Материалы по тегу: h100
|
12.05.2024 [21:57], Сергей Карасёв
ИИ федерального значения: правительственные учреждения США получат 17-Пфлопс суперкомпьютер на базе NVIDIA DGX SuperPOD H100Компания NVIDIA сообщила о том, что её система DGX SuperPOD ляжет в основу нового вычислительного комплекса для задач ИИ, который будет использоваться различными правительственными учреждениями США для проведения исследований в области климатологии, здравоохранения и кибербезопасности. Внедрением суперкомпьютера занимается MITRE — американская некоммерческая организация, специализирующаяся в области системной инженерии. Она ведёт разработки и исследования в интересах госорганов США, включая Министерство обороны (DoD), Федеральное управление гражданской авиации (FAA) и пр. Система DGX SuperPOD станет основой вычислительной платформы MITRE Federal AI Sandbox, доступ к ресурсам которой будет предоставляться различным организациям на федеральном уровне. Государственные учреждения смогут сообща использовать суперкомпьютер для обучения больших языковых моделей (LLM), развёртывания генеративных приложений и других современных ИИ-решений. 
Источник изображения: NVIDIA В состав MITRE Federal AI Sandbox войдут 32 системы NVIDIA DGX H100, а общее количество ускорителей NVIDIA H100 составит 256 штук. Производительность на операциях ИИ будет достигать примерно 1 Эфлопс. Быстродействие FP64 — приблизительно 17 Пфлопс. Ввод суперкомпьютера в эксплуатацию состоится позднее в текущем году. «Развёртывание MITRE DGX SuperPOD поможет ускорить реализацию инициатив федерального правительства США в области ИИ. Технологии ИИ обладают огромным потенциалом для улучшения государственных услуг в гражданской области и решения серьёзных проблем, в том числе в сфере кибербезопасности», — сказал Энтони Роббинс (Anthony Robbins), вице-президент NVIDIA.
10.05.2024 [23:47], Сергей Карасёв
Eviden представила семейство ИИ-серверов BullSequana AIКомпания Eviden (дочерняя структура Atos) анонсировала серверы серии BullSequana AI, предназначенные для решения ИИ-задач. В зависимости от модификации и уровня производительности устройства подходят для различных сценариев использования — от НРС-платформ до периферийных вычислений. Наиболее производительными серверами семейства являются решения BullSequana AI 1200H. Они могут применяться в составе облачных и гибридных инфраструктур, а также в дата-центрах заказчиков. По сути, это суперкомпьютер корпоративного уровня, специально разработанный для ресурсоёмких задач, таких как точная настройка ИИ-систем или обучение больших языковых моделей (LLM). Конфигурация BullSequana AI 1200H включает суперчипы NVIDIA Grace Hopper, а также интерконнект NVIDIA Quantum-2 InfiniBand. Задействовано программное обеспечение Eviden Jarvice XE, Eviden Smart Energy Management Suite, Eviden Smart Management Center и NVIDIA AI Enterprise. 
Источник изображения: Eviden Серверы BullSequana AI 1200H, насчитывающие в общей сложности 1456 ускорителей NVIDIA H100, выбраны для модернизации французского суперкомпьютера Jean Zay. Производительность этого НРС-комплекса увеличится более чем в три раза — с 36,85 до 125,9 Пфлопс. Кроме того, в новое семейство серверов вошли производительные устройства BullSequana AI 800, системы BullSequana AI 600 с воздушным и гибридным охлаждением, модели BullSequana AI 200 для частных и гибридных облачных сред, а также BullSequana AI 100 для периферийных вычислений. 
Источник изображения: Eviden В целом, как отмечается, каждая модель BullSequana AI предлагает различные уровни производительности, масштабируемости и гибкости. Таким образом, заказчики могут подобрать наиболее подходящий для себя вариант в зависимости от конкретного варианта использования, бюджета и размера бизнеса.
22.03.2023 [20:32], Алексей Степин
Экспортный китайский вариант NVIDIA H100 получил модельный номер H800В связи с санкционными ограничениями некоторые разновидности сложных микроэлектронных чипов запрещено экспортировать в Китайскую Народную Республику. Однако производители находят выход. В частности, компания NVIDIA анонсировала экспортный вариант ускорителя H100, не нарушающий никаких санкций. Модельный номер у такого варианта изменён на H800. Введённые правительством США в 2022 году санкции сделали «невыездными» два наиболее продвинутых продукта NVIDIA: A100 и H100. Такие процессоры сегодня являются основой наиболее динамично развивающейся вычислительной отрасли — нейросетевой. Именно на кластерах из таких ускорителей «натаскивают» мощные нейросети вроде ChatGPT и подобных. 
Ускоритель Hopper H100 в SXM-исполнении. Источник изображений здесь и далее: NVIDIA Ещё осенью прошлого года NVIDIA анонсировала A800 — экспортный вариант A100, не попадающий под ограничения за счёт некоторого снижения пропускной способности NVLink, с 600 до 400 Гбайт/с. Сейчас пришло время архитектуры Hopper, которая запущена в массовое производство. По аналогии с флагманом Ampere модернизированный чип получил модельный номер H800. Ограничения в нём реализованы схожим образом: как известно, NVLink в H100 имеет производительность 900 Гбайт/с в базовом SXM-варианте. 
H100 также существует в PCIe-варианте Версия H800 использует примерно половину этого потенциала, что, впрочем, не делает её в Китае менее популярной: новинка уже используется китайскими облачными гигантами, такими, как Alibaba, Baidu и Tencent. Есть ли у H800 другие отличия от H100, не говорится — NVIDIA пока отказывается предоставлять такую информацию. Достоверно известно лишь то, что они полностью соответствуют всем санкционным ограничениям. Интересно, появится ли в будущем вариант H800 NVL на базе NVIDIA H100 NVL.
21.03.2023 [20:45], Владимир Мироненко
NVIDIA запустила облачный сервис DGX Cloud — доступ к ИИ-супервычислениям прямо в браузереNVIDIA запустила сервис ИИ-супервычислений DGX Cloud, предоставляющий предприятиям доступ к инфраструктуре и программному обеспечению, необходимым для обучения передовых моделей для генеративного ИИ и других приложений. DGX Cloud предлагает выделенные ИИ-кластеры NVIDIA DGX в сочетании с фирменным набором ПО NVIDIA. С его помощью предприятие сможет получить доступ к облачному ИИ-суперкомпьютеру, используя веб-браузер и без надобности в приобретении, развёртывании и управлении собственной HPC-инфраструктурой. Правда, удовольствие это всё равно не из дешёвых — стоимость инстансов DGX Cloud начинается от $36 999/мес., причём деньги получает в первую очередь сама NVIDIA. Для сравнения — полностью укомплектованная система DGX A100 в Microsoft Azure обойдётся примерно в $20 тыс. Облачные кластеры DGX предлагаются предприятиям на условиях ежемесячной аренды, что гарантирует им возможность быстро масштабировать разработку больших рабочих нагрузок. «DGX Cloud предоставляет клиентам мгновенный доступ к супервычислениям NVIDIA AI в облаках глобального масштаба», — сообщил Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. 
Источник изображения: NVIDIA Развёртыванием инфраструктуры DGX Cloud компания NVIDIA будет заниматься в сотрудничестве с ведущими поставщиками облачных услуг. Первым среди них стала платформа Oracle Cloud Infrastructure (OCI), предлагающая суперкластер (SuperCluster) с объединёнными RDMA-сетью (в том числе на базе BlueField-3 и Connect-X7) системами DGX (bare metal), которые дополняет высокопроизводительное локальное и блочное хранилище. Cуперкластер может включать до 32 768 ускорителей, но этот рекорд был поставлен с использованием DGX A100, а вот предложение DGX H100 пока что ограничено. В следующем квартале похожее решение появится в Microsoft Azure, а потом в Google Cloud и у других провайдеров. 
Источник изображения: NVIDIA Первыми пользователями DGX Cloud стали Amgen, одна из ведущих мировых биотехнологических компаний, лидер рынка страховых технологий CCC Intelligent Solutions (CCC) и провайдер цифровых бизнес-платформ ServiceNow. «Мощные вычислительные и многоузловые возможности DGX Cloud позволили нам в 3 раза ускорить обучение белковых LLM с помощью BioNeMo и до 100 раз ускорить анализ после обучения с помощью NVIDIA RAPIDS по сравнению с альтернативными платформами», — сообщил представитель Amgen. Для управления нагрузками в DGX Cloud предлагается NVIDIA Base Command. Также DGX Cloud включает в себя набор инструментов NVIDIA AI Enterprise для создания и запуска моделей, который предоставляет комплексные фреймворки и предварительно обученные модели для ускорения обработки данных и оптимизации разработки и развёртывания ИИ. DGX Cloud предоставляет поддержку экспертов NVIDIA на всех этапах разработки ИИ. Клиенты смогут напрямую работать со специалистами NVIDIA, чтобы оптимизировать свои модели и быстро решать задачи разработки с учётом сценариев отраслевого использования.
21.03.2023 [19:45], Игорь Осколков
Толстый и тонкий: NVIDIA представила самый маленький и самый большой ИИ-ускорители L4 и H100 NVLНа весенней конференции GTC 2023 компания NVIDIA представила два новых ИИ-ускорителя, ориентированных на инференес: неприличной большой H100 NVL, фактически являющийся парой обновлённых ускорителей H100 в формате PCIe-карты, и крошечный L4, идущий на смену T4. 
Изображения: NVIDIA NVIDIA H100 NVL действительно выглядит как пара H100, соединённых мостиками NVLink. Более того, с точки зрения ОС они выглядят как пара независимых ускорителей, однако ПО воспринимает их как единое целое, а обмен данными между двумя картам идёт в первую очередь по мостикам NVLink (600 Гбайт/с). Новинка создана в первую очередь для исполнения больших языковых ИИ-моделей, в том числе семейства GPT, а не для их обучения. 
NVIDIA H100 NVL Однако аппаратно это всё же не просто пара обычных H100 PCIe. По уровню заявленной производительности NVL-вариант вдвое быстрее одиночного ускорителя H100 SXM, а не PCIe — 3958 и 7916 Тфлопс в разреженных (в обычных показатели вдвое меньше) FP16- и FP8-вычислениях на тензорных ядрах соответственно, что в 2,6 раз больше, чем у H100 PCIe. Кроме того, NVL-вариант получил сразу 188 Гбайт HBM3-памяти с суммарной пропускной способностью 7,8 Тбайт/с. 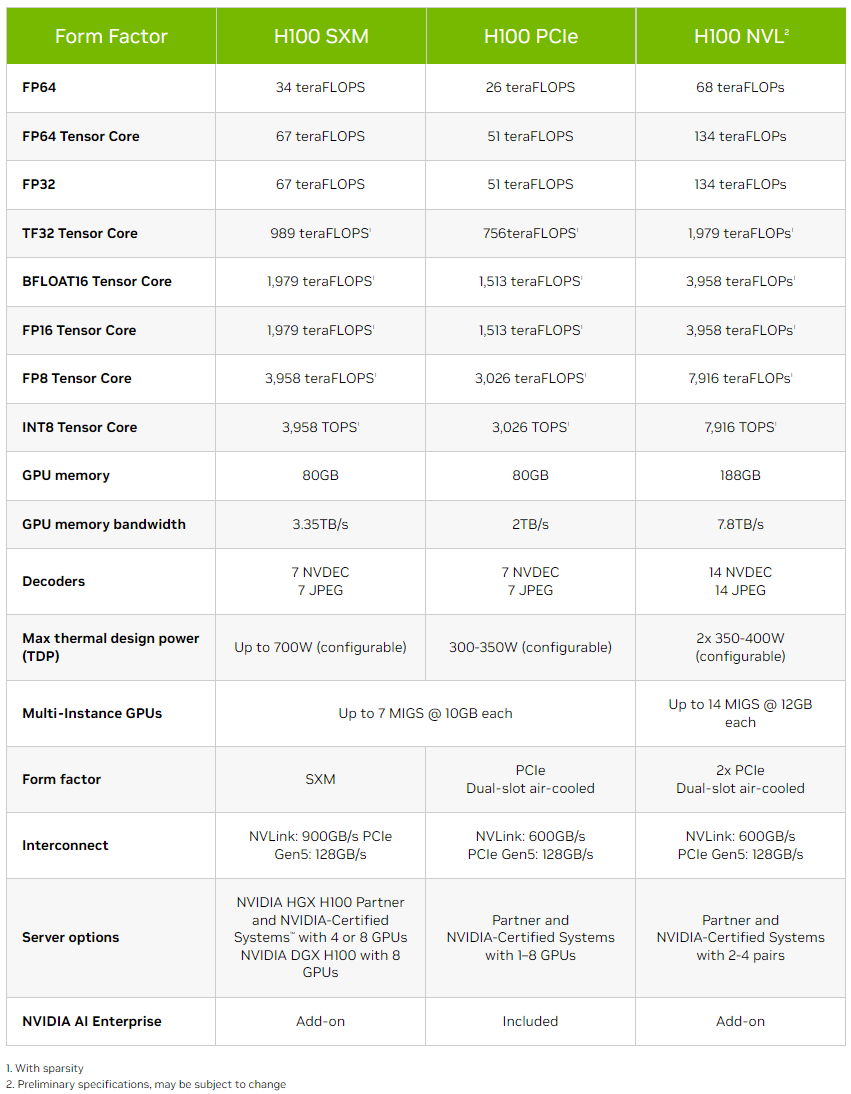 NVIDIA утверждает, что форм-фактор H100 NVL позволит задействовать новинку большему числу пользователей, хотя четыре слота и TDP до 800 Вт подойдут далеко не каждой платформе. NVIDIA H100 NVL станет доступна во второй половине текущего года. А вот ещё одну новинку, NVIDIA L4 на базе Ada, в ближайшее время можно будет опробовать в облаке Google Cloud Platform, которое первым получило этот ускоритель. Кроме того, он же будет доступен в рамках платформы NVIDIA Launchpad, да и ключевые OEM-производители тоже взяли его на вооружение. 
NVIDIA L4 Сама NVIDIA называет L4 поистине универсальным серверным ускорителем начального уровня. Он вчетверо производительнее NVIDIA T4 с точки зрения графики и в 2,7 раз — с точки зрения инференса. Маркетинговые упражнения компании при сравнении L4 с CPU оставим в стороне, но отметим, что новинка получила новые аппаратные ускорители (де-)кодирования видео и возможность обработки 130 AV1-потоков 720p30 для мобильных устройств. С L4 возможны различные сценарии обработки видео, включая замену фона, AR/VR, транскрипцию аудио и т.д. При этом ускорителю не требуется дополнительное питание, а сам он выполнен в виде HHHL-карты. 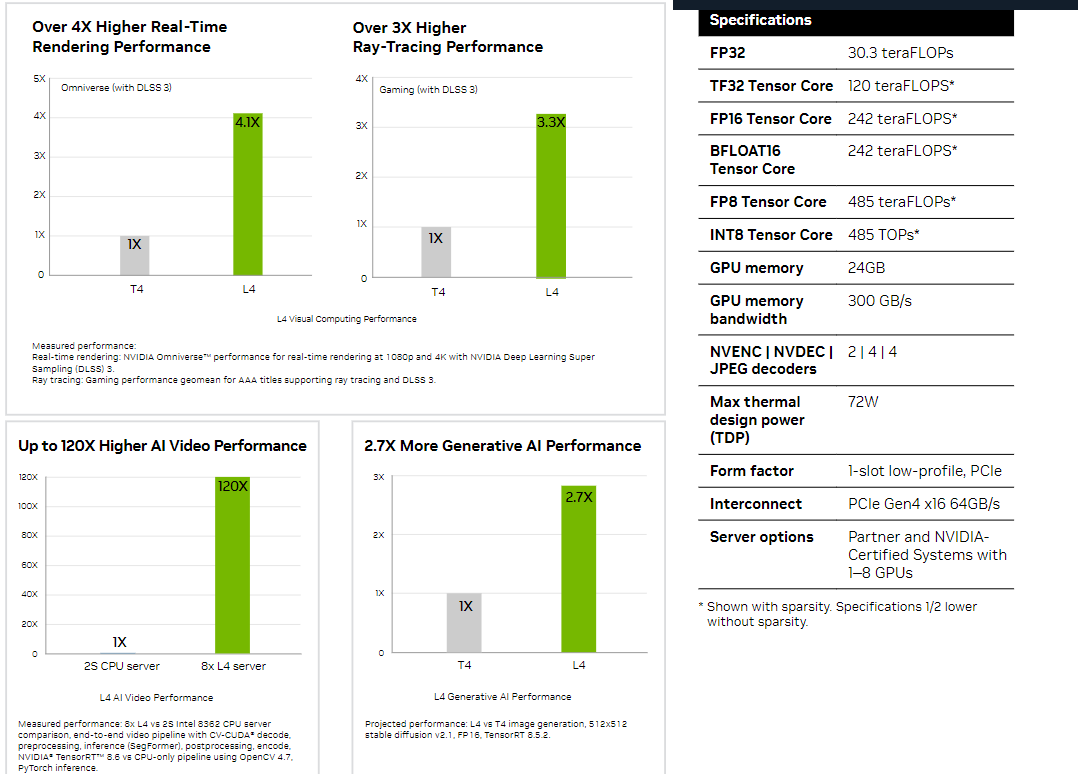
21.03.2023 [19:15], Сергей Карасёв
NVIDIA представила систему DGX Quantum для гибридных квантово-классических вычисленийКомпания NVIDIA в партнёрстве с Quantum Machines анонсировала DGX Quantum — первую систему, объединяющую GPU и квантовые вычисления. Решение использует новую открытую программную платформу CUDA Quantum. Утверждается, что система предоставляет революционно архитектуру для исследователей, работающими с гибридными вычислениями с низкой задержкой. NVIDIA DGX Quantum объединяет средства ускоренных вычислений на базе Grace Hopper (Arm-процессор + ускоритель H100), модели программирования с открытым исходным кодом CUDA Quantum и передовую квантовую управляющую платформу Quantum Machines OPX+. Такая комбинация позволяет создавать ресурсоёмкие приложения, сочетающие квантовые вычисления с современными классическими вычислениями. При этом в числе прочего обеспечивается работа гибридных алгоритмов и коррекция ошибок. 
Источник изображения: NVIDIA Представленное решение предполагает соединение Grace Hopper и Quantum Machines OPX+ посредством интерфейса PCIe. Это обеспечивает задержку менее микросекунды между ускорителем и блоками квантовой обработки (QPU). Отмечается, что OPX+ — это универсальная система квантового управления. Таким образом, можно максимизировать производительность QPU и предоставить разработчикам новые возможности при использовании квантовых алгоритмов. Системы Grace Hopper и OPX+ можно масштабировать в соответствии с потребностями — от QPU с несколькими кубитами до суперкомпьютера с квантовым ускорением. 
Источник изображения: NVIDIA О намерении интегрировать CUDA Quantum в свои платформы уже заявили компании по производству квантового оборудования Anyon Systems, Atom Computing, IonQ, ORCA Computing, Oxford Quantum Circuits и QuEra, разработчики ПО Agnostiq и QMware, а также некоторые суперкомпьютерные центры.
22.03.2022 [18:40], Игорь Осколков
NVIDIA анонсировала 4-нм ускорители Hopper H100 и самый быстрый в мире ИИ-суперкомпьютер EOS на базе DGX H100На GTC 2022 компания NVIDIA анонсировала ускорители H100 на базе новой архитектуры Hopper. Однако NVIDIA уже давно говорит о себе как создателе платформ, а не отдельных устройств, так что вместе с H100 были представлены серверные Arm-процессоры Grace, в том числе гибридные, а также сетевые решения и обновления наборов ПО. 
NVIDIA H100 (Изображения: NVIDIA) NVIDIA H100 использует мультичиповую 2.5D-компоновку CoWoS и содержит порядка 80 млрд транзисторов. Но нет, это не самый крупный чип компании на сегодняшний день. Кристаллы новинки изготавливаются по техпроцессу TSMC N4, а сопровождают их — впервые в мире, по словам NVIDIA — сборки памяти HBM3 суммарным объёмом 80 Гбайт. Объём памяти по сравнению с A100 не вырос, зато в полтора раза увеличилась её скорость — до рекордных 3 Тбайт/с. 
NVIDIA H100 (SXM) Подробности об архитектуре Hopper будут представлены чуть позже. Пока что NVIDIA поделилась некоторыми сведениями об особенностях новых чипов. Помимо прироста производительности от трёх (для FP64/FP16/TF32) до шести (FP8) раз в сравнении с A100 в Hopper появилась поддержка формата FP8 и движок Transformer Engine. Именно они важны для достижения высокой производительности, поскольку само по себе четвёртое поколение ядер Tensor Core стало втрое быстрее предыдущего (на всех форматах). 
NVIDIA H100 CNX (PCIe) TF32 останется форматом по умолчанию при работе с TensorFlow и PyTorch, но для ускорения тренировки ИИ-моделей NVIDIA предлагает использовать смешанные FP8/FP16-вычисления, с которыми Tensor-ядра справляются эффективно. Хитрость в том, что Transformer Engine на основе эвристик позволяет динамически переключаться между ними при работе, например, с каждым отдельным слоем сети, позволяя таким образом добиться повышения скорости обучения без ущерба для итогового качества модели. На больших моделях, а именно для таких H100 и создавалась, сочетание Transformer Engine с другими особенностями ускорителей (память и интерконнект) позволяет получить девятикратный прирост в скорости обучения по сравнению с A100. Но Transformer Engine может быть полезен и для инференса — готовые FP8-модели не придётся самостоятельно конвертировать в INT8, движок это сделает на лету, что позволяет повысить пропускную способность от 16 до 30 раз (в зависимости от желаемого уровня задержки). 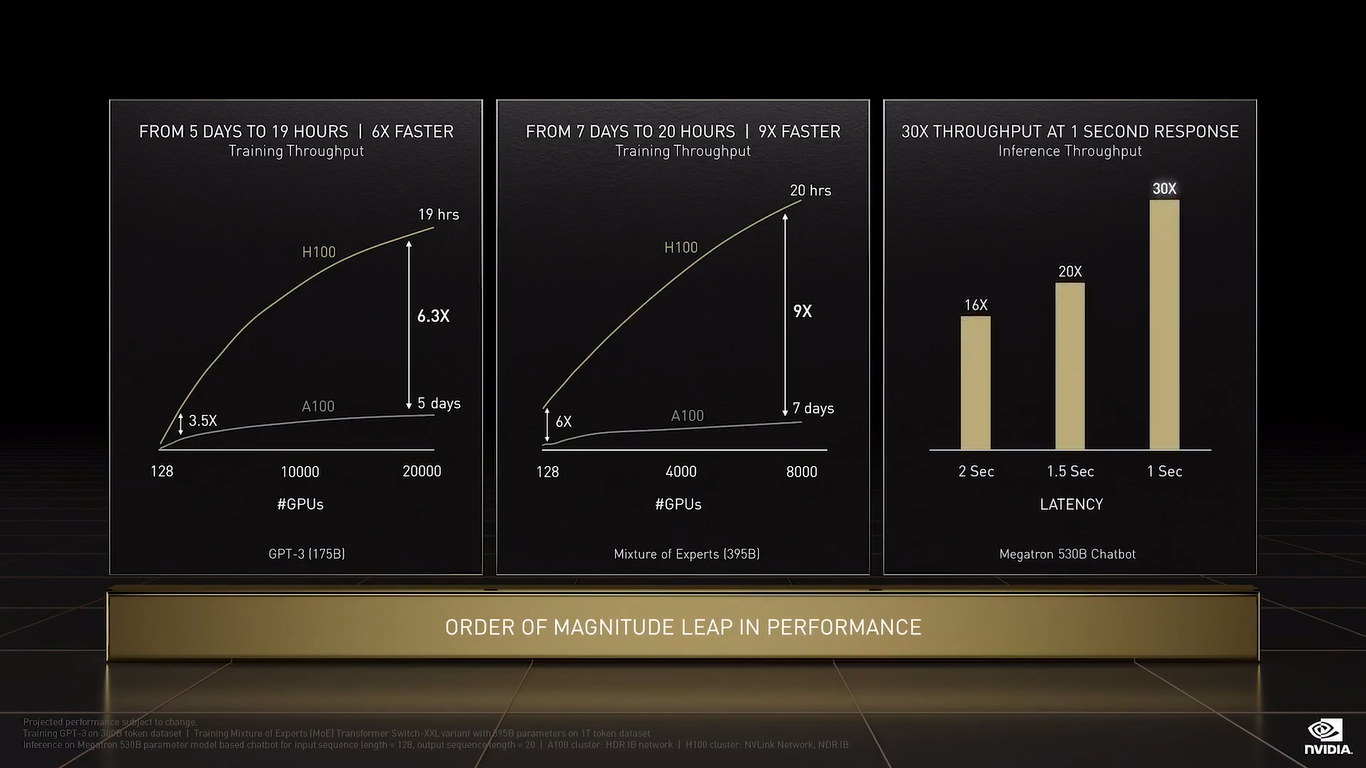 Другое любопытное нововведение — специальные DPX-инструкции для динамического программирования, которые позволят ускорить выполнение некоторых алгоритмов до 40 раз в задачах, связанных с поиском пути, геномикой, квантовыми системами и при работе с большими объёмами данных. Кроме того, H100 получили дальнейшее развитие виртуализации. В новых ускорителях всё так же поддерживается MIG на 7 инстансов, но уже второго поколения, которое привнесло больший уровень изоляции благодаря IO-виртуализации, выделенным видеоблокам и т.д.  Так что MIG становится ещё более предпочтительным вариантом для облачных развёртываний. Непосредственно к MIG примыкает и технология конфиденциальных вычислений, которая по словам компании впервые стала доступна не только на CPU. Программно-аппаратное решение позволяет создавать изолированные ВМ, к которым нет доступа у ОС, гипервизора и других ВМ. Поддерживается сквозное шифрование при передаче данных от CPU к ускорителю и обратно, а также между ускорителями.  Память внутри GPU также может быть изолирована, а сам ускоритель оснащается неким аппаратным брандмауэром, который отслеживает трафик на шинах и блокирует несанкционированный доступ даже при наличии у злоумышленника физического доступа к машине. Это опять-таки позволит без опаски использовать H100 в облаке или в рамках колокейшн-размещения для обработки чувствительных данных, в том числе для задач федеративного обучения.  NVIDIA HGX H100 Но главная инновация — это существенное развитие интерконнекта по всем фронтам. Суммарная пропускная способность внешних интерфейсов чипа H100 составляет 4,9 Тбайт/с. Да, у H100 появилась поддержка PCIe 5.0, тоже впервые в мире, как утверждает NVIDIA. Однако ускорители получили не только новую шину NVLink 4.0, которая стала в полтора раза быстрее (900 Гбайт/с), но и совершенно новый коммутатор NVSwitch, который позволяет напрямую объединить между собой до 256 ускорителей! Пропускная способность «умной» фабрики составляет до 70,4 Тбайт/с.  Сама NVIDIA предлагает как новые системы DGX H100 (8 × H100, 2 × BlueField-3, 8 × ConnectX-7), так и SuperPOD-сборку из 32-х DGX, как раз с использованием NVLink и NVSwitch. Партнёры предложат HGX-платформы на 4 или 8 ускорителей. Для дальнейшего масштабирования SuperPOD и связи с внешним миром используются 400G-коммутаторы Quantum-2 (InfiniBand NDR). Сейчас NVIDIA занимается созданием своего следующего суперкомпьютера EOS, который будет состоять из 576 DGX H100 и получит FP64-производительность на уровне 275 Пфлопс, а FP16 — 9 Эфлопс.  Компания надеется, что EOS станет самой быстрой ИИ-машиной в мире. Появится она чуть позже, как и сами ускорители, выход которых запланирован на III квартал 2022 года. NVIDIA представит сразу три версии. Две из них стандартные, в форм-факторах SXM4 (700 Вт) и PCIe-карты (350 Вт). А вот третья — это конвергентный ускоритель H100 CNX со встроенными DPU Connect-X7 класса 400G (подключение PCIe 5.0 к самому ускорителю) и интерфейсом PCIe 4.0 для хоста. Компанию ей составят 400G/800G-коммутаторы Spectrum-4. |
|

