Материалы по тегу: nvidia
|
10.06.2025 [18:55], Руслан Авдеев
Германия получит суперкомпьютер Blue Lion на новейших ускорителях NVIDIA Vera RubinНемецкий Суперкомпьютерный центр Лейбница (Leibniz Supercomputing Centre, LRZ), входящий в HPC-группу Gauss Centre for Supercomputing, получит в своё распоряжение суперкомпьютер Blue Lion на базе ускорителей Vera Rubin. Ожидается, что он будет приблизительно в 30 раз производительнее своего предшественника — SuperMUC-NG. Ожидается, что платформа NVIDIA нового поколения кардинально изменит подход к научным исследованиям, сообщается в блоге компании. Это второй анонс машины на базе Vera Rubin после американского суперкомпьютера Doudna. По словам NVIDIA, новая аппаратная платформа — это «слиянии симуляций, данных и ИИ в единый движок для науки с высокой пропускной способностью, низкой задержкой, когерентными вычислениями и общей памятью». Непосредственно суперкомпьютер будет использовать платформу HPE Cray нового поколения с СЖО с тёплой водой (до +40 °C) на входе и 100-% безвентиляторным дизайном. Тепло системы будет использоваться для отопления близлежащих зданий. 
Источник изображения: NVIDIA Суперкомпьютер будет использоваться для исследований в областях климата, турбулентности, физики и машинного обучения — с комбинацией классических компьютерных симуляций и современного ИИ-моделирования. Также он станет помощником для реализации международных исследовательских проектов по всей Европе. Постройка новых компьютеров имеет важное значение, поскольку речь идёт о новой вехе в развитии суперкомпьютеров, которые теперь проектируются с прицелом на работу в реальном времени. ИИ более не является простым дополнением исследованиям, а данные постоянно находятся «в движении», поэтому стоящие за этим системы приходится постоянно поддерживать в актуальном состоянии, говорит NVIDIA.
10.06.2025 [17:45], Руслан Авдеев
Великобритания потратит £1 млрд на развитие ИИ-инфраструктуру: Nscale развернёт 10 тыс. ускорителей NVIDIA, а Nebius — ещё 4 тыс.Британское правительство объявило о намерении потратить £1 млрд ($1,36 млрд) на масштабирование национальных вычислительных мощностей «в 20 раз», сообщает Datacenter Dynamics со ссылкой на премьер-министра Кира Стармера (Keir Starmer). Участвовать в развитии ИИ на острове намерены и другие компании, в том числе Nebius. Никаких деталей о том, как будут тратиться средства, не сообщалось. Ранее цель двадцатикратного прироста ставилась на 2030 год. Дополнительно Стармер пообещал оптимизировать нормативную базу для получения разрешений на строительство ЦОД в Великобритании, анонсировав «технологическую неделю» в стране вместе с главой NVIDIA Дженсеном Хуангом (Jensen Huang). По словам чиновника, это означает, что Великобритания может стать «производителем» ИИ, а не только «потребителем», в том числе страна сможет предоставлять больше ИИ-услуг в государственном секторе. Министр пообещал ускорить строительство крупных ИИ-лабораторий и дата-центров. Специальный законопроект Planning and Infrastructure Bill, упрощающий многие процедуры в этой сфере, уже ожидает рассмотрения британскими парламентариями. Он способен «изменить правила игры». 
Истчоник изображения: Benjamin Davies/unsplash.com Одновременно с докладом Стармера NVIDIA объявила, что будет инвестировать в страну и заключила сделки с облачным провайдером Nscale для внедрения 10 тыс. ускорителей Blackwell к концу 2026 года, Nebius может рассчитывать на 4 тыс. ускорителей, причём речь идёт о B300. NVIDIA — один из участников группы UK Sovereign AI Industry Forum, в число основателей которой также входят Babcock, BAE Systems, BT, National Grid и Standard Chartered. По мнению Хуанга, Великобритания находится в идеальных условиях для развития ИИ. Возможность строительства в стране мощных ИИ-суперкомпьютеров будет привлекать всё больше стартапов. Он отметил, что нация имеет богатую историю создания стартапов и добавил, что условия идеальны для «взлёта», пока не хватает лишь суверенной ИИ-инфраструктуры. В Соединённом Королевстве уже обозначили намерение превратиться в «ИИ-сверхдержаву». Правда, пока непонятно, хватит ли на это энергии.
09.06.2025 [14:02], Руслан Авдеев
Перегрев, плохое ПО и сила привычки: китайские компании не горят желанием закупать ИИ-ускорители HuaweiНесмотря на дефицит передовых ИИ-ускорителей на китайском рынке, китайская компания Huawei, выпустившая модель Ascend 910C, может столкнуться с проблемами при её продвижении. Она рассчитывала помочь китайскому бизнесу в преодолении санкций на передовые полупроводники, но перспективы нового ускорителя остаются под вопросом, сообщает The Information. Китайские гиганты вроде ByteDance, Alibaba и Tencent всё ещё не разместили крупных заказов на новые ускорители. Основная причина в том, что экосистема NVIDIA доминирует во всём мире (в частности, речь идёт о программной платформе CUDA), а решения Huawei недостаточно развиты. В результате компания продвигает продажи государственным структурам (при поддержке самих властей КНР) — это косвенно свидетельствует о сложности выхода на массовый рынок. Китайский бизнес годами инвестировал в NVIDIA CUDA для ИИ- и HPC-задач. Соответствующий инструментарий, библиотеки и сообщество разработчиков — настолько развитая экосистема, что альтернатива в лице Huawei CANN (Compute Architecture for Neural Networks) на её фоне выглядит весьма слабо. У многих компаний всё ещё хранятся огромные запасы ускорителей NVIDIA, накопленные в преддверии очередного раунда антикитайских санкций, поэтому у их владельцев нет стимула переходить на новые и незнакомые решения. Они скорее предпочтут оптимизировать программный стек, как это сделала DeepSeek, чтобы повысить утилизацию имеющегося «железа». Если бы, например, та же DeepSeek перешла на ускорители Huawei, это подтолкнуло бы к переходу и других разработчиков, но пока этого не происходит. Кроме того, некоторые компании вроде Tencent и Alibaba не желают поддерживать продукты конкурентов, что усложняет Huawei продвижение её ускорителей. 
Источник изображения: Huawei Есть и технические проблемы. Самый передовой ускоритель Huawei Ascend 910C периодически перегревается, поэтому возникла проблема доверия к продукции. Поскольку сбои во время длительного обучения модели обходятся весьма дорого. Кроме того, он не поддерживает ключевой для эффективного обучения ИИ формат FP8. Ascend 910С представляет собой сборку из двух чипов 910B. Он обеспечивает производительность на уровне 800 Тфлопс (FP16) и пропускную способность памяти 3,2 Тбайт/с, что сопоставимо с параметрами NVIDIA H100. Также Huawei представила кластер CloudMatrix 384. Наконец, проблема в собственно американских санкциях. В мае 2025 года Министерство торговли США предупредило, что использование чипов Huawei без специального разрешения может расцениваться, как нарушение экспортных ограничений — якобы в продуктах Huawei незаконно используются американские технологии. Такие ограничения особенно важны для компаний, ведущих международный бизнес — даже если они китайского происхождения. Хотя NVIDIA ограничили продажи в Китае, она по-прежнему демонстрирует рекордные показатели. По данным экспертов UBS, у компании есть перспективные проекты суммарной мощностью «десятки гигаватт» — при этом, каждый гигаватт ИИ-инфраструктуры, по заявлениям NVIDIA, приносит ей $40–50 млрд. Если взять вероятную очередь проектов на 20 ГВт с периодом реализации два-три года, то только сегмент ЦОД может обеспечить NVIDIA около $400 млрд годовой выручки. Это подчеркивает доминирующее положение компании на рынке аппаратного обеспечения для ИИ.
02.06.2025 [22:50], Руслан Авдеев
NVIDIA якобы разрабатывает для Китая «антисанкционный» ИИ-ускоритель B30 с возможностью объединения в кластерыПосле запрета США на экспорт в Китай ИИ-ускорителей H20 NVIDIA занялась разработкой альтернативного продукта на базе Blackwell. Ранее уже появилась информация о имеется модели B40 на основе видеокарты RTX Pro 6000D. Тогда же упоминалось, что компания ведёт разработку ещё одного чипа. Теперь источники The Information сообщили о модели B30, причём с возможностью объединения в кластеры. По имеющимся данным, модель будет использовать память GDDR7 и GB20x — те же, что лежат в основе игровых видеокарт серии RTX 5000. Хотя многие предполагают, что B30 получат поддержку NVLink, в потребительских продуктах последнего поколения поддержка этого интерконнекта не предусмотрена. С другой стороны, у компании теперь есть серверы на основе RTX Pro Blackwell, которые объединяют до восьми GPU посредством платы с адаптерами ConnectX-8 SuperNIC со встроенными коммутаторами PCIe 6.0 для связи между ускорителями. Аналогичная конфигурация применяется для связи систем DGX Spark. В своё время глава NVIDIA Дженсен Хуанг (Jensen Huang) прямо заявил, что возможности архитектуры Hopper в плане её ослабления исчерпаны, и компания больше не будет использовать её для выпуска ослабленных ускорителей для Китая. При этом американские власти своими санкциями специально нацелились на снижение пропускной способности памяти и интерконнектов чипов для КНР.  Хотя NVIDIA соблюдает санкционные требования, компания давно находится в оппозиции к американским регуляторам — сам Хуанг недавно раскритиковал экспортные ограничения, заявив, что те только помогают Китаю нарастить собственные компетенции в сфере ИИ. NVIDIA уже потеряла $4,6 млрд из-за запрета на экспорт H20 в Китай, а в перспективе потеряет более $15 млрд. AMD после запрета на экспорт чипов MI308 сообщила о вероятных потерях $800 млн. По словам Хуанга, США, вводя новые меры, США рискуют потерять конкурентные преимущества в сфере ИИ, если китайские конкуренты вроде Huawei будут вынуждены форсировать инновации из-за отсутствия доступа к передовому оборудованию. В результате новые китайские продукты, возможно, не только смогут конкурировать с продукцией NVIDIA, но и начнут задавать будущие мировые стандарты в сфере ИИ-полупроводников.
02.06.2025 [17:48], Сергей Карасёв
Dell построит один из первых суперкомпьютеров на базе NVIDIA Vera Rubin — Doudna для Министерства энергетики СШАМинистерство энергетики США (DOE) объявило о заключении контракта с Dell Technologies на создание нового суперкомпьютера под названием Doudna, в основу которого лягут ИИ-ускорители NVIDIA Vera Rubin. НРС-комплекс расположится в Национальной лаборатории им. Лоуренса в Беркли (Berkeley Lab) в Калифорнии (США). Система Doudna, также известная как NERSC-10, станет флагманским суперкомпьютером Национального вычислительного центра энергетических исследований США (NERSC) в составе Berkeley Lab. Комплекс назван в честь Дженнифер Даудны (Jennifer Doudna) — американского биохимика и генетика, исследователя геномики, одной из создателей технологии редактирования генома CRISPR-Cas9. Ожидается, что Doudna по производительности в «научных результатах» превзойдёт своего предшественника — суперкомпьютер Perlmutter — более чем в 10 раз. При этом энергопотребление возрастёт только в 2–3 раза. Теоретически, как отмечает The Register, система должна демонстрировать FP64-быстродействие до 790 Пфлопс при потреблении 5,8–8,7 МВт. Однако на практике, скорее всего, показатели будут иными. Дело в том, что детальная информация о производительности суперчипов Vera Rubin пока не раскрывается. Но в случае NVIDIA Blackwell Ultra, например, быстродействие на операциях двойной точности, которое считается необходимым для научных вычислений, было принесено в жертву широкому использованию форматов с 4-бит точностью, адаптированных для рабочих нагрузок ИИ. Так, у GB300 NVL72 FP64-производительность составляет 100 Тфлопс, а у его предшественника GB200 NVL72 — 2880 Тфлопс. Эта тенденция может сохраниться и в случае Vera Rubin. AMD, по слухам, готовит два варианта ускорителей Instinct: MI430X с поддержкой FP64 и MI450X без таковой. 
Источник изображения: Berkeley Lab Джек Донгарра (Jack Dongarra), один из крупнейших в мире специалистов области HPC и один создателей рейтинга самых мощных суперкомпьютеров в мире TOP500, предупреждает, что ИИ не сможет решить всех проблем научного сообщества, а отказ американских производителей от выпуска необходимых учёным чипов грозит большими проблемами уже всей стране. «Именно поэтому NVIDIA заявляет о более чем 10-кратном приросте "научного результата", а не производительности», — подчёркивает The Register. Таким образом, машина Doudna задумывается как нечто вроде «швейцарского армейского ножа», способного выполнять различные рабочие нагрузки, охватывающие и HPC-, и ИИ-задачи. Основой послужат системы Dell Integrated Rack Scalable Systems и серверы PowerEdge с ИИ-ускорителями NVIDIA Vera Rubin. Говорится об использовании платформы NVIDIA Quantum-X800 InfiniBand. Сообщается, что суперкомпьютер будут использовать примерно 11 тыс. специалистов и ученых, которые ведут исследования в таких областях, как термоядерная энергетика, материаловедение, разработка лекарственных препаратов, астрономия и многое другое. Машина заработает в 2026 году.
30.05.2025 [10:19], Руслан Авдеев
Япония планирует крупные закупки ИИ-чипов для сокращения торгового дефицита с СШАВ преддверии переговоров Японии и США относительно американских пошлин, японские власти предложили закупить в Соединённых Штатах полупроводники на несколько миллиардов долларов. Предполагается, что это поможет «задобрить» США и сократить торговый дефицит с Японией, сообщает Digitimes. Источники в японском правительстве сообщили, что в ходе последних обсуждений тарифной политики Япония предложила планы закупок полупроводников, основным поставщиком в которых рассматривается американская NVIDIA — речь идёт о «многомиллиардных» закупках. Японское правительство намерено поощрять и субсидировать телекоммуникационные и IT-компании, чтобы те выступили операторами новых дата-центров и закупали больше ИИ-ускорителей. Если инициатива будет успешно реализована, импорт из США увеличится на сумму от сотен миллиардов до триллиона японских иен (около $7 млрд), что потенциально компенсирует дефицит приблизительно на 10 %. Торговый дефицит с Японией в 2024 году для США составлял $68,5 млрд. 
Источник изображения: JJ Ying/unsplash.com Помимо закупок чипов, Япония также предложила поддержать поставки ключевых материалов для производства полупроводников, таких как пластины и химические компоненты, в США. Совместное укрепление цепочки поставок должно усилить и экономическую безопасность стран. По имеющимся данным, США не намерены менять позицию и готовы только к переговорам о дополнительных дифференцированных пошлинах (помимо единой 10 % пошлины для всех). При этом они не хотят «оптимизировать» ставки на отдельные группы товаров, например — автомобили. Япония же настаивает, что пошлины на автомобили, на которые приходится около 30 % местного экспорта в США, должны быть снижены, поэтому позиции двух стран пока не меняются. Рёсей Аказава (Ryosei Akazawa), в 2024 году получивший в японском правительстве сразу несколько министерских портфелей, связанных с экономикой и развитием, должен был посетить США 29 мая для четвёртого раунда переговоров с министром финансов США Скоттом Бессентом (Scott Bessent) и другими представителями федеральных американских властей. Переговоры посвящены импортно-экспортным пошлинам двух стран. Весьма вероятно, что цель правительства несколько другая. В феврале сообщалось, что SoftBank Group и OpenAI объединились для продвижения ИИ-сервисов среди японских корпоративных клиентов, а в марте появились данные о том, что SoftBank купит за $676 млн заброшенный объект Sharp для строительства ИИ ЦОД, вероятно, в интересах OpenAI. Кроме того, SoftBank участвует в создании двух крупных платформ на базе DGX B200 и GB200 NVL72. Сейчас американскими властями очень много внимания уделяется ИИ-проекту Stargate, в котором японская SoftBank является одним из ключевых игроков наряду с OpenAI. Не исключено, что очередной кампус Stargate по результатам переговоров появится именно в Японии. Расширение проекта за пределы США уже началось, OpenAI и G42 построят 5-ГВт кампус в Абу-Даби.
29.05.2025 [23:00], Владимир Мироненко
NVIDIA значительно увеличила выручку и прибыль, несмотря на потери из-за санкций СШАNVIDIA опубликовала отчёт о финансовых результатах за I квартал 2026 финансового года, завершившийся 27 апреля 2025 года. Несмотря на ужесточение экспортных ограничений США на поставки чипов в Китай, крупнейший рынок для NVIDIA, компания сообщила о рекордной выручке, превысившей ожидания Уолл-стрит, драйвером которой стали продажи в сегменте решений для ЦОД. Выручка NVIDIA за I финансовый квартал составила $44,06 млрд, что на 12 % больше, чем в предыдущем квартале и на 69 % больше год к году. Показатель оказался выше консенсус-прогноза аналитиков, опрошенных LSEG, равного $43,31 млрд. Чистая прибыль (GAAP) компании выросла на 26 % с $14,88 млрд или $0,60 на разводнённую акцию годом раннее до $18,78 млрд или $0,76 на акцию. Скорректированная чистая прибыль (Non-GAAP) составила $19,89 млрд или $0,96 на разводнённую акцию, что выше консенсус-прогноза от LSEG в размере $0,93 на акцию. В сегменте решений для ЦОД выручка NVIDIA выросла на 73 % по сравнению с прошлым годом до $39,1 млрд, и теперь составляют 88 % от общего дохода компании. При этом решения для вычислений принесли компании на 76 % больше выручки, составившей $34,16 млрд, а выручка от продаж сетевого оборудование выросла за квартал на 56 % до $4,96 млрд. Компания сообщила, что на поставки для крупных облачных гиперскейлеров, таких как Microsoft, AWS и Meta✴, приходится чуть менее половины общего дохода от решений для ЦОД. Кроме того, $5 млрд продаж в подразделении были связаны с сетевыми продуктами InfiniBand, которые используются для формирования ИИ-кластеров. «Архитектура Blackwell обеспечила почти 70 % выручки в сегементе ЦОД-вычислений в квартале, переход с Hopper почти завершён, — сказала финансовый директор Колетт Кресс (Colette Kress). — В среднем, каждый из крупных гиперскейлеров развёртывает около 1000 стоек NVL72 или 72 тыс. ускорителей Blackwell в неделю и находится на пути к дальнейшему наращиванию в этом квартале». NVIDIA отметила, что из-за экспортных ограничений администрации Трампа на поставки H20 в Китай, она понесла расходы в размере $4,5 млрд в I квартале 2026 финансового года, связанные с избыточными запасами и закупочными обязательствами по H20, поскольку спрос на эти чипы снизился. Также было недополучено $2,5 млрд продаж — компании удалось поставить H20 примерно на $4,6 млрд из запланированных $7,1 млрд. По словам Колетт Кресс, если бы не было ограничений, валовая прибыль компании составила бы 71,3 % в отчётном квартале, а не 61 %. Сумма потерь оказалась ниже ожидавшихся $5,5 млрд, поскольку компании удалось сэкономить $1 млрд, благодаря повторному использованию некоторых материалов. 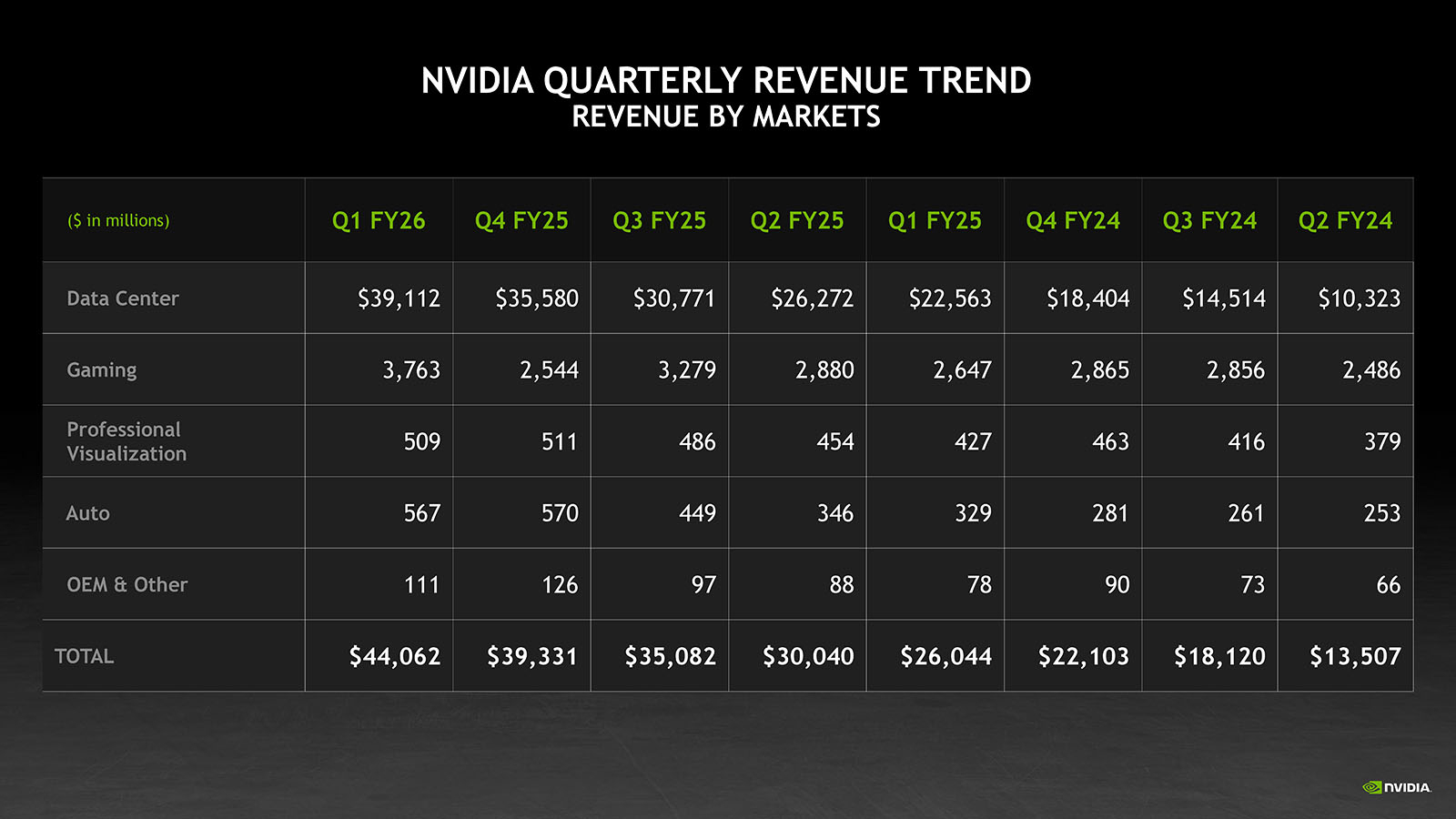
Источник изображения: NVIDIA В интервью аналитику Бену Томпсону (Ben Thompson) гендиректор NVIDIA Дженсен Хуанг (Jensen Huang) сказал, что этот шаг был «крайне болезненным» и может привести к потере $15 млрд дохода. «Ни одна компания в истории не списывала столько запасов, — отметил Хуанг. — Мы потеряли продажи на $15 млрд, а казна, вероятно, потеряла налоги на сумму $3 млрд (потерянных для казны)». Также из этих ограничений NVIDIA недополучит в текущем квартале порядка $8 млрд. Гендиректор NVIDIA сообщил аналитикам, что рынок ИИ-чипов в Китае объёмлм $50 млрд «фактически закрыт для промышленности США». Он добавил, что запрет на экспорт H20 положит конец бизнесу компании по выпуску Hopper для ЦОД в Китае. Китайский рынок принёс компании меньшую долю выручки, чем в предыдущие два квартала — 12,5 % в I квартале по сравнению с примерно 14 % и 15 % в предыдущие два квартала соответственно. 
Источник изображения: NVIDIA «Китайский ИИ движется вперёд, с американскими чипами или без них. У него есть вычислительные мощности для обучения и развёртывания передовых моделей. Вопрос не в том, будет ли у Китая ИИ — он уже есть. Вопрос в том, будет ли один из крупнейших в мире ИИ-рынков работать на американских платформах», — поясняет Хуанг. «Ограждение китайских производителей чипов от конкуренции со стороны США только усиливает их за рубежом и ослабляет позиции Америки», — отметил глава NVIDIA. Но NVIDIA явно не собирается отказываться от китайского рынка. Хуанг сказал, что компания «посмотрит, сможем ли мы предложить интересные продукты, которые могли бы продолжать обслуживать китайский рынок», но добавил: «на данный момент у нас ничего нет». Ожидается, что для КНР будет выпущен ускоритель B40. Другие подразделения NVIDIA тоже продемонстрировали рост в отчётном квартале. Игровое подразделение компании, которое включает чипы для 3D-игр, увеличило выручку на 42 % в годовом исчислении до $3,8 млрд. Автомобильное и робототехническое подразделение компании сообщило о росте продаж год к году на 72 % до $567 млн. В сегменте профессиональной визуализации продажи выросли на 19 % до $509 млн. 
Источник изображения: NVIDIA Во II квартале финансового года 2026 года NVIDIA ожидает получить выручку в размере $45 млрд, что ниже прогноза Уолл-стрит в размере $45,9 млрд. Дженсен Хуанг указал в своем заявлении на невероятно высокий глобальный спрос на ИИ-инфраструктуру NVIDIA. «Страны по всему миру признают ИИ как важную инфраструктуру — так же, как электричество и интернет — и NVIDIA находится в центре этой глубокой трансформации», — подчеркнул он.
29.05.2025 [13:18], Руслан Авдеев
Перегрев, протечки и нестабильность затормозили массовый выпуск NVIDIA GB200 NVL72, но теперь все проблемы решеныПоставщики ИИ-серверов на базе NVIDIA GB200 NVL72, включая Dell, Foxconn, Inventec и Wistron, увеличили выпуск серверов. Для этого им пришлось решить ряд технических проблем, которые ранее привели к задержкам поставок продуктов клиентам, сообщает The Financial Times. Компании совершили «серии прорывов», что позволило им начать своевременные поставки серверов GB200 NVL72. Как сообщил один из инженеров неназванного производственного партнёра NVIDIA, внутренние тесты выявили «проблемы с подключением» в серверах, но поставщики организовали совместную работу с NVIDIA, и вопрос был решён два или три месяца назад. Впрочем, это не первая проблема с чипами семейства Blackwell. В конце 2024 года стало известно о перегреве суперускорителей NVL72. По слухам, разработчику чипов пришлось просить производителей внести немало изменений в эталонный вариант стоек, чтобы решить проблему. Также поступала информация о проблемах межчипового интерконнекта, программных багах и протечках охлаждающих жидкостей. В результате поставщикам пришлось увеличить число протоколов проверки — оборудование стали тестировать намного внимательнее перед поставками клиентам. При этом производителям уже нужно готовиться к выпуску систем на базе GB300. NVIDIA GB300 NVL72 всё так же использует полностью жидкостное охлаждение. Суперускоритель оснащён 72 чипами Blackwell Ultra и 36 процессорами Grace. В продажу решение должно поступить в III квартале 2025 года. 
Источник изображения: NVIDIA Впрочем, как сообщают журналисты, чтобы ускорить внедрение GB300-серверов, NVIDIA отказалась от более совершенного дизайна платы Cordelia позволявшего заменять отдельные компоненты, в пользу текущей версии Bianca, применяемой для GB200. Это решение может усложнить ремонт, но ускорит развёртывание систем. По словам трёх источников, знакомых с вопросом, NVIDIA сообщила поставщикам, что намерена перейти дизайн Cordelia в следующем поколении ИИ-продуктов.
28.05.2025 [15:49], Руслан Авдеев
NVIDIA и промышленная династия Валленбергов создадут ИИ-инфраструктуру в ШвецииNVIDIA и группа компаний, за которыми стоит влиятельная шведская семья Валленберг, займутся созданием современной ИИ-инфраструктуры в Швеции, сообщает Bloomberg. В число партнёров входят AstraZeneca Plc, Ericsson AB, Saab AB, SEB AB и инвестиционная группа Валленбергов. Вместе они намерены построить «крупнейший в Швеции» ИИ-суперкомпьютер. Также NVIDIA готовится создать первый в стране центр ИИ-технологий для продвижения исследований совместно с производственными компаниями. По словам главы NVIDIA Дженсена Хуанга (Jensen Huang), страна создаёт первую ИИ-инфраструктуру, закладывая основу для прорывов в науке, промышленности и обществе в целом. 
Источник изображения: Raphael Andres/unsplash.com В рамках новой инициативы Saab объявила об использовании ИИ для ускоренной разработки оборонных технологий. Использовать искусственный интеллект в своих интересах намерены и другие партнёры. По словам председателя Wallenberg Investments AB Маркуса Валленберга (Marcus Wallenberg), результатом инициативы станут «ценные сопутствующие эффекты». Валленберги — известная с XIX века промышленная династия. Они остаются активными акционерами некоторых ключевых европейских компаний, в основном благодаря долям в Investor AB и FAM. Их финансовая система включает сеть фондов, ежегодно направляющих более Kr2,9 млрд ($287 млн) на поддержку научных и образовательных проектов в Швеции. В Швеции и без того активно развиваются проекты в сфере искусственного интеллекта. Так, в декабре 2024 года было объявлено, что страна станет базой для одной из ИИ-фабрик EuroHPC.
27.05.2025 [14:12], Руслан Авдеев
Sophia Space разработала «ИИ-плитки» для сборки космических ЦОД
hardware
nvidia
nvidia jetson
qualcomm
snapdragon
ии
космос
микро-цод
облако
периферийные вычисления
спутник
сша
цод
Финансирование получил очередной космический стартап, намеренный вывести на орбиту дата-центры. Sophia Space из Сиэтла (США) привлекла $3,5 млн — раунд финансирования возглавила Unlock Ventures, участие также приняли «бизнес-ангелы», заинтересованные в орбитальных периферийных вычислениях и космических ЦОД, сообщает Datacenter Dynamics. 
Источник изображений: Sophia Space В Sophia Space заявили, что мир находится на заре новой эры, в которой спрос на ИИ-технологии не должен приносить ущерба планете из-за энергетических ограничений. Компанию основали два выходца из Лаборатории реактивного движения NASA (JPL), а также ветеран Intel и Microsoft. Компания предлагает готовую, автономную, защищённую от радиации вычислительную платформу TILE, оптимизированную для ИИ-задач, в том числе в коммерческих и оборонных секторах. Каждый сервер TILE Edge представляет «плитку» размерами 1 × 1 и толщиной 1 см, оснащённую собственной солнечной панелью и пассивной системой охлаждения. Вычислительная часть представлена связкой Qualcomm Snapdragon 865 и Cloud AI 100 или NVIDIA Jetson и Blackwell. «Плитки» можно объединять друг с другом, формируя кластер необходимой мощности.  Периферийные вычисления в космосе ценятся за возможность решить проблему перегрузки спутников, генерирующих больше данных, чем когда бы то ни было. Для использования этих огромных массивов информации требуются значительные ресурсы, поэтому предварительная обработка на периферийной платформе может сослужить неоценимую службу владельцам — предназначенные для передачи на Землю данные фильтруются ещё в космосе. Тема будет становиться всё более актуальной, поскольку правительствам и военным нужны всё более сложные системы мониторинга и съёмки на орбите. Компании вроде Axiom Space, Starcloud (ранее Lumen Orbit), NTT, Lonestar, Ramon.Space и Blue Origin давно рассматривают возможность развертывания вычислительных систем на орбите. В мае уже произошли два важных события, связанных с космическими дата-центрами. Во-первых, в начале месяца Эрик Шмидт (Eric Schmidt) купил Relativity Space, чтобы заняться запуском космических ЦОД, а несколько дней назад появилась информация, что китайская ADA Space вывела на орбиту первые 13 из 2,8 тыс. спутников для создания космического ИИ ЦОД. |
|

