) и 512 Гбайт DDR4-памяти. Эти узлы объединены в сеть интерконнектом HPE Slingshot 10 (осенью он будет обновлен до Slingshot 11) и подключены к сдвоенному 100-Пбайт Lustre-хранилищу (Grand и Eagle). Заявленная пиковая производительность должна составить 44 Пфлопс. «Polaris примерно в четыре раза быстрее нашего суперкомпьютера Theta, что делает его самым мощным компьютером в Аргонне на сегодняшний день», — отметил Майкл Папка (Michael Papka), директор Argonne Leadership Computing Facility (ALCF). Он добавил, что возможности Polaris позволят пользователям выполнять моделирование, анализ данных и ИИ-задачи с такими масштабом и скоростью, которые были невозможны с предыдущими вычислительными системами. 
Фото: ANL Помимо работы над подготовкой к запуску Aurora, суперкомпьютер Polaris будет обслуживать внутренние потребности лаборатории, например, работу с комплексом Advanced Photon Source (APS) X-ray. «Благодаря тесной интеграции суперкомпьютеров ALCF с APS, CNM и другими экспериментальными установками мы можем помочь ускорить проведение анализа данных и предоставить информацию, которая позволит исследователям управлять своими экспериментами в режиме реального времени», — заявил Майкл Папка.
21.06.2022 [14:32], Алексей Степин
AMD представила индустриальные процессоры Ryzen Embedded R2000: до четырёх ядер Zen+Семейство процессоров AMD Ryzen Embedded довольно консервативно: серия R1000 была представлена еще в 2019 году и включала в себя лишь двухъядерные модели на базе архитектуры Zen первого поколения, а представленные в 2020 году чипы V2000 предлагали до восьми ядер Zen2. Сегодня Advanced Micro Devices объявила о выпуске новых процессоров R2000 с теплопакетом от 12 до 54 Вт и чуть более современной (по сравнению с R1000) архитектурой Zen+. Эти максимально экономичные процессоры предназначены для индустриального применения, в том числе в системах машинного зрения, IoT, тонких клиентах, видеостенах, киосках и тому подобном оборудовании. В серию вошли модели R2544, R2514, R2314 и R2312. 
Источник: AMD В сравнении с R1000 производительность новинок выросла на 81%, и неудивительно — количество процессорных ядер возросло с двух до четырёх. Соответственно, с 1 до 2 Мбайт увеличился объём кеша L2, а также появилась поддержка памяти DDR4-3200 (два канала). Нового в Ryzen Embedded R2000 немного, за исключением более совершенной архитектуры ядер, но в количественном отношении новые процессоры во всём лучше старых: больше ядер, вдвое более производительная подсистема памяти, возросшее с 8 до 16 количество линий PCI Express 3.0. Также доступно до двух портов SATA-3 и до шести портов USB (3.2 Gen2 и 2.0). 
Текущий модельный ряд AMD Ryzen Embedded. Источник: AMD С трёх до четырёх возросло и количество подключаемых дисплеев с поддержкой разрешения 4К, хотя поддержка HDMI по-прежнему ограничена версией 2.0b. Но есть и DisplayPort 1.4 с eDP 1.3. Можно отметить наличие встроенного сопроцессора безопасности AMD Secure Processor, позволяющего шифровать содержимое оперативной памяти на лету. Поскольку новая серия относится к промышленной, срок сопровождения составляет 10 лет. В число поддерживаемых ОС вошли Windows 10/11 и Ubuntu LTS. В число партнёров AMD, которые представили или собираются представить свои решения на базе Ryzen Embedded R2000, входят компании Advantech, DFI, IBASE и Sapphire Technology. Среди анонсированных продуктов есть платформы для игровых автоматов, цифровые киоски, промышленные системные платы, платформы SD-WAN и многое другое. |
|


