Материалы по тегу: nvidia
|
21.03.2024 [23:54], Владимир Мироненко
В Google Cloud появятся ускорители NVIDIA Grace BlackwellGoogle Cloud и NVIDIA объявили о расширении партнёрства, в рамках которого новая ИИ-платформа NVIDIA Grace Blackwell и NVIDIA DGX Cloud на её основе появятся в Google Cloud Platform, а клиентам станут доступны инференс-микросервисы NVIDIA NIM. Также было сказано об общедоступности DGX Cloud на базе NVIDIA H100. 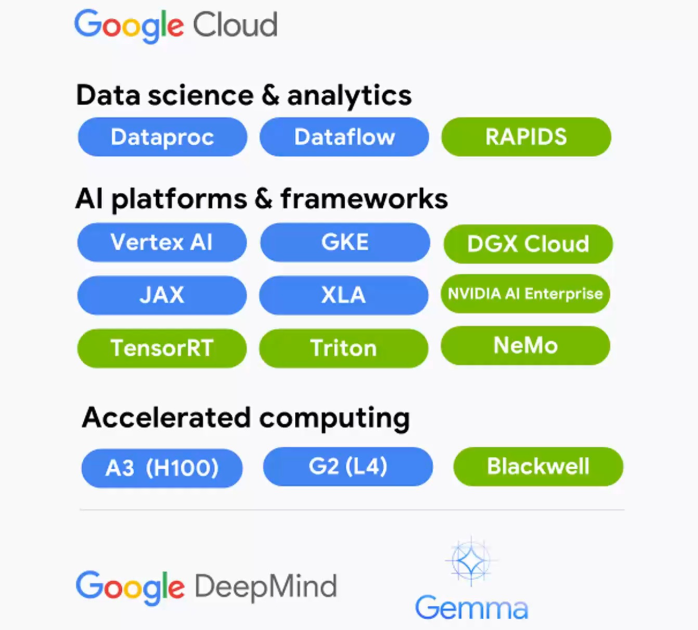
Источник изображения: NVIDIA Среди ключевых нововведений отмечены следующие:
21.03.2024 [22:21], Сергей Карасёв
Eviden создаст для Дании ИИ-суперкомпьютер Gefion на базе NVIDIA DGX SuperPOD H100Компания Eviden, дочерняя структура Atos, объявила о заключении соглашения с Датским центром инноваций в области искусственного интеллекта (Danish Centre for AI Innovation) на создание передового суперкомпьютера для решения ИИ-задач. Вычислительный комплекс под названием Gefion, как ожидается, заработает до конца текущего года. Как сообщается, в основу Gefion ляжет платформа NVIDIA DGX SuperPOD. Конфигурация включает 191 систему NVIDIA DGX H100, а общее количество ускорителей NVIDIA H100 составит 1528 штук. Говорится о применении интерконнекта NVIDIA Quantum-2 InfiniBand. В состав суперкомпьютера также войдут 382 процессора Intel Xeon Platinum 8480C поколения Sapphire Rapids. Эти чипы насчитывают 56 ядер (112 потоков), работающих на частоте 2,0/3,8 ГГц. Для подсистемы хранения выбрано решение DataDirect Networks (DDN). Ожидаемая ИИ-производительность Gefion на операциях FP8 составит около 6 Эфлопс. В рамках проекта Eviden отвечает за доставку компонентов комплекса, монтаж и пуско-наладочные работы. Система разместится в дата-центре Digital Realty. Её питание будет на 100 % обеспечиваться за счёт энергии из возобновляемых источников. 
Источник изображения: NVIDIA Датский центр инноваций в области ИИ принадлежит фонду Novo Nordisk Foundation и Экспортно-инвестиционному фонду Дании. При этом Novo Nordisk Foundation, основанный в Дании ещё в 1924 году, представляет собой корпоративный фонд с филантропическими целями. Его видение заключается в улучшении здоровья людей, повышении устойчивости общества и планеты. Отмечается, что Novo Nordisk Foundation обеспечит финансирование центра в размере примерно 600 млн датских крон (около $87,5 млн), а Экспортно-инвестиционный фонд — 100 млн датских крон ($14,6 млн).
21.03.2024 [22:16], Сергей Карасёв
HP оснастит рабочие станции ускорителями NVIDIA A800, предназначавшимися для КитаяКомпания HP, по сообщению ресурса Tom's Hardware, готовит к выпуску новые рабочие станции серии Z, рассчитанные на приложения ИИ. В оснащение этих компьютеров войдут ускорители NVIDIA A800, которые изначально создавались для Китая в качестве «урезанной» версии А100 (40 Гбайт). Предполагалось, что операторы дата-центров в КНР смогут закупать решения A800, которые проектировались специально с учётом санкционных ограничений со стороны США. Стоимость этих ускорителей, по имеющимся данным, на начальном этапе составляла $14,5 тыс. Однако в связи с введением новых экспортных ограничений США на поставку в Китай современных технологий отгрузки A800 в Поднебесную стали невозможны. Вместо них NVIDIA подготовила ускорители H20, L20 и L2. А выпущенные A800 пришлось перераспределять в другие регионы. Однако из-за того, что у A800 пропускная способность интерконнекта NVLink в угоду санкциям снижена до 400 Гбайт/с против 600 Гбайт/с у А100, «урезанные» ускорители оказались не слишком популярны среди заказчиков. В такой ситуации установка A800 в рабочие станции НР поможет NVIDIA реализовать имеющиеся запасы продукции. 
Источник изображения: NVIDIA Характеристики систем НР серии Z пока не раскрываются. Высказываются предположения, что в их основу лягут либо процессоры Intel Xeon Emerald Rapids (или, возможно, Xeon Sapphire Rapids), либо чипы AMD Ryzen Threadripper Pro 7000 WX. Сама NVIDIA ещё в ноябре 2023 года фактически анонсировала A800 для западных рынков, заявив, что это «идеальная платформа для рабочих станций для ИИ, анализа данных и высокопроизводительных вычислений». В числе партнёров NVIDIA, которые занимаются продвижением A800, значатся PNY, Colfax International, ASK и Elsa.
21.03.2024 [00:51], Владимир Мироненко
Облачный ИИ-суперкомпьютер AWS Project Ceiba получит 21 тыс. суперчипов NVIDIA GB200
aws
b100
dgx cloud
gb200
gtc 2024
hardware
nvidia
ии
инференс
информационная безопасность
облако
суперкомпьютер
Amazon Web Services (AWS) и NVIDIA объявили о расширении сотрудничества, в рамках которого ускорители GB200 и B100 вскоре появятся в облаке AWS. Кроме того, компании объявили об интеграции Amazon SageMaker с NVIDIA NIM для предоставления клиентам более быстрого и дешёвого инференса, о появлении в AWS HealthOmics новых базовых моделей NVIDIA BioNeMo, а также о поддержке AWS обновлённой платформы NVIDIA AI Enterprise. Сотрудничество двух компаний позволило объединить в единую инфраструктуру их новейшие технологии, в том числе многоузловые системы на базе чипов NVIDIA Blackwell, ПО для ИИ, AWS Nitro, сервис управления ключами AWS Key Management Service (AWS KMS), сетевые адаптеры Elastic Fabric (EFA) и кластеры EC2 UltraCluster. Предложенная инфраструктура и инструменты позволят клиентам создавать и запускать LLM с несколькими триллионами параметров быстрее, в больших масштабах и с меньшими затратами, чем позволяли EC2-инстансы с ускорителями NVIDIA прошлого поколения. AWS предложит кластеры EC2 UltraClusters из суперускорителей GB200 NVL72, которые позволят объединить тысячи чипов GB200. GB200 будут доступны и в составе инстансов NVIDIA DGX Cloud. AWS также предложит EC2 UltraClusters с ускорителями B100. Amazon отмечает, что сочетание AWS Nitro и NVIDIA GB200 ещё больше повысит защиту ИИ-моделей: GB200 обеспечивает шифрование NVLink, EFA шифрует данные при передаче между узлами кластера, а KMS позволяет централизованно управлять ключами шифрования. 
Источник изображения: NVIDIA Аппаратный гипервизор AWS Nitro, как и прежде, разгружает CPU узлов, беря на себя обработку IO-операций, а также защищает код и данные во время работы с ними. Эта возможность, доступная только в сервисах AWS, была проверена и подтверждена NCC Group. Инстансы с GB200 поддерживают анклавы AWS Nitro Enclaves, что позволяет напрямую взаимодействовать с ускорителем и данными в изолированной и защищённой среде, доступа к которой нет даже у сотрудников Amazon. 
Источник изображения: NVIDIA Чипы Blackwell будут использоваться в обновлённом облачном суперкомпьютере AWS Project Ceiba, который будет использоваться NVIDIA для исследований и разработок в области LLM, генерация изображений/видео/3D, моделирования, цифровой биологии, робототехники, беспилотных авто, предсказания климата и т.д. Эта первая в своём роде машина на базе GB200 NVL72 будет состоять из 20 736 суперчипов GB200, причём каждый из них получит 800-Гбит/с EFA-подключение. Пиковая FP8-производительность системы составит 414 Эфлопс.
20.03.2024 [15:25], Руслан Авдеев
BNY Mellon стал первым транснациональным банком, внедрившим ИИ-суперкомпьютер NVIDIA на базе DGX SuperPOD H100Банк Bank of New York Mellon Corporation (BNY Mellon) стал первой структурой подобного профиля и масштаба, приступившей к внедрению собственного ИИ-суперкомпьютера на основе систем NVIDIA. Банку получил кластер DGX SuperPOD из нескольких десятков систем DGX H100, объединённых интерконнектом NVIDIA InfiniBand. Основанный в 2007 году в результате слияния The Bank of New York и Mellon Financial Corporation банк намерен использовать новый суперкомпьютер вкупе с NVIDIA AI Enterprise для создания и внедрения ИИ-приложений и управления ИИ-инфраструктурой своего бизнеса. Банк уже использует более 20 ИИ-решений, в том числе для прогнозирования в сфере депозитов, автоматизации платежей, предиктивной торговой аналитики и т.д. Всего же компания нашла более 600 вариантов использования ИИ в своей банковской системе. Как заявляют в руководстве BNY Mellon, внедрение ИИ-суперкомпьютера увеличит возможности по обработке данных и запуску ИИ-проектов, помогающих управлять активами клиентов и обеспечивать их защиту. 
Источник изображения: NVIDIA Компания пока не сообщила, где будет расположен суперкомпьютер и его полные характеристики. Ранее банку принадлежал дата-центр в Нью-Джерси, также он управлял IT-объектами в Пенсильвании и Теннесси.
20.03.2024 [02:17], Владимир Мироненко
Oracle и NVIDIA предложат суверенные ИИ-фабрики
dgx cloud
gb200
gtc 2024
nvidia
oracle
oracle cloud infrastructure
software
ии
конфиденциальность
облако
частное облако
Oracle и NVIDIA объявили о расширении сотрудничества для предоставления суверенного ИИ клиентам по всему миру — программно-аппаратные решения обеих компаний позволят правительствам и предприятиями формировать ИИ-фабрики, говорится в пресс-релизе. Облачные сервисы Oracle используют ряд платформ NVIDIA, включая аппаратную инфраструктуру и программную платформу NVIDIA AI Enterprise, в том числе недавно анонсированные микросервисы вывода NVIDIA NIM. Такие ИИ-фабрики позволят развернуть облачные сервисы, работающие локально и размещённые в безопасных кампусах на территории страны или организации. Сочетание полнофункциональной ИИ-платформы NVIDIA с корпоративным ИИ-инструментами Oracle, которые можно развернуть в выделенном регионе OCI, позволит получить современное ИИ-решение с повышенным уровенем контроля, защиты и безопасности. По словам Oracle, компания является единственным гиперскейлером, способным предоставлять ИИ-решения и полноценные облачные услуги локально и в любом месте. Oracle также задействует чипы NVIDIA Blackwell (GB200 и B200) в OCI Supercluster и OCI Compute. OCI Supercluster станет значительно быстрее благодаря новым bare metal-инстансам, RDMA-сети со сверхмалой задержкой и высокопроизводительному хранилищу. В OCI появятся и сервисы NVIDIA NIM и CUDA-X, а также NVIDIA NeMo Retriever. 
Источник изображения: NVIDIA Наконец, в DGX Cloud on OCI станут доступны инстансы на базе суперускорителей GB200 NVL72 для работы с LLM с триллионами параметров. Полный кластер DGX Cloud будет включать более 20 тыс. ускорителей GB200, интерконнект NVLink 5 и сеть NVIDIA InfiniBand XDR.
20.03.2024 [01:00], Владимир Мироненко
Microsoft и NVIDIA объявили об интеграции своих решений для ускорения внедрения генеративного ИИ на предприятияхMicrosoft и NVIDIA объявили о расширении давнего сотрудничество с целью внедрения новейших технологий генеративного ИИ NVIDIA и Omniverse в Microsoft Azure и ИИ-сервисы Azure, Microsoft Fabric и Microsoft 365. Сатья Наделла (Satya Nadella), председатель и гендиректор Microsoft заявил, что все новые инициативы, от внедрения ускорителей GB200 Grace Blackwell в Azure до новой интеграции между DGX Cloud и Microsoft Fabric, обеспечат клиентам наиболее полные платформы и инструменты на всех уровнях стека Copilot, от «кремния» до ПО, и позволят создать им новые прорывные ИИ-приложения. Microsoft станет одной из первых, кто развернёт в облаке ускорители GB200 и вкупе с InfiniBand-интерконнектом на базе Quantum-X800, предоставив новейшие базовые модели с триллионом параметров. Заодно компания объявила о доступности инстансов Azure NC H100 v5 на базе H100 NVL. Серия NC среднего уровня, предназначенная для обучения и инференса, предлагает клиентам два класса виртуальных машин с одним или двумя PCIe-ускорителями H100 (94 Гбайт). 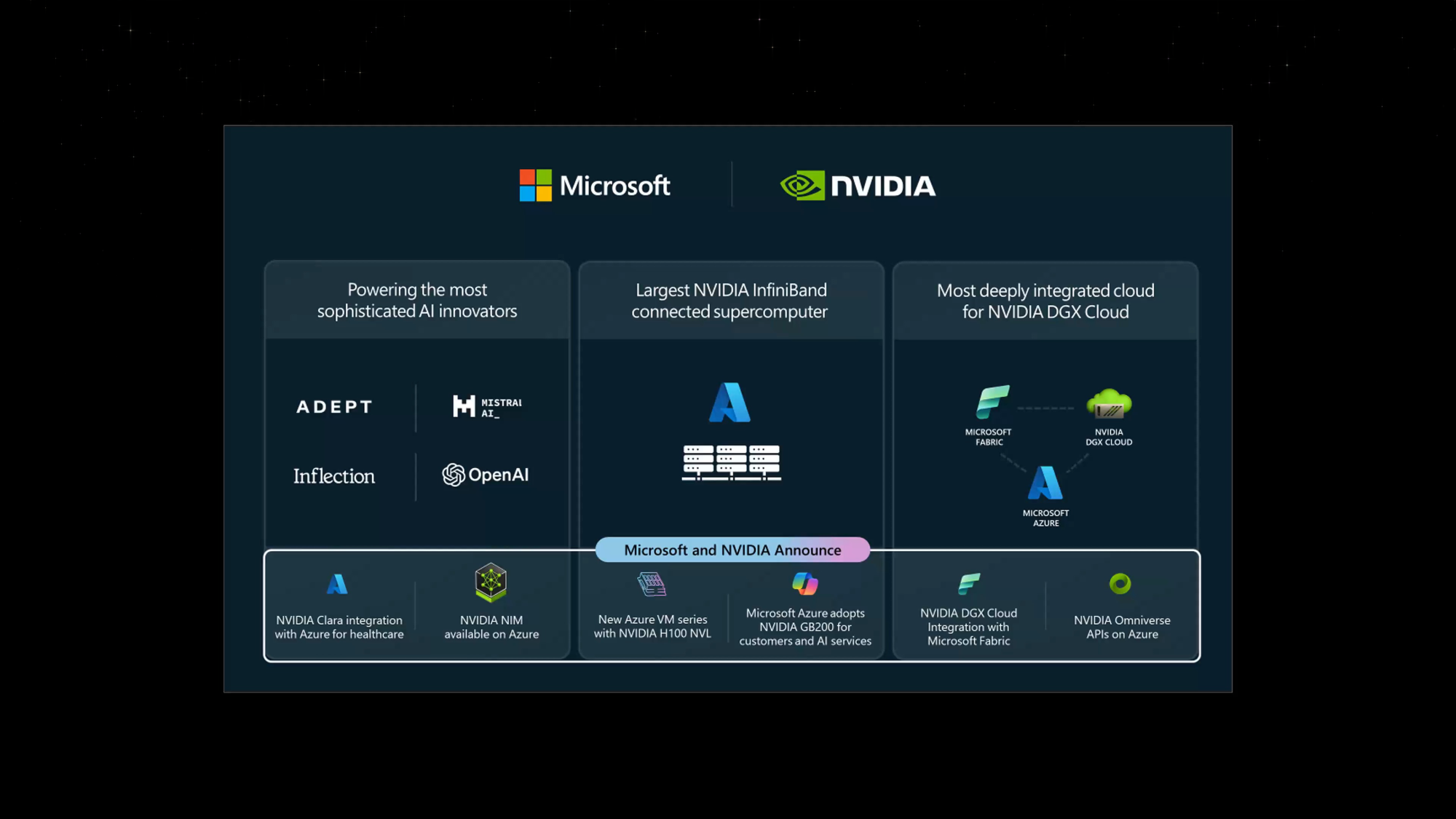
Изображение: NVIDIA Кроме того, компания предложит комплексный набор решений на базе Microsoft Azure, NVIDIA DGX Cloud и NVIDIA Clara поставщикам медицинских сервисов, фармацевтическим и биотехнологическим компаниям, а также разработчикам медицинского оборудования. А индустриальные компании получат в своё распоряжение API NVIDIA Omniverse Cloud. Наконеw, в Azure AI и Azure Marketplace станут доступны микросервисы инференса NVIDIA NIM.
19.03.2024 [22:37], Сергей Карасёв
HPE выпустила локальный суперкомпьютер для генеративного ИИКомпания HPE сообщила о доступности модульной суперкомпьютерной системы для генеративного ИИ. Платформа, предназначенная для локального размещения в инфраструктуре заказчика, построена на суперчипах NVIDIA GH200 Grace Hopper. О подготовке системы HPE заявила в ноябре 2023 года. В её основу положены серверы ProLiant DL380a Gen11. В общей сложности могут быть задействованы до 168 суперчипов GH200. Кроме того, применяются Ethernet-платформа NVIDIA Spectrum-X и DPU NVIDIA BlueField-3. Решение дополнено платформой машинного обучения и аналитическим программным обеспечением HPE, платформой для работы с ИИ-приложениями NVIDIA AI Enterprise 5.0, которая включает микросервисы на базе загружаемых программных контейнеров, а также сервисом NVIDIA NeMo Retriever и другими библиотеками для обработки данных и ИИ. Суперкомпьютерная система ориентирована на крупные предприятия, исследовательские институты и правительственные учреждения. 
Источник изображения: HPE Утверждается, что в конфигурации с 16 узлами комплекс может оптимизировать модель Llama 2 с 70 млрд параметров всего за 6 минут. Высокая производительность позволяет клиентам повысить продуктивность бизнеса с помощью приложений генеративного ИИ, таких как виртуальные помощники, умные чат-боты и средства корпоративного поиска. При этом софт HPE Machine Learning Inference позволит предприятиям быстро и безопасно развертывать масштабные модели машинного обучения. Компания HPE также сообщила о намерении выпустить продукты следующего поколения, использующие аппаратные решения NVIDIA на базе архитектуры Blackwell. Речь идёт о гибридных суперчипах GB200, а также изделиях HGX B200 и HGXB100. Подробности о новых системах будут раскрыты позднее.
19.03.2024 [22:31], Сергей Карасёв
ASRock Rack представила серверы с поддержкой ускорителей NVIDIA Blackwell и HopperКомпания ASRock Rack на конференции GTC 2024 анонсировала свои самые мощные серверы для обучения ИИ-моделей — системы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200. Кроме того, дебютировали решения с поддержкой новейших ускорителей NVIDIA Blackwell. Серверы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200 выполнены в форм-факторе 6U. Они рассчитаны на установку восьми ускорителей NVIDIA H100 и H200 соответственно. Возможно использование двух процессоров Intel Xeon Sapphire Rapids или Xeon Emerald Rapids с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5-5600, 12 отсеков для SFF-накопителей NVMe с интерфейсом PCIe 5.0 x4 (четыре также имеют поддержку SATA), два коннектора М.2 2280/22110 (PCIe 3.0 x4), восемь слотов HHHL PCIe5.0 x16 и пять слотов FHHL PCIe5.0 x16. Питание обеспечивают восемь блоков мощностью 3000 Вт с сертификатом 80 PLUS Platinum/Titanium. ASRock Rack также представила двухсокетный barebone-сервер 4UMGX с поддержкой восьми ускорителей NVIDIA H100 NVL или H200 в форм-факторе 4U. Система может комплектоваться шестью DPU NVIDIA BlueField-3 или шестью сетевыми адаптерами NVIDIA ConnectX-7. Модель 4UMGX также поддерживает ускорители NVIDIA Blackwell. В основу сервера положена модульная архитектура NVIDIA MGX, предназначенная для создания ИИ-систем на базе CPU, GPU и DPU. 
Источник изображений: ASRock Rack Кроме того, дебютировали двухсокетные 4U серверы 4U8G-EGS2, 4U10G-EGS2, 4U8G-GENOA2 и 4U10G-GENOA2. Первые два рассчитаны на чипы Intel Xeon Sapphire Rapids или Xeon Emerald Rapids, два других — на процессоры AMD EPYC 9004 (Genoa). Они могут оснащаться ускорителями NVIDIA H100 NVL и H200 NVL, а в перспективе — NVIDIA Blackwell. Устройства 4U8G поддерживают восемь двухслотовых карт FHFL с интерфейсом PCIe 5.0 x16, решения 4U10G — десять. Intel-системы снабжены 32 слотами для модулей памяти DDR5, AMD-модели — 24-мя.  ASRock Rack также готовит суперускоритель GB200 NVL72, серверы с поддержкой конфигурации NVIDIA HGX B200 8-GPU и другие решения на основе аппаратных компонентов NVIDIA.
19.03.2024 [03:18], Владимир Мироненко
Всё своё ношу с собой: NVIDIA представила контейнеры NIM для быстрого развёртывания оптимизированных ИИ-моделейКомпания NVIDIA представила микросервис NIM, входящий в платформу NVIDIA AI Enterprise 5.0 и предназначенный для оптимизации запуска различных популярных моделей ИИ от NVIDIA и её партнёров. NVIDIA NIM позволяет развёртывать ИИ-модели в различных инфраструктурах: от локальных рабочих станций до облаков. Предварительно созданные контейнеры и Helm Chart'ы с оптимизированными моделями тщательно проверяются и тестируются на различных аппаратных платформах NVIDIA, у поставщиков облачных услуг и на дистрибутивах Kubernetes. Это обеспечивает поддержку всех сред с ускорителями NVIDIA и гарантирует, что компании смогут развёртывать свои приложения генеративного ИИ где угодно, сохраняя полный контроль над своими приложениями и данными, которые они обрабатывают. Разработчики могут получить доступ к моделям посредством стандартизированных API, что упрощает разработку и обновление приложений. 
Источник изображений: NVIDIA NIM также может использоваться для оптимизации исполнения специализированных решений, поскольку не только использует NVIDIA CUDA, но и предлагает адаптацию для различных областей, таких как большие языковые модели (LLM), визуальные модели (VLM), а также модели речи, изображений, видео, 3D, разработки лекарств, медицинской визуализации и т.д. NIM использует оптимизированные механизмы инференса для каждой модели и конфигурации оборудования, обеспечивая наилучшую задержку и пропускную способность и позволяя более просто и быстро масштабироваться по мере роста нагрузок. 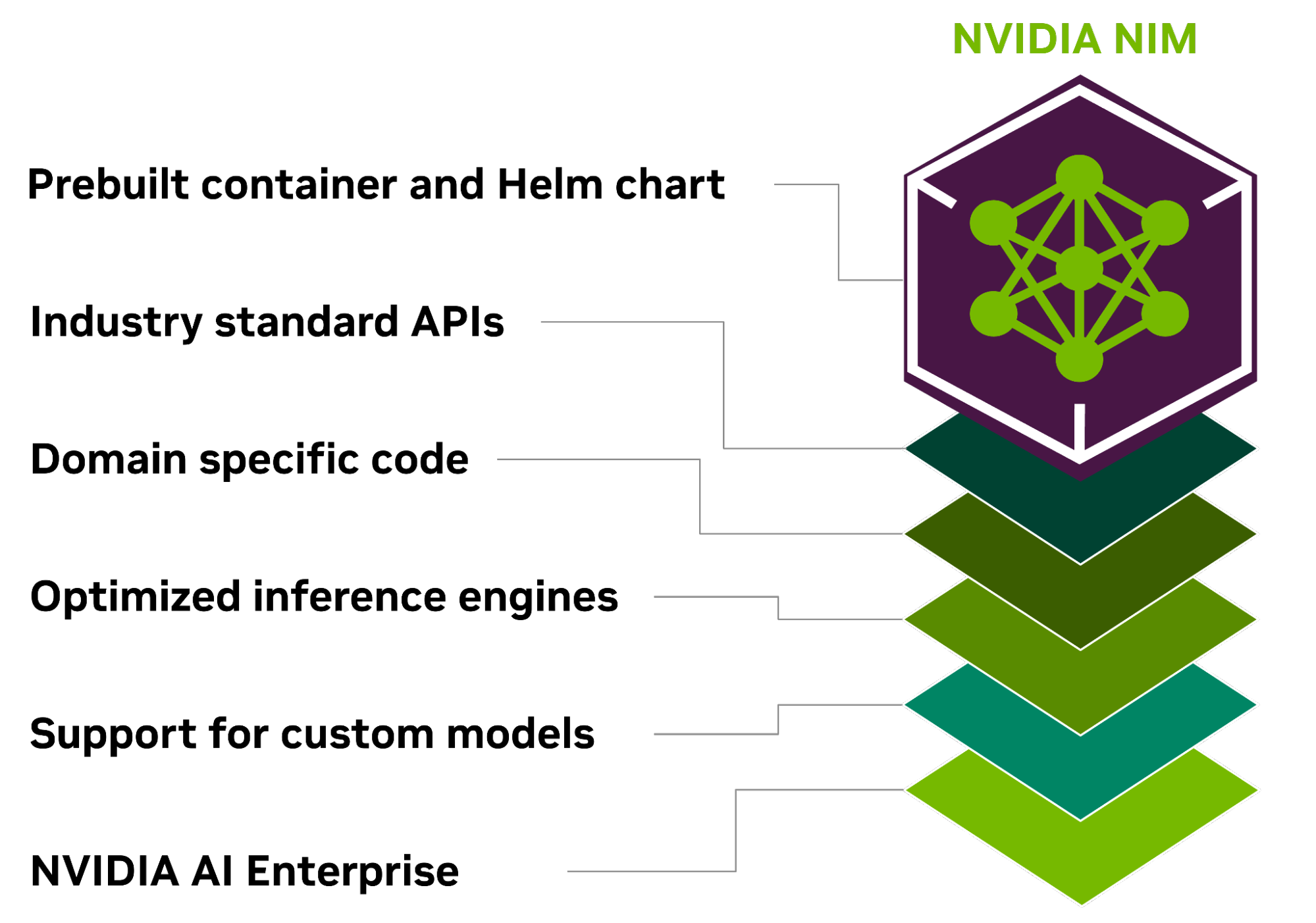 В то же время NIM позволяет дообучить и настроить модели на собственных данных, поскольку можно не только воспользоваться облачными API NVIDIA для доступа к готовым моделями, но и самостоятельно развернуть NIM в Kubernetes-средах у крупных облачных провайдеров или локально, что сокращает время разработки, сложность и стоимость подобных проектов и позволяет интегрировать NIM в существующие приложения без необходимости глубокой настройки или специальных знаний. |
|

