Материалы по тегу: инференс
|
06.06.2025 [17:58], Руслан Авдеев
AMD купила команду разработчика ИИ-чипов Untether AI, но не саму компанию, которая тут же закрыласьКомпания AMD объявила об очередной за несколько дней корпоративной покупке. Она наняла неназванное количество сотрудников Untether AI, разрабатывающей ИИ-чипы для энергоэффективного инференса в ЦОД и на периферии, сообщает Silicon Angle. Первым информацией о сделке поделился представитель рекрутинговой компании SBT Industries, специализирующейся на полупроводниковой сфере. Позже в AMD подтвердили, что компания приобрела «талантливую команду инженеров по аппаратному и программному ИИ-обеспечению» у Untether AI. Новые сотрудники помогут оптимизировать разработку компиляторов и ядер ИИ-систем, а также улучшить проектирование чипсетов, их проверку и интеграцию. Вероятно, сделку завершили в прошлом месяце, причём в команду не вошёл глава Untether Крис Уокер (Chris Walker), перешедший в стартап из Intel и возглавивший его в начале 2024 года. Судя по информации из соцсетей, Уокер покинул компанию в мае. Сделка довольно необычна, поскольку никаких активов компании не покупалось, но Untether AI уже объявила о закрытии бизнеса и поставок или поддержки чипов speedAI и ПО imAIgine Software Development Kit (SDK). 
Источник изображения: Untether AI Untether AI была основана 2018 году в Торонто (Канада). В июле 2021 года стартап привлёк $125 млн в раунде финансирования, возглавленном венчурным подразделением Intel Capital. Компания разрабатывала энергоэффективные чипы для инференса для периферийных решений, потребляющих мало энергии. В одной упаковке объединялись модули для вычислений и память. В октябре 2024 года начала продажи чипа speedAI240 Slim (развитие speedAI240). speedAI240 Slim, по данным компании, втрое энергоэффективнее аналогов в сегменте ЦОД. Помимо Intel, Untether AI имела партнёрские отношения с Ampere Computing, Arm Holdings и NeuReality. Буквально в минувшем апреле Уокер сообщил журналистам, что компания отметила большой спрос на свои чипы для инференса со стороны покупателей, ищущих альтернативы продуктам NVIDIA с более высокой энергоёмкостью. Более того, в прошлом году компания договорилась с индийской Ola-Krutrim о совместной разработке ИИ-ускорителей не только для инференса, но и для тюнинга ИИ-моделей. Покупка состоялась всего через два дня после объявления о приобретении малоизвестного стартапа Brium, специализировавшегося на инструментах разработки и оптимизации ИИ ПО. Вероятно, AMD заинтересована в использовании его опыта для оптимизации инференса на отличном от NVIDIA оборудовании. Сделка с Brium состоялась всего через шесть дней после того, как AMD объявила о покупке разработчика систем кремниевой фотоники Enosemi. Это поможет AMD нарастить компетенции в соответствующей сфере, поскольку всё больше клиентов пытаются объединять тысячи ускорителей для поддержки интенсивных ИИ-нагрузок.
02.06.2025 [09:02], Сергей Карасёв
EnCharge AI представила аналоговые ИИ-ускорители EN100Компания EnCharge AI анонсировала изделия семейства EN100 — аналоговые ИИ-ускорители для in-memory вычислений. Дебютировали устройства в форм-факторе M.2 для ноутбуков и карты расширения PCIe для настольных рабочих станций. Стартап EnCharge AI, основанный в 2022 году, разрабатывает чипы, которые дают возможность перенести ИИ-нагрузки из облака на локальные платформы. Для этого применяется концепция вычислений в оперативной памяти, позволяющая увеличить эффективность и устранить узкие места, связанные с перемещением данных. NPU-ядра EnCharge AI, как утверждает сам разработчик, обеспечивают производительность на уровне 40 Топс/Вт (8-бит точность). Ускоритель EN100 для ноутбуков имеет типоразмер M.2 2280. В оснащение входят 32 Гбайт памяти с пропускной способностью до 68 Гбайт/с. Быстродействие превышает 200 Топс при общем энергопотреблении не более 8,25 Вт. Для оркестрации задействована многопоточная архитектура RISC-V. 
Источник изображений: EnCharge AI На рабочие станции ориентированы ускорители EN100 в виде карт расширения PCIe HHHL. Они несут на борту 128 Гбайт памяти с суммарной пропускной способностью 272 Гбайт/с. Производительность составляет около 1 Попс. Изделия обоих типов изготавливаются с применением 16-нм CMOS-технологии. 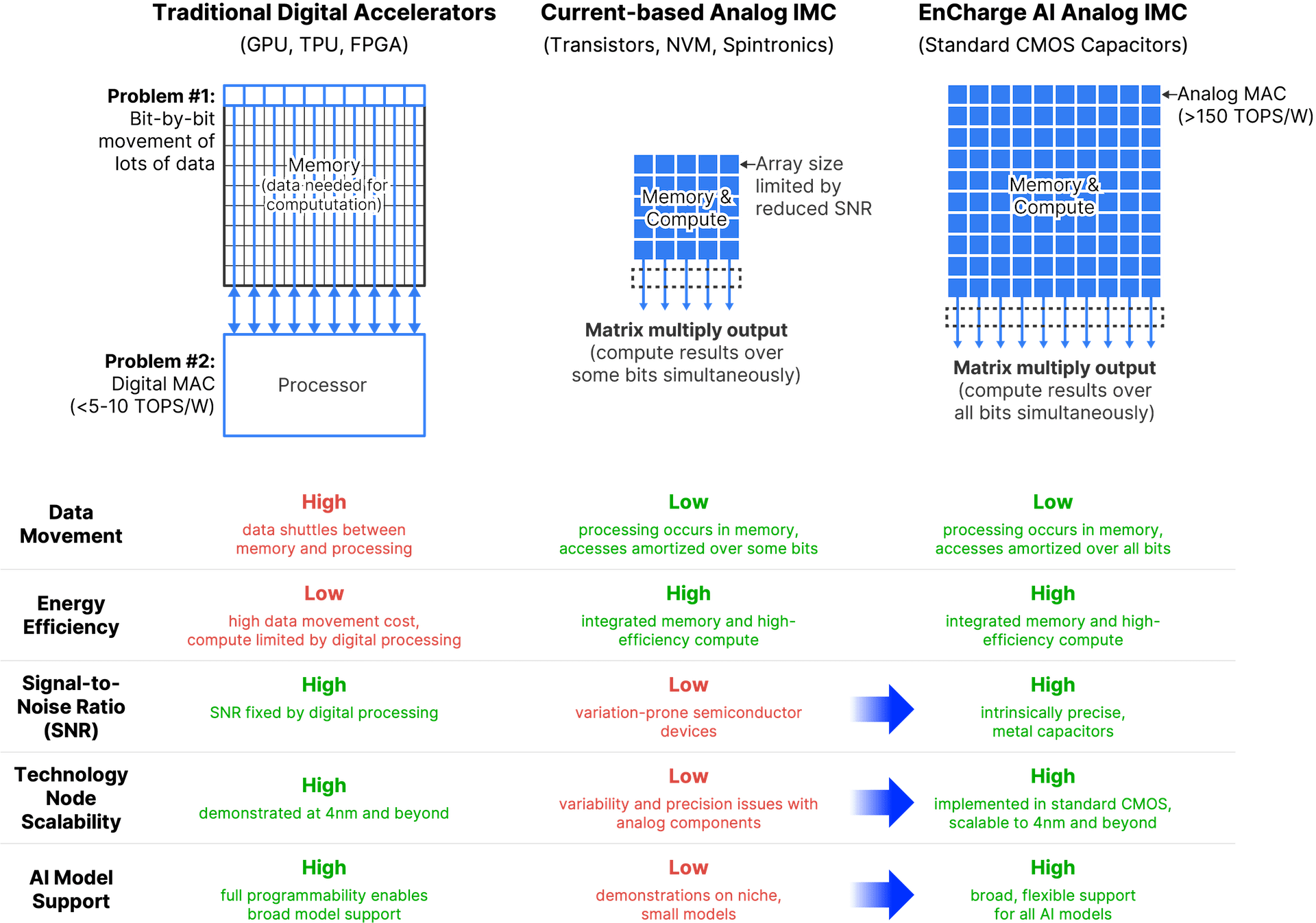 Навин Верма (Naveen Verma), генеральный директор EnCharge AI, заявляет, что решения компании позволят выполнять ресурсоёмкие задачи ИИ локально, не полагаясь на облачную инфраструктуру. Утверждается, что такие устройства по сравнению с современными ИИ-ускорителями обеспечат в 20 раз более высокую энергоэффективность (Топс/Вт) и в 9 раз более высокую плотность вычислений (Топс/мм2) при 10-кратном снижении совокупной стоимости владения (TCO).
23.05.2025 [13:46], Руслан Авдеев
ИИ-парковка: Tonomia интегрировала серверы в парковочные навесы с солнечными батареями и аккумуляторамиКомпания Tonomia предлагает размещение ИИ-ускорителей на… автопарковках — оборудование будет снабжаться энергией благодаря навесным солнечным элементам. Основанный в 2023 году бельгийский стартап сотрудничает с британским поставщиком оборудования Panchaea над созданием и продвижением комплекса eCloud, сообщает Datacenter Dynamics. Солнечные панели, используемые в качестве своеобразных «навесов» на парковках, нередко используются для подпитки АКБ электромобилей. Tonomia предложила использовать получаемую таким образом энергию и для питания ИИ-ускорителей своей облачной платформы. В компании полагают, что повсеместная установка таких «солнечных навесов» навесов в Европе и США позволит увеличить выработку энергии и снизить нагрузки на электросети, а интеграция вычислительного оборудования позволит получить дополнительный доход. Компания предложила объединить ИИ-серверы и действующие солнечные модули системы eParking с литий-ионными или натрий-ионными аккумуляторами. В Tonomia утверждают, что навесы способны генерировать до 600 Вт в Европе или 750 Вт в США (из-за большей площади парковок). Как утверждают в Panchaea, только в Европе есть более 350 млн наземных парковочных мест, причём большинство из них пустуют 80 % времени. Tonomia готова превратит автопарковки в «активы двойного назначения». 
Источник изображения: Tonomia Tonomia готова предложить ИИ-серверы Supermicro, MITAC или Panchaea. Конфигурации кластеров подбираются под особенности индивидуальных бизнес-моделей. Предполагается, что каждое парковочное место потенциально позволяет генерировать до 20 кВт∙ч ежедневно, т.е. около £8 ($10,74) в денежном эквиваленте, если исходить из стоимости инференса £0,40 ($0,53) за кВт·ч. Дополнительный доход может принести и зарядка электромобилей, передача энергии в электросеть и отдача избыточного тепла на обогрев близлежащих зданий. 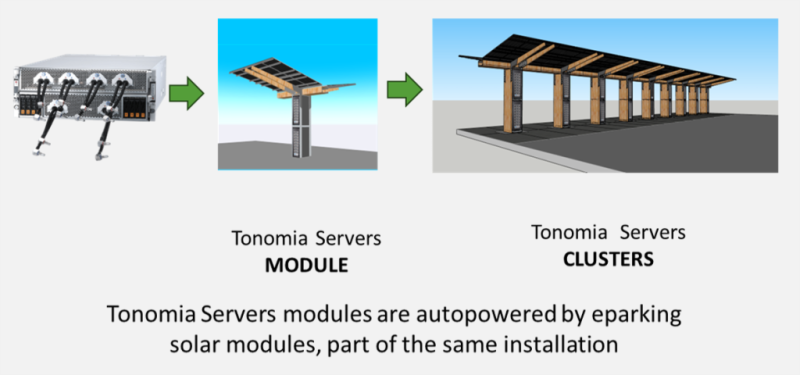
Источник изображения: Tonomia Tonomia разработала eCloud на основе оригинального продукта eParking после того, как к ней обратились игроки ИИ-сектора, заинтересованные в локальной генерации энергии. По словам компании, городам необходима подобная многофункциональная инфраструктура, а предприятиям нужны мощности для периферийных вычислений в непосредственной близости от потребителей. Кроме того, такая экоустойчивая система должна понравиться и регуляторам. Солнечная энергия активно используется в разных странах. Впрочем, как показывает европейский опыт, слишком много «зелёной» энергии — не всегда хорошо: Нидерланды уже столкнулись с определёнными проблемами.
16.05.2025 [08:38], Владимир Мироненко
Qualcomm возвращается на рынок серверных процессоровQualcomm Technologies возвращается на рынок серверных процессоров. Это подтверждает меморандум о взаимопонимании, подписанный компанией и ИИ-стартапом Humain, принадлежащим Суверенному фонду Саудовской Аравии, с целью «запуска ИИ ЦОД, предложения гибридного ИИ на периферии и в облаке, а также сервисов “от облака до периферии” в Королевстве Саудовская Аравия и за его пределами». Меморандум о взаимопонимании был подписан в ходе Саудовско-американского инвестиционного форума в Эр-Рияде. Ранее о партнёрстве с Humain объявили NVIDIA, AMD и AWS, а также Cisco. В документе закреплено обязательство Qualcomm «разработать и поставлять современные ИИ-решения и CPU для ЦОД». Также стороны планируют интегрировать семейство арабских больших языковых моделей Humain (ALLaM, совместно разработанных с SDAIA) с широкой экосистемой периферийных ИИ-устройств на базе процессоров Qualcomm, предоставляя возможности гибридного ИИ-инференса от облака до периферии для широкого спектра устройств. В дальнейшем компании будут сотрудничать с Министерством связи и информационных технологий Саудовской Аравии (MCIT) с целью создания в Саудовской Аравии Центра проектирования полупроводниковых технологий мирового класса. 
Источник изображения: Qualcomm Согласно документу, Qualcomm и Humain намерены «разработать и построить передовые ИИ ЦОД в Саудовской Аравии, предназначенные для предоставления высокоэффективных масштабируемых гибридных решений ИИ-инференса от облака до периферии (cloud-to-edge) для местных и международных клиентов на основе решений Qualcomm». Также партнёры планируют ускорить использование инфраструктуры за счет применения процессоров Snapdragon и Dragonwing. Ранее Qualcomm и Cerebras договорились об использовании ускорителей Cloud AI для инференса, в том числе в интересах заказчиков из Саудовской Аравии. Qualcomm и Humain заявили, что их ЦОД и экосистема предназначены для предоставления как государственным, так и корпоративным организациям доступа к высокопроизводительной и энергоэффективной облачной ИИ-инфраструктуре на основе CPU, а также cloud-to-edge сервисам. Согласно пресс-релизу, эти предложения позволят развёртывать ИИ-решения, которые могут делать прогнозы и принимать решения в реальном времени, а также значительно повышать доступность и ценность передовых приложений с поддержкой ИИ. 
Источник изображения: Qualcomm Слухи о планируемом Qualcomm возврате к разработке серверных процессоров курсируют длительное время. В 2017 году компания выпустила 10-нм 48-ядерные чипы Centriq 2400, но затем отменила проект в 2019 году. Позже компания приобрела стартап Nuvia, который разрабатывал серверные Arm-процессоры. Qualcomm использовала наработки Nuvia в процессорах Snapdragon для компьютеров на базе Windows. Слухи разгорелись с новой силой, когда в начале года Qualcomm наняла Сайлеша Коттапалли (Sailesh Kottapalli) в качестве старшего вице-президента. Ранее он был главным архитектором серверных процессоров Xeon. Теперь Qualcomm не скрывает своих намерений. Она разместила на сайте вакансии, связанные с разработкой серверных процессоров, включая «архитектора управления питанием сервера», «архитектора ПО для управления питанием и температурой серверных SoC» и «архитектора серверной платформы». Причём, как отметил ресурс Computer Base, каждая вакансия сопровождается примечанием: «Команда Qualcomm Data Center разрабатывает высокопроизводительное и энергоэффективное серверное решение для ЦОД». На форуме JPMorgan финансовый директор и главный операционный директор Акаш Палхивала (Akash Palkhiwala) заявил, что у компании есть «ведущий в мире процессор» и NPU. «Изменения, которые происходят в ЦОД, очевидно, связаны с переходом к инференсу, который становится всё более важным, как и низкое энергопотребления, и именно здесь Qualcomm на высоте», — отметил Палхивала, добавив, что компания использует имеющиеся технологии в будущих серверных процессорах.
06.05.2025 [21:12], Руслан Авдеев
Meta✴ Llama API задействует ИИ-ускорители Cerebras и GroqMeta✴ объединила усилия с Cerebras и Groq для инференс-сервиса с применением API Llama. Открыв API-доступ к собственным моделям, Meta✴ становится чуть более похожа на облачных провайдеров. Как утверждают в Cerebras, разработчики, применяющие API для работы с моделями Llama 4 Cerebras, могут получить скорость инференса до 18 раз выше, чем у традиционных решений на базе GPU. В компании объявили, что такое ускорение позволит использовать новейшее поколение приложений, которые невозможно построить на других ИИ-технологиях. Речь, например, идёт о «голосовых» решениях с низкой задержкой, интерактивной генерации кода, мгновенном многоэтапном рассуждении и т. п. — многие задачи можно решать за секунды, а не минуты. После запуска инференс-платформы в 2024 году Cerebras обеспечила для Llama самый быстрый инференс, обрабатывая миллиарды токенов через собственную ИИ-инфраструктуру. Теперь прямой доступ к альтернативам решений OpenAI получит широкое сообщество разработчиков. По словам компании, партнёрство Cerebras и Meta✴ позволит создавать ИИ-системы, «принципиально недосягаемые для ведущих облаков». Согласно замерам Artificial Analysis, Cerebras действительно предлагает самые быстрые решения для ИИ-инференса, более 2600 токенов/с для Llama 4 Scout. 
Источник изображения: Meta✴ При этом Cerebras не единственный партнёр Meta✴. Она также договорилась с Groq об использовании ускорителей Language Processing Units (LPU), которые обеспечивают высокую скорость (до 625 токенов/с), низкую задержку и хорошую масштабируемость при довольно низких издержках. Groq использует собственную вертикально интегрированную архитектуру, полностью контролируя и железо, и софт. Это позволяет добиться эффективности, недоступной в облаках на базе универсальных ИИ-чипов. Партнёрство с Meta✴ усиливает позиции Groq и Cerebras в борьбе с NVIDIA. Для Meta✴ новое сотрудничество — очередной шаг в деле выпуска готовых open source ИИ-моделей, которые позволят сосредоточиться на исследованиях и разработке, фактически передав инференс надёжному партнёру. Разработчики могут легко перейти на новый стек без необходимости дообучения моделей или перенастройки ускорителей — API Llama совместимы с API OpenAI. Пока что доступ к новым API ограничен. Цены Meta✴ также не сообщает. Meta✴ активно работает над продвижением своих ИИ-моделей. Так, она даже выступила с довольно необычной инициативой, предложив «коллегам-конкурентам» в лице Microsoft и Amazon, а также другим компаниям, поделиться ресурсами для развития и обучения моделей Llama.
06.05.2025 [14:36], Руслан Авдеев
«Билайн» готовит российский сервис ИИ-инференса на отечественном оборудовании«Билайн» и один из российских производителей серверов ведут переговоры о возможной доработке решений для ИИ-инференса — весьма перспективной в обозримом будущем услуги. Сама «Билайн» разрабатывает инфраструктурное ПО, входящее в часть специального программно-аппаратного комплекса, сообщают «Ведомости». На основе таких комплексов партнёры смогут развернуть ИИ-модели, а «Билайн» в перспективе сможет предлагать их в своих дата-центрах, продавая доступ к соответствующим мощностям бизнес-клиентам. По словам одного из источников, сейчас «Билайн» договаривается с OpenYard. Последняя подтвердила, что ведёт переговоры с рядом телеком-операторов, но подробности возможных сделок раскрывать не стала. Тем временем в «Билайне» отмечают рост спроса на аренду стоек с GPU-серверами. Правда, платить за это готовы «не все», отмечают в компании. По оценкам экспертов, сотрудничество «Билайн» с OpenYard позволит первой запустить новые сервисы, а для второй — получить крупного заказчика на оборудование. Для крупных компаний, как считают эксперты, такой совместный сервис будет обходиться в 100–200 млн руб. в год. 
Источник изображения: Lyubomyr (Lou) Reverchuk/unsplash.com Ожидается, что в первую очередь новое решение заинтересует банки (для создания чат-ботов и скоринга), IT-компании и просто крупный бизнес (для ИИ-аналитики), а также, например, телеком-операторов и промышленный сектор. Как ранее писали «Ведомости», к 2030 году в российских ЦОД будут развёрнуты ускорители, эквивалентные по производительности 70 тыс. ускорителей NVIDIA A100. Стоимость закупки, вероятно, составит $1,5–$2 млрд. Впрочем, уникальность инференс-решений для России — под вопросом. Например, в октябре прошлого года Selectel запустил бета-тестирование собственного инференс-сервиса для ускорения запуска ИИ-моделей. В конце апреля 2025 года Cloud.ru представил «первый в России» управляемый облачный сервис для инференса ИИ-моделей — Evolution ML Inference.
05.05.2025 [13:28], Сергей Карасёв
GigaIO и d-Matrix предоставят инференс-платформу для масштабных ИИ-развёртыванийКомпании GigaIO и d-Matrix объявили о стратегическом партнёрстве с целью создания «самого масштабируемого в мире» решения для инференса, ориентированного на крупные предприятия, которые разворачивают ИИ в большом масштабе. Ожидается, что новая платформа поможет устранить узкие места в плане производительности и упростить внедрение крупных ИИ-систем. В рамках сотрудничества осуществлена интеграция ИИ-ускорителей d-Matrix Corsair в состав НРС-платформы GigaIO SuperNODE. Архитектура Corsair основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости около 150 Тбайт/с. По заявлениям d-Matrix, ускоритель обеспечивает непревзойдённую производительность и эффективность инференса для генеративного ИИ. Устройство выполнено в виде карты расширения с интерфейсом PCIe 5.0 х16. Быстродействие достигает 2,4 Пфлопс с (8-бит вычисления). Изделие имеет двухслотовое исполнение, а показатель TDP равен 600 Вт. В свою очередь, SuperNODE использует фирменную архитектуру FabreX на базе PCIe, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. По сравнению с обычными серверными кластерами SuperNODE обеспечивает более эффективное использование ресурсов. 
Источник изображения: d-Matrix Новая модификация SuperNODE поддерживает десятки ускорителей Corsair в одном узле. Производительность составляет до 30 тыс. токенов в секунду при времени обработки 2 мс на токен для таких моделей, как Llama3 70B. По сравнению с решениями на базе GPU обещаны трёхкратное повышение энергоэффективности и в три раза более высокое быстродействие при сопоставимой стоимости владения. «Наша система избавляет от необходимости создания сложных многоузловых конфигураций и упрощает развёртывание, позволяя предприятиям быстро адаптироваться к меняющимся рабочим нагрузкам ИИ, при этом значительно улучшая совокупную стоимость владения и операционную эффективность», — говорит Alan Benjamin (Алан Бенджамин), генеральный директор GigaIO.
28.04.2025 [07:54], Сергей Карасёв
SambaNova уволила 15 % персонала и переключилась на инференс в облакеРазработчик ИИ-ускорителей SambaNova, по сообщению EE Times, проводит реорганизацию, направленную на трансформацию бизнеса. Стартап, в частности, намерен сосредоточиться на предоставлении облачных услуг в сфере ИИ, включая, ресурсы для инференса. SambaNova была основана в 2017 году. Актуальный ИИ-ускоритель компании SN40L RDU (Reconfigurable Dataflow Unit) объединяет два крупных чиплета, которые оперируют 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM и 64 Гбайт HBM3. Восьмипроцессорная система на базе SN40L, по заявлениям SambaNova, способна запускать и обслуживать ИИ-модели с 5 трлн параметров и глубиной запроса более 256k. Осенью прошлого года SambaNova объявила о запуске самой быстрой на тот момент облачной платформы для ИИ-инференса. В этом вопросе она соревнуется с Cerebras и Groq, ещё двумя заметными стартапами, которые пытаются составить конкуренцию NVIDIA. Стоит отметить, что Groq также сменила бизнес-подход, отказавшись от продажи отдельных ускорителей в пользу оснащения целых ИИ ЦОД для инференса. 
Источник изображения: SambaNova В рамках реорганизации SambaNova сократила численность персонала примерно на 15 %: уволены 77 из 500 сотрудников. Отмечается, что масштабные коммерческие ИИ-нагрузки смещаются от обучения в сторону инференса. В результате стартапы в сфере ускорителей и другого ИИ-оборудования для дата-центров переключились на предоставление обалчного доступа к LLM посредством API. «Мы оперативно переориентировались на предоставление облачных решений, которые помогают предприятиям и разработчикам развёртывать открытые ИИ-модели в масштабе. В рамках трансформации операций пришлось принять трудное решение о сокращении примерно 75 сотрудников и сместить фокус команды для поддержания следующего этапа роста», — заявили представители SambaNova.
18.04.2025 [15:47], Владимир Мироненко
Cloud.ru представил первый в России управляемый облачный сервис для инференса ИИ-моделей — Evolution ML InferenceПровайдер Cloud.ru представил Evolution ML Inference — первый, по словам компании, в России управляемый облачный сервис для инференса больших языковых моделей (LLM), который позволит эффективно управлять вычислительными ресурсами. С его помощью клиенты смогут помимо моделей GigaChat от Cloud.ru запускать и развертывать собственные ИИ-модели, а также open source модели из библиотеки Hugging Face на базе облачных ускорителей. Это полностью управляемый сервис — пользователю достаточно настроить конфигурацию, модель и тип масштабирования, Cloud.ru предоставит доступ к мощным ускорителям, а также будет отвечать за полное администрирование и обслуживание инфраструктуры. Сервис отличается простотой и гибкостью управления, что позволяет запускать модели без необходимости сборки образа напрямую из Hugging Face, а также запускать собственные образы со своим окружением.  Благодаря поддержке технологии Shared GPU, позволяющей распределять GPU-ресурсы с учётом потребления количества vRAM, необходимого для эффективной работы модели без задержек, а также с возможностью динамически перераспределять ресурсы в зависимости от текущих потребностей, сервис обеспечивает повышение утилизации мощностей в ИИ-проектах от 15 до 45 % в сравнении со сценарием, когда GPU используется целиком. Тем самым обеспечивается высокая степень адаптации и рациональное использование доступных ресурсов с одновременным запуском нескольких моделей на одном GPU. «Это делает технологию наиболее оптимальной для распределённых систем с разнородной вычислительной инфраструктурой и помогает эффективно масштабировать нагрузку», — отметила Cloud.ru. Ещё одно отличие сервиса — поддержка режима скайлирования (эффективного масштабирования), когда оплата за использование модели начисляет только с момента обращения к ней. По оценкам Cloud.ru, около 70 % заказчиков используют GPU-ресурсы, зарезервированные под инференс в процессе эксплуатации ML-моделей, менее чем на 55 %. При внедрении ИИ в большинстве случаев базой становится именно среда исполнения модели. Поэтому для рационального использования ресурсов и оптимизации затрат при обработке ИИ-нагрузок, особенно генеративного ИИ, необходима производительная инфраструктура с гибким масштабированием в реальном времени, отметил глава Cloud.ru.
13.04.2025 [23:54], Владимир Мироненко
ИИ-агенты под присмотром: Google Distributed Cloud заработает на on-premise платформах NVIDIA Blackwell DGX/HGX
b200
dgx
google cloud platform
hardware
hgx
nvidia
гибридное облако
ии
ии-агент
инференс
конфиденциальность
облако
частное облако
NVIDIA объявила о стратегическом партнёрстве с Google Cloud с целью внедрения агентного ИИ на предприятиях, которые хотели бы локально использовать семейство моделей Google Gemini с помощью платформ NVIDIA Blackwell HGX/DGX, а также функции NVIDIA Confidential Computing для повышения безопасности данных. Интеграция платформы NVIDIA Blackwell с портфелем программно-аппаратных решений Google Distributed Cloud позволяет локальным ЦОД соответствовать нормативным требованиям и законам о суверенитете данных, блокируя доступ к конфиденциальной информации, включая истории болезни пациентов, финансовые транзакции и секретную правительственную информацию. NVIDIA Confidential Computing защищает конфиденциальный код в моделях Gemini от несанкционированного доступа и утечек данных — запросы пользователя к API Gemini, а также данные, которые они использовали для тонкой настройки, остаются в безопасности и защищены от несанкционированного доступа или изменений. Сачин Гупта (Sachin Gupta), вице-президент и генеральный менеджер по инфраструктуре и решениям в Google Cloud, отметил, что партнёрство позволяет предприятиям в полной мере использовать весь потенциал агентного ИИ, внедряя модели Gemini в локальные системы, и объединяя производительность NVIDIA Blackwell и возможности конфиденциальных вычислений. Хотя многие уже могут использовать модели с мультимодальным рассуждением — интегрируя текст, изображения, код и другие типы данных для решения сложных проблем и создания облачных приложений агентного ИИ, предприятия с повышенными требованиями к безопасности или суверенитету данных столкнулись с трудностями при внедрении этих технологий. Данное партнёрство позволит решить эти проблемы, благодаря чему Google Cloud становится одним из первых поставщиков, предлагающих возможности конфиденциальных вычислений для защиты рабочих нагрузок ИИ-агентов в любой среде, как облачной, так и гибридной. 
Источник изображения: NVIDIA Масштабирование агентного ИИ требует надёжного мониторинга и безопасности для обеспечения стабильной производительности и соответствия требованиям. Google Cloud представила новый шлюз GKE Inference Gateway, созданный для оптимизации развёртывания рабочих нагрузок ИИ-агентов с расширенной маршрутизацией и масштабируемостью. Интеграция с NVIDIA Triton Inference Server и NVIDIA NeMo Guardrails обеспечивает интеллектуальную балансировку нагрузки, которая повышает производительность и снижает затраты на обслуживание, также обеспечивая централизованную безопасность и управление моделями. В дальнейшем Google Cloud планирует улучшить отслеживания рабочих нагрузок агентского ИИ, интегрировав NVIDIA Dynamo, библиотеку с открытым исходным кодом, предназначенную для обслуживания и масштабирования рассуждающих моделей. Этот перспективный подход гарантирует, что предприятия смогут уверенно масштабировать свои приложения агентского ИИ, сохраняя при этом безопасность и соответствие требованиям. |
|

