Материалы по тегу: облако
|
25.10.2025 [22:25], Сергей Карасёв
К масштабному сбою AWS привела ошибка в средствах автоматизации DNSКомпания Amazon опубликовала развёрнутый отчёт о причинах масштабного сбоя в работе облака Amazon Web Services (AWS). Проблемы, затронувшие многочисленные сервисы, возникли из-за ошибки в программном обеспечении для автоматизации. Сбой произошел в регионе us-east-1 в Северной Вирджинии. Утверждалось, что первопричиной проблем стала ошибка DNS. В общей сложности были затронуты более 110 собственных служб AWS. По данным сайта Downdetector, который отслеживает сбои в работе интернета, от пользователей по всему миру поступили более 8,1 млн сообщений о проблемах. Пострадали такие платформы, как Signal, Snapchat, Roblox, Duolingo, Apple Music, Apple TV, Lyft, Fortnite, Disney+, Venmo, Doordash, Hulu и многие другие. Как сообщает Amazon, сбой возник из-за неполадок в работе DynamoDB, с которой связаны сотни тысяч записей DNS, необходимых для работы огромного гетерогенного парка балансировщиков нагрузки в каждом регионе. При этом применяются средства автоматизации для обновления записей DNS и устранения любых проблем. 
Источник изображения: Amazon Однако 20 октября система управления DNS для DynamoDB в ЦОД Amazon в Северной Вирджинии оказалась в состоянии гонки (race condition), в результате чего DNS-запись для региональной точки подключения к DynamoDB (dynamodb.us-east-1.amazonaws.com) оказалась пустой, хотя резервирование систем DNS как раз должно было предотвратить подобную ситуацию. Устранить неполадку самостоятельно система автоматизации не смогла, поэтому пришлось привлечь к решению проблемы специалистов. При этом DynamoDB оказалась недоступна для десятков собственных сервисов AWS и бесчисленного множества клиентских служб и приложений, которые используют её в своей работе, что привело к каскадным сбоям онлайн-сервисов. Amazon временно отключила систему автоматизации DNS для DynamoDB по всему миру, пообещав исправить в ней баги и добавив новые проверки. Также дополнительные механизмы контроля и новые системы проверки получат балансировщики NLB и службы EC2. Впрочем, эксперты отмечают, что данный инцидент наглядно показал, насколько мир может быть зависимым от единых точек отказа. Это касается не только AWS, но и других крупных облачных провайдеров, на инфраструктуру которых полагается огромное количество интернет-сервисов.
24.10.2025 [14:40], Руслан Авдеев
Crusoe развернёт облачную ИИ-платформу на спутнике StarcloudCrusoe, известная в качестве застройщика первого ИИ-кампуса OpenAI Stargate. намерена развернуть свою облачную платформу на спутнике Starcloud (бывшей Lumen Orbit), запуск которого запланирован на конец 2026 года. Ограниченный доступ к ИИ-мощностям в космосе должен появиться к началу 2027 года, сообщает Datacenter Dynamics. Соглашение о партнёрстве заключено незадолго до запуска спутника Starcloud-1. Starcloud-1 на платформе Corvus-Micro компании Astro Digital размером с небольшой холодильник (60 кг) будет оснащён ИИ-ускорителем NVIDIA H100 и позволит на практике оценить концепцию космических вычислений. После примерно 11 месяцев службы он сойдёт с орбиты на высоте 325 км и сгорит в атмосфере. Если тестирование признают успешным, Crusoe рассмотрит создание более крупного ЦОД в космосе — мощностью до 5 ГВт и с солнечными панелями площадью 4 км2. По словам Starcloud, Crusoe станет основным поставщиком облачных услуг на её. Подчёркивается, что опыт Crusoe в создании надёжных, эффективных и масштабируемых вычислительных решений делает компанию идеальным партнёром для пионеров новой космической эры. В Crusoe считают, что космос сыграет важную роль в будущем облачных вычислений, поскольку позволяет практически неограниченно масштабировать ИИ-инфраструктуру благодаря доступу к безлимитной солнечной энергии. Как будут решаться вопросы охлаждения космических ЦОД и защиты от радиации, которая не позволяет надёжно использовать в течение длительного времени современные чипы с тонкими техпроцессами, пока не уточняется. 
Источник изображения: Starcloud В космосе намерены развернуть свои дата-центры многие компании, включая Axiom Space, NTT, Ramon.Space и Sophia Space. Ранее в 2025 году стартап Lonestar успешно разместил небольшой тестовый ЦОД даже на Луне, хотя тот проработал не очень долго. В октябре основатель Amazon Джефф Безос (Jeff Bezos) уже прогнозировал появление гигаваттных ЦОД в космосе через десять лет, а один из основателей Google Эрик Шмидт (Eric Schmidt) объявил, что именно поэтому им куплена авиакосмическая компания Relativity Space. Также появились сообщения о том, что Crusoe привлекла $1,4 млрд в ходе раунда финансирования, возглавленного Mubadala Capital и Valor Equity Partners, в результате оценка компании выросла до $10 млрд.
24.10.2025 [13:15], Руслан Авдеев
1 млн TPU и 1 ГВт: Anthropic расширит использование ИИ-ускорителей и сервисов Google CloudКомпания Anthropic объявила о знаковом расширении использования чипов TPU Google Cloud. Это обеспечит компании доступ к вычислительным ресурсам, необходимым для обучения и обслуживания ИИ-моделей Claude новых поколений. В 2026 году Anthropic рассчитывает получить доступ к мощностям, превышающим 1 ГВт, сообщает пресс-служба Google Cloud. Речь идёт о крупнейшем увеличении использования TPU компанией Anthropic за всё время использования ей тензорных ускорителей Google. Она получит доступ к 1 млн чипов, а также дополнительным сервисам Google Cloud. По оценкам некоторых экспертов, это примерная пятая часть всех TPU Google, но в 2026 году компания намерена развернуть ещё 2,5 млн TPU. Предполагается, что сделка обеспечит R&D-группы Anthropic передовой инфраструктурой, оптимизированной для ИИ-проектов, на годы вперёд. Как сообщают в Google, Anthropic выбрала TPU из-за привлекательного соотношения цены и производительности, а также благодаря имеющемуся опыту обучения и эксплуатации ИИ-моделей именно с помощью TPU. О стратегическом партнёрстве Anthropic и Google Cloud объявили в 2023 году. На сегодняшний день моделями семейства Claude компании Anthropic в Google Cloud активно пользуются тысячи компаний, включая Figma, Palo Alto Networks, Cursor и др. 
Источник изображения: Google Cloud В Anthropic подчеркнули, что с Google компания давно сотрудничает, а последнее расширение поможет и дальше наращивать вычислительные мощности, необходимые для наращивания возможностей ИИ-систем. В числе клиентов — как компании из списка Fortune 500, так и ИИ-стартапы, которые полагаются на Claude. Расширение вычислительных возможностей гарантирует, что компания сможет удовлетворить стремительно растущий спрос, сохраняя актуальность ИИ-продуктов. В Google Cloud отметили, что Anthropic использует TPU уже несколько лет с оптимальным для неё соотношением цены и производительности, в Google продолжают инновации, опираясь на «зрелое» портфолио ИИ-ускорителей, включая TPU седьмого поколения — Ironwood.
23.10.2025 [15:49], Андрей Крупин
Yandex B2B Tech поможет компаниям быстро разворачивать инфраструктуру для ИИ-сервисов по модели On‑PremiseYandex B2B Tech (бизнес-группа «Яндекса», объединяющая технологии и инструменты компании для корпоративных пользователей, включая продукты Yandex Cloud и «Яндекс 360») сообщила о планах по запуску в первом квартале 2026 года нового инфраструктурного решения Yandex Cloud Stackland, с помощью которого организации смогут оперативно разворачивать инфраструктуру для управления ИИ‑нагрузками в закрытом контуре по модели on‑premise. Yandex Cloud Stackland предложит пользователям следующие компоненты для построения интегрированной ИИ-среды: платформу AI Studio для разработки ИИ-приложений и агентов, модуль речевой аналитики SpeechSense, BI-систему DataLens, контейнерный оркестратор, масштабируемое объектное S3-хранилище, управляемые СУБД PostgreSQL, ClickHouse, Kafka, а также векторные базы данных, которые распространены в RAG-решениях. В дополнение к этому будут представлены инструменты для обеспечения приложений доступом к графическим ускорителям и высокопроизводительным сетям, таким как InfiniBand, для задач распределённого инференса. Отдельное внимание будет уделено безопасности и защите обрабатываемых данных: Stackland получит встроенные средства IAM для гибкого разграничения доступов и инструменты для защищённого хранения паролей, токенов и сертификатов. 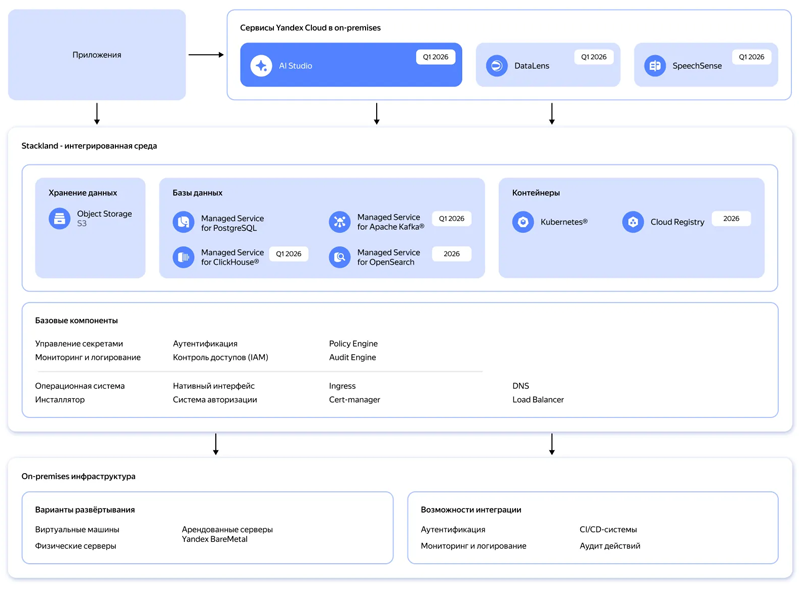
Архитектура Yandex Cloud Stackland (источник изображения: yandex.cloud/services/stackland) Stackland базируется на Kubernetes, что позволит компаниям применять привычные подходы и инструменты для управления микросервисными приложениями, а также управлять PaaS-сервисами Yandex Cloud через Kubernetes API. Ожидается, что интерес к Stackland проявят организации из сфер электронной коммерции, финтеха, ритейла и промышленного сектора, которые хотят использовать ИИ-решения на базе облачных технологий, но не могут сделать это из-за внутренних или регуляторных требований. Как передают «Ведомости», по оценке «Яндекса», в 2025 г. объём рынка контейнеризации составит 4–6 млрд руб., а к 2030 г. вырастет до 9–14 млрд руб. С новым решением компания планирует занять полоивину рынка инфраструктурного ПО для ИИ. Лицензирование Yandex Cloud Stackland будет производиться по количеству ядер CPU. Все инфраструктурные компоненты, в частности управляемые базы данных, будут включены в лицензию. Для отдельных сервисов, таких как AI Studio, DataLens и SpeechSense, нужно будет приобретать отдельные лицензии.
23.10.2025 [13:50], Руслан Авдеев
Неудобные вопросы: казначейство Великобритании выясняет, почему сбой AWS по ту сторону океана нарушил работу госведомств Соединённого Королевства
aws
lloyds banking
software
банк
великобритания
госуслуги
информационная безопасность
кии
конфиденциальность
облако
сбой
От правительства Великобритании потребовали ответить, почему многочасовой сбой в работе сервисов AWS (Amazon) на другом берегу Атлантики нарушил функциональность информационных систем британских структур, включая налоговую службу HMRC и Lloyds Banking Group, сообщает Computer Weekly. Многочасовой сбой 20 октября во флагманском регионе AWS US-East-1 в Северной Вирджинии (США) нарушил работу компаний и организаций по всему миру, в том числе и в Соединённом Королевстве. Поэтому в Великобритании и других странах растёт обеспокоенность тем, что частный и государственный сектора зависят от заокеанских служб — вновь появились призывы сохранить услуги национального значения под локальным контролем. Так, Казначейству Великобритании уже предложено отчитаться о том, почему предоставленные в январе этого года полномочия не помогли гарантировать надёжность сервисов в секторе финансовых услуг. В частности, почему платформа AWS (и не только она), которая является облачным провайдером большого числа финансовых учреждений Великобритании, до сих пор не включена в список критически важных третьих сторон (Critical Third Parties, CTP), который позволяет требовать от сторонних компаний соблюдения тех же высоких стандартов, что и от финансовых учреждений. Также чиновников попросили уточнить, не беспокоит ли их тот факт, что ключевые фрагменты британской IT-инфраструктуры размещены за рубежом, с учётом последствий недавнего сбоя. Также предлагается объяснить, какую работу проводят совместно с HMRC, чтобы предотвратить аналогичные сбои в будущем. В Министерстве финансов Великобритании заявили журналистам, что работают с регуляторами над внедрением режима CTP. В AWS же предложили спросить у самой HMRC, почему сбой в США так повлиял на неё. 
Источник изображения: Tom Athawes/unspalsh.com У AWS с 2016 года есть собственный облачный регион в Великобритании, причём платформа позволяет британским структурам получать доступ к локальным версиям публичных облачных сервисов. В AWS придерживаются «модели общей ответственности», при которой клиенты должны сами внимательно выбирать сервисы для размещения в облаке. Утверждается, что такой подход обеспечивает гибкость и контроль со стороны клиента. По мнению некоторых экспертов, сбой свидетельствует о том, что часть инфраструктуры HMRC и Lloyds зависела от американских мощностей, и это мог быть осознанный выбор британских структур, а не вина AWS. С другой стороны, инцидент показал, как сложна и взаимосвязана современная облачная инфраструктура. Заказчики могли не знать какие сервисы размещены в рамках их пакетов услуг в Великобритании и насколько они устойчивы. Например, Microsoft в своё сообщила, что не может гарантировать суверенитет данных полиции Великобритании, хранящихся и обрабатываемых на её платформе. Позже выяснилось, что данные британской полиции могут обрабатываться более чем в 100 странах, причём пользователи об этом не знали. 
Источник изображения: Jud Mackrill/unsplash.com В Forrester сообщают, что AWS осознаёт проблему и намерена запустить в Европе «идеальную копию» своих сервисов в рамках предложения суверенного облака. Первый изолированный регион предусмотрен в Германии. Фактически, единственный надёжный способ избавиться от иностранной зависимости — физическая и логическая изоляция облачных регионов, используемых клиентами. По словам экспертов, чем более «концентрированной» становится инфраструктура, тем более хрупкой и зависимой от внешнего управления она становится. Если Европа настроена на обретение цифрового суверенитета, ей необходимо скорее принять необходимые для этого меры. В частности, следует переосмыслить систему закупок, финансировать суверенные альтернативы и сделать обеспечение надёжности базовым требованием. Ранее эксперты пришли к выводу, что сбой в работе AWS наглядно продемонстрировал опасную зависимость всего мира от нескольких облачных гигантов из США. Европа так и не смогла избавиться от бремени американских гиперскейлеров, которые открыто признают, что даже не могут гарантировать суверенитет данных. При этом к AWS есть вопросы и у других британских регуляторов.
22.10.2025 [12:35], Руслан Авдеев
Сбой в работе AWS показал опасную зависимость мира от нескольких облачных гигантов из СШАМасштабный сбой в работе облака AWS в понедельник коснулся множества сервисов по всему миру во многих секторах экономики и общественной деятельности. Инцидент вызвал разговоры о зависимости пользователей от крупных облачных провайдеров из США, необходимости повышения цифрового суверенитета и диверсификации рисков, сообщает Datacenter Knowledge. В компании объявили, что причина — в «эксплуатационном инциденте» в регионе us-east-1, именно там расположен крупнейший кластер ЦОД провайдера. Облачный регион находится в т.н. «Аллее ЦОД» в Северной Вирджинии и состоит из 158 объектов общей мощностью 2,544 ГВт. По оценкам Amazon, более 90 % компаний из рейтинга Fortune 100 используют именно облачные сервисы AWS. Сбой стал крупнейшим инцидентом в работе интернета с тех пор, как в 2024 году из-за ошибки обновления Crowdstrike из строя по всему миру вышли миллионы систем Microsoft. По словам IDC, последний инцидент демонстрирует, как масштабные вычисления могут привести к масштабным проблемам. Хотя предприятия в целом приняли идею отказа от собственной инфраструктуры ЦОД, происшествие привлекает внимание к необходимости диверсификации рисков. Это может привести к созданию распределённых архитектур, охватывающих несколько облачных регионов в рамках пакетного предложения одного провайдера, и более широкому использованию нескольких облаков разных провайдеров одновременно. 
Оригинал: xkcd.com/2347 Эксперты обеспокоены зависимостью предприятий всего мира от американских гиперскейлеров — последствия инцидента носят трансграничный характер и касаются не только клиентов одного поставщика облачных сервисов. Многие уже задаются вопросом — стоит ли сохранять зависимость государственных учреждений, от налоговых служб государство до крупных банков службам, расположенным на другом побережье Атлантического океана. Европа так и не смогла избавиться от бремени американских гиперскейлеров, которые открыто признают, что даже не могут гарантировать суверенитет данных. Как заявляют в британской Asanti Data Centres, многие организации активно приняли концепцию публичных облаков, но сбой показал, что может случиться, когда всё построено на одном фундаменте. Проблема затронула не только структуры, напрямую использующие сервисы AWS, но и всех остальных в цепочке поставок услуг. Большинство организаций ведут дела с клиентами AWS, в результате чего речь идёт о каскадном, общесистемном ущербе. 
Источник изображения: Oğuzhan Akdoğan/unspalsh.com В IDC подчёркивают, что роль в купировании негативных эффектов от будущих инцидентов может сыграть ИИ. Хотя у AWS в целом довольно хорошая репутация среди пользователей, на устранение последствий инцидента потребовалось слишком много времени, поэтому возникают сомнения, сможет ли AWS поддерживать репутацию по мере роста бизнеса и усложнения технологий. ИИ может помочь, создавая агентов, способных заранее выявлять и устранять проблемы до того, как они негативно скажутся на клиентах. Стоит отметить, что концентрация облачных ресурсов в одном месте может действительно крайне негативно сказаться на деятельности целых государств. Недавний пожар в южнокорейском ЦОД показывает, к каким катастрофическим последствиям для государственных услуг может привести консолидация облачных мощностей в одном месте. Более того, даже концентрация крупных ЦОД разных операторов в одном месте грозит тем, что сбой одного из них приведёт к проблемам у соседних. Особенно в случае ИИ ЦОД.
21.10.2025 [00:35], Владимир Мироненко
Ещё одна альтернатива платформам NVIDIA — IBM объединила усилия с GroqIBM и Groq объявили о стратегическом партнёрстве с целью предоставления клиентам возможностей высокоскоростного ИИ-инференса по доступной цене путём объединения watsonx Orchestrate от IBM с аппаратными решениями Groq, что позволит ускорить развёртывание агентных систем ИИ. В рамках партнёрства Groq и IBM планируют интегрировать и усовершенствовать технологию Red Hat vLLM с архитектурой LPU Groq. Ожидается, что совместное решение позволит клиентам использовать возможности watsonx Orchestrate привычным образом и с привычными инструментам в инференс-платформе GroqCloud, предоставляющей разработчикам доступ к высокоскоростной и недорогой обработке LLM. Эта интеграция позволит удовлетворить ключевые потребности разработчиков ИИ-решений, включая оркестрацию инференса, балансировку нагрузки и аппаратное ускорение, что в конечном итоге оптимизирует сам процесс инференса. Также планируется поддержка моделей IBM Granite в GroqCloud для клиентов IBM. IBM отметила, что предприятия при переводе ИИ-агентов из пилотной версии в промышленную эксплуатацию продолжают сталкиваться с проблемами обеспечения скорости, стоимости и надёжности. Партнёрство IBM и Groq позволяет объединить скорость инференса Groq, экономическую эффективность и доступ к новейшим open source моделям с оркестрацией агентского ИИ IBM, предоставляя клиентам инфраструктуру, необходимую для их масштабирования, говорит компания. 
Источник изображения: Groq IBM сообщила, что LPU обеспечивают минимум в пять раз более быстрый и экономичный инференс, чем системы на ускорителях конкурентов, имея, по всей видимости, в виду NVIDIA. Это позволяет обеспечить стабильно низкую задержку и производительность при масштабировании нагрузок, что особенно важно для ИИ-агентов в регулируемых отраслях. В качестве примера IBM привела деятельность клиентов из сферы здравоохранения, которые одновременно получают тысячи сложных вопросов пациентов. Благодаря Groq ИИ-агенты IBM смогут анализировать информацию в режиме реального времени и мгновенно предоставлять точные ответы, позволяя организациям в этой сфере принимать более оперативные и обоснованные решения. В нерегулируемых отраслях клиенты IBM с помощью платформы GroqCloud смогут ускорить работу ИИ-агентов и повысить автоматизацию кадровых процессов и производительность сотрудников. IBM объявила, что сразу же предоставит клиентам доступ к возможностям GroqCloud, а совместные с Groq команды сосредоточатся на предоставлении заказчикам IBM следующих возможностей:
Groq привлекла инвестиции в размере $1,8 млрд, включая раунд финансирования на сумму $750 млн в прошлом месяце с оценкой в $6,9 млрд. В числе её инвесторов — Cisco и Samsung. Также Groq сотрудничает с саудовской Aramco Digital. По данным WSJ, компания развернула в этом году 12 ЦОД и намерена развернуть как минимум ещё 12 в 2026 году. В 2024 году Groq сменила модель работы — с тех пор она больше не продаёт свои ИИ-ускорители, предлагая вместо этого создание ЦОД или облака.
20.10.2025 [14:16], Владимир Мироненко
AWS столкнулась с серьёзным сбоем из-за ошибки DNS — падение одного сервиса потянуло за собой ещё 110 служб [Обновлено]Облако Amazon Web Services (AWS) столкнулось со серьёзным сбоем, из-за которого сейчас могут быть недоступны такие онлайн-сервисы, как Perplexity, Snapchat, Fortnite, Airtable, Canva, Amazon, Slack, Signal, PlayStation, Clash Royale, Brawl Stars, Epic Games Store и Ring Cameras, пишет Data Center Dynamics. Согласно отчёту Amazon, наблюдается «значительный уровень ошибок в запросах к DynamoDB в регионе US-EAST-1», который находится в Северной Вирджинии. Компания отметила, что эта проблема также затрагивает другие сервисы AWS в регионе US-EAST-1, а у клиентов может не быть возможности создавать или обновлять запросы в службу поддержки. Первопричиной проблем стала ошибка DNS. AWS её исправила и теперь занимается восстановлением доступности других сервисов. 
Источник изображения: AWS Проблема DynamoDB затронула другие сервисы AWS, включая AWS Global Accelerator, AWS VPCE PrivateLink, AWS Security Token Service, AWS Step Functions, AWS Systems Manager, Amazon CloudFront, Amazon DynamoDB, Amazon Elastic Compute Cloud, Amazon EventBridge, Amazon EventBridge Scheduler, Amazon GameLift Servers, Amazon Kinesis Data Streams, Amazon SageMaker и Amazon VPC Lattice — всего 82 службы. Сбои в работе сервисов AWS наблюдаются в других регионах по всему миру. Проблемы в работе AWS в регионе US-East-1 привели к масштабным сбоям в 2023, 2021 и 2020 годах, в результате чего было отключено множество веб-сайтов и платформ. Лишь спустя несколько часов было восстановлено нормальное обслуживание, сообщил The Verge. UPD: по состоянию на 21:45 МСК AWS продолжает работать над устранением проблем. По уточнённым данным, проблемы наблюдаются в 110 сервисах облака. Работа ещё 25 сервисов восстановлена. В качестве причины названы проблемы с сетью в US-EAST-1.
20.10.2025 [01:23], Владимир Мироненко
Ускорителей хватит на всех — Alibaba Aegaeon оптимизировал обработку ИИ-нагрузок, снизив использование дефицитных NVIDIA H20 на 82 %Alibaba Cloud представила Aegaeon, систему пулинга вычислений, позволяющую сократить количество ускорителей NVIDIA, необходимых для обслуживания ИИ-моделей, на 82 %, пишет ресурс SCMP. По словам разработчиков, благодаря Aegaeon количество ускорителей NVIDIA H20, необходимых для обслуживания десятков моделей с 72 млрд параметров, удалось сократить с 1192 до 213 единиц. «Aegaeon — это первое решение на рынке, которое выявило чрезмерные затраты, связанные с обслуживанием параллельных рабочих нагрузок LLM», — сообщили исследователи из Пекинского университета и Alibaba Cloud. Провайдеры облачных сервисов, такие как Alibaba Cloud и ByteDance Volcano Engine, предоставляют пользователям одновременно тысячи ИИ-моделей — множество вызовов API обрабатывается одновременно. Однако на практике для инференса чаще всего используются лишь несколько моделей, таких как Qwen и DeepSeek, а большинство других моделей применяются лишь эпизодически. Это приводит к неэффективному использованию вычислительных ресурсов: исследователи обнаружили, что 17,7 % ускорителей выделяется на обслуживание лишь 1,35 % запросов в Alibaba Cloud. Aegaeon выполняет «автоматическое масштабирование» на уровне токенов, обеспечивая переключение ускорителей между обслуживанием различных моделей в процессе генерации. В рамках системы один ускоритель поддерживает обработку до семи моделей по сравнению с двумя-тремя моделями в альтернативных системах. При этом задержка, связанная с переключением между моделями, снижена на 97 %, заявили исследователи. Alibaba Cloud сообщила, что решение уже используется на её торговой площадке моделей Bailian. 
Источник изображения: Alibaba Глава NVIDIA Дженсен Хуанг (Jensen Huang) объявил, что из-за экспортных ограничений доля компании на рынке передовых чипов в Китае сократилась с 95 % до нуля. Этому также способствовала стратегия Пекина, направленная на самообеспечение местного рынка. В связи с этим планы NVIDIA возобновить отгрузки ИИ-ускорителей H20, на которые ранее были установлены ограничения правительством США, встретили в Китае довольно прохладно. Более того, в Китае вынесли запрет местным компаниям на покупку разработанного специально для местного рынка ускорителя NVIDIA RTX Pro 6000D, поскольку пришли к выводу, что китайские ИИ-чипы не уступают продукции NVIDIA, разрешённой к экспорту в Китай.
17.10.2025 [14:49], Андрей Крупин
VK Cloud, Yandex Cloud и «Флант» создадут первую в России некоммерческую ассоциацию по облачным технологиямКомпании VK Cloud, Yandex Cloud и «Флант» объявили о планах по созданию некоммерческой Ассоциации облачно-ориентированных технологий (АОТ) — первой в РФ организации, которая займётся развитием новых подходов, стандартов и архитектуры нативных облачных технологий без привязки к конкретному вендору. АОТ призвана объединить игроков отечественного облачного рынка для популяризации облачных технологий, таких как Kubernetes и Cloud-native. Ключевыми задачами ассоциации станут продвижение и внедрение Cloud-native-решений через стандартизацию подходов и компетенций в разработке ПО, поддержка и развитие Open Source-продуктов, а также их внедрение в бизнес-среде, популяризация облачных технологий и Kubernetes, а также развитие и объединение профессионального сообщества. 
Источник изображения: Monisha Selvakumar / unsplash.com Стать партнёром АОТ сможет любая компания, использующая в работе облачные технологии, а участником — любой IT-специалист. Статус партнёра предполагает ежегодные взносы, которые идут на проекты ассоциации, и открывает доступ к проектам и ресурсам АОТ. «Мы считаем, что базовые облачные технологии должны быть доступны всем, и у каждого должна быть возможность вносить в них свой вклад. Наша совместная задача с партнёрами из Ассоциации облачно-ориентированных технологий — объединить усилия крупнейших организаций и всех инженеров, которым не безразличен Open Source, чтобы ускорить развитие индустрии в целом», — прокомментировали инициативу в компании «Флант». |
|

