Материалы по тегу: llm
|
04.05.2024 [17:55], Владимир Мироненко
PowerML привлекла $25 млн на развитие ИИ-платформы Lamini, в том числе от AMD и Louis VuittonСтартап PowerML Inc., разработчик платформы Lamini для обучения и развёртывания ИИ-моделей, сообщил о привлечении $25 млн в ходе двух раундов финансирования. В раундах приняли участие компании Amplify Partners, возглавившая раунд Series A, First Round Capital, возглавившая Seed-раунд, AMD Ventures, пионер ИИ Эндрю Ын (Andrew Ng), соучредитель OpenAI Андрей Карпати (Andrej Karpathy), руководители Dropbox Inc., Figma Inc. и LVMH, материнской компании Louis Vuitton. Разработанная PowerML программная платформа предназначена для обучения и запуска больших языковых моделей (LLM) на ускорителях AMD или NVIDIA как в облачных, так и в локальных средах. В последнем случае можно развернуть Lamini в изолированной инфраструктуре. Платформа была создана с расчётом на крупномасштабные ИИ-проекты, которым может потребоваться более 1000 ускорителей. 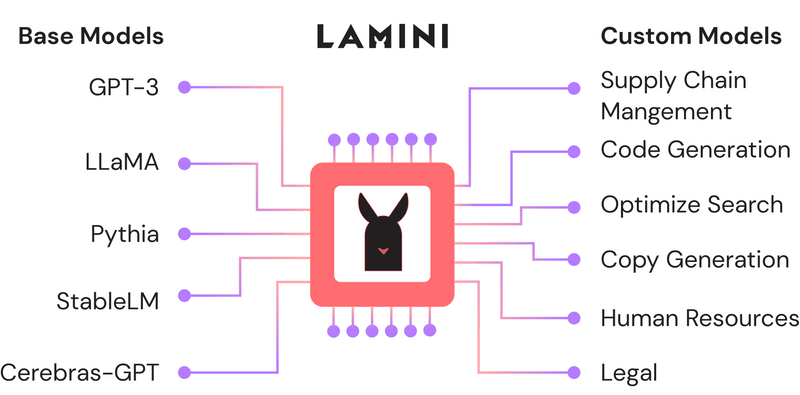
Источник изображений: Lamini Одной из наиболее сложных задач, связанных с обучением LLM, является настройка гиперпараметров. Lamini предоставляет готовые наборы гиперпараметров, устраняя необходимость всё настраивать с нуля. Вместе с тем остаётся возможность определения пользовательских настроек LLM. Платформа также может использоваться для точной настройки уже обученных моделей ИИ под конкретную задачу. Lamini использует подход PEFT, который позволяет значительно сократить количество изменений параметров, а также снизить стоимость адаптации LLM к выполнению новых задач. Вместе с тем Lamini поддерживает методику RAG (Retrieval Augmented Generation), которая позволяет дообучать модель на собственных данных без изменения кода. Заодно Lamini предоставляет панель мониторинга, которая позволяет разработчикам сравнивать корректность точной настройки своих ИИ-моделей с исходной версией.  PowerML также упрощает развёртывание готовых ИИ-моделей, предоставляя различные настройки инференса и позволяя управлять стилем генерации, форматом выводимых данных и т.д. Компания утверждает, что её платформа в инференс-задачах более экономична по сравнению с проприетарными LLM-платформами, такими как Claude 3. Полученные инвестиции PowerML планирует использовать для найма большего количества сотрудников и расширения своей инфраструктуры ИИ, в частности, за счёт ускорителей большего количества ускорителей AMD, поскольку стартап делает ставку на решения AMD: ускорители Instinct и стек ROCm. Компания также планирует разработать «более глубокую техническую оптимизацию» для рабочих нагрузок машинного обучения.
30.04.2024 [12:39], Сергей Карасёв
Утилита llamafile для быстрого запуска ИИ-моделей получила расширенную поддержку ускорителей AMD и свежих LLMКомпания Mozilla анонсировала обновлённую версию инструмента llamafile с индексом 0.8.1. В данном релизе устранены ошибки, из-за которых происходило некорректное распознавание ускорителей AMD на базе GPU. Кроме того, реализованы некоторые другие изменения. Напомним, llamafile даёт возможность упаковать веса большой языковой модели (LLM) в исполняемый файл, который без установки можно запустить практически на любой современной платформе. Поддерживаются архитектуры x86-64 и ARM64, а также системы macOS, Windows, Linux, FreeBSD, OpenBSD и NetBSD. Как отмечается, изначально в llamafile корректно определялись только числовые идентификаторы графических блоков AMD GFX, из-за чего возникали сбои при использовании определённого оборудования AMD Instinct/Radeon. Например, ускоритель Instinct MI250 имеет обозначение GFX90A IP, и символ «A» ранее не распознавался должным образом. В результате, при работе с такими GPU происходили ошибки. Теперь данная проблема устранена. 
Источник изображения: AMD Кроме того, в llamafile 0.8.1 имеется поддержка модели Phi-3 Mini 4k, а также LLaMA3, Grok, Mixtral 8x22b и Command-R. Производительность F16 повышена приблизительно на 20 % на платформе Raspberry Pi 5, примерно на 30 % — на Intel Skylake и на 60 % — на Apple M2.
20.09.2023 [20:05], Алексей Степин
SambaNova представила ИИ-ускоритель SN40L с памятью HBM3, который в разы быстрее GPUБум больших языковых моделей (LLM) неизбежно порождает появление на рынке нового специализированного класса процессоров и ускорителей — и нередко такие решения оказываются эффективнее традиционного подхода с применением GPU. Компания SambaNova Systems, разработчик таких ускорителей и систем на их основе, представила новое, третье поколение ИИ-процессоров под названием SN40L. Осенью 2022 года компания представила чип SN30 на базе уникальной тайловой архитектуры с программным управлением, уже тогда вполне осознавая тенденцию к увеличению объёмов данных в нейросетях: чип получил 640 Мбайт SRAM-кеша и комплектовался оперативной памятью объёмом 1 Тбайт. 
Источник изображений здесь и далее: SambaNova (via EE Times) Эта наработка легла и в основу новейшего SN40L. Благодаря переходу от 7-нм техпроцесса TSMC к более совершенному 5-нм разработчикам удалось нарастить количество ядер до 1040, но их архитектура осталась прежней. Впрочем, с учётом реконфигурируемости недостатком это не является. Чип SN40L состоит из двух больших чиплетов, на которые приходится 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной HBM3. Последняя была добавлена в SN40L в качестве буфера между сверхбыстрой SRAM и относительно медленной DDR. Это должно улучшить показатели чипа при работе в режиме LLM-инференса. Для эффективного использования HBM3 программный стек SambaNova был соответствующим образом доработан. 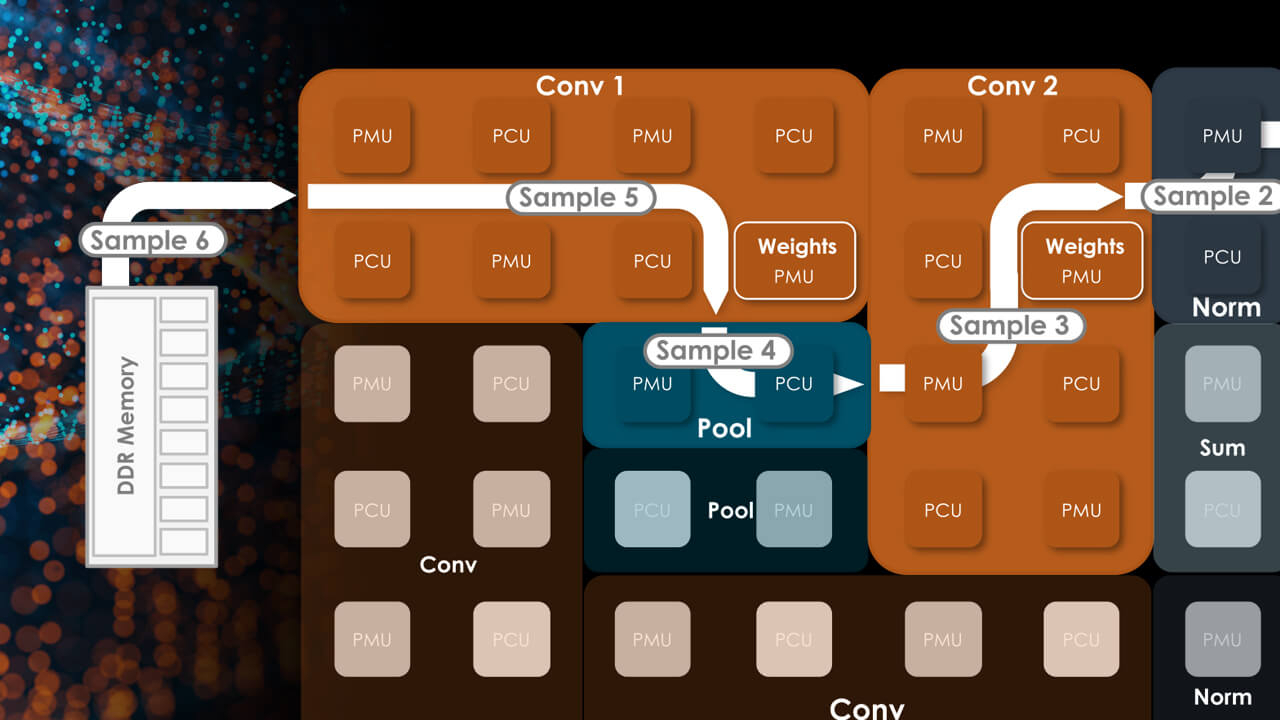
Тайловая архитектура SambaNova состоит из вычислительных тайлов PCU, SRAM-тайлов PMU, управляющей логики и меш-интерконнекта По сведениям SambaNova, восьмипроцессорная система на базе SN40L сможет запускать и обслуживать ИИ-модель поистине титанических «габаритов» — с 5 трлн параметров и глубиной запроса более 256к. В описываемой модели речь идёт о наборе экспертных моделей с LLM Llama-2 в качестве своеобразного дирижёра этого оркестра. Архитектура с традиционными GPU потребовала бы для запуска этой же модели 24 сервера с 8 ускорителями каждый; впрочем, модель ускорителей не уточняется. Как и прежде, сторонним клиентам чипы SN40L и отдельные вычислительные узлы на их основе поставляться не будут. Компания продолжит использовать модель Dataflow-as-a-Service (DaaS) — расширяемую платформу ИИ-сервисов по подписке, включающей в себя услуги по установке оборудования, вводу его в строй и управлению в рамках сервиса. Однако SN40L появится в рамках этой услуги позднее, а дебютирует он в составе облачной службы SambaNova Suite.
15.09.2023 [20:52], Алексей Степин
Groq назвала свои ИИ-чипы TSP четырёхлетней давности идеальными для LLM-инференсаТензорный процессор TSP, разработанный стартапом Groq, был анонсирован ещё осенью 2019 года и его уже нельзя назвать новым. Тем не менее, как сообщает Groq, TSP всё ещё является достаточно мощным решением для инференса больших языковых моделей (LLM). Теперь Groq позиционирует своё детище как LPU (Language Processing Unit) и продвигает его в качестве идеальной платформы для запуска больших языковых моделей (LLM). Согласно имеющимся данным, в этом качестве четырёхлетний процессор проявляет себя весьма неплохо. Groq открыто хвастается своим преимуществом над GPU, но в последних раундах MLPerf участвовать не желает. 
Источник изображений здесь и далее: Groq В своё время Groq разработала не только сам тензорный процессор, но и дизайн ускорителя на его основе, а также продумала вопрос взаимодействия нескольких TSP в составе вычислительного узла с дальнейшим масштабированием до уровня мини-кластера. Именно для такого кластера и опубликованы свежие данные о производительности Groq в сфере LLM. 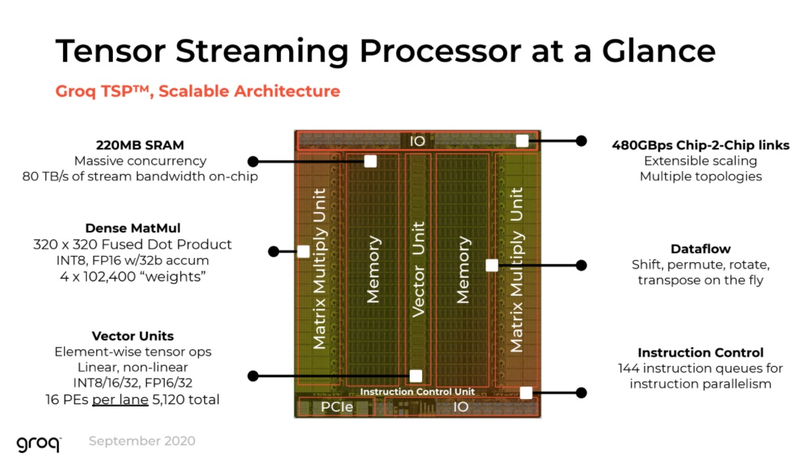 Система разработки, содержащая в своём составе 640 процессоров Groq TSP, была успешно использована для запуска модели Meta✴ Llama-2 с 70 млрд параметров. Как показали результаты тестов, модель на данной платформе работает с производительностью 240 токенов в секунду на пользователя. Для адаптации и развёртывания Llama-2, по словам создателей Groq, потребовалось всего несколько дней. В настоящее время усилия Groq будут сконцентрированы на адаптации имеющейся платформы в сфере LLM-инференса, поскольку данный сектор рынка растёт быстрее, нежели сектор обучения ИИ-моделей. Для LLM-инференса важнее умение эффективно масштабировать потоки небольших блоков (8–16 Кбайт) на большое количество чипов. 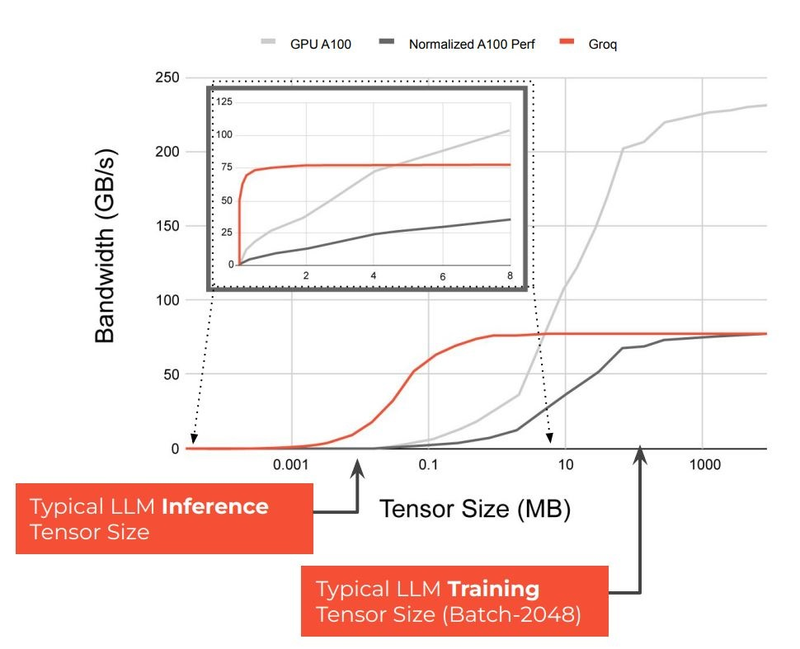 В этом Groq TSP превосходит NVIDIA A100: если в сравнении двух серверов выиграет решение NVIDIA, то уже при 40 серверах показатели латентности у Groq TSP будут намного лучше. В распоряжении Groq имеется пара 10-стоечных кластеров с 640 процессорами, один из которых используется для разработки, а второй — в качестве облачной платформы для клиентов Groq в области финансовых услуг. Работает система Groq и в Аргоннской национальной лаборатории (ALCF), где она используется для исследований в области термоядерной энергетики.  В настоящее время Groq TSP производятся на мощностях GlobalFoundries, а упаковка чипов происходит в Канаде, но компания работает над вторым поколением своих процессоров, которое будет производиться уже на заводе Samsung в Техасе. Параллельно Groq работает над созданием 8-чипового ускорителя на базе TSP первого поколения. Это делается для уплотнения вычислений, а также для более полного использования проприетарного интерконнекта и обхода ограничений, накладываемых шиной PCIe 4.0. Также ведётся дальнейшая оптимизация ПО для кремния первого поколения. 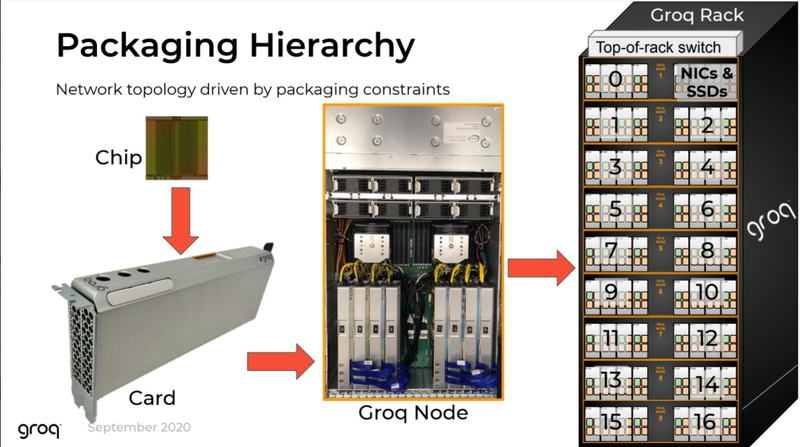 Простота и скорость разработки ПО для платформы Groq TSP объясняется историей создания этого процессора — начала Groq с создания компилятора и лишь затем принялась за проектирование кремния с учётом особенностей этого компилятора. Перекладывание на плечи компилятора всех задач оркестрации вычислений позволило существенно упростить дизайн TSP, а также сделать предсказуемыми показатели производительности и латентности ещё на этапе сборки ПО. При этом архитектура Groq TSP вообще не предусматривает использования «ядер» (kernels), то есть не требует блоков низкоуровневого кода, предназначенного для общения непосредственно с аппаратной частью. В случае с TSP любая задача разбивается на набор небольших инструкций, реализованных в кремнии и выполняемых непосредственно чипом. 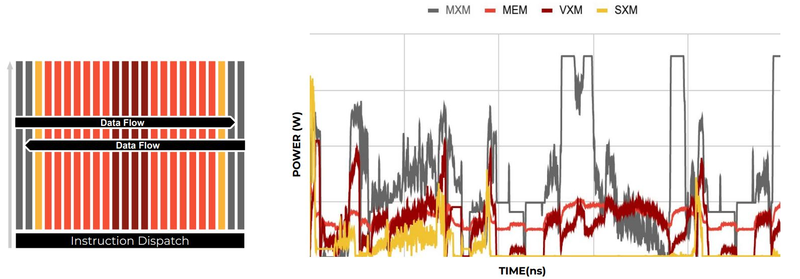
Компилятор Groq позволяет визуализировать и предсказывать энергопотребление с точностью до наносекунд. Источник: Groq Предсказуемость Groq TSP распространяется и на энергопотребление: оно полностью профилируется ещё на этапе компиляции, так что пики и провалы можно спрогнозировать с точностью вплоть до наносекунд. Это позволяет добиться от платформы более надёжного функционирования, избежав так называемой «тихой» порчи данных — сбоев, происходящих в результате резких всплесков энергетических и тепловых параметров кремния. 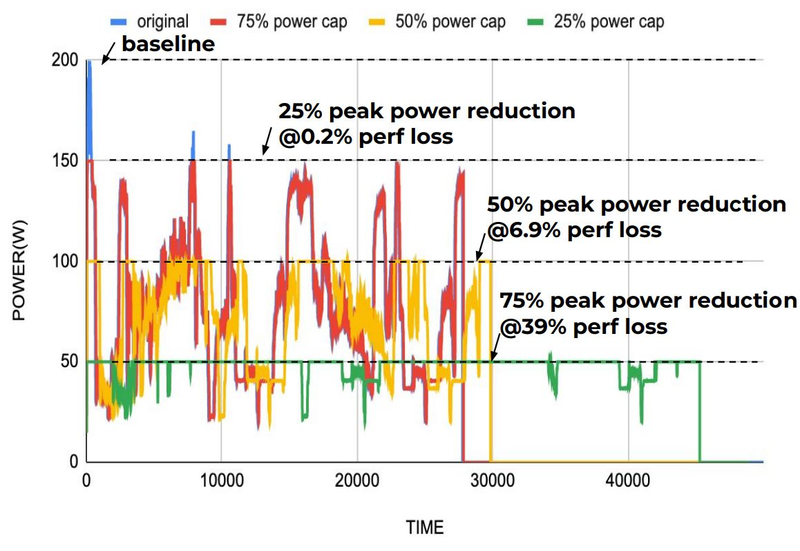
Энергопотребление Groq TSP поддаётся тонкой настройке на уровне программного обеспечения. Источник: Groq Что касается будущего LLM-инференса, то Groq считает, что этой отрасли есть, куда расти. В настоящее время LLM дают ответ на запрос сразу, и затем пользователи могут уточнить его в последующих итерациях, но в будущем они начнут «рефлексировать» — то есть, «продумывать» несколько вариантов одновременно, используя совокупный результат для более точного «вывода» и ответа. Разумеется, такой механизм потребует больших вычислительных мощностей, и здесь масштабируемая и предсказуемая архитектура Groq TSP может прийтись как нельзя более к месту. |
|

