Материалы по тегу: qualcomm
|
02.04.2025 [18:06], Руслан Авдеев
Arm собиралась купить Alphawave ради передовой технологии SerDes для выпуска ИИ-чипов — теперь её хочет купить QualcommПринадлежащий SoftBank разработчик архитектурных решений для полупроводников — компания Arm недавно собиралась приобрести британскую Alphawave для получения критически важной технологии, необходимой для создания ИИ-ускорителей. Об этом сообщили Reuters три независимых источника, «знакомых с вопросом». Теперь над покупкой Alphawave раздумывает Qualcomm, уточняет SiliconAngle. Alphawave владеет интеллектуальной собственностью, связанной с полупроводниковыми технологиями, и даже обсуждала с инвестиционными банкирами возможность продажи — после того как Arm и другие потенциальные покупатели выразили интерес к приобретению компании. Однако, по данным двух источников, в итоге было решено отказаться от сделки. На фоне новостей акции Alphawave взлетели на 21 % — рекордный рост с сентября 2021 года. По данным на конец торгов в понедельник капитализация компании составила £707 млн ($914 млн), а цена акции — 93,5 пенса. Arm рассчитывала получить от Alphawave технологию создания SerDes-блоков, которые определяют скорость передачи данных на чип и с него. Эта технология критически важна для ИИ-систем, таких как ChatGPT, где тысячи чипов должны работать согласованно. Так, SerDes является ключевым преимуществом Broadcom, помогая компании привлекать клиентов вроде Google и OpenAI. 
Источник изображения: Arm Arm с головным офисом в Великобритании на 90 % принадлежит японской SoftBank Group. Компания сама не разрабатывает чипы, а продаёт «основные строительные блоки» для их создания, а также прочую интеллектуальную собственность. Основные доходы Arm получает за счёт лицензионных отчислений от других бизнесов, а также роялти за каждый проданный чип, использующий её технологии. Недавно сообщалось, что она рассчитывает, что её архитектура займёт 50 % на рынке чипов для ЦОД уже к концу 2025 года. У AWS, Google Cloud и Microsoft Azure уже есть собственные серверные Arm-процесоры: Graviton, Axion и Cobalt 100. Конечно, компания стремилась повысить прибыль и выручку, в том числе не исключалась самостоятельная разработка чипов и прямая конкуренция с собственными клиентами. Планы покупки Alphawave частично раскрылись в декабре 2024 года в ходе судебной тяжбы с Qualcomm. Однако руководство Arm заявило, что речь шла об обычном обмене идеями между менеджерами. Тем не менее, в ходе того же процесса в феврале стало известно, что компания искала специалистов, способных вывести на рынок чип собственной разработки. Теперь же выяснилось, что Qualcomm сама не прочь приобрести Alphawave — компания должна сделать предложение до 29 апреля или полностью отказаться от сделки. У Arm нет столь передовой технологии SerDes, какой располагает Alphawave. Хотя подробностей немного, известно, что SerDes-блоки служат основой многомиллиардных полупроводниковых бизнесов Broadcom и Marvell Technology. По прогнозам Bernstein, соответствующий рынок к 2028 году вырастет до $60 млрд. NVIDIA также разработала собственный вариант SerDes и уже заявила о намерении продавать лицензии на него другим компаниям. Создание передовых решений в этой сфере критически важно для выпуска ИИ-чипов, способных выгодно отличаться от продукции конкурентов. При этом, по мнению экспертов, разработка SerDes с нуля требует специфических навыков и около двух лет. Покупка Alphawave смогла бы сэкономить Arm значительное количество времени и ресурсов.
14.01.2025 [12:23], Владимир Мироненко
Qualcomm наняла главного архитектора Intel Xeon для разработки серверных Arm-процессоровРесурсу CRN стало известно, что компания Qualcomm наняла Сайлеша Коттапалли (Sailesh Kottapalli) в качестве старшего вице-президента. Ветеран Intel с 28-летним стажем, являвшийся главным архитектором серверных процессоров Xeon, сообщил в понедельник в соцсети в LinkedIn, что он присоединился к Qualcomm после ухода из Intel, поскольку разработчик чипов формирует команду для выхода на рынок CPU для ЦОД. «Возможность внедрять инновации и расти, помогая при этом расширять горизонты, была для меня чрезвычайно привлекательной — возможность, которая выпадает раз в карьере и которую я не мог упустить», — написал Коттапалли в LinkedIn. Это не первая попытка Qualcomm выйти на рынок серверных процессоров. В 2017 году компания выпустила 10-нм 48-ядерные чипы Centriq 2400, но вскоре забросила развитие этого направления. 
Источник изображения: Intel Пост Коттапалли в LinkedIn, ранее занимавшего должность ведущего инженера по чипам Itanium и Xeon в Intel, прежде чем стать главным архитектором Xeon в компании, появился чуть более чем через месяц после того, как стало известно, что у Qualcomm есть подразделение Qualcomm Data Center, которое занимается созданием «высокопроизводительного, энергоэффективного серверного решения». Разработчик чипов раскрыл эту информацию в опубликованной в декабре вакансии архитектора безопасности серверной системы на кристалле (SoC). В ней говорилось, что команда Qualcomm Data Center сосредоточена на создании «эталонных платформ» на основе Snapdragon. Подходящий соискатель возглавит разработку «системной архитектуры для конфиденциальных вычислений в продуктах ЦОД». Конфиденциальные вычисления, позволяющие изолировать данные во время их обработки, стали стандартной функцией в Intel Xeon и AMD EPYC, отметил ресурс CRN. 
Источник изображения: Qualcomm Qualcomm разрабатывает серверные ИИ-ускорители Qualcomm Cloud AI, которые она поставляла таким компаниям, как AWS, HPE и Lenovo. Кроме того, компания сотрудничает с Cerebras, ещё одним разработчиком ИИ-ускорителей. Недавно стало известно о планах компании выпустить ускорители Cloud AI 80 (AIC080) для ИИ-задач. В 2021 году Qualcomm приобрела за $1,4 млрд стартап NUVIA, который изначально занимался серверного Arm-процессора Phoenix. Qualcomm утверждала, что будет использовать технологии NUVIA в ноутбуках, смартфонах, ADAS, AR/VR и т.п., но в прошлом году объявила, что также планирует продолжить разработку серверных процессоров. Из-за поглощения NUVIA между Arm и Qualcomm уже несколько лет идут судебные разбирательства.
06.01.2025 [19:00], Владимир Мироненко
Qualcomm представила энергоэффективные ИИ-микросерверы AI On-Prem Appliance SolutionQualcomm Technologies анонсировала Qualcomm AI On-Prem Appliance Solution — компактное энергоэффективное аппаратное решение для локальной обработки рабочих нагрузок инференса и компьютерного зрения. Также компания представила готовый к использованию набор ИИ-приложений, библиотек, моделей и агентов Qualcomm Cloud AI Inference Suite, способный работать и на периферии, в облаках. Согласно пресс-релизу, сочетание новых продуктов позволяет малым и средним предприятиям и промышленным организациям запускать кастомные и готовые приложения ИИ на своих объектах, включая рабочие нагрузки генеративного ИИ. Qualcomm отметила, что инференс на собственных мощностях позволит значительно снизить эксплуатационные расходы и общую совокупную стоимость владения (TCO) по сравнению с арендой сторонней ИИ-инфраструктуры. 
Источник изображений: Qualcomm С помощью AI On-Prem Appliance Solution совместно с AI Inference Suite клиенты смогут использовать генеративный ИИ на базе собственных данных, точно настроенные модели и технологическую инфраструктуру для автоматизации процессов и приложений практически в любой среде, например, в розничных магазинах, ресторанах, торговых точках, дилерских центрах, больницах, на заводах и в цехах, где рабочие процессы хорошо отлажены, повторяемы и готовы к автоматизации.  «Решения AI On-Prem Appliance Solution и Cloud AI Inference Suite меняют TCO ИИ, позволяя обрабатывать рабочие нагрузки генеративного ИИ не в облаке, а локально», — заявила компания, подчеркнув, что AI On-Prem Appliance Solution позволяет значительно снизить эксплуатационные расходы на приложения ИИ для корпоративных и промышленных нужд в самых разных областях. Кроме того, локальное развёртывание обеспечивает защиту от утечек чувствительных данных.  Платформа Qualcomm AI On-Prem Appliance Solution работает на базе семейства ускорителей Qualcomm Cloud AI. Сообщается, что новинка поддерживает широкий спектр возможностей, в том числе:
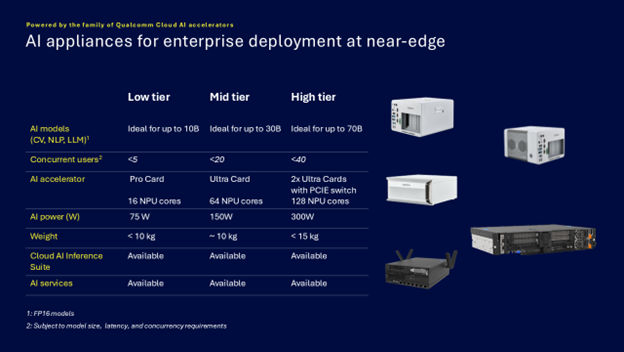 В свою очередь Qualcomm Cloud AI Inference Suite предлагает полный набор инструментов и библиотек для разработки или переноса приложений генеративного ИИ на AI On-Prem Appliance Solution или другие платформы на базе ускорителей Qualcomm Cloud AI. Набор предлагая множество API для управления пользователями и администрирования, для работы чатов, для генерации изображений, аудио и видео. Заявлена совместимость с API OpenAI и поддержка RAG. Кроме того, доступна интеграция с популярными моделями генеративного ИИ и фреймворками. Возможно развёртывание с использованием Kubernetes и bare metal.
10.10.2024 [21:18], Алексей Степин
«Элитный» Wi-Fi 7 с ИИ-поддержкой: Qualcomm представила сетевую платформу Pro A7 EliteКомпания Qualcomm объявила о выпуске новой беспроводной сетевой платформы Pro A7 Elite класса «всё-в-одном» с поддержкой беспроводного стандарта Wi-Fi 7 (802.11be) и XGS-PON. Платформа предназначена для размещения на периферии и оснащена широким спектром самых современных сетевых возможностей, дополненных ИИ-функциями. 
Источник изображений: Qualcomm Сердцем новинки является четырёхъядерный процессор, тип и модель которого Qualcomm не разглашает, известно лишь, что в основе лежит 14-нм техпроцесс, а ядра работают на частоте 1,8 ГГц. Процессор работает в паре с памятью DDR3L/DDR4, в качестве накопителя возможно использование флеш-памяти NOR, NAND или eMMC. Зато часть, ответственная за ИИ, хорошо известна — это один из вариантов Qualcomm Hexagon NPU с заявленной производительностью 40 Топс (INT8). Его целью является улучшение работы Wi-Fi, в том числе реализация функций умного классификатора трафика, интеллектуальное управление усилением беспроводного сигнала, детектирование ошибок и др. 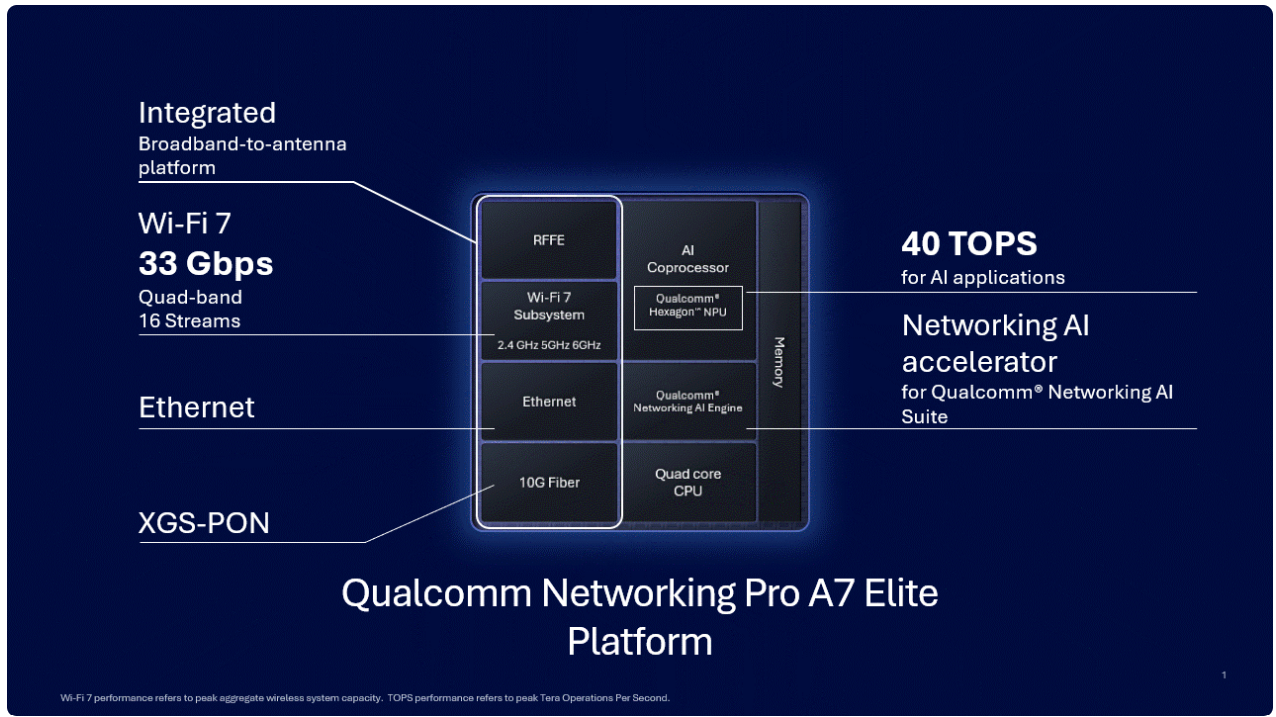 Платформа может похвастаться развитой сетевой подсистемой: во-первых, в ней реализована поддержка подключений XGS-PON, допускающая работу в качестве шлюза/терминала HGS/ONT или SFU/SFU+ ONU. При этом поддерживается скорость 10 Гбит/с как в восходящем, так и в нисходящем потоках. Проводная Ethernet-часть представлена двумя портами 2.5GbE и одним 10GbE (USXGMII/SGMII+). 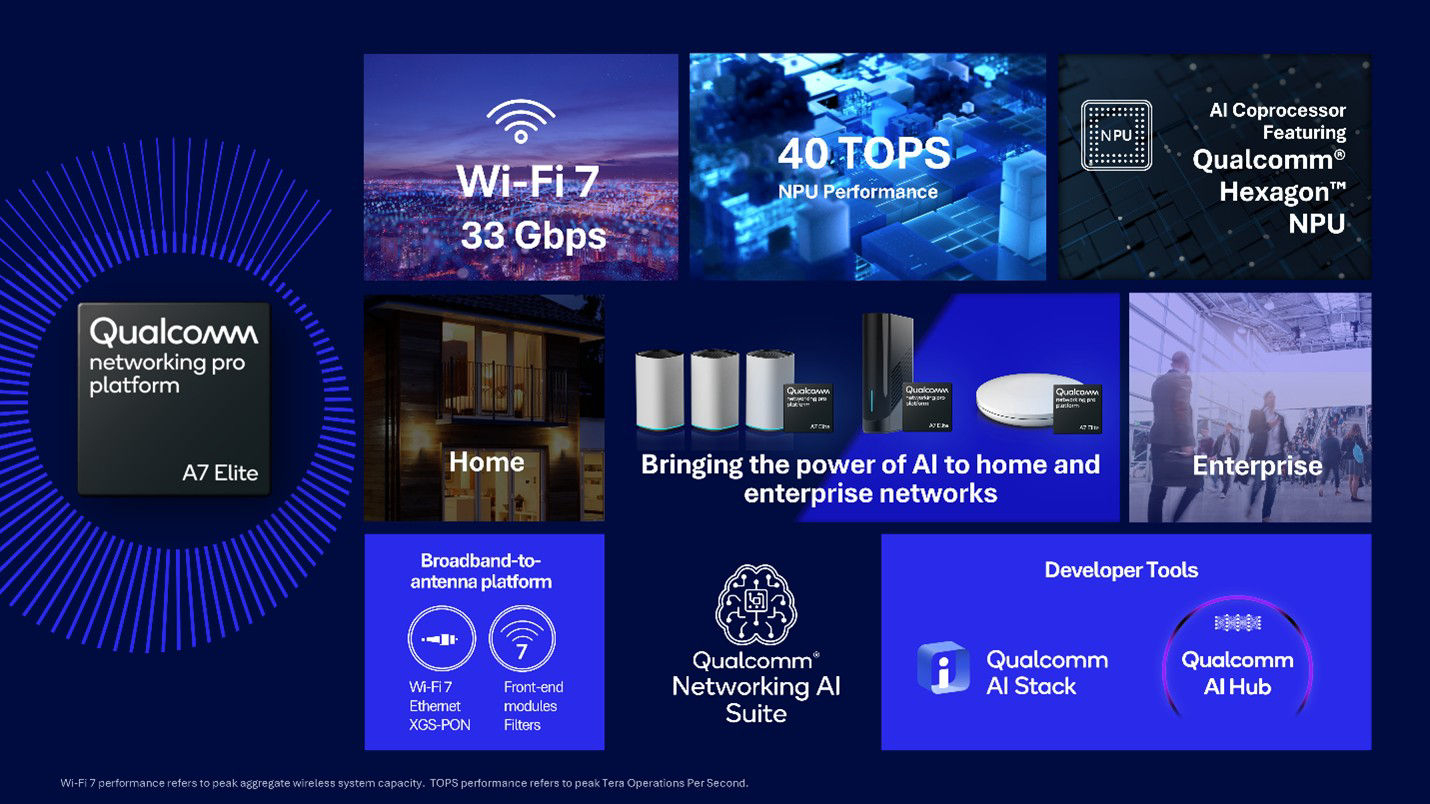 Wi-Fi-часть Pro A7 Elite предлагает пиковую агрегированную канальную скорость до 33 Гбит/с. Есть поддержка Wi-Fi 7 (802.11be) и Wi-Fi 6/6E (802.11ax), а также совместимость с Wi-Fi 5/4. Радиочасть может обслуживать четыре диапазона одновременно (6/5/2,4 ГГц) и 16 пространственных потоков. Максимальная ширина канала составляет 320 МГц. Для улучшения качества и скорости подключений реализованы технологии Qualcomm Automatic Frequency Coordination (AFC) Service, Simultaneous & Alternating Multi Link и Adaptive Interference Puncturing. Поддерживается WPA3 Personal/Enterprise/Easy Connect. Опционально доступна поддержка 4G/5G FWA, 802.15.4 (Zigbee/Thread) и Bluetooth, реализуемая посредством отдельных модулей. Дополнительно предусмотрено четыре порта PCIe 3.0, порты USB 2.0/3.0, а также интерфейсы I²C, I²S, PTA Coex, SPI и UART. SoC совместима с популярным открытым ПО: OpenWRT, RDK, TiP OpenWiFi, prplOS и OpenSync. Qualcomm уже поставляет образцы Pro A7 Elite.
05.10.2024 [15:55], Сергей Карасёв
Qualcomm готовит «урезанные» ИИ-ускорители Cloud AI 80Qualcomm, по сообщению Phoronix, планирует выпустить ускорители Cloud AI 80 (AIC080) для ИИ-задач. Информация о них появилась на сайте самого разработчика, а также в драйверах Linux. Речь идёт об «урезанных» версиях изделий Cloud AI 100, уже доступных на рынке. Базовая версия Cloud AI 100 Standard выполнена в виде HHHL-карты (68,9 × 169,5 мм) с интерфейсом PCIe 4.0 х8 и пассивным охлаждением. Объём памяти LPDDR4x-2133 с пропускной способностью 137 Гбайт/с составляет 16 Гбайт. Есть также 126 Мбайт памяти SRAM. TDP равен 75 Вт. Заявленное быстродействие достигает 350 TOPS на операциях INT8 и 175 Тфлопс при вычислениях FP16. От них в своё время отказалась Meta✴, сославшись на сырость программной экосистемы и предпочтя разработать собственные ИИ-ускорители MTIA. 
Источник изображений: Qualcomm Кроме того, существует решение Cloud AI 100 Ultra в виде карты FH3/4L (111,2 × 237,9 мм). Для обмена данными служит интерфейс PCIe 4.0 х16; значение TDP равно 150 Вт. В оснащение входят 128 Гбайт памяти LPDDR4x, пропускная способность которой достигает 548 Гбайт/с. Объём памяти SRAM — 576 Мбайт. INT8-производительность составляет до 870 TOPS, FP16 — до 288 Тфлопс.  Сообщается, что к выпуску готовятся «урезанные» ускорители Cloud AI 80 Standard и Cloud AI 80 Ultra. Их характеристики в точности соответствуют таковым у Cloud AI 100 Standard и Cloud AI 100 Ultra. Отличия заключаются исключительно в пониженном быстродействии. Так, у Cloud AI 80 Standard производительность INT8 находится на уровне 190 TOPS, FP16 — 86 Тфлопс. У Cloud AI 80 Ultra значения равны 618 TOPS и 222 Тфлопс.  Нужно отметить, что в старшее семейство также входит модель Cloud AI 100 Pro в формате карты HHHL с интерфейсом PCIe 4.0 х8 и TDP 75 Вт. Она несёт на борту 32 Гбайт памяти LPDDR4x (137 Гбайт/с) и 144 Мбайт памяти SRAM. Производительность INT8 составляет до 400 TOPS, FP16 — до 200 Тфлопс. Появится ли подобная модификация в серии Cloud AI 80, пока не ясно.
16.09.2024 [10:51], Руслан Авдеев
Aramco Digital объявила о партнёрстве с Cerebras, Groq и Qualcomm для развития ИИ и 5G IoT в Саудовской АравииПодразделение нефтегазовой саудовской Aramco — Aramco Digital анонсировало серию соглашений с компаниями, действующими в сфере ИИ и беспроводных технологий. По информации Datacenter Dynamics, компания подписала меморандумы о взаимопонимании с Cerebras Systems, развитии передовой ИИ-модели Norous совместно с Groq и сотрудничестве в сфере 5G-технологий совместно с Qualcomm. Aramco принадлежит государству и является крупнейшим в мире добытчиком нефти и газа, располагая вторыми по величине разведанными запасами сырой нефти в мире. Её подразделение Aramco Digital — попытка диверсифицировать бизнес, уделив внимание освоению информационных технологий. Сотрудничество с Cerebras Systems позволит обеспечить высокопроизводительными ИИ-решениями промышленность, университеты и коммерческие предприятия Саудовской Аравии. В рамках соглашения компания будет применять вычислительные системы Cerebras CS-3 на сусперускорителях WSE-3 в облачном бизнесе, чтобы ускорить создание, обучение и внедрение больших языковых моделей и ИИ-приложений. Тем временем партнёрство с Groq поможет Aramco Digital вывести на рынок управляемую голосом ИИ-модель Norous. 
Источник изображения: M Zaedm/unsplash.com В будущем планируется создать систему управления цепочками поставок, способную генерировать миллиарды токенов в секунду. Как сообщают арабские СМИ, пока Aramco Digital планирует обеспечивать до 25 млн токенов к концу I квартала 2025 года, а в этом году будет обеспечено 20 % от заявленных показателей. В Groq заявляют, что компания намерена стать экспортёром вычислительных мощностей для приблизительно 4 млрд человек, этого будет достаточно для «близлежащих континентов» и позволит обеспечивать части Европы, Африки и, возможно, даже часть Индии. Также совместно с Qualcomm компания Aramco Digital задействует 5G-чипы для частотного диапазона 450 МГц. IoT-решения Qualcomm QCS8550/QCS6490 будут поддерживать умные устройства с возможностью периферийных вычислений. Решение включает ряд компонентов, от модема до собственно передатчика, усилителя и систем фильтрации сигнала, а также другие элементы. Эксперты утверждают, что этот диапазон можно эффективно использовать как в помещениях, так и вне их, поэтому новое решение станет одним из важнейших элементов цифровой трансформации Саудовской Аравии. Партнёры также работают над «инкубатором стартапов» совместно с саудовским Управлением по вопросам исследований, развития и инноваций (RDIA). Программа Design in Saudi Arabia (DISA) будет поддерживать стартапы, занимающиеся разработкой и внедрением ИИ, беспроводных технологий и Интернета вещей, обеспечив им техническую помощь, бизнес-коучинг и прочую помощь. Резиденты инкубатора также получат доступ к технологическим платформам Qualcomm и Aramco Saudi Accelerated Innovation Lab. Предполагается, что это простимулирует новую волну технологических инноваций в Саудовской Аравии и коммерциализацию разработок стартапов.
01.08.2024 [11:20], Сергей Карасёв
Одноплатный компьютер Particle Tachyon с чипом Qualcomm, 5G и Wi-Fi 6E рассчитан на задачи ИИПровайдер IoT-платформы Particle разработал одноплатный компьютер Tachyon на аппаратной платформе Qualcomm. Новинка, доступная для предварительного заказа по цене от $149, предназначена для создания перифейриных устройств и изделий для Интернета вещей с поддержкой ИИ. В основу Tachyon положен процессор Qualcomm QCM6490. Он содержит восемь ядер Kryo в конфигурации 1 × 2,7 ГГц, 3 × 2,4 ГГц и 4 × 1,9 ГГц. В состав чипа входят графический блок Adreno 643 и узел Hexagon 770 с ИИ-ускорителем, обеспечивающим производительность до 12 TOPS. 
Источник изображения: Particle Одноплатный компьютер располагает 4 Гбайт оперативной памяти и флеш-накопителем UFS вместимостью 64 Гбайт. В оснащение входят адаптеры Wi-Fi 6E и Bluetooth 5.2, а также сотовый модем 5G. Реализованы интерфейсы USB Type-C 3.1 (DisplayPort), PCIe 3.0 (2 линии), DSI (4 линии), 2 × CSI (4 линии). Питание возможно через разъём USB Type-C или от литий-ионного аккумулятора. Говорится о совместимости с различными датчиками камер (например, IMX519, OV13850) с разрешением до 25 Мп. 
Источник изображения: Particle Новинка располагает 40-контактной колодкой GPIO, совместимой с Raspberry Pi. Допускается применение дополнительных плат Raspberry Pi HAT, расширяющих функциональность. Кроме того, можно подключить USB-C-модуль с коннекторами USB Type-A, портом 1GbEи разъёмом HDMI. Tachyon поставляется с Ubuntu 24.04, но также упомянута совместимость с Yocto Linux, Android 13 и Windows 11. На платформе Kickstarter проект Tachyon по состоянию на 1 августа 2024 года привлёк почти $130 тыс., а до окончания сбора средств остаётся приблизительно месяц. Поставки новинки планируется начать в январе 2025-го.
13.03.2024 [22:40], Алексей Степин
Больше флопс за те же ватты: Cerebras представила царь-ускоритель WSE-3 и подружилась с QualcommКомпания Cerebras Systems, известная своими разработками в области сверхбольших ИИ-процессоров, рассказала о третьем поколении чипов Wafer Scale Engine. В своё время компания произвела фурор, представив процессор, занимающий всю площадь кремниевой пластины (46225 мм2). В первом поколении WSE речь шла о 1,2 трлн транзисторов при 400 тыс. ядер и 18 Гбайт сверхбыстрой памяти. WSE-2 состоял из 2,6 трлн транзисторов, имел 850 тыс. ядер и 40 Гбайт интегрированной памяти. В WSE-3 разработчики перешли на использование 5-нм техпроцесса TSMC, что позволило разместить на пластине такого же размера уже 4 трлн транзисторов, составляющих 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность набортной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. 
Источник изображений: Cerebras Казалось бы, выигрыш в количестве ядер по сравнению с WSE-2 не так уж велик, однако на этот раз Cerebras сделала упор на архитектуру. Если верить заявлениям разработчиков, WSE-3 практически вдвое быстрее WSE-2 при сопоставимом уровне энергопотребления (15 кВт) и той же цене: 125 Пфлопс против 75 Пфлопс в разреженных FP16-вычислениях. WSE-3 в 62 раза быстрее NVIDIA H100, хотя и сам чип WSE-3 в 57 раз больше. 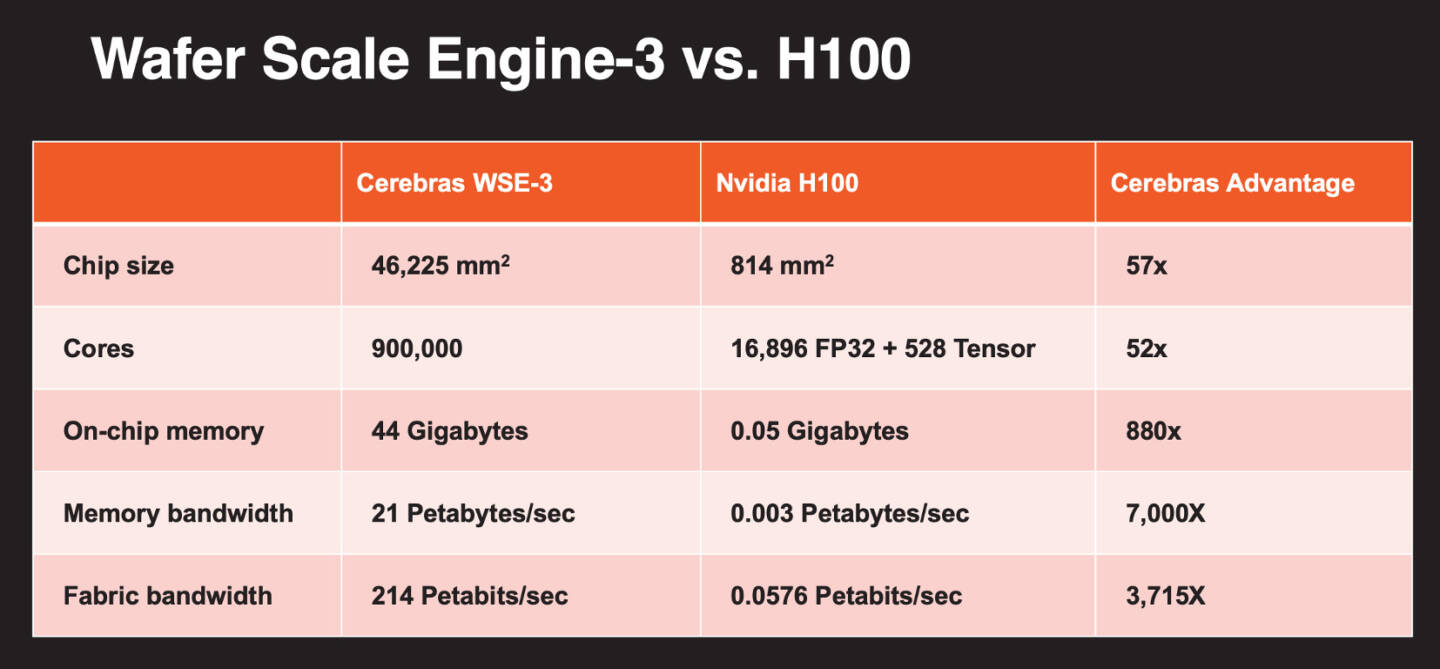 WSE-3 по-прежнему требует специфического окружения. Он станет сердцем новой системы CS-3 (23 кВт), содержащей всю необходимую сопутствующую инфраструктуру, включая СЖО, подсистемы питания, а также сетевого интерконнекта Ethernet. Последний не изменился и состоит из 12 каналов со скоростью 100 Гбит/с. Для подготовки «сырых» данных по-прежнему будет использоваться внешний суперсервер. А для их хранения будут использоваться узлы MemoryX ёмкостью до 1200 Тбайт (1,2 Пбайт). 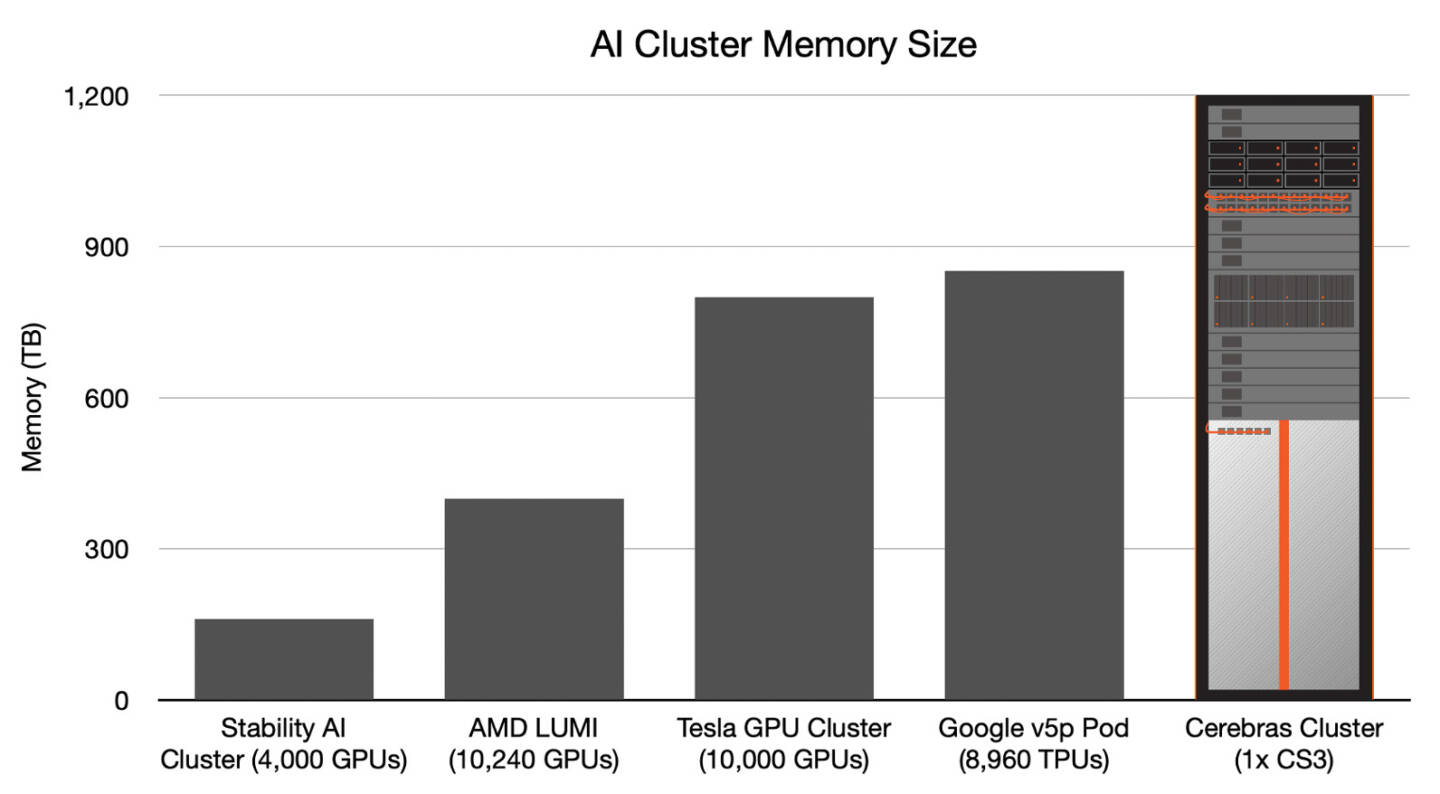 Главной задачей CS-3 станет «натаскивание» сверхбольших языковых моделей, в 10 раз превышающих по количеству параметров GPT-4 и Google Gemini. Cerebras говорит о 24 трлн параметров, причём без необходимости различных ухищрений для эффективного распараллеливания процесса обучения, что требуется в случае с GPU-кластерами. По словам компании, для обучения Megatron 175B на таких кластерах требуется 20 тыс. строка кода Python/C++/CUDA, а в случае WSE-3 потребуется лишь 565 строк на Python.  CS-3 поддерживает масштабирование вплоть до 2048 систем. Такая конфигурация вкупе с MemoryX сможет обучить модель типа Llama 70B всего за день. Первый суперкомпьютер на базе CS-3 — 8-Эфлопс Condor Galaxy 3 — будет скромнее и получит всего 64 стойки CS-3, которые разместятся в Далласе (США). В совокупности с уже имеющимися кластерами на базе CS-1 и CS-2 вычислительная мощность систем Cerebras должна достигнуть 16 Эфлопс. В сотрудничестве c группой G42 запланировано создание ещё шести систем CS-3, что в сумме позволит довести производительность до 64 Эфлопс.  Condor Galaxy 3 будет отличаться от предшественников ещё одним нововведением: в рамках сотрудничества с Qualcomm Cerebras установит в новом кластере существенное число инференс-ускорителей Qualcomm Cloud AI100 Ultra. Каждый такой ускоритель имеет 64 ядра, 128 Гбайт памяти LPDDR4x, потребляет 140 Вт и развивает 870 Топс на INT8-операциях. Причём програмнный стек полностью интегрирован, что позволит в один клик запустить обученные WSE-3 модели на ускорителях Qualcomm. 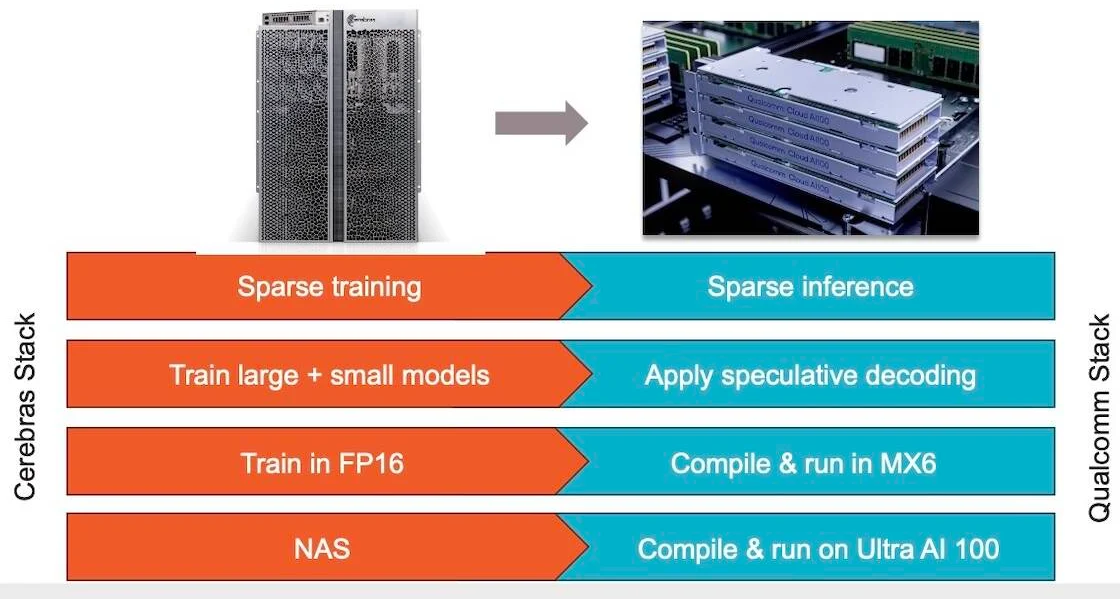 Сотрудничество Cerebras и Qualcomm носит официальный характер, его целью является оптимизация ИИ-моделей для запуска на AI100 Ultra с учетом различных продвинутых техник, таких как разреженные вычисления, спекулятивное исполнение (сочетание малых LLM для получения быстрого результата с проверкой большой LLM), использование «сжатого» формата MxFP6 для весов и других. Благодаря мощностям, предоставляемым WSE-3, цикл разработки, оптимизации и тестирования таких моделей удастся существенно ускорить, что в итоге должно обеспечить десятикратное улучшение удельной производительности новых решений.
01.04.2022 [21:41], Владимир Мироненко
Meta✴ назвала ИИ-чипы Qualcomm Cloud AI 100 наиболее эффективными, но отказалась от них из-за проблем с ПОQualcomm, крупнейший в мире поставщик процессоров для мобильных устройств, заявил в 2019 году о намерении использовать свои наработки в области повышения энергоэффективности микросхем для выхода на быстрорастущий рынок чипов искусственного интеллекта, используемых в центрах обработки данных. Согласно данным The Information, чипмейкер пытался заинтересовать Meta✴ (Facebook✴) в использовании своего первого серверного ИИ-ускорителя Qualcomm Cloud AI 100. Осенью 2020 года Meta✴ сравнила его с рядом альтернатив, включая ускорители, которые она уже использует, и специализированный ИИ-чип собственной разработки. По словам источников The Information, чип Qualcomm показал лучшую производительность в пересчёте на Ватт, что позволило бы значительно снизить операционные расходы Meta✴, чьи дата-центры обслуживают миллиарды пользователей. На масштабах в десятки тысяч серверов даже небольшое увеличение энергоэффективности приводит к экономии значительных средств. 
Источник: Qualcomm Однако энергоэффективность — это далеко не единственный фактор. Как утверждают источники The Information, весной прошлого года Meta✴ решила отказаться от использования чипа Qualcomm. По их словам, Meta✴ задалась вопросом, достаточно ли проработано программное обеспечение Qualcomm для того, чтобы можно было добиться максимальной производительности и будущих задачах компании. После оценки этого аспекта, Meta✴ отказалась от массового внедрения Cloud AI 100. Наиболее полный спектр программно-аппаратных решений для ИИ-нагрузок сейчас предлагает NVIDIA, однако крупные гиперскейлеры обращаются к собственными разработкам. Так, у Google есть уже четвёртое поколение TPU. Amazon в конце прошлого года вместе с анонсом третьего поколения собственных CPU Graviton3 представила и ускорители Trainium для обучения ИИ-моделей, которые дополняют уже имеющиеся чипы Inferentia. У Alibaba тоже есть связка из собственных процессора Yitian 710 и ИИ-ускорителя Hanguang 800.
13.01.2021 [19:03], Игорь Осколков
Qualcomm поглощает Nuvia, разработчика серверных Arm-процессоровQualcomm Incorporated объявила, что её дочерняя компания Qualcomm Technologies, Inc. заключила окончательное соглашение о приобретении NUVIA примерно за $1,4 млрд. Решения компании должны дополнить экосистему Snapdragon, включающую GPU, ИИ-движки, DSP и мультимедийные ускорители. Сделка ждёт одобрения со стороны регуляторов. Любопытно, что Qualcomm говорит об использовании решений NUVIA во флагманских смартфонах, ноутбуках следующего поколения, системах автопилотирования и приборных панелях авто, а также для сетевой инфраструктуры и подключённых устройств. Однако NUVIA разрабатывала SoC Orion c Arm-процессором Phoenix собственного дизайна, которая ориентирована на совершенно другой сегмент — на облачных провайдеров и гиперскейлеров. Компания обещала, что её чипы будут быстрее и энергоэффективнее AMD EPYC и Intel Xeon. Осенью она получила дополнительные $240 млн для производства первых чипов. 
Источник изображений: NUVIA У двух крупных игроков, Qualcomm и Broadcom, с серверными Arm-процессорами не заладилось. Первая забросила Centriq, а наследие проекта Vulcan второй в результате череды слияний и поглощений оказалось в руках Marvell, которая этими же руками проект, судя по всему, и похоронила. Так что на этом рынке к концу 2020 года осталось только два заметных игрока: Ampere, уже представившая свои чипы (очень неплохие, надо сказать), и подающие надежды NUVIA. Из альтернатив остаются Amazon Graviton2, который доступен только в облаке AWS, и Kunpeng от Huawei, которая находится под санкциями США и будущее её несколько туманно. Qualcomm, судя по сегодняшнему релизу, пока не очень заинтересована в развитии серверных Arm-процессоров. Вероятно, она надеется, что NUVIA поможет ей догнать Apple — Qualcomm традиционно отставала от последней в выводе на рынок SoC на базе новых архитектур Arm. Среди основателей NUVIA числится Джерард Уильямс III (Gerard Williams III), который почти десять лет руководил разработкой Arm-чипов в Apple, был научным сотрудником Arm и ведущим дизайнером Texas Instruments. В конце 2019 года Apple подала к нему иск. Двое других основателей NUVIA имеют не менее солидный послужной список: Ману Гулати (Manu Gulati) и Джон Бруно (John Bruno) в разное время работали в AMD, Apple и Google, в том числе в должности архитектора. К компании также присоединились бывший вице-президент Intel по маркетингу Джон Карвилл (Jon Carvill), работавший в Facebook✴, Qualcomm, Globalfoundries, AMD и ATI, а также Энтони Скарпино (Anthony Scarpino), проработавший 24 года в ATI и AMD. |
|

